
A Deformable Convolutional Neural Network with Spatial-Channel Attention for Remote Sensing Scene Classification

Abstract
:
1. Introduction
- (1)
- Remote sensing scenes have a complex outline and structure, whether the scene is a natural scene (island) or artificial scene (church), as shown in Figure 1a.
- (2)
- The spatial distribution of remote sensing scenes is complex. Remote sensing images are a bird’s-eye view, so the direction, size, and position of the scenes are arbitrary. As shown in Figure 1b, the size of circular farmland is not fixed, and the position of spark residential is arbitrary.
- (3)
- There is intra-class diversity in remote sensing scenes. Affected by season, weather, light, and other factors, the same scene may have different forms of expression. As shown in Figure 1c, the forest has an obvious color difference due to different seasons; the church has a distinct shape difference due to different cultures.
- (4)
- There is inter-class similarity in remote sensing scenes. As shown in Figure 1d, the parking lot and container are highly similar in color, shape, direction, and spatial distribution in remote sensing images. The same situation also exists in the highway and bridge.
- (1)
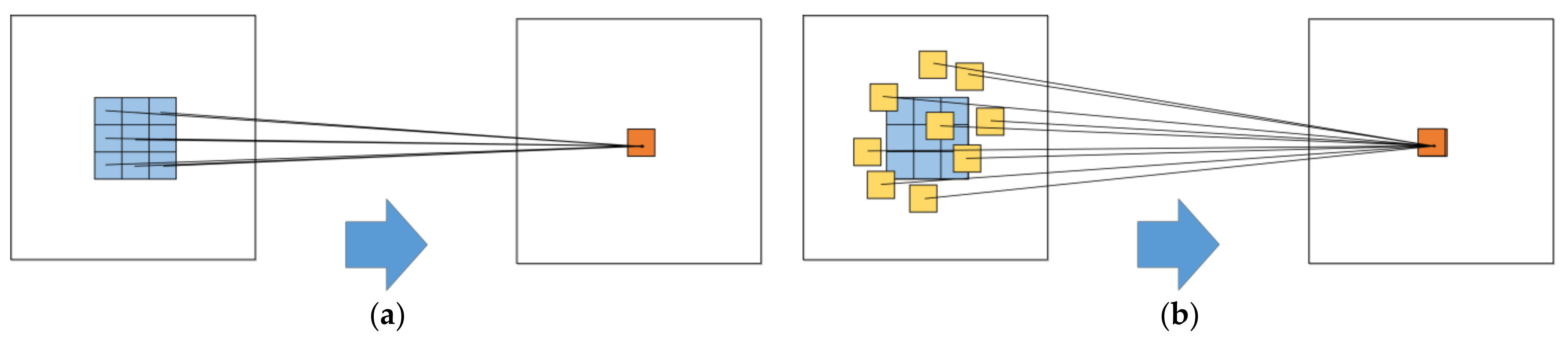
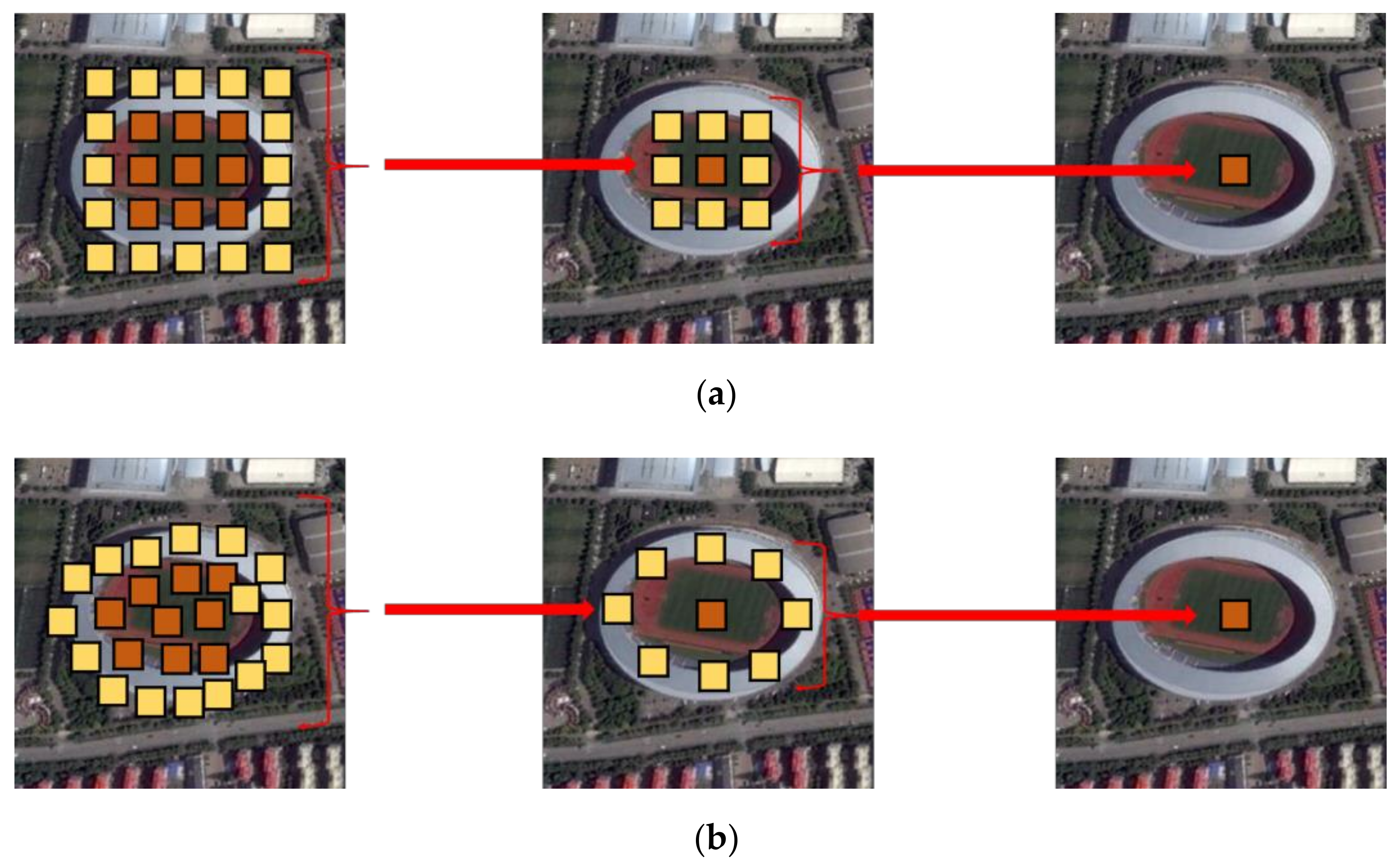
- A Deformable CNN (D-CNN) is proposed. D-CNN breaks through the limitation of fixed convolution kernel size and enhances the feature extraction ability of remote sensing scenes with complex structure and spatial distribution.
- (2)
- A Spatial-Channel Attention (SCA) is proposed. SCA enhances the effective information of remote sensing scenes by assigning weight to the important positions and channels in the CNN feature maps of remote sensing images.
2. Materials and Methods
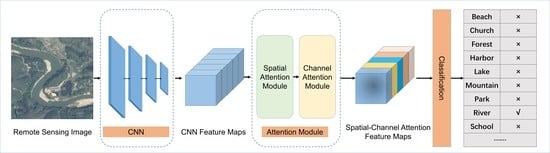
2.1. Overall Architecture
2.2. Feature Extraction
2.3. Feature Enhancement
2.3.1. Spatial Attention Module
2.3.2. Channel Attention Module
2.4. Classification
3. Experiment and Analysis
3.1. Datasets
- (1)
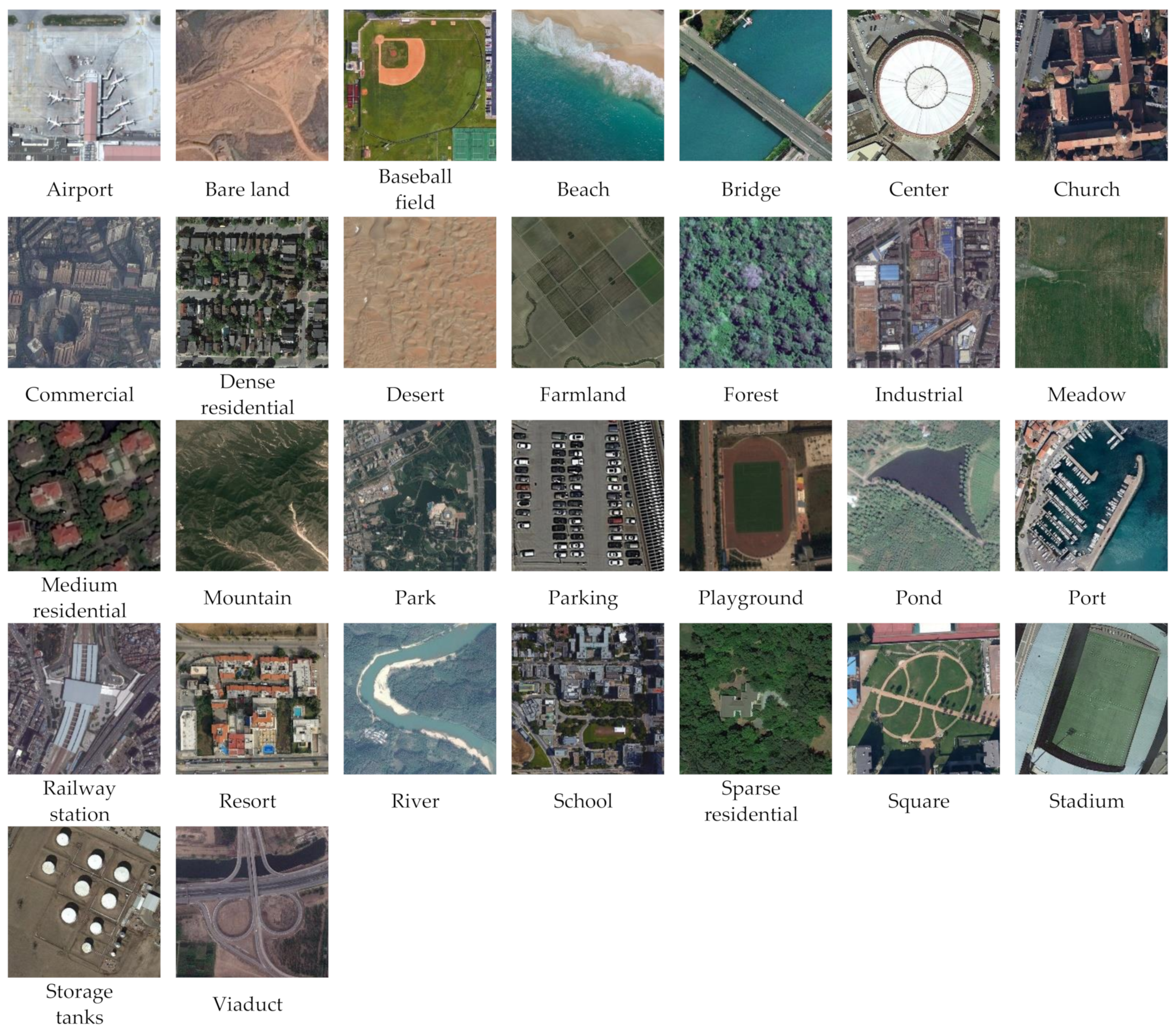
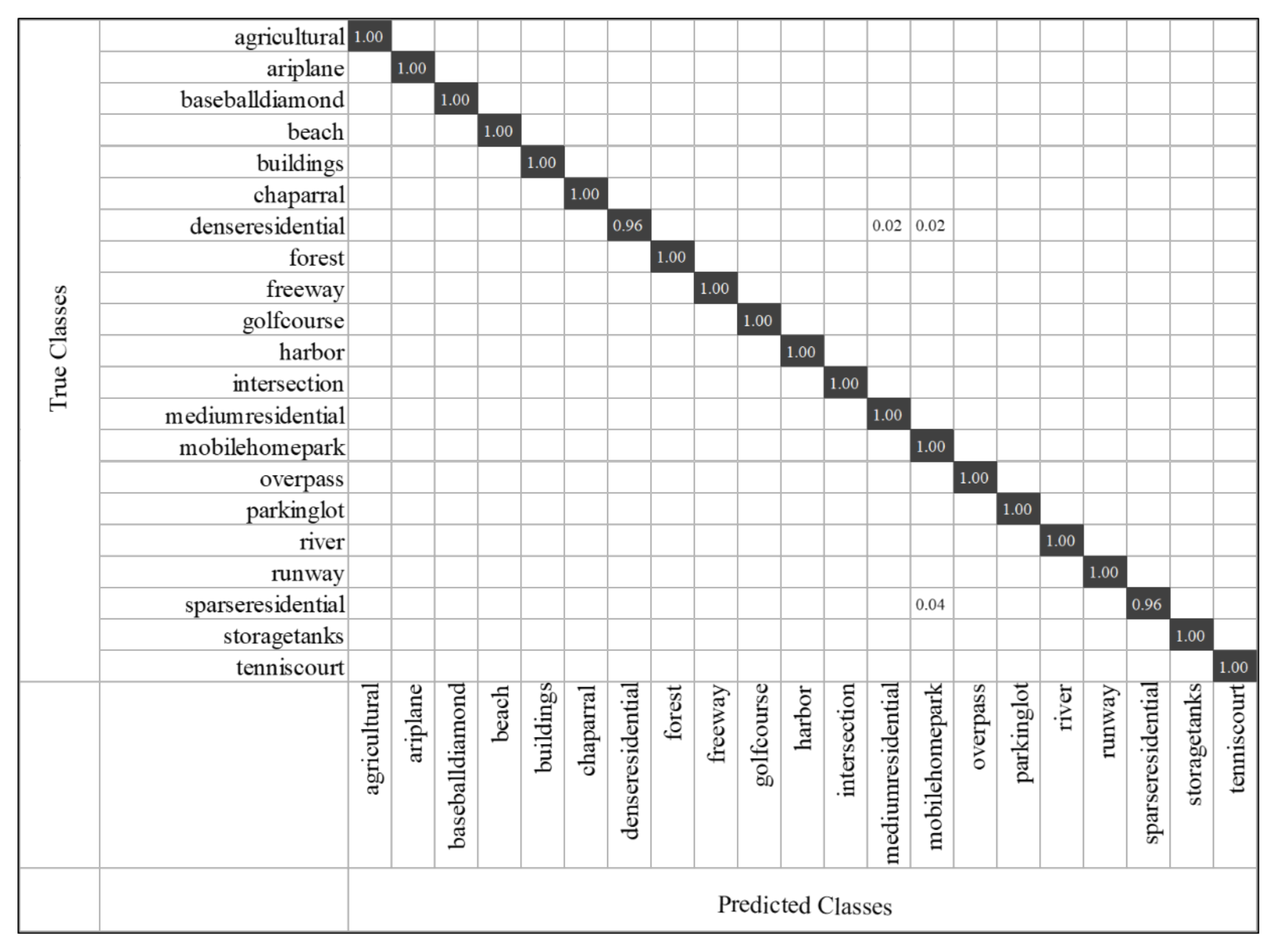
- UCM: UC Merced Land Use dataset [16] was constructed by Yang et al. of the University of California at Merced using the United States Geological Survey National Map. The dataset contains 21 land use classes, with 100 samples in each class and a total of 2100 images. The size of each image is 256 × 256, with a spatial resolution of 0.3 m per pixel. Some samples from the UCM dataset are shown in Figure 7. UCM is an early proposed remote sensing scene dataset, and it is also one of the most widely used datasets.
- (2)
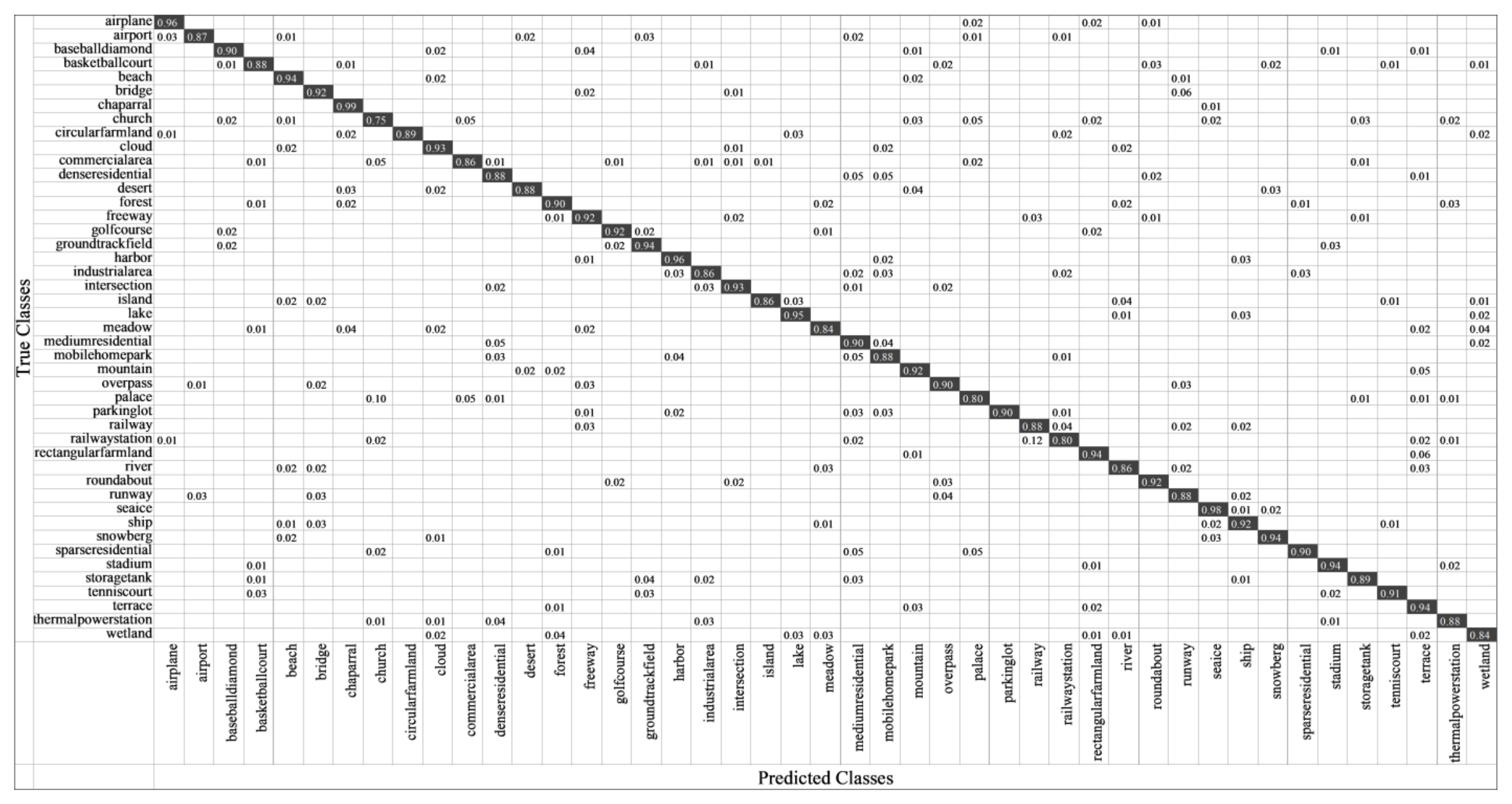
- NWPU: NWPU-RESISC45 dataset [35] was built by Cheng et al. of Northwestern Polytechnical University using Google Earth. The dataset contains 45 scenes, with 700 samples in each class and a total of 31,500 images. The size of each image is 256 × 256, with a spatial resolution of 0.2–30 m per pixel. Some samples from the NWPU Dataset are shown in Figure 8. NWPU is the remote sensing scene dataset with the richest scene categories and the largest number of samples so far. Besides, there are great variations in translation, spatial resolution, viewpoint, object pose, illumination, background, and occlusion, which makes it difficult for remote sensing scene classification.
- (3)
- AID: Aerial Image dataset [36] was built by Xia et al. of Wuhan University using Google Earth. The dataset contains 30 scenes, with 200−400 samples in each class and a total of 10,000 images. The size of each image is 600 × 600, with a spatial resolution of 0.5−8 m per pixel. Some samples from the AID Dataset are shown in Figure 9. Among the current remote sensing scene datasets, AID has the largest image size, which provides richer information for scene classification.
3.2. Evaluating Indexes
- (1)
- OA: It is defined as the proportion of the number of correctly classified samples to the total number of samples in the test set. It simply and effectively represents the prediction capacity of the model on the overall dataset. OA is calculated as follows:where is the total number of samples in the test set; and are the total number of categories and the number of samples of each category, respectively; is a classification function that predicts the category of a single sample in the test set; is the sample label indicating the real category of the sample; is the indicator function, which takes the value of 1 when it is true and 0 when it is false.
- (2)
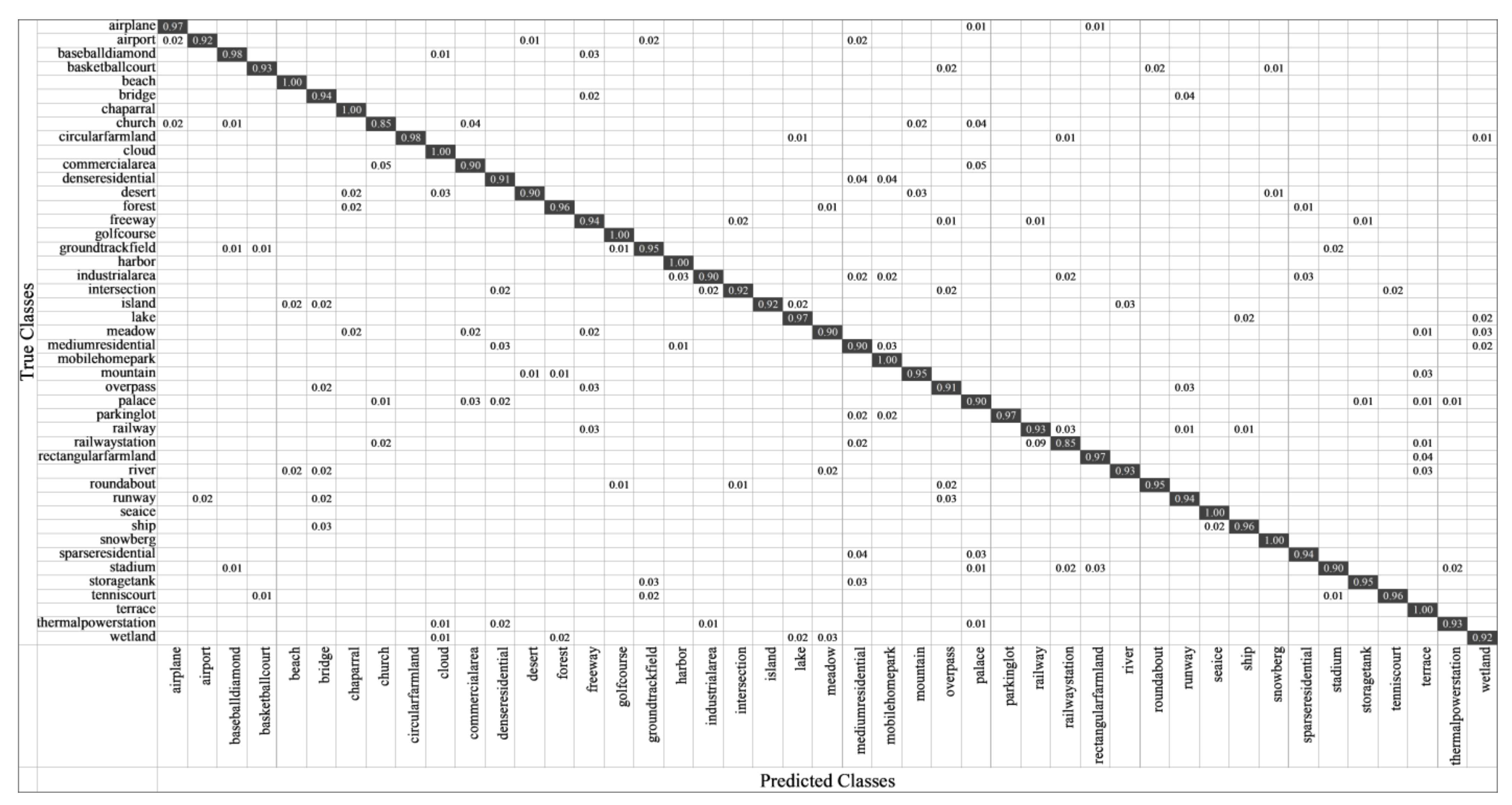
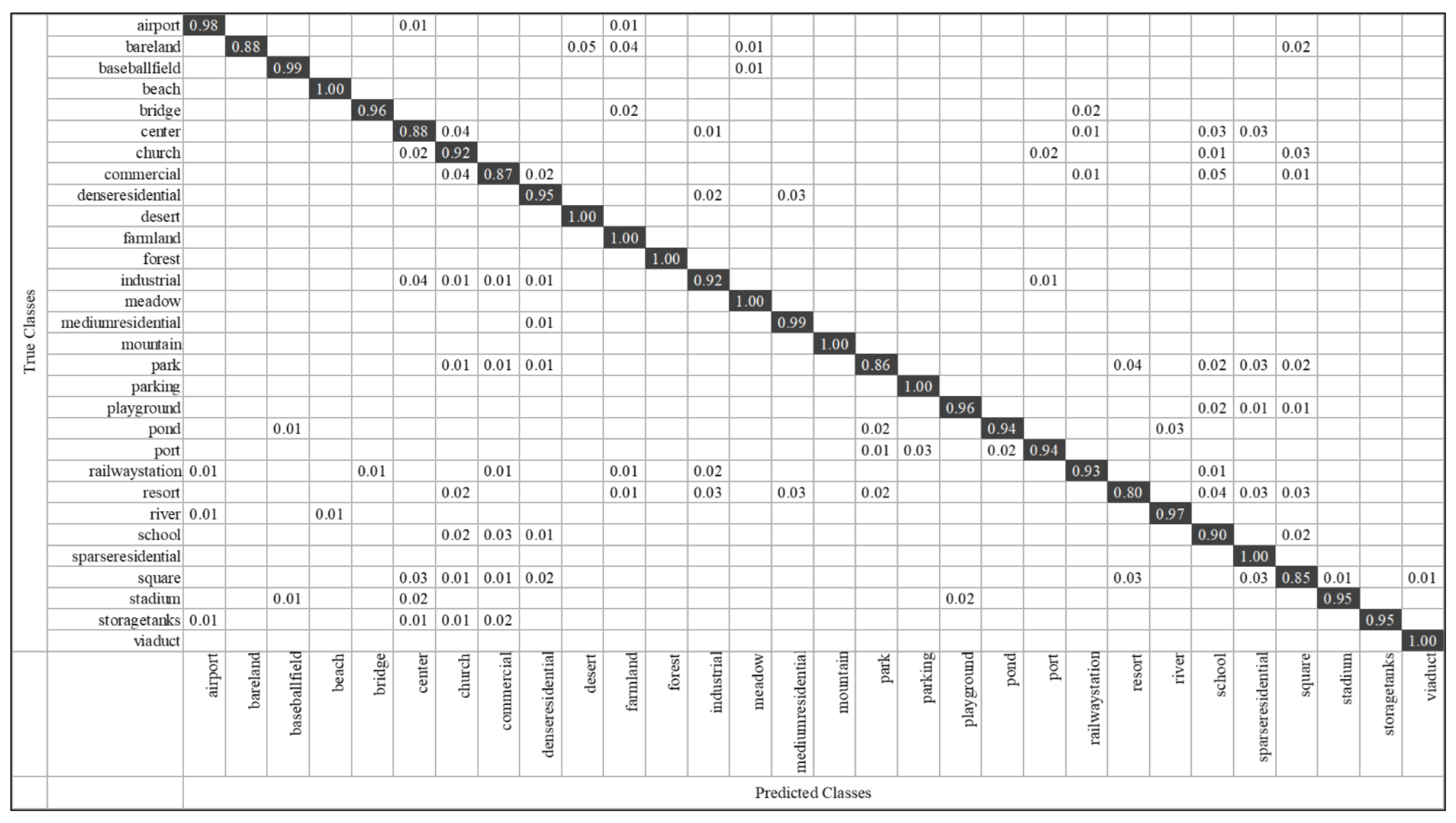
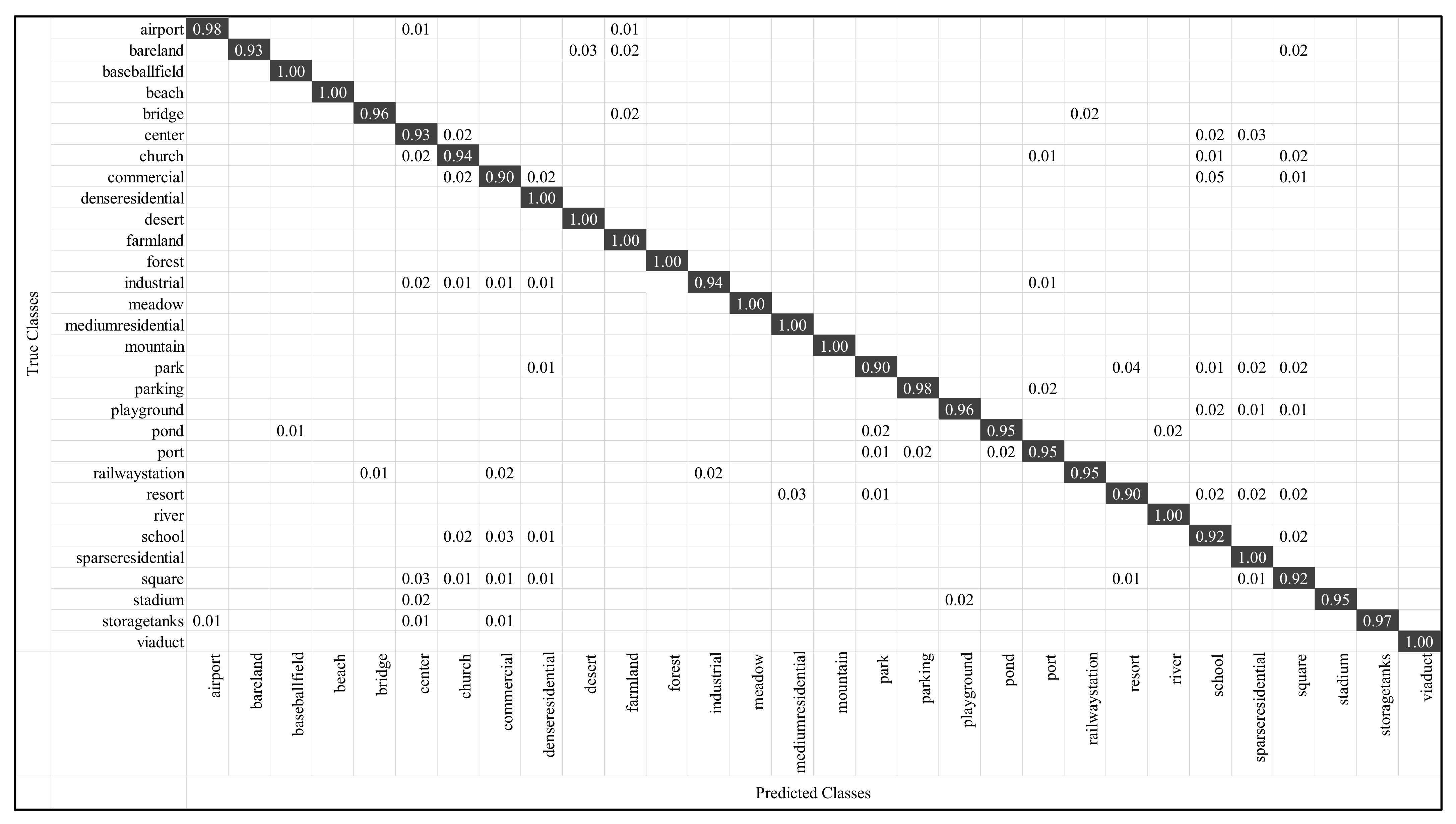
- CM: It uses a matrix of N rows and N columns to represent the classification effect, where each row represents the actual category and each column represents the predicted value. It can indicate the categories that are prone to confusion, thus more intuitively representing the performance of the algorithm.
3.3. Implementation Details
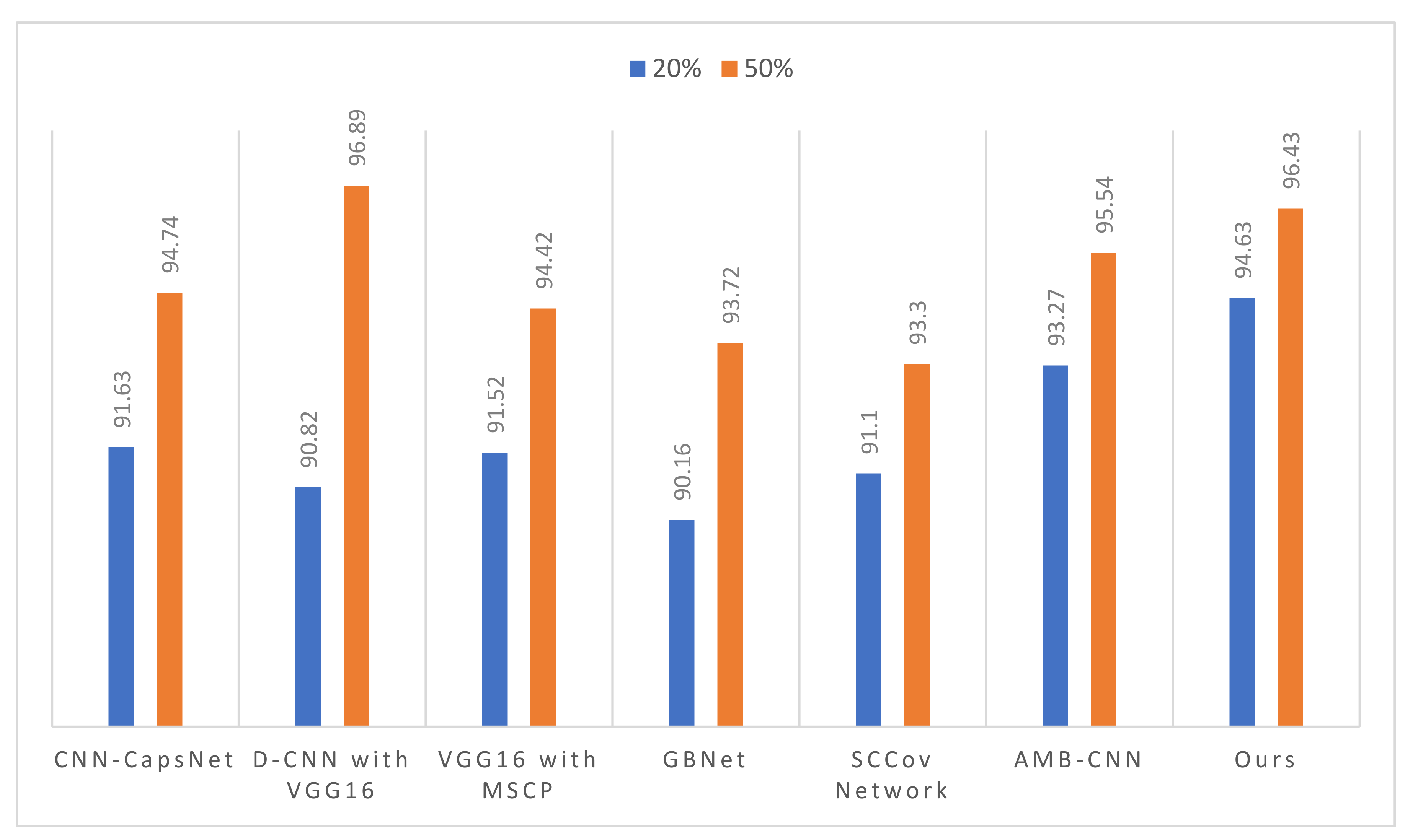
3.4. The Performance of the Proposed Method
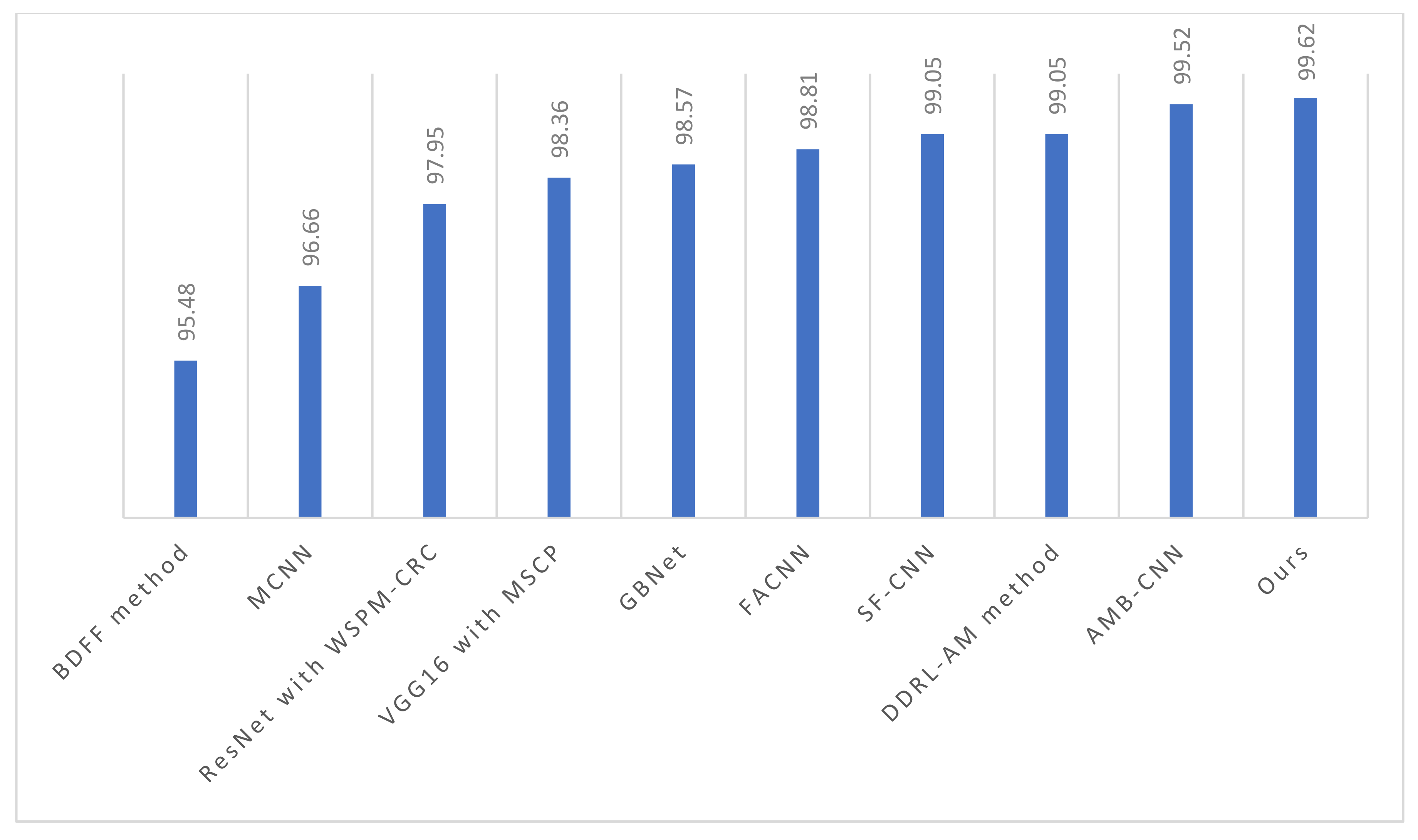
3.4.1. Results on UCM
3.4.2. Results on NWPU
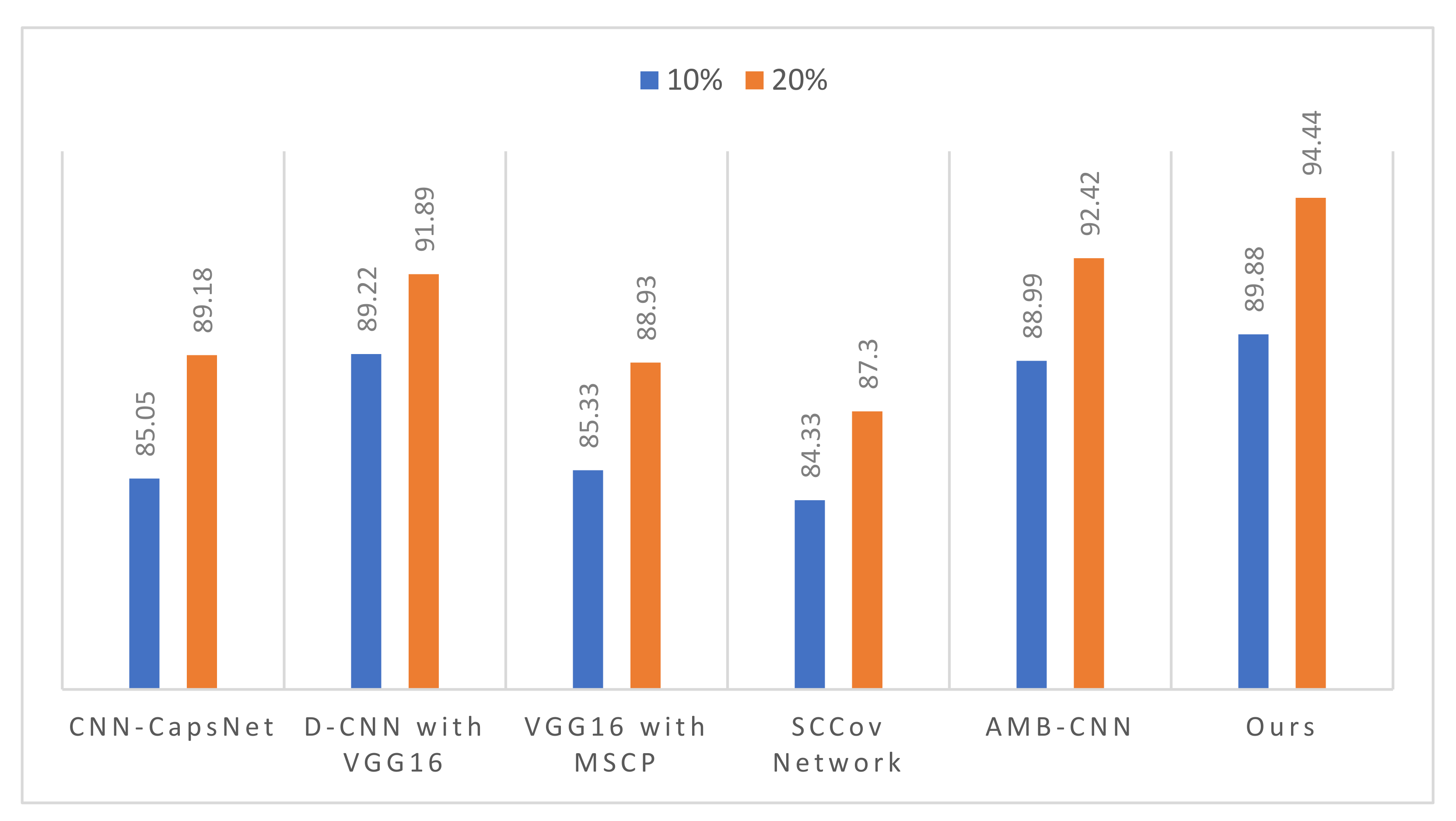
3.4.3. Results on AID
4. Discussion
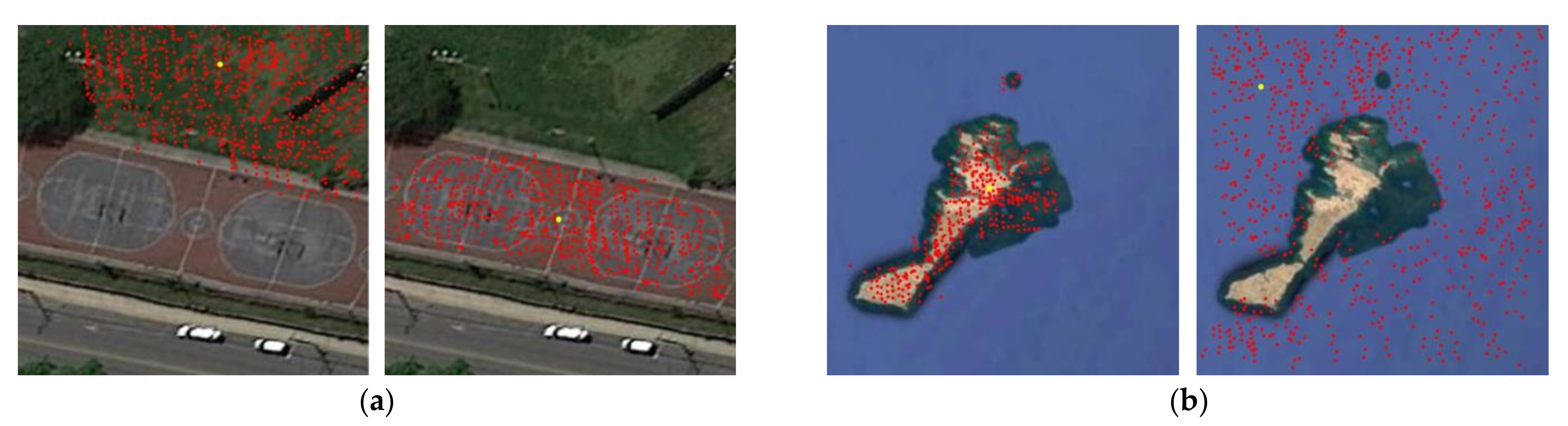
4.1. Analysis of D-CNN
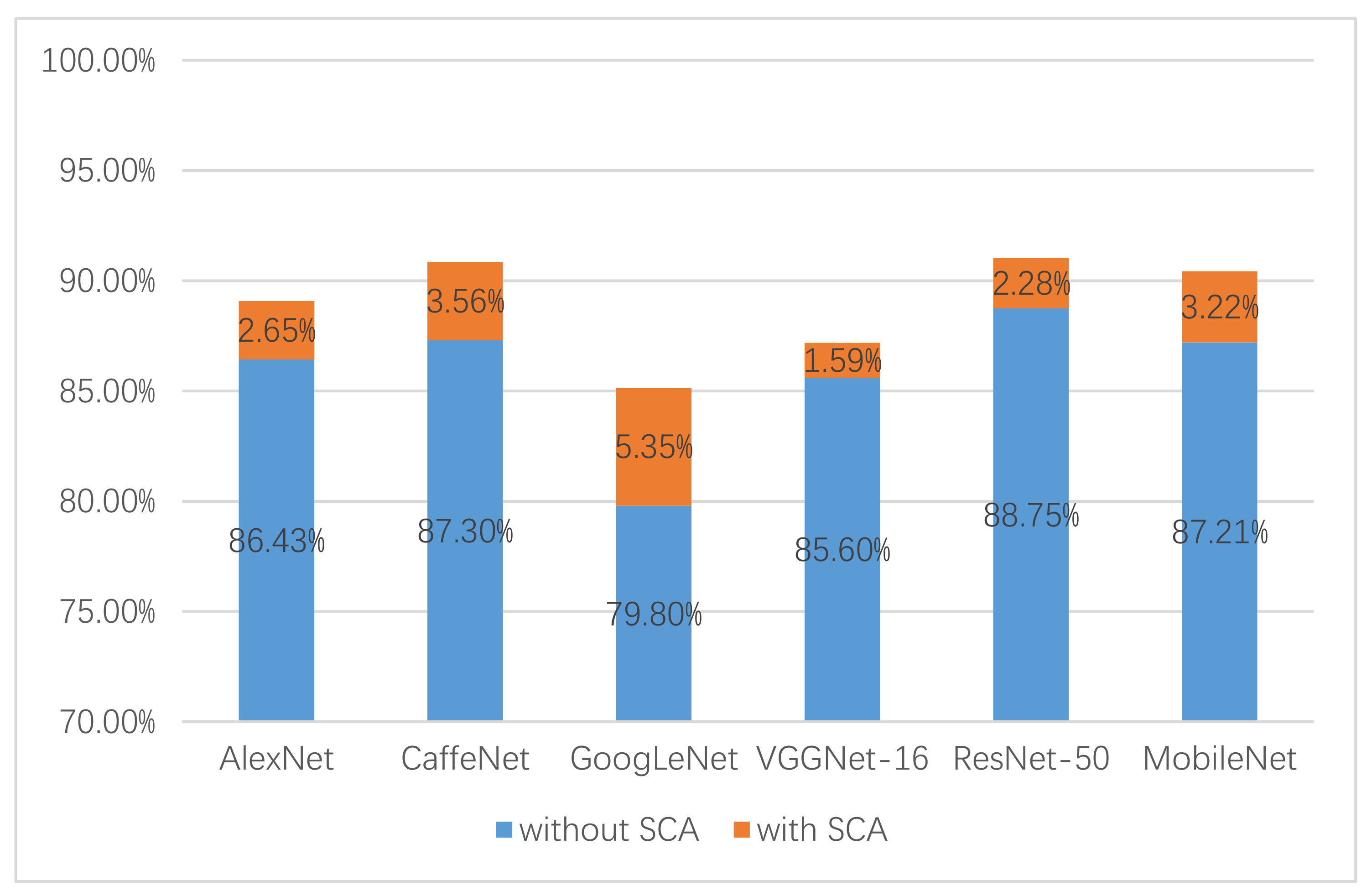
4.2. Analysis of SCA
4.3. Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qi, K.; Wu, H.; Shen, C.; Gong, J. Land-use scene classification in high-resolution remote sensing images using improved correlatons. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2403–2407. [Google Scholar]
- Weng, Q.; Mao, Z.; Lin, J.; Liao, X. Land-use scene classification based on a CNN using a constrained extreme learning machine. Int. J. Remote Sens. 2018, 39, 6281–6299. [Google Scholar] [CrossRef]
- Wu, H.; Liu, B.; Su, W.; Zhang, W.; Sun, J. Hierarchical coding vectors for scene level land-use classification. Remote Sens. 2016, 8, 436. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Pan, Y.; Zhang, J.; Hu, T.; Zhao, J.; Li, N.; Chen, Q. A generalized approach based on convolutional neural networks for large area cropland mapping at very high resolution. Remote Sens. Environ. 2020, 247, 111912. [Google Scholar] [CrossRef]
- Shi, S.; Chang, Y.; Wang, G.; Li, Z.; Hu, Y.; Liu, M.; Li, Y.; Li, B.; Zong, M.; Huang, W. Planning for the wetland restoration potential based on the viability of the seed bank and the land-use change trajectory in the Sanjiang Plain of China. Sci. Total Environ. 2020, 733, 139208. [Google Scholar] [CrossRef]
- Zheng, X.; Yuan, Y.; Lu, X. A deep scene representation for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4799–4809. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhang, L.; Li, D. Adaptive deep sparse semantic modeling framework for high spatial resolution image scene classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6180–6195. [Google Scholar] [CrossRef]
- Tayyebi, A.; Pijanowski, B.C.; Tayyebi, A.H. An urban growth boundary model using neural networks, GIS and radial parameterization: An application to Tehran, Iran. Landsc. Urban Plan. 2011, 100, 35–44. [Google Scholar] [CrossRef]
- Fingas, M.; Brown, C. Review of oil spill remote sensing. Mar. Pollut. Bull. 2014, 83, 9–23. [Google Scholar] [CrossRef] [Green Version]
- Yi, Y.; Zhang, Z.; Zhang, W.; Jia, H.; Zhang, J. Landslide susceptibility mapping using multiscale sampling strategy and convolutional neural network: A case study in Jiuzhaigou region. CATENA 2020, 195, 104851. [Google Scholar] [CrossRef]
- Gitas, I.; Polychronaki, A.; Katagis, T.; Mallinis, G. Contribution of remote sensing to disaster management activities: A case study of the large fires in the Peloponnese, Greece. Int. J. Remote Sens. 2008, 29, 1847–1853. [Google Scholar] [CrossRef]
- Risojević, V.; Babić, Z. Fusion of global and local descriptors for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2013, 10, 836–840. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Perronnin, F.; Sánchez, J.; Mensink, T. Improving the fisher kernel for large-scale image classification. In Proceedings of the European Conference on Computer Vision, Heidelberg, Germany, 5 September 2010; pp. 143–156. [Google Scholar]
- Jégou, H.; Perronnin, F.; Douze, M.; Sánchez, J.; Pérez, P.; Schmid, C. Aggregating local image descriptors into compact codes. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1704–1716. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Li, E.; Xia, J.; Du, P.; Lin, C.; Samat, A. Integrating multilayer features of convolutional neural networks for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5653–5665. [Google Scholar] [CrossRef]
- Lu, X.; Ji, W.; Li, X.; Zheng, X. Bidirectional adaptive feature fusion for remote sensing scene classification. Neurocomputing 2019, 328, 135–146. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Remote sensing scene classification using multilayer stacked covariance pooling. IEEE Trans. Geosci. Remote. Sens. 2018, 56, 6899–6910. [Google Scholar] [CrossRef]
- Flores, E.; Zortea, M.; Scharcanski, J. Dictionaries of deep features for land-use scene classification of very high spatial resolution images. Pattern Recognit. 2019, 89, 32–44. [Google Scholar] [CrossRef]
- Fang, J.; Yuan, Y.; Lu, X.; Feng, Y. Robust space–frequency joint representation for remote sensing image scene classification. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 7492–7502. [Google Scholar] [CrossRef]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote sensing scene classification by gated bidirectional network. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 82–96. [Google Scholar] [CrossRef]
- Bi, Q.; Qin, K.; Li, Z.; Zhang, H.; Xu, K.; Xia, G.-S. A multiple-instance densely-connected ConvNet for aerial scene classification. IEEE Trans. Image Process. 2020, 29, 4911–4926. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Zhang, Z.; Zhang, W.; Yi, Y.; Zhang, C.; Xu, Q. A convolutional neural network based on grouping structure for scene classification. Remote Sens. 2021, 13, 2457. [Google Scholar] [CrossRef]
- Xie, H.; Chen, Y.; Ghamisi, P. Remote sensing image scene classification via label augmentation and intra-class constraint. Remote Sens. 2021, 13, 2566. [Google Scholar] [CrossRef]
- Chen, J.; Huang, H.; Peng, J.; Zhu, J.; Chen, L.; Tao, C.; Li, H. Contextual information-preserved architecture learning for remote-sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602614. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Zhong, Y.; Qin, Q. Scene classification based on multiscale convolutional neural network. IEEE Trans. Geosci. Remote. Sens. 2018, 56, 7109–7121. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.-D.; Meng, J.; Xie, W.-Y.; Shao, S.; Li, Y.; Wang, Y. Weighted spatial pyramid matching collaborative representation for remote-sensing-image scene classification. Remote Sens. 2019, 11, 518. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Sun, H.; Zheng, X. A feature aggregation convolutional neural network for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7894–7906. [Google Scholar] [CrossRef]
- Xie, J.; He, N.; Fang, L.; Plaza, A. Scale-free convolutional neural network for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6916–6928. [Google Scholar] [CrossRef]
- Li, J.; Lin, D.; Wang, Y.; Xu, G.; Zhang, Y.; Ding, C.; Zhou, Y. Deep discriminative representation learning with attention map for scene classification. Remote Sens. 2020, 12, 1366. [Google Scholar] [CrossRef]
- Shi, C.; Zhao, X.; Wang, L. A multi-branch feature fusion strategy based on an attention mechanism for remote sensing image scene classification. Remote Sens. 2021, 13, 1950. [Google Scholar] [CrossRef]
- Wei, Z.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, J.; Plaza, A. Skip-connected covariance network for remote sensing scene classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1461–1474. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Type | Filters | Size | |
|---|---|---|---|---|
| deformable convolution | deformable convolution | 64 | 7 × 7 | |
| deformable pooling | deformable pooling | 3 × 3 | ||
| deformable convolution block 1 | convolution | 64 | 1 × 1 | × 3 |
| deformable convolution | 64 | 3 × 3 | ||
| convolution | 256 | 1 × 1 | ||
| deformable convolution block 2 | convolution | 128 | 1 × 1 | × 4 |
| deformable convolution | 128 | 3 × 3 | ||
| convolution | 512 | 1 × 1 | ||
| deformable convolution block 3 | convolution | 256 | 1 × 1 | × 6 |
| deformable convolution | 256 | 3 × 3 | ||
| convolution | 1024 | 1 × 1 | ||
| deformable convolution block 4 | convolution | 512 | 1 × 1 | × 3 |
| deformable convolution | 512 | 3 × 3 | ||
| convolution | 2048 | 1 × 1 |
| Datasets | Scene Classes | Images Per Class | Total Images | Image Sizes | Spatial Resolution (in meters) |
|---|---|---|---|---|---|
| UCM | 21 | 100 | 2100 | 256 × 256 | 0.3 |
| NWPU | 45 | 700 | 31,500 | 256 × 256 | 0.2–30 |
| AID | 30 | 220−400 | 10,000 | 600 × 600 | 0.5–8 |
| Method | OA (%) under the Training Ratio of 20% | OA (%) under the Training Ratio of 50% |
|---|---|---|
| D-CNN | 87.62 | 88.35 |
| D-CNN + spatial | 90.28 | 92.23 |
| D-CNN + channel | 89.67 | 91.56 |
| D-CNN + channel + spatial | 93.28 | 94.26 |
| D-CNN + spatial + channel | 94.63 | 96.43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Lan, J. A Deformable Convolutional Neural Network with Spatial-Channel Attention for Remote Sensing Scene Classification. Remote Sens. 2021, 13, 5076. https://doi.org/10.3390/rs13245076
Wang D, Lan J. A Deformable Convolutional Neural Network with Spatial-Channel Attention for Remote Sensing Scene Classification. Remote Sensing. 2021; 13(24):5076. https://doi.org/10.3390/rs13245076
Chicago/Turabian StyleWang, Di, and Jinhui Lan. 2021. "A Deformable Convolutional Neural Network with Spatial-Channel Attention for Remote Sensing Scene Classification" Remote Sensing 13, no. 24: 5076. https://doi.org/10.3390/rs13245076
APA StyleWang, D., & Lan, J. (2021). A Deformable Convolutional Neural Network with Spatial-Channel Attention for Remote Sensing Scene Classification. Remote Sensing, 13(24), 5076. https://doi.org/10.3390/rs13245076