Abstract
We introduce a novel regularization function for hyperspectral image (HSI), which is based on the nuclear norms of gradient images. Unlike conventional low-rank priors, we achieve a gradient-based low-rank approximation by minimizing the sum of nuclear norms associated with rotated planes in the gradient of a HSI. Our method explicitly and simultaneously exploits the correlation in the spectral domain as well as the spatial domain. Our method exploits the low-rankness of a global region to enhance the dimensionality reduction by the prior. Since our method considers the low-rankness in the gradient domain, it more sensitively detects anomalous variations. Our method achieves high-fidelity image recovery using a single regularization function without the explicit use of any sparsity-inducing priors such as , and total variation (TV) norms. We also apply this regularization to a gradient-based robust principal component analysis and show its superiority in HSI decomposition. To demonstrate, the proposed regularization is validated on a variety of HSI reconstruction/decomposition problems with performance comparisons to state-of-the-art methods its superior performance.
1. Introduction
Convex optimization techniques have gained broad interest in many hyperspectral image processing applications including image restoration [1,2,3,4,5,6,7,8], decomposition [9,10], unmixing [11,12,13], classification [14,15], and target detection [16]. The success of such tasks strongly depends on regularization, which is based on a priori information of a latent clear image. Total Variation (TV) is one of the exemplary models often used for regularization in convex optimization approaches [17,18,19,20,21]. Some convex optimization methods specializing in low-rank regularization have been proposed in recent years [22,23]; these use the spectral information directly and achieve high-quality image restoration.
In this paper, we propose a regularization scheme that directly and simultaneously considers correlation in the spatio-spectral domains. We name the regularization function as Total Nuclear Norms of Gradients (TNNG), which calculates nuclear norms for all planes in the gradient domain of a HSI to exploit correlations in all spatio-spectral directions and obtains a low-rank approximation of its structure. The function utilizes the a priori property, where each gradient possesses strong inter-band correlation, and it directly controls each gradient that expresses smoothness in the spatial direction and correlation in the spectral direction. We also apply the TNNG regularization scheme to a Gradient-based Robust Principal Component Analysis (GRPCA) and show its superior performance in image decomposition.
There are many methods with low-rank priors [18,22,23], but there are few approaches that exploit low-rankness in global regions of the and planes (x, y, and z indicate horizontal/vertical/spectral directions, respectively). Recently, a joint approach of low-rank restoration and non-local filtering has been proposed [24]. The method achieves high-fidelity restoration by incorporating subspace learning with the non-local filtering. However, this method works well only for image denoising tasks.
The efficiency of our method is due to the following three features:
- Exploiting the low-rankness of a global region (i.e., a high-dimensional matrix) allows us to enhance the dimensionality reduction by the prior.
- Inherently, HSIs have little correlation in oblique directions within the and planes. We efficiently exploit this property through our regularization.
- Since our method considers the low-rankness in the gradient domain, not the low-rankness in the image domain, it more sensitively detects anomalous variations.
Another notable property in our regularization is that our method does not explicitly use any sparsity-inducing norms such as or norms. Taking the nuclear norms on all the and planes, we implicitly reduce variations on spatial domains as well. In the end, our simple regularization simultaneously exploits the low-rank property and sparsity in spatial variations as a single function. Due to this property, we can apply our regularization function to RPCA as well as the HSI restoration, and unlike conventional methods, our method is efficient for various applications in image restoration and decomposition.
We solve convex optimization problems using primal-dual splitting (PDS) [25] and apply it to various hyperspectral image processing tasks. Experimentally, we conduct HSI restoration, RPCA-based image decomposition, and HSI pansharpening problems as examples to confirm their performance.
This paper is organized as follows. After reviewing conventional methods on HSI processing in Section 2, we describe the details of the algorithm and the solutions for the proposed optimization problem in Section 3. In Section 4, we present several experiments on image reconstruction/decomposition to illustrate the superiority of the proposed method. Section 6 presents a summary of this study and future prospects.
2. Related Work
Many restoration methods based on TV for multi-channel images have previously been proposed [17,18,19,20,21]. Yuan et al. [21] proposed a hyperspectral TV (HTV), which is an expansion of the TV model to HSI. They also proposed a spectral-spatial adaptive HTV (SSAHTV), which introduces adaptive weights to HTV. SSAHTV uses spectral information for its weighting and shows superior performance over HTV. The structure tensor TV (STV) [17] was proposed for multi-channel images and considers low-rankness of gradient vectors in local regions. Furthermore, its arranged version (ASTV) was proposed in [18] and outperforms STV in some image restoration problems. These methods show high performance on HSI restoration, but they only consider correlation in the spatial domain explicitly. Meanwhile, spectral information is limited to indirect use in these regularization schemes; therefore, it is relatively prone to excessive smoothing because of the substantial impact received from the spatial properties. Some of them consider the spectral gradients, few methods exploit the low-rankness in the gradient domain by a single regularization function.
It is well known that there exist high correlations among HSI along the spectral direction, especially in aerial images, as each spectral signature can be well represented by a linear combination of a small number of pure spectral endmembers, which induces the low-rank property. Low-rank matrix recovery (LRMR) [23], which utilizes the low-rankness of local blocks in HSI, has been shown to have higher performance than SSAHTV and even VBM3D [26], which is one of the most superior methods for non-local noise reduction. Furthermore, the spatio-spectral TV (SSTV) was proposed in [27]; it applies TV to the HSI gradient in the spectral direction. It is a regularization scheme that indirectly considers spatial correlation through the application of TV to the spectral gradient. Although it is a simple method, SSTV is confirmed to be superior to LRMR. Contrary to STV and ASTV, noise tends to remain in the restoration results of LRMR and SSTV because of the weak influence from the spatial properties. The methods such as LRTV [22], HSSTV [28], and LRTDTV [29] attempt to improve the performance of STV, SSTV, and its variants by introducing new regularization. However, future tasks are still to be elucidated, such as over-smoothing.
Recent DNN-based approaches have been successful for 2D image restoration tasks such as super-resolution [30,31]. Although there are a few successful methods for HSI such as [32,33,34,35,36], the superiority of DNN for HSI restoration is limited. This is due to the following reasons: (1) Acquiring high-quality large HSI data sets is not straightforward. (2) DNN-based methods are sensitive to attributes such as the number of spectral bands, spectral ranges of wavelengths, types of sensor, and thus such a domain mismatch in attributes between training and test data often degrades performance. On the other hand, regularization-based approaches like ours are more flexible and can be applied to many restoration tasks, such as restoration, unmixing, and classification.
3. Proposed Method
3.1. Low-Rankness of Spectral Gradients
Letting the spatial coordinates be x, y, and spectral coordinates z, we define “front” as the direction in which we view the planes along the z axis. The “top” and “side” are defined as the directions in which we view the and planes, respectively. Here, we define to be a HSI with an image size of and number of bands B. Furthermore, we define to be a combined 3D gradient image where the three gradient images for (w.r.t. vertical, horizontal, and spectral directions) observed from the top view, are concatenated to form a 3D cuboid. Similarly, we define to be the 3D cuboid of the gradient images observed from the side view. We will explain detailed formulation in Section 3.2.
We represent the sum of ranks for all single-structure planes in and as follows:
where represents the i-th plane extracted from and similarly is the i-th plane extracted from . Given that , which is observed from the top view, possesses size B in the vertical direction and size in depth, the total number of is . Similarly, the total number of is .
Since (1) uses rank with a discrete value and is a non-convex function, the minimization problem with (1) is NP-hard. Therefore, we incorporate the nuclear norm (), which is the optimal relaxation of the rank constraint, and substitute
for (1). We refer to this regularization as the Total Nuclear Norms of Gradients (TNNG). TNNG is used as regularization to approximate and through a low-rank model.
Figure 1 shows diagonal matrices of the image PaviaU, where singular value decomposition () is performed on some of the HSI. The red lines show enlarged views of the top 15 singular values. possesses singular values of as diagonal components. In any diagonal matrix , we can observe that there is energy concentration to a handful of singular values, and most of the values are close to 0. This observation shows that approximately forms a low-rank structure. In of the noisy HSI, there is energy dispersion, which violates the low-rank structure, while there is energy concentration in a portion of in the restored HSI. Therefore, one can see that the restored image has a low-rank structure and more closely approximates the original HSI. As this property can be seen in most images, it is expected that the low-rank approximation in the gradient domain using TNNG will work for restoration.
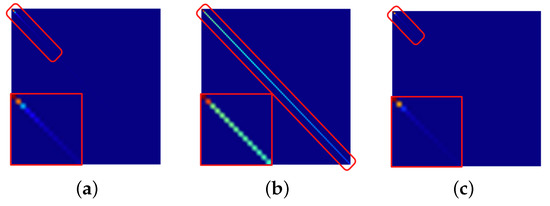
Figure 1.
An example for the diagonal matrix of PaviaU in which the diagonal elements are singular values of . The three images show of the original input, noisy image, and restoration results, respectively. (a) original, (b) noisy, (c) restoration.
3.2. TNNG Regularization
In this section, we design and , and specifically formulate TNNG. We redefine a HSI with an image size of and the number of bands B as a vector . A single plane represents the image of the j-th band of , and represents the transposed .
We define the linear operator to find the spatio-spectral gradients. Let the vertical and horizontal difference operators be , and let the spectral difference operator be as:
where is an identity matrix, and is a zero matrix. Using these single-direction operators, we define the spatio-spectral difference operator as follows:
Then, we calculate the spatio-spectral gradients of HSI, . This procedure is illustrated in the left part of Figure 2. , , and represent the vectorized versions of the three 3D components (vertical, horizontal, and spectral, respectively) of the gradient image.
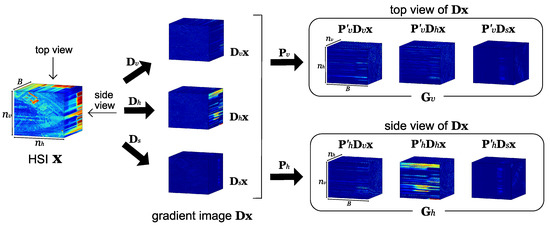
Figure 2.
Gradient images and rotation by and .
Next, we introduce two operators , which rearrange pixels so that the upper and side planes of are located in the front:
where is a matrix that rotates each of , , and such that the , , and planes face in the directions of “front”, “side”, and “top”, respectively, and similarly has a role of rotating the cuboids such that the , , and planes faces in the directions of “front”, “side”, and “top”, respectively (see the right part of Figure 2). In addition, we use the operator , which converts a vector into a 3D cuboid, to rewrite the vectors as follows:
The right side of Figure 2 shows an image diagram when and are designed using , , and . Rewriting (2) using , , and defined by (4) and (5), TNNG in (2) is expressed as follows:
where represents the nuclear norm of the i-th plane in the 3D cuboid .
3.3. HSI Restoration Model
In this section, we formulate an image restoration problem. The HSI observation model is represented by the following equation using an original image and an observed image :
where is the linear operator that represents deterioration (for example, it represents random sampling in the case of compressed sensing [37,38]), and represents additive noise. Based on the observation model, the convex optimization problem for the HSI restoration using TNNG can be formulated as follows:
Here, is the weight of TNNG, represents the box constraint of the pixel values in the closed convex set, and , represent the minimum and maximum pixel values taken by , respectively. In addition, is a data-fidelity function, and it is necessary to select a suitable depending on the observed distribution of noise. We assume that the additive noise follows a Gaussian distribution, and thus we use the -norm to express the convex optimization problem of Problem (9) as follows:
3.4. Gradient-Based Robust Principal Component Analysis
We apply TNNG to 3D Robust Principal Component Analysis (RPCA). RPCA [39] has been used in many computer vision and image processing applications. The goal of RPCA in the case of 2D images is to decompose an image matrix to a low-rank component and a sparse residual by solving the following equation:
We extend this to HSI image decomposition by applying TNNG as follows:
By solving (12), we achieve the decomposition of the observed measurement as , where is low-rank in the gradient domain, and is the sparse component. The two constraints in (12) guarantee the exact reconstruction and the reasonable range of pixel values. Unlike the existing 3D RPCA methods [40,41], we analyze the low-rankness of an HSI in the gradient domain. As it is gradient-based, it also has the capability of excluding sparse anomalies more sensitively, so it is expected that the performance of the decomposition improves. We call this Gradient-based RPCA (GRPCA). This problem is also convex optimization, and thus one efficiently obtains a global optimum solution by convex optimization algorithms.
3.5. HSI Pansharpening Model
Pan sharpening is a technique for generating an HSI with high spatial and spectral resolutions by combining a panchromatic image (pan image) with a high spatial resolution and a HSI with a high spectral resolution. It is important in the field of remote sensing and earth observation.
Let be a true HSI with high spatial resolution, be an observed HSI with low spatial resolution, and be an observed gray-scale pan image. The observation model of HSI for pansharpening can be formulated as follows:
where and represent the lowpass operator and sub-sampling operator, respectively. The matrix represents an average operator. In our setting, we simply average all bands to makes a gray-scale image. and represent additive noise.
The goal of the pansharpening problem is to recover the full spatial and spectral resolution image , which is similar to , from the observed two images and . Using the proposed regularization defined by (7), we adopt the following convex optimization problem to estimate .
where and are user-defined parameters that controls the fidelity of .
3.6. Optimization
In this study, we adopt primal-dual splitting (PDS) [25] to solve the convex optimization problems in (10), (12), and (14). PDS is an iterative algorithm to solve a convex optimization problem of the form
where F represents a convex function where the gradient is -Lipschitz continuous and differentiable, G and H represent the non-smooth convex functions where the proximity operator can be efficiently calculated, and is a linear operator. Proximity operator [42,43] is defined using the lower semi-continuous convex function and index , as
The PDS algorithm to solve Problem (15) is given as follows [25,44,45]:
where is the gradient of F, is the primal variable, is the dual variable of , is the mediator variable to calculate , and the superscript indicates the k-th iteration. The algorithm converges to an optimal solution of Problem (15) by iteratively solving (17) under appropriate conditions on and .
In the paper, we explain only the procedure to solve Problem (10), but one can also solve Problem (12) and (14) in a similar way. The respective algorithms are shown in shown in Algorithm 1 and Algorithm 2. To apply PDS to Problem (10), we define the indicator function with a closed convex set as follows:
We use this indicator function to turn Problem (10) into a convex optimization problem with no apparent constraints as follows:
Problem (19) is formed by the convex functions allowing efficient calculation of the proximity operator. To represent (19) in the same format as Problem (15), to which PDS can be applied, we separate each term of Problem (19) into F, G, and H as follows:
The function is formed only by the differentiable -norm, and thus its gradient is obtained by
The function becomes the indicator function . The of (17) becomes , the projection that is the proximity operator to the box constraint. If we set the projection to , then the projection can be given, for , as follows:
We perform the operation separately for each element in . The function corresponds to the regularization function, and the dual variable and linear operator can be given as follows:
Here, and are dual variables corresponding to and , respectively. Given that TNNG uses a nuclear norm, the performs soft-thresholding with respect to singular values of each matrix in (7). Here, the singular value decomposition of becomes . Thus, the proximity operator, is given as follows:
where represents a diagonal matrix with diagonal elements , and M is the maximum number of singular values.
Based on the above discussion, we can solve the convex optimization problem of Problem (10) using PDS, whose steps are shown in Algorithm 3. The calculation for the projection (step 4) is indicated in (22), and the proximity operator of nuclear norms (steps 7, 8) is given by (24). We set the stopping criterion to .
| Algorithm 1 PDS Algorithm for Solving Problem (12) |
|
We turn Problem (12) into a convex optimization problem with no apparent constraints as follows:
Problem (25) is formed by the convex functions allowing efficient calculation of the proximity operator. To represent (25) in the same format as Problem (15), to which PDS can be applied, we separate each term of Problem (25) into F, G, and H as follows:
Steps 12 of Algorithm 1 is the proximity operator, is given as follows:
for i = 1,...,NB, where denotes the sign of , is .
We turn Problem (14) into a convex optimization problem with no apparent constraints as follows:
Problem (28) is formed by the convex functions allowing efficient calculation of the proximity operator. To represent (28) in the same format as Problem (15), to which PDS can be applied, we separate each term of Problem (28) into F, G, and H as follows:
| Algorithm 2 PDS Algorithm for Solving Problem (14) |
|
Steps 12 and 13 of Algorithm 2 is updated by using the following ball projection:
where is the radius of the -norm sphere. And, is define as .
| Algorithm 3: PDS Algorithm for Solving Problem (10) |
|
4. Results
To show the effectiveness of the proposed method, we conducted several experiments on compressed sensing (CS), signal decomposition, and pansharpening. There results were compared the results with some conventional methods.
We used PSNR and Structural Similarity Index (SSIM) [46] as objective measures of CS and signal decomposition, and SAM [47], ERGAS [48], and Q2n [49] for pansharpening. The evaluation methods for SAM, ERGAS, and Q2n are explained below. is a grandtruth image, is a restored image.
- SAM is defined as follows:where is denotes the norm.
- ERGAS is defined as follows:where d is resolution ratio between HSI with low spatial resolution and gray-scale pan images, is the sample mean of k-th band of .
- Q2n is defined as follows:where the definition of each variable is , ,, , .
For PSNR, SSIM, and Q2n, higher values indicate better performance, and for SAM and ERGAS, lower values indicate better performance. We used 17 HSIs for the evaluation available online such as [50,51], which have 102 to 198 spectral bands. Variation on the dynamic range of HSIs is very high, and thus for consistent evaluation on images with various ranges, we linearly scale the images to the range , and then the standard metrics are used. For CS and signal decomposition, we experimentally adjusted the weight and adopted the values where the PSNR was the highest value. For pansharpening, was calculated from the noise levels of and , and was calculated from the noise levels of and . For the parameters of the conventional methods, we experimentally adopted parameters at which the PSNR was the highest value.
4.1. Compressed Sensing
We conducted experiments on compressed sensing, in which the observation model is represented by , and the linear operator denotes a known random sampling matrix (r is the ratio of sampling points). The convex optimization problem for the compressed sensing reconstruction using the regularization function is as follows:
We compared the performances by replacing the regularization function. Additive noise is fixed to the Gaussian noise with standard deviation , and the sampling ratio is set to and . Table 1 shows the numerical results of the compressed sensing reconstruction. As LRTDTV is not designed for the compressed sensing and yielded inferior results in our implementation, we did not include it in the experiment. The proposed method reported the 0.9–2.2 dB higher values in PSNR on the average and the best SSIM scores for most of the images. Moreover, we confirmed the strong superiority of the proposed method for any sampling ratio r.

Table 1.
Numerical values for CS reconstruction (PSNR [dB]/SSIM).
Figure 3 shows the experimental results for the sampling ratio . Each PSNR[db] is 31.02 for (c), 32.75 for (d), 35.02 for (e), and 35.86 for (f). From this figure, we can observe increased blurring in ASTV and HSSTV to recover the resolution loss and remove the noise caused by the reconstruction. In the experiments on ASTV and HSSTV, the blurring was reduced by decreasing the weight , but we confirmed that the insufficient HSI reconstruction led to a decreased evaluation in PSNR and SSIM. For SSTV, the noise remained in the restored results. SSTV has weak smoothing effects in the spatial direction; therefore, the noise remains regardless of the weight λ. The proposed method has better restoration results than the conventional methods because the detailed areas are maintained while the noise and loss caused by the reconstruction are reduced.

Figure 3.
Results for CS reconstruction experiments in it Stanford (130th band). (a) original image, (b) observation, (c) ASTV, (d) SSTV, (e) HSSTV, (f) TNNG (ours)
4.2. Robust Principal Component Analysis
4.2.1. Image Decomposition
To evaluate our GRPCA, we first applied it to a standard sparse component decomposition. Following conventional methods such as [41], we randomly selected 30% of pixels in a HSI and replaced them with random values with a uniform distribution, which is a typical example to measure the performance of RPCA. The goal is to decompose the corrupted image to a latent low-rank HSI and the random values. We evaluated the performance with PSNR and SSIM between the corrupted image and the obtained HSI in (12) and compared it with the low-rank based decomposition methods, TRPCA [41] and LRTDTV [29].
We show the results in Table 2, where one can confirm that our method outperforms the conventional methods for most of the HSIs. This result shows that the proposed regularization function is able to correctly evaluate the image based on its low-rank nature. In addition, we believe that the proposed regularization function can evaluate the low-rank property of the image better than the conventional methods.
Table 2.
Numerical results for image decomposition (PSNR [dB] / SSIM).
4.2.2. Mixed Anomaly Removal
We have tested the decomposition capability for images with mixed anomalies composed of dead lines/circles and impulsive noise. We compared our performance with TRPCA and LRTDTV. We conducted the removal of the anomaly pattern: sparsely scattered impulsive noise and dead lines/circles, where we prepare a mask for the dead lines and circles and generate images with dead pixels by multiplying the mask and an image (See Figure 4). We assume that anomalies sparsely appear, and then they can be removed in the low-rank component in (12).
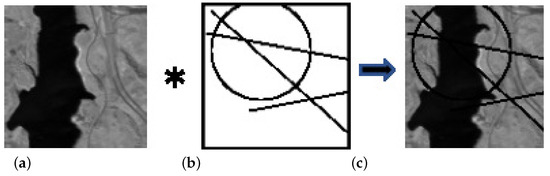
Figure 4.
Dead lines/circles are generated by pixel-wise multiplication with mask. (a) original image, (b) mask, (c) generated image
We show our decomposition results in Figure 5 and the objective comparison in Table 3, where one can confirm that our method outperforms the conventional methods for most of the HSIs. Under mixed anomalies, we experimentally confirmed that TNNG maintains stable performance compared with the conventional methods, while the performance depends on experimental conditions and types of images in LRTDTV and TRPCA. This indicates that the image can be restored by using the spectral information of other pixels even if there is a defect in the gradient region due to the evaluation of low rankness.

Figure 5.
Results for GRPCA in Washington (76th band). (a) Input image, (b) Image with anomalies, (c) Low-rank component, (d) Sparse component
Table 3.
Numerical results for mixed anomaly removal experiments: impulse (d = 10%) + dead lines/circles (PSNR [dB]/SSIM).
4.3. Pansharpening
We compared the proposed method defined by (14), with four conventional pansharpening methods: GFPCA [52], BayesNaive and BayesSparse [53], and HySure [54]. We conducted experiments on three types of noise levels, Type I (), Type II (), Type III (), where and are the standard deviation of noises added on a hyperspectral and a pan image, respectively.
Table 4 shows the comparison with the conventional methods. One can see from the results that our method outperforms the conventional methods in many cases. For subjective comparison, we show an example of the estimated HSIs from the data with Type I on PaviaC as shown in Figure 6.
Table 4.
Numerical results for pansharpening: I (), II (), III ().

Figure 6.
Data for Pansharpening in PaviaC ( Type I ). (a)original image, (b) pan image, (c) HSI.
The estimated HSIs with high spatial resolution are shown in Figure 7. Each PSNR[db] is 25.45 for (b), 26.90 for (c), 28.86 for (d), 30.0 for (e), and 31.16 for (f). We divided the band of these HSIs into three parts and visualized the average of each as RGB images. The details of the results obtained by GFPCA and BayesNaive are over-smoothed and its shading is unnatural. BayesSparse and HySure can estimate sharper images than those images, however, the texture of trees and buildings is lost. In contrast, the proposed method is particularly accurate in the restoration of the shading on the upper right and the texture of the central building on the upper left. As shown in (14), the optimization problem for pan-sharpening is the equation that minimizes the regularization function using the proposed method, and the number of hyperparameters is reduced by using constraints on HS and PAN images.

Figure 7.
Results for Pansharpening experiments in PaviaC. (a) original image, (b) GFPCA, (c) BayesNaive, (d) BayesSparse, (e) HySure, (f) TNNG (ours).
5. Discussion
Computing Time
All methods are executed using Matlab 2019a on a MacBook Air (Retina, 13-inch, 2019), 1.6 GHz dual core Intel Core i5, and 16 GB 2133 MHz LPDDR3. The proposed method takes much more time than the conventional method. This is because the singular value decomposition of equation (7) needs to be performed times. Speeding up the processing is a major issue for the future, and we plan to pursue this point in the future.
- Compressed SensingThe maximum execution time for each method was about 2000 s for ASTV, 530 s for SSTV, 670 s for HSSTV, and 2500 s for TNNG (ours).
- Image DecompositionThe maximum execution time for each method was about 1600 s for LRTDTV, 610 s for TRPCA, 2400 s for TNNG (ours).
- Mixed Anomaly RemovalThe maximum execution time for each method was about 1680 s for LRTDTV, 620 s for TRPCA, 2500 s for TNNG (ours).
- PansharpeningThe maximum execution time for each method was about 4.2 s for GFPCA, 1.7 s for BayesNative, 130 s for BayesSparse, 110 s for HySure, and 7200 s for TNNG (ours).
6. Conclusions
In this paper, we proposed a new regularization scheme for HSI reconstruction called TNNG. We focused on the HSI property where the gradient image possesses strong inter-band correlation and utilized this property in the convex optimization. TNNG is a regularization scheme aimed at enforcing the low-rank gradient structure when observed from the spectral direction. We achieved high-performance HSI restoration by solving this regularized convex optimization problem using PDS. In experiments, we conducted compressed sensing reconstruction, image decomposition, and pansharpening. While the efficiencies of conventional methods depend on applications, the proposed method is superior to the conventional methods through both subjective and objective evaluations in various applications. In the proposed method, the process is done for a whole image without exploiting local features. It would be necessary for the future to consider further advances in performance by introducing local processing. And, the improvement of the calculation speed is also an issue.
Author Contributions
Methodology, R.Y., R.K., R.M. and M.O.; software, R.Y. and R.K.; validation, R.Y., R.K., R.M. and M.O.; formal analysis, R.Y., R.K., R.M. and M.O.; investigation, R.Y., R.K., R.M. and M.O.; data curation, R.Y. and R.K.; writing—original draft preparation, R.Y., R.K., R.M. and M.O.; writing—review and editing, R.Y., R.K., R.M. and M.O.; project administration, M.O.; funding acquisition, M.O. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Ministry of Internal Affairs and Communications of Japan under the Strategic Information and Communications R&D Promotion Programme, from 2017 to 2019, No. 3620.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ghamisi, P.; Yokoya, N.; Li, J.; Liao, W.; Liu, S.; Plaza, J.; Rasti, B.; Plaza, A. Advances in hyperspectral image and signal processing: A comprehensive overview of the state of the art. IEEE Geosci. Remote Sens. Mag. 2017, 5, 37–78. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Fang, L.; Bioucas-Dias, J. Hyperspectral Image Super-Resolution via Local Low-Rank and Sparse Representations. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4003–4006. [Google Scholar]
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A.; et al. Recent advances in techniques for hyperspectral image processing. Remote Sens. Environ. 2009, 113, S110–S122. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral Remote Sensing Data Analysis and Future Challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Fu, Y.; Zheng, Y.; Sato, I.; Sato, Y. Exploiting spectral-spatial correlation for coded hyperspectral image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3727–3736. [Google Scholar]
- Khan, Z.; Shafait, F.; Mian, A. Joint group sparse PCA for compressed hyperspectral imaging. IEEE Trans. Image Process. 2015, 24, 4934–4942. [Google Scholar] [CrossRef]
- Shaw, G.; Manolakis, D. Signal processing for hyperspectral image exploitation. IEEE Signal Process. Mag. 2002, 19, 12–16. [Google Scholar] [CrossRef]
- Rizkinia, M.; Baba, T.; Shirai, K.; Okuda, M. Local spectral component decomposition for multi-channel image denoising. IEEE Trans. Image Process. 2016, 25, 3208–3218. [Google Scholar] [CrossRef]
- Jin, X.; Gu, Y. Superpixel-based intrinsic image decomposition of hyperspectral images. IEEE Trans. Geosci. Remote Sens 2017, 55, 4285–4295. [Google Scholar] [CrossRef]
- Zheng, Y.; Sato, I.; Sato, Y. Illumination and reflectance spectra separation of a hyperspectral image meets low-rank matrix factorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1779–1787. [Google Scholar]
- Akhtar, N.; Shafait, F.; Mian, A. Futuristic greedy approach to sparse unmixing of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2157–2174. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral Unmixing Overview: Geometrical, Statistical, and Sparse Regression-Based Approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef]
- Rizkinia, M.; Okuda, M. Joint Local Abundance Sparse Unmixing for Hyperspectral Images. Remote Sens. 2017, 9, 1224. [Google Scholar] [CrossRef]
- Liu, Y.; Condessa, F.; Bioucas-Dias, J.M.; Li, J.; Du, P.; Plaza, A. Convex Formulation for Multiband Image Classification with Superpixel-Based Spatial Regularization. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2704–2721. [Google Scholar] [CrossRef]
- Zhang, H.; Li, J.; Huang, Y.; Zhang, L. A nonlocal weighted joint sparse representation classification method for hyperspectral imagery. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 2014, 7, 2056–2065. [Google Scholar] [CrossRef]
- Stein, D.W.J.; Beaven, S.G.; Hoff, L.E.; Winter, E.M.; Schaum, A.P.; Stocker, A.D. Anomaly detection from hyperspectral imagery. IEEE Signal Process. Mag. 2002, 19, 58–69. [Google Scholar] [CrossRef]
- Lefkimmiatis, S.; Roussos, A.; Maragos, P.; Unser, M. Structure tensor total variation. SIAM J. Imag. Sci. 2015, 8, 1090–1122. [Google Scholar] [CrossRef]
- Ono, S.; Shirai, K.; Okuda, M. Vectorial total variation based on arranged structure tensor for multichannel image restoration. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4528–4532. [Google Scholar]
- Prasath, V.B.S.; Vorotnikov, D.; Pelapur, R.; Jose, S.; Seetharaman, G.; Palaniappan, K. Multiscale Tikhonov-total variation image restoration using spatially varying edge coherence exponent. IEEE Trans. Image Process. 2015, 24, 5220–5235. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H. Hyperspectral image denoising with cubic total variation model. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, I-7, 95–98. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhang, L.; Shen, H. Hyperspectral image denoising employing a spectral-spatial adaptive total variation model. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3660–3677. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Total-variation-regularized low-rank matrix factorization for hyperspectral image restoration. IEEE Trans. Geosci. Remote Sens. 2016, 54, 178–188. [Google Scholar] [CrossRef]
- Zhang, H.; He, W.; Zhang, L.; Shen, H.; Yuan, Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4729–4743. [Google Scholar] [CrossRef]
- Sun, L.; He, C.; Zheng, Y.; Tang, S. SLRL4D: Joint Restoration of Subspace Low-Rank Learning and Non-Local 4-D Transform Filtering for Hyperspectral Image. Remote Sens. 2020, 12, 2979. [Google Scholar] [CrossRef]
- Condat, L. A primal-dual splitting method for convex optimization involving Lipschitzian, proximable and linear composite terms. J. Optim. Theory Appl. 2013, 158, 460–479. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Egiazarian, K. Video denoising by sparse 3D transform-domain collaborative filtering. In Proceedings of the European Signal Processing Conference, Poznan, Poland, 3–7 September 2007. [Google Scholar]
- Aggarwal, H.K.; Majumdar, A. Hyperspectral image denoising using spatio-spectral total variation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 442–446. [Google Scholar] [CrossRef]
- Takeyama, S.; Ono, S.; Kumazawa, I. Hyperspectral image restoration by hybrid spatio-spectral total variation. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 4586–4590. [Google Scholar]
- Wang, Y.; Peng, J.; Zhao, Q.; Leung, Y.; Zhao, X.L.; Meng, D. Hyperspectral image restoration via total variation regularized low-rank tensor decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1227–1243. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 4. [Google Scholar]
- Park, D.; Kim, K.; Chun, S.Y. Efficient module based single image super resolution for multiple problems. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018; Volume 5. [Google Scholar]
- Nie, S.; Gu, L.; Zheng, Y.; Lam, A.; Ono, N.; Sato, I. Deeply Learned Filter Response Functions for Hyperspectral Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4767–4776. [Google Scholar]
- Qu, Y.; Qi, H.; Kwan, C. Unsupervised Sparse Dirichlet-Net for Hyperspectral Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2511–2520. [Google Scholar]
- Shi, Z.; Chen, C.; Xiong, Z.; Liu, D.; Wu, F. Hscnn+: Advanced cnn-based hyperspectral recovery from rgb images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; Volume 3, p. 5. [Google Scholar]
- Matsuoka, R.; Ono, S.; Okuda, M. Transformed-domain robust multiple-exposure blending with Huber loss. IEEE Access 2019, 7, 162282–162296. [Google Scholar] [CrossRef]
- Imamura, R.; Itasaka, T.; Okuda, M. Zero-Shot Hyperspectral Image Denoising with Separable Image Prior. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Baraniuk, R.G. Compressive sensing. IEEE Signal Process. Mag. 2007, 24, 118–121. [Google Scholar] [CrossRef]
- Candès, E.; Wakin, M. An introduction to compressive sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM (JACM) 2011, 58, 11. [Google Scholar] [CrossRef]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor robust principal component analysis: Exact recovery of corrupted low-rank tensors via convex optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5249–5257. [Google Scholar]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor Robust Principal Component Analysis with A New Tensor Nuclear Norm. arXiv 2018, arXiv:1804.03728. [Google Scholar] [CrossRef] [PubMed]
- Combettes, P.L.; Pesquet, J.C. Proximal Splitting Methods in Signal Processing; Springer: Berlin/Heidelberg, Germany, 2011; pp. 185–212. [Google Scholar]
- Moreau, J.J. Fonctions convexes duales et points proximaux dans un espace hilbertien. C. R. Acad. Sci. Paris Ser. A Math. 1962, 255, 2897–2899. [Google Scholar]
- Chambolle, A.; Pock, T. A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imag. Vis. 2010, 40, 120–145. [Google Scholar] [CrossRef]
- Combettes, P.L.; Pesquet, J.C. Primal-dual splitting algorithm for solving inclusions with mixtures of composite, Lipschitzian, and parallel-sum type monotone operators. Set Valued Variation. Anal. 2012, 20, 307–330. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Kruse, F.; Lefkoff, A.; Boardman, J.; Heidebrecht, K.; Shapiro, A.; Barloon, P.; Goetz, A. The spectral image processing system (SIPS)—interactive visualization and analysis of imaging spectrometer data. Remote Sens. Environ. 1993, 44, 145–163. [Google Scholar] [CrossRef]
- Wald, L. Quality of high resolution synthesised images: Is there a simple criterion? In Third Conference “Fusion of Earth Data: Merging Point Measurements, Raster Maps and Remotely Sensed Images”; Ranchin, T., Wald, L., Eds.; SEE/URISCA: Sophia Antipolis, France, 2000; pp. 99–103. [Google Scholar]
- Garzelli, A.; Nencini, F. Hypercomplex Quality Assessment of Multi/Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2009, 6, 662–665. [Google Scholar] [CrossRef]
- Hyperspectral Remote Sensing Scenes. Available online: http://www.ehu.eus/ccwintco/index.php (accessed on 20 October 2017).
- Skauli, T.; Farrell, J. A collection of hyperspectral images for imaging systems research. In Proceedings of the SPIE Electronic Imaging, San Francisco, CA, USA, 3–7 February 2013. [Google Scholar]
- Liao, W.; Huang, X.; Van Coillie, F.; Gautama, S.; Pizurica, A.; Philips, W.; Liu, H.; Zhu, T.; Shimoni, M.; Moser, G.; et al. Processing of Multiresolution Thermal Hyperspectral and Digital Color Data: Outcome of the 2014 IEEE GRSS Data Fusion Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2984–2996. [Google Scholar] [CrossRef]
- Wei, Q.; Dobigeon, N.; Tourneret, J. Bayesian Fusion of Multi-Band Images. IEEE J. Sel. Top. Signal Process. 2015, 9, 1117–1127. [Google Scholar] [CrossRef]
- Simoes, M.; Bioucas-Dias, J.; Almeida, L.B.; Chanussot, J. A Convex Formulation for Hyperspectral Image Superresolution via Subspace-Based Regularization. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3373–3388. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).