
Fine-Grained Urban Air Quality Mapping from Sparse Mobile Air Pollution Measurements and Dense Traffic Density

 ,
,  , and
, and
Abstract
:1. Introduction
- We develop a general approach to integrate various contextual features and aggregate sparse mobile air quality measurements into our air quality inference model for fine-grained urban air quality mapping.
- We utilize three different types of contextual features, including meteorology, road network and traffic flow to characterize the spatiotemporal distribution of NO2.
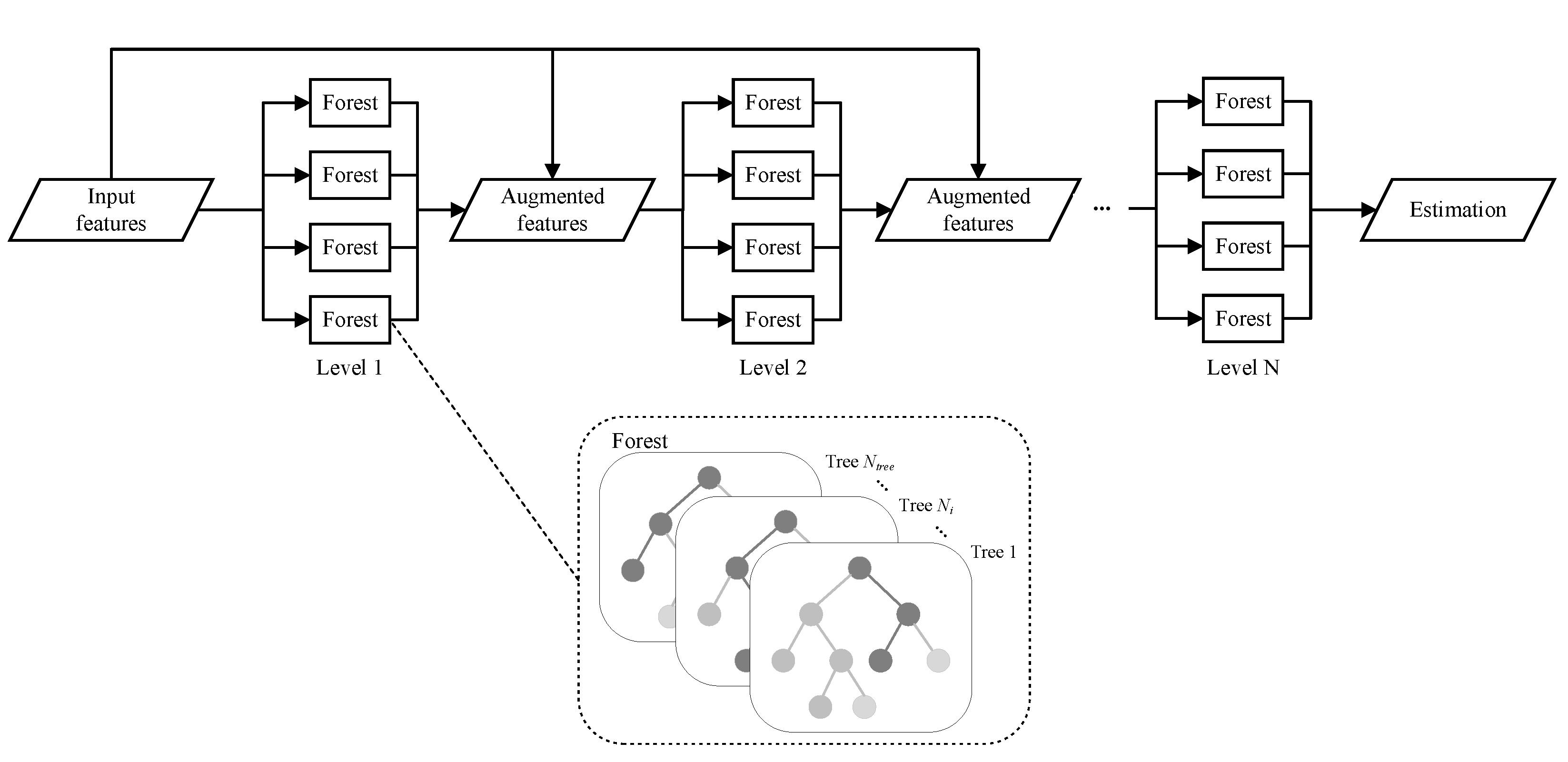
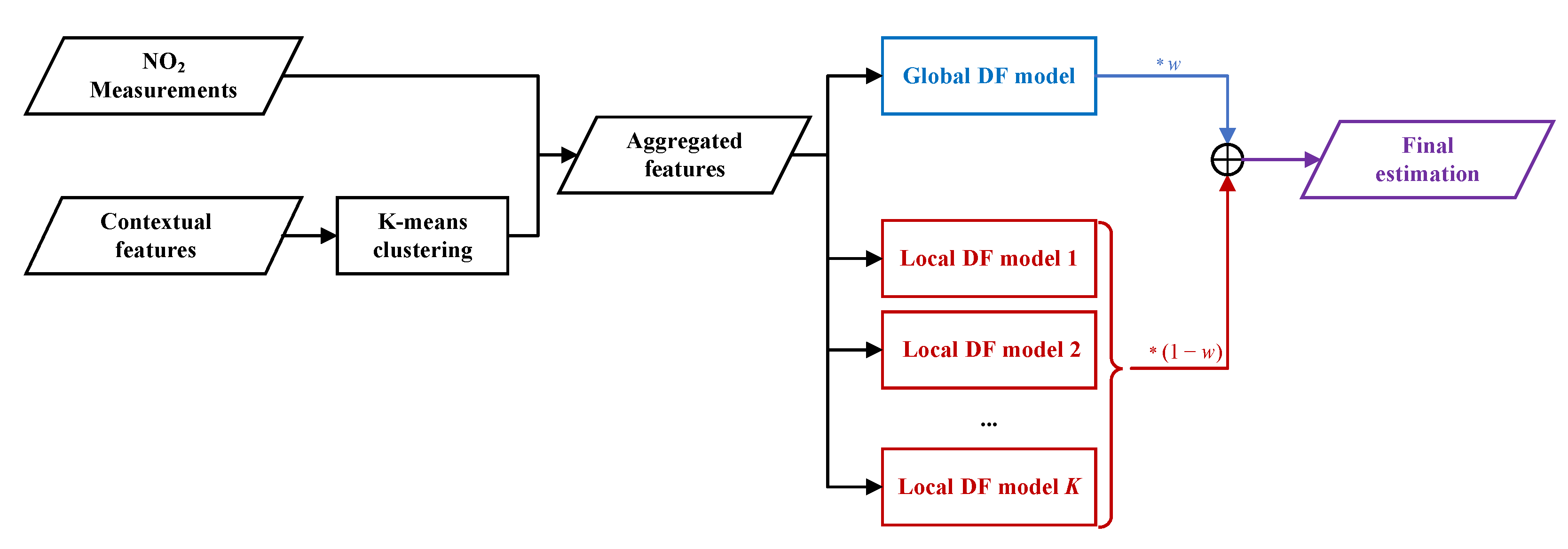
- We propose a novel air quality inference model called CLADF, which introduces deep forests to build context-aware local models, to generate a fine-grained air quality map.
- We demonstrate through evaluation experiments on a real-world data set that the CLADF model has superior performance in comparison with different baseline models, including RF, DF, XGBoost and SVR.
2. Materials and Methods
2.1. Data Collection
2.2. Data Processing
2.3. Methodology
2.3.1. Contextual Features
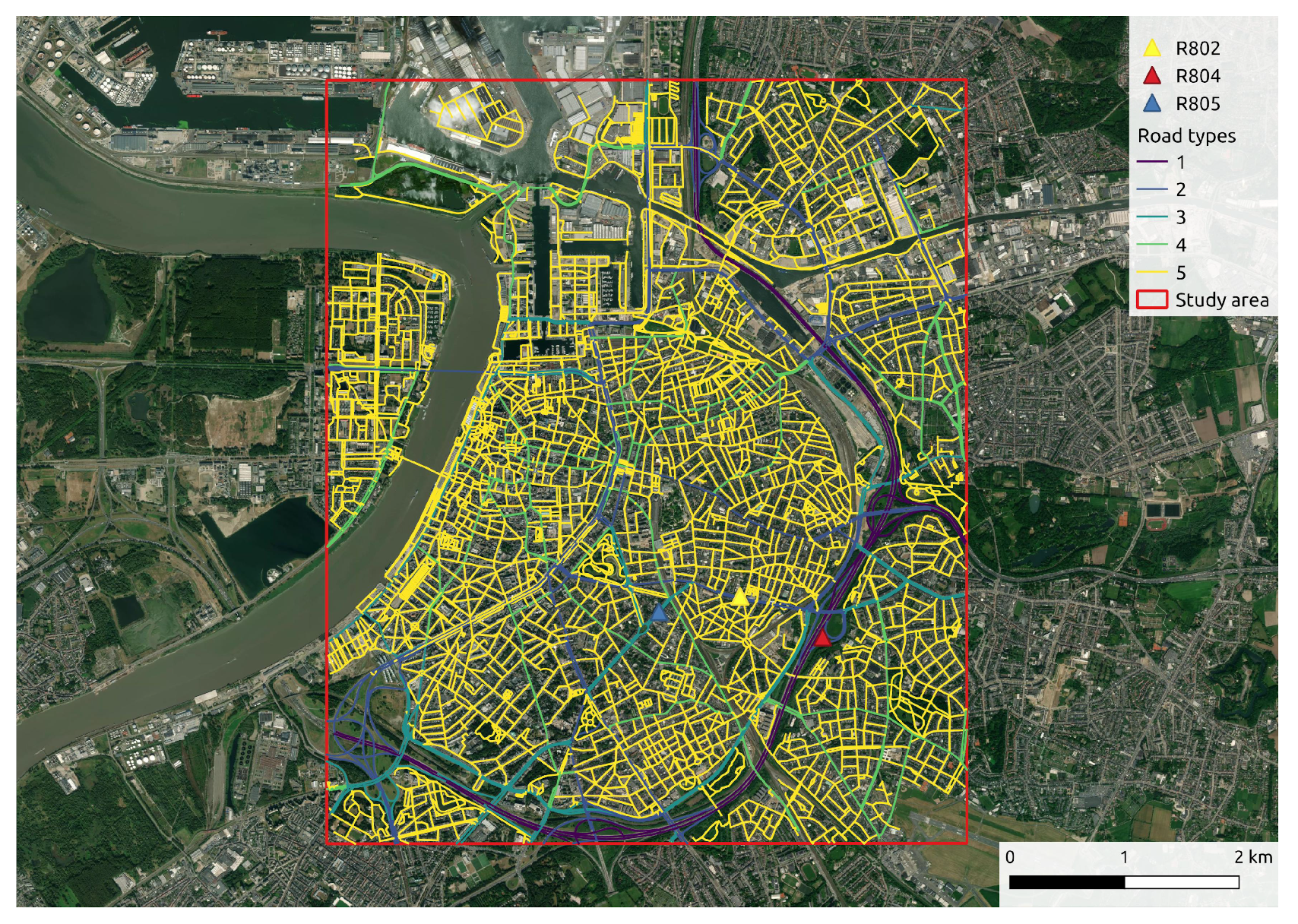
- Time variant but space invariant: contextual features change over time but remain constant within a certain region. Meteorology belongs to this category, as it can change instantaneously during a day but can differ slightly across a city. The meteorological features we consider of interest are temperature, relative humidity, wind speed, and wind direction, owing to their important influence on the dispersion and transport processes of air pollutants. We acquired the hourly aggregated meteorological data from a stationary monitoring station (M802) in Antwerp provided by the Flanders Environment Agency (VMM). These data can be downloaded from VMM’s website (https://www.vmm.be/, accessed on 10 April 2022).
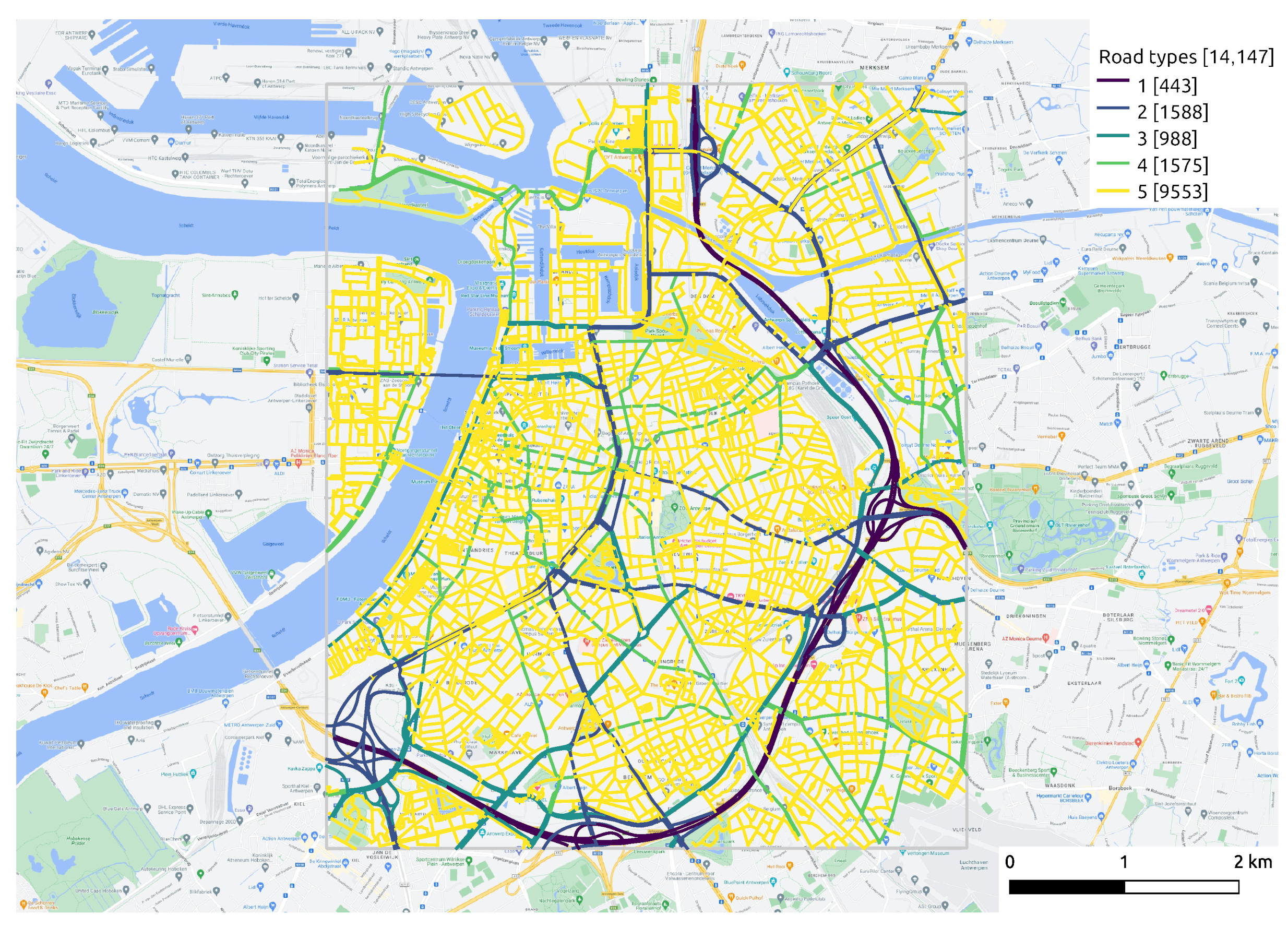
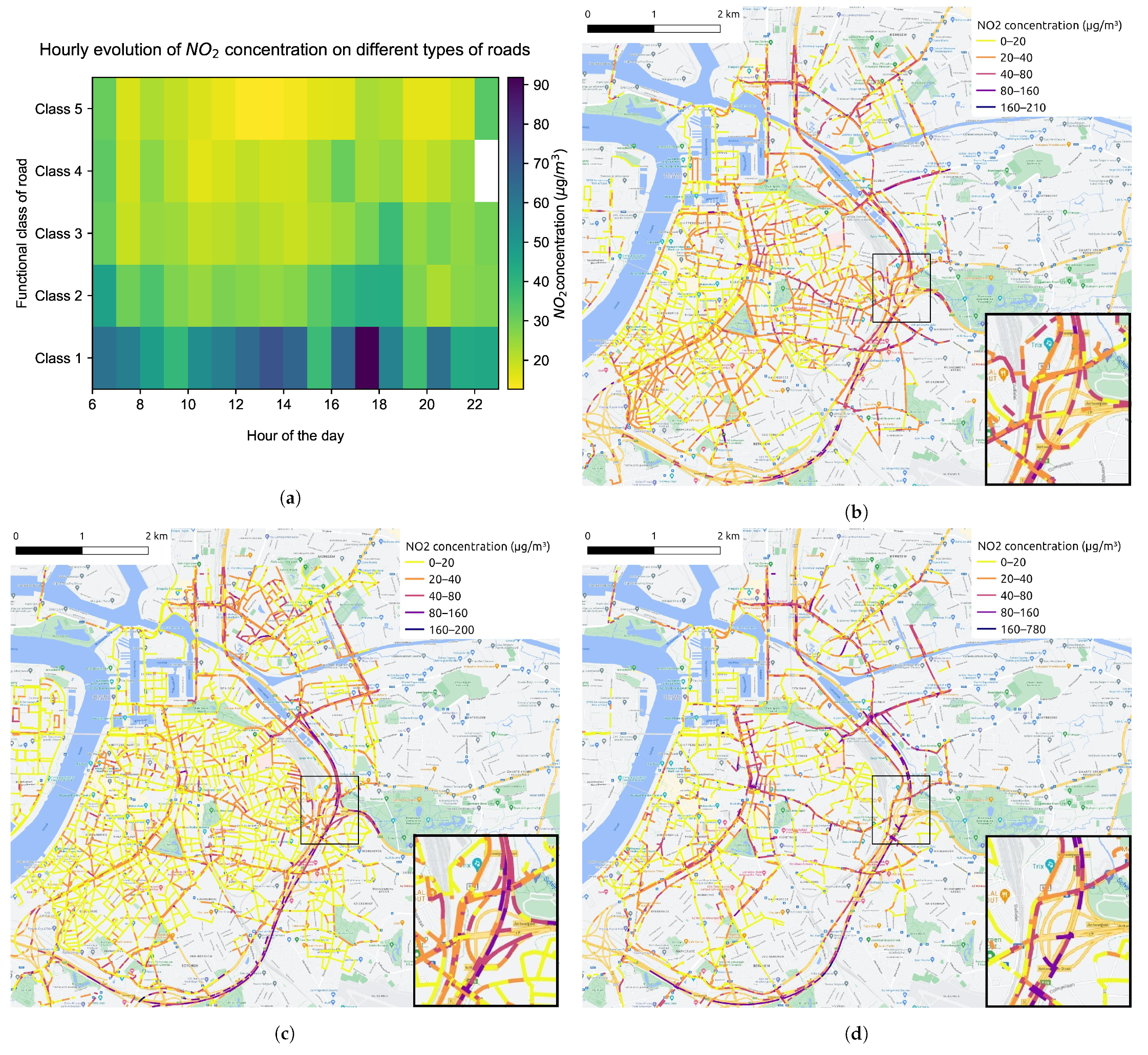
- Space variant but time invariant: contextual features change according to geographical location but remain unchanged over a short period of time, such as a road network. Features, such as road type and speed limits, differ from segment to segment, but remain constant for a long time. We extract the road network of study area from OpenStreetMap (OSM) (https://www.openstreetmap.org/, accessed on 10 April 2022). Figure 5 displays the functional classes of road segments defined by the “Flanders Spatial Structure Plan” (Ruimtelijk Structuurplan Vlaanderen). Class 1 represents main roads, connecting between large areas and cities, which are always busy with high traffic volumes and fast speeds. Class 2 denotes primary roads I, serving as a supplement to main roads. Class 3 indicates primary roads II that give access to the city center and limit traffic flow by increasing traffic signals. Class 4 indicates secondary roads that link different small towns. Class 5 represents local roads with access to communities.
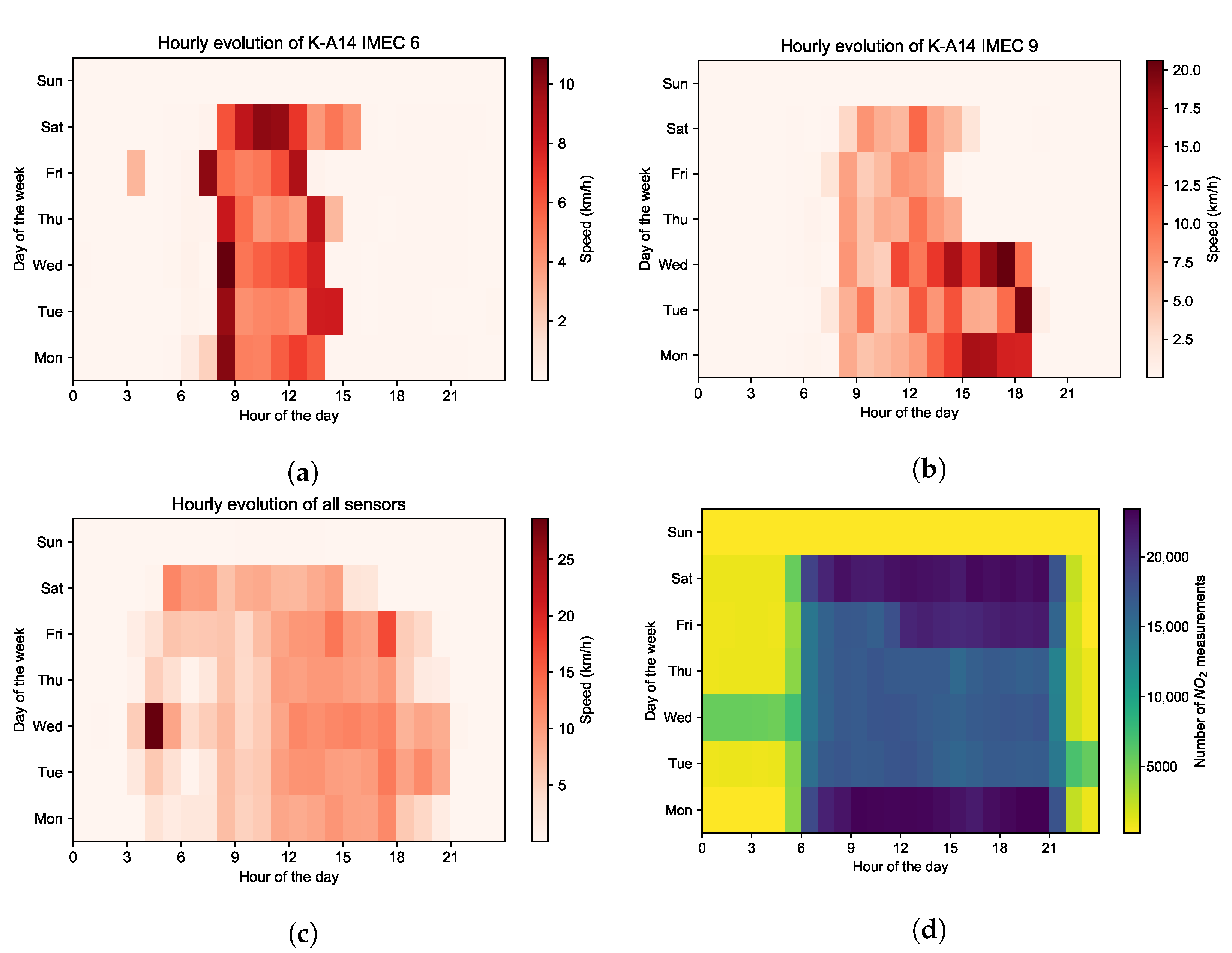
- Time- and space variant: these contextual features change both over time and space. For example, traffic flow can vary considerably by road segment and time slot. The average speed of vehicles on the road and the traffic density are the two traffic features we concern mainly. The traffic flow data used in this study are provided by the company HERE Technologies (https://www.here.com/, accessed on 10 April 2022).As an example, Figure 8 provides the evolution of traffic volumes on the road network at four time points (9:00, 13:00, 17:00 and 21:00) during a given day (10 June 2021). Taking into account road types in Figure 5, it is easy to find the temporal variation and spatial distribution of traffic flow. Due to the capacity and location of roads, it is not surprising that the six-lane highway ring road carries the heaviest traffic flow, followed by main roads with relatively more vehicles, and finally, the smaller traffic volume is on minor roads in some neighborhoods. In addition, as it was a weekday, the morning peak (Figure 8a) and evening peak (Figure 8c) contributed heavily to the traffic flow. The road network was still busy during the midday hour (Figure 8b) but less so than in the morning rush hour, and there was much less traffic volume when night fell (Figure 8d).
2.3.2. Creating a Fine-Grained Air Quality Map from Sparse Measurements
2.4. Performance Evaluation
2.4.1. Validation Experiments
2.4.2. Performance Metrics
3. Results and Discussion
3.1. Model Performance
- SVR model: radial basis kernel function (rbf) with kernel coefficient and regularization parameter C = 1.
- XGBoost model: number of gradient boosted trees = 200.
- RF model: number of trees in the forest = 200.
- DF model: maximum number of cascade layers = 20, number of estimator in each cascade layer = 4, number of trees in each estimator = 200.
- Proposed CLADF model: number of estimator in each cascade layer = 4, number of trees in each estimator = 200, weighting factor , number of clusters K = 120, 200, 40 for R802, R804, R805 respectively in leave-one-station-out validation experiments and K = 5, 20, 10, 10, 40 for Class 1 to 5 in the five-fold cross validation experiments based on road type.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. WHO Global Air Quality Guidelines: Particulate Matter (PM2.5 and PM10), Ozone, Nitrogen Dioxide, Sulfur Dioxide and Carbon Monoxide; World Health Organization: Geneva, Switzerland, 2021. [Google Scholar]
- World Bank and Institute for Health Metrics and Evaluation. The Cost of Air Pollution: Strengthening the Economic Case for Action; World Bank: Washington, DC, USA, 2016. [Google Scholar] [CrossRef]
- Samoli, E.; Peng, R.; Ramsay, T.; Pipikou, M.; Touloumi, G.; Dominici, F.; Burnett, R.; Cohen, A.; Krewski, D.; Samet, J.; et al. Acute Effects of Ambient Particulate Matter on Mortality in Europe and North America: Results from the APHENA Study. Environ. Health Perspect. 2008, 116, 1480–1486. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beelen, R.; Raaschou-Nielsen, O.; Stafoggia, M.; Andersen, Z.J.; Weinmayr, G.; Hoffmann, B.; Wolf, K.; Samoli, E.; Fischer, P.; Nieuwenhuijsen, M.; et al. Effects of Long-term Exposure to Air Pollution on Natural-Cause Mortality: An Analysis of 22 European Cohorts within the Multicentre ESCAPE Project. Lancet 2014, 383, 785–795. [Google Scholar] [CrossRef]
- Burnett, R.; Chen, H.; Szyszkowicz, M.; Fann, N.; Hubbell, B.; Pope, C.A.; Apte, J.S.; Brauer, M.; Cohen, A.; Weichenthal, S.; et al. Global estimates of mortality associated with long-term exposure to outdoor fine particulate matter. Proc. Natl. Acad. Sci. USA 2018, 115, 9592–9597. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, K.; Breitner, S.; Wolf, K.; Stafoggia, M.; Sera, F.; Vicedo-Cabrera, A.M.; Guo, Y.; Tong, S.; Lavigne, E.; Matus, P.; et al. Ambient carbon monoxide and daily mortality: A global time-series study in 337 cities. Lancet Planet. Health 2021, 5, e191–e199. [Google Scholar] [CrossRef]
- Carvalho, H. The air we breathe: Differentials in global air quality monitoring. Lancet Respir. Med. 2016, 4, 603–605. [Google Scholar] [CrossRef]
- Karner, A.A.; Eisinger, D.S.; Niemeier, D.A. Near-Roadway Air Quality: Synthesizing the Findings from Real-World Data. Environ. Sci. Technol. 2010, 44, 5334–5344. [Google Scholar] [CrossRef]
- Marshall, J.D.; Nethery, E.; Brauer, M. Within-Urban Variability in Ambient Air Pollution: Comparison of Estimation Methods. Atmos. Environ. 2008, 42, 1359–1369. [Google Scholar] [CrossRef]
- Tang, H.; Apon, F. Integrative Air Quality Management Airshed by Using Multigas Passive Sampling Technology in Canada. WIT Trans. Ecol. Environ. 2012, 162, 517–528. [Google Scholar]
- Rosario, L.; Pietro, M.; Francesco, S.P. Comparative Analyses of Urban Air Quality Monitoring Systems: Passive Sampling and Continuous Monitoring Stations. Energy Procedia 2016, 101, 321–328. [Google Scholar] [CrossRef]
- Zou, B.; Li, S.; Zheng, Z.; Zhan, B.F.; Yang, Z.; Wan, N. Healthier Routes Planning: A New Method and Online Implementation for Minimizing Air Pollution Exposure Risk. Comput. Environ. Urban Syst. 2020, 80, 101456. [Google Scholar] [CrossRef]
- Luo, J.; Boriboonsomsin, K.; Barth, M. Consideration of Exposure to Traffic-related Air Pollution in Bicycle Route Planning. J. Transp. Health 2020, 16, 100792. [Google Scholar] [CrossRef]
- Apparicio, P.; Gelb, J.; Carrier, M.; Mathieu, M.È.; Kingham, S. Exposure to Noise and Air Pollution by Mode of Transportation during Rush Hours in Montreal. J. Transp. Geogr. 2018, 70, 182–192. [Google Scholar] [CrossRef]
- Isakov, V.; Touma, J.S.; Khlystov, A. A method of assessing air toxics concentrations in urban areas using mobile platform measurements. J. Air Waste Manag. Assoc. 2007, 57, 1286–1295. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Apte, J.S.; Messier, K.P.; Gani, S.; Brauer, M.; Kirchstetter, T.W.; Lunden, M.M.; Marshall, J.D.; Portier, C.J.; Vermeulen, R.C.; Hamburg, S.P. High-resolution air pollution mapping with Google street view cars: Exploiting big data. Environ. Sci. Technol. 2017, 51, 6999–7008. [Google Scholar] [CrossRef]
- Mueller, M.D.; Hasenfratz, D.; Saukh, O.; Fierz, M.; Hueglin, C. Statistical modelling of particle number concentration in Zurich at high spatio-temporal resolution utilizing data from a mobile sensor network. Atmos. Environ. 2016, 126, 171–181. [Google Scholar] [CrossRef]
- Kaivonen, S.; Ngai, E.C.H. Real-time air pollution monitoring with sensors on city bus. Digit. Commun. Netw. 2020, 6, 23–30. [Google Scholar] [CrossRef]
- Elen, B.; Peters, J.; Poppel, M.V.; Bleux, N.; Theunis, J.; Reggente, M.; Standaert, A. The Aeroflex: A Bicycle for Mobile Air Quality Measurements. Sensors 2013, 13, 221–240. [Google Scholar] [CrossRef]
- Franco, J.F.; Segura, J.F.; Mura, I. Air Pollution alongside Bike-Paths in Bogotá-colombia. Front. Environ. Sci. 2016, 4, 77. [Google Scholar] [CrossRef] [Green Version]
- McKercher, G.R.; Vanos, J.K. Low-Cost Mobile Air Pollution Monitoring in Urban Environments: A Pilot Study in Lubbock, Texas. Environ. Technol. 2018, 39, 1505–1514. [Google Scholar] [CrossRef]
- Hofman, J.; Samson, R.; Joosen, S.; Blust, R.; Lenaerts, S. Cyclist Exposure to Black Carbon, Ultrafine Particles and Heavy Metals: An Experimental Study along Two Commuting Routes near Antwerp, Belgium. Environ. Res. 2018, 164, 530–538. [Google Scholar] [CrossRef]
- Mead, M.; Popoola, O.; Stewart, G.; Landshoff, P.; Calleja, M.; Hayes, M.; Baldovi, J.; McLeod, M.; Hodgson, T.; Dicks, J.; et al. The Use of Electrochemical Sensors for Monitoring Urban Air Quality in Low-Cost, High-Density Networks. Atmos. Environ. 2013, 70, 186–203. [Google Scholar] [CrossRef] [Green Version]
- SM, S.N.; Yasa, P.R.; Narayana, M.; Khadirnaikar, S.; Rani, P. Mobile Monitoring of Air Pollution Using Low Cost Sensors to Visualize Spatio-Temporal Variation of Pollutants at Urban Hotspots. Sustain. Cities Soc. 2019, 44, 520–535. [Google Scholar] [CrossRef]
- Chen, G.; Knibbs, L.D.; Zhang, W.; Li, S.; Cao, W.; Guo, J.; Ren, H.; Wang, B.; Wang, H.; Williams, G.; et al. Estimating Spatiotemporal Distribution of PM1 Concentrations in China with Satellite Remote Sensing, Meteorology, and Land Use Information. Environ. Pollut. 2018, 233, 1086–1094. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.; Labzovskii, L.D.; Mak, H.W.L.; Fung, J.C.; Lau, A.K.; Kenea, S.T.; Bilal, M.; Hey, J.D.V.; Lu, X.; Ma, J. Observation of PM2.5 Using a Combination of Satellite Remote Sensing and Low-Cost Sensor Network in Siberian Urban Areas with Limited Reference Monitoring. Atmos. Environ. 2020, 227, 117410. [Google Scholar] [CrossRef]
- Guttikunda, S.K.; Nishadh, K.; Jawahar, P. Air Pollution Knowledge Assessments (APnA) for 20 Indian Cities. Urban Clim. 2019, 27, 124–141. [Google Scholar] [CrossRef]
- Giani, P.; Castruccio, S.; Anav, A.; Howard, D.; Hu, W.; Crippa, P. Short-Term and Long-Term Health Impacts of Air Pollution Reductions from COVID-19 Lockdowns in China and Europe: A Modelling Study. Lancet Planet. Health 2020, 4, e474–e482. [Google Scholar] [CrossRef]
- Lim, C.C.; Kim, H.; Vilcassim, M.R.; Thurston, G.D.; Gordon, T.; Chen, L.C.; Lee, K.; Heimbinder, M.; Kim, S.Y. Mapping Urban Air Quality Using Mobile Sampling with Low-Cost Sensors and Machine Learning in Seoul, South Korea. Environ. Int. 2019, 131, 105022. [Google Scholar] [CrossRef]
- Mo, Y.; Booker, D.; Zhao, S.; Tang, J.; Jiang, H.; Shen, J.; Chen, D.; Li, J.; Jones, K.C.; Zhang, G. The Application of Land Use Regression Model to Investigate Spatiotemporal Variations of PM2.5 in Guangzhou, China: Implications for the Public Health Benefits of PM2.5 Reduction. Sci. Total Environ. 2021, 778, 146305. [Google Scholar] [CrossRef]
- Christopher, S.A.; Gupta, P. Satellite Remote Sensing of Particulate Matter Air Quality: The Cloud-Cover Problem. J. Air Waste Manag. Assoc. 2010, 60, 596–602. [Google Scholar] [CrossRef]
- Mogollón-Sotelo, C.; Casallas, A.; Vidal, S.; Celis, N.; Ferro, C.; Belalcazar, L. A Support Vector Machine Model to Forecast Ground-Level PM2.5 in a Highly Populated City with a Complex Terrain. Air Qual. Atmos. Health 2021, 14, 399–409. [Google Scholar] [CrossRef]
- Araki, S.; Shima, M.; Yamamoto, K. Spatiotemporal Land Use Random Forest Model for Estimating Metropolitan NO2 Exposure in Japan. Sci. Total Environ. 2018, 634, 1269–1277. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Yu, L.; Wang, C.; Shuai, C.; Zhu, J.; Qu, S.; Taiebat, M.; Xu, M. Urban Air Pollution Mapping Using Fleet Vehicles as Mobile Monitors and Machine Learning. Environ. Sci. Technol. 2021, 55, 5579–5588. [Google Scholar] [CrossRef] [PubMed]
- Do, T.H.; Tsiligianni, E.; Qin, X.; Hofman, J.; La Manna, V.P.; Philips, W.; Deligiannis, N. Graph-deep-learning-based inference of fine-grained air quality from mobile IoT sensors. IEEE Internet Things J. 2020, 7, 8943–8955. [Google Scholar] [CrossRef]
- Do, T.H.; Nguyen, D.M.; Tsiligianni, E.; Aguirre, A.L.; La Manna, V.P.; Pasveer, F.; Philips, W.; Deligiannis, N. Matrix Completion with Variational Graph Autoencoders: Application in Hyperlocal Air Quality Inference. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7535–7539. [Google Scholar]
- Qin, X.; Do, T.H.; Hofman, J.; Rodrigo, E.; Panzica, V.L.M.; Deligiannis, N.; Philips, W. Street-Level Air Quality Inference Based on Geographically Context-Aware Random Forest Using Opportunistic Mobile Sensor Network. In Proceedings of the 2021 the 5th International Conference on Innovation in Artificial Intelligence, Xiamen, China, 5–8 March 2021; pp. 221–227. [Google Scholar]
- Cogliani, E. Air Pollution Forecast in Cities by an Air Pollution Index Highly Correlated with Meteorological Variables. Atmos. Environ. 2001, 35, 2871–2877. [Google Scholar] [CrossRef]
- Kovač-Andrić, E.; Brana, J.; Gvozdić, V. Impact of Meteorological Factors on Ozone Concentrations Modelled by Time Series Analysis and Multivariate Statistical Methods. Ecol. Inform. 2009, 4, 117–122. [Google Scholar] [CrossRef]
- Banerjee, T.; Srivastava, R.K. Evaluation of Environmental Impacts of Integrated Industrial Estate—pantnagar through Application of Air and Water Quality Indices. Environ. Monit. Assess. 2011, 172, 547–560. [Google Scholar] [CrossRef] [PubMed]
- Shekarrizfard, M.; Faghih-Imani, A.; Tétreault, L.F.; Yasmin, S.; Reynaud, F.; Morency, P.; Plante, C.; Drouin, L.; Smargiassi, A.; Eluru, N.; et al. Regional Assessment of Exposure to Traffic-Related Air Pollution: Impacts of Individual Mobility and Transit Investment Scenarios. Sustain. Cities Soc. 2017, 29, 68–76. [Google Scholar] [CrossRef]
- Ho, C.C.; Chan, C.C.; Cho, C.W.; Lin, H.I.; Lee, J.H.; Wu, C.F. Land Use Regression Modeling with Vertical Distribution Measurements for Fine Particulate Matter and Elements in an Urban Area. Atmos. Environ. 2015, 104, 256–263. [Google Scholar] [CrossRef]
- Ito, K.; Johnson, S.; Kheirbek, I.; Clougherty, J.; Pezeshki, G.; Ross, Z.; Eisl, H.; Matte, T.D. Intraurban Variation of Fine Particle Elemental Concentrations in New York City. Environ. Sci. Technol. 2016, 50, 7517–7526. [Google Scholar] [CrossRef]
- Brokamp, C.; Jandarov, R.; Rao, M.; LeMasters, G.; Ryan, P. Exposure Assessment Models for Elemental Components of Particulate Matter in an Urban Environment: A Comparison of Regression and Random Forest Approaches. Atmos. Environ. 2017, 151, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Hofman, J.; Do, T.H.; Qin, X.; Bonet, E.R.; Philips, W.; Deligiannis, N.; La Manna, V.P. Spatiotemporal Air Quality Inference of Low-Cost Sensor Data: Evidence from Multiple Sensor Testbeds. Environ. Model. Softw. 2022, 149, 105306. [Google Scholar] [CrossRef]
- Van den Bossche, J.; Theunis, J.; Elen, B.; Peters, J.; Botteldooren, D.; De Baets, B. Opportunistic Mobile Air Pollution Monitoring: A Case Study with City Wardens in Antwerp. Atmos. Environ. 2016, 141, 408–421. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.H.; Feng, J. Deep Forest. Natl. Sci. Rev. 2019, 6, 74–86. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Janssen, S.; Thunis, P.; Carnevale, C.; Cuvelier, C.; Durka, P.; Georgieva, E.; Guerreiro, C.; Malherbe, L.; Maiheu, B.; Meleux, F.; et al. FAIRMODE Guidance Document on Modelling Quality Objectives and Benchmarking; The Forum for Air quality Modeling in Europe: Athens, Greece, 2017. [Google Scholar]
- Lu, W.Z.; Wang, W.J. Potential Assessment of the “Support Vector Machine” Method in Forecasting Ambient Air Pollutant Trends. Chemosphere 2005, 59, 693–701. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Processing Procedure | Number of Measurements |
|---|---|
| Remove data outside study area | 3,619,540 |
| Remove data outside working hour | 3,486,617 |
| Map matching | 2,000,188 |
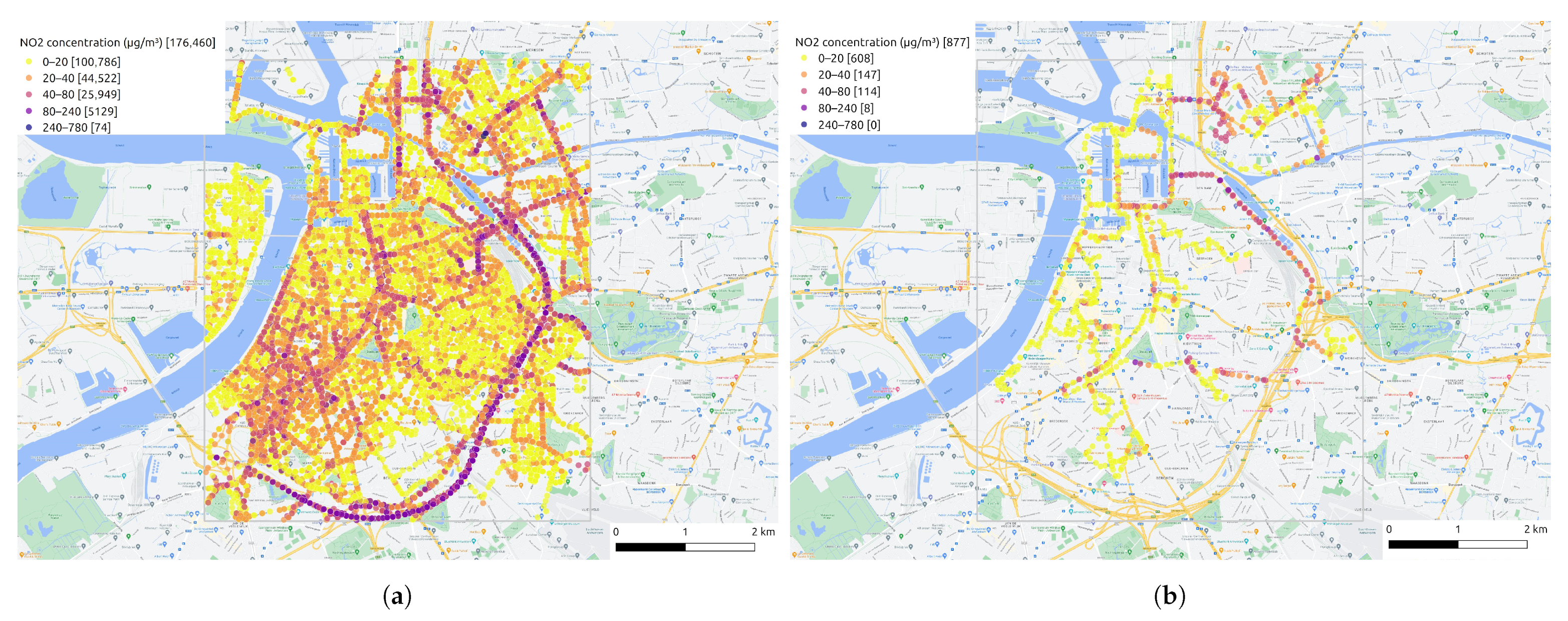
| Data aggregation | 176,460 |
| Dataset | Reference Station | Road Functional Class | ||||||
|---|---|---|---|---|---|---|---|---|
| R802 | R804 | R805 | Class 1 | Class 2 | Class 3 | Class 4 | Class 5 | |
| Training | 103,027 | 103,046 | 103,016 | 1317 | 17,678 | 10,536 | 14,136 | 33,859 |
| Test | 445 | 426 | 456 | 395 | 5901 | 3488 | 4909 | 11,253 |
| Model | Station | RMSE | MAE | IA | Acc. | r | NMB | NMSD | MQI |
|---|---|---|---|---|---|---|---|---|---|
| RF | R802 | 21.80 | 17.04 | 0.49 | 0.36 | 0.30 | 0.45 | 0.40 | 0.79 |
| DF | R802 | 16.49 | 13.46 | 0.61 | 0.50 | 0.38 | 0.30 | 0.12 | 0.63 |
| SVR | R802 | 13.41 | 10.73 | 0.54 | 0.60 | 0.28 | 0.13 | 0.55 | |
| XGB | R802 | 13.08 | 10.34 | 0.62 | 0.61 | 0.42 | 0.10 | 0.56 | |
| CLADF | R802 | 13.03 | 9.88 | 0.70 | 0.63 | 0.50 | 0.05 | 0.54 | |
| SVR | R805 | 14.11 | 10.81 | 0.50 | 0.59 | 0.25 | 0.64 | ||
| RF | R805 | 13.16 | 10.09 | 0.61 | 0.62 | 0.35 | 0.06 | 0.55 | |
| DF | R805 | 12.17 | 9.59 | 0.64 | 0.64 | 0.41 | 0.06 | 0.51 | |
| XGB | R805 | 11.97 | 9.17 | 0.52 | 0.66 | 0.30 | −0.04 | 0.52 | |
| CLADF | R805 | 11.55 | 8.66 | 0.71 | 0.67 | 0.50 | 0.00 | 0.49 | |
| RF | R804 | 41.27 | 35.57 | 0.33 | 0.14 | 0.25 | 0.83 | 0.42 | 1.01 |
| XGB | R804 | 39.21 | 32.87 | 0.38 | 0.20 | 0.34 | 0.74 | 0.38 | 0.98 |
| DF | R804 | 36.41 | 29.56 | 0.36 | 0.28 | 0.30 | 0.67 | 0.14 | 0.94 |
| SVR | R804 | 32.85 | 26.44 | 0.35 | 0.36 | 0.29 | 0.56 | −0.43 | 0.90 |
| CLADF | R804 | 23.28 | 18.88 | 0.39 | 0.54 | 0.35 | 0.34 | 0.08 | 0.72 |
| RF | Avg | 25.41 | 20.90 | 0.48 | 0.37 | 0.30 | 0.45 | 0.25 | 0.78 |
| DF | Avg | 21.69 | 17.54 | 0.54 | 0.47 | 0.36 | 0.34 | 0.04 | 0.69 |
| XGB | Avg | 21.42 | 17.46 | 0.51 | 0.49 | 0.35 | 0.27 | −0.04 | 0.69 |
| SVR | Avg | 20.12 | 15.99 | 0.46 | 0.52 | 0.27 | 0.15 | −0.34 | 0.70 |
| CLADF | Avg | 15.95 | 12.47 | 0.60 | 0.61 | 0.45 | 0.11 | 0.03 | 0.58 |
| Model | Road Type | RMSE | MAE | IA | Acc. | r | NMB | NMSD | MQI |
|---|---|---|---|---|---|---|---|---|---|
| SVR | Class 1 | 37.33 | 27.91 | 0.38 | 0.56 | 0.45 | −0.12 | −0.81 | 1.15 |
| RF | Class 1 | 23.45 | 17.33 | 0.87 | 0.73 | 0.80 | −0.01 | −0.25 | 0.62 |
| XGB | Class 1 | 22.80 | 16.95 | 0.89 | 0.73 | 0.81 | −0.01 | −0.17 | 0.60 |
| DF | Class 1 | 22.95 | 16.51 | 0.89 | 0.74 | 0.81 | −0.01 | −0.16 | 0.60 |
| CLADF | Class 1 | 21.80 | 15.40 | 0.90 | 0.76 | 0.83 | −0.01 | −0.16 | 0.57 |
| SVR | Class 2 | 26.17 | 18.02 | 0.46 | 0.41 | 0.40 | −0.16 | −0.66 | 1.13 |
| XGB | Class 2 | 21.47 | 14.63 | 0.77 | 0.52 | 0.65 | 0.02 | −0.29 | 0.83 |
| DF | Class 2 | 21.02 | 14.01 | 0.78 | 0.54 | 0.66 | 0.02 | −0.32 | 0.82 |
| RF | Class 2 | 20.76 | 13.91 | 0.78 | 0.54 | 0.67 | 0.03 | −0.32 | 0.81 |
| CLADF | Class 2 | 20.66 | 13.77 | 0.79 | 0.55 | 0.68 | 0.02 | −0.28 | 0.80 |
| SVR | Class 3 | 20.14 | 14.31 | 0.47 | 0.37 | 0.41 | −0.17 | −0.66 | 0.94 |
| XGB | Class 3 | 16.26 | 10.89 | 0.79 | 0.52 | 0.66 | −0.01 | −0.24 | 0.70 |
| DF | Class 3 | 15.55 | 10.19 | 0.81 | 0.55 | 0.70 | 0.00 | −0.26 | 0.67 |
| RF | Class 3 | 15.51 | 10.18 | 0.81 | 0.55 | 0.70 | 0.00 | −0.28 | 0.67 |
| CLADF | Class 3 | 15.43 | 9.97 | 0.82 | 0.56 | 0.70 | 0.00 | −0.22 | 0.66 |
| SVR | Class 4 | 24.07 | 14.77 | 0.47 | 0.33 | 0.42 | −0.29 | −0.66 | 1.15 |
| XGB | Class 4 | 19.17 | 11.51 | 0.79 | 0.48 | 0.66 | −0.02 | −0.25 | 0.82 |
| DF | Class 4 | 19.04 | 10.80 | 0.80 | 0.51 | 0.68 | −0.01 | −0.20 | 0.80 |
| RF | Class 4 | 18.72 | 10.66 | 0.81 | 0.52 | 0.69 | 0.00 | −0.29 | 0.78 |
| CLADF | Class 4 | 17.98 | 10.46 | 0.81 | 0.53 | 0.71 | 0.00 | −0.18 | 0.77 |
| SVR | Class 5 | 17.09 | 11.29 | 0.56 | 0.34 | 0.46 | −0.26 | −0.56 | 0.83 |
| XGB | Class 5 | 13.42 | 9.07 | 0.80 | 0.47 | 0.69 | 0.00 | −0.29 | 0.62 |
| DF | Class 5 | 12.61 | 8.24 | 0.83 | 0.52 | 0.74 | 0.02 | −0.26 | 0.58 |
| RF | Class 5 | 12.58 | 8.16 | 0.84 | 0.53 | 0.74 | 0.02 | −0.25 | 0.57 |
| CLADF | Class 5 | 12.39 | 7.98 | 0.85 | 0.54 | 0.75 | 0.01 | −0.22 | 0.56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, X.; Do, T.H.; Hofman, J.; Bonet, E.R.; La Manna, V.P.; Deligiannis, N.; Philips, W. Fine-Grained Urban Air Quality Mapping from Sparse Mobile Air Pollution Measurements and Dense Traffic Density. Remote Sens. 2022, 14, 2613. https://doi.org/10.3390/rs14112613
Qin X, Do TH, Hofman J, Bonet ER, La Manna VP, Deligiannis N, Philips W. Fine-Grained Urban Air Quality Mapping from Sparse Mobile Air Pollution Measurements and Dense Traffic Density. Remote Sensing. 2022; 14(11):2613. https://doi.org/10.3390/rs14112613
Chicago/Turabian StyleQin, Xuening, Tien Huu Do, Jelle Hofman, Esther Rodrigo Bonet, Valerio Panzica La Manna, Nikos Deligiannis, and Wilfried Philips. 2022. "Fine-Grained Urban Air Quality Mapping from Sparse Mobile Air Pollution Measurements and Dense Traffic Density" Remote Sensing 14, no. 11: 2613. https://doi.org/10.3390/rs14112613
APA StyleQin, X., Do, T. H., Hofman, J., Bonet, E. R., La Manna, V. P., Deligiannis, N., & Philips, W. (2022). Fine-Grained Urban Air Quality Mapping from Sparse Mobile Air Pollution Measurements and Dense Traffic Density. Remote Sensing, 14(11), 2613. https://doi.org/10.3390/rs14112613