1. Introduction
Hyperspectral image (HSI) classification is an analysis technique that characterizes ground objects by abundant spectral and spatial information. Its main task is to assign a class label to each pixel of HSIs and generate specific classification maps. Motivated by the rapid development of deep learning in computer vision, natural language processing and other fields, classification methods based on deep neural networks have become a research hotspot in HSI domain. Unlike traditional methods that rely on expert experience and parameter adjustment to manually design feature, deep learning methods extract highly robust and discriminative semantic features from hyperspectral data in a data-driven and automatic parameter tuning manner. Generally speaking, shallower layers capture structured features, such as texture and edge information, and deeper layers acquire more complex semantic features.
Typical deep learning architectures, including deep belief networks (DBNs), stacked auto-encoders (SAEs), recurrent neural networks (RNNs), and convolutional neural networks (CNNs) have been widely used for HSI classification. In [
1], Chen et al. introduced deep neural network to hyperspectral image classification for the first time, and proposed a joint spectral–spatial classification method based on deep stack auto-encoder. It employs SAEs to learn deep spectral–spatial features in neighborhoods and sends them to a logistic regression (LR) model to obtain classification results. This method shows the great potential of the deep learning framework for HSI classification. In HSI data analysis, DBNs, as a variant of auto-encoders (AEs), perform feature extraction in an unsupervised manner [
2]. For example, Liu et al. [
3] proposed an effective classification framework based on DBNs and active learning to extract deep spectral features and iteratively select high-quality labeled samples as training samples. As a method of processing sequence information, RNNs are extremely suitable for analyzing hyperspectral data, each pixel of which can be regarded as a continuous spectral vector. Reference [
4] applied the concept of RNN to spectral classification by developing a new activation function and an improved gated recurrent unit (GRU) to effectively analyzing hyperspectral pixels as sequence data. The above methods only accept vector inputs, which leads to the inability to preserve the spatial structure characteristics of HSIs. In contrast, CNNs process spectral and spatial features flexibly, and become the most popular deep learning model for HSI classification.
According to the types of extracted features, CNN-based models can be divided into spectral CNNs and spectral–spatial CNNs. Spectral CNNs are designed to extract deep features in the spectral domain. For example, Hu et al. proposed a deep learning model composed of 1D CNNs [
5], which extract deep features and implement the classification in the spectral domain, and achieved excellent performance that is superior to support vector machines (SVM). Li et al. presented a 1D CNN models to capture pixel pair features (PPFs), which employs a combination of the center pixel and neighborhood pixels as the input and explores the spectral similarity between pixels [
6]. The input of pixel pairs significantly increases the training samples and relieves the pressure of network training. In addition, Wu et al. [
7] proposed a combination model of 1D CNN and RNN, exploiting the deep spectral features extracted by 1D CNN as the input of RNN to further improve the discrimination of features. Previous studies on HSI classification have proved that spatial information contributes to further improve the classification accuracy. It is due to the spatial consistency of the ground truth distribution.
The spectral–spatial CNNs take spatial neighbor patches as inputs and employ 2D or 3D CNN to extract joint deep spectral–spatial features. Spectral-spatial CNNs with stronger representation capability and classification performance than spectral CNNs, become more popular by researchers. Aptoula et al. combined powerful spatial-spectral attribute profiles (APs) and a CNN with nonlinear representation capacity to achieve remarkable classification performances [
8]. He et al. exploited multi-scale covariance maps obtaining by local spectral–spatial information of different window sizes to train a CNN model [
9]. Besides using handcrafted spectral–spatial features training networks to implement spectral–spatial CNNs, combining CNNs with other models is an alternative strategy to extract spectral and spatial features separately. For example, Zhao et al. proposed a classification method based on spectral–spatial features (SSFC), which designs a balanced local discriminant embedding (BLDE) algorithm to extract spectral features and uses 2D CNN to learn spatial features [
10]. In [
11], a two-branch network composed of 1D CNN and 2D CNN was proposed to extract spectral and spatial information respectively. References [
12,
13] also proposed two-branch classification networks based on 3D CNN and attention mechanism, which capture spectral and spatial features and utilize the attention mechanism to further refine feature maps. Further, some studies attempt to extract spectral–spatial features simultaneously. HSIs are 3D data cubes composed of 1D spectral dimensions and 2D spatial dimensions. The application of 3D CNN is a natural fashion to acquire high-level spectral–spatial features for effective classification without any pre- and post-processing procedures. For example, Chen et al. first introduced 3D CNN for HSI classification to achieve the effective spectral–spatial feature extraction [
14]. Reference [
15] presented an attention-based adaptive spectral–spatial kernel improved residual network (A2S2K-ResNet) to achieve the automatic selection of spectral–spatial 3D convolutional kernels and the adaptive adjustment of receptive filed. However, in the face of limited labeled samples, it is challenging to train deeper 3D-CNNs. To this end, the HybridSN model combining 3D CNN and 2D CNN was proposed to learn spectral–spatial features by using 3D CNN and 2D CNN in turns [
16]. Compared with using 3D CNN alone, the hybrid model reduces the complexity. Zhang et al. also proposed a 3D lightweight convolutional network to alleviate the small sample problem [
17].
The above patch-based CNNs can take full advantage of spectral–spatial information. However, these methods have unavoidable redundant computations caused by overlapped areas of adjacent pixels and limited receptive fields. To address the above problems, researchers try to introduce the fully convolution framework into the field of hyperspectral classification. The fully convolutional network (FCN) proposed by Lang et al. provides a novel idea to get rid of fixed input size and limitation of the receptive fields for pixel-level tasks [
18]. Replacing the fully connected layer (FC)
convolutional layer as a classifier, FCN can accept inputs of any size and produce corresponding outputs through effective reasoning and learning. In [
19], a multi-scale spectral–spatial CNN (HyMSCN) was proposed to expand the receptive field and extract multi-scale spatial features by dilated convolutions of different sizes. Zheng et al. presented a fast patch-free global learning framework (FPGA), which contains an encode-decoder-based FCN and adopts a global random hierarchical sampling (GS2) strategy to ensure fast and stable convergence [
20]. To solve the sample problem of insufficiency and imbalance, Zhu et al. designed a spectral–spatial dependent global learning (SSDGL) framework based on FPAG [
21]. Although the above methods all employ FCN as the basis for image-based classification and achieve significant classification performances, they still exist limitations on the extraction of global information. Xu et al. proposed a two-branch spectral–spatial fully convolutional networks (SSFCN-CRF), which extracts spectral and spatial features separately, and introduces the dense conditional random field (dense CRF) to further balance the local and global information [
22]. However, it is unable to achieve end-to-end training and difficult to optimize globally.
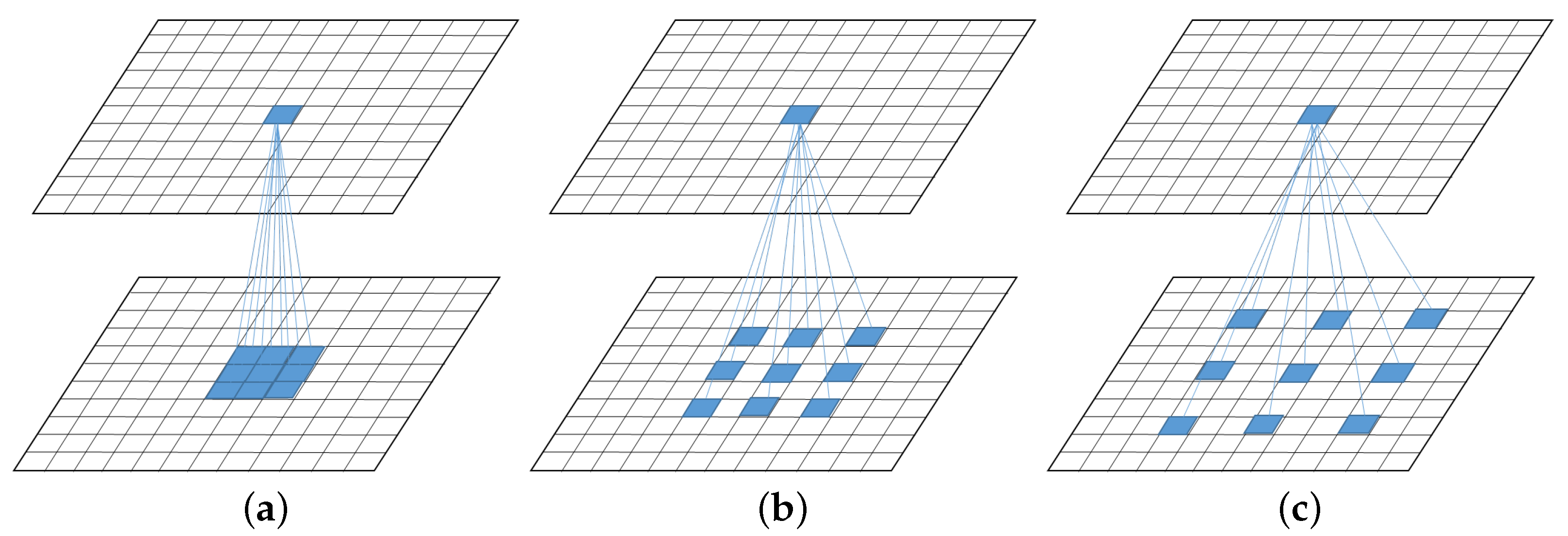
From the previous analysis, there are some problems that limit the improvement of hyperspectral classification performance. First, the input size of patch-based frameworks limits the learning of local information. Generally, a larger input size will make the network learn more robust features and improve the classification accuracy. At the same time, a large number of overlapping areas between different input patches lead higher calculation costs. Second, current networks mainly rely on local information. When the number of training samples is small, the structured neighborhood features provided by the samples are limited, resulting in weak classification performance. Many complex spatial structures cannot be learned by the network. Pixels located at the boundary of different classes are easily misclassified. Third, most networks ignore the global representation of HSIs and lack the ability to adaptively capture global information.
To solve the above problems, we propose a fully convolutional network based on class feature fusion (CFF-FCN) containing the local feature extraction block (LFEB) and the class feature fusion block (CFFB), which receives the whole HSI as the input and takes the local spatial structures and the global context into full consideration at the low computational cost. Specifically, LFEB based on dilated convolutions and reverse loop mechanism is designed to extract multi-level spectral–spatial information. Inspired by the idea of coarse-to-fine segmentation [
23,
24], the coarse classification is utilized to obtain the key class representations for CFFB. CFFB calculates the affinity matrix by the similarity between each pixel and each class feature, which are served to reconstruct the more robust global features. The global class features obtained by CFFB are aggregated with the local features further refined by reverse loop mechanism to enhance the discrimination of classification features. The main contributions of our study can be summarized as follows.
A coarse-to-fine CFF-FCN with LEFB and CFFB is proposed for HSI classification, which is based on the fully convolutional layer to avoid data preprocessing and redundant calculations. The LFEB with the reverse loop mechanism not only retains low-level detailed information but also extracts high-level abstract features to provides semantic information of multiple levels and local features of multiple receptive fields and further improves the discrimination of features.
The proposed CFFB can capture the global class information by coarse classification and propagate it to each pixel according to the similarity. Compared with the pixel-by-pixel global calculation, the CFFB allows several key class features to update the pixel features that reduces computational costs and redundant information and enhances the representation ability of classification features.
Experiments on three real hyperspectral data sets demonstrate that the proposed CFF-FCN achieves the most reliable and robust classification with fewer network parameters and lower computational time, and improves the misclassification phenomenon of category boundaries.
The remainder of this paper is organized as follows.
Section 2 briefly reviews the related works.
Section 3 describes the proposed framework.
Section 4 and
Section 5 provides the details and the discussion of the experimental results. Finally,
Section 6 concludes this paper.
3. Methodology
The architecture of CFF-FCN is shown in
Figure 3. Assuming the HSI
as the input of CFF-FCN, the output
can be obtain that indicates the class probabilities of each pixel. Here,
N,
H,
W,
B and
C represent the batch size, height, width, number of spectral bands and number of land-cover classes, respectively. Since HSI classification is the pixel-level task based on single image, the batch size
N of CFF-FCN is 1. In
Figure 3, the original HSI after dimensionality reduction by
is send to LFEB and CFFB to extract the local and global information, which are aggregated and delivered to the classifier consisting of the convolutional classification layer
and softmax layer. The following subsections describe the details of each block.
3.1. Local Feature Extraction Block
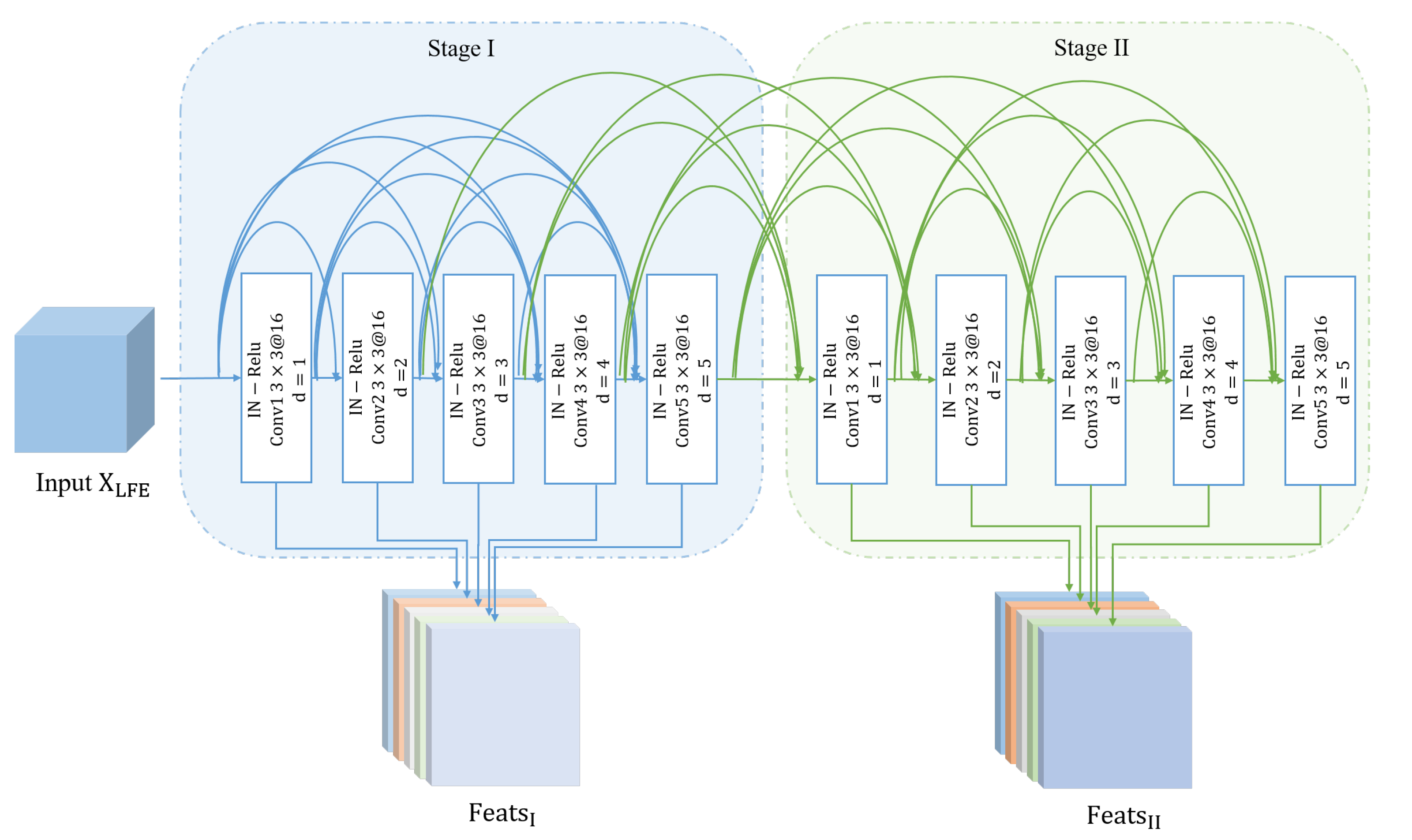
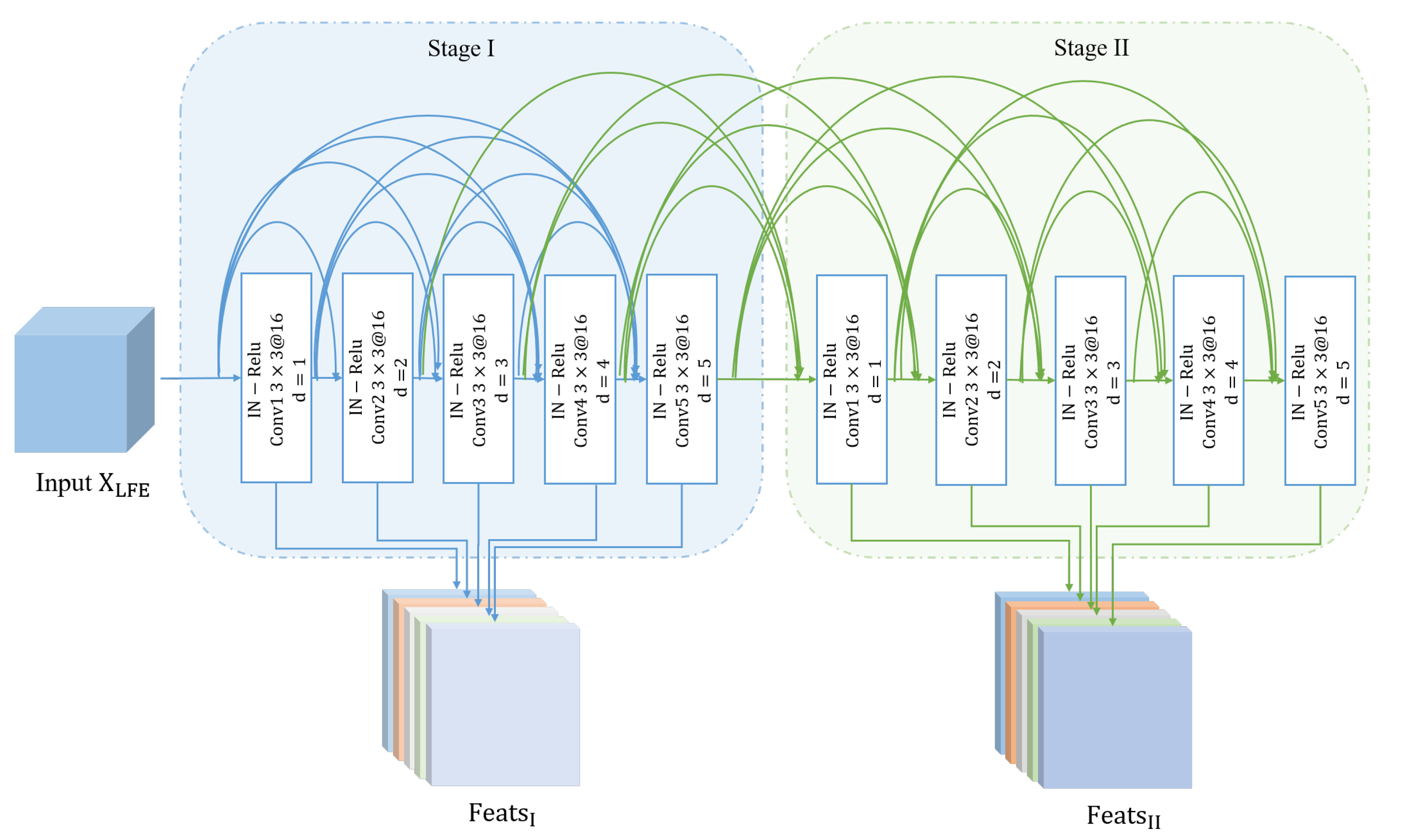
As the backbone of CFF-FCN, LFEB is a two-stage network based on dilated convolutions with dense connections and reverse loop mechanism. The stacking of dilated convolutions with different dilation rates fully considers the local information of different scales. Dense connections ensure the maximum information transmission in the network [
31]. Let
be the input of LFEB, which contains five dilated convolutions with convolution kernels of
. The specific architecture is displayed in
Figure 4. To ensure the continuity of local information while avoiding gridding effect, we employ a set of incremental dilation rates that set as
. The nonlinear transformation
of each convolutional layer is composed of instance normalization (IN) [
32], rectified linear unit (ReLU) and convolution (Conv).
The network structure of the multi-layer stack yields the deviation of the data distribution. To reduce the impact of the distribution changes, normalization strategy is usually used in neural networks to map the data to a certain interval. Neural networks taking patches as input generally use batch normalization (BN) [
33] to normalize data in a whole batch of images. While the batch size of the FCN-based classification network is 1, BN is not applicable. Therefore, we use IN for normalization in the channel dimension. Normalization operation is performed within single sample. The specific operation can be expressed as:
where
represents the tensor to be normalized,
K is the number of channels.
denotes the normalized result.
and
are parameters to be learned.
and
represent the mean and variance of
Z, which are calculated as follows:
Here,
h,
w, and
k represent the index subscript of the spatial location and the channel dimension, respectively. IN can be seen as an adjustment of global information to ensure fast convergence of networks.
In the first stage (Stage-I), each layer takes the outputs of all previous layers as input, and its output is also directly delivered to all subsequent layers. Let
be the output of
i-th convolutional layer in Stage I, the calculation of LFEB can be represented as:
denotes the cascade operation of features. For each dilated convolutional layer, the corresponding maximum and minimum receptive field can be calculated as:
is set to 1. Receptive fields cover
to
after Stage-I. In Stage-I, each layer is directly connected to the subsequent layers. The network learns and retains richer features by feature reuse at different levels, which enhances the feature transfer from shallow to deep. At the same time, the implementation of multi-scale receptive fields can adaptively capture and fuse semantic information in different scale, which is conducive to retaining local details and obtaining more complex and robust feature maps. The output of each layer is aggregated as the first stage feature of LFEB:
means continuous cascade operation for feature maps.
Inspired by the alternate update clique [
33], we introduce the loop mechanism based on parameter reuse into LFEB and further refine
on the basis of the first-stage network, which modulate low-level features with high-level semantic information. The specific unfold of LFEB is shown in
Figure 4. The second stage network (Stage-II) uses the latest output results of other layers to update weights of the current layer. The output of Stage-II can be expressed as:
In Stage-II, second stage features of all the previous layers and first stage features of all subsequent layers are concatenated to update the current layer. The higher-level semantic information is fed back into low-level layers to refine features of each layer in an alternate update manner.
Table 1 displays the forward propagation of LEFB.
denotes parameters of convolution from
to
. Stage-I can be regarded as a layer-by-layer initialization process. After Stage-II, any layer has two-way connections to other layers. The update layer receives the most advanced feedback information.It realizes top-down refinement. The feedback structure maximizes communication between all layers. Outputs of all layers in Stage-II are connected as the second feature of LFEB:
Forward propagation networks usually employ the highest-level semantic features as the classification feature. In fact, fine-grained features captured by low-level layers can provide more structural information for classification. In order to take full advantage of different levels of features, we deliver into CFFB to extract global class information, which is aggregated with to generate the final classification feature.
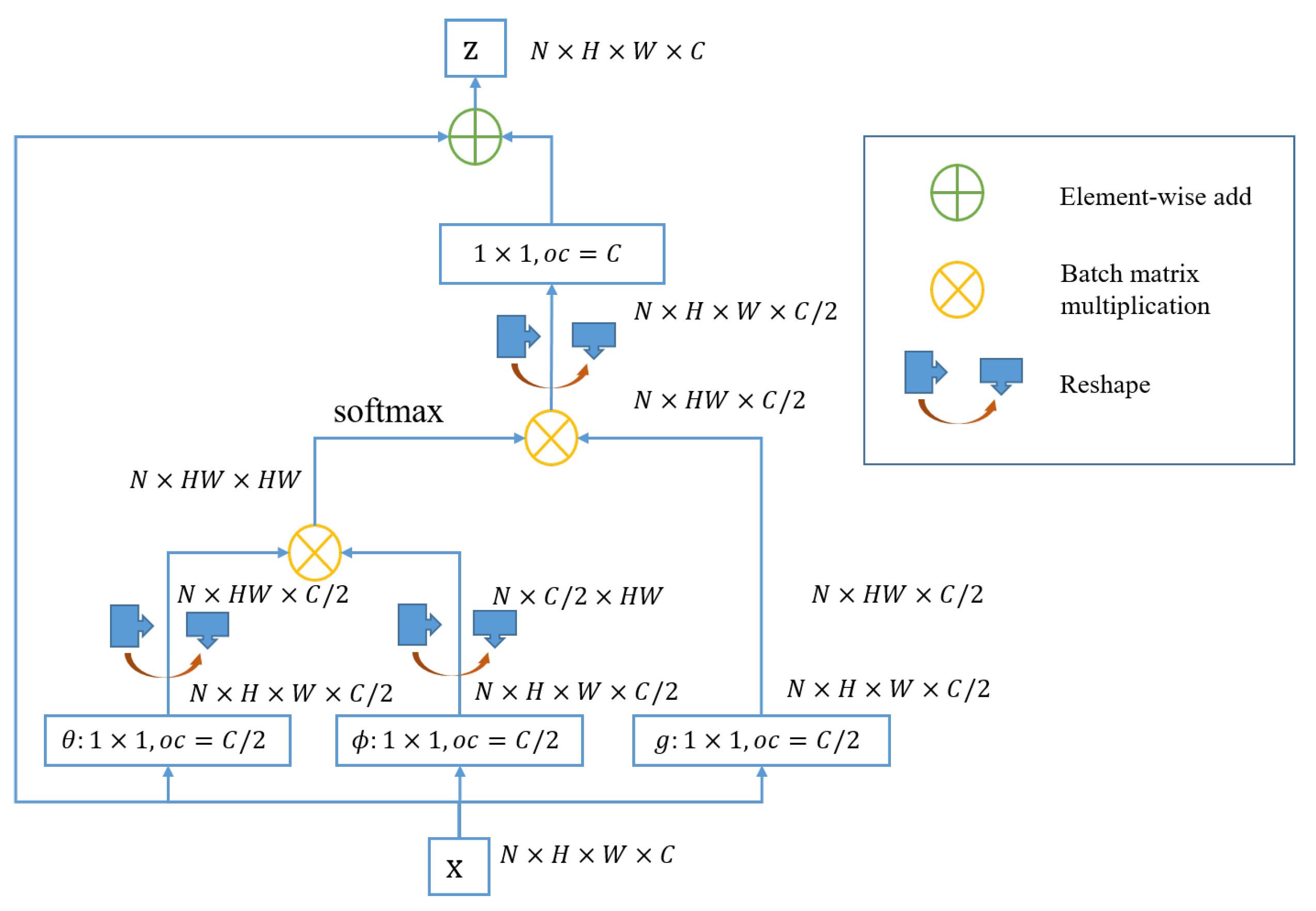
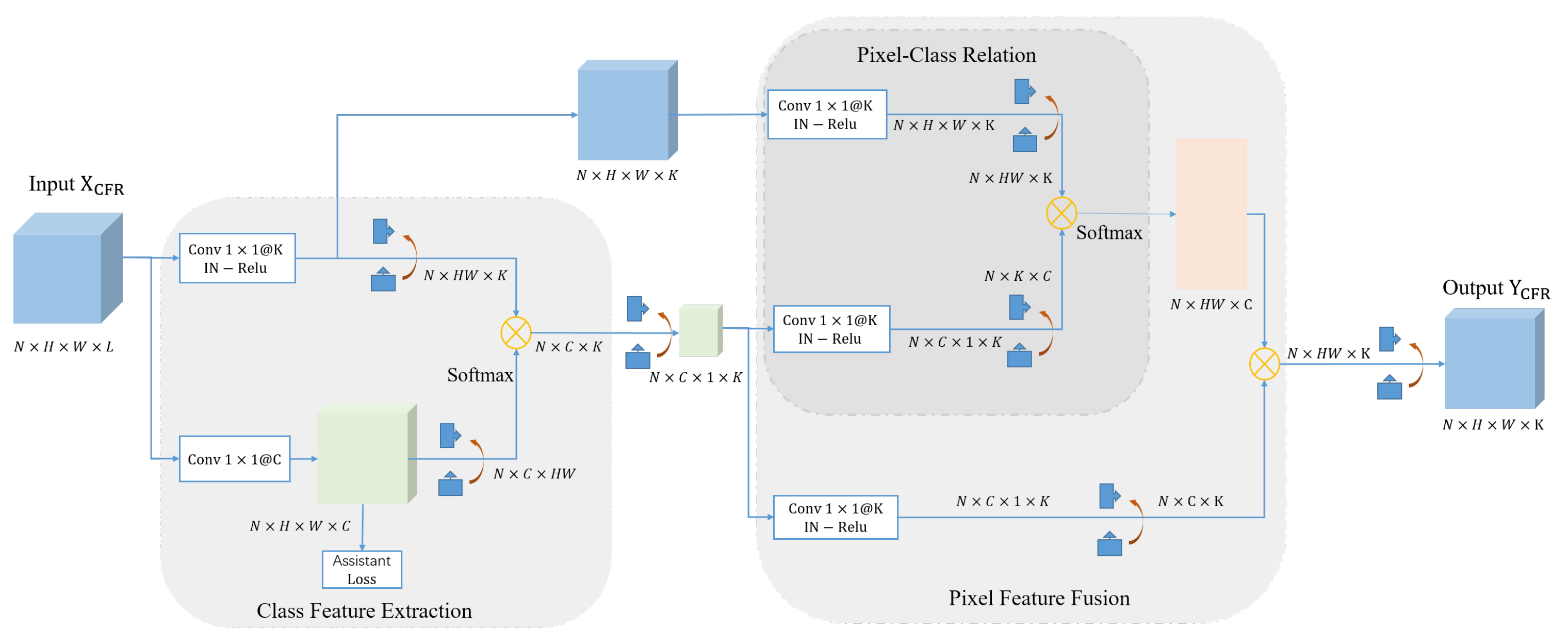
3.2. Class Feature Fusion Block
Non-local neural networks explore the similarity relationship between all pixels and update pixel features with global information. Taking into account the characteristics of HSIs, the pixel-by-pixel global information not only contains a large amount of highly correlated redundant information, but also brings high calculation cost. In response to this problem, we design CFFB to reconstruct pixel information by more representative global class context features, which reduces the computational cost while improving the discrimination of pixel features. The specific structure is shown in
Figure 5, which mainly includes two parts: class feature extraction and pixel feature fusion.
The most intuitive way to obtain the class representation in HSI is to take the average of all pixel features of the current category as the class center. In actual classification, the labels of all pixels is not available in advance. To this end, we employ a coarse classification mechanism to classify by the intermediate features and obtain the class probability of each pixel in a supervised manner. Through the weighted average of the pixel features and the corresponding class probability, the approximate class center is obtained as the class representation. Let the input of CFFB be
, where
L is the number of input channels. The class probabilities of pixels on the spatial position
is calculated as follows:
represents the input feature of pixel
i.
denotes the classifier that maps the input from
to
. The class representation of the
c-th class can be defined by the weighted average with features of all pixels and their probability belonging to the
c-th class:
where
is the
c-th element of
, and
aims to calculate the pixel feature.
and
are implemented by
convolution. If the coarse classification result shows that the pixel belongs to the
c-th class, the pixel has the largest contribution to the
c-th class representation. Class features allow the network to capture the overall representation of each class from a global view. Coarse classification provides powerful supervision information in training phase to learn more discriminative features of each class.
Pixel feature fusion aims to learn relations between pixels and class representations, and exploit global class context information to enhance the features of each pixel. We utilize the relationship estimation method of non-local block and calculate relations between each pixel and each class (affinity matrix):
where
is affinity matrix, and
is an element of
A that indicates the contribution degree of the class feature
to the reconstructed pixel
i.
and
are
convolutions. The global estimation of the pixel
i can be expressed as:
is a class feature transform function implemented by
convolution. Therefore, the output of CFFB can be described as:
The global class representation learned in a supervised manner is obtained from highly correlated pixel features of the same category. The process of coarse classification can be seen as clustering of pixels, which can adaptively gather semantically related pixels and enlarge the differences between classes. Pixel feature mapping by category features and similarity matrix allow the network to re-estimate pixel features with key semantic information, which reduces intra-class differences and comprehensively improve the discrimination of fusion features.
Finally, we concatenate fusion features with second-stage features of the backbone network to obtain the final classification feature
that is sent to the classification layer. Due to existing unlabeled samples in hyperspectral images, we only calculate the loss function for labeled training samples. In this paper, cross entropy loss is used for coarse classification and final classification. The cross entropy loss is described as:
where
m is the total number of training samples,
is the
c-th value of a label vector for pixel
i, and
is the the corresponding probability. The loss function of CFF-FCN can be written as:
is the weight factors to balance the two loss functions.
4. Experimental Results
4.1. Experimental Data Sets
To evaluate the performance of the proposed method, we conducted experiments and analyses on three widely used public data sets, including Indian Pines (IP), University of Pavia (UP), and Kennedy Space Center (KSC). The details of these three data sets are described as follows.
Table 2 lists category names and the number of corresponding labeled samples.
IP data sets were the earliest test data used for HSI classification. They were collected by the Airborne Visible Infrared Imaging Spectrometer (AVIRIS) in Northwest Indiana, USA. A subset of the whole data set with a size of is cut and annotated for HSI classification. The wavelength range is 0.4–2.5 μm, including 224 reflection bands. After removing the noise and water absorption bands, the remaining 200 bands are used as research objects. The spatial resolution is about 20 m, which is easy to produce mixed pixels and brings difficulty to classification. The IP data set includes 16 classes of ground truth. Moreover, 9 categories with labeled samples larger than 400 were selected for the experiment.
The UP data set was collected by the Reflective Optics System Imaging Spectrometer (ROSIS) from the University of Pavia, Italy. It contains 115 bands in the wavelength range of 0.43–0.86 μm, with a spatial resolution of m. Moreover, 12 bands were eliminated due to the influence of noise. The size of UP was , covering 9 classes, including trees, asphalt roads, bricks, pastures, etc.
The KSC data set was acquire by the AVIRIS at the Kennedy Space Center in Florida, USA. The image contains data of 224 bands from 0.4–2.5 μm, with a spatial resolution of 18 m. After removing the water absorption and noise bands, the remaining 176 bands were used for experiments. KSC contains pixels and 13 land cover types.
4.2. Experimental Setup
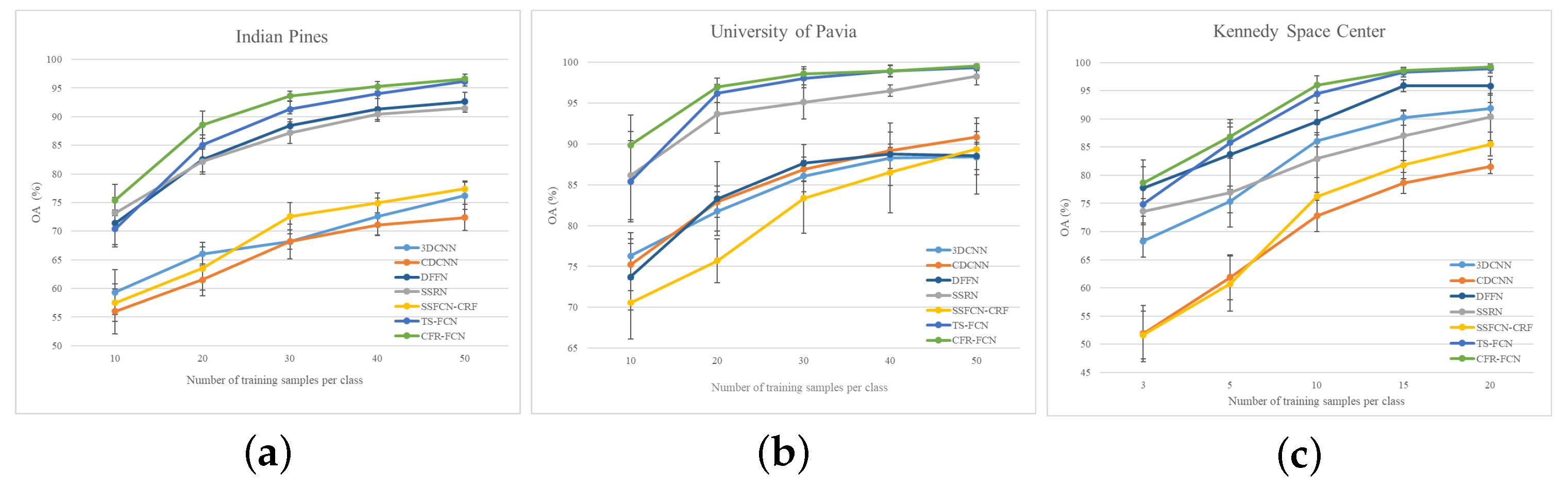
Each data set was divided into a training set, validation set, and test set. The training set was served for back propagation to optimize model parameters. The validation set did not participate in the training, but evaluated the temporary model in the training phase. The test set evaluated the classification ability of the final model. For IP and UP data sets, 30 labeled samples of each class were randomly selected for training and validation. The remaining labeled samples were used for testing. For the KSC data set, 10 labeled samples for each class were randomly selected for training and verification.
We adopted class-based accuracy, overall accuracy (OA), average accuracy (AA), and kappa coefficient to the evaluation classification performance. The experiment was implemented on the PyTorch framework. The hardware platform included an Intel E5-2650 CPU, an NVIDIA GTX2080Ti GPU. The number of training iterations was 1000, and the learning rate was 0.0003.
We compared the proposed CFF-FCN with several state-of-the-art deep learning-based classifiers, including 3D-CNN [
34], the contextual deep CNN (CDCNN) [
35], the deep feature fusion network (DFFN) [
36], the spectral–spatial residual network (SSRN) [
37], and the spectral–spatial fully convolutional network (SSFCN-CRF) [
22]. These methods all employ spectral–spatial features to implement HSI classification. Among them, 3D-CNN, CDCNN, DFFN, and SSRN are patch-based CNNs, and SSFCN-CRF is an image-based fully convolutional framework. The network settings of the above methods follow the corresponding references. Meanwhile, we also conducted experiments on two-stage networks (TSFCN) without CFFB, which can be regarded as the backbone of our proposed CFF-FCN. The specific numerical results and full classification maps are listed in
Table 3,
Table 4 and
Table 5 and
Figure 6,
Figure 7 and
Figure 8.
4.3. Classification Maps and Categorized Results
4.3.1. Indian Pines
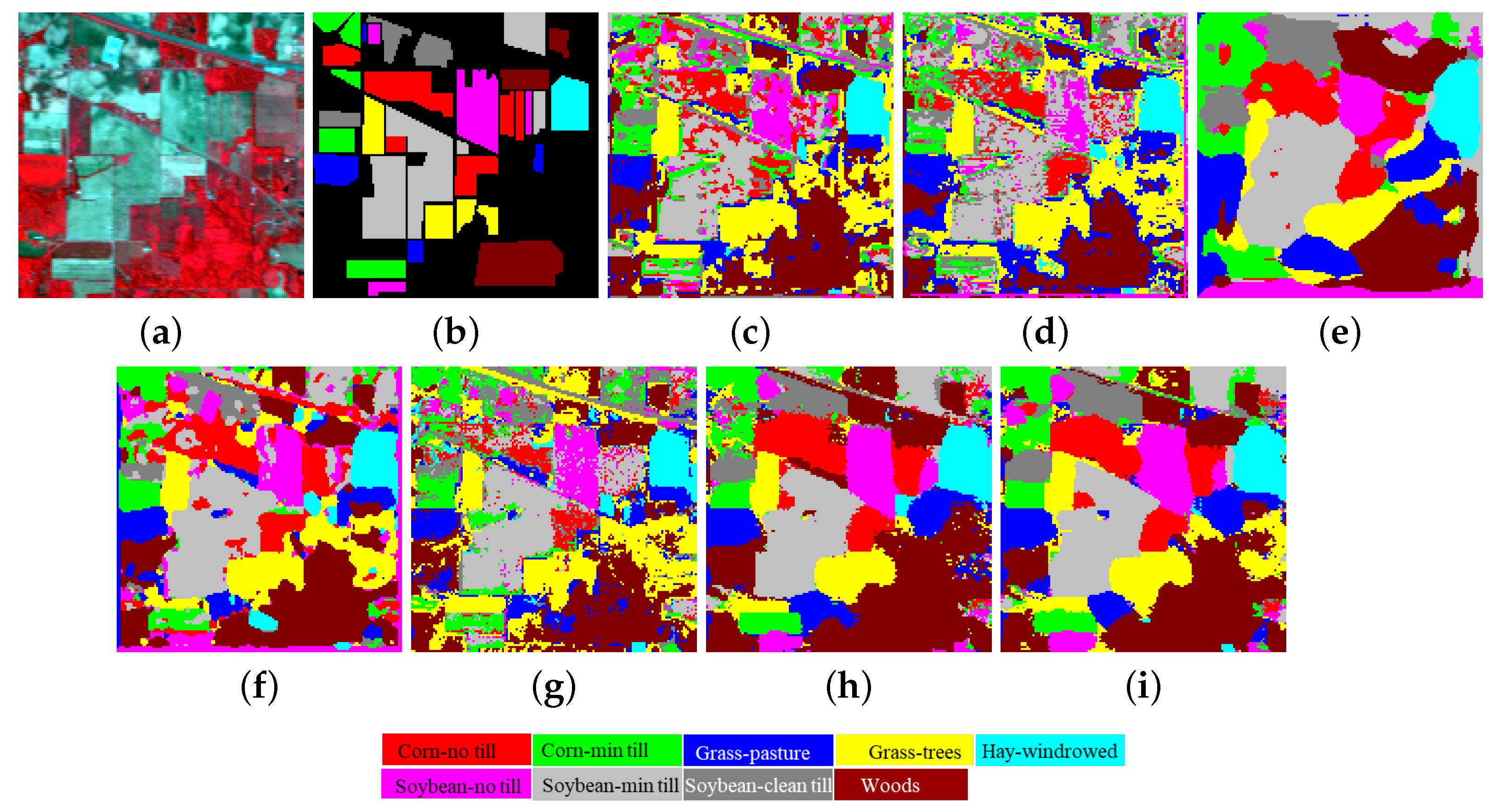
Figure 6 and
Table 3 respectively show the classification maps and numerical results of different methods in the IP data set. The TSFCN and CFF-FCN proposed in this paper are significantly better than other methods in three overall indicators. TSFCN achieves 100% classification accuracy on class 8 (Hay-windrowed), and CFF-FCN maintains the best accuracy on other classes. The introduction of global class context information makes OA increase by 2.31%. Due to the limitation of the number of training samples, 3DCNN, CDCNN and SSFCN-CRF cannot extract reliable spectral–spatial features, and the classification performance is relatively weak. Classification accuracies of DFFN and SSRN is preceded only to the proposed methods.
Figure 6c,d,f also indicate that 3DCNN, CDCNN, and SSFCN-CRF have obvious class mixing and salt and pepper noise. Classification map of DFFN is smoother than SSRN’s. However, DFFN seems to have a certain degree of overfitting. The classification maps of TSFCN and CFF-FCN show the best visual effects, especially the use of global information makes the category edges of CFF-FCN smoother.
4.3.2. University of Pavia
Table 4 reports the classification accuracies for the UP data set. CFF-FCN shows the best performance in most categories and overall indexes. CFF-FCN and SSRN have achieved 100% class accuracy in class 5 (metal sheets). Compared with TSFCN, the OA of CFF-FCN is increased by 0.45%, indicating the effectiveness of CFFB.
Figure 7 display the classification map of different methods. The 3DCNN, CDCNN, and SSFCN-CRF all have large regions of misclassification, and the class edges are not smooth. DFFN can observe obvious overfitting phenomenon in the UP data set. Compared with other methods, classification maps of TSFCN and CFF-FCN obviously have fewer misclassification points, and the class boundaries are clearer and smoother. Comparing TSFCN and CFF-FCN, it can be observed that global class information can alleviate the confusion of category boundaries to a certain extent.
4.3.3. Kennedy Space Center
Table 5 and
Figure 8 present the experimental results of different methods on the KSC data set.
Table 5 indicates that the performance of our proposed TSFCN and CFF-FCN is significantly better than other methods, achieving 100% classification accuracies for classes 7, 11, and 13. Compared with TSFCN, the OA of CFF-FCN increases by 1.56%. The classification accuracy of DFFN is second only to the proposed TSFCN and CFF-FCN.
Table 5 shows that class 4 (CP) and class 6 (Oak) are difficult to distinguish correctly. Compared with other classifiers, CFF-FCN has achieved better accuracy in these two categories. From
Figure 8b, it can be seen that the labeled samples of KSC only occupy a very small part of the entire image and are loosely distributed. In the classification map of CDCNN, there exists a lot of salt and pepper noise. DFFN still exhibits overfitting. SSFCN-CRF can detect all objects on the water surface. However, its classification map does not have clear category boundaries.
Figure 8h also shows that the classification map of CFF-FCN is closer to the ground-truth map.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}