
UAV-Assisted Wide Area Multi-Camera Space Alignment Based on Spatiotemporal Feature Map

 ,
,
Abstract
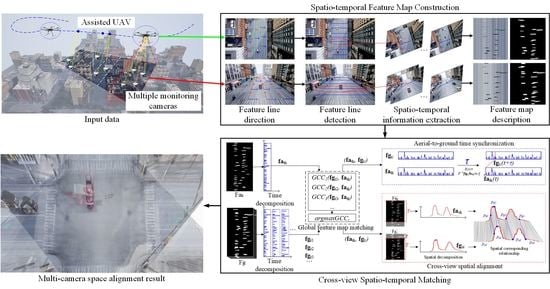
1. Introduction
1.1. Related Work
1.2. Main Contribution
- We propose a multi-camera wide-area space alignment approach with UAV assistance to realize the unification of cameras’ imaging coordinate system. Unlike current additional marker-based methods, this paper employs UAV to build visual connection across cameras which shows superior flexibility and efficiency in large-scale environment.
- We present a novel cross-view feature description algorithm, called spatiotemporal feature map, to overcome perspective gap between aerial-view images captured by UAV and street-view images collected by ground cameras. It makes full use of motion consistency among different views, which can implement synchronization on both time and space.
- To better evaluate the proposed method, we establish a new traffic monitoring database collected in both simulation and real environment. This database provides abundant monitoring data captured by multiple cameras at different fixed positions from various scenarios, including crossroad, T-junction, straight road, multi-lane road, etc. Extensive experiments demonstrate that our system returns encouraging space alignment results.
2. UAV-Assisted Wide Area Multi-Camera Space Alignment Based on Spatiotemporal Feature Map
2.1. Spatiotemporal Feature Map Construction
2.1.1. Feature Line Detection
2.1.2. Spatiotemporal Information Extraction
2.1.3. Feature Map Description
2.2. Cross-View Spatiotemporal Matching
2.2.1. Global Feature Map Matching
2.2.2. Aerial-to-Ground Time Synchronization
2.2.3. Cross-View Spatial Alignment
3. Experiments
3.1. Database
- Database in simulation environment
- Database in real scene
3.2. System Performance Evaluation on Simulation Environment
3.3. System Performance Evaluation on Real Environment
3.4. Extended Applications
4. Discussion
4.1. Performance Comparison
4.1.1. Comparison of Cross-View Matching
4.1.2. Comparison of Multi-Camera Space Alignment
4.2. Parameter Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tang, Z.; Naphade, M.; Liu, M.; Yang, X.; Birchfield, S.; Wang, S.; Kumar, R.; Anastasiu, D.C.; Hwang, J. CityFlow: A City-Scale Benchmark for Multi-Target Multi-Camera Vehicle Tracking and Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8797–8806. [Google Scholar]
- Yang, T.; Li, Z.; Zhang, F.; Xie, B.; Li, J.; Liu, L. Panoramic UAV Surveillance and Recycling System Based on Structure-Free Camera Array. IEEE Access 2019, 7, 25763–25778. [Google Scholar] [CrossRef]
- Deng, H.; Fu, Q.; Quan, Q.; Yang, K.; Cai, K. Indoor Multi-Camera-Based Testbed for 3-D Tracking and Control of UAVs. IEEE Trans. Instrum. Meas. 2020, 69, 3139–3156. [Google Scholar] [CrossRef]
- Yang, T.; Ren, Q.; Zhang, F.; Xie, B.; Ren, H.; Li, J.; Zhang, Y. Hybrid Camera Array-Based UAV Auto-Landing on Moving UGV in GPS-Denied Environment. Remote Sens. 2018, 10, 1829. [Google Scholar] [CrossRef]
- Hsu, H.; Wang, Y.; Hwang, J. Traffic-Aware Multi-Camera Tracking of Vehicles Based on ReID and Camera Link Model. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 964–972. [Google Scholar]
- Cai, W.; Yang, J.; Yu, Y.; Song, Y.; Zhou, T.; Qin, J. PSO-ELM: A Hybrid Learning Model for Short-Term Traffic Flow Forecasting. IEEE Access 2020, 8, 6505–6514. [Google Scholar] [CrossRef]
- Truong, A.M.; Philips, W.; Deligiannis, N.; Abrahamyan, L.; Guan, J. Automatic Multi-Camera Extrinsic Parameter Calibration Based on Pedestrian Torsors †. Sensors 2019, 19, 4989. [Google Scholar] [CrossRef]
- Khoramshahi, E.; Campos, M.B.; Tommaselli, A.M.G.; Vilijanen, N.; Mielonen, T.; Kaartinen, H.; Kukko, A.; Honkavaara, E. Accurate Calibration Scheme for a Multi-Camera Mobile Mapping System. Remote Sens. 2019, 11, 2778. [Google Scholar] [CrossRef]
- Yin, L.; Luo, B.; Wang, W.; Yu, H.; Wang, C.; Li, C. CoMask: Corresponding Mask-Based End-to-End Extrinsic Calibration of the Camera and LiDAR. Remote Sens. 2020, 12, 1925. [Google Scholar] [CrossRef]
- Castanheira, D.; Silva, A.; Gameiro, A. Set Optimization for Efficient Interference Alignment in Heterogeneous Networks. IEEE Trans. Wirel. Commun. 2014, 13, 5648–5660. [Google Scholar] [CrossRef][Green Version]
- Lv, F.; Zhao, T.; Nevatia, R. Camera Calibration from Video of a Walking Human. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1513–1518. [Google Scholar] [PubMed]
- Liu, J.; Collins, R.; Liu, Y. Surveillance Camera Autocalibration based on Pedestrian Height Distributions. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; pp. 1–11. [Google Scholar]
- Liu, J.; Collins, R.T.; Liu, Y. Robust Autocalibration for A Surveillance Camera Network. In Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision, Clearwater Beach, FL, USA, 15–17 January 2013; pp. 433–440. [Google Scholar]
- Bhardwaj, R.; Tummala, G.K.; Ramalingam, G.; Ramjee, R.; Sinha, P. AutoCalib: Automatic Traffic Camera Calibration at Scale. ACM Trans. Sens. Netw. 2018, 14, 19:1–19:27. [Google Scholar] [CrossRef]
- Wu, F.; Hu, Z.; Zhu, H. Camera Calibration with Moving One-dimensional Objects. Pattern Recognit. 2005, 38, 755–765. [Google Scholar] [CrossRef]
- Zhang, Z. A Flexible New Technique for Camera Calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Abdel-Aziz, Y.I.; Karara, H.M. Direct Linear Transformation from Comparator Coordinates into Object Space Coordinates in Close-Range Photogrammetry. Photogramm. Eng. Remote Sens. 2015, 81, 103–107. [Google Scholar] [CrossRef]
- Marcon, M.; Sarti, A.; Tubaro, S. Multi-camera Rig Calibration by Double-sided Thick Checkerboard. IET Comput. Vis. 2017, 11, 448–454. [Google Scholar] [CrossRef]
- Unterberger, A.; Menser, J.; Kempf, A.; Mohri, K. Evolutionary Camera Pose Estimation of a Multi-Camera Setup for Computed Tomography. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 464–468. [Google Scholar]
- Huang, L.; Da, F.; Gai, S. Research on Multi-camera Calibration and Point Cloud Correction Method based on Three-dimensional Calibration Object. Opt. Lasers Eng. 2019, 115, 32–41. [Google Scholar] [CrossRef]
- Yin, H.; Ma, Z.; Zhong, M.; Wu, K.; Wei, Y.; Guo, J.; Huang, B. SLAM-Based Self-Calibration of a Binocular Stereo Vision Rig in Real-Time. Sensors 2020, 20, 621. [Google Scholar] [CrossRef] [PubMed]
- Mingchi, F.; Panpan, J.; Yibo, L.; Jingshu, W. Research on Calibration Method of Multi-camera System without Overlapping Fields of View Based on SLAM. J. Phys. Conf. Ser. 2020, 1544, 012047. [Google Scholar]
- Xu, Y.; Gao, F.; Zhang, Z.; Jiang, X. A Calibration Method for Non-overlapping Cameras based on Mirrored Absolute Phase Target. Int. J. Adv. Manuf. Technol. 2019, 104, 9–15. [Google Scholar] [CrossRef]
- Mingchi, F.; Shuai, H.; Jingshu, W.; Bin, Y.; Taixiong, Z. Accurate Calibration of A Multi-camera System Based on Flat Refractive Geometry. Appl. Opt. 2017, 56, 9724. [Google Scholar]
- Sarmadi, H.; Mu noz-Salinas, R.; Berbís, M.Á.; Carnicer, R.M. Simultaneous Multi-View Camera Pose Estimation and Object Tracking With Squared Planar Markers. IEEE Access 2019, 7, 22927–22940. [Google Scholar] [CrossRef]
- Van Crombrugge, I.; Penne, R.; Vanlanduit, S. Extrinsic Camera Calibration for Non-overlapping Cameras with Gray Code Projection. Opt. Lasers Eng. 2020, 134, 106305. [Google Scholar] [CrossRef]
- Yin, L.; Wang, X.; Ni, Y.; Zhou, K.; Zhang, J. Extrinsic Parameters Calibration Method of Cameras with Non-Overlapping Fields of View in Airborne Remote Sensing. Remote Sens. 2018, 10, 1298. [Google Scholar] [CrossRef]
- Jeong, J.; Cho, Y.; Kim, A. The Road is Enough! Extrinsic Calibration of Non-overlapping Stereo Camera and LiDAR using Road Information. IEEE Robot. Autom. Lett. 2019, 4, 2831–2838. [Google Scholar] [CrossRef]
- Dubská, M.; Herout, A.; Juránek, R.; Sochor, J. Fully Automatic Roadside Camera Calibration for Traffic Surveillance. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1162–1171. [Google Scholar] [CrossRef]
- Cobos, M.; Antonacci, F.; Comanducci, L.; Sarti, A. Frequency-Sliding Generalized Cross-Correlation: A Sub-Band Time Delay Estimation Approach. IEEE ACM Trans. Audio Speech Lang. Process. 2020, 28, 1270–1281. [Google Scholar] [CrossRef]
- Berndt, D.J.; Clifford, J. Using Dynamic Time Warping to Find Patterns in Time Series. In Proceedings of the AAAI Workshop on Knowledge Discovery in Databases, Seattle, WA, USA, 31 July 1994; pp. 359–370. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Proceedings of the International Conference on Field and Service Robotics, Zurich, Switzerland, 12–15 September 2017; Volume 5, pp. 621–635. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Sarlin, P.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning Feature Matching With Graph Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4937–4946. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Schönberger, J.L.; Frahm, J.M. Structure-from-Motion Revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Schönberger, J.L.; Zheng, E.; Pollefeys, M.; Frahm, J.M. Pixelwise View Selection for Unstructured Multi-View Stereo. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 501–518. [Google Scholar]
- Brahmbhatt, S.; Gu, J.; Kim, K.; Hays, J.; Kautz, J. Geometry-Aware Learning of Maps for Camera Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2616–2625. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| N | The number of ground monitoring cameras |
| M | The number of UAV’s hovering positions |
| The set of ground monitoring videos | |
| The set of UAV assisted videos | |
| V | An example of monitoring video |
| The number of frames obtained from V deframing | |
| The number of feature lines detected from V | |
| An example of feature line in V | |
| The number of ground spatiotemporal feature maps | |
| The set of ground spatiotemporal feature maps | |
| ith ground feature map | |
| kth aerial feature map | |
| The set of feature vectors of in time dimension | |
| Feature vector of in time dimension | |
| Feature vector of in time dimension | |
| Time delay | |
| ith ground feature map after cutting | |
| kth aerial feature map after cutting | |
| Feature vector of in space dimension | |
| Feature vector of in space dimension | |
| Corresponding coordinate set between and |
| Environmental Parameter | Sensor Parameter | |||
|---|---|---|---|---|
| Simulation Environment | Environment intensity | 1.0 | Ground camera number | 11 |
| Directional light actor | light source | Ground camera resolution | 1920 × 1080 | |
| Colors determined by sun position | Yes | Ground camera FOV | 90° | |
| Sun brightness | 75 | Aerial camera position | 5 | |
| Sun height | 0.348239 | Aerial camera resolution | 1920 × 1080 | |
| Horizon Falloff | 3.0 | Aerial camera FOV | 90° | |
| Diffuse boost | 1.0 | Acquisition frame rate | 25 fps | |
| Real Scene | Scene type | Mixed traffic system | Ground camera number | 4 |
| Acquisition time | 15:00 p.m. | Ground camera resolution | 1920 × 1080 | |
| Scene width | ≈60 m | Aerial camera position | 1 | |
| Scene length | ≈50 m | Aerial camera resolution | 1920 × 1080 | |
| Ground camera height | ≈7 m | Aerial camera FOV | 58° | |
| UAV flight altitude | ≈80 m | Acquisition frame rate | 25 fps | |
| Scene | Crossroad | T-Junction | Straight Road | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Camera | 1 | 2 | 3 | 4 | AVG | 1 | 2 | 3 | AVG | 1 | 2 | 3 | AVG |
| Pixel error | 23.76 | 16.33 | 23.71 | 16.29 | 20.02 | 22.09 | 17.23 | 21.65 | 20.32 | 14.11 | 10.13 | 5.78 | 10.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Xie, Y.; Li, C.; Dai, Y.; Ma, J.; Dong, Z.; Yang, T. UAV-Assisted Wide Area Multi-Camera Space Alignment Based on Spatiotemporal Feature Map. Remote Sens. 2021, 13, 1117. https://doi.org/10.3390/rs13061117
Li J, Xie Y, Li C, Dai Y, Ma J, Dong Z, Yang T. UAV-Assisted Wide Area Multi-Camera Space Alignment Based on Spatiotemporal Feature Map. Remote Sensing. 2021; 13(6):1117. https://doi.org/10.3390/rs13061117
Chicago/Turabian StyleLi, Jing, Yuguang Xie, Congcong Li, Yanran Dai, Jiaxin Ma, Zheng Dong, and Tao Yang. 2021. "UAV-Assisted Wide Area Multi-Camera Space Alignment Based on Spatiotemporal Feature Map" Remote Sensing 13, no. 6: 1117. https://doi.org/10.3390/rs13061117
APA StyleLi, J., Xie, Y., Li, C., Dai, Y., Ma, J., Dong, Z., & Yang, T. (2021). UAV-Assisted Wide Area Multi-Camera Space Alignment Based on Spatiotemporal Feature Map. Remote Sensing, 13(6), 1117. https://doi.org/10.3390/rs13061117