
A Method for Classifying Complex Features in Urban Areas Using Video Satellite Remote Sensing Data



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Sources
- City represented by the video satellite remote sensing data: New Delhi, India;
- Size of the data: 600 × 950 pixels;
- Ground resolution of the data: approximately 1.13 m;
- Bandwidths of the data: blue band, 437–512 nm; green band, 489–585 nm; and red band: 580–723 nm;
- Dynamic range of the data: 8 bits (0–255) for each channel;
- Data acquisition duration: 28 s; number of observation angles (frames): 700.
2.2. Experimental Methods
3. Results
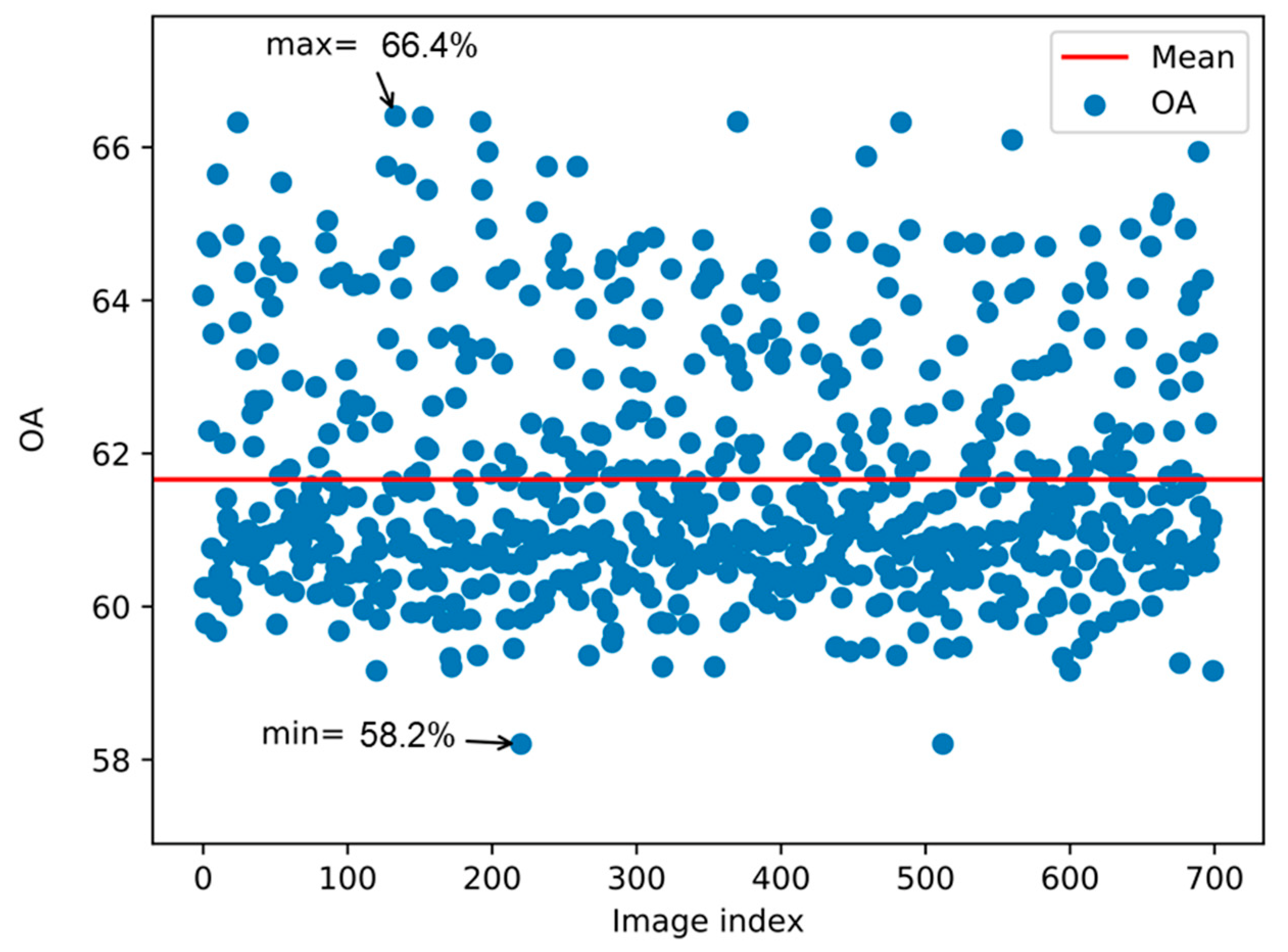
3.1. Classification Results Obtained Using Single-Angle Data
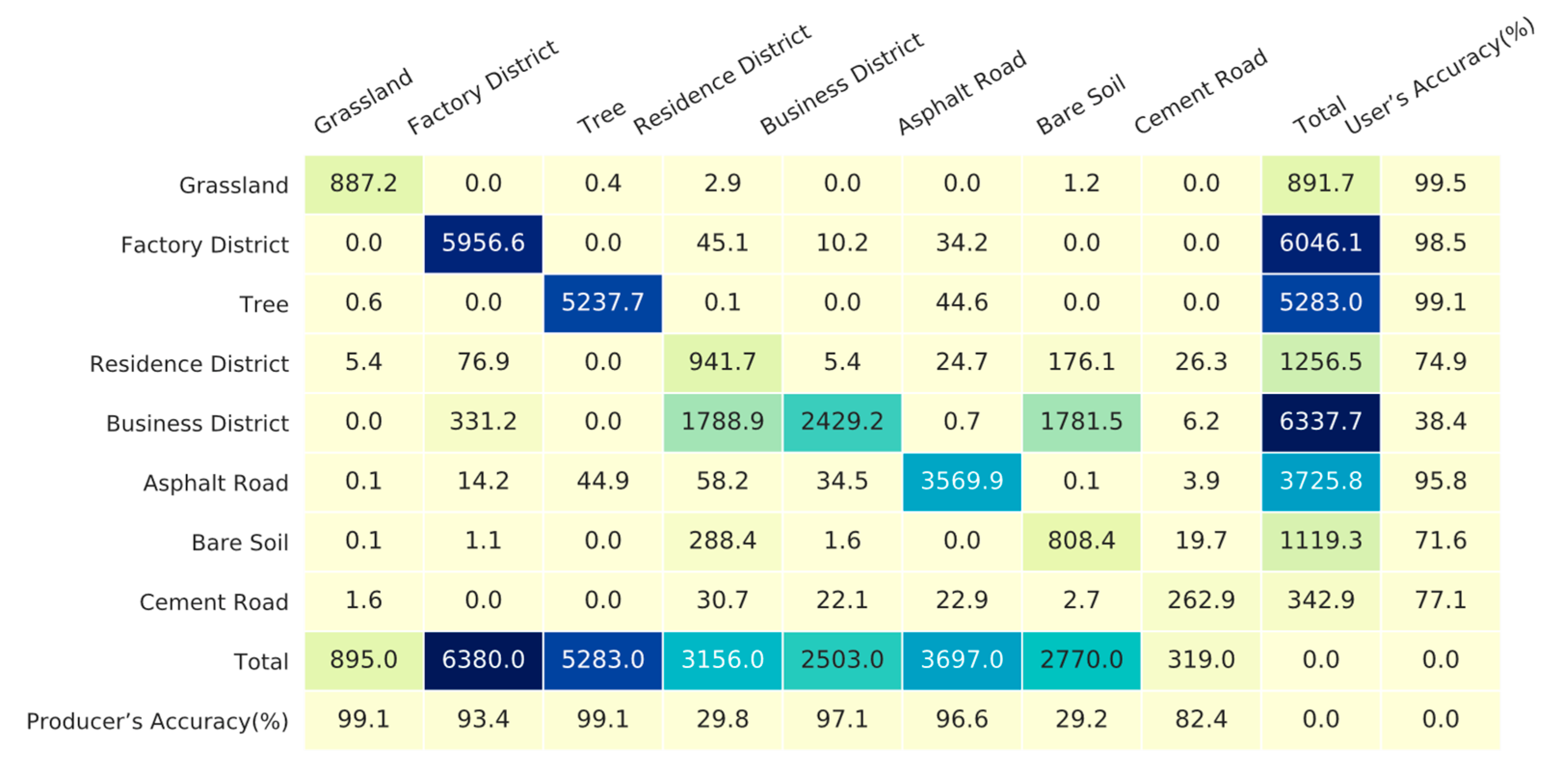
3.2. Confusion Matrix Comparative Analysis between Single-Angle Images and Multiangle Images
3.3. Results Derived Using the SVM Classification Method
3.4. Results Derived Using the Ensemble Learning Classification Method
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gu, Y.; Liu, H.; Wang, T.; Li, S.; Gao, G. Deep feature extraction and motion representation for satellite video scene classification. Sci. China Inf. Sci. 2020, 63, 93–107. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Gu, Y.; Wang, T.; Jin, X.; Gao, G. Detection of Event of Interest for Satellite Video Understanding. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7860–7871. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. Spatiotemporal Scene Interpretation of Space Videos via Deep Neural Network and Tracklet Analysis. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 11–16 July 2016; pp. 1823–1826. [Google Scholar] [CrossRef]
- Liu, C. Study on ground feature characteristics of multi angle remote sensing satellite images. Surv. Mapp. Tech. Equip. 2021, 23, 5. [Google Scholar]
- Yang, X.F.; Wang, X.M. Classification of MISR multi- angle imagery based on decision tree classifier. J. Geo-Inf. Sci. 2016, 18, 416–422. [Google Scholar] [CrossRef]
- Yang, X.F.; Ye, M.; Mao, D.L. Multi-angle remote sensing image classification based on artificial bee colony algorithm. Remote Sens. Land Resour. 2018, 30, 48–54. [Google Scholar]
- Zhang, H.; Yang, Z.; Zhang, L.; Shen, H. Super-resolution reconstruction for multi-angle remote sensing images considering resolution differences. Remote Sens. 2014, 6, 637–657. [Google Scholar] [CrossRef] [Green Version]
- Kong, F.; Li, X.; Wang, H.; Xie, D.; Li, X.; Bai, Y. Land cover classification based on fused data from GF-1 and MODIS NDVI time series. Remote Sens. 2016, 8, 741. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Huang, B.; Xu, B. Multi-source remotely sensed data fusion for improving land cover classification. ISPRS J. Photogramm. Remote Sens. 2017, 124, 27–39. [Google Scholar] [CrossRef]
- Chen, C.; Knyazikhin, Y.; Park, T.; Yan, K.; Lyapustin, A.; Wang, Y.; Yang, B.; Myneni, R.B. Prototyping of lai and fpar retrievals from modis multi-angle implementation of atmospheric correction (maiac) data. Remote Sens. 2017, 9, 370. [Google Scholar] [CrossRef] [Green Version]
- Hall, F.G.; Hilker, T.; Coops, N.C.; Lyapustin, A.; Huemmrich, K.F.; Middleton, E.; Margolis, H.; Drolet, G.; Black, T.A. Multi-angle remote sensing of forest light use efficiency by observing PRI variation with canopy shadow fraction. Remote Sens. Environ. 2018, 112, 3201–3211. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Ren, C.; Cai, M.; Edward, N.Y.Y.; Wu, T. Classification of local climate zones using ASTER and Landsat data for high-density cities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3397–3405. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High-Resolution Images. Remote Sens. 2021, 13, 239. [Google Scholar] [CrossRef]
- Xu, K.; Jiang, Y.; Zhang, G.; Zhang, Q.; Wang, X. Geometric potential assessment for ZY3-02 triple linear array imagery. Remote Sens. 2017, 9, 658. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Li, L.T.; Jiang, Y.H.; Shi, X.T. On-orbit relative radiometric calibration of optical video satellites without uniform calibration sites. Int. J. Remote Sens. 2019, 40, 5454–5474. [Google Scholar] [CrossRef]
- Wu, J.; Wang, T.; Yan, J.; Zhang, G.; Jiang, X.; Wang, Y.; Bai, Q.; Yuan, C. Satellite video point-target tracking based on Hu correlation filter. Chin. Space Sci. Technol. 2019, 39, 55–63. [Google Scholar]
- Li, H.; Chen, L.; Li, F.; Huang, M. Ship detection and tracking method for satellite video based on multiscale saliency and surrounding contrast analysis. J. Appl. Remote Sens. 2019, 13, 026511. [Google Scholar] [CrossRef]
- Joe, J.F. Enhanced Sensitivity of Motion Detection in Satellite Videos Using Instant Learning Algorithms. In Proceedings of the IET Chennai 3rd International Conference on Sustainable Energy and Intelligent Systems (SEISCON 2012), Tiruchengode, India, 27–29 December 2012; pp. 424–429. [Google Scholar]
- Shao, Z.; Cai, J.; Wang, Z. Smart monitoring cameras driven intelligent processing to big surveillance video data. IEEE Trans. Big Data 2017, 4, 105–116. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Class Name | Number of Samples |
|---|---|---|
| 1 | Grasslands | 924 |
| 2 | Trees | 6715 |
| 3 | Bare soils | 5561 |
| 4 | Building (factory district) | 3322 |
| 5 | Building (residential district) | 2634 |
| 6 | Building (business district) | 3891 |
| 7 | Asphalt roads | 2915 |
| 8 | Concrete roads | 335 |
| Total | \ | 26,315 |
| Training Set Radio | 1% | 2.5% | 5% | 10% | 20% | 40% | 80% | |
|---|---|---|---|---|---|---|---|---|
| Number of Angles | ||||||||
| 1 | 56.9 | 60.0 | 61.7 | 63.6 | 65.1 | 64.2 | 66.2 | |
| 2 | 60.6 | 61.0 | 63.4 | 64.5 | 65.6 | 64.9 | 67.3 | |
| 4 | 62.4 | 63.1 | 69.1 | 69.5 | 69.5 | 69.7 | 72.8 | |
| 8 | 65.7 | 69.7 | 72.1 | 73.0 | 75.9 | 76.5 | 77.0 | |
| 16 | 69.3 | 70.8 | 73.7 | 74.8 | 77.2 | 77.8 | 78.6 | |
| 32 | 70.3 | 73.1 | 76.8 | 78.1 | 79.4 | 80.2 | 80.9 | |
| 64 | 70.7 | 74.5 | 78.5 | 79.9 | 81.0 | 82.0 | 83.1 | |
| 128 | 71.3 | 76.9 | 79.7 | 81.3 | 82.6 | 83.7 | 84.9 | |
| 256 | 71.5 | 77.0 | 80.5 | 82.1 | 83.7 | 84.8 | 85.9 | |
| 512 | 71.6 | 77.7 | 80.7 | 82.4 | 84.2 | 85.4 | 85.5 | |
| 700 | 75.1 | 78.0 | 81.0 | 82.7 | 85.1 | 85.6 | 88.0 | |
| Training Set Ratio | 1% | 2.5% | 5% | 10% | 20% | 40% | 80% | |
|---|---|---|---|---|---|---|---|---|
| Number of Angles | ||||||||
| 1 | 51.5 | 52.7 | 54.5 | 54.5 | 55.6 | 56.2 | 60.4 | |
| 2 | 55.0 | 56.4 | 56.6 | 56.6 | 57.0 | 57.9 | 62.9 | |
| 4 | 61.8 | 64.2 | 63.8 | 64.5 | 64.1 | 66.6 | 67.7 | |
| 8 | 64.6 | 66.5 | 66.9 | 66.8 | 67.0 | 68.9 | 69.3 | |
| 16 | 65.9 | 70.3 | 72.4 | 71.8 | 72.4 | 72.3 | 73.5 | |
| 32 | 67.3 | 73.1 | 74.3 | 74.7 | 75.9 | 76.0 | 76.4 | |
| 64 | 68.4 | 74.6 | 76.6 | 77.4 | 77.9 | 78.0 | 78.0 | |
| 128 | 68.7 | 76.9 | 78.0 | 79.1 | 79.7 | 80.0 | 80. 8 | |
| 256 | 68.5 | 79.0 | 80.0 | 80.2 | 80.6 | 81.0 | 81.1 | |
| 512 | 68.5 | 79.6 | 80.7 | 81.1 | 81.6 | 82.2 | 82.4 | |
| 700 | 72.0 | 81.0 | 80.8 | 81.4 | 81.9 | 82.7 | 83.0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, F.; Ai, T.; Wang, J.; Yao, Y.; Zhou, Z. A Method for Classifying Complex Features in Urban Areas Using Video Satellite Remote Sensing Data. Remote Sens. 2022, 14, 2324. https://doi.org/10.3390/rs14102324
Ye F, Ai T, Wang J, Yao Y, Zhou Z. A Method for Classifying Complex Features in Urban Areas Using Video Satellite Remote Sensing Data. Remote Sensing. 2022; 14(10):2324. https://doi.org/10.3390/rs14102324
Chicago/Turabian StyleYe, Fanghong, Tinghua Ai, Jiaming Wang, Yuan Yao, and Zheng Zhou. 2022. "A Method for Classifying Complex Features in Urban Areas Using Video Satellite Remote Sensing Data" Remote Sensing 14, no. 10: 2324. https://doi.org/10.3390/rs14102324
APA StyleYe, F., Ai, T., Wang, J., Yao, Y., & Zhou, Z. (2022). A Method for Classifying Complex Features in Urban Areas Using Video Satellite Remote Sensing Data. Remote Sensing, 14(10), 2324. https://doi.org/10.3390/rs14102324