1. Introduction
The central theme of change detection is recognizing differences in the state of a phenomenon via contrast at the same position at different times [
1]. Remote sensing platforms and sensors have seen rapid development in recent years. Continuous and repeated remote sensing observations of land surface have been realized. Lots of high-resolution RSI data have been accumulated, which record land surface changes in detail. The availability of massive very-high-resolution RSI has also promoted the development of RSI analysis, especially CD. As a major focus of RSI analysis and an essential approach for monitoring land surface changes, CD has been widely used in many remote sensing applications, including land cover survey [
2], urban planning [
3], natural disaster assessment [
4], and ecosystem monitoring [
5].
Since the 1970s, domestic and foreign research scholars have been conducting various studies of CD based on RSI. A method based on image difference was proposed to detect changes in a coastal zone in [
6], which opened the era of remote sensing change detection. After more than 40 years of development, many CD algorithms have been published. The current algorithms can be grouped into four categories with different strategies, including image algebra methods [
6,
7,
8,
9], classification methods [
10,
11,
12], image transformation methods [
13,
14,
15], and deep-learning-based methods [
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28].
Image algebra methods require strict preprocessing of dual-temporal remote sensing images, including geometric registration and radiometric normalization. The corresponding bands are processed by simple algebraic calculation methods, such image difference [
6] and image ratio [
7], to acquire the difference map. Then, the difference image is segmented by the threshold to obtain the binary map. Such algorithms are characterized by simplicity and interpretability, but they can only display changed and unchanged information without changing category. Change vector analysis (CVA) solves this problem very well. CVA is a multivariate method that accepts n spectral features, transformers, or bands as input from each scene pair [
8]. The difference image generated by CVA contains the multispectral change direction and magnitude [
9]. The change vector direction is used to determine the category of changes. The change magnitude represents the intensity of the changes, which is the basis for distinguishing whether the pixel is changed or unchanged.
Classification methods mostly adopt post-classification techniques [
10]. The remote sensing images are first classified separately to obtain their classification results. The classification results are compared according to the corresponding positions. Finally, the change map with change category is generated. However, the accuracy of the change detection relies on the two individual classifications, which will result in cumulative error in the image classification of individual pieces of data [
9].
Image transformation methods map the raw data into a separable high-dimensional space, which can weaken the activation level of the unchanged features and strengthen the activation level of the changed features. In [
13], eigenvector space is generated by principal component analysis (PCA) on difference image blocks, and feature vectors are obtained by projecting a patch of data around each pixel onto the space. Then, the generated vectors are divided into two clusters using the k-means algorithm. Finally, the algorithm classifies every pixel according to the minimum Euclidean distance to each cluster to obtain the binary change map.
Traditional CD methods tend to generate difference map and use threshold segmentation [
8] or clustering [
13] to determine the change map based on the difference map. Due to the method of generating a difference map in traditional methods being simple and less robust, deep learning algorithms and traditional methods are integrated in [
29,
30]. A deep change vector analysis (DCVA) framework was proposed in [
29], which is an unsupervised and context-sensitive method. This method combines convolution neural networks and CVA [
9] for CD in multi-temporal RSI. In [
30], an unsupervised approach was proposed. This method integrates neural networks and slow feature analysis (SFA) [
31] for CD in multi-temporal RSI.
Deep-learning-based methods completely integrate the generation and discrimination of the difference map within a neural network framework to produce the change map coherently, which achieves an end-to-end training pattern. Since the proposal of AlexNet [
32], DCNNs have shown strong feature representation power in computer vision and developed rapidly. VGGNet [
33] was proposed to increase the depth of the network by using a smaller 3 × 3 convolution kernel. Subsequently, InceptionNets [
34,
35,
36] were proposed to strengthen multi-scale ability by using convolutional layers with different kernel sizes. The training difficulty increases as the network become deeper, so an additional module was proposed in ResNet [
37]. As the backbone network becomes more and more advanced, the extracted features also become more and more representative.
In recent years, the fully convolutional network [
38], designed for semantic segmentation, has been applied to achieve CD in RSI. In contrast with traditional methods, which require manually designed features, the features captured by deep learning methods always contain richer semantic information and more robust information. Compared to the aforementioned three types of methods, deep-learning-based methods can often achieve more promising results. According to the treatment approach of bi-temporal images or features, the deep learning algorithms can be divided into three categories: image-fused methods [
17,
18,
19,
20,
21], feature-fused methods [
16,
17,
23], and metric-based methods [
22,
24,
25,
26,
27,
28].
The image-fused methods concatenate a prechanged image and postchanged image as an input with six channels before feeding into our network. In [
17], an image-fused and fully convolutional architecture (FC-EF) is proposed. The architecture is modified from U-Net [
39], which is a model for biomedical image segmentation. In FC-EF, the prechanged image and postchanged image are concatenated directly on the channels dimension and sent into the model to generate a change map. Similarly, a model with deep supervision and multiple outputs is proposed in [
18]. The backbone of the network is based on UNet++ [
40], which is an improved U-Net architecture.
The feature-fused methods capture the features of the raw images separately using a Siamese network, fuse the two branches at the end of the encoder phase, and generate the change map using the decoder. In [
17], two feature-fused Siamese architectures are presented for the first time, namely FC-Siam-conc and FC-Siam-diff. In [
16], the proposed network addresses the problems of low representativeness of raw image features and heterogeneous feature fusion.
The metric-based methods introduce the Siamese encoder to capture the features of the raw images separately and directly compute the distances between each pair of the feature, while the image-fused and feature-fused methods need to fuse the raw images or captured features. These approaches are commonly based on metrics, such as L1 or L2 distance. In the training process, the objective function aims to enlarge the distance of pixel pairs that are changed and reduce the distance of pixel pairs that are unchanged. Contrastive loss [
41] and triplet loss [
28] are introduced in these methods. Compared to contrastive loss, triplet loss can exploit more spatial relationships among pixels. In [
24], a fully convolutional and dual attentive Siamese (DAS) network is presented, which introduces the dual attention mechanism [
42] and proposes an improved contrastive loss named WDMC. In addition, a high-resolution and dynamic multiscale triplet network (HRTNet) is proposed in [
25]. The HRTNet adopts the high-resolution network (HRNet) as the backbone. The Euclidean distance is measured as the distances between the extracted features generated by dynamic inception module (DIM).
However, a majority of change detection networks [
16,
17,
18,
19,
20,
21] are modified from image semantic segmentation models [
38,
39,
40,
43], which was also pointed out in [
16,
25]. There still exist some crucial issues with modifying these networks for change detection. We empirically summarize that most of the existing fusion-based methods for CD in bi-temporal RSI have two problems and limitations: (1) the performance is extremely sensitive to the sequence of bi-temporal images, and the robustness is extremely poor in terms of different sequences of bi-temporal images. In change point detection tasks, whether it is a multivariate time series [
44] or high-dimensional time series [
45], the time series usually contains complex correlations. The sequences of bi-temporal images are equally critical in CD tasks, and there is a certain correlation. For example, two sequences of bi-temporal RSI exist, the sequence of image t1 to image t2 and image t2 to image t1. Suppose we superimpose image t1 on image t2 and send it into the model for training. In the same way, image t1 is also superimposed on image t2 for testing, and the model will perform well. Once we superimpose image t2 on image t1 to feed into the model for testing, which is equivalent to changing the bi-temporal image sequence from image t1 to image t2 into image t2 to image t1, the performance of the model is very poor. However, according to the definition of CD in [
1], time should be irrelevant in detecting the difference between the two images in a CD task. For example, the detection result from image t1 to image t2 is changed or unchanged, and the detection result from image t2 to image t1 should also be changed or unchanged correspondingly. It is necessary to remember that the reason for this limitation is the sequence of image concatenation in image-fused methods or the sequence of feature fusion in feature-fused methods. The model only learns the changes from image t1 to image t2 or feature A to feature B and does not realize that the changes are relative. The change detection results should not be related to the sequence of image t1 and image t2. (2) Changes in small targets are easily missed in the change map. A large number of the proposed CD network architectures are based on encoder-decoder [
43]. For instance, the three models proposed in [
39] are based on the U-Net. Specifically, the models are based on UNet++ [
40], including UNet++MSOF [
18], DifUNet++ [
20], SNUNet-CD [
23], and DCFFNet [
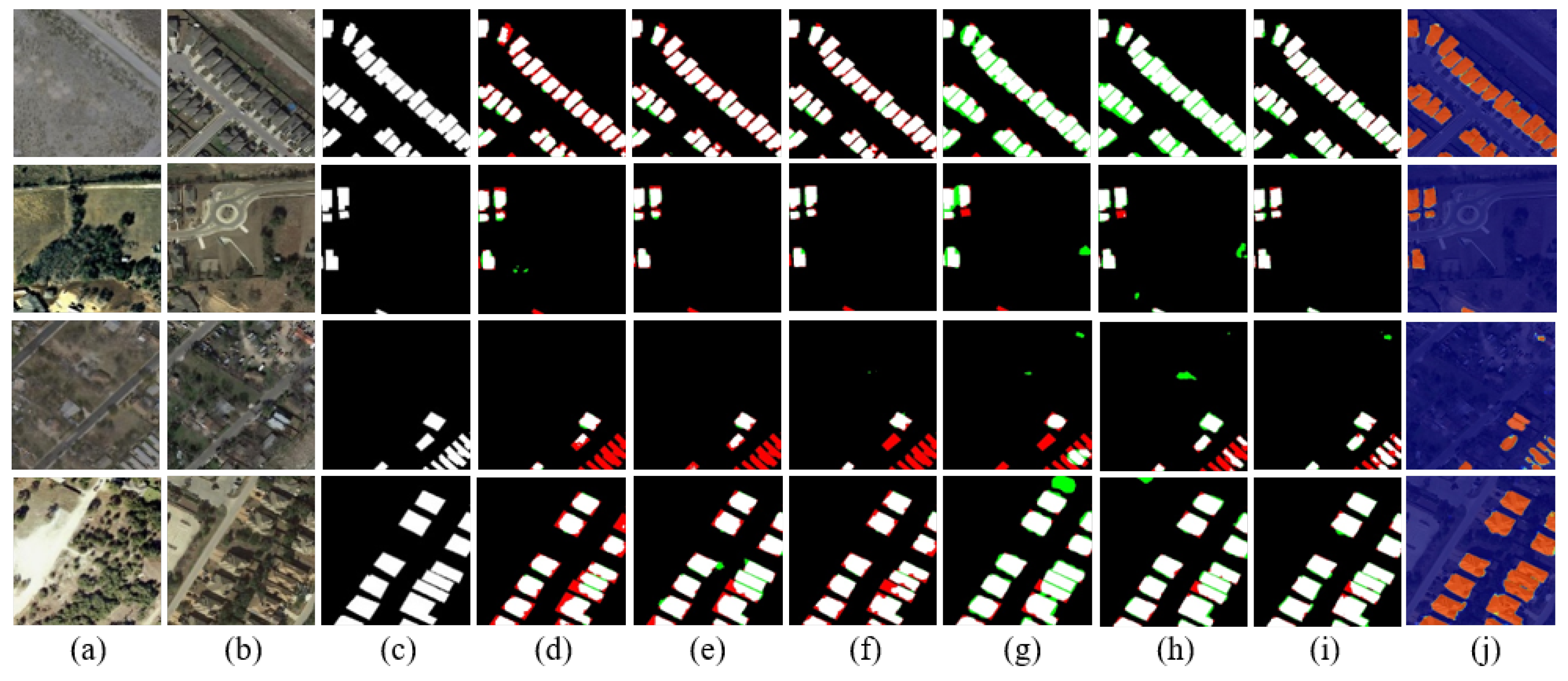
21]. The change detection network receives bi-temporal images and generates a binary map. The spatial resolution of the binary map is the same as the input images. In the architecture of encoder-decoder, networks first learn low-resolution representations and subsequently recover high-resolution representations. Due to downsampling, a part of the high-resolution spatial information will be lost gradually. Thereby, the features of small changes will be missed. The lost high-resolution spatial features are compensated by skip connections, but these methods are sophisticated and ineffective. Therefore, the changes in small regions are missed in the prediction change map. This also one of the bottlenecks that urgently needs to be overcome to improve CD performance.
The first limitation in feature-fused and image-fused methods is that they need to fuse features or directly concatenate the raw images, which are still the mainstream methods. The robustness of these methods with fusion operation is extremely poor in terms of the different sequences of bi-temporal images. We can distinguish these methods from the previous methods, including CVA, DCVA, DSFA, and metric-based methods, according to whether the raw bi-temporal images or their features are fused. The second problem appears in almost all CD methods. To solve the aforementioned limitation, we design a new objective function that is inspired by the solution of rotation invariance in [
46] to learn a temporal-reliable feature and propose an effective network that is inspired by [
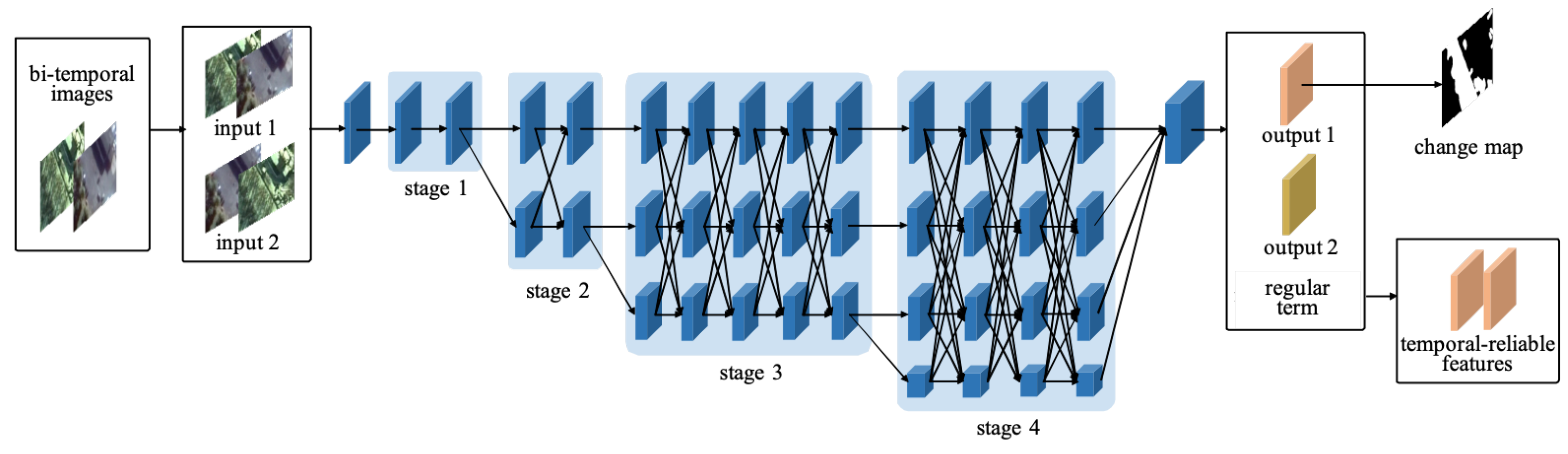
47] to solve the lack of small changes for CD in high-resolution bi-temporal RSI. The difference from the training of traditional change detection models, which only optimize the classification error of each pixel, is that the proposed model is trained by optimizing a novel objective function via forcing a regular term on the training loss. The regular term aims to enforce the bi-temporal images before and after exchanging the sequence to share similar features to realize temporal reliability. As depicted in
Figure 1, input1 and input2 are the results before and after exchanging the sequence of bi-temporal images, and output1 and output2 are the features extracted by our model. The goal of the regular term is to enable the same backbone network to capture the same difference information when the input is input1 and input2. The extracted features are called temporal-reliable features in our paper. Recently, a high-resolution network (HRNet) was presented in [
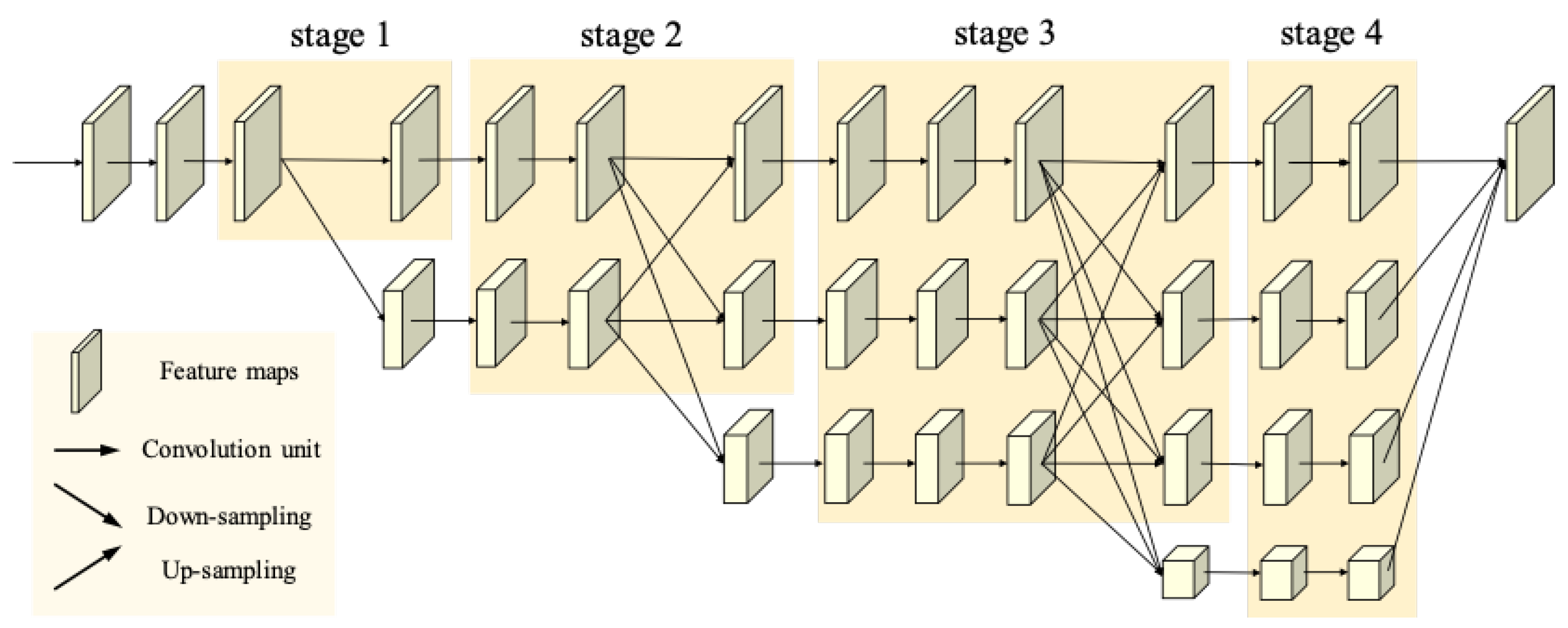
47]. We propose an effective network based on HRNet by repeatedly exchanging information across different resolutions, which benefits the extraction of semantically richer and more spatially precise information. Numerous experimental results show that our network can dramatically optimize the detection outcome of small target changes, such as car, shed, and narrow path. In addition, our proposed model can increase the robustness of the sequence of bi-temporal images, which is unattainable in other deep-learning-based models that commonly contain image concatenation or feature fusion of bi-temporal images. In summary, the major innovations and contributions of our work can be summarized as follows:
- (1)
We first point out a serious problem with the definition of change detection, which exists in early-fusion and late-fusion methods, and propose a novel objective function that brilliantly solves the problem and greatly improves the robustness of these two types of methods;
- (2)
Due to the importance of spatial information in RSI CD tasks and the defect of partial high-resolution information loss due to the encoder-decoder structure, we design an improved HRNet that solves the difficulty of small target CD to a certain extent;
- (3)
On two challenging public datasets, we demonstrate the potential of our algorithm through comprehensive experiments and comparisons.
The rest of our work is presented as follows.
Section 2 briefly introduces the architecture of HRNet and illustrates the framework of TRCD and a novel objective function for the optimization of the network.
Section 3 presents comparative experiments on two public datasets for CD in high-resolution RSI. A discussion of the details and hyper-parameters in the experiment is provided in
Section 4. Finally,
Section 5 concludes this work and looks to our future work.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}