1. Introduction
Mapping roads from satellite imagery is an important image processing research topic to improve urban planning, transportation systems, and agricultural organization [
1,
2]. For tropical forest regions, such as the Amazon biome, roads are one of the main drivers of forest change by deforestation [
3,
4,
5], increasing the likelihood of fires [
6] and threats to protected areas [
7]. Therefore, mapping and monitoring roads from space are crucial for identifying threats to tropical forests and the tradition and indigenous people living in the region. The first efforts to map roads in the Brazilian Amazon biome used visual interpretation of Landsat imagery [
8,
9], revealing an overwhelming spread and extent of illegal roads in this region. However, mapping and monitoring roads were still dependent on visual interpretation mapping protocols, which are time-consuming [
8,
10] and prone to biases of human performance [
11].
It is also difficult to automate the detection and mapping of roads using medium-spatial-resolution satellite data such as Sentinel-2 (i.e., 10–20 m pixel size). The road detection algorithm has to account for geometric (length, width, and shape), radiometric (spectral response), topological (connectivity), functional (use), and textural (local spectral variability) attributes to build a fully automated road detection model [
12]. Because of the challenges described above to automate road detection and mapping, researchers had used Landsat satellite imagery to develop a road mapping protocol for the Brazilian Amazon biome based on visual interpretation followed by hand digitizing [
6,
7]. The road mapping protocol was applied to map and monitor road expansion over several years (2008 through 2016), resulting in an unprecedented Amazon Road Dataset (ARD). The ARD has been used to understand road geometry and spatial pattern and its correlation with deforestation and forest fragmentation [
13,
14], the proximity effect of roads to deforestation [
7] and fires [
6], and to improve deforestation risk models [
15,
16]. Additionally, the ARD has also been used to elucidate road-building processes, functions, and drivers [
17,
18] and to understand the impact of roads on biodiversity [
19]. These ARD applications demonstrate the relevance of road mapping and monitoring to scientific, conservation, and policy applications. However, manual mapping of roads with satellite imagery is a laborious task, making frequent monitoring over large areas challenging.
Automated road detection methods have been developed for very-high-spatial-resolution imagery based on deep learning algorithms [
12,
20]. Artificial Intelligence (AI), particularly the convolutional neural network (CNN) deep learning algorithm, has been used successfully to detect and map rural roads in large forested areas of Canada with RapidEye imagery [
11]. The AI-CNN method in Canada did not produce full-connected vectorized roads, requiring post-classification techniques, resulting in a recall accuracy of 89–97% and precision of 85–91% [
11]. A U-Net [
21], a CNN variant, was first used for segmentation in medical imaging. It is [
22] considered a state-of-art for image segmentation because it is based on the deconstruction and reconstruction of images for feature extraction, increasing object detection in various applications [
2,
23,
24]. U-Net’s differentiating characteristics are its accuracy and high-speed discriminative learning capacity from a small number of training images [
21]. As a result, several U-Net remote sensing applications have been proposed, including road extraction using high-resolution imagery [
2,
22,
23,
24]. Therefore, the U-Net algorithm is promising to automate the detection of rural roads of the Brazilian Amazon, overcoming the visual interpretation mapping protocol [
8] used to build the ARD. We modified the original U-Net algorithm, which erodes image input chips (256 × 256 pixels), making road discontinuity a problem, and changed the activation and loss functions of the model to make it more sensitive to detect roads using Sentinel-2 10 m spatial-resolution imagery.
This study then used the ARD to train our modified U-Net algorithm to detect rural roads in the Brazilian Amazon. First, we selected a sub-area of the ARD to randomly define samples to train, calibrate, and test the U-Net model to detect roads using Sentinel-2 imagery. Then, we applied it to the U-Net road model to map roads over the entire Brazilian Amazon. Next, we implemented a post-AI road detection algorithm to generate a fully connected vectorized road map for 2020. Furthermore, we built a workflow to integrate the Sentinel-2 OpenHub and Microsoft Azure Cloud Platform to implement the U-Net road and post-AI road detection algorithms. Sentinel OpenHub was used to select and filter cloud-free Sentinel-2 scenes. At the same time, Azure provided the computational power to preprocess the Sentinel-2 imagery, train and test our modified U-Net model, and export the data to our Azure Blob Storage. Our main goal with this study is to develop an automated AI model to monitor roads more frequently in the Brazilian Amazon and assess the correlation of forests with roads. Our road detection models applied to the Sentinel-2 images allowed mapping of the road location and extension over the entire Brazilian Legal Amazon, showing that an intricate and complex road network cuts a significant percentage of the Brazilian Amazon forest. The AI road model revealed more roads than human-based road mapping efforts using moderate-spatial-resolution imagery, improving the understanding of their harmful ecological effects.
2. Materials and Methods
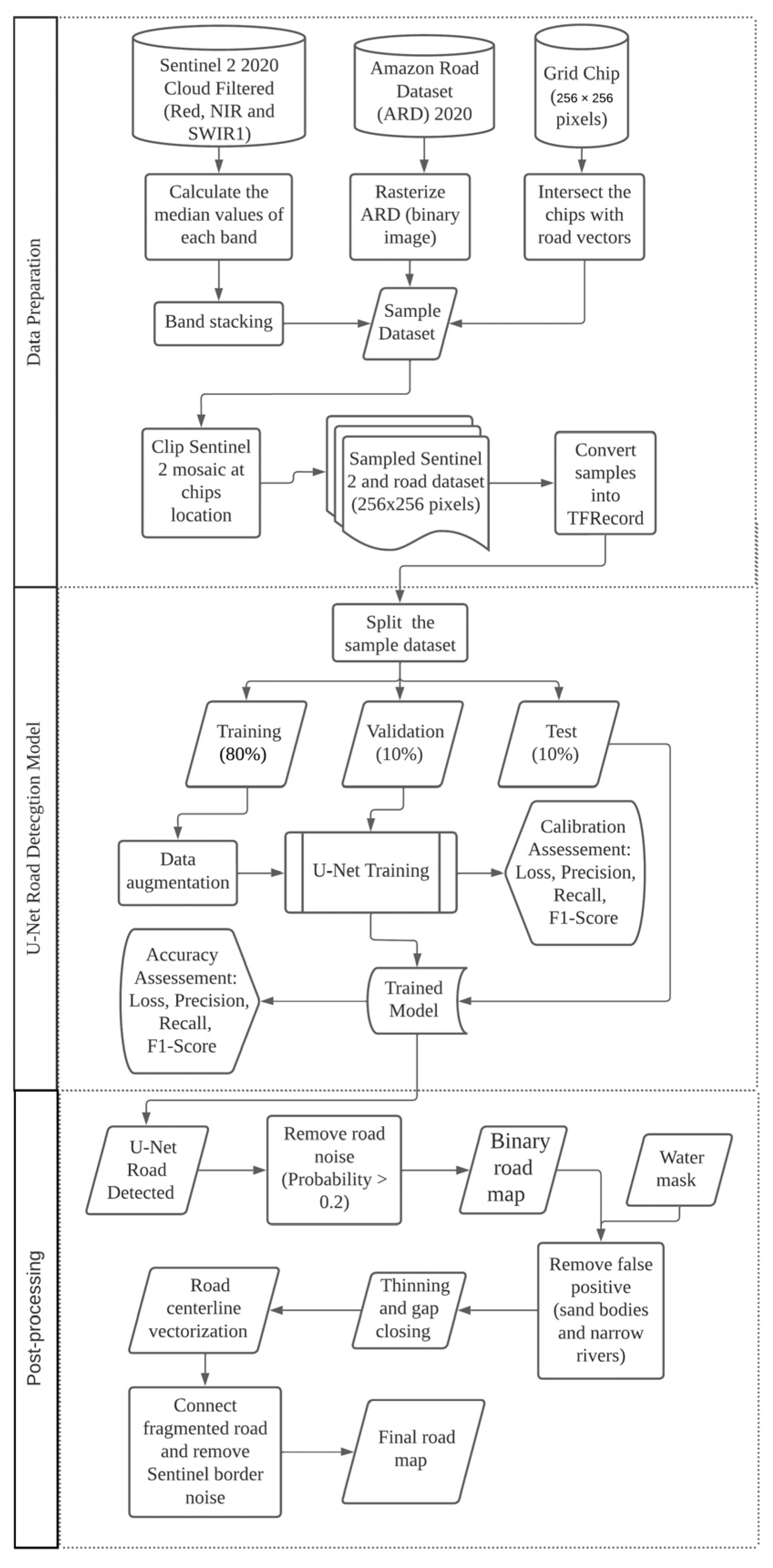
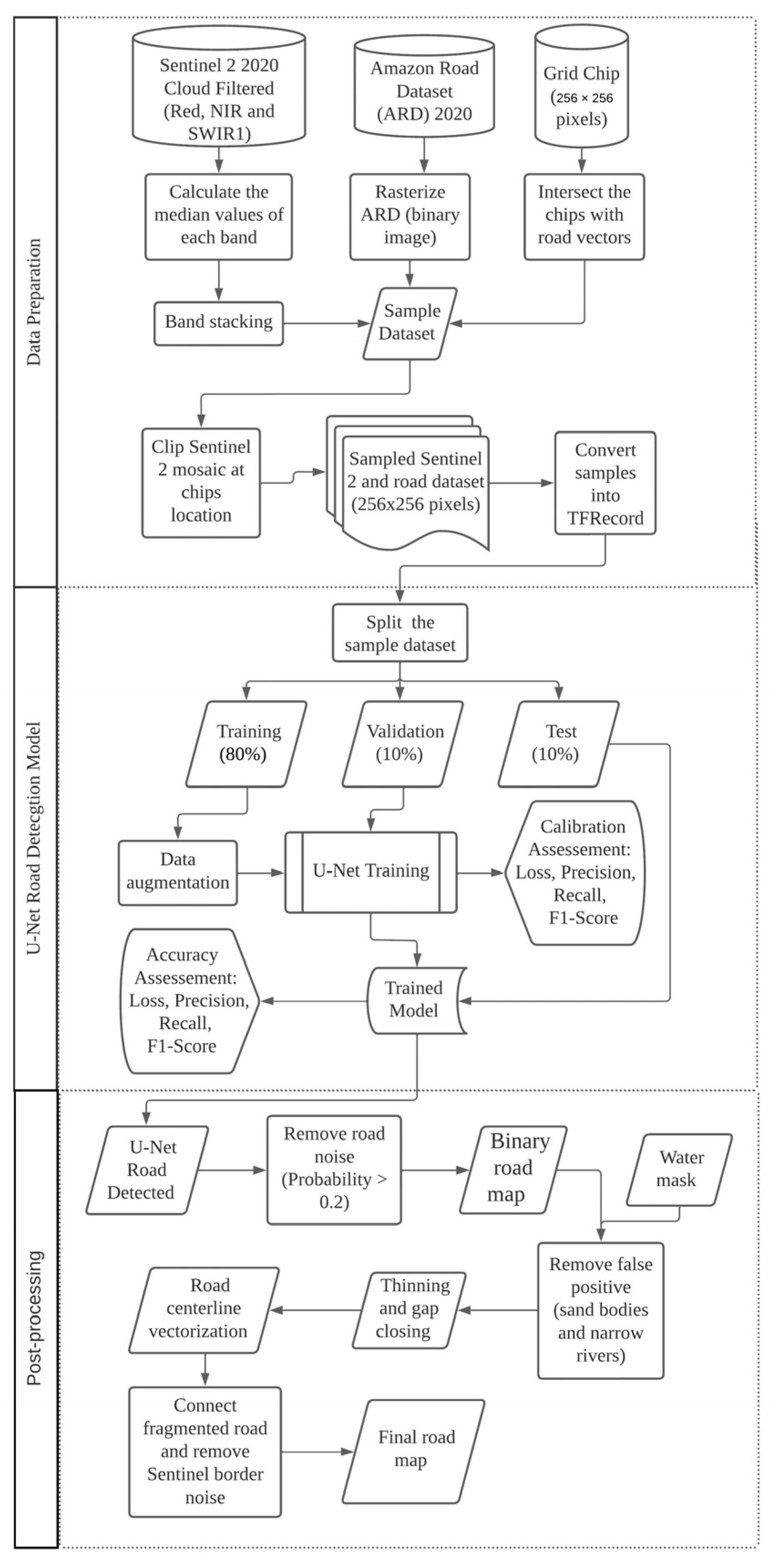
We used Microsoft Azure Planetary Computer resources to acquire and store data from Sentinel-2 and ARD to train and make predictions with our modified U-Net road detection model. We selected the Sentinel-2 satellite imagery based on location, date, bands, and cloud cover. Then, we used the ARD to define random sample locations (i.e, image chips of 256 × 256 pixels) for acquiring training data for the AI road detection algorithm, composed of sampled Sentinel-2 images and rasterized binary images of roads. Finally, we converted the gathered information into the TFRecord format to minimize size and seemingly integrate with the Tensorflow AI library inside the Microsoft Azure Cloud Machine Learning resource. We implemented a post-AI processing workflow to remove classification errors, automate road vectorization, and connect isolated road segments.
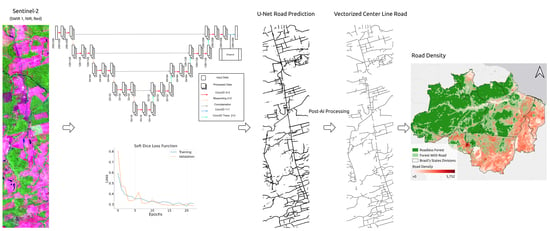
Figure 1 summarizes the entire U-Net road detection and post-AI algorithms. We provide information about the study area and explain the steps of the road detection algorithms in detail in the following sections.
2.1. Study Area
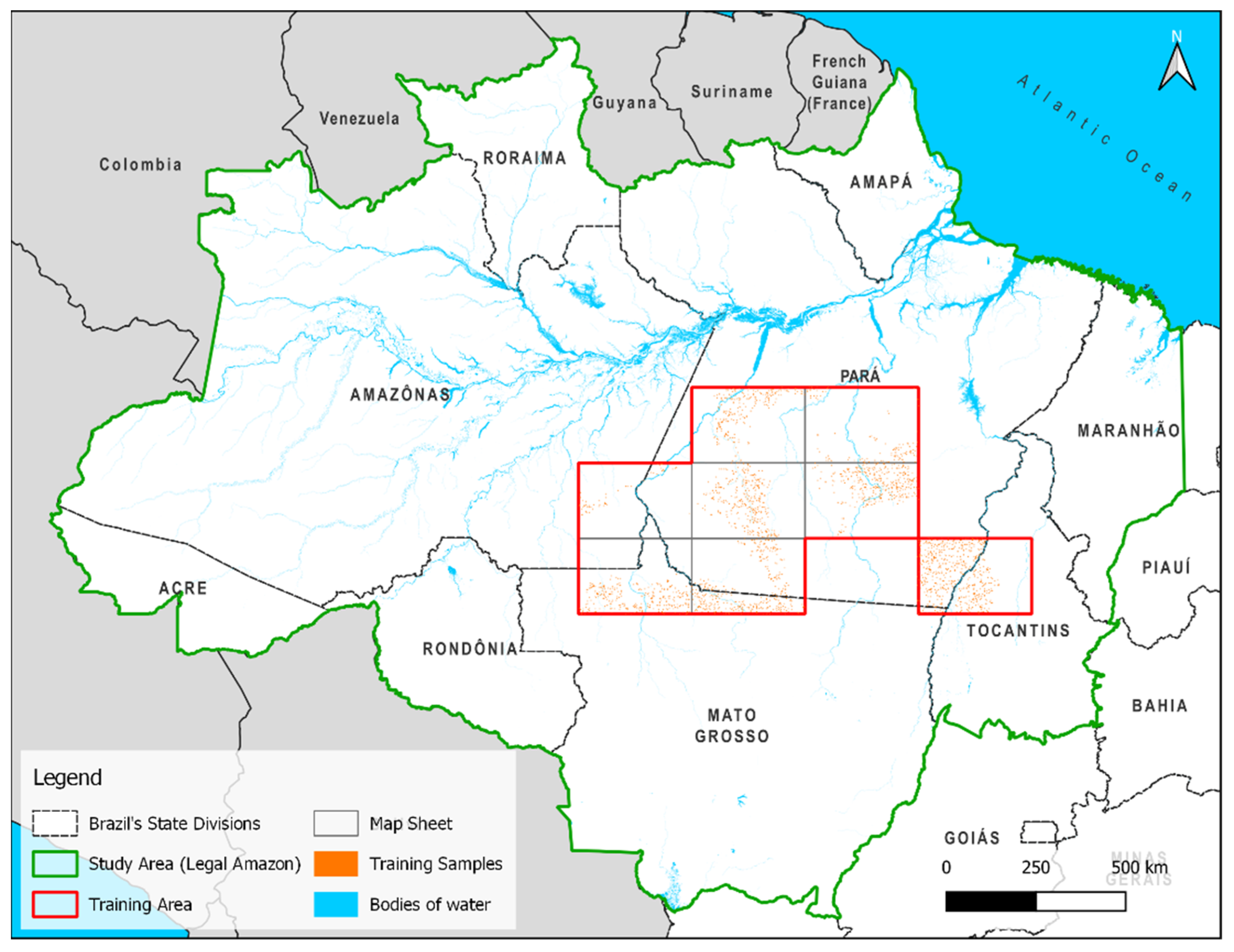
The study area covers the entire Brazilian Legal Amazon area. The training chips’ location concentrated on the Southern Region of the Pará state, which has diverse road geometries (i.e., dendritic, geometric, and fishbone) [
25] (
Figure 2). The road geometry diversity increased the variety in our training dataset by providing different road shapes and forms for the AI model to generalize the presence of rural roads in the Amazon region. The sub-area chosen for training and validating the model is approximately 586 thousand km
2 and is delimited by eight International Millionth Map of the World sheets (SB-21-X, SB-21-Y, SB-21-Z, SB-22-V, SC-21-V, SC-21-X, and SC-22-X) [
26] (
Figure 2). The sub-area is mainly covered by dense forests, including old-growth and secondary forests [
27], and by pasturelands, logging, and, to a lesser extent, gold mining. We then sampled the region into small chunks of data (chips) and randomly selected 2500 chips based on road density estimated from the ARD. The samples were composed of chips with 256 × 256 pixels of Sentinel-2 images at 10 m spatial resolution collected from June 2020 to October 2020.
2.2. Satellite Data to Detect Roads
We used Sentinel-2 imagery data to train and apply the AI road detection model at a 10 m pixel size. We acquired the Sentinel-2 image scenes using the Azure Blob data request API by filters including scene location, date, bands, and percent of cloud cover. Acquired during June and October 2020, the image scenes included the Shortwave Infrared 1 (SWIR1), Near-Infrared (NIR), and Red spectral bands with less than 30% cloud cover. We chose the timespan for image acquisition between June and October due to a lesser cloud persistence. In addition, the bands SWIR1, NIR, and Red are more suitable for detecting roads in non-urban areas and differentiating from other linear features (e.g., powerlines and geological lineaments) [
8].
With the selected Sentinel-2 scenes, we then built a spatial-temporal mosaic by calculating the median of each band separately and stacking them afterward. The final preprocessing step included the application of histogram contrast stretching to enhance the types of roads we aimed to detect with the AI U-Net algorithm (
Figure 3). Image analysts have recognized three types of roads using RGB color composite images from the Amazon [
8,
9]: (i) visible: continuous straight or curved lines visible to the naked eye; (ii) fragmented roadways: discontinued straight or curved lines that are not continuous but discernible to the naked and possibly traced and connected; (iii) partially visible roads: linear characteristics, straight or curved, directly visible in the color composite but recognized and digitized based on their context and spatial arrangement (i.e., adjacent deforested areas and canopy damage due to selective logging) (
Figure 3).
2.3. Amazon Road Dataset (ARD)
The ARD encompasses ten years of road mapping through visual interpretation and manually traced mapping roads using a protocol for mapping unofficial roads with satellite imagery in the Amazon [
8]. This road dataset is composed of official roads (80 thousand km) and unofficial roads (454 thousand km) totaling 534 thousand kilometers. The ARD mapping protocol was applied to different satellites throughout the years, including Landsat-5 (2006–2011), Resourcesat (2012), and Landsat-8 (2016). We used the ARD 2016 data to sample areas of interest to build our training, calibration and test datasets. We applied a vector grid to divide the region into smaller chunks of data over the study area. These sample points were selected randomly based on the road’s density (i.e., km of roads per km
2) inside the chip areas of 256 × 256 pixels—approximately 6.5 km
2.
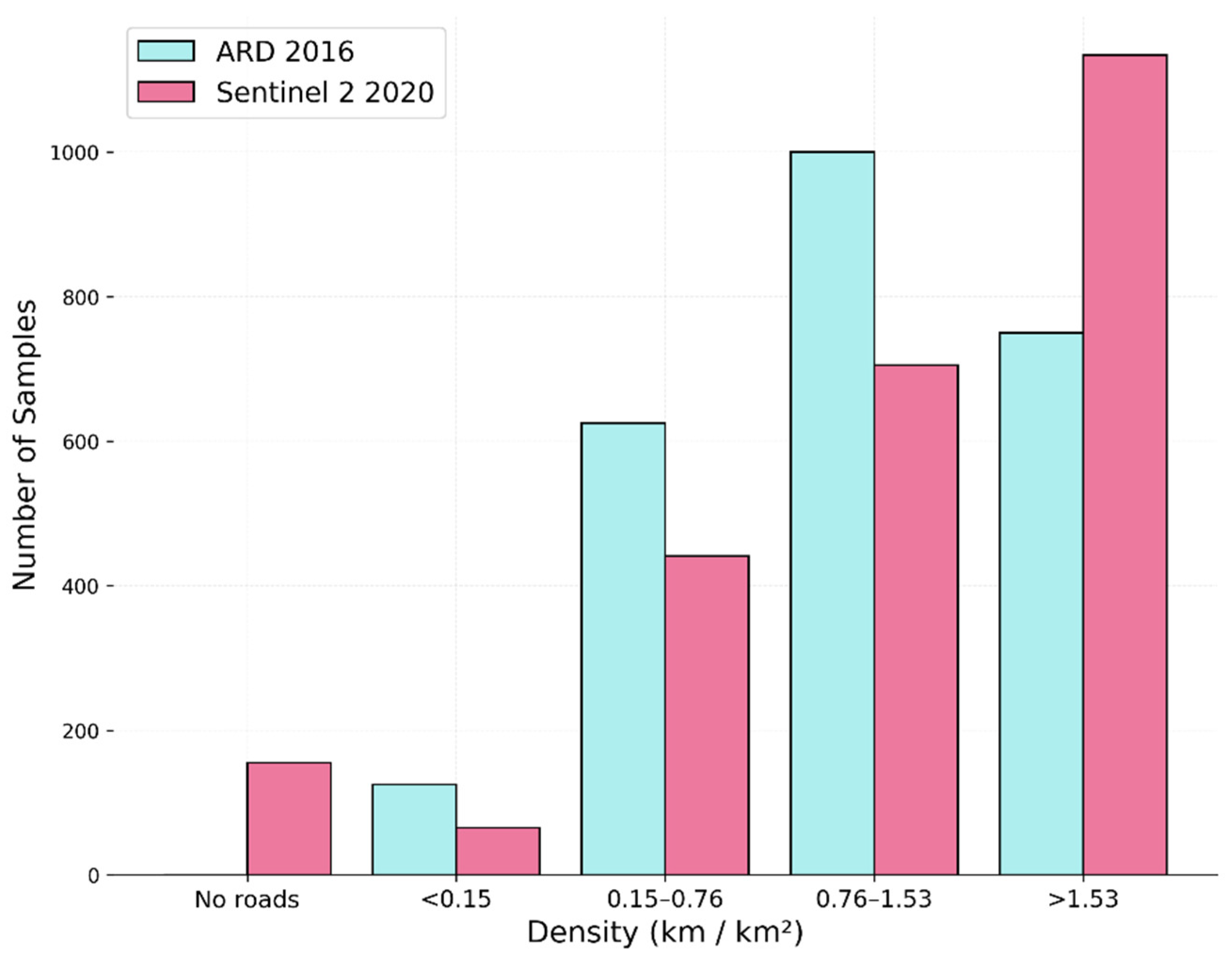
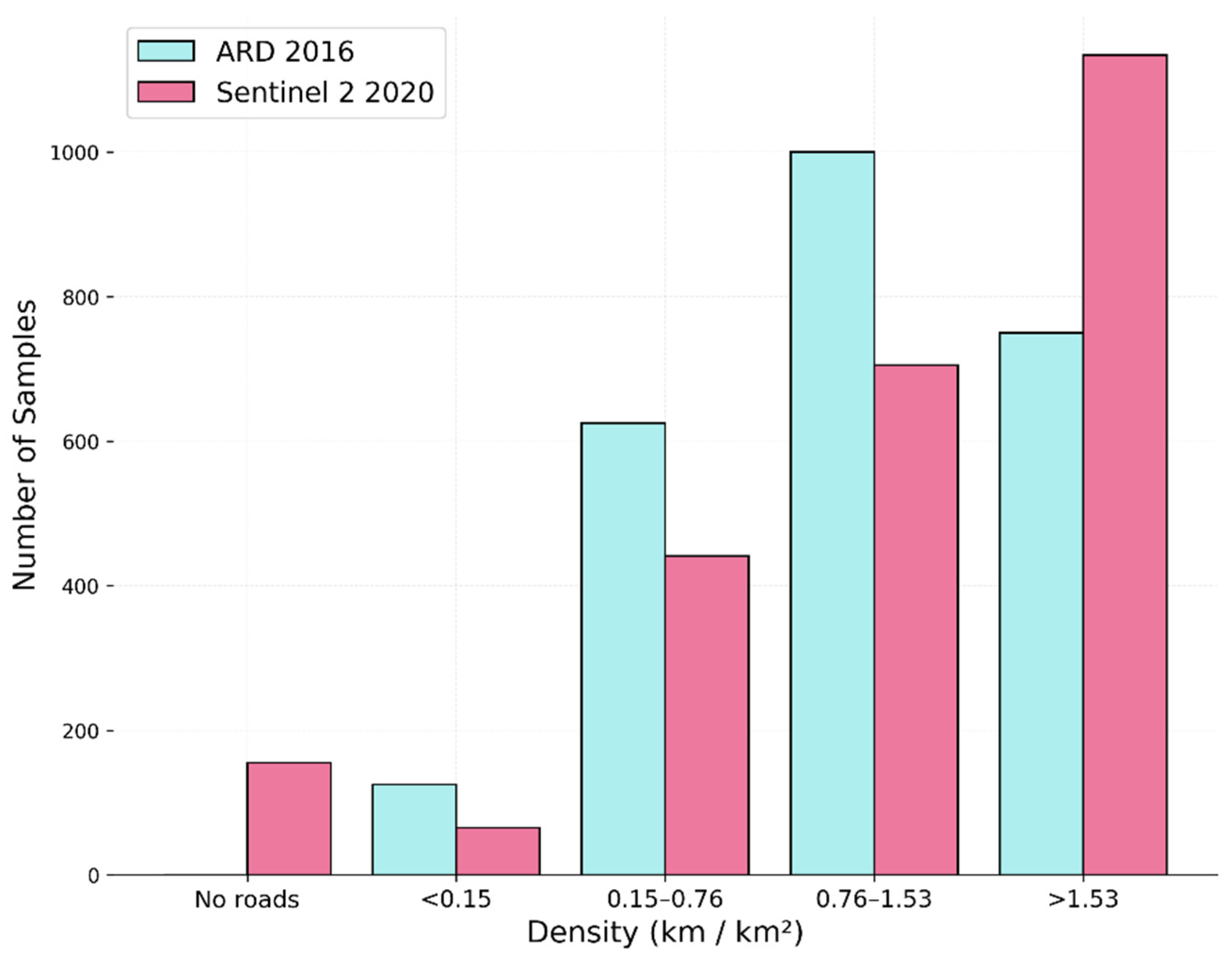
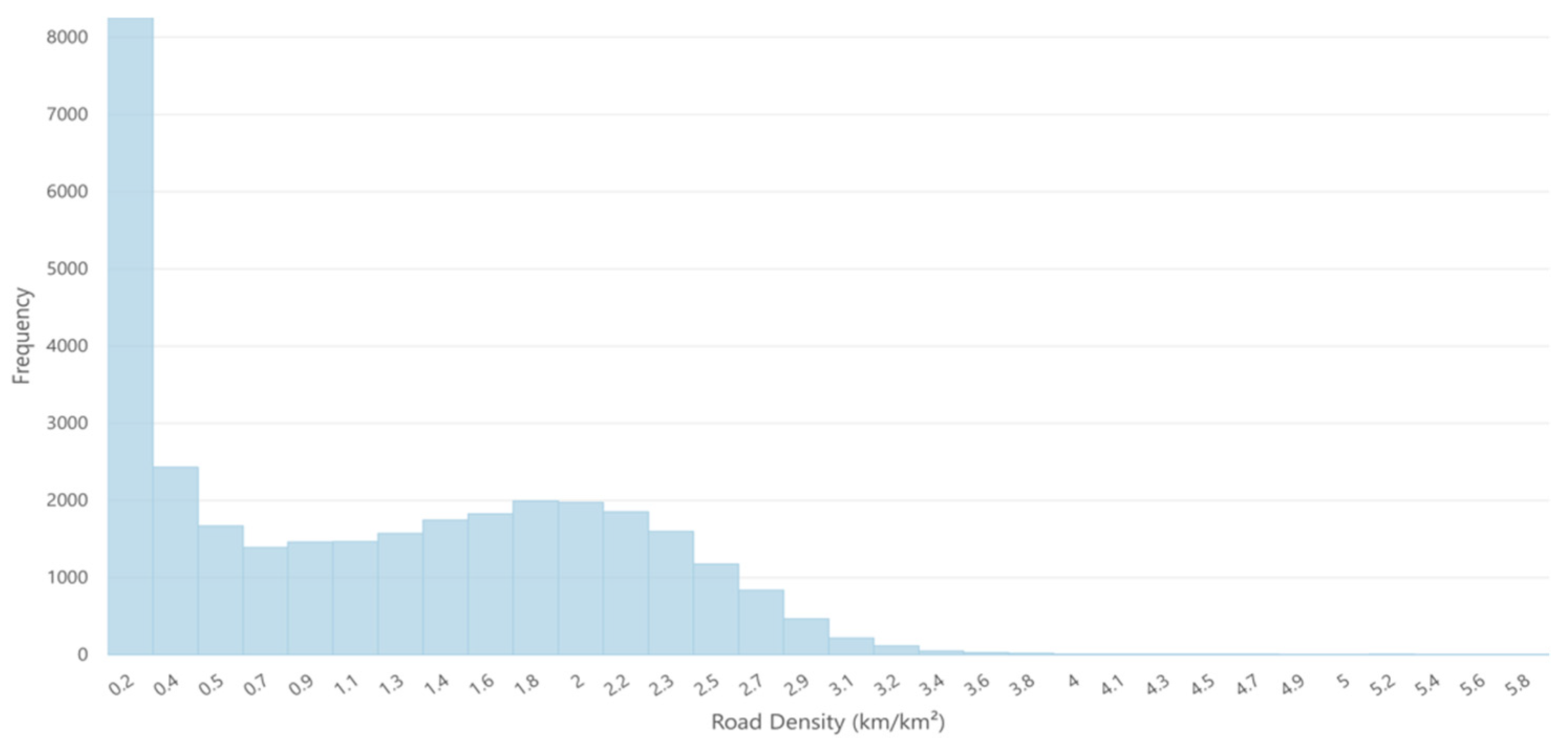
We randomly sampled 2500 chips to manually remap roads to update the road map to Sentinel-2 2020 imagery. This process created new road information for the chip areas at a 10 m spatial resolution to train, calibrate, and validate the U-Net road detection model. We sampled the chip areas (6.5 km2) for updating the road information for the AI model into five categories:
No road;
0 < road density ≤ 0.15 km;
0.15 < road density ≤ 0.76 km;
0.76 < road density ≤ 1.53 km;
Road density > 1.53 km.
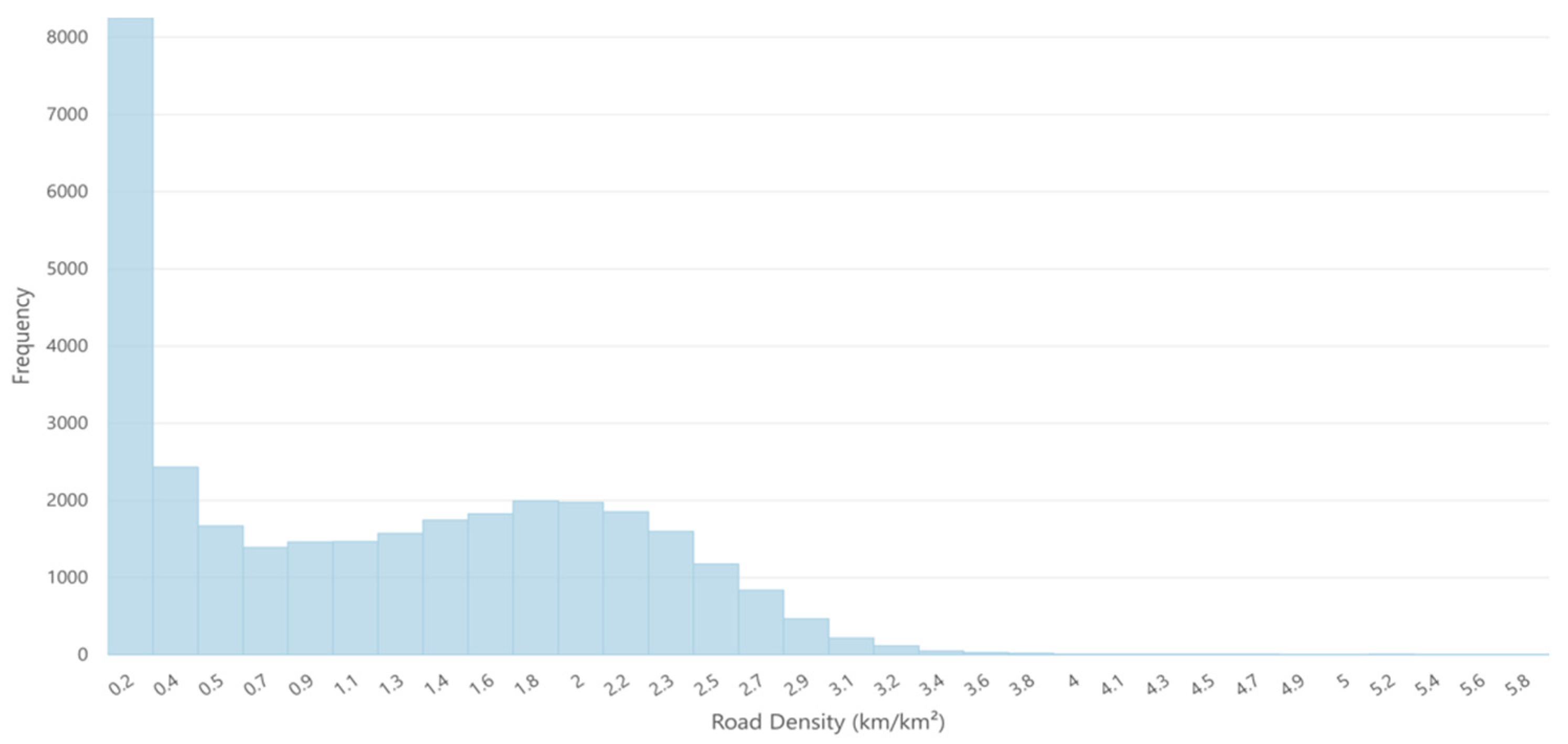
The number of image chips samples per road density is shown in
Figure 4. We observed an increase in samples with road density. Therefore, we manually added roads to the Sentinel-2 2020 samples, following Ref. [
8] to update the 2016 ARD dataset (
Figure 4).
2.4. Sampling and Data Preparation
To maximize training speed and performance, we broke down the Sentinel-2 mosaic and the ARD raster into smaller chunks of data by creating a grid of 256 × 256 cells within the training area. We used the existing ARD from 2016 to select grids that intersected with the ARD data to build a reference road dataset to train the U-Net road detection model. Next, the Sentinel-2 image was clipped with the selected grids (256 × 256 grid), resulting in 2500 samples. We updated the roads within the sampled grids through visual interpretation and hand digitizing following the protocol proposed by Ref. [
8], which was further rasterized to a 10 m pixel size. Finally, we stacked the Sentinel-2 RGB bands and the updated raster roads and divided the 2500 chip samples into training, validation, and test datasets. We randomly split the chip samples in 80% for training purposes and separated the 20% equally for validation and test, i.e., 250 each (
Figure 1).
Before exporting the datasets to Azure Blob Storage, we applied data conversion from raster data into TFRecord tensor arrays compatible with Tensorflow data API [
28], which facilitated data consumption during training. In addition, we added each chip’s coordinates information to the TFRecord, consolidating its contents: image data information (pixel values), upper left x-coordinate, upper left y-coordinate, lower right x-coordinate, and lower right y-coordinate (
Figure 1).
To minimize the effects of our class imbalance and to prevent overfitting our model, we applied data augmentation processes to the datasets to increase the variability number of samples. The transformations applied to the images were rotations of 90°, 180°, and 270° degrees; horizontal and vertical mirroring; three repetitions, increasing the number of tiles from 2500 to 23,400.
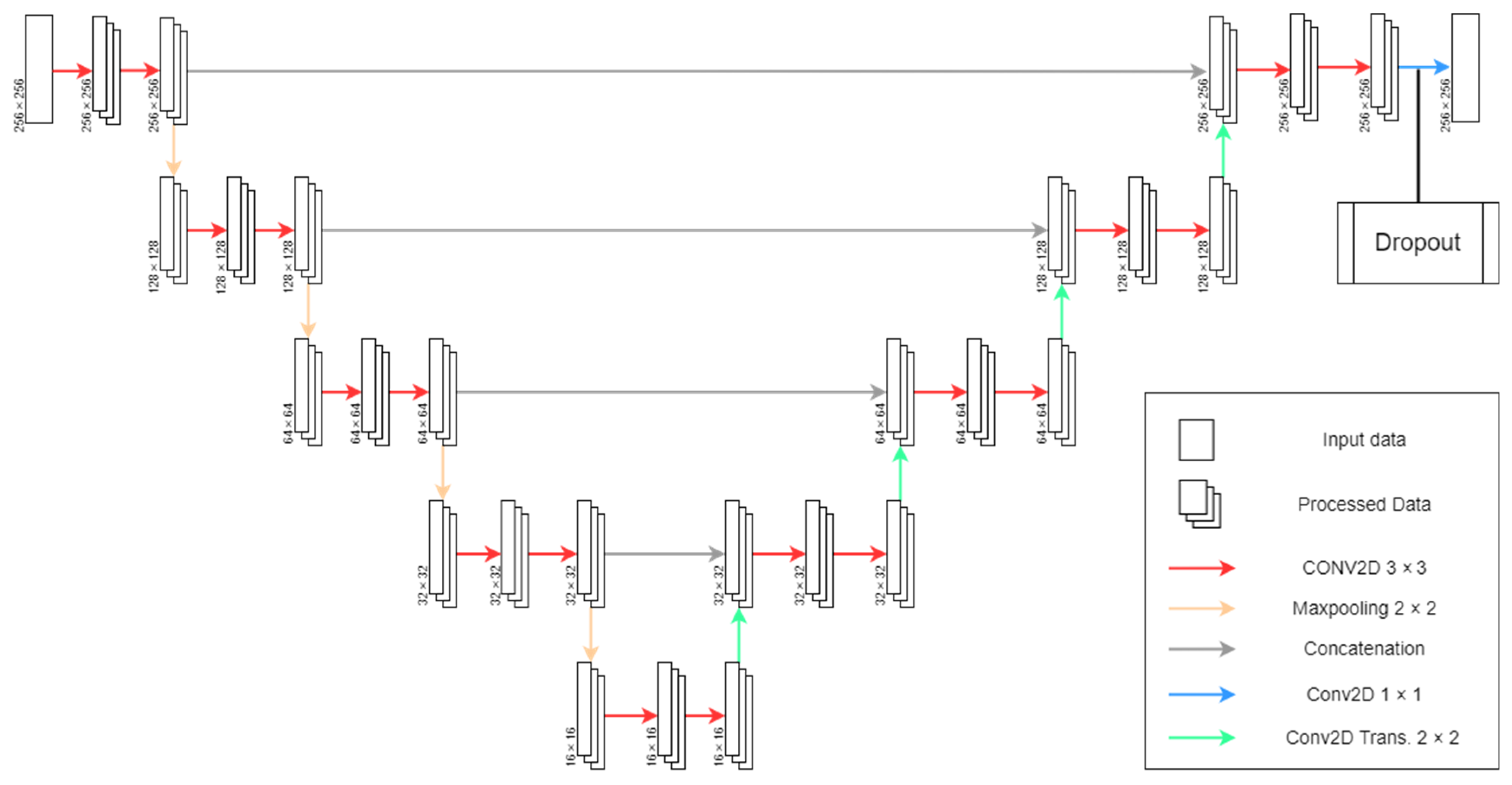
2.5. U-Net Model for Road Detection
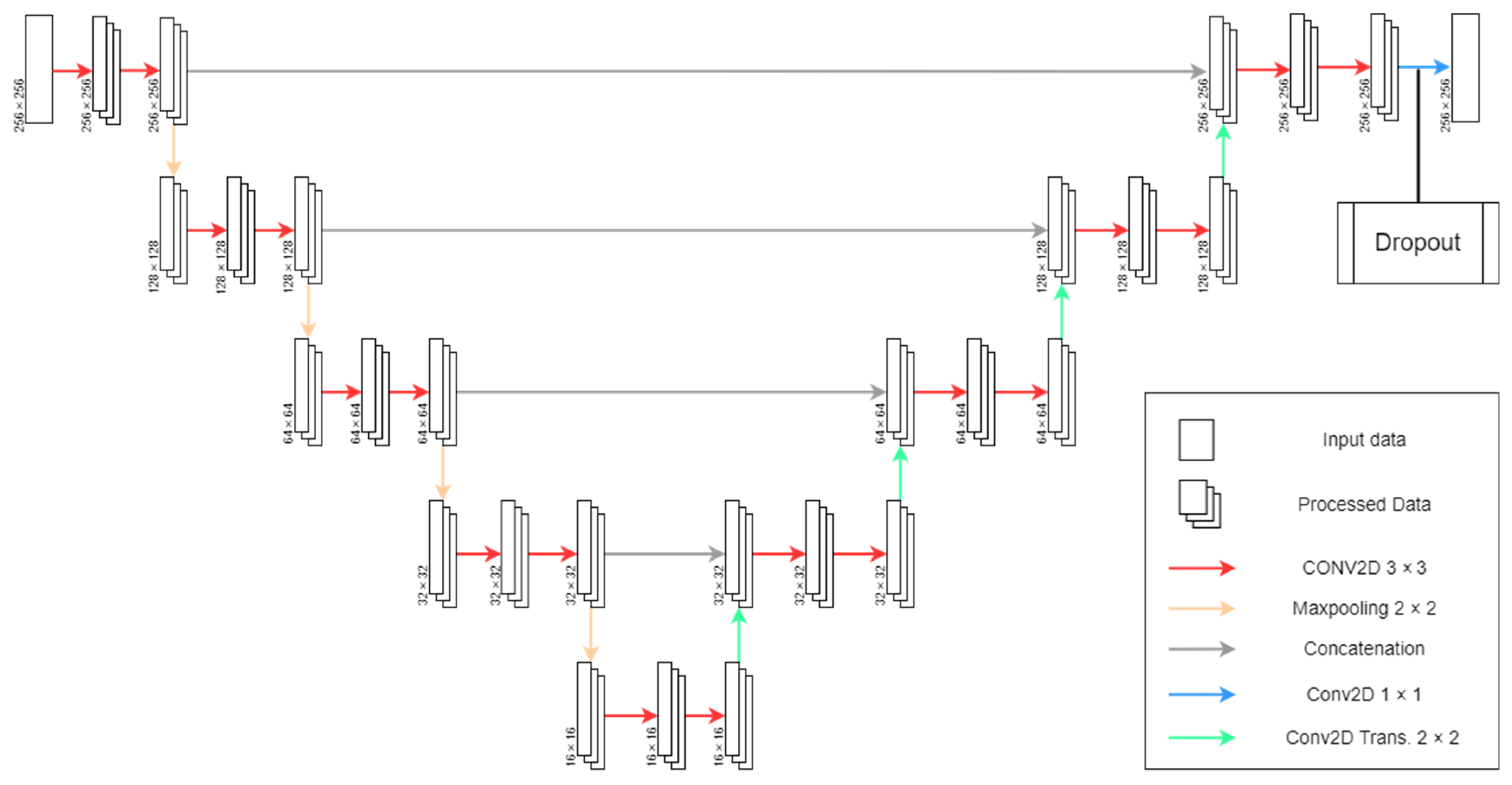
We modified the original U-Net architecture [
21] layers and hyperparameters to detect roads from Sentinel-2 imagery. First, regarding layers, we altered the padding parameters on convolutional layers to create a zero-padding border around the images, allowing for the same input (256 × 256) and output (256 × 256) data size to prevent border data neglection [
29,
30]. Furthermore, instead of using the Rectified Linear Unit activation function (ReLU), we opted for its variation, Leaky Rectified Linear Unit (LeakyReLU) [
31], due to the dying neuron problem. In addition, we added a dropout layer of 0.3 before the last convolutional layer to prevent overfitting [
32], which provided variability to the model structure. Finally, the soft dice loss function [
33] replaced the original loss function (i.e., pixel-wise cross-entropy loss function) to minimize the impact of imbalanced classes for image segmentation problems and Nadam [
34] as the optimizer (
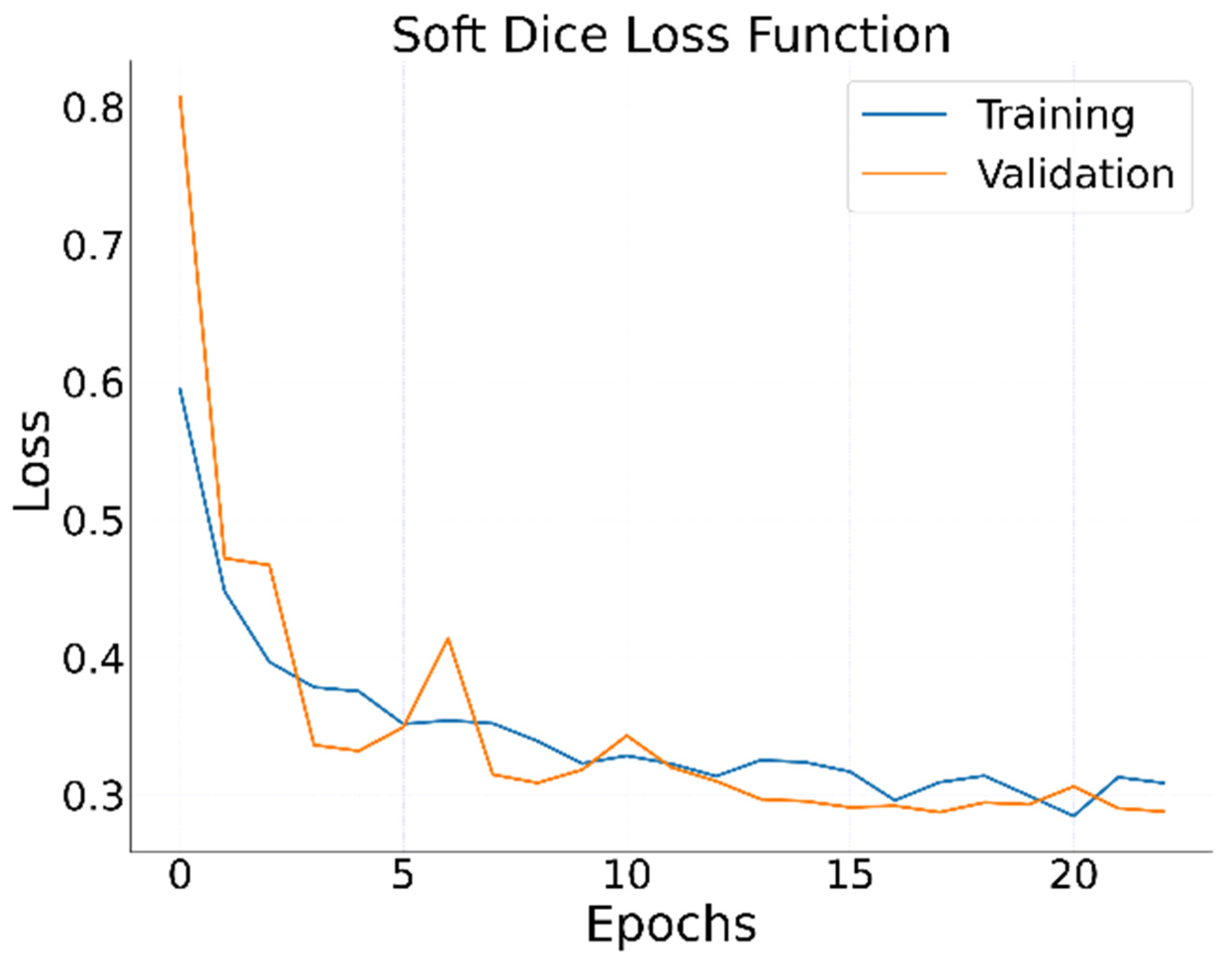
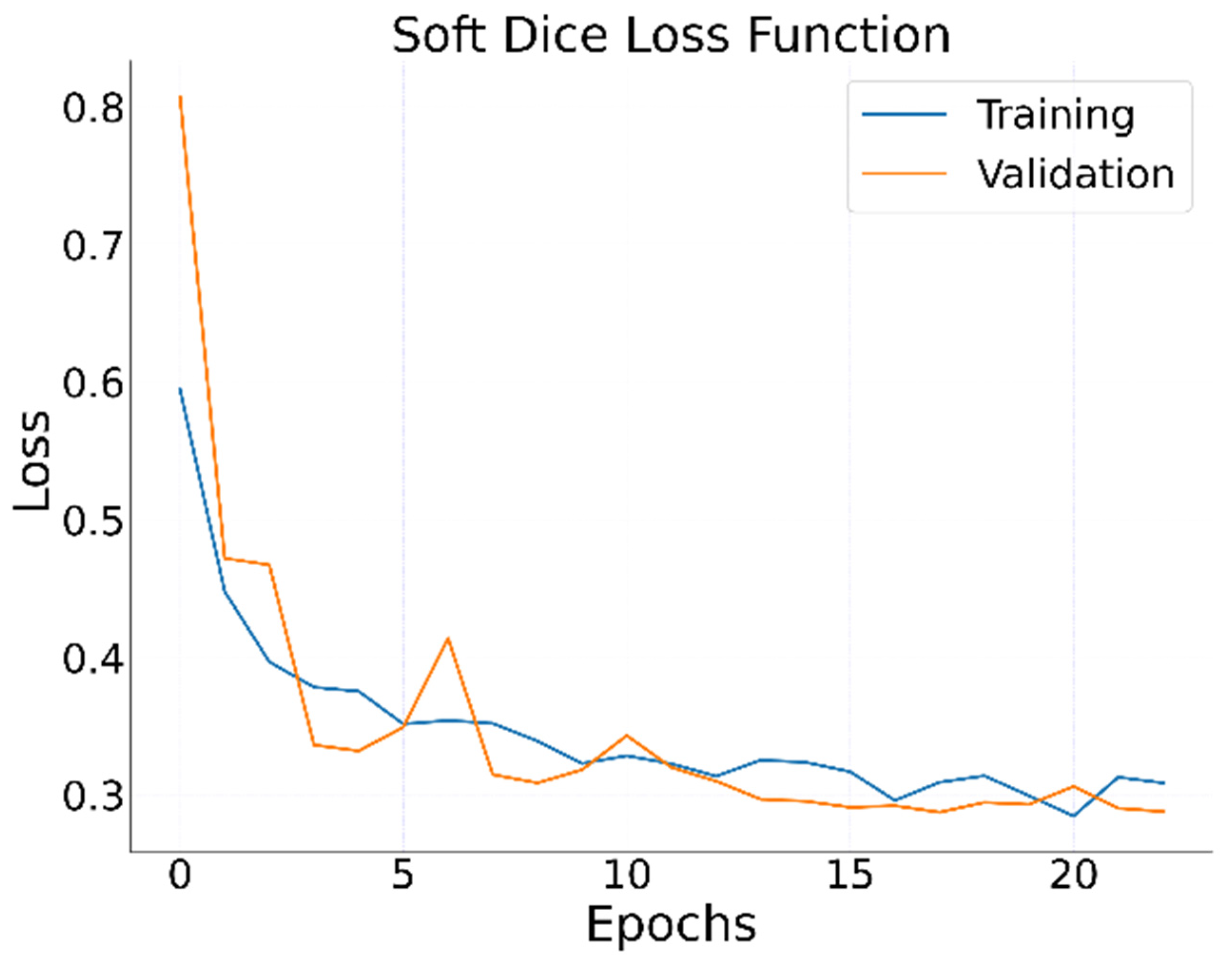
Figure 5).
As for the model training parameters, we applied an 8-size mini-batch with a learning rate of
set to iterate over 25 epochs. We set the learning process to stop at the 25th epoch because the loss value was minimized around the 21st and 23rd. We also included other training parameters to prevent unnecessary computational power usage and save checkpoint versions of the model, such as early stopping and TensorFlow checkpoints. We set early stopping to end the training process if there was no improvement over nine epochs, which helped with the generalization problem and prevented resource usage. We also defined checkpoints to assess whether the validation loss function value had improved between epochs. The implementation code of the U-Net road detection model can be accessed on Github through
https://github.com/JonasImazon/Road_detection_model.git (accessed on 1 June 2022).
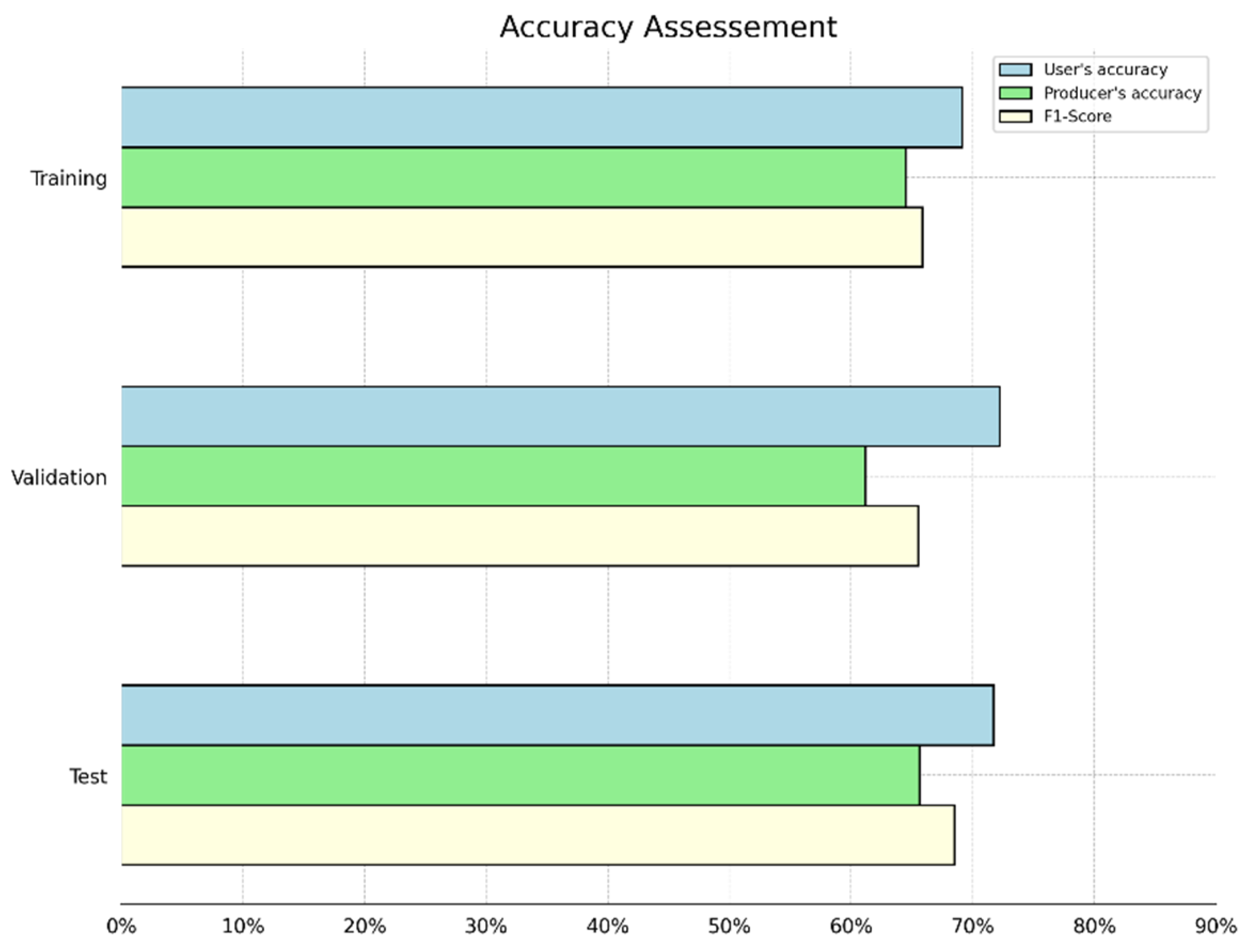
2.6. Accuracy Assessment
We performed the prediction accuracy analysis of our U-Net road model using the validation and test datasets (250 chip samples each). Our validation sample metrics (precision, recall, and
F1-
Score) were calculated during training and saved onto a log file to assess the model calibration. In addition, we used an independent test dataset to generate the following accuracy metrics: user’s, producer’s, and
F1-
Score (i.e., a harmonic mean calculated from both precision and recall values) metrics on both datasets. The accuracy metrics assessed are shown below. First, the
Precision metric utilizes
TP (true positives) and
FP (false positives) to assess the number of actual valid positive results over the model’s total number of positive cases.
Differently,
Recall uses
FN (false negatives) to measure the number of true positives over the reference data total number of positive information:
The culmination of both
Precision and
Recall lies in the usage of
F1-
Score.
We calculated the accuracy assessment metrics in a pixel-wise approach, allowing us to estimate for each pixel TP, TN (true negative), FP, and FN (false negative).
2.7. Post-Processing
Given that the U-Net road model outputs the same data type (i.e., a raster image) as its inputs, we ended with an image representing each pixel’s probability of being one of two classes: road and no-road. To detect the road center line, we first empirically define a confidence threshold of 20% (i.e., pixels with a probability value equal to or greater than 0.2) over the output values, creating a road binary image. The output image data (in raster format) are helpful for visual interpretation and comparison between the road mapping results and the reference road dataset. However, the road raster output does not provide road attribute information regarding length, shape, and connectivity. We then applied post-processing techniques to convert the raster road map into a vector road center line and extracted attributes of road segments (e.g., length and connectivity). These processes include georeferencing the TFRecord file, road vectorization, connecting flawed road segments, and noise removal (e.g., natural geomorphological lineaments such as narrow rivers and geological faults). We explain these steps in detail below.
First, we applied the georeferencing process by accessing each chip’s coordinate information presented in its TFRecord file. Then, using Gdal [
35], we set the result image’s geographic location by setting its extent and resolution (10 m). Each georeferenced image is stored in memory to be quickly accessed by the following processes. Next, we applied a water body mask with a 200 m buffer to remove false positives created by natural linear features (i.e., primarily channels) along rivers. Furthermore, a sequence of dilation and erosion processes was applied to fix some of the missing links between road segments using a geometric orientation of a 10 × 1 rectangle. The rectangle was rotated around each pixel to increase the reach between close pixels. Finally, a skeletonization process was applied to create 1 × 1 pixel segments.
Finally, we converted the chip’s raster data into vector data using the Grass Python Module [
36]. In addition, we used the model also to remove other identified false positives, such as small unconnected segments and scene borders. We divided the process into four steps: (i) deletion of segments with a length less than 1 km; (ii) removal of segments that match the geographic location of charts borders; (iii) removal of segments that match the geographic location of scenes border (i.e., 100 m); (iv) deletion of segments inside areas with road density less than 10 km per 100 km
2. These steps allowed us to deal with different categories of false positive road detection in an automated manner. The final road map is in a shapefile format containing segments of roads in vector format, which enables statistical and geospatial analyses and also the cartographic representation of the road dataset, including estimation of the total length.
4. Discussion
With the development of new cloud-based computing technologies and advances in Artificial Intelligence, large-scale mapping for various scenarios has become faster and more common [
30,
38,
39]. In addition, open-source code allowed for an adaptation of the original U-Net architecture to train and map roads in the Amazon in a fraction of the time required to identify and trace roads [
8] visually. Our new U-Net road model detected approximately 3.46 million kilometers of roads in the Legal Amazon region within 7 h of cloud computing to run the U-Net model and post-processing and vectorize the data. This process generally would take several months of human analysis and visual interpretation. The previous effort to monitor road expansion in the Amazon region paid off because it provided valuable data for assessing the negative road impact on the Amazon. The ARD also offered vital information to build the new AI model by statistically selecting areas to create the training, calibration, and road datasets. The new Brazilian Amazon road map for 2020 cannot be directly compared with the ARD from 2016. First, the latter focused the road mapping in the Amazon biome region, an area 22% smaller than the Brazilian Legal Amazon. Second, the U-Net road map is more detailed than the ARD one because it detects more road segments, especially in rural properties.
We estimated the forest area affected by roads in the Amazon biome with the road density map within a 10 km grid cell. We used the forest area obtained from the MapBiomas project [
40] for 2016 and 2020 to estimate the expansion of roads in forested areas (excluding 0.2 million km
2 of second-growth forests and highly degraded forests). We found that of the 3.1 million km
2 of remaining forest, 1.83 million km
2 were roadless forests (i.e., 59%). The remaining forests in 2020, i.e., 1.27 million km
2 (41%), are carved by roads or within 10 km of all roads (
Figure 9) and, consequently, are under deforestation and forest degradation pressure. Further analysis is required to understand the relationship of roads with forest fragmentation, fires, and deforestation in light of this new road dataset we obtained with AI U-Net road post-AI detection models, as well as the estimation of the roadless forests in the Brazilian Amazon.
Several applications can also be implemented with the new road dataset obtained with the AI U-NET mode. Previous analysis of the correlation of road distance with deforestation [
41] and fires [
6] can be updated. We already used the new AI-mapped road to update a deforestation risk model for the Amazon. As one of the predictor variables, the original deforestation risk model used the ARD map based on visual interpretation with data from 2016 [
16]. The deforestation risk model depends on the annual update of roads (as the distance to roads is one of the most important predictor variables [
16], a task considered prohibitive using human interpretation). The new AI road model allowed us to update the ARD to 2020 and operationalized the deforestation risk model (see:
https://previsia.org accessed on 1 June 2020).
Other applications can be explored with the new AI ARD, such as transportation and logistic planning for agriculture and agroforestry commodities, model landscape fragmentation, determining roadless forest landscape, and access to logging and settlement roads, e.g., Ref. [
13]. The new AI road detection model will allow for keeping the ARD updated for these and other applications and support forest conservation efforts and the protection of (open) public lands.
Although our results are accurate and somehow better than the road maps produced with human interpretation of satellite imagery, some challenges persist in reducing false-positive road detection. One possible and standard solution to overcome this problem is to improve the training dataset of roads by increasing data samples and data variation. This is the case for our model because most of the false positives were found in areas with a low density of training data. The second-largest mapping issue is the discontinuity of road segments, which happens for various reasons. First, the spectral signal of roads can be obscured by vegetation cover and by the spectral similarity of adjacent pasture and agricultural lands with the road substrate, which is mainly formed by dirty compacted soil. The road discontinuities can be partially fixed by automatically setting line snapping thresholds, but this works only for small distances (i.e., <100 m). Further research and AI modeling is needed to determine a fully automatic solution to deal with fragmented roads; meanwhile, a task will be implemented with human aid. We also recommend comparing our proposed U-Net road detection model with another AI algorithm for future research. Our next goal is to expand our model to create historical maps of roads in the Amazon, with available Landsat and Sentinel datasets. Preliminary learning transfer tests applying our U-Net AI road model built with Sentinel-2 to Landsat imagery showed promising results.
5. Conclusions
The ARD, generated with human effort throughout the years, together with open-source algorithms and cloud-based computing, allowed the development of a new AI road detection model. The updated road maps for the Amazon region will enable the implementation of scientific, societal, and policy applications. The correlation of roads with deforestation, fire occurrence, and landscape fragmentation can be further investigated with the more detailed and extensive AI road dataset. Our initial learning transfer of the AI road model obtained with Sentinel-2 imagery is promising to apply the U-Net road model to the Landsat data archive to reconstruct the road dynamic of the region. Further research includes improving the post-road center line vectorization of fragmented roads and road categorization. Finally, our results pointed out that large portions of the Brazilian Amazon forests are dominated by an intricate and complex road network expanded from the main official roads and prolonged over the pristine forests and protected areas for conservation. The AI U-Net road model revealed more roads than the human-based road mapping efforts requiring further research to understand their negative ecological impacts. In addition, because roads predominantly come first, the new AI road detection model opens up an untried class of forest monitoring, avoiding future deforestation and forest degradation.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}