1. Introduction
Land Cover (LC) maps can be used to extract key information for a series of national applications, such as environmental monitoring, identification of land degradation trends, spatial planning, and for a wide range of scientific research fields. However, continuous monitoring and reporting of land cover maps requires regular updating, the use of standardized methods, and the adoption of a robust validation framework ensuring that every estimate is accurate and consistent over time. Such land cover mapping solutions are very rare to find in countries due to the inherent technical and financial challenges found in both traditional and modern LC mapping methods.
The most traditional methods that have been typically used in the last two decades have been based, initially, on visual image interpretation and pixel (or object) classification, relying on the use of very high-resolution images (commercial satellite images and ortho-photos), and subsequently, on the combination of Earth Observations and in situ data for calibration and validation of automatic classification models. Such solutions have been extensively used in the research community [
1,
2,
3,
4].
FAO adopted a visual interpretation approach in 2015 to deliver the first edition of the Lesotho Land Cover Atlas [
5]. The methodology relied on a manual labeling of segmented objects from very high-resolution preprocessed satellite imagery using a visual image interpretation. Preprocessing of the satellite imagery included pen-sharpening of Rapid Eye 2014 single date imagery with ortho-photos collected in 2014. The resulting cloud-free mosaic, at 1.5 m/2 m spatial resolution, was then subjected to segmentation using the E-Cognition proprietary algorithm [
6]. A collection of nearly 1 million polygons was derived and divided into nine tiles, which were assigned to a group of 30 dedicated image interpreters. Each polygon was visually interpreted and assigned to one of the 32 level-II land cover classes, which had been defined following the FAO Land Cover Classification System (LCCS) system. While this mapping approach was crucial to establish the first national baseline, it could not be replicated easily as it is resource intensive—outputs are delivered with a significant time lag and introduce subjectivity in the object classification.
After 2015, with the advent of free high-resolution satellite imagery from the Sentinel fleet operated by the Copernicus program of the European Union, together with the availability of a low-cost cloud computing facility and rich machine learning libraries, it is now possible to carry out land cover mapping in a much more cost-efficient way by integrating Machine Learning (ML) and Open Access Geospatial Data [
7]. The short revisit period of Sentinel-1 and Sentinel-2 images (4 to 5 days) has allowed for developing land cover mapping approaches based on dense time series as opposed to monotemporal image analysis; this has increased the capacity of classifiers to better discriminate vegetation types with positive impacts on the overall accuracy of results. Studies have been conducted on mapping land cover in different areas of the world including Europe, Africa, and Asia, using optical data alone (Sentinel-2) or a combination of optical and SAR data (Sentinel-2 and Sentinel-1) [
8,
9,
10,
11].
Despite the proliferation of these new approaches, all supervised classification algorithms remain dependent on the utilization of a sufficiently large set of representative training samples to generate accurate land cover maps. The quality of land cover maps, typically measured with accuracy statistics derived from the confusion matrix [
12], depends on the quality of the in-situ dataset, its accurate geographical positioning, its spectral consistency, and the representativeness of the dataset of the full range of land cover conditions in the field. However, in situ data of adequate quality and sufficient quantity are rarely available in countries, due to the high costs and logistic problems associated with the collection of these data on a large scale on a regular basis. The lack of in situ data poses a major challenge to the establishment of an efficient and sustainable land cover mapping solution at the national level and is an important limiting factor for the uptake of EO methods by National Statistics Offices in the production of official land cover statistics [
13,
14].
In response to these issues, alternative solutions for the collection of field data for the purpose of land cover mapping have been developed by using training data, extracted, for instance, from the visual interpretation of satellite images [
15,
16]. Despite this approach being more practical than the implementation of field surveys, it is still time-consuming and subject to the introduction of classification errors due to the subjective nature of the interpretation by the operator. Alternatively, training data can be extracted from existing land cover maps. The Climate Change Initiative Global Land Cover (CCI_LC) dataset, produced by the European Space Agency (ESA, Paris, France), was used to extract the spatial–temporal spectral signature of each land-cover type, and subsequently, to classify Landsat Operational Land Imager (OLI) data, producing a land cover map of China [
17]. Samples were extracted from the National Agricultural Statistics Service (NASS, Washington, DC, USA) Cropland Data Layer (CDL) dataset [
18] and used as training data to produce the 2011 National Land Cover Database (NLCD) product [
19]. Samples extracted from the Moderate Resolution Imaging Spectroradiometer (MODIS) (NASA, Washington, DC, USA) land cover products (MCD12Q1.006) were used to train a random forest algorithm to produce a land cover map in an area of northern China by classifying LandSat time series data using Google Earth Engine [
20].
Costa et al. (2018) [
21] proposed a general framework for routine monitoring and statistical reporting of land cover and land cover change in Portugal using training pixels extracted from Google street view and ortho-photo maps; in this paper, Landsat images were interpreted using a combination of three machine learning classifiers (ANN, RF, and SVM). Cong Lin et al. (2019) [
22] applied a knowledge transfer technique to transfer label information from the Globeland30 global dataset and map the rapidly urbanizing region within the Yangtze River Delta city cluster in China.
Even though training data extracted from existing land cover products are a potentially useful source of information, their application is still not straightforward. Such data are not fully reliable since they may embed classification errors, inherited by the source land cover product, due to both misclassification errors in the original product and land cover changes linked to the different timings of extraction of the pixel imageries. Furthermore, training data are usually aggregated at the polygon level, which often include heterogeneous areas and result in spectral inconsistency of the object. Lastly, there may be a semantic gap between map legends and Remote Sensing (RS) data [
17].
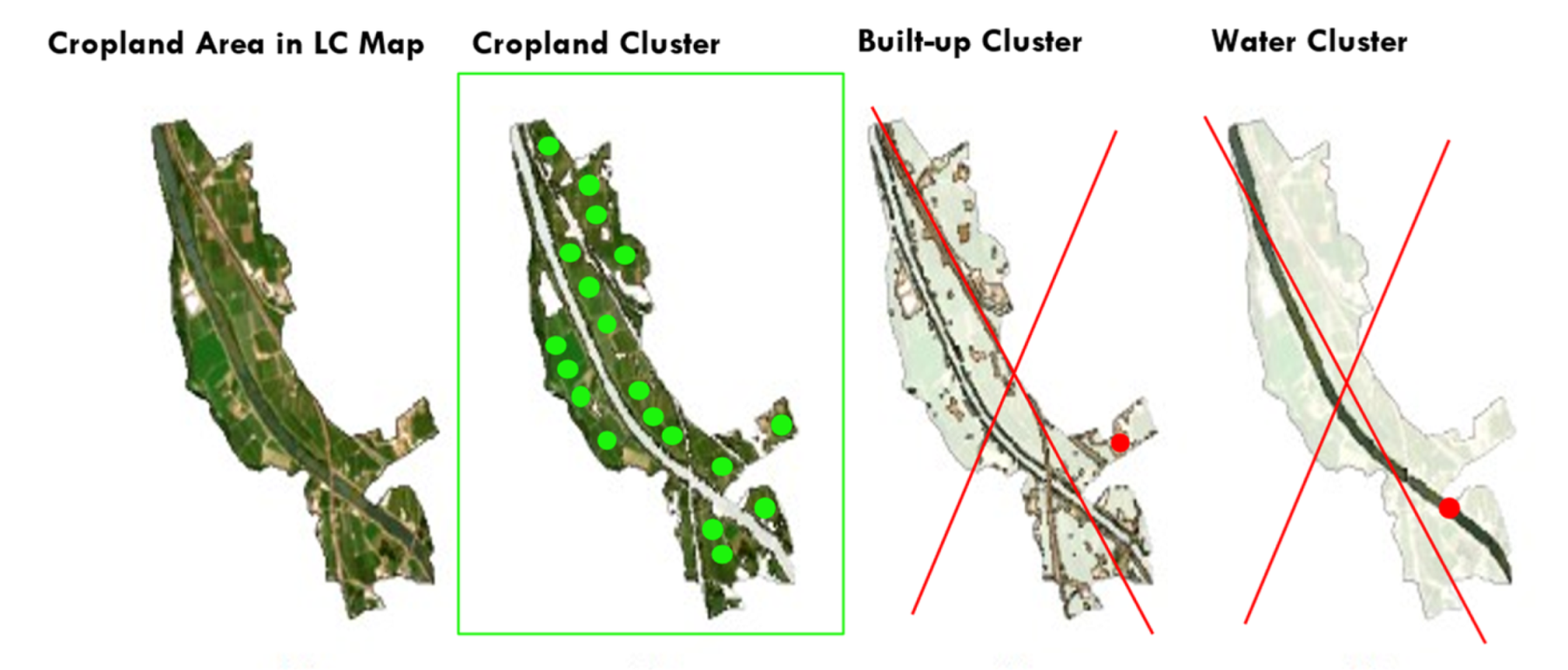
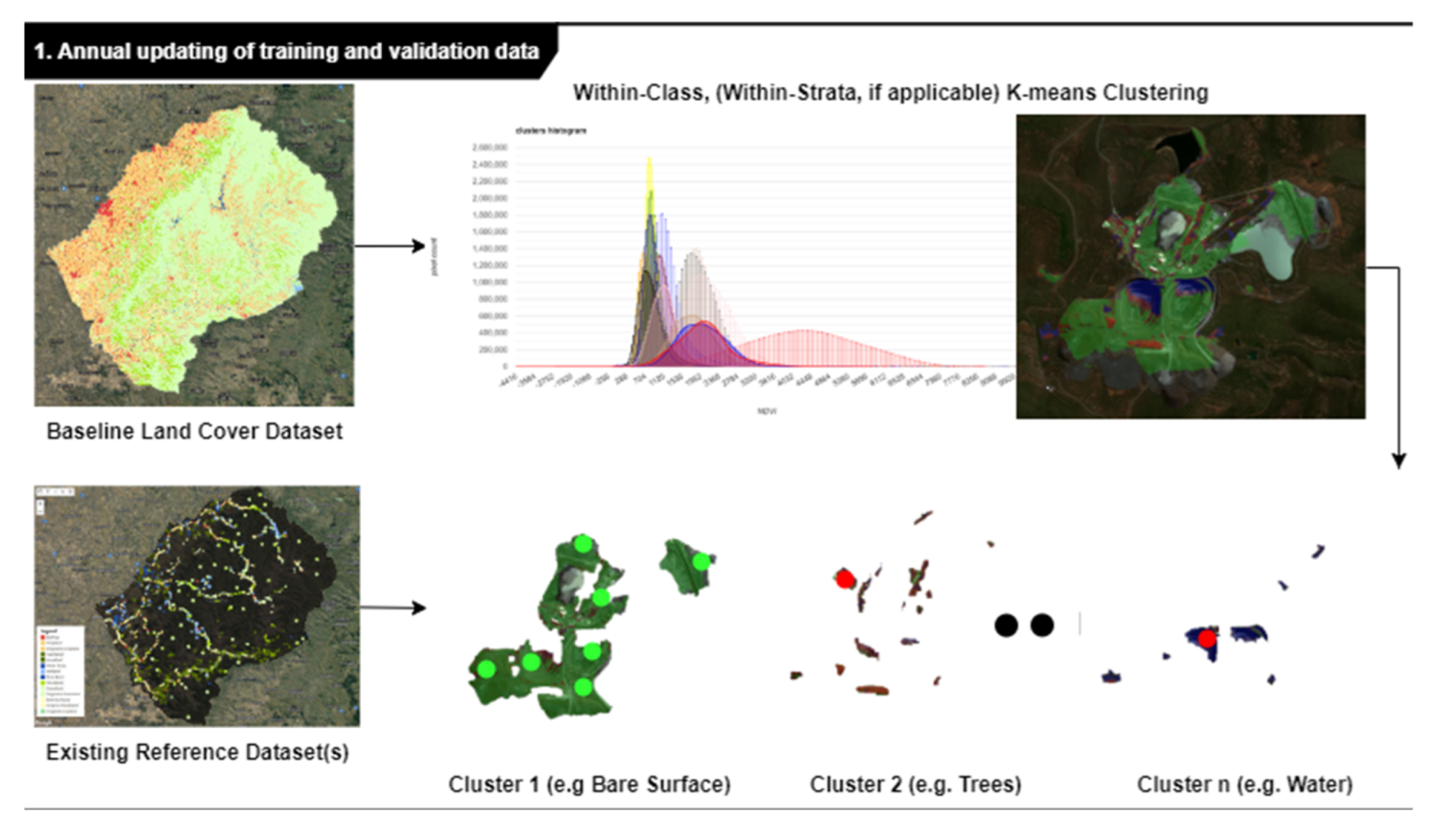
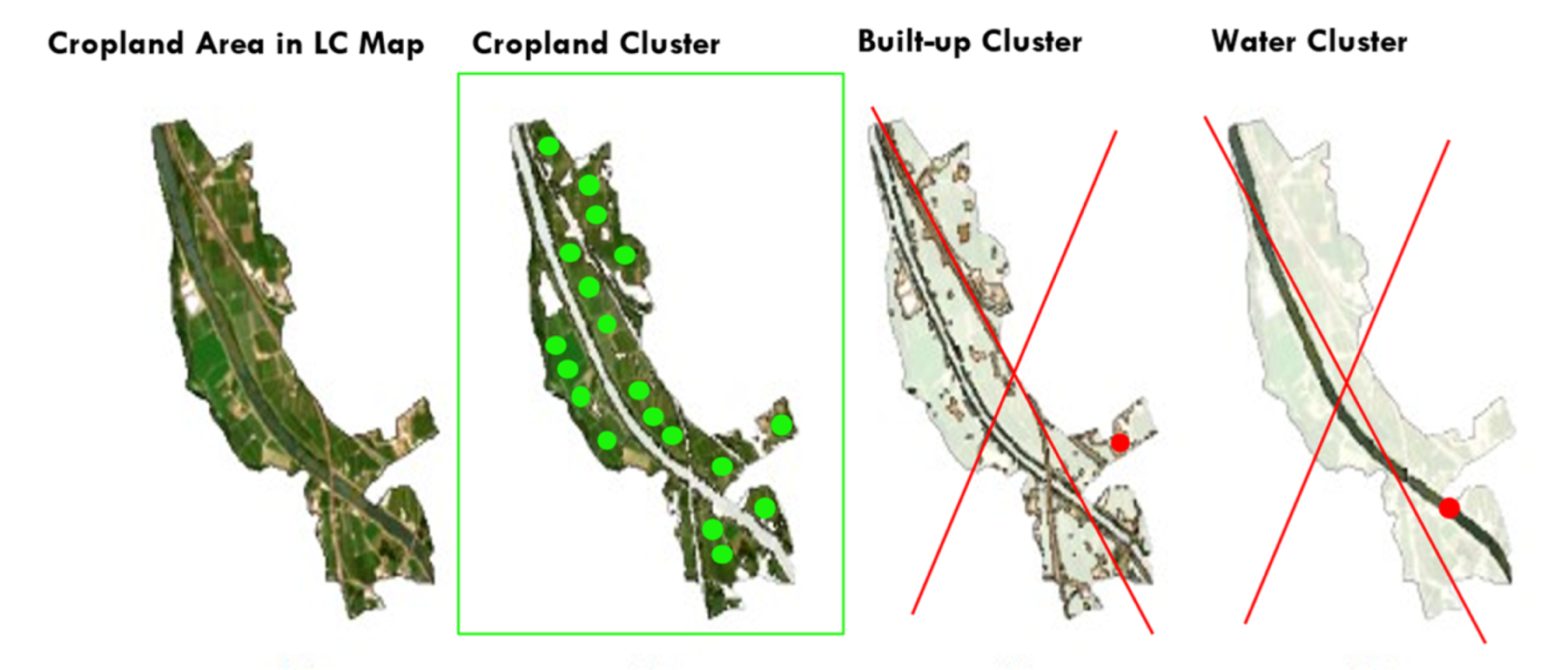
Several approaches have been developed to curate the training data to ensure positional and spectral quality. For example, when a time series of LC maps is available, pixels, which do not change land cover class over a period of three years, are selected [
23]. Additionally, training data can be sampled so that the LC class proportions of the training dataset are representative of the population they were extracted from. In 2020, Paris and Bruzzone developed a novel approach for the unsupervised extraction of reliable training samples from thematic products [
24], which ensures the spectral coherence of the training data and is better suited to automatize the imagery interpretation process.
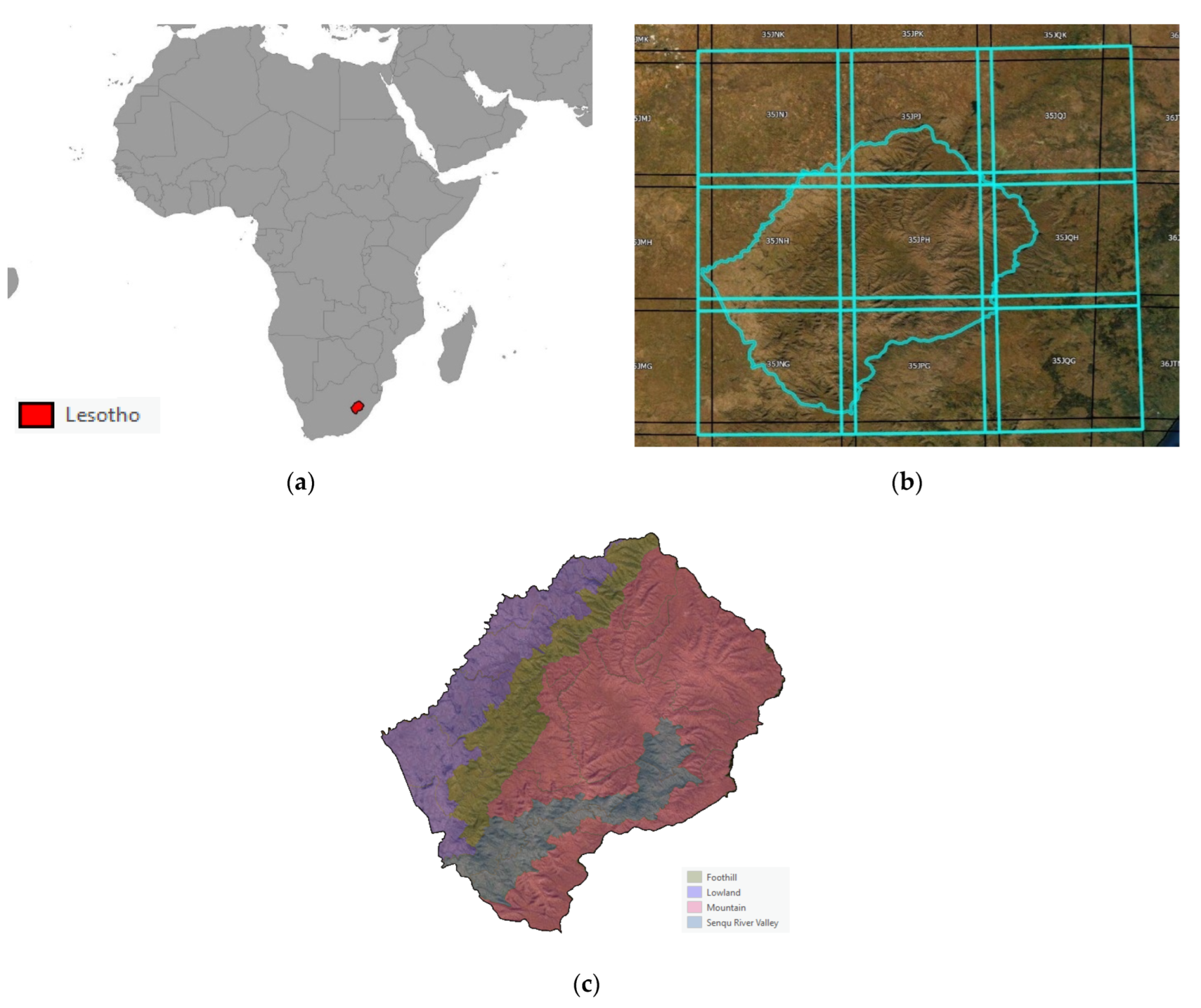
In order to solve the fundamental challenge of the lack of in situ data of adequate quality, which is hindering the establishment of operational land cover mapping systems in countries, in 2021, FAO developed a new methodology that was tested in Lesotho under the auspices of the national Integrated Catchment Management (ICM) program implemented by the Government of Lesotho and funded by a multi donor consortium (comprising the European Union, the Deutsche Gesellschaft für Internationale Zusammenarbeit (GIZ), and the Government of Lesotho).
The solution named EOSTAT Land Cover Mapper, is provided free of cost and is currently hosted on Google Earth Engine. The codes developed by FAO can be accessed in the
Supplementary Materials section.
The solution has the following characteristics:
It allows for the production of next-generation standardized annual land cover maps;
It copes with the lack of in situ data and the limited resources available in most countries for the collection of training and validation data;
It is provided free of operating costs;
It is user friendly and can be easily operated by national staff.
The paper is structured with the following sections: (i) Introduction, where, after providing background information on the country project implemented in Lesotho, the main methods for large-scale land cover mapping and for gathering in situ data are described; (ii) Data, where the definition of a machine-learning-friendly legend, using FAO LCCS, the production of Sentinel-2 Analysis Ready Data cubes, and the available in situ data for the baseline are presented; (iii) Methods, where the automatic generation of in situ data using K-means, the use of Random Forest for the classification of the national land cover maps, and the framework for the accuracy analysis of the annual land cover estimates and their consistency over time are reported; (iv) and (v) Main Results and Discussion, where the final outputs are presented and areas for possible enhancement of the method for the automatic generation of training data are described; (vi) Conclusions, which summarize the most important takeaways from the paper.
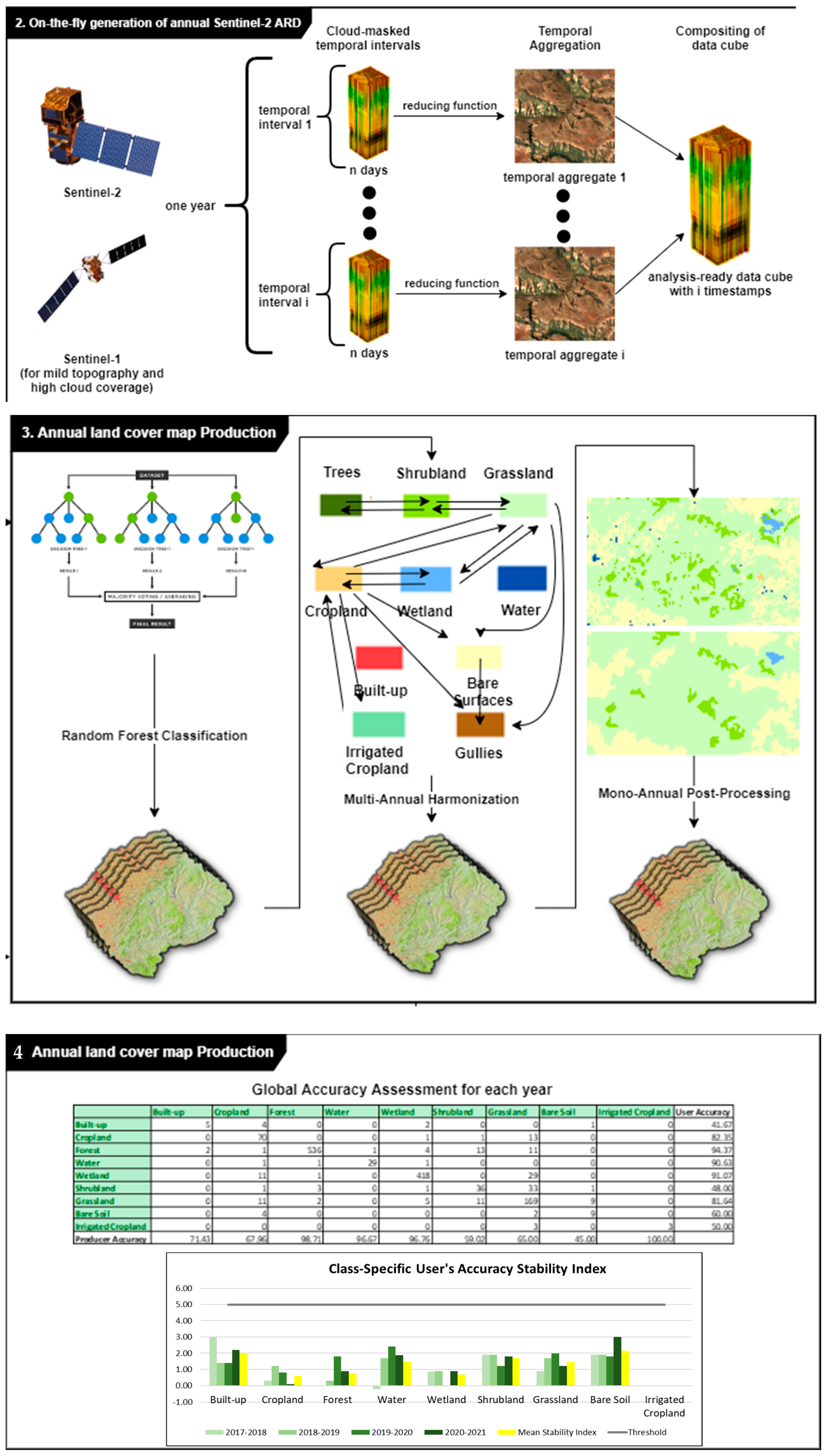
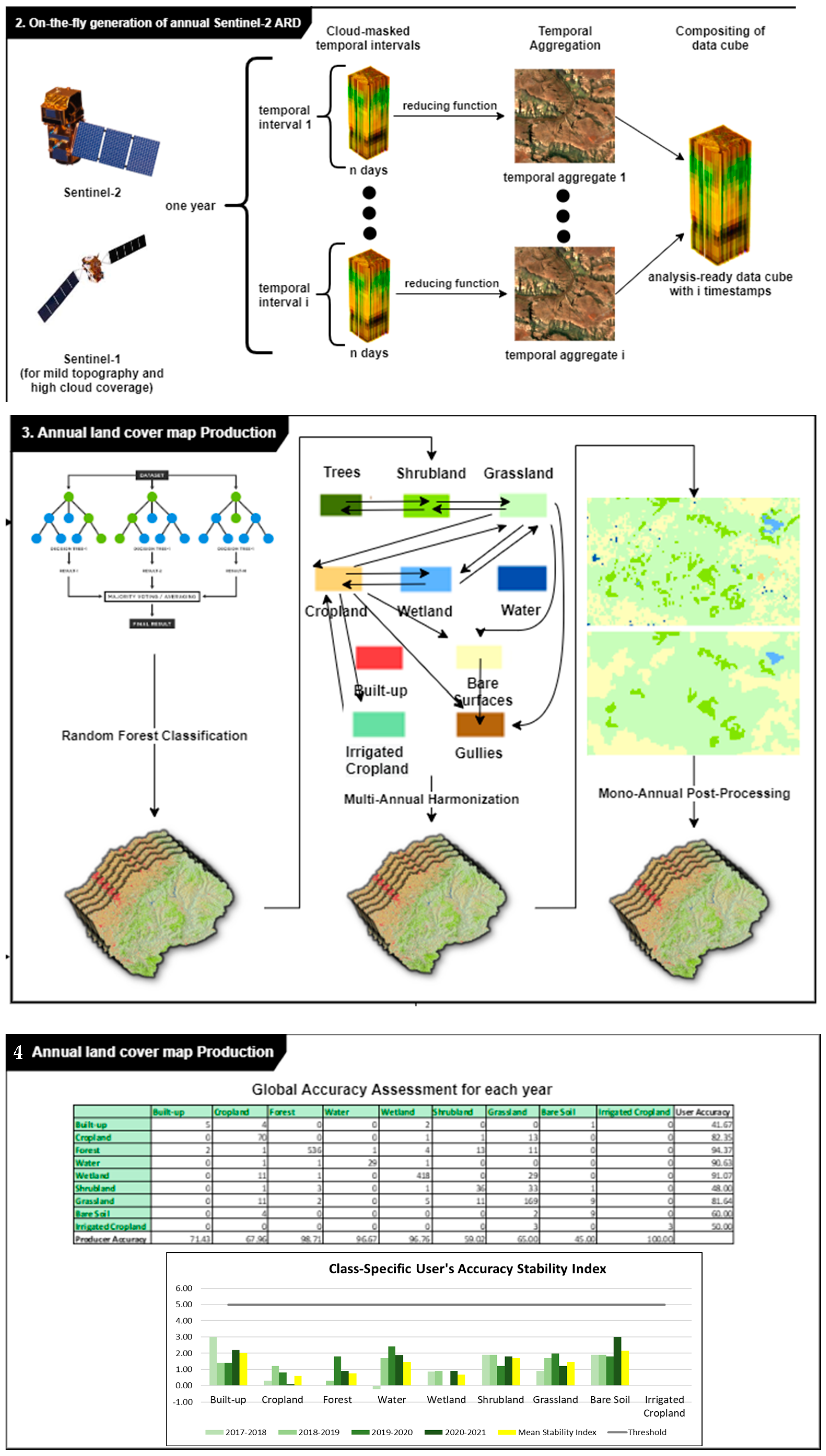
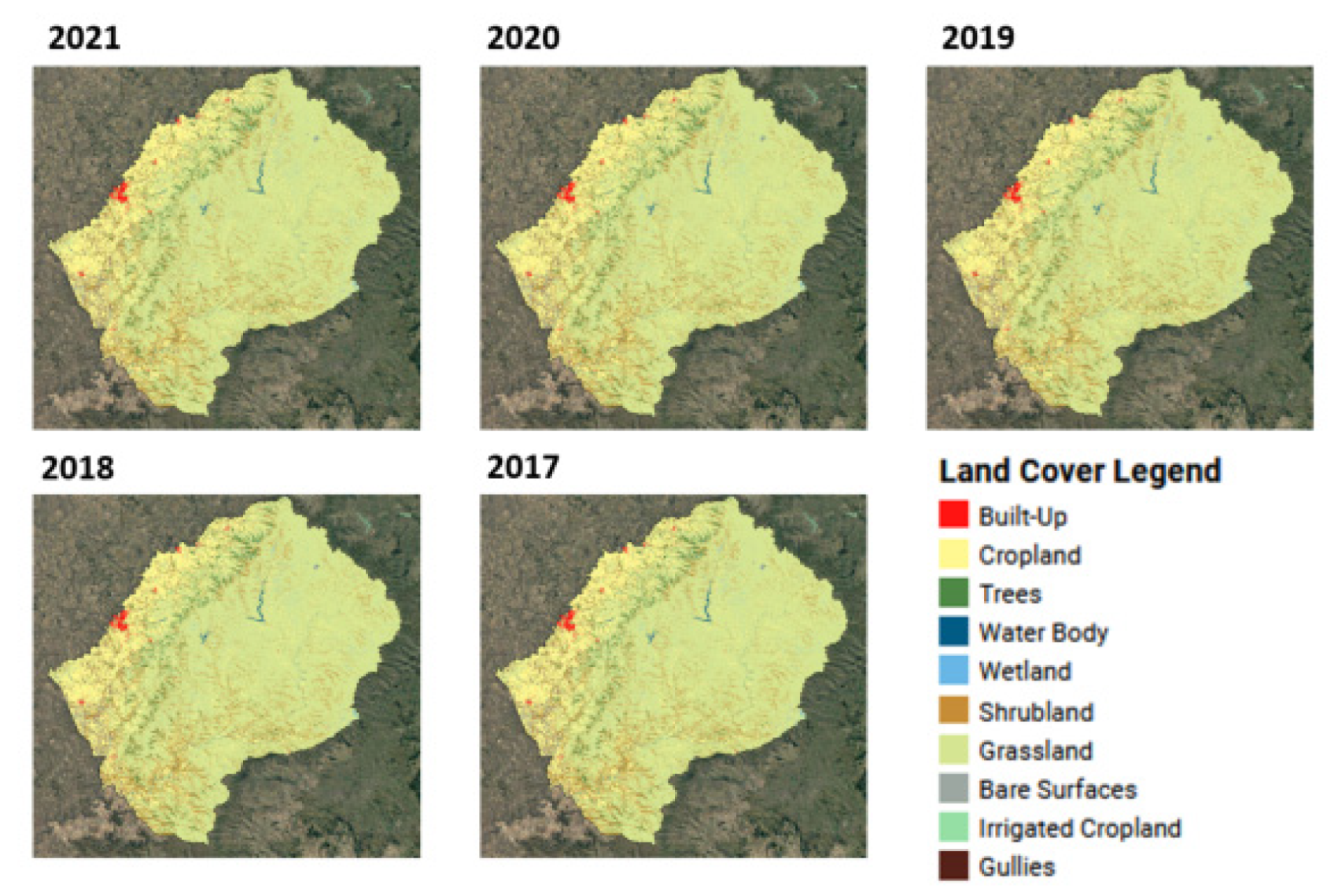
4. Main Results
4.1. Land Cover Maps and Land Cover Statistics
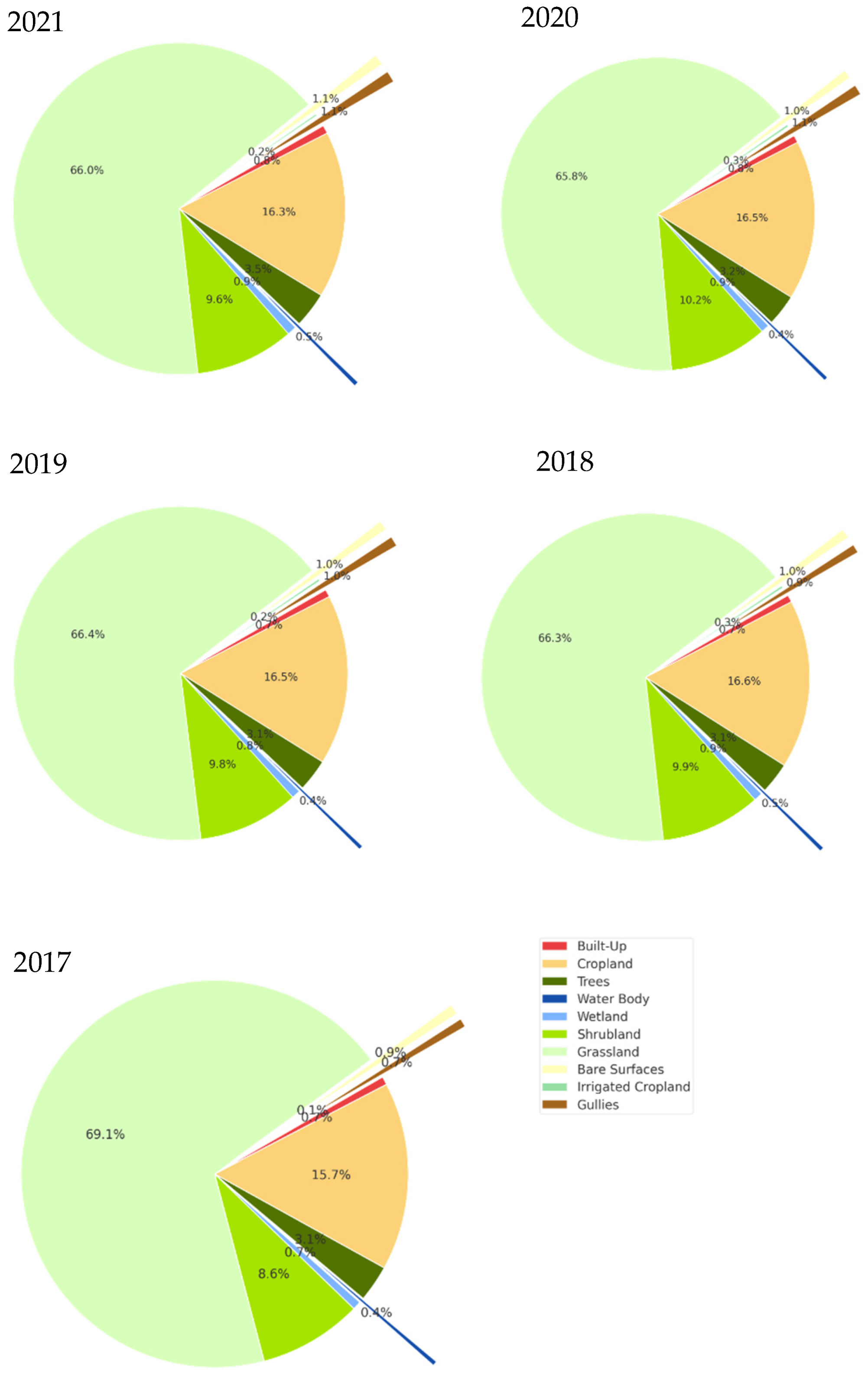
Five annual land cover maps were produced for the period 2017–2021, as shown in
Figure 8.
Land cover area statistics were extracted from the baseline year (2021), as shown in
Table 10. Grassland was the dominant class with over 2 M ha, occupying 66% of the entire national territory, followed by Cropland (rainfed and irrigated), with just above 500K ha (16.3%). Shrubland was the third largest class with almost 300K ha (9.6%). Trees occupied the 4th largest class with just above 100K ha (3.5). Gullies and Bare areas measured nearly 33K ha each, followed by Wetlands (28K ha), Built-up (24K ha), and Water Body (14K). The least represented class was Irrigate Crops with only 6K ha.
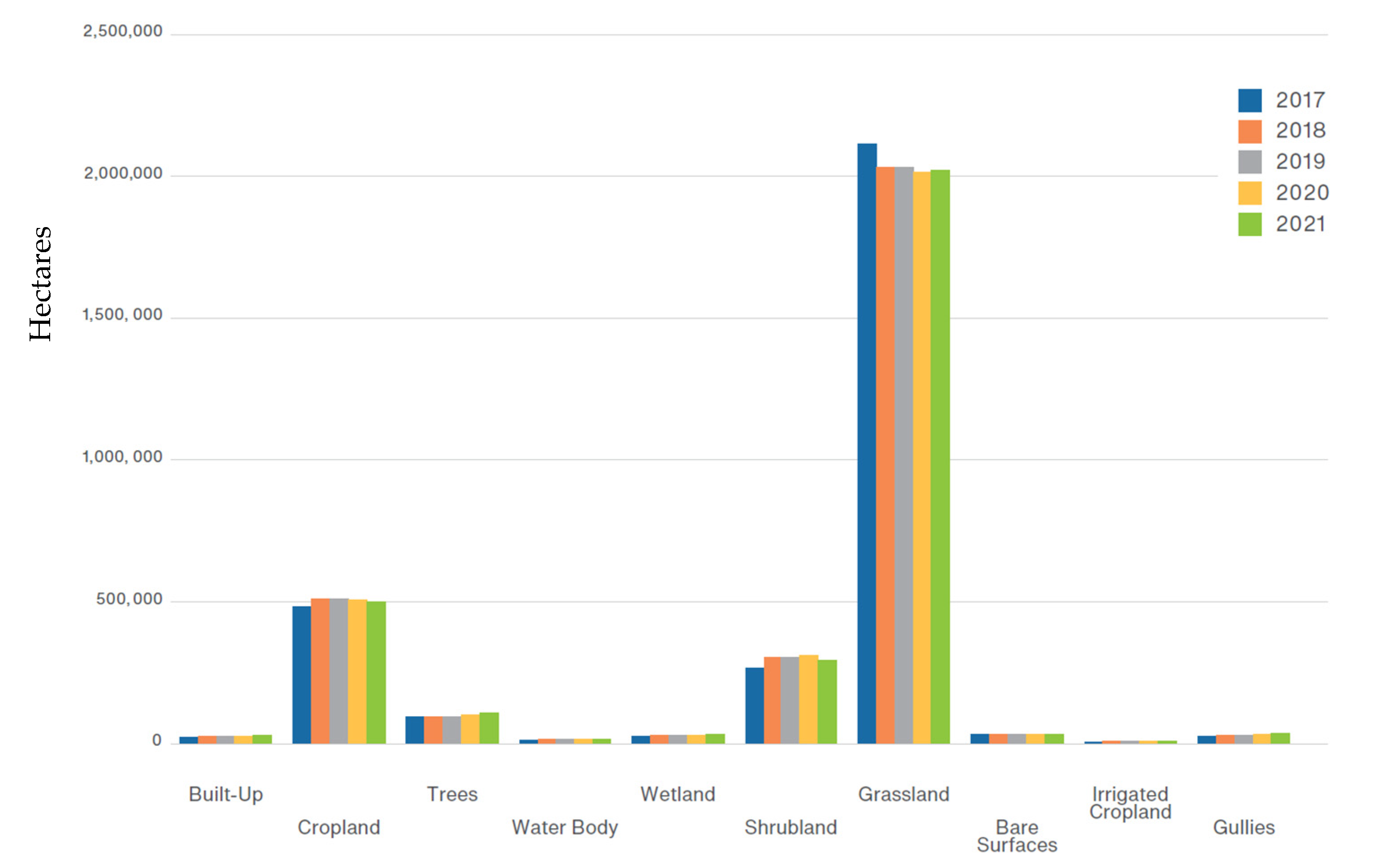
Land cover statistics extracted for the time series maps 2017–2021 are shown in
Figure 9 and
Figure 10. Minor increases were recorded for every class over the 5-year period, with the exception of Grassland, which decreased across the whole country.
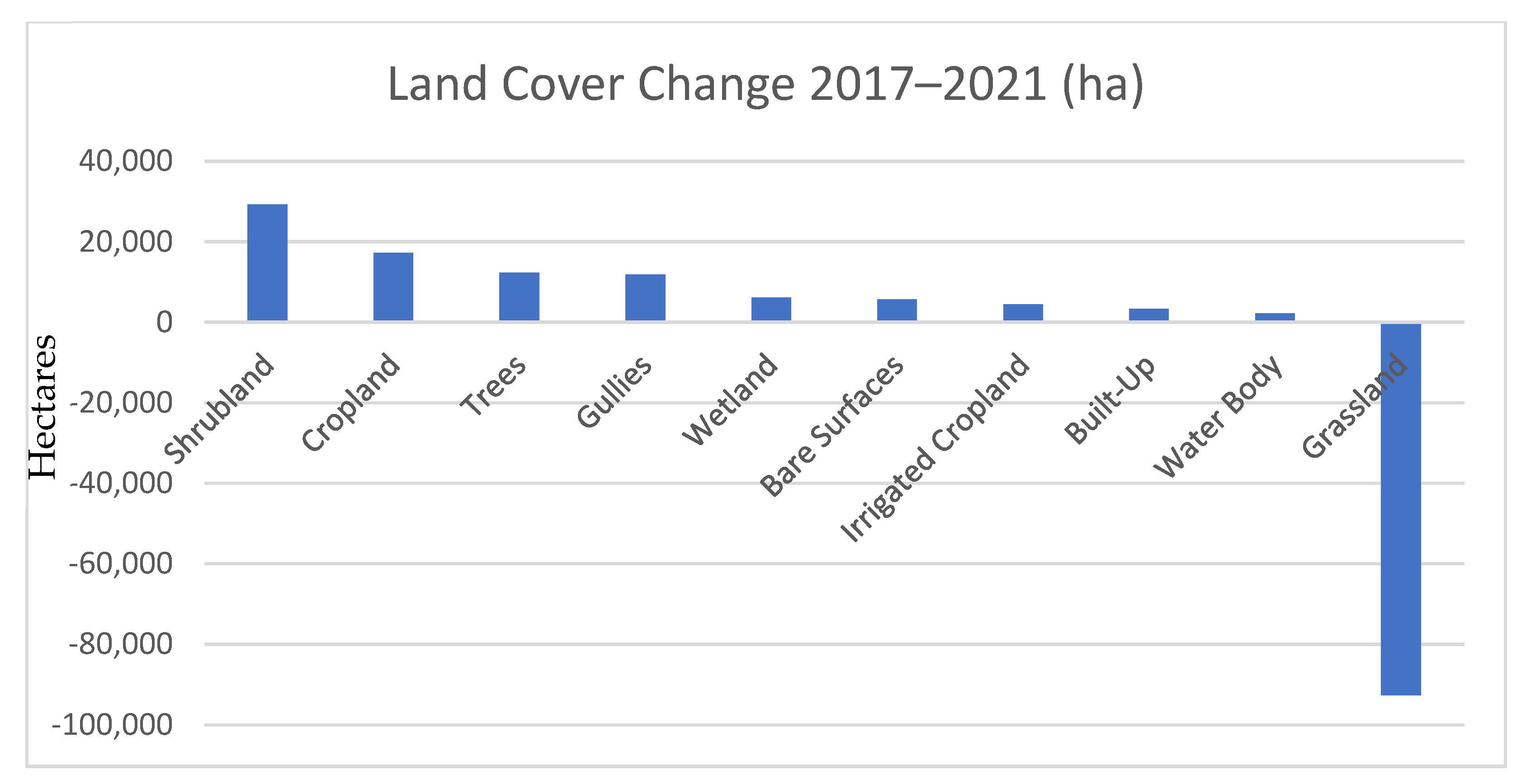
The five largest gains in absolute terms were recorded in Shrubland with almost 30K hectares, Cropland with 17K ha, Trees with 12K ha, Gullies with 12K ha, and Wetlands with 6.1K ha, as shown in
Figure 11. Bare soil area increased by 5.6K ha, Irrigated cropland area by 4.4K ha, Built-up area by 3.3K ha, and Water bodies area by 2.2K ha. Grassland area decreased by −92K ha. These initial figures were consistent with the overall land degradation processes ongoing in the country [
42], including degradation of rangelands due to overgrazing and encroachment of invasive species; generalized soil loss due to erosion which is accelerated by poor crop practices; expansion of Gullies; and loss of vegetation indicated by the increase in Bare surfaces [
43,
44]. The expansion of built-up area was coherent with the demographic growth recorded in the last five years (+4%). Increases in cropland, both rainfed and irrigated, confirmed the expansion of cropland into rangelands in response to increased food requirements, as well as national institutional efforts into land restoration and recovery of agricultural land. The increase in Tree area together with Wetland area are a positive sign of the environmental resilience of the country.
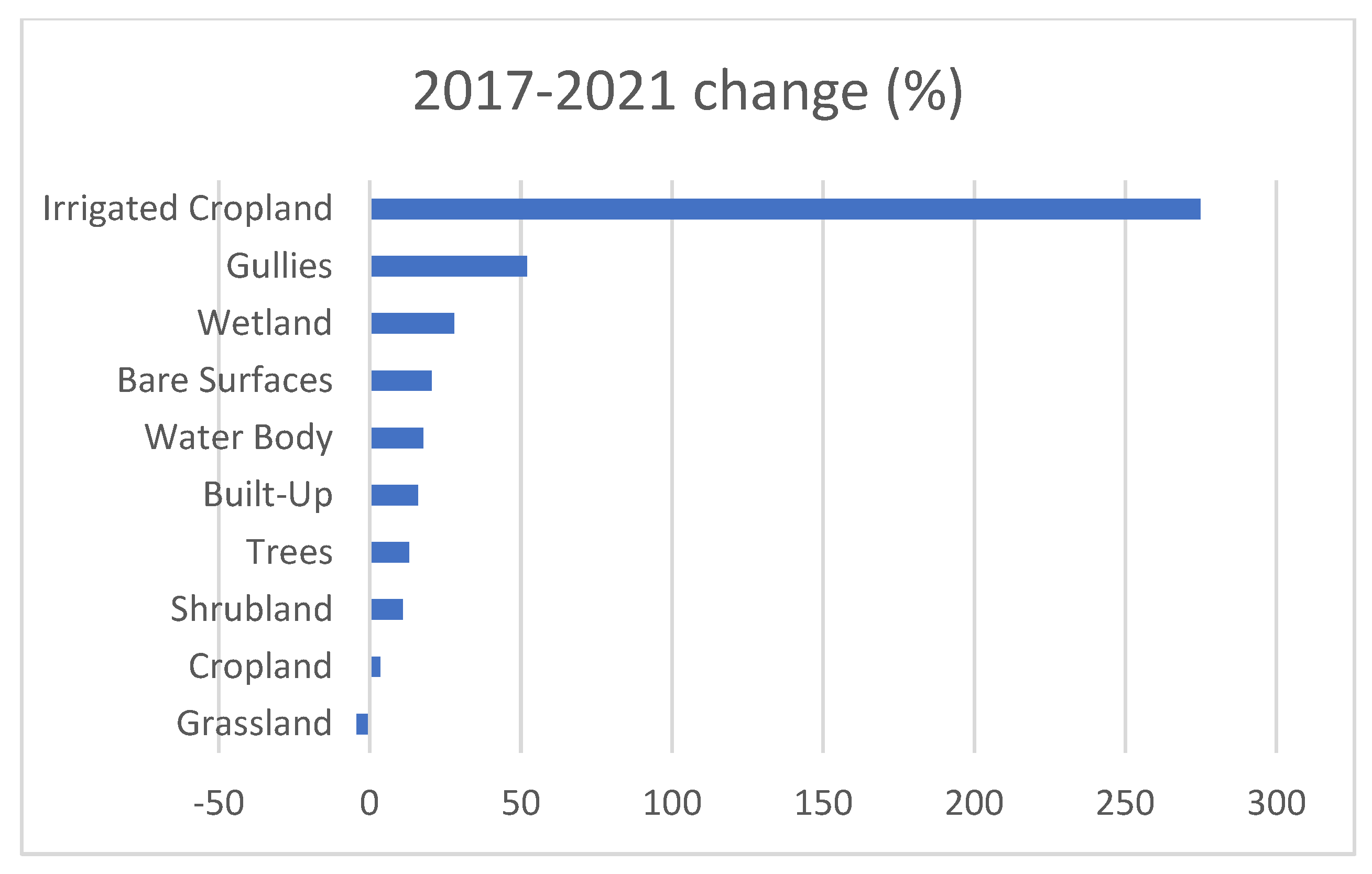
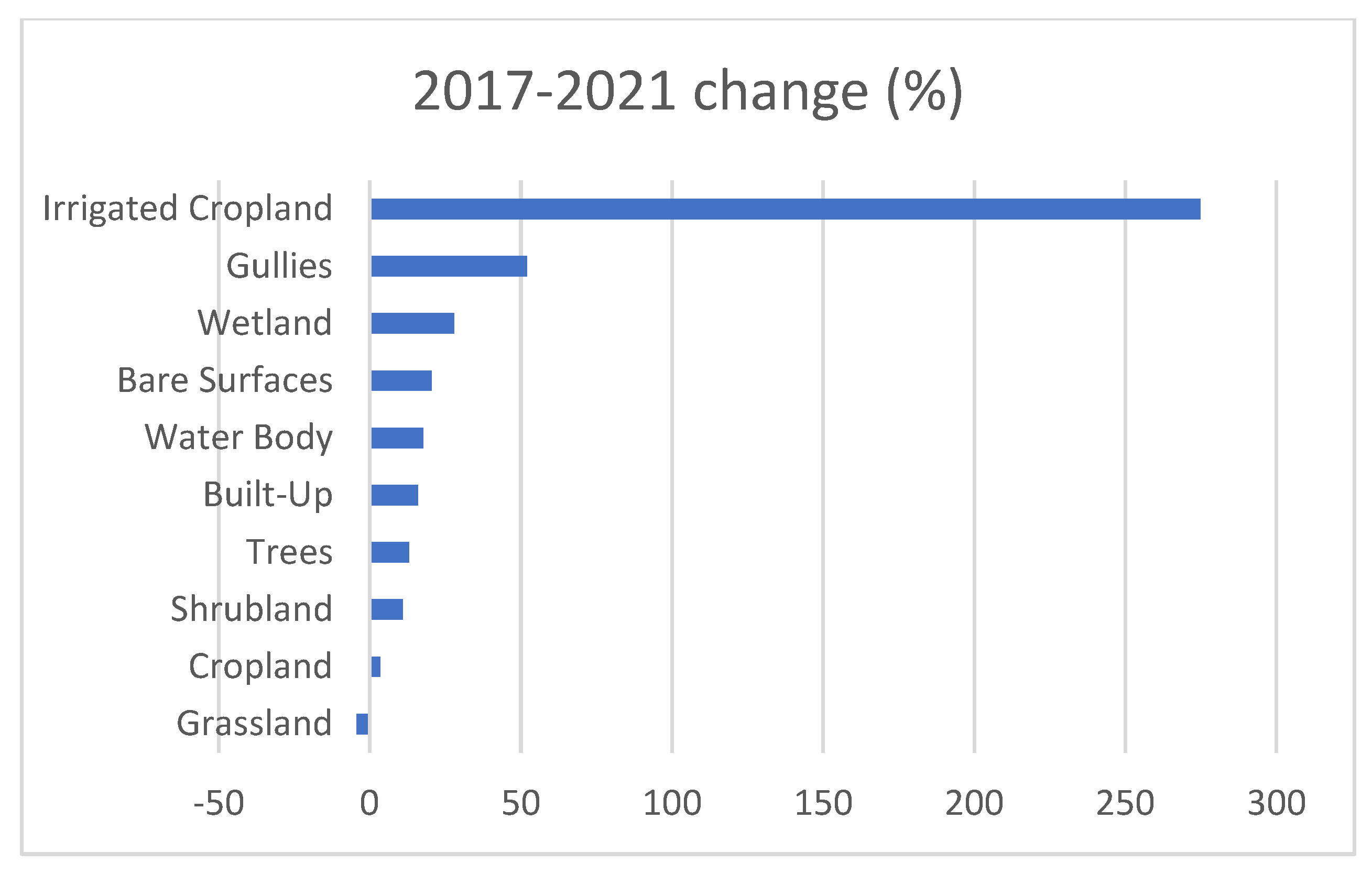
Land cover proportional changes (%) were analyzed as shown in
Figure 12. The five largest changes were recorded in Irrigated Cropland (275%), followed by Gullies (52%), Wetland (28%), Bare surface (20.5%), and Water body (17.7%). Shrubland recorded the smallest change (−4.3%).
The irrigated cropland, which represents a minor portion of the total cropland (1.2%), recorded the largest proportional gain (+275%). This is expected as there is ongoing expansion of irrigation activities as a result of the national efforts to improve farming management practices. The second and third largest proportional gains were found in Gullies and Bare surfaces, indicating the advancement of land degradation processes.
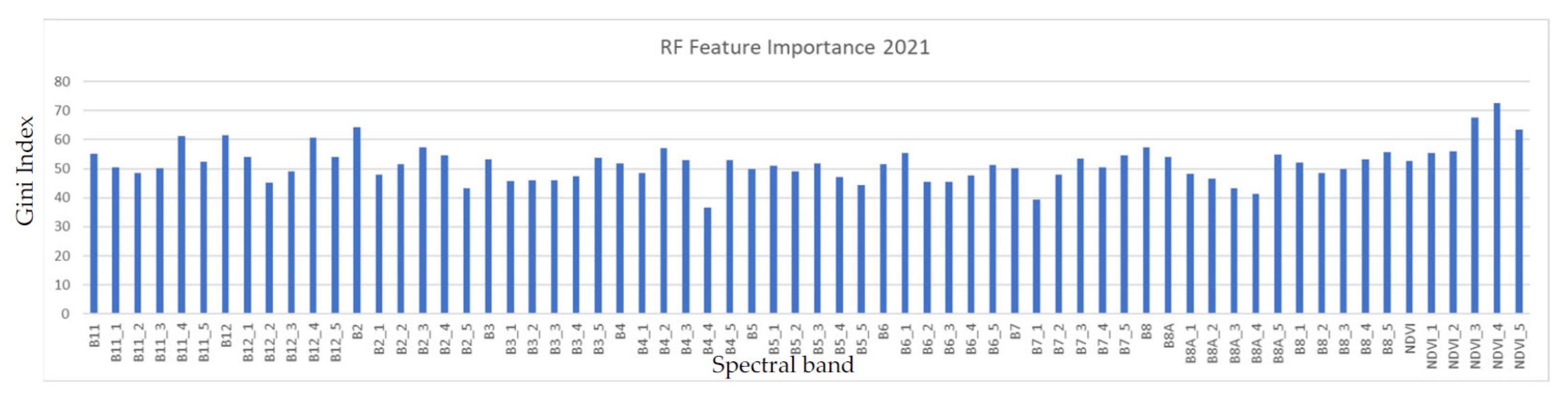
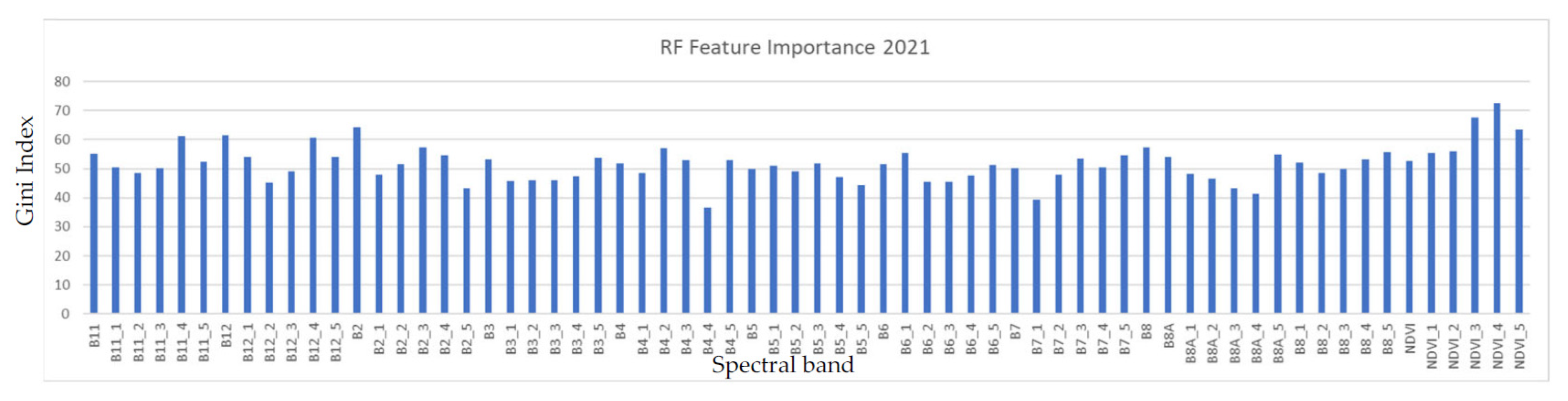
4.2. Feature Importance
Feature importance (Gini Index) was calculated for all the input features into the RF across each predicted year (2017–2022), as shown in
Figure 13. The Gini index [
45] is a statistical measure that quantitatively evaluates the ability of a feature to separate instances from different classes [
46].
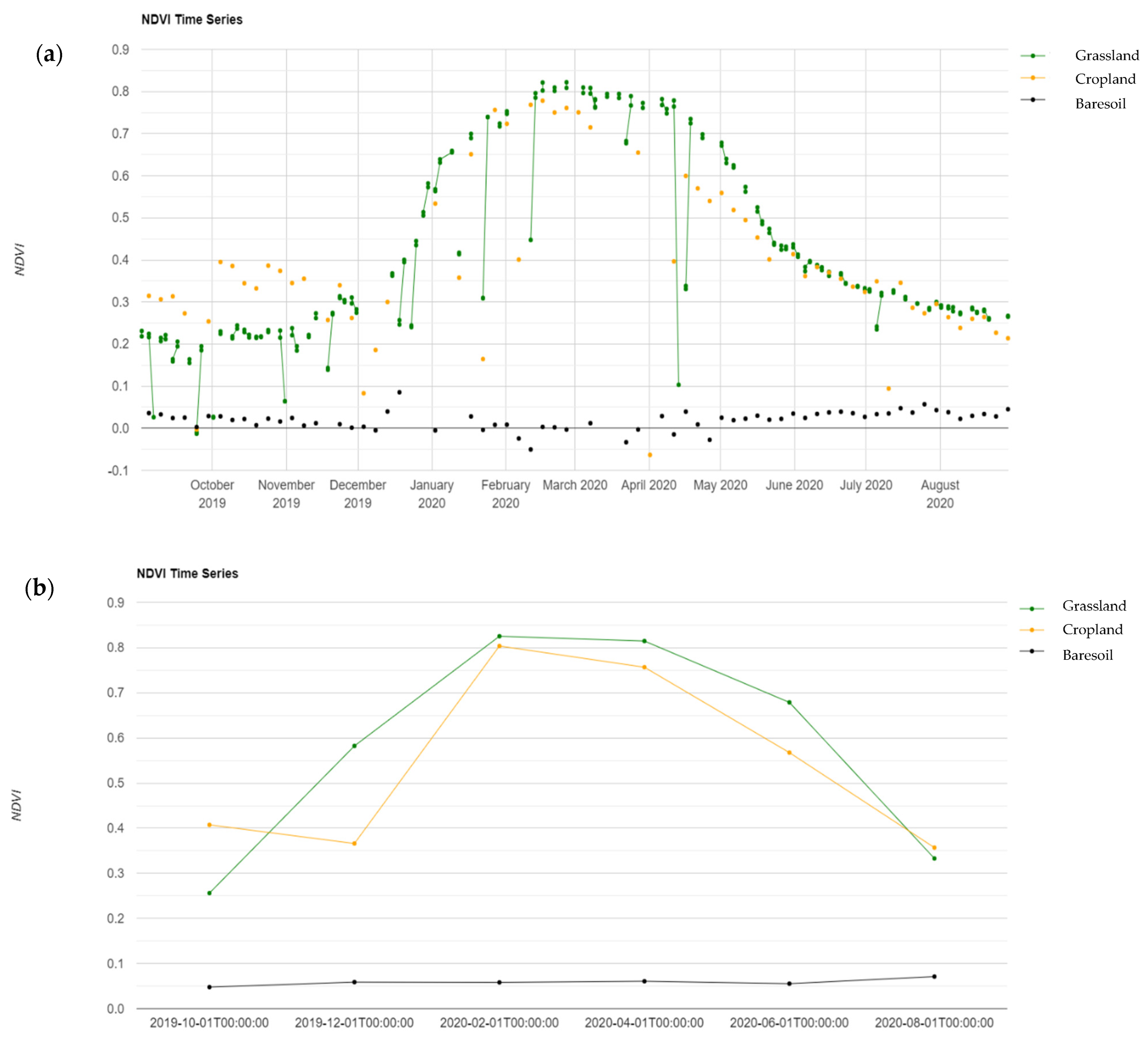
NDVI_4 (NDVI for the September–October period), B12_1 (SWIR2 for the January–February period), and B12_4 (SWIR2 band for the September–October period) showed a consistently high importance across all years. While Jan–Feb corresponds to the peak of vegetation growth in Lesotho, September–October corresponds to the green-up onset; these are both key phenological stages in the year and could explain, in part, the importance of those bands.
4.3. Accuracy Measures
Validation of the land cover map 2021 yielded an overall accuracy (OA) of 88.55% and K statistics of 86.13% as shown in
Table 11.
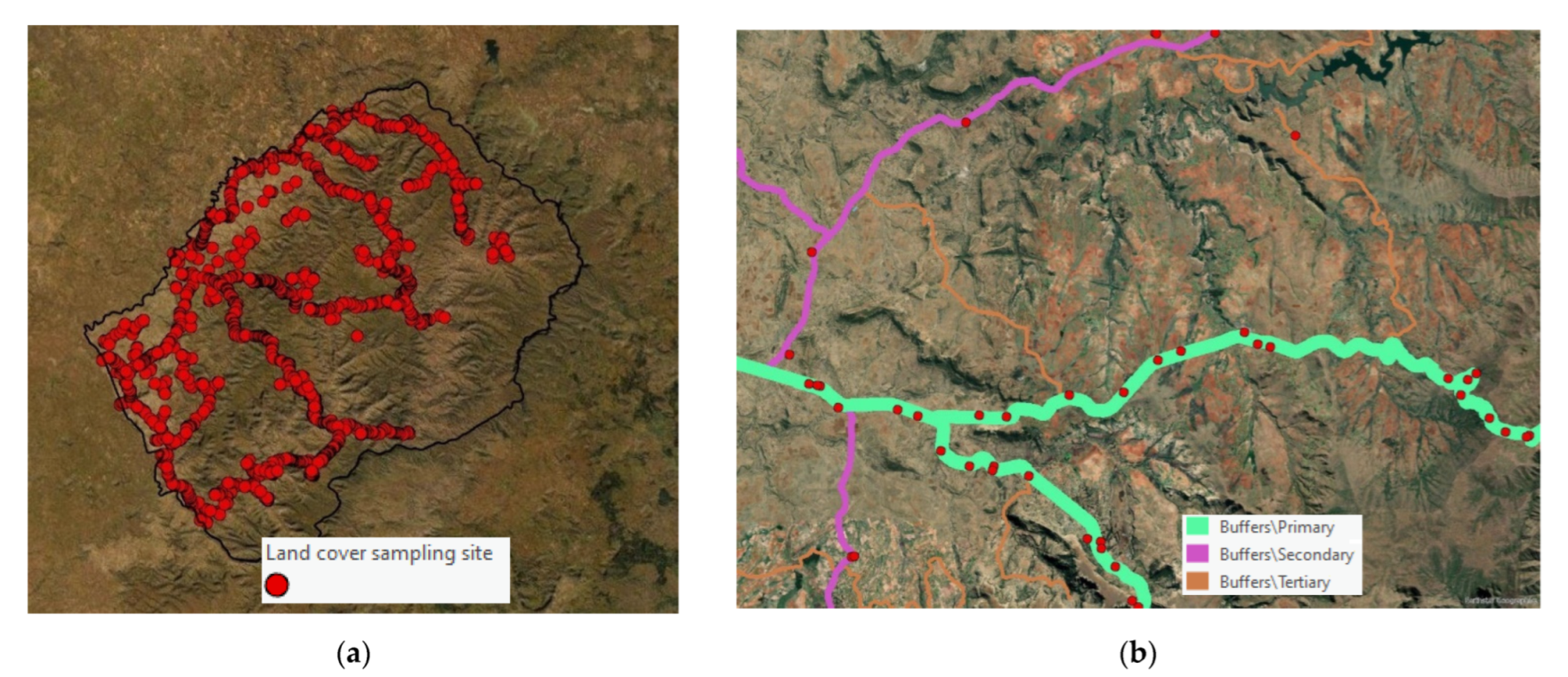
Almost all land cover classes scored high Precision (UA) and Recall (PA) values as well as F1 scores. Trees, Wetland, Water, and Cropland scored the highest combined UA and PU (97%/99%, 91%/97%, 91%/97%, and 91%/74%, respectively). This is explained by various factors: (i) the distinct spectral signature and spatially correlated distribution of trees across south-facing slopes and along rivers (
Figure 14a,b); (ii) the availability of a high quality and quantity of in situ data for wetlands gathered through a dedicated survey [
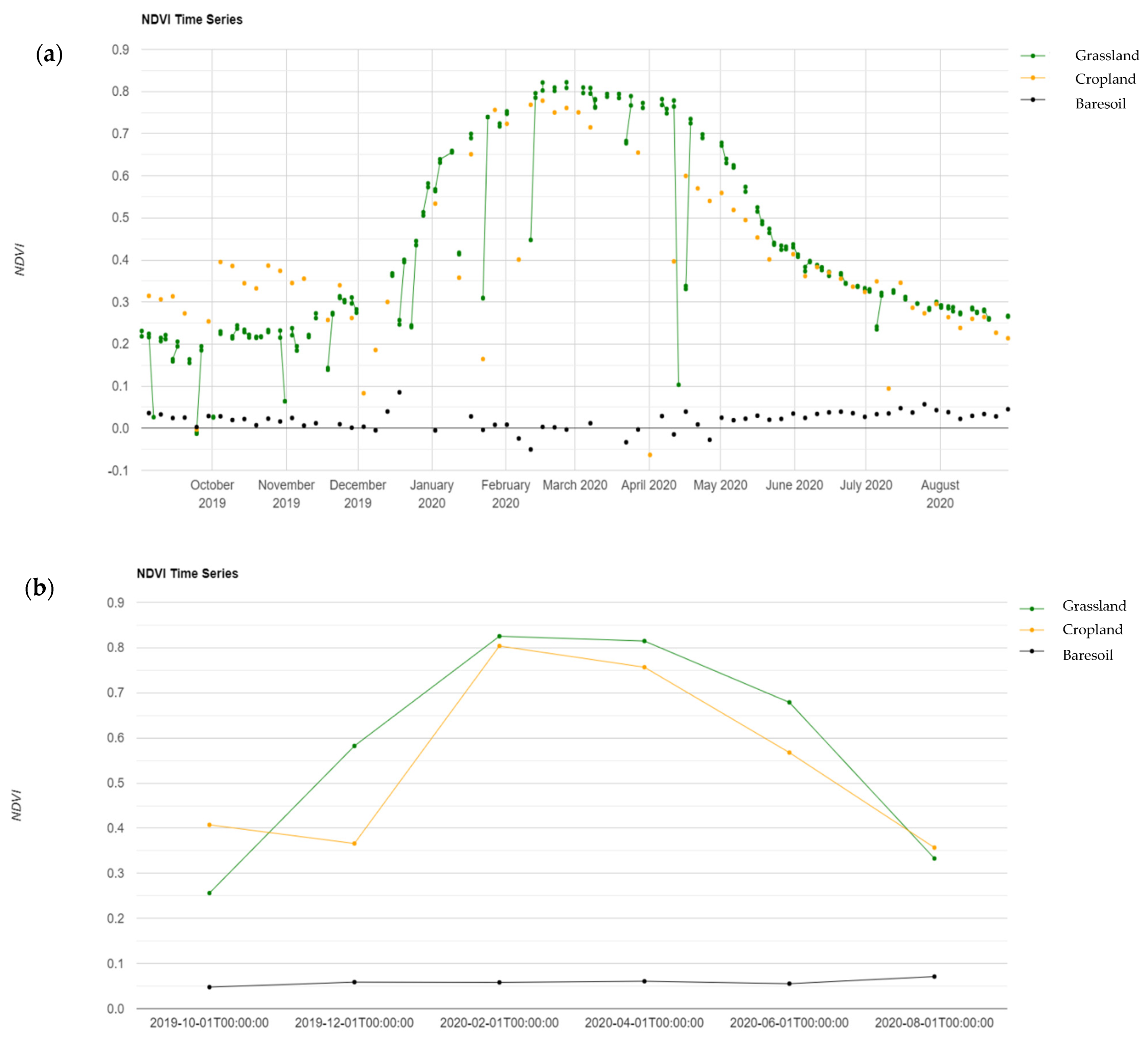
47]; (iii) the distinct spectral signature of water (e.g., flat NDVI and Fcover signal); (iv) the seasonal NDVI signature of crops, which helps in discriminating from natural vegetation.
Grassland, being the largest land cover type in Lesotho (69% of total area), scored a UA of 86% and a PA of 70%. The lower PA was caused mainly by the misclassification of Grassland in correspondence of Wetland (29) and Shrubland (33) sites. This can be explained by (i) the similarity of the three classes, (ii) the high spatial mixing of Shrubland and Grassland features, and (iii) the seasonal fluctuations of wetland water contents. Not surprisingly, Shrubland scored a low UA of 47.6% and a PA of 68.97%, both due mainly to the confusion with Grassland for both omission and commission errors.
Bare Soil scored an UA of 83% and a PA of 65%. The lower PA values were impacted by the erroneous prediction of Bare soil in correspondence with Built-up (2) and Shrubland (6). This is explained by the fact that Shrubland can be very patchy, especially in more degraded areas affected by soil loss and erosion. Furthermore, the Built-up features, especially in rural areas, are mainly surrounded by Bare soil; this may introduce mixed pixels issues when features are smaller than 10-m pixels, which is the resolution of Sentinel-2 imagery.
Irrigated crops scored a UA of 67% and a PA of 100%. This very minor class (0.2%) was under sampled compared with the other classes; however, this reflects the extremely limited availability of such a feature in the field. Under conditions such as Accuracy measures, the PA especially are not significant.
4.4. Unbiased Error Estimation
Additionally, we calculated unbiased area estimates of each land cover class, the standard error of area estimates, and the confidence intervals based on 95% confidence [
48]. Results are shown in
Table 12.
While the user’s accuracy does not change in the unbiased calculation, the producer’s accuracy differs based on the area estimates. In fact, the unbiased PA resulted in higher scores for Built-up, Cropland, Water, and Grassland (90%, 80%, 98.6%, 91.8% respectively. Trees, Wetland, and Bare soil scored lower PA values (77.2%, 40.2%, 52.8%, respectively). The causes of confusion, which were explained in the previous section, are here compounded by the higher standard errors of the area estimates.
4.5. Overall Accuracy over Time
Unbiased error matrixes were calculated for each annual land cover map and results were compared, as shown in
Table 13. The OA was generally satisfactory (above 80% in any year).
The highest OA (86.96%) was scored for the reference year 2021 and decreased progressively across the target years the further apart these are from the reference year (
Table 12). The OA reached its minimum value in the year 2017 (83.10%).
The overall analysis of the confusion matrixes across all years showed that Shrubland and Grassland classes exhibited a relatively high degree of confusion. This is explained by the fact that these classes are highly spatially mixed in the field, and this results into mixed Sentinel-2 pixels. The landscape constantly evolves and switches between the two classes over time, making it a real challenge to discriminate between the two classes. However, when combined into a single class, Rangeland, the overall class accuracy is 95%.
Confusion between Tree and Shrubland classes was detected, although to a lesser extent. This was related to the fact that young trees, even though they were labeled as “trees” in the reference dataset, were more likely to match the spectral signature of Shrubland than mature “trees”, hence the confusion.
Lastly there was confusion between Cropland, Grassland, and Wetland classes. This can be explained by the fact that cropland encroachment into wetlands is a common phenomenon in Lesotho, and wetland/cropland systems are common, which can lead to mixed Sentinel-2 pixels. Moreover, grassland and cropland can also be confused when fallowed cropland does not exhibit any crop phenology. In such instances, the fallow plot may be misclassified as grassland, or bare surface in the case of a bare fallow.
Gullies were not included in the confusion matrix because the mapping of this class was carried out using a separate approach, described in
Section 3.4. Gullies were visually validated in all the big agricultural basins of Lesotho, especially in Lower, Middle, and Upper Caledon, and no false positives were observed out of 50 locations inspected.
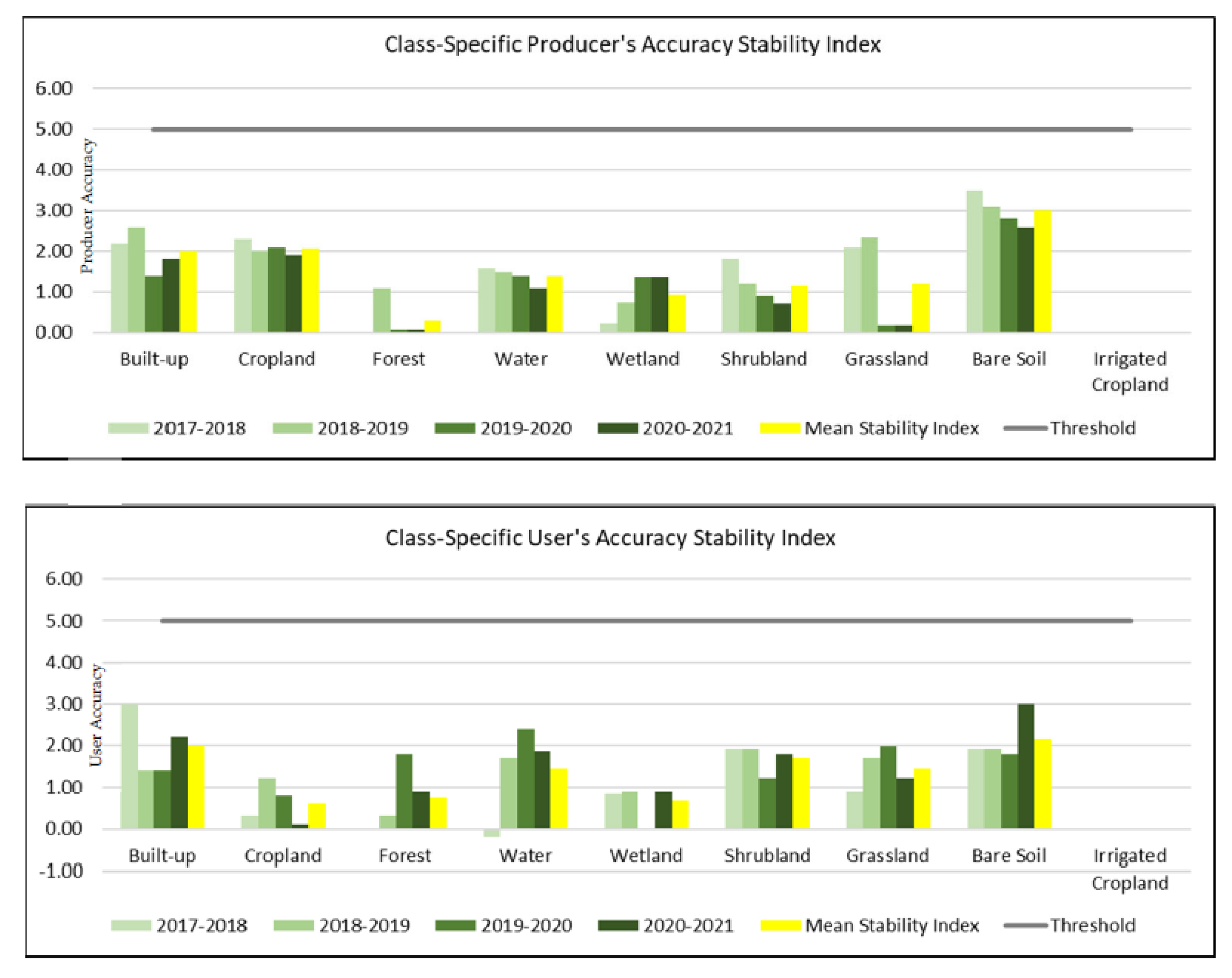
4.6. Stability of Accuracy Measures over Time
We assessed the stability of the classes’ accuracy across the period 2017–2021 (
Figure 15). The results show that the NextGen LC product was stable across the reporting period, for all of the classes (stability index < 5%). Bare soil class was the class exhibiting the highest instability, both for producer and user accuracy.
5. Discussion of the Results
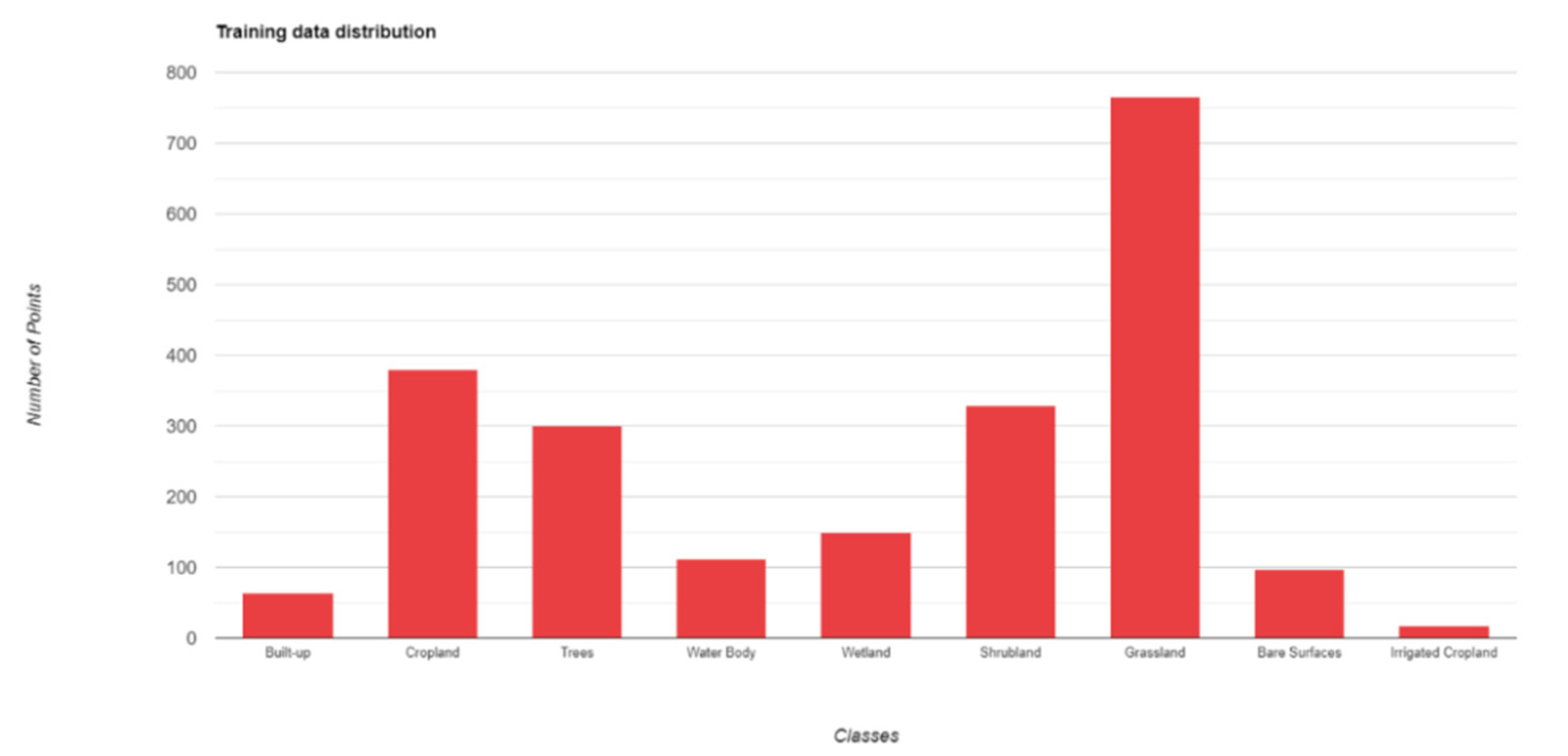
We produced five annual land cover maps using Sentinel-2 and a RF classifier. We used the default hyperparameters provided by the GEE library, except for the number of trees that was fixed at 50. To ensure the maximum accuracy of the outputs of the RF and to minimize the risk of overfitting, the following strategies were used: (i) we gathered a very large sample of in situ data (4222 points), (ii) the sample was split into two subsets for training and validation purposes (respectively, 80% and 20% of the total), (iii) a 5 k-fold cross validation to avoid overfitting. By optimizing the RF hyperparameters, either manually or automatically [
49], the depth of trees and the number of variables sampled at each split could be reduced, and this could further increase accuracy and decrease the risk of overfitting.
Besides the Random Forest, other machine learning classifiers could be tested and added to the system, and the results compared. For instance, the XGBoost, SVM, and Bagged Trees have been successfully used in the past to perform land cover mapping [
50]. The results obtained with our RF-based solution were overall rather accurate, as the 2021 land cover map obtained an OA of 89.86% and an error-adjusted OA of 86.97%: such values can be evaluated as satisfactory for a national land cover product. The main source of the confusion was mainly due to commission errors in shrubland, grassland, and bare soil, and omission errors in wetlands. Two main factors are responsible for these inaccuracies: firstly, the similar spectral signatures across the vegetation classes; secondly, the size of the features, which may be smaller than a Sentinel-2 cell and, hence, lead to a mixed pixel image. The addition of Sentinel-1 data, as input to the Random Forest classifier, could improve the separability of the classes in the multivariate space; however, the issue of the size of the features could only be addressed by using very high-resolution imagery (less than 10 m-cell-size), with a direct impact on the projected financial sustainability.
The four annual land cover maps, which were produced using the automatically generated training and validation data for the years 2020–2017, scored an overall accuracy spanning from 85.69% to 83.10%, respectively. Their accuracy can be evaluated very positively for a national and highly automatized land cover product, as they are slightly lower than the 2021 baseline year and decrease only marginally over the reference period (
Table 12). The main factor explaining their lower accuracy is the inherent higher uncertainty associated with predicting land cover over longer time horizons. However, the analysis of the stability of the land cover classes’ accuracy over time indicates that the maps (and the land cover area estimates) are consistent over the years.
Nevertheless, the accuracy of our estimates for the years when no in situ data were collected (2017–2020), were still higher than those obtained using alternative data sources, such as global land cover products. For instance, we clipped the ESA CCI 2020 and the Copernicus LC 2020 to the entire land area of Lesotho and validated the results against the automatically generated validation dataset for 2020. The maps scored an OA of 58% and 69%, respectively, without correction for the area standard error.
Pivotal to the production of land cover maps across all years, regardless of the availability of in situ data, was the routine for the automatic generation of training and validation data, which ensures that land cover maps can be regularly produced and validated every year. This is extremely important, as it allows for updating baselines for years when no in situ data are available because of limited financial resources or other restrictions to field work—such as those experienced because of the COVID-19 pandemic, for instance. Field surveys are also very resource intensive and, therefore, are not frequently implemented. In this context, our solution is totally automatized and very inexpensive; therefore, it is an ideal tool that can be used to fill data gaps in those years when no surveys are implemented. Alternative solutions to field surveys, such as visual interpretation of very high-resolution images, would still be highly resource intensive, which would require a large team of interpreters and introduce bias due to subjective interpretation.
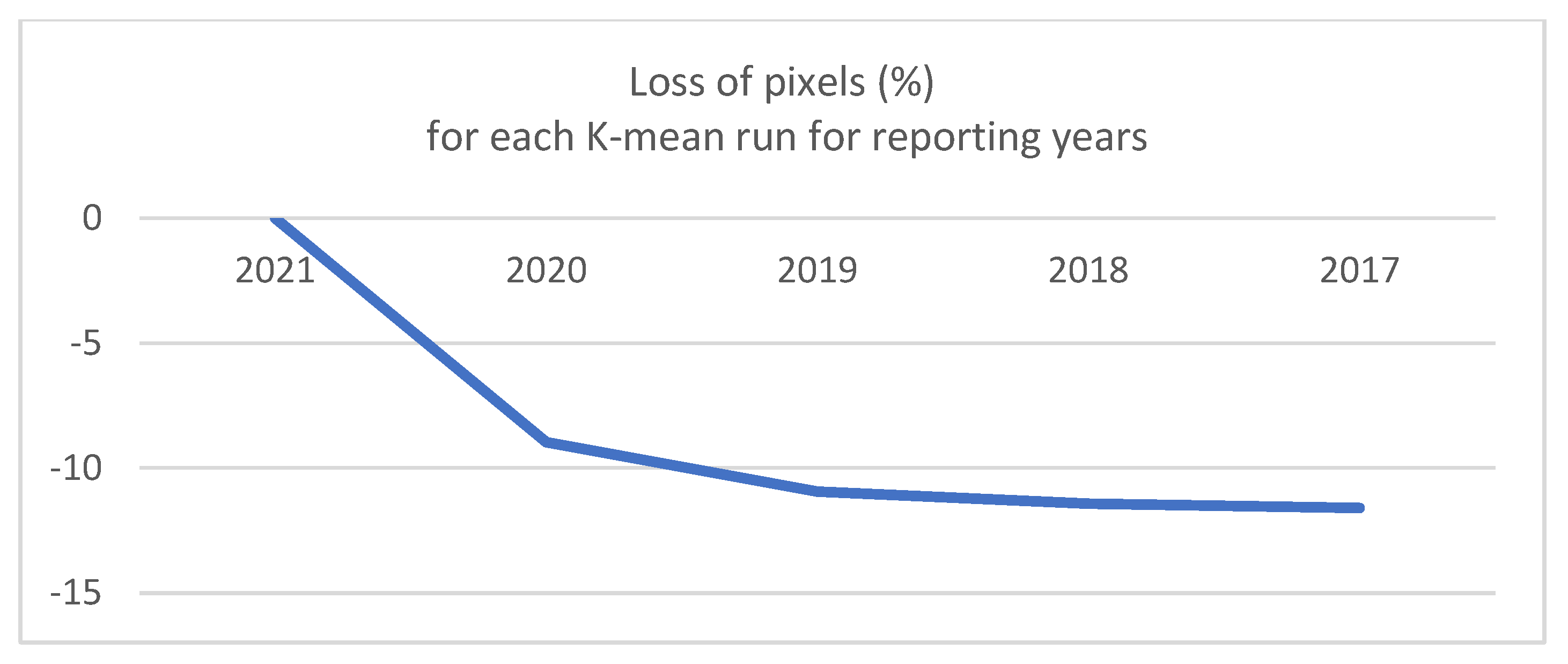
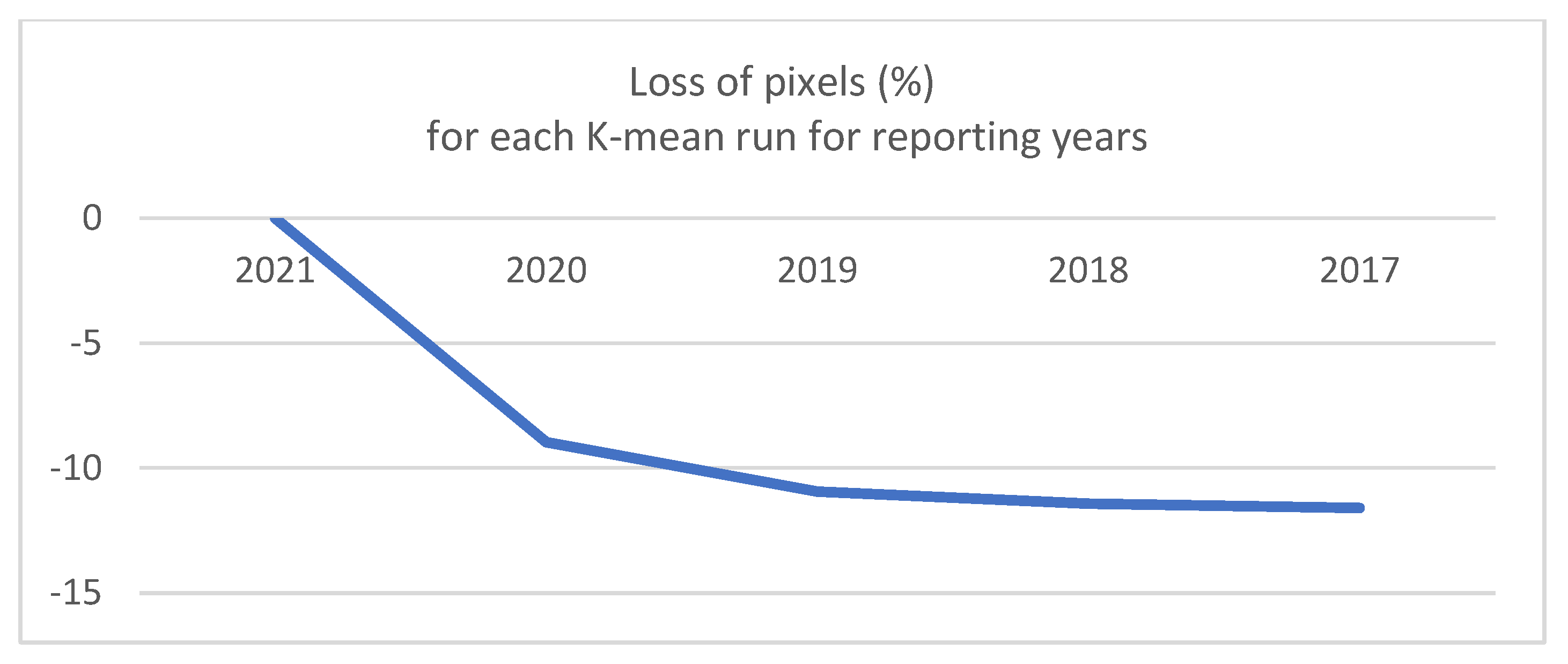
However, the number of years for which the K-means approach can be used to automatically generate training and validation data is limited. In fact, for every additional prediction year, the training and validation datasets are progressively trimmed because of the filtering of the minor clusters. The constant loss of pixels over time is shown in
Figure 16: a steep decrease from 2021 to 2019 can be seen, followed by a milder decrease in the following years (from 2019 to 2017) for a total loss of about 10% pixels across 4 years. In such a context, the calibration and validation of maps for the period 2017–2020 relied on smaller datasets compared with 2021. Although the differences between the subsets are marginal, from a formal point of view, this constitutes an issue as it introduces heterogeneity in the process, increasing the uncertainty of the results and affecting the comparability of the maps.
To solve such an issue in the future, the number of training and validation points could be kept fixed across all years, using the smallest dataset as a benchmark. However, we recommend that the automatic generation of training and validation data should be used for a maximum of 4–5 years and then be followed by a new field survey.
We used the NDVI calculated from a single Sentinel-2 composite (November–December) as an input to the K-means. The reasons for this choice were to (i) focus on the vegetation peak period and (ii) simplify the routing for automation and reduction of computation burden. In the future, the procedure could be enhanced by including more features from all the Sentinel bands, and for all the bimonthly composites as input to a multivariate K-means. This would likely improve the capacity of the K-means to identify pixels that are representative of land cover classes across the year, considering the effects of seasonality. This could reduce the number of discarded pixels, which are, in fact, perfectly valid.
In addition, the survey design could be further enhanced by using a B-FAST analysis to identify areas of change. This information could be used to increase the number of samples in such areas.
The other important aspects of our solution were the postprocessing and harmonization processes described in
Section 3.4, which aimed to provide a harmonized, stable, and consistent account of long-term land cover status, unaffected by short-term seasonal and temporary changes (e.g., crop rotation, snow cover in winter, burnt areas in forests, etc.). We used evidence from both relevant literature and empirical considerations to define the criteria.
We implemented a consistency analysis at pixel level adopting a three-year time window, which is considered a sufficient interval to discriminate between land cover status and land cover seasonality.
We adopted a series of empirical rules (
Section 3.4) to exclude unlikely land cover changes. For instance, land cover changes such as Water to Built-Up, Built-up to Cropland, and Built-Up to Bare Soil were excluded. Such changes are very unlikely to occur, even if a small possibility always exists. For instance, a water body, such as a river, could reduce its size in time, and the riverbanks could become cropland.
Due to the lack of sufficient training data for Gullies and Irrigated Cropland, two special routines were adopted for these two classes. Gullies’ features were extracted from the LC2015. Such a process may have introduced some bias, given that the LC2015 was developed using a different methodology, different satellite products, and was not validated using error matrixes.
For the “Irrigated Cropland” class, features were not sufficiently available even in the LC2015; therefore, an irrigated/non-irrigated map was generated from the cropland class extracted from the 2021 land cover map, using a K-means and by labeling the cluster with the small integral with highest mean NDVI calculated over growing season, plus additional rules, as described in
Section 3.4. Such a solution is very robust theoretically, and the results of the confusion matrix show the highest possible class accuracy (
Table 11): however, given the extremely limited number of validation points, we consider this class not fully validated and acknowledge the need to gather more validation data points on the ground.
Lastly, we consider the special routines for Gullies and Irrigated Crops as temporary solutions until sufficient in situ data are gathered for both classes. In fact, such manual routines would limit the applicability of this solution to other countries.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}