
Lifting Scheme-Based Sparse Density Feature Extraction for Remote Sensing Target Detection



Abstract
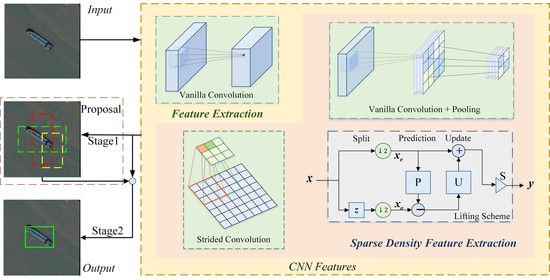
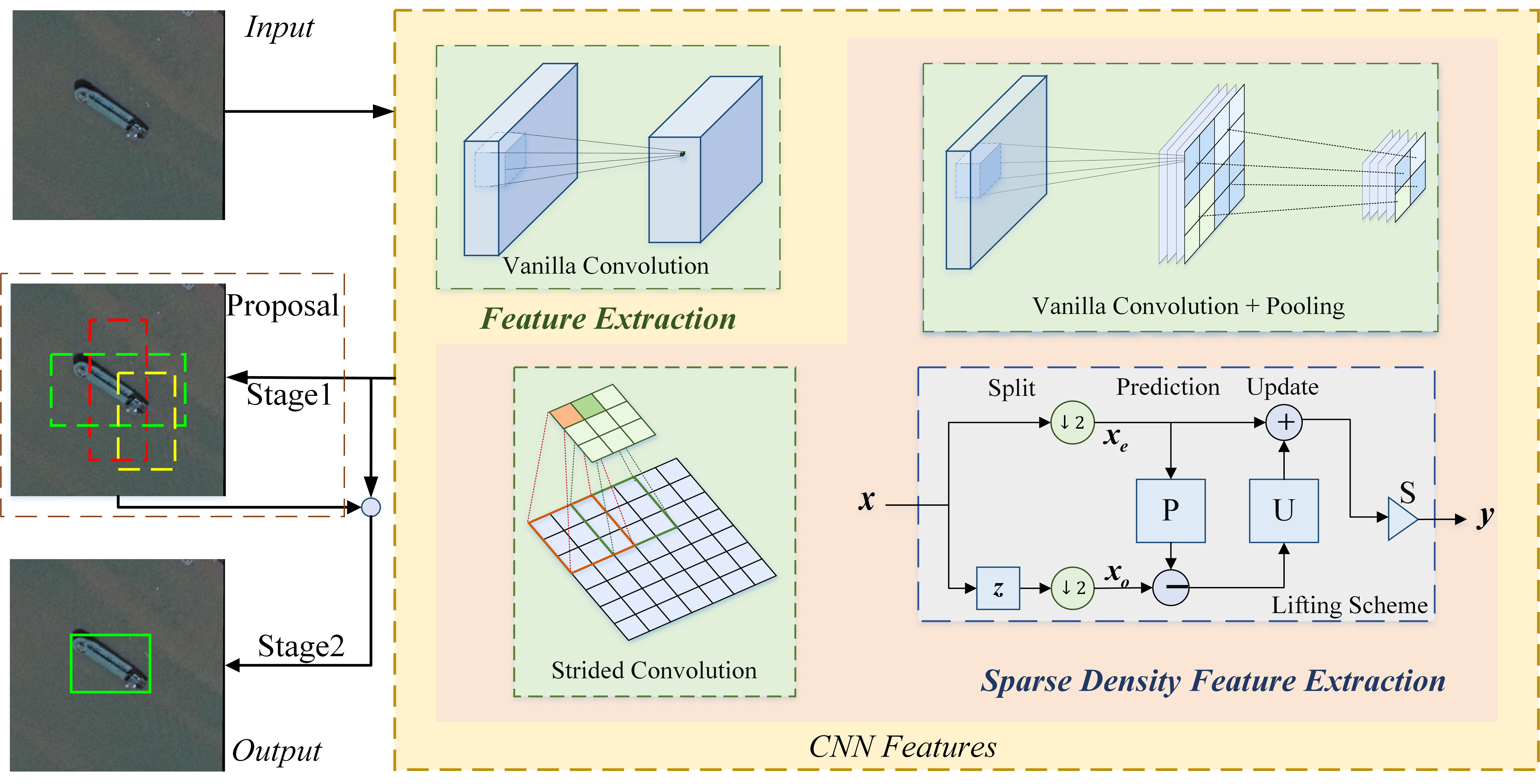
1. Introduction
1.1. Problems and Motivations
1.2. Contributions and Structure
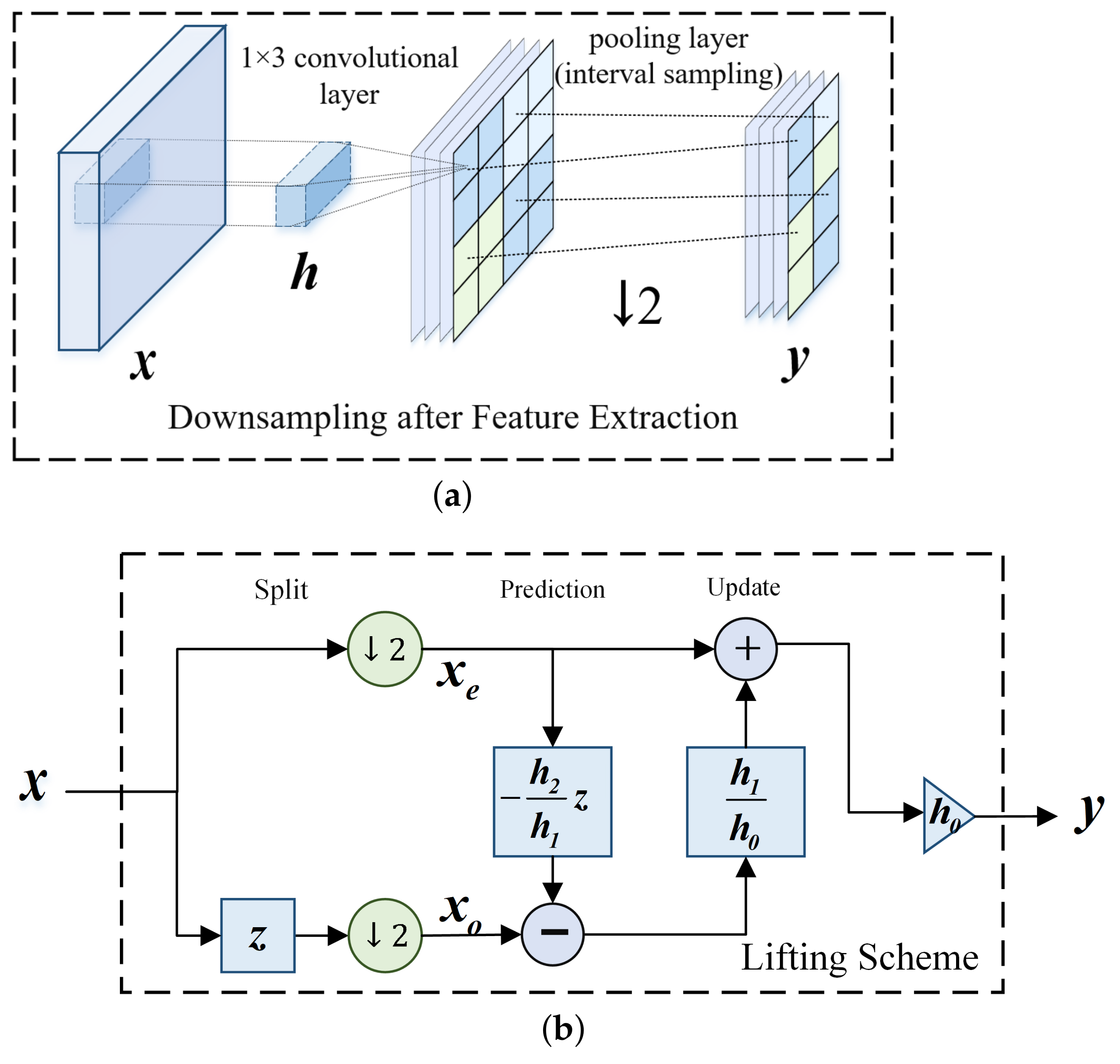
- The lifting scheme is proved to be an approximate implementation of the downsampling after extraction approach, having the same output but with a half of calculations.
- A lifting scheme layer is presented and applied in the detection network backbone as the sparse density feature extraction layer. Compared with the strided convolution, the lifting scheme layer performs better with respect to the metric of detection precision, while the computational complexity is almost the same.
- Experiments are carried out on the remote sensing target detection task on the SAR image dataset SSDD [24] and AIR-SAR [25] and the optical remote sensing image dataset DOTA [26]. The results indicate that the proposed method is more effective compared with the strided convolution on the metrics of detection precision and computational complexity.
2. Related Work
2.1. Target Detection Networks
2.2. Sparse Density Feature Extraction
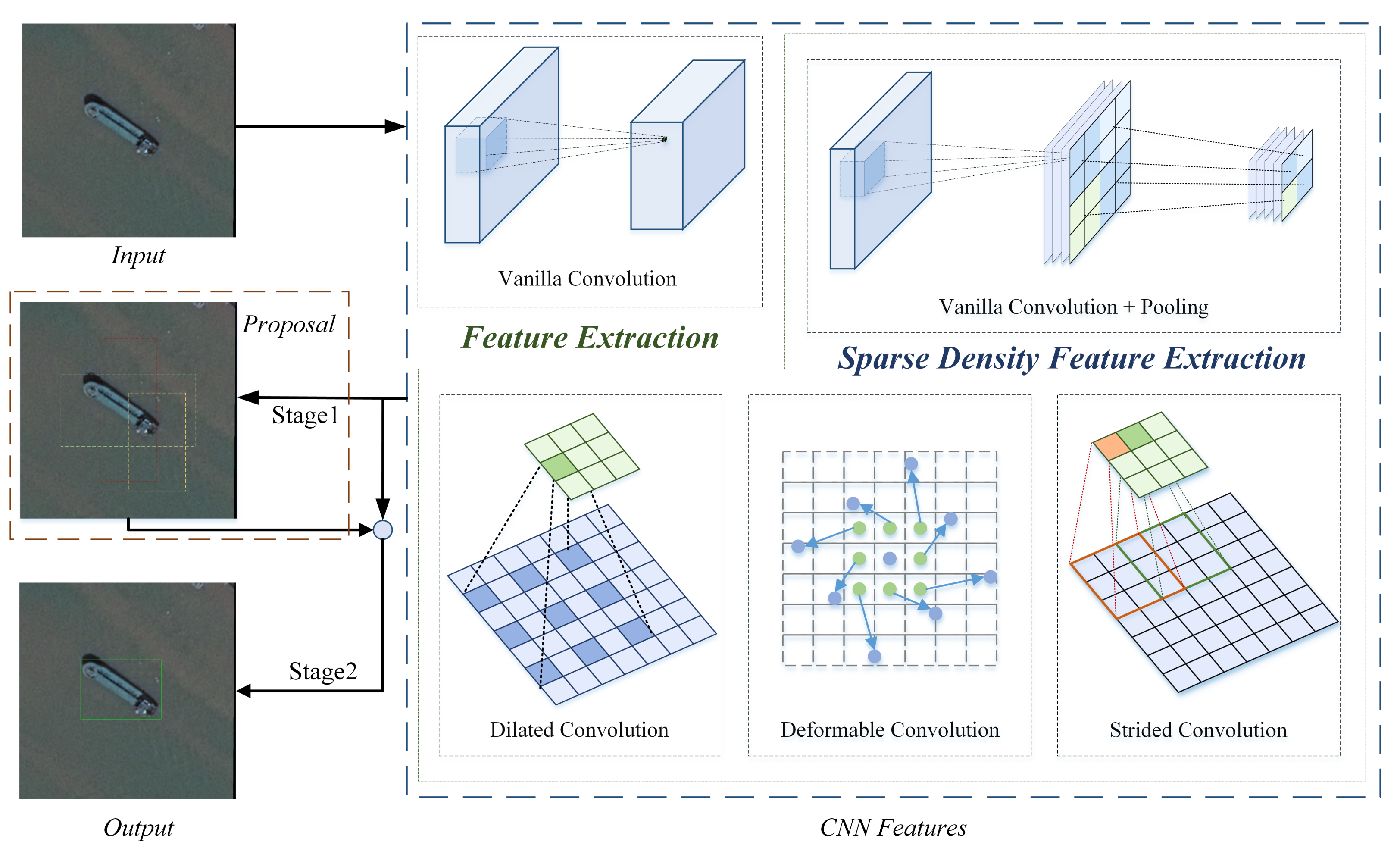
- Downsampling after extraction: It is used in some typical CNNs, such as LeNet [8], AlexNet proposed by Alex Krizhevsky et al. [31], and VGG by Visual Geometry Group [2]. Features are extracted by a stride 1 vanilla convolutional layer and then downsampled by a pooling layer. The whole process can be viewed as reducing the extraction density. With the pooling layer, the dimensions of feature maps are decreased and so does the spatial resolution, which may lead to the loss of internal data structure and spatial hierarchical information.
- Dilated convolution [9]: It inserts holes in the feature maps from the vanilla convolutional layer to increase the receptive field without harming spatial resolution. Compared with vanilla convolution, there is an additional hyper-parameter in the dilated convolution named dilated rate, which is the span between holes. The dilated convolution reduces the feature extraction density since not all pixels in the feature maps are used in the computation. The dilated convolution reserves the inner data structure but its checker-board form leads to the gridding effect and the loss of the information continuity.
- Deformable convolution [10]: It is similar to the dilated convolution as it also reduces feature extraction density in a sparse way. A learnable offset variable is added to the position of each sampling point in the convolution kernel so that the convolution kernel can sample randomly near the current location to fit the irregular shape of the object. The number of parameters and calculations of deformable convolution is more than vanilla convolution.
- Strided convolution: Strided convolutional layer is used for dimensional reduction in many detection networks. It is a learnable dimensional reduction layer superior to the pooling layer since it overcomes the drawbacks of the pooling layer, such as fixed structure and irreversible information loss. However, the strided convolutional layer loses the information about adjacent feature points which leads to the omission of some useful features. Compared with the downsampling after extraction method, the strided convolutional layer decreases the detection precision [15].
2.3. From Wavelet to Lifting Scheme
- Split: The input signal is split into two non-overlapping subsets A and B.
- Prediction: Subset A is predicted by subset B with some predicted error produced.
- Update: Subset B is updated with the prediction error to maintain the same average as the input signal.
2.4. Lifting Scheme for Vanilla Convolutional Layer
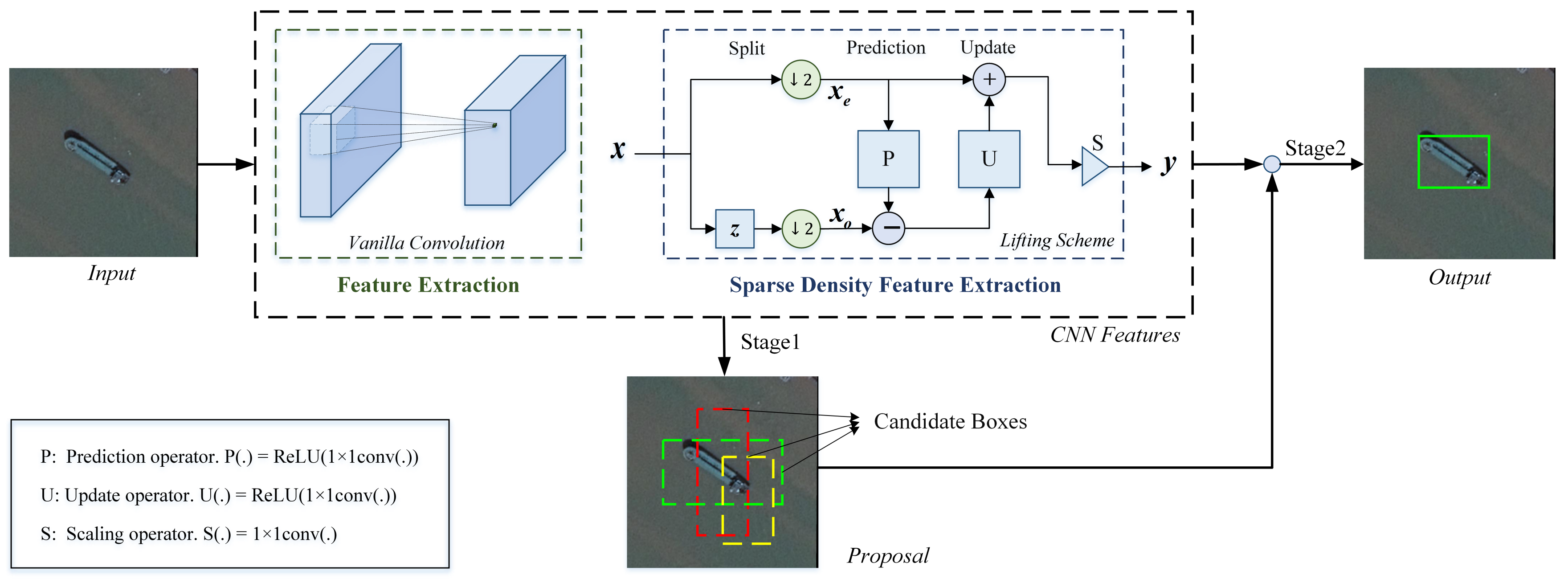
3. Proposed Method
3.1. Lifting Scheme for the Downsampling after Extraction Method
3.2. Lifting Scheme Layer
3.3. Lifting Scheme-Based Detection Network Flowchart
4. Experimental Results
4.1. Dataset Description
4.1.1. SAR Image Dataset
4.1.2. Optical Remote Sensing Image Dataset
4.2. Evaluation Metrics
4.2.1. Detection Performance Metrics
4.2.2. Network Efficiency Metrics
4.3. Compared Methods
- Cascade R-CNN. The baseline in the experiment. It is a two-stage detection network with the ResNet-50 backbone. Strided convolutional layer is the sparse density feature extraction module in the backbone.
- Cascade R-CNN-CP. The structure and settings are the same as the baseline except that the strided convolutional layer is substituted by a stride 1 convolutional layer (vanilla convolutional layer) followed by a pooling layer. Thus, this method is to evaluate the feature downsampling after extraction method and compare it with the strided convolution method. The pooling layer used in this paper is max-pooling.
- Cascade R-CNN-DCN. Deformable convolutional layer substitutes all of the stride 1 and strided convolutional layers with the size of in one module if its condition is set “True”. This network is to evaluate the effectiveness of the deformable convolution in remote sensing target detection and illustrate the advancement of our proposed method.
- Cascade R-CNN-LS. The proposed lifting scheme layer is used as the sparse density feature extraction module to replace the strided convolutional layer in the baseline. Other structures and settings of Cascade R-CNN-LS are the same as the baseline.
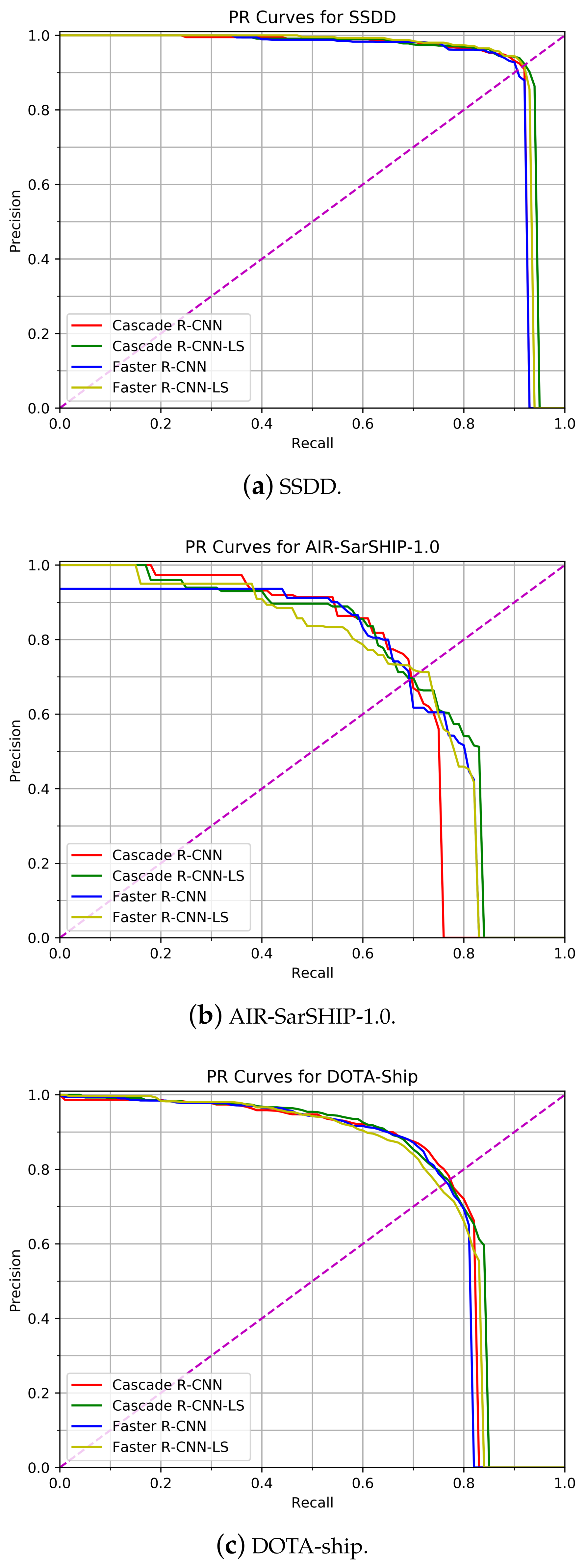
4.4. Results on SAR Image Datasets
4.5. Results on Optical Remote Sensing Image Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. Densenet: Implementing efficient convnet descriptor pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the NIPS’15: Proceedings of the 28th International Conference on Neural Information Processing Systems, Bali, Indonesia, 8–12 December 2021; pp. 91–99. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Sweldens, W. Lifting scheme: A new philosophy in biorthogonal wavelet constructions. In Proceedings of the International Society for Optics and Photonics, San Diego, CA, USA, 9–14 July 1995; Volume 2569, pp. 68–80. [Google Scholar]
- Sweldens, W. The lifting scheme: A custom-design construction of biorthogonal wavelets. Appl. Comput. Harmon. Anal. 1996, 3, 186–200. [Google Scholar] [CrossRef]
- Sweldens, W. The lifting scheme: A construction of second generation wavelets. SIAM J. Math. Anal. 1998, 29, 511–546. [Google Scholar] [CrossRef]
- Heijmans, H.J.; Goutsias, J. Nonlinear multiresolution signal decomposition schemes. II. Morphological wavelets. IEEE Trans. Image Process. 2000, 9, 1897–1913. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Wang, R.; Li, J. Nonlinear wavelets and bp neural networks adaptive lifting scheme. In Proceedings of the 2010 International Conference on Apperceiving Computing and Intelligence Analysis Proceeding, Chengdu, China, 17–19 December 2010; pp. 316–319. [Google Scholar]
- Calderbank, A.; Daubechies, I.; Sweldens, W.; Yeo, B.L. Wavelet transforms that map integers to integers. Appl. Comput. Harmon. Anal. 1998, 5, 332–369. [Google Scholar] [CrossRef]
- Daubechies, I.; Sweldens, W. Factoring wavelet transforms into lifting steps. J. Fourier Anal. Appl. 1998, 4, 247–269. [Google Scholar] [CrossRef]
- He, C.; Shi, Z.; Qu, T.; Wang, D.; Liao, M. Lifting Scheme-Based Deep Neural Network for Remote Sensing Scene Classification. Remote Sens. 2019, 11, 2648. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Xian, S.; Zhirui, W.; Yuanrui, S.; Wenhui, D.; Yue, Z.; Kun, F. AIR-SARShip–1.0: High Resolution SAR Ship Detection Dataset. J. Radars 2019, 8, 852–862. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1440–1448. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Mallat, S.G. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Oppenheim, A.V.; Schafer, R.W. Discrete—Time Signal Processing; Pearson: Chennai, India, 1977. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | AP (%) | IT (ms) | #Params (MB) | BFLOPs |
|---|---|---|---|---|---|
| Cascade R-CNN | ResNet-50 | 90.8 | 46.3 | 552 | 91.05 |
| Cascade R-CNN-CP | ResNet-50-CP | 92.8 (+2.0) | 38 | 552.6 | 96.49 |
| Cascade R-CNN-DCN | ResNet-50-DCN | 92.1 (+1.3) | 43 | 557 | 83.86 |
| Cascade R-CNN-LS | ResNet-50-LS | 92.6 (+1.8) | 39 | 541 | 90.65 |
| Faster R-CNN | ResNet-50 | 90.6 | 37.5 | 330 | 63.66 |
| Faster R-CNN-LS | ResNet-50-LS | 92.0 (+1.4) | 34.6 | 322.5 | 63.26 |
| Method | Backbone | AP (%) | IT (ms) | #Params (MB) | BFLOPs |
|---|---|---|---|---|---|
| Cascade R-CNN | ResNet-50 | 67.8 | 55.55 | 552 | 91.05 |
| Cascade R-CNN-CP | ResNet-50-CP | 68.3 (+0.5) | 54 | 552.6 | 96.49 |
| Cascade R-CNN-DCN | ResNet-50-DCN | 69.6 (+1.8) | 55 | 557 | 83.86 |
| Cascade R-CNN-LS | ResNet-50-LS | 72.0 (+4.2) | 37 | 541 | 90.65 |
| Faster R-CNN | ResNet-50 | 70.0 | 37 | 330 | 63.66 |
| Faster R-CNN-LS | ResNet-50-LS | 70.1 (+0.1) | 37.3 | 322.5 | 63.26 |
| Method | Backbone | AP (%) | IT (ms) | #Params (MB) | BFLOPs |
|---|---|---|---|---|---|
| Cascade R-CNN | ResNet-50 | 76.6 | 44.49 | 552 | 91.05 |
| Cascade R-CNN-CP | ResNet-50-CP | 77.8 (+1.2) | 40 | 552.6 | 96.49 |
| Cascade R-CNN-LS | ResNet-50-LS | 77.9 (+1.3) | 45 | 541 | 90.65 |
| Faster R-CNN | ResNet-50 | 75.8 | 44.8 | 330 | 63.66 |
| Faster R-CNN-LS | ResNet-50-LS | 76.5 (+0.7) | 40 | 322.5 | 63.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, L.; Cao, Y.; Shi, Z.; He, B.; He, C.; Li, D. Lifting Scheme-Based Sparse Density Feature Extraction for Remote Sensing Target Detection. Remote Sens. 2021, 13, 1862. https://doi.org/10.3390/rs13091862
Tian L, Cao Y, Shi Z, He B, He C, Li D. Lifting Scheme-Based Sparse Density Feature Extraction for Remote Sensing Target Detection. Remote Sensing. 2021; 13(9):1862. https://doi.org/10.3390/rs13091862
Chicago/Turabian StyleTian, Ling, Yu Cao, Zishan Shi, Bokun He, Chu He, and Deshi Li. 2021. "Lifting Scheme-Based Sparse Density Feature Extraction for Remote Sensing Target Detection" Remote Sensing 13, no. 9: 1862. https://doi.org/10.3390/rs13091862
APA StyleTian, L., Cao, Y., Shi, Z., He, B., He, C., & Li, D. (2021). Lifting Scheme-Based Sparse Density Feature Extraction for Remote Sensing Target Detection. Remote Sensing, 13(9), 1862. https://doi.org/10.3390/rs13091862