1. Introduction
With the development of technology, it has become easier to obtain remote sensing images, which offers unprecedented conveniences and opportunities for many research directions. These fields include remote sensing image scene classification, change detection, geographic imaging, video retrieval, land-use classification, and automatic target recognition [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. As an essential problem in remote sensing images, the scene classification task aims to accurately classify satellite images to the correct category (e.g., airplane, river, highway, and farm) for unlabeled aerial images, which has been applied to some image interpretation tasks such as environmental monitoring, residential planning, and land resource management [
11,
12]. However, the remote sensing scene images have small target objects, dense distribution, different target orientations, and higher image resolution than natural images [
13,
14]. For example, an airport area consists of many different geographic structures such as airplanes with different orientations and sizes, airstrips, and terminals, which can lead these images to have different semantic classes. These features result in low interclass disparity and high within-class variability in aerial images [
15]. Therefore, remote scene images with the same semantic label may have a high difference, making scene classification more complex than natural images.
Usually, the scene classification of the remote-sensing image method needs to first extract global low-level features as the visual descriptor [
15]. In this phase, the bag-of-visual-words (BOVW) model is a common and promising tool to extract visual descriptors. A set of visual words is acquired by the BOVW. The image is represented by simple statistical values for each visual word occurrence based on the visual dictionary. The method can narrow the gap between low-level features and high-level semantics [
15]. These statistical results are regarded as training data to improve classification performance. Several improved variants of BOVW have been developed to further the ability to describe these complex images, such as spatial pyramid match kernel (SPMK) [
16], randomized spatial partition (RSP) [
17], spatial pyramid co-occurrence kernel (SPCK) [
18], and pyramid of spatial relations (PSR) [
19]. However, these methods rely heavily on handcrafted low-level features and the design of mid-level feature representation. Gaining these features requires a large amount of prior information, limiting portability across domains and datasets. In addition, using these methods cannot model the spatial relationship of an image by simply counting the occurrences of the local features. The method based on BOVW has limited descriptive ability for these features, which makes it difficult to achieve further remote sensing scene classification performance.
In recent years, deep learning (DL) has been widely used in many image tasks. From deep confidence networks (DBN) and deep restricted Boltzmann machines (DBM) to deep convolutional neural networks (CNN), dramatic improvements have been obtained in different image domains. In particular, CNNs are acknowledged as the most popular method due to their ability to learn hierarchical level abstraction of input data by encoding input data on different layers [
20]. Compared with the traditional method, CNN methods have achieved far better classification performance. The early method of CNN for scene classification prefers to train from scratch. However, CNN is a data-oriented model, and the quality of data determines the performance of the CNN model. Thus, during the training phase, a quantity of well-annotated data is necessary for the CNN model. Unfortunately, compared with natural images, remote sensing image data are tricky to obtain and annotate. The few high-quality annotated data are easily overfitted when training a CNN model, which affects the final classification accuracy. To solve this problem, pretrained CNN models as extractors for deep features have gained considerable attention [
21]. Recently, some works demonstrated that existing CNN models pretrained on large dataset such as ImageNet can be transferred to other image tasks [
20]. This transfer strategy can avoid most drawbacks in training a CNN from scratch, especially the problem of lack of training data. Various models based on ImageNet have achieved many competitive results compared to early state-of-the-art work [
2].
However, the ImageNet dataset is a natural image dataset, and it has only a small amount of remote sensing images. A recent survey [
22] revealed that the model trained from random initialization was not worse than the ImageNet pretrained model. Although the research demonstrated that pretraining with ImageNet could speed up convergence, training from random initialization can achieve the same performance after enough iterations. The pretrained model does not automatically give better regularization, and the fine-tuned phase needs sufficient data and new hyperparameters need to be selected to avoid overfitting. In other words, it is not convenient to use ImageNet for pretraining. For example, ImageNet pretrained models show no benefit when the target tasks/metrics are more sensitive to spatial predictions [
22]. Compared with natural images, aerial images have more spatial features, including highly complex geometrical structures, and the content of the image varies greatly in scale, shape, and orientation. These characteristics show that CNN models based on natural images are not necessarily suitable for the specific spatial patterns of remote sensing images. ImageNet pretrained models limit the scene classification performance of aerial images. Therefore, it is urgent to design an original model to solve aerial images instead of using pretrained CNN models directly.
Nevertheless, designing a neural network architecture directly for remote sensing images requires expert knowledge and takes ample time. Trial and error is a time-consuming process. Most recently, there has been a focus on designing a CNN model for image tasks using a machine automatically. This approach can save time and manpower compared to the manual design of neural architectures. Neural architecture search (NAS) [
23], a rapidly developing research direction in automated machine learning, aims to automatically design a CNN model with good performance and high accuracy. Early NAS methods have achieved impressive empirical performance in various tasks, such as image classification, but these approaches are still time-consuming and computationally expensive. In addition, most of the current methods of NAS are performed on natural images, and few works in the literature have solved high spatial resolution aerial image tasks because these tasks require many computing resources in the search phase. Gradient-based NAS has been proposed in recent years, which has reduced time consumption and computational cost. It is possible to apply gradient-based NAS to solve remote sensing images with few computational resources.
In this paper, we conclude the limitation of the high-level features extracted from a pretrained model and confirm the effectiveness of large-scale datasets for training NAS methods. To address these constraints from pretrained methods and create a suitable aerial image model, a new paradigm is proposed to automatically design a CNN model for remote sensing scene classification. The contributions to this paper are summarized as follows.
(1) We present a novel framework called RS-DARTS and use it to search optimal cells, stacking a new CNN model to improve remote sensing scene classification performance. The method in the paper can help to automatically design a more suitable CNN model for aerial images, which solves problems faced by existing handcrafted CNNs based on natural images. It can also handle the collapse issue in searched phases of neural architecture search methods based on remote sensing images.
(2) Some efficient architecture regularization schemes are proposed to improve the efficiency of the search process and reduce the advantage of skip connections to avoid model collapse. Some new strategies are presented to promise a high correlation between the search and evaluation phases. In addition, a noise is added to suppress the skip connections and ensure classification accuracy.
(3) To reduce the consumption of computing resources in the searched phases, we sample the neural architecture in a particular proportion to speed up these search phases. Compared with other previous methods, our method needs less time in the searched phases while still obtaining better classification accuracy.
(4) The effectiveness of the proposed RS-DARTS framework is demonstrated on four public benchmark datasets. Extensive experiments reveal that the final discovered optimal CNN model achieves better classification than the fully trained and pre-trained CNN model. Moreover, the framework performance is better than that of other NAS methods (includes some NAS methods applied to natural images and remote images, respectively) in terms of search efficiency and time consumption. By comparison, RS-DARTS achieved state-of-the-art accuracy of remote sensing image scene classification and improved search time cost by nearly five times compared to DARTS.
The remainder of this article is organized as follows.
Section 2 discusses and summarizes CNN models and development of the NAS frameworks.
Section 3 describes the principle of differentiable architecture search methods, then we present our approach. In
Section 4 and
Section 5, the description of dataset, experiment setup, and classification result are shown. Finally, the conclusion is shown in
Section 6.
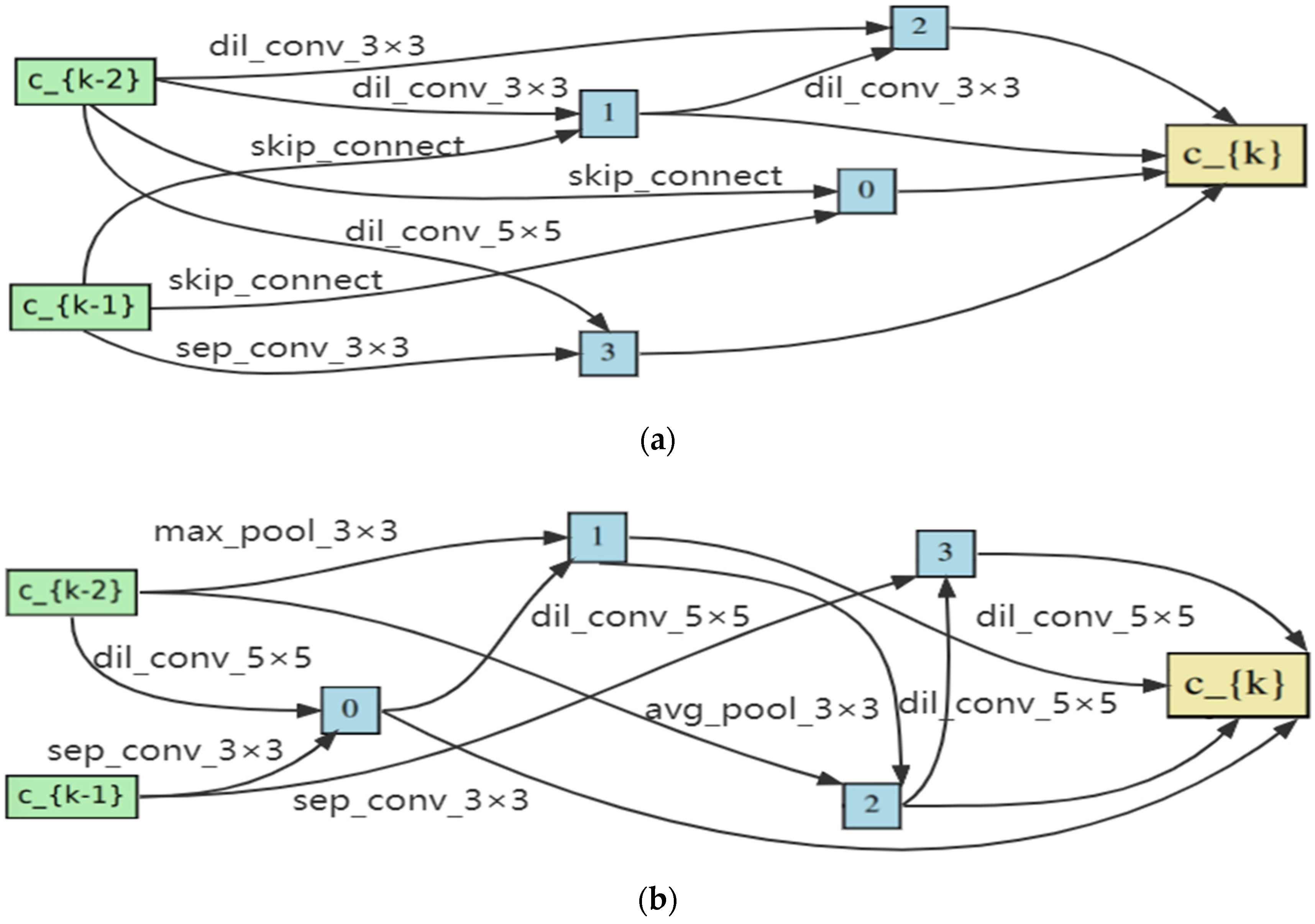
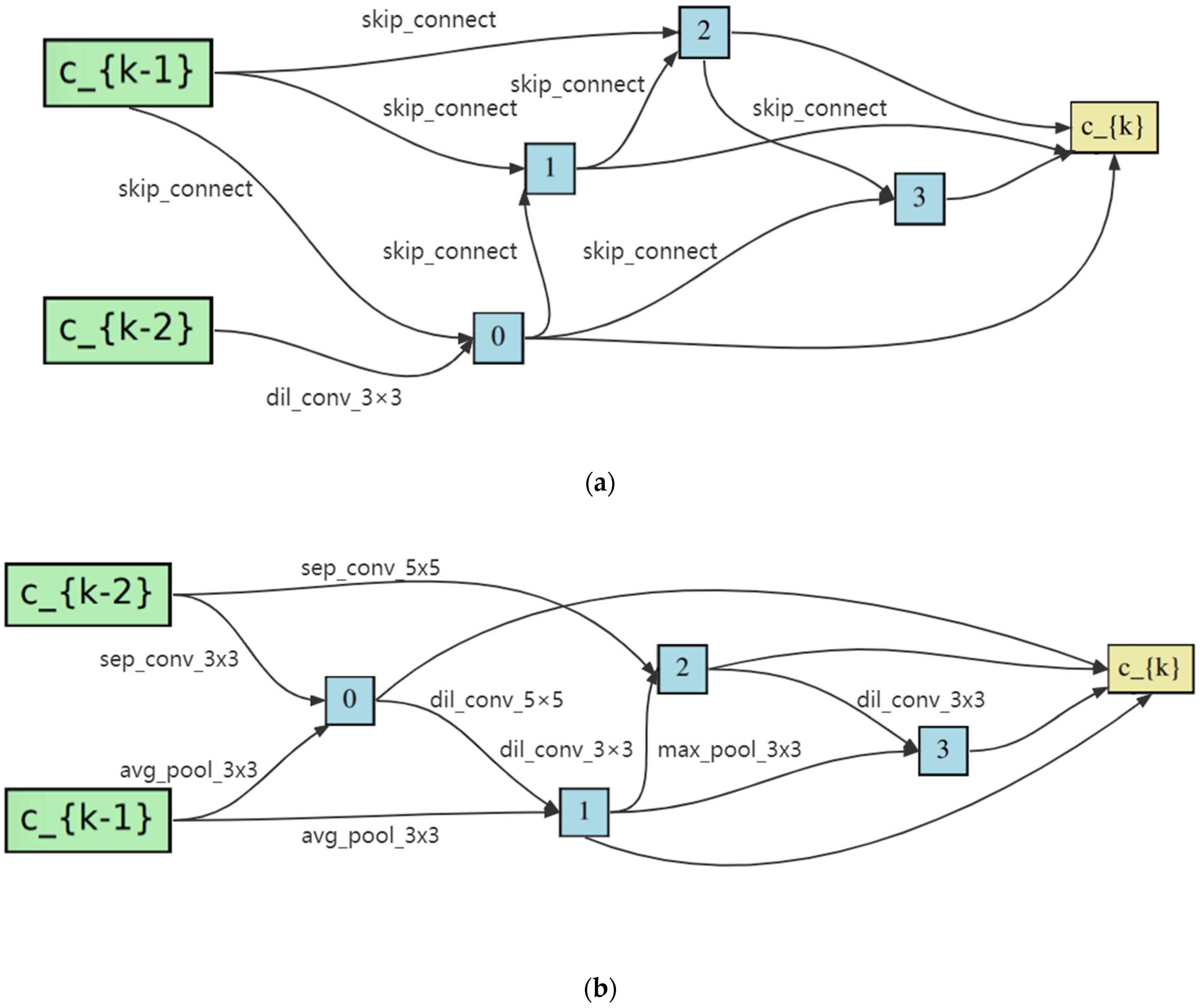
3. The Proposed Method
In this section, the differentiable architecture search methods (DARTS) are introduced, and the limitations of the methods are analyzed [
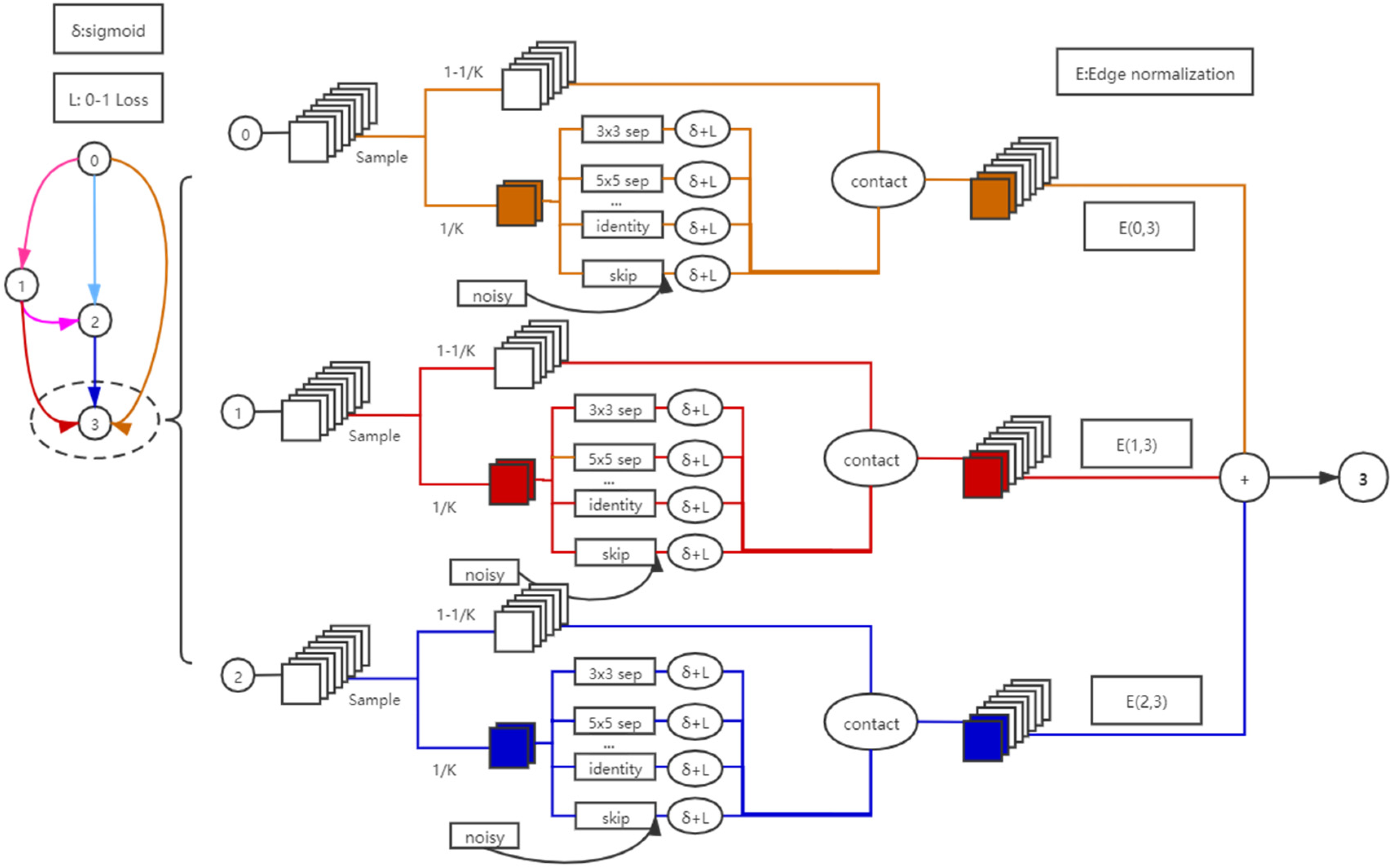
41]. Then, the proposed search framework is described, and some rules are introduced to strengthen the correlation between the search and evaluation phases. In addition, noise is added to alleviate the collapse in the search phase, and the sample rule is proposed to reduce redundancy in the search phase. The overall framework of the algorithm in this work is illustrated in
Figure 1.
As an example, we investigate how information is propagated to node
3. There are three symbols during the search phase, namely,
,
and
. Here,
represents the sigmoid function.
L represents the 0–1 Loss function, and
E represents edge normalization. These functions and symbols are explained in
Section 3.2. To determine the calculation results, we only sample a subset,
, of channels and connect them to the next stage so that the memory consumption is reduced by
K times [
42,
43]. During sample processing,
and
are used to make the calculation smoother and distinguish candidate operations easily. Meanwhile, noise was added to the skip connection to reduce competitiveness with other operations. Then, to minimize the uncertainty incurred by sampling, we use
for normalization.
3.1. Preliminary: DARTS
As a gradient-based approach, DARTS is much simpler than other search frameworks and can produce high-performance architectures in many tasks. Compared with RL-based and EA-based NAS methods, DARTS does not use the controller [
36,
44], hypernetworks [
45], and performance predictors [
46]. Gradient descent mechanism allows DARTS to find suitable network architectures with few GPU days.
Following these works [
33,
40,
41], DARTS first searched for an optimal computation cell in the search phase. The searched optimal cells stack to form a convolutional network or are recursively connected to form a recurrent network. A cell, as a directed acyclic graph (DAC), consists of an ordered sequence of
N nodes. Each node
is a latent representation, which represents a feature map in a convolutional neural network. Each directed edge (
i,j) in the DAG represents a candidate computational operation
that transforms
. In DARTS, it sets the cell to have two input nodes and one output node. Each intermediate node is calculated based on its predecessor nodes [
39]. Node
is obtained by calculating node
via Equation (1).
where
represents the candidate computing operation (e.g., convolution, max pooling, zero) for edge
. To make the search space continuous, DARTS uses the softmax function to relax the categorical choice of a particular operation. The softmax function calculation formula is as follows.
where the operation mixing weights for
are parameterized by a vector
of dimension
. The task of the search method reduces learned a set of continuous variables
. After of the relaxation, the architecture
and the weights
are jointly learned within all the mixed operations (e.g., weights of the convolution filters). The
and
denote loss function for training and validation in the search phase, and determine both the architecture parameters
and the weight
in the network. The goal for architecture search is to find
that minimizes the validation loss
, where the weights
associated with the architecture are obtained by minimizing training loss
[
31]. DARTS uses a bilevel optimization approach to realize this goal, shown in Equations (3) and (4), where
is the higher-level variable, and
is the lower-level variable.
Bilevel optimization is more complex than other optimization methods, which requires lots of computation resources. DARTS applies an approximate approach to solve the problem. The approximation scheme as follows:
where
denotes current weights maintained by the algorithm, and
is learning rate for a step of the inner optimization. If
has reached the local partial optimum, namely
, Equation (5) can be simplified as
. In other words, we update the training parameters by the crossover method and finally achieve convergence. For instance, we first update
and used it to update the network weight
. Then, the new network weight
is used to update the operations weight
. The method has been applied to many works, such as meta-learning for model migration [
47], gradient-based hyperparameter fine-tuning [
48], and unfolded generative adversarial networks [
49].
Although DARTS dramatically reduces the search time, there are still some problems. First, the optimal normal cell seared by DARTS involves many skip connections in the selected architecture, making the architecture shallow and exhibiting poor performance. First, a shallow network has fewer learnable parameters than a deep network, and thus, it has weaker expressive power. Second, the redundant space of network architecture causes heavy memory and computation overheads. At the same time, the problem is exacerbated by processing high-resolution remote sensing images. These problems prevent the search process from using a larger batch size to either speed up or obtain higher stability [
43]. A novel search framework is proposed to address these drawbacks, which is more efficient and suitable to solve remote sensing image tasks. The details of our presented framework are shown in
Section 3.2.
3.2. Remote Sensing DARTS for Scene Classfication
3.2.1. Collaboration Mechanism and Binarization of Structural Parameters
In the search phase of DARTS, the skip connection is similar to the residual connection of ResNet [
50]. It can help the framework obtain superior accuracy in the search phase. However, the
value of the skip connection becomes large when the number of search epochs is large. Thus, the number of skip connections increases in the selected architecture, which can cause collapse in the search phases. Meanwhile, the softmax function is based on exclusive competition, and it enhances the growth of the unfair competitive advantage of the skip-connection [
51].
To solve the unfair competition between skip-connections and other operations, we use a cooperative mechanism to limit it. The sigmoid function
is used to replace softmax function to calculation parameter
. It can help each operation selected independently without any competition. Equation (2) is modified as follows,
At the same time, when discretizing continuous encoding, DARTS suffers from discrepancies [
39]. In the search phases of DARTS, the structure parameter
takes a value in the range of
. The range is too narrow to distinguish between good and bad candidate operations [
51]. For instance, we select an edge of the cell, [0.1310, 0.1193, 0.1164, 0.1368, 0.1247, 0.1205, 0.1304, 0.1210], and these values are very close to each other. The highest value is 0.1368, and the next highest value is 0.1310, so it is hard to say an operation weighted by 0.1368 is better than another weighted by 0.1310. To solve the problem, the 0–1 loss function is proposed to restrict the sigmoid function results produced. The value of the structure weight can only be 0 or 1. Therefore, when selecting the final operation, we will choose the operation with a weight value of 1. If there are multiple weights of 1 in a set of data, these operations are tried and selected as the most profitable operation. The processing is similar to DARTS, where the two operations with the highest weight are selected [
39]. The 0–1 loss function is expressed as follows.
where the Equation (8) is like L2-norm, it easily makes the weight of operations achieved 0 or 1 and helps distinguish between good and bad operations. A control variable
is added to control the strength of the
function. The final loss function is as follows:
Then, Equation (3) will be modified to 10.
3.2.2. Adding Noise in Skip-Connection
Using only a collaboration mechanism is not an excellent solution to solve the unfair competition in search phases. The collapse of the model still occurs when searching computation cells. Unbiased random noise is applied in the output of skip connects [
52]. This not only suppresses unfair competition but also helps the training of deep models [
53]. Thus, a small and unbiased noise is introduced, which has zero mean and small variance.
As random noise
adds to the output of skip connection, and
represents the structural weight of skip connection. The expression of the loss function for skip connection can be written as,
where
represents the validated loss function and
represents the sigmoid function to calculate
. If the noise is much smaller than the output values, then we can get Equation (12),
In the noisy scenario, the derivation of the skip connection is expressed in Equation (13).
As mentioned above, if
, there is no effect on the computed output. In this work, the Gaussian noise is used to attenuate the unfair competition of the skip connection. Equation (6) should be modified to (14),
3.2.3. Sample 1/K of All Channels into Mixed Computation
Despite its sophisticated design, DARTS still has a spatial redundancy problem in search phases and suffers from heavy memory and computation overheads [
48]. To solve this problem, we randomly sample a subset while bypassing the rest directly in a shortcut [
43]. The ideal method avoids sending all channels into the operation selection. The computation on this subset is an approximate agent and calculation on all channels. It can cause a tremendous reduction in the memory and computation costs and help to avoid getting stuck in local optima.
Using the strategy can significantly increase the batch size and speed up the trained processing. Specifically, as only 1/
K of channels are randomly sampled for an operation selection, it reduces the memory burden by almost
K times [
42,
43]. The rule allows using a
K times large batch size during training, which not only speeds up the network search but also makes the process, particularly for large scale datasets, more stable. The parameter
is introduced to define whether the channel is marked or not. The selected channel is marked as 1, and the unselected channel is marked as 0. Therefore, Equation (14) in determining the channel is expressed as follows.
where
represents the selected channels and
represents the unselected channels. But the sampled strategy can cause undesired fluctuation in the resultant network architecture [
43]. To alleviate the problem, we introduce edge normalization, the computation of
becomes:
where
represents the normalization operation on
. These parameter
and
decide the connectivity of edge
. The modified optimization process codenamed RS-DARTS is shown in Algorithm 1. Paying attention to the value of
, it is assigned to the learning rate for the optimizer of the network weight
.
| Algorithm 1 Remote Sensing DARTS for Scene Classification algorithm |
Input: Initialize the following parameters: Architecture parameter , network weight , noise control parameter 0–1 Loss control parameter , learning rate , Epoch Max While: not reach Epoch Max do Data segmentation:
1: Initialize the network weight , learning rate ; 2: Sample 1/K feature map using computation; 3: Inject random Gaussian noise into the skip connection output; 4: Update architecture by descending ; 5: Update the network weight by ;
Endwhile Derive the final architecture and output the architecture parameter
|




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}