
Object Detection Based on Adaptive Feature-Aware Method in Optical Remote Sensing Images


Abstract
:
1. Introduction
- (1)
- For the impact of complex background and inter-class similarity of remote sensing images on the object detection mission, an adaptive feature-aware module is developed. The module performed pixel-by-pixel adaptive enhancement of features using an adaptive growth matrix.
- (2)
- An object positioning module is introduced to detect small-scale or densely arranged objects precisely. The high-level semantic information of the deep features is used to generate a location-sensitive feature map fused with the shallow elements to accurately predict the object’s location.
- (3)
- An object detection model for remote sensing images with balanced accuracy and speed is proposed.
2. Related Work
3. Methodology
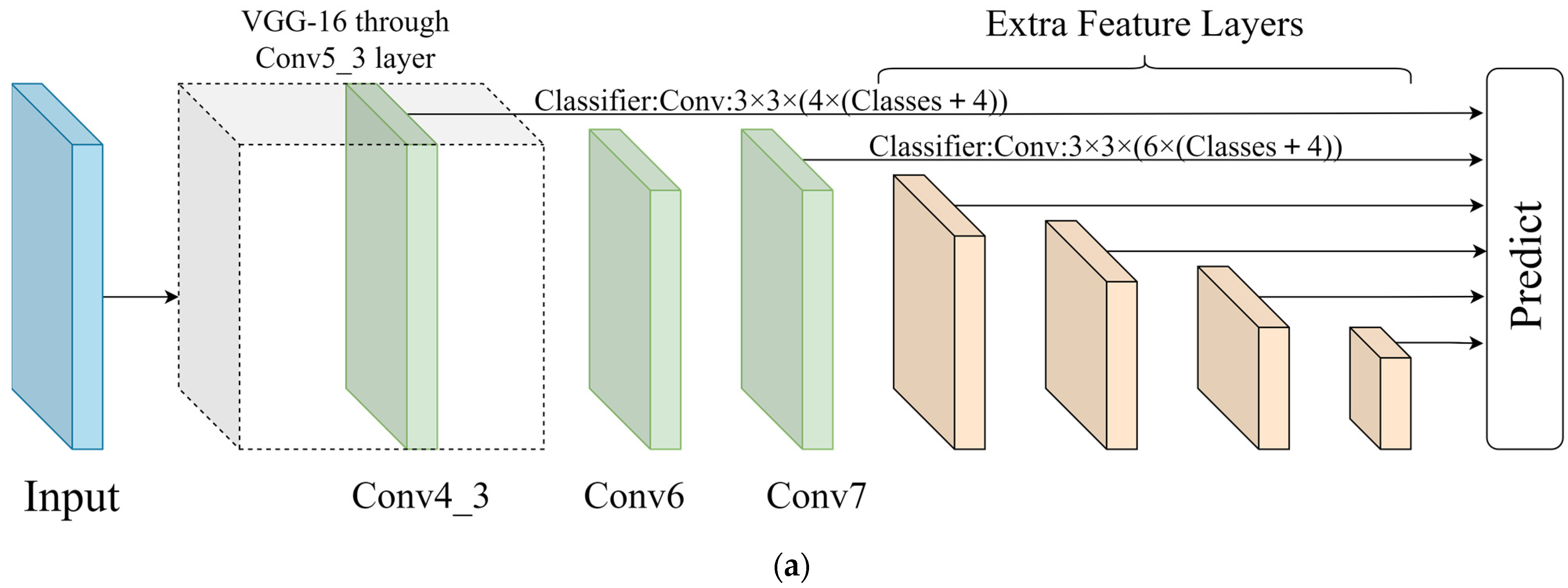
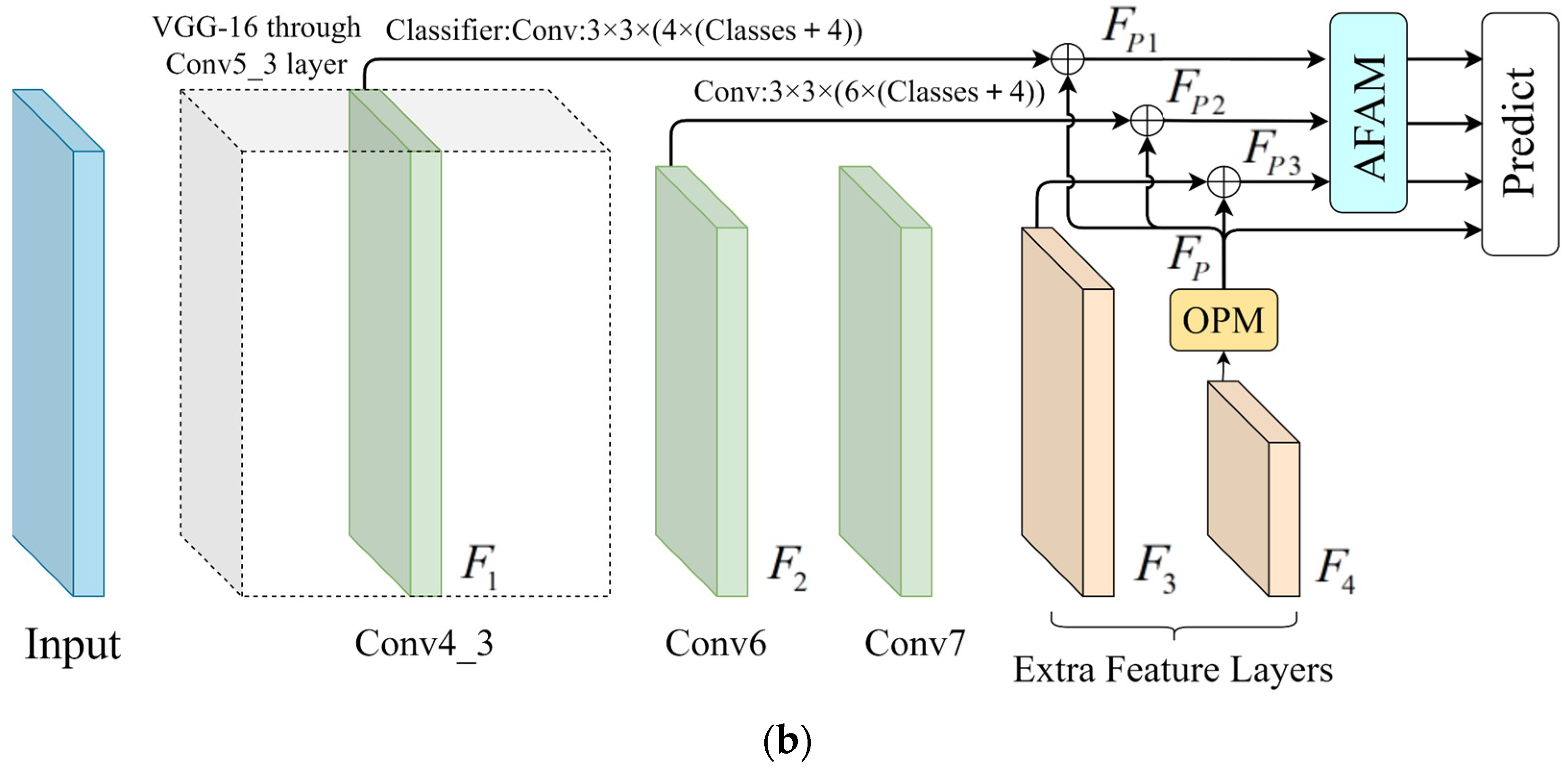
3.1. Overall Structure of Model
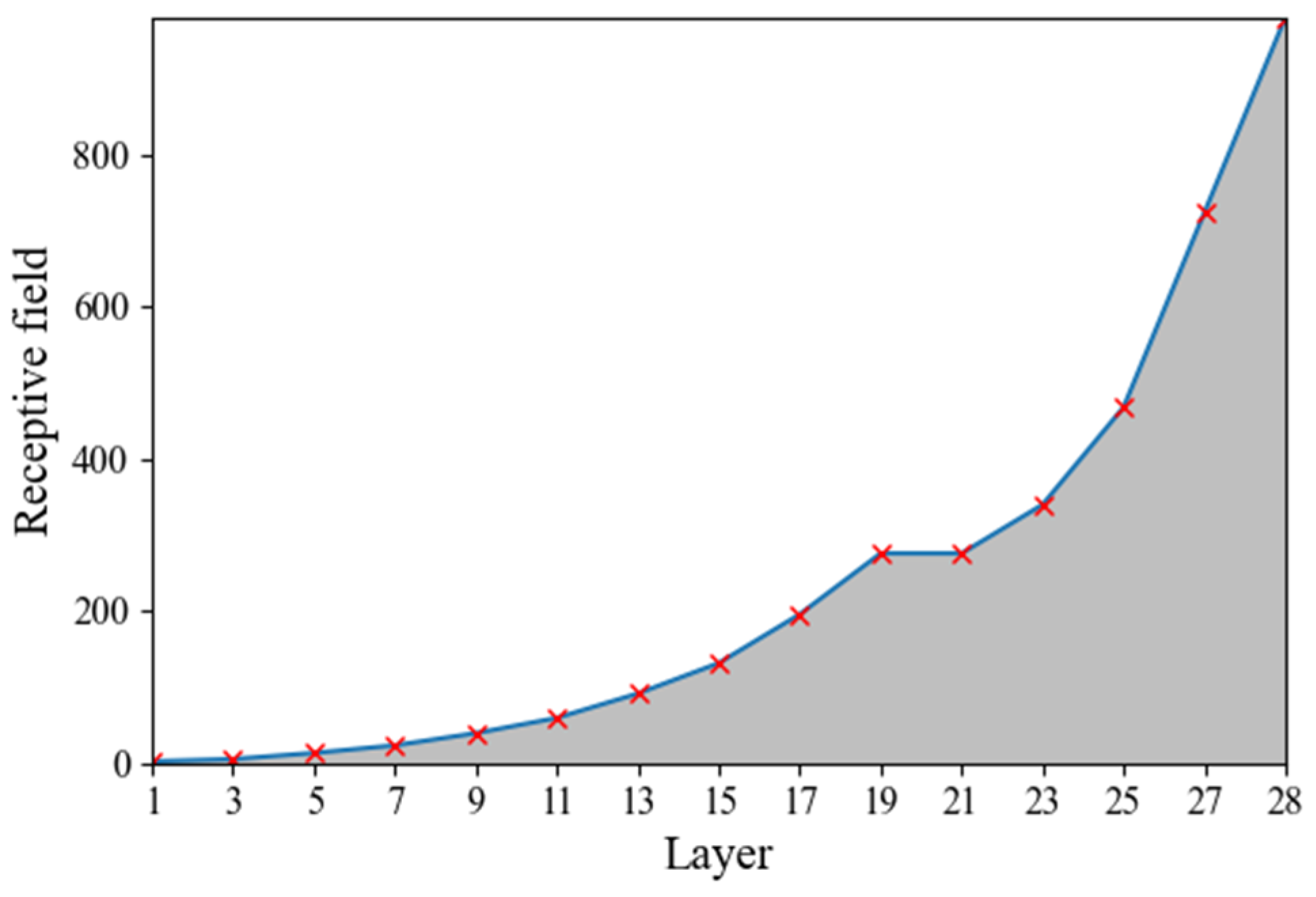
3.2. Receptive Field Analysis and Anchor Box
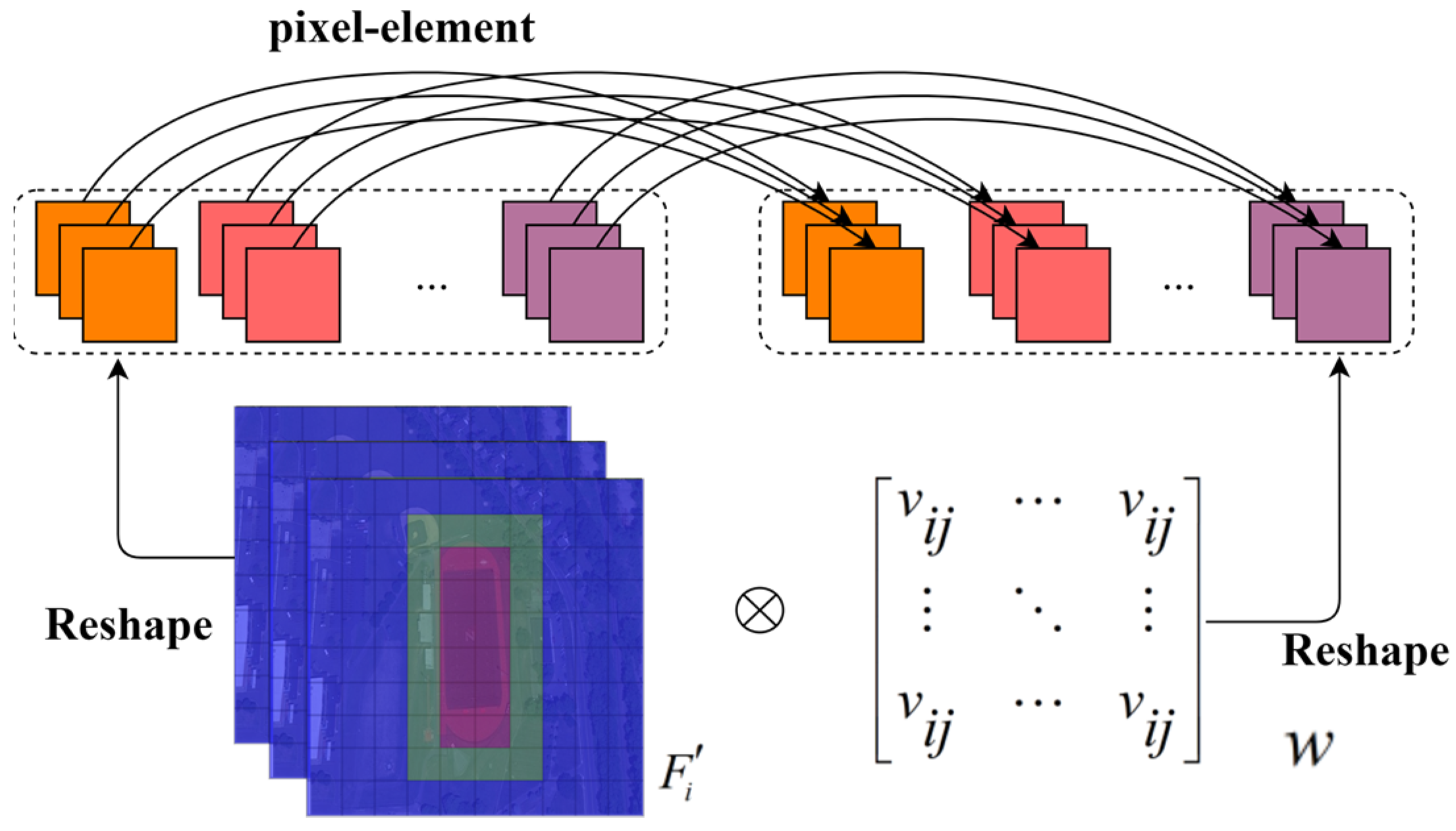
3.3. Adaptive Feature-Aware Module
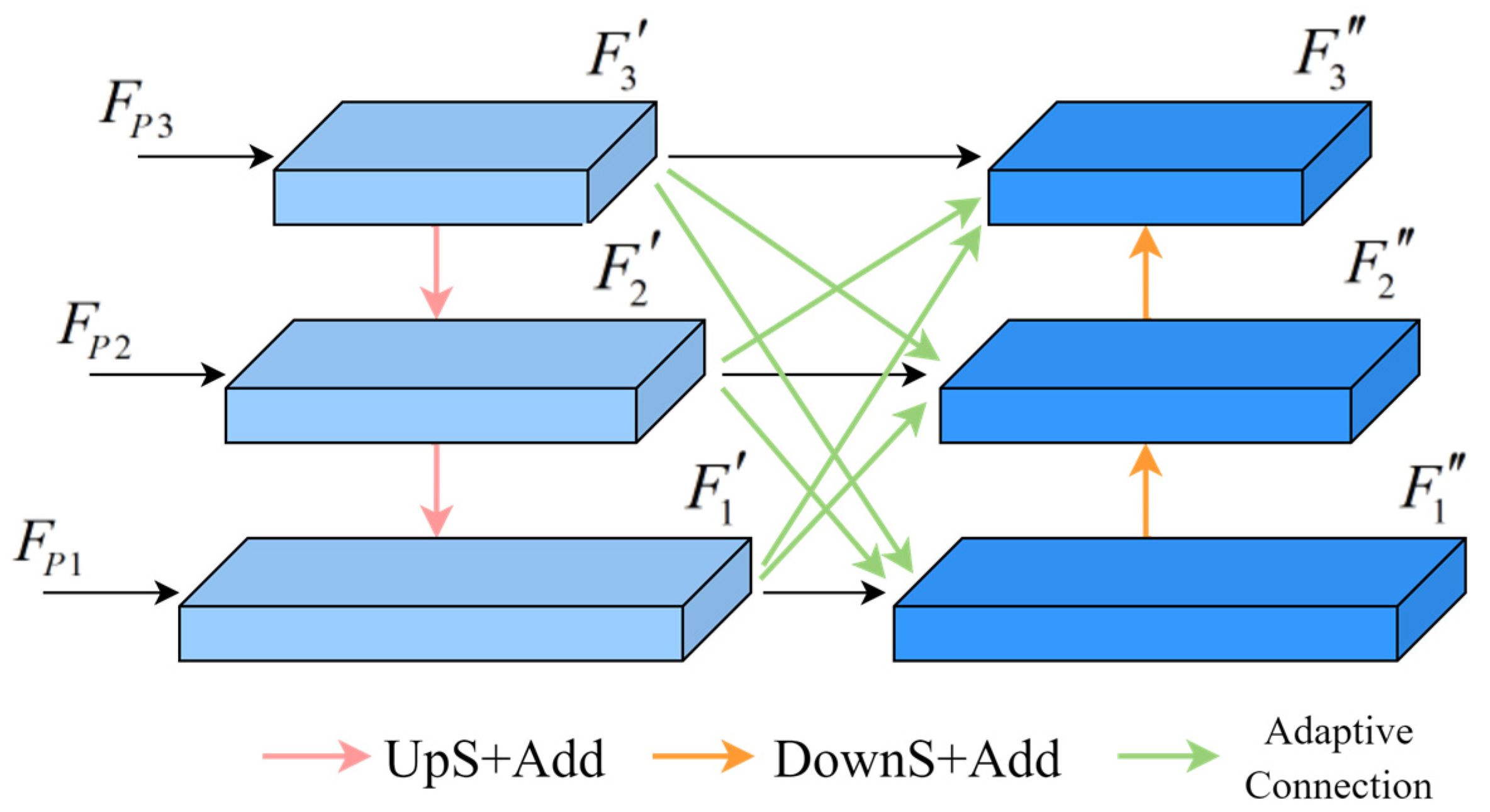
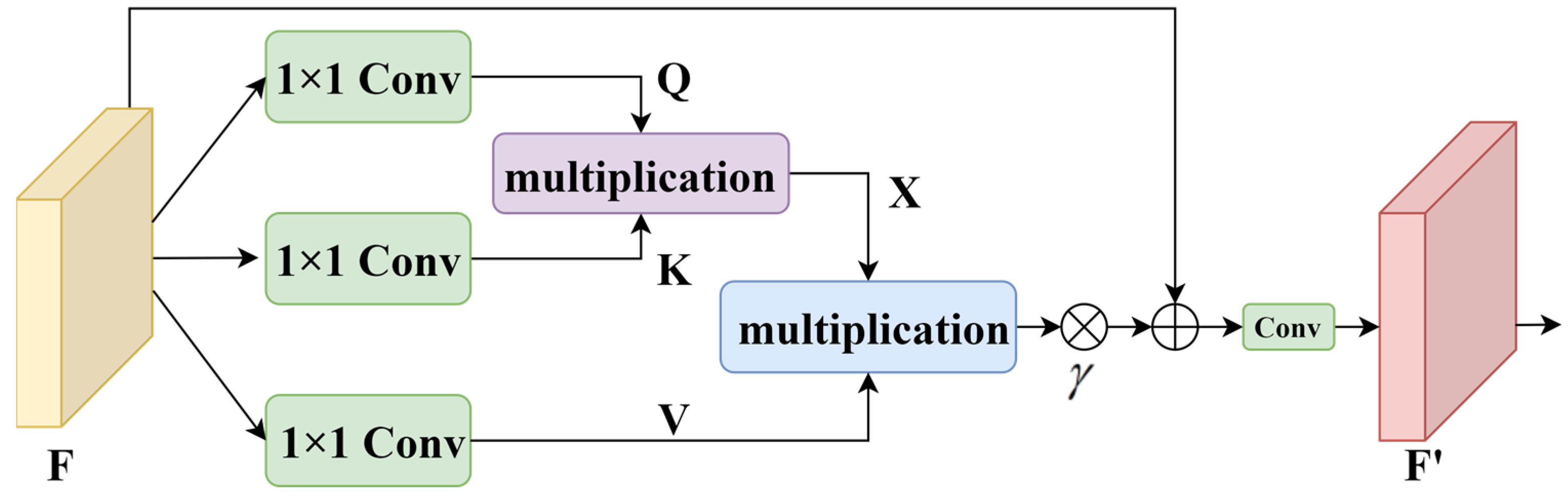
3.4. Object Positioning Module
3.5. Loss Function
4. Experimental Data and Evaluation Metrics
4.1. Datasets
4.2. Evaluation Metrics
4.3. Training
5. Experiment and Analysis
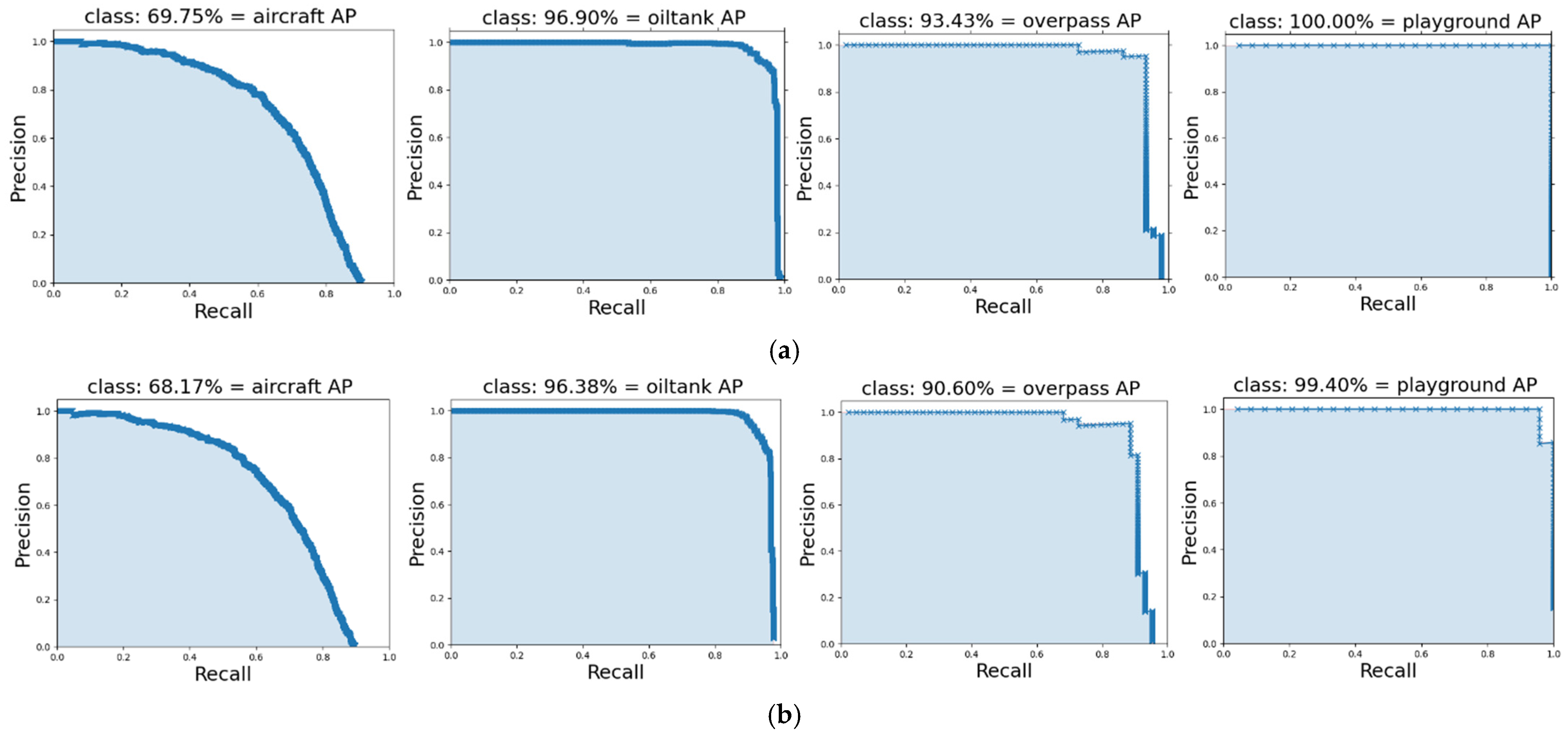
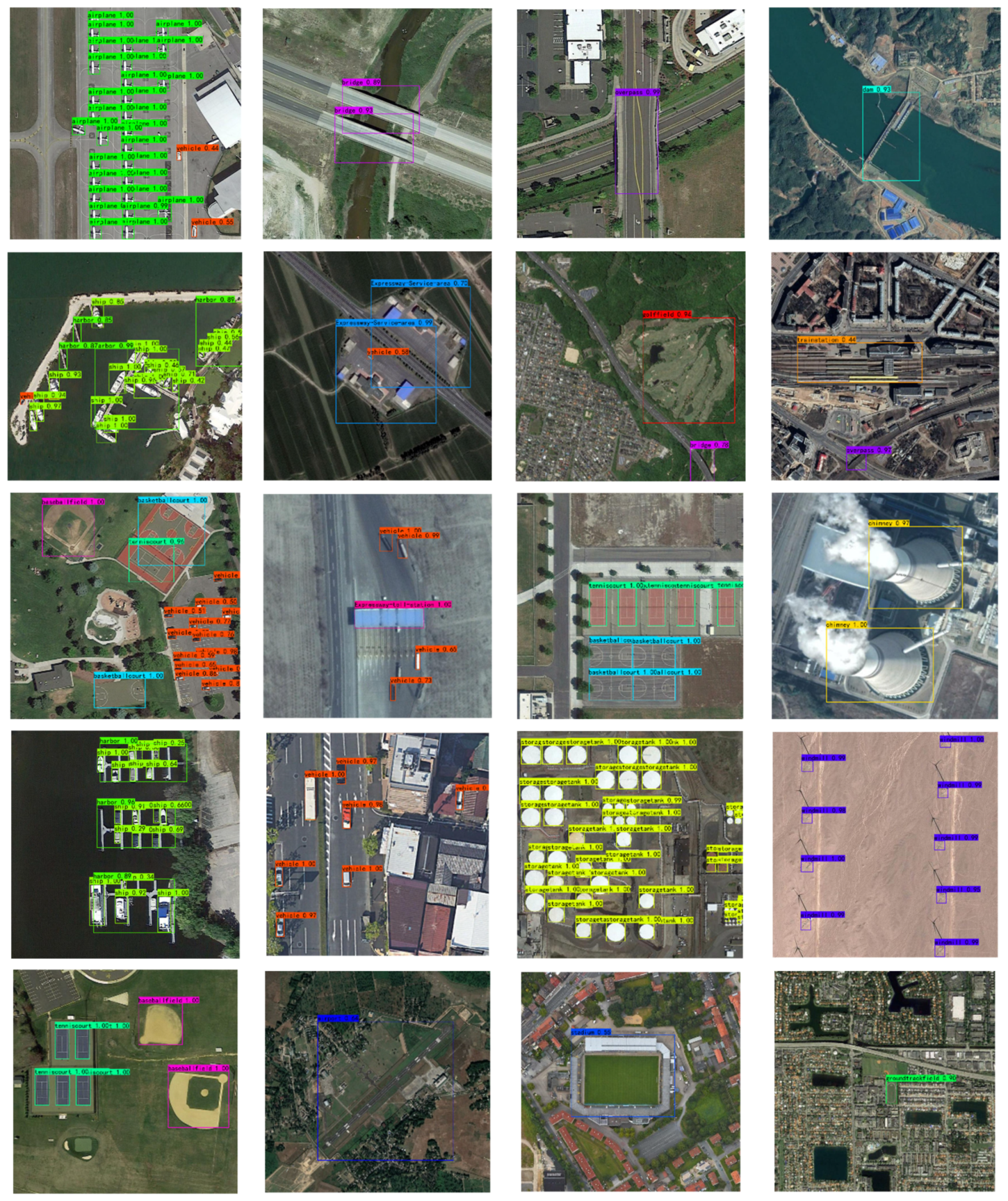
5.1. Quantitative Accuracy Analysis
5.2. Ablation Experiments
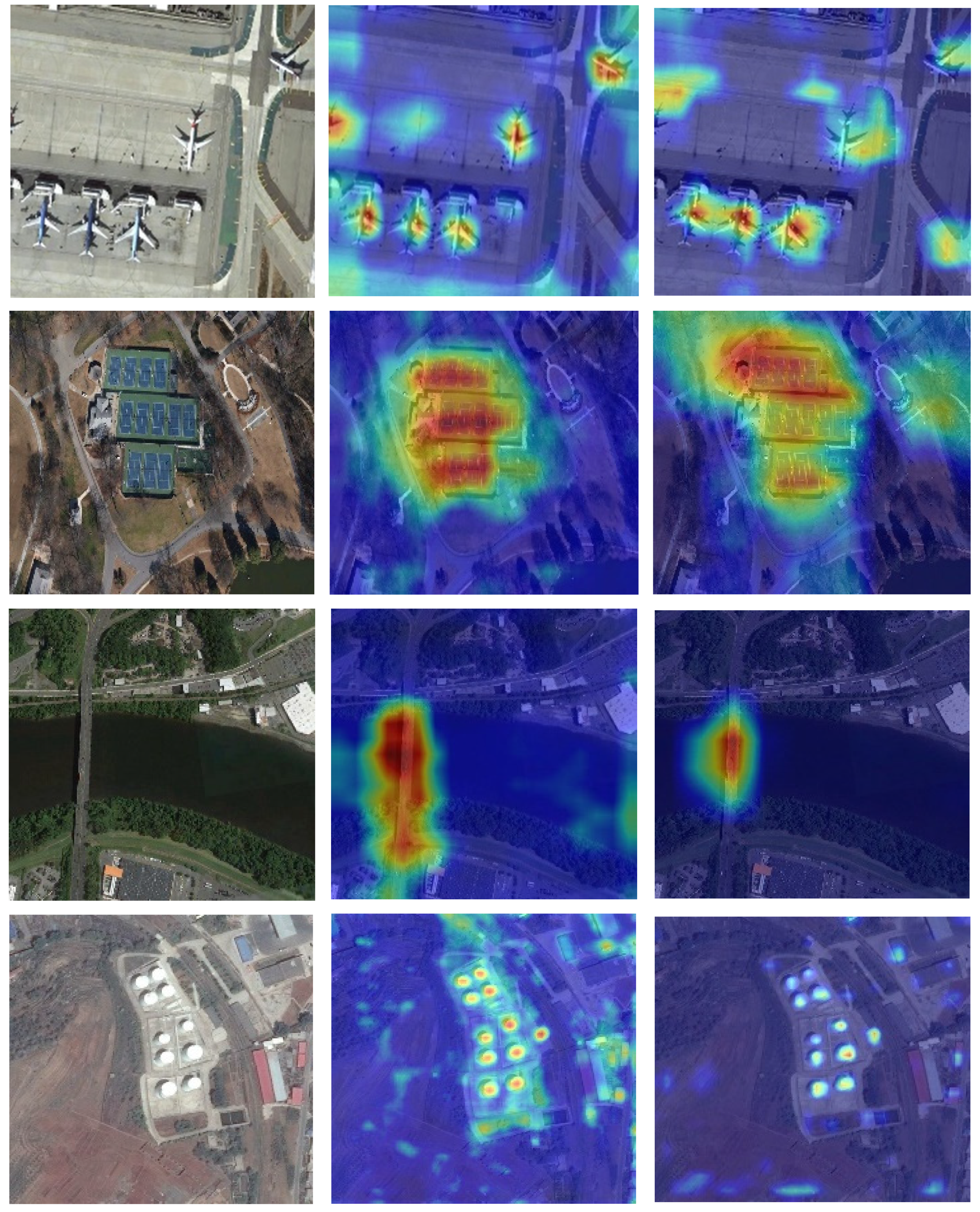
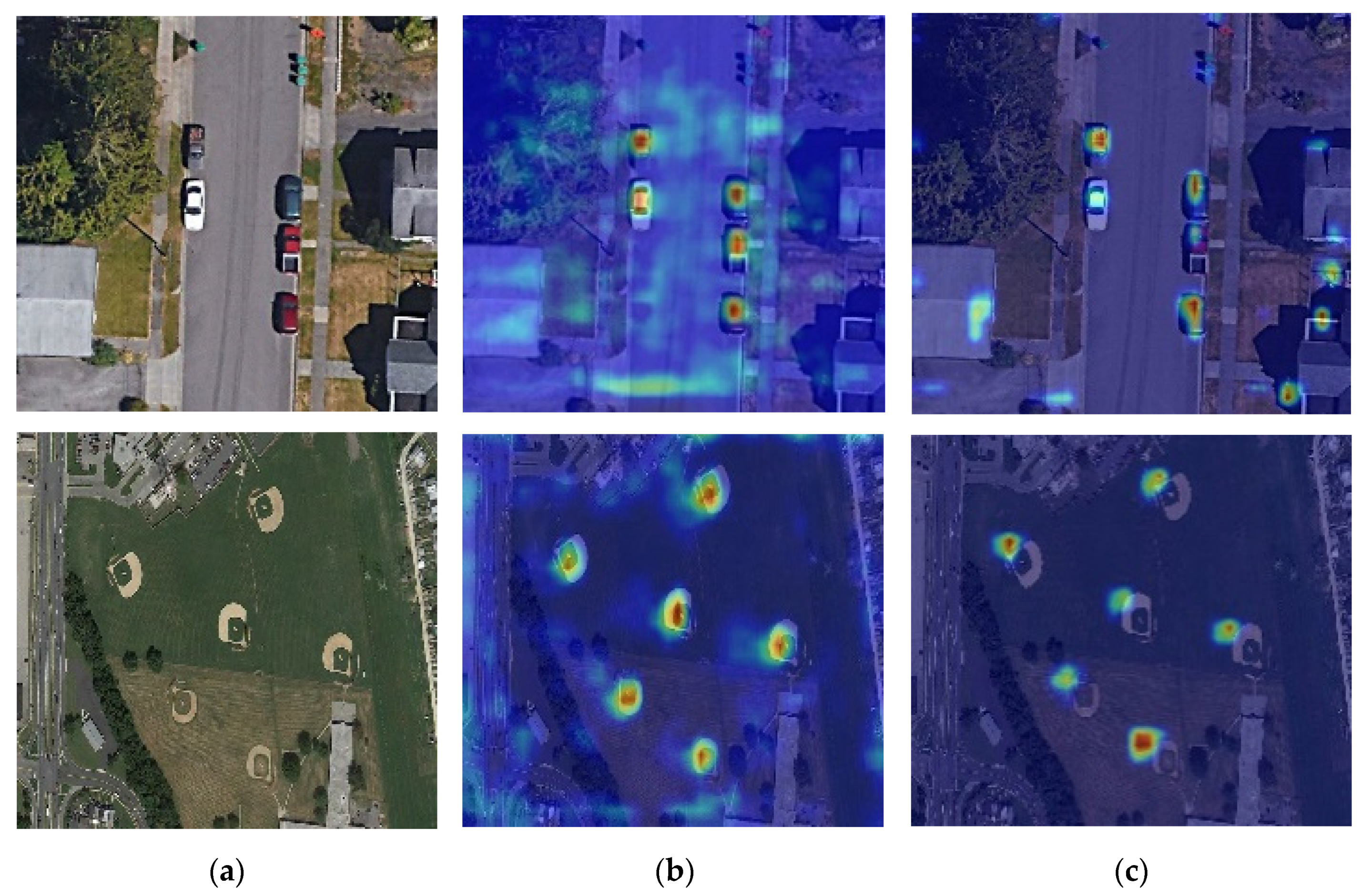
5.3. Feature Visualization
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-Scale Feature Fusion for Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 431–435. [Google Scholar] [CrossRef]
- Xu, T.; Sun, X.; Diao, W.; Zhao, L.; Fu, K.; Wang, H. ASSD: Feature Aligned Single-Shot Detection for Multiscale Objects in Aerial Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Xia, X.-G.; Wu, X.; Cai, Z.; Tao, R. A Novel Nonlocal-Aware Pyramid and Multiscale Multitask Refinement Detector for Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar] [CrossRef]
- Qian, X.; Lin, S.; Cheng, G.; Yao, X.; Ren, H.; Wang, W. Object Detection in Remote Sensing Images Based on Improved Bounding Box Regression and Multi-Level Features Fusion. Remote Sens. 2020, 12, 143. [Google Scholar] [CrossRef] [Green Version]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Cheng, G.; Lang, C.; Wu, M.; Xie, X.; Yao, X.; Han, J. Feature enhancement network for object detection in optical remote sensing images. J. Remote Sens. 2021, 2021, 9805389. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, Y.; Chang, Z.; Li, H.; Wang, H.; Sun, X. Oriented objects as pairs of middle lines. ISPRS J. Photogramm. Remote Sens. 2020, 169, 268–279. [Google Scholar] [CrossRef]
- Huang, W.; Li, G.; Chen, Q.; Ju, M.; Qu, J. CF2PN: A Cross-Scale Feature Fusion Pyramid Network Based Remote Sensing Target Detection. Remote Sens. 2021, 13, 847. [Google Scholar] [CrossRef]
- Wang, G.; Zhuang, Y.; Chen, H.; Liu, X.; Zhang, T.; Li, L.; Dong, S.; Sang, Q. FSoD-Net: Full-scale object detection from optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Zhang, T.; Zhuang, Y.; Wang, G.; Dong, S.; Chen, H.; Li, L. Multiscale Semantic Fusion-Guided Fractal Convolutional Object Detection Network for Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–20. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Xia, X.G.; Wang, H.; Jie, F.; Tao, R. LO-Det: Lightweight Oriented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Li, L.; Cao, G.; Liu, J.; Tong, Y. Efficient Detection in Aerial Images for Resource-Limited Satellites. IEEE Geosci. Remote Sens. Lett. 2021, 19, 6001605. [Google Scholar] [CrossRef]
- Liu, N.; Celik, T.; Zhao, T.; Zhang, C.; Li, H.-C. AFDet: Toward More Accurate and Faster Object Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12557–12568. [Google Scholar] [CrossRef]
- Li, P.; Che, C. SeMo-YOLO: A multiscale object detection network in satellite remote sensing images. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Lang, L.; Xu, K.; Zhang, Q.; Wang, D. Fast and Accurate Object Detection in Remote Sensing Images Based on Lightweight Deep Neural Network. Sensors 2021, 21, 5460. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive Balanced Network for Multiscale Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Ye, Y.; Ren, X.; Zhu, B.; Tang, T.; Tan, X.; Gui, Y.; Yao, Q. An Adaptive Attention Fusion Mechanism Convolutional Network for Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 516. [Google Scholar] [CrossRef]
- Li, W.T.; Li, L.W.; Li, S.Y.; Mou, J.C.; Hei, Y.Q. Efficient Vertex Coordinate Prediction-Based CSP-Hourglass Net for Object OBB Detection in Remote Sensing. IEEE Geosci. Remote Sens. Lett. 2021, 19, 6503305. [Google Scholar] [CrossRef]
- Ma, W.; Li, N.; Zhu, H.; Jiao, L.; Tang, X.; Guo, Y.; Hou, B. Feature Split–Merge–Enhancement Network for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Wu, Y.; Zhang, K.; Wang, Q. FRPNet: A Feature-Reflowing Pyramid Network for Object Detection of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, K.; Wang, J.; Wang, Y.; Wang, Q.; Li, X. GCWNet: A Global Context-Weaving Network for Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Han, W.; Kuerban, A.; Yang, Y.; Huang, Z.; Liu, B.; Gao, J. Multi-Vision Network for Accurate and Real-Time Small Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Liu, J.; Yang, D.; Hu, F. Multiscale Object Detection in Remote Sensing Images Combined with Multi-Receptive-Field Features and Relation-Connected Attention. Remote Sens. 2022, 14, 427. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Cong, R.; Zhang, Y.; Fang, L.; Li, J.; Zhao, Y.; Kwong, S. RRNet: Relational Reasoning Network With Parallel Multiscale Attention for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Zhang, K.; Wu, Y.; Wang, J.; Wang, Y.; Wang, Q. Semantic Context-Aware Network for Multiscale Object Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Yu, D.; Ji, S. A New Spatial-Oriented Object Detection Framework for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Zhu, P.; Chen, P.; Tang, X.; Li, C.; Jiao, L. Foreground Refinement Network for Rotated Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Wang, J.; He, X.; Faming, S.; Lu, G.; Jiang, Q.; Hu, R. Multi-Size Object Detection in Large Scene Remote Sensing Images Under Dual Attention Mechanism. IEEE Access 2022, 10, 8021–8035. [Google Scholar] [CrossRef]
- Bai, J.; Ren, J.; Yang, Y.; Xiao, Z.; Yu, W.; Havyarimana, V.; Jiao, L. Object Detection in Large-Scale Remote-Sensing Images Based on Time-Frequency Analysis and Feature Optimization. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Zhu, D.; Xia, S.; Zhao, J.; Zhou, Y.; Niu, Q.; Yao, R.; Chen, Y. Spatial hierarchy perception and hard samples metric learning for high-resolution remote sensing image object detection. Appl. Intell. 2021, 52, 3193–3208. [Google Scholar] [CrossRef]
- Cheng, B.; Li, Z.; Xu, B.; Dang, C.; Deng, J. Target detection in remote sensing image based on object-and-scene context constrained CNN. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Araujo, A.; Norris, W.; Sim, J. Computing Receptive Fields of Convolutional Neural Networks. Distill 2019, 4, e21. [Google Scholar] [CrossRef]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 29, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Mei, H.; Ji, G.P.; Wei, Z.; Yang, X.; Wei, X.; Fan, D.-P. Camouflaged Object Segmentation with Distraction Mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8772–8781. [Google Scholar] [CrossRef]
- Su, H.; Wei, S.; Yan, M.; Wang, C.; Shi, J.; Zhang, X. Object Detection and Instance Segmentation in Remote Sensing Imagery Based on Precise Mask R-CNN. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1454–1457. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Xiao, Z.; Liu, Q.; Tang, G.; Zhai, X. Elliptic Fourier transformation-based histograms of oriented gradients for rotationally invariant object detection in remote-sensing images. Int. J. Remote Sens. 2015, 36, 618–644. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, 28, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Van Etten, A. You only look twice: Rapid multi-scale object detection in satellite imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AE | AO | BF | BC | BR | CN | DM | ES | ET | HB | GC | GF | OP | SP | SD | ST | TC | TS | VC | WM | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster-RCNN [42] | 51.35 | 61.62 | 62.21 | 80.66 | 26.96 | 74.18 | 37.26 | 53.46 | 45.12 | 43.76 | 69.63 | 61.81 | 48.97 | 56.14 | 41.82 | 39.56 | 73.88 | 44.74 | 33.98 | 65.32 | 53.61 |
| YOLOv3 [43] | 68.86 | 55.39 | 66.74 | 87.14 | 35.01 | 73.96 | 34.63 | 56.15 | 49.81 | 55.16 | 67.98 | 69.59 | 52.51 | 87.71 | 42.05 | 68.93 | 84.56 | 33.62 | 49.82 | 72.37 | 60.60 |
| YOLOv4-Tiny [44] | 58.61 | 55.99 | 71.57 | 74.52 | 22.19 | 72.11 | 47.26 | 54.83 | 48.50 | 60.11 | 64.46 | 51.09 | 46.92 | 41.93 | 55.42 | 37.18 | 79.78 | 36.27 | 26.49 | 52.23 | 52.87 |
| SSD [17] | 59.50 | 72.70 | 72.40 | 75.70 | 29.70 | 65.80 | 56.60 | 63.50 | 53.10 | 65.30 | 68.60 | 49.40 | 48.10 | 59.20 | 61.00 | 46.60 | 76.30 | 55.10 | 27.40 | 65.70 | 58.60 |
| YOLT [45] | 64.77 | 68.98 | 62.85 | 87.89 | 32.37 | 71.57 | 45.86 | 54.93 | 55.86 | 49.93 | 65.68 | 66.35 | 49.97 | 87.74 | 30.36 | 73.39 | 82.06 | 29.95 | 52.45 | 73.96 | 60.29 |
| ASSD-lite [2] | 73.70 | 75.70 | 69.50 | 85.40 | 27.80 | 74.60 | 59.20 | 61.90 | 49.00 | 76.70 | 72.22 | 61.00 | 50.50 | 76.50 | 75.80 | 49.70 | 82.50 | 56.50 | 31.30 | 57.20 | 63.30 |
| LO-Det [11] | 72.63 | 65.04 | 76.72 | 84.66 | 33.46 | 73.71 | 56.83 | 75.86 | 57.51 | 66.29 | 68.01 | 60.91 | 51.50 | 88.63 | 68.04 | 64.31 | 86.26 | 47.57 | 42.44 | 76.70 | 65.85 |
| FANet [15] | 58.16 | 55.62 | 72.39 | 76.01 | 25.86 | 73.03 | 43.31 | 55.43 | 51.39 | 58.94 | 66.03 | 51.30 | 48.69 | 70.41 | 51.82 | 53.34 | 82.46 | 38.78 | 32.60 | 63.33 | 56.45 |
| CF2PN [7] | 78.32 | 78.29 | 76.48 | 88.40 | 37.00 | 70.95 | 59.90 | 71.23 | 51.15 | 75.55 | 77.14 | 56.75 | 58.65 | 76.06 | 70.61 | 55.52 | 88.84 | 50.83 | 36.89 | 86.36 | 67.25 |
| CSFF [1] | 57.20 | 79.60 | 70.10 | 87.40 | 46.10 | 76.60 | 62.70 | 82.60 | 73.20 | 78.20 | 81.60 | 50.70 | 59.50 | 73.30 | 63.40 | 58.90 | 85.90 | 61.90 | 42.90 | 68.00 | 68.00 |
| FCOS [46] | 73.50 | 68.01 | 69.86 | 85.11 | 34.66 | 73.60 | 49.33 | 52.06 | 47.56 | 67.21 | 68.67 | 46.31 | 51.06 | 72.24 | 59.84 | 64.61 | 81.17 | 42.72 | 42.17 | 74.78 | 61.17 |
| Centernet [47] | 73.58 | 57.98 | 69.73 | 88.46 | 36.20 | 76.88 | 47.90 | 52.66 | 53.90 | 45.68 | 60.54 | 62.62 | 52.60 | 88.21 | 63.74 | 76.21 | 83.66 | 51.32 | 54.43 | 79.53 | 63.86 |
| AFADet | 85.56 | 66.49 | 76.32 | 88.09 | 37.42 | 78.32 | 53.59 | 61.84 | 58.41 | 54.32 | 67.20 | 70.36 | 53.08 | 82.72 | 62.78 | 63.94 | 88.24 | 50.32 | 43.95 | 79.16 | 66.12 |
| Model | LO-Det | CF2PN | FANet | CSFF | Simple-CNN | AFADet | AFADet-300 |
|---|---|---|---|---|---|---|---|
| GPU | RTX3090 | RTX2080Ti | RTX2080Ti | RTX3090 | GT710 | RTX2080Ti | RTX2080Ti |
| Input Size | 320 | - | 416 | - | 416 | 608 | 300 |
| FPS | 66.71 | 19.70 | 227.90 | 15.21 | 13.51 | 25.68 | 61.00 |
| mAP | 49.12 | 67.25 | 56.45 | 68.00 | 66.50 * | 66.12 | 57.40 |
| Model | Aircraft | Oil Tank | Overpass | Playground | mAP |
|---|---|---|---|---|---|
| CF2PN | 95.52 | 99.42 | 83.82 | 95.68 | 93.61 |
| FANet | 87.10 | 98.97 | 56.58 | 97.86 | 85.13 |
| SSD-300 | 68.17 | 96.38 | 90.60 | 99.40 | 88.64 |
| AFADet | 92.17 | 98.43 | 94.23 | 97.33 | 95.54 |
| AFADet-300 | 69.75 | 96.90 | 93.43 | 99.99 | 90.02 |
| Model | AE | BD | GF | HB | ST | SP | TC | VC | BC | BR | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SSD* | 98.26 | 97.70 | 99.76 | 83.37 | 63.70 | 58.97 | 82.51 | 51.56 | 79.87 | 67.95 | 78.36 |
| SSD* + FL | 98.74 | 97.43 | 99.87 | 87.25 | 56.71 | 60.65 | 77.96 | 49.67 | 82.69 | 80.31 | 79.13 |
| SSD* + FL + AFAM | 98.55 | 97.00 | 99.80 | 92.90 | 54.43 | 68.10 | 86.11 | 64.05 | 91.54 | 85.97 | 83.87 |
| SSD* + FL + AFAM + OPM | 98.78 | 97.39 | 100.00 | 91.97 | 67.82 | 73.53 | 88.31 | 68.08 | 87.62 | 90.91 | 86.44 |
| Model | AE | AO | BF | BC | BR | CN | DM | ES | ET | HB | GC | GF | OP | SP | SD | ST | TC | TS | VC | WM | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSD* | 80.71 | 57.92 | 72.70 | 88.87 | 30.64 | 76.90 | 46.56 | 56.63 | 54.35 | 52.05 | 66.17 | 64.00 | 49.41 | 82.94 | 62.64 | 59.44 | 87.14 | 46.55 | 38.92 | 73.03 | 62.38 |
| SSD* + FL | 82.65 | 58.81 | 75.15 | 88.80 | 32.08 | 76.62 | 44.24 | 55.65 | 53.56 | 52.58 | 65.92 | 66.40 | 51.17 | 83.13 | 62.93 | 62.58 | 87.28 | 45.16 | 40.50 | 75.74 | 63.05 |
| SSD* + FL + AFAM | 84.27 | 65.03 | 72.62 | 88.58 | 37.94 | 77.83 | 53.42 | 61.32 | 59.26 | 54.92 | 68.34 | 72.61 | 54.36 | 82.73 | 64.58 | 62.63 | 85.93 | 51.35 | 42.05 | 79.02 | 65.94 |
| SSD* + FL + AFAM + OPM | 85.56 | 66.49 | 76.32 | 88.09 | 37.42 | 78.32 | 53.59 | 61.84 | 58.41 | 54.32 | 67.20 | 70.36 | 53.08 | 82.72 | 62.78 | 63.94 | 88.24 | 50.32 | 43.95 | 79.16 | 66.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Gong, Z.; Liu, X.; Guo, H.; Yu, D.; Ding, L. Object Detection Based on Adaptive Feature-Aware Method in Optical Remote Sensing Images. Remote Sens. 2022, 14, 3616. https://doi.org/10.3390/rs14153616
Wang J, Gong Z, Liu X, Guo H, Yu D, Ding L. Object Detection Based on Adaptive Feature-Aware Method in Optical Remote Sensing Images. Remote Sensing. 2022; 14(15):3616. https://doi.org/10.3390/rs14153616
Chicago/Turabian StyleWang, Jiaqi, Zhihui Gong, Xiangyun Liu, Haitao Guo, Donghang Yu, and Lei Ding. 2022. "Object Detection Based on Adaptive Feature-Aware Method in Optical Remote Sensing Images" Remote Sensing 14, no. 15: 3616. https://doi.org/10.3390/rs14153616
APA StyleWang, J., Gong, Z., Liu, X., Guo, H., Yu, D., & Ding, L. (2022). Object Detection Based on Adaptive Feature-Aware Method in Optical Remote Sensing Images. Remote Sensing, 14(15), 3616. https://doi.org/10.3390/rs14153616