
Ship Detection in Visible Remote Sensing Image Based on Saliency Extraction and Modified Channel Features


Abstract
:
1. Introduction
- Since the type of ships and sensor parameters are different, the scales of the ship targets are also inconsistent.
- Color, texture, and other factors of the ship cause a low correlation of target grayscale.
- Sea clutter, ship wakes, islands, clouds, and low light intensity may bring some interference to the detection.
- Target rotation causes poor robustness of the relevant feature.
- Huge computation burden for the large-scale remote sensing data leads to the reduction of detection speed.
2. Candidate Region Extraction
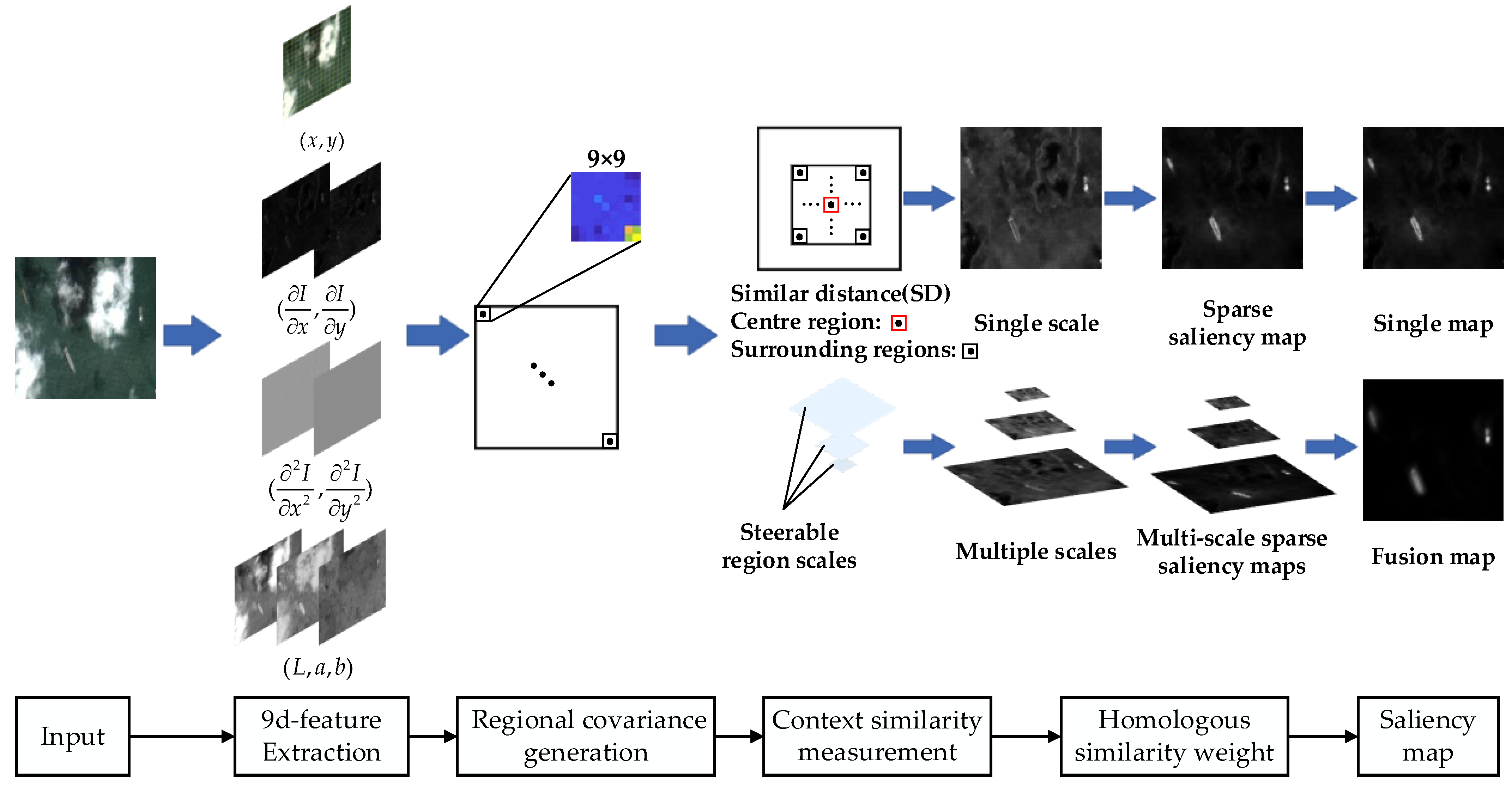
2.1. The Proposed Visual Saliency Model
2.2. Multi-Scale Fusion of Saliency Maps
2.3. Candidate Target Extraction
3. Ship Target Identification
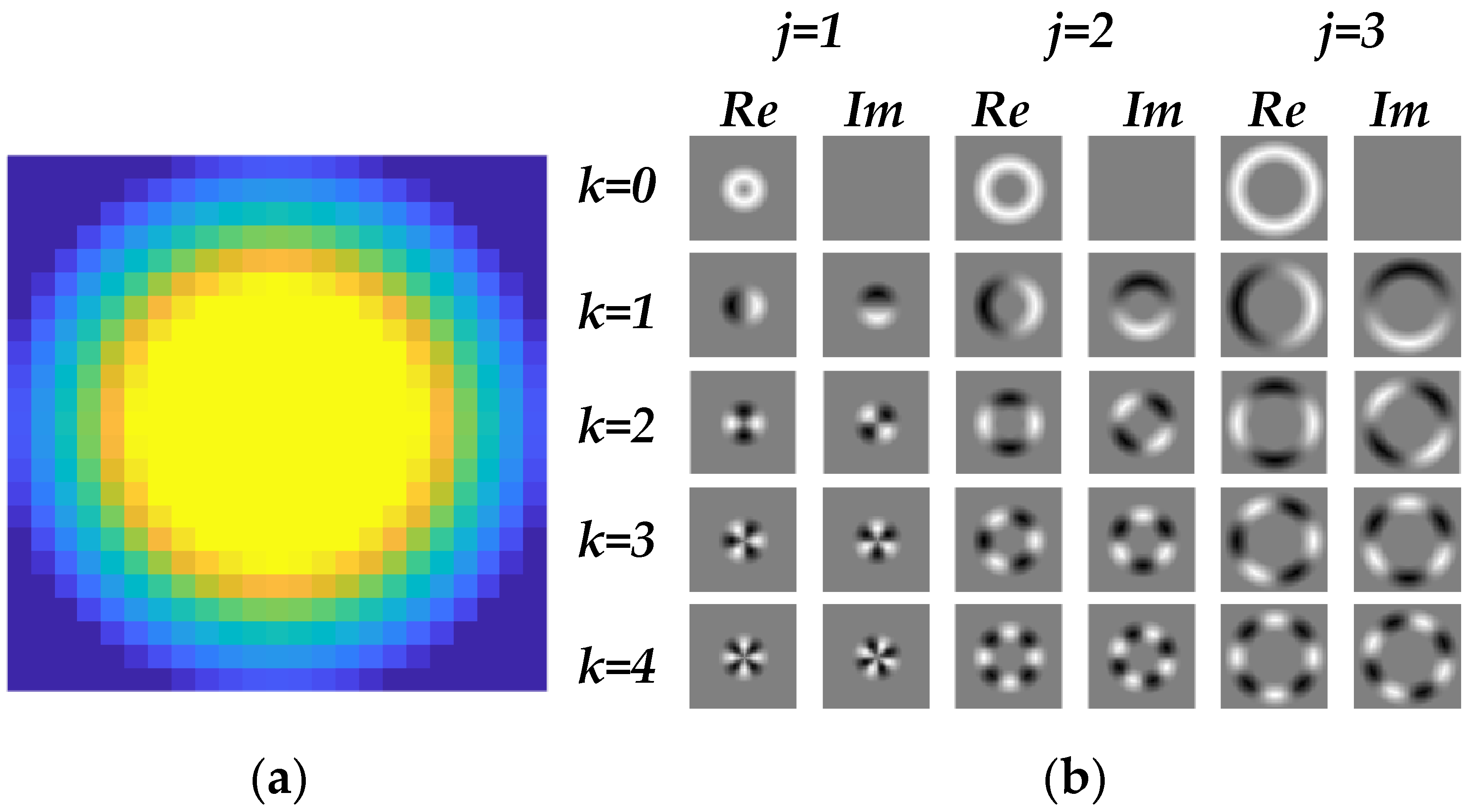
3.1. Fourier HOG Convolution Feature Generation
3.2. CF Feature Generation
3.3. CF-Fourier HOG Channel Feature Classification
4. Experiment Results
4.1. VRS Ship Dataset
4.2. The Comparative Experiments of Saliency Extraction
4.2.1. Subjective Comparison
- If multiple targets exist in a small range, our saliency result shows less aggregation phenomenon (in the first row of Figure 13), which is conducive to obtaining every target after the following threshold segmentation.
- If the contrast between the targets and the background is low, such as the presence of the thin cloud (in the second row of Figure 13), our method can guarantee the integrity of the target. In addition, if there is the interference from thick cloud (in the third row of Figure 13), our saliency method removes cloud interference further and is more effective.
- If there is interference such as the wake waves and the islands (in the fourth, fifth and sixth row of Figure 13), our saliency method performs best in comparison with all the above algorithms. In terms of the proposed model, not only can it remove most of the interference, but also is best in the edge weakening effect than other methods.
4.2.2. Quantitative Comparison
4.3. Rotation-Invariant Channels Verification
4.4. Overall Detection Performance and Comparison
4.4.1. Preparations
4.4.2. Comparison of Overall Detection Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, J.; Tian, J.; Gao, P.; Li, L. Ship Detection and Fine-Grained Recognition in Large-Format Remote Sensing Images Based on Convolutional Neural Network. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Waikoloa, HI, USA, 26 September–2 October 2020. [Google Scholar]
- Lei, Y.; Leng, X.; Ji, K. Marine Ship Target Detection in SAR Image Based on Google Earth Engine. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 11–16 July 2021. [Google Scholar]
- Zhang, R.; Su, Y.; Li, Y.; Zhang, L.; Feng, J. Infrared and Visible Image Fusion Methods for Unmanned Surface Vessels with Marine Applications. J. Mar. Sci. Eng. 2022, 10, 588. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Harvey, N.; Porter, R.; Theiler, J. Ship Detection in Satellite Imagery Using Rank-Order Grayscale Hit-or-Miss Transforms. In Proceedings of the Conference on Visual Information Processing XIX, Orlando, FL, USA, 6–7 April 2010. [Google Scholar]
- Wang, S.; Stahl, J.; Bailey, A.; Dropps, M. Global Detection of Salient Convex Boundaries. Int. J. Comput. Vis. 2007, 71, 337–359. [Google Scholar] [CrossRef]
- Yan, H. Aircraft Detection in Remote Sensing Images Using Centre-Based Proposal Regions and Invariant Features. Remote Sens. Lett. 2020, 11, 787–796. [Google Scholar] [CrossRef]
- Shi, Z.; Yu, X.; Jiang, Z.; Li, B. Ship Detection in High-Resolution Optical Imagery Based on Anomaly Detector and Local Shape Feature. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4511–4523. [Google Scholar]
- Tang, J.; Deng, C.; Huang, G.; Zhao, B. Compressed-Domain Ship Detection on Spaceborne Optical Image Using Deep Neural Network and Extreme Learning Machine. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1174–1185. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Ship Detection in Spaceborne Optical Image with SVD Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Xu, F.; Liu, J.; Sun, M.; Zeng, D.; Wang, X. A Hierarchical Maritime Target Detection Method for Optical Remote Sensing Imagery. Remote Sens. 2017, 9, 280. [Google Scholar] [CrossRef] [Green Version]
- Nie, T.; Han, X.; He, B.; Li, X.; Liu, H.; Bi, G. Ship Detection in Panchromatic Optical Remote Sensing Images Based on Visual Saliency and Multi-Dimensional Feature Description. Remote Sens. 2020, 12, 152. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Xie, X.; Wei, X.; Tang, W. Ship Detection and Classification from Optical Remote Sensing Images: A survey. Chin. J. Aeronaut. 2021, 34, 145–163. [Google Scholar] [CrossRef]
- Zhou, H.T.; Zhuang, Y.; Chen, L.; Shi, H. Signal and Information Processing, Networking and Computers, 3rd ed.; Springer: Singapore, 2018; pp. 164–171. [Google Scholar]
- Uijlings, J.; van de Sande, K.; Gevers, T.; Smeulders, A. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Xie, M. Beyond Sliding Windows: Object Detection Based on Hierarchical Segmentation Model. In Proceedings of the International Conference on Communications, Circuits and Systems (ICCCAS), Chengdu, China, 15–17 November 2013. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A Model of Saliency-Based Visual Attention for Rapid Scene Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Achanta, R.; Estrada, F.; Wils, P.; Silsstrunk, S. Salient Region Detection and Segmentation. In Proceedings of the International Conference on Computer Vision Systems (ICVS), Santorini, Greece, 12–15 May 2008. [Google Scholar]
- Hou, X.; Zhang, L. Saliency detection: A Spectral Residual Approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Yang, F.; Xu, Q.; Gao, F.; Hu, L. Ship Detection from Optical Satellite Images Based on Visual Search Mechanism. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015. [Google Scholar]
- Yang, F.; Xu, Q.; Li, B.; Ji, Y. Ship Detection from Thermal Remote Sensing Imagery through Region-Based Deep Forest. IEEE Geosci. Remote. Sens. Lett. 2018, 15, 449–453. [Google Scholar] [CrossRef]
- Dong, C.; Liu, J.; Xu, F. Ship Detection in Optical Remote Sensing Images Based on Saliency and A Rotation-Invariant Descriptor. Remote Sens. 2018, 10, 400. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Hong, D.; Tian, J.; Chanussot, J.; Li, W.; Tao, R. ORSIm Detector: A Novel Object Detection Framework in Optical Remote Sensing Imagery Using Spatial-Frequency Channel Features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5146–5158. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Ma, L.; Chen, H. Arbitrary-Oriented Ship Detection Framework in Optical Remote-Sensing Images. IEEE Geosci. Remote. Sens. Lett. 2018, 15, 937–941. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hong, Z.; Yang, T.; Tong, X.; Zhang, Y.; Jiang, S.; Zhou, R.; Han, Y.; Wang, J.; Yang, S.; Liu, S. Multi-Scale Ship Detection from SAR and Optical Imagery Via a More Accurate YOLOv3. IEEE J. Sel. Top Appl Earth Obs. Remote Sens. 2021, 14, 6083–6101. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2020, arXiv:1804.02767. [Google Scholar]
- Wang, C.; Liao, H.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid Attention Network for Semantic Segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Shi, Q.; Li, W.; Tao, R.; Sun, X.; Gao, L. Ship Classification Based on Multi-feature Ensemble with Convolutional Neural Network. Remote Sens. 2019, 11, 419. [Google Scholar] [CrossRef] [Green Version]
- Wang, N.; Li, B.; Wei, X.; Wang, Y.; Yan, H. Ship Detection in Spaceborne Infrared Image Based on Lightweight CNN and Multisource Feature Cascade Decision. IEEE Trans Geosci. Remote Sens. 2021, 59, 4324–4339. [Google Scholar] [CrossRef]
- You, Y.; Cao, J.; Zhang, Y.; Liu, F.; Zhou, W. Nearshore Ship Detection on High-Resolution Remote Sensing Image via Scene-Mask R-CNN. IEEE Access 2019, 7, 128431–128444. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, H.; Shi, Z.; Zou, Z.X. Fully Convolutional Network with Task Partitioning for Inshore Ship Detection in Optical Remote Sensing Images. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 1665–1669. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Liu, B.; Wu, H.; Su, W.; Zhang, W.; Sun, J. Rotation-Invariant Object Detection Using Sector-ring HOG and Boosted Random Ferns. Vis. Comput. 2018, 34, 707–719. [Google Scholar] [CrossRef]
- Goferman, S.; Zelnik-Manor, L.; Tal, A. Context-Aware Saliency Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1915–1926. [Google Scholar] [CrossRef] [Green Version]
- Viola, P.; Jones, M. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Hong, X.; Chang, H.; Shan, S.; Chen, X.; Gao, W. Sigma Set: A Small Second Order Statistical Region Descriptor. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Erdem, E.; Erdem, A. Visual Saliency Estimation by Nonlinearly Integrating Features Using Region Covariances. J. Vis. 2013, 13, 11. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, H.; Zhang, L.; Yan, Y.; Liao, H. Visual Saliency Detection Based on Homology Similarity and An Experimental Evaluation. J. Vis. Commun. Image Represent. 2016, 40, 251–264. [Google Scholar] [CrossRef]
- Tuzel, O.; Porikli, F.; Meer, P. Region Covariance: A Fast Descriptor for Detection and Classification. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006. [Google Scholar]
- Peuwnuan, K.; Woraratpanya, K.; Pasupa, K. Modified Adaptive Thresholding Using Integral Image. In Proceedings of the International Joint Conference on Computer Science and Software Engineering (JCSSE), Khon Kaen, Thailand, 13–15 July 2016. [Google Scholar]
- Liu, K.; Skibbe, H.; Schmidt, T.; Blein, T.; Palme, K.; Brox, T.; Ronneberger, O. Rotation-Invariant HOG Descriptors Using Fourier Analysis in Polar and Spherical Coordinates. Int. J. Comput. Vis. 2014, 106, 342–364. [Google Scholar] [CrossRef]
- Kawato, S.; Tetsutani, N. Circle-Frequency Filter and Its Application. Ieice Tech. Rep. Image Eng. 2001, 100, 49–54. [Google Scholar]
- Yang, B.; Yan, J.; Lei, Z.; Li, S. Aggregate Channel Features for Multi-view Face Detection. In Proceedings of the IEEE/IAPR International Joint Conference on Biometrics (IJCB), Clearwater, FL, USA, 29 September–2 October 2014. [Google Scholar]
- Dollar, P.; Appel, R.; Belongie, S.; Perona, P. Fast Feature Pyramids for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-Class Geospatial Object Detection and Geographic Image Classification Based on Collection of Part Detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselines. In Proceedings of the International Conference on Pattern Recognition Applications and Methods (ICPRAM), Porto, Portugal, 24–26 February 2017. [Google Scholar]
- Gallego, A.J.; Pertusa, A.; Gil, P. Automatic Ship Classification from Optical Aerial Images with Convolutional Neural Networks. Remote Sens. 2018, 10, 4. [Google Scholar] [CrossRef] [Green Version]
- Al-Saad, M.; Aburaed, N.; Panthakkan, A.; Al Mansoori, S.; Al Ahmad, H.; Marshall, S. Airbus Ship Detection from Satellite Imagery using Frequency Domain Learning. In Proceedings of the Conference on Image and Signal Processing for Remote Sensing XXVII, Electric Network, online, 13–17 September 2021. [Google Scholar]
- Jiang, H.; Wang, J.; Yuan, Z.; Wu, Y.; Zheng, N.; Li, S. Salient Object Detection: A Discriminative Regional Feature Integration Approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Zhou, X.; Wang, D.; Krhenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Images | Class | Ship Instances | Image Size | Source |
|---|---|---|---|---|---|
| NWPU VHR-10 | 800 | 10 | 302 | / | Google Earth |
| HRSC2016 | 1061 | 3 | 2976 | 300 × 300~1500 × 900 | Google Earth |
| Airbus Ship dataset | 192,570 | 2 | / | 768 × 768 | Google Earth |
| MASATI | 6212 | 7 | 7389 | 512 × 512 | Aircraft |
| VRS ship dataset | 893 | 6 | 1162 | 512 × 512 | Google Earth |
| Methods | Backbone | Recall | Precision | F1 | AP@0.5 | AP@0.75 | AP@0.5:0.95 | Running Time (s) |
|---|---|---|---|---|---|---|---|---|
| HOG | / | 78.89% | 46.11% | 0.58 | 71.89% | / | / | 0.4852 |
| SSD | VGG-16 | 84.88% | 79.58% | 0.82 | 86.69% | 66.20% | 53.63% | 0.0089 |
| MobileNetv2 | 89.19% | 80.69% | 0.85 | 87.02% | 57.03% | 52.81% | 0.0083 | |
| Method in [24] | / | 90.16% | 88.24% | 0.89 | 87.25% | / | / | 0.2248 |
| Yolov3 | DarkNet-53 | 92.67% | 90.09% | 0.91 | 90.04% | 21.37% | 37.91% | 0.0154 |
| Fourier HOG | / | 89.84% | 94.12% | 0.92 | 91.47% | 64.56% | 59.28% | 1.3954 |
| Faster R-CNN | ResNet-50 | 84.57% | 92.49% | 0.88 | 91.61% | 52.50% | 50.14% | 0.0556 |
| EfficientNet | 88.34% | 91.59% | 0.93 | 92.05% | 62.17% | 58.39% | 0.0439 | |
| CenterNet | ResNet-50 | 94.33% | 91.45% | 0.93 | 92.34% | 76.38% | 65.42% | 0.0125 |
| Yolov4 | CSPDarknet53 | 92.79% | 86.31% | 0.89 | 91.55% | 39.51% | 46.27% | 0.0206 |
| Yolov5-Nano | CSPDarknet53 | 90.69% | 95.27% | 0.93 | 90.44% | 66.63% | 57.84% | 0.0124 |
| Yolov5s | CSPDarknet53 | 93.89% | 95.76% | 0.95 | 94.61% | 74.47% | 63.16% | 0.0125 |
| Yolov5m | CSPDarknet53 | 92.79% | 95.17% | 0.94 | 94.22% | 76.43% | 64.70% | 0.0161 |
| Yolov5l | CSPDarkNet53 | 93.62% | 92.22% | 0.93 | 94.32% | 79.03% | 66.15% | 0.0252 |
| Yolov5x | CSPDarknet53 | 95.10% | 93.37% | 0.94 | 95.70% | 80.30% | 68.10% | 0.0390 |
| Proposed Method | / | 94.27% | 92.73% | 0.93 | 94.46% | 77.99% | 65.37% | 0.1162 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Y.; Liu, J.; Zhu, S.; Xu, F.; Bai, G.; Liu, C. Ship Detection in Visible Remote Sensing Image Based on Saliency Extraction and Modified Channel Features. Remote Sens. 2022, 14, 3347. https://doi.org/10.3390/rs14143347
Tian Y, Liu J, Zhu S, Xu F, Bai G, Liu C. Ship Detection in Visible Remote Sensing Image Based on Saliency Extraction and Modified Channel Features. Remote Sensing. 2022; 14(14):3347. https://doi.org/10.3390/rs14143347
Chicago/Turabian StyleTian, Yang, Jinghong Liu, Shengjie Zhu, Fang Xu, Guanbing Bai, and Chenglong Liu. 2022. "Ship Detection in Visible Remote Sensing Image Based on Saliency Extraction and Modified Channel Features" Remote Sensing 14, no. 14: 3347. https://doi.org/10.3390/rs14143347
APA StyleTian, Y., Liu, J., Zhu, S., Xu, F., Bai, G., & Liu, C. (2022). Ship Detection in Visible Remote Sensing Image Based on Saliency Extraction and Modified Channel Features. Remote Sensing, 14(14), 3347. https://doi.org/10.3390/rs14143347