1. Introduction
As an essential element of the earth life support system, water is crucial for sustainable development [
1]. The extraction of water body information is of great significance to many fields, such as flood monitoring, military reconnaissance, wetland protection, and cartography [
2,
3,
4]. With the development of remote sensing, the acquisition of water body information from remote sensing images has become the main approach with high efficiency and low cost. However, it is still a challenging task to accurately extract water bodies from remote sensing images. On the one hand, water bodies usually show different appearances due to the effect of many factors, such as green algae and sediments. Moreover, there are many types of water bodies including lakes, ponds, rivers with many small branches, which leads to the great difference in size and shape. As a result, it is difficult to identify all the water bodies simultaneously. On the other hand, the edge of the water body is irregular by the influence of surrounding shadows, soil, vegetation, etc., making the water edge detection more complex than buildings and roads [
5]. How to accurately extract a water body from remote sensing images, especially high-resolution images, is one of the hot topics in recent years.
In the past decades, many water body detection methods have been published in the literature, and they can be roughly categorized into water index methods, traditional machine learning algorithms and deep learning algorithms. Water index methods are simple and widely used; they rely on manual characteristics, such as the bands ratio. The normalized difference water index (NDWI) is one of the most popular methods [
6,
7]. It uses the characteristic that the water body absorbs more energy in the NIR band than in the green band to calculate the water index and extract water bodies in which NDWI is bigger than a certain threshold [
8]. As NDWI relies too much on spectral information and ignores spatial characteristics, it is difficult to determine the threshold when there are other categories of objects, such as buildings, shadows, and roads, in the images [
9]. Because the similar reflection patterns of water and shadow would lead to misclassification, Feyisa et al. [
10] designed the automated water extraction index (AWEI) to increase the gap between water and non-water bodies, and the AWEI has good performance on the Landsat dataset. Fisher et al. [
11] proposed WI
2015 based on WI
2006 and compared it with NDWI and AWEI. The experimental results show that NDWI has high commission errors in quarry, soil, and urban areas, while WI
2015 and AWEI have good accuracies, especially for cloud-shadow pixels. However, the AWEI and WI
2015 do not produce unified results for all kinds of data [
12], and the AWEI is confined to five case studies and one step [
13].To meet the requirements of automation, researchers try to use some machine learning algorithms to automatically extract water bodies from remote sensing images [
14], such as pure Bayesian (NB), decision tree (DT), and support vector machine (SVM). Yao et al. [
7] proposed an automatic water body extraction method combining SVM with NDWI. In the method, SVM is used to determine the optimal coefficient of the water index and generate a dark building shadow removal model. As the building and shadow do not always satisfy the proposed geometric relationship, the segmentation accuracy of this method may be greatly impacted [
15]. At the same time, considering that the water surface may be covered by phytoplankton or aquatic vegetation, it is impossible to exactly detect water bodies [
7]. Khandelwal et al. [
13] created a new classification model by using seven reflectance bands of two MODIS products with 500 m resolution and SVM classification model and combined the model with the noise correction method, which shows a good effect. Tri et al. [
16] used J48 decision tree (JDT) to identify water body in images. Although its segmentation accuracy is fine, it requires professional knowledge as well as strict parameter and data selection. More importantly, similar to the water index methods, the traditional machine learning algorithms cannot acquire the context information of the images.
In recent years, the convolutional neural network (CNN) has shown strong feature expression ability and has been widely used in the field of remote sensing [
17,
18]. Yu et al. [
19] introduced CNN to water body detection in remote sensing images. However, due to the shallow network structure, it is insufficient in learning ability and robustness. Because the shallow layers are generally universal filters and the wetland species in Canada are similar, Rezaee et al. [
20] used the pre-trained model to fine-tune the parameters rather than complete training to predict the RapidEye imagery. Different from the methods of putting image slices into CNN, a fully convolutional network (FCN) abandons traditional fully connected layers and utilizes convolutional networks to classify an entire image at pixel level [
21]. For this property, FCN not only can meet the condition of different image sizes, but greatly improves the efficiency and precision of the segmentation. Isikdogan et al. [
22] proposed the FCN-based model, named DeepWaterMap, which changes the number of model parameters and the way of layer splicing, making the network more suitable for water segmentation. Li et al. proposed a method based on FCN to extract water information from high-resolution remote sensing images [
15]. Compared with other methods mentioned above, the FCN can obtain better results, but the edges of the final predicted water bodies are always blurred. What is more, small water bodies are often missed as lots of feature in the process of continuous downsampling, which expands the receptive fields. To overcome this deficiency, U-Net for biomedical image segmentation is presented [
23]. The U-Net employs a symmetrical encoder–decoder structure, which is linked by skip connections to settle the problem of resolution degradation. Feng et al. used Deep U-Net and a superpixel-based conditional random field (CRF) model to detect water bodies [
24]. It has poor performance on small water areas, as it directly concatenates different levels of feature maps and makes the characteristics confusing [
25]. Inspired by Resnet’s ability to continuously reuse information and Densenet’s ability to acquire new features, Shamsolmoali et al. [
26] combined Resnet and Densenet to achieve better segmentation while being GPU-friendly. Multi-scale water extraction convolutional neural network (MWEN) [
9] adds a multi-scale dilated convolution in the last layer to combine the information in different scales, but it is insufficient since the multi-scale extractor is only added on the last layer. Considering these aspects, a multi-feature extraction and combination network (MECNet) [
5] is proposed to integrate different receptive fields and channel information. However, MECNet only considers global information and ignores spatial information, which leads to the detail loss. What is more, the several methods mentioned above are based on the structure of the encoder–decoder, though this structure alleviates the problem of information loss during the downsampling process, the low-level feature maps also lose unrecoverable details that are vital for the prediction. Different from the traditional encoder–decoder architecture, a novel network HRnet V2 [
27] is proposed. In this network, four parallel branches are used to acquire and fuse features, and the first branch maintains a full resolution image. However, if HRnet V2 is directly applied to water segmentation without considering the characteristics of water bodies, it still leads to location information loss. Additionally, it is known that high accuracy lies in enough labeled samples for training almost all DL methods. However, due to the lack of labeled samples in real applications, the deep learning methods are difficult to achieve ideal results in practical remote sensing application. At same time, the mount of labeling samples is costly. The multiscale residual network (MSRnet) obtains the semantic information of the images through self-supervised learning strategies and predicts unlabeled images through the combination of semantic information and supervised learning parameters [
28]. Although the MSRnet has great performance, it needs labeled samples, as it directly shares the parameters of supervised learning. Among all the above methods, the water index methods lack automatic detection abilities, and the machine learning methods rely on feature and data selections. Although the water detection accuracy produced by DL is improved, the DL methods cannot obtain semantic and location information simultaneously and require the mount of labeled samples, which indicates that although there are many excellent water segmentation studies, there exists room for progress.
To overcome these defects mentioned above, a selective feature enhancement and multi-scale feature fusion network based on domain adaptation (SFnet-DA) is proposed in this work. To improve the ability of anti-noise and identification under the premise of ensuring the location information, the SFnet develops a spatial information-based selective self-attention (SSA) mechanism that employs different feature enhancement methods for various branch fusions, which selectively increases the details or semantic information of the images, making the top-down branches hold a state of increasing semantic information and decreasing location information. With SSA structure, the network can resist the noise disturbances, such as clouds and green algae, while having the ability to identify small and vast water bodies simultaneously. A multi-scale feature fusion (MFF) module is designed to enhance the location and detailed information of the feature map without increasing the number of network parameters, which raises the accuracy and connectivity of the water edge. Furthermore, to predict more refined images, the fully connected CRFs [
29] are applied to post-process the predicted images. To avoid image labeling, the domain adaptation, which utilizes the existing labeled dataset to predict the target unlabeled dataset, is preferred. The feature distribution of the labeled dataset is related to but likely different from the feature distribution of the target dataset. The labeled dataset is defined as the source domain, and the target dataset is defined as the target domain. The SFnet-DA builds an adversarial relationship between the feature extractor and domain classifier to make the feature distribution of source domain and target domain consistent, namely domain invariance. Specifically, the feature extractor maps the images of the source domain and the target domain so that the domain classifier determines that the features from the source domain and the target domain are source domain features as much as possible, and the domain classifier correctly determines whether the features come from the source domain or the target domain as much as possible. In addition, to ensure the prediction effect of unlabeled samples, we connect the feature extractor with SFnet to train through source domain images and labels. After learning, the mapped features from –source domain and target domain are both domain invariant and discriminative, so the target domain can predict the unlabeled samples by using the parameters trained in the source domain.
The main contributions of this paper can be summarized as the following.
- (1)
We designed a novel SFnet composed of SSA, MFF, and fully connected CRF post-processing modules. Specifically, SSA selectively intensifies the features of different scales and enhances the capability of anti-noise. The combination of fully connected CRFs and MFF, which changes the proportion of each branch feature, and the splicing method not only can improve the position information of feature maps, but can optimize the edges of water bodies.
- (2)
To reduce the demand for labeled samples, the adversarial domain adaptation method, for the first time, is embedded in the proposed SFnet-DA. Specifically, through the adversarial relationship between the feature extractor and the domain classifier, the labeled dataset and the unlabeled dataset are connected, which enables us to directly use the parameters trained by the labeled dataset to predict the unlabeled images.
- (3)
The designed water detection method combines SFnet with adversarial domain adaptation (SFnet-DA), and the test results of our method on public datasets are better than other advanced methods.
The rest of the paper is structured as follows.
Section 2 introduces the methods, including the design of SFnet, the domain adaptation method, and fully connected CRFs. The evaluation data, experimental settings, algorithm results, and discussion are shown in
Section 3 and
Section 4. Finally, the summarization is given in
Section 5.
2. The Proposed Method
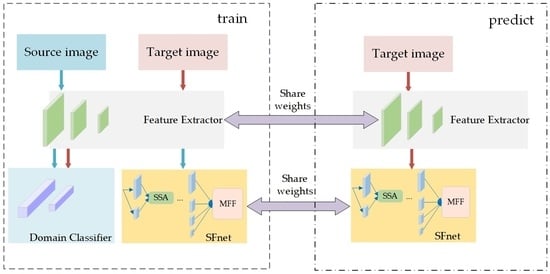
With the domain adaptation (DA) mechanism, the proposed SFnet-DA has four branches. The lower branches of SFnet are responsible for the location and detailed information of the water bodies, and the upper branches of SFnet are responsible for the semantic information. To obtain the water body information of different sizes and alleviate the influence of noises, the SSA is embedded into SFnet. To obtain an accurate water edge, SFnet embeds the MFF module and takes the fully connected CRFs as the post-process method. Then the combination of SFnet and DA is used to construct SFnet-DA to avoid labeling tasks.
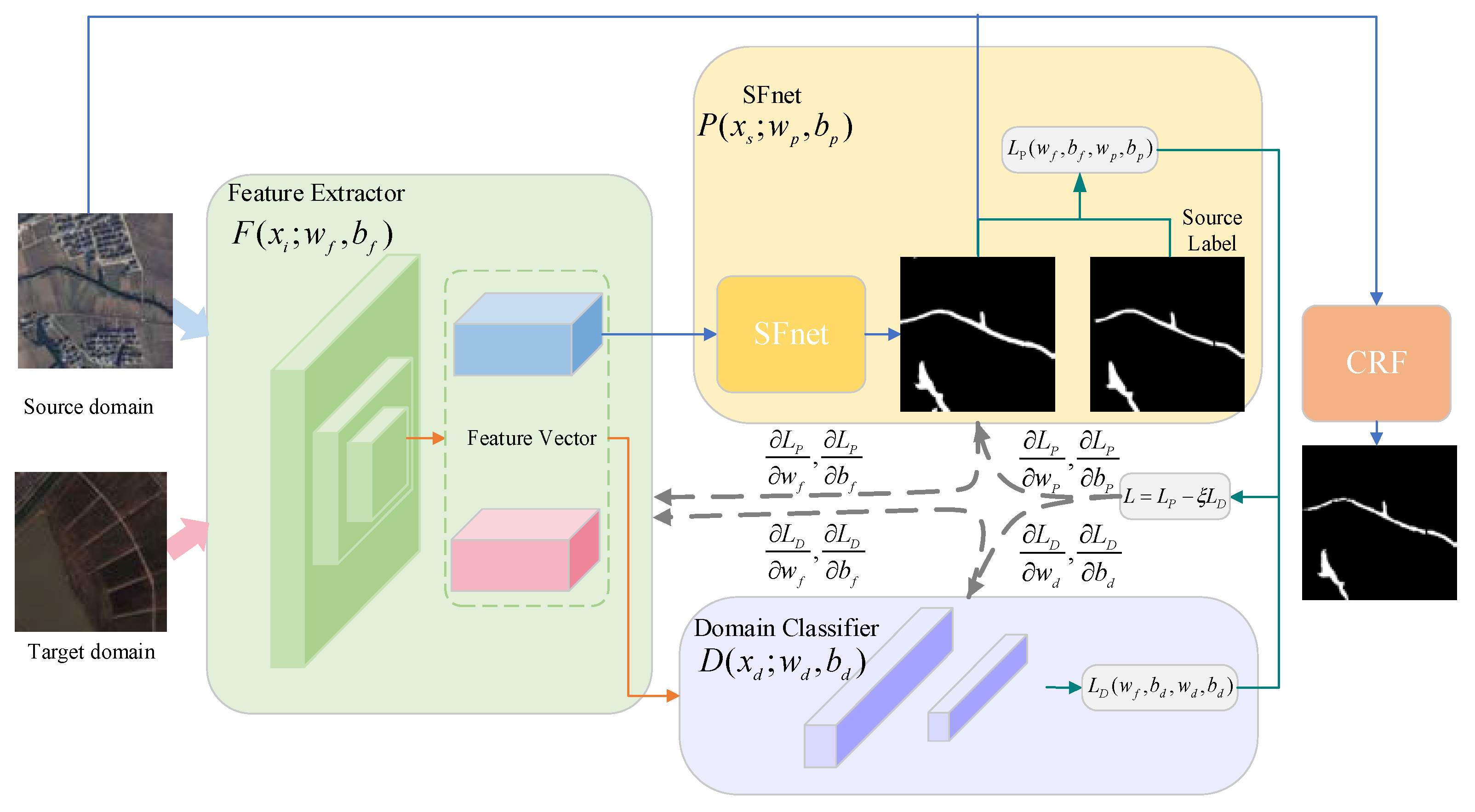
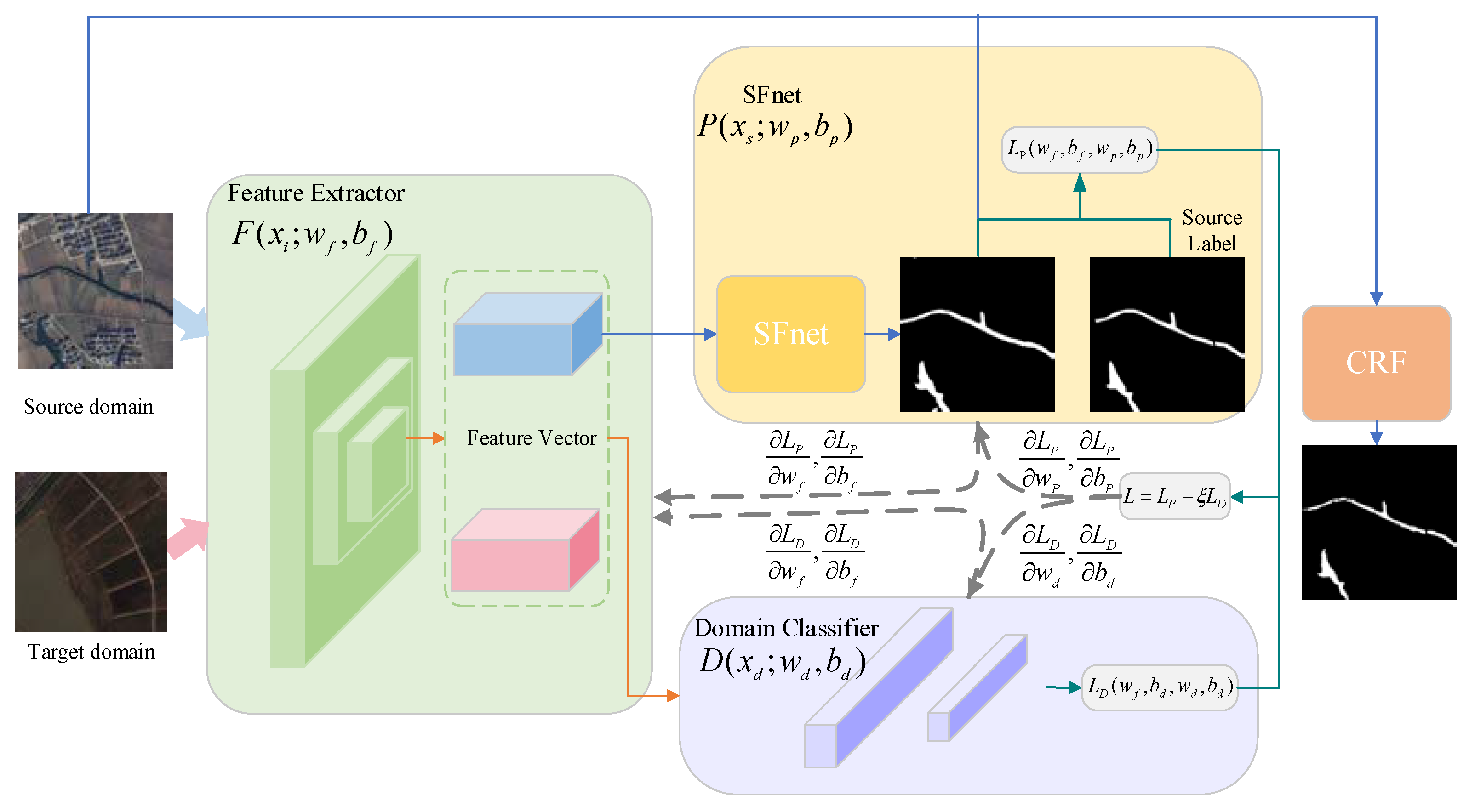
Figure 1 is the flowchart of the proposed method. First, we mark the source domain images as 0 and the target domain images as 1, and put them into the feature extractor to generate the feature vectors, which would enter the domain classifier. The feature extractor maps the images of the source and target domains, and the domain classifier determines which domain the mapped feature vectors come from, so that the resulting adversarial relationship makes the features mapped in the source and target domains similar and achieves domain invariance of the feature vectors. Then, the feature vectors of the source domain images generated by feature extractor will be processed by SFnet. The SFnet trains parameters together with the source domain labels, which guarantees the discriminability of the mapped feature vectors, i.e., the water segmentation performance of the network. After training, the mapped features from source domain and target domain are both discriminative and domain invariant, so the target domain can directly use the SFnet, trained in the source domain, to predict its own unlabeled samples.
2.1. Structure of SFnet
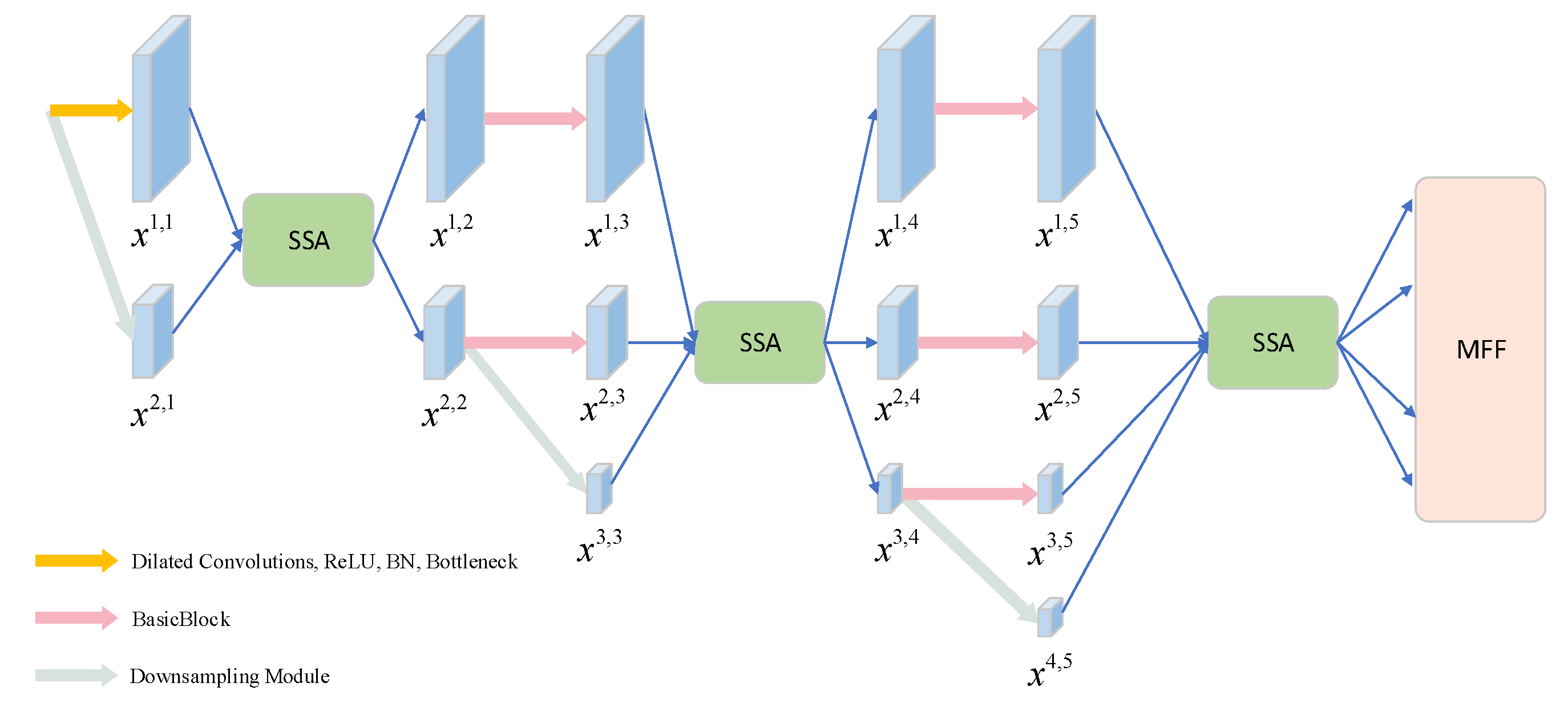
HRnet V2 is a high-resolution neural network for human pose estimation, and it is used as a basic framework for SFnet. The structure of the SFnet is shown in
Figure 2. The SFnet is composed of four branches. The first branch is used to extract features in the full resolution of input images for ensuring the spatial position of the image objects. The feature maps of the other three branches are 1/4 of the characteristic graphs of each previous branch for capturing more context information. To ensure that the entire network is performed with a small amount of calculation, the first feature extraction module of the first branch is different from other modules. Specifically, it consists of two dilated convolutions, the rectified linear unit (ReLU) activation function, the batch normalization (BN) layer, and the BottleNeck. The BasicBlock used in other feature extraction branches is to deepen the network and extract the feature map. At the same time, it can catch the count of feature channels and image resolution without change. For the purpose of expressing characteristics better, the downsampling module is a dilated convolution whose output channels are twice that of input channels.
Let xm,n represent the feature map after the BottleNeck, BasicBlock or downsampling modules, where m denotes which branch the feature map is located in, and n indexes the feature extraction stage. The features located in different branches at the same stage enter the SSA for integration among them. In the relatively primary branch, the SSA prefers to enhance the edge and detail information of the advanced branch by training a self-attention parameter and guides the high-level feature to adaptatively discover the salient area of each image. Similarly, in the relatively advanced branch, the SSA prefers to enhance the ability to detect water bodies of different sizes by helping the primary branch make full use of the large receptive field information of a high-level map. After the last SSA operation, the network gains four-level feature maps with gradually decreasing resolution and increasing channel numbers as well as semantic information. The feature graphs in the low feature branches hold more detailed information but have lower semantic information and larger noise, while the feature graphs in the high-level feature branches have more semantic information and poor perception of details. To make use of their advantages, a multi-scale feature fusion (MFF) module is used to effectively combine low-level features with high-level features so that the image location information and semantic information can be assured. The SSA and MFF are introduced in detail in the following.
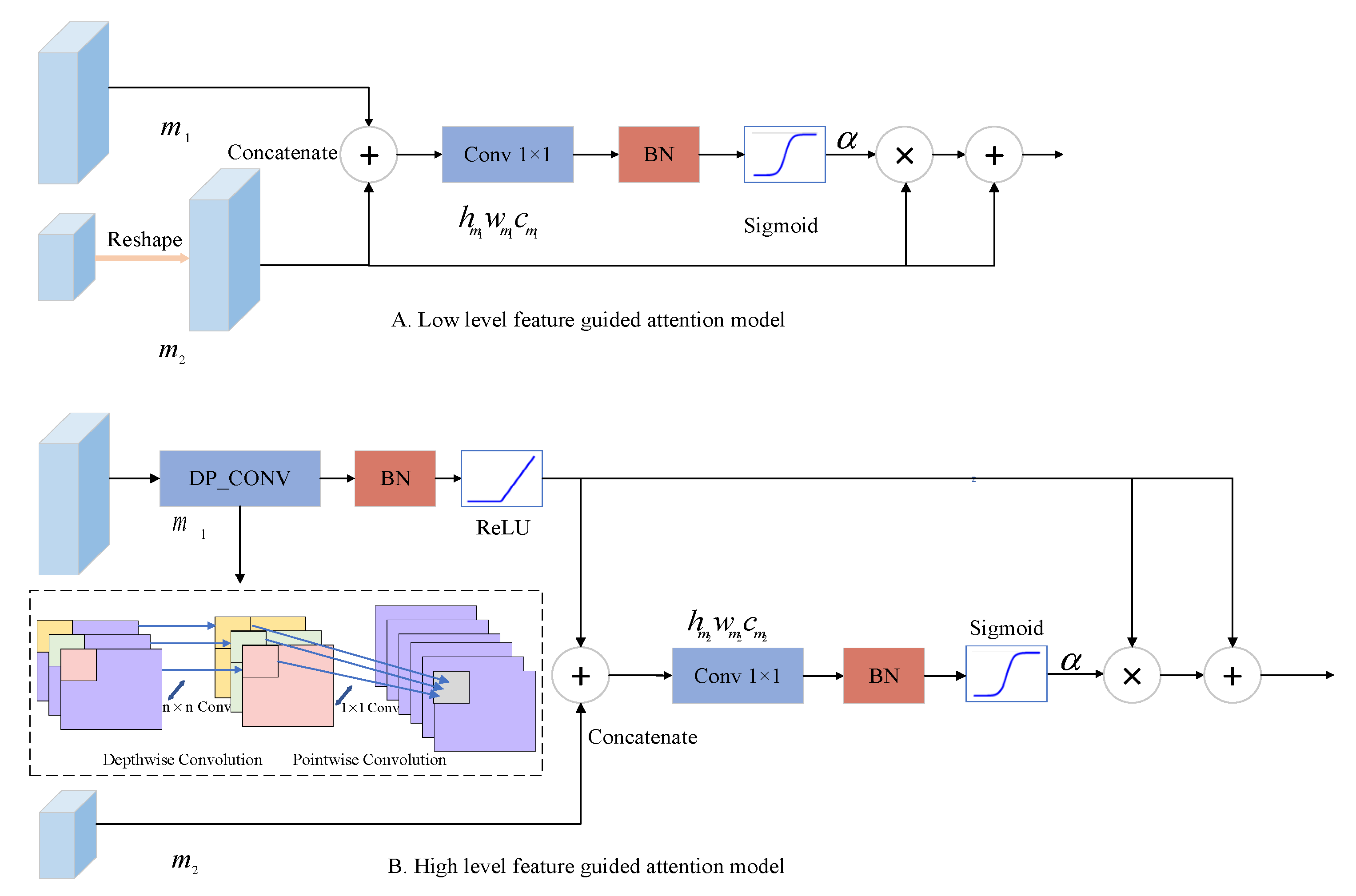
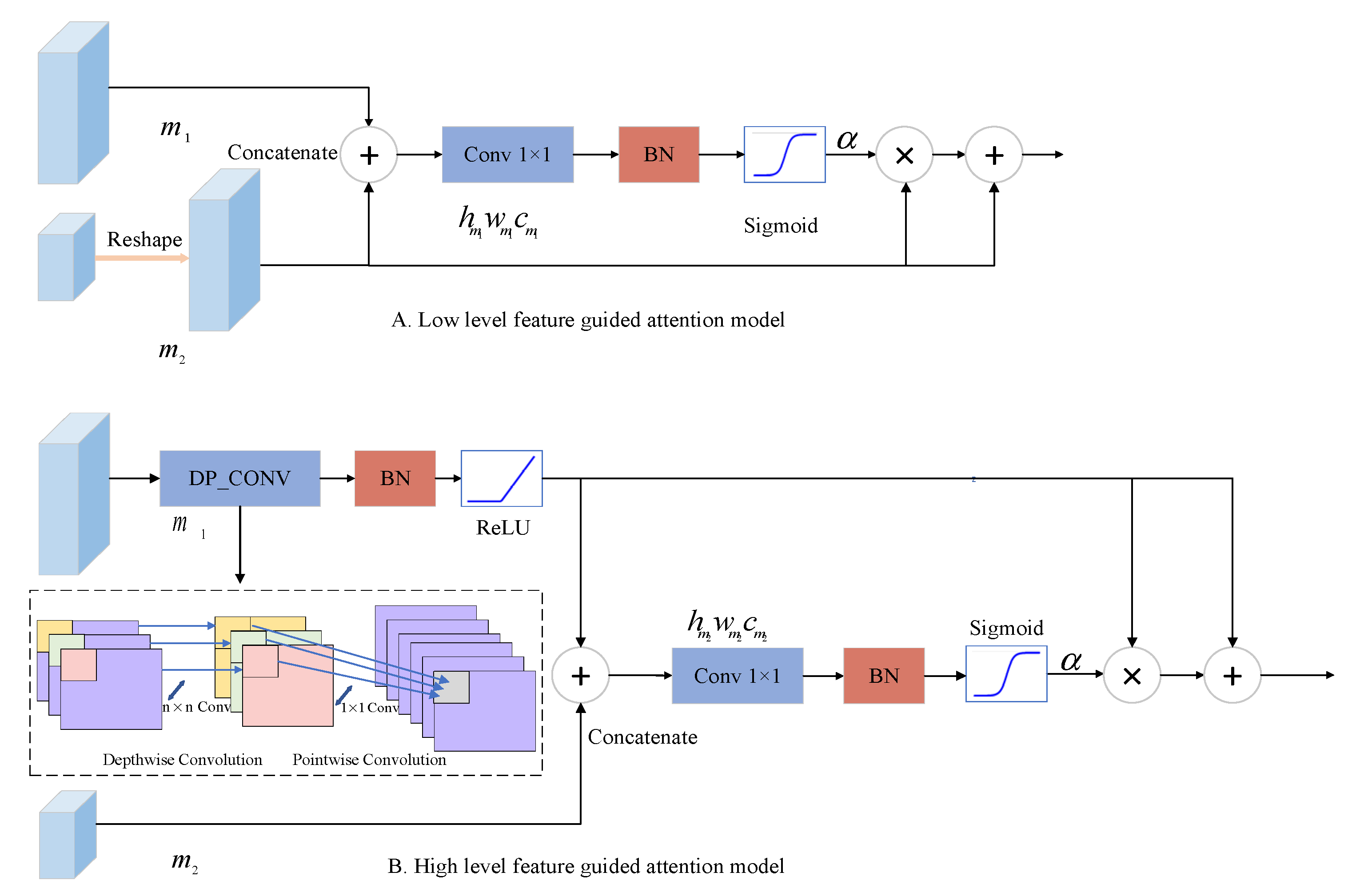
2.1.1. Selective Self-Attention (SSA) Mechanism
Since the first branch retains the resolution and the other branches expand the receptive field progressively, the functions of the four branches are different. The relatively primary feature branches are responsible for guaranteeing the contour accuracy and connectivity of water bodies. The advanced feature branches after downsampling, possessing larger receptive fields and feature channels, can resist the interference of noise and effectively identify water bodies of different size. To make different branches have different functions, we propose a simple but effective selective self-attention (SSA) mechanism which automatically adjusts the self-attention coefficient according to the feature branch number. By the self-attention coefficient, the SSA uses the characteristic of the feature branch to weight the characteristics of another branch in the feature reuse phase to realize the feature magnification.
The structure of the SSA is shown in
Figure 3.
Figure 3A shows the shallow feature guiding the deep feature branch and
Figure 3B shows the deep feature map guiding the shallow feature branch. In Equations (1) and (2), we pick out the feature map of the first stage of the first branch
and the map of the
n-th phase of the
m-th branch
:
where
h and
w are the height and width of the feature map in the first stage of the first branch, respectively. The resolution of the other branch is
of the original resolution. The counting of characteristic channels in the first branch is stated by
C, and the number of characteristic channels of
m-th branch is
.
To identify the salient areas of the images and choose to enhance the details or semantic information of the water body, SSA employs a differentiable soft attention mechanism. The self-attention coefficient
guided by a low level feature would be automatically updated, and the importance of each pixel is adaptatively determined when the network is backpropagated, so it is easy to identify the salient areas of the images and keep the details of water bodies. The
guided by the deep feature conducts the shallow feature to enhance the semantic information of the primary branch, so that the network would boost the capacity to distinguish petty and vast water bodies, and not be influenced by noise, such as roads and shadows. No matter what kind of guidance SSA adopts, the sum of low-level and high-level features is used to generate the self-attention coefficient
, which considers the global information of the feature maps. Instead of choosing a generalized global average pooling, the combination of 1 × 1 convolution and BN layer is used to acquire a grid signal based on position information, which is conducive to interacting and integrating different channel information. What is more, the SSA is lightweight, since the output channel number is 1. The sigmoid activation function is used to obtain a convergent coefficient since the consequent use of softmax results in a sparse output.
where
B denotes the batch normalization (BN) layer, and
and
denote the weight and bias, respectively.
denotes the map which retains its own branch,
denotes the map which is processed by the network to get the same size with
, and
is the output of the SSA mechanism. For the case of selecting the primary characteristic branch to be reserved in
Figure 3A,
and
, where
U denotes the upsampling process. In
Figure 3B, when the feature processed by SSA is retained in the advanced feature branch, depthwise separable convolution (DP_CONV) is utilized to lessen the storage of the SSA, namely
where
denotes the weight of the depthwise convolution with kernel size n × n and the pointwise convolution with kernel size 1 × 1.
,
m represents channel expansion and
RB represents the ReLU activation function combined with the BN layer.
To maintain the original characteristics of the branch and let the branch with a larger
m contain more semantic information, we add all feature maps in the same branch after passing through the SSA mechanism, and then add the sum with the feature
of the branch itself:
where
K is the maximum number of branches, and
is used to represent the SSA mechanism whether the SSA is located in the low-level feature branch or the high-level feature branch.
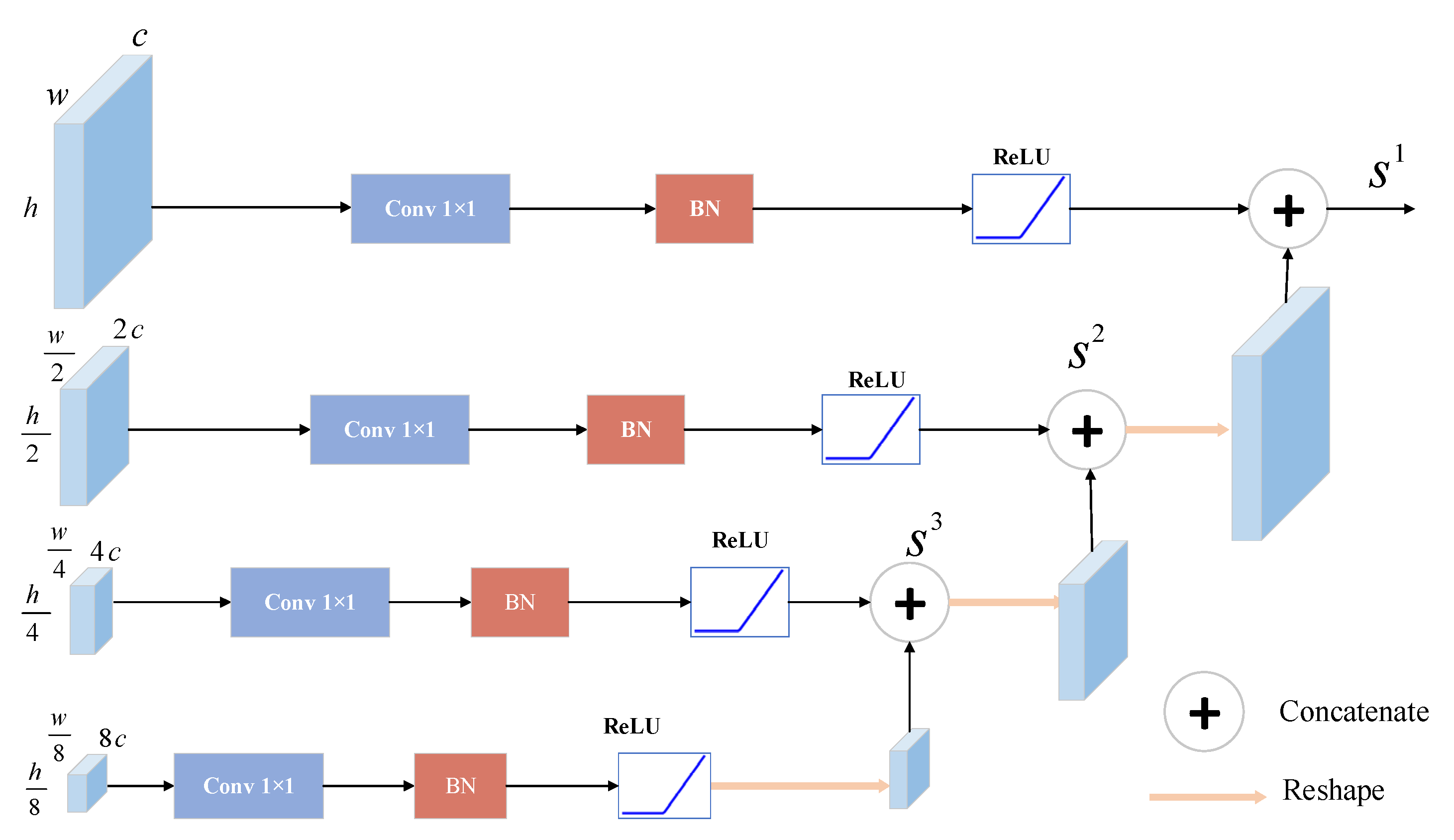
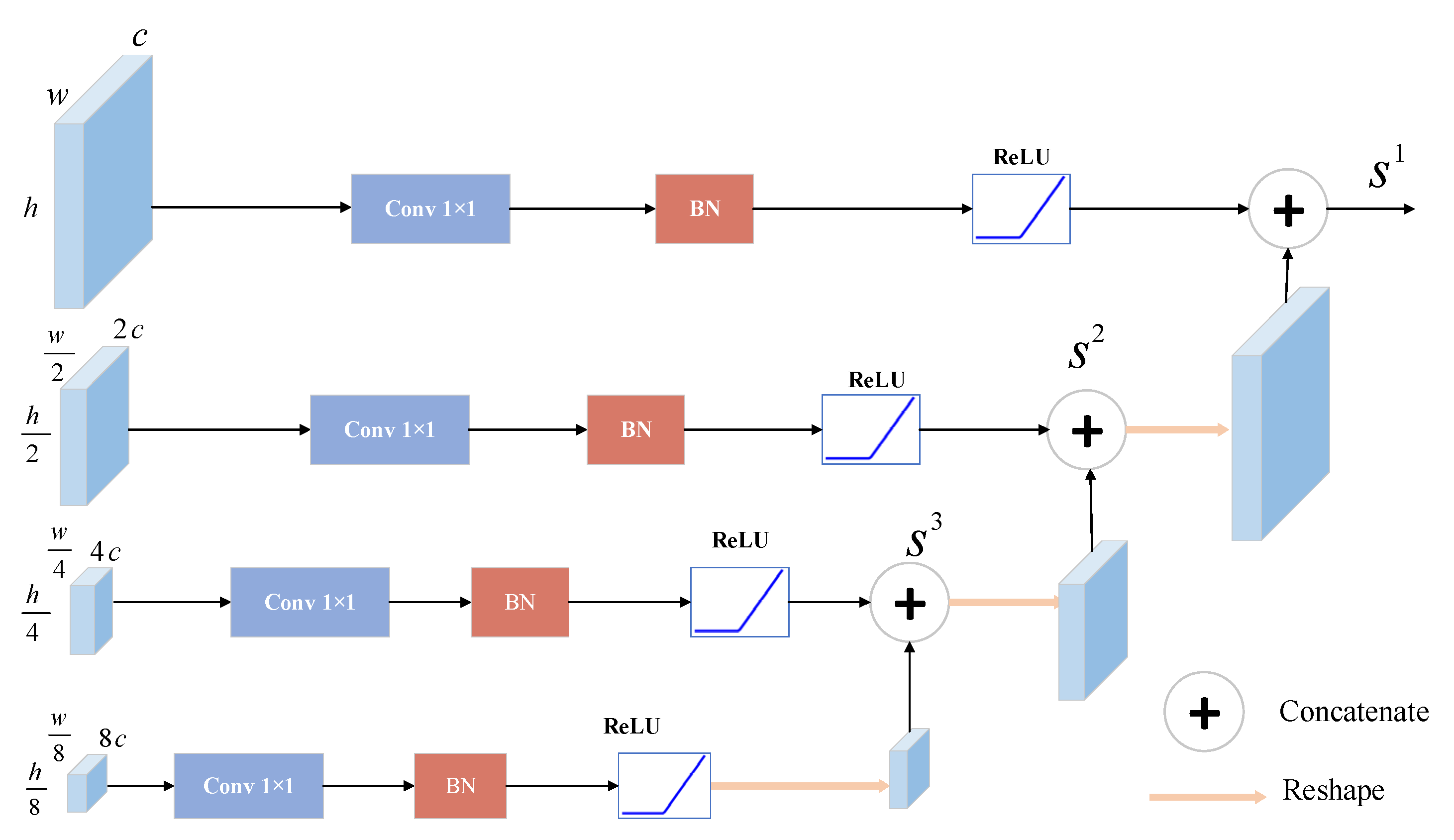
2.1.2. Muti-Scale Feature Fusion (MFF) Module
Generally, if the deep network is simply connected at the end, the details of the feature maps would be lost, and the edges of the water bodies would be blurred. To better maintain the detailed features, we design a light multi-scale feature fusion (MFF) module which integrates the location and semantic information while avoiding the network over-fitting. To the proposed SFnet, a basic purpose is that the primary features of the images are extracted by shallower branches, and the advanced characteristics of the graph are perceived by deeper branches. In the downsampling process that expands the category expression ability of the images, the number of feature channels of the branch is changed to . After the last SSA mechanism and adding process, we obtain four-level features and the high-ranking feature channels become 8C; simple splicing would inevitably pay much attention to the rich semantic information of the deep feature map and neglect the basic characteristics. However, for the water segmentation of high-resolution remote sensing images, the accurate location of the water body is instrumental in the correct positioning and area calculation. Hence, we use a standard convolution module including the 1 × 1 convolution layer, BN layer and ReLU activation function to reduce the number of feature channels from to C, which increases the proportion of low-level feature branches while reducing the model parameters.
What is more, compared with the direct splicing, ‘stepped’ concatenating is adopted. That is, the advanced feature branch is not directly upsampled to the first branch after the standard convolution module, but only upsampled to four times that of the advanced feature map and concatenated with the previous images after the standard convolution module. The structure of MFF is shown in
Figure 4 and the overall process is as follows:
where
is the dimension concatenating,
is the output of the MFF, and
is the standard convolution module of the m branch, which includes the 1 × 1 convolution layer, BN layer and RELU activation function.
,
and
. We use this structure to lighten the network and improve the accuracy of the water detection.
2.2. SFnet Based on Domain Adaptation (SFnet-DA)
Generally, the water detection methods based on deep convolution neural network utilize a large array of labeled samples for training; however, manual labeling is extremely time consuming and expensive. To skip labeling, we attempt to use the existing labeled dataset to predict the unlabeled target dataset. However, the model trained on one labeled dataset cannot directly predict another unlabeled dataset since there are huge differences, such as shooting area, and image resolution. Additionally, the characters of water bodies are generally different from each other in different regions, especially in high-resolution images. To the different datasets, these differences in water bodies are more common and lead to a domain shift, namely dataset bias. To address this problem, we built up our semantic segmentation network (SFnet) based on domain adaptation, which reduces the domain shift in the feature space. If the water body features of one unlabeled remote sensing imagery set need to be predicted, the domain adaptation can reduce the domain shift between unlabeled target datasets and existing labeled datasets that are highly likely to be distributed differently, making it possible to skip labeling work and directly predict unlabeled samples. The unlabeled samples are denoted as the target domain, and the labeled samples are denoted as the source domain. The input spaces of the source domain and target domain are assumed to be X. The annotation space of the source domain is assumed to be Y = {1, 2, …, L}, where L refers to the number of categories of image segmentation. The distributions of source domain and target domain are represented by and , respectively, and ≠ . The parameters is used to denote images of source and target domain, and denotes the labels of target domain, respectively. The parameters and are used to denote the image counts of the source domain Is and target domain IT, respectively, and , . We mark all images from the source domain as 0, and all images from the target domain as 1.
To reduce the dataset bias between source domain and target domain, SFnet-DA defines the feature extractor and the domain classifier with an adversarial relationship. As the high-resolution features of remote sensing images and the large discrepancies in the scales of different water bodies, multiple convolution layers and a max pool layer are combined to define the feature extractor
, it makes it possible to prevent a large loss of resolution while extracting features.
F maps the input images of the source domain and the target domain into the eigenvectors
, which attempts to enhance the similar parts between the images of the source domain and the target domain, and reduce the dissimilar parts so that the distribution of the features in the feature space is the same, i.e.,
. The domain classifier
uses the domain discrimination label to determine whether the images come from the source domain or the target domain, that is, we define
A simple adversarial realized method, named gradient reversion [
30], achieved by ξ is to reverse the gradient in the backpropagation, and keep the input unchanged during forward propagation. Furthermore, to guarantee the ability of segmentation, namely discriminativeness,
F is connected with SFnet, whose structure does not require any changes since
. The objective loss is defined as
L:
where
and
represent the loss of the semantic segmentation and domain classifier respectively.
and
.
represents that SFnet trains the parameters by the source domain images and source domain labels to realize discriminability. Benefiting from gradient reversion, the adversarial relationship can reduce the dataset bias. On the one hand,
causes the parameters
of the feature extractor to be updated to make the mapped features as consistent as possible so that the domain discriminator
makes the wrong judgment, that is, all judgments are 0, and maximizes
. On the other hand, the parameters
of the domain discriminator are modified to identify where the images come from as much as possible, that is, judge the source domain image as 0 and the target domain image as 1, and minimize
. The specific back-propagation process of finding saddle points
can be expressed as Equations (15) and (16). Equation (15) is used to minimize the
by updating the parameters
for improving the water body segmentation capability of the network. At the same time, due to the gradient reversion, the
would be maximized, and the ability of the feature extractor to make the feature vectors mapped by different domains become uniformly distributed is improved. Equation (16) updates the parameters
to minimize
, and improve the classification ability of the domain classifier:
Therefore, the features learned by the feature extractor have both discriminability and domain invariance. When a set of optimal parameters is learned, the feature extractor almost satisfies . When we want to predict the target domain images without labels, we put the target domain images into the feature extractor to make the , and use the SFnet parameters trained with the source domain labels to segment unlabeled images.
2.3. Fully Connected CRFs
The performance of a network depends on enough fine samples. When the labels themselves are not fine enough, the network will lead to the predictions not being close to the original images. Additionally, owing to the restricted storage of the GPU, initial downsampling is necessary. This operation always loses the detailed information and makes the edge of water blurred and the classification of small water regions error. In recent years, conditional random fields (CRFs) were widely utilized to smooth rough segmented images [
29]. However, CRFs only use single potential energy on a pixel or paired potential energies on adjacent pixels. This property results in a sparse structure that can only couple adjacent points and implement modeling between short-distance pixels. In contrast to CRFs, each pixel in fully connected CRFs is coupled with all other pixels to form connecting edges, which greatly enlarges the quantity of paired connections and is conducive to establishing long-distance connections, restoring edges, and identifying small water bodies. Accordingly, we combine our network with fully connected CRFs.
For any conditional random field (
I, X), the probability distribution can be described by the Gibbs distribution:
where
refers to the random field, and
is the pixel label, namely water or background.
indicates the images of input with size
N, and
is the normalization factor.
is the complete graph on
X, and
is the largest subgraph in
G.
denotes the potential function of
.
In fully connected CRFs, the energy of Gibbs is as follows:
where the unary potential function is denoted as
, and
indicates the probability value of the output of the SFnet. Even though
contains the situation and color information of the water body, it is only related to the pixel point
, and has no association with pixels in other locations. Note that pixels with similar colors and positions are usually of the same type, so the pairwise potential function
is used to determine the probability of two events occurring at the same time:
when
,
; otherwise,
. In this definition,
would constrain the conduction condition between pixels and penalize adjacent pixels of different labels.
denotes a combination of linear weights,
and
indicate position vectors, while
and
signify color vectors. The first appearance kernel adopts parameters
and
to control the similarity and proximity while considering location and color information. The second smoothing kernel that uses the parameter
to control the scale of the Gaussian kernel only considers spatial information and aims to remove small isolated water bodies.
We put the original images and the water segmentation maps predicted by SFnet into fully connected CRFs post-processing module to obtain the energy of Gibbs through calculating , and finally obtain the optimized water segmentation map.
4. Discussion
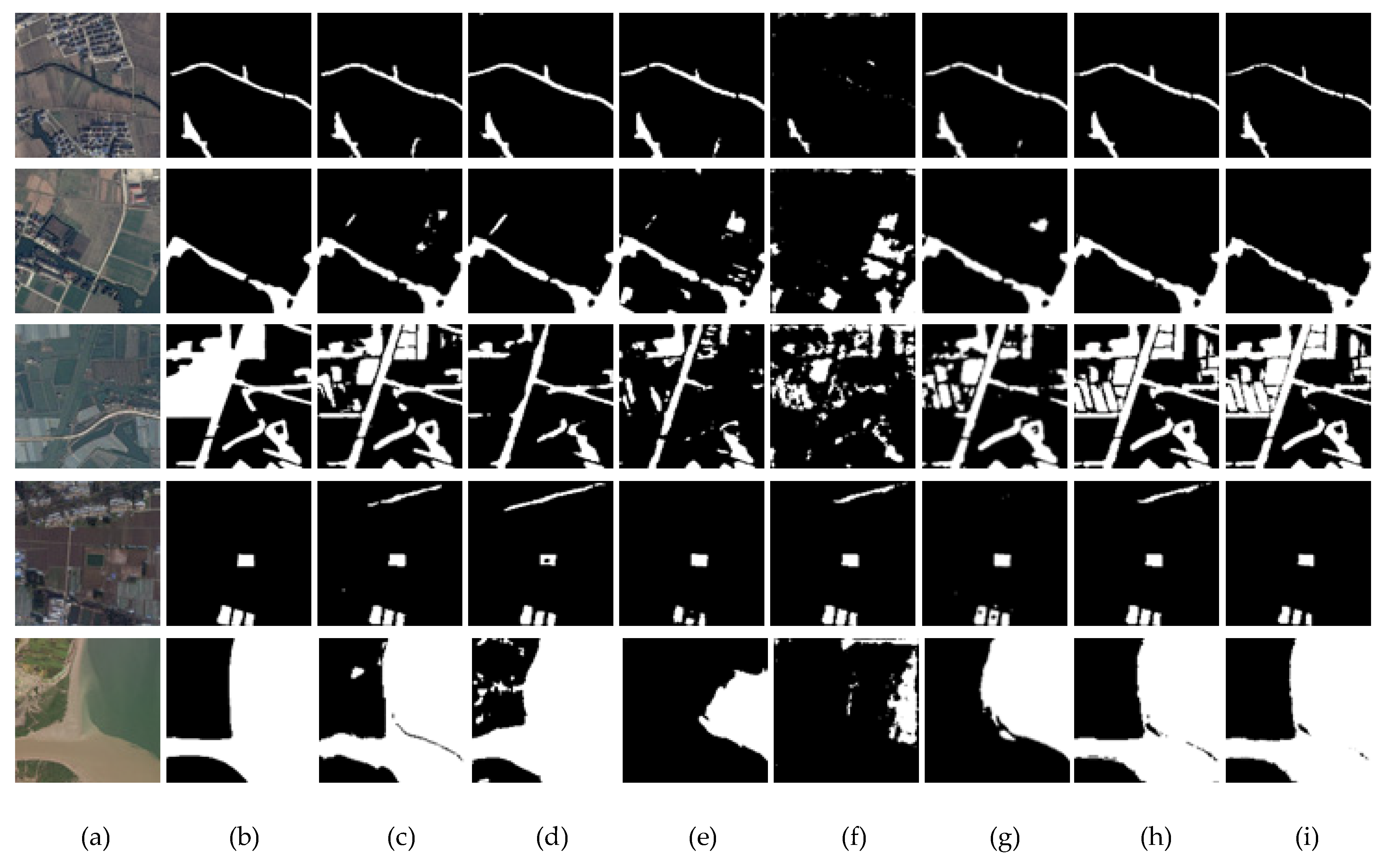
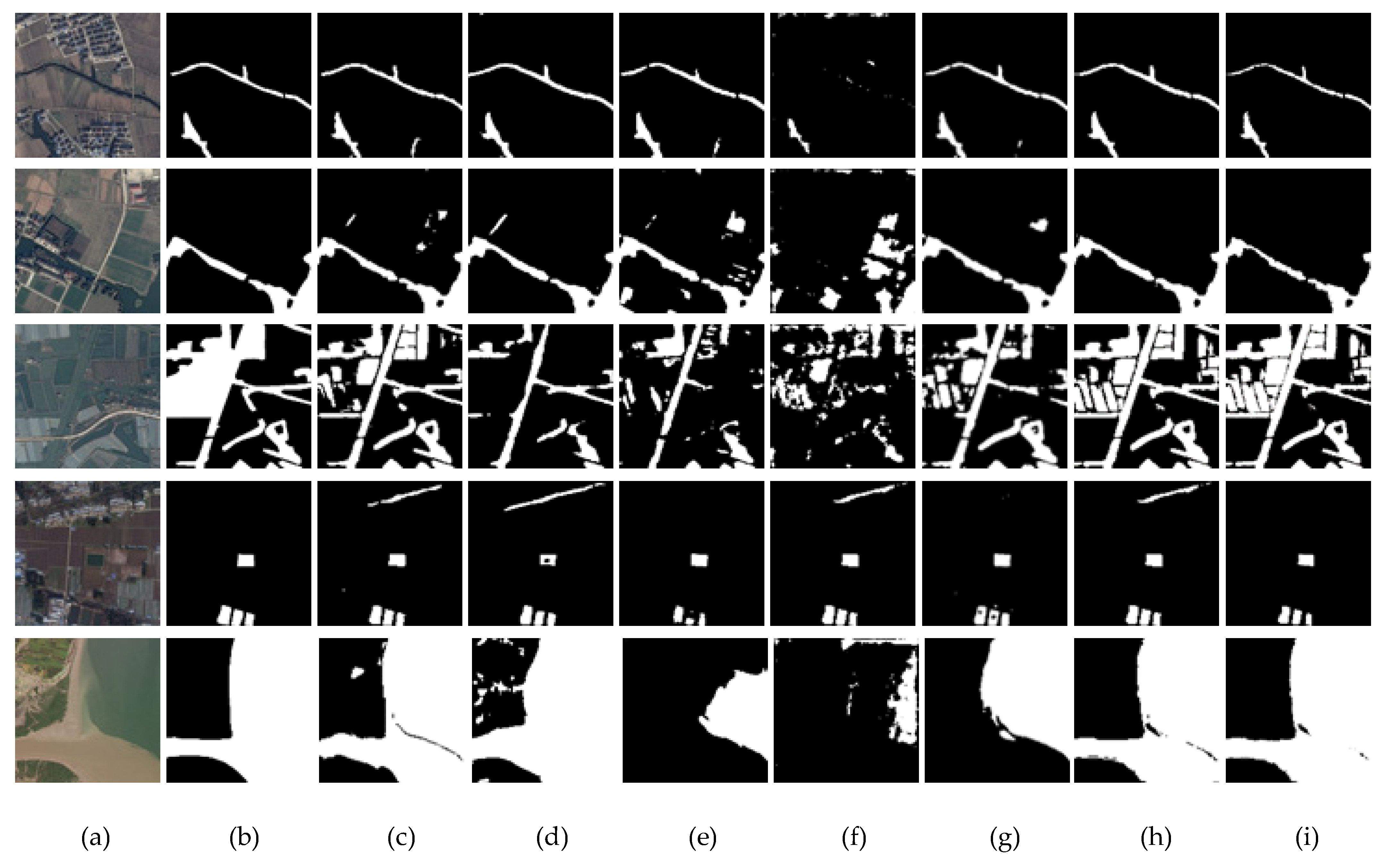
Our research aims at the automatic extraction of water information from remote sensing images, and the experimental results show that our method is better than other compared methods. From the experimental results in
Section 3.3.1, it can be found that Bisenet and HRnet V2 have better detections for small rivers because they retain shallow information, but the detection effects are poor in complex scenes. Deeplab V3+ uses dilated convolution to obtain context information, which makes it have a good effect in complex backgrounds, but Deeplab V3+ has missed detection for small rivers. Noting the phenomenon that shallow information is helpful for detailed information and deep information is helpful for semantic information, our method adopts the SSA module to selectively enhance shallow or deep information and uses MFF to refine the edge of the water body. The quantitative and visual results show that our method has good performance in the source domain. To further test the advantages of our network, ablation experiments are conducted here. We sequentially deleted the fully connected CRFs, MFF module and SSA mechanism in the network, and compared them with the backbone network HRnet V2 under the same source domain dataset. The experimental results are shown in
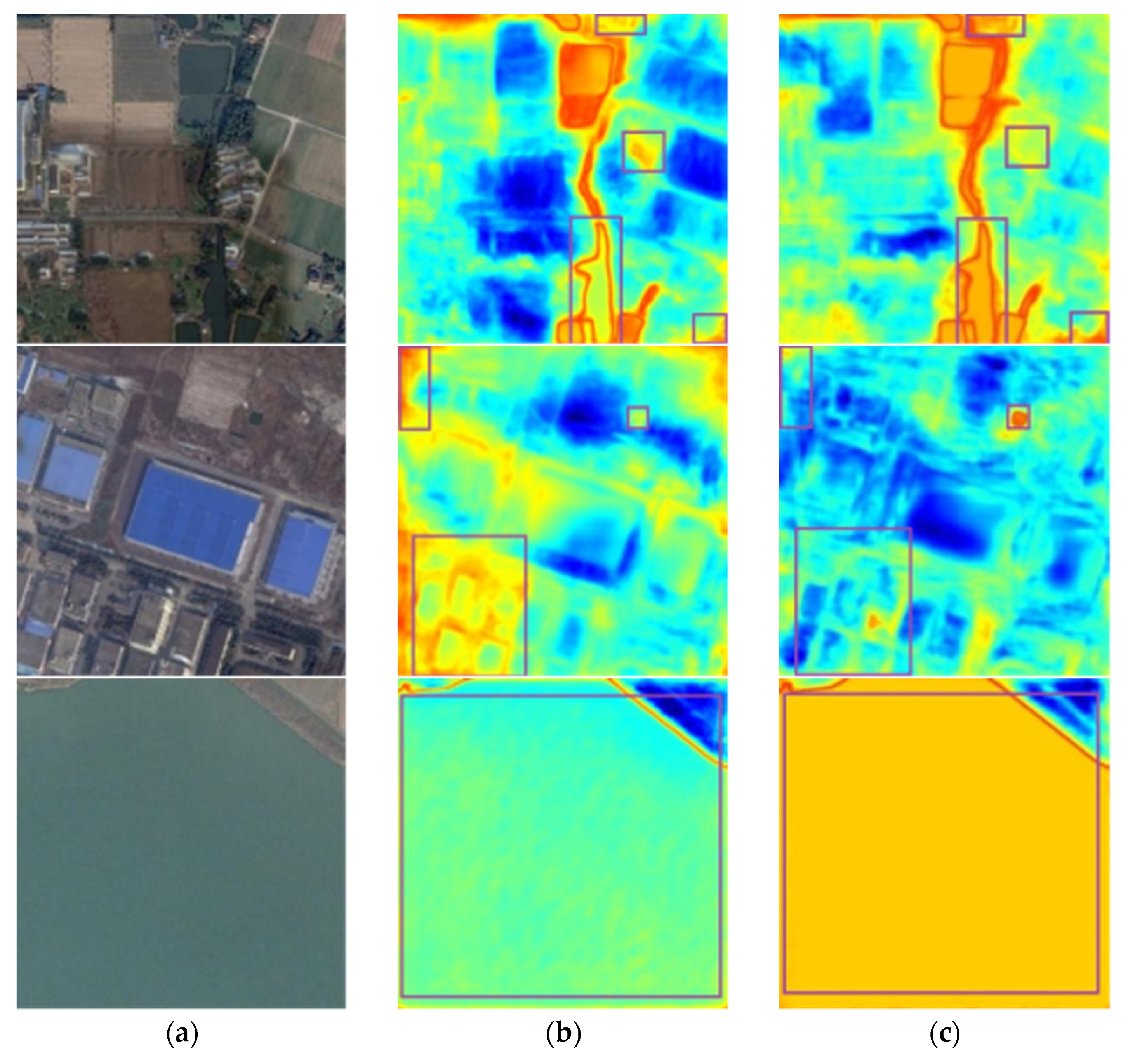
Table 3. It can be found that SSA improves
MIOU by 1.4%, MFF by 0.42%, and CRF by 0.42%. To further evaluate the SSA mechanism, we visualize the output images before and after the SSA mechanism in the form of a heat map, as shown in
Figure 7. It can be found that the network after adding SSA can efficaciously resist the interference of noises such as the shadow, buildings, green algae, and vegetation, reducing the false or missed detections. Additionally, the network after joining SSA has better identification effects and robustness for vast lakes and small water regions. Comparing the images in
Figure 8, it can be seen that the network can better obtain the edge information of the images after adding MFF. In addition, from the experimental results in
Section 3.3.2, it can be found that the effects of simple unsupervised detections are not ideal, while our method has been greatly improved compared with them because of the powerful feature extraction ability of DL. From
Table 1 and
Table 2, it can be found that in the source domain, our method is faster than some networks but slower than efficient networks, and in the target domain, it is faster than other methods but slower than K-means, which needs to be improved in the future.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}