1. Introduction
Change detection is a process of qualitatively and quantitatively analyzing and determining changes on the earth’s surface in different time dimensions. It is one of the essential technologies in the field of remote sensing applications, and it has been widely and deeply applied in the fields of land planning, urban changes, disaster monitoring, military, agriculture, and forestry [
1,
2]. Buildings are one of the most dynamic structures in cities, and their changes can reflect the process of urbanization to a large extent. Accurate and effective evaluation of building changes is a powerful means to obtain reliable urban change information, and it is also an urgent need in some fields such as government management, economic construction, and sociological research [
3,
4].
With the continuous development of remote sensing technology and computer technology, more and more satellite-borne and airborne sensors such as QuickBird, Worldview, GaoFen, Sentinel, ZY, Pléiades, et al. are designed, manufactured, and put into operation. In this case, massive and diverse remote sensing data are produced, which also enriches the data sources of change detection [
5]. The available data types for change detection have expanded from the medium- and low-resolution optical remote sensing images to high resolution or very high resolution (HR/VHR) optical remote sensing images, light detection and ranging (LiDAR), or synthetic aperture radar (SAR) data. HR/VHR remote sensing images contain richer spectral, texture, and shape features of ground objects, allowing a detailed comparison of geographic objects in different periods. Furthermore, non-optical image data such as LiDAR or SAR can provide observation information with different ground physical mechanisms and solve the technical problem of optical sensors being affected by weather conditions. It can also make up for the shortcoming, that is, HR/VHR remote sensing images can provide a macro view of the earth observation, but it is difficult to fully reflect the types and attributes of objects in the observation area [
6]. Multi-source remote sensing data such as HR/VHR remote sensing images, LiDAR, or SAR data can provide rich information for the observed landscape through various physical and material perspectives. If these data are used comprehensively and collaboratively, the data sources of change detection will be significantly enriched, and the detection results can describe the change information more accurately and comprehensively [
7]. However, due to the diverse sources of multi-source remote sensing data, it is difficult to compare and analyze these heterogeneous data based on one method. Most of the current related research focuses on the use of homogeneous remote sensing data for change detection [
8,
9,
10,
11,
12]. Therefore, in order to use remote sensing data for change detection more fully and effectively, it is exigent to develop a change detection method that can comprehensively use multi-source remote sensing data.
Some traditional change detection methods, such as image difference [
13], image ratio [
14], change vector analysis (CVA) [
15], compressed CVA (C
2VA) [
16], robust CVA (RCVA) [
17], principal component analysis (PCA) [
18], slow feature analysis (SFA) [
19], multivariate alteration detection (MAD) [
20], depth belief network [
21], etc.; almost all rely solely on medium- and low-resolution remote sensing images or HR/VHR remote sensing images, and analyze image change information through image algebra or image space transformation to obtain change areas. Another important branch of change detection, the classification-based change detection method, is to determine the change state and change attributes of the research object by comparing the category labels of the object to be detected after the image is independently classified [
6,
22]. In this kind of method, analysis methods such as compound classification rule for minimum error [
23], an ensemble of nonparametric multitemporal classifiers [
24], minimum error Bayes rule [
25], and pattern measurement [
26], etc., are referenced and applied. Although they have achieved good detection results, these methods only consider the non-linear correlation of the image data level and need to weigh the association of complex training data. In general, the traditional change detection methods: image algebra, image transformation, and classification-based methods have failed to solve the technical difficulties of multi-source remote sensing data fusion, parallelism, and complementarity. However, with the continuous improvement of the spectral, spatial, and temporal resolution of remote sensing images, and the advantage that SAR data is not affected by weather and other conditions, more and more research is devoted to more refined and higher-dimensional change detection [
7]. Furthermore, traditional change detection methods generally only consider 2D image information, and are powerless when faced with a change detection task with a finer scale and higher dimensional requirements (3D).
Buildings have unique geographic attributes and play an essential role in the process of urbanization. The accurate depiction of their temporal and spatial dynamics is an effective way to strengthen land resource management and ensure sustainable urban development [
27]. Therefore, BCD has always been a research hotspot in the field of change detection. At present, the application of HR/VHR remote sensing images has been popularized, which provides a reliable data source for change detection tasks, especially for identifying detailed structures (buildings, etc.) on the ground. In addition, LiDAR and SAR data have also received extensive attention in urban change detection. Related researches have appeared one after another, such as extracting linear features from bitemporal SAR images to detect changing pixels [
28], using time series SAR images and combining likelihood ratio testing and clustering identification methods to identify objects in urban areas [
29], fusing aerial imagery and LiDAR point cloud data, using height difference and gray-scale similarity as change indicators, and integrating spectral and geometric features to identify building targets [
30]. However, most of these studies are only based on SAR images, and some use optical remote sensing images as their auxiliary data, so the degree of data fusion is low, and some methods cannot even be directly applied to optical images. In addition, the degree of 3D change detection is relatively low, and there is almost no suitable method capable of simultaneously performing 2D and 3D change detection.
In recent years, with the deepening of deep learning research, deep learning methods have proven to be quite successful in various pattern recognition and remote sensing image processing tasks [
31,
32,
33]. As far as the processing of remote sensing images (HR/VHR remote sensing images, SAR images) is concerned, the deep learning method is more capable of capturing various spectral, spatial, and temporal features in the images, deeply mining high-level semantic features and understanding abstract expressions in high-dimensional features [
6,
11,
34]. In the field of change detection research, various task-driven deep neural networks and methods have been designed. In [
35], a structured deep neural network (DNN) was used to design a change detection method for multi-temporal SAR images. In [
36], a deep siamese convolutional network was designed, which can extract features based on weight sharing convolution branches for change detection of aerial images. In [
37], the researchers considered the advantages of long-short-term memory (LSTM) networks that are good at processing sequence data, and designed an end-to-end recurrent neural network (RNN) to perform multispectral/hyperspectral image change detection tasks. In addition, various combinations and variants of deep networks have also been proposed to perform specific tasks. For example, a novel and universal deep siamese convolutional multiple-layers recurrent neural network (SiamCRNN) was proposed in [
5], which combines the advantages of convolutional neural network (CNN) and RNN. The three sub-networks of its overall structure have clear division of labor and are well connected, which can achieve the purpose of extracting image features, mining change information, and predicting change probability. In [
6], a novel recurrent convolutional neural network (ReCNN) structure was proposed, which combines CNN and RNN into an end-to-end network for extracting rich spectral-spatial features and effectively analyzes temporal dependence in bi-temporal images. In this network, it is possible to learn the joint spectral-spatial-temporal feature representation in a unified framework to detect changes in multispectral images. Although these new networks have shown excellent performance according to their specific tasks, they use data in a single form or are not highly transferable. They can only be used for one data source and cannot use multiple sources as input at the same time. Moreover, few studies consider the internal relationship of input data, that is, the interdependence between bands or characteristic channels.
A fully convolutional network (FCN) has been successfully applied to the end-to-end semantic segmentation of optical remote sensing images [
38], showing the flexibility of its structure and the superiority of feature combination strategy. Moreover, with the unique advantages of taking into account local and global information, segmenting images of any size, and achieving pixel-level labeling, it has achieved better results than traditional CNN in remote sensing image classification [
39,
40] and change detection [
41,
42,
43,
44]. U-Net [
45,
46], developed from FCN, has proved to have better performance than FCN. It is used in many tasks in the field of remote sensing, such as image classification, change detection, and object extraction (buildings, water bodies, roads, etc.). In many studies, various network variants based on FCN or U-Net have been proposed. These networks have achieved corresponding functions according to specific research content and have received certain results. For example, the authors in [
47] used a region-based FCN (R-FCN), which was combined with the ResNet-101 network to try to determine the center pixel of the object before segmenting the image. Related research in [
48,
49], the introduction of the residual module into U-Net brought about an improvement in model performance and efficient information dissemination. Although these types of networks overcome the shortcomings of single segmentation scale and low information dissemination that exist in FCN or U-Net to a certain extent, they have not considered combining multiple data as input. A variety of features derived from remote sensing data tend to show characteristics such as stable nature, little impact by radiation differences, and not easily affected by remote sensing image time phase changes [
3]. Using spatial or spectral features to detect changes in the state of objects or regions has become a hot spot for researchers. In addition, the phenomenon of “the same object with the different spectrum, the same spectrum of different matter” appears in large numbers in HR/VHR remote sensing images, making it more difficult to detect small and complex objects such as buildings or roads in cities. Emerging deep learning methods have the potential to extract features of individual buildings in complex scenes. However, the feature extraction method of deep learning represented by convolution operation only extracts the abstract features of the original image through the continuous deepening of the number of convolution layers and do not consider the use of useful derivative features of the ground objects [
3,
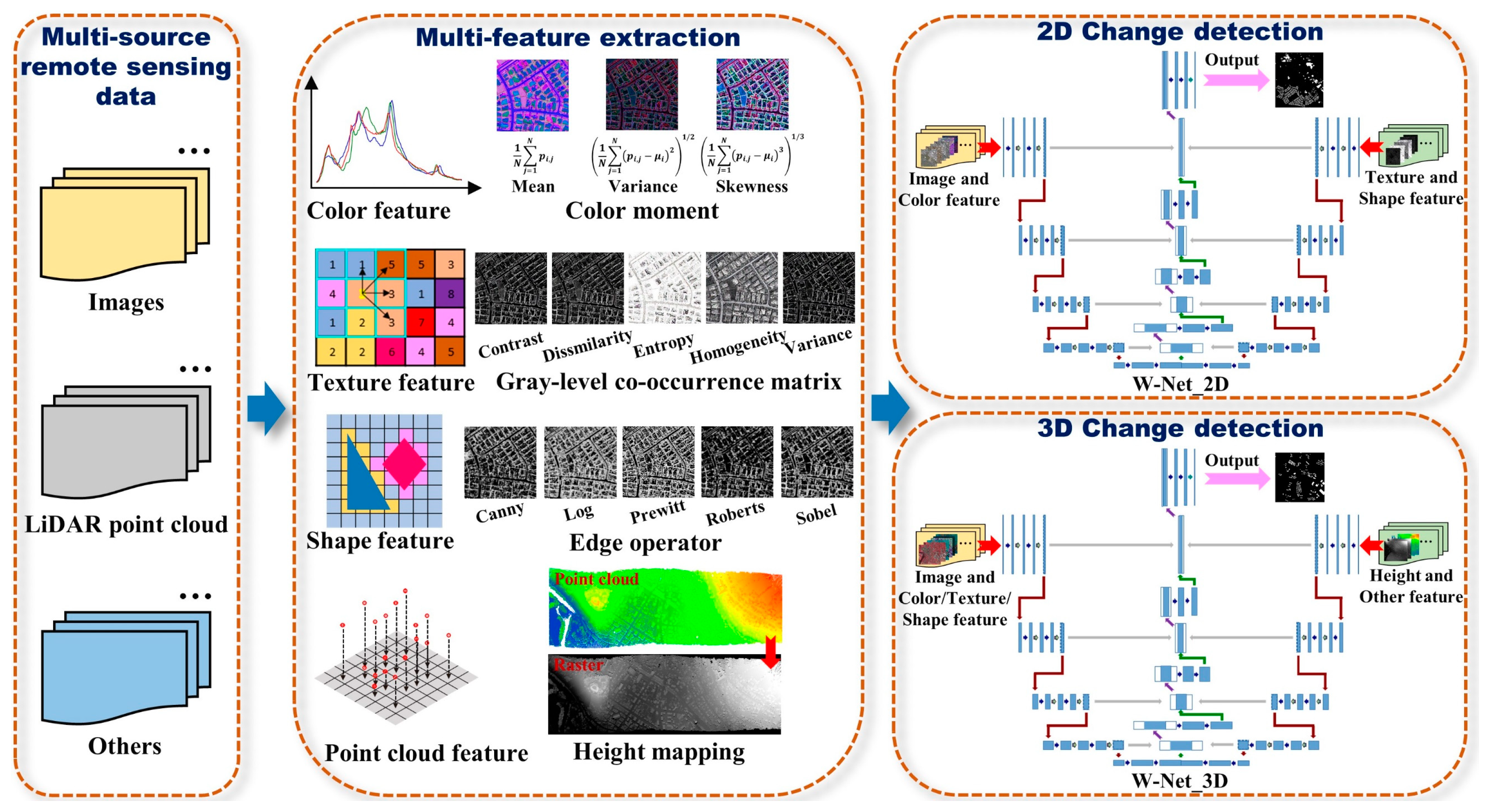
27]. Various feature information derived from the original image, such as color, texture, shape, et al., can also be used as input to the network to participate in the process of information mining and abstraction. As far as we know, many existing networks fail to take multiple features as input to participate in task execution.
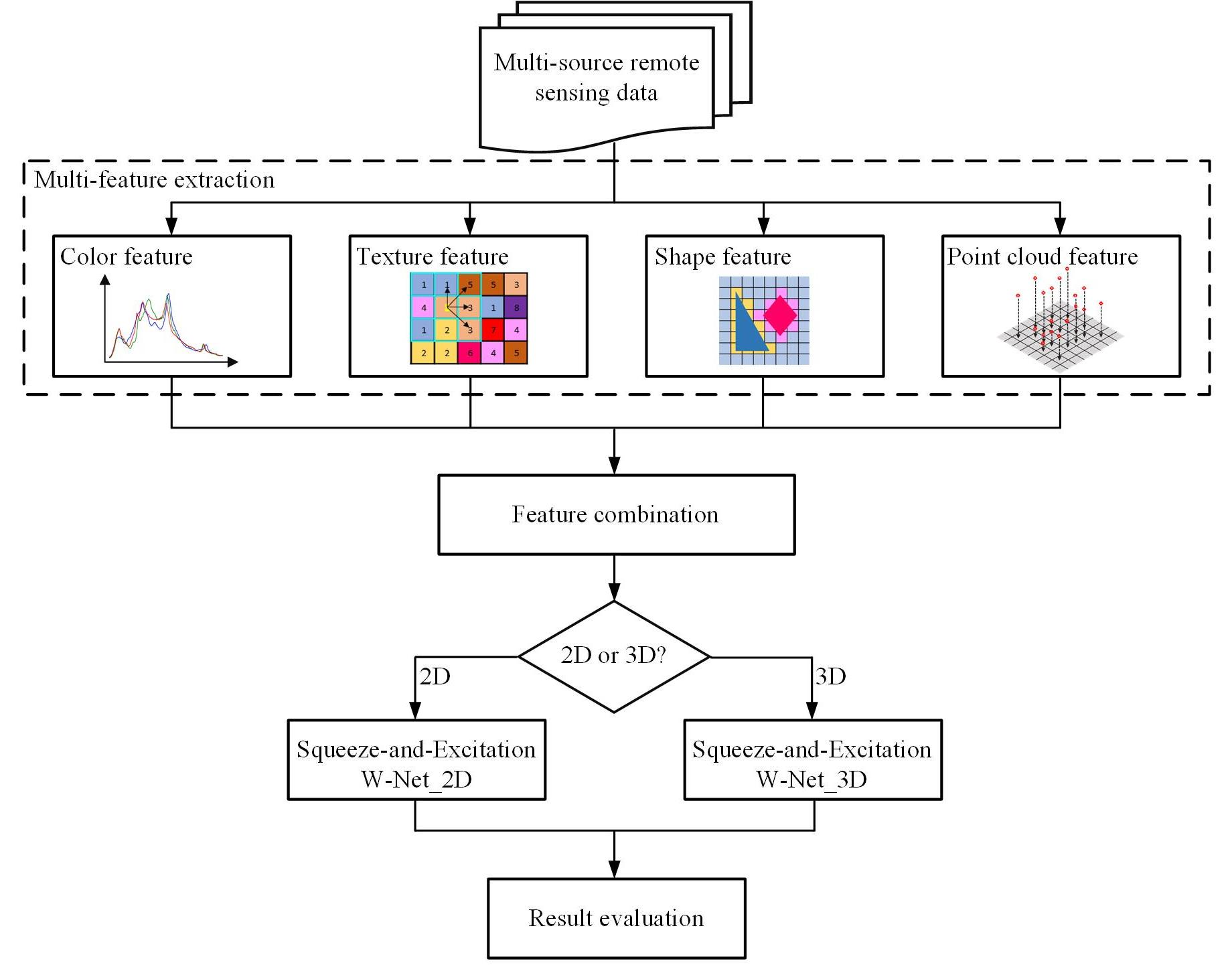
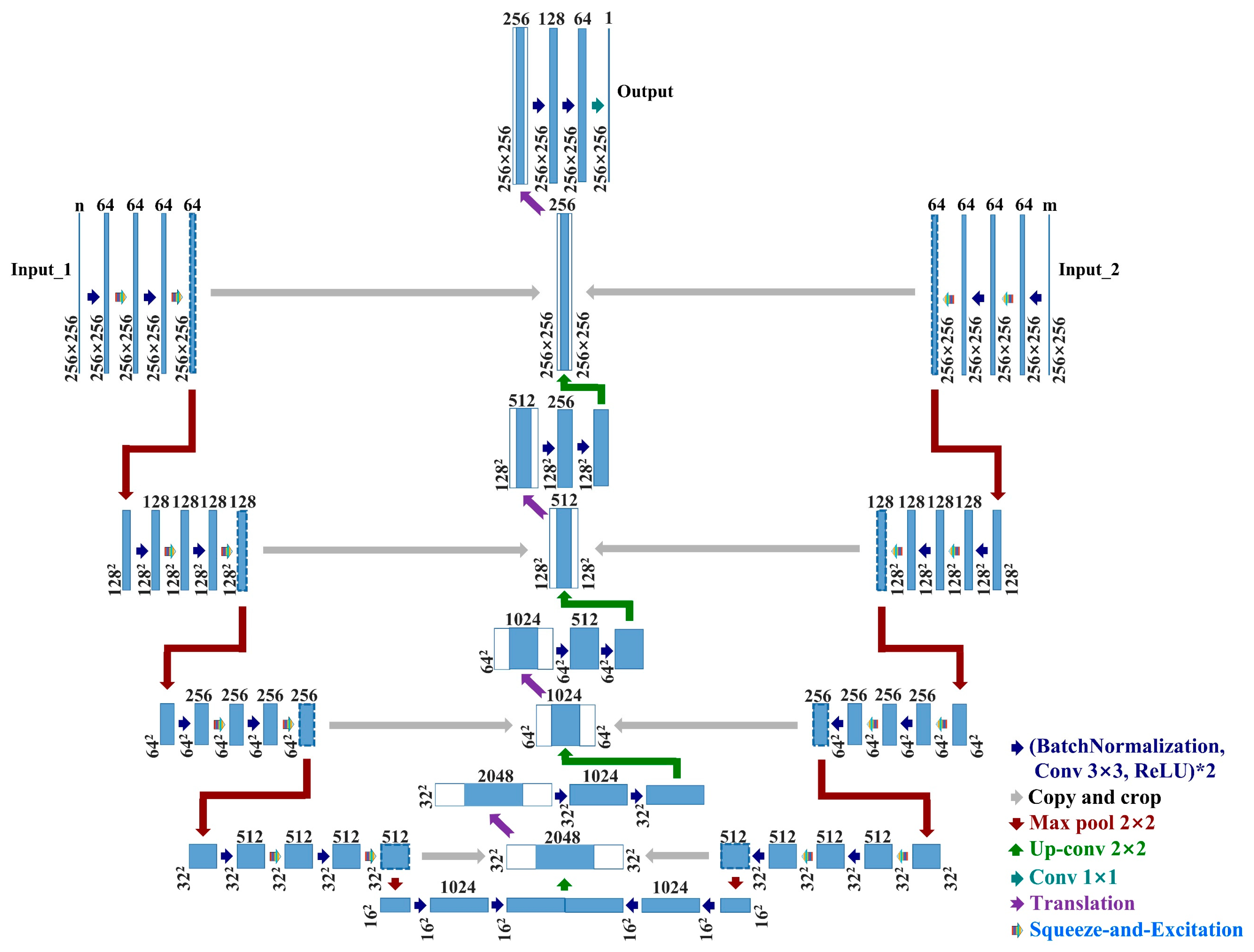
In this article, based on U-Net, we designed a new type of bilateral end-to-end W network. It can simultaneously input multi-source/multi-feature homogeneous and heterogeneous data and consider the internal relationship of input data through the squeeze-and-excitation strategy. We named it squeeze-and-excitation W-Net. Although there have been related studies on network transformation based on U-Net [
50,
51], as far as we know, we are the first to transform U-Net into a more valuable network. It has two-sided input and single-output, independent weights on both sides can take into account the data on both sides (homogeneous and heterogeneous data) and can be used for change detection tasks in the field of remote sensing. The main contributions of this article are concluded as follows:
- (1)
The proposed squeeze-and-excitation W-Net is a powerful and universal network structure, which can learn the abstract features contained in homogeneous and heterogeneous data through a structured symmetric system.
- (2)
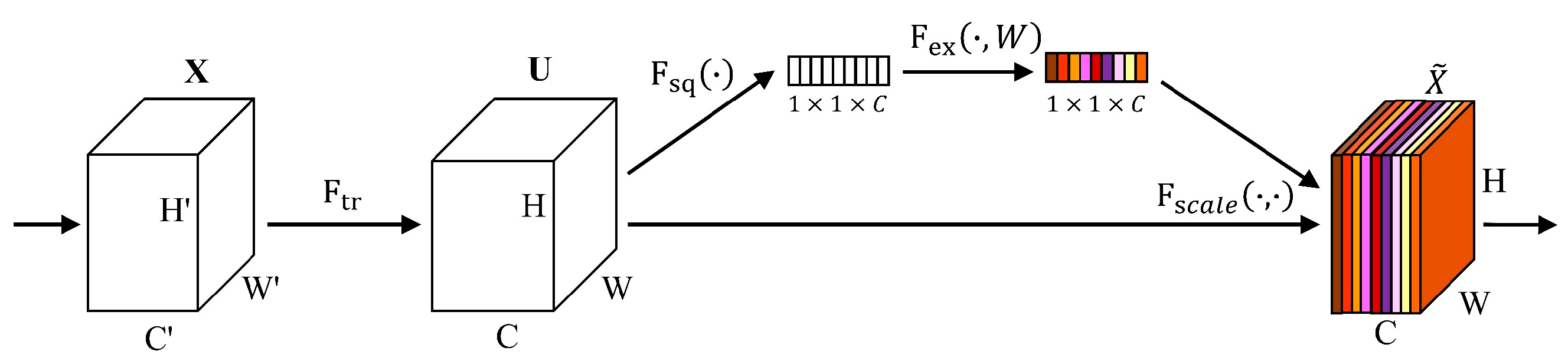
The form of two-sided input not only satisfies the input of multi-source data but also is suitable for multiple features derived from multi-source data. We innovatively introduced the squeeze-and-excitation module as a strategy for explicit modeling of the interdependence between channels, which makes the network more directional and can recalibrate the feature channels, emphasize essential features, and suppress secondary features. Moreover, the squeeze-and-excitation module is embedded between each convolution operation, which can overcome the insufficiency of the convolution operation that can only take into account the features information in the local receptive field and improve the global reception ability of the network.
- (3)
The idea of multi-source and multi-feature combination as model input integrates information advantages such as spectrum, texture, and structure, which can significantly improve the robustness of the model. For buildings, which present complex spatial patterns, have multi-scale features, and have large differences between individuals, they are more targeted, and the detection accuracy of the model is significantly higher.
The rest of the article is organized as follows. The second section introduces in detail the construction process of squeeze-and-excitation W-Net, the production details of multi-feature input, and the evaluation method of the network. The third section is the data set information, network settings, experiments, and results. The fourth section is the discussion part. And the fifth section summarizes the article.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}