
Encoder-Decoder Structure with Multiscale Receptive Field Block for Unsupervised Depth Estimation from Monocular Video


Abstract
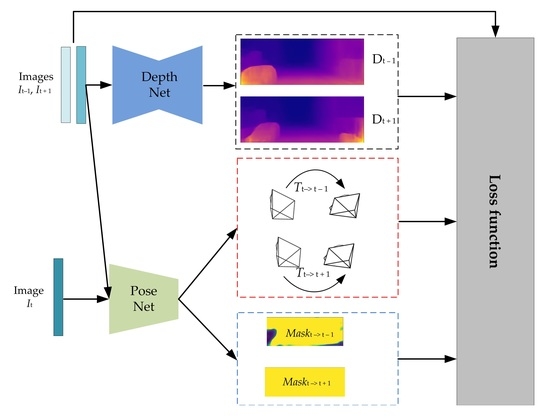
:
1. Introduction
2. Method
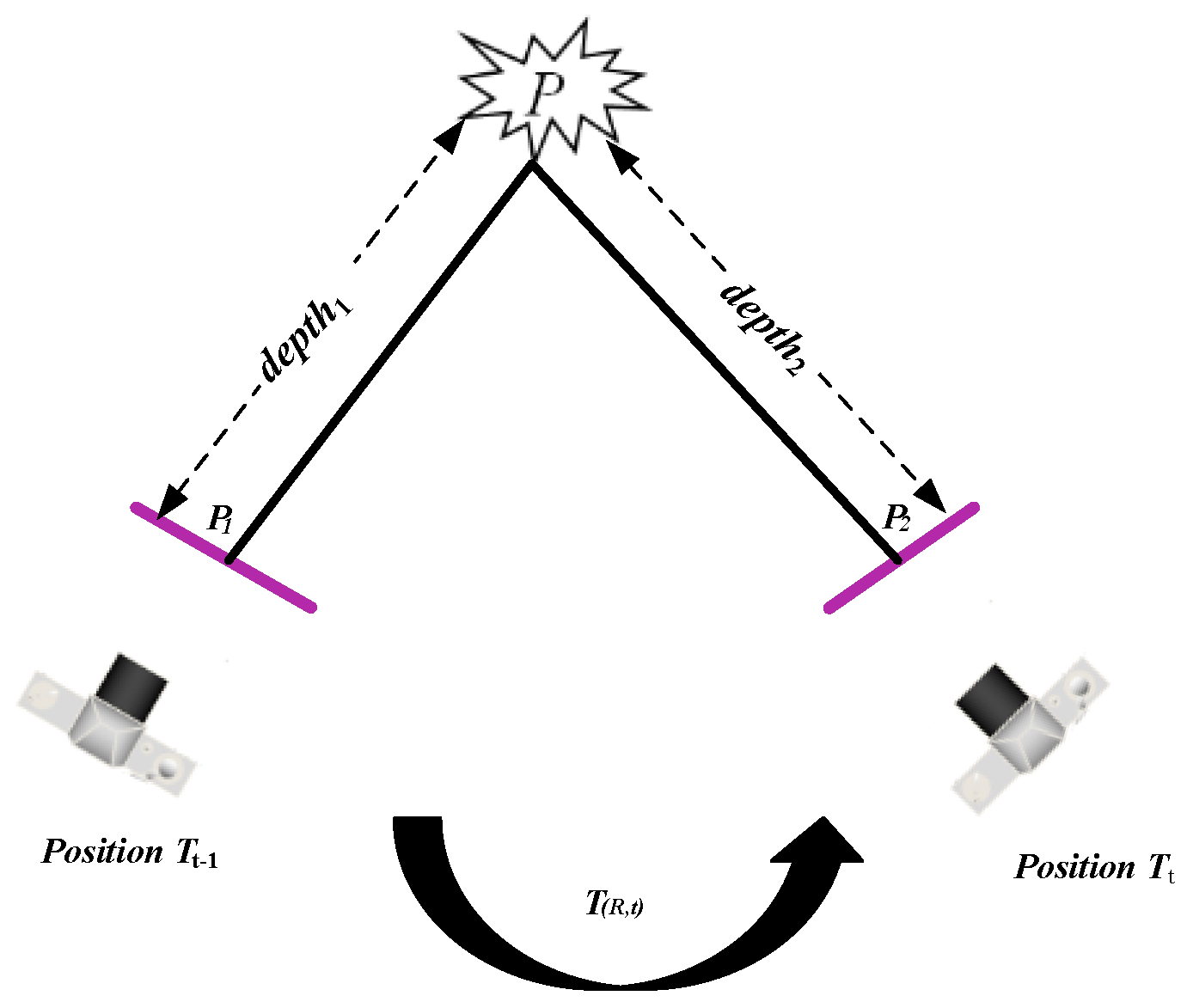
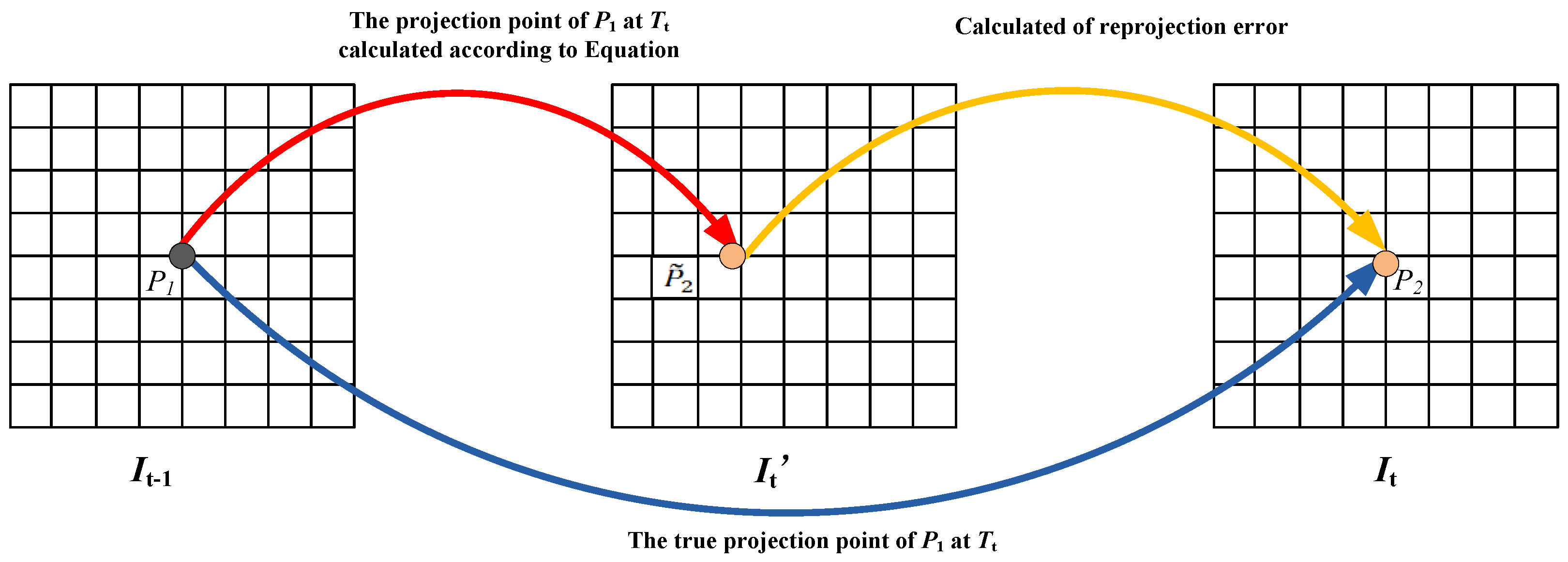
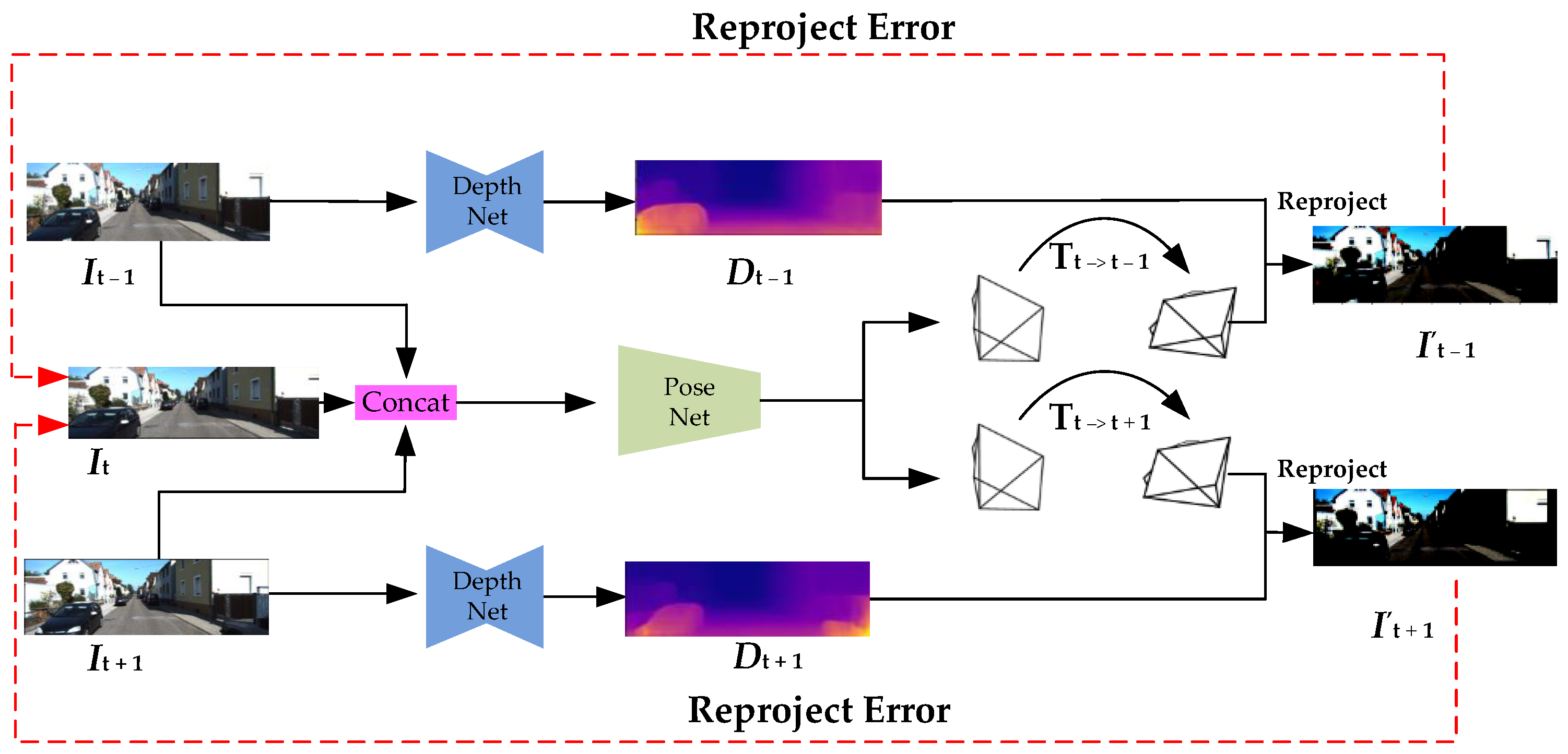
2.1. Reprojection Error
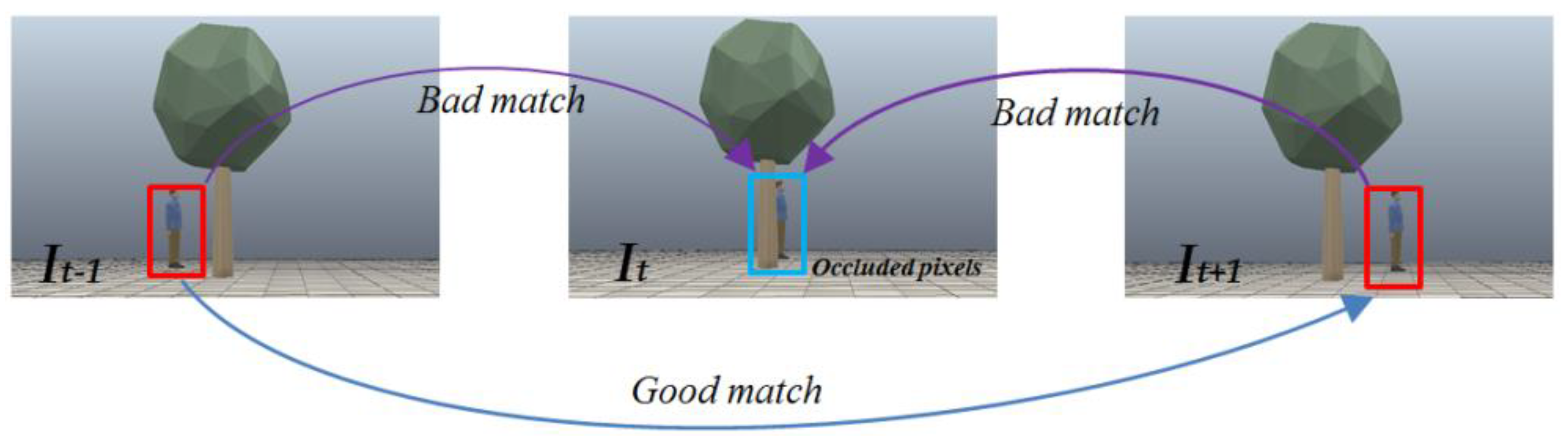
2.2. Occlusion Error
2.3. Neural Network Model
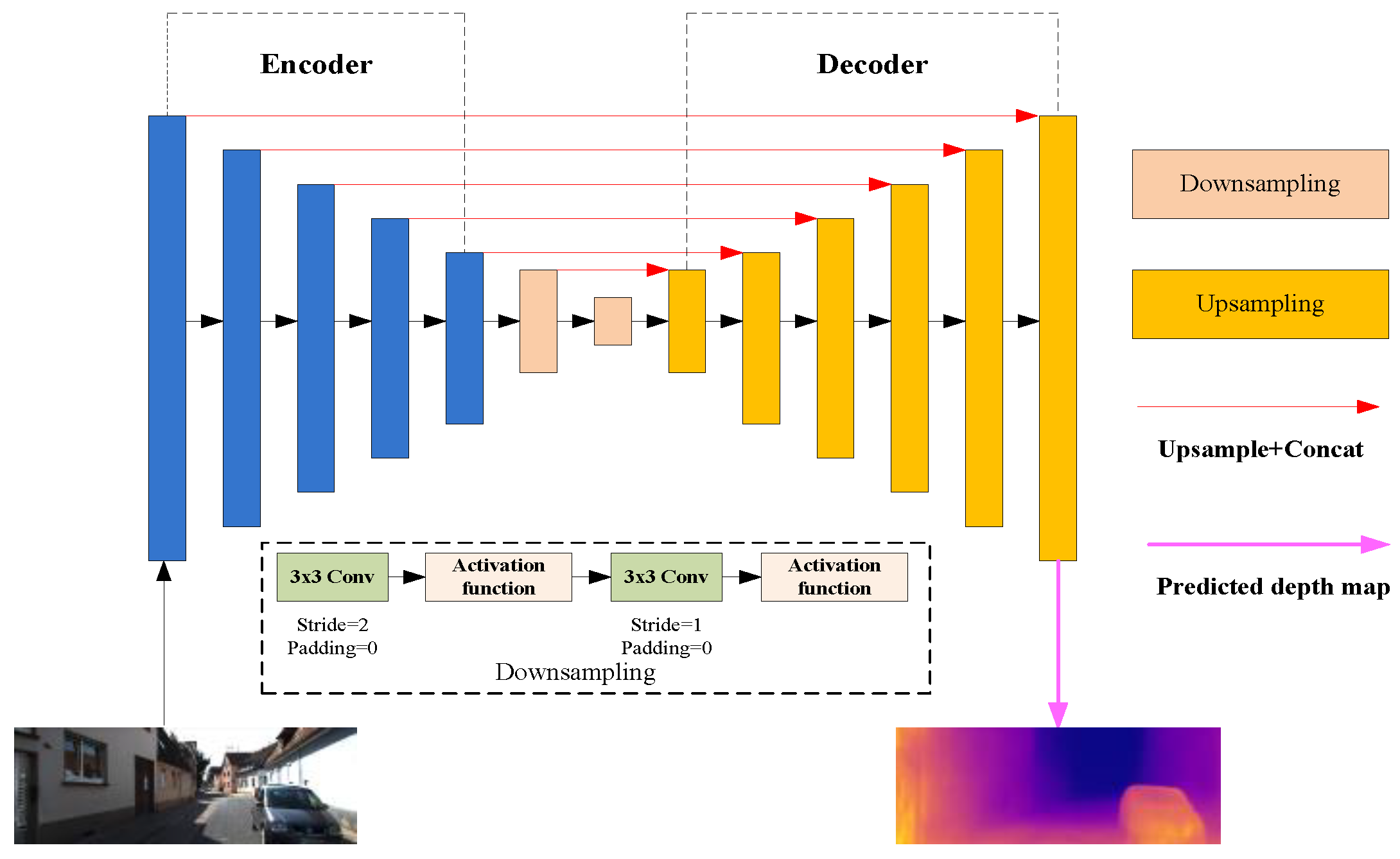
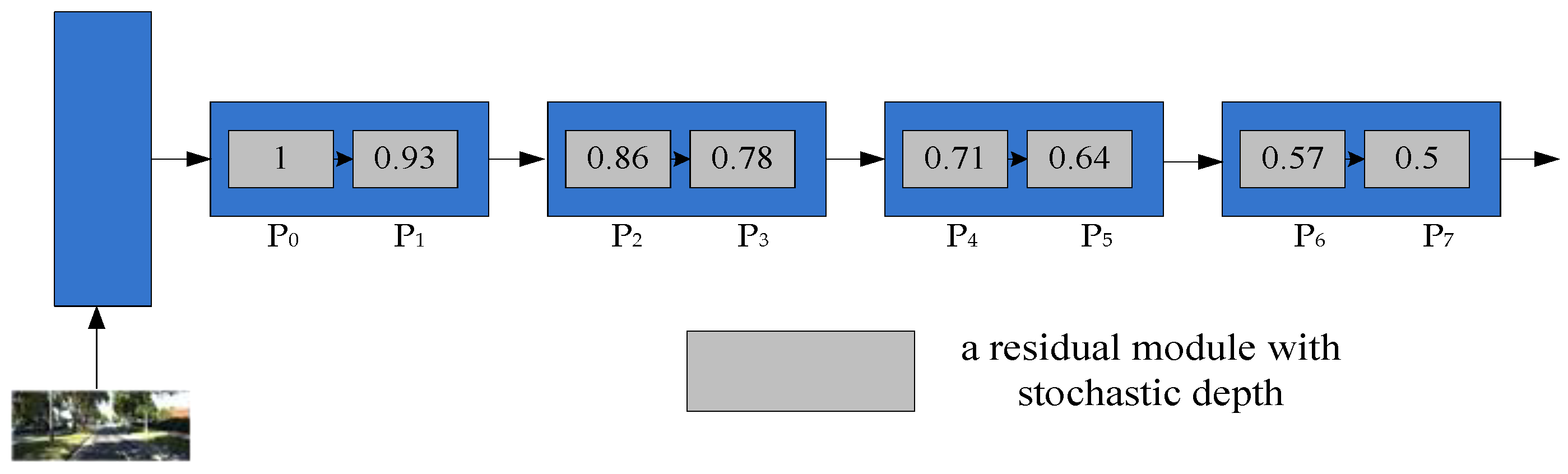
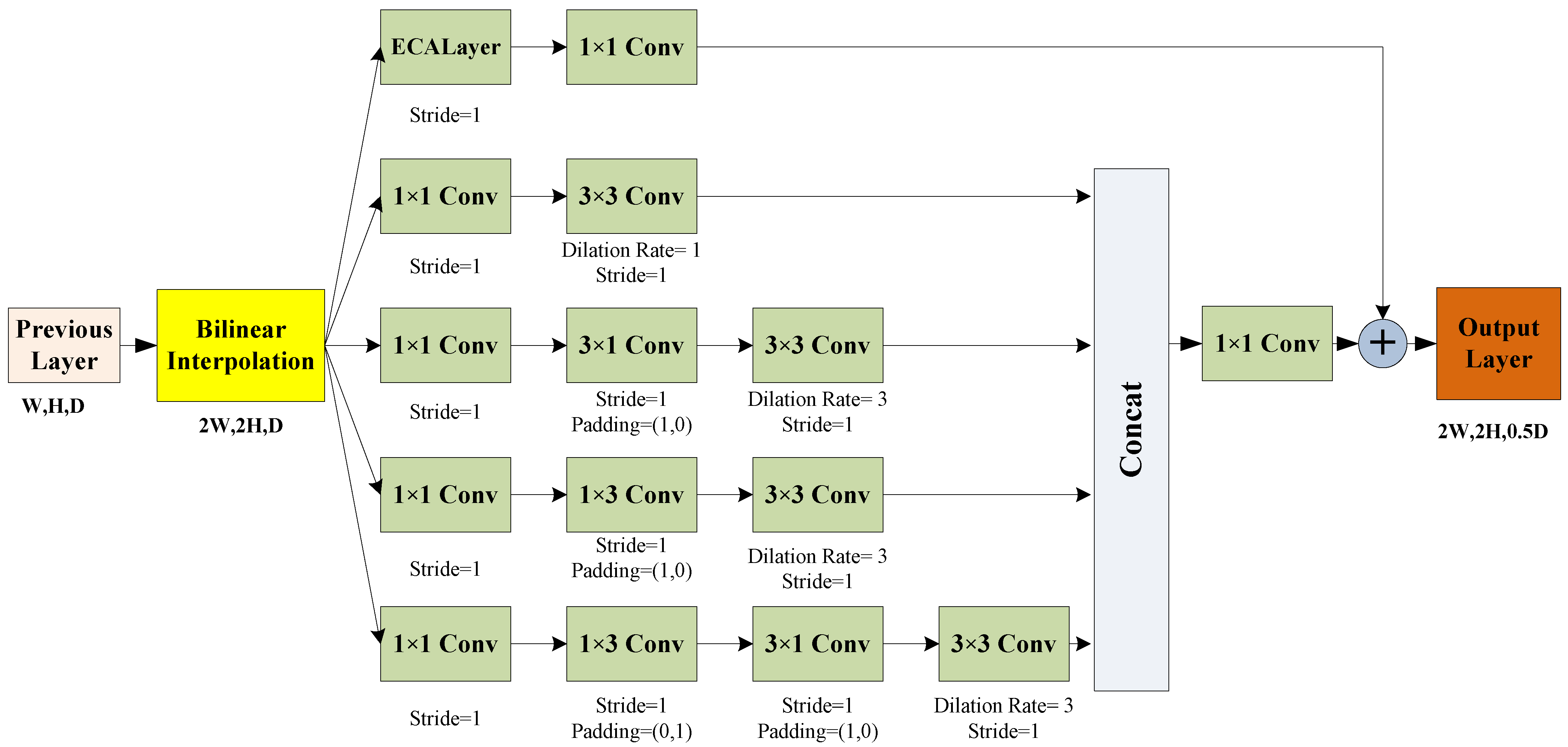
2.3.1. Depth Estimation Network
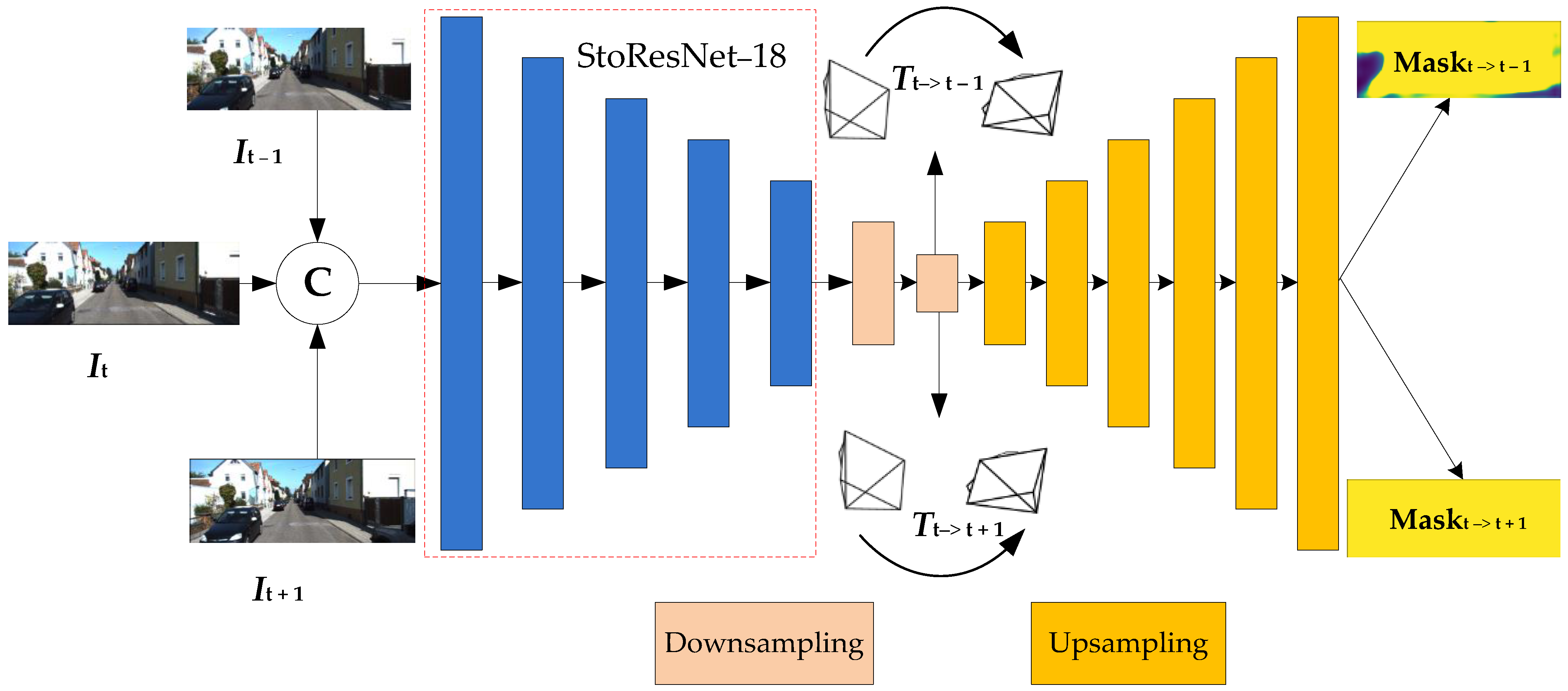
2.3.2. Pose and Mask Estimation Network
2.4. Data Preprocessing and Augmentation
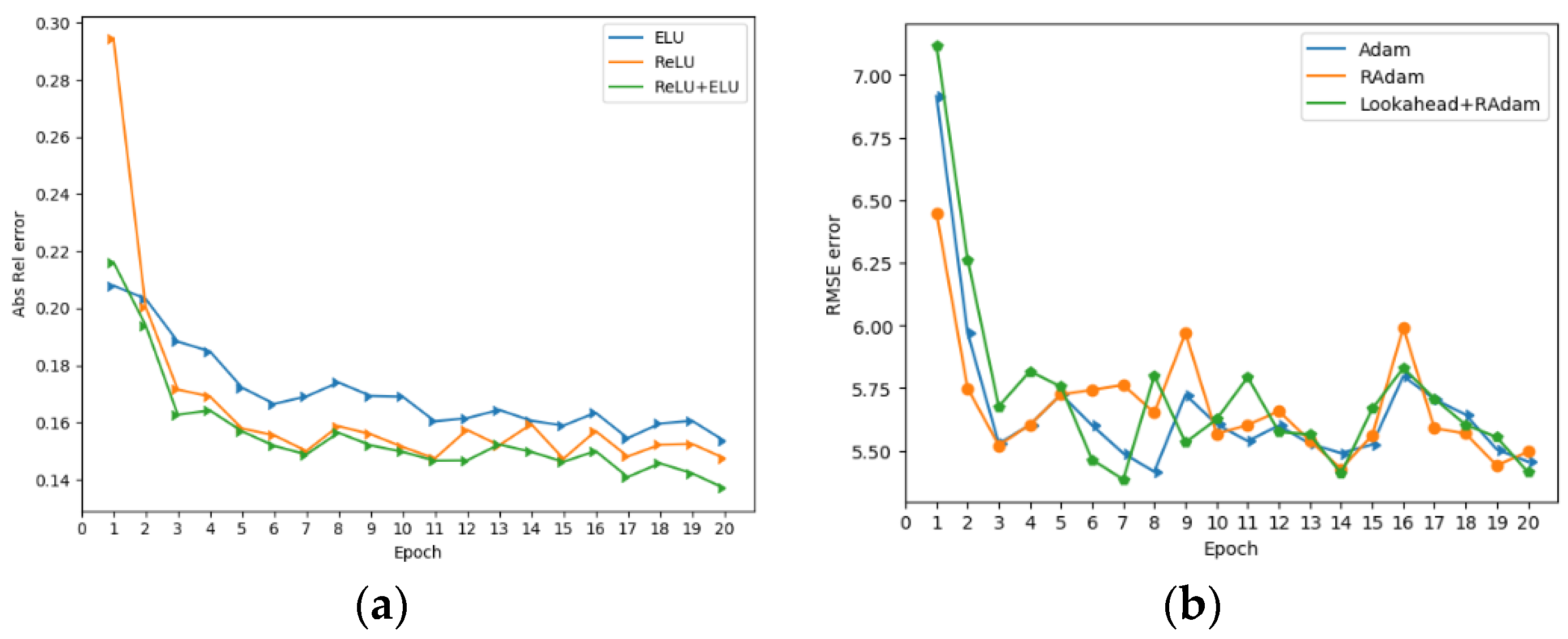
2.5. Optimizer and Activation Function
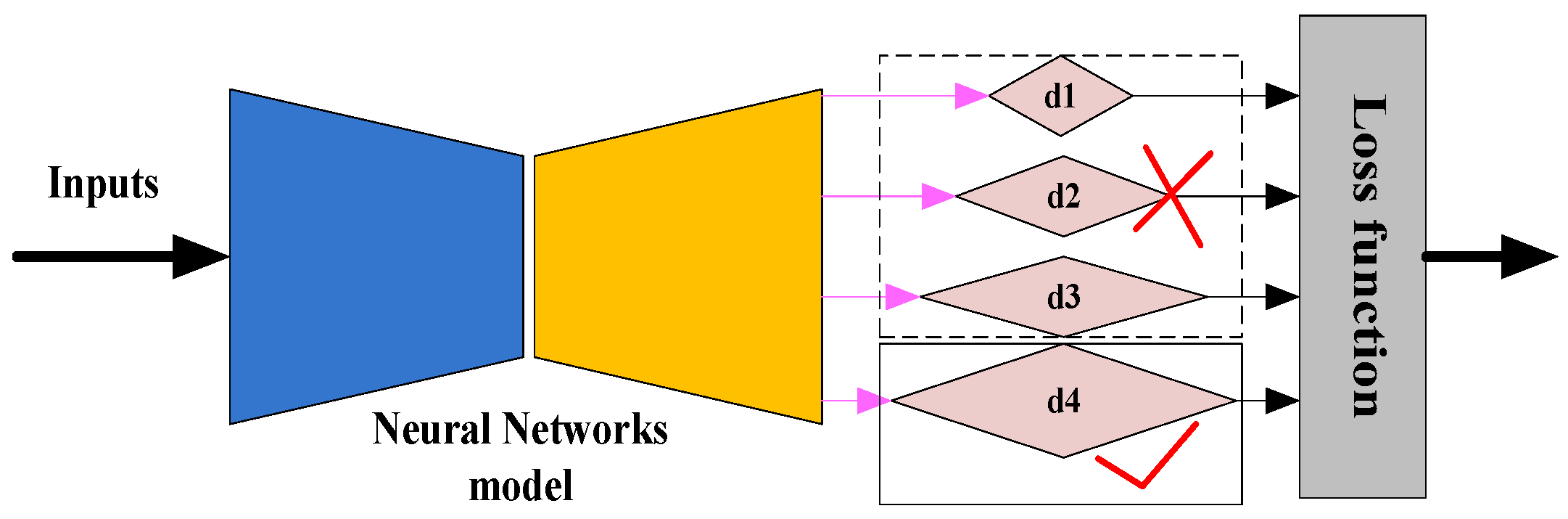
2.6. Loss Function
3. Experimental Result
3.1. Training Datasets and Details
3.2. Generalization on Make3D Dataset
3.3. Evaluation Criteria
- Mean absolute relative error (Abs Rel):
- Mean square relative error (Sq Rel):
- Root mean squared error (RMSE):
- Root mean squared error log scale (RMSElog):
- Threshold accuracy:
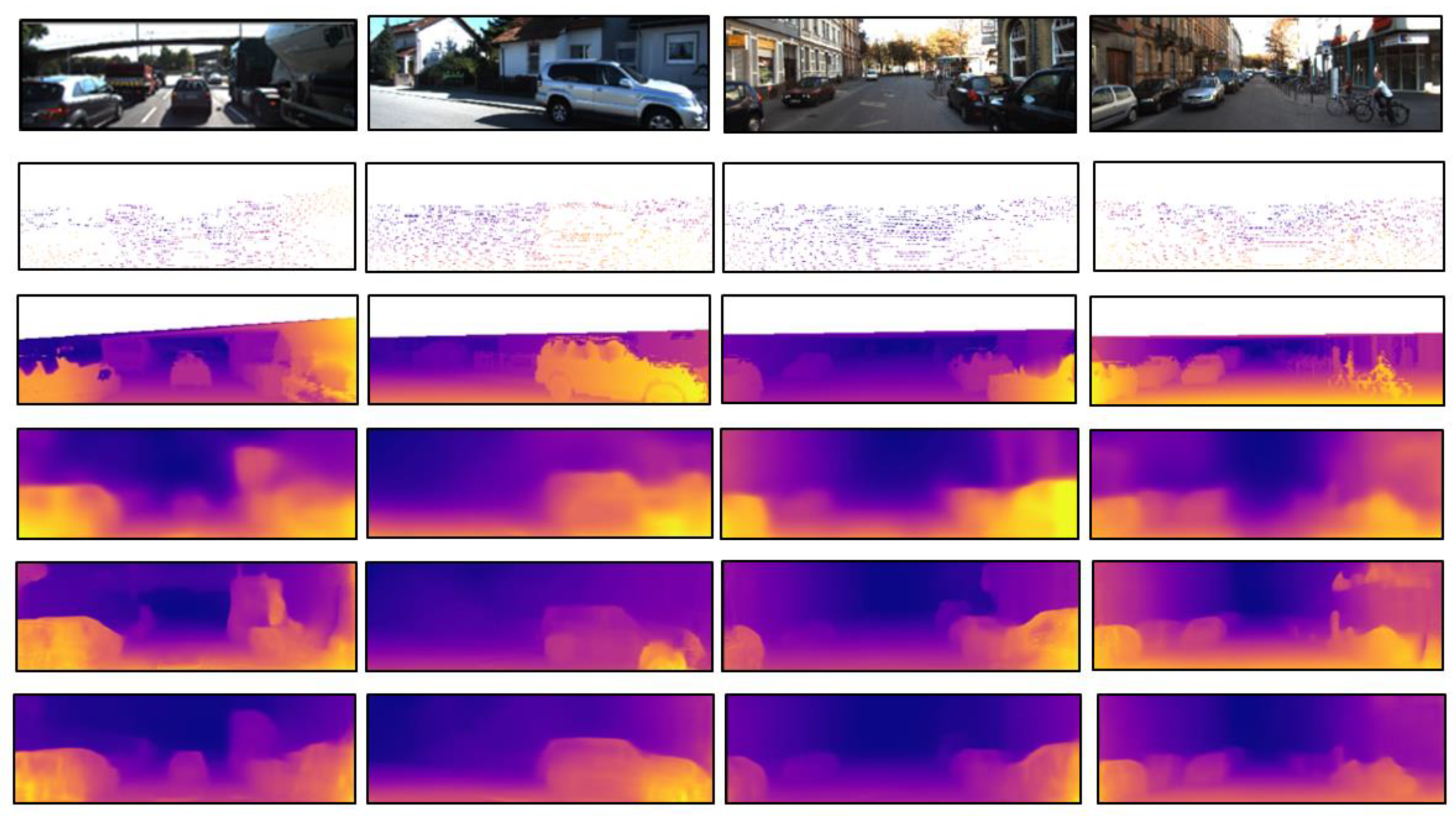
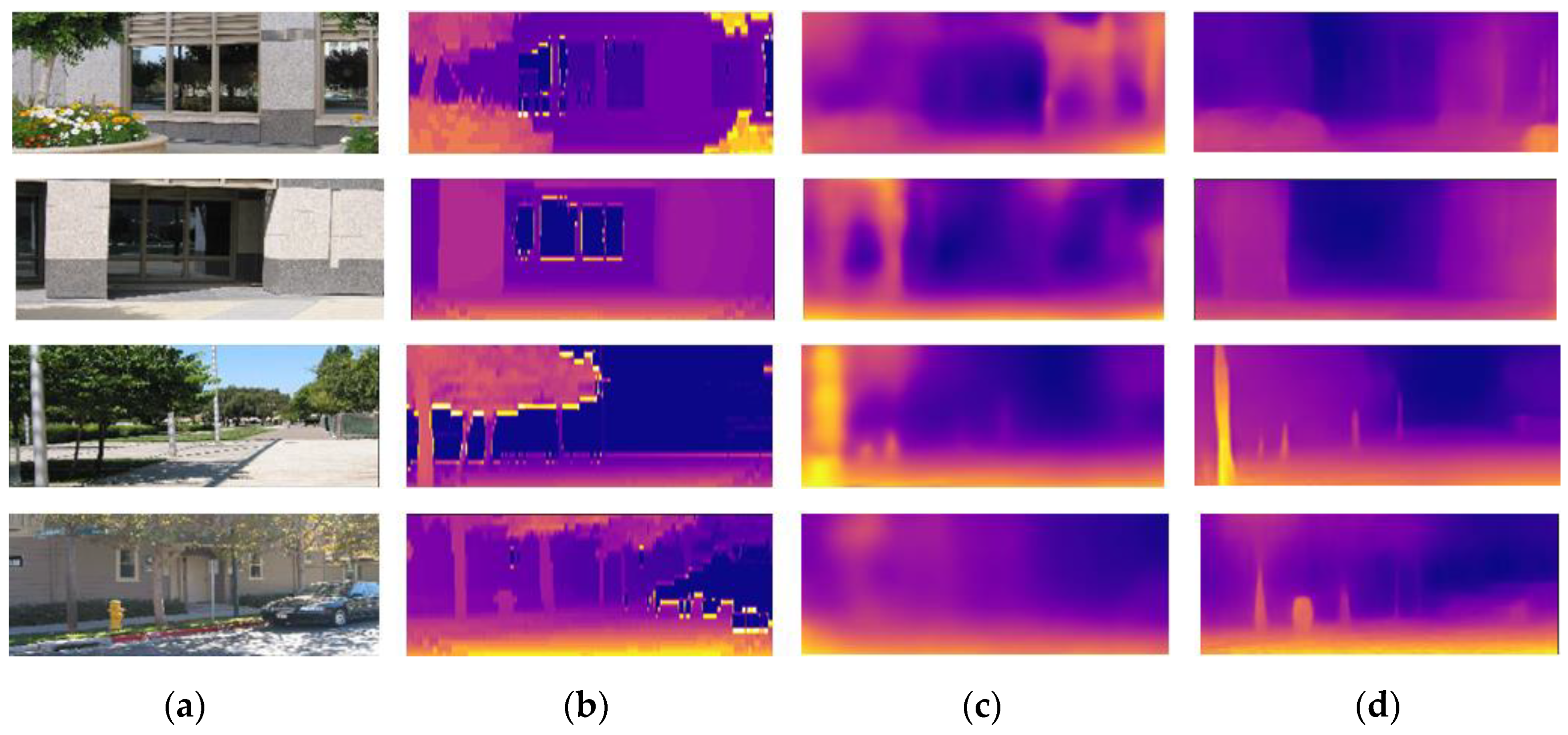
3.4. Confidence Mask Visualization
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tulsiani, S.; Gupta, S.; Fouhey, D.; Efros, A.A.; Malik, J. Factoring Shape, Pose, and Layout from the 2D image of a 3D scene. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 302–310. [Google Scholar]
- Gupta, S.; Arbelaez, P.; Girshick, R.; Malik, J. Aligning 3D models to RGB-D images of cluttered scenes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4731–4740. [Google Scholar]
- Xu, B.; Chen, Z. Multi-level Fusion Based 3D Object Detection from Monocular Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2345–2353. [Google Scholar]
- Wang, Y.; Chao, W.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-LiDAR From Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8445–8453. [Google Scholar]
- Sun, L.; Yang, K.; Hu, X.; Wang, K. Real-time Fusion Network for RGB-D Semantic Segmentation Incorporating Unexpected Obstacle Detection for Road-driving Images. IEEE Robot. Autom. Lett. 2020, 5, 5558–5565. [Google Scholar] [CrossRef]
- Hu, X.; Yang, K.; Fei, L.; Wang, K. ACNet: Attention Based Network to Exploit Complementary Features for RGBD Semantic Segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, China, 22–25 September 2019; pp. 1440–1444. [Google Scholar]
- Deng, L.Y.; Yang, M.; Li, T.Y.; He, Y.S.; Wang, C.X. RFBNet: Deep Multimodal Networks with Residual Fusion Blocks for RGB-D Semantic Segmentation. arXiv 2019, arXiv:1907.00135. [Google Scholar]
- Ma, F.C.; Karaman, S. Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 4796–4803. [Google Scholar]
- Liu, F.Y.; Shen, C.H.; Lin, G.S.; Reid, I. Learning Depth from Single Monocular Images Using Deep Convolutional Neural Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gupta, A.; Efros, A.A.; Hebert, M. Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics. In Proceedings of the European Conference on Computer Vision (ECCV), Hersonissos, Greece, 5–11 September 2010; pp. 482–496. [Google Scholar]
- Hedau, V.; Hoiem, D.; Forsyth, D. Thinking Inside the Box: Using Appearance Models and Context Based on Room Geometry. In Proceedings of the European Conference on Computer Vision (ECCV), Hersonissos, Greece, 5–11 September 2010; pp. 224–237. [Google Scholar]
- Lee, D.C.; Gupta, A.; Hebert, M.; Kanade, T. Estimating Spatial Layout of Rooms using Volumetric Reasoning about Objects and Surfaces. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 4–7 December 2010; pp. 1288–1296. [Google Scholar]
- Schwing, A.G.; Urtasun, R. Efficient Exact Inference for 3D Indoor Scene Understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 299–313. [Google Scholar]
- Liu, B.; Gould, S.; Koller, D. Single image depth estimation from predicted semantic labels. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1253–1260. [Google Scholar]
- Russell, B.C.; Torralba, A. Building a database of 3D scenes from user annotations. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 2711–2718. [Google Scholar]
- Wu, C.; Frahm, J.; Pollefeys, M. Repetition-based Dense Single-View Reconstruction. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3113–3120. [Google Scholar]
- Karsch, K.; Liu, C.; Kang, S.B. Depth Transfer: Depth Extraction from Video Using Non-parametric Sampling. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2144–2158. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Konrad, J.; Brown, G.; Wang, M.; Ishwar, P.; Mukherjee, D. Automatic 2D-to-3D image conversion using 3D examples from the internet. Proc. SPIE Int. Soc. Opt. Eng. 2012, 8288, 12. [Google Scholar]
- Konrad, J.; Wang, M.; Ishwar, P. 2D-to-3D image conversion by learning depth from examples. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 16–22. [Google Scholar]
- Liu, M.; Salzmann, M.; He, X. Discrete-Continuous Depth Estimation from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 716–723. [Google Scholar]
- Yamaguchi, K.; Mcallester, D.; Urtasun, R. Efficient Joint Segmentation, Occlusion Labeling, Stereo and Flow Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 4–13 September 2014; pp. 756–771. [Google Scholar]
- Bleyer, M.; Rhemann, C.; Rother, C. PatchMatch Stereo—Stereo Matching with Slanted Support Windows. In Proceedings of the British Machine Vision Conference (BMVC), Dundee, UK, 29 August–2 September 2011; pp. 14.1–14.11. [Google Scholar]
- Scharstein, D.; Szeliski, R.; Zabih, R. A Taxonomy and Evaluation of Dense Two-Frame Stereo Correspondence Algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Zhang, K.; Fang, Y.Q.; Min, D.B.; Sun, L.F.; Yang, S.Q.; Yan, S.C.; Tian, Q. Cross-Scale Cost Aggregation for Stereo Matching. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 965–976. [Google Scholar] [CrossRef] [Green Version]
- Yang, Q.X. A non-local cost aggregation method for stereo matching. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1402–1409. [Google Scholar]
- Heise, P.; Klose, S.; Jensen, B.; Knoll, A. PM-Huber: PatchMatch with Huber Regularization for Stereo Matching. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 2360–2367. [Google Scholar]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Modeling the world from internet photo collections. Int. J. Comput. Vis. 2008, 80, 189–210. [Google Scholar] [CrossRef] [Green Version]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-Motion Revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–14 December 2014; pp. 2366–2374. [Google Scholar]
- Xu, D.; Wang, W.; Tang, H.; Liu, H.; Sebe., N.; Ricci, E. Structured Attention Guided Convolutional Neural Fields for Monocular Depth Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3917–3925. [Google Scholar]
- Chen, X.T.; Chen, X.J.; Zha, Z.J. Structure-Aware Residual Pyramid Network for Monocular Depth Estimation. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Macao, China, 10–16 August 2019; pp. 694–700. [Google Scholar]
- Mayer, N.; Ilg, E.; Husser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Kundu, J.N.; Uppala, P.K.; Pahuja, A.; Babu, R.V. AdaDepth: Unsupervised content congruent adaptation for depth estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2656–2665. [Google Scholar]
- Chen, W.; Fu, Z.; Yang, D.; Deng, J. Single-Image Depth Perception in the Wild. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 730–738. [Google Scholar]
- Li, Z.; Snavely, N. MegaDepth: Learning Single-View Depth Prediction from Internet Photos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2041–2050. [Google Scholar]
- Li, Z.; Dekel, T.; Cole, F.; Tucker, R.; Snavely, N.; Liu, C.; Freeman, W.T. Learning the Depths of Moving People by Watching Frozen People. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4516–4525. [Google Scholar]
- Garg, R.; BGV, K.; Reid, I. Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 740–756. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6602–6611. [Google Scholar]
- Pilzer, A.; Xu, D.; Puscas, M.; Ricci, E.; Sebe, N. Unsupervised Adversarial Depth Estimation using Cycled Generative Networks. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 587–595. [Google Scholar]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D. Patchmatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. (SIGGRAPH) 2009, 28, 24. [Google Scholar] [CrossRef]
- Zhan, H.; Garg, R.; Weerasekera, C.S.; Li, K.; Agarwal, H.; Reid, I. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 340–349. [Google Scholar]
- Zhou, T.H.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6612–6619. [Google Scholar]
- Wang, C.; Buenaposada, J.M.; Zhu, R.; Lucey, S. Learning Depth from Monocular Videos using Direct Methods. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2022–2030. [Google Scholar]
- Bian, J.W.; Li, Z.; Wang, N.; Zhan, H.; Shen, C.; Cheng, M.M.; Reid, I. Unsupervised Scale-consistent Depth and Ego-motion Learning from Monocular Video. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 4724–4730. [Google Scholar]
- Yang, Z.; Wang, P.; Xu, W.; Zhao, L.; Nevatia, R. Unsupervised learning of geometry with edge-aware depth-normal consistency. arXiv 2017, arXiv:1711.03665. [Google Scholar]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5667–5675. [Google Scholar]
- Zou, Y.; Luo, Z.; Huang, J. DF-Net: Unsupervised joint learning of depth and flow using cross-task consistency. In Proceedings of the European Conference on Computer Vision(ECCV), Munich, Germany, 8–14 September 2018; pp. 38–55. [Google Scholar]
- Shen, T.; Luo, Z.; Lei, Z.; Deng, H.; Long, Q. Beyond Photometric Loss for Self-Supervised Ego-Motion Estimation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6359–6365. [Google Scholar]
- Casser, V.; Pirk, S.; Mahjourian, R.; Angelova, A. Unsupervised monocular depth and egomotion learning with structure and semantics. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 381–388. [Google Scholar]
- Klodt, M.; Vedaldi, A. Supervising the new with the old: Learning SFM from SFM. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 713–728. [Google Scholar]
- Yin, Z.; Shi, J. GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar]
- Ranjan, A.; Jampani, V.; Balles, L.; Kim, K.; Sun, D.; Wulff, J.; Black, M.J. Competitive Collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12232–12241. [Google Scholar]
- Liu, L.Y.; Jiang, H.M.; He, P.C.; Chen, W.Z.; Liu, X.D.; Gao, J.F.; Han, J.W. On the variance of the adaptive learning rate and beyond. arxiv 2019, arXiv:1908.03265. [Google Scholar]
- Zhang, M.R.; Lucas, J.; Hinton, G.; Ba, J. Lookahead Optimizer: K steps forward, 1 step back. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Cananda, 8–14 December 2019; pp. 9593–9604. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? In the kitti vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Chen, S.N.; Tang, M.X.; Kan, J.M. Monocular Image Depth Prediction without Depth Sensors: An Unsupervised Learning Method. Appl. Soft Comput. 2020, 97, 106804. [Google Scholar] [CrossRef]
- Gao, H.; Yu, S.; Zhuang, L.; Sedra, D.; Weinberger, K. Deep Networks with Stochastic Depth; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 646–661. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Djork-Arné, C.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arxiv 2015, arXiv:1511.07289. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units improve Restricted Boltzmann Machines vinod Nair. In Proceedings of the International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Chintala, S. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Jia, D.; Wei, D.; Socher, R.; Li, L.J.; Kai, L.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale | Cap | Lower Is Better | Higher Is Better | |||||
|---|---|---|---|---|---|---|---|---|
| Abs Rel | Sq Rel | RMSE | RMSElog | α1 | α2 | α3 | ||
| Multiscale | 0–80 m | 0.154 | 1.196 | 5.637 | 0.233 | 0.796 | 0.929 | 0.971 |
| Largest scale (ours) | 0–80 m | 0.137 | 1.018 | 5.355 | 0.216 | 0.814 | 0.943 | 0.978 |
| Method | Cap | Dataset | Lower Is Better | Higher Is Better | |||||
|---|---|---|---|---|---|---|---|---|---|
| Abs Rel | Sq Rel | RMSE | RMSElog | α1 | α2 | α3 | |||
| Eigen [30] | 0–80 m | K(D) | 0.203 | 1.548 | 6.307 | 0.282 | 0.702 | 0.890 | 0.958 |
| Liu [9] | 0–80 m | K(D) | 0.202 | 1.614 | 6.523 | 0.275 | 0.678 | 0.895 | 0.965 |
| AdaDepth [34] | 0–80 m | K(D*) | 0.167 | 1.257 | 5.578 | 0.237 | 0.771 | 0.922 | 0.971 |
| Godard [39] | 0–80 m | K(S) | 0.148 | 1.344 | 5.927 | 0.257 | 0.803 | 0.922 | 0.964 |
| Garg [38] | 0–80 m | K(S) | 0.152 | 1.226 | 5.849 | 0.246 | 0.784 | 0.921 | 0.967 |
| Zhan [42] | 0–80 m | K(S) | 0.144 | 1.391 | 5.869 | 0.241 | 0.803 | 0.928 | 0.969 |
| Zhou [43] | 0–80 m | K(M) | 0.208 | 1.768 | 6.856 | 0.283 | 0.678 | 0.885 | 0.957 |
| Klodt [51] | 0–80 m | K(M) | 0.166 | 1.490 | 5.998 | - | 0.778 | 0.919 | 0.966 |
| Yang [46] | 0–80 m | K(M) | 0.182 | 1.481 | 6.501 | 0.267 | 0.725 | 0.906 | 0.963 |
| Mahjourian [47] | 0–80 m | K(M) | 0.163 | 1.240 | 6.220 | 0.250 | 0.762 | 0.916 | 0.968 |
| Wang [44] | 0–80 m | K(M) | 0.151 | 1.257 | 5.583 | 0.228 | 0.810 | 0.936 | 0.974 |
| GeoNet [52] | 0–80 m | K(M) | 0.155 | 1.296 | 5.857 | 0.233 | 0.793 | 0.931 | 0.973 |
| Bian [45] | 0–80 m | K(M) | 0.149 | 1.137 | 5.771 | 0.230 | 0.799 | 0.932 | 0.973 |
| Zou [48] | 0–80 m | K(M) | 0.150 | 1.124 | 5.507 | 0.223 | 0.806 | 0.933 | 0.973 |
| Shen [49] | 0–80 m | K(M) | 0.156 | 1.309 | 5.73 | 0.236 | 0.797 | 0.929 | 0.969 |
| Ours | 0–80 m | K(M) | 0.137 | 1.018 | 5.355 | 0.216 | 0.814 | 0.943 | 0.978 |
| Garg [38] | 0–50 m | K(S) | 0.169 | 1.080 | 5.104 | 0.273 | 0.740 | 0.904 | 0.962 |
| Godard [39] | 0–50 m | K(S) | 0.140 | 0.976 | 4.471 | 0.232 | 0.818 | 0.931 | 0.969 |
| Zhan [42] | 0–50 m | K(S) | 0.135 | 0.905 | 4.366 | 0.225 | 0.818 | 0.937 | 0.973 |
| Zhou [43] | 0–50 m | K(M) | 0.201 | 1.391 | 5.181 | 0.264 | 0.696 | 0.900 | 0.966 |
| Mahjourian [47] | 0–50 m | K(M) | 0.155 | 0.927 | 4.549 | 0.231 | 0.781 | 0.931 | 0.975 |
| GeoNet [52] | 0–50 m | K(M) | 0.147 | 0.936 | 4.348 | 0.218 | 0.810 | 0.941 | 0.977 |
| Zou [48] | 0–50 m | K(M) | 0.149 | 1.010 | 4.360 | 0.222 | 0.812 | 0.937 | 0.973 |
| Ours | 0–50 m | K(M) | 0.132 | 0.801 | 4.076 | 0.204 | 0.837 | 0.951 | 0.981 |
| Method | Dataset | Abs Rel |
|---|---|---|
| Karsch [17] | Ma(D) | 0.428 |
| Liu [20] | Ma(D) | 0.475 |
| AdaDepth [34] | K(D*) | 0.452 |
| AdaDepth [34] | K(M) | 0.647 |
| Godard [39] | K*(M) | 0.544 |
| Wang [44] | K(M) | 0.387 |
| Zhou [43] | K*(M) | 0.383 |
| Zou [48] | K*(M) | 0.331 |
| Ours | K(M) | 0.323 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Han, J.; Tang, M.; Dong, R.; Kan, J. Encoder-Decoder Structure with Multiscale Receptive Field Block for Unsupervised Depth Estimation from Monocular Video. Remote Sens. 2022, 14, 2906. https://doi.org/10.3390/rs14122906
Chen S, Han J, Tang M, Dong R, Kan J. Encoder-Decoder Structure with Multiscale Receptive Field Block for Unsupervised Depth Estimation from Monocular Video. Remote Sensing. 2022; 14(12):2906. https://doi.org/10.3390/rs14122906
Chicago/Turabian StyleChen, Songnan, Junyu Han, Mengxia Tang, Ruifang Dong, and Jiangming Kan. 2022. "Encoder-Decoder Structure with Multiscale Receptive Field Block for Unsupervised Depth Estimation from Monocular Video" Remote Sensing 14, no. 12: 2906. https://doi.org/10.3390/rs14122906
APA StyleChen, S., Han, J., Tang, M., Dong, R., & Kan, J. (2022). Encoder-Decoder Structure with Multiscale Receptive Field Block for Unsupervised Depth Estimation from Monocular Video. Remote Sensing, 14(12), 2906. https://doi.org/10.3390/rs14122906