1. Introduction
Three-dimensional city modeling has significantly advanced in recent decades as we move towards the concept of Digital Twin Cities (DTCs) [
1], where 3D point clouds are widely used as a major input [
2,
3,
4]. The development of a three-dimensional city model requires a detailed 3D survey of the urban fabric. Lidar technology is widely used for this purpose. It allows capturing geometric and spectral information of objects in the form of 3D point clouds. This acquisition system provides a large amount of precise data with a high level of detail, quickly and reliably. Nevertheless, the transition from 3D point clouds to the urban model is tedious, essentially manual, and time-consuming [
2]. Today, the major challenge is to automate the process of 3D digital model reconstruction from 3D Lidar point clouds [
3] while reducing the costs associated with it. Deep Learning (DL) methods are increasingly used to improve the semantic segmentation of 3D point clouds [
4]. Semantically segmented point clouds are the foundation for creating 3D city models. The resulting semantic models are used to create DTCs that support a plethora of urban applications [
5].
In the literature, different approaches to reconstructing 3D urban models from Lidar data have been proposed. Among the developed methods, Martinovic et al. [
6] proposed a methodology for 3D city modeling using 3D facade splitting, 3D weak architectural principles, and 3D semantic classification. It is a technique that produces state-of-the-art results in terms of computation time and precision. Furthermore, Zhang et al. [
7] used a pipeline with residual recurrent, Deep-Q, and Convolutional Neural Networks (CNN) to classify and reconstruct urban models from 3D Lidar data. Additionally, Murtiyoso et al. [
8] and Gobeawan et al. [
9] presented two workflows for the generation of CityGML models for roof extraction and tree objects from point clouds, respectively. Moreover, several research teams have focused on merging the point clouds with other data sources to take advantage of the benefits of each. For instance, Loutfia et al. [
10] developed a simple semi-automatic methodology to generate a 3D digital model for the urban environment based on the fusion of ortho-rectified imagery and Lidar data. In the proposed workflow, data semantic segmentation was carried out with an overall precision of almost 83.51%. The obtained results showed that the proposed methodology could successfully detect several types of buildings, and the Level of Detail (LoD2) was created by integrating the roof structures in the model [
10]. Similarly, Kwak et al. [
11] introduced an innovative framework for fully automated building model generation by exploiting the advantages of images and Lidar datasets. The main drawback of the proposed methodology was that it could only model the types of buildings that decompose into rectangles. Comparably, Chen et al. [
12] obtained the buildings’ present status and their reconstruction models by integrating Terrestrial Laser Scanning (TLS) and UAV (Unmanned Aerial Vehicle) photogrammetry.
Two main stages are essential to building a three-dimensional city model from 3D point clouds: semantic segmentation and 3D modeling of the resulting semantic classes. The first consists of assigning semantic information for each point based on homogeneous criteria [
13]. In the literature, many developments were conducted in the field of 3D semantic segmentation of point clouds, which can be classified into three families. The first one is based on the raw point clouds; the second is based on a derived product from the point clouds; the third combines 3D point clouds and additional information (optical images, classified images, etc.). The richness and the accuracy of a 3D urban model created from point clouds depend on the acquisition, semantic segmentation, and modeling processes.
DL in geospatial sciences has been an active research field since the first CNN (Convolutional Neural Network) was developed for road network extraction [
14]. Thanks to their capacity for processing large multi-source data with good performance, DL techniques revolutionize the domain of computer vision and are state-of-the-art in several tasks, including semantic segmentation [
15,
16]. Now, there is a lot of interest in developing DL algorithms for processing three-dimensional spatial data.
For the 3D semantic segmentation task, several papers have stated that the fusion of 3D point clouds with other sources (drone images, satellite images, etc.) is promising [
17,
18,
19,
20] thanks to the planimetric continuity of the images and the altimetric precision of point clouds. Currently, the scientific research in this niche of multi-source data fusion for semantic segmentation is oriented more towards the use of large amounts of additional information (point clouds, multispectral, hyperspectral, etc.). It requires significant financial and material resources, as well as a lot of computational memory and consequently a high computation time. Furthermore, these data-intensive approaches need to collect different types of data in a minimal time interval to avoid any change in the urban environment [
21]. In addition, some information would not add much to the differentiation of urban objects. This motivates us to develop a new methodology of fusion that requires less additional information while ensuring high performance.
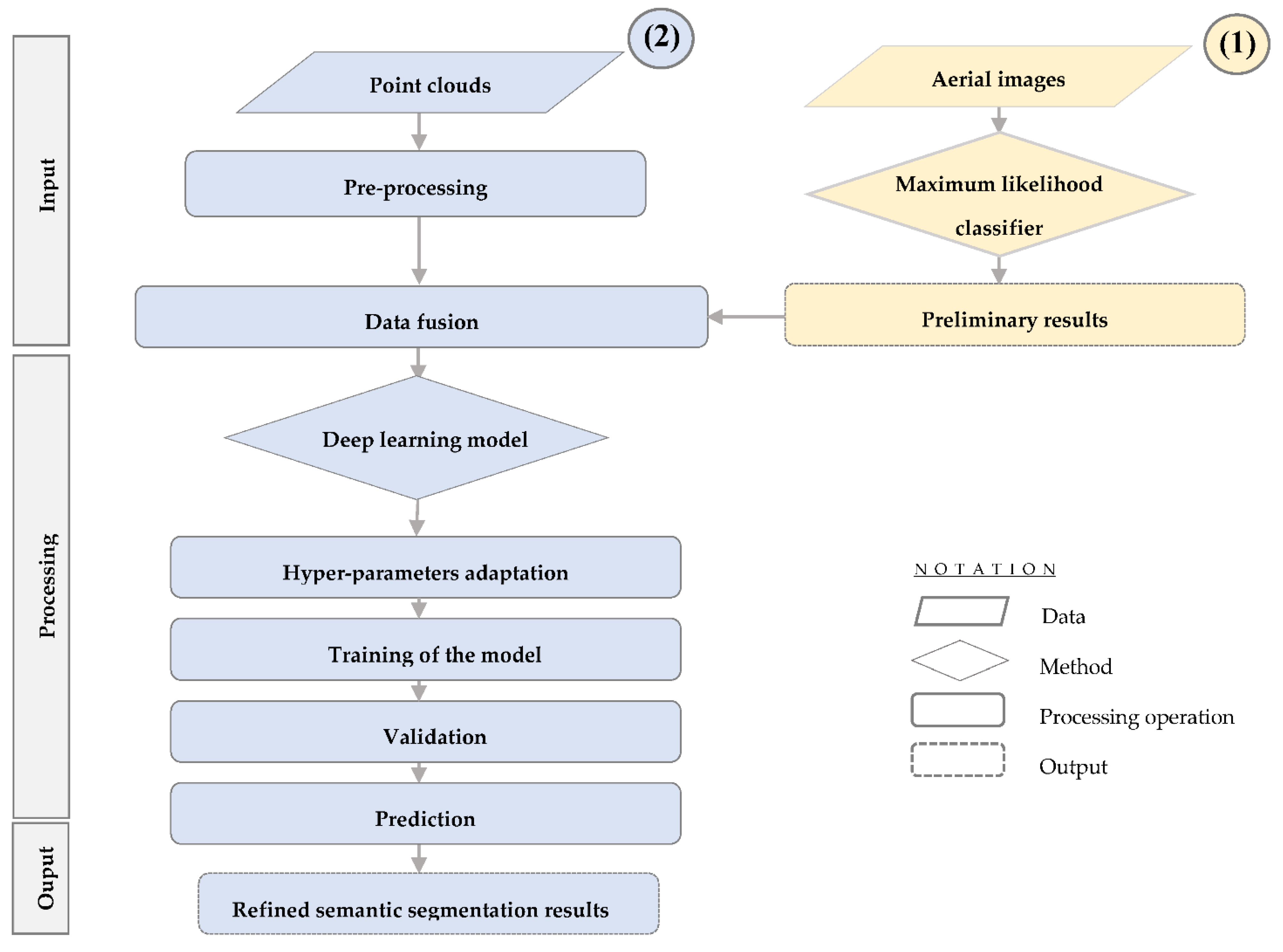
In this paper, a semantic segmentation approach was developed. It is based on multi-source data (raw point clouds and aerial images) and adopted an advanced deep neural network model. The proposed process can serve as an operational methodology to extract the urban fabric from point clouds and images with better accuracy. It uses a standard method for image classification, in which the training areas were chosen according to the classes present in the Lidar dataset. This technique solves the problem posed by the incoherence of the semantic classes present in the Lidar and image datasets.
To briefly summarize, this paper makes the following four major contributions:
A less data-intensive fusion approach for 3D semantic segmentation using optical imagery and 3D point clouds;
An adaptation of an advanced DL method (RandLaNet) to improve the performance of three-dimensional semantic segmentation;
A solution to solve the problem of the incoherence of the semantic classes present in the Lidar and image datasets at the fusion step;
A new airborne 3D Lidar dataset for semantic segmentation.
The present paper is structured as follows: In
Section 2, the main developments in fusion-based approaches for semantic segmentation of Lidar point clouds are presented.
Section 3 provides a comprehensive description of the proposed fusion approach. The experiments and results analysis are the subjects of
Section 4. Finally, the paper ends with a conclusion.
2. Related Work
With the increasing demand for three-dimensional land use and urban classification, 3D semantic segmentation of multi-sensor data has become a current research topic. Data fusion methodologies have achieved good results in semantic segmentation [
22], and several studies have demonstrated that fusing 3D point clouds and image data can improve segmentation results [
23,
24,
25].
Various datasets available online, such as S3DIS [
26], Semantic3D [
27], SensatUrban [
28], etc., have further boosted the scientific research of DL on 3D Lidar data, with an increasing number of techniques being proposed to address several problems related to 3D point cloud processing, mainly 3D semantic segmentation [
4]. There has been an increasing number of research studies about adapting DL techniques or introducing new ones to semantically segment 3D point clouds. The developed methodologies can be classified into four methods: (1) projection of the point cloud into a 3D occupancy grid such as in [
29]; (2) projection of the point cloud on images, and then the semantic segmentation of each image using DL techniques of image semantic segmentation [
30]; (3) the use of CRFs to work more on graphs of the cloud as in the case of the SegCloud technique [
31] or more by conducting convolutions on graphs as in the case of the SPGraph method [
32]; (4) the use of networks that directly consume the point clouds and that can respect the ensemblist properties of a point cloud such as RandLaNet [
33]. However, CNNs do not yet obtain similar performance on 3D point clouds as those achieved for image or voice analysis [
32]. This opens the way to intensify the scientific research in this direction to enhance their performance.
Recently, research studies concluded that Lidar and multispectral images have distinct characteristics that render them better in several applications [
23,
34]. The fusion of multispectral images and 3D point clouds would achieve good performance in several applications compared to using a single type of data source. Indeed, the imagery, although relevant for the delineation of accurate object contours, is less suitable for the acquisition of detailed surface models. Lidar data, while considered a major input for the production of very detailed surface models, is less suitable for the delimitation of object limits [
23] and can simply distinguish urban objects based on height values. Furthermore, due to the lack of spectral information, Lidar data can present semantic segmentation confusion between some urban objects (e.g., artificial objects and natural objects); consequently, the fusion of multispectral images and 3D point clouds can compensate for each other [
23] towards more accurate and reliable semantic segmentation results [
22].
Four fusion levels exist to merge Lidar and image data [
35]. The first one is prior-level fusion. It assigns 2D land cover (prior knowledge) from a multispectral image to the 3D Lidar point clouds and then uses a DL technique to obtain 3D semantic segmentation results. The second is point-level fusion which assigns spectral information from image data to the points and then trains the classifier using a deep neural network to classify the 3D point clouds with multispectral information. The third is feature-level fusion which concatenates the features extracted from 3D points clouds and image data by a deep neural network and deep convolutional neural network, respectively. After concatenation, the features can be fed to an MLP (MultiLayer Perceptron) to derive the 3D semantic segmentation results. The fourth is decision-level fusion, which consists of semantically segmenting the 3D Lidar data and multispectral image to obtain 3D and 2D semantic segmentation results, respectively. Subsequently, the two types of data are combined using a fusion technique as a heuristic fusion rule [
36]. In this research, a new prior-level approach is proposed, in which the classified images and the raw point clouds are linked and then classified by an advanced deep neural network structure. The major objective is to improve the performance of 3D semantic segmentation.
The previous methods can be classified into two categories: (1) images based approaches and (2) point clouds-based approaches.
2.1. Image-Based Approaches
In these approaches, 3D point clouds represent auxiliary data for 2D urban semantic segmentation, while the multispectral image is the primary data. Point clouds are usually rasterized to Digital Surface Models (DSM) and other structural features, notably deviation angle and height difference.
Past research studies demonstrated the potential of the use of multi-source aerial data for semantic segmentation, where the 3D point cloud is transformed into a regular form that is easy to manipulate and segment [
37]. The first study that showed the difficulty of differentiating regions with similar spectral features using only multispectral data was proposed by [
38], where the authors used DSMs as a complementary feature to further improve the semantic segmentation results. They investigated four fusion processes based on the proposed DSMF (DSM Fusion) module to highlight the most suitable method and then designed four DSMFNets (DSM Fusion Networks) according to the corresponding process. The proposed methodologies were evaluated using the Vaihingen dataset, and all DSMFNets attained favorable results, especially DSMFNet-1, which reached an overall accuracy of 91.5% on the test dataset. In the same direction, Pan et al. [
39] presented a novel CNN-based methodology named FSN (Fine Segmentation Network) for semantic segmentation of Lidar data and high-resolution images. It follows the encoder–decoder paradigm, and multi-sensor fusion is realized at the feature level using MLP (Multi-Layer Perceptron). The evaluation of this process using ISPRS (International Society for Photogrammetry and Remote Sensing) Vaihingen and Potsdam benchmarks shows that this methodology can bring considerable improvements to other related networks. Furthermore, Zhang et al. [
40] proposed a fusion method for semantic segmentation of DSMs with infrared or color imagery. They deducted an optimized scheme for the fusion of layers with elevation and image into a single FCN (Fully Convolutional Networks) model. The methodology was evaluated using the ISPRS Potsdam dataset and the Vaihingen 2D Semantic Labeling dataset and demonstrated significant potential. Comparably, Lodha et al. [
41] transformed Lidar data into a regular bidimensional grid, which they georegistered to grey-scale airborne imagery of the same grid size. After fusing the intensity and height data, they generated a 5D feature space of image intensity, height, normal variation, height variation, and Lidar intensity. The work achieved a precision of around 92% using the “AdaBoost.M2” extension for multi-class categorization. Furthermore, Weinmann et al. [
42] proposed the fusion of multispectral, hyperspectral, color, and 3D point clouds collected by aerial sensor platforms for semantic segmentation in urban areas. The MUUFL Gulfport Hyperspectral and Lidar aerial datasets were used to assess the potential of the combination of different feature sets. The results showed good quality, even for a complex scene collected with a low spatial resolution. Similarly, Onojeghuo et al. [
43] proposed a framework for combining Lidar data with hyperspectral and multispectral imagery for object-based habitat mapping. The integration of spectral information with all Lidar-derived measures produced a good overall semantic segmentation.
To sum up, previous studies state that although the networks have the strength to utilize the convolution operation for both elevation information and multispectral image, data may be distorted principally in case of sparse data interpolation. This distortion can affect the results of semantic segmentation depending upon transformation techniques or the efficacy of the interpolation. In addition, the transformation of 3D point clouds into DSM or 2.5D data can provide obscure data, but, in terms of the prospects of fusion techniques by DL methods, these methods are relatively simpler and easier, as they consider the geometric information as a two-dimensional image representation [
17].
2.2. Point Clouds Based Approaches
In these methods, 3D point clouds play a key role in 3D semantic segmentation; the multispectral image represents the auxiliary data, and its spectral information is often simply interpolated as an attribute of 3D point clouds [
44].
Among the methodologies developed in this sense, Poliyapram et al. [
17] proposed a neural network for aerial image and 3D points clouds point-wise fusion (PMNet) that respects the permutation invariance characteristics of 3D Lidar data. The major objective of this work is to improve the semantic segmentation of 3D point clouds by fusing additional aerial images acquired from the same geographical area. The comparative study conducted using two datasets collected from the complex urban area of the University of Osaka and Houston, Japan, shows that the proposed network fusion “PointNet (XYZIRGB)” surpasses the non-fusion network “PointNet (XYZI)” [
17]. Another fusion method named LIF-Seg was proposed in [
18]. It is simple and makes full use of the contextual information of image data. The obtained results show performance superior to state of the art methods by a large margin [
18]. On the other hand, some research works are based on extracting features from the image data using a neural network and merging them with the Lidar data as in [
19], which demonstrated that additional spectral information improves the semantic segmentation results of 3D points. Furthermore, Megahed et al. [
34] developed a methodology by which Lidar data were first georegistered to airborne imagery of the same location so that each point inherits its corresponding spectral information. The geo-registration added red, green, blue, and near-infrared bands to the Lidar’s intensity and height feature space as well as the calculated normalized difference vegetation index. The addition of spectral characteristics to the Lidar’s height values boomed the semantic segmentation results to surpass 97%. Semantic segmentation errors occurred among different semantic classes due to independent acquisition of airborne imagery and Lidar data as well as orthorectification and shadow problems from airborne imagery. Furthermore, Chen et al. [
36] proposed a fusion method of semantic segmentation that combines multispectral information, including the near-infrared, red, etc., and point clouds. The proposed method achieved global accuracy of 82.47% on the ISPRS dataset. Finally, the authors of [
20] proceed by mapping the preliminary segmentation results obtained by images to point clouds according to their coordinate relationships in order to use the point clouds to extract the plane of buildings directly.
To summarize, the aforementioned approaches, in which 3D point clouds are the primary data, show notable performance, especially in terms of accuracy. Among their benefits, they preserve the original characteristics of point clouds, including precision and topological relationships [
37].
2.3. Summary
Scientific research is more oriented to the use of several spatial data attributes (X, Y, Z, red, green, blue, near-infrared, etc.) [
34,
36,
42,
43] by developing fusion-based approaches for semantic segmentation. These last ones have shown good performance in terms of precision, efficiency, and robustness. However, they are more data-intensive and require performant computing platforms [
21]. This is due to the massive characteristics of the fused data, which can easily exceed the memory limit of desktop computers. To overcome these problems, it seems useful to envisage less costly fusion approaches based on less additional information while maintaining precision and performance. To achieve this objective, a prior-level fusion approach combining images and point clouds is proposed, which is able to improve the performance of semantic segmentation, including contextual image information and geometrical information.
4. Experiments and Results Analysis
4.1. Implementation
The RandLA-Net model described above was used for the implementation of the Plf4SSeg approach. This choice is justified by the fact that this model uses random point sampling instead of more complex point selection methods. Therefore, it is computationally and memory efficient. Moreover, it introduces a local feature aggregation module in order to progressively increase the receptive field for each tridimensional point, thus, preserving the geometric details.
Additionally, “Ubuntu with python” was used to perform both approaches: it is a GNU/Linux distribution and a grouping of free software that can be adapted by the user. For Python libraries, the choice is not obvious. Indeed, many DL frameworks are available; each has its limitations and its advantages. The Scikit-Learn library was chosen due to its efficiency: this is a free Python library for machine learning, which provides a selection of efficient tools for machine learning and statistical modeling, including semantic segmentation, regression, and clustering via a consistent interface in Python. The TensorFlow deep learning API was used for the implementation of DL architecture. It was developed to simplify the programming and the use of deep networks.
All computations were processed by Python programming language v 3.6, on Ubuntu v 20.04.3. Cloud Compare v 2.11.3 was used to visualize the 3D Lidar point clouds. The code framework of the RandLaNet model adopted was Tensorflow-gpu v 1.14.0. The code was tested with CUDA 11.4. All experiments were conducted on an NVIDIA GeForce RTX 3090. Data analysis was carried out on a workstation with the following specifications: Windows 10 Pro for workstations OS 64-bit, 3.70 GHz processor, and memory of 256G RAM.
The RandLaNet model used for the implementation of the Plf4SSeg approach was implemented by stacking random sampling layers and multiple local feature aggregation. A source code of its original version was used to train and test this DL model. It was published in open access on GitHub (
https://github.com/QingyongHu/RandLA-Net (accessed on 15 June 2022)); this code was tested using the prepared data (Each cloud contains: XYZ coordinates, intensity information, and corresponding classified image as an attribute of the cloud). Furthermore, the basic hyper-parameters were kept as they are crucial for the performance, speed, and quality of the algorithm. The Adam optimization algorithm was adopted with an initial learning rate equal to 0.01, an initial noise parameter equal to 3.5, and batch size during training equal to 4. During the test phase, two sets of point clouds (from the created dataset) were prepared according to the formalities of the Plf4SSeg approach (i.e., each point cloud must contain the attributes X, Y, Z, intensity, and image classification). Subsequently, these data were introduced into the pre-trained network to deduce the semantic labels for each group of homogeneous points without any pre/postprocessing such as block partitioning.
4.2. Results
The performance of the Plf4SSeg approach was evaluated using the created dataset. Several evaluation criteria were adopted. In addition to the metrics (accuracy, recall, F1 score, and overall accuracy), the visual quality of the results was also considered. This section demonstrates the obtained results and provides a comparative analysis with the non-fusion approach, which uses the raw point clouds only.
4.2.1. Metrics
The accuracy of the semantic segmentation results is influenced by several factors, such as the urban context, the DL technique, and the quality of the training and evaluation data. Precision, recall, accuracy, intersection over union, and F1 score are often used to evaluate the effect of a point cloud semantic segmentation [
51]. The following are the evaluation metrics that were used to assess the semantic segmentation results:
TP, TN, FP, and FN are true positive, true negative, false positive, and false negative, respectively.
TP, FP, and FN are true positive, false positive, and false negative, respectively.
4.2.2. Quantitative and Qualitative Assessments
As already mentioned, the results of the evaluation of both metrics and visual examination of the proposed process are presented in
Table 1. Subsequently, the results obtained were compared with the non-fusion approach (
Table 2). The objective was to study the contribution of data fusion to semantic segmentation quality.
- A.
Results of Plf4SSeg approach
The quality assessment of the semantic segmentation was evaluated through the aforementioned metrics by comparing the output of the model and the reference test data that were labeled.
Table 1 below report the resulting metrics.
From
Table 1, it appears that the quality of predictions of the different classes is significantly better on the reference samples except for the water class. Additionally, the metrics obtained for the building and vegetation classes are slightly higher than the cars and impervious surfaces classes. The obtained results indicate that the model is reliable for the prediction of unseen data. It should be noted that the low metrics obtained in the water class are justified by its confusion with vegetation classes since they present almost the same altitude. In addition, the Plf4SSeg approach tends to fail in the water class due to the lack of water surfaces in the study area.
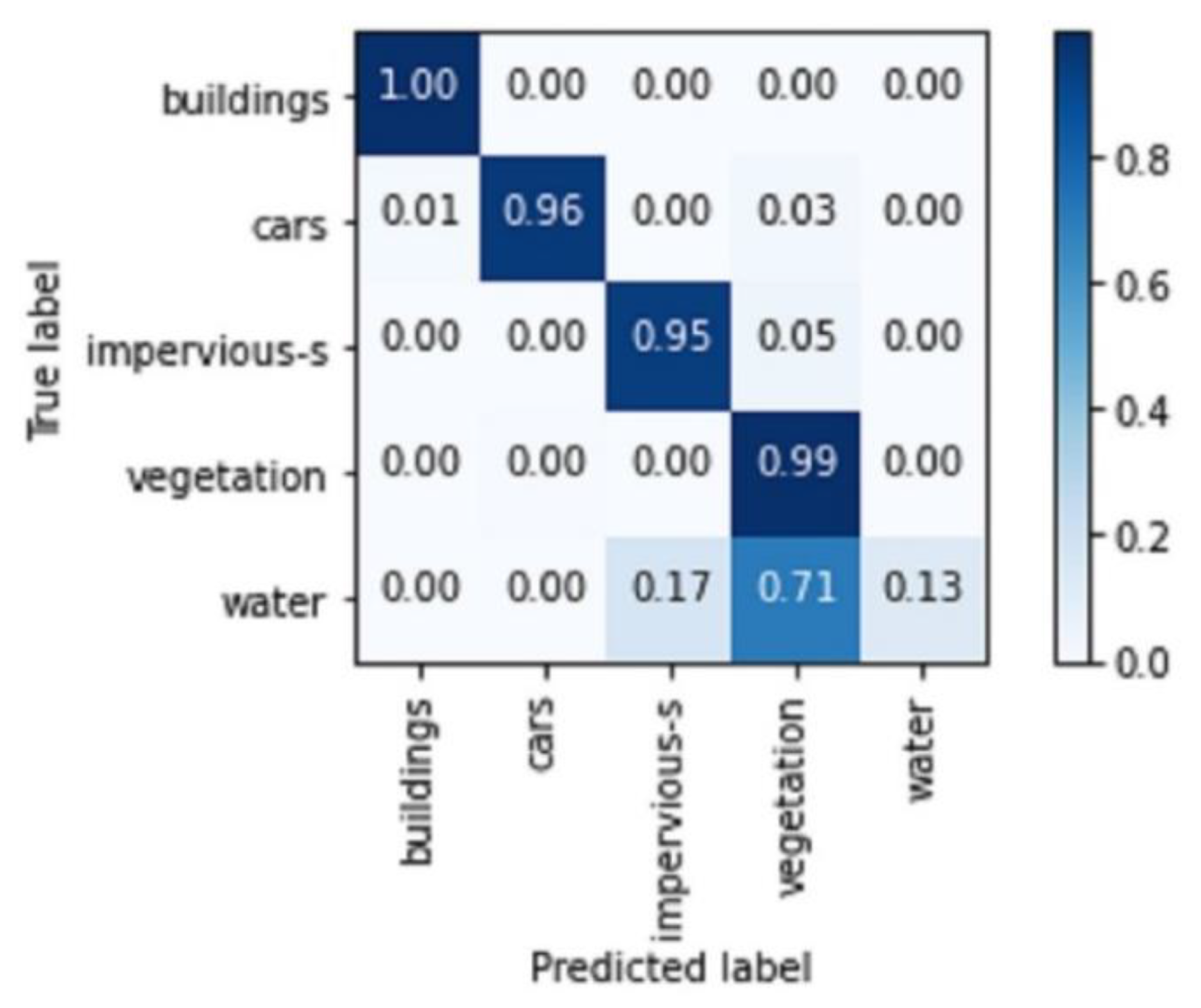
The confusion matrix presented below (
Figure 8) shows that the model very accurately classified buildings (100% correct), cars (96% correct), impervious surfaces (95% correct), and vegetation (99%). The analysis of this matrix also shows that the confusion between the different semantic classes is low, except for the water class, which is strongly confused with vegetation.
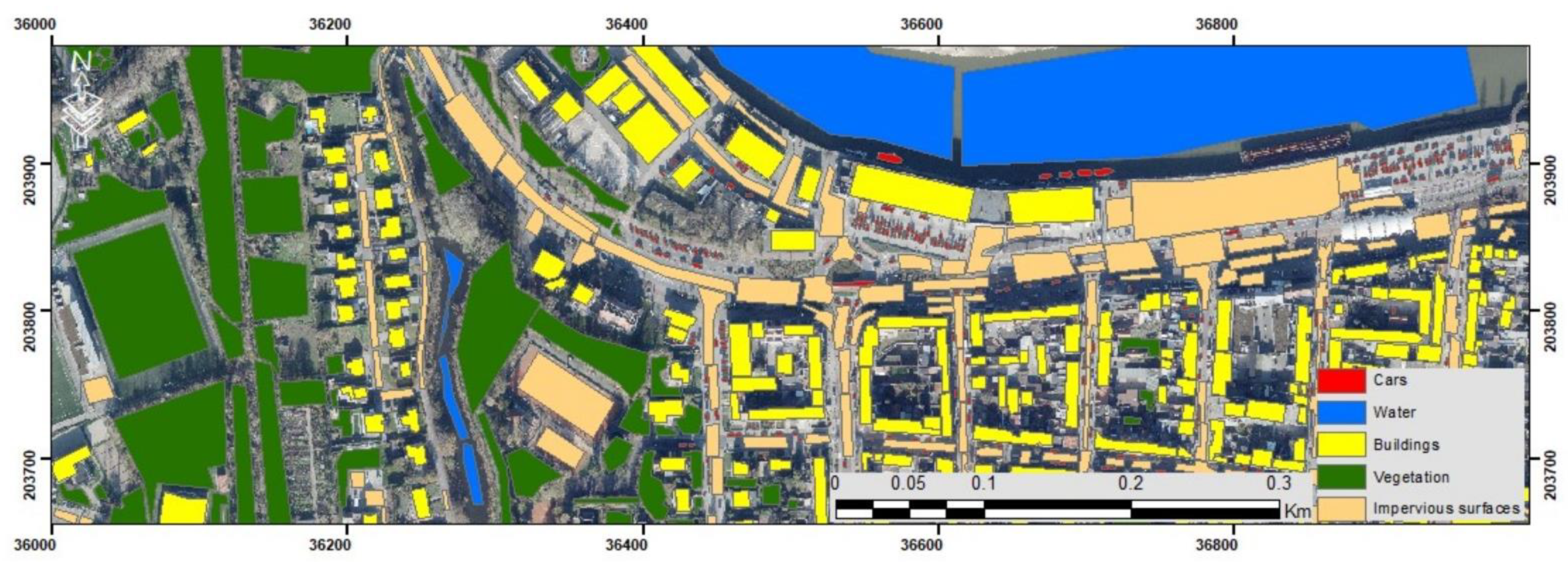
Finally, the semantic segmentation approach based on data fusion of raw point clouds and classified images highlights the different urban objects present in the study area. To better visually evaluate these semantic segmentation results, these last ones were superimposed on point clouds of the study area. The examples of point clouds (
Figure 9A) and their corresponding semantic segmentation results (
Figure 9B) are illustrated below (
Figure 9).
At first sight, the obtained predictions are very close to the reference image. This leads us to conclude that the Plf4SSeg approach is successful in associating semantic labels for the different urban objects with better quality, where buildings, vegetation, cars, and impervious surfaces were extracted accurately with clear boundaries.
- B.
Comparison with the non-fusion approach
In this research, the contribution of classified images in the 3D semantic segmentation using as attributes the raw point clouds and the classification of the corresponding images was studied. The obtained results were then compared with the non-fusion approach, which uses XYZ coordinates and intensity only.
Table 2 show the quantitative evaluation of the test results for different approaches.
Table 2 uses metrics such as precision, F1 score, accuracy, recall, and intersection over union to evaluate the performance in detail. RandLaNet (X, Y, Z, intensity information, image classification) shows a significant improvement compared to RandLaNet (X, Y, Z, I) in terms of both precision (0.98) and F1 score (0.97), and hence, it demonstrates that the fusion method is more performant than the one using only (X, Y, Z, I) (
Table 2). It significantly outperforms the other process in terms of accuracy (0.98) and IoU (0.96).
The calculation of the different metrics allows us to quantitatively evaluate the quality of the semantic segmentation results produced in the two study cases. The results show a clear improvement in the case of the Plf4SSeg approach compared to the non-fusion methodology with an intersection over union of 0.96 and an F1 score of 0.97. The overall accuracy of the semantic segmentation improves (98%) as well as the other calculated metrics. Consequently, the potential attributes proposed are important to include in the segmentation process, given their interest in the differentiation of the urban objects present in the captured scene.
To summarize, an adequate parameterization of the DL model with an appropriate choice of the different attributes to be included is relevant for a very good performance of semantic segmentation.
4.3. Discussion
Three-dimensional Lidar semantic segmentation is a fundamental task for producing 3D city models and DTCs for city management and planning. However, semantic segmentation is still a challenging process which requires high investment in terms of material and financial resources. In this paper, a new less-data-intensive fusion DL approach based on merging point clouds and aerial images was proposed to meet this challenge.
The particularity of the Plf4SSeg fusion approach compared to most existing fusion methods is that it requires less additional information by combining Lidar point clouds and classified images. The latter was obtained by a classification of RGB images using the MLC. The majority of users avoid using fusion approaches due to their high cost in terms of additional information, as well as required hardware resources for processing and computing. The Plf4SSeg method offers the possibility of using classified images from different data sources, namely satellite images, UAV images, etc., which increases its feasibility and usability. In addition, the developed methodology is adapted to different Lidar datasets. Indeed, the use of a standard method for image classification offers the possibility to choose the semantic categories according to those present in the 3D Lidar datasets. This technique conserves the semantic richness of the Lidar datasets instead of opting for an adaptation of the semantic classes present in the Lidar and image datasets. Furthermore, compared to the methods from the literature that transform the point cloud into a regular shape, the Plf4SSeg approach treats the 3D Lidar data without any interpolation operation and preserves its original quality.
The Plf4SSeg approach takes into consideration geometric and radiometric information. Additionally, the merging of different data sources was conducted during the data preparation step. This way of combination improves the learning of the DL method, which can positively influence the model prediction results. Finally, the developed semantic segmentation process applies to airborne data acquired in large-scale urban environments, so it is very useful to highlight the different urban objects present in the city scale (buildings, vegetation, etc.). On the other hand, for the training, validation, and testing of the DL technique, an airborne Lidar dataset was created, and that will be published online later. The created dataset presents the main semantic classes that are very useful for different urban applications, which are buildings, vegetation, impervious surfaces, cars, and water. The results are satisfactory for all semantic classes except for the water class, representing a very small percentage in the dataset. The comparative study shows that the Plf4SSeg approach improves all metrics over the non-fusion approach using the test data.
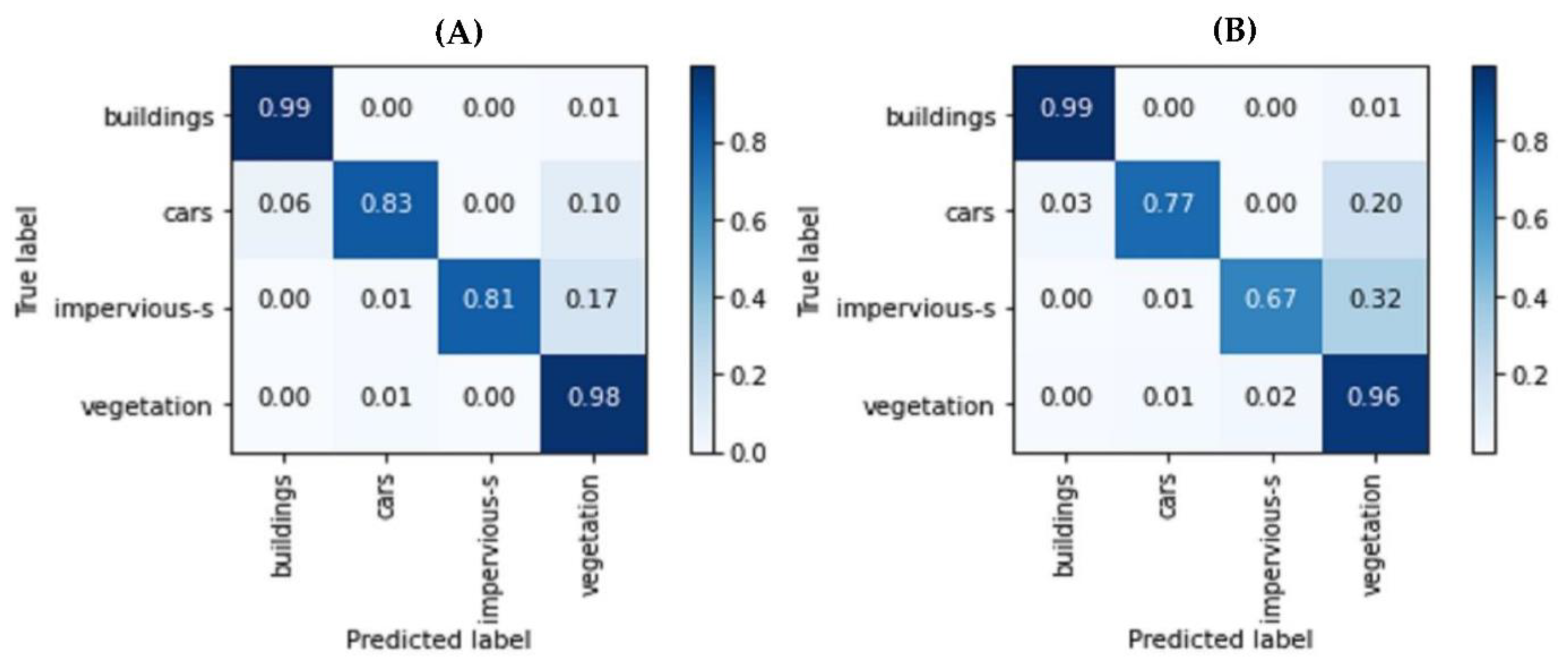
Three-dimensional semantic segmentation results were studied in detail by computing a percentage-based confusion matrix with a ground truth label. In
Figure 10 below, A (the Plf4SSeg approach) and B (non-fusion approach) show the percentage-based confusion matrix for a point cloud from the test data, respectively. This percentage-based analysis provides an idea about the percentage of consistent and non-consistent points. The Plf4SSeg approach shows a higher percentage of consistency than the non-fusion approach. Additionally, in the case of the non-fusion approach, confusion in some semantic classes was observed, for example, cars and impervious surfaces with vegetation. However, in the case of the proposed approach, low confusion between these classes was obtained. The height consistency obtained can be justified by the addition of already classified spectral information, which facilitated the distinction of the different classes.
The evaluation of the Plf4SSeg approach that requires less additional information compared to data-intensive approaches combining large amounts of additional information (point clouds, multispectral, hyperspectral, etc.) shows that the developed methodology can achieve compared or superior results against these expensive methodologies. Some examples of common semantic classes are taken; for example, in the case of the class buildings, higher accuracy was obtained compared to those obtained by [
43] at the level of the built-up area class, with all tested techniques using the merged Eagle MNF Lidar datasets. Similarly, in the case of the class of cars, higher accuracy was achieved compared to the one obtained by [
36] (71.4), which used the ISPRS dataset. Another example is the revealed confusion between the two semantic classes, buildings and vegetation, in [
34], contrary to this work, in which the two semantic classes are well classified (
Table 1).
Finally, it should be noted that this research work presents certain limitations, including the choice of the training zones that is conducted manually in the case of image classification. Additionally, the Plf4SSeg approach should be tested in other urban contexts that contain numerous objects. As a perspective, we suggest investigating the proposed semantic segmentation process in several urban contexts by choosing numerous semantic classes and by also considering the case of other terrestrial and airborne datasets. The objective is to evaluate the performance and the limitations of the proposed approach when confronted with other contexts.
5. Conclusions
In this study, a prior-level and less data-intensive approach for 3D semantic segmentation based on images and airborne point clouds was proposed and compared with a process based only on point clouds. The proposed approach assigns the raster values from each classified image to the corresponding point cloud. Moreover, it adopted an advanced deep neural network (RandLaNet) to improve the performance of 3D semantic segmentation. Another main contribution of the proposed methodology is that the semantic segmentation of aerial images is based on training zones selected accordingly to the semantic classes of the Lidar dataset, which allows solving the problem of the incoherence of the semantic classes present in the Lidar and image datasets. Consequently, the proposed approach was adapted for all Lidar dataset types. Another advantage of the proposed process was its flexibility in the choice of image type to use; that is, all types of images, including satellites, drones, etc., can be used. The Plf4SSeg approach, although it is based on less additional information, demonstrated good performance compared to both the non-fusion process based only on point clouds and the state-of-the-art methods. The experimental results using the created dataset show that the proposed data-intensive approach delivers a good performance, which is manifested mainly in intersection over union (96%) and F1 score (97%) metrics that are high in the 3D semantic segmentation results. Therefore, an adequate parameterization of the DL model with an appropriate choice of the different attributes to be included allowed us to achieve a very good performance. However, the proposed process was a bit long, and the image classification part required a little human intervention when manual identification of training zones. Low precision was obtained in the water class due to the lack of water surfaces in the study area. We suggest investigating the proposed approach in other urban contexts to evaluate its performance and limitations when confronted with other contexts.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}