
FCAU-Net for the Semantic Segmentation of Fine-Resolution Remotely Sensed Images

Abstract
:1. Introduction
- (1)
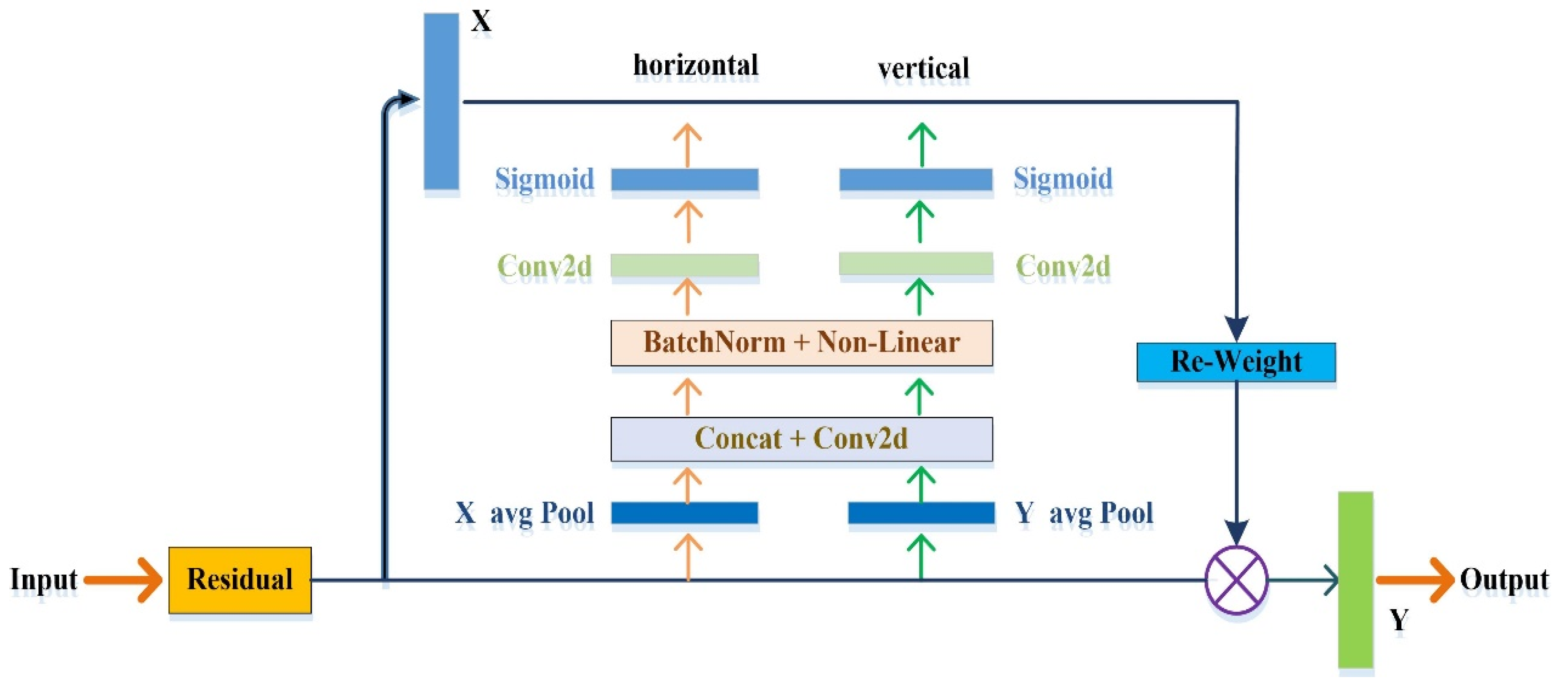
- A novel CA mechanism is introduced into the encoding process to effectively simulate channel-wise relationships. Accurate position information is used to capture long-term dependencies, enabling the model to accurately locate and identify objects of interest.
- (2)
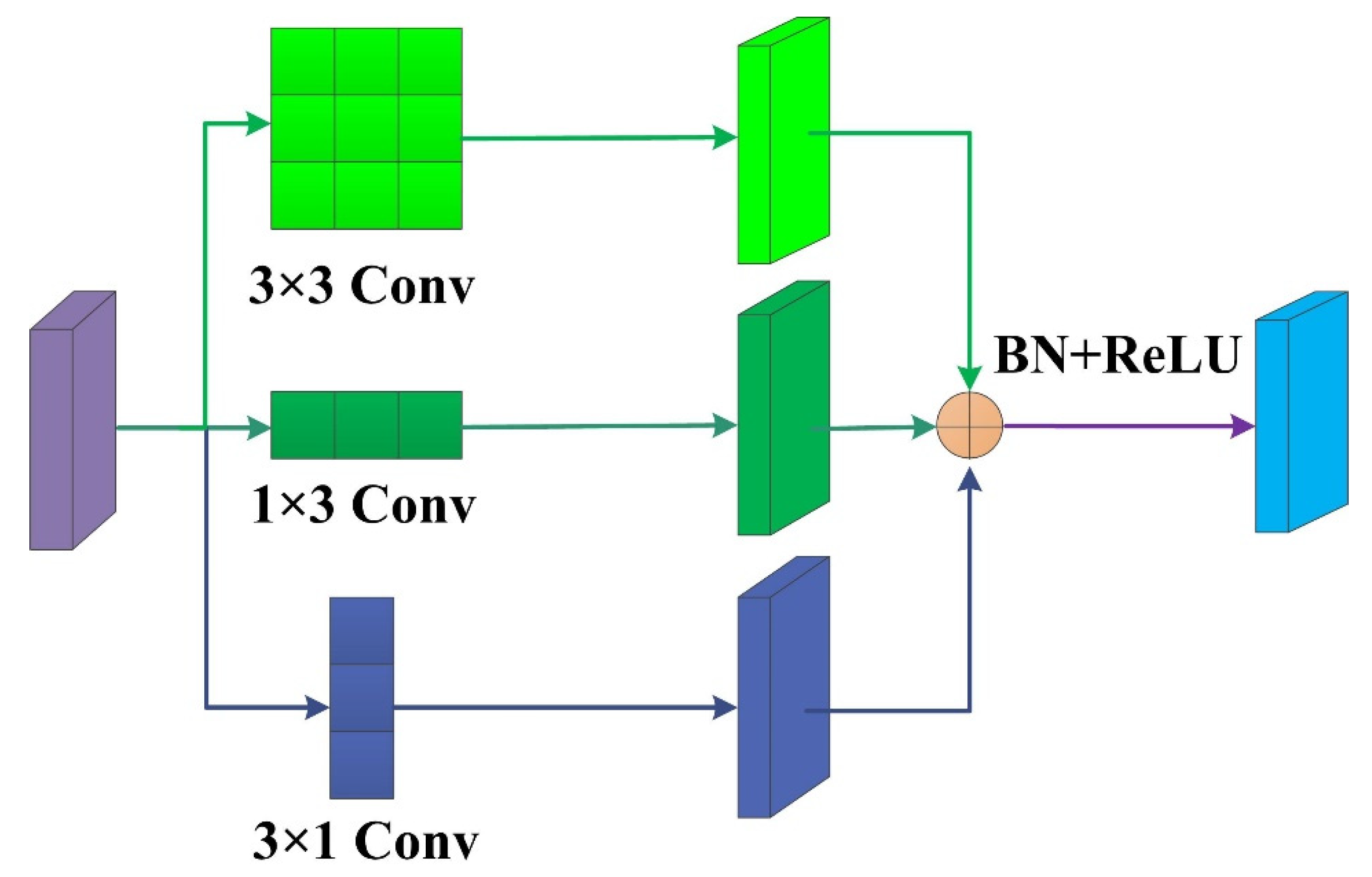
- In the decoding process, we use an ACB to capture and refine the obtained features by enhancing the weights of the central crisscross positions to improve the convolutional layer’s representation capabilities.
- (3)
- We design an RFB to combine low-level spatial data with high-level abstract features to take advantage of feature information. The RFB can fully utilize the benefits of advantages of these aspects based on the representations of various levels.
- (4)
- To avoid the imbalance between the target and nontarget areas, which may cause the learning process to fall into the local minimum of the loss function and strongly bias the classifier toward the background class, we utilize a combination of the cross-entropy loss function and Dice loss function, which solves the sample imbalance issue.
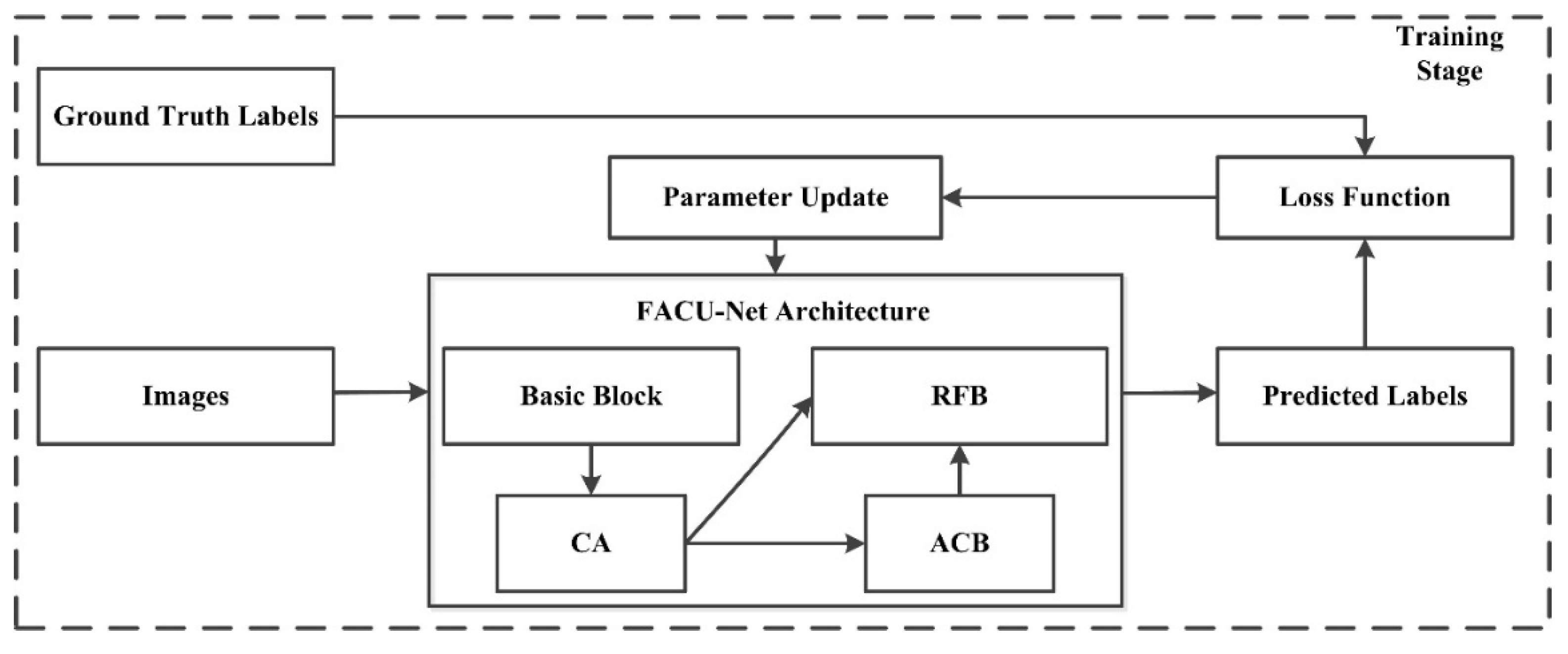
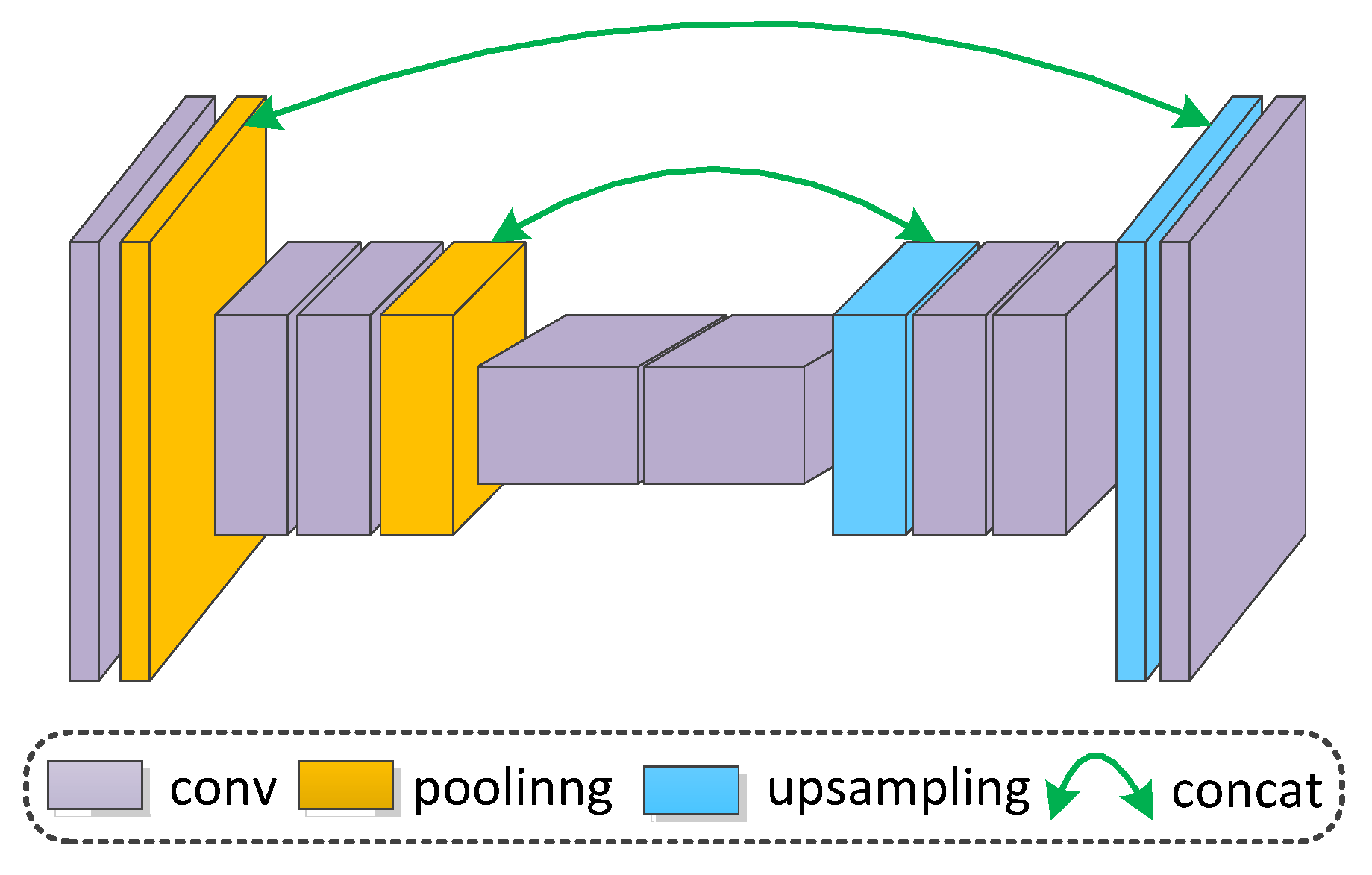
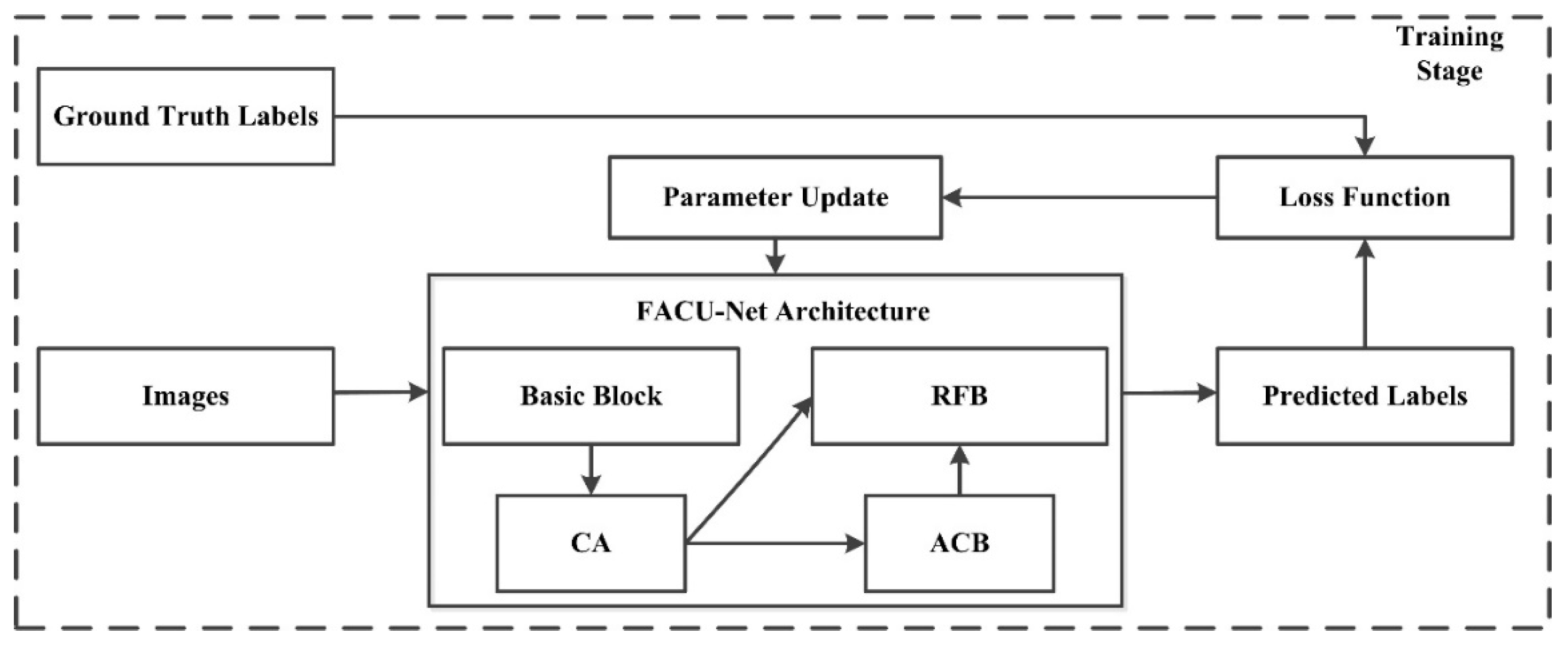
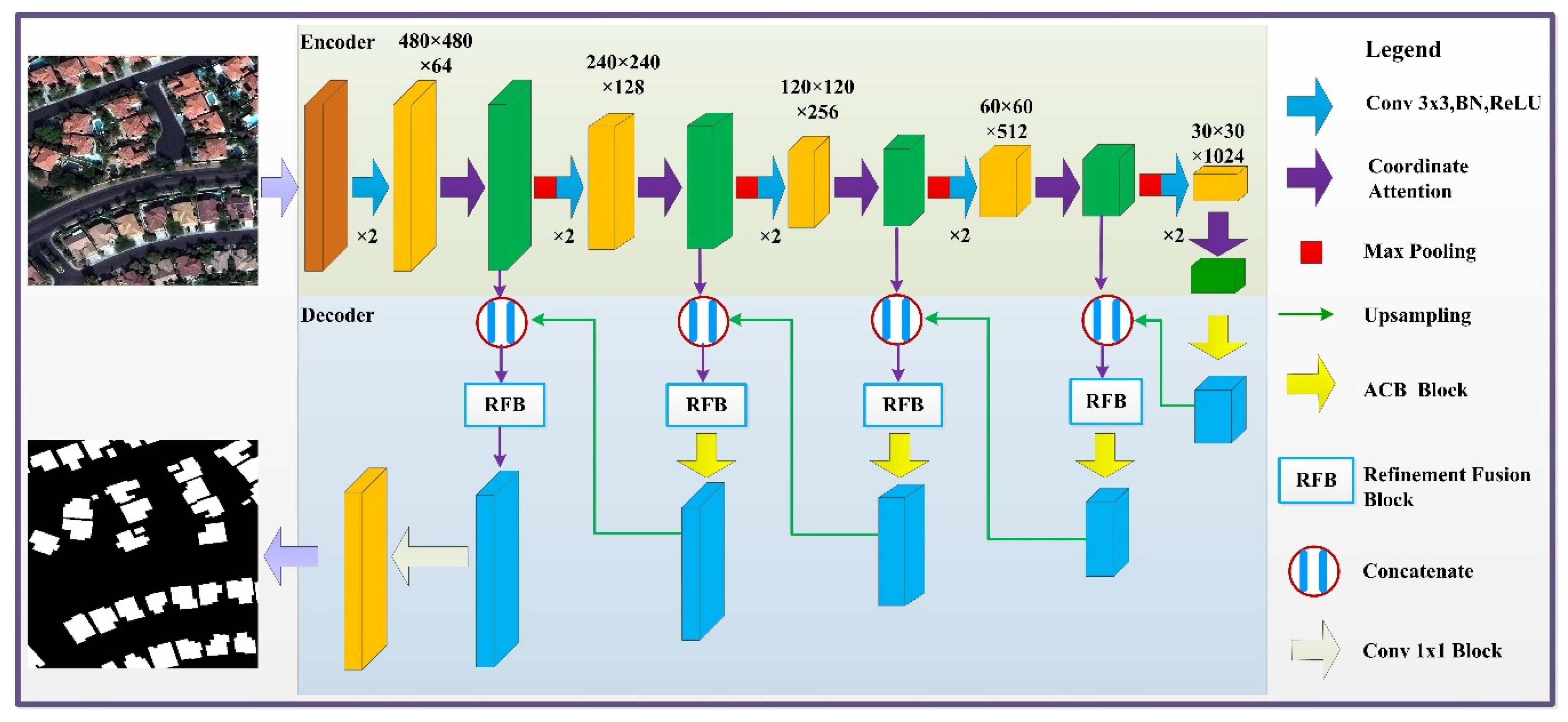
2. Methodology
2.1. CA Module
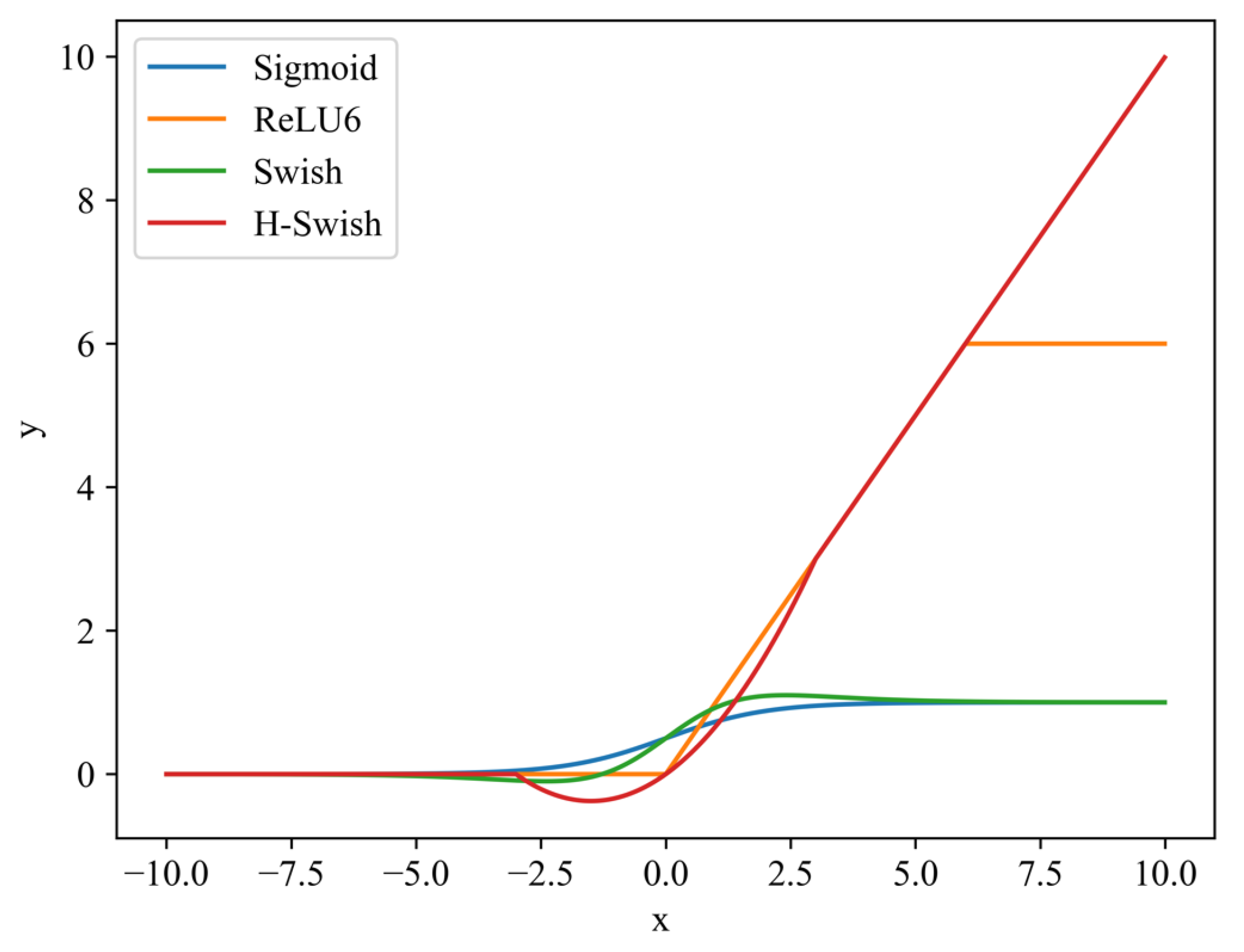
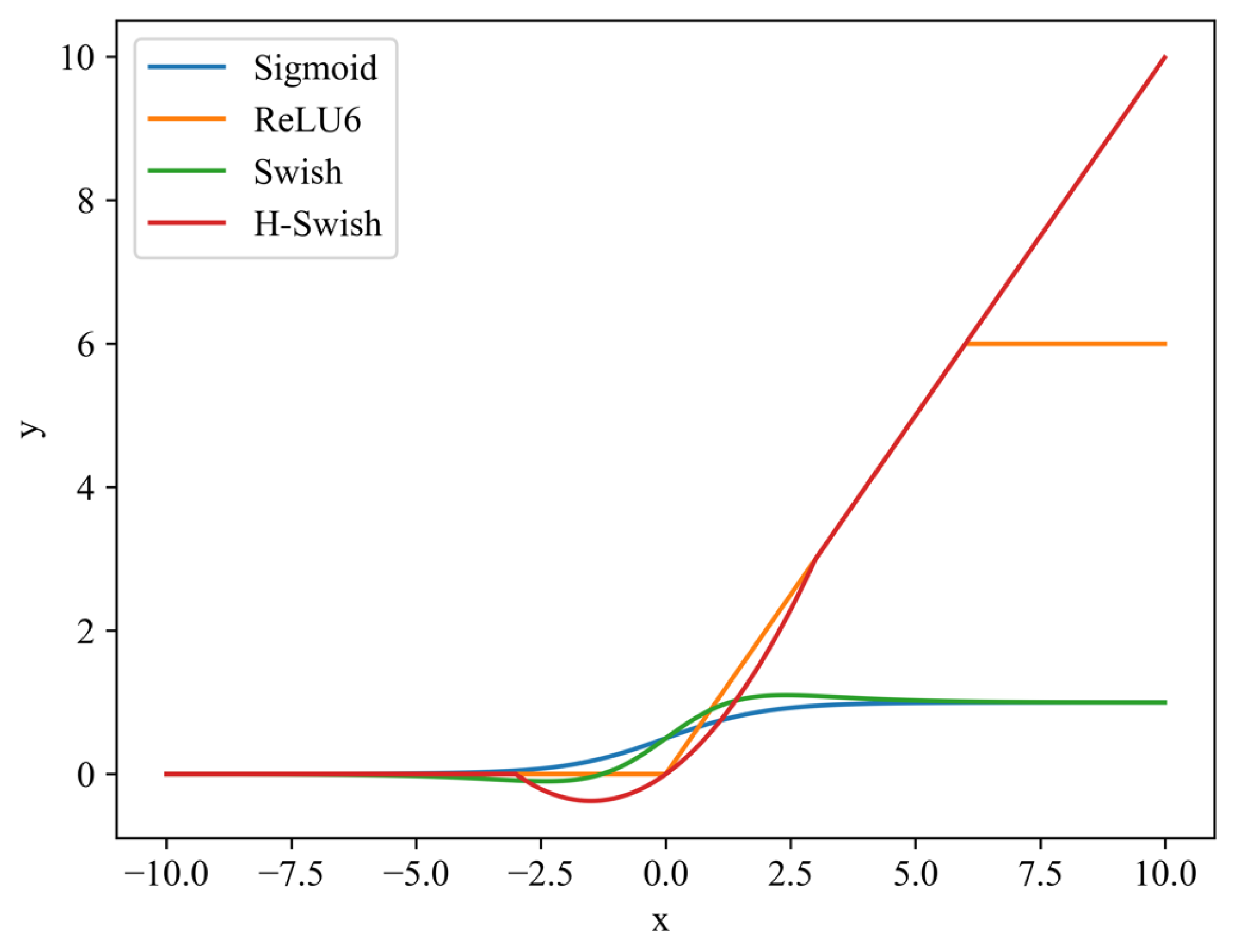
2.2. ACB Module
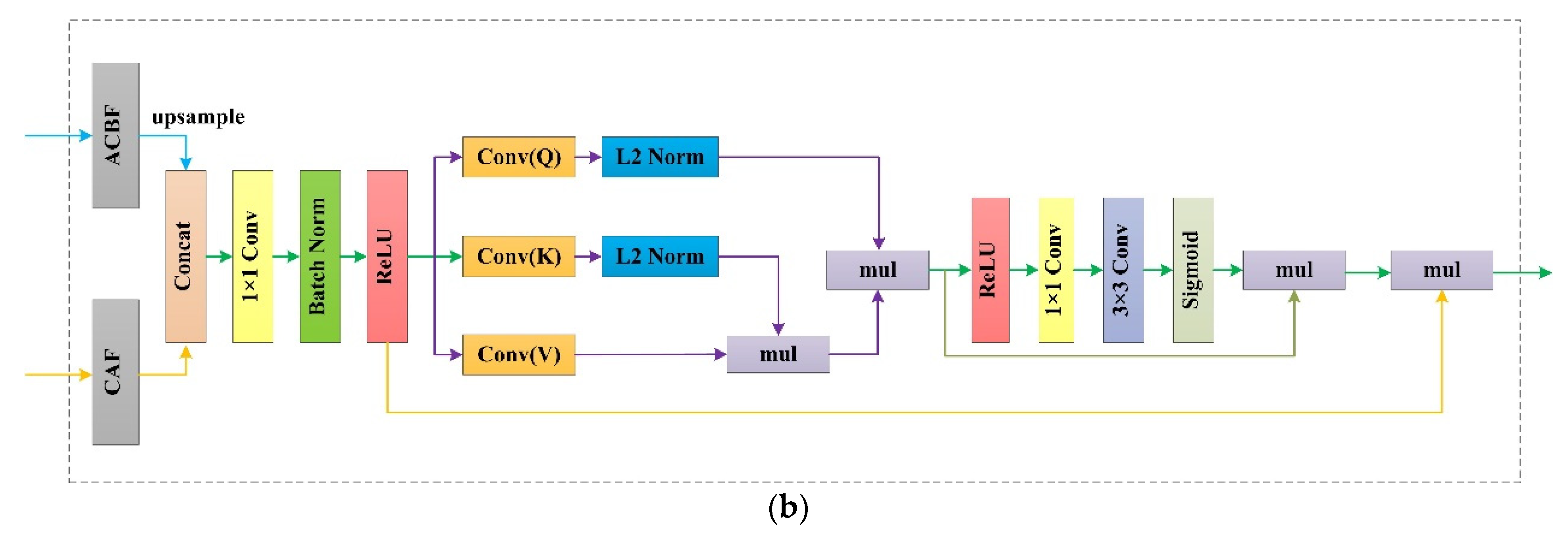
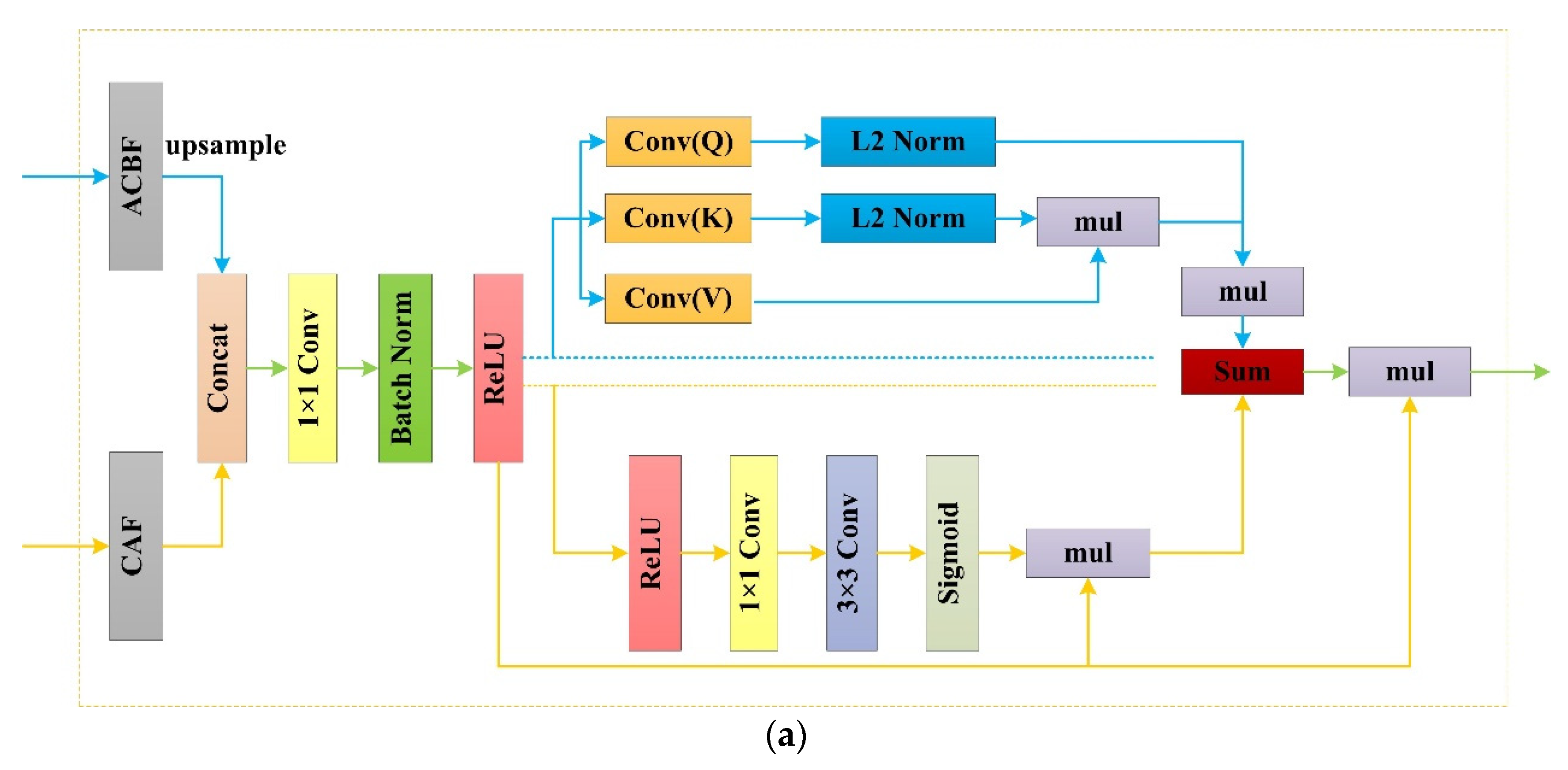
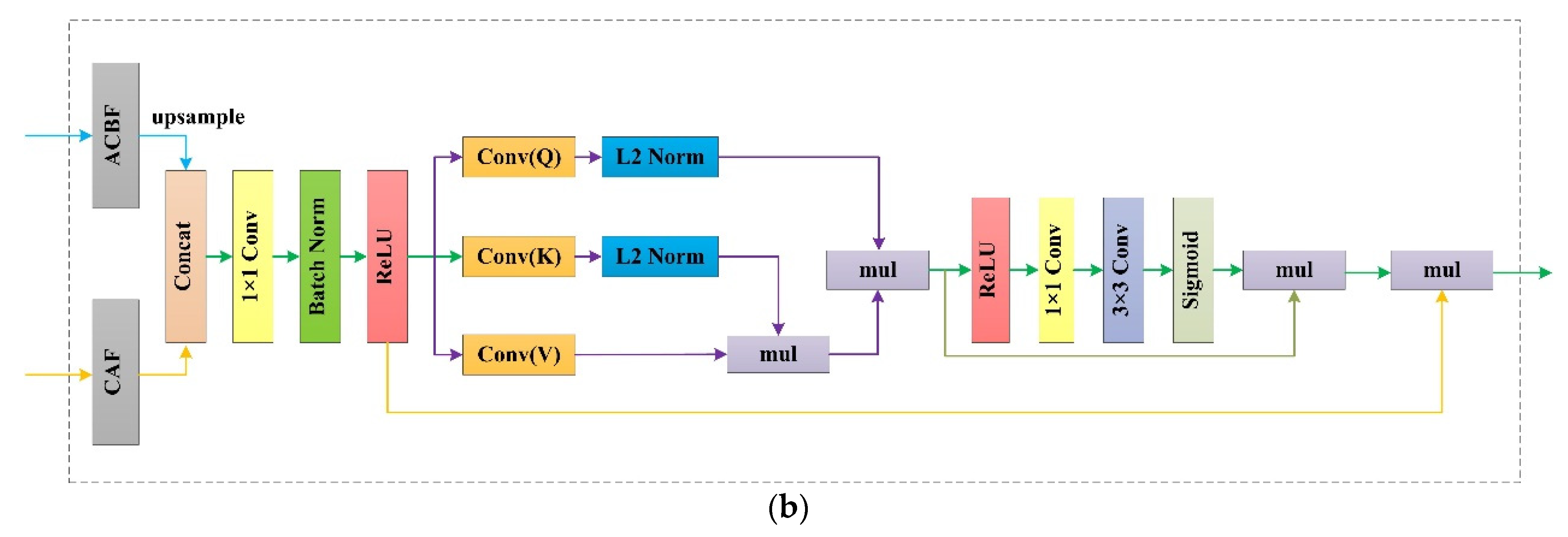
2.3. RFB Module
3. Experimental Results
3.1. Datasets
3.2. Implementation Details
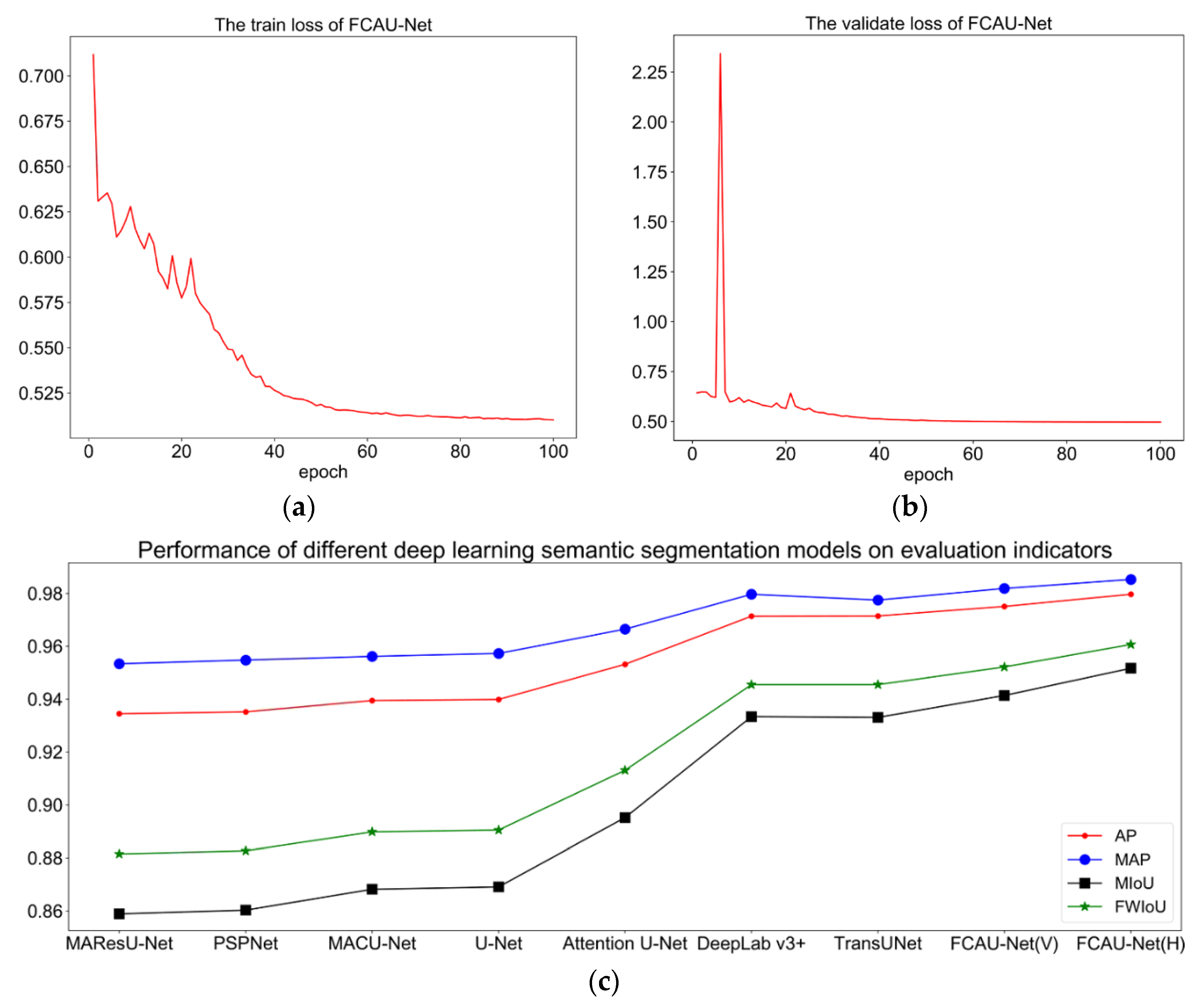
The Loss Function
3.3. Evaluation Metrics
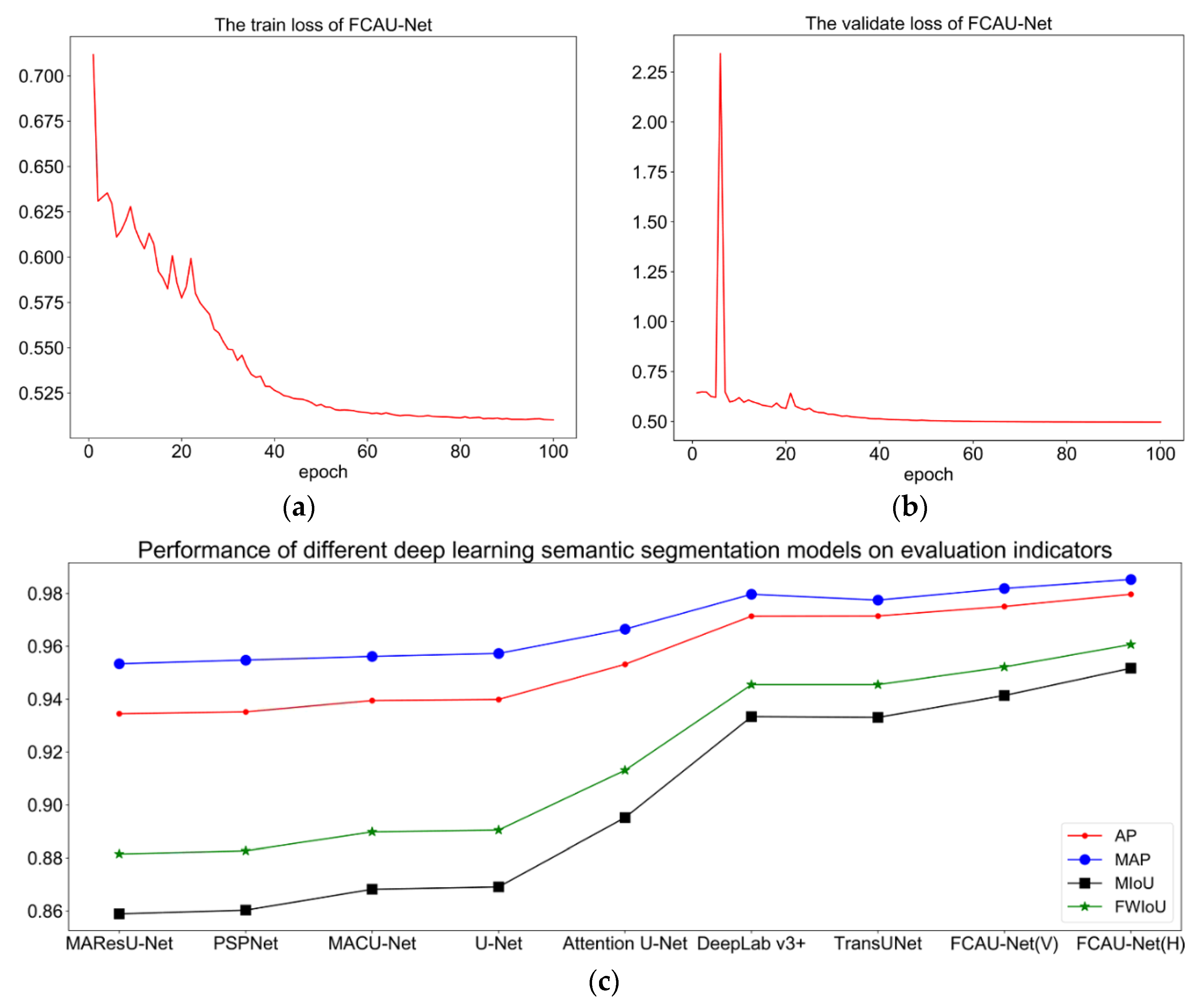
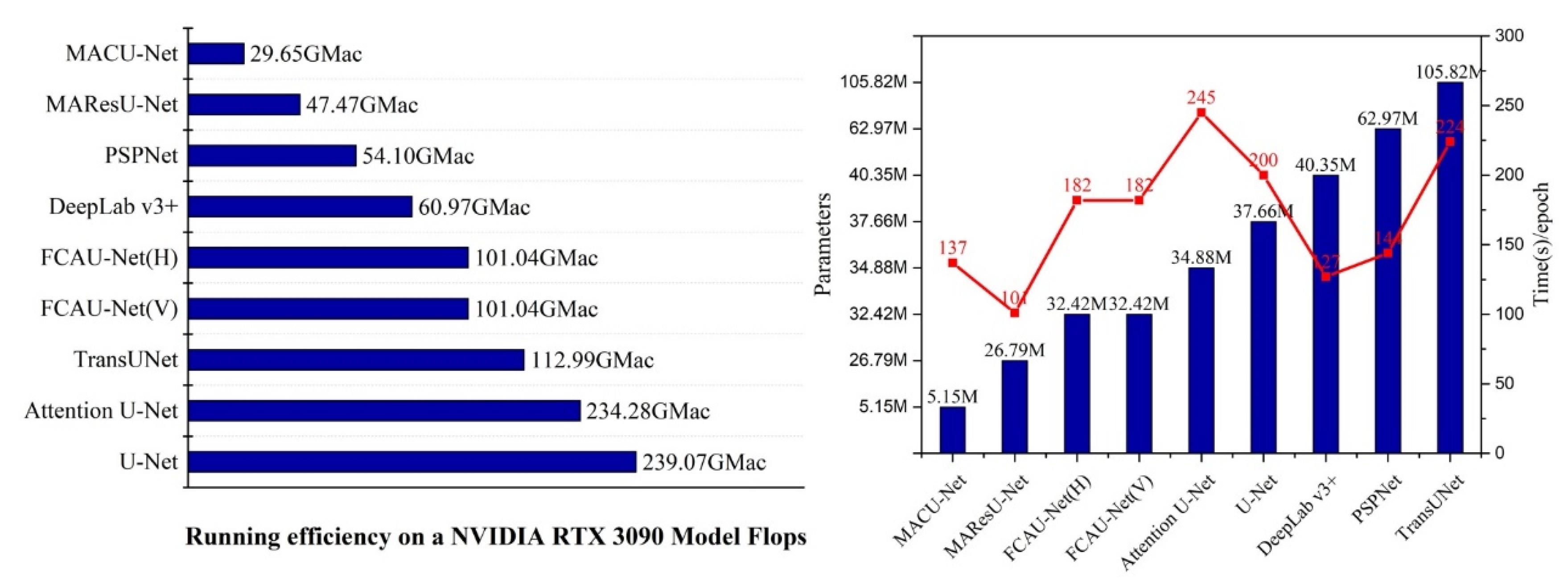
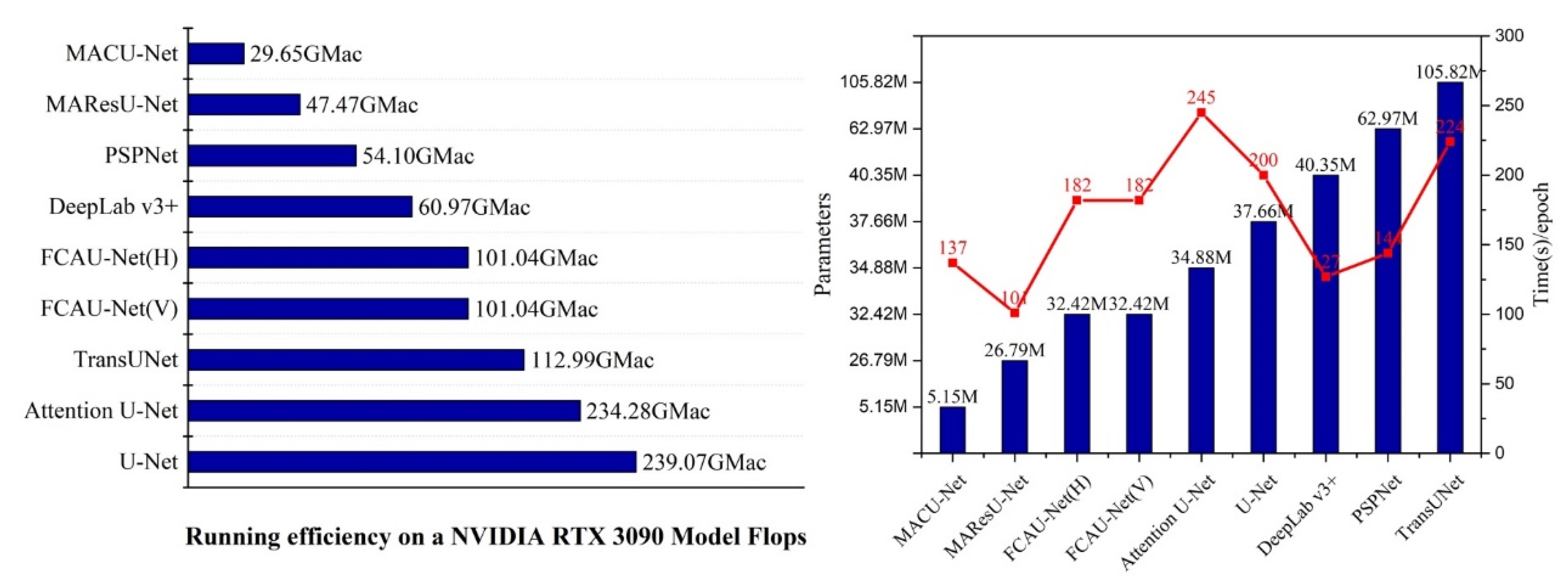
3.4. Experimental Results
4. Discussion
4.1. Ablation Study
4.2. Influence of the Input Size
4.3. Optimization
4.4. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, Q.; Liu, J.H.; Li, Y.W.; Zhang, H. Semantic Segmentation with Attention Mechanism for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 1–13. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, G.; Zhang, G.X. Collaborative Network for Super-Resolution and Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 1–12. [Google Scholar] [CrossRef]
- Zheng, X.W.; Wu, X.J.; Huan, L.X.; He, W.; Zhang, H.Y. A Gather-to-Guide Network for Remote Sensing Semantic Segmentation of RGB and Auxiliary Image. IEEE Trans. Geosci. Remote Sens. 2021, 1–15. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.Y.; Duan, C.X. Feature Pyramid Network with Multi-Head Attention for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. arXiv 2021, arXiv:2102.07997. [Google Scholar]
- Li, R.; Zheng, S.Y.; Zhang, C.; Duan, C.X.; Wang, L.B.; Atkinson, P.M. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of Fine-Resolution remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2021, 18, 84–98. [Google Scholar] [CrossRef]
- Wang, L.B.; Li, R.; Wang, D.Z.; Duan, C.X.; Wang, T.; Meng, X.L. Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Yang, X.; Li, S.S.; Chen, Z.C.; Jocelyn, C.; Jia, X.P.; Zhang, B.; Li, B.P.; Chen, P. An fusion network for semantic segmentation of very-high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]
- Deng, G.H.; Wu, Z.C.; Wang, C.J.; Xu, M.Z.; Zhong, Y.F. CCANet: Class-Constraint Coarse-to-Fine Attentional Deep Network for Subdecimeter Aerial Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2021, 1–20. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Duan, C.X.; Pan, J.; Li, R. Thick Cloud Removal of Remote Sensing Images Using Temporal Smoothness and Sparsity Regularized Tensor Optimization. Remote Sens. 2020, 12, 3446. [Google Scholar] [CrossRef]
- Zhang, C.; Harrison, P.A.; Pan, X.; Li, H.; Sargent, I.; Atkinson, P.M. Scale Sequence Joint Deep Learning (SS-JDL) for land use and land cover classification. Remote Sens. Environ. 2020, 237, 111593. [Google Scholar] [CrossRef]
- Huang, Y.; Qin, R.J.; Chen, X.Y. Unmanned Aerial Vehicle for Remote Sensing Applications—A Review. Remote Sens. 2019, 11, 1443. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Segment-before-Detect: Vehicle Detection and Classification through Semantic Segmentation of Aerial Images. Remote Sens. 2017, 9, 368. [Google Scholar] [CrossRef] [Green Version]
- Matikainen, L.; Karila, K. Segment-Based Land Cover Mapping of a Suburban Area-Comparison of High-Resolution Remotely Sensed Datasets Using Classification Trees and Test Field Points. Remote Sens. 2011, 3, 1777–1804. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.L.; Seto, K.C. Mapping urbanization dynamics at regional and global scales using multi-temporal DMSP/OLS nighttime light data. Remote Sens. Environ. 2011, 115, 2320–2329. [Google Scholar] [CrossRef]
- Wei, Y.N.; Wang, Z.L.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Li, E.; Femiani, J.; Xu, S.; Zhang, X.; Wonka, P. Robust Rooftop Extraction from Visible Band Images Using Higher Order CRF. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4483–4495. [Google Scholar] [CrossRef]
- Li, R.; Duan, C.X.; Zheng, S.Y.; Zhang, C.; Atkinson, P.M. MACU-Net for semantic segmentation of fine-resolution remotely sensed images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Rutherford, G.N.; Guisan, A.; Zimmermann, N.E. Evaluating sampling strategies and logistic regression methods for modelling complex land cover changes. J. Appl. Ecol. 2007, 44, 414–424. [Google Scholar] [CrossRef]
- Du, Q.; Chang, C.I. A linear constrained distance-based discriminant analysis for hyperspectral image classification. Pattern Recognit. 2001, 34, 361–373. [Google Scholar] [CrossRef]
- Maulik, U.; Saha, I. Automatic fuzzy clustering using modified differential evolution for image classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3503–3510. [Google Scholar] [CrossRef]
- Guo, Y.P.; Jia, X.P.; Paull, D. Effective Sequential Classifier Training for SVM-Based Multitemporal Remote Sensing Image Classification. IEEE Trans. Image Process. 2018, 27, 3036–3048. [Google Scholar]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Adede, C.; Oboko, R.; Wagacha, P.W.; Atzberger, C. A mixed model approach to vegetation condition prediction using artificial neural networks (ANN): Case of Kenya’s operational drought monitoring. Remote Sens. 2019, 11, 1099. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Pan, X.; Li, H.P.; Gardiner, A.; Sargent, I.; Hare, J.; Atkinson, P.M. A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification. ISPRS J. Photogramm. Remote Sens. 2018, 140, 133–144. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.K.; Zhu, J.; Cao, Y.G.; Feng, D.J.; Hu, M.J.; Li, W.L.; Zhang, Y.H.; Fu, L. Refined extraction of building outlines from high-resolution remote sensing imagery based on a multifeature convolutional neural network and morphological filtering. IEEE J. Sel. Top Appl. Earth Obs. Remote Sens. 2020, 13, 1842–1855. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.Y.; Duan, C.X.; Yang, Y.; Wang, X.Q. Classification of hyperspectral image based on double-branch dual-attention mechanism network. Remote Sens. 2020, 12, 582. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.Y.; Zhang, C.; Duan, C.X.; Su, J.L.; Wang, L.B.; Atkinson, P.M. Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 1–13. [Google Scholar] [CrossRef]
- Jung, H.; Choi, H.S.; Kang, M. Boundary Enhancement Semantic Segmentation for Building Extraction from Remote Sensed Image. IEEE Trans. Geosci. Remote Sens. 2021, 1–12. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.W.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J.M. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep learning in medical image analysis and multimodal learning for clinical decision support, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Li, R.; Zheng, S.Y.; Duan, C.X.; Su, J.L.; Zhang, C. Multistage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Huang, H.M.; Lin, L.F.; Tong, R.F.; Hu, H.J.; Zhang, Q.W.; Iwamoto, Y.; Han, X.H.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.W.; Jia, J.Y. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Peng, C.L.; Ma, J.Y. Semantic segmentation using stride spatial pyramid pooling and dual attention decoder. Pattern Recognit. 2020, 107, 107498. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaise, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Tsotsos, J.K. A Computational Perspective on Visual Attention; MIT Press: London, UK, 2011. [Google Scholar]
- Tsotsos, J.K. Analyzing vision at the complexity level. Behav. Brain Sci. 2011, 13, 423–469. [Google Scholar] [CrossRef]
- Li, R.; Su, J.L.; Duan, C.X.; Zheng, S.Y. Linear attention mechanism: An efficient attention for semantic segmentation. arXiv 2020, arXiv:2007.14902. [Google Scholar]
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.M.; Li, H.F. MAP-Net: Multiple attending path neural network for building footprint extraction from remote sensed imagery. IEEE Transactions on Geoscience and Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6169–6181. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.J.; Li, Y.; Bao, Y.J.; Fang, Z.W.; Lu, H.Q. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2018; pp. 3–19. [Google Scholar]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Liu, S.C.; Zhao, H.; Du, Q.; Bruzzone, L.; Samat, A.; Tong, X.H. Novel Cross-Resolution Feature-Level Fusion for Joint Classification of Multispectral and Panchromatic Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Zheng, Y.J.; Liu, S.C.; Du, Q.; Zhao, H.; Tong, X.H.; Dalponte, M. A novel multitemporal deep fusion network (MDFN) for short-term multitemporal HR images classification. IEEE J-STARS 2021, 14, 10691–10704. [Google Scholar]
- Nigam, I.; Huang, C.; Ramanan, D. Ensemble Knowledge Transfer for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1499–1508. [Google Scholar]
- Ullah, I.; Abinesh, S.; Smyth, D.L.; Karimi, N.B.; Drury, B.; Glavin, F.G.; Madden, M.G. A virtual testbed for critical incident investigation with autonomous remote aerial vehicle surveying, artificial intelligence, and decision support. In Proceedings of the ECML PKDD 2018 Workshops, Dublin, Ireland, 10–14 September 2018; pp. 216–221. [Google Scholar]
- Ding, X.H.; Guo, Y.C.; Ding, G.G.; Han, J.G. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1911–1920. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Chen, L.C.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, J.N.; Lu, Y.Y.; Yu, Q.H.; Luo, X.D.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y.Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Huang, J.F.; Zhang, X.C.; Xin, Q.C.; Sun, Y.; Zhang, P.C. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Label | |||
|---|---|---|---|
| True | False | ||
| GT data | True | TP | FN |
| (True Positive) | (False Negative) | ||
| False | FP | TN | |
| (False Positive) | (True Negative) | ||
| Method | ZY-3 | DeepGlobe | ||||||
|---|---|---|---|---|---|---|---|---|
| PA | mPA | mIoU | FWIoU | PA | mPA | mIoU | FWIoU | |
| MAResU-Net | 93.45 | 95.34 | 85.89 | 88.15 | 93.78 | 88.45 | 82.02 | 88.49 |
| PSPNet | 93.52 | 95.48 | 86.03 | 88.27 | 93.29 | 88.37 | 81.01 | 87.74 |
| MACU-Net | 93.95 | 95.62 | 86.82 | 88.98 | 93.72 | 88.88 | 82.04 | 88.45 |
| U-Net | 93.99 | 95.73 | 86.91 | 89.05 | 92.94 | 87.14 | 79.94 | 87.11 |
| Attention U-Net | 95.32 | 96.65 | 89.52 | 91.31 | 92.58 | 85.61 | 78.70 | 86.40 |
| DeepLab v3+ | 97.14 | 97.97 | 93.34 | 94.55 | 93.85 | 89.50 | 82.50 | 88.71 |
| TransUNet | 97.15 | 97.75 | 93.31 | 94.55 | 94.28 | 90.19 | 83.58 | 89.43 |
| FCAU-Net(V) | 97.51 | 98.19 | 94.14 | 95.22 | 94.78 | 90.97 | 84.86 | 90.28 |
| FCAU-Net(H) | 97.97 | 98.53 | 95.17 | 96.07 | 95.05 | 91.27 | 85.54 | 90.74 |
| Method | Time (s)/Epoch | Flops (GMac) | Parameters (M) |
|---|---|---|---|
| MAResU-Net | 101 | 47.47 | 26.79 |
| PSPNet | 144 | 54.10 | 62.97 |
| MACU-Net | 137 | 29.65 | 5.15 |
| U-Net | 200 | 239.07 | 37.66 |
| Attention U-Net | 245 | 234.28 | 34.88 |
| DeepLab v3+ | 127 | 60.97 | 40.35 |
| TransUNet | 224 | 112.99 | 105.82 |
| FCAU-Net(V) | 182 | 101.04 | 32.42 |
| FCAU-Net(H) | 182 | 101.04 | 32.42 |
| Dataset | Method | PA | mPA | mIoU | FWIoU |
|---|---|---|---|---|---|
| ZY-3 | Baseline | 93.99 | 95.73 | 86.91 | 89.05 |
| ACB | 96.49 | 97.49 | 91.95 | 93.38 | |
| ACB-RFB(V) | 97.08 | 97.91 | 93.21 | 94.44 | |
| ACB-RFB(H) | 97.39 | 98.13 | 93.89 | 95.01 | |
| ACB-RFB(V)-CA | 97.51 | 98.19 | 94.14 | 95.22 | |
| ACB- RFB (H)-CA | 97.97 | 98.53 | 95.17 | 96.07 | |
| DeepGlobe | Baseline | 92.94 | 87.14 | 79.94 | 87.11 |
| ACB | 93.53 | 90.12 | 82.04 | 88.27 | |
| ACB- RFB(V) | 94.38 | 91.11 | 84.04 | 89.66 | |
| ACB- RFB(H) | 94.58 | 90.77 | 84.39 | 89.96 | |
| ACB- RFB(V)-CA | 94.78 | 90.97 | 84.86 | 90.28 | |
| ACB- RFB(H)-CA | 95.05 | 91.27 | 85.54 | 90.74 |
| Dataset | Input_Size | PA | mPA | mIoU | FWIoU |
|---|---|---|---|---|---|
| ZY-3 | [480,480,3] | 97.97 | 98.53 | 95.17 | 96.07 |
| [256,256,3] | 97.27 | 97.87 | 93.60 | 94.77 | |
| [224,224,3] | 97.27 | 97.82 | 93.59 | 94.77 | |
| DeepGlobe | [480,480,3] | 95.05 | 91.27 | 85.54 | 90.74 |
| [256,256,3] | 92.14 | 85.42 | 77.84 | 85.75 | |
| [224,224,3] | 92.37 | 86.05 | 78.50 | 86.16 |
| Loss | PA | mPA | MIoU | FWIoU |
|---|---|---|---|---|
| both Dice and CE losses (α = β = 0.5) | 97.24 | 97.84 | 93.56 | 94.74 |
| both Dice and CE losses (α = β = 2.0) | 97.26 | 97.86 | 93.58 | 94.76 |
| both Dice and CE losses (α = β = 1.0) | 97.27 | 97.87 | 93.60 | 94.77 |
| both Dice and CE losses (α = 1, β = 0.5) | 97.24 | 97.83 | 93.54 | 94.73 |
| both Dice and CE losses (α = 1, β = 2.0) | 97.25 | 97.85 | 93.56 | 94.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, X.; Zeng, Q.; Luo, X.; Chen, L. FCAU-Net for the Semantic Segmentation of Fine-Resolution Remotely Sensed Images. Remote Sens. 2022, 14, 215. https://doi.org/10.3390/rs14010215
Niu X, Zeng Q, Luo X, Chen L. FCAU-Net for the Semantic Segmentation of Fine-Resolution Remotely Sensed Images. Remote Sensing. 2022; 14(1):215. https://doi.org/10.3390/rs14010215
Chicago/Turabian StyleNiu, Xuerui, Qiaolin Zeng, Xiaobo Luo, and Liangfu Chen. 2022. "FCAU-Net for the Semantic Segmentation of Fine-Resolution Remotely Sensed Images" Remote Sensing 14, no. 1: 215. https://doi.org/10.3390/rs14010215
APA StyleNiu, X., Zeng, Q., Luo, X., & Chen, L. (2022). FCAU-Net for the Semantic Segmentation of Fine-Resolution Remotely Sensed Images. Remote Sensing, 14(1), 215. https://doi.org/10.3390/rs14010215