1. Introduction
As one of the most critical types of natural hazards, landslides are triggered by various external factors in most cases, including earthquakes, rainfall, variation of water level storms, and river erosion [
1]. Once landslides develop into geological hazards, there is a great potential to cause devastating damage to natural structures and infrastructure, leading to human casualties and property damage [
2]. A detailed landslide inventory records the location, date, and type of landslide in a given area, which can serve as a basis for further investigation and provide geologists with scientific data used to assess landslide risk [
3,
4]. Additionally, studies have shown that the legacy effect may lead to a higher chance of landslides occurring on previous landslide paths in the next decade. Therefore, generating landslide inventory is the first step in hazards management and susceptibility evaluation [
5,
6]. The development of advanced earth observation techniques provides unique opportunities for the comprehensive assessment of disaster losses [
7], thus massive amounts of satellite images are gradually replacing field surveys as a low-cost resource for building a landslide database. As a consequence, how to detect landslides rapidly in large-scale remote sensing datasets is of great significance for disaster mitigation [
8,
9,
10].
The main landslide detection methods based on remote sensing include (1) Pixel-based, (2) Object-oriented, (3) Machine Learning, and (4) Deep Learning. Among them, the adjacent pixels are not taken into account in the pixel-based method which mainly extracts landslides by comparing the images’ intensity or the band difference between two-phase images. For example, Nichol and Wong [
11] attempted to extract landslide data using single-band difference, band ratio, and post-classification comparison. Zhao et al. [
12] selected the normalized difference vegetation index (NDVI), enhanced vegetation index, and soil-adjusted vegetation index as features to classify the landslides. Mondini et al. [
13] detected the rainfall-induced landslides by adopting four change detection. However, the pixel-based method has rigorous requirements for image acquisition and processing. Besides, the improved resolution and differences in the distribution of landslides may introduce pepper noise [
3]. The object-oriented approach is a knowledge-driven approach (OOA), in compliance with the assumption that pixels with neighbors belong to the same class and treat landslides as collections of pixels [
14]. For example, Lu et al. [
15] used temporal principal component analysis, spectral angle mapper, Reed-Xiaoli detection, and textural analysis to derive object features as segmentation metrics and performed multilevel segmentation through a multiscale optimization approach. Rau et al. [
16] adopted a multilevel segmentation and hierarchical semantic network for landslide detection. Eeckhaut et al. [
17] only used derivatives of LiDAR for landslide detection in high vegetation cover areas. Although OOA takes the shape and texture properties of landslides into consideration to refine the result, the parameters, such as segmentation scale and features, are subjectively optimized by the user, resulting in a time-consuming process and low automation [
18,
19].
Machine learning [ML] has excellent potential in classification and capacity to handle data of high dimensionality and to map classes with very complex characteristics. Commonly used methods include support vector machines (SVM), decision trees (DTs), random forest (RF), and artificial neural networks (ANN) [
20]. Among them, [
21,
22] have demonstrated that RF exhibited stable portability on new data compared to SVM and ANN. Piralilou et al. [
23] proposed a landslide detection method connecting the result of OOA with logistic regression, multilayer perceptron, and RF by the Dempster-Shafer theory. Although machine learning is widely applied in the field of remote sensing, high-dimension data may overfit models or introduce noise, causing performance deterioration. Hence, uncertainties analysis in ML-based models is an indispensable part to select important variables, evaluate the sensibility of the input data and the generalization of the new samples [
24,
25]. For example, Adnan et al. [
26] and Rossi et al. [
27] combined the landslide susceptibility maps generated by models to address the uncertainty from the single model.
As a hot field in computer vision, deep learning (DL) has shown outstanding performance in image classification and segmentation [
28,
29,
30]. In terms of landslide susceptibility mapping (LSM), Dao et al. [
31] probed into the performance of the DL model which significantly improved the ability to predict future landslides compared to three ML models. Similarly, by introducing nine controlling factors related to landslides, Bui et al. [
32] investigated the capability of the DL model in LSM compared to SVM, C4.5 and RF, and the results indicated that the DL model had a more stable classification performance. On the other hand, CNN equipped with VGGNet, ResNet, and DenseNet has been widely applied in landslide detection. For example, Cai et al. [
33] and Liu et al. [
34] incorporated controlling factors into samples to test the feasibility of Dense-Net in landslide extraction, while Nava et al. [
35] explored the performance of the network when topographic factors were fused into SAR images. Furthermore, Ghorbanzadeh et al. [
36] attempted to fuse landslide detection results generated from CNN trained with different datasets through the Dempster-Shafer model. Regarding ResU-Net, Prakash et al. [
37] first explored the potential of U-Net with ResNet34 in landslide mapping, demonstrating the utility of deep learning based on EO data for regional landslide mapping. Furthermore, Qi et al. [
38] proved that the U-Net with ResNet50 can improve the performance of the model on rainfall-induced landslide detection. Ghorbanzadeh et al. [
39] firstly used the free Sentinel-2 data in landslide identification by evaluating the performance of U-Net and ResU-Net in three different landslide areas, the result indicated that ResU-Net obtained the highest F1-score. To alleviate the lack of generalization of the model caused by various landslide morphologies, Yi et al. [
18] introduced an attention mechanism to assign weights for important feature maps in ResU-Net, the F1-score on the proposed model was improved by 7% compared to ResU-Net. Recently, Ghorbanzadeh et al. [
40] designed a novel approach for landslide extraction. By integrating an OBIA-based model and ResU-Net, the proposed model addressed the fuzzy landslide boundaries problem by enhancing and refining the results generated by ResU-Net and possessed higher precision, recall, and F1-score. Besides, Ghorbanzadeh et al. [
41] created a public landslide dataset for the landslide detection community, denoted as Landslide4Sense, which contains 3799 images fusing optical bands from Sentinel-2 with DEM and slope. Overall, CNN possesses robustness and scalability, and features are automatically extracted through hierarchical structure and convolution, avoiding the involvement of excessive domain knowledge [
42]. However, studies have shown that the actual receptive field in CNN is much smaller than the theoretical size, which is not conducive to making full use of global information [
43].
The proposal of a transformer provides an efficient parallel network to natural language processing (NLP) [
44,
45], and its architecture dominated by multi-head self-attention (MSA) abandons recursion and convolution. Different from CNN that expands the receptive field by stacking convolutions, MSA captures global contextual information at the beginning of feature extraction and establishes long-range dependencies on the target [
46,
47]. It has been confirmed that the inherent inductive biases, such as transition equivalence and locality, are excluded in the transformer. Among them, the former well respects the nature of the imaging process while the latter controls the model complexity by sharing parameters across space [
48]. Nevertheless, the transformer still outperforms CNN when pretraining to a transformer with a large dataset [
49,
50].
The outstanding performance of the vision transformer (ViT) on classification confirmed that a transformer can be directly used in computer vision. For example, Bazi et al. [
51] verified that ViT achieved high classification accuracy on four datasets. Reedha et al. [
52] introduced ViT into vegetation classification with a small dataset, achieving higher F1-score compared to EfficienNet and ResNet. Recently, research by Park and Kim [
53] showed that MSA will flatten the loss value, guiding the model to converge along a smooth trajectory. In addition, MSA is equivalent to a low-pass filter for aggregating feature maps, while convolution is similar to a high-pass filter, making feature maps more diverse, such phenomenon demonstrated that MSA and convolution complement each other when capturing features. As a consequence, numerous studies aiming to combine the CNN and transformer have appeared, for instance, Deng et al. [
54] proposed CTNet, which introduced the ViT to explore global semantic features and employed CNN to compensate for the loss of local structural information. Zheng et al. [
45] designed a segmentation network called SETR to model the global context of images based on the pure transformer. The proposed model could obtain excellent results only by combining with a simple decoder. Horry et al. [
55] introduced a highly scalable and accurate ViT model into a low-parameter CNN for land use classification, aiming to cope with the growing amount of satellite data. Similarly, Xu et al. [
56] proposed an end-to-end network, called ET-GSNet, to improve the generalization of the different tasks by knowledge distillation. Besides, transformer and convolution-based SAR image despeckling networks were proposed by Perera et al. [
57] that also possessed superior performance compared to the pure CNN.
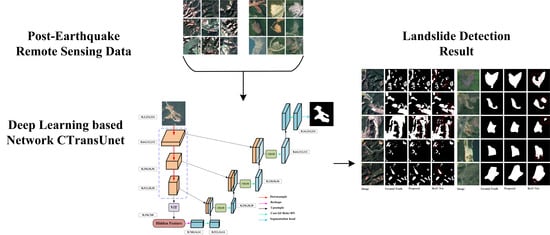
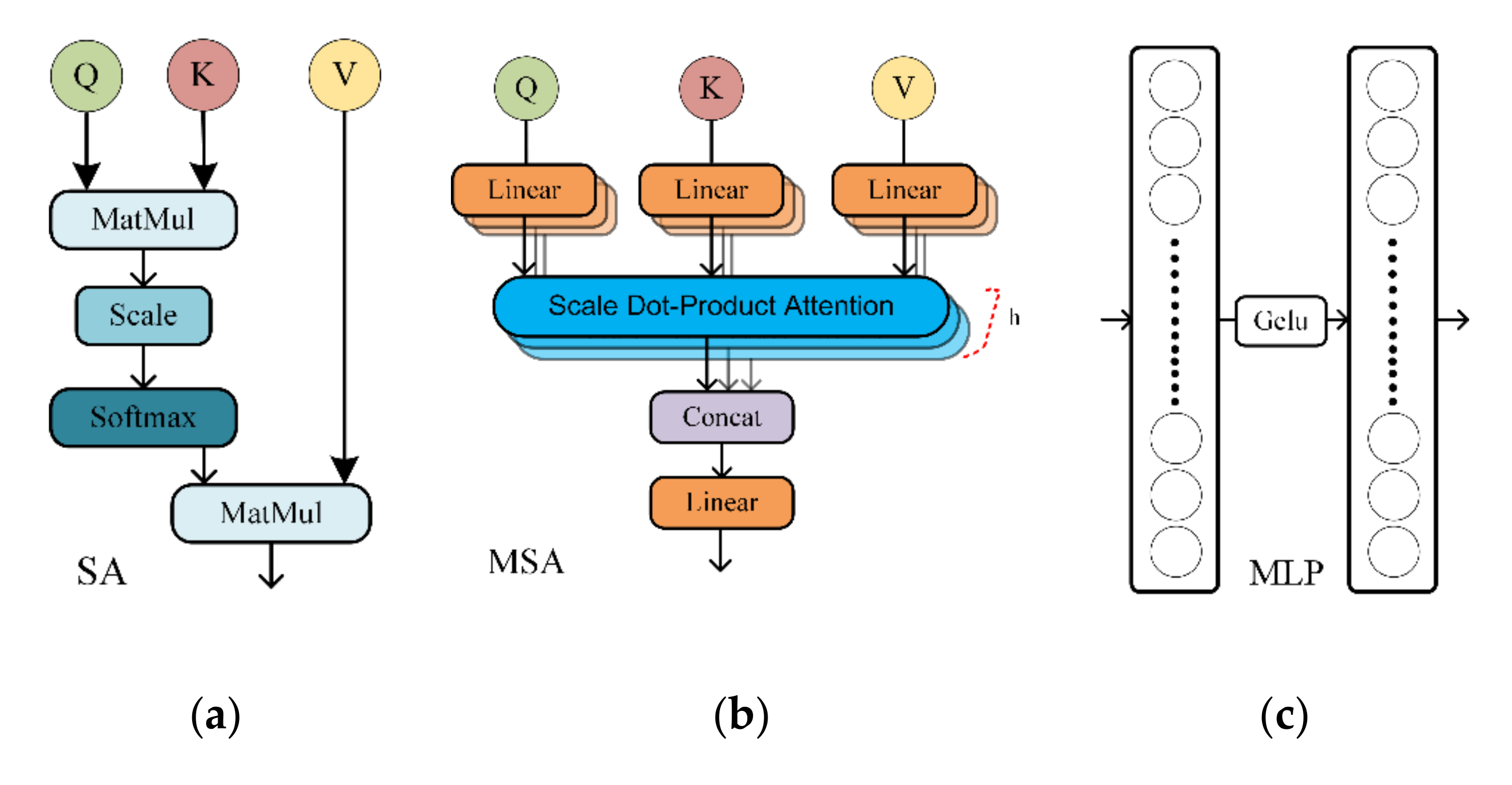
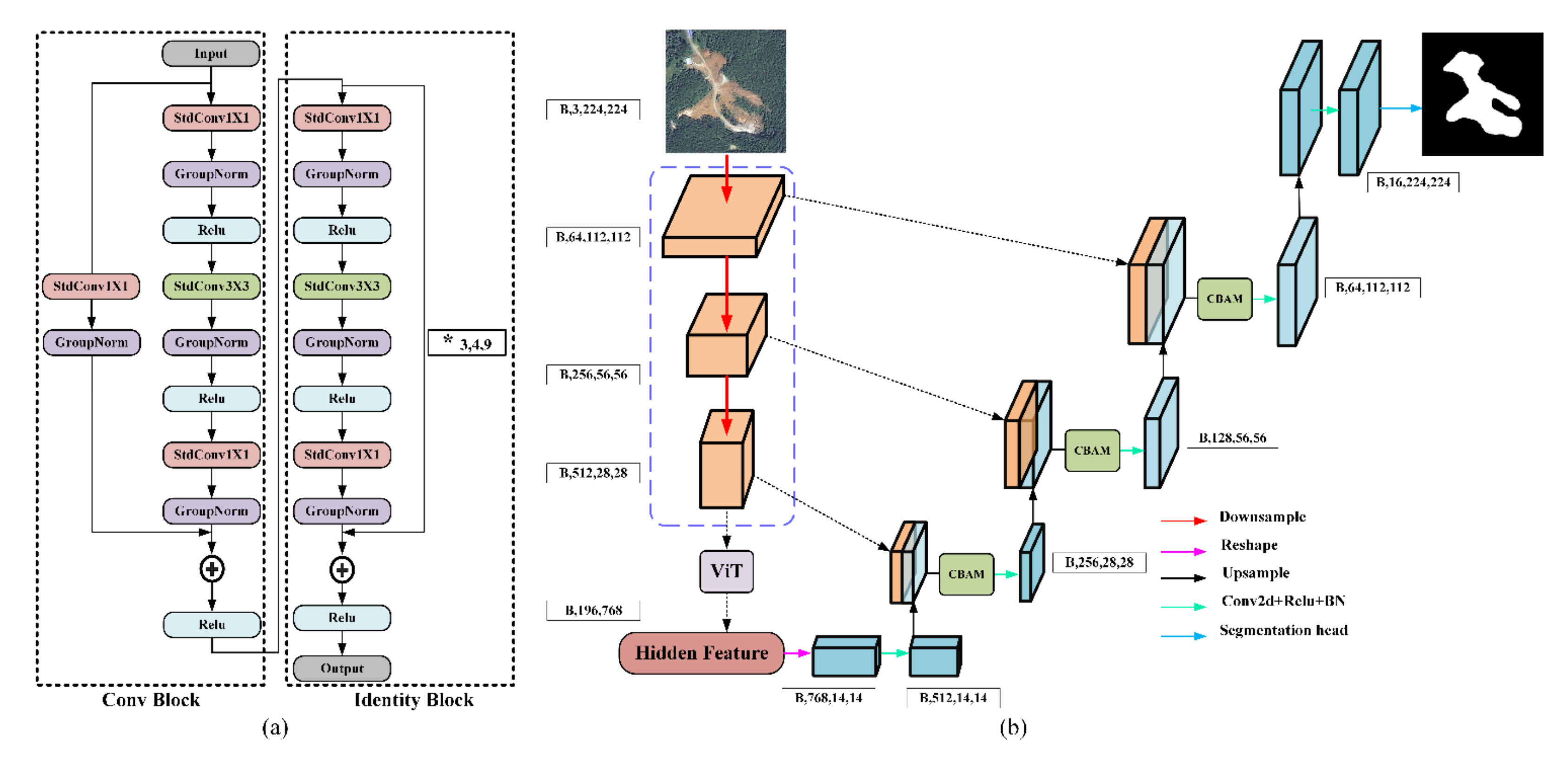
Given the strength of transformer in global context modeling, and that, as far as we know, there has been no research evaluating its potential in landslide detection. In this study, a segmentation network incorporating a transformer in ResU-Net proposed by Chen et al. [
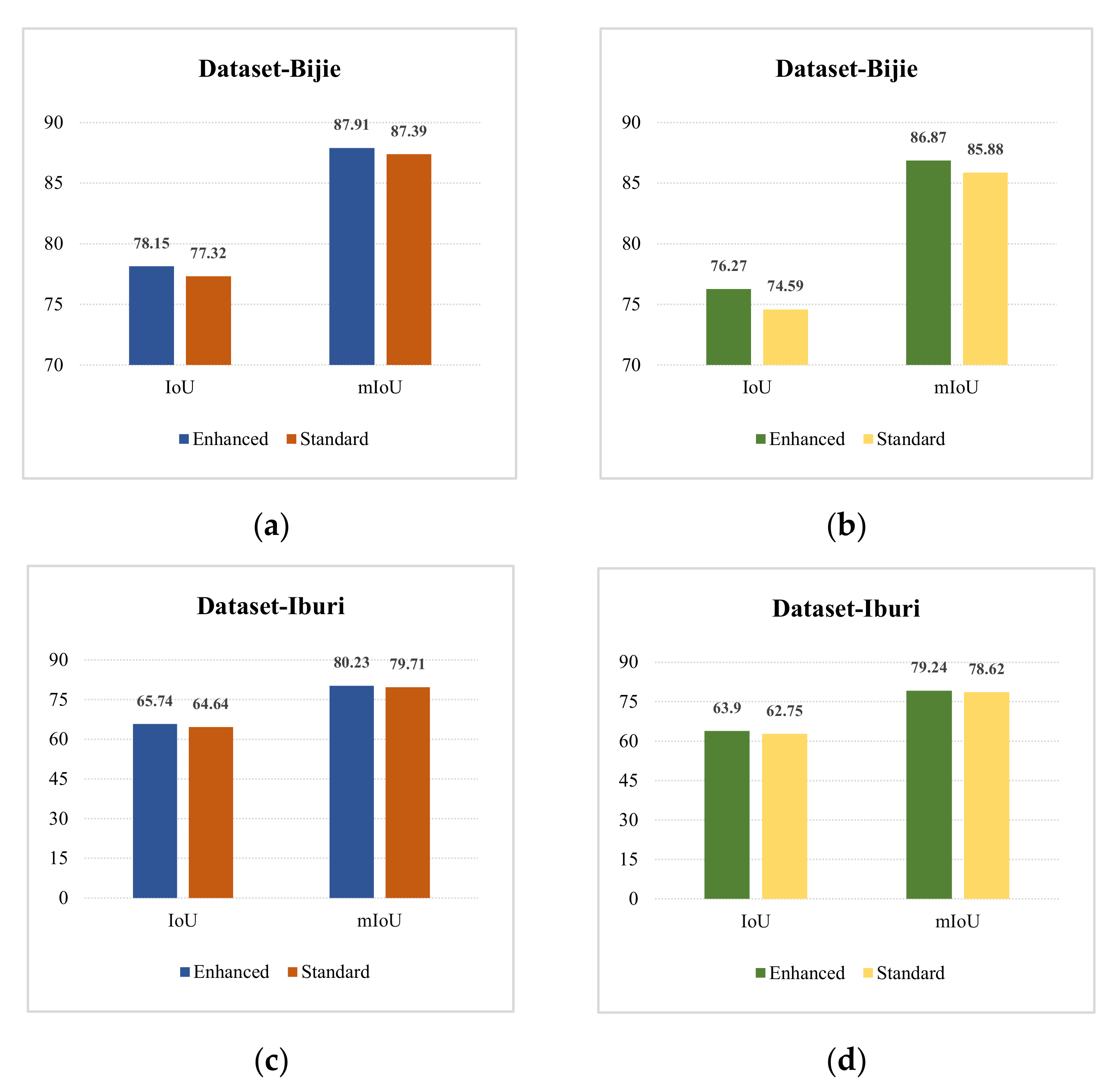
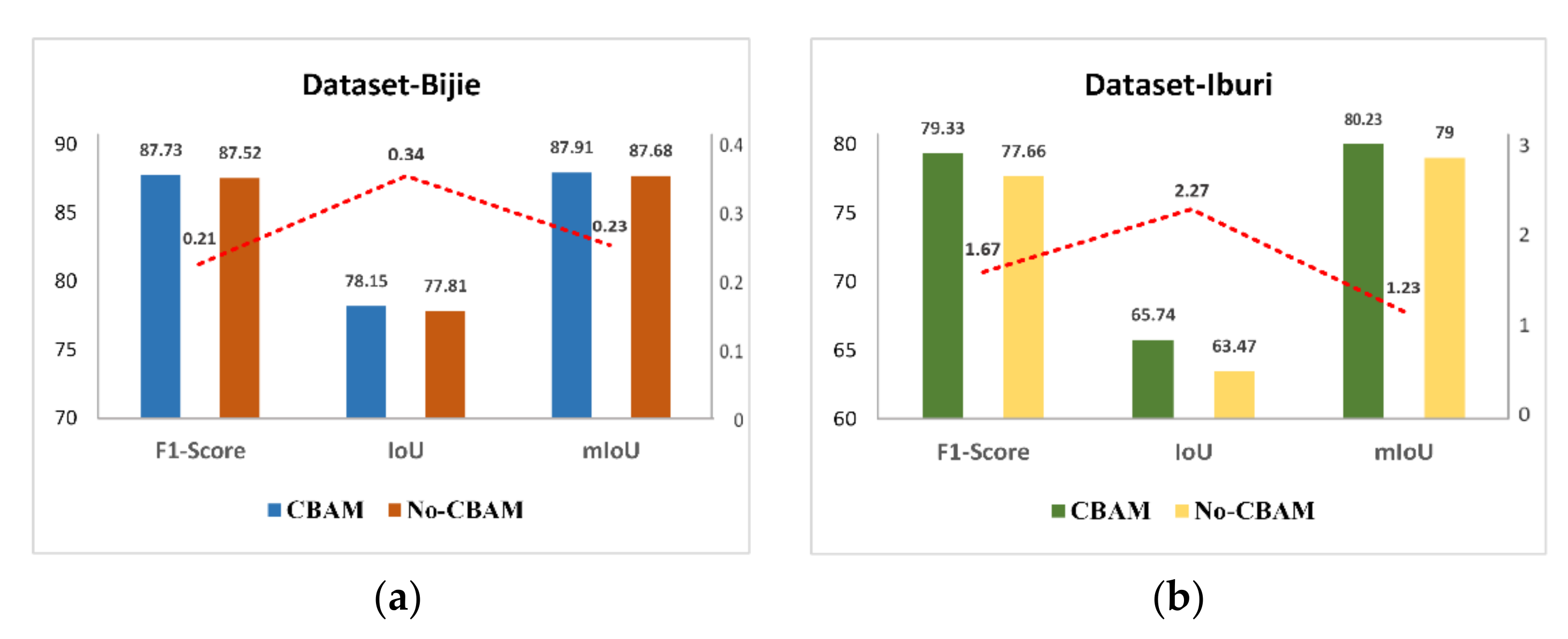
58] was selected to validate its effectiveness in landslide detection with small datasets, and the pre-trained weight on Imagenet21K was introduced to accelerate model convergence. To better fuse the feature maps from transformer and CNN, a spatial and channel attention module was embedded into the decoder. Finally, two landslide datasets with different characteristics were chosen to confirm the potential of the proposed model thoroughly.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}