
Uncertainty-Aware Interpretable Deep Learning for Slum Mapping and Monitoring

 ,
,  ,
,
Abstract
:
1. Introduction
- We present our U-Net model which is the first deployment of a convolutional deep learning model to identify slum buildings in individual pixels in free and publicly available multispectral satellite images.
- We introduce our regional testing approach which we use to test our model against the Random Forest model that represents the current state-of-the-art for pixel-level classification. This testing method allows for more representative performance scores to be obtained, measuring more realistically how well models generalise to unseen whole geographical regions giving users greater confidence in applying the model.
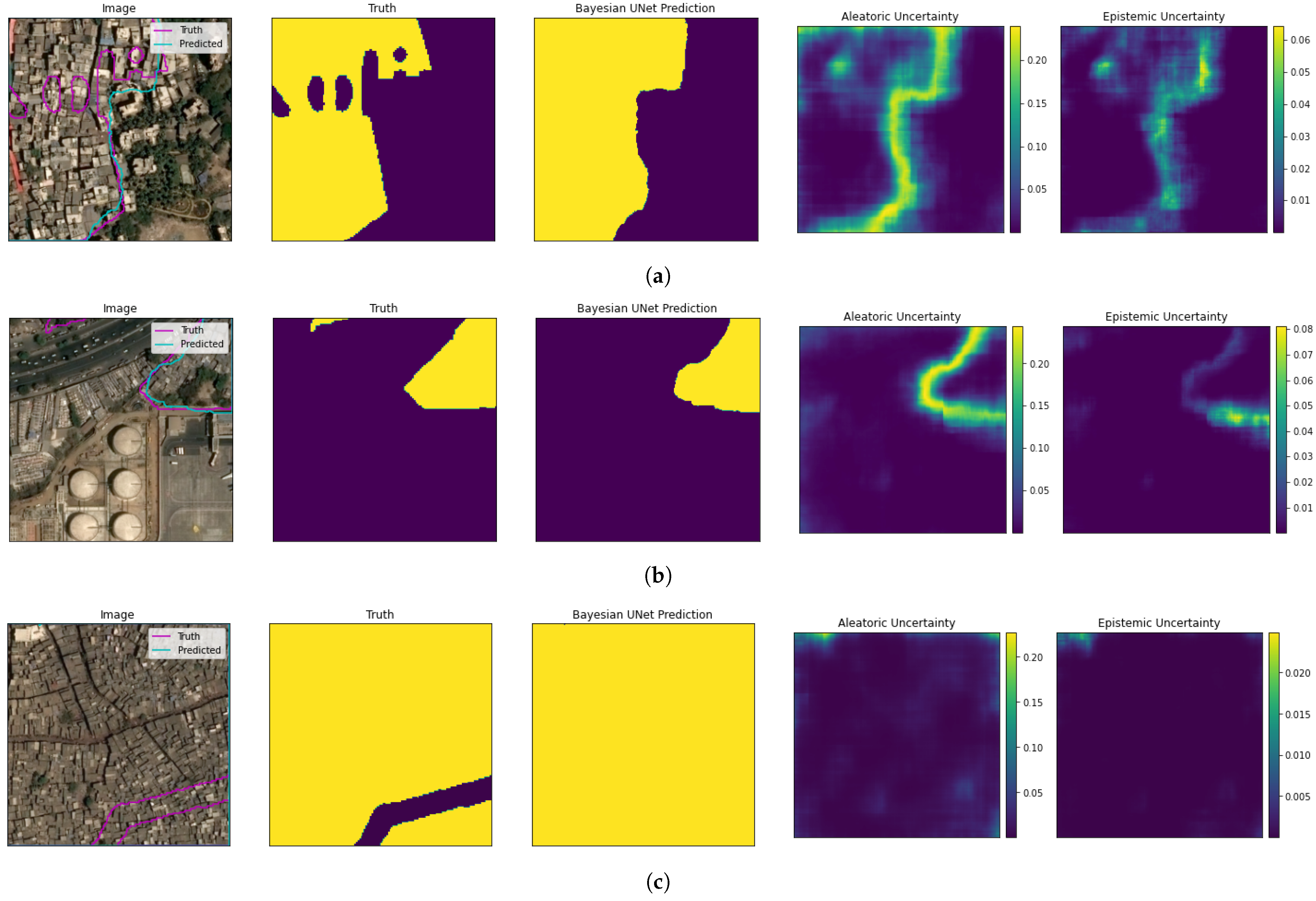
- We demonstrate that confidence measurements can be obtained per pixel within an input image by using Monte Carlo Dropout (MCD) in our U-Net model, demonstrating for the first time uncertainty quantification built into a deep learning slum mapping model. This produces uncertainty values that we measure alongside AUPRC (Area Under the Precision-Recall Curve) within our regional testing framework, showing that our U-Net model with MCD achieves a 9% improved regional test AUPRC and orders of magnitude decreased regional test uncertainty compared to the Random Forest model.
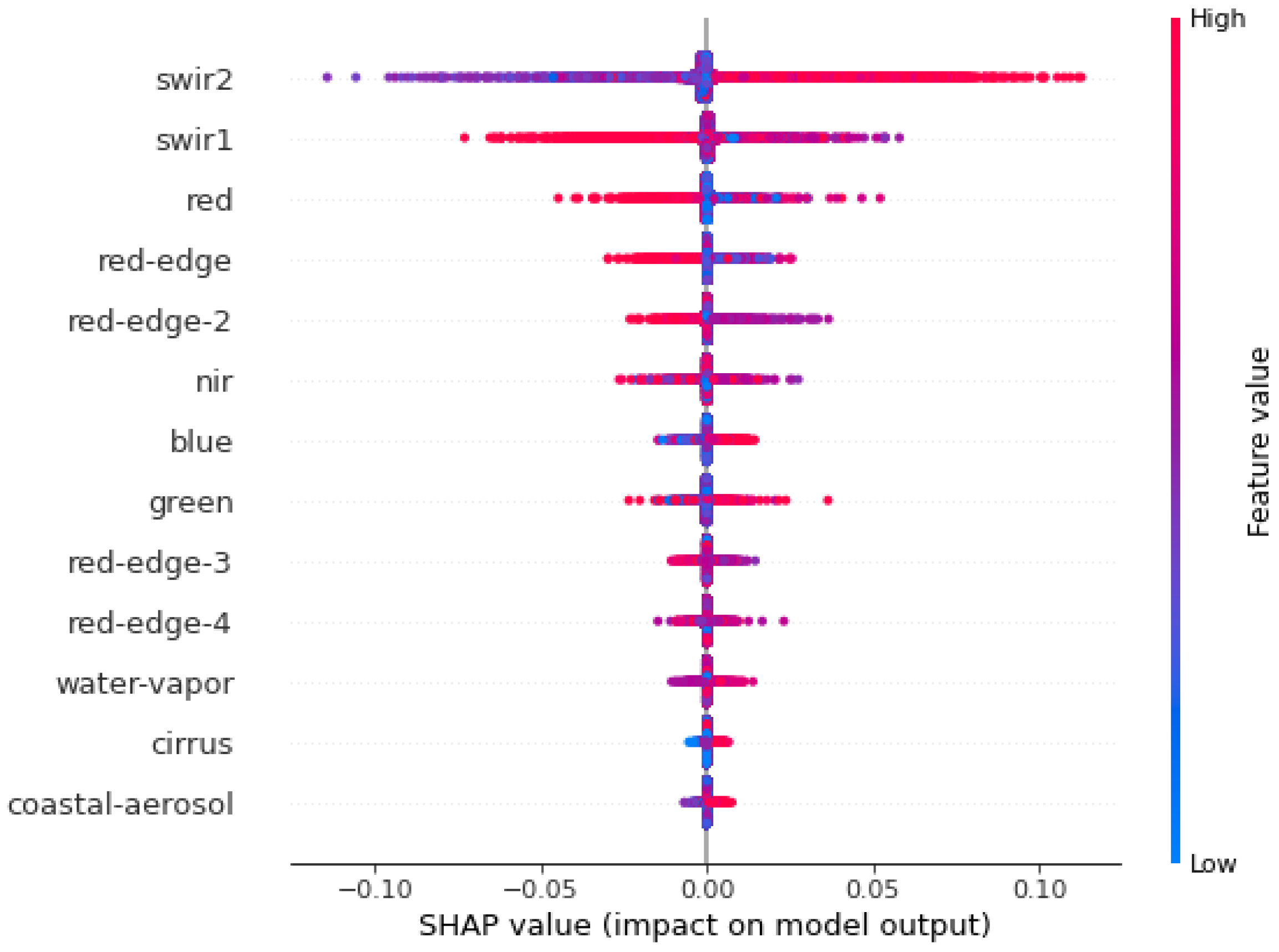
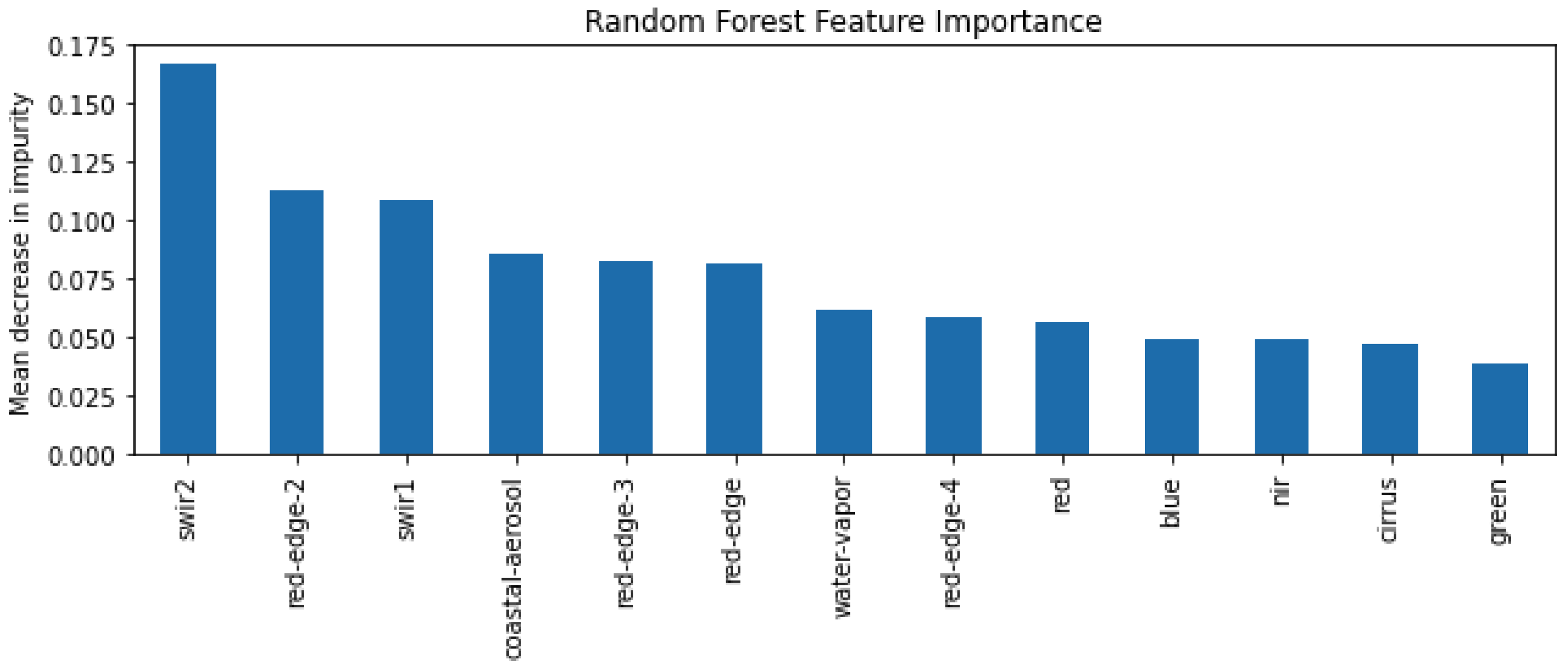
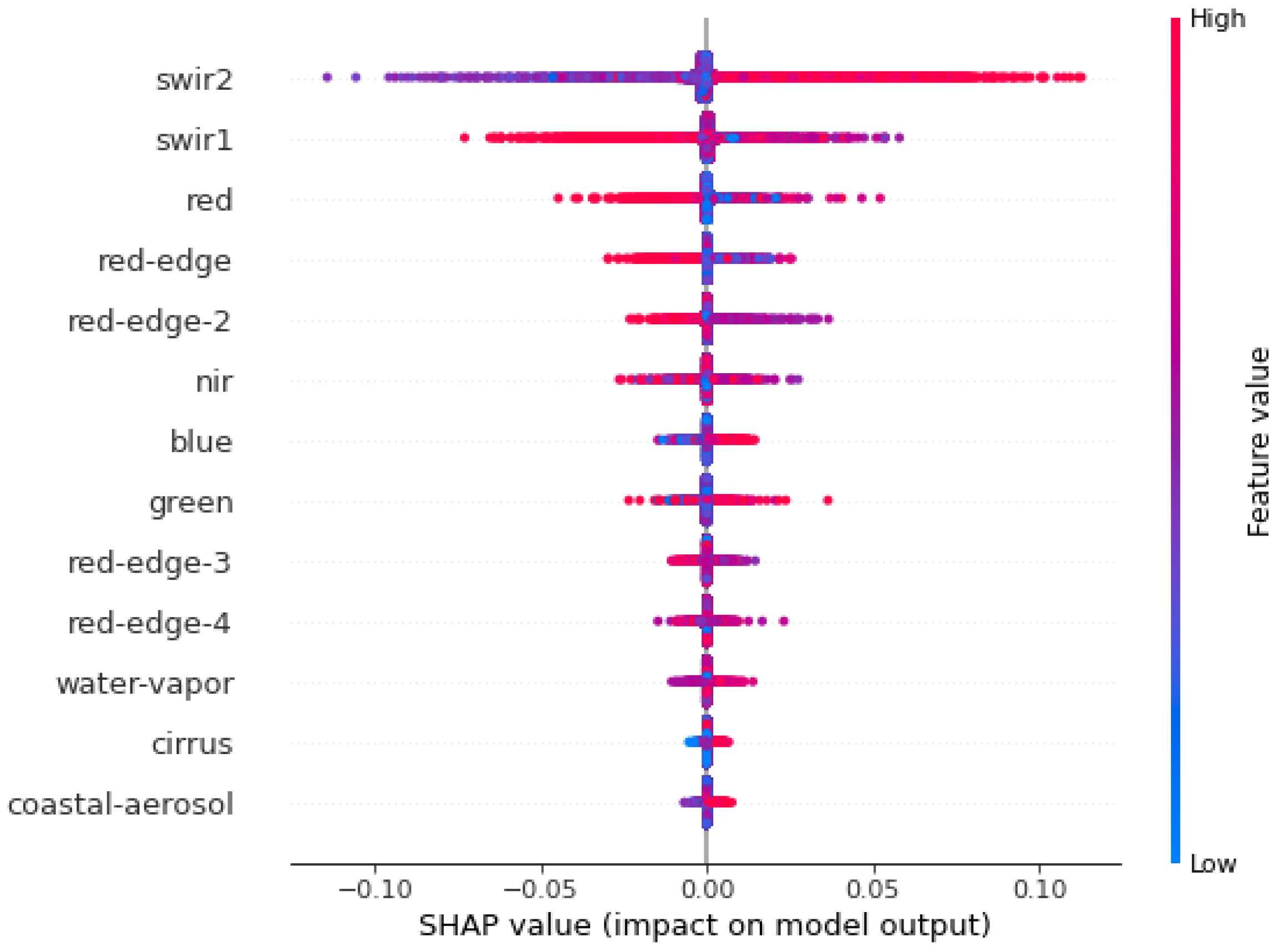
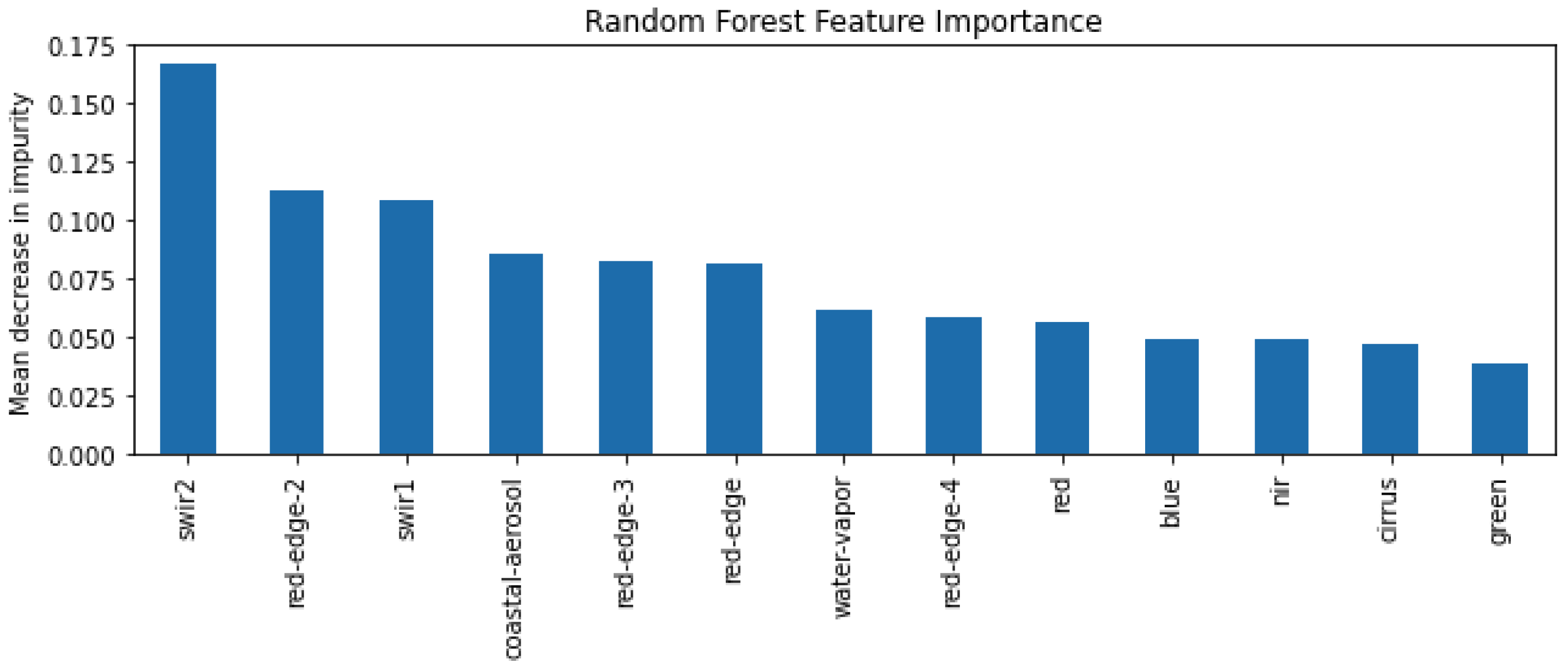
- We investigate the interpretability of the models and show that certain multispectral bands, particularly a shortwave infrared band, are the most powerful features for both the U-Net and Random Forest models. We demonstrate the strength of our U-Net model with a slum area monitoring example, showing that knowledge of the uncertainty provides us with much greater confidence in the application of the model.
2. Literature Review
2.1. Slum Mapping without Uncertainty Quantification
2.2. Slum Mapping with Uncertainty Quantification
3. Materials and Methods
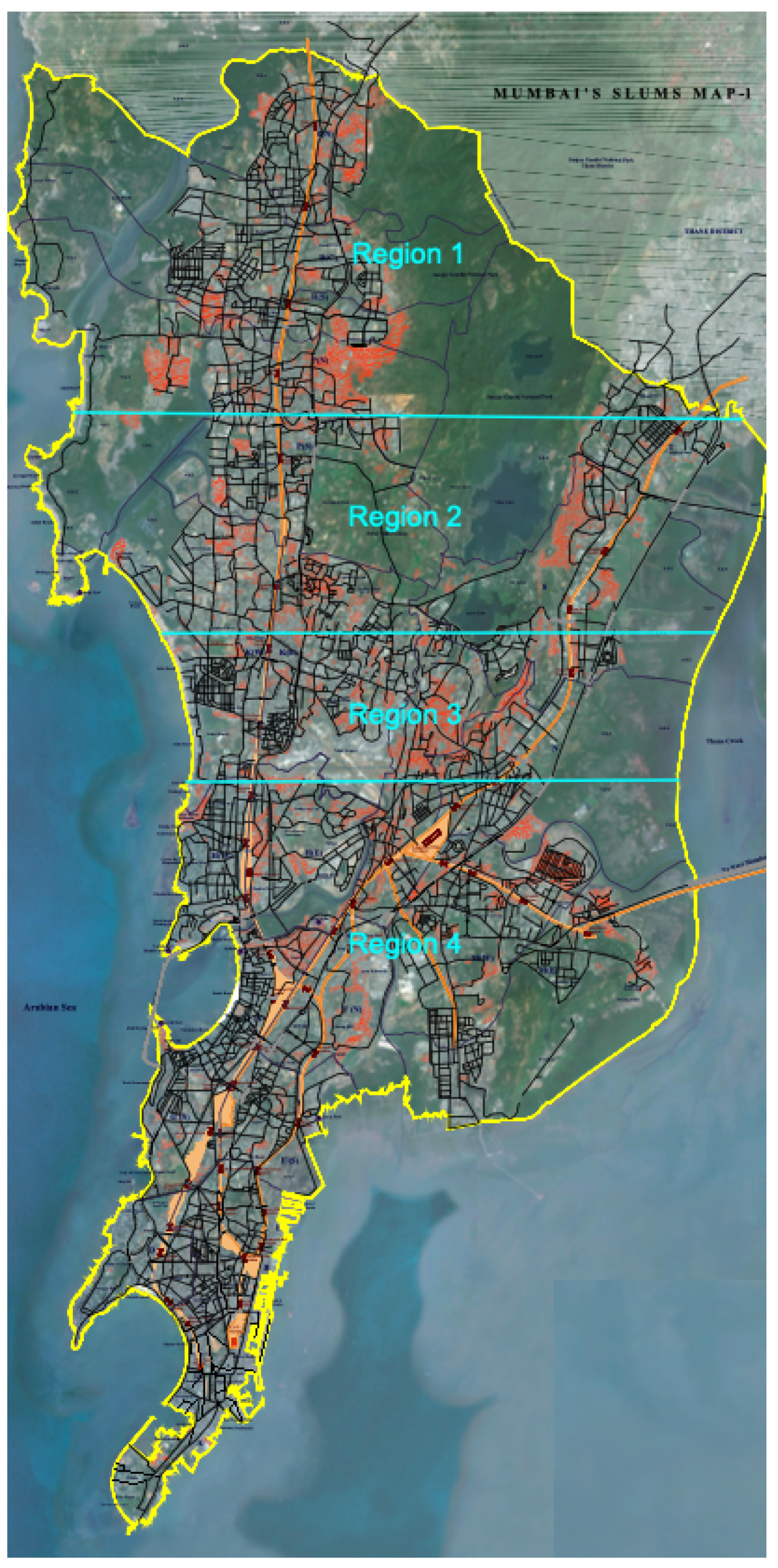
3.1. Dataset
3.2. Problem Statement
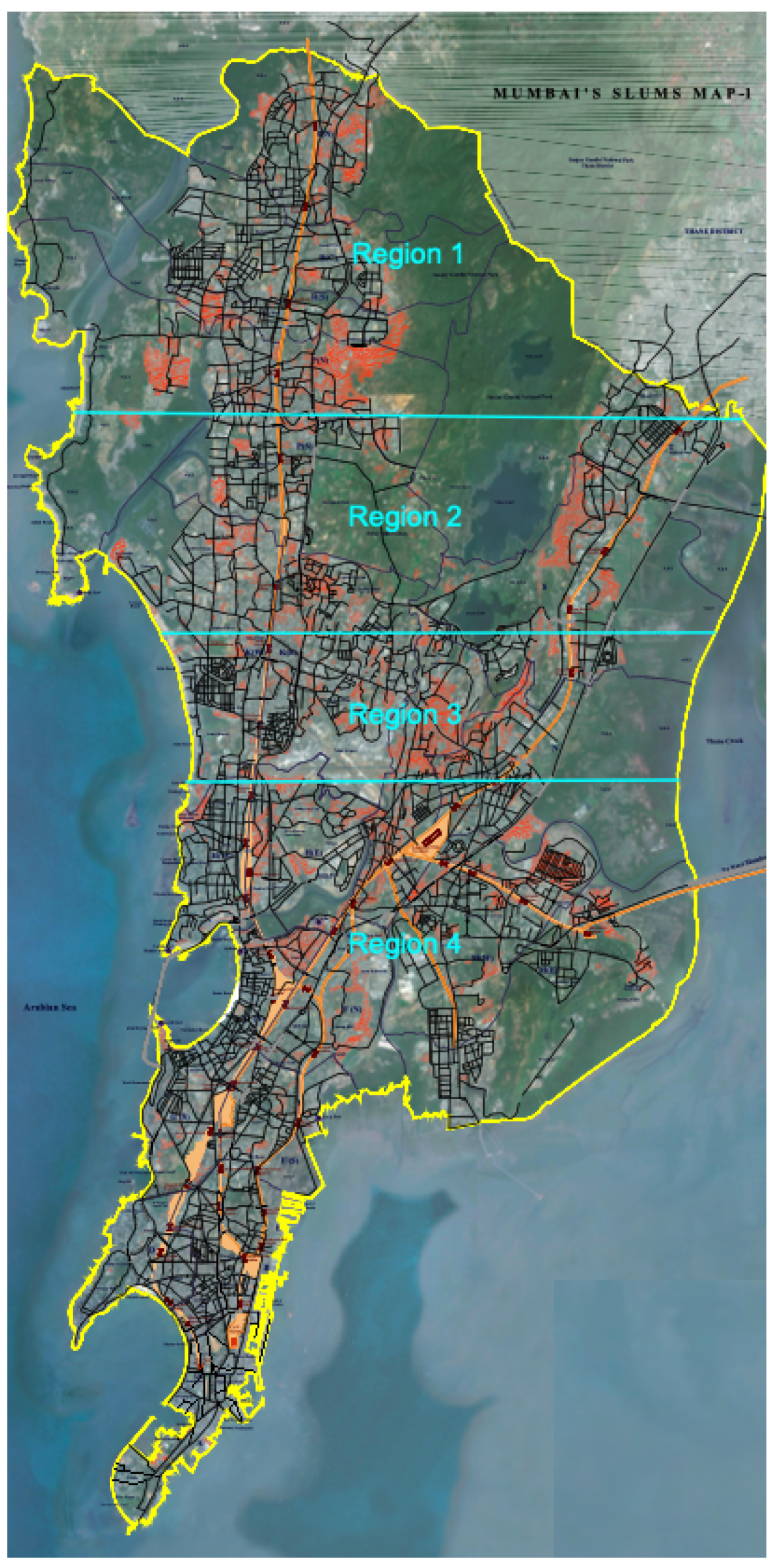
3.3. Regional Testing
3.4. Metrics
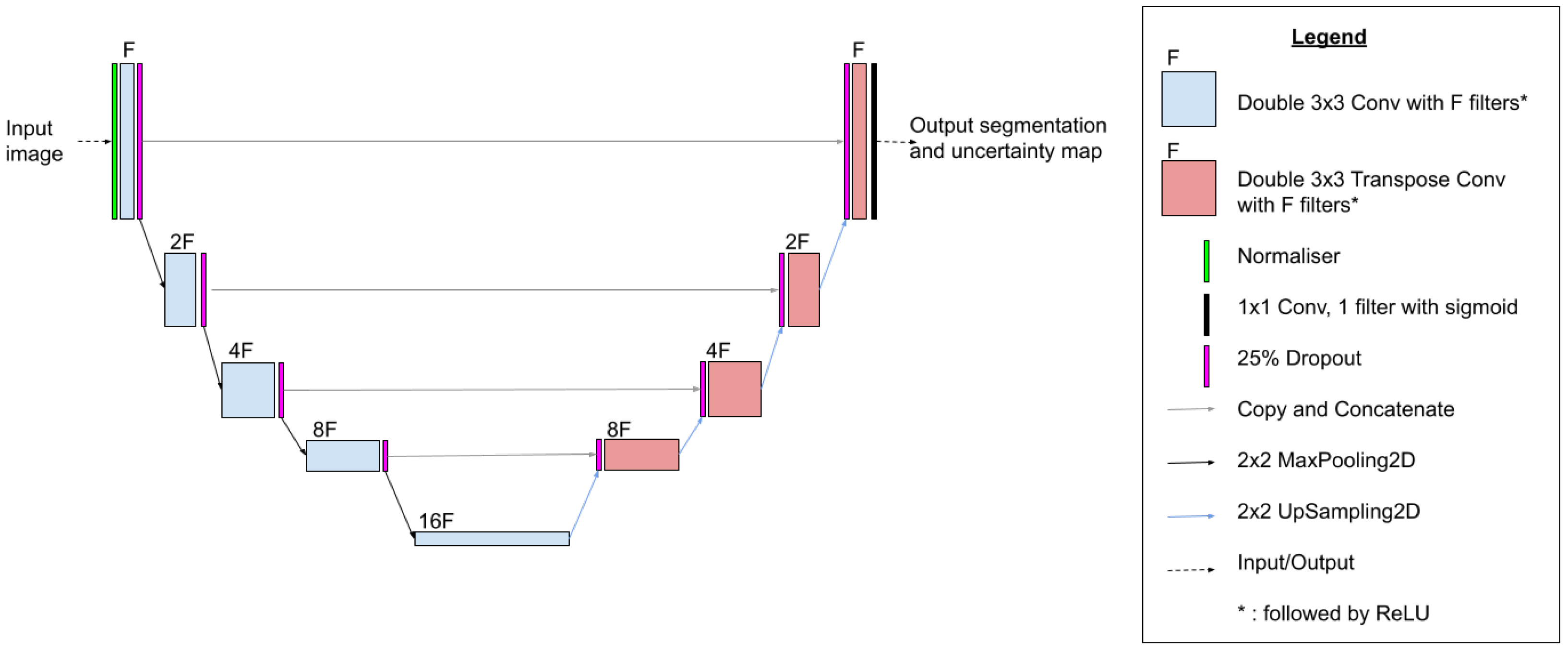
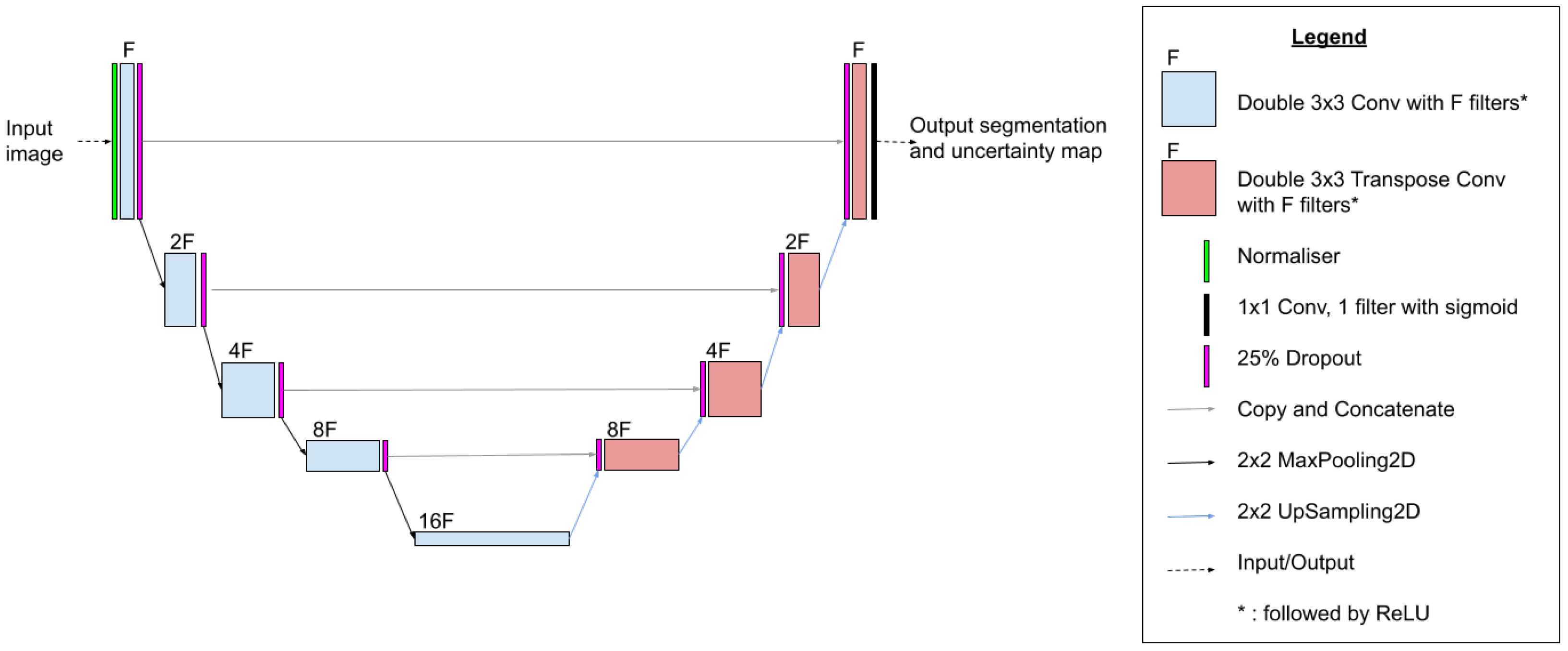
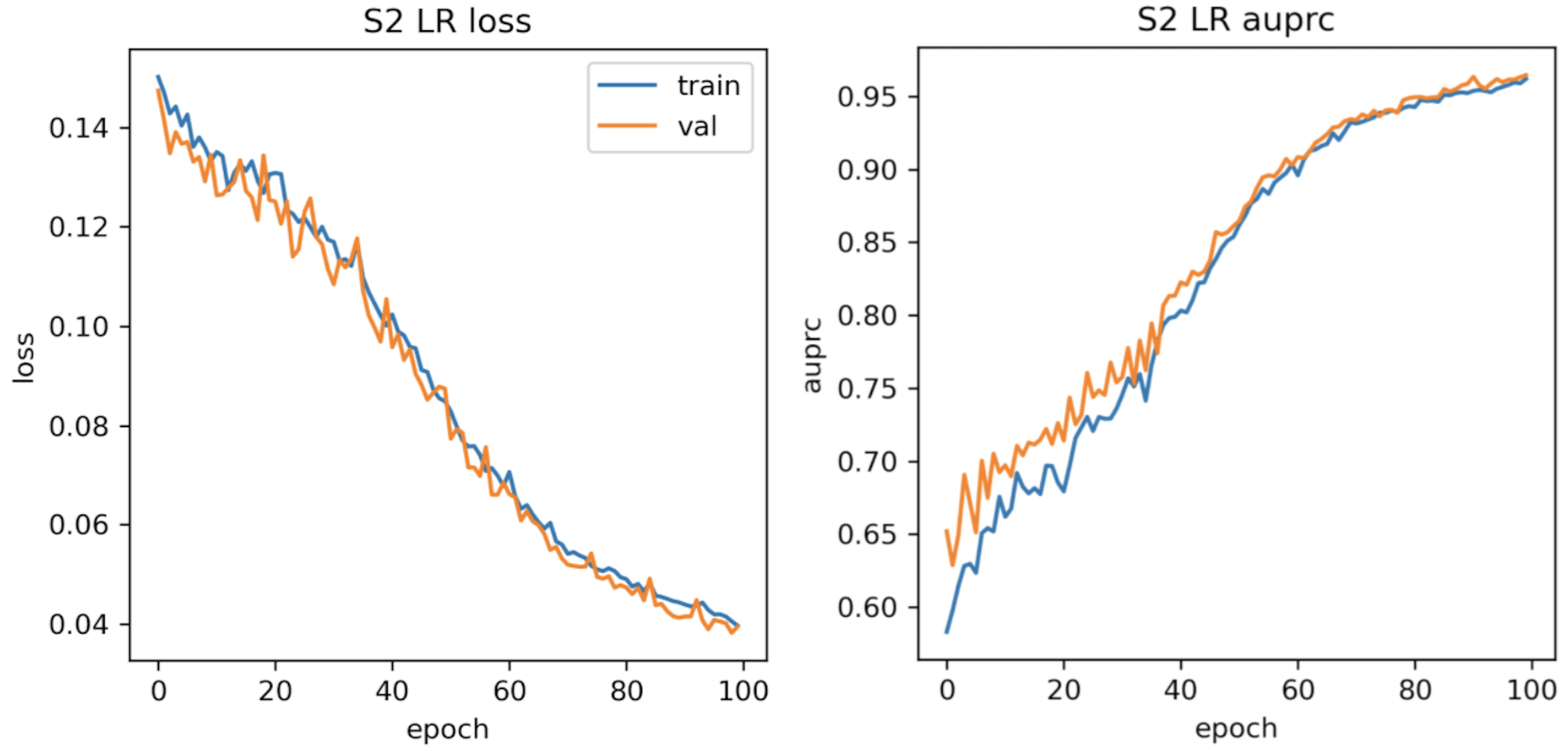
3.5. Proposed Uncertainty-Aware U-Net
3.6. Baseline Model: Random Forest
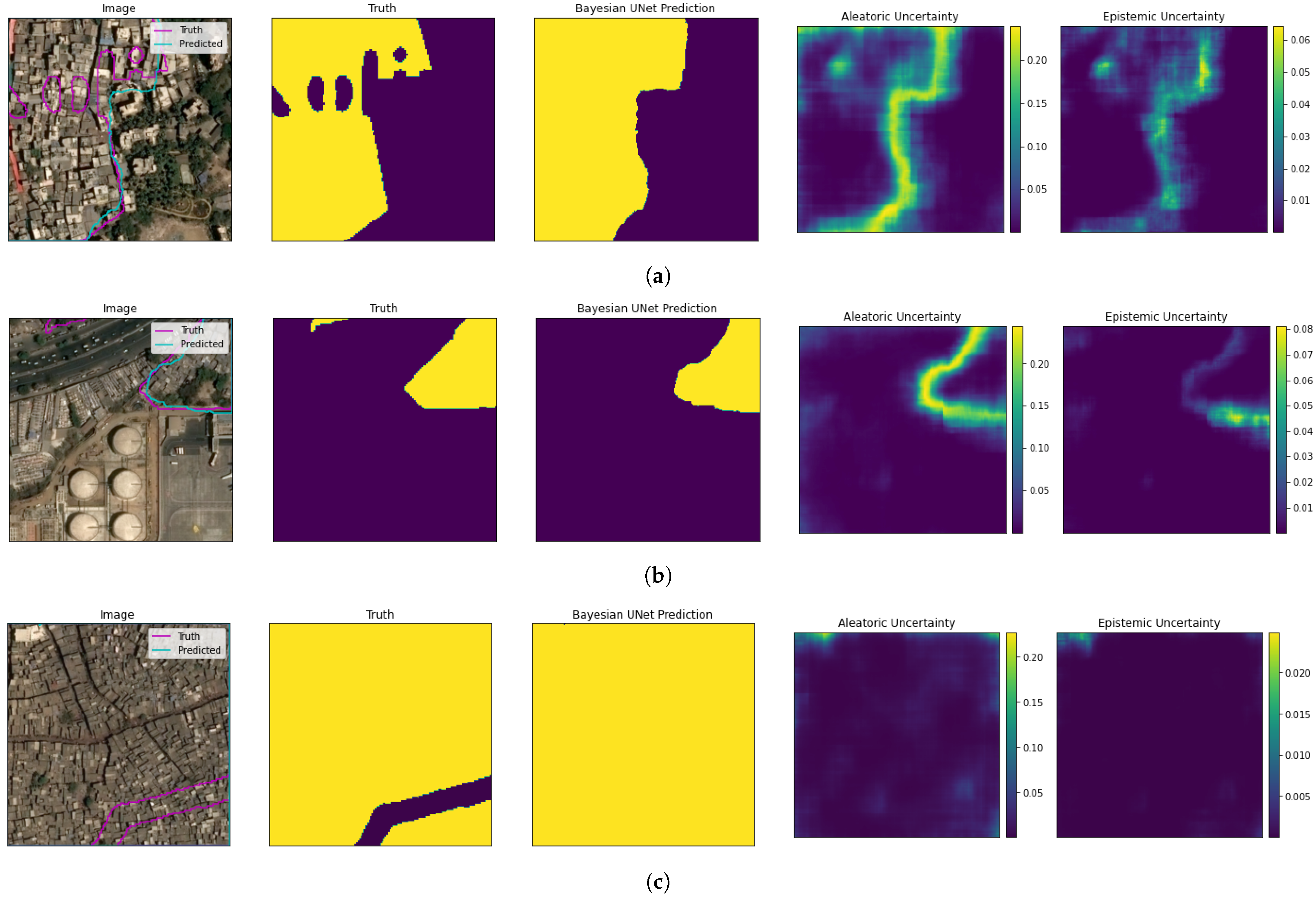
3.7. Calculation of Uncertainty
3.8. Comparison Strategy
3.9. Example U-Net Model Predictions
4. Results
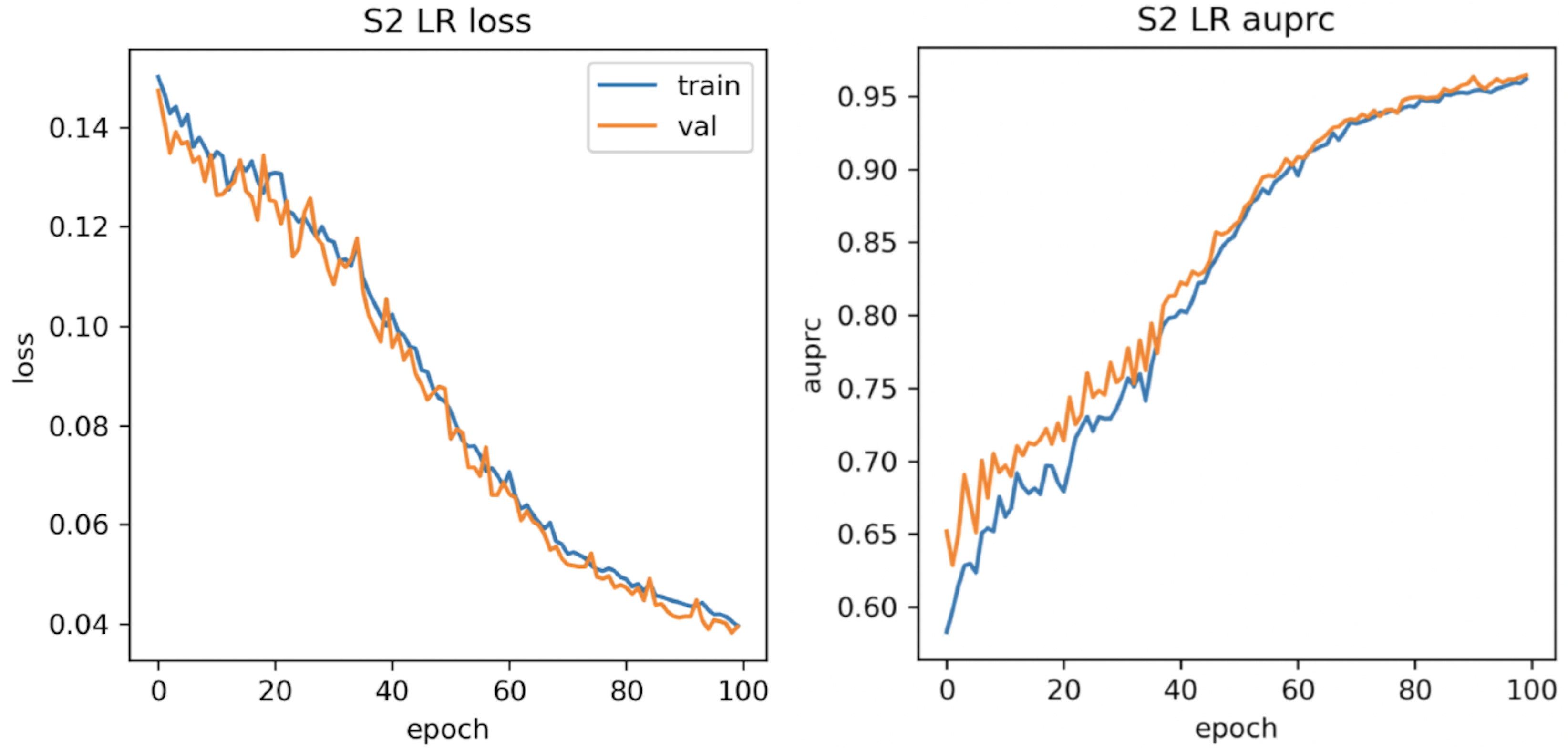
4.1. Regional Test AUPRC
4.2. Regional Test Uncertainty
4.3. Model Interpretability
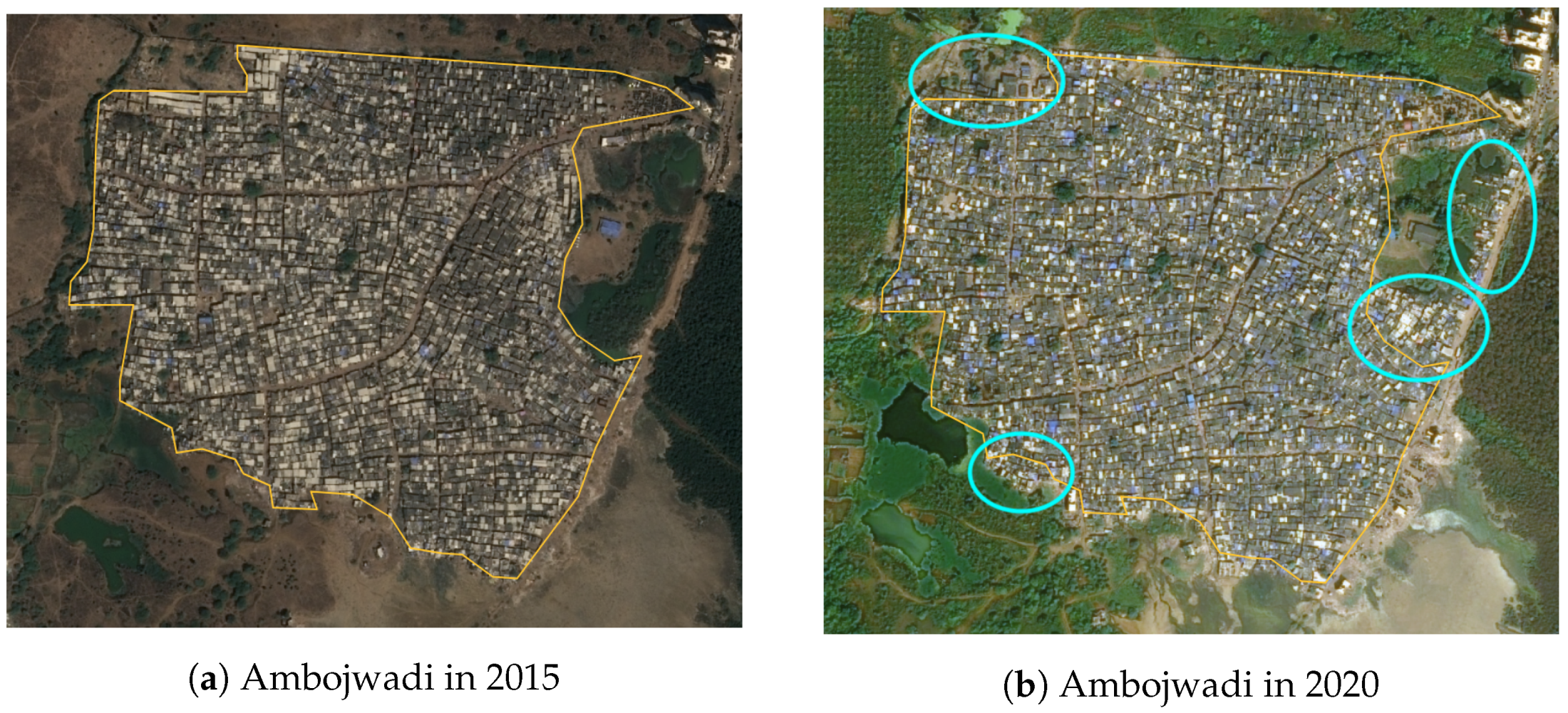
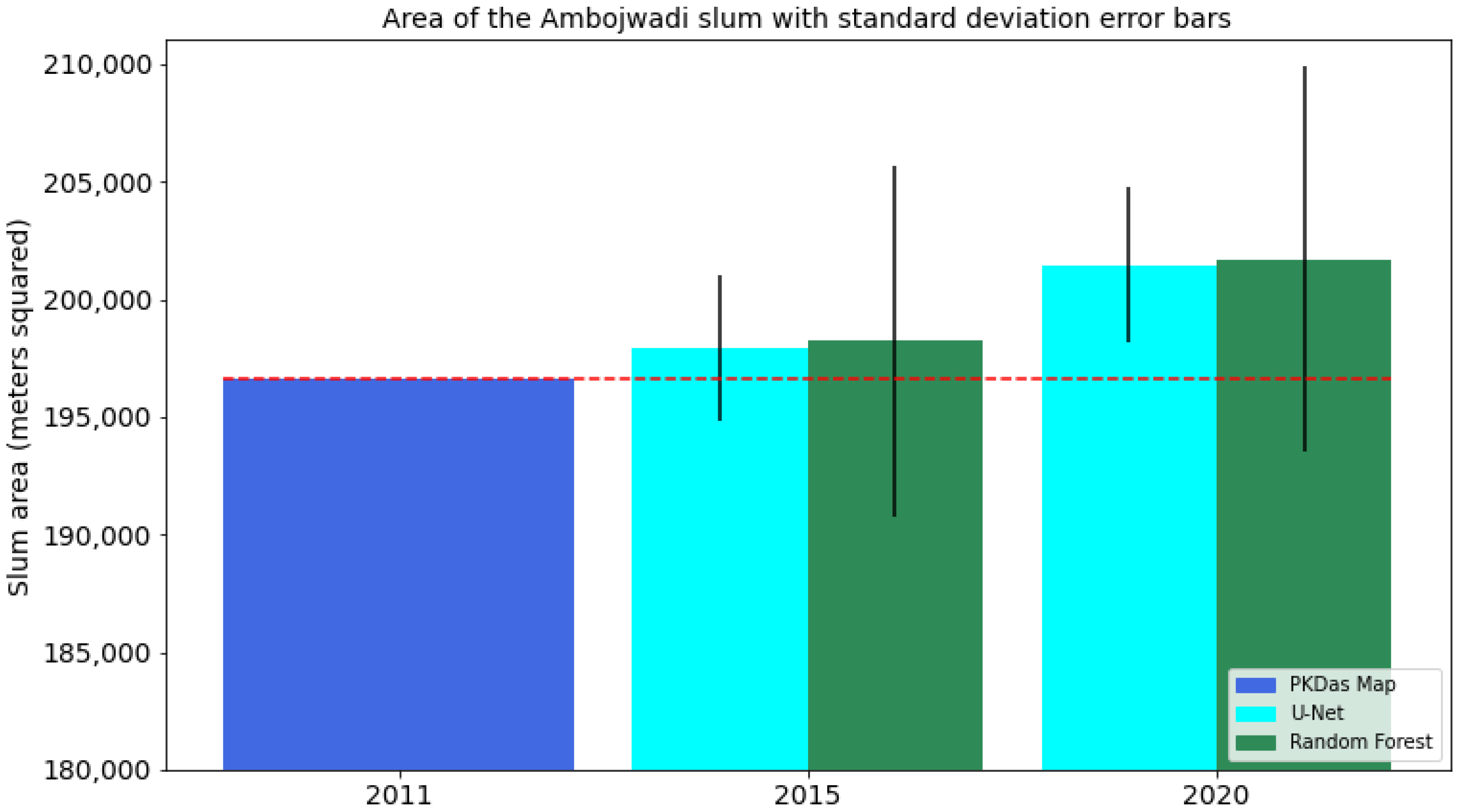
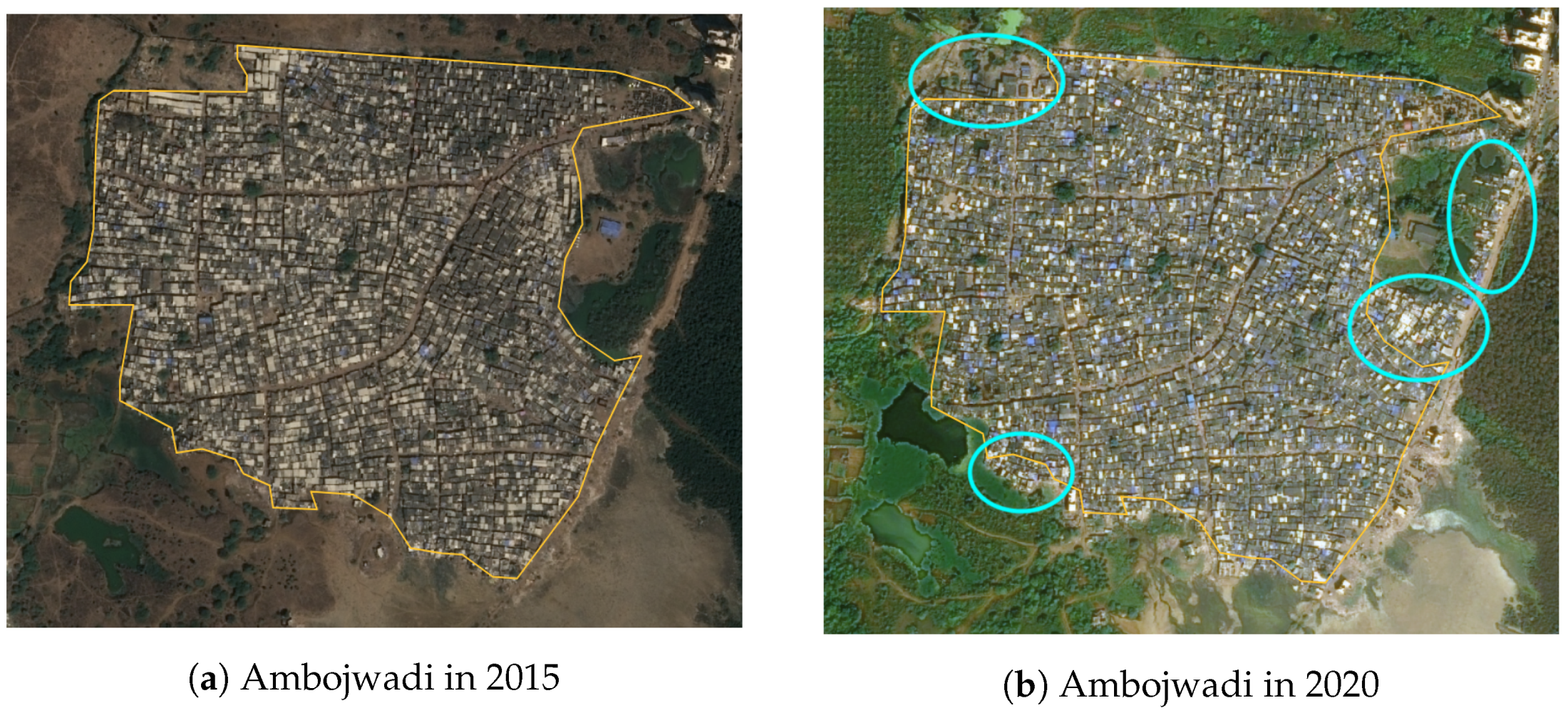
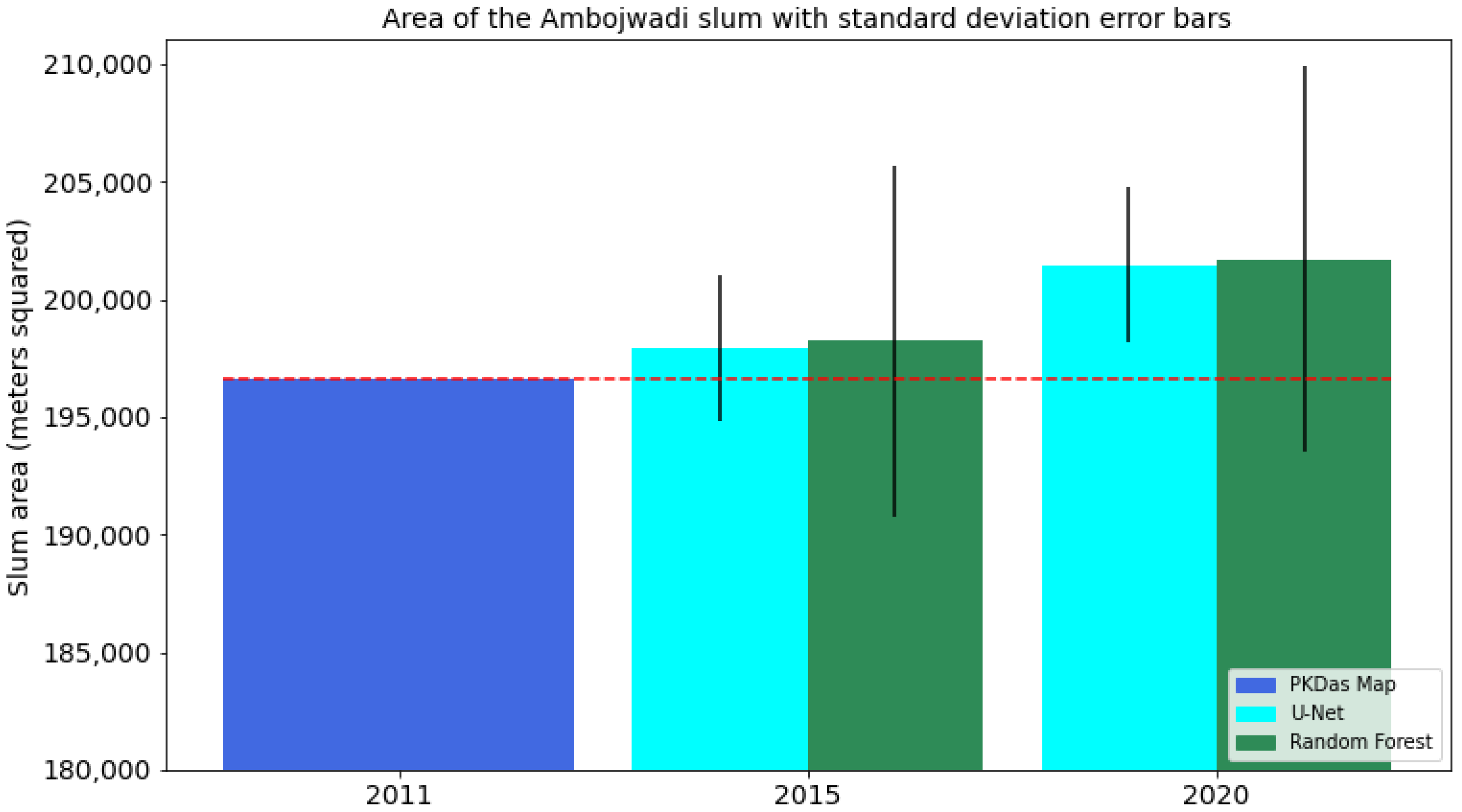
4.4. Slum Area Monitoring
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Department of Economic and Social Affairs. World Urbanization Prospects: The 2018 Revision; United Nations: Rome, Italy, 2019. [Google Scholar] [CrossRef] [Green Version]
- Kuddus, M.A.; Tynan, E.; McBryde, E. Urbanization: A problem for the rich and the poor? Public Health Rev. 2020, 41, 1–4. [Google Scholar] [CrossRef]
- United Nations Development Program. Rapid Urbanisation: Opportunities and Challenges to Improve the Well-Being of Societies|Human Development Reports; United Nations Development Program: New York, NY, USA, 2018. [Google Scholar]
- Trindade, T.C.; MacLean, H.L.; Posen, I.D. Slum infrastructure: Quantitative measures and scenarios for universal access to basic services in 2030. Cities 2021, 110, 103050. [Google Scholar] [CrossRef]
- Department of Economic and Social Affairs. Inequality in a Rapidly Changing World; United Nations: Rome, Italy, 2020; p. 216. [Google Scholar]
- Yue, L.; Xue, D.; Draz, M.U.; Ahmad, F.; Li, J.; Shahzad, F.; Ali, S. The Double-Edged Sword of Urbanization and Its Nexus with Eco-Efficiency in China. Int. J. Environ. Res. Public Health 2020, 17, 446. [Google Scholar] [CrossRef] [Green Version]
- Kohli, D.; Stein, A.; Sliuzas, R. Uncertainty analysis for image interpretations of urban slums. Comput. Environ. Urban Syst. 2016, 60, 37–49. [Google Scholar] [CrossRef]
- Lucci, P.; Bhatkal, T.; Khan, A.; Berliner, T. What Works in Improving the Living Conditions of Slum Dwellers. Available online: https://cdn.odi.org/media/documents/10188.pdf (accessed on 16 June 2022).
- UN Habitat. Urbanization and Development: Emerging Futures—World Cities Report 2016; United Nations Human Settlements Programme: Nairobi, Kenya, 2016; pp. 1–196. [Google Scholar]
- Abbott, J. An analysis of informal settlement upgrading and critique of existing methodological approaches. Habitat Int. 2002, 26, 303–315. [Google Scholar] [CrossRef]
- Anand, N.; Rademacher, A. Housing in the Urban Age: Inequality and Aspiration in Mumbai. Antipode 2011, 43, 1748–1772. [Google Scholar] [CrossRef] [Green Version]
- Friesen, J.; Taubenböck, H.; Wurm, M.; Pelz, P.F. The similar size of slums. Habitat Int. 2018, 73, 79–88. [Google Scholar] [CrossRef]
- Ooi, G.L.; Phua, K.H. Urbanization and slum formation. J. Urban Health 2007, 84, 27–34. [Google Scholar] [CrossRef] [Green Version]
- Verma, D.; Jana, A.; Ramamritham, K. Transfer learning approach to map urban slums using high and medium resolution satellite imagery. Habitat Int. 2019, 88, 101981. [Google Scholar] [CrossRef]
- UN-Habitat. Unpacking the Value of Sustainable Urbanization. In World Cities Report 2020: The Value of Sustainable Urbanization; UN-Habitat: Nairobi, Kenya, 2020; pp. 43–74. [Google Scholar] [CrossRef]
- Fulmer, S. World Population Review. 2021. Available online: https://worldpopulationreview.com/ (accessed on 16 June 2022).
- Amegah, A.K. Slum decay in Sub-Saharan Africa. Environ. Epidemiol. 2021, 5, e158. [Google Scholar] [CrossRef]
- United Nations. The Sustainable Development Goals Report; United Nations Publications: New York, NY, USA, 2021; pp. 1–56. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, B.; Acioly, C.; Gebre-Egziabher, A.; Clos, J.; Dietrich, K. Streets as Tools for Urban Transformation in Slums: A Street-Led Approach to Citywide Slum Upgrading; UN-Habitat: Nairobi, Kenya, 2012; Volume 23, pp. 1–86. [Google Scholar]
- Mahabir, R.; Croitoru, A.; Crooks, A.; Agouris, P.; Stefanidis, A. A Critical Review of High and Very High-Resolution Remote Sensing Approaches for Detecting and Mapping Slums: Trends, Challenges and Emerging Opportunities. Urban Sci. 2018, 2, 8. [Google Scholar] [CrossRef] [Green Version]
- Owusu, M.; Kuffer, M.; Belgiu, M.; Grippa, T.; Lennert, M.; Georganos, S.; Vanhuysse, S. Towards user-driven earth observation-based slum mapping. Comput. Environ. Urban Syst. 2021, 89, 101681. [Google Scholar] [CrossRef]
- Mahabir, R.; Crooks, A.; Croitoru, A.; Agouris, P. The study of slums as social and physical constructs: Challenges and emerging research opportunities. Reg. Stud. Reg. Sci. 2016, 3, 399–419. [Google Scholar] [CrossRef] [Green Version]
- Pugalis, L.; Giddings, B.; Anyigor, K. Reappraising the World Bank responses to rapid urbanisation: Slum improvements in Nigeria. Local Econ. 2014, 29, 519–540. [Google Scholar] [CrossRef]
- Thomson, D.R.; Kuffer, M.; Boo, G.; Hati, B.; Grippa, T.; Elsey, H.; Linard, C.; Mahabir, R.; Kyobutungi, C.; Maviti, J.; et al. Need for an Integrated Deprived Area “Slum” Mapping System (IDEAMAPS) in Low- and Middle-Income Countries (LMICs). Soc. Sci. 2020, 9, 80. [Google Scholar] [CrossRef]
- Duque, J.; Patino, J.; Betancourt, A. Exploring the Potential of Machine Learning for Automatic Slum Identification from VHR Imagery. Remote Sens. 2017, 9, 895. [Google Scholar] [CrossRef] [Green Version]
- Gevaert, C.M.; Kohli, D.; Kuffer, M. Challenges of mapping the missing spaces. In Proceedings of the 2019 Joint Urban Remote Sensing Event (JURSE), Vannes, France, 22–24 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Kuffer, M.; Pfeffer, K.; Sliuzas, R. Slums from space-15 years of slum mapping using remote sensing. Remote Sens. 2016, 8, 455. [Google Scholar] [CrossRef] [Green Version]
- Wurm, M.; Stark, T.; Zhu, X.X.; Weigand, M.; Taubenböck, H. Semantic segmentation of slums in satellite images using transfer learning on fully convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2019, 150, 59–69. [Google Scholar] [CrossRef]
- Lilford, R.; Kyobutungi, C.; Ndugwa, R.; Sartori, J.; Watson, S.I.; Sliuzas, R.; Kuffer, M.; Hofer, T.; Porto De Albuquerque, J.; Ezeh, A. Because space matters: Conceptual framework to help distinguish slum from non-slum urban areas. BMJ Glob. Health 2019, 4, e001267. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Emtehani, S. Monitoring urban deprived areas with remote sensing and machine learning in case of disaster recovery. Climate 2021, 9, 58. [Google Scholar] [CrossRef]
- Stark, T.; Wurm, M.; Taubenböck, H.; Zhu, X.X. Slum Mapping in Imbalanced Remote Sensing Datasets Using Transfer Learned Deep Features. In Proceedings of the 2019 Joint Urban Remote Sensing Event (JURSE), Vannes, France, 22–24 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Gram-Hansen, B.; Helber, P.; Varatharajan, I.; Azam, F.; Coca-Castro, A.; Kopackova, V.; Bilinski, P. Mapping Informal Settlements in Developing Countries using Machine Learning and Low Resolution Multi-spectral Data. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019. [Google Scholar] [CrossRef] [Green Version]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Zhou, X.; Liu, H.; Pourpanah, F.; Zeng, T.; Wang, X. A Survey on Epistemic (Model) Uncertainty in Supervised Learning: Recent Advances and Applications. Neurocomputing 2022, 489, 449–465. [Google Scholar] [CrossRef]
- Pratomo, J.; Kuffer, M.; Martinez, J.; Kohli, D. Coupling Uncertainties with Accuracy Assessment in Object-Based Slum Detections, Case Study: Jakarta, Indonesia. Remote Sens. 2017, 9, 1164. [Google Scholar] [CrossRef] [Green Version]
- Kendall, A.; Gal, Y. What uncertainties do we need in Bayesian deep learning for computer vision? In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation: South Lake Tahoe, NV, USA, 2017; pp. 5575–5585. Available online: https://dl.acm.org/doi/10.5555/3295222.3295309 (accessed on 16 June 2022).
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Abdar, M.; Samami, M.; Mahmoodabad, S.D.; Doan, T.; Mazoure, B.; Hashemifesharaki, R.; Liu, L.; Khosravi, A.; Acharya, U.R.; Makarenkov, V.; et al. Uncertainty quantification in skin cancer classification using three-way decision-based Bayesian deep learning. Comput. Biol. Med. 2021, 135, 104418. [Google Scholar] [CrossRef]
- Abdar, M.; Fahami, M.A.; Chakrabarti, S.; Khosravi, A.; Pławiak, P.; Acharya, U.R.; Tadeusiewicz, R.; Nahavandi, S. BARF: A new direct and cross-based binary residual feature fusion with uncertainty-aware module for medical image classification. Inf. Sci. 2021, 577, 353–378. [Google Scholar] [CrossRef]
- Abdar, M.; Salari, S.; Qahremani, S.; Lam, H.K.; Karray, F.; Hussain, S.; Khosravi, A.; Acharya, U.R.; Makarenkov, V.; Nahavandi, S. UncertaintyFuseNet: Robust uncertainty-aware hierarchical feature fusion model with ensemble Monte Carlo dropout for COVID-19 detection. arXiv 2021, arXiv:2105.08590. [Google Scholar] [CrossRef]
- Leibig, C.; Allken, V.; Ayhan, M.S.; Berens, P.; Wahl, S. Leveraging uncertainty information from deep neural networks for disease detection. Sci. Rep. 2017, 7, 17816. [Google Scholar] [CrossRef] [Green Version]
- Michelmore, R.; Kwiatkowska, M.; Gal, Y. Evaluating Uncertainty Quantification in End-to-End Autonomous Driving Control. arXiv 2018, arXiv:1811.06817. [Google Scholar]
- Yu, J.; Lam, M.W.; Hu, S.; Wu, X.; Li, X.; Cao, Y.; Liu, X.; Meng, H. Comparative study of parametric and representation uncertainty modeling for recurrent neural network language models. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Graz, Austria, 15–19 September 2019; International Speech Communication Association: Baixas, France, 2019; pp. 3510–3514. [Google Scholar] [CrossRef] [Green Version]
- Wurm, M.; Taubenböck, H. Detecting social groups from space – assessment of remote sensing-based mapped morphological slums using income data. Remote Sens. Lett. 2018, 9, 41–50. [Google Scholar] [CrossRef]
- Maiya, S.R.; Babu, S.C. Slum segmentation and change detection: A deep learning approach. arXiv 2018, arXiv:1811.07896. [Google Scholar]
- Leonita, G.; Kuffer, M.; Sliuzas, R.; Persello, C. Machine learning-based slum mapping in support of slum upgrading programs: The case of Bandung City, Indonesia. Remote Sens. 2018, 10, 1522. [Google Scholar] [CrossRef] [Green Version]
- Balachandran, M. The world’s biggest survey of slums is underway in India. 2016. Available online: https://qz.com/india/717519/the-worlds-biggest-survey-of-slums-is-underway-in-india/ (accessed on 16 June 2022).
- PKDas. 2011. Available online: http://www.pkdas.com/maps/3-Mumbai’s-Slums-Map.pdf (accessed on 16 June 2022).
- Davis, J.; Goadrich, M. The Relationship between Precision-Recall and ROC Curves; ACM International Conference Proceeding Series; ACM Press: New York, NY, USA, 2006; Volume 148, pp. 233–240. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:cs.LG/1412.6980. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, ICML’16, New York, NY, USA, 20–22 June 2016; Volume 48, pp. 1050–1059. [Google Scholar]
- Abdar, M.; Fahami, M.A.; Rundo, L.; Radeva, P.; Frangi, A.; Acharya, U.R.; Khosravi, A.; Lam, H.; Jung, A.; Nahavandi, S. Hercules: Deep Hierarchical Attentive Multi-Level Fusion Model with Uncertainty Quantification for Medical Image Classification. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Duerr, O. Probabilistic Deep Learning: With Python, Keras and TensorFlow Probability; Manning Publications Company: Shelter Island, NY, USA, 2020. [Google Scholar]
- Gal, Y. Uncertainty in Deep Learning. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 2016. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Segal, M.R. Machine Learning Benchmarks and Random Forest Regression; Center for Bioinformatics and Molecular Biostatistics, UCSF: San Francisco, CA, USA, 2004; pp. 1–14. Available online: https://escholarship.org/uc/item/35x3v9t4 (accessed on 16 June 2022).
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer New York Inc.: New York, NY, USA, 2001. [Google Scholar]
- Rainforth, T.; Wood, F. Canonical Correlation Forests. arXiv 2015, arXiv:1507.05444. [Google Scholar]
- Goodfellow, I.J.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 16 June 2022).
- Kwon, Y.; Won, J.H.; Kim, B.J.; Paik, M.C. Uncertainty quantification using Bayesian neural networks in classification: Application to biomedical image segmentation. Comput. Stat. Data Anal. 2020, 142, 106816. [Google Scholar] [CrossRef]
- Hernandez-Orallo, J.; Flach, P.; Ferri, C. Brier Curves: A New Cost-Based Visualisation of Classifier Performance. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; Omnipress: Madison, WI, USA, 2011. ICML’11. pp. 585–592. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [Green Version]
- Kotthaus, S.; Smith, T.E.; Wooster, M.J.; Grimmond, C.S. Derivation of an urban materials spectral library through emittance and reflectance spectroscopy. ISPRS J. Photogramm. Remote Sens. 2014, 94, 194–212. [Google Scholar] [CrossRef] [Green Version]
- Zha, Y.; Gao, J.; Ni, S. Use of normalized difference built-up index in automatically mapping urban areas from TM imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | Random Forest | U-Net |
|---|---|---|
| 1 | 0.62 | 0.67 |
| 2 | 0.73 | 0.82 |
| 3 | 0.70 | 0.74 |
| 4 | 0.68 | 0.72 |
| Average | 0.68 | 0.74 |
| Region | Random Forest | U-Net |
|---|---|---|
| 1 | 2.0 | 12.9 |
| 2 | 1.8 | 11.1 |
| 3 | 1.5 | 7.2 |
| 4 | 1.9 | 7.5 |
| Average | 1.8 | 9.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fisher, T.; Gibson, H.; Liu, Y.; Abdar, M.; Posa, M.; Salimi-Khorshidi, G.; Hassaine, A.; Cai, Y.; Rahimi, K.; Mamouei, M. Uncertainty-Aware Interpretable Deep Learning for Slum Mapping and Monitoring. Remote Sens. 2022, 14, 3072. https://doi.org/10.3390/rs14133072
Fisher T, Gibson H, Liu Y, Abdar M, Posa M, Salimi-Khorshidi G, Hassaine A, Cai Y, Rahimi K, Mamouei M. Uncertainty-Aware Interpretable Deep Learning for Slum Mapping and Monitoring. Remote Sensing. 2022; 14(13):3072. https://doi.org/10.3390/rs14133072
Chicago/Turabian StyleFisher, Thomas, Harry Gibson, Yunzhe Liu, Moloud Abdar, Marius Posa, Gholamreza Salimi-Khorshidi, Abdelaali Hassaine, Yutong Cai, Kazem Rahimi, and Mohammad Mamouei. 2022. "Uncertainty-Aware Interpretable Deep Learning for Slum Mapping and Monitoring" Remote Sensing 14, no. 13: 3072. https://doi.org/10.3390/rs14133072
APA StyleFisher, T., Gibson, H., Liu, Y., Abdar, M., Posa, M., Salimi-Khorshidi, G., Hassaine, A., Cai, Y., Rahimi, K., & Mamouei, M. (2022). Uncertainty-Aware Interpretable Deep Learning for Slum Mapping and Monitoring. Remote Sensing, 14(13), 3072. https://doi.org/10.3390/rs14133072