
Point Projection Network: A Multi-View-Based Point Completion Network with Encoder-Decoder Architecture




Abstract
:1. Introduction
- A multi-view-based method using encoder–decoder architecture is proposed to complete the point cloud, which is performed through projections in multiple directions of an incomplete point cloud.
- For the projection stage, a boundary feature extraction method is proposed, which can eliminate the overlap caused by projection and make the network focus on the characteristic profile information.
- A new joint loss function is designed to combine the projected loss with adversarial loss to make the output point cloud more evenly distributed and closer to the ground truth.
2. Materials and Methods
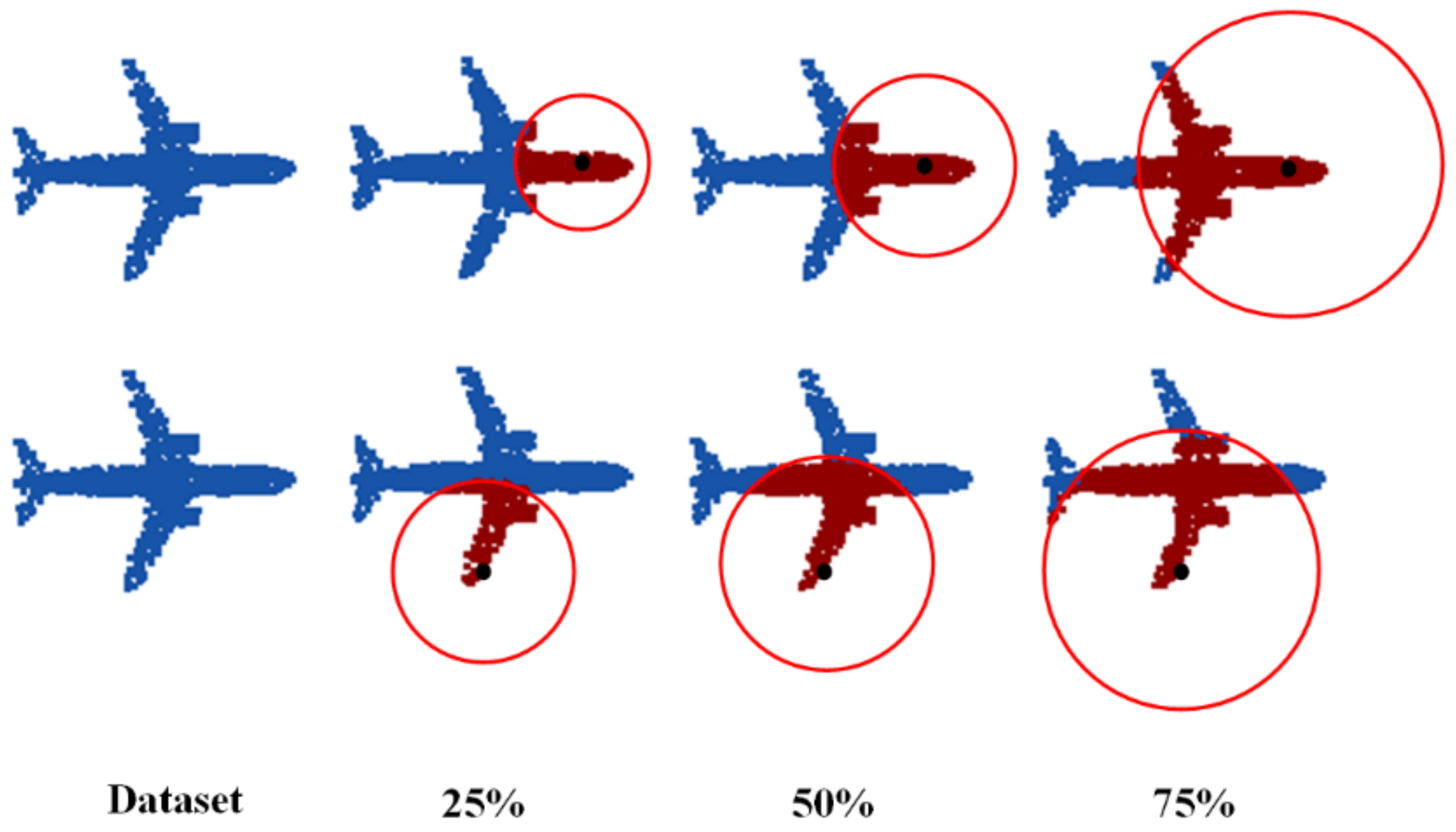
2.1. Data Preprocessing
2.2. Network Structure Overview
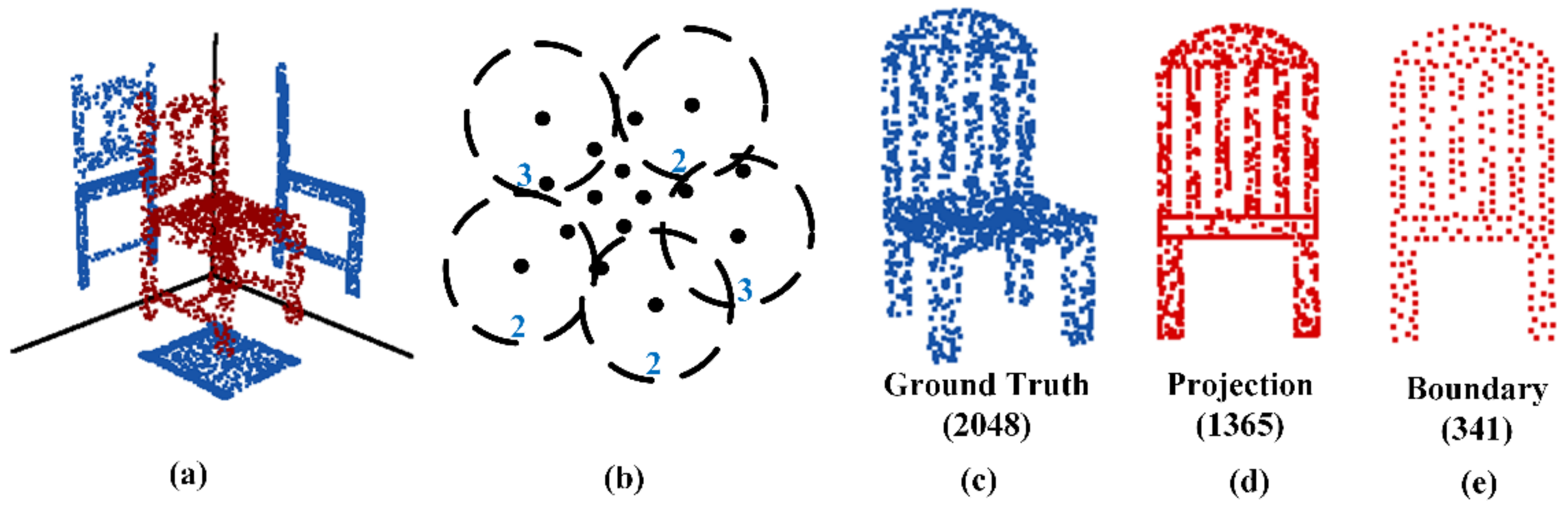
2.3. PBE
2.4. MRE
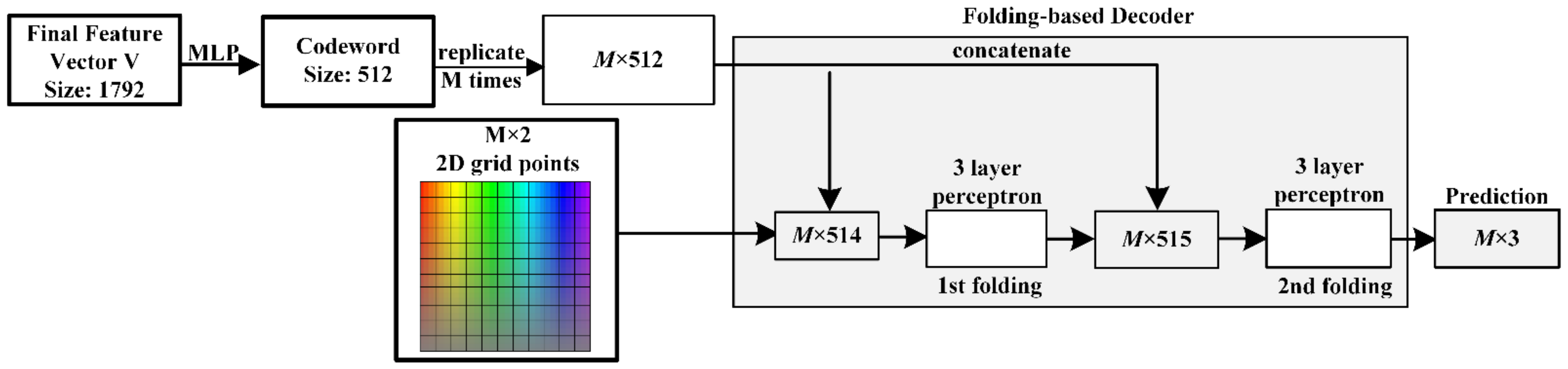
2.5. FBD
2.6. Loss Function
2.6.1. Multi-Directional Projection Distance Loss
2.6.2. Adversarial Loss
2.6.3. Joint Loss
3. Experiment and Result Analysis
3.1. Experimental Implementation Details
3.2. Evaluation Standard
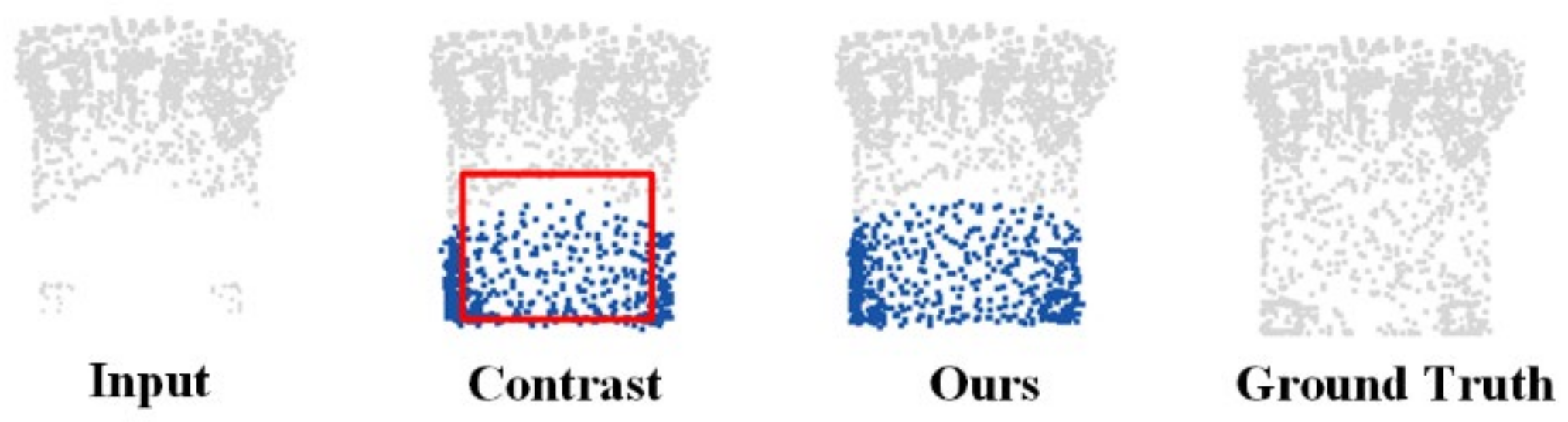
3.3. Experimental Results
3.4. Comparison with Other Methods
4. Discussion
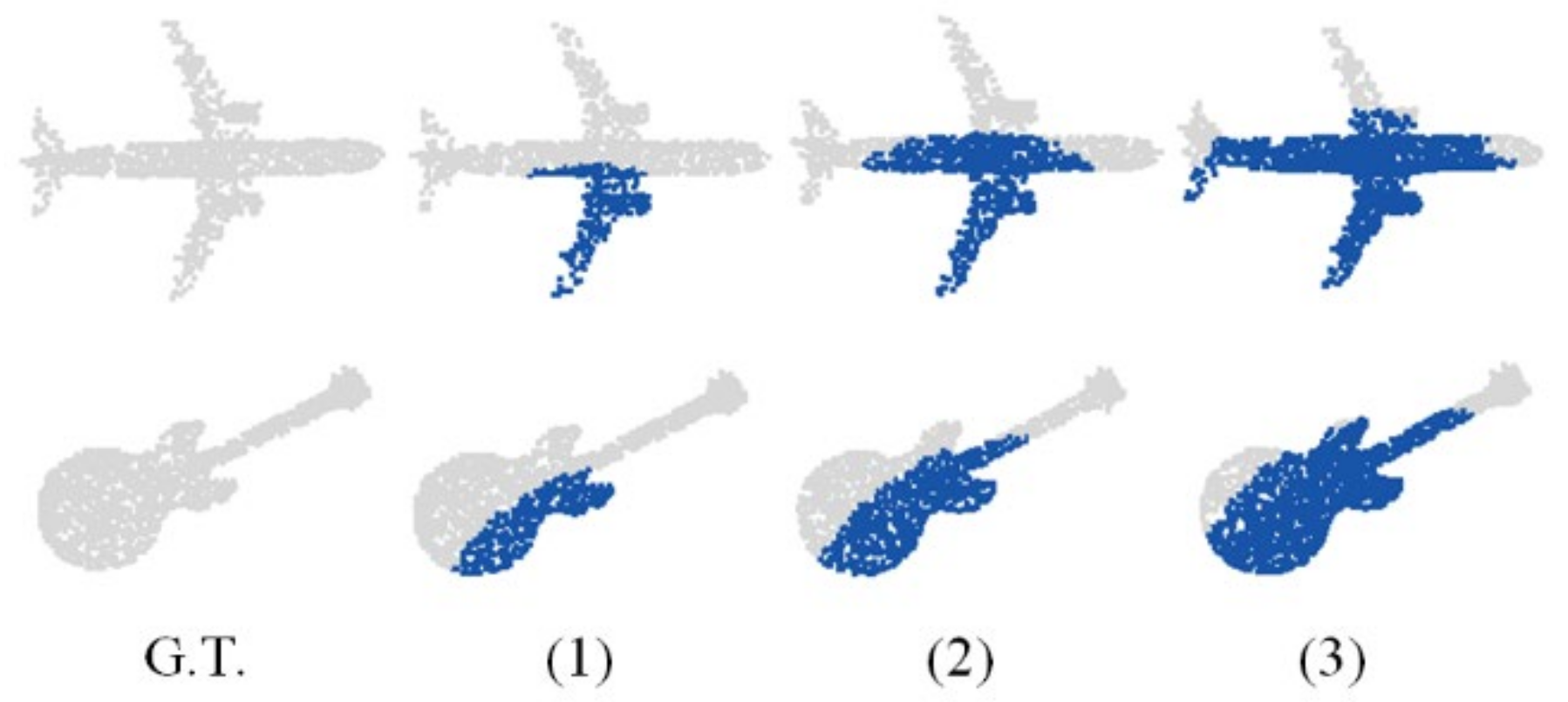
4.1. Boundary Extraction Analysis
4.2. Plane Folding Analysis
4.3. Loss Function Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, H.; Ye, Q.; Wang, H.; Chen, L.; Yang, J. A Precise and Robust Segmentation-Based Lidar Localization System for Automated Urban Driving. Remote Sens. 2019, 11, 1348. [Google Scholar] [CrossRef] [Green Version]
- Jing, Z.; Guan, H.; Zhao, P.; Li, D.; Yu, Y.; Zang, Y.; Wang, H.; Li, J. Multispectral LiDAR Point Cloud Classification Using SE-PointNet++. Remote Sens. 2021, 13, 2516. [Google Scholar] [CrossRef]
- Wan, J.; Xie, Z.; Xu, Y.; Zeng, Z.; Yuan, D.; Qiu, Q. DGANet: A Dilated Graph Attention-Based Network for Local Feature Extraction on 3D Point Clouds. Remote Sens. 2021, 13, 3484. [Google Scholar] [CrossRef]
- Lundell, J.; Verdoja, F.; Kyrki, V. Beyond Top-Grasps Through Scene Completion. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 545–551. [Google Scholar]
- Lundell, J.; Verdoja, F.; Kyrki, V. Robust Grasp Planning Over Uncertain Shape Completions. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 1526–1532. [Google Scholar]
- Varley, J.; DeChant, C.; Richardson, A.; Ruales, J.; Allen, P. Shape Completion Enabled Robotic Grasping. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 2442–2447. [Google Scholar]
- Mayuku, O.; Surgenor, B.W.; Marshall, J.A. A Self-Supervised near-to-Far Approach for Terrain-Adaptive off-Road Autonomous Driving. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Wang, P.; Liu, D.; Chen, J.; Li, H.; Chan, C.-Y. Decision Making for Autonomous Driving via Augmented Adversarial Inverse Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Wei, B.; Ren, M.; Zeng, W.; Liang, M.; Yang, B.; Urtasun, R. Perceive, Attend, and Drive: Learning Spatial Attention for Safe Self-Driving. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Rad, M.; Lepetit, V. BB8: A Scalable, Accurate, Robust to Partial Occlusion Method for Predicting the 3D Poses of Challenging Objects Without Using Depth. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 20–29 October 2017; pp. 3828–3836. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-Time Seamless Single Shot 6D Object Pose Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 292–301. [Google Scholar]
- Kehl, W.; Manhardt, F.; Tombari, F.; Ilic, S.; Navab, N. SSD-6D: Making RGB-Based 3D Detection and 6D Pose Estimation Great Again. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 20–29 October 2017; pp. 1521–1529. [Google Scholar]
- Sipiran, I.; Gregor, R.; Schreck, T. Approximate Symmetry Detection in Partial 3D Meshes. Comput. Graph. Forum 2014, 33, 131–140. [Google Scholar] [CrossRef] [Green Version]
- Sung, M.; Kim, V.G.; Angst, R.; Guibas, L. Data-Driven Structural Priors for Shape Completion. ACM Trans. Graph. 2015, 34, 175. [Google Scholar] [CrossRef]
- Thrun, S.; Wegbreit, B. Shape from Symmetry. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; pp. 1824–1831. [Google Scholar]
- Nguyen, D.T.; Hua, B.-S.; Tran, K.; Pham, Q.-H.; Yeung, S.-K. A Field Model for Repairing 3D Shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5676–5684. [Google Scholar]
- Zhao, W.; Gao, S.; Lin, H. A Robust Hole-Filling Algorithm for Triangular Mesh. Vis. Comput. 2007, 23, 987–997. [Google Scholar] [CrossRef]
- Sorkine, O.; Cohen-Or, D. Least-Squares Meshes. In Proceedings of the Proceedings Shape Modeling Applications, Genova, Italy, 7–9 June 2004; pp. 191–199. [Google Scholar]
- Gupta, S.; Arbelaez, P.; Girshick, R.; Malik, J. Aligning 3D Models to RGB-D Images of Cluttered Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4731–4740. [Google Scholar]
- Xu, Y.; Xie, Z.; Chen, Z.; Xie, M. Measuring the similarity between multipolygons using convex hulls and position graphs. Int. J. Geogr. Inf. Sci. 2021, 35, 847–868. [Google Scholar] [CrossRef]
- Pauly, M.; Mitra, N.J.; Giesen, J.; Gross, M.; Guibas, L.J. Example-Based 3D Scan Completion. In Proceedings of the Proceedings of the third Eurographics symposium on Geometry processing, Vienna Austria, 4–6 July 2005; Eurographics Association: Goslar, Germany, 2005; p. 23. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the Proceedings of the Eurographics Symposium on Geometry Processing, Graz, Austria, 6–8 July 2015; Eurographics Association: Goslar, Germany, 2015; pp. 1912–1920. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012 [cs]. [Google Scholar]
- Yang, B.; Wen, H.; Wang, S.; Clark, R.; Markham, A.; Trigoni, N. 3D Object Reconstruction from a Single Depth View with Adversarial Learning. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 679–688. [Google Scholar]
- Yu, C.; Wang, Y. 3D-Scene-GAN: Three-dimensional Scene Reconstruction with Generative Adversarial Networks. February 2018. Available online: https://openreview.net/forum?id=SkNEsmJwf (accessed on 2 December 2021).
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2536–2544. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Feng, Y.; You, H.; Zhang, Z.; Ji, R.; Gao, Y. Hypergraph Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3558–3565. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Fan, B.; Xiang, S.; Pan, C. Relation-Shape Convolutional Neural Network for Point Cloud Analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8895–8904. [Google Scholar]
- Kanezaki, A.; Matsushita, Y.; Nishida, Y. RotationNet: Joint Object Categorization and Pose Estimation Using Multiviews From Unsupervised Viewpoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5010–5019. [Google Scholar]
- He, X.; Zhou, Y.; Zhou, Z.; Bai, S.; Bai, X. Triplet-Center Loss for Multi-View 3D Object Retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1945–1954. [Google Scholar]
- Dai, A.; Ruizhongtai Qi, C.; Niessner, M. Shape Completion Using 3D-Encoder-Predictor CNNs and Shape Synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5868–5877. [Google Scholar]
- Wang, W.; Huang, Q.; You, S.; Yang, C.; Neumann, U. Shape Inpainting Using 3D Generative Adversarial Network and Recurrent Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2298–2306. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Huang, Z.; Yu, Y.; Xu, J.; Ni, F.; Le, X. PF-Net: Point Fractal Network for 3D Point Cloud Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7662–7670. [Google Scholar]
- Achlioptas, P.; Diamanti, O.; Mitliagkas, I.; Guibas, L. Learning Representations and Generative Models for 3D Point Clouds. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 40–49. [Google Scholar]
- Luo, J.; Xu, Y.; Tang, C.; Lv, J. Learning Inverse Mapping by AutoEncoder Based Generative Adversarial Nets. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; Liu, D., Xie, S., Li, Y., Zhao, D., El-Alfy, E.-S.M., Eds.; Springer International Publishing: Cham, Germany, 2017; pp. 207–216. [Google Scholar]
- Yuan, W.; Khot, T.; Held, D.; Mertz, C.; Hebert, M. PCN: Point Completion Network. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 728–737. [Google Scholar]
- Sarmad, M.; Lee, H.J.; Kim, Y.M. RL-GAN-Net: A Reinforcement Learning Agent Controlled GAN Network for Real-Time Point Cloud Shape Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5898–5907. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-View Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 945–953. [Google Scholar]
- Yu, T.; Meng, J.; Yuan, J. Multi-View Harmonized Bilinear Network for 3D Object Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 186–194. [Google Scholar]
- Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. GVCNN: Group-View Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 264–272. [Google Scholar]
- Yang, Z.; Wang, L. Learning Relationships for Multi-View 3D Object Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7505–7514. [Google Scholar]
- Qi, C.R.; Su, H.; Niessner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and Multi-View CNNs for Object Classification on 3D Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5648–5656. [Google Scholar]
- Wei, X.; Yu, R.; Sun, J. View-GCN: View-Based Graph Convolutional Network for 3D Shape Analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1850–1859. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. FoldingNet: Point Cloud Auto-Encoder via Deep Grid Deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 206–215. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J. A Point Set Generation Network for 3D Object Reconstruction From a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Gadelha, M.; Wang, R.; Maji, S. Multiresolution Tree Networks for 3D Point Cloud Processing. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 14–18 September 2018; pp. 103–118. [Google Scholar]
- Lin, C.-H.; Kong, C.; Lucey, S. Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Pred→GT/GT→Pred |
|---|---|
| L-GAN | 5.388/2.679 |
| PCN | 4.276/2.724 |
| PF-Net | 2.469/2.168 |
| PP-Net | 2.455/2.166 |
| Missing Ratio | |||
|---|---|---|---|
| Airplane | 0.973/0.951 | 0.962/0.968 | 0.996/0.989 |
| Guitar | 0.459/0.477 | 0.452/0.486 | 0.473/0.495 |
| Category | L-GAN [37] | PCN [39] | PF-Net [36] | PP-Net |
|---|---|---|---|---|
| Airplane | 3.342/1.205 | 4.936/1.278 | 1.121/1.076 | 1.091/1.072 |
| Bag | 5.642/5.478 | 3.124/4.484 | 3.957/3.867 | 4.414/3.466 |
| Cap | 8.935/4.628 | 7.159/4.365 | 5.295/4.812 | 6.898/4.237 |
| Car | 4.653/2.634 | 2.673/2.245 | 2.495/1.840 | 2.238/1.812 |
| Chair | 7.246/2.372 | 3.835/2.317 | 2.093/1.955 | 2.232/2.046 |
| Guitar | 0.895/0.565 | 1.395/0.665 | 0.473/0.458 | 0.484/0.551 |
| Lamp | 8.534/3.715 | 10.37/7.256 | 5.237/3.611 | 4.222/3.799 |
| Laptop | 7.325/1.538 | 3.105/1.346 | 1.242/1.067 | 1.134/1.063 |
| Motorbike | 4.824/2.172 | 4.975/1.984 | 2.253/1.898 | 1.897/1.865 |
| Mug | 6.274/4.825 | 3.574/3.620 | 3.067/3.175 | 3.078/3.763 |
| Pistol | 4.075/1.538 | 4.739/1.479 | 1.268/1.067 | 1.046/1.051 |
| Skateboard | 5.736/1.586 | 3.069/1.784 | 1.131/1.335 | 1.043/1.232 |
| Table | 2.567/2.578 | 2.638/2.589 | 2.376/2.025 | 2.073/2.211 |
| Mean | 5.388/2.679 | 4.276/2.724 | 2.469/2.168 | 2.455/2.166 |
| Method | Boundary | Projection |
|---|---|---|
| Pred→GT/GT→Pred errors | 2.014/1.755 | 2.347/2.228 |
| Method | Grid Point | Projection |
|---|---|---|
| Pred→GT/GT→Pred errors | 2.014/1.755 | 1.974/1.804 |
| Method | Joint Loss | CD Loss |
|---|---|---|
| Pred→GT error/GT→Pred error | 2.014/1.755 | 2.296/1.763 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, W.; Xie, Z.; Xu, Y.; Zeng, Z.; Wan, J. Point Projection Network: A Multi-View-Based Point Completion Network with Encoder-Decoder Architecture. Remote Sens. 2021, 13, 4917. https://doi.org/10.3390/rs13234917
Wu W, Xie Z, Xu Y, Zeng Z, Wan J. Point Projection Network: A Multi-View-Based Point Completion Network with Encoder-Decoder Architecture. Remote Sensing. 2021; 13(23):4917. https://doi.org/10.3390/rs13234917
Chicago/Turabian StyleWu, Weichao, Zhong Xie, Yongyang Xu, Ziyin Zeng, and Jie Wan. 2021. "Point Projection Network: A Multi-View-Based Point Completion Network with Encoder-Decoder Architecture" Remote Sensing 13, no. 23: 4917. https://doi.org/10.3390/rs13234917
APA StyleWu, W., Xie, Z., Xu, Y., Zeng, Z., & Wan, J. (2021). Point Projection Network: A Multi-View-Based Point Completion Network with Encoder-Decoder Architecture. Remote Sensing, 13(23), 4917. https://doi.org/10.3390/rs13234917