1. Introduction
For relative height, the existing DSM (Digital Surface Model) data or DEM (Digital Elevation Model) data and the existing tools are usually used to obtain the relative elevation of the corresponding area. A Digital Surface Model is an elevation model that captures the environment’s natural and artificial features. This includes the tops of buildings, trees, powerlines, and other objects. As DSM describes the elevation information of the ground surface, it has a wide range of applications in mapping [
1,
2,
3], hydrology [
4,
5], meteorology [
6], geomorphology [
5], geology [
7], soil [
8], engineering construction, building detection [
9], communications, military [
10] and other national economic and national defense construction, as well as in humanities and natural sciences. Due to these characteristics, DSM enables researchers to analyze various information sources in the region of interest easily. However, at present, the main methods of relative height extraction are airborne Light detection [
11] and ranging (Lidar) or Interferometric Synthetic-Aperture Radar (InSAR) [
12,
13], or constructing optical satellite stereo pairs [
14,
15,
16]. These methods can provide very high-resolution relative height but require a lot of data pre-processing and data post-processing, including accurate denoising of the input data. In addition, these methods are expensive because they require strong expertise and high computational efficiency. At the same time, a problem similar to relative height estimation is the semantic segmentation [
17] of optical satellites. In a broad sense, for the same region, the relative height information is roughly the same, which means that these two tasks can promote each other.
Generally, these two tasks can be summarized as generation tasks. The input is the attractive remote sensing image block, and the corresponding relative height estimation and semantic segmentation map are obtained through a function
G
where
X,
Y, and
Z represent remote sensing images, corresponding relative height estimation, and semantic segmentation images, respectively. At present, the mainstream method of relative height is to collect multi-view remote sensing images to generate the relative height of the corresponding region. However, if an optimal projection method can be obtained, the corresponding relative height can be obtained through a single remote sensing image, although such a projection may not exist [
18]. On the one hand, because relative height estimation is realized through a single view, this mapping relationship is complex and obtained based on laws, which is different from the previous generation of corresponding regional relative height by analyzing imaging model and satellite motion. It is thus unrealistic to realize relative height estimation by manually analyzing the distribution of data. On the other hand, with the rapid development of Artificial Intelligence (AI) [
19], we can build a DL model and use the data-driven method to automatically learn the complex internal mapping relationship for the region of interest.
At present, the development of Artificial Intelligence mainly focuses on Computer Vision (CV) [
20,
21], Natural Language Processing (NLP) [
22,
23] and Speech Processing [
24,
25]. In particular, Computer Vision has developed rapidly since 2012, mostly focusing on image classification [
26,
27], semantic segmentation [
28], instance segmentation [
29], etc., and most of the methods are based on CNN (convolutional neural networks). With the introduction of Transformer [
30], Transformer has surpassed the performance of CNN in various fields of computer vision. Compared with CNN, Transformer has the following advantages: 1. Stronger modeling capabilities. Convolution can be regarded as a kind of template matching, and different positions in the image are filtered using the same template. The attention unit in Transformer is an adaptive filter, and the template weight is determined by the combinability of two pixels. This adaptive computing module has stronger modeling capabilities. 2. It can be complementary to convolution. Convolution is a local operation, and a convolutional layer usually only models the relationship between neighboring pixels. The Transformer is a global operation. A Transformer layer can model the relationship between all pixels, and the two sides can complement each other well. 3. There is no need to stack very deep networks in the network design. Compared with CNN, Transformer can essentially focus on global information and local information at the same time and does not rely on the stacking of convolutional layers to obtain a larger receptive field, which simplifies the network design.
At present, there are few types of research works on relative height estimation in the field of remote sensing and even fewer on multi-task learning using Transformer for relative height estimation and semantic segmentation. Most of them analyze remote sensing mechanisms or use multi-view remote sensing images to realize relative height estimation by dense matching [
31]. Some of them apply deep learning to relative height estimation for classification [
32,
33] or super-resolution [
34,
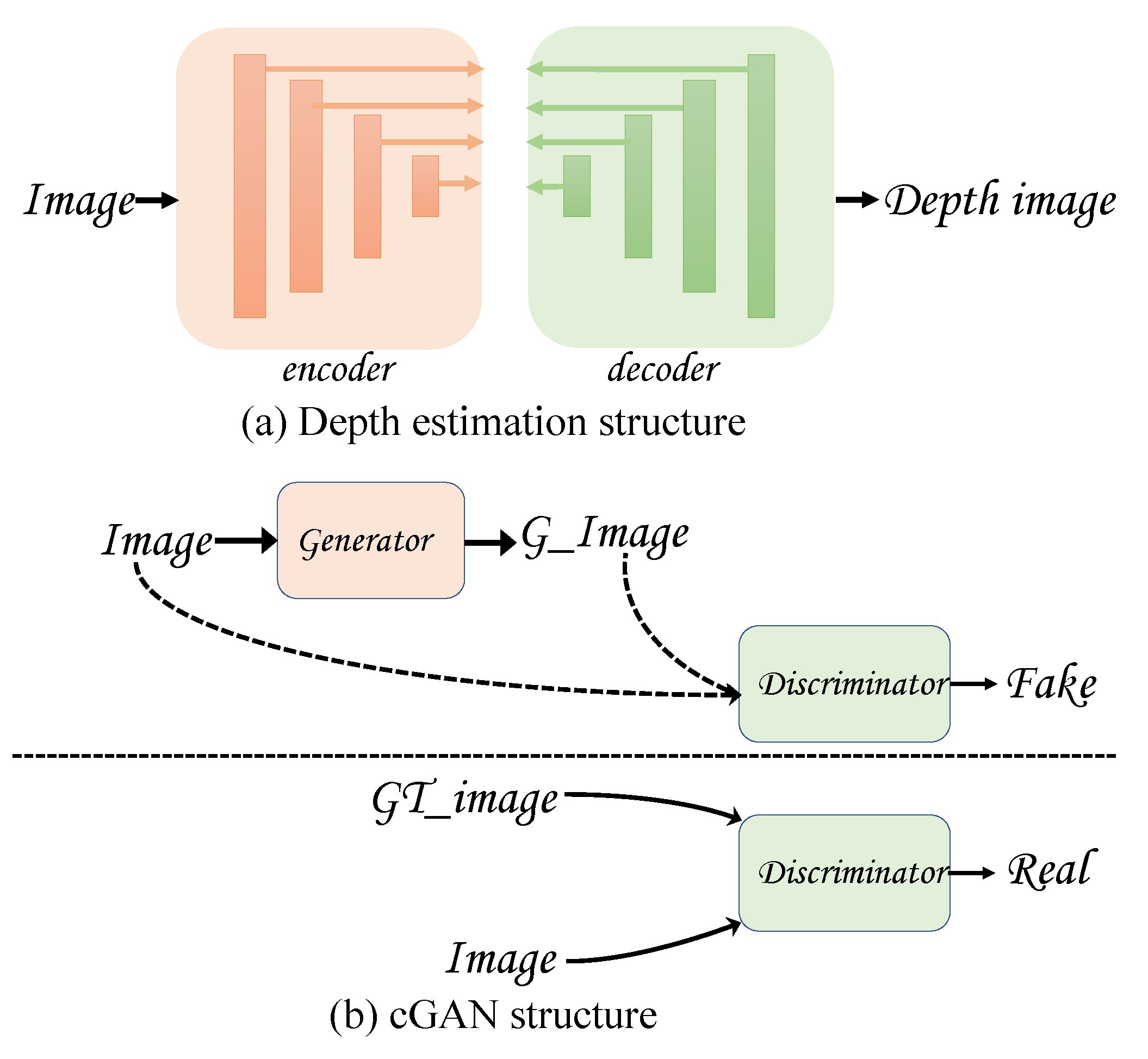
35]. However, these networks are usually designed to accomplish only one specific task. For a real application scenario, a network that can perform multiple tasks at the same time is far more efficient and ideal than building a group of independent networks (a different network for each task). In recent years, relative height estimation using depth learning methods is mostly realized by generation methods, such as GAN (Generative Adversarial Networks) [
36] and VAE (Variational Auto-Encoder) [
37], and some are realized by depth estimation [
38], but they are still generation tasks in essence. For semantic segmentation tasks, most of the work adopts pixel-level classification, which is essentially a classification task. The combination of these two tasks may cause an imbalance. The final result may be that one task occupies the dominant position in the optimization fault, and the purpose of mutual promotion between the two tasks is not achieved.
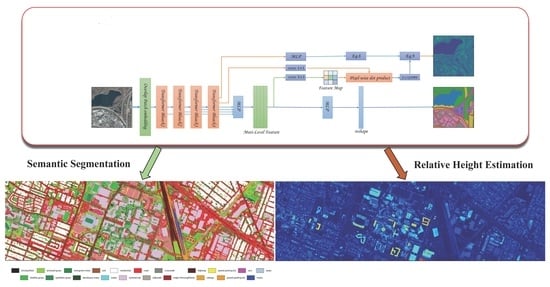
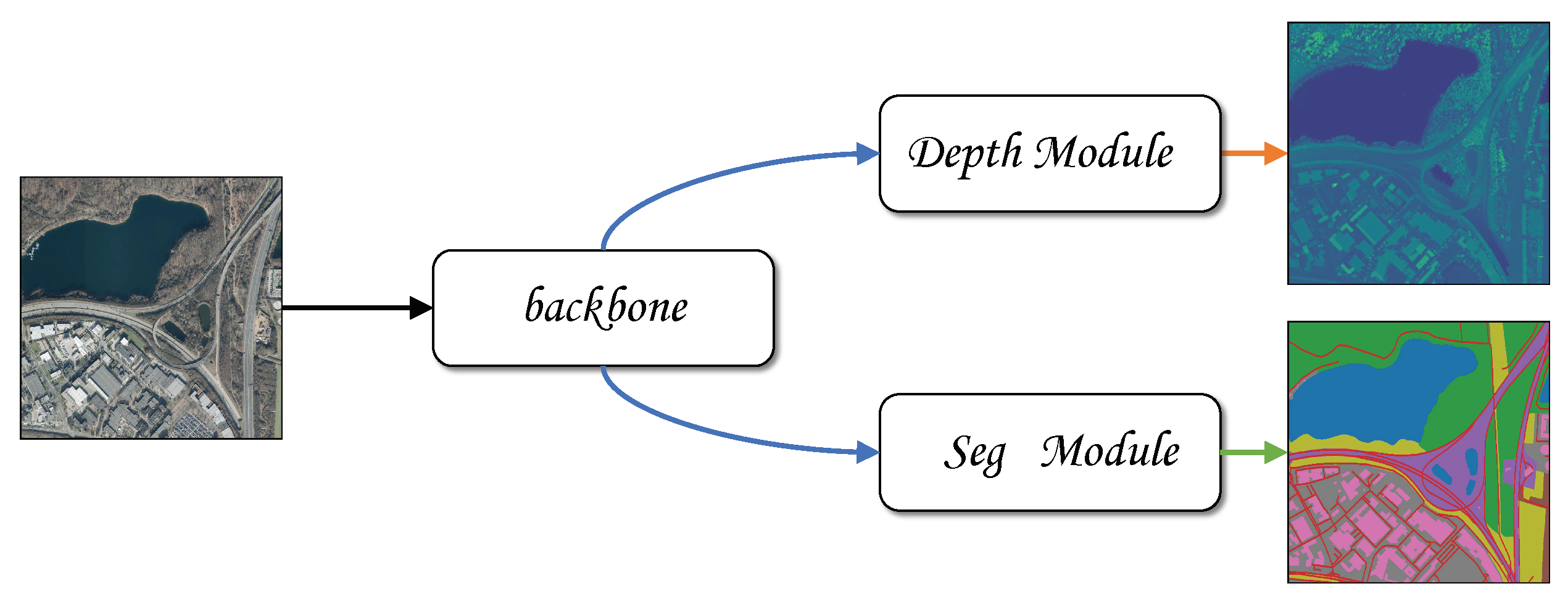
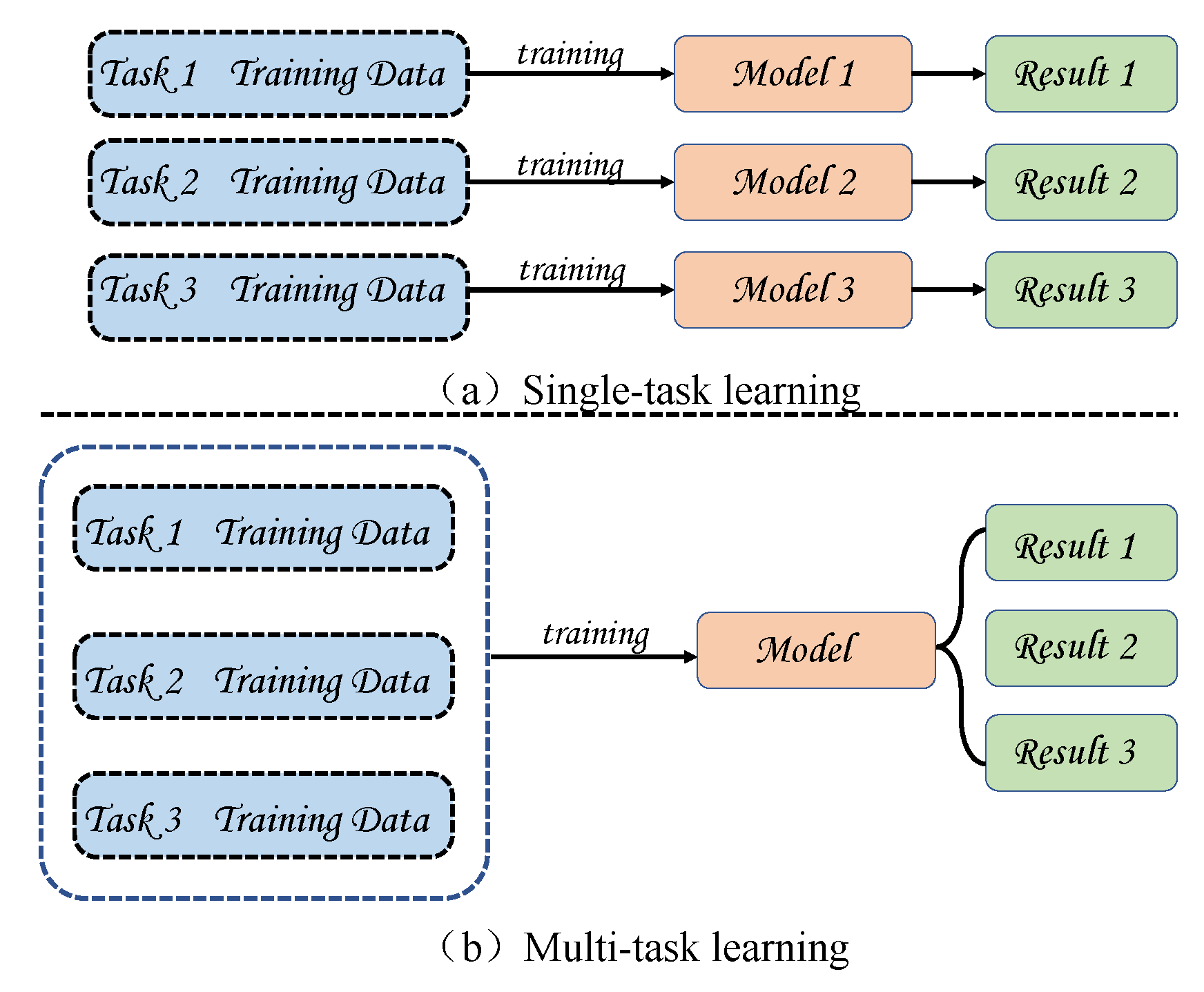
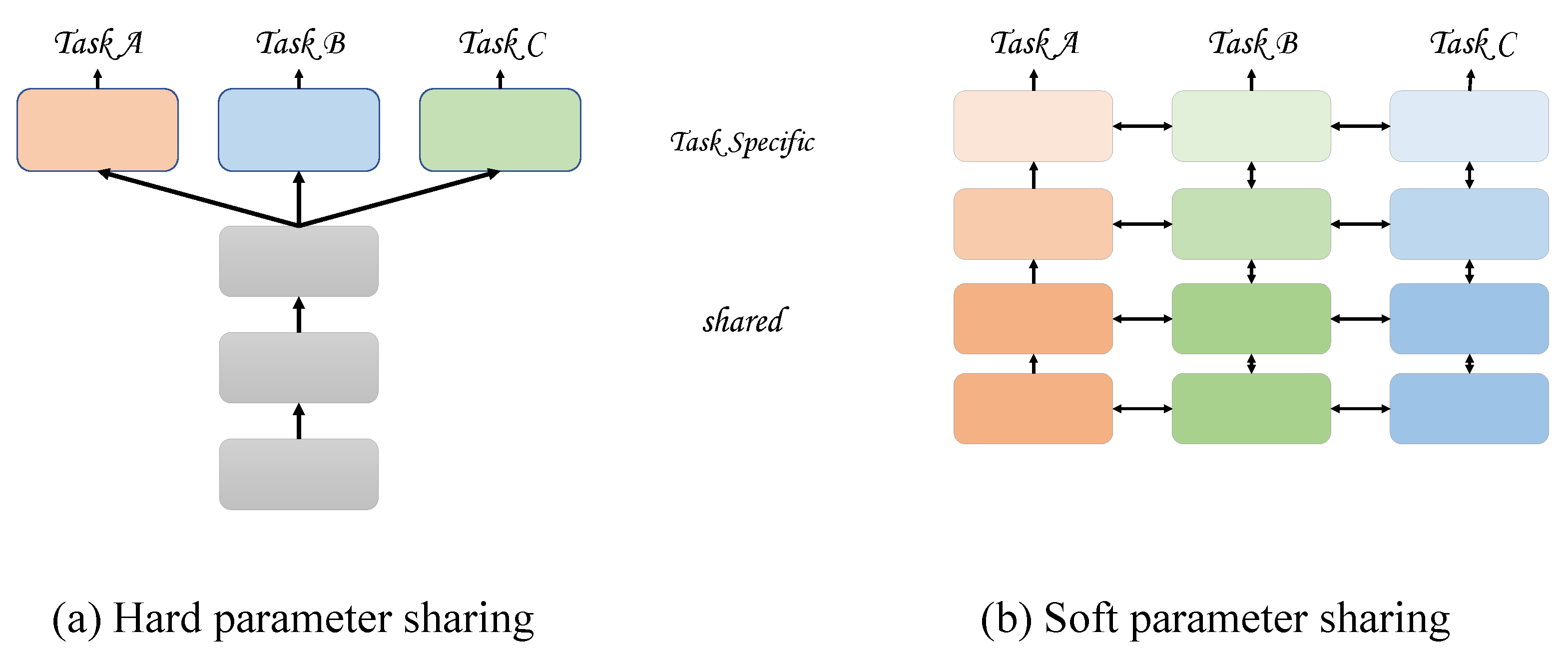
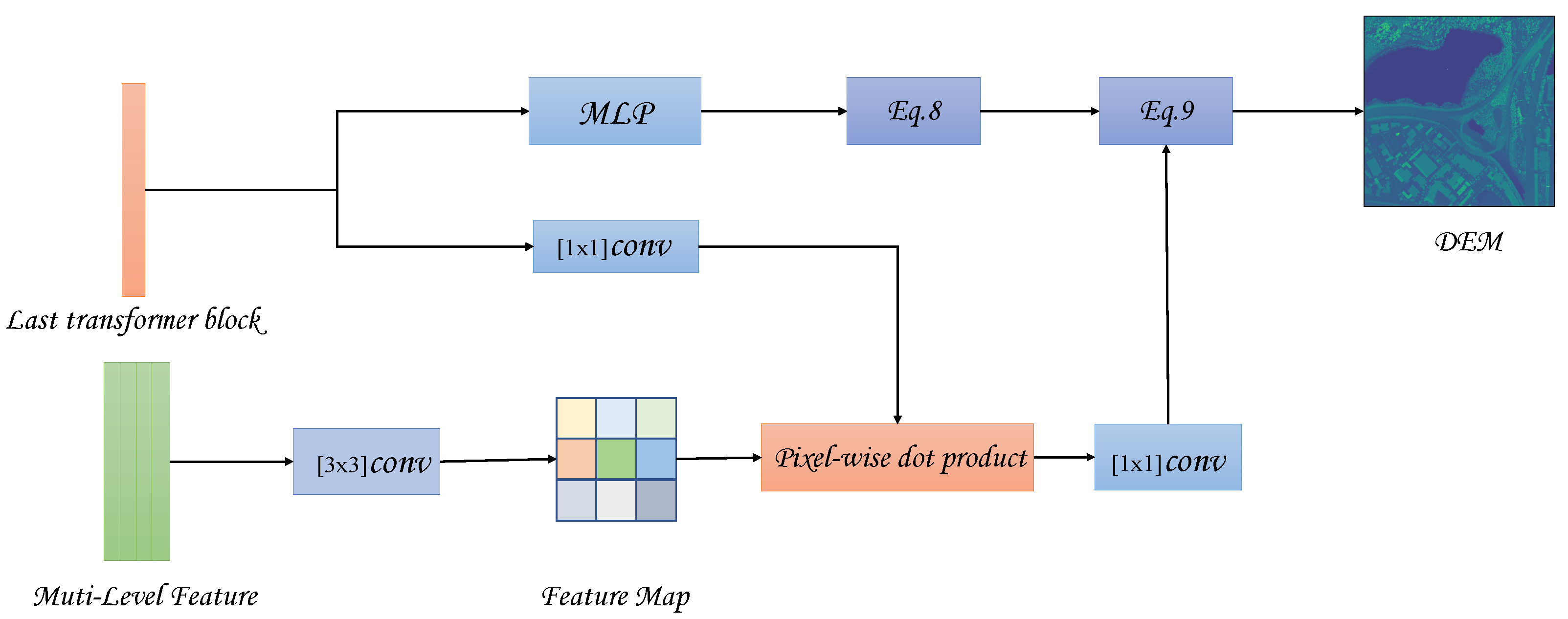
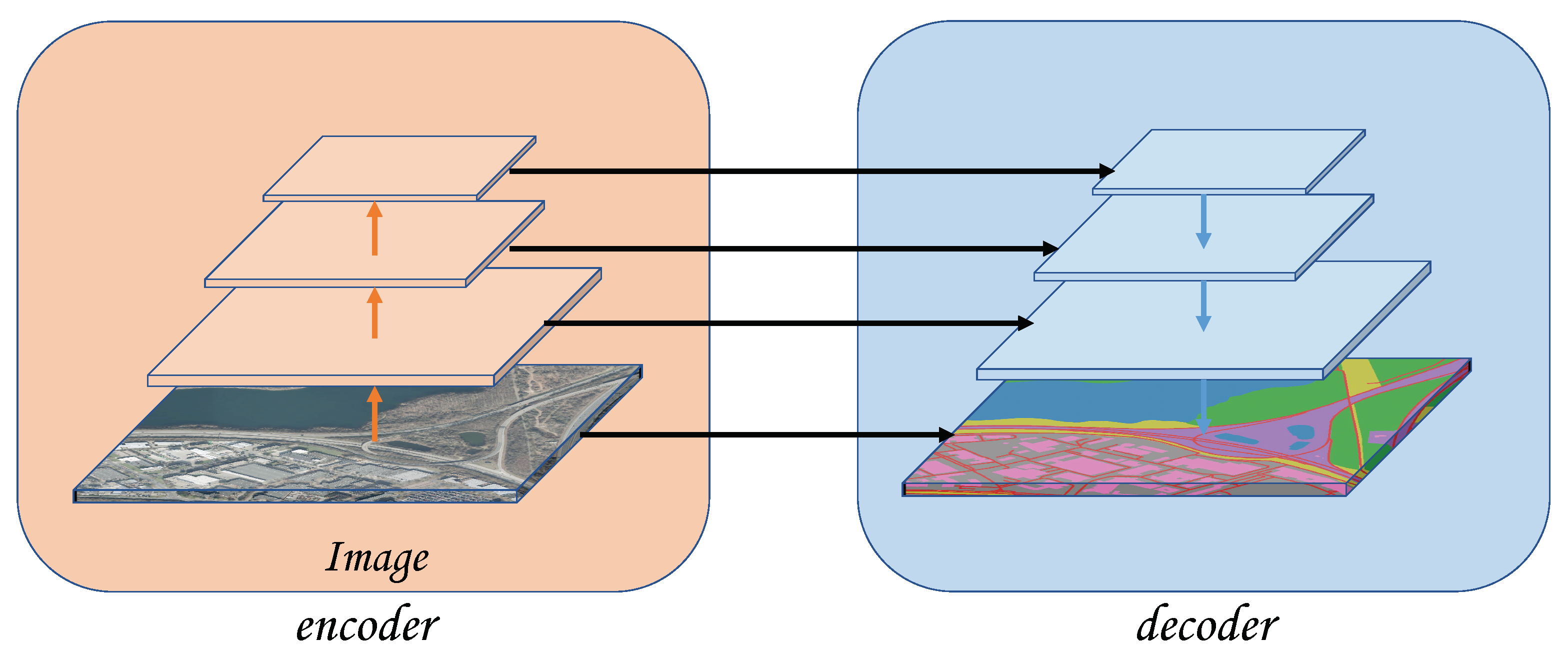
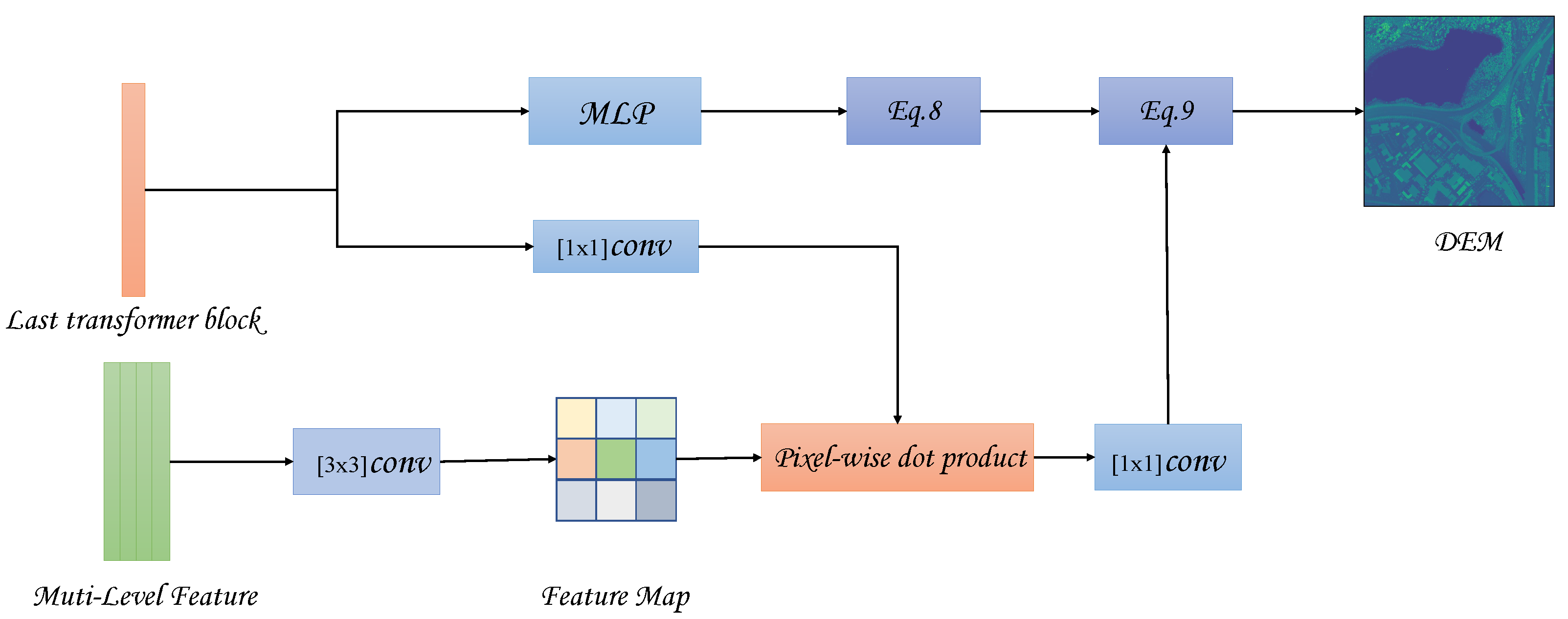
In this paper, we combine the relative height estimation task and semantic segmentation task into one task (as shown in
Figure 1). We hope that this multi-task learning [
39] can mutually promote in training, so an outcome better than the single task method can emerge. Experiments show that our method is superior to the recent multi-task learning and is significantly smaller than other models in parameter quantity. In summary, the main contributions of this paper are as follows:
We change the relative height estimation in multi-task learning from a regression task to a classification task and the whole multi-task learning into a classification task to better balance the tasks.
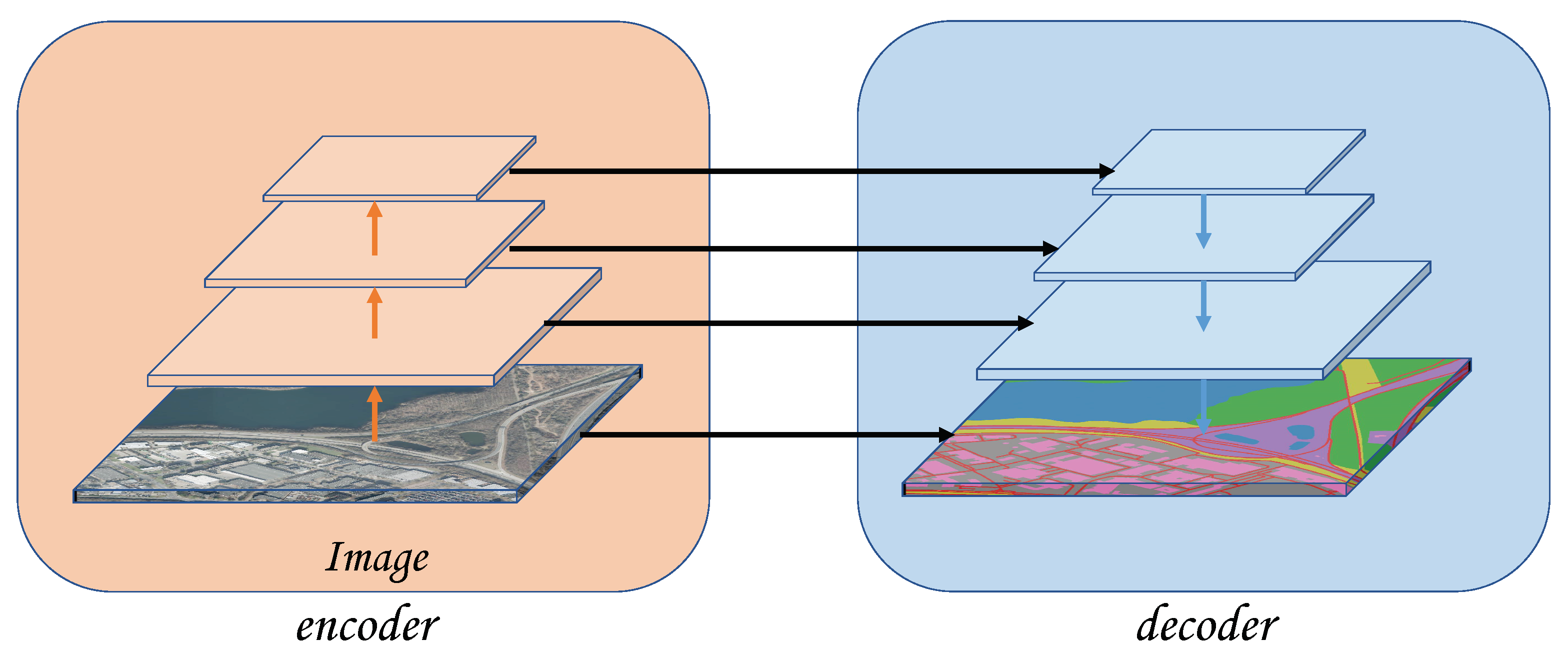
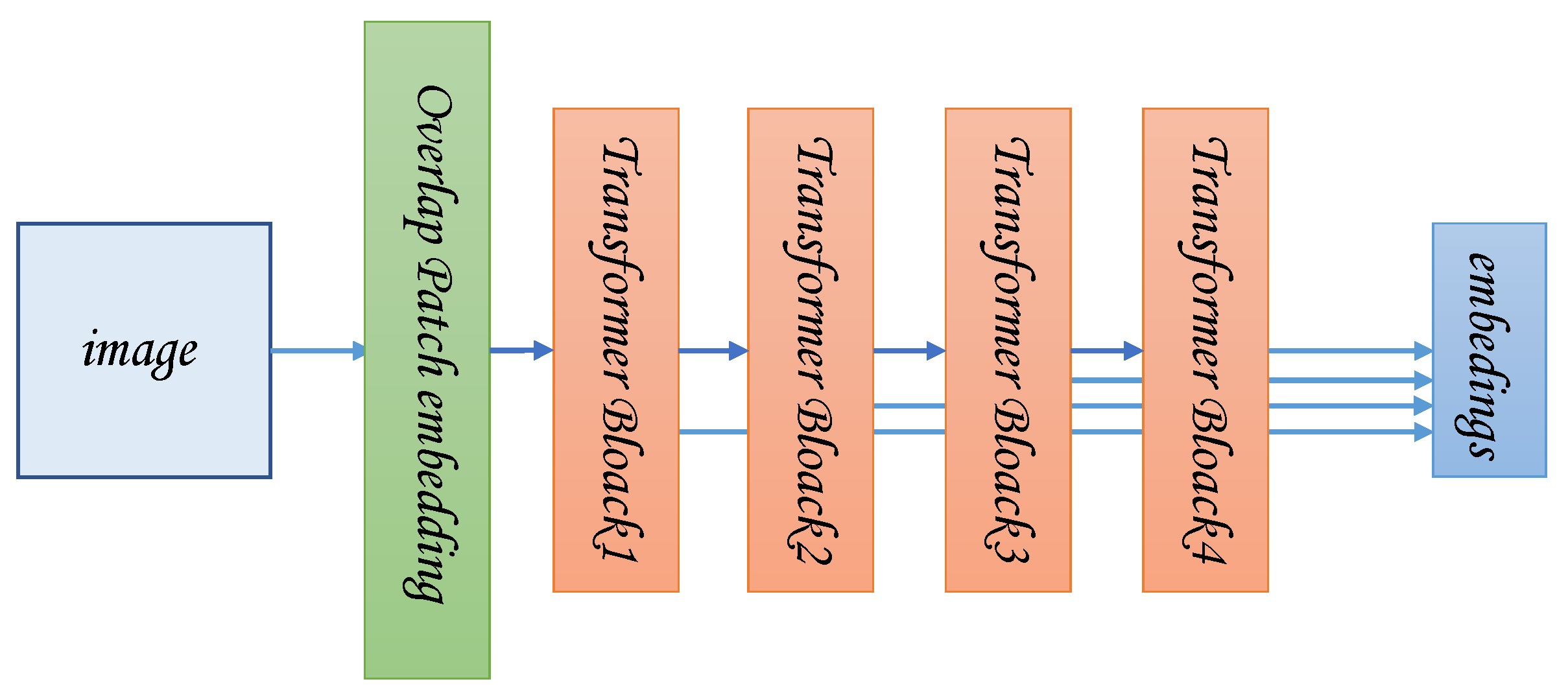
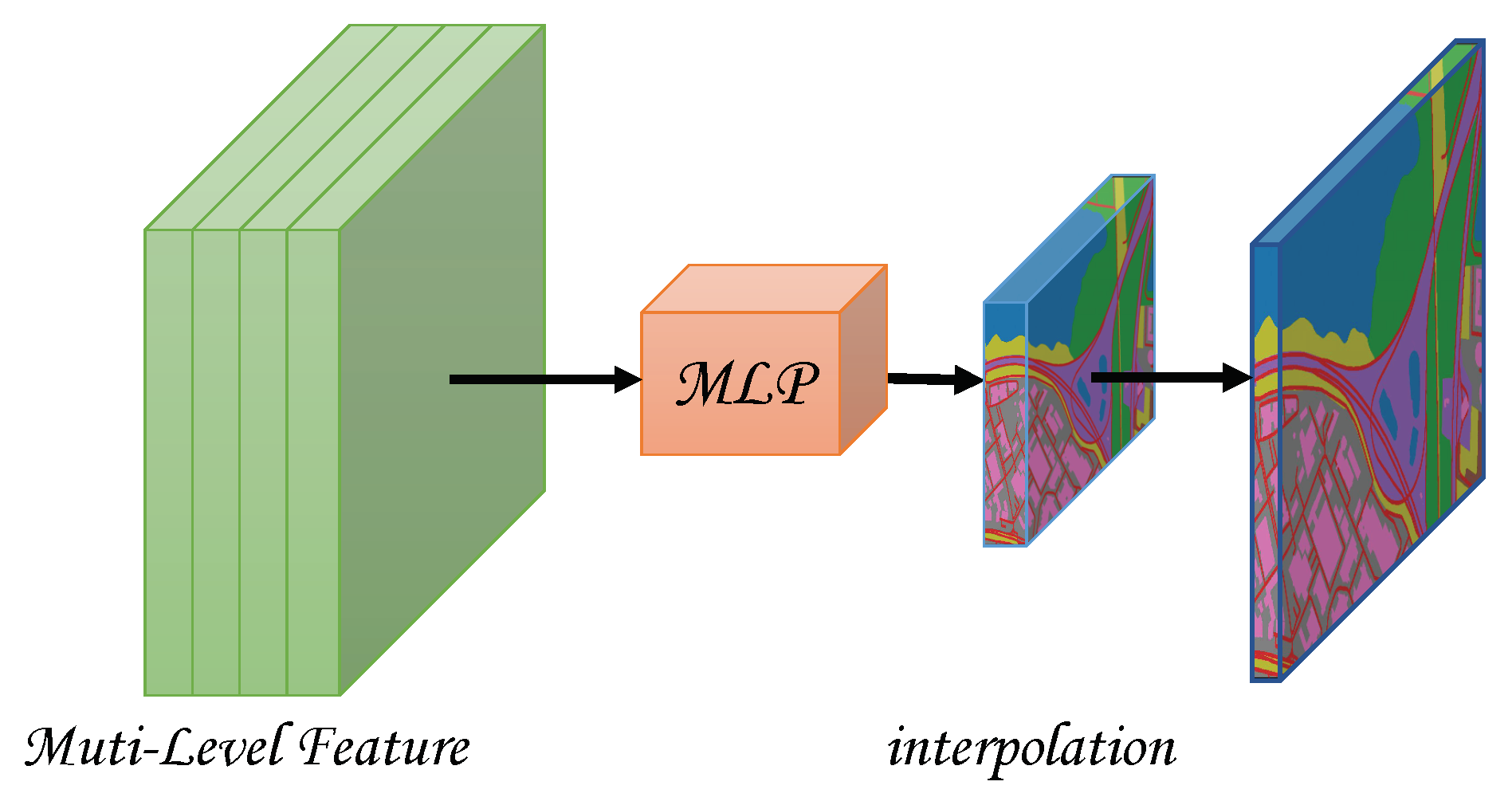
A unified architecture to realize semantic segmentation and relative height estimation. Our backbone uses a pure transformer structure, and only a small amount of convolution and MLP layers are used in the Segmentation module and Depth module (
Figure 1).
In the relative height estimation module, we transform the original continuous value regression into ordinal number regression.
The whole neural network adopts an end-to-end structure, and only pairs of images are required for training.
4. Experiment
4.1. Dataset
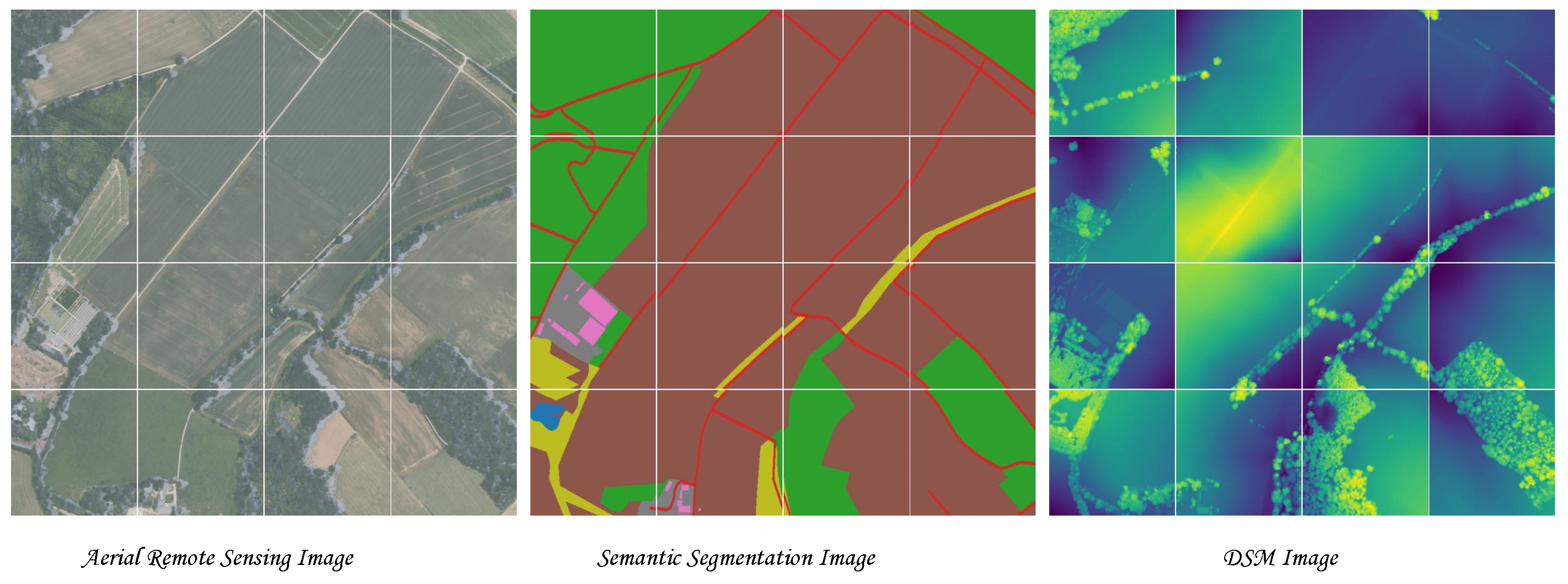
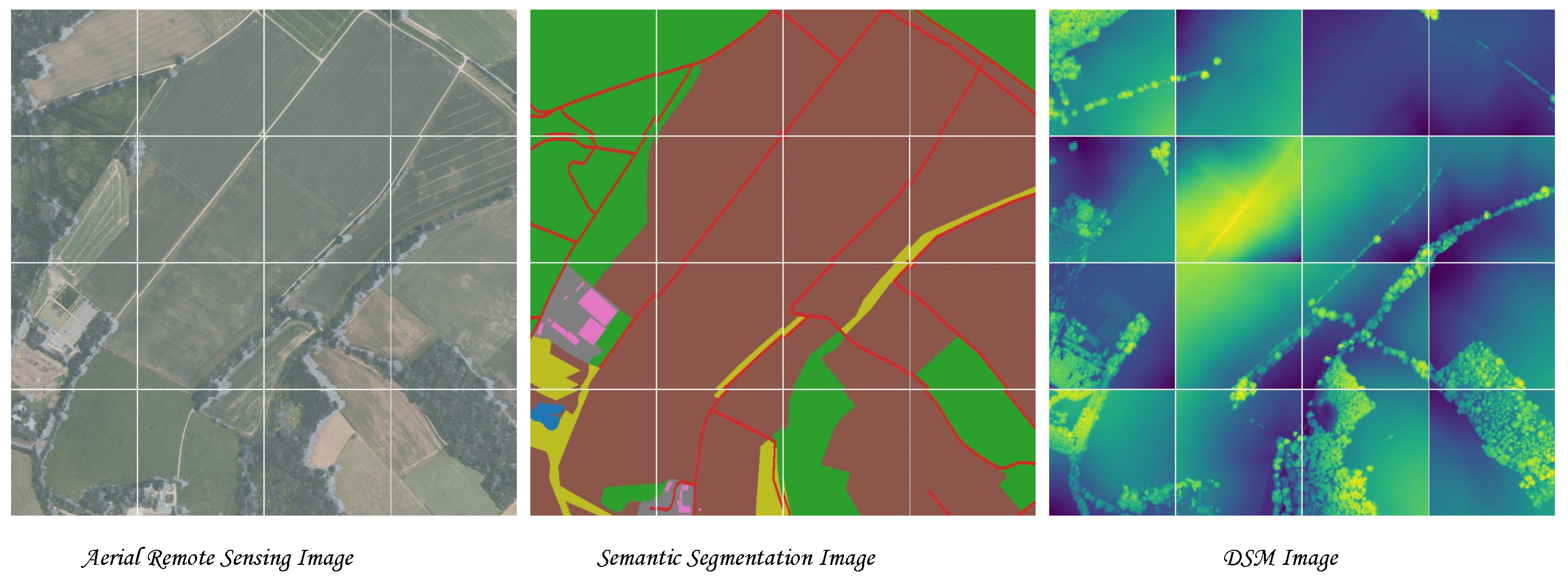
GeoNRW [72]. We use the high-resolution remote sensing dataset GeoNRW to verify the effectiveness of our method. The dataset includes remote sensing satellite images, semantic segmentation images, and DSM images, and the relationship between them is a one-to-one correspondence. See
Figure 10 for the distribution of feature types in the dataset. For DSM images, we change the minimum value of each image to 0, converting the original DSM to relative height [
53].
The dataset includes orthophoto-corrected aerial photos, light detection and ranging (LIDAR)-derived DSM and 10 types of land cover maps from the German state of North-Rhine Westphalia. The pre-processing of the dataset includes downsampling the orthophoto-corrected aerial photos with a resolution of 10 cm to 1 m, which conveniently keeps the aerial remote sensing image and DSM image at the exact resolution. In our experiments, we found that there are partial annotation problems in the semantic segmentation of the dataset, including the inaccurate classification of objects and more than 10 categories.
Through statistical analysis of ground types, the following problems exist in the distribution of original data:
There are obvious problems of unbalanced distribution in data distribution. Some categories have a large number, while others have a small number.
Through the examination of DSM distribution, we find that the DSM data distribution is too large, which increases the difficulty of DSM generation, and the transformation into relative elevation estimation will greatly reduce the task difficulty.
The first problem mentioned above is usually solved by directly weighing different types of losses in training. In our training, we also adopted this method. Specifically, for each category, the weight calculation formula is as follows:
Before processing, we divided the original
image into
image with partial overlap, as shown in
Figure 11.
Data Fusion Contest 2018 (DFC2018) dataset [
73]. The dataset is a collection of multisource optical images from Houston, Texas. The data include ultra-high resolution (VHR) color images resampled at 5 cm/pixel, hyperspectral images, and DSM and DEM obtained with lidar, particularly at 50 cm/pixel resolution. The original DCF2018 dataset does not contain a height map, so we use DSM minus DEM to obtain the height within the area.
Figure 12 shows the distribution of the dataset.
The OSI dataset [
54]. The dataset is an optical image set from Dublin, including the height obtained by lidar and the corresponding color image, with a 15 cm/pixel resolution. In particular, all data are collected by UAV, with a flight height of about 300 m and a total coverage area of 5.6 square kilometers.
4.2. Data Augmentation
Data augmentation is an indispensable step in deep learning image processing. It refers to performing transformation operations on the training sample data to generate new data. The fundamental purpose of data expansion is to provide more abundant training samples through image transformation, increase the robustness of the training model and avoid model over-fitting.
For our definition of the task, because remote sensing images are the data source, the imaging process of the sensor captures the same image objects of different points of view that will be displayed on the image of different locations and shapes. This can make model transformation after the sample much easier to understand regarding the characteristics of the rotating invariance, to better adapt to the different forms of the image. Therefore, we introduced geometric transformation in training, including horizontal and vertical flips.
Meanwhile, since we need to obtain relative height information from the image, there is no hard data augmentation for the image. Since relative height data are distributed in an extensive range, we must manually map relative height data. The specific formula is as follows:
Through the above equation, we shift the minimum height value of each image to 0, which can help the model better learn the concept of relative height.
4.3. Network Training Strategy and Evaluation Metric
In deep learning experiments, warmup is usually added in training to prevent the model from fitting data too early, reducing the risk of over-fitting and improving the model’s expression ability. Warmup usually has 1–3 epochs at the beginning of training. In our experiment, we used 2000 iterations.
Evaluation Metric is divided into Pixel Accuracy, Mean Accuracy, Mean IoU (MIoU), test height Error ABS, test height Error REL, RMSE, MAE, and SSIM. Among them, the first three items are all evaluation indexes to measure semantic segmentation, and the last five are to measure relative height estimation accuracy. The calculation formula of each evaluation index is as follows:
where
represents the ground true value,
represents the result of model prediction,
and
represent the true value of model prediction at
,
and
are the mean values of
X and
Y,
and
are the standard deviations of
X and
Y,
,
, and
are constants, respectively.
4.4. Implementation Details
On the experimental platform, we used an AMD core R9-5900x 3.70 GHz 12 core processor with 32.0 GB memory (Micro DDR4 3200 mhz) and a Geforce RTX 3090 graphics card with 24 GB video memory. In terms of the software environment, we used the Ubuntu operating system. The programming language used is Python, and the deep learning framework used is PyTorch. For the design of experimental parameters, we design batchsize = 64, learning rate = 6 × 10
−4, warm-up iterations = 2000, total iterations = 100,000, and we use AdamW optimization algorithm to accelerate the training of the model, where
,
,
. For more details, the code for our work will be available at
https://github.com/Neroaway/Multi-Task-Learning-of-Relative-Height-Estimation-and-Semantic-Segmentation-from-Single-Airborne-RGB.
6. Conclusions
This paper proposes a novel multi-task learning model different from previous multi-task learning based on attention mechanisms. Based on the transformer, this paper uses multi-level semantic information and global information to carry out semantic segmentation and relative height estimation at the same time, and the whole model uses only a small amount of convolution structure, which makes the calculation and parameters of the whole model less than the previous methods. In order to balance the competition and network deviation in multi-task learning, we design a momentum method to measure the task’s difficulty and further determine the optimization direction of the network. The model was tested on three data sets, and its performance is significantly better than other state-of-the-art methods, and the reasoning speed is also significantly faster than other methods. The results show that the model can effectively model problems in related fields. Moreover, in order to further illustrate the rationality of the model design, we conducted a relevant ablation study for part of the loss function design.
For future work, there remain many avenues where our method can be further studied and explored. (1) Design a more reasonable multi-task model. Although our model has achieved good results, the relative height estimation module design can still be further explored. (2) A more reasonable multi-task learning balance method. In our model, we only consider the momentum lost by the model and do not balance multi-tasks from the perspective of the gradient. Methods to design a better multi-task learning balance model is the key to multi-task learning. (3) More reasonable loss function. Regarding the loss function, it helps the model better mine the information in the image. For multi-task, the loss function design can accelerate the model’s convergence and improve the model’s robustness. (4) More robust data enhancement. In our experiment, we only use the flip operation as to not affect the original image data distribution. For the deep learning model, data enhancement is key. Better data enhancement can make the model more robust and effective. The method proposed in this paper is simple and feasible, and the model performs far better than the other most advanced deep learning methods. In this method, the corresponding region’s classification result and relative height can be obtained using a single RGB image without other additional information. Compared with the traditional method of obtaining relative height, this method dramatically reduces the time and labor cost of data collection and the difficulties brought by subsequent complex data processing.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}