1. Introduction
Image registration is the process of geometric synchronization between a reference image and a current image from the same area. These images are acquired from different times and viewpoints by different sensors [
1]. Thus, image registration is an essential preprocess step in many remote sensing applications because the main process, which includes change detection, image fusion, image mosaic, environment monitoring, and map updating can be drastically influenced by these differences [
1,
2]. Many types of image registration techniques have been developed in the areas of remote sensing over the past few decades. The registration frameworks can be classified into two categories—area-based frameworks and feature-based frameworks [
1].
We introduce the two conventional image registration frameworks for the two categories—area-based frameworks and feature-based frameworks. In area-based frameworks, the registration problem is transformed into an optimization problem, where the similarity between reference and sensed images is maximized. Conventional area-based registration frameworks find correspondences at multiple key-points between input and reference images using similarity measures such as mutual information (MI) [
3,
4] or normalized cross-correlation (NCC) [
5]. The detected correspondences are used in the estimation of the global geometric transform. However, they are sensitive to illumination changes and noise [
1]. Liang et al. proposed spatial and mutual information (SMI) as the similarity metric for searching similar local regions using ant colony optimization [
3]. Patel and Thakar employed mutual information (MI) based on maximum likelihood to expedite MI computation [
4]. In contrast, feature-based frameworks are less susceptible to attacks and geometric distortions as they involve the matching of prominent features, such as points, lines, and regions. Scale invariant feature transform (SIFT) [
6], speeded-up robust features [
7], histogram of oriented gradients [
8], and maximally stable extremal regions [
9] are some of the widely applied feature detectors in practice. The SIFT-based framework is a well-known geometric transform approach [
10]. Other approaches focus on the shape features or geometric structures. Ye et al. proposed the histogram of oriented phase congruency as a feature descriptor representing the structural properties of images, and then they used NCC as a reference matching similarity metric [
11]. Yang et al. proposed a combination of shape context features and SIFT feature descriptors for remote sensing image registration [
12]. There are approaches that integrate the advantages of the area-based and feature-based frameworks. The iterative multi-level strategy proposed by Xu at el. could re-extract and re-match features by adjusting the parameters [
13]. The coarse-to-fine image registration framework by Gong et al. acquired coarse results from SIFT and then obtained precise registration based on MI [
14].
Conventional feature-based frameworks require domain knowledge to design a feature extractor. This makes the handcrafted features less generic for diverse applications and data. Researchers often recommend feature-based frameworks if the images contain distinct artifacts. Feature-based frameworks are used in remote sensing image applications because the remote sensing images contain distinct artifacts [
1]. To ensure the accuracy of feature-based frameworks, a well-designed feature extractor that can extract reliable features through trial and error is required. Aerial images used for remote sensing applications contain a large amount of appearance distortions caused by radiometric and geometric factors, attitude acquisition-related factors, seasonal factors, and so on. Consequently, many registration frameworks suffer poor correspondence between points detected by handcrafted feature extractors. In worst-case scenarios, these handcrafted feature extractors may be unable to detect a sufficient number of correspondence points to achieve satisfactory registration.
In recent years, deep learning has proven to be superior and robust in the field of remote sensing imaging—object detection [
15,
16], image classification [
17,
18], and image registration [
19]. In particular, patch-based convolutional neural network (CNN) architectures have been extensively used in the area of image matching. Finding accurate correspondences between patches is instrumental to a broad range of applications, including wide-baseline stereo matching, multi-view reconstruction, image stitching, and structure from motion. Conventional patch matching methods use handcrafted features and distance measures. Zagoruyko and Komodakis proposed a CNN-based model that directly trains a general similarity function for comparing image patches from image data [
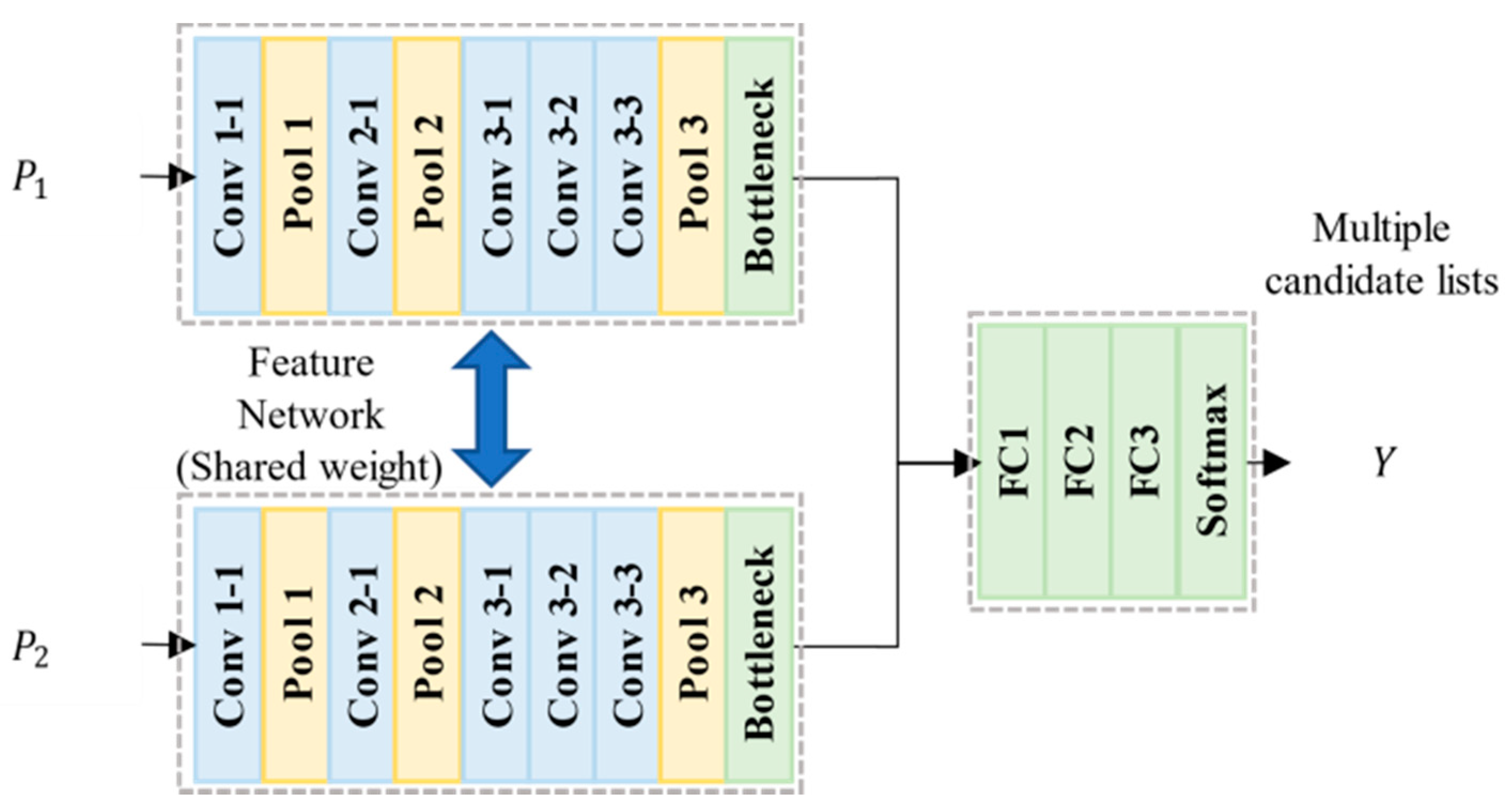
20]. CNNs can generate powerful feature descriptors that are more robust to appearance changes than classical descriptors. These approaches divide the input image into a set of local patches and extract descriptors individually from each patch. The extracted descriptors are then compared with an appropriate distance measure to measure the similarity score even for a binary matching/unmatching decision. Han et al. proposed “MatchNet”, which extracts patch pair features from two identical CNNs via the Siamese network for image patch matching [
21]. Alternatively, Zagoruyko and his colleagues proposed an image matching method by training the joint features of patches from two input images and evaluating the features extracted from two similar CNNs or two different CNNs [
22].
Wang and his colleagues proposed a deep learning framework for remote sensing image registration [
19]. They employed the deep belief network (DBN) to maintain the invariance feature against the distortion characteristics of remote-sensed images. Unlike conventional feature-based frameworks, their proposal directly trained an end-to-end mapping function by taking the image patch pairs as inputs using DBN and matching the labels as output. Furthermore, they attempted to reduce the computation cost in the training step. Their framework not only reduced the training time but also demonstrated better registration performance. As vectorized one-dimensional data from two-dimensional images are fed into the DBN, which may remove the spatial information for patch matching, they cannot handle geometric invariances in terms of rotation, translation, scale, shearing and so on. These variance factors in DBN may generate distortion in the registration result. To address this problem, Lee and Oh have proposed a MatchNet-based method which can improve the registration accuracy by maintaining the spatial information of features [
23]. However, there still exists geometric distortion as shown in
Figure 1. Rocco and his colleagues recently proposed the CNN architecture for geometric matching where they could handle global changes of appearance and incorrect matches between two matched images in a robust way [
24]. However, it is not efficient to apply their model to applications which require a precise local patch matching process in each matched patch of two input images such as remote sensing image registration. Therefore, their robust model should be modified for remote sensing image registration.
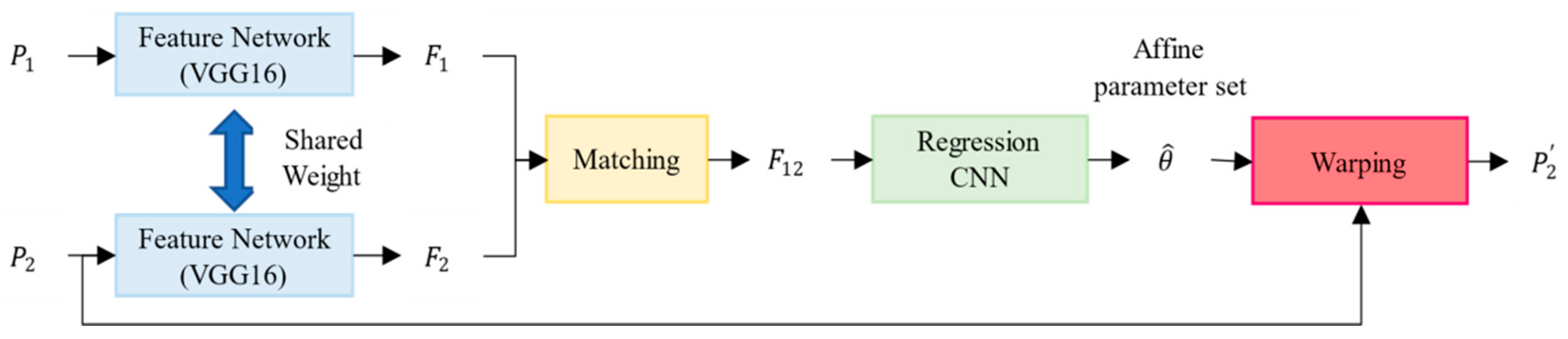
In this paper, we propose a CNN-based registration framework for remote sensing that can improve the registration accuracy between two remote-sensed images acquired from different times and viewpoints. The framework can be summarized as follows: First, multiple key-points and their patches are extracted from two input images using scale–space extrema detection. Each patch contains one key-point at its center. Using the conventional network, finding the corresponding patch pair in the matching step would yield geometric distortions, such as translation, scale, and shearing because learning the invariance mapping function is difficult. For an accurate local patch matching process, we adopt the geometric CNN proposed in [
24] to compensate the geometric distortion of each matched patch pair. From now on, the geometric CNN is called GMatchNet. A local geometric transformation is estimated from each matched patch pair. Using this local geometric transform, the corresponding center coordinate of each input patch is finely adjusted. Then, we compute the global geometric affine parameter set from all the adjusted coordinates by the random sample consensus algorithm (RANSAC). Finally, a registered image is generated after warping the input sensed image by the global affine parameter set. The proposed framework is evaluated on the KOMPSAT-3 dataset by comparing the conventional frameworks based on machine learning and deep-learning-based frameworks. We perform registration of images in which magnetic north is aligned with the universal transverse Mercator coordinate system. It is shown that the proposed high-accuracy registration framework can improve the accuracy of image registration by compensating the geometric distortion between matched patch pairs and can be applied to other registration frameworks based on patches.
The remainder of this paper is structured as follows:
Section 2 introduces related work on image registration, deep learning, and patch matching.
Section 3 details the proposed registration framework that uses the estimated geometric transformation in the corresponding patch pairs.
Section 4 discusses the experimental results, and, finally,
Section 4 summarizes the conclusions of the study.
3. Results
In this study, we constructed datasets for both patch matching and registration using multispectral red, green, and blue images of cities around Seoul, South Korea, captured by the KOMPSAT-3 satellite with a resolution of 2.8 meter. Regions in Seoul are densely populated and their landscape is frequently changed by the emergence of new skyscrapers. On the other hand, areas around Seoul are agricultural areas with different colors depending on the seasonal conditions. The experiment was performed on a computer powered by an Intel (R) Core i7-8700K 3.40 GHz CPU with an NVIDIA GeForce GTX 1080 Ti GPU. In the following sections, we discuss the training and validation methods for patch matching via MatchNet and the evaluation metrics, and evaluate the performance of each remote sensing image registration framework.
We also explain the details of the dataset used for MatchNet. The training sets and validation sets for patch matching consisted of images from Suwon City. This dataset came with patches extracted using the scale–space extrema detection for extracting the key-points [
6]. The size of the image patch used was 64 × 64 pixels. The resulting dataset was divided into 130k for training sets and 50k for validation sets. We used a sampler to generate an equal number of matched and unmatched patch pairs in each batch so that the network would not be overly biased toward the unmatched decision [
25].
3.1. Evaluation Datasets and Metrics for Remote Sensing Image Registration Frameworks
The datasets for evaluation of remote sensing image registration consisted of images from Seoul and its surroundings from different times—three areas in the city and one area around it.
Table 2 lists the detailed information of those images. In the same area, the upper row represents the reference image and the lower row represents the sensed image. All satellite images were divided into 500 × 500 images. Each pair of images consisted of images from the same area captured at different times. The characteristics for each area are as follows: Area 1 dataset consists of images of residential areas, Area 2 dataset consists of images of residential and green lung areas, Area 3 dataset consists of images of industrial facilities, and Area 4 dataset consists of images of skyscrapers.
The metrics from [
26] were employed in this study to objectively evaluate the proposed high-accuracy registration framework, which are as follows: the number of control points
; the root-mean-square error (
) based on all control points and normalized to the pixel size
; the
computed by the control point residuals based on the leave-one-out method
; the statistical evaluation of the residual distribution across quadrants
; the bad point proportion with a norm greater than 1.0
; the statistical evaluation of the presence of a preference axis on the residual scatter plot
; the statistical evaluation of the goodness of control points distribution across the image
; and the weighted sum of the above seven measures, the cost function
. Smaller values indicate better performance for six metrics except
. The cost function was used as an objective tool to evaluate the different control points for the pair of images. The equation of the cost function
is expressed as follows:
The registration accuracy was measured in terms of and . The quantity and quality of matching points were measured in terms of and , respectively. The lower the values of these metrics, the better . We can observe that both and equal or tend to the subpixel error, which are significant results of registration. measures the number of points that have been matched correctly. Further, a larger and a smaller imply a higher accuracy of point matching.
3.2. Evaluation of Remote Sensing Image Registration Framework
The proposed frameworks were compared with the conventional feature-based image registration framework, SIFT, and the state-of-the-art deep learning-based image registration framework. We used the DBN network structure proposed by Wang et al. [
19]. The deep learning-based frameworks were experimented with two trained methods—the conventional method and proposed training method. We defined the improved accuracy,
, of
as follows:
where
and
are the
values of the SIFT-based framework and each DNN-based framework, respectively.
measures the number of correct corresponding points. A larger
and a smaller
imply more accurate point matching.
Table 3 summarize the experimental results using eight metrics on four evaluation datasets. The last line in
Table 3 illustrates the averaged results using eight metrics for the evaluation datasets in all areas. In the DBN-based framework of Wang et al. [
19], although the number of control points
was large, it had mismatched points and therefore an increased
value. For qualitative assessment, we used the checkerboard mosaic image, which can demonstrate the subjective quality better than any other image in terms of edge continuity and region overlapping.
In
Table 3, on the one hand, the DBN-based framework generated a large
, but the
values increased due to the
for all control points. On the other hand, the proposed framework for the Area 1 dataset had a smaller
, but the lowest
value representing the pixel error. In addition, the smallest
of 0.855 was obtained for the quality of matching points
. The performance of the proposed framework was 40.2% better than that of the SIFT-based framework in Area 1.
Figure 7a,b illustrate the pair of images from Area 1, which were acquired by the KOMPSAT-3 satellite in March 2014 and October 2015. The green boxes indicate the same region in the three images and show smooth edges.
In Area 2, on the one hand, the DBN-based framework increased the
values representing the quality of the matching point because the points did not match. Thus, the performance reduced by 79.54%. On the other hand, the proposed framework on the Area 2 dataset had a relatively large
and the lowest
value representing the pixel error. In addition, the smallest result of 1.478 was obtained from the quality of matching points
. The performance of the proposed framework was 68.98% better than that of the SIFT-based framework in Area 2.
Figure 8a,b illustrate the pair of images from Area 2 acquired by the satellite in April 2014 and October 2015. The green boxes in the three images represent the same region and demonstrate smooth edges. The red boxes in the three images indicate the same region and highlight the deviation of results of the conventional frameworks from those of the proposed framework.
In Area 3, on the one hand, using the DBN-based framework increased the
values because the points did not match. Thus, the performance reduced by 315.32%. On the other hand, using the proposed framework on the Area 3 dataset produced the largest
and the least
value representing the pixel error. In addition, the smallest result of 3.093 was obtained from the quality of matching points
. The proposed framework performed 85.88% better the SIFT-based framework in Area 3. The greatest performance improvement was observed in the industrial facility areas.
Figure 9a,b illustrates the pair of images from Area 3 acquired by KOMPSAT-3 satellite in April 2014 and October 2015. The green boxes in the three images represent the same region and demonstrate smooth edges.
In Area 4, on the one hand, the DBN-based framework generated a large
along with an increased
. On the other hand, the proposed framework produced the second-largest
but the lowest
representing the pixel error. In addition, the smallest result of 29.187 was obtained from the quality of matching points
. The proposed framework performed 78.63% better than the SIFT-based framework in Area 4. The largest performance improvement occurred in the industrial facility areas.
Figure 10a,b illustrate the pair of images from Area 4 acquired in December 2014 and October 2015. The changes observed in
Figure 10 are large owing to the difference between skyscrapers and viewports. The SIFT-based framework failed to register the image. By contrast, the two proposed models successfully registered the images.
Figure 10c,d are the image registration results of the SIFT-based framework and the DBN-based framework, respectively. Both frameworks failed to register the images.
In the KOMPSAT-3 image datasets, the DBN-based framework generated the largest along with a larger value representing the matching point quality because the points did not match. The DBN-based framework reduced the value representing the registration accuracy by 165.786, but the value of the proposed framework significantly reduced to 34.922. The DBN-based framework reduced the value representing the matching points quality by 41.904, but that of the proposed framework significantly reduced to 8.653. The proposed framework achieved a performance improvement of 68.4%. The remarkable improvement in the performance of the proposed framework can be observed in the difference between the high-rise building and the image as the viewpoint shifts.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}