
Class-Shared SparsePCA for Few-Shot Remote Sensing Scene Classification



Abstract
:1. Introduction
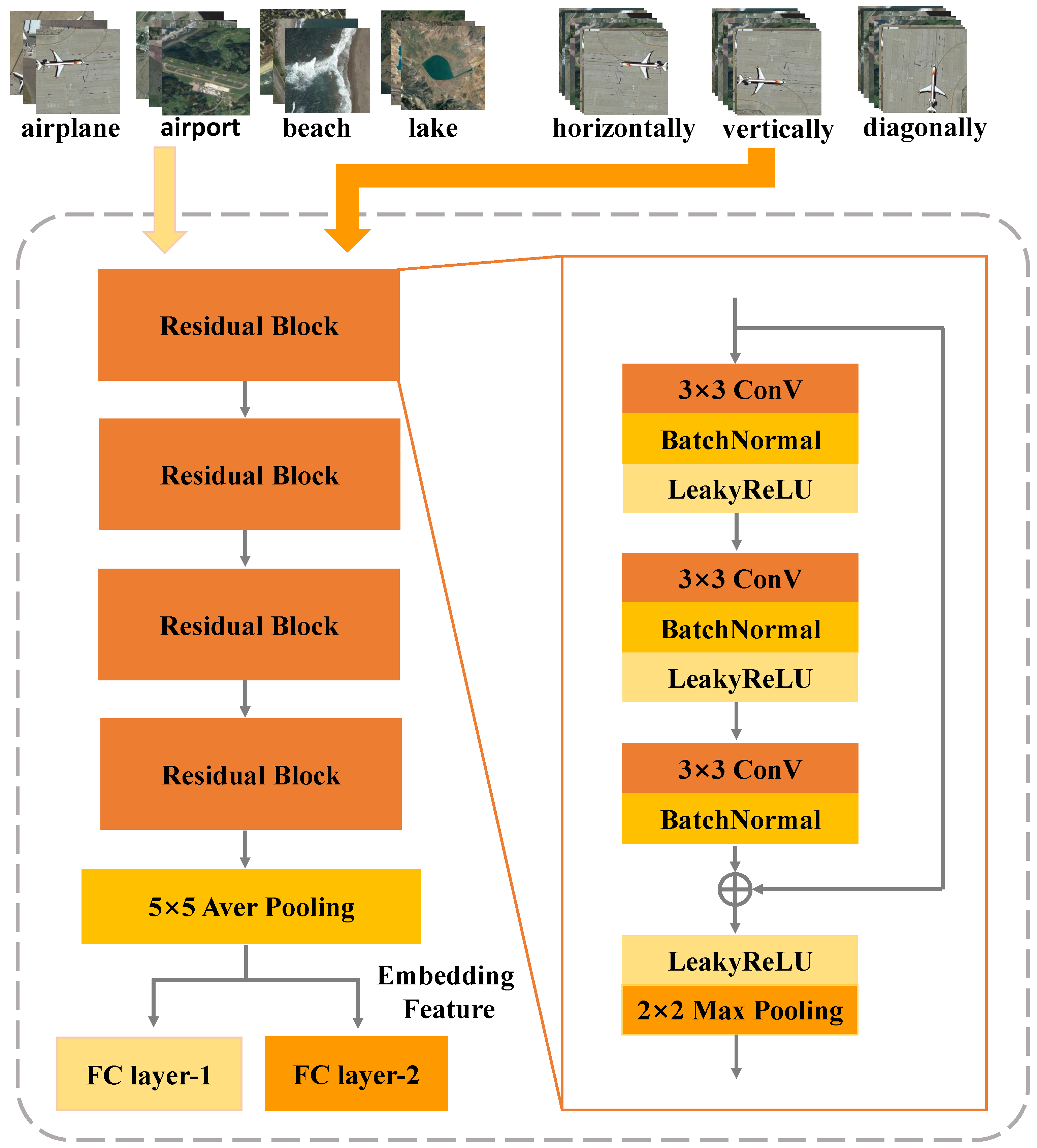
- We use self-supervised learning-assisted feature extractor training since the few-shot remote sensing scene data are thus less likely to over-fit the model problem. By constructing self-supervised auxiliary data and labels, the model performance is improved effectively.
- We introduce the subspace learning method into the framework of the few-shot remote sensing scene classification task and propose a novel method: the few-shot remote sensing scene classification method. Further experiments show that the proposed method can effectively solve the problem of “negative migration”.
- We propose a novel few-shot remote sensing scene classification based on the Class-Shared SparsePCA method, called CSSPCA. The CSSPCA maps the novel data features to more discriminant subspace to obtain more discriminant reconstruction features, thus improving classification performance.
- We test on two few-shot remote sensing scene datasets that have proved our proposed method’s validity and rationality.
2. Related Work
3. Problem Setup
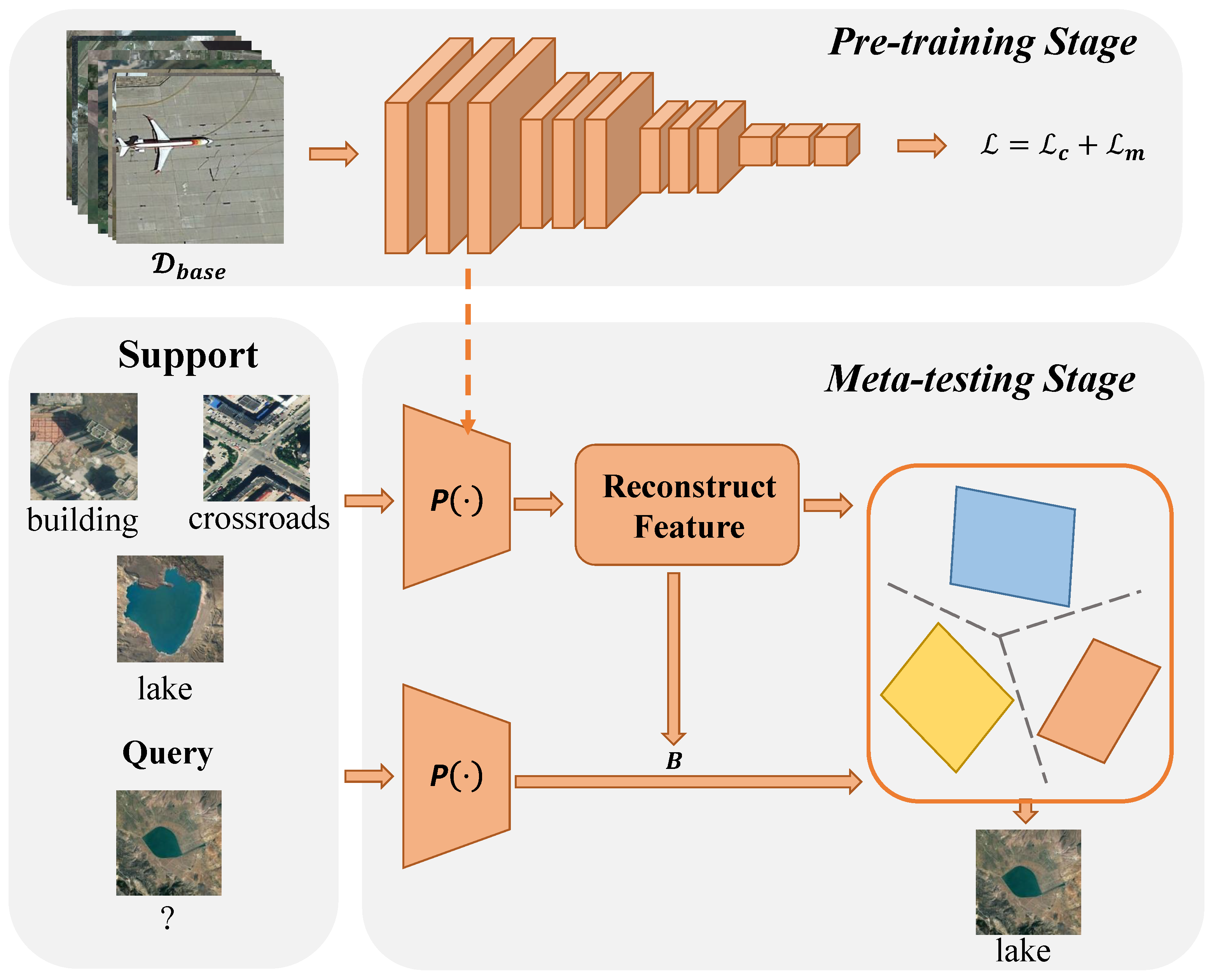
4. Proposed Method
4.1. Overview Framework of the Proposed Method
4.2. Feature Extractor
4.3. Class-Shared SparsePCA Classifier
4.4. Classification Scheme
5. Experiments and Results
5.1. Datasets
5.2. Implementation Details
5.3. Experimental Results
5.4. Ablation Studies
5.4.1. Influence of Self-Supervised Mechanism
5.4.2. Influence of Reconstructive Feature
5.4.3. Influence of Parameters
5.4.4. Influence of Meta-Testing SHOT
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LLSR | Lifelong learning for scene recognition in remote sensing images |
| MAML | Model-agnostic meta-learning for fast adaptation of deep networks |
| ProtoNet | Prototypical networks for few-shot learning |
| RelationNet | Learning to compare: Relation network for few-shot learning |
| MatchingNet | Matching networks for one-shot learning |
| Meta-SGD | Meta-SGD: Learning to learn quickly for few-shot learning |
| DLA-MatchNet | DLA-MatchNet for few-shot remote sensing image scene classification |
| TADAM | TADAM: Task-dependent adaptive metric for improved few-shot learning |
| MetaOptNet | Meta-learning with differentiable convex optimization |
| DSN-MR | Adaptive subspaces for few-shot learning |
| D-CNN | Remote sensing image scene classification via learning discriminative CNNs |
| MetaLearning | Few-shot classification of aerial scene images via meta-Learning |
| deepEMD | Few-shot image classification with differentiable earth mover’s distance |
| MA-deepEMD | Multi-attention deepEMD for few-shot learning in remote sensing |
| TPN | Learning to propagate labels: Transductive propagation network for few-shot learning |
| TAE-Net | Task-adaptive embedding learning with dynamic kernel fusion for few-shot remote sensing scene classification |
| MKN | Metakernel networks for few-shot remote sensing scene classification |
References
- Zhu, Q.; Wu, W.; Xia, T.; Yu, Q.; Yang, P.; Li, Z.; Song, Q. Exploring the Use of Google Earth Imagery and Object-Based Methods in Land Use/Cover Mapping. Remote Sens. 2013, 5, 6026–6042. [Google Scholar]
- Johnson, B.A. Scale Issues Related to the Accuracy Assessment of Land Use/Land Cover Maps Produced Using Multi-Resolution Data: Comments on “The Improvement of Land Cover Classification by Thermal Remote Sensing”. Remote Sens. 2015, 7(7), 8368–8390. Remote Sens. 2015, 7, 13436–13439. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.S.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Geosci. Remote Sens. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Cheng, H.F.; Zhang, W.B.; Chen, F. Advances in researches on application of remote sensing method to estimating vegetation coverage. Remote Sens. Land Resour. 2008, 1, 13–17. [Google Scholar]
- Bechtel, B.; Demuzere, M.; Stewart, I.D. A Weighted Accuracy Measure for Land Cover Mapping: Comment on Johnson et al. Local Climate Zone (LCZ) Map Accuracy Assessments Should Account for Land Cover Physical Characteristics that Affect the Local Thermal Environment. Remote Sens. 2019, 12, 1769. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef] [Green Version]
- Solari, L.; Del Soldato, M.; Raspini, F.; Barra, A.; Bianchini, S.; Confuorto, P.; Nicola Casagli, N.; Crosetto, M. Review of satellite interferometry for landslide detection in Italy. Remote Sens. 2020, 12, 1351. [Google Scholar] [CrossRef]
- Manfreda, S.; McCabe, M.F.; Miller, P.E.; Lucas, R.; Pajuelo Madrigal, V.; Mallinis, G.; Ben Dor, E.; Helman, D.; Estes, L.; Ciraolo, G. On the use of unmanned aerial systems for environmental monitoring. Remote Sens. 2018, 10, 641. [Google Scholar] [CrossRef] [Green Version]
- Połap, D.; Włodarczyk-Sielicka, M.; Wawrzyniak, N. Automatic ship classification for a riverside monitoring system using a cascade of artificial intelligence techniques including penalties and rewards. ISA Trans. 2021, 12, 232–239. [Google Scholar]
- Połap, D.; Włodarczyk-Sielicka, M. Classification of Non-Conventional Ships Using a Neural Bag-Of-Words Mechanism. Sensors 2020, 20, 1608. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef] [Green Version]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Jegou, H.; Perronnin, F.; Douze, M.; Sánchez, J.; Perez, P.; Schmid, C. Aggregating local image descriptors into compact codes. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1704–1716. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Xu, K.; Huang, H.; Li, Y.; Shi, G. Multilayer feature fusion network for scene classification in remote sensing. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1894–1898. [Google Scholar] [CrossRef]
- Wang, J.; Liu, W.; Ma, L.; Chen, H.; Chen, L. IORN: An effective remote sensing image scene classification framework. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1695–1699. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. 2017, 30, 4077–4087. [Google Scholar]
- Lee, K.; Maji, S.; Ravichandran, A.; Soatto, S. Meta-learning with differentiable convex optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10657–10665. [Google Scholar]
- Shao, S.; Xing, L.; Xu, R.; Liu, W.F.; Wang, Y.J.; Liu, B.D. MDFM: Multi-Decision Fusing Model for Few-Shot Learning. IEEE Trans. Circuits Syst. Video Technol. 2021. [Google Scholar] [CrossRef]
- Xing, L.; Shao, S.; Liu, W.F.; Han, A.X.; Pan, X.S.; Liu, B.D. Learning Task-specific Discriminative Embeddings for Few-shot Image Classification. Neurocomputing 2022, 488, 1–3. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, Y.; Krishnan, D.; Tenenbaum, J.B.; Isola, P. Rethinking few-shot image classification: A good embedding is all you need? In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 266–282. [Google Scholar]
- Zou, H.; Hastie, T.; Tibshirani, R. Sparse principal component analysis. J. Comput. Graph. Stat. 2006, 15, 265–286. [Google Scholar] [CrossRef] [Green Version]
- Abdi, H.; Williams, L.J. Principal component analysis. WIley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1126–1135. [Google Scholar]
- Rajeswaran, A.; Finn, C.; Kakade, S.M.; Levine, S. Meta-Learning with Implicit Gradients. In Proceedings of the Advances in Neural Information Processing Systems 33, Vancouver, BC, Canada, 6–12 December 2020; pp. 113–124. [Google Scholar]
- Zhou, P.; Yuan, X.T.; Xu, H.; Yan, S.; Feng, J. Efficient meta learning via minibatch proximal update. In Proceedings of the Advances in Neural Information Processing Systems 33, Vancouver, BC, Canada, 6–12 December 2020; pp. 1534–1544. [Google Scholar]
- Alajaji, D.A.; Alhichri, H. Few shot scene classification in remote sensing using meta-agnostic machine. In Proceedings of the 2020 6th Conference on Data Science and Machine Learning Applications, Riyadh, Saudi Arabia, 4–5 March 2020; pp. 77–80. [Google Scholar]
- Alajaji, D.; Alhichri, H.S.; Ammour, N.; Alajlan, N. Few-shot learning for remote sensing scene classification. In Proceedings of the 2020 Mediterranean and Middle-East Geoscience and Remote Sensing Symposium, Tunis, Tunisia, 9–11 March 2020; pp. 81–84. [Google Scholar]
- Zhang, P.; Bai, Y.; Wang, D.; Bai, B.; Li, Y. Few-shot classification of aerial scene images via meta-learning. Remote Sens. 2021, 13, 108. [Google Scholar] [CrossRef]
- Li, L.; Han, J.; Yao, X.; Cheng, G.; Guo, L. DLA-MatchNet for few-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote 2020, 99, 1–10. [Google Scholar] [CrossRef]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Proc. Adv. Neural Inf. Process. Syst. 2016, 29, 4077–4087. [Google Scholar]
- Yuan, Z.; Huang, W. Multi-attention DeepEMD for Few-Shot Learning in Remote Sensing. In Proceedings of the IEEE 9th Joint International Information Technology and Artificial Intelligence Conference, Chongqing, China, 11–13 December 2020; pp. 1097–1102. [Google Scholar]
- Zhang, C.; Cai, Y.; Lin, G.; Shen, C. Deepemd: Few-shot image classification with differentiable earth mover’s distance and structured classifiers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12203–12213. [Google Scholar]
- Dvornik, N.; Schmid, C.; Mairal, J. Diversity with cooperation: Ensemble methods for few-shot classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3723–3731. [Google Scholar]
- Yue, Z.; Zhang, H.; Sun, Q.; Hua, X.S. Interventional Few-Shot Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2734–2746. [Google Scholar]
- Shao, S.; Xing, L.; Wang, Y.; Xu, R.; Zhao, C.Y.; Wang, Y.J.; Liu, B.D. Mhfc:Multi-head feature collaboration for few-shot learning. In Proceedings of the 2021 ACM on Multimedia Conference, Chengdu, China, 20–24 October 2021. [Google Scholar]
- Wang, Y.; Xu, C.; Liu, C.; Zhang, L.; Fu, Y. Instance credibility inference for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12836–12845. [Google Scholar]
- Rubinstein, R. The Cross-Entropy Method for Combinatorial and Continuous Optimization. Methodol. Comput. Appl. Probab. 1999, 1, 127–190. [Google Scholar] [CrossRef]
- Xing, L.; Shao, S.; Ma, Y.T.; Wang, Y.J.; Liu, W.F.; Liu, B.D. Learning to Cooperate: Decision Fusion Method for Few-Shot Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Horn, R.A.; Johnson, C.R. Matrix Analysis; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar]
- Zhai, M.; Liu, H.; Sun, F. Lifelong learning for scene recognition in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1472–1476. [Google Scholar] [CrossRef]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-sgd: Learning to learn quickly for few-shot learning. arXiv 2018, arXiv:1707.09835. [Google Scholar]
- Oreshkin, B.; Rodríguez López, P.; Lacoste, A. TADAM: Task dependent adaptive metric for improved few-shot learning. In Proceedings of the Advances in Neural Information Processing Systems 31, Long Beach, CA, USA, 4–9 December 2017; pp. 719–729. [Google Scholar]
- Simon, C.; Koniusz, P.; Nock, R.; Harandi, M. Adaptive Subspaces for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4136–4145. [Google Scholar]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, E.; Hwang, S.J.; Yang, Y. Learning to Propagate Labels: Transductive Propagation Network for Few-shot Learning. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Cui, Z.; Yang, W.; Chen, L.; Li, H. MKN: Metakernel networks for few shot remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4705611. [Google Scholar] [CrossRef]
- Zhang, P.; Fan, G.; Wu, C.; Wang, D.; Li, Y. Task-Adaptive Embedding Learning with Dynamic Kernel Fusion for Few-Shot Remote Sensing Scene Classification. Remote Sens. 2021, 13, 4200. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | All | Meta-Training | Meta-Validation | Meta-Testing |
|---|---|---|---|---|
| NWPU-RESISC45 | 45 | 25 | 8 | 12 |
| RSD46-WHU | 46 | 26 | 8 | 12 |
| Method | Backbone | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|---|
| LLSR [45] | ConV-4 | ||
| MAML [27] | ConV-4 | ||
| ProtoNet [20] | ConV-4 | ||
| RelationNet [46] | ConV-4 | ||
| MatchingNet [34] | Conv-5 | ||
| Meta-SGD [47] | ConV-5 | ||
| DLA-MatchNet [33] | ConV-5 | ||
| MAML [27] | Resnet-12 | ||
| ProtoNet [20] | Resnet-12 | ||
| RelationNet [46] | Resnet-12 | ||
| TADAM [48] | Resnet-12 | ||
| MetaOptNet [21] | Resnet-12 | ||
| DSN-MR [49] | Resnet-12 | ||
| D-CNN [14] | Resnet-12 | ||
| MetaLearning [32] | Resnet-12 | ||
| TPN [50] | Resnet-12 | ||
| MKN [51] | Resnet-12 | ||
| TAE-Net [52] | Resnet-12 | ||
| Ours | Resnet-12 |
| Method | Backbone | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|---|
| LLSR [45] | ConV-4 | ||
| MAML [27] | ConV-4 | ||
| ProtoNet [20] | ConV-4 | ||
| RelationNet [46] | ConV-4 | ||
| MAML [27] | Resnet-12 | ||
| ProtoNet [20] | Resnet-12 | ||
| RelationNet [46] | Resnet-12 | ||
| TADAM [48] | Resnet-12 | ||
| MetaOptNet [21] | Resnet-12 | ||
| DSN-MR [49] | Resnet-12 | ||
| D-CNN [14] | Resnet-12 | ||
| MetaLearning [32] | Resnet-12 | ||
| Ours | Resnet-12 |
| Weight | NWPU-RESISC45 | RSD46-WHU | ||
|---|---|---|---|---|
| 1-Shot | 5-Shot | 1-Shot | 5-Shot | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Wang, X.; Xing, L.; Liu, B.-D.; Li, Z. Class-Shared SparsePCA for Few-Shot Remote Sensing Scene Classification. Remote Sens. 2022, 14, 2304. https://doi.org/10.3390/rs14102304
Wang J, Wang X, Xing L, Liu B-D, Li Z. Class-Shared SparsePCA for Few-Shot Remote Sensing Scene Classification. Remote Sensing. 2022; 14(10):2304. https://doi.org/10.3390/rs14102304
Chicago/Turabian StyleWang, Jiayan, Xueqin Wang, Lei Xing, Bao-Di Liu, and Zongmin Li. 2022. "Class-Shared SparsePCA for Few-Shot Remote Sensing Scene Classification" Remote Sensing 14, no. 10: 2304. https://doi.org/10.3390/rs14102304
APA StyleWang, J., Wang, X., Xing, L., Liu, B.-D., & Li, Z. (2022). Class-Shared SparsePCA for Few-Shot Remote Sensing Scene Classification. Remote Sensing, 14(10), 2304. https://doi.org/10.3390/rs14102304