
3DeepM: An Ad Hoc Architecture Based on Deep Learning Methods for Multispectral Image Classification

 , , , ,
, , , , 
Abstract

1. Introduction
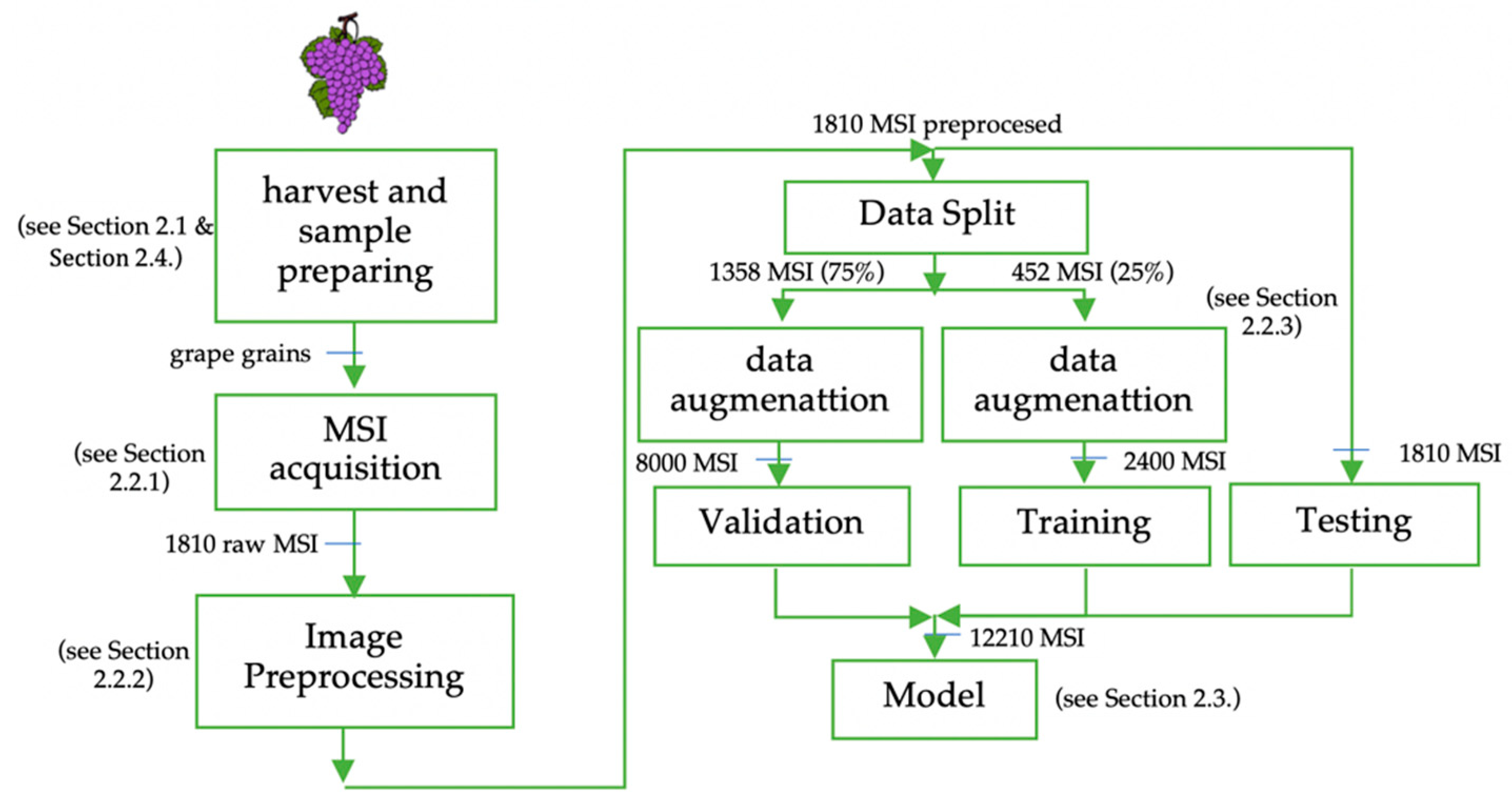
2. Materials and Methods
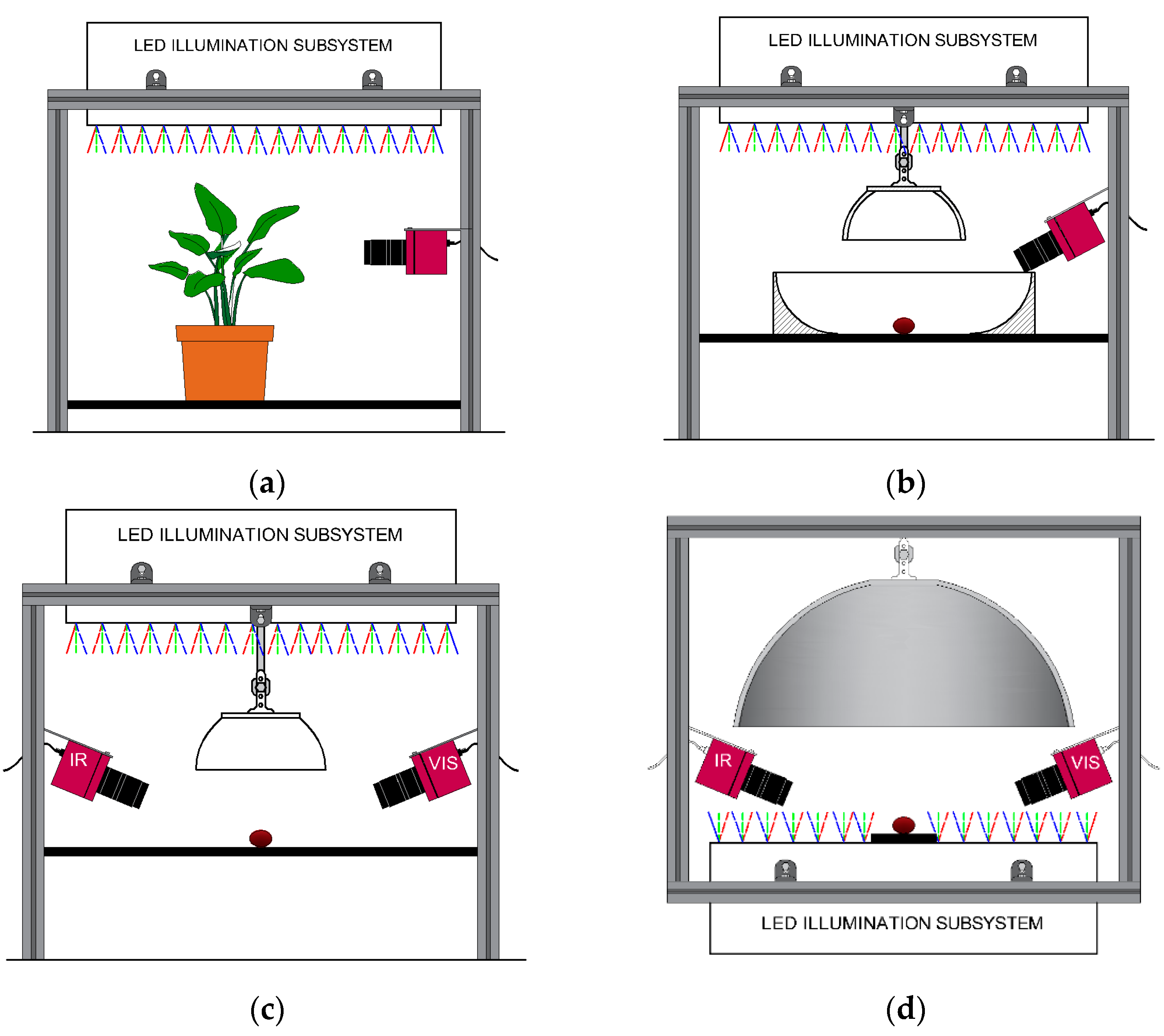
2.1. Multispectral Computer Vision System
2.1.1. Dark Chamber
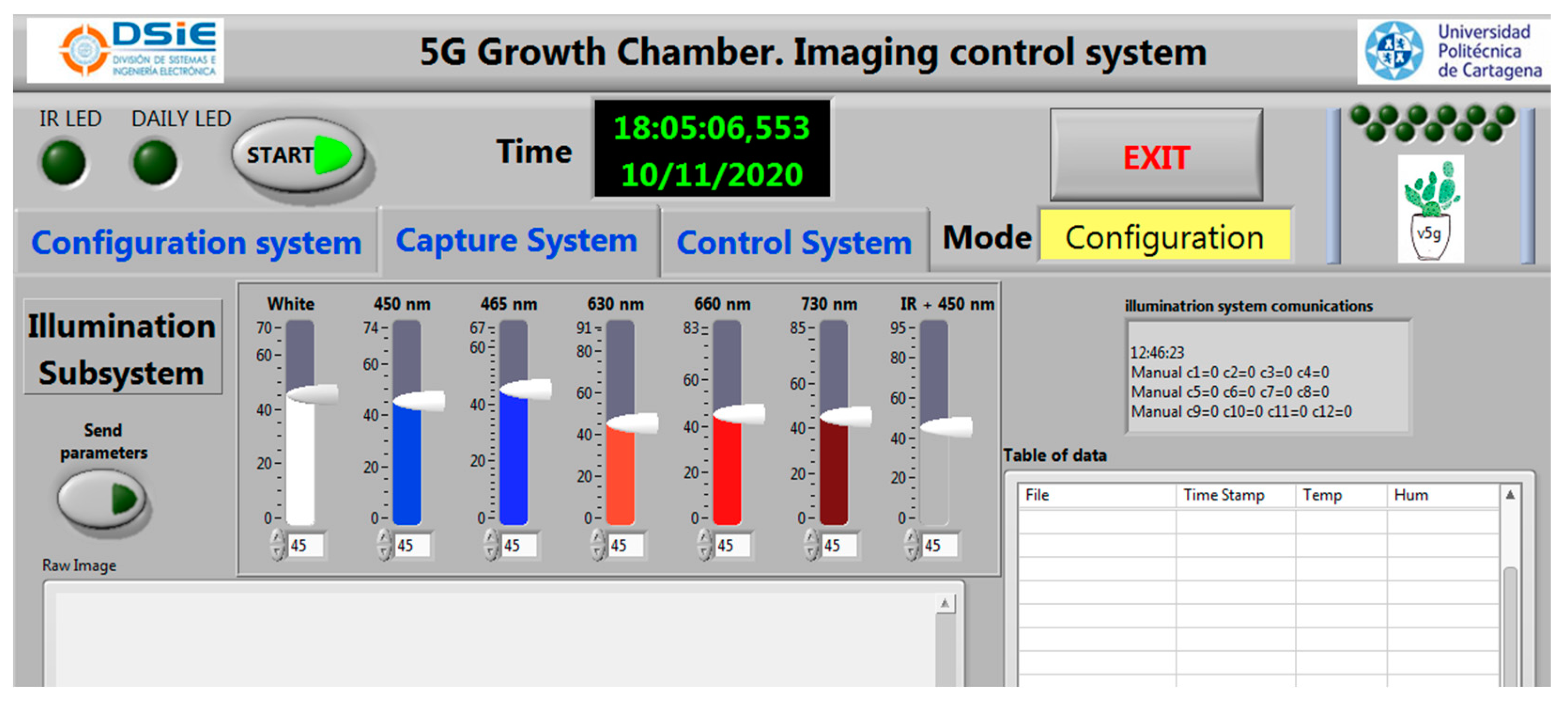
2.1.2. Illumination Subsystem
2.1.3. MSI Acquisition Subsystem
2.2. MSI Acquisition Process and Image Pre-Processing
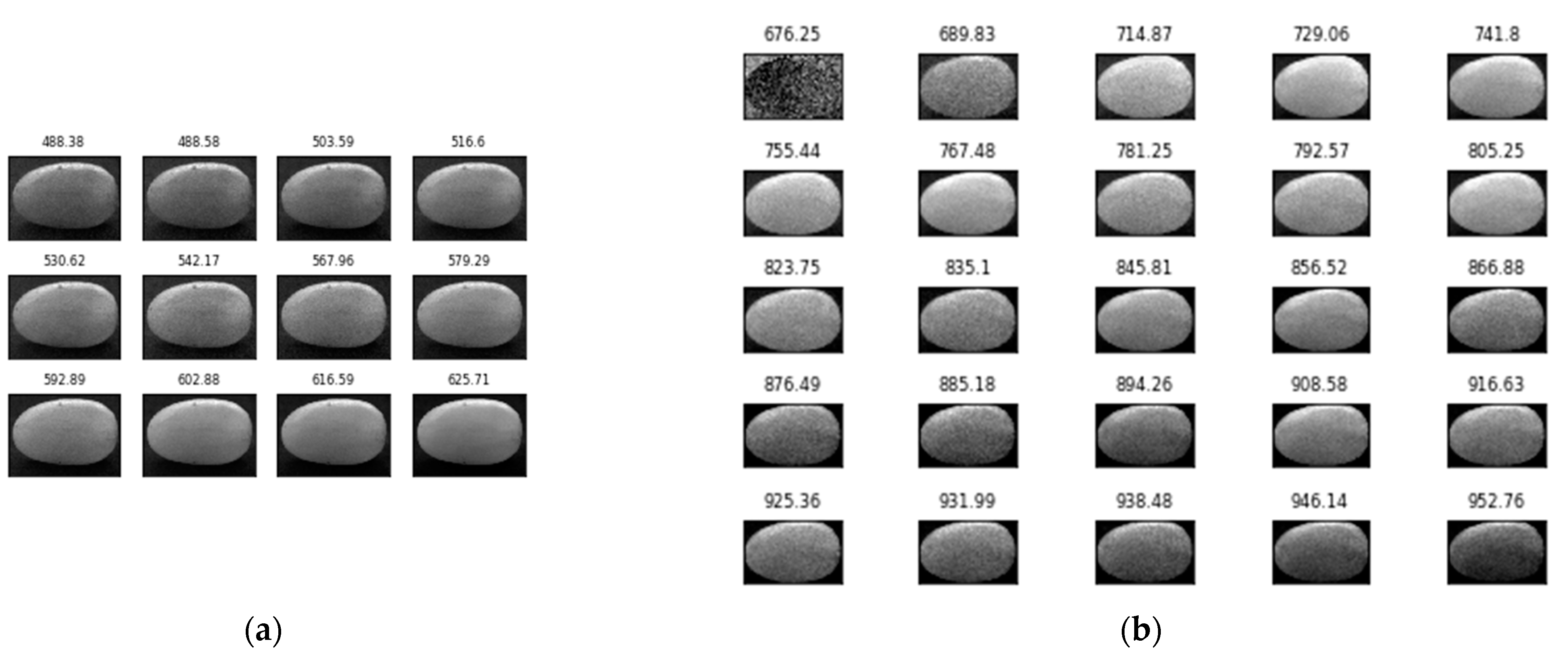
2.2.1. MSI Acquisition Process
2.2.2. Image Pre-Processing
- Load an MSI consisting of N bands: MSI = {B0,…,BN}.
- Calculate the mean Shannon entropy for all the bands of the MSI (MSE), as well as for each band: {SE0,…,SEN}.
- For each entropy value SEi:
- If MSE > SEi, we consider that the image has an acceptable information distribution and the Otsu [27] thresholding method will be applied, obtaining a new set of black-and-white images {BW0,…,BWN}.
- Otherwise, we consider that the image has a low information distribution, and the bands will be limited with a threshold value of 10, obtaining a new set of black-and-white images {BW0,…,BWN}.
- A contour search algorithm will be applied to the images {BW0,…,BWN}, obtaining a new set of contours {C0,…,CM}. From the set, those contours {C0,…,CK} that verify the area and roundness restriction criteria given by Equation (2) will be selected:
- From the set of contours {C0,…,Cj,…,CM}, which verify the area and roundness restrictions, the one with the largest area, Cm, will be selected as the best segmentation of the grape. The window containing the contour Cm(y:y+h,x:x+w) will be used to segment all of the grapes of each band of the MSI, where (y,x) is the upper-left corner of the rectangle, h the height and w the width.
- Each MSI has been resized to a size of 140 × 200 pixels.
- Go to step 1.
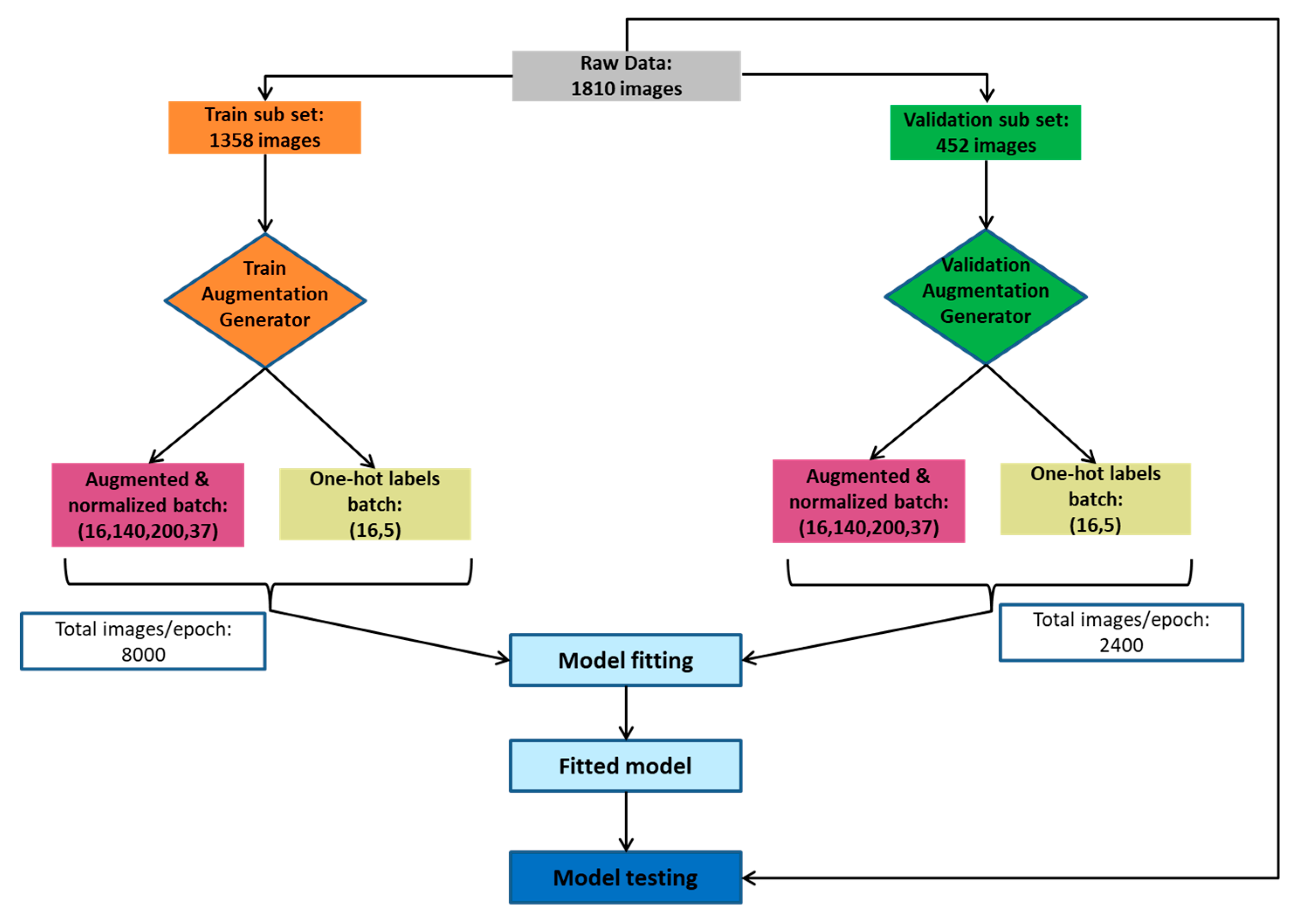
2.2.3. Data Augmentation
2.3. Deep Learning Methods
- Input layer. This is the data input layer of the CNN and is composed of the normalised training images. These images can have a single channel or multiple channels, such as multispectral, video or medical images (i.e., magnetic resonance imaging (MRI) and computerised tomography (CT) scans).
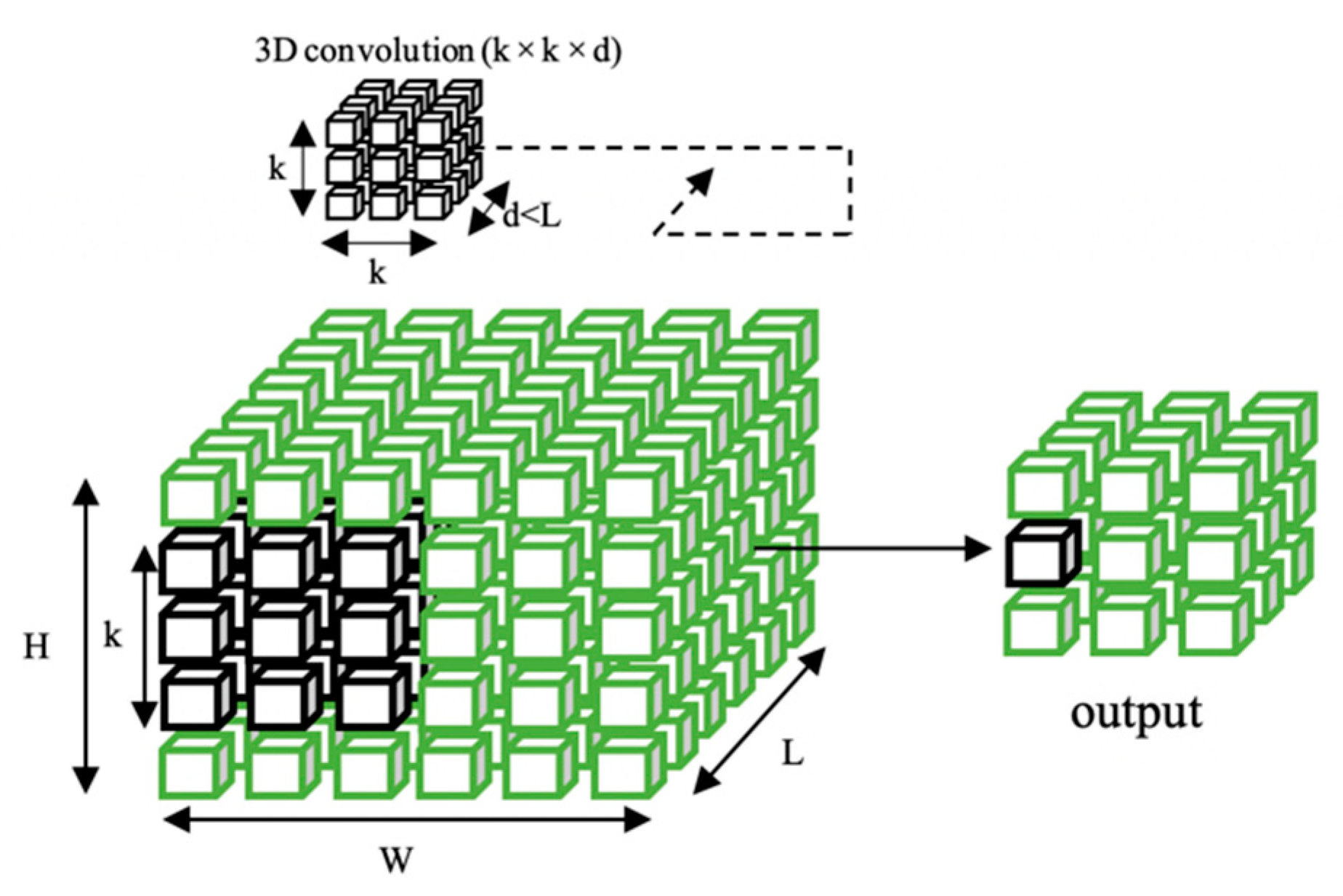
- Convolutional layers. These units have the ability to extract the most relevant characteristics from the images. The convolutions on the images are usually 2D. Given an image I and a convolution kernel K, the 2D convolution operation is defined by Equation (3).
- Fully connected layers. These layers are those layers where all the inputs from one layer are connected to every unit of the next layer. They have the capacity to make decisions, and in our architecture, they will carry out the classification of the data into various classes.
- Activation layer. It has the capacity to apply a nonlinear function as output of the neurons [31]. The most commonly used activation function is the rectified linear unit (ReLU), and it is defined in Equation (4).
- Batch normalisation layer. This layer standardises the mean and variance of each unit in order to stabilise learning, reducing the number of training epochs required to train deep networks [29].
- Pooling layer. The pooling layer modifies the output of the network at a certain location with a summary statistic of the nearby outputs, and it produces a down-sampling operation over the network parameters. For example, the Max Pooling layer uses the maximum value from each of the clusters of neurons at the prior layer [32]. Another common pooling operation is the calculation of the mean value of each possible cluster of values of the tensor of the previous layer, which is implemented in the Average Pooling layer. Both of these kinds of pooling operations can be applied to the whole tensor of the prior layer instead of just a cluster of its values in a sliding window that moves along it. These layers are called Global Max Pooling and Global Average Pooling, and they reduce a tensor to its maximum or mean value, respectively. Additionally, every pooling operation can be applied two- or three-dimensionally, which means that they act along the first 2 or 3 axes of the given tensor. For instance, a 3D Global Average Pooling layer would reduce a tensor of size w × h × d × f (width times height times depth times features) to a 1 × f one, thus spatially compressing the information of every feature to just one value, its mean.
- Output layer. In CNNs for classification, this layer is formed by the last layer of the fully connected block and contains the activation layer, which obtains the probability of belonging to a particular class.
2.3.1. Pretrained DL Architectures
- LeNet-5 was published in 1998 and was originally conceived to recognise handwritten digits in banking documents. It is one of the first widely used CNN and has served as the foundation for many of the more recently developed architectures. The original design consisted of two 2D convolution layers with a kernel size of 5 × 5, each one followed by an average pooling layer, after which a flattening layer and 3 dense layers were placed, the last one being the output layer. It did not make use of batch normalisation and the activation layer was tanh instead of the now widely used ReLU [33].
- AlexNet was published in 2012 and won the contest of ImageNet LSVRC-2010, which consisted of the classification of 1.2 million images of 1000 distinct classes. The network has a significantly larger number of parameters compared to LeNet-5, about 60 million. It consists of a total of five 2D convolutional layers, of varying kernel size that decrease with the depth of the layer: 11 × 11, 5 × 5 and 3 × 3 for the last 3. In between the first three convolutional layers and after the last one, there are a total of 4 Max Pooling layers. Then, a flattening layer and three dense layers follow, including the final output layer. The innovations of this CNN are the usage of the ReLU activation function and the dropout layers to reduce overfitting. Also, the usage of GPUs to train any CNN model with more than a million parameters, which is now commonplace, can be traced back to the inception of this architecture [34].
- VGG16 was published in 2014 as a result of the investigation of the effect of the kernel size on the results achieved with a deep learning model. It was found that with small kernel sizes of 3 × 3 but an increased number of convolutional layers, 16 in this case, the performance experienced a significant improvement. This architecture won the ImageNet challenge of 2014 and consists of 16 convolutional layers, all with kernel size 3 × 3, grouped in blocks of two or three layers each. The groups are followed by Max Pooling layers, and after the last convolution block, there are three dense layers, including the output layer. This architecture showed that the deeper the CNN is, the better the results achieved by it usually are, but the memory requirements also increase and must be taken into account. The number of parameters of this architecture is very high, 137 million, but the authors created an even deeper network, called VGG19, with 144 million parameters [35].
- Inception was published in 2014 and competed with VGG16 in the same ImageNet challenge, where it achieved results as impressive as those of VGG16 but using far less parameters, only 5 million. To accomplish this, the architecture makes use of the so-called inception blocks, which consist of 4 convolutions applied in a parallel manner to the input of the block, each one of a different kernel size, and whose outputs are, in turn, concatenated. The network is made of 3 stacked convolutional layers and then 9 Inception blocks, followed by the output layer. There are also 2 so-called auxiliary classifiers that emerge from 2 Inception blocks, whose purpose is to mitigate the vanishing gradient problem that accompanies a large neuronal network like this. These two branches are discarded at inference time, being used only during training. The kernel sizes of all the convolutional layers were chosen by the authors to optimise the computational resources. After this architecture was published, the authors designed improved versions like InceptionV3 in 2015 and Inception V4 in 2016. InceptionV3 focused on improving the computation efficiency and elimination of representational bottlenecks [36], and InceptionV4 took some inspiration from the ResNet architecture and combined its residual connections, which will be briefly discussed below, with the core ideas of InceptionV3 [37]. In 2016, yet another variant of Inception was published, called Xception. Its main feature is the replacement of all the convolutions by depth-wise separable convolutions to increase the efficiency even further [38].
- ResNet was published in 2015 and won the first place of the ILSVRC classification task of the year. The main new feature of this architecture are the skip connections and the consistent usage of batch normalisation layers after every convolutional layer. The purpose of these features is to ease the training of very deep CNNs, like the implementations ResNet-50 and ResNet-101, which have 50 and 101 convolutional layers, respectively. The architecture is composed of so-called convolutional and identity blocks, in which the input to the block is concatenated to its output, creating the skip connections that help to train the networks [39].
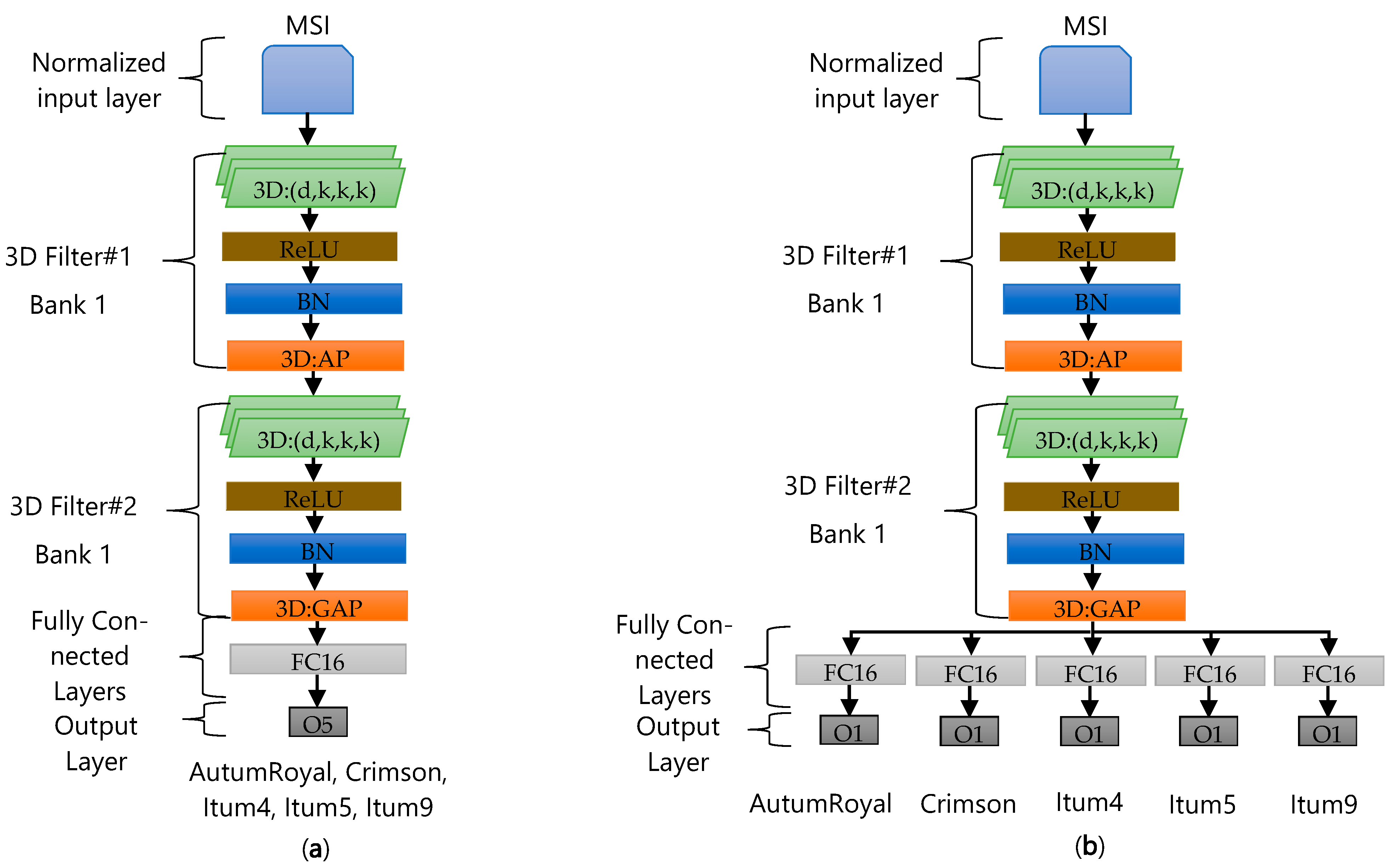
2.3.2. Ad hoc Deep Learning Architecture Design
- (1)
- Optimal 3D kernel size. In this test, both architectures were evaluated with symmetric kernel sizes: (5 × 5 × 5), (7 × 7 × 7) and (10 × 10 × 10). The different kernels will allow different space–time relationships to be captured for the multispectral images and the evaluation of the size that produces the best result in the classification process.
- (2)
- Optimal kernel sequence: In this experiment, architectures with three types of kernel sequences were evaluated: increasing F#1(5 × 5 × 5) + F#2(10 × 10 × 10), decreasing F#1(10 × 10 × 10) + F#2(5 × 5 × 5) and constant F#1(7 × 7 × 7) + F#2(7 × 7 × 7). The results will allow the influence of the sequence order of the kernels on the classification process to be determined.
2.4. Plant Material
3. Results
3.1. Configuration of the Models
- (1)
- Training dataset, which consists of 8000 images, 75% of the images obtained in the data augmentation process (Section 2.2.2)
- (2)
- Validation dataset, consisting of 2400 images, which corresponds to 25% of the images obtained in the data augmentation process (Section 2.2.2)
- (3)
- Test dataset, made up of 1810 images, which constitute the set of images without the initial data augmentation
3.2. Performance Metrics
4. Discussion
4.1. Grape Classification
4.2. Remote Sensing Applications
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lowe, A.; Harrison, N.; French, A.P. Hyperspectral image analysis techniques for the detection and classification of the early onset of plant disease and stress. Plant Methods 2017, 13, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Pereira, C.S.; Morais, R.; Reis, M.J.C.S. Deep Learning Techniques for Grape Plant Species Identification in Natural Images. Sensors 2019, 19, 4850. [Google Scholar] [CrossRef]
- Santos, T.T.; de Souza, L.L.; dos Santos, A.A.; Avila, S. Grape detection, segmentation, and tracking using deep neural networks and three-dimensional association. Comput. Electron. Agric. 2020, 170, 105247. [Google Scholar] [CrossRef]
- Qasim El-Mashharawi, H.; Alshawwa, I.A.; Elkahlout, M. Classification of Grape Type Using Deep Learning. Int. J. Acad. Eng. Res. 2020, 3, 41–45. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Hsieh, T.H.; Kiang, J.F. Comparison of CNN algorithms on hyperspectral image classification in agricultural lands. Sensors 2020, 20, 1734. [Google Scholar] [CrossRef]
- Bhosle, K.; Musande, V. Evaluation of Deep Learning CNN Model for Land Use Land Cover Classification and Crop Identification Using Hyperspectral Remote Sensing Images. J. Indian Soc. Remote Sens. 2019, 47, 1949–1958. [Google Scholar] [CrossRef]
- Xie, B.; Zhang, H.K.; Xue, J. Deep convolutional neural network for mapping smallholder agriculture using high spatial resolution satellite image. Sensors 2019, 19, 2398. [Google Scholar] [CrossRef]
- Steinbrener, J.; Posch, K.; Leitner, R. Hyperspectral fruit and vegetable classification using convolutional neural networks. Comput. Electron. Agric. 2019, 162, 364–372. [Google Scholar] [CrossRef]
- Kandpal, L.; Lee, J.; Bae, J.; Lohumi, S.; Cho, B.-K. Development of a Low-Cost Multi-Waveband LED Illumination Imaging Technique for Rapid Evaluation of Fresh Meat Quality. Appl. Sci. 2019, 9, 912. [Google Scholar] [CrossRef]
- Li, B.; Cobo-Medina, M.; Lecourt, J.; Harrison, N.B.; Harrison, R.J.; Cross, J.V. Application of hyperspectral imaging for nondestructive measurement of plum quality attributes. Postharvest Biol. Technol. 2018, 141, 8–15. [Google Scholar] [CrossRef]
- Veys, C.; Chatziavgerinos, F.; AlSuwaidi, A.; Hibbert, J.; Hansen, M.; Bernotas, G.; Smith, M.; Yin, H.; Rolfe, S.; Grieve, B. Multispectral imaging for presymptomatic analysis of light leaf spot in oilseed rape. Plant Methods 2019, 15, 4. [Google Scholar] [CrossRef]
- Bravo, C.; Moshou, D.; West, J.; McCartney, A.; Ramon, H. Early disease detection in wheat fields using spectral reflectance. Biosyst. Eng. 2003, 84, 137–145. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. Dense connectivity based two-stream deep feature fusion framework for aerial scene classification. Remote Sens. 2018, 10, 1158. [Google Scholar] [CrossRef]
- Perez-Sanz, F.; Navarro, P.J.; Egea-Cortines, M. Plant phenomics: An overview of image acquisition technologies and image data analysis algorithms. Gigascience 2017, 6, gix092. [Google Scholar] [CrossRef] [PubMed]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep learning classifiers for hyperspectral imaging: A review. Isprs J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Lacar, F.M.; Lewis, M.M.; Grierson, I.T. Use of hyperspectral imagery for mapping grape varieties in the Barossa Valley, South Australia. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Sydney, NSW, Autralia, 9–13 July 2001; Volume 6, pp. 2875–2877. [Google Scholar]
- Knauer, U.; Matros, A.; Petrovic, T.; Zanker, T.; Scott, E.S.; Seiffert, U. Improved classification accuracy of powdery mildew infection levels of wine grapes by spatial-spectral analysis of hyperspectral images. Plant Methods 2017, 13, 47. [Google Scholar] [CrossRef]
- Qiao, S.; Wang, Q.; Zhang, J.; Pei, Z. Detection and Classification of Early Decay on Blueberry Based on Improved Deep Residual 3D Convolutional Neural Network in Hyperspectral Images. Sci. Program. 2020, 4, 1–12. [Google Scholar] [CrossRef]
- Russell, B.; Torralba, A.; Freeman, W.T. Labelme: The Open Annotation Tool. Available online: http://labelme.csail.mit.edu/Release3.0/browserTools/php/dataset.php (accessed on 30 December 2020).
- Santos, T.; de Souza, L.; Andreza, d.S.; Avila, S. Embrapa Wine Grape Instance Segmentation Dataset–Embrapa WGISD. Available online: https://zenodo.org/record/3361736#.YCx3LXm-thE (accessed on 17 January 2021).
- Navarro, P.J.; Fernández, C.; Weiss, J.; Egea-Cortines, M. Development of a configurable growth chamber with a computer vision system to study circadian rhythm in plants. Sensors 2012, 12, 15356–15375. [Google Scholar] [CrossRef]
- Navarro, P.J.; Pérez Sanz, F.; Weiss, J.; Egea-Cortines, M. Machine learning for leaf segmentation in NIR images based on wavelet transform. In Proceedings of the II Simposio Nacional de Ingeniería Hortícola. Automatización y TICs en agricultura, Alemeria, Spain, 10–12 February 2016; p. 20. [Google Scholar]
- Díaz-Galián, M.V.; Perez-Sanz, F.; Sanchez-Pagán, J.D.; Weiss, J.; Egea-Cortines, M.; Navarro, P.J. A proposed methodology to analyze plant growth and movement from phenomics data. Remote Sens. 2019, 11, 2839. [Google Scholar] [CrossRef]
- Multispectral Camera MV1-D2048x1088-HS03-96-G2 | Photonfocus AG. Available online: https://www.photonfocus.com/products/camerafinder/camera/mv1-d2048x1088-hs03-96-g2/ (accessed on 2 January 2021).
- Multispectral Camera MV1-D2048x1088-HS02-96-G2 | Photonfocus AG. Available online: https://www.photonfocus.com/products/camerafinder/camera/mv1-d2048x1088-hs02-96-g2/ (accessed on 2 January 2021).
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; Volume 2015, pp. 4489–4497. [Google Scholar]
- Behnke, S. Hierarchical neural networks for image interpretation. Lect. Notes Comput. Sci. Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform. 2003, 2766, 1–220. [Google Scholar]
- Yamaguchi, K.; Sakamoto, K.; Akabane, T.; Fujimoto, Y. A Neural Network for Speaker-Independent Isolated Word Recognition. In Proceedings of the First International Conference on Spoken Language Processing (ICSLP 90), Kobe, Japan, 18–22 November 1990. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2323. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. Acm 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015–Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hong, S.; Kim, S.; Joh, M.; Songy, S.K. Globenet: Convolutional neural networks for typhoon eye tracking from remote sensing imagery. arXiv 2017, arXiv:1708.03417. [Google Scholar]
- Zhao, S.; Liu, X.; Ding, C.; Liu, S.; Wu, C.; Wu, L. Mapping Rice Paddies in Complex Landscapes with Convolutional Neural Networks and Phenological Metrics. GIScience Remote Sens. 2020, 57, 37–48. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, M. Remote Sensing Image Classification Based on AlexNet Network Model. In Lecture Notes in Electrical Engineering; Springer: Berlin/Heidelberg, Germany, 2020; Volume 551, pp. 913–918. [Google Scholar]
- Rezaee, M.; Mahdianpari, M.; Zhang, Y.; Salehi, B. Deep Convolutional Neural Network for Complex Wetland Classification Using Optical Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3030–3039. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very deep convolutional neural networks for complex land cover mapping using multispectral remote sensing imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef]
- Liu, K.; Yu, S.; Liu, S. An Improved InceptionV3 Network for Obscured Ship Classification in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4738–4747. [Google Scholar] [CrossRef]
- Ma, H.; Liu, Y.; Ren, Y.; Wang, D.; Yu, L.; Yu, J. Improved CNN classification method for groups of buildings damaged by earthquake, based on high resolution remote sensing images. Remote Sens. 2020, 12, 260. [Google Scholar] [CrossRef]
- Li, W.; Wang, Z.; Wang, Y.; Wu, J.; Wang, J.; Jia, Y.; Gui, G. Classification of High-Spatial-Resolution Remote Sensing Scenes Method Using Transfer Learning and Deep Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1986–1995. [Google Scholar] [CrossRef]
- Jie, B.X.; Zulkifley, M.A.; Mohamed, N.A. Remote Sensing Approach to Oil Palm Plantations Detection Using Xception. In 2020 11th IEEE Control and System Graduate Research Colloquium, ICSGRC 2020−Proceedings; IEEE: Piscataway, NJ, USA, 2020; pp. 38–42. [Google Scholar]
- Zhu, T.; Li, Y.; Ye, Q.; Huo, H.; Tao, F. Integrating saliency and ResNet for airport detection in large-size remote sensing images. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing, ICIVC 2017, Chengdu, China, 2–4 June 2017; pp. 20–25. [Google Scholar]
- Terry, M.I.; Ruiz-Hernández, V.; Águila, D.J.; Weiss, J.; Egea-Cortines, M. The Effect of Post-harvest Conditions in Narcissus sp. Cut Flowers Scent Profile. Front. Plant Sci. 2021, 11, 2144. [Google Scholar] [CrossRef] [PubMed]
- de Castro, C.; Torres-Albero, C. Designer Grapes: The Socio-Technical Construction of the Seedless Table Grapes. A Case Study of Quality Control. Sociol. Rural. 2018, 58, 453–469. [Google Scholar] [CrossRef]
- Royo, C.; Torres-Pérez, R.; Mauri, N.; Diestro, N.; Cabezas, J.A.; Marchal, C.; Lacombe, T.; Ibáñez, J.; Tornel, M.; Carreño, J.; et al. The major origin of seedless grapes is associated with a missense mutation in the MADS-box gene VviAGL11. Plant Physiol. 2018, 177, 1234–1253. [Google Scholar] [CrossRef] [PubMed]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 25, 120–125. [Google Scholar]
- 54. Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Kai, L.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Institute of Electrical and Electronics Engineers (IEEE); IEEE: Piscataway, NJ, USA, 2010; pp. 248–255. [Google Scholar]
- Seng, J.; Ang, K.; Schmidtke, L.; Rogiers, S. Grape Image Database–Charles Sturt University Research Output. Available online: https://researchoutput.csu.edu.au/en/datasets/grape-image-database (accessed on 30 December 2020).
- Franczyk, B.; Hernes, M.; Kozierkiewicz, A.; Kozina, A.; Pietranik, M.; Roemer, I.; Schieck, M. Deep learning for grape variety recognition. In Procedia Computer Science; Elsevier: Amsterdam, The Netherlands, 2020; Volume 176, pp. 1211–1220. [Google Scholar]
- Śkrabánek, P. DeepGrapes: Precise Detection of Grapes in Low-resolution Images. Ifac Pap. 2018, 51, 185–189. [Google Scholar] [CrossRef]
- Ramos, R.P.; Gomes, J.S.; Prates, R.M.; Simas Filho, E.F.; Teruel, B.J.; dos Santos Costa, D. Non-invasive setup for grape maturation classification using deep learning. J. Sci. Food Agric. 2020. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel | C1 | C2 | C3 | C4 | C5 | C6 | C7 |
|---|---|---|---|---|---|---|---|
| Spectra | White | 450 nm | 465 nm | 630 nm | 660 nm | 730 nm | IR 1 |
| Power | 24 W | 24 W | 24 W | 24 W | 24 W | 24 W | 100 W |
| Transformation | Range |
|---|---|
| Brightness | (−0.15,+0.15) |
| Contrast | (−0.15,+0.15) |
| Rotation | (−90,+90°) |
| X axis shift | (−0.006,+0.006) |
| Y axis shift | (−0.006,+0.006) |
| Scale | (−0.3,+0.3) |
| Architecture Layer | SBO (5 × 5 × 5) [(0 × 10 × 10) | SBO (10 × 10 × 10) (5 × 5 × 5) | SBO (7 × 7 × 7) (7 × 7 × 7) | MBO (5 × 5 × 5) (10 × 10 × 10) | MBO (10 × 10 × 10) (5 × 5 × 5) | MBO (7 × 7 × 7) (7 × 7 × 7) | |
|---|---|---|---|---|---|---|---|
| Input | 0 | 0 | 0 | 0 | 0 | 0 | |
| Filter#1 | 3D:Conv | 1008 | 8008 | 2752 | 1008 | 8008 | 2752 |
| ReLU | 0 | 0 | 0 | 0 | 0 | 0 | |
| BN | 32 | 32 | 32 | 32 | 32 | 32 | |
| 3D:MP | 0 | 0 | 0 | 0 | 0 | 0 | |
| Filter#2 | 3D:Conv | 128,016 | 16,016 | 43,920 | 128,016 | 16,016 | 43,920 |
| ReLU | 0 | 0 | 0 | 0 | 0 | 0 | |
| BN | 64 | 64 | 64 | 64 | 64 | 64 | |
| 3D:GAP | 0 | 0 | 0 | 0 | 0 | 0 | |
| FC16 | 272 | 272 | 272 | 1360 1 | 1360 1 | 1360 1 | |
| Output | 85 | 85 | 85 | 85 2 | 85 2 | 85 2 | |
| Total Parameters | 129,477 | 24,477 | 47,125 | 130,565 | 25,565 | 48,213 | |
| Parameter Name | Value |
|---|---|
| Batch size | 16 |
| Number of epochs | 20 |
| Optimisation algorithm | Adam |
| Loss function | Categorical cross Entropy |
| Metric | Accuracy |
| Learning rate | 0.001 |
| Momentum | None |
| Activation function in convolutional layers | ReLU |
| Activation function in last layers | Softmax |
| Architecture | SBO Kernel Sizes | MBO Kernel Sizes | ||||
|---|---|---|---|---|---|---|
| Metrics | (5 × 5 × 5) (10 × 10 × 10) | (10 × 10 × 10) (5 × 5 × 5) | (7 × 7 × 7) (7 × 7 × 7) | (5 × 5 × 5) (10 × 10 × 10) | (10 × 10 × 10) (5 × 5 × 5) | (7 × 7 × 7) (7 × 7 × 7) |
| Train. acc. {%) | 100.00 | 100.00 | 100.00 | 100.00 | 99.89 | 100.00 |
| Train. loss | 0.00072 | 0.0063 | 0.00030 | 0.00035 | 0.01379 | 0.00069 |
| Val. acc. (%) Epoch | 100.00 11 | 82.708 14 | 100.00 7 | 100.00 10 | 100.00 13 | 100.00 15 |
| Val. loss | 0.00202 | 0.583 | 3.693 × 10−5 | 0.00012 | 0.00018 | 0.00025 |
| Test acc. (%) | 100.00 | 83.20 | 100.00 | 100.00 | 100.0 | 100.00 |
| 3D Conv. | Variety | Autumn Royal | Crimson Seedless | Itum4 | Itum5 | Itum9 |
|---|---|---|---|---|---|---|
| F#1(5 × 5 × 5) F#2(10 × 10 × 10) | Autumn Royal | 100% | 0 | 0 | 0 | 0 |
| Crimson | 0 | 100% | 0 | 0 | 0 | |
| Itum4 | 0 | 0 | 100% | 0 | 0 | |
| Itum5 | 0 | 0 | 0 | 100% | 0 | |
| Itum9 | 0 | 0 | 0 | 0 | 100% | |
| F#1(10 × 10 × 10) F#2(5 × 5 × 5) | Autumn Royal | 100% | 0 | 0 | 0 | 0 |
| Crimson | 34.55% | 63.95% | 1.33% | 0.17% | 0 | |
| Itum4 | 1.02% | 0 | 98.98% | 0 | 0 | |
| Itum5 | 15.69% | 0 | 0 | 84.31% | 0 | |
| Itum9 | 10.26% | 0 | 0 | 0 | 89.74% | |
| F#1(7 × 7 × 7) F#2(7 × 7 × 7) | Autumn Royal | 100% | 0 | 0 | 0 | 0 |
| Crimson | 0 | 100% | 0 | 0 | 0 | |
| Itum4 | 0 | 0 | 100% | 0 | 0 | |
| Itum5 | 0 | 0 | 0 | 100% | 0 | |
| Itum9 | 0 | 0 | 0 | 0 | 100% |
| 3D Conv. | Variety | Autumn Royal | Crimson Seedless | Itum4 | Itum5 | Itum9 |
|---|---|---|---|---|---|---|
| F#1(5 × 5 × 5) F#2(10 × 10 × 10) | Autumn Royal | 100% | 0 | 0 | 0 | 0 |
| Crimson | 0 | 100% | 0 | 0 | 0 | |
| Itum4 | 0 | 0 | 100% | 0 | 0 | |
| Itum5 | 0 | 0 | 0 | 100% | 0 | |
| Itum9 | 0 | 0 | 0 | 0 | 100% | |
| F#1(10 × 10 × 10) F#2(5 × 5 × 5) | Autumn Royal | 100% | 0 | 0 | 0 | 0 |
| Crimson | 0 | 100% | 0 | 0 | 0 | |
| Itum4 | 0 | 0 | 100% | 0 | 0 | |
| Itum5 | 0 | 0 | 0 | 100% | 0 | |
| Itum9 | 0 | 0 | 0 | 0 | 100% | |
| F#1(7 × 7 × 7) F#2(7 × 7 × 7) | Autumn Royal | 100% | 0 | 0 | 0 | 0 |
| Crimson | 0 | 100% | 0 | 0 | 0 | |
| Itum4 | 0 | 0 | 100% | 0 | 0 | |
| Itum5 | 0 | 0 | 0 | 100% | 0 | |
| Itum9 | 0 | 0 | 0 | 0 | 100% |
| Author | Architecture Type | Image Type | Total Dataset | Classes | Accuracy | Number of Parameters |
|---|---|---|---|---|---|---|
| [2] | AlexNet | RGB | 201,824 | 6 | 77.30% | 62,379,752 |
| [56] | Resnet | RGB | 3967 | 5 | 99.92%. | >25.6 × 106 |
| [57] | Ad hoc | RGB | 4000 | 1 | 97.35% | 293,426 |
| [4] | Ad hoc | RGB | 4565 | 6 | 100.00% | 3,459,275 |
| [58] | Ad hoc | MSI | 1260 | 3 | 93.41% | 704,643 |
| 3DeepM | Ad hoc | MSI | 12,210 | 5 | 100.00% | 25,565 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Navarro, P.J.; Miller, L.; Gila-Navarro, A.; Díaz-Galián, M.V.; Aguila, D.J.; Egea-Cortines, M. 3DeepM: An Ad Hoc Architecture Based on Deep Learning Methods for Multispectral Image Classification. Remote Sens. 2021, 13, 729. https://doi.org/10.3390/rs13040729
Navarro PJ, Miller L, Gila-Navarro A, Díaz-Galián MV, Aguila DJ, Egea-Cortines M. 3DeepM: An Ad Hoc Architecture Based on Deep Learning Methods for Multispectral Image Classification. Remote Sensing. 2021; 13(4):729. https://doi.org/10.3390/rs13040729
Chicago/Turabian StyleNavarro, Pedro J., Leanne Miller, Alberto Gila-Navarro, María Victoria Díaz-Galián, Diego J. Aguila, and Marcos Egea-Cortines. 2021. "3DeepM: An Ad Hoc Architecture Based on Deep Learning Methods for Multispectral Image Classification" Remote Sensing 13, no. 4: 729. https://doi.org/10.3390/rs13040729
APA StyleNavarro, P. J., Miller, L., Gila-Navarro, A., Díaz-Galián, M. V., Aguila, D. J., & Egea-Cortines, M. (2021). 3DeepM: An Ad Hoc Architecture Based on Deep Learning Methods for Multispectral Image Classification. Remote Sensing, 13(4), 729. https://doi.org/10.3390/rs13040729