
RBFA-Net: A Rotated Balanced Feature-Aligned Network for Rotated SAR Ship Detection and Classification





Abstract
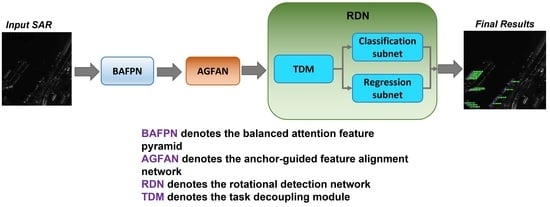
:
1. Introduction
- Balanced rotated feature-aligned network (RBFA-Net) is proposed for SAR ship recognition.
- A balanced-attention FPN is used for fusing multi-scale features and reducing the negative impact of the imbalance of different scale ships.
- A rotational detection module is used for fixing the position of ships with rotated bounding boxes and classifying the categories of ships.
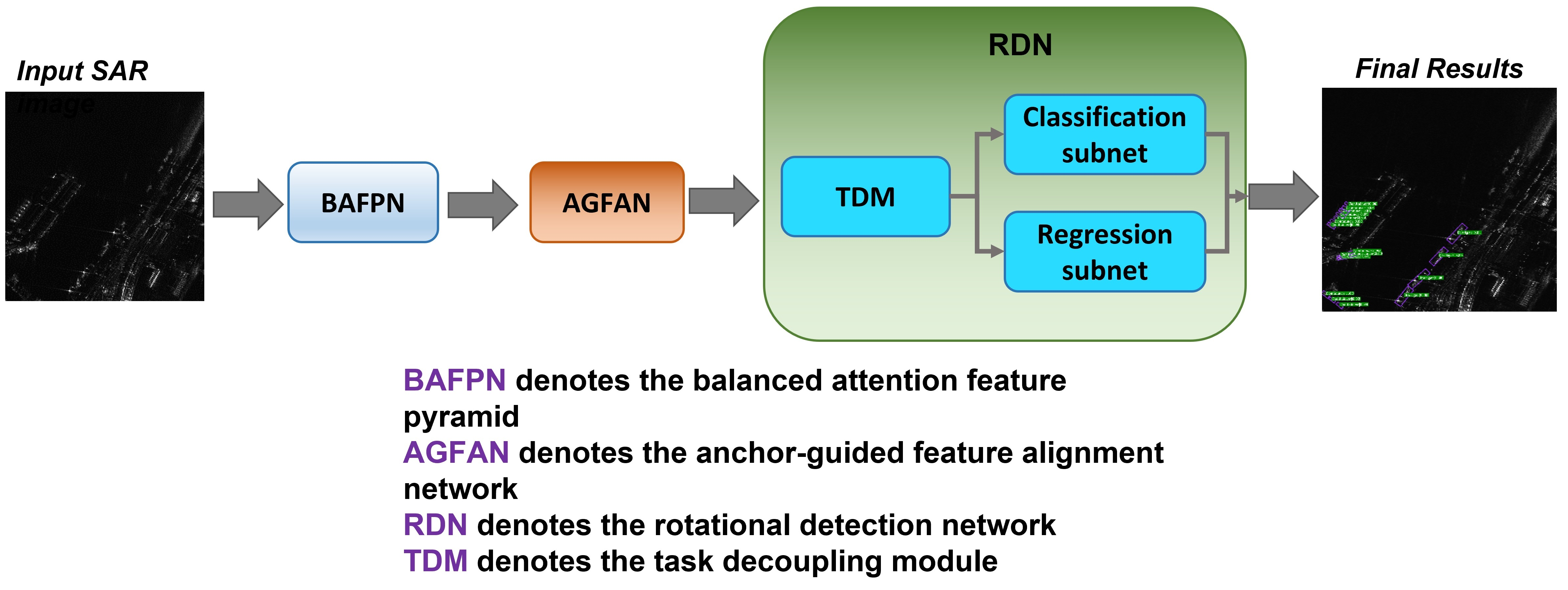
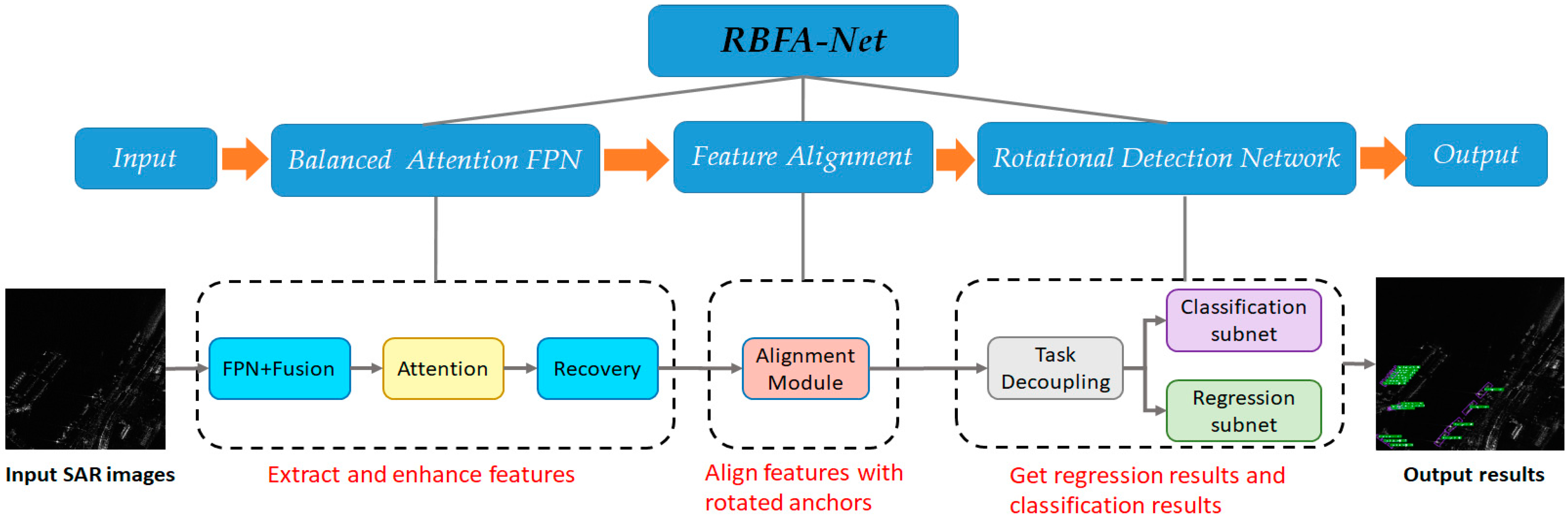
2. Proposed Methods
2.1. Balanced-Attention FPN
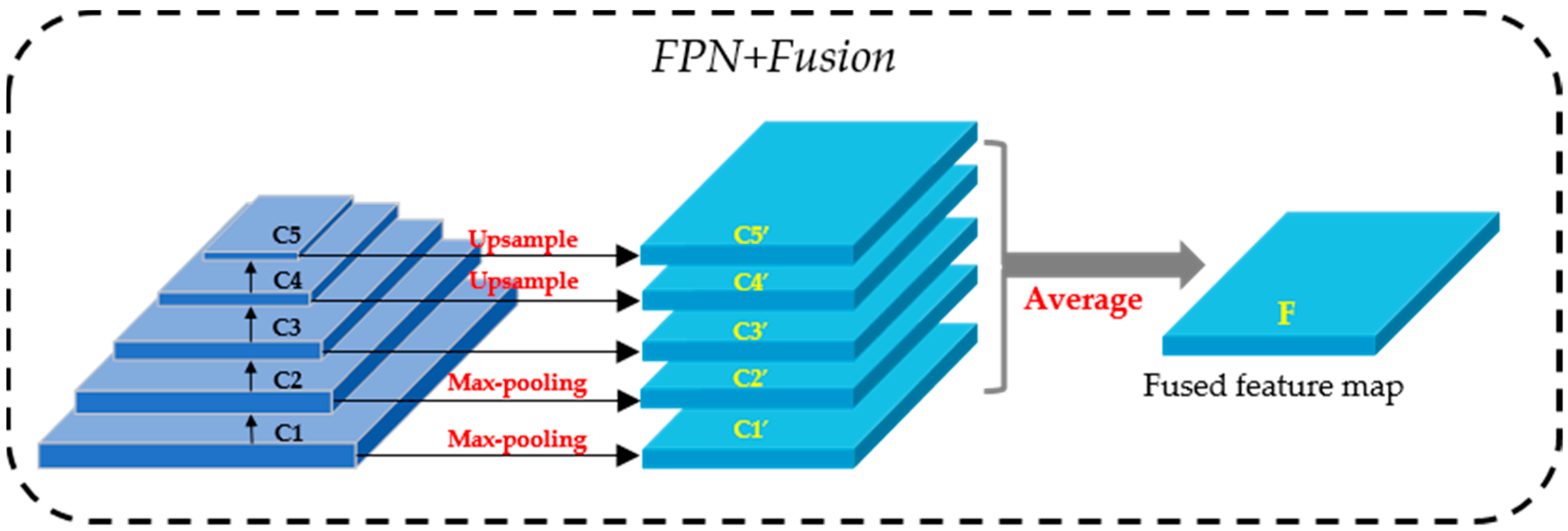
2.1.1. Feature Extraction and Fusion
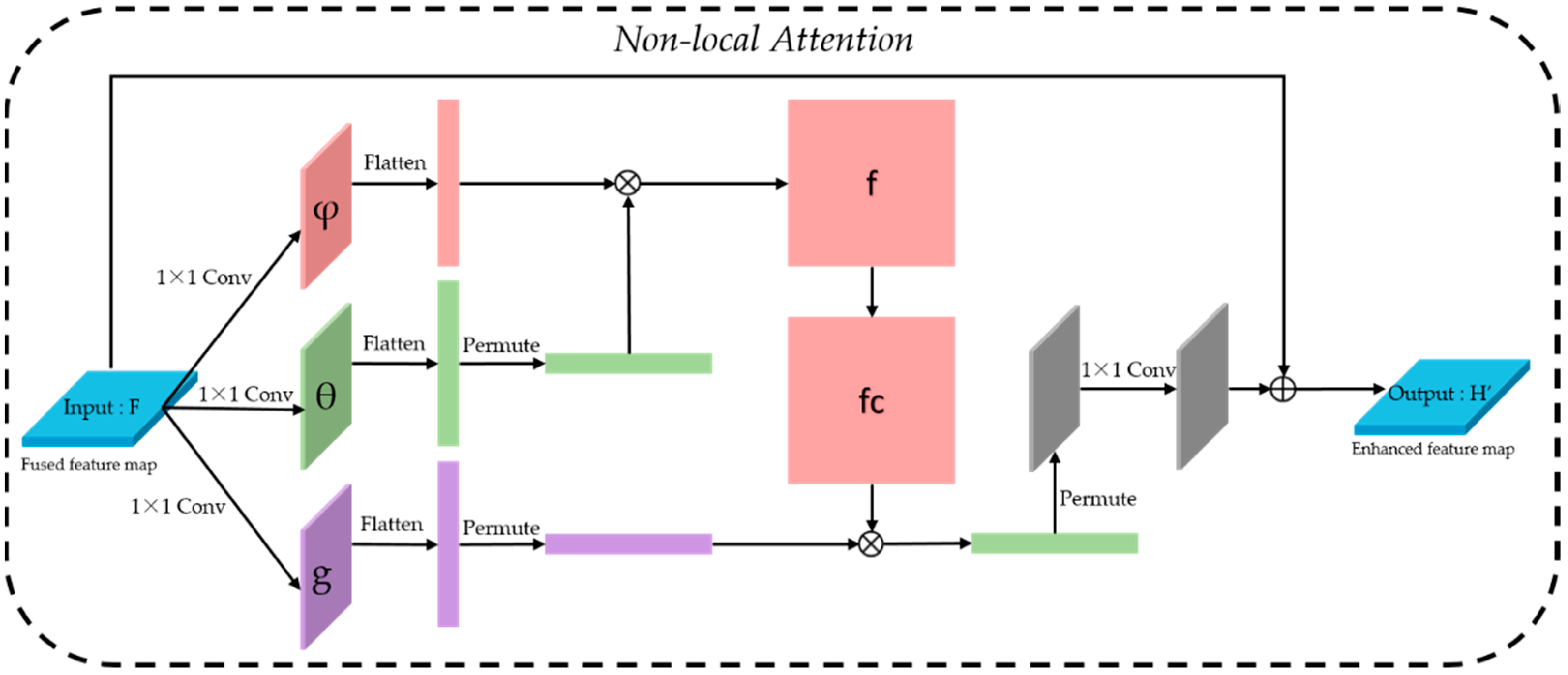
2.1.2. Attention Module
- Use convolution for down-sampling to obtain three variants: , and .
- and perform channel merging and transposing, respectively, and then perform matrix multiplication to gain similarity .
- The similarity is normalized by a soft-max function, and then multiply with the channel-merged .
- The obtained results first restore the original size and then restore the number of channels through convolution.
- Finally, add it to the original input to form a complete residual non-local module.
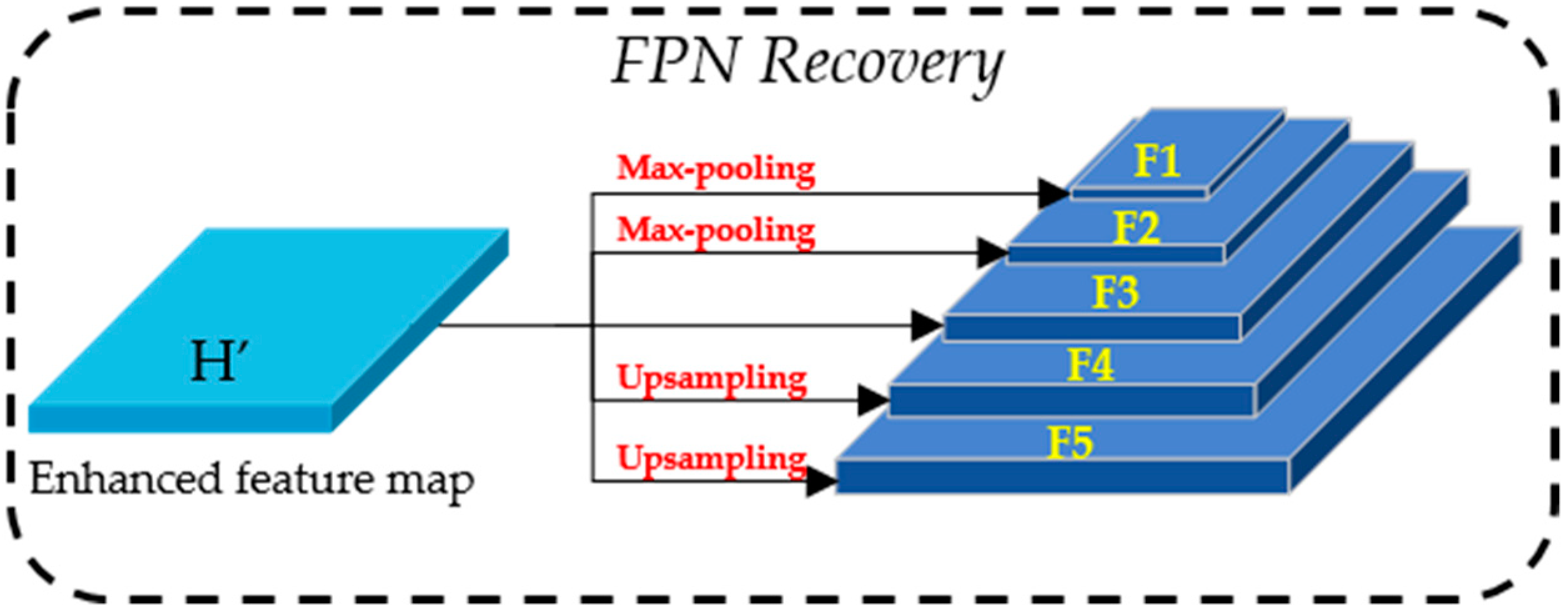
2.1.3. Feature Pyramid Recovery
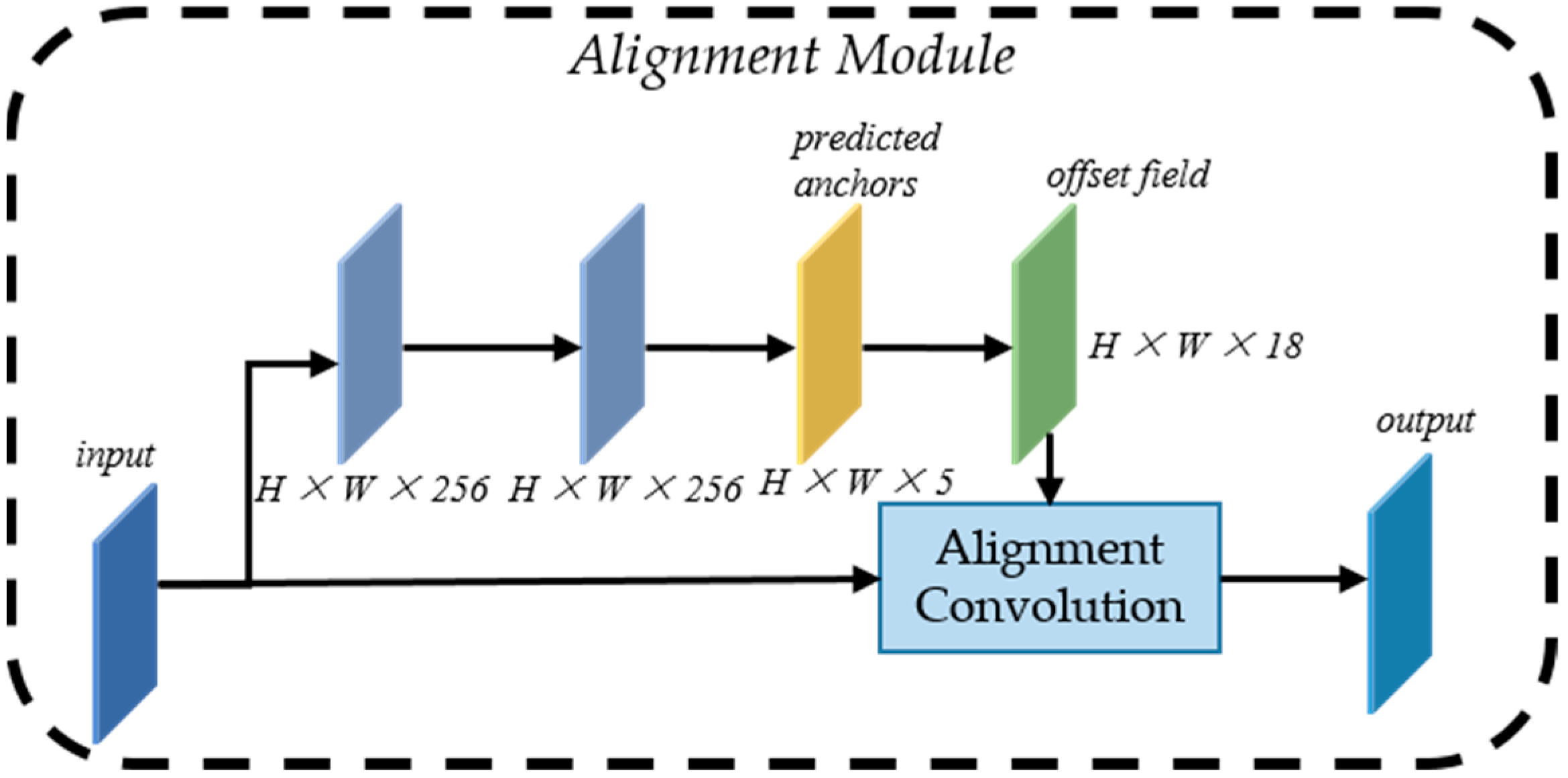
2.2. Anchor-Guided Feature Alignment Network
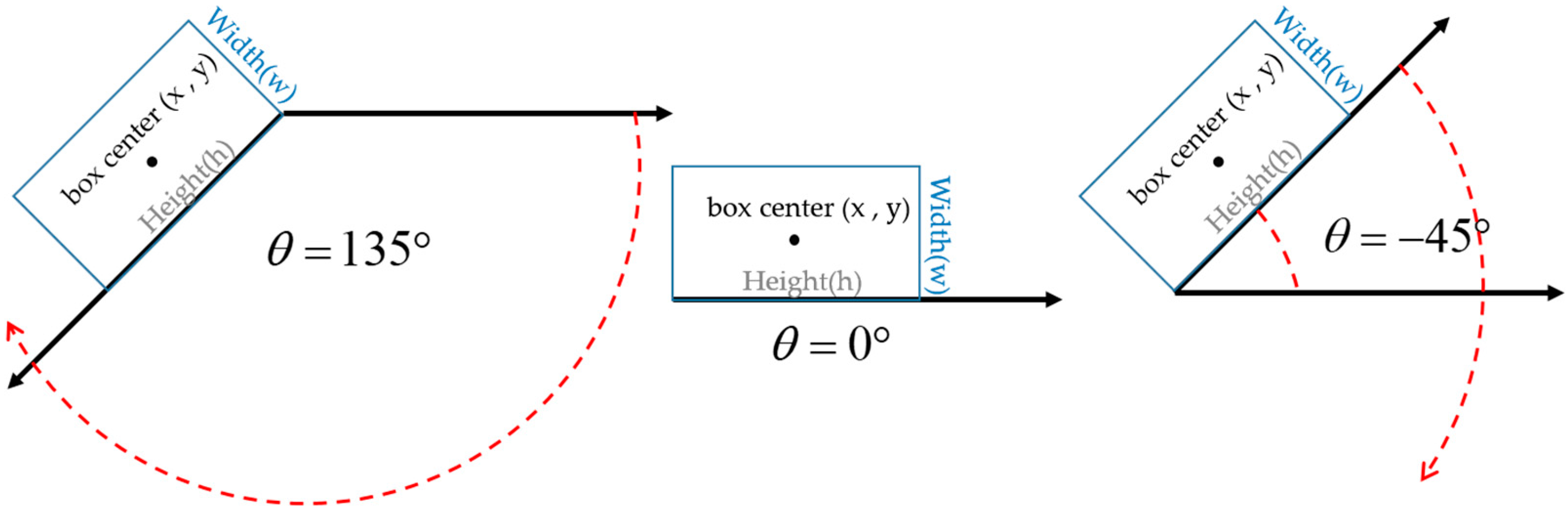
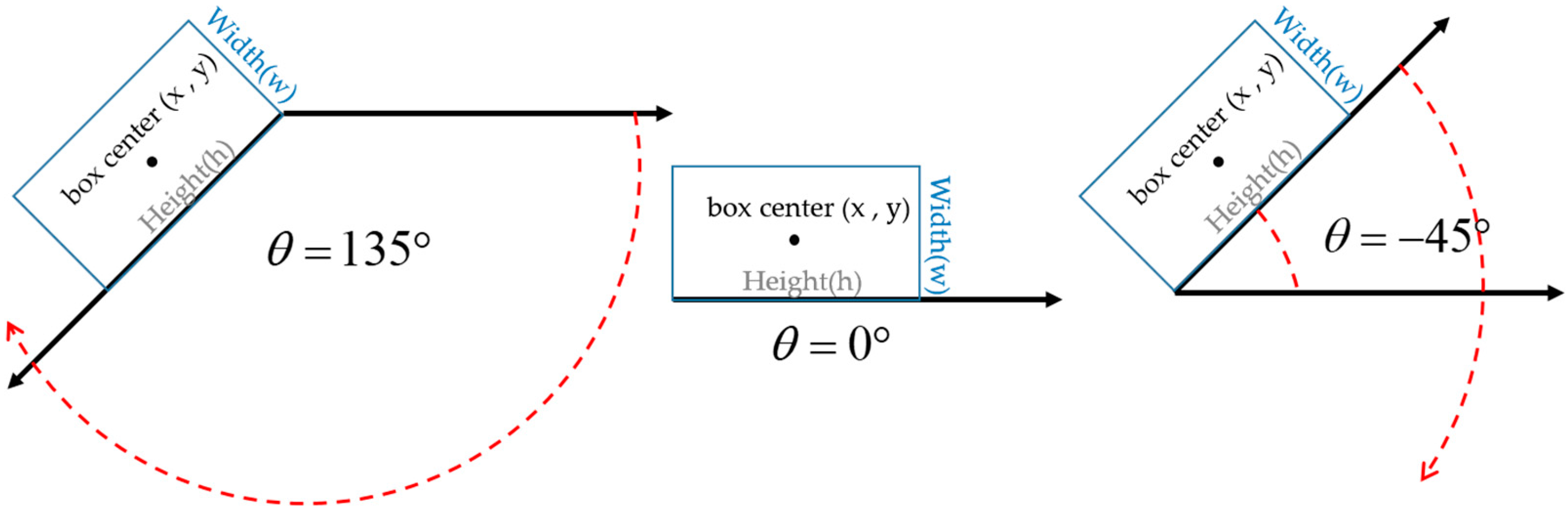
2.2.1. Introduction to Rotated Bounding Box
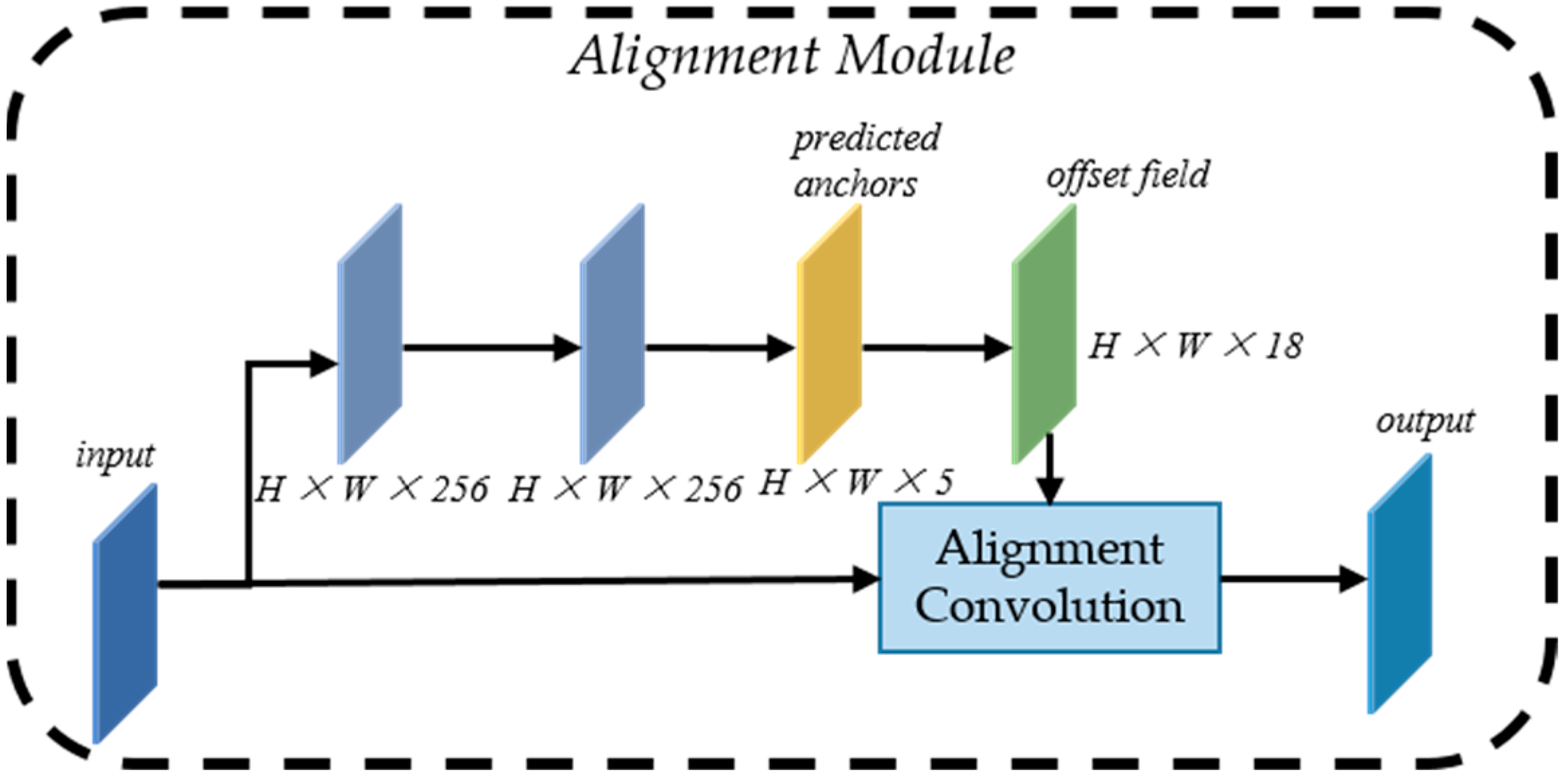
2.2.2. Anchor-Guided Feature Alignment Network
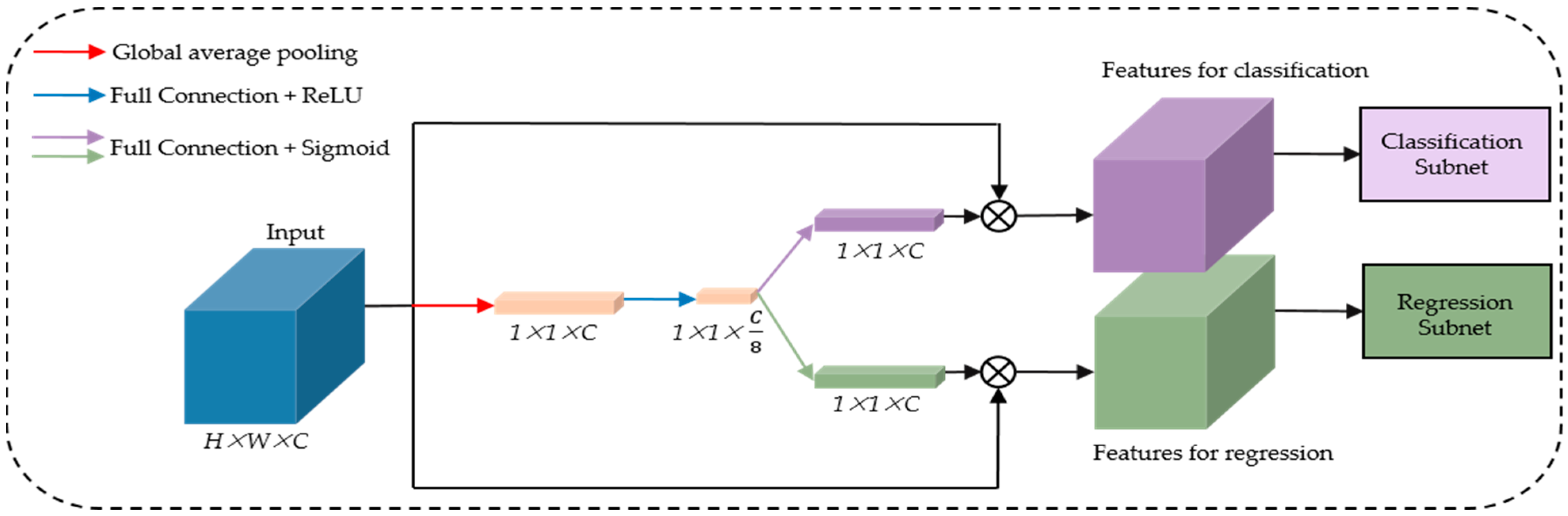
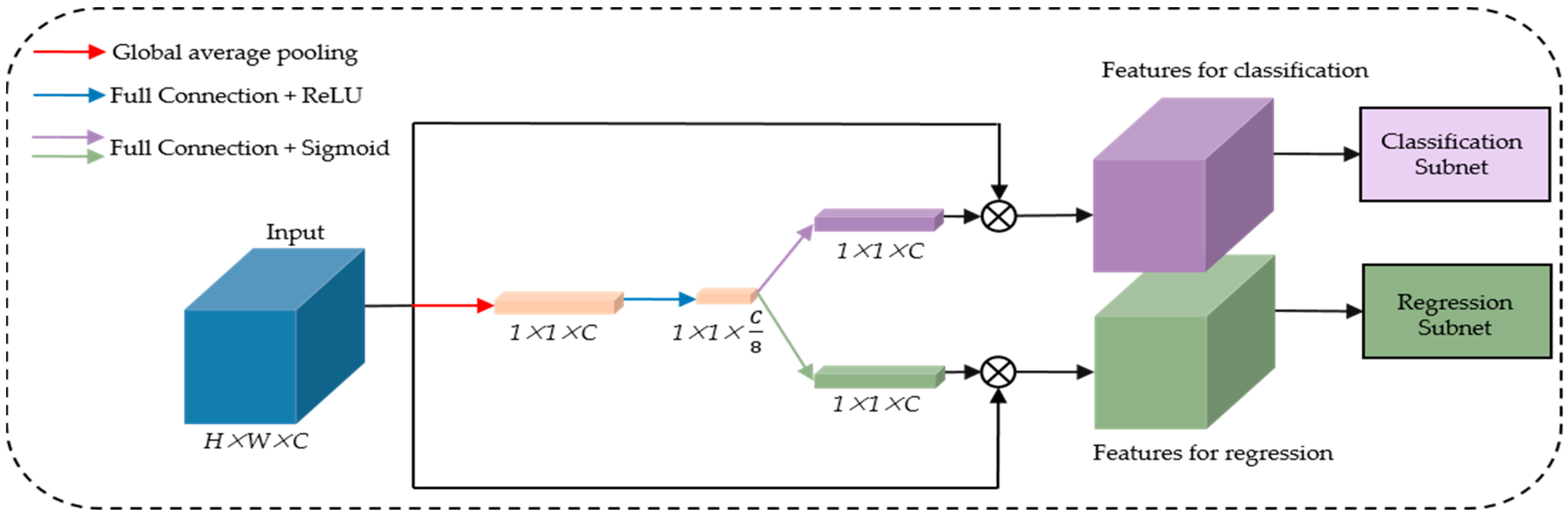
2.3. Rotational Detection Network
2.4. Loss Function
3. Experiments
3.1. Experimental Datasets
3.2. Experimental Details
3.3. Training Process
- Obtain the SAR image dataset preprocessed by SRSDD publisher.
- Input the SAR image data into RBFA-Net for forward propagation to obtain the regression score and classification score.
- Input the regression score and classification score and the ground truth into the loss function to obtain loss value.
- Determine the gradient vector by back propagation.
- Adjust each weight to make the loss value tend to zero or converge. We use the stochastic gradient descent (SGD) method for adjustment.
- Repeat the above process until the set number of training times (training epoch) or loss value does not decrease.
3.4. Evaluation Indices
4. Results
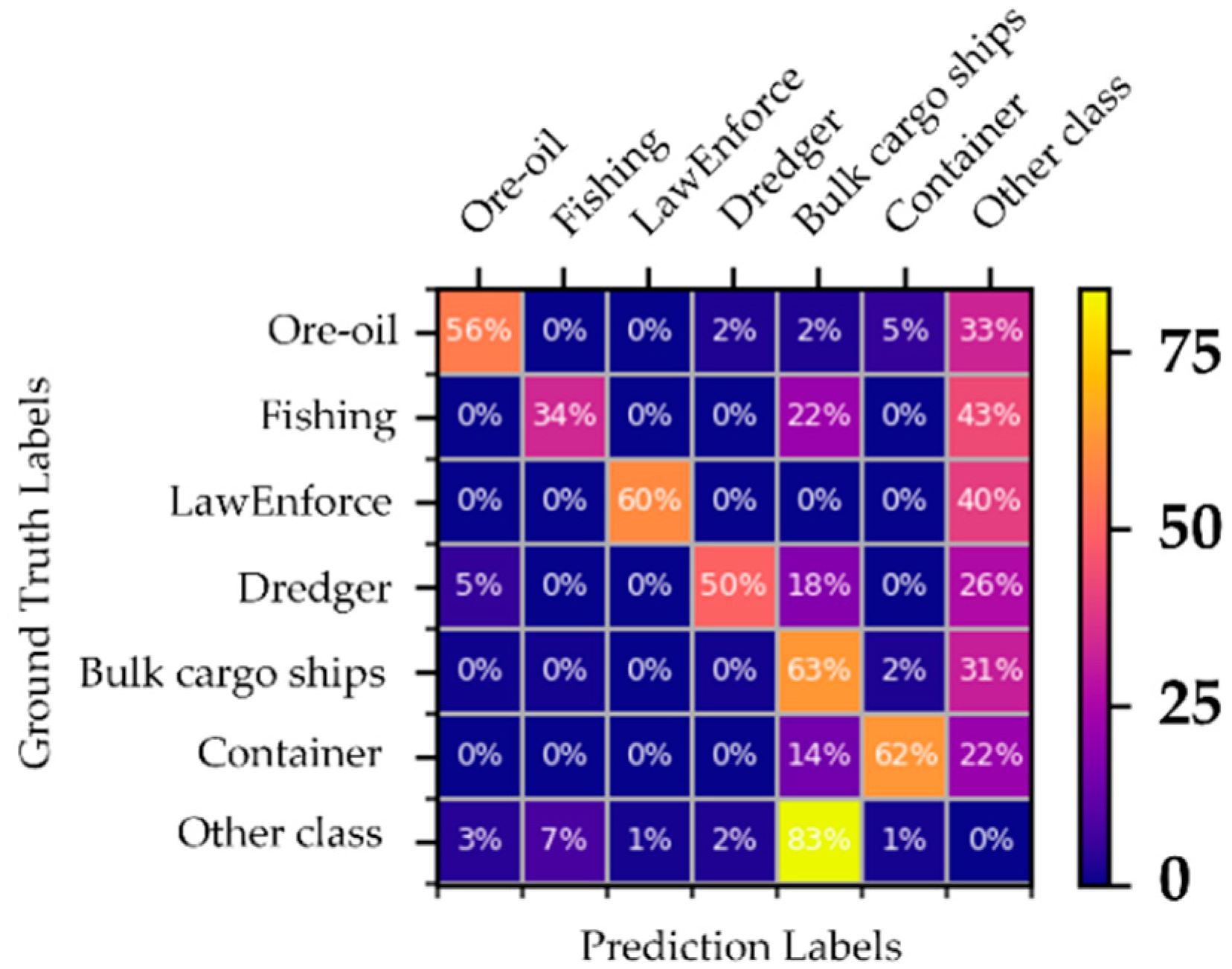
4.1. Qualitative and Quantitative Analyses of Results
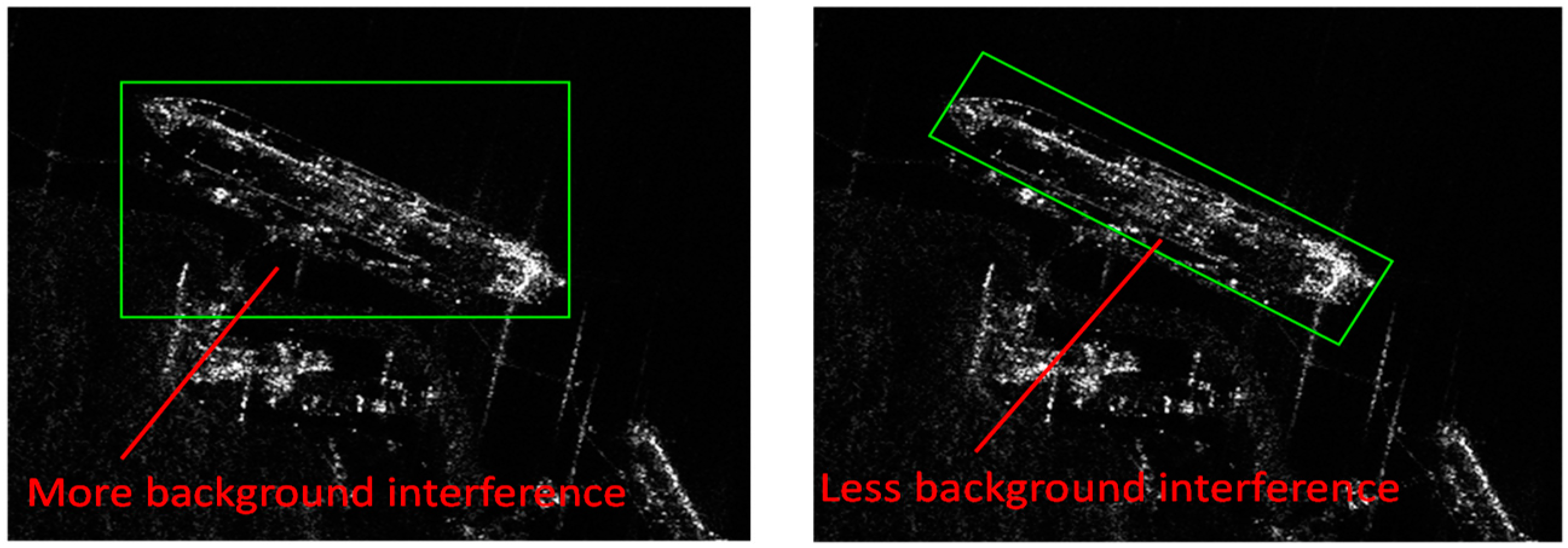
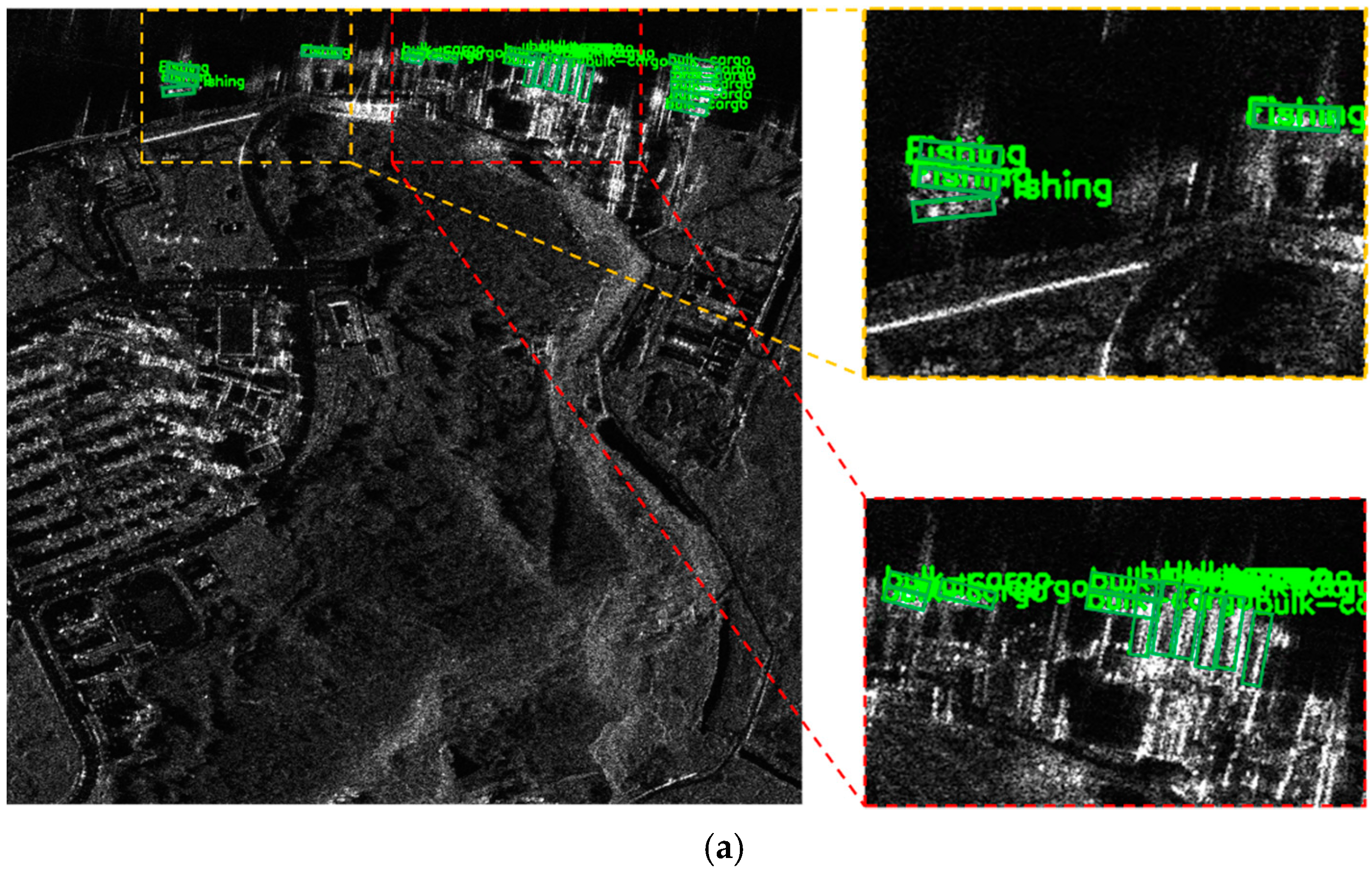
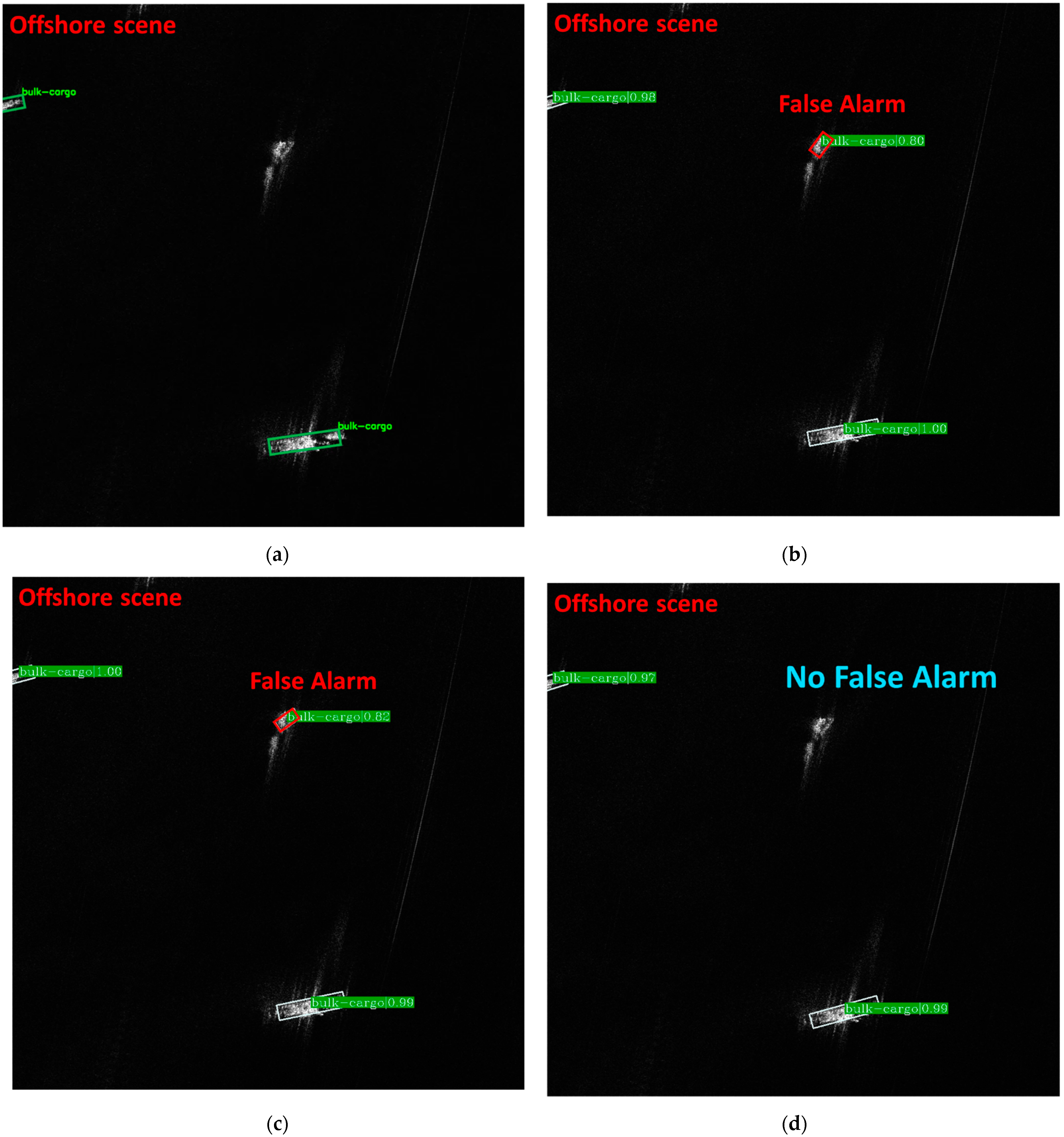
- RBFA-Net net can avoid some missing inspection of some densely arranged inshore small ships. As shown in Figure 11, RBFA-Net detects more fishing boats and bulk cargo than O-RCNN. This is because RBFA-Net uses AGFAN to align the feature map with the rotating anchor boxes, which reduces the negative impact of densely arranged ships and background interference.
- For inshore ship detection, RBFA-Net has better detection accuracy, as shown in Figure 11. In the same SAR image, RBFA-Net can detect and correctly classify the inshore ships and the complex coastal background. This is because RBFA-Net uses FAFPN to fuse and enhance multi-scale features, which enhances the ability of focusing on global information of SAR images.
- For the problem of difficult target ship detection, RBFA-Net has a higher detection effect, as shown in Figure 11. RBFA-Net can successfully classify the fishing boat, which has similar features with bulk cargo ships. This is because RBFA-Net uses the task decoupling module to adaptively enhance the feature map, making it better in the classification network.
- Nevertheless, there are still some problems in our network. For example, there is still the problem of missing inspection when there are too many nearshore ships. For some ships whose characteristics are not obvious, there will also be classification errors. Finally, for some ships in specific directions, there is also the problem of dislocation of detection frame.
4.2. Ablation Study
4.2.1. Effect of BAFPN
4.2.2. Effect of AGFAN
4.2.3. Effect of TDM
4.2.4. Effect of Balanced L1 Loss
5. Discussion
6. Conclusions
- We will improve the detection accuracy of rotation angle of the rotated bounding boxes. The structure of the regression network is relatively simple, which may not meet the requirements of rotation detection.
- We will improve the detection and classification accuracy of small sample ships, such as fishing boats and law enforcement ships. We suppose that BAFPN does not fully mine the unobvious features of small samples of ships. Ship segmentation can also be considered in the future.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zhang, X. Injection of Traditional Hand-Crafted Features into Modern CNN-Based Models for SAR Ship Classification: What, Why, Where, and How. Remote Sens. 2021, 13, 2091. [Google Scholar] [CrossRef]
- Liu, T.; Zhang, J.; Gao, G.; Yang, J.; Marino, A. CFAR Ship Detection in Polarimetric Synthetic Aperture Radar Images Based on Whitening Filter. IEEE Trans. Geosci. Remote Sens. 2020, 58, 58–81. [Google Scholar] [CrossRef]
- Huang, X.; Yang, W.; Zhang, H.; Xia, G.-S. Automatic Ship Detection in SAR Images Using Multi-Scale Heterogeneities and an A Contrario Decision. Remote Sens. 2015, 7, 7695–7711. [Google Scholar] [CrossRef] [Green Version]
- Schwegmann, C.P.; Kleynhans, W.; Salmon, B.P. Synthetic aperture radar ship detection using Haar-like features. IEEE Geosci. Remote Sens. Lett. 2016, 14, 154–158. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. Depthwise Separable Convolution Neural Network for High-Speed SAR Ship Detection. Remote Sens. 2019, 11, 2483. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Zhang, X.; Zhang, T. Lite-YOLOv5: A Lightweight Deep Learning Detector for On-Board Ship Detection in Large-Scene Sentinel-1 SAR Images. Remote Sens. 2022, 14, 1018. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Zhang, T.; Zhang, X. High-Speed Ship Detection in SAR Images Based on a Grid Convolutional Neural Network. Remote Sens. 2019, 11, 1206. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Zhang, T.; Zhang, X. ShipDeNet-20: An Only 20 Convolution Layers and <1-MB Lightweight SAR Ship Detector. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1234–1238. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Zhang, T.; Zhang, X.; Liu, C.; Shi, J.; Wei, S.; Ahmad, I.; Zhan, X.; Zhou, Y.; Pan, D.; Li, J.; et al. Balance learning for ship detection from synthetic aperture radar remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 182, 190–207. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: Cnn architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Lei, S.; Lu, D.; Qiu, X.; Ding, C. SRSDD-v1.0: A High-Resolution SAR Rotation Ship Detection Dataset. Remote Sens. 2021, 13, 5104. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X. Quad-FPN: A Novel Quad Feature Pyramid Network for SAR Ship Detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]
- Sun, K.; Liang, Y.; Ma, X.; Huai, Y.; Xing, M. DSDet: A Lightweight Densely Connected Sparsely Activated Detector for Ship Target Detection in High-Resolution SAR Images. Remote Sens. 2021, 13, 2743. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. Automatic Ship Detection Based on RetinaNet Using Multi-Resolution Gaofen-3 Imagery. Remote Sens. 2019, 11, 531. [Google Scholar] [CrossRef] [Green Version]
- Jiao, J.; Zhang, Y.; Sun, H. A densely connected end-to-end neural network for multiscale and multiscene SAR ship detection. IEEE Access 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Liu, L.; Pan, Z.; Lei, B. Learning a rotation invariant detector with rotatable bounding box. arXiv 2017, arXiv:1711.09405. [Google Scholar]
- Yang, R.; Pan, Z.; Jia, X. A novel CNN-based detector for ship detection based on rotatable bounding box in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1938–1958. [Google Scholar] [CrossRef]
- Pan, Z.; Yang, R.; Zhang, Z. MSR2N: Multi-Stage Rotational Region Based Network for Arbitrary-Oriented Ship Detection in SAR Images. Sensors 2020, 20, 2340. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, S.; Zhang, J.; Zhan, R. R2FA-Det: Delving into High-Quality Rotatable Boxes for Ship Detection in SAR Images. Remote Sens. 2020, 12, 2031. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2849–2858. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR Dataset of Ship Detection for Deep Learning under Complex Backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef] [Green Version]
- Yang, R.; Wang, G.; Pan, Z.; Lu, H.; Zhang, H.; Jia, X. A Novel False Alarm Suppression Method for CNN-Based SAR Ship Detector. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1401–1405. [Google Scholar] [CrossRef]
- Jiang, B.; Luo, R.; Mao, J. Acquisition of localization confidence for accurate object detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 784–799. [Google Scholar]
- Zhang, T.; Zhang, X. A Polarization Fusion Network with Geometric Feature Embedding for SAR Ship Classification. Pattern Recognit. 2021, 123, 108365. [Google Scholar] [CrossRef]
- He, J.; Wang, Y.; Liu, H. Ship Classification in Medium-Resolution SAR Images via Densely Connected Triplet CNNs Integrating Fisher Discrimination Regularized Metric Learning. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3022–3039. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. Squeeze-and-Excitation Laplacian Pyramid Network with Dual-Polarization Feature Fusion for Ship Classification in SAR Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4019905. [Google Scholar] [CrossRef]
- Zeng, L.; Zhu, Q.; Lu, D.; Zhang, T.; Wang, H.; Yin, J.; Yang, J. Dual-Polarized SAR Ship Grained Classification Based on CNN With Hybrid Channel Feature Loss. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4011905. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Liu, C.; Xu, X.; Zhan, X.; Wang, C.; Ahmad, I.; Zhou, Y.; Pan, D.; et al. HOG-ShipCLSNet: A Novel Deep Learning Network with HOG Feature Fusion for SAR Ship Classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5210322. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 765–781. [Google Scholar]
- Zhou, K.; Zhang, M.; Wang, H.; Tan, J. Ship Detection in SAR Images Based on Multi-Scale Feature Extraction and Adaptive Feature Fusion. Remote Sens. 2022, 14, 755. [Google Scholar] [CrossRef]
- Zhang, Y.; Sheng, W.; Jiang, J.; Jing, N.; Wang, Q.; Mao, Z. Priority Branches for Ship Detection in Optical Remote Sensing Images. Remote Sens. 2020, 12, 1196. [Google Scholar] [CrossRef] [Green Version]
- Chen, P.; Li, Y.; Zhou, H.; Liu, B.; Liu, P. Detection of Small Ship Objects Using Anchor Boxes Cluster and Feature Pyramid Network Model for SAR Imagery. J. Mar. Sci. Eng. 2020, 8, 112. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S.; Wang, J.; Li, J.; Su, H.; Zhou, Y. Balance Scene Learning Mechanism for Offshore and Inshore Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2020, 19, 4004905. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the SAR in Big Data Era: Models, Methods and Applications, Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. HyperLi-Net: A hyper-light deep learning network for high-accurate and high-speed ship detection from synthetic aperture radar imagery. ISPRS J. Photogramm. Remote Sens. 2020, 167, 123–153. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. arXiv 2019, arXiv:1904.02701. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. arXiv 2017, arXiv:1711.07971. [Google Scholar]
- Zhou, Y.; Yang, X.; Zhang, G. MMRotate: A Rotated Object Detection Benchmark using Pytorch. arXiv 2022, arXiv:2204.13317. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; Loy, C.C.; Lin, D. Region proposal by guided anchoring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2965–2974. [Google Scholar]
- Song, G.; Liu, Y.; Wang, X. Revisiting the sibling head in object detector. arXiv 2020, arXiv:2003.07540. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. arXiv 2019, arXiv:1908.05612. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point Set Representation for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 29 October–1 November 2019; pp. 9656–9665. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Part IV. pp. 630–645. [Google Scholar]
- Zhang, T.; Zhang, X. A Full-Level Context Squeeze-and-Excitation ROI Extractor for SAR Ship Instance Segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4506705. [Google Scholar] [CrossRef]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented Object Detection in Aerial Images with Box Boundary-A ware V ectors. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual, 5–9 January 2021; pp. 2149–2158. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J. Oriented R-CNN for Object Detection. arXiv 2021, arXiv:2108.05699. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of images | 666 |
| Waveband | C |
| Image Size | 1024 |
| Image Mode | Spotlight Mode |
| Polarization | HH, VV |
| Resolution(m) | 1 |
| Ship Classes | 6 |
| Position | Nanjing, Hongkong, Zhoushan, Macao, Yokohama |
| Category | Train Number | Test Number | Total Number |
|---|---|---|---|
| Ore–oil ships | 132 | 34 | 166 |
| Bulk cargo ships | 1603 | 450 | 2053 |
| Fishing boats | 206 | 82 | 288 |
| Law enforcement | 20 | 5 | 25 |
| Dredger ships | 217 | 46 | 263 |
| Container ships | 67 | 22 | 89 |
| Total | 2245 | 639 | 2884 |
| Models | C1 | C2 | C3 | C4 | C5 | C6 | mAP | Model Size |
|---|---|---|---|---|---|---|---|---|
| FR-O [16] | 55.62 | 30.86 | 27.27 | 77.78 | 46.71 | 85.33 | 53.93 | 315 MB |
| R-RetinaNet [13] | 30.37 | 11.47 | 2.07 | 67.71 | 35.79 | 48.94 | 32.73 | 277 MB |
| ROI [31] | 61.43 | 32.89 | 27.27 | 79.41 | 48.89 | 76.41 | 54.38 | 421 MB |
| R3Det [55] | 44.61 | 18.32 | 1.09 | 54.27 | 42.98 | 73.48 | 39.12 | 468 MB |
| BBAVectors [61] | 54.33 | 21.03 | 1.09 | 82.21 | 34.84 | 78.51 | 45.33 | 829 MB |
| R-FCOS [40] | 54.88 | 25.12 | 5.45 | 83.00 | 47.36 | 81.11 | 49.49 | 244 MB |
| Glid Vertex [63] | 43.41 | 34.63 | 27.27 | 71.25 | 52.80 | 79.63 | 51.50 | 315 MB |
| O-RCNN [62] | 63.55 | 35.35 | 27.27 | 77.50 | 57.56 | 76.14 | 56.23 | 315 MB |
| RBFA-Net (Ours) | 59.39 | 41.51 | 73.48 | 77.17 | 57.36 | 71.62 | 63.42 | 302 MB |
| BAFPN | AGFAN | TDM | mAP (%) |
|---|---|---|---|
| -- | -- | -- | 41.26 |
| ✓ | 45.74 | ||
| ✓ | ✓ | 59.08 | |
| ✓ | ✓ | ✓ | 63.42 |
| Models | C1 (%) | C2 (%) | C3 (%) | C4 (%) | C5 (%) | C6 (%) | mAP (%) |
|---|---|---|---|---|---|---|---|
| FPN | 60.01 | 60.85 | 35.07 | 43.80 | 73.43 | 76.50 | 58.28 |
| Balanced-FPN (Ours) | 59.39 | 57.36 | 41.51 | 73.48 | 77.17 | 71.62 | 63.42 |
| Models | C1 (%) | C2 (%) | C3 (%) | C4 (%) | C5 (%) | C6 (%) | mAP (%) |
|---|---|---|---|---|---|---|---|
| × | 35.77 | 43.98 | 33.03 | 27.27 | 75.87 | 49.67 | 44.27 |
| ✓ | 59.39 | 57.36 | 41.51 | 73.48 | 77.17 | 71.62 | 63.42 |
| Models | C1 (%) | C2 (%) | C3 (%) | C4 (%) | C5 (%) | C6 (%) | mAP (%) |
|---|---|---|---|---|---|---|---|
| × | 62.20 | 57.15 | 36.87 | 48.25 | 73.68 | 82.91 | 60.17 |
| ✓ | 59.39 | 57.36 | 41.51 | 73.48 | 77.17 | 71.62 | 63.42 |
| Regression Loss Types | C1 (%) | C2 (%) | C3 (%) | C4 (%) | C5 (%) | C6 (%) | mAP (%) |
|---|---|---|---|---|---|---|---|
| Smooth L1 | 58.12 | 55.11 | 36.45 | 63.64 | 73.71 | 71.00 | 60.16 |
| Balanced L1 loss (Ours) | 59.39 | 57.36 | 41.51 | 73.48 | 77.17 | 71.62 | 63.42 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, Z.; Zhang, X.; Zhang, T.; Xu, X.; Zeng, T. RBFA-Net: A Rotated Balanced Feature-Aligned Network for Rotated SAR Ship Detection and Classification. Remote Sens. 2022, 14, 3345. https://doi.org/10.3390/rs14143345
Shao Z, Zhang X, Zhang T, Xu X, Zeng T. RBFA-Net: A Rotated Balanced Feature-Aligned Network for Rotated SAR Ship Detection and Classification. Remote Sensing. 2022; 14(14):3345. https://doi.org/10.3390/rs14143345
Chicago/Turabian StyleShao, Zikang, Xiaoling Zhang, Tianwen Zhang, Xiaowo Xu, and Tianjiao Zeng. 2022. "RBFA-Net: A Rotated Balanced Feature-Aligned Network for Rotated SAR Ship Detection and Classification" Remote Sensing 14, no. 14: 3345. https://doi.org/10.3390/rs14143345
APA StyleShao, Z., Zhang, X., Zhang, T., Xu, X., & Zeng, T. (2022). RBFA-Net: A Rotated Balanced Feature-Aligned Network for Rotated SAR Ship Detection and Classification. Remote Sensing, 14(14), 3345. https://doi.org/10.3390/rs14143345