
Improving Image Clustering through Sample Ranking and Its Application to Remote Sensing Images

Abstract
:
1. Introduction
2. Related Work
3. Method
3.1. Sample Ranking
| Algorithm 1: Sample ranking and robust majority voting |
Input: images in cluster c: , Parameter: , n, , m, Output: m groups of images
|
3.2. Model Training
3.3. Evaluation
4. Experiments
4.1. Comparison to the State-of-the-Art
4.1.1. Dataset
4.1.2. Results
4.2. Applied to Remote Sensing Images
4.2.1. Dataset
4.2.2. Results
5. Discussion
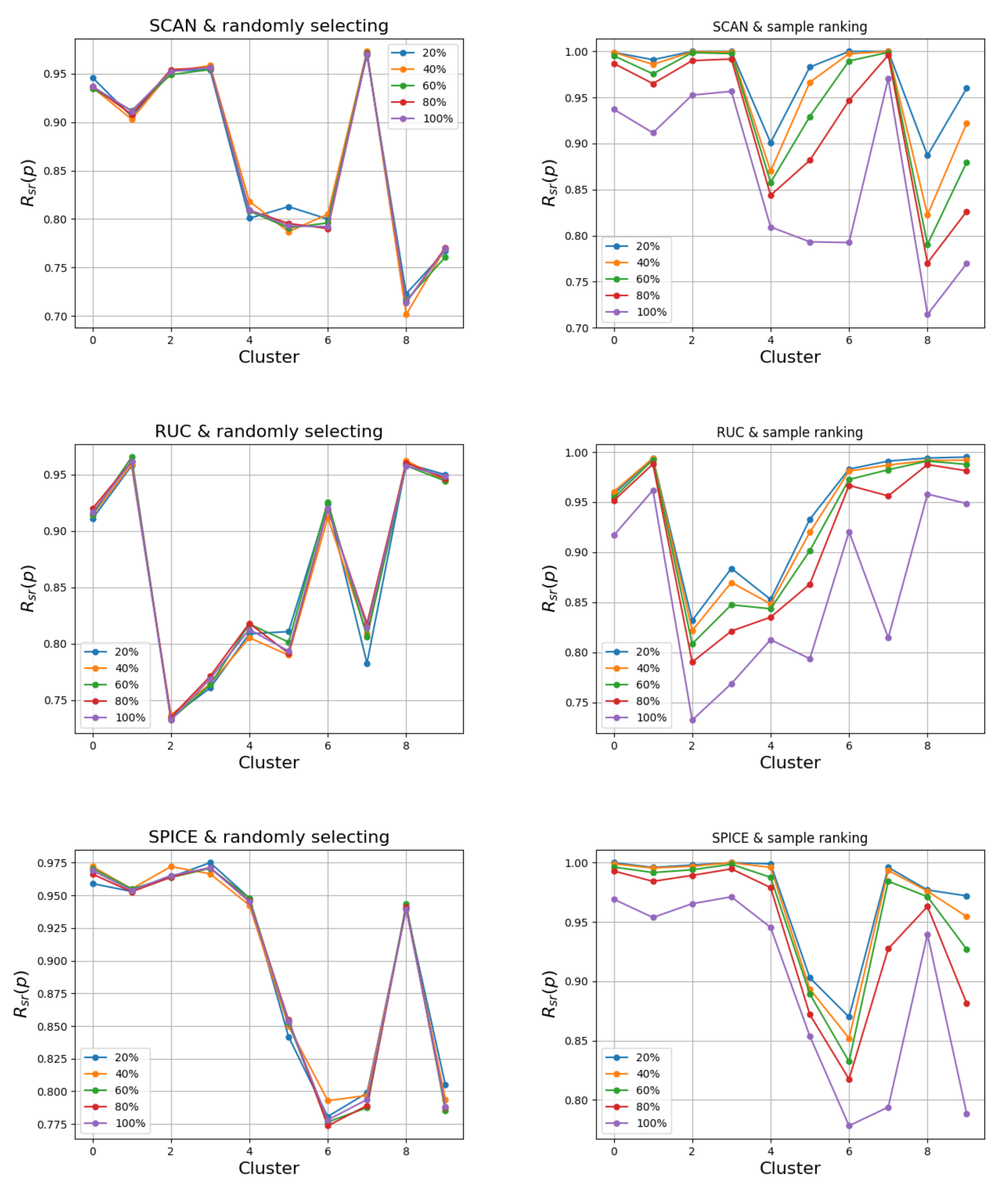
5.1. Performance of Sample Ranking Algorithm
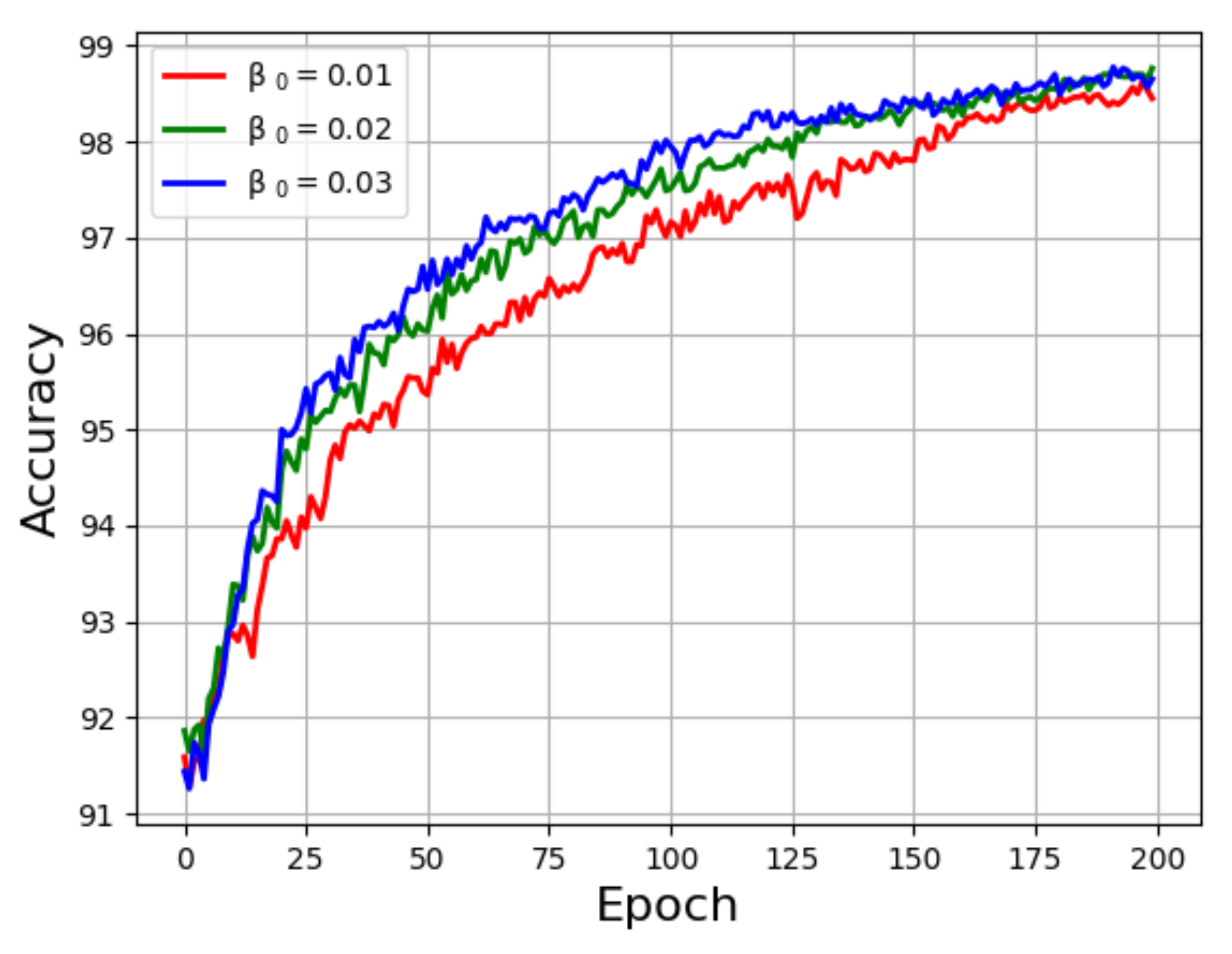
5.2. Ablation Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. The Performance of Ranking Samples of Freeway in UCMerced LandUse



Appendix B. The Performance of Ranking Samples of Beach in UCMerced LandUse



References
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised Visual Representation Learning by Context Prediction. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1422–1430. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9910, pp. 69–84. [Google Scholar]
- Kim, D.; Cho, D.; Yoo, D.; Kweon, I.S. Learning image representations by completing damaged jigsaw puzzles. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 793–802. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised Representation Learning by Predicting Image Rotations. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kolesnikov, A.; Zhai, X.; Beyer, L. Revisiting self-supervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1920–1929. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9907, pp. 649–666. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Learning representations for automatic colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 577–593. [Google Scholar]
- Wang, X.; Gupta, A. Unsupervised learning of visual representations using videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2794–2802. [Google Scholar]
- Van den Oord, A.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Ye, M.; Zhang, X.; Yuen, P.C.; Chang, S.F. Unsupervised embedding learning via invariant and spreading instance feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6210–6219. [Google Scholar]
- Henaff, O. Data-efficient image recognition with contrastive predictive coding. In Proceedings of the International Conference on Machine Learning, Online, 13–18 July 2020; pp. 4182–4192. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Multiview Coding. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12356, pp. 776–794. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Online, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Henaff, O.J.; Razavi, A.; Doersch, C.; Eslami, S.M.A.; Oord, A.V.d. Data-Efficient Image Recognition with Contrastive Predictive Coding. arXiv 2019, arXiv:1905.09272. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 609–616. [Google Scholar]
- Tang, Y.; Salakhutdinov, R.; Hinton, G. Robust boltzmann machines for recognition and denoising. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2264–2271. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Ren, Z.; Lee, Y.J. Cross-domain self-supervised multi-task feature learning using synthetic imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 762–771. [Google Scholar]
- Jenni, S.; Favaro, P. Self-supervised feature learning by learning to spot artifacts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2733–2742. [Google Scholar]
- Xie, Q.; Dai, Z.; Du, Y.; Hovy, E.; Neubig, G. Controllable invariance through adversarial feature learning. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Donahue, J.; Simonyan, K. Large Scale Adversarial Representation Learning. In Proceedings of the NIPS’19: Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, QC, Canada, 8–14 December 2019; pp. 10541–10551. [Google Scholar]
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep Clustering for Unsupervised Learning of Visual Features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11218, pp. 139–156. [Google Scholar]
- Huang, J.; Dong, Q.; Gong, S.; Zhu, X. Unsupervised Deep Learning by Neighbourhood Discovery. In Proceedings of the ICML, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 2849–2858. [Google Scholar]
- Asano, Y.M.; Rupprecht, C.; Vedaldi, A. Self-labelling via simultaneous clustering and representation learning. In Proceedings of the International Conference on Learning Representations 2020 (ICLR 2020), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Li, Q.; Li, B.; Garibaldi, J.M.; Qiu, G. On Designing Good Representation Learning Models. arXiv 2021, arXiv:2107.05948. [Google Scholar]
- Gansbeke, W.V.; Vandenhende, S.; Georgoulis, S.; Proesmans, M.; Gool, L.V. SCAN: Learning to Classify Images Without Labels. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12355, pp. 268–285. [Google Scholar]
- Rosenberg, C.; Hebert, M.; Schneiderman, H. Semi-supervised self-training of object detection models. In Proceedings of the 2005 Seventh IEEE Workshops on Applications of Computer Vision (WACV/MOTION’05), Breckenridge, CO, USA, 5–7 January 2005; Volume 1, pp. 29–36. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 3, p. 896. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10687–10698. [Google Scholar]
- Sohn, K.; Berthelot, D.; Li, C.L.; Zhang, Z.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Zhang, H.; Raffel, C. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. arXiv 2020, arXiv:2001.07685. [Google Scholar]
- Park, S.; Han, S.; Kim, S.; Kim, D.; Park, S.; Hong, S.; Cha, M. Improving Unsupervised Image Clustering With Robust Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 12278–12287. [Google Scholar]
- Niu, C.; Wang, G. SPICE: Semantic Pseudo-labeling for Image Clustering. arXiv 2021, arXiv:2103.09382. [Google Scholar]
- Gong, Z.; Zhong, P.; Hu, W. Diversity in machine learning. IEEE Access 2019, 7, 64323–64350. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey; University of Wisconsin-Madison Department of Computer Sciences: Madiso, WI, USA, 2009. [Google Scholar]
- Settles, B. Active learning. Synth. Lect. Artif. Intell. Mach. Learn. 2012, 6, 1–114. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Frénay, B.; Verleysen, M. Classification in the presence of label noise: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 845–869. [Google Scholar] [CrossRef]
- Angluin, D.; Laird, P. Learning from noisy examples. Mach. Learn. 1988, 2, 343–370. [Google Scholar] [CrossRef] [Green Version]
- Gao, W.; Wang, L.; Zhou, Z.H. Risk minimization in the presence of label noise. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Pathak, D.; Kraähenbuähl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Colorization as a Proxy Task for Visual Understanding. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 840–849. [Google Scholar]
- Mundhenk, T.N.; Ho, D.; Chen, B.Y. Improvements to Context Based Self-Supervised Learning. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9339–9348. [Google Scholar]
- Noroozi, M.; Vinjimoor, A.; Favaro, P.; Pirsiavash, H. Boosting Self-Supervised Learning via Knowledge Transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9359–9367. [Google Scholar]
- Baldi, P. Autoencoders, Unsupervised Learning, and Deep Architectures. In Proceedings of the ICML Unsupervised and Transfer Learning, Bellevue, WA, USA, 2 July 2012; Volume 27, pp. 37–50. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial Feature Learning. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Jung, H.; Oh, Y.; Jeong, S.; Lee, C.; Jeon, T. Contrastive Self-Supervised Learning With Smoothed Representation for Remote Sensing. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Ciocarlan, A.; Stoian, A. Ship Detection in Sentinel 2 Multi-Spectral Images with Self-Supervised Learning. Remote Sens. 2021, 13, 4255. [Google Scholar] [CrossRef]
- Stojnić, V.; Risojević, V. Self-Supervised Learning of Remote Sensing Scene Representations Using Contrastive Multiview Coding. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 1182–1191. [Google Scholar]
- Li, H.; Li, Y.; Zhang, G.; Liu, R.; Huang, H.; Zhu, Q.; Tao, C. Global and local contrastive self-supervised learning for semantic segmentation of HR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Akiva, P.; Purri, M.; Leotta, M. Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks. arXiv 2021, arXiv:2112.01715. [Google Scholar]
- Ayush, K.; Uzkent, B.; Meng, C.; Tanmay, K.; Burke, M.; Lobell, D.; Ermon, S. Geography-Aware Self-Supervised Learning. arXiv 2021, arXiv:2011.09980. [Google Scholar]
- Dong, H.; Ma, W.; Wu, Y.; Zhang, J.; Jiao, L. Self-Supervised Representation Learning for Remote Sensing Image Change Detection Based on Temporal Prediction. Remote Sens. 2020, 12, 1868. [Google Scholar] [CrossRef]
- Xu, Y.; Luo, W.; Hu, A.; Xie, Z.; Xie, X.; Tao, L. TE-SAGAN: An Improved Generative Adversarial Network for Remote Sensing Super-Resolution Images. Remote Sens. 2022, 14, 2425. [Google Scholar] [CrossRef]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 478–487. [Google Scholar]
- Chang, J.; Wang, L.; Meng, G.; Xiang, S.; Pan, C. Deep Adaptive Image Clustering. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV) 2017, Venice, Italy, 22–29 October 2017; pp. 5880–5888. [Google Scholar]
- Caron, M.; Bojanowski, P.; Mairal, J.; Joulin, A. Unsupervised Pre-Training of Image Features on Non-Curated Data. In Proceedings of the ICCV, Seoul, Korea, 27 October–2 November 2019; pp. 2959–2968. [Google Scholar]
- Ji, X.; Vedaldi, A.; Henriques, J.F. Invariant Information Clustering for Unsupervised Image Classification and Segmentation. In Proceedings of the ICCV, Seoul, Korea, 27 October–2 November 2019; pp. 9864–9873. [Google Scholar]
- Hu, W.; Miyato, T.; Tokui, S.; Matsumoto, E.; Sugiyama, M. Learning Discrete Representations via Information Maximizing Self-Augmented Training. In Proceedings of the ICML, Sydney, Australia, 6–11 August 2017; pp. 1558–1567. [Google Scholar]
- Han, S.; Park, S.; Park, S.; Kim, S.; Cha, M. Mitigating embedding and class assignment mismatch in unsupervised image classification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 768–784. [Google Scholar]
- Bachman, P.; Alsharif, O.; Precup, D. Learning with Pseudo-Ensembles. In Proceedings of the NIPS, Montreal, QC, Canada, 8–13 December 2014; Neural Information Processing Systems Foundation: La Jolla, CA, USA, 2014; pp. 3365–3373. [Google Scholar]
- Sukhbaatar, S.; Bruna, J.; Paluri, M.; Bourdev, L.; Fergus, R. Training convolutional networks with noisy labels. arXiv 2014, arXiv:1406.2080. [Google Scholar]
- Estévez, P.A.; Tesmer, M.; Perez, C.A.; Zurada, J.M. Normalized mutual information feature selection. IEEE Trans. Neural Netw. 2009, 20, 189–201. [Google Scholar] [CrossRef] [Green Version]
- Amelio, A.; Pizzuti, C. Is normalized mutual information a fair measure for comparing community detection methods? In Proceedings of the 2015 IEEE/ACM international Conference on Advances in Social Networks Analysis and Mining 2015, Paris, France, 25–28 August 2015; pp. 1584–1585. [Google Scholar]
- Rand, W.M. Objective criteria for the evaluation of clustering methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Vinh, N.X.; Epps, J.; Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 2010, 11, 2837–2854. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Taoyuan, Taiwan, 13–15 November 2011; pp. 215–223. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 1 January 1967; Volume 1, pp. 281–297. [Google Scholar]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 9–14 December 2002; pp. 849–856. [Google Scholar]
- Franti, P.; Virmajoki, O.; Hautamaki, V. Fast agglomerative clustering using a k-nearest neighbor graph. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1875–1881. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Zhou, P.; Hou, Y.; Feng, J. Deep adversarial subspace clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1596–1604. [Google Scholar]
- Chang, J.; Guo, Y.; Wang, L.; Meng, G.; Xiang, S.; Pan, C. Deep discriminative clustering analysis. arXiv 2019, arXiv:1905.01681. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef] [Green Version]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Introducing EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 204–207. [Google Scholar]
- Ma, A.; Zhong, Y.; Zhang, L. Adaptive multiobjective memetic fuzzy clustering algorithm for remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4202–4217. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010 2010; pp. 270–279. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Pixel RES | Class # | Training Image # | Testing Image # |
|---|---|---|---|---|
| CIFAR-10 | 10 | 50,000 | 10,000 | |
| CIFAR-100 | 100/20 | 50,000 | 10,000 | |
| STL-10 | 10 | 5000 | 8000 | |
| ImageNet-10 | resized to | 10 | 13,000 | 0 |
| Method | CIFAR-10 | CIFAR-100-20 | ||||
|---|---|---|---|---|---|---|
| Evaluation | ACC | NMI | ARI | ACC | NMI | ARI |
| k-means [76] | 22.9 | 8.7 | 4.9 | 13.0 | 8.4 | 2.8 |
| SC [77] | 24.7 | 10.3 | 8.5 | 13.6 | 9.0 | 2.2 |
| AC [78] | 22.8 | 10.5 | 6.5 | 13.8 | 9.8 | 3.4 |
| GAN [79] | 31.5 | 26.5 | 17.6 | 15.1 | 12.0 | 4.5 |
| DEC [60] | 30.1 | 25.6 | 16.1 | 18.5 | 13.6 | 5.0 |
| DAC [80] | 55.2 | 39.6 | 30.9 | 23.8 | 18.5 | 8.8 |
| DeepCluster [27] | 37.4 | - | - | 18.9 | - | - |
| DDC [81] | 52.4 | 42.4 | 32.9 | - | - | - |
| IIC [63] | 61.7 | - | - | 25.7 | - | - |
| TSUC [65] | 61.7 | - | - | 35.5 | - | - |
| SCAN [31] | 88.7 | 80.4 | 78.0 | 50.6 | 47.5 | 32.9 |
| SCAN + RUC [36] | 90.3 | 83.2 | 80.9 | 54.3 | 55.1 | 38.7 |
| SPICE [37] | 92.6 | 85.8 | 84.3 | 53.8 | 56.7 | 38.7 |
| SCAN + ICSR | 93.4 | 86.0 | 86.3 | 54.4 | 51.7 | 35.9 |
| SCAN + RUC + ICSR | 94.0 | 87.2 | 87.3 | 57.3 | 58.5 | 41.2 |
| SPICE + ICSR | 94.7 | 88.6 | 88.9 | 58.8 | 59.6 | 42.1 |
| STL-10 | ImageNet-10 | |||||
| k-means [76] | 19.2 | 12.5 | 6.1 | 24.1 | 11.9 | 5.7 |
| SC [77] | 15.9 | 9.8 | 4.8 | 27.4 | 15.1 | 7.6 |
| AC [78] | 33.2 | 23.9 | 14.0 | 24.2 | 13.9 | 6.7 |
| GAN [79] | 29.8 | 21.0 | 13.9 | 34.6 | 22.5 | 15.7 |
| DEC [60] | 35.9 | 27.6 | 18.6 | 38.1 | 28.2 | 20.3 |
| DAC [80] | 47.0 | 36.6 | 25.7 | 52.7 | 39.4 | 30.2 |
| DeepCluster [27] | 33.4 | - | - | - | - | - |
| DDC [81] | 48.9 | 37.1 | 26.7 | 57.7 | 43.3 | 34.5 |
| IIC [63] | 61.0 | - | - | - | - | - |
| TSUC [65] | 62.0 | - | - | - | - | - |
| SCAN [31] | 81.4 | 69.8 | 64.6 | - | - | - |
| SCAN + RUC [36] | 86.7 | 77.8 | 74.2 | - | - | - |
| SPICE [37] | 92.0 | 85.2 | 83.6 | 95.9 | 90.2 | 91.2 |
| SCAN + ICSR | 95.0 | 89.4 | 89.5 | - | - | - |
| SCAN + RUC + ICSR | 94.8 | 89.0 | 89.2 | - | - | - |
| SPICE + ICSR | 98.0 | 95.1 | 95.8 | 98.1 | 94.8 | 95.7 |
| Method | CIFAR-10 | CIFAR-100-20 | ||||
|---|---|---|---|---|---|---|
| Evaluation | ACC | NMI | ARI | ACC | NMI | ARI |
| supervised | 93.8 | - | - | 80.0 | - | - |
| SCAN | 88.3 | 79.7 | 77.2 | 50.7 | 48.6 | 33.3 |
| SCAN + RUC | 89.1 | 81.5 | 78.7 | 53.4 | 54.9 | 37.8 |
| SPICE | 91.8 | 85.0 | 83.6 | 53.5 | 56.5 | 40.4 |
| SCAN + ICSR | 90.5 | 80.8 | 80.6 | 51.6 | 48.0 | 35.9 |
| SCAN + RUC + ICSR | 91.0 | 81.8 | 81.6 | 52.5 | 50.3 | 34.7 |
| SPICE + ICSR | 92.8 | 85.1 | 85.1 | 54.8 | 52.6 | 36.4 |
| Method | CIFAR-10 | STL-10 | ||||
|---|---|---|---|---|---|---|
| Evaluation | ACC | NMI | ARI | ACC | NMI | ARI |
| SCAN | 82.2 | 72.1 | 67.7 | 79.2 | 67.1 | 61.8 |
| SCAN + ICRS | 90.3 | 82.9 | 81.3 | 95.1 | 89.4 | 89.6 |
| Improved | 8.1 | 10.8 | 12.6 | 15.9 | 22.3 | 27.8 |
| Method | CIFAR-10 | STL-10 | ||||
|---|---|---|---|---|---|---|
| Evaluation | ACC | NMI | ARI | ACC | NMI | ARI |
| LCT | 83.2 | 73.1 | 69.3 | 53.3 | 47.8 | 35.5 |
| LCT + ICRS | 90.8 | 82.7 | 81.7 | 73.7 | 66.1 | 58.8 |
| Improved | 7.6 | 9.6 | 12.4 | 20.4 | 18.3 | 23.3 |
| Dataset | Pixel RES | Spatial RES | Class # | Image # | Source |
|---|---|---|---|---|---|
| HMHR | 2.39 m | 5 | 533 | GoogleEarth | |
| EuroSAT | 10 m | 10 | 27,000 | Sentinel2 | |
| SIRI WHU | 2 m | 12 | 2400 | GoogleEarth | |
| UCMerced | 0.3 m | 21 | 2100 | USGS National Map | |
| AID | 0.5–8 m | 30 | 10,000 | GoogleEarth | |
| PatternNet | 0.062–4.693 m | 38 | 30,400 | GoogleMap | |
| NWPU | 0.2–30 m | 45 | 31,500 | GoogleEarth |
| Dataset | Evaluation | LCT | LCT + ICSR | Improved |
|---|---|---|---|---|
| ACC | 86.3 | 89.1 | 2.8 | |
| HMHR | NMI | 68.3 | 72.9 | 4.6 |
| ARI | 69.9 | 75.0 | 5.1 | |
| ACC | 90.0 | 94.8 | 4.8 | |
| EuroSAT | NMI | 84.4 | 89.7 | 5.3 |
| ARI | 80.3 | 89.3 | 9.0 | |
| ACC | 66.2 | 90.7 | 24.5 | |
| SIRI WHU | NMI | 66.8 | 86.1 | 19.3 |
| ARI | 53.3 | 82.0 | 28.7 | |
| ACC | 72.9 | 84.9 | 12.0 | |
| UCMerced | NMI | 78.3 | 86.5 | 8.2 |
| ARI | 62.3 | 77.5 | 15.2 | |
| ACC | 71.0 | 77.9 | 6.9 | |
| AID | NMI | 76.3 | 80.0 | 3.7 |
| ARI | 60.2 | 67.6 | 7.4 | |
| ACC | 90.9 | 97.1 | 6.2 | |
| PatternNet | NMI | 94.2 | 97.3 | 3.1 |
| ARI | 87.8 | 95.1 | 7.3 | |
| ACC | 76.1 | 85.4 | 9.3 | |
| NWPU | NMI | 80.5 | 84.8 | 4.3 |
| ARI | 66.9 | 75.4 | 8.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Qiu, G. Improving Image Clustering through Sample Ranking and Its Application to Remote Sensing Images. Remote Sens. 2022, 14, 3317. https://doi.org/10.3390/rs14143317
Li Q, Qiu G. Improving Image Clustering through Sample Ranking and Its Application to Remote Sensing Images. Remote Sensing. 2022; 14(14):3317. https://doi.org/10.3390/rs14143317
Chicago/Turabian StyleLi, Qinglin, and Guoping Qiu. 2022. "Improving Image Clustering through Sample Ranking and Its Application to Remote Sensing Images" Remote Sensing 14, no. 14: 3317. https://doi.org/10.3390/rs14143317
APA StyleLi, Q., & Qiu, G. (2022). Improving Image Clustering through Sample Ranking and Its Application to Remote Sensing Images. Remote Sensing, 14(14), 3317. https://doi.org/10.3390/rs14143317