1. Introduction
Over the last decade, the Earth Observation (EO) industry has experienced a dramatic decrease in the cost of accessing space [
1]. With the introduction of CubeSats, nanosatellites and microsatellites with wet mass up to 60 kg [
2], the rapid development of remote sensing technologies was amplified [
3]. As of 2021, more than 1500 CubeSats have been launched [
4], and according to [
5], it will increase up to a thousand satellites per year till 2028. Naturally, as the number of satellites grows, satellite imagery becomes readily available. Harvested data plays a significant role in various disciplines like environmental protection, agriculture engineering, land or mineral resource exploration, geosciences, or military reconnaissance [
6,
7]. In line with the amount of remote sensing data acquired, the bandwidth resources for the data transmission inclines to be overloaded. Therefore, new techniques for efficient bandwidth resources management must be investigated and developed.
Several studies estimate that approximately
of the Earth’s surface is covered with clouds [
6,
8,
9]. Consequently, most of the remote sensing imageries (RSI) will be contaminated by them, which devalues the quality of RSI and negatively affects the post-processing [
6]. Cloudy conditions impair satellite sensor capabilities to obtain clear views of the Earth’s surface, and hence the quick and accurate detection of the cloudy images is necessary [
6,
10,
11]. In general, the current methods for cloud coverage estimation or classification are mainly categorized into traditional and machine-learning-based approaches [
12]. Traditional ones consist of threshold-based (fixed or adaptive), time differentiation, and statistical methods. The threshold-based approaches rely on a visible reflection and infrared temperature of the clouds, therefore its performance weakens on low-contrasted (cloud vs. surface) images [
13,
14,
15]. Time differentiation methods effectively identify the changing pixel values as clouds in multi-temporal images, however, they do not consider changes in the top of atmosphere reflectance affected by floods [
12,
16]. Statistical methods combine spectral and spatial features extracted from RSIs with classical machine learning algorithms (support vector machine, decision tree), but they lack to obtain the desired results [
17,
18]. To sum up, traditional methods provide some capabilities of cloud detection, though, they are susceptible to the backgrounds, are non-universal and subjective [
12].
A more efficient approach to cloudy image detection comprises convolutional neural networks (CNNs), simple linear iterative clustering, or semantic segmentation algorithms [
12]. Especially attractive are CNNs, which provide state-of-the-art results for many different tasks, including image classification, segmentation, and object detection. This success is often achieved thanks to models with a huge number of parameters which means the large size and limited ability for the deployment on resource-constrained hardware. In recent years, there has been a tendency to deploy these models in line with the edge computing paradigm on resource-constrained hardware [
12,
19,
20,
21]. Various hardware accelerators are available on the market ranging from microcontrollers for smaller models to boards equipped with GPU, visual processing unit (VPU), or field-programmable gate array (FPGA). FPGA in particular provides interesting capabilities in terms of cost, flexibility, performance, and power consumption. A possible disadvantage is the long time to market in comparison to GPU or VPU solutions. Nevertheless, this gap is being closed by recent advancements in the hardware deployment of machine learning models [
22,
23] created in well-known machine learning frameworks like Pytorch or Tensorflow. Considering the payload limitations of the CubeSats, the optimal solution of the CubeSat’s cloud detection system is a system estimating RSI cloud coverage running directly on board. To reduce the costs and development time of such real-time detection systems, Commercial-Off-The-Shelf (COTS) components provide a favorable deployment option [
24]. The crucial criterion for an onboard detection system is its power consumption, whereas the usual limit is below
and the ratio of the falsely discarded images below
[
12,
19,
20]. Generally, remote-sensing satellites can be equipped with a palette of sensors providing information in various bands. From the simplest one (RGB imageries) followed by multispectral imageries (usually a combination of RGB and near-infrared band (NIR)) to the hyperspectral imageries providing a complex spectrum of the sensed area [
25,
26].
In line with the above mentioned, Zhang et al. [
27] introduced a lightweight CNN for cloud detection based on U-Net using red, green, blue, and infrared waveband images from the Landsat-8 dataset. Applying the LeGall-5/3 wavelet transform (4 levels) for dataset compression and processing time acceleration, the authors reported
of overall accuracy running on an ARM-based platform. Similarly, in [
28], the authors applied depthwise separable convolutions to compress the model of U-Net and accelerate the inference speed. The Study reported the best accuracy of
verified on Landsat 8 remote sensing images. Another utilization of a lightweight MobU-Net trained on Landsat 8 dataset and using JPEG compression strategy was performed by [
29]. The achieved overall accuracy was around
for a model deployed on ARM9 processor on Zynq-7020 board. Maskey et al. [
3] proposed an ultralight CNN designed for on-orbit binary image classification called CubeSatNet. The model was trained on BIRDS3 satellite images and deployed on ARM Cortex M7 MCU. An accuracy of 90% was achieved when classifying images as “bad” for cloudy, sunburnt, facing space, or saturated images and “good” in all other cases. A promising method for cloud detection using RS-Net and RGB bands exclusively was published by [
30]. For model training, the Sentinel-2 dataset was used, and
of accuracy was reported by the model deployed on an ARM-based platform. Another possibility is to use the Forwards Looking Imager instrument, which provides analysis of the upcoming environment of the satellite. This approach was examined in [
31], testing various lightweight CNNs deployed on the Zynq-7020 board using FPGA. The authors reported high accuracy of
, however, 100 images only were used for testing. Vieilleville et al. [
32] investigated the possibilities of the deep neural network (DNN) distillation process in order to reduce the size of DNN while accommodating efficiency in terms of both accuracy and inference cost. The authors were able to reduce the number of DNN parameters from several million to less than one with a minimal drop in performance in the image segmentation process.
To sum up, lightweight CNNs provide a competitive on-board cloud detection performance in comparison to the state-of-the-art deep convolutional neural networks, like CDNetV1 [
6], CDNetV2 [
10] or CD-FM3SFs [
33]. CDNetV1 is a neural network for cloud mask extraction from ZY-3 satellite thumbnails with the accuracy of
[
6]. Its extended version, CDNetV2, focuses on adaptively fusing multi-scale feature maps and remedying high-level semantic information diluted at decoder layers to improve cloud detection accuracy with cloud-snow coexistence. The authors confirmed the robustness of the proposed method using validation on several other datasets like Landsat-8 or GF-1. Lately, Li et al. [
33] introduced a lightweight network for cloud detection, fusing multiscale spectral and spatial features (CD-FM3SFs) using Sentinel-2A multispectral images. The best accuracy of
was achieved using the CPU as a computational unit.
To the best of our knowledge, the CloudScout cloud detection method proposed by Giuffrida et al. [
34] and later extended by Rapuano et al. [
20] is the most related work to this study. The method was developed in the frame of the Phisat-1 ESA mission, which exploits a hyperspectral camera to distinguish between the clear and cloud-covered images. To reduce the bandwidth, the mission has set a criterion that only images that present less than
of the cloudiness are transmitted to the ground. CloudScout was trained using Sentinel-2 hyperspectral data and achieved the
of accuracy,
of false positives with the power consumption of 1.8 W deployed on re-configurable Myriad-2 VPU by Movidius Intel [
34]. Nevertheless, the authors identified multiple drawbacks due to the Myriad-2 design, which is not specifically suitable for the space environment (not based on a radiation-tolerant technology) [
20]. Therefore, the authors extended their work and proposed an FPGA-based hardware accelerator for CloudScout CNN. The authors compared the Myriad-2 VPU with two FPGA boards: Zynq Ultrascale+ ZCU106 development board and Xilinx Kintex Ultrascale XQRKU060 radiation-hardened board. Results obtained by Zynq Ultrascale+ ZCU106 show that the FPGA-based solution reduced the inference time by 2.4 times (141.68 ms) but at the cost of 1.8 times greater power consumption (3.4 W) [
20]. Inference time estimated for the Xilinx Kintex Ultrascale XQRKU060 board was 1.3 times faster (264.7 ms) in comparison with the Myriad-2 device, however, the power consumption was not reported.
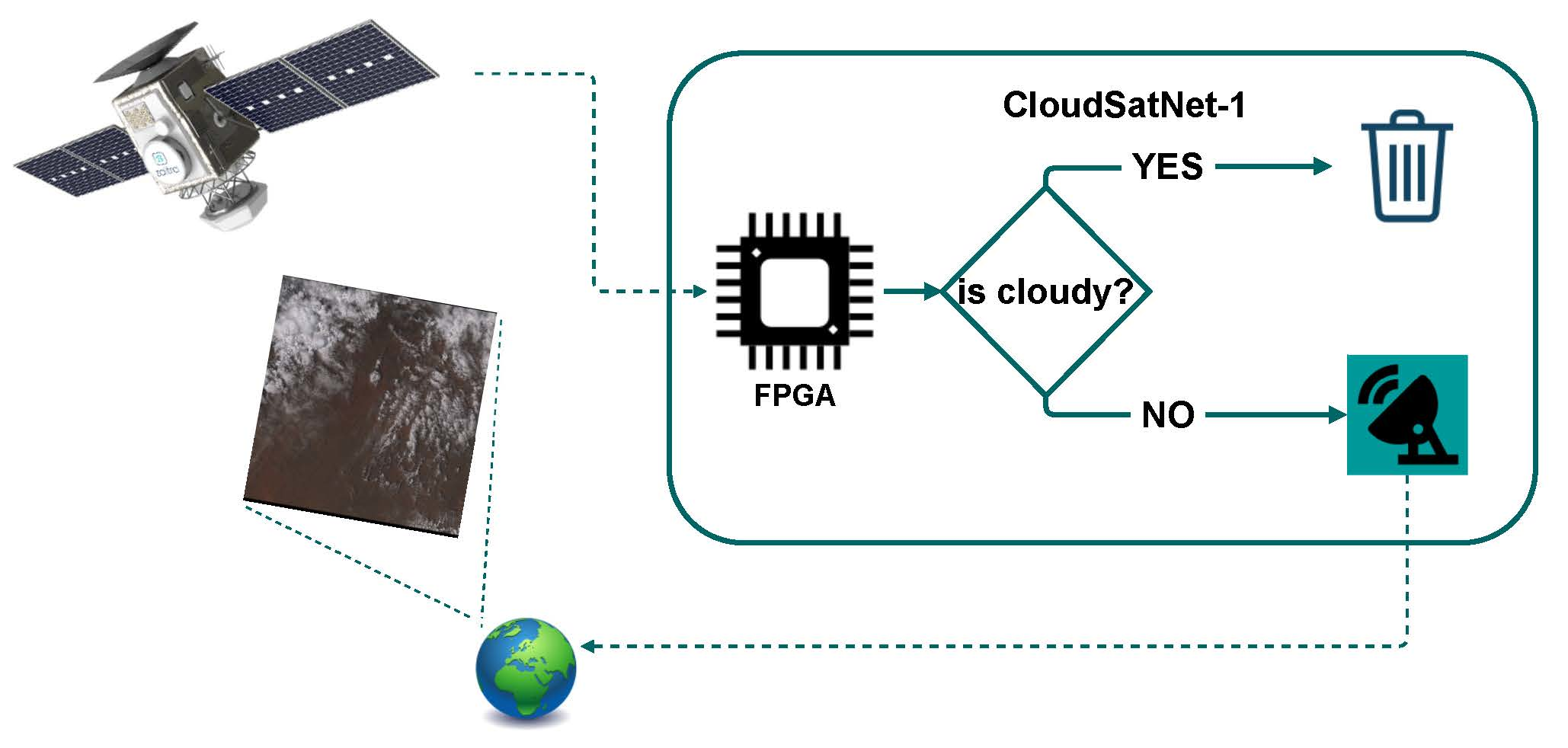
Regarding the presented achievements of the related works and trends in the CubeSats development, we may expect a new era of smart nanosatellites equipped with reconfigurable, programmable hardware accelerators with an on-demand edge computing paradigm at payload level [
3,
12,
19,
20,
27,
28,
29,
31,
34]. A usual aspect of the presented studies is the employment of multispectral or hyperspectral RSI for the cloud detection system. Generally, the bands’ composition of multi/hyperspectral RSI differs for individual missions, yet all are equipped with an RGB camera. Therefore, a cloud detection system built on RGB bands only may provide better portability for various missions independent of its multi/hyperspectral bands. In addition, the RGB cameras are several times cheaper and more convenient for short-term CubeSats missions. To the best of our knowledge, we identified only three studies [
20,
21,
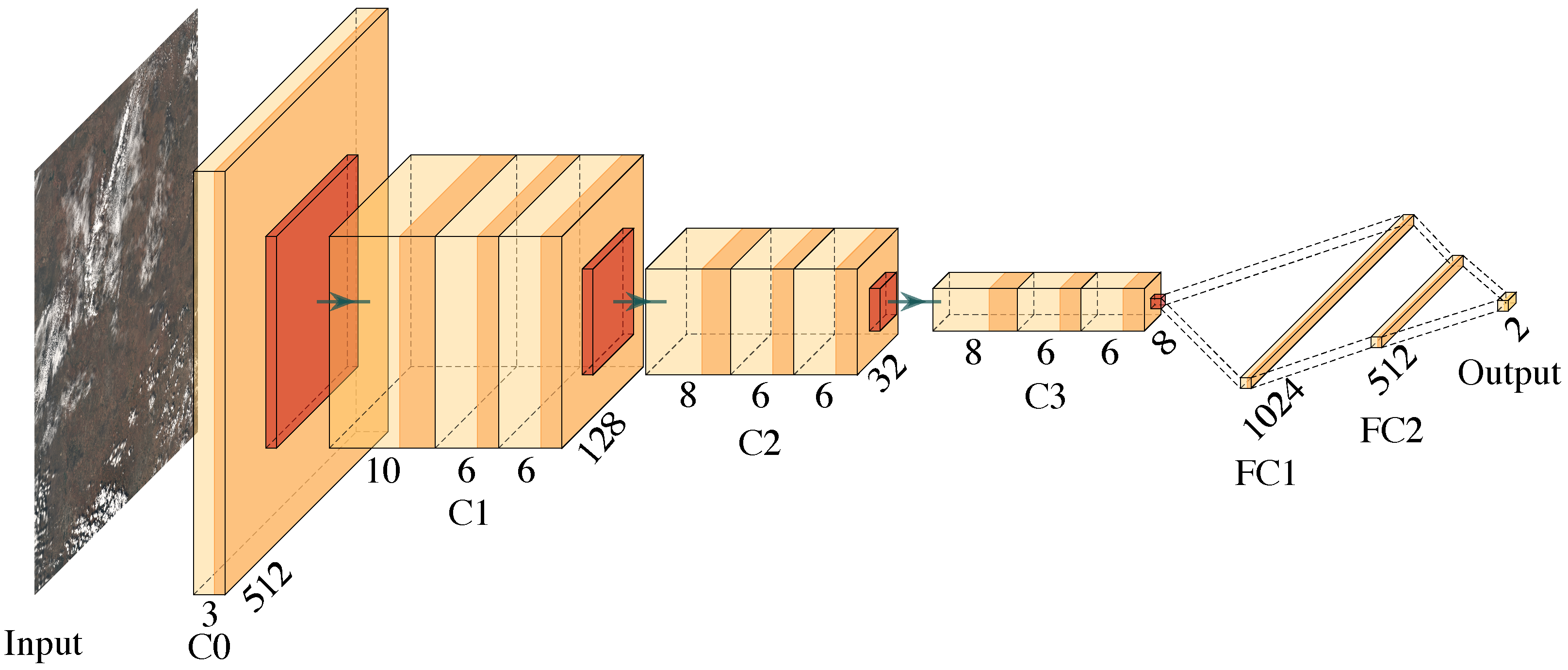
31] that performed deployment and evaluation of the CNN-based cloud detection method on an FPGA-based platform. Hence, in the scope of this study, we would like to present CloudSatNet-1: an FPGA-based hardware-accelerated quantized CNN for satellite on-board cloud coverage classification. More specifically, we aim to:
explore effects of quantization introduced to the proposed CNN architecture for cloud coverage classification,
investigate and optimize the performance of cloud coverage classification by biomes diversity and its false-positive identifications,
explore hardware architecture design space to identify optimal FPGA resource utilization.
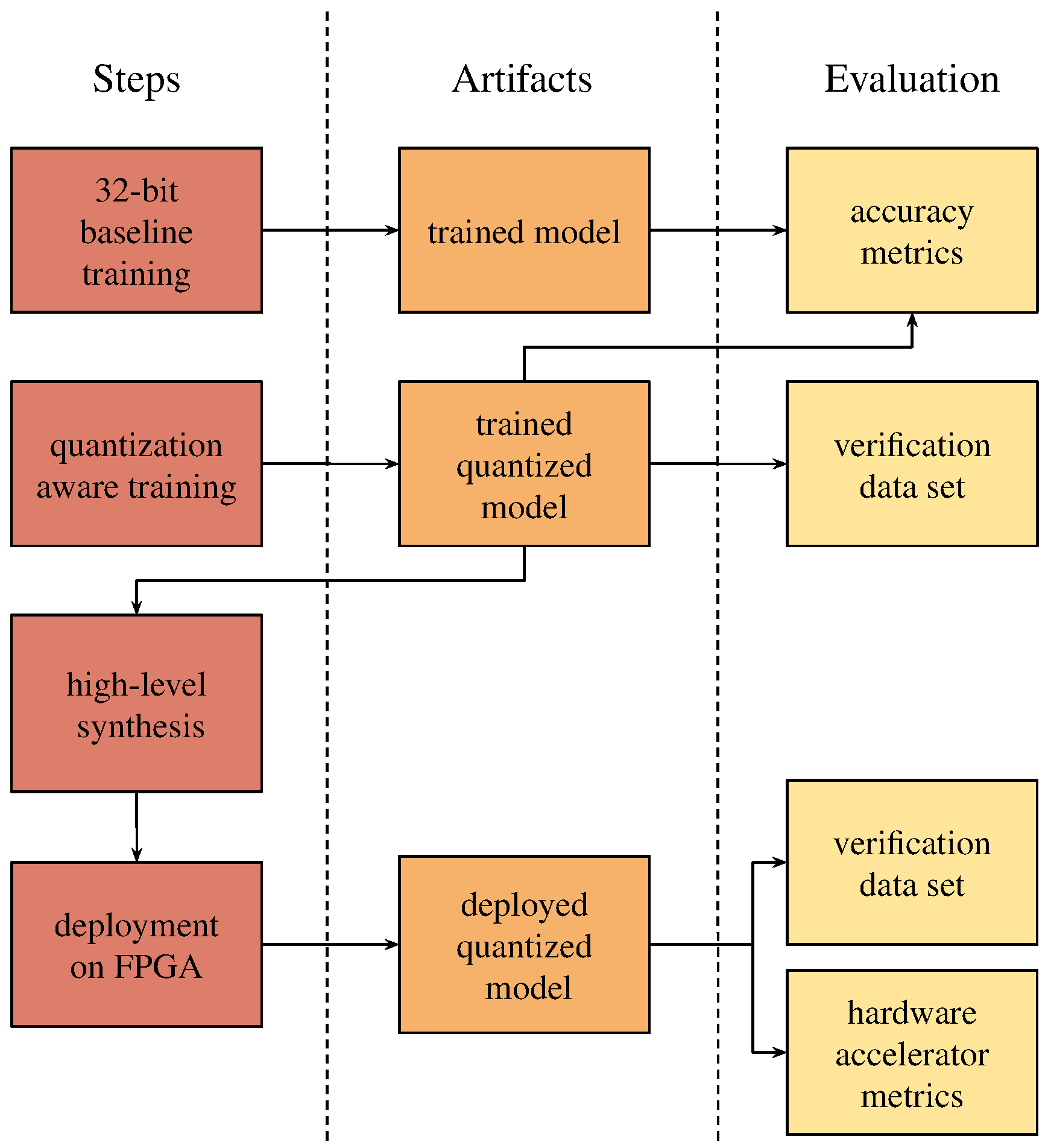
The rest of the paper is organized as follows.
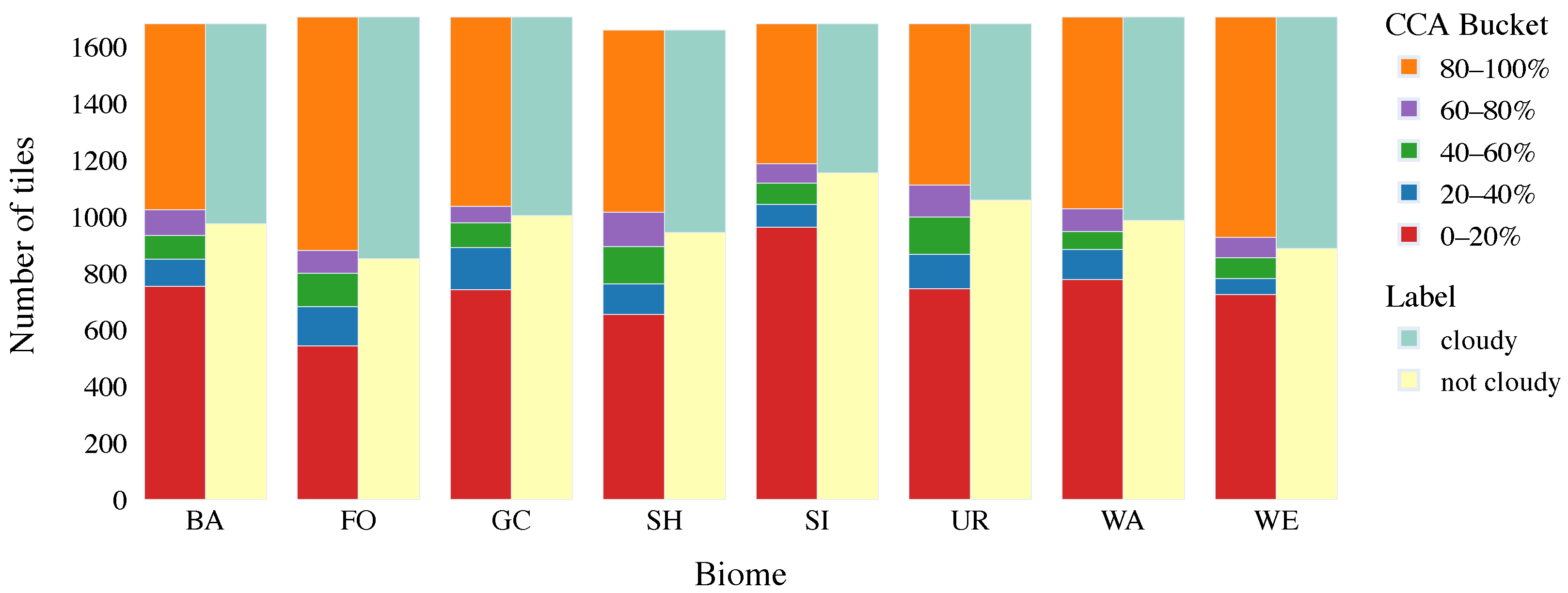
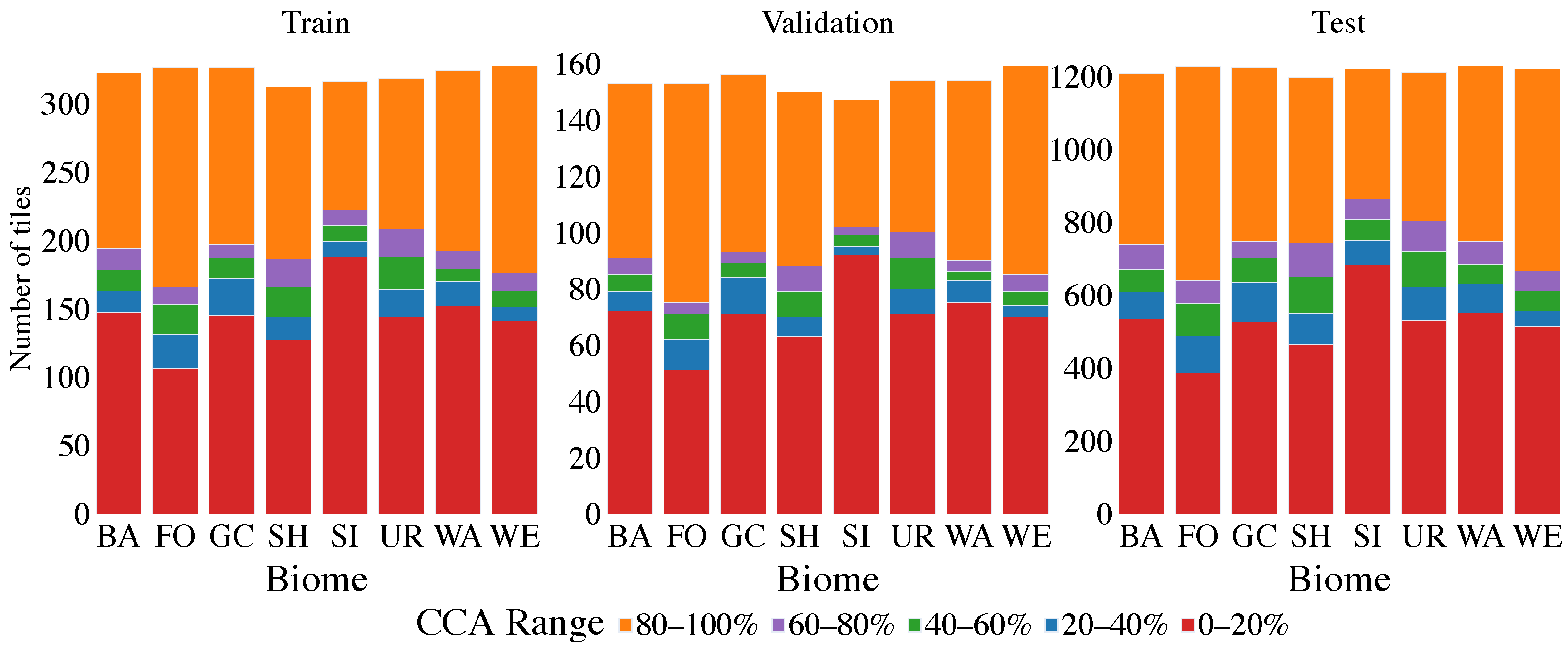
Section 2.1 describes the used dataset and its preprocessing. Methodology is described in
Section 2.3. In
Section 3, the results are summarized. The discussion can be found in
Section 4 and the conclusions are drawn in
Section 5.
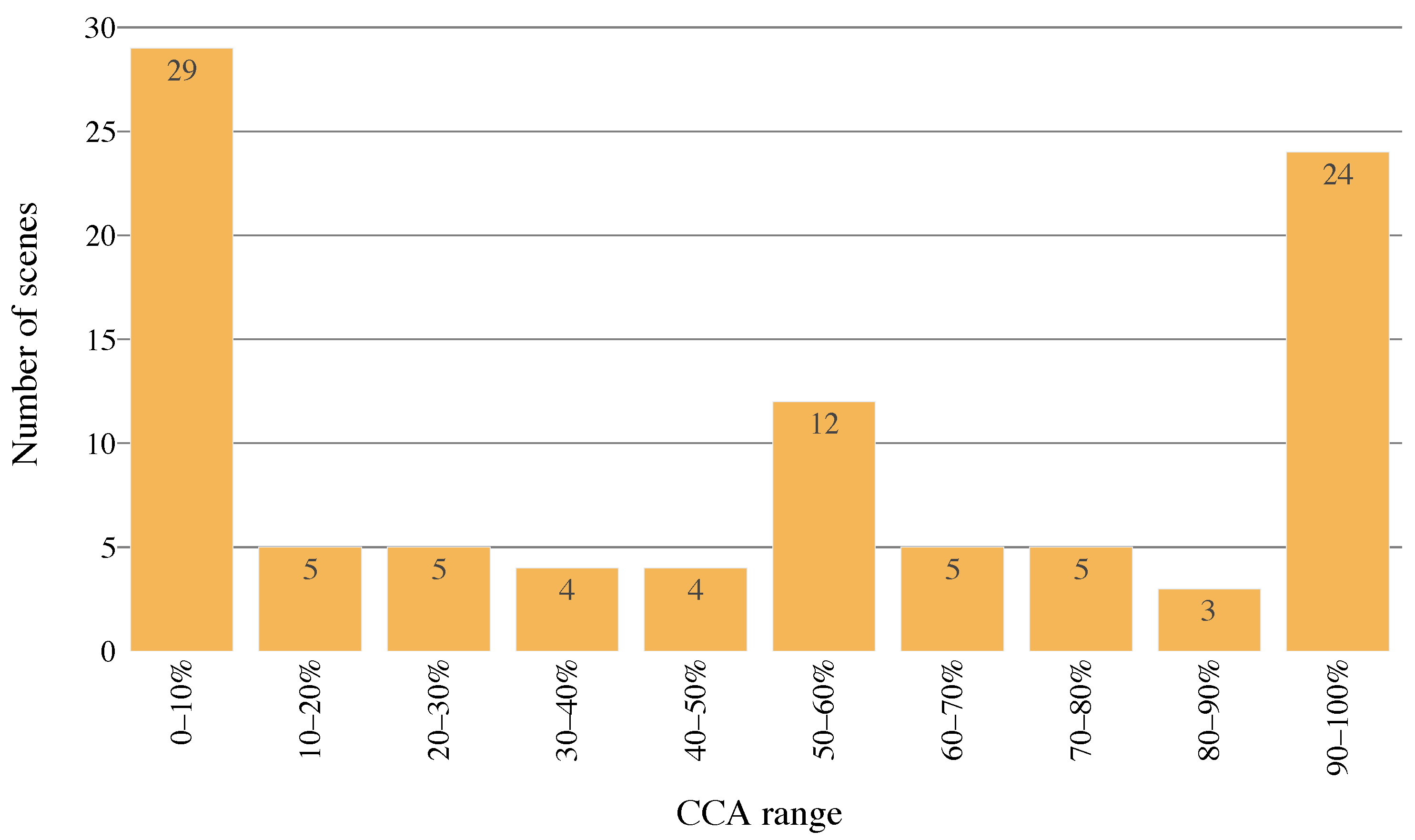
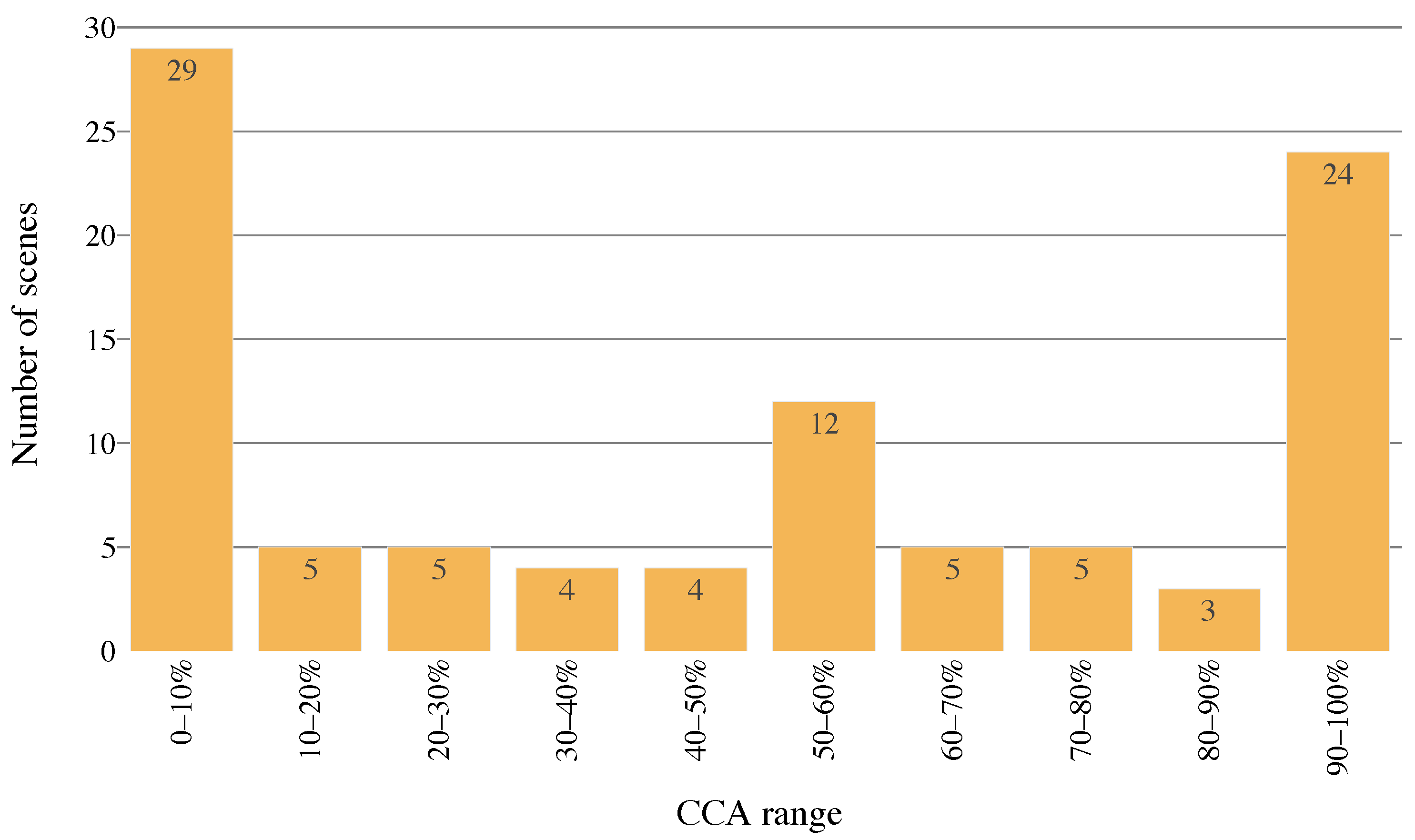
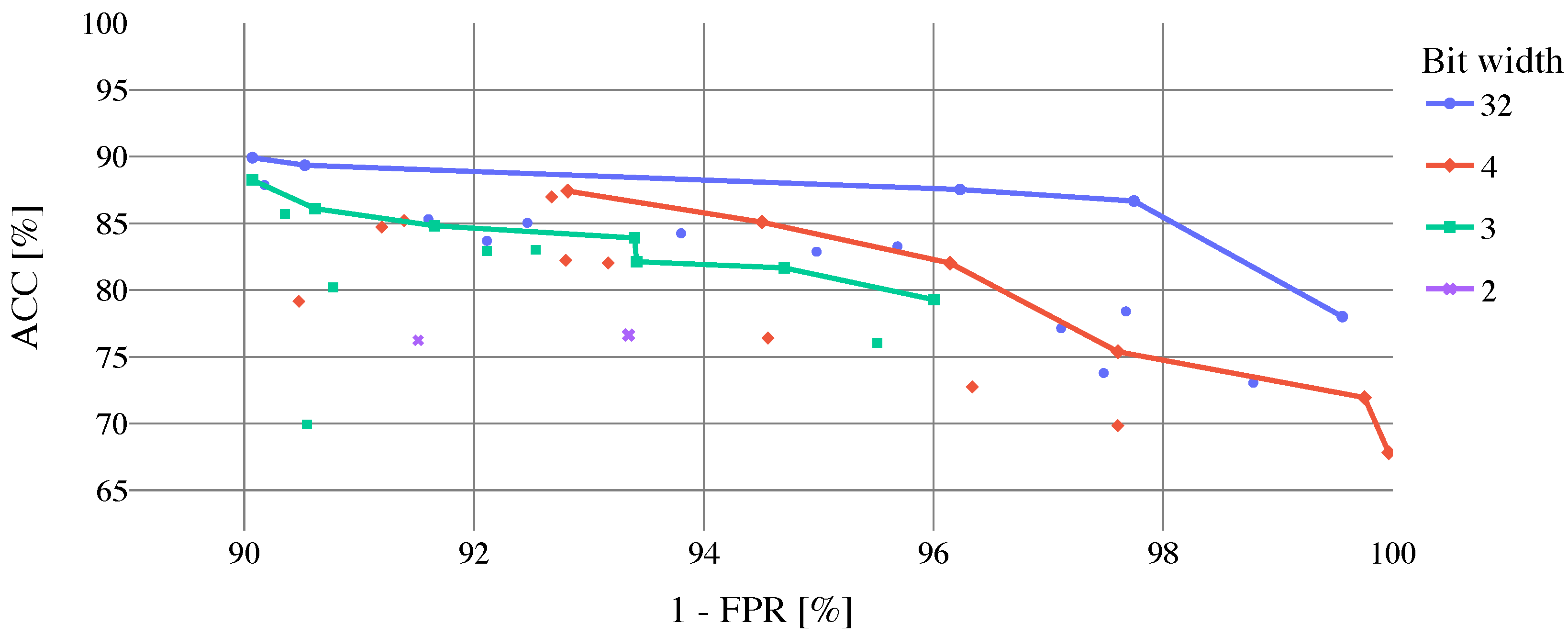
3. Results
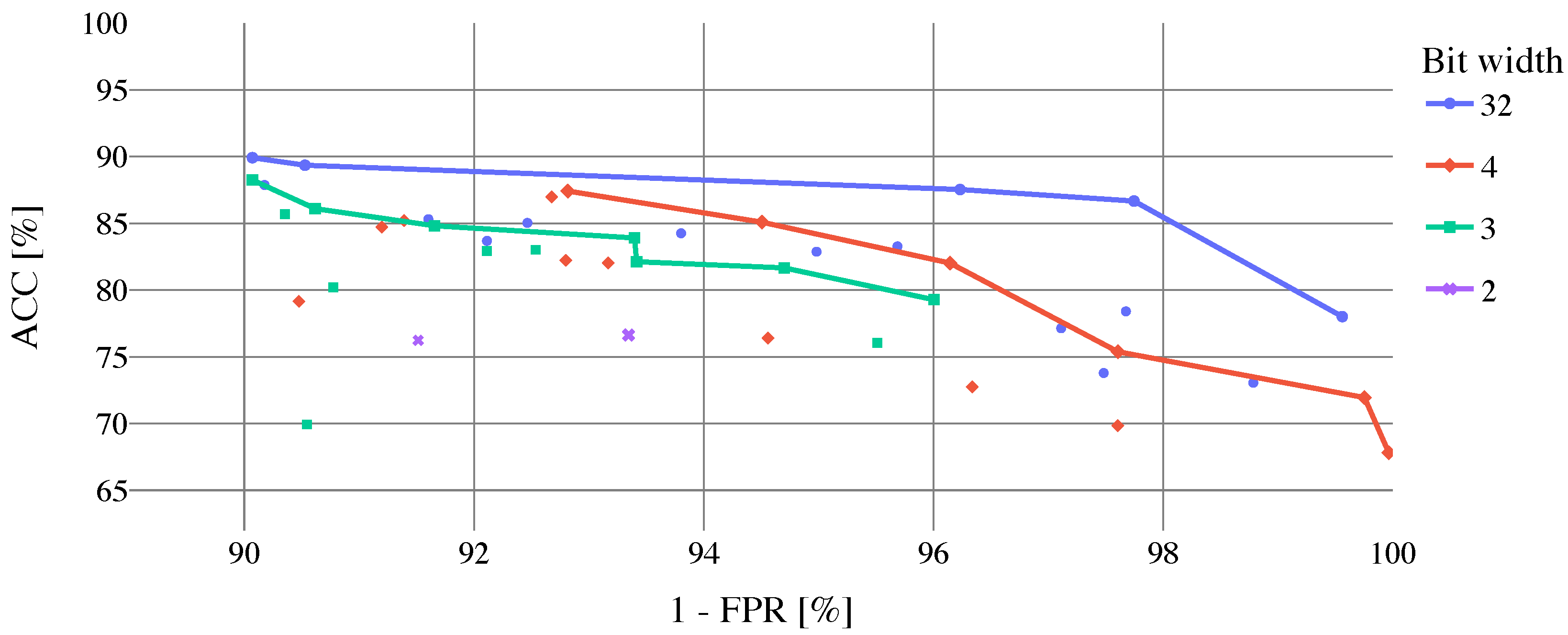
The results of cloud coverage classification employing the full
biome dataset to train and evaluate proposed CloudSatNet-1 CNN are shown in
Table 4. In the upper part of the table, the most accurate models for each analyzed bit width (weight and activation) selected by ACC are presented. Top models for 32, 4, and 3-bit width provide similar classification performance (
–
,
–
). Though, the best-performed 2-bit width model lags with
and
. In the bottom part of
Table 4, top models for each analyzed bit width selected by FPR are shown (models are selected from the top 10 models sorted by ACC). Marginal change of classification performance can be observed (1–
), except the model based on 32-bit width, where FPR was reduced to
at the expense of approx.
of ACC. For more insights, the dependence of model ACC on FPR (with FPR value inverted for better readability) can be seen in
Figure 9.
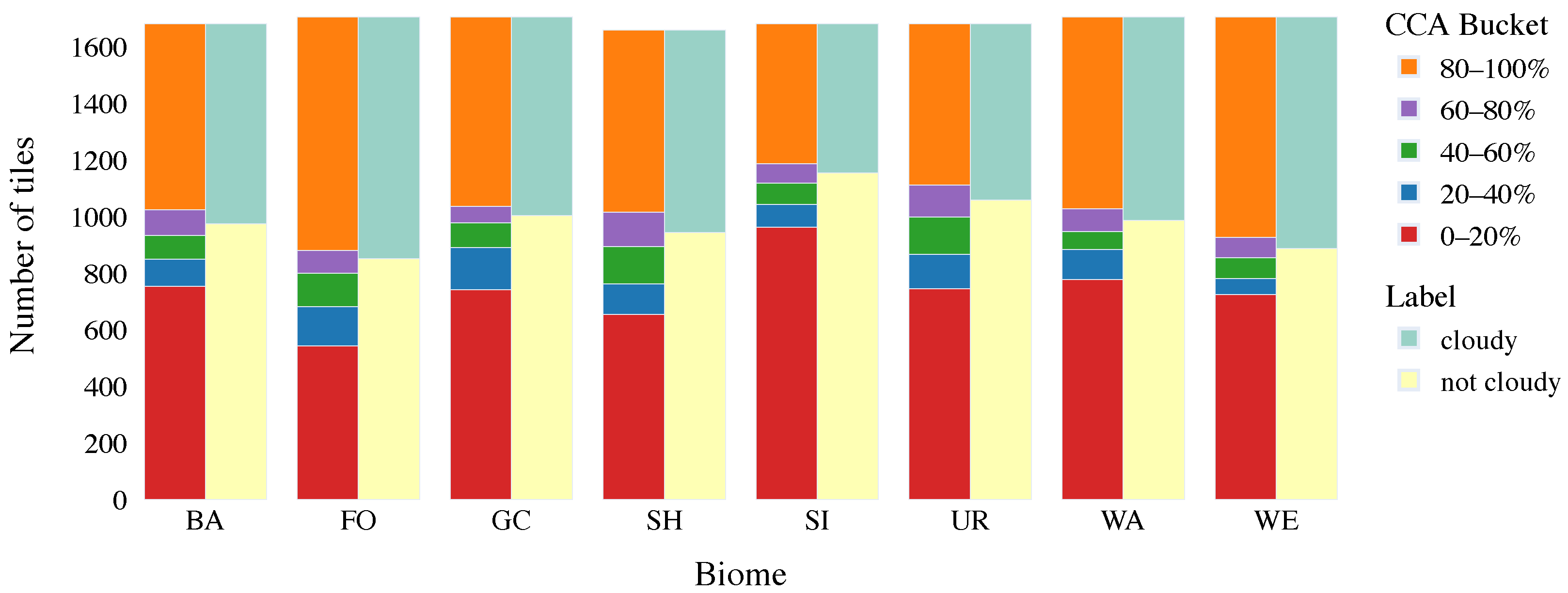
Optimal solutions, which represent a trade-off between ACC and FPR, are stressed out by Pareto fronts. Results of cloud coverage classification for best-performed 4-bit width models (4-bit width models are selected due to best accuracy/FPR ratio from quantized models) per biome using the full
biome dataset are shown in
Table 5. Models are selected by the highest ACC. The model performed best on the Grass/Crops biome (
and
). However the best
was achieved in the Forest biome, though with low
. The worst performance (
and
) was achieved on the Snow/Ice biome. Based on the results of the cloud coverage classification per biome, hypothesis is made that excluding the Snow/Ice biome (cloud coverage classification on Snow/Ice biome using natural color composite is irrelevant) from model training will improve overall model performance (especially FPR). For a better illustration of the problem, the examples of FP tiles are presented in
Figure 10.
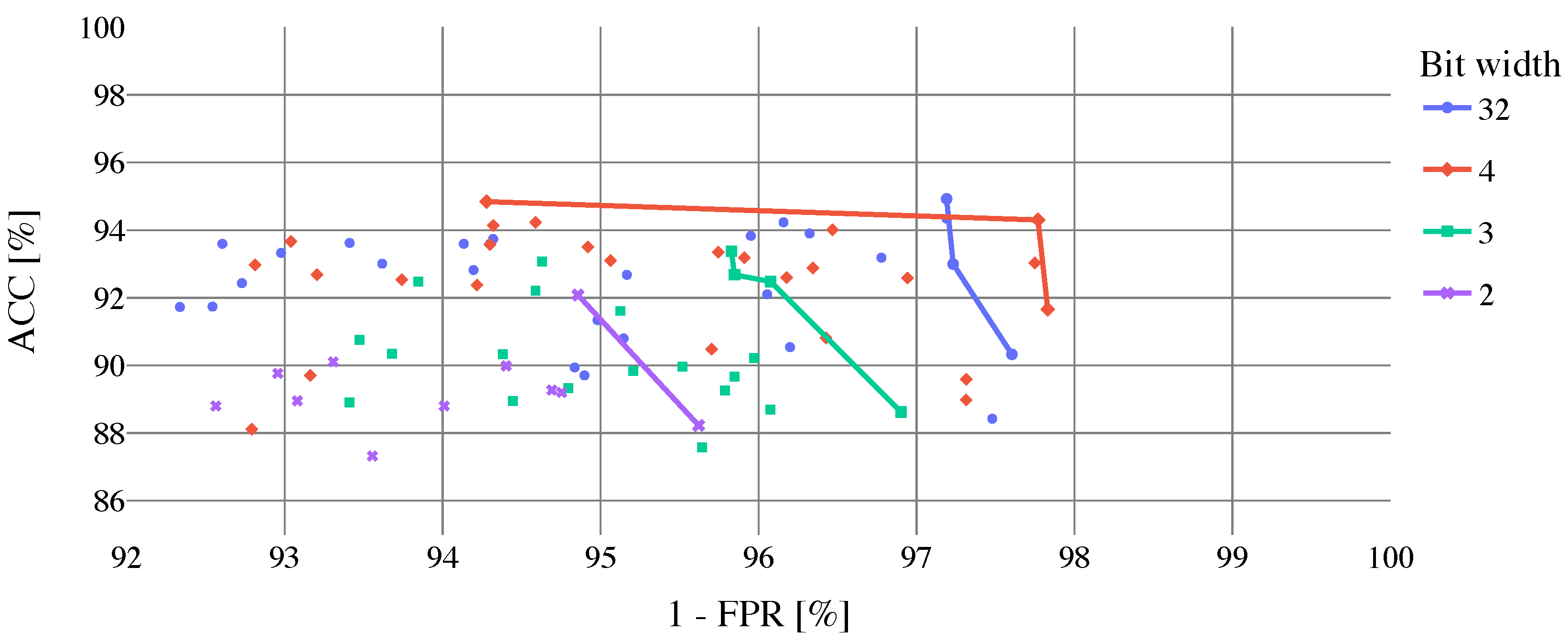
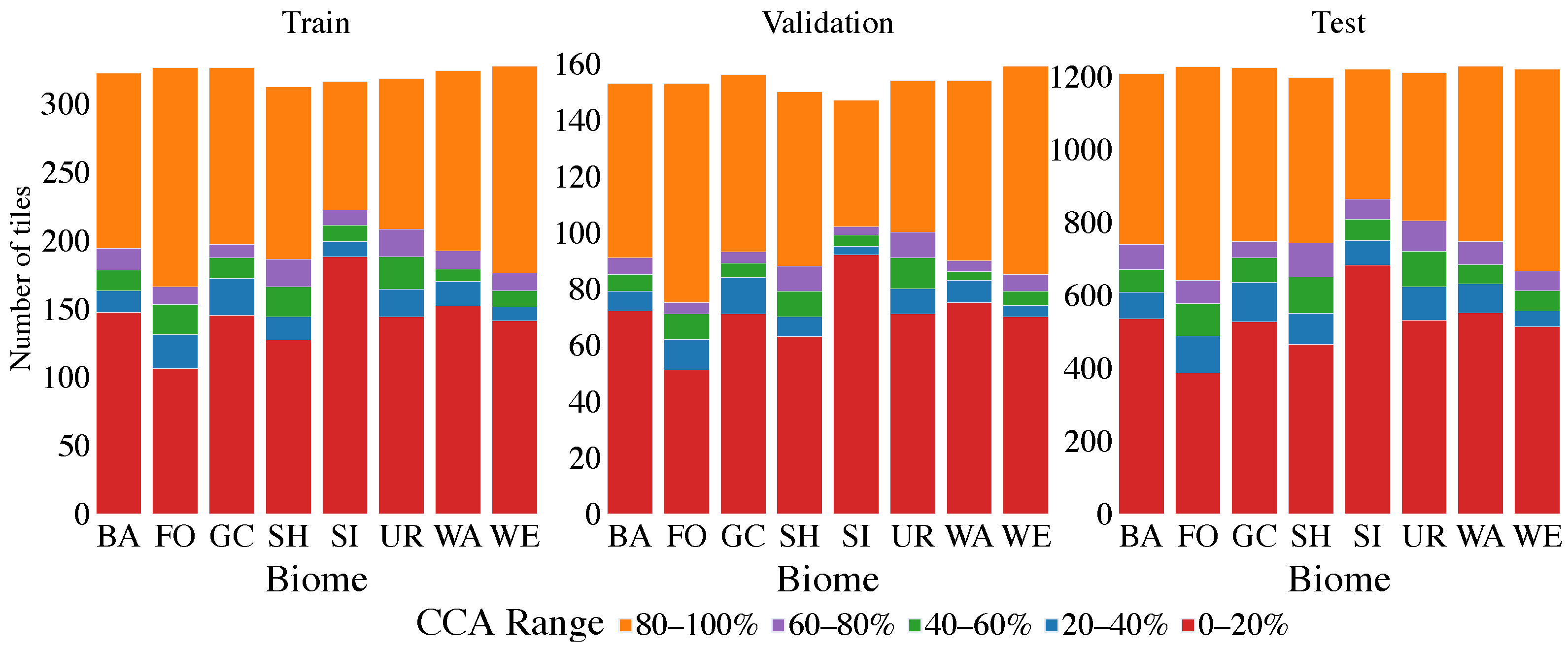
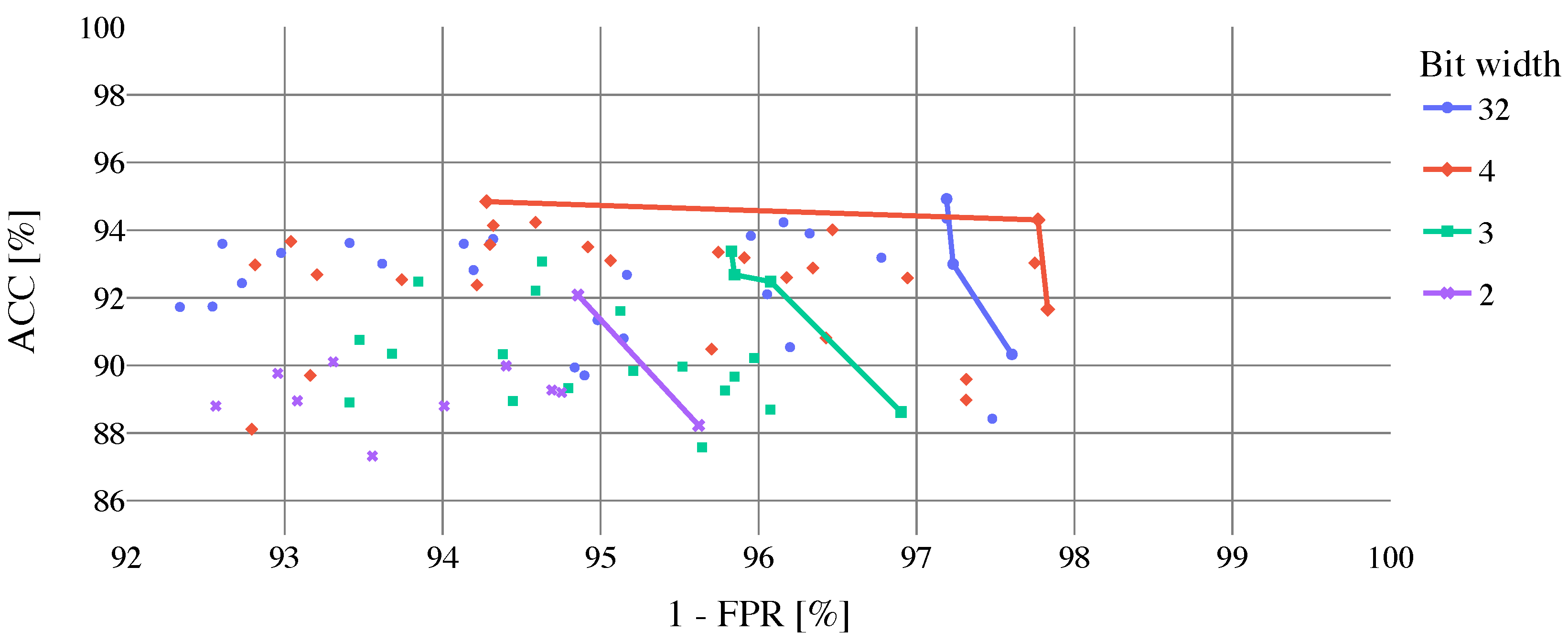
Results of cloud coverage classification using the
biome dataset without Snow/Ice biome to train, validate and test the proposed CNN are shown in
Table 6. In the upper part of the table, best-performed models selected by ACC are presented. As can be noticed, in comparison with previous models trained by the full
biome dataset the classification performance was improved (
–
,
–
). In the bottom part of
Table 6, top models selected by FPR are shown (models are selected from the top 10 models sorted by ACC). In case of the 32 and 2-bit width models, there is no change in performance. However, FPR for 4 and 3-bit width models is lower, whereas 4-bit model outperforms the 32-bit width one. For a better illustration, the dependence of model ACC on FPR can be seen in
Figure 11, where optimal solutions are highlighted by Pareto fronts.
Finally, the results of hardware architecture design space exploration are summarized. In
Table 7, the overview of resource utilization measurements of quantized models using different bit widths can be found. Maximum and base folding setup was compared together with folding setup targeting 10 FPS. Even though the FPS is changing from
to
, the average power consumption is stable at around 2.5 W. The parallelization settings and their respective estimated number of clock cycles for targeting specifically 10 FPS are reported in
Table 8. Results of cloud coverage classification for best-performed quantized models on FPGA can be seen in
Table 9. Classification ACC and FPGA resource utilization is reported for quantized models trained using the full
biome dataset and dataset excluding the Snow/Ice biome from the dataset. The best-performed model is a quantized 4-bit width model with Snow/Ice biome excluded from training and evaluation (
).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}