
PCAN—Part-Based Context Attention Network for Thermal Power Plant Detection in Remote Sensing Imagery


Abstract
1. Introduction
- (1)
- We construct a one-stage end-to-end detection framework called Part-based Context Attention Networks (PCAN). The model adaptively generates multi-scale feature maps containing context and part-based attention, which is more accurate and effective for thermal power plants detection in high-resolution remote sensing imagery.
- (2)
- We propose a Context attention Multi-scale feature extraction Network (CMN) with deformable convolution, which strengthen the feature representations through the combination of context attention and multi-scale feature extraction.
- (3)
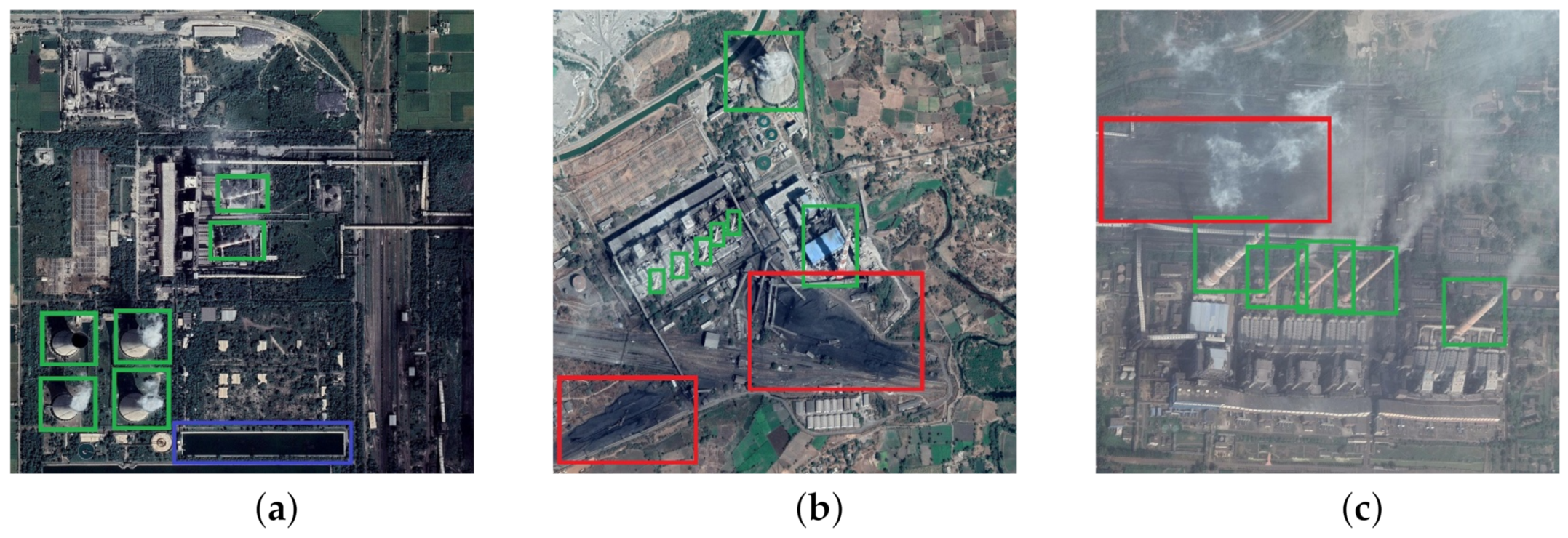
- As facility objects generally consist of several components, a part-based attention module is designed for the adaption of such facility objects, which effectively help discover distinctive object components.
2. Methods
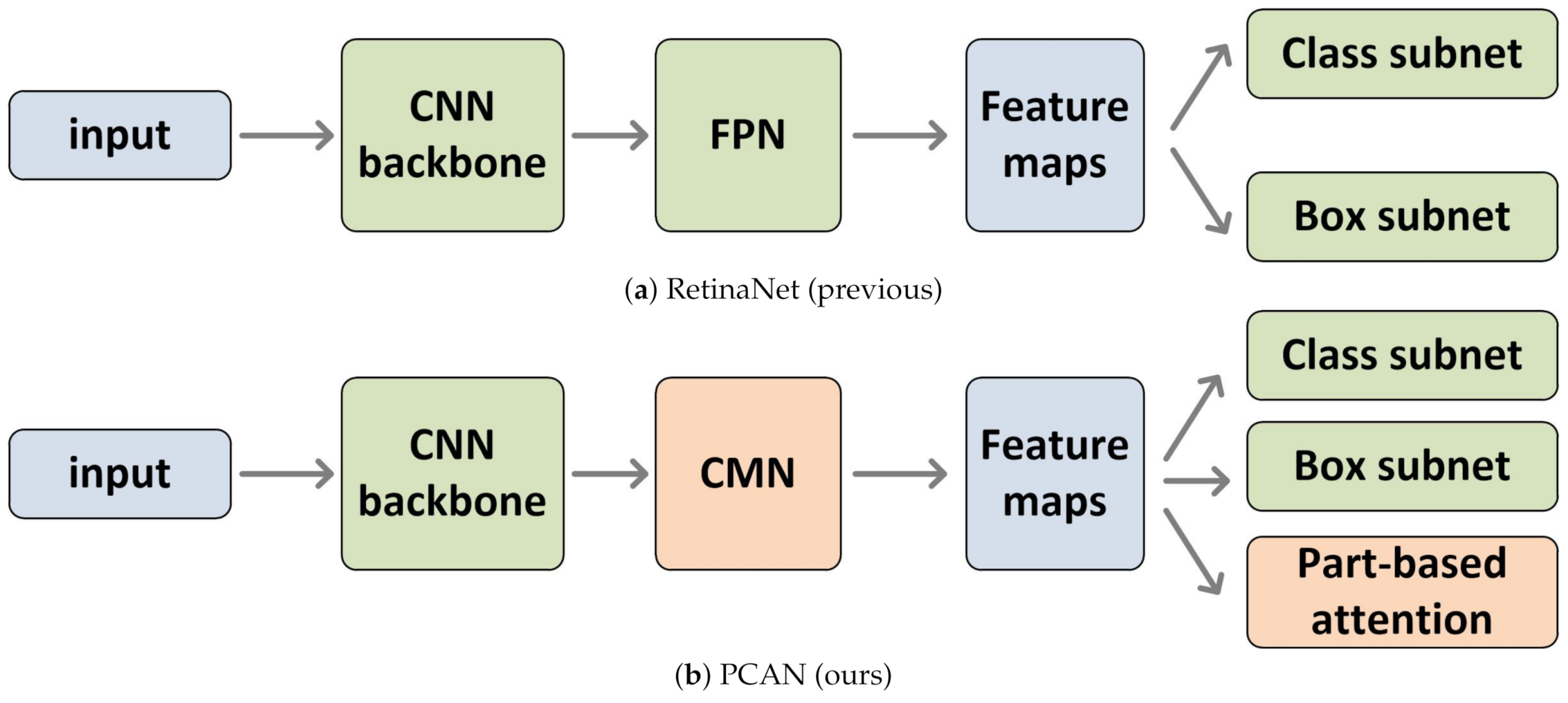
2.1. Network Architecture
2.2. Context Attention Multi-Scale Feature Extraction Network (CMN)
2.3. Part-Based Attention Module
3. Experiments
3.1. Dataset and Settings
3.1.1. Dataset
3.1.2. Evaluation Metrics
3.1.3. Parameter Settings
3.2. Ablation Study
3.2.1. Effect of CMN
3.2.2. Effect of Part-Based Attention Module
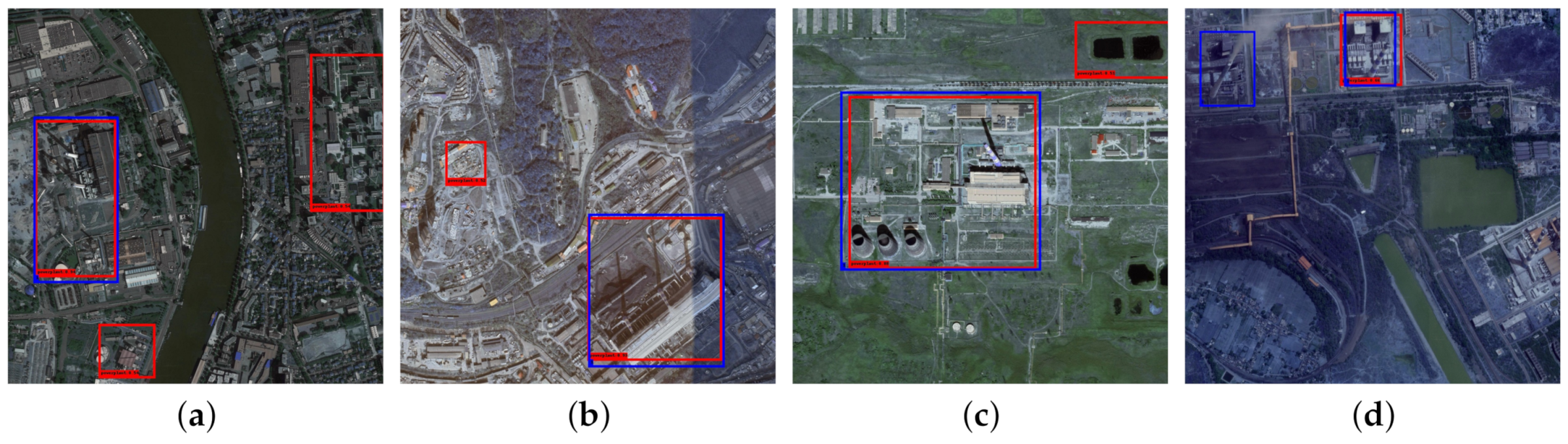
3.3. Comparison with State-of-the-Arts
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, Y.; Zhang, Y.; Du, B.; Zhang, C.; Tu, W. Parallel discriminative subspace for city target detection from high dimension images. GeoInformatica 2020. [Google Scholar] [CrossRef]
- Dong, Y.; Du, B.; Zhang, L.; Hu, X. Hyperspectral Target Detection via Adaptive Information—Theoretic Metric Learning with Local Constraints. Remote Sensing 2018, 10, 1415. [Google Scholar] [CrossRef]
- Nasrabadi, N. Hyperspectral Target Detection: An Overview of Current and Future Challenges. Signal Process. Mag. IEEE 2014, 31, 34–44. [Google Scholar] [CrossRef]
- Sumbul, G.; Cinbis, R.; Aksoy, S. Multisource Region Attention Network for Fine-Grained Object Recognition in Remote Sensing Imagery. IEEE Trans. Geosci. Remote. Sens. 2019. [Google Scholar] [CrossRef]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An Efficient and Accurate Scene Text Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape Robust Text Detection With Progressive Scale Expansion Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and Accurate Arbitrary-Shaped Text Detection With Pixel Aggregation Network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8440–8449. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. DeepReID: Deep Filter Pairing Neural Network for Person Re-identification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar] [CrossRef]
- Zhao, H.; Tian, M.; Sun, S.; Shao, J.; Yan, J.; Yi, S.; Wang, X.; Tang, X. Spindle Net: Person Re-identification with Human Body Region Guided Feature Decomposition and Fusion. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 907–915. [Google Scholar] [CrossRef]
- Han, J.; Yao, X.; Cheng, G.; Feng, X.; Xu, D. P-CNN: Part-Based Convolutional Neural Networks for Fine-Grained Visual Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Good, I.J. Some Terminology and Notation in Information Theory. Proc. IEEE Part Monogr. 1956, 103, 200–204. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and Spatial Extensions for Land-use Classification. In Proceedings of the 18th ACM SIGSPATIAL International Symposium on Advances in Geographic Information Systems, ACM-GIS 2010, San Jose, CA, USA, 3–5 November 2010; pp. 270–279. [Google Scholar] [CrossRef]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 23 June 2018. [Google Scholar]
- Fan, Q.; Brown, L.; Smith, J. A closer look at Faster R-CNN for vehicle detection. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gotenburg, Sweden, 19–22 June 2016; pp. 124–129. [Google Scholar] [CrossRef]
- Yin, S.; Li, H.; Teng, L. Airport Detection Based on Improved Faster RCNN in Large Scale Remote Sensing Images. Sens. Imaging 2020, 21. [Google Scholar] [CrossRef]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-merged single-shot detection for multiscale objects in large-scale remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3377–3390. [Google Scholar] [CrossRef]
- Sun, X.; Shi, A.; Huang, H.; Mayer, H. BAS4 Net: Boundary-Aware Semi-Supervised Semantic Segmentation Network for Very High Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5398–5413. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef]
- Sun, X.; Wang, Z.; Sun, Y.; Diao, W.; Zhang, Y.; Fu, K. AIR-SARShip-1.0: High-resolution SAR ship detection dataset. J. Radars 2019, 8, 852–862. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP | mAP | max | FLOPs | |||
|---|---|---|---|---|---|---|---|
| RetinaNet | - | - | - | 0.6309 | - | 0.665 | 192.31G |
| +Deform() | ✓ | ✓ | ✓ | 0.6486 | +1.77% | 0.686 | 202.23G |
| +Context() | ✓ | ✓ | ✓ | 0.6564 | +2.55% | 0.678 | 192.32G |
| +CMN() | ✓ | - | - | 0.6530 | +2.21% | 0.680 | 199.84G |
| +CMN() | - | ✓ | - | 0.6618 | +3.09% | 0.697 | 194.23G |
| +CMN() | - | - | ✓ | 0.6494 | +1.85% | 0.672 | 192.81G |
| +CMN() | ✓ | ✓ | - | 0.6729 | +4.20% | 0.713 | 201.75G |
| +CMN() | ✓ | - | ✓ | 0.6449 | +1.40% | 0.679 | 200.33G |
| +CMN() | - | ✓ | ✓ | 0.6632 | +3.23% | 0.702 | 194.72G |
| +CMN() | ✓ | ✓ | ✓ | 0.6734 | +4.25% | 0.719 | 202.25G |
| mAP | max | |
|---|---|---|
| 0 | 0.6309 | 0.665 |
| 0.10 | 0.6502 | 0.677 |
| 0.25 | 0.6558 | 0.681 |
| 0.50 | 0.6550 | 0.679 |
| 0.75 | 0.6487 | 0.674 |
| 0.99 | 0.6213 | 0.622 |
| 0.25+CMN | 0.6815 | 0.731 |
| Method | mAP | max | FPS(/s) | FLOPs | Paras(MB) |
|---|---|---|---|---|---|
| RetinaNet [12] | 0.6309 | 0.665 | 19.61 | 192.31G | 34.67 |
| Faster-RCNN [28] | 0.6443 | 0.672 | 10.3 | 250.13G | 26.97 |
| Cascade-RCNN [29] | 0.6518 | 0.680 | 5.33 | 294.06G | 93.75 |
| Our PCAN | 0.6815 | 0.731 | 16.24 | 246.37G | 35.28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, W.; Diao, W.; Wang, P.; Gao, X.; Li, Y.; Sun, X. PCAN—Part-Based Context Attention Network for Thermal Power Plant Detection in Remote Sensing Imagery. Remote Sens. 2021, 13, 1243. https://doi.org/10.3390/rs13071243
Yin W, Diao W, Wang P, Gao X, Li Y, Sun X. PCAN—Part-Based Context Attention Network for Thermal Power Plant Detection in Remote Sensing Imagery. Remote Sensing. 2021; 13(7):1243. https://doi.org/10.3390/rs13071243
Chicago/Turabian StyleYin, Wenxin, Wenhui Diao, Peijin Wang, Xin Gao, Ya Li, and Xian Sun. 2021. "PCAN—Part-Based Context Attention Network for Thermal Power Plant Detection in Remote Sensing Imagery" Remote Sensing 13, no. 7: 1243. https://doi.org/10.3390/rs13071243
APA StyleYin, W., Diao, W., Wang, P., Gao, X., Li, Y., & Sun, X. (2021). PCAN—Part-Based Context Attention Network for Thermal Power Plant Detection in Remote Sensing Imagery. Remote Sensing, 13(7), 1243. https://doi.org/10.3390/rs13071243