1. Introduction
Remote sensing images and image processing technology have been widely used in land description and change detection in urban and rural areas. Detailed information about land utilization/cover is a valuable resource in many fields [
1]. Semantic segmentation in aerial orthophotos is vitally important for the detection of buildings, forests, water and their variations, such as research on urbanization speed [
2], deforestation [
3] and other man-made changes [
4].
There were still some defects in existing land cover classification models. Among the traditional remote sensing image classification methods, the maximum likelihood (ML) method [
5] was widely used. This method obtained the mean value and variance of each category through the statistics and calculation of the region of interest, thereby determining the corresponding classification functions. Then each pixel in the image was substituted into the classification function of each category, and the category with the largest return value was regarded as the attribution category of the scanned pixel. Other similar methods relied on the ability of trainers to perform spectral discrimination on the image feature space. However, with the development of remote sensing technology, image resolution continued to be improved, and spectral features were becoming more abundant, which led to the problems that spectral classes may have small difference and the same classes may present big difference. It was often insufficient to accurately extract target objects by spectral features. The classification algorithms based on machine learning such as support vector machine [
6], artificial shallow neural network [
7], decision tree [
8] and random forest [
9] were not suitable for massive data. When they were used for classification, the input features only underwent a few linear or non-linear transformations, and the rich structural information and complex regular information were often not well described by above methods. Especially for the high-resolution remote sensing images with large difference in features and complex spectral texture information, the above classification results were unsatisfactory.
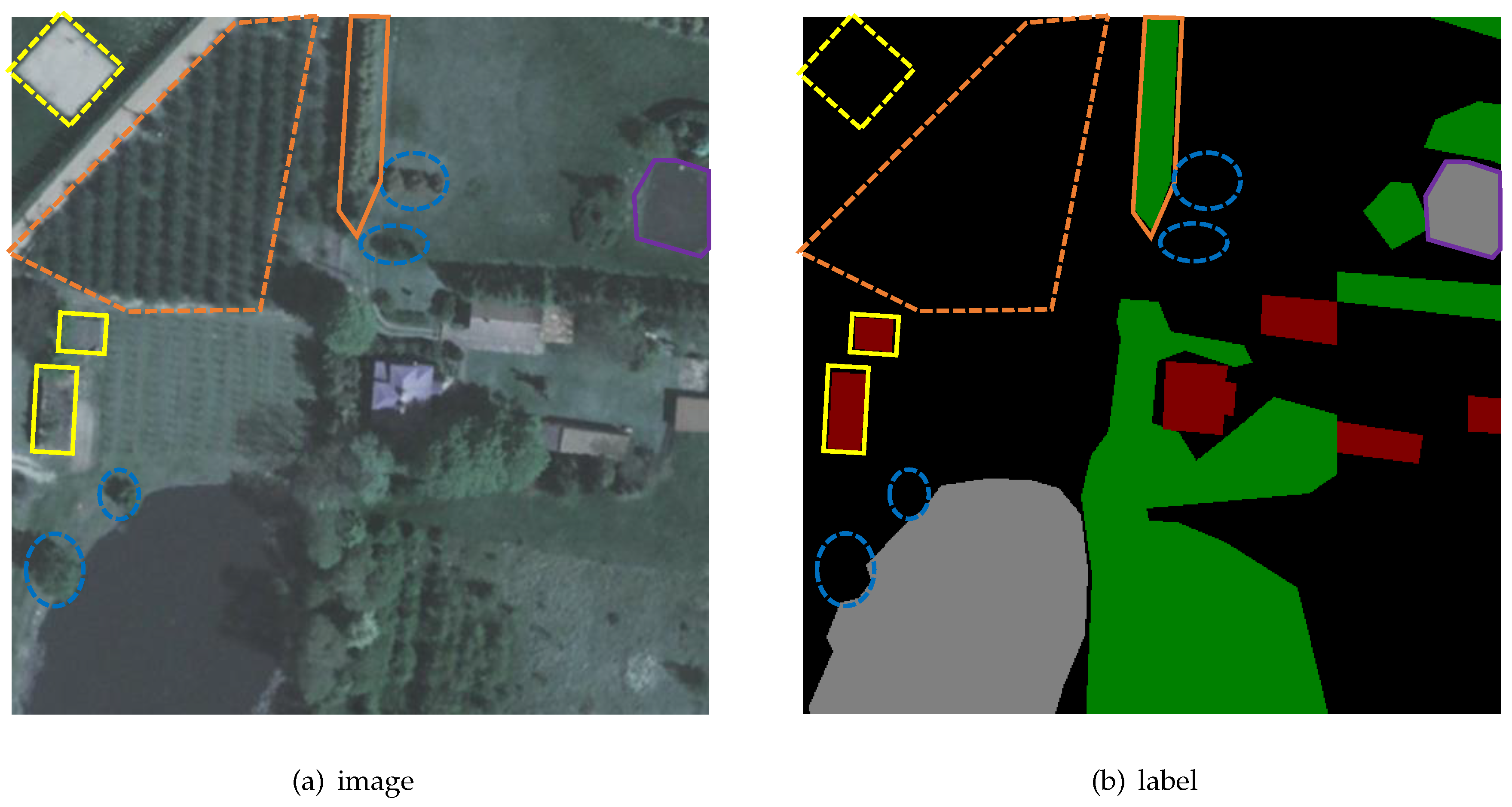
For the land cover analysis [
10], aerial orthophotos are used widely. There are various ways of land occupation, among which the size of the land covered by the buildings varies greatly, and the buildings are easily confused with greenhouses in terms of appearance in orthographic projection. Woodland is the land covered with trees standing in close proximity, and the area covered with single trees and orchards is difficult to be distinguished from the woodland. Moreover, there are many types of planted trees, which are different in irrigation methods and soil types. Water is divided into flowing water and stagnant water, and ponds and pools are included and ditches and riverbeds are excluded. These characteristics make it very difficult to extract features from remote sensing images when feature extraction is the basis of classification. Besides, the above traditional methods [
5,
6,
7,
8,
9] usually required manual participation in parameter selection and feature selection, which further increased the difficulty of feature extraction. In addition, remote sensing images, especially aerial images, are developing in the direction of higher resolution and larger time and space span, and problem that the same objects may have different spectrum whereas different objects may share the same spectrum becomes more often. In summary, traditional remote sensing image classification methods had limited capabilities of feature extraction and poor generalization, and could not achieve accurate pixel-level classification of remote sensing images.
In the field of deep learning, since Long et al. [
11] proposed a fully convolutional neural network (FCN) in 2015, many subsequent FCN-based deep convolutional neural networks have achieved end-to-end pixel-level classification. For example, Ronneberger et al. [
12] proposed a U-shaped network (U-Net) that could simultaneously obtain context information and location information. The pyramid pooling module proposed by Zhao et al. [
13] could aggregate the contextual information of different regions, thereby improving the ability to obtain global information. Chen et al. [
14] used cascaded or parallel atrous convolutions to capture multi-scale context by using different atrous rates. Yu et al. [
15] proposed a Discriminative Feature Network (DFN) to solve the problems of intra-class inconsistency and inter-class indistinction. In Huan et al.’s work [
16], the features of different levels from the main network and the semantic features from the auxiliary network were dimensionally reduced by principal component analysis (PCA), respectively. And then these features were fused to output the classification results. In Yakui et al.’s work [
17], the efficiency of information dissemination was improved by adding the nonlinear combination of the same level features, and the fusion of different layer features was used to achieve the goal of accurate target location. Compared with traditional remote sensing image classification methods such as ML and SVM based on the single source data, deep learning methods learn to extract the main features rather than designed by experts, which is more robust in complex and changeable situations. In addition, deep learning methods greatly enhance the capabilities of feature extraction and generalization, and could achieve more accurate pixel-level classification; therefore, they are more suitable for high-resolution remote sensing image classification.
With the use of unmanned aerial vehicles, aerial image datasets become more and more popular, and they are developing in the direction of high resolution, multi-temporal, and wide coverage. Traditional methods based on hand-made feature extractors and rules have low efficiency and poor scalability when the amount and the variance of data are large. In recent years, convolutional neural networks (CNNs) have played a key role in automatic detection of changes in aerial images [
18] [
19]. However, the low-level features learned by CNNs are biased toward positioning information, and the high-level features are biased toward semantic information. In the land cover classification model, the model needs to know not only the category, but also the location of the category, so as to complete the land cover classification task, which is actually a semantic segmentation task. There are two common neural network architectures used for semantic segmentation. One is the spatial pyramid pooling style networks, such as Pyramid Scene Parsing Network (PSPNet) [
13], ParseNet [
20] and Deeplabv2 [
21], and the other is the encoder-decoder style networks, such as SegNet [
22], Multi-Path Refinement Networks (RefineNet) [
23], U-Net [
12] and Deeplabv3+ [
24]. The former networks could detect incoming features at multiple scales and multiple effective receptive fields by using filters or performing pooling operations, thereby encoding multi-scale context information. The latter networks could capture clearer object boundaries by gradually recovering spatial information. In the land cover classification problem, objects of the same classes vary widely in time and space, but the requirement for multi-scale information of each class is not high.
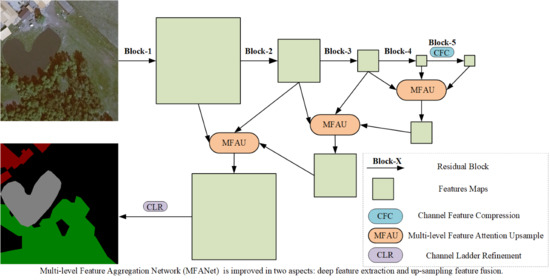
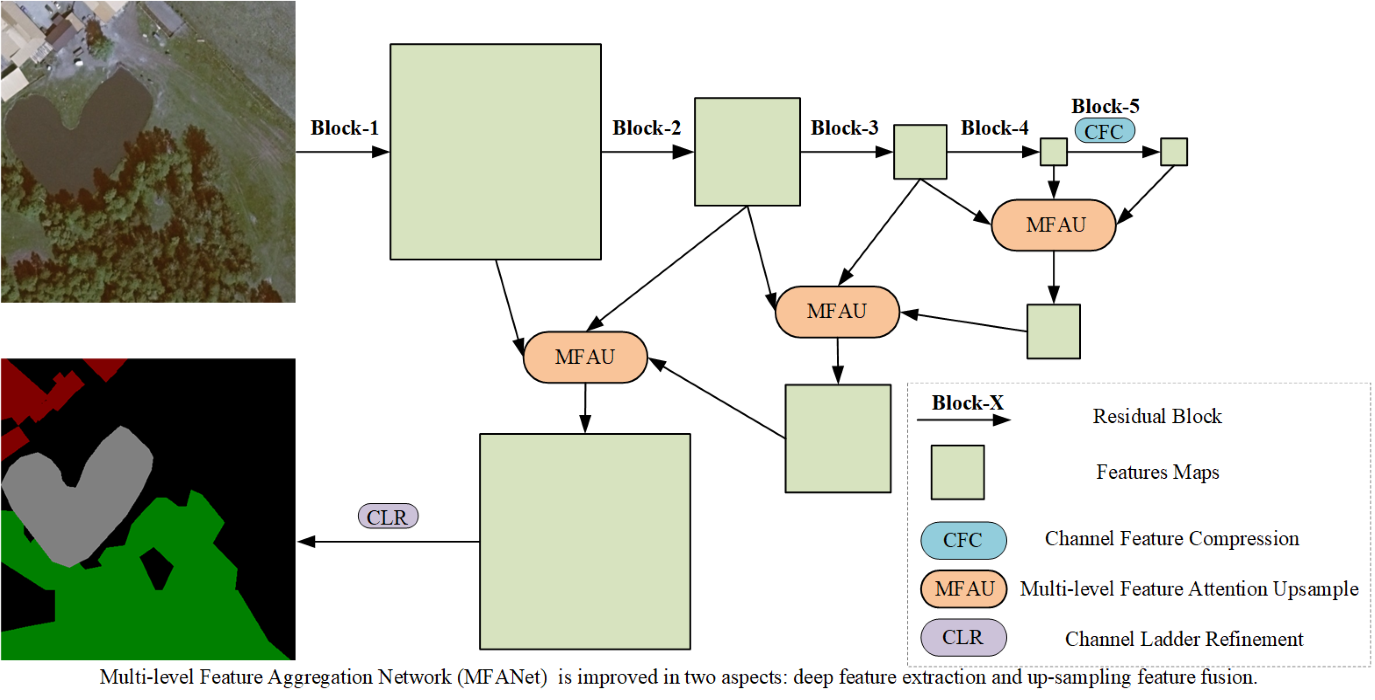
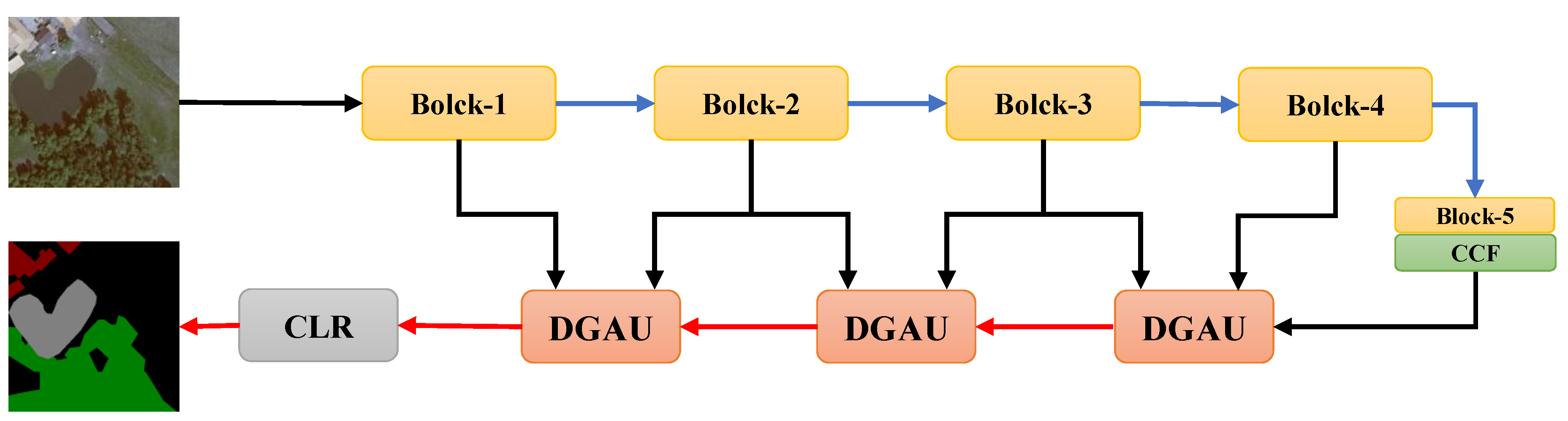
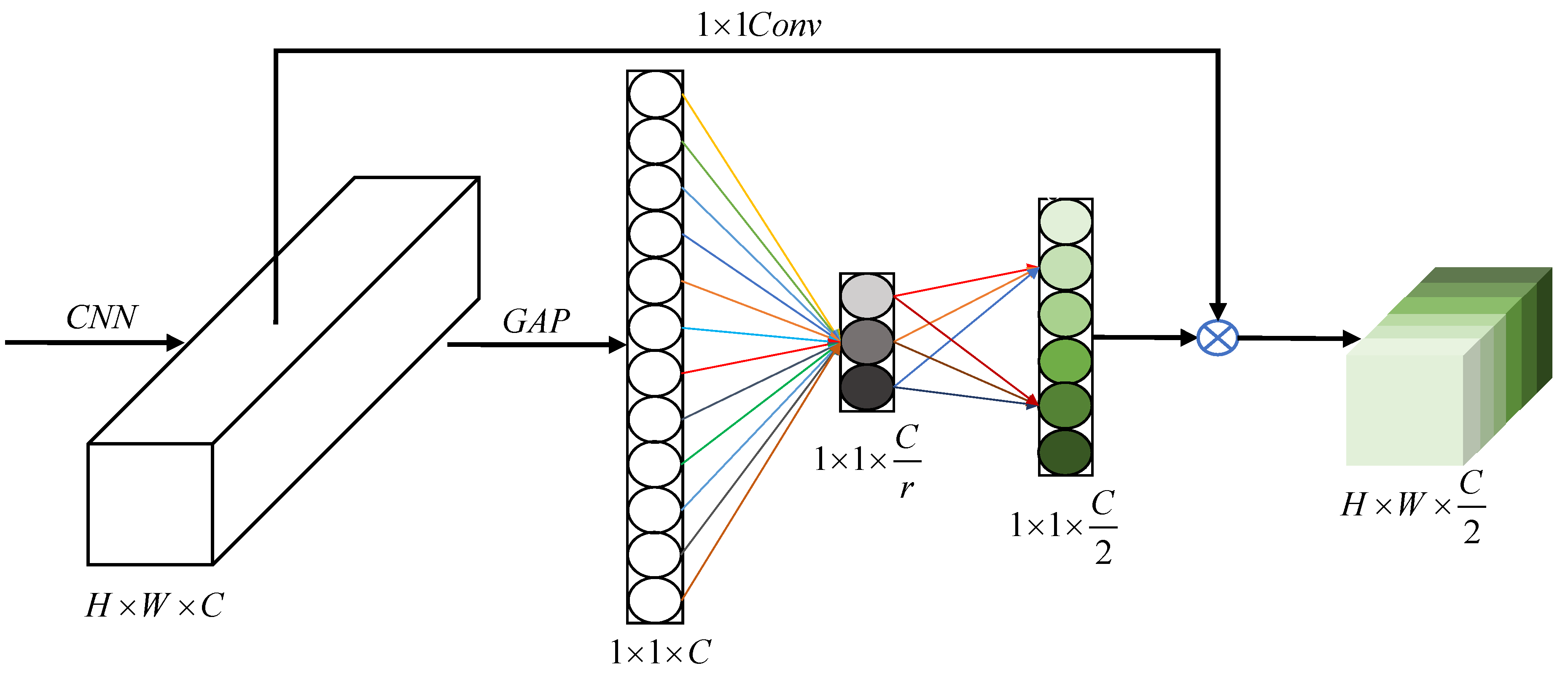
Since down-sampling operations are usually used in convolutional neural networks to extract abstract semantic features, high-resolution details are easily lost, and some problems e.g. inaccurate details and blurred edges emerge in the segmentation results. There are two mainstream solutions to solve the detail loss of high-resolution image. The first solution is that high-resolution feature maps are used and kept throughout the network. This method requires higher hardware performance, which results in low popularity. The representative networks include convolutional neural fabrics [
25] and High Resolution Network (HRNet) [
26]. The second solution is that high-resolution detail information are learnt and restored from low-resolution feature maps. This method is used by most semantic segmentation networks such as PSPNet [
13], Deeplabv3+ [
24] and Densely connected Atrous Spatial Pyramid Pooling (DenseASPP) [
27]. However, this scheme needs to recover the lost information and the result is unsatisfactory. Therefore, the land cover classification models based on semantic segmentation still need to be improved in both deep feature extraction and up-sampling feature fusion. In order to solve the above problems, a multi-level feature aggregation network (MFANet) is proposed for land cover segmentation in this work. In terms of deep feature extraction, a Channel Feature Compression (CFC) module is proposed. Although the structure of CFC module is similar to Squeeze-and-Excitation (SE) module [
28], their functions are different. The SE module is embedded in the building block unit of the original network structure, aiming to improve the network’s presentation ability by enabling it to perform dynamic channel feature recalibration. While the proposed CFC module placed in the middle of the encoder and the decoder, compresses and extracts the deep global features of high-resolution remote sensing images in the channel direction, and provides more accurate global and semantic information for the subsequent up-sampling process. This alleviates the phenomenon of the same thing with different spectrum to a certain extent. In terms of up-sampling feature fusion, we propose another two modules, Multi-level Feature Attention Upsample (MFAU) and Channel Ladder Refinement (CLR). The MFAU module is used to restore high-resolution details. The MFAU module uses multi-level features, rather than only two levels of features are used in traditional up-sampling modules like Global Attention Upsample (GAU) [
29] and traditional networks like U-Net [
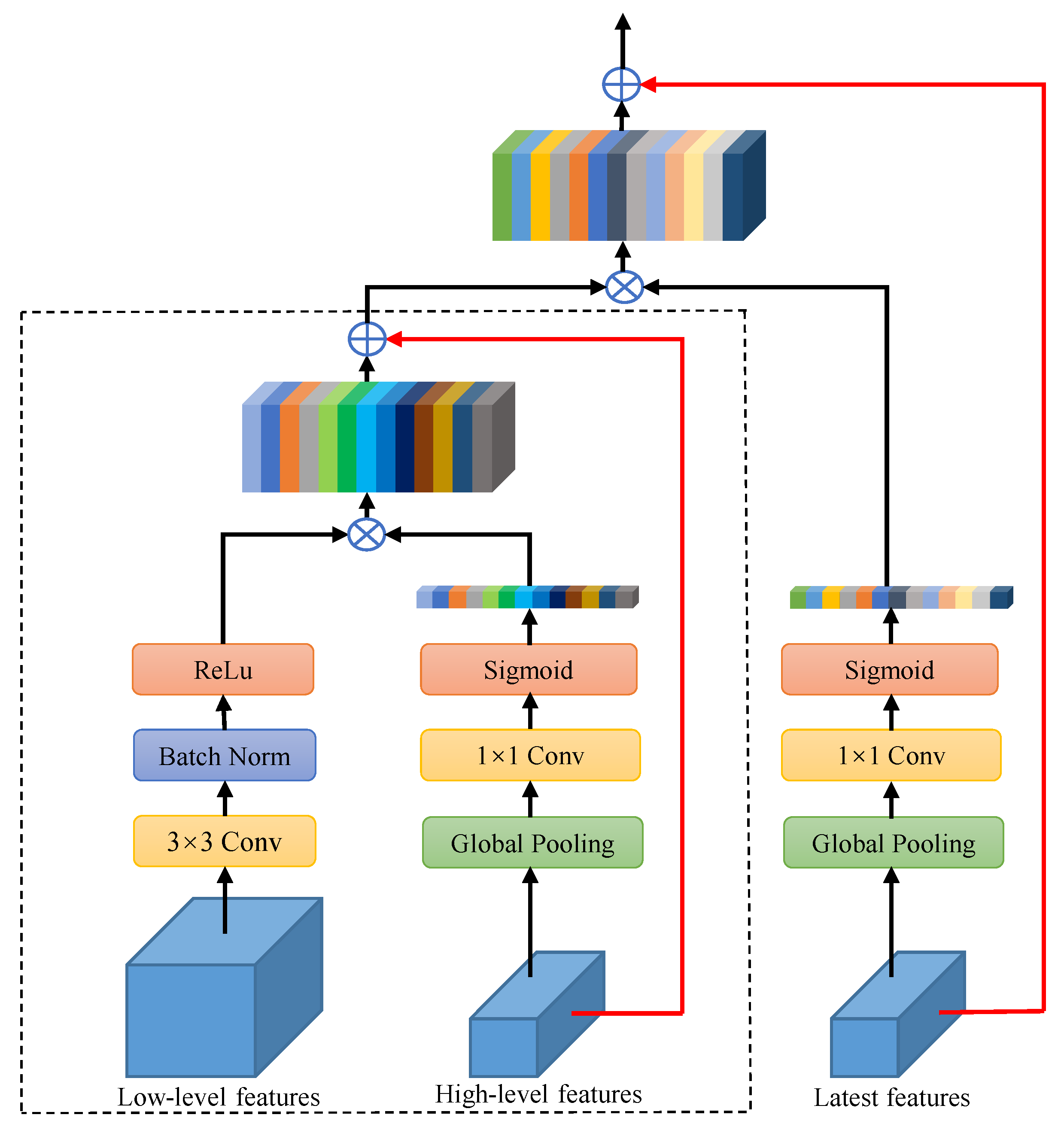
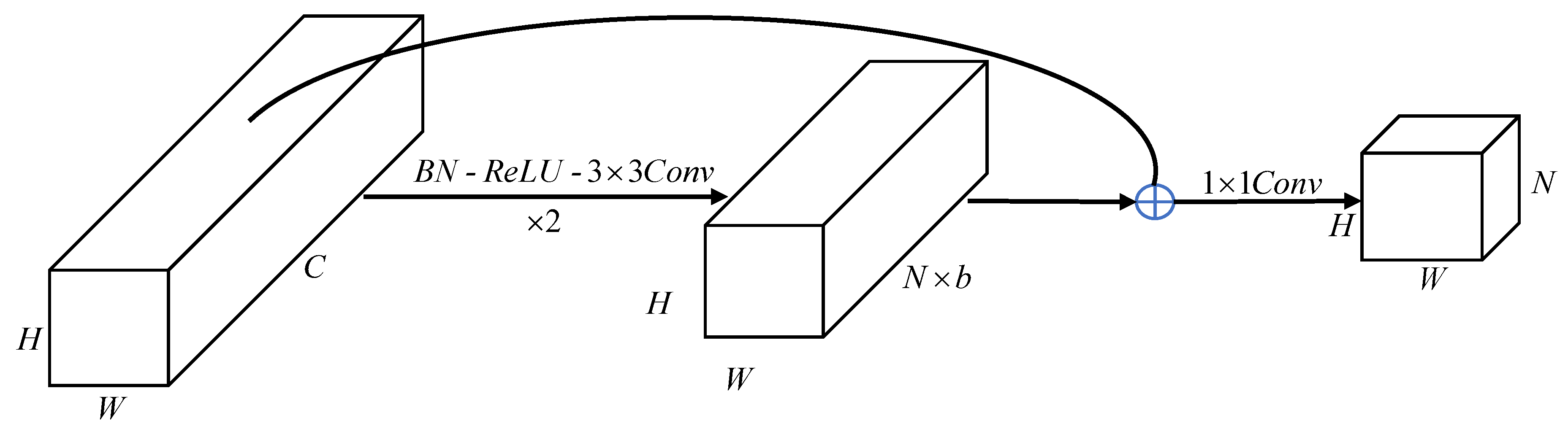
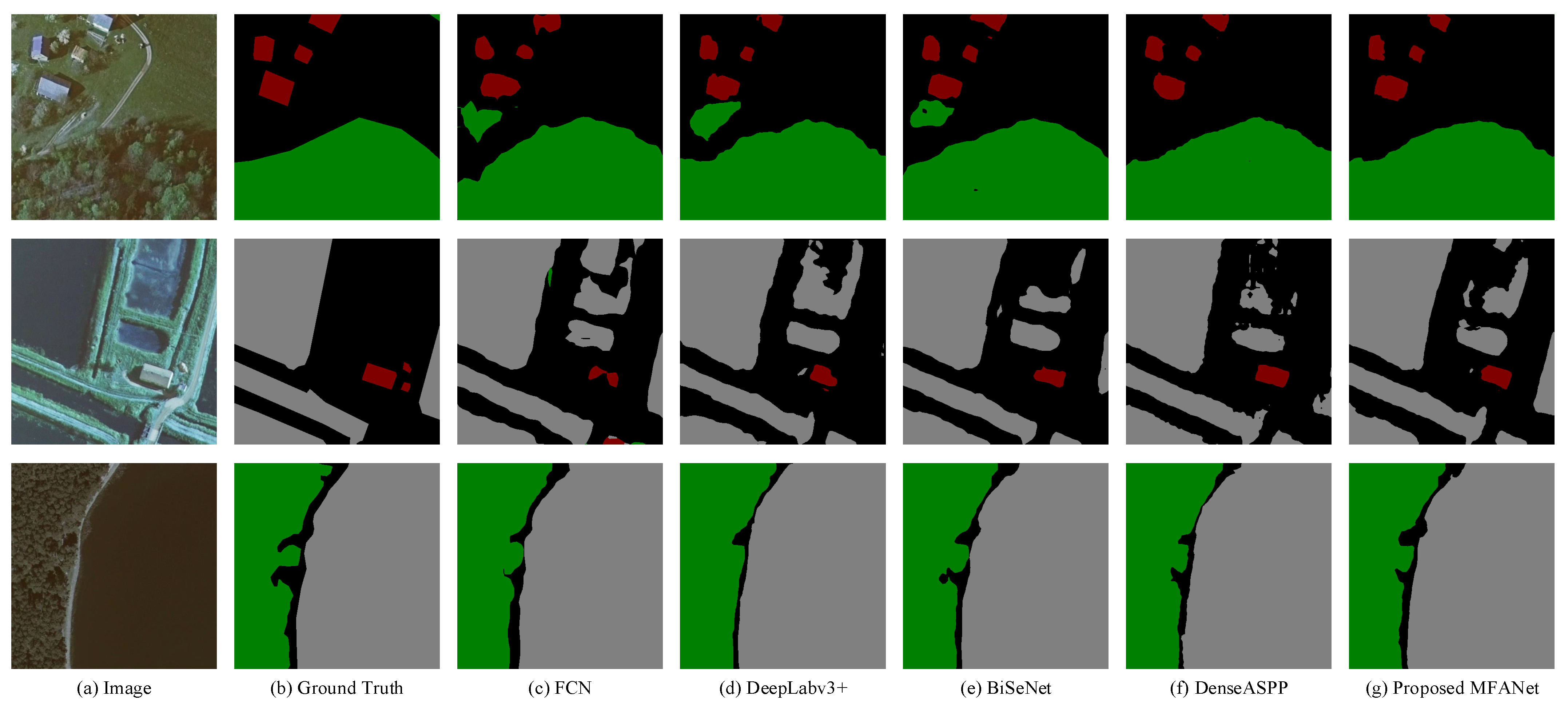
12]. At the same time, each MFAU module also generates a twice-weighted feature combination by performing different convolution and global pooling operations. These two innovations give the MFAU module a powerful ability to recover detailed information for high-resolution remote sensing images. To achieve the purpose of smooth transition to a specific land cover classification task, the proposed Channel Ladder Refinement (CLR) module is placed at the end of the network and gradually refines the restored high-resolution feature maps by decreasing progressively the number of channels.
In general, there are four contributions in our work:
A channel feature compression module placed at the end of the feature extraction network is proposed to extract the deep global features of high-resolution remote sensing images by compressing or filtering redundant information, and therefore to optimize the learned context.
A multi-level feature attention upsample module is proposed, and it uses higher-level features to provide guidance information for low-level features, which generates new features. The high-level features further provide guidance information for newly obtained features, and are re-weighted to obtain the latest features. This is of great significance for restoring the positioning of high-resolution remote sensing images.
This work also proposes a channel ladder refinement module, which is placed before the last up-sampling, with the purpose of gradually refining the restored higher resolution features for any specific land cover classification task.
A network combines the three modules with the feature extraction network is proposed to achieve the purpose of segmenting high-resolution remote sensing images.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}