
Ship Detection via Dilated Rate Search and Attention-Guided Feature Representation



Abstract
:
1. Introduction
- A novel framework for ship detection is proposed, which can efficiently detect ships of different scales under the interference of complex environments such as clouds, sea clutter and mist.
- A multi-branch dilated rate search architecture is presented, which adaptively captures target context information of different scales and different receptive fields.
- An attention-wise feature extraction strategy is adopted, which enhances the representation of feature map by encoding the spatial position information.
2. Previous Related Research
2.1. Dilated Rate Strategy for Object Detection
2.2. Attention-Wise Design in Learning Network
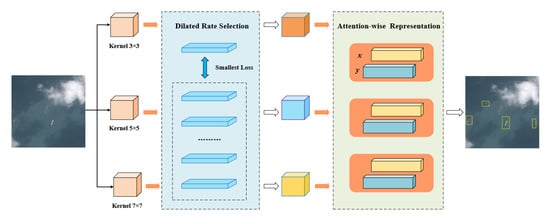
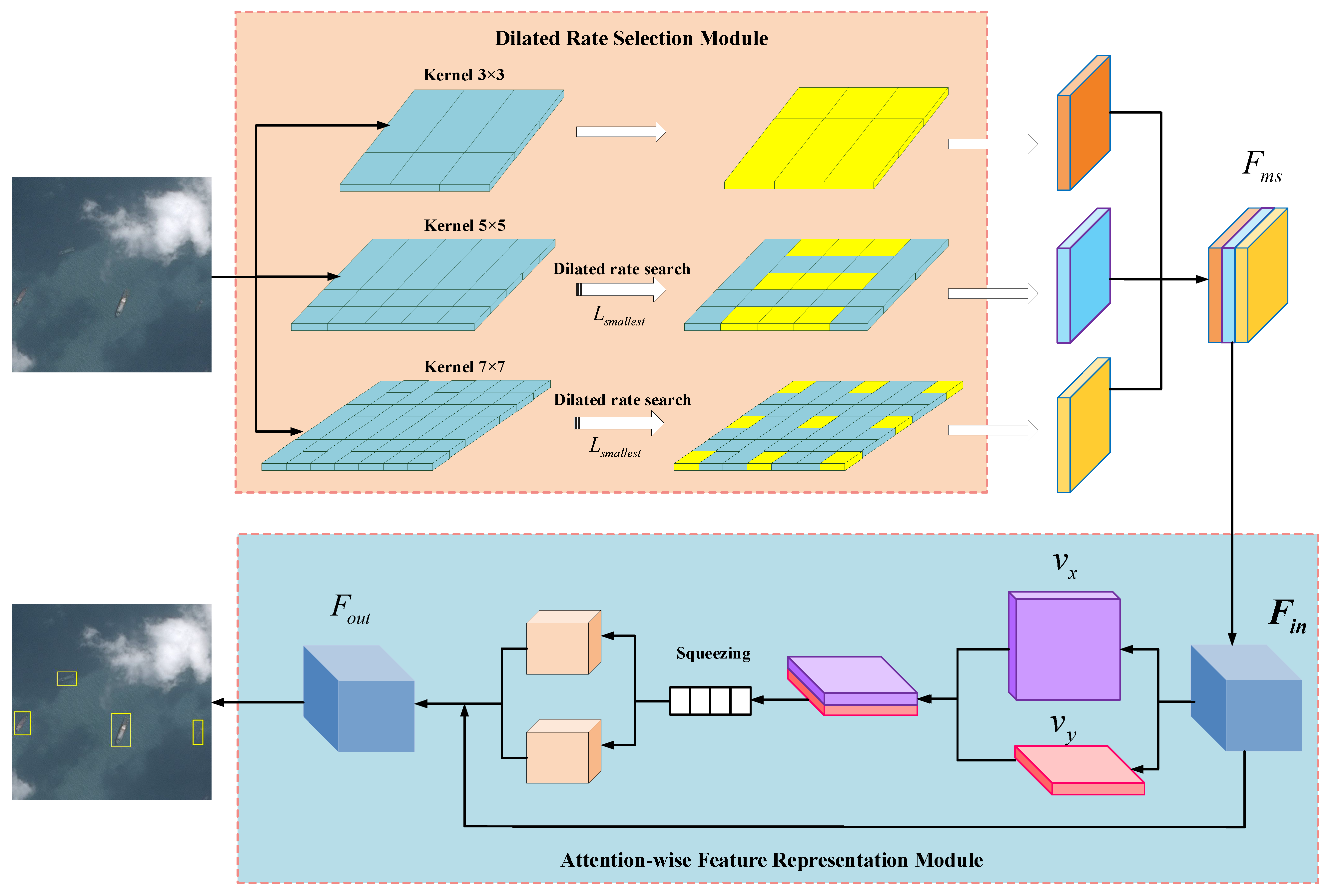
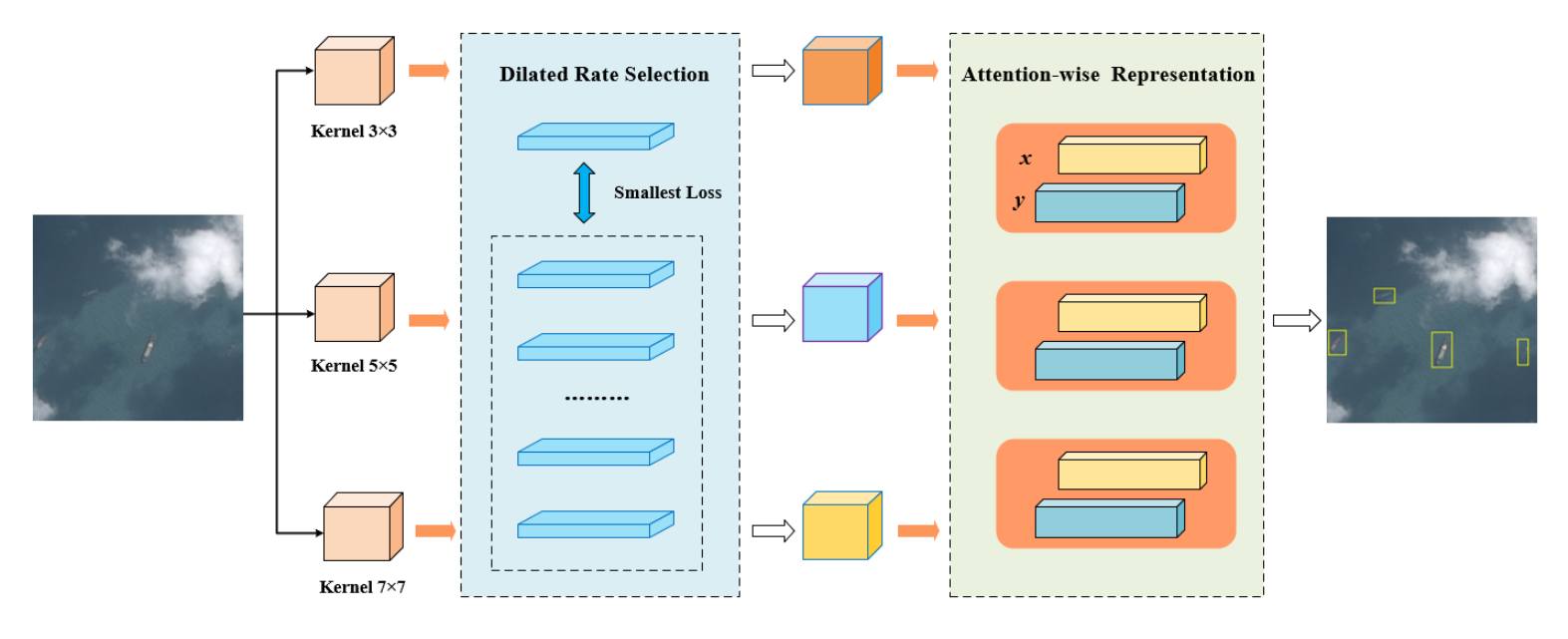
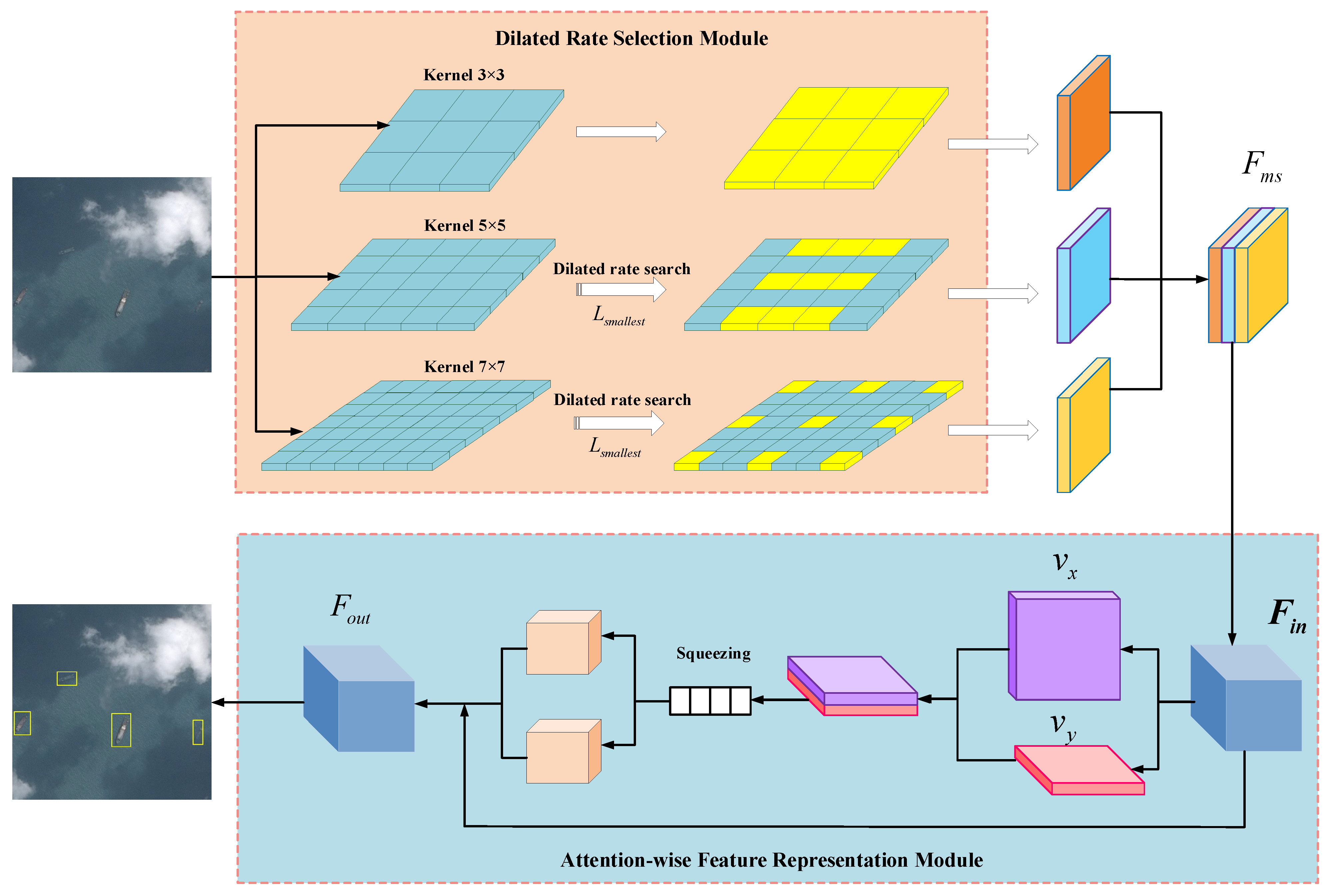
3. Proposed Method
3.1. Method Overview
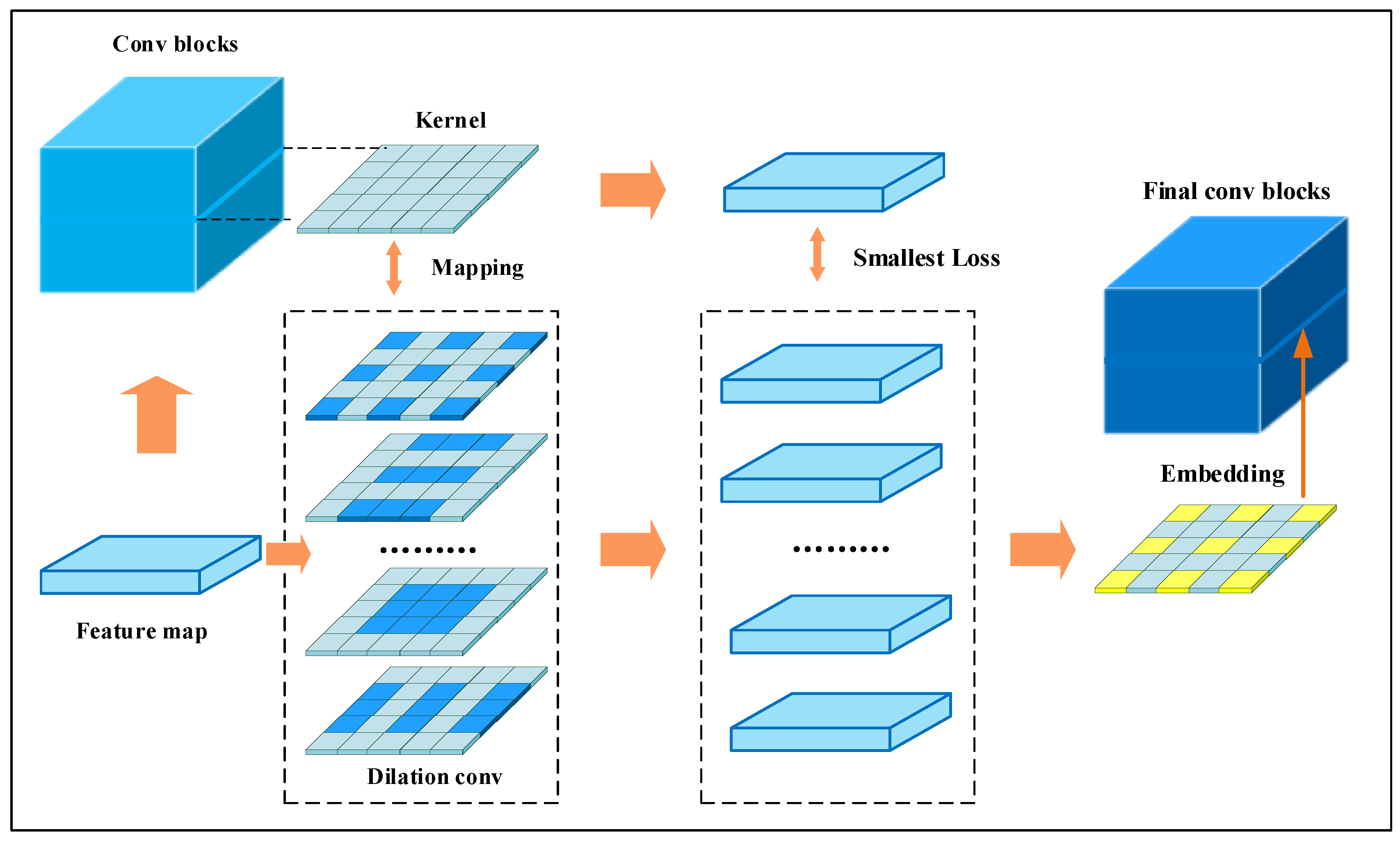
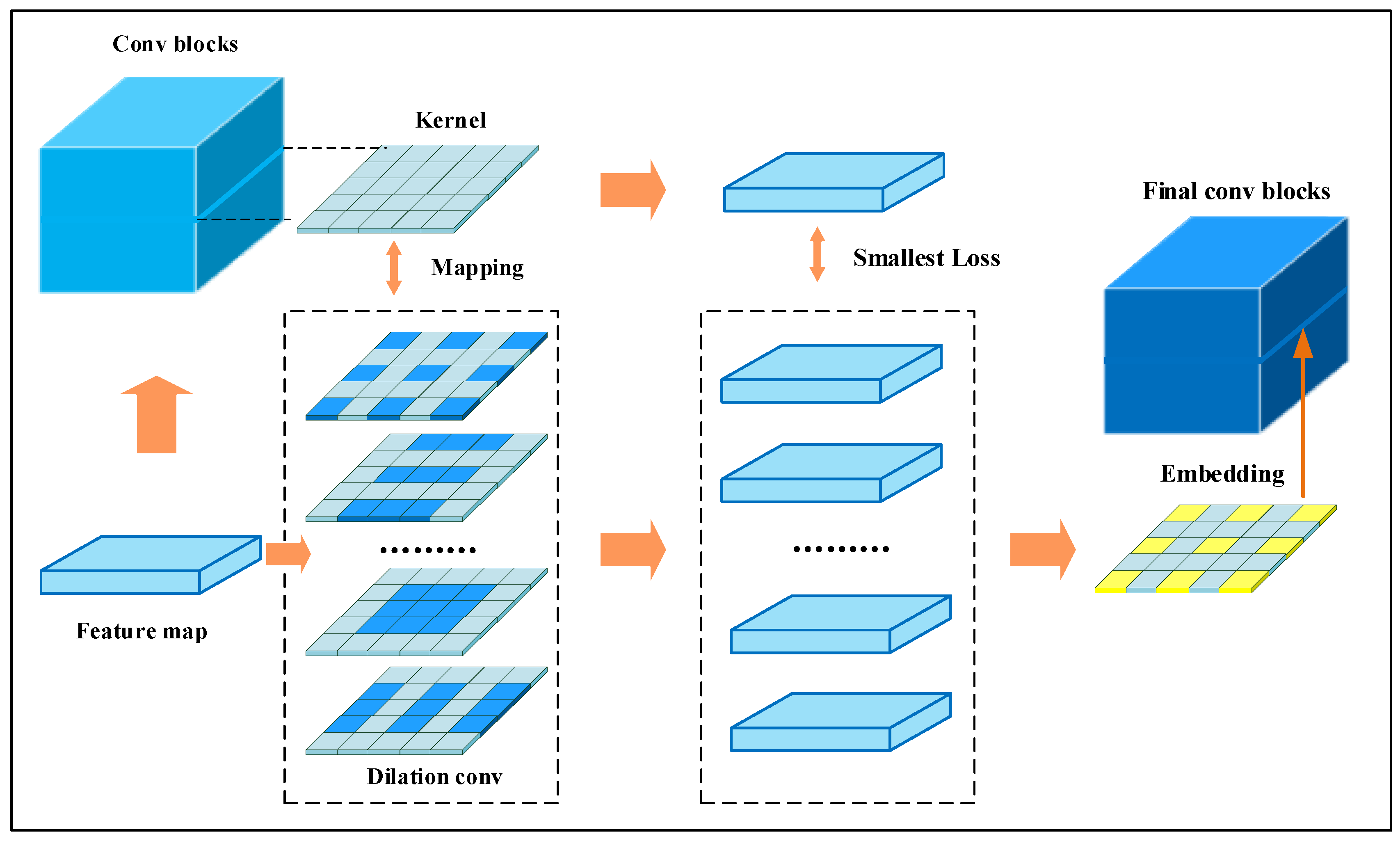
3.2. Dilated Rate Selection for Multi-Scale Extraction
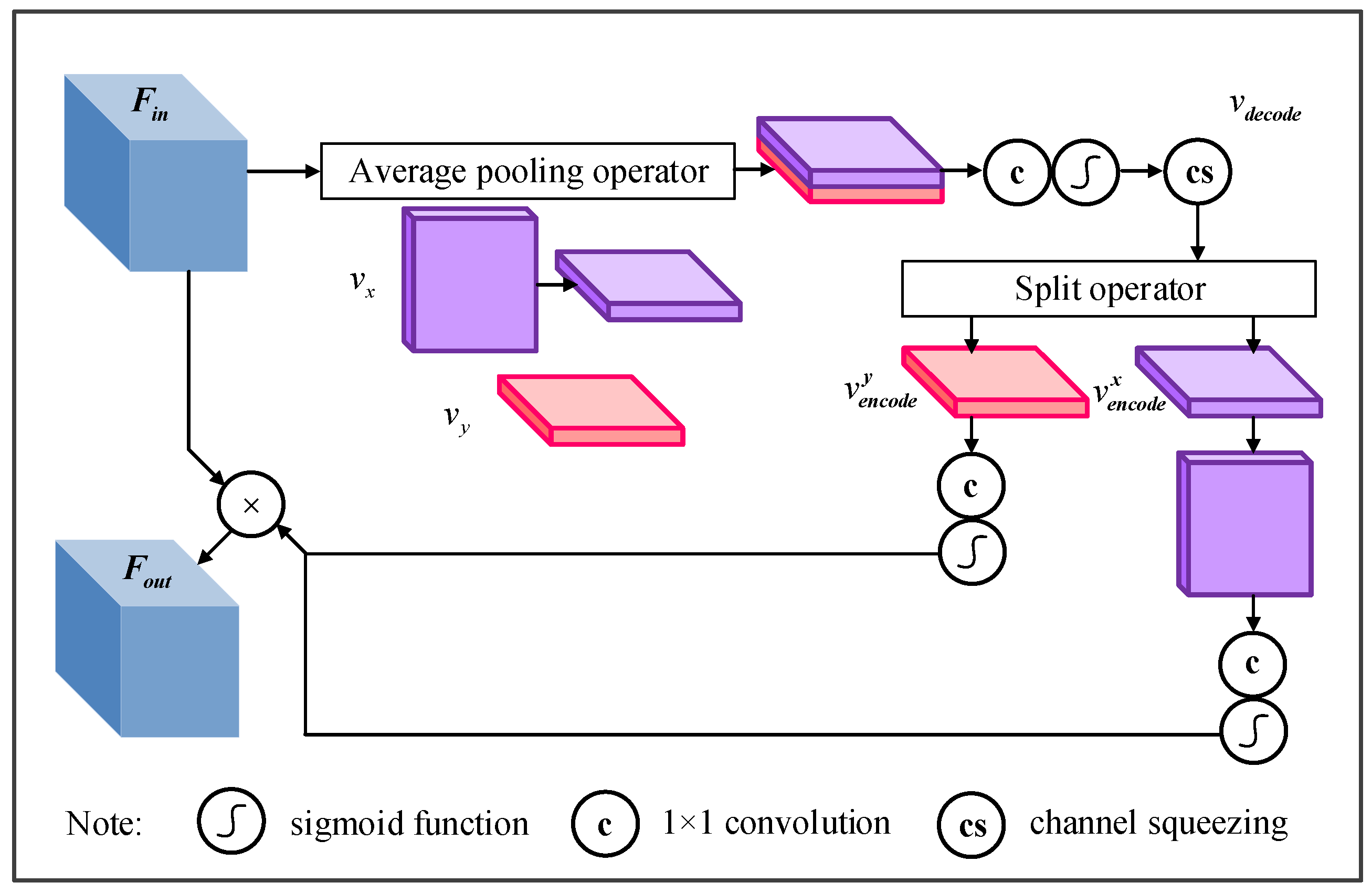
3.3. Attention-Wise Feature Representation
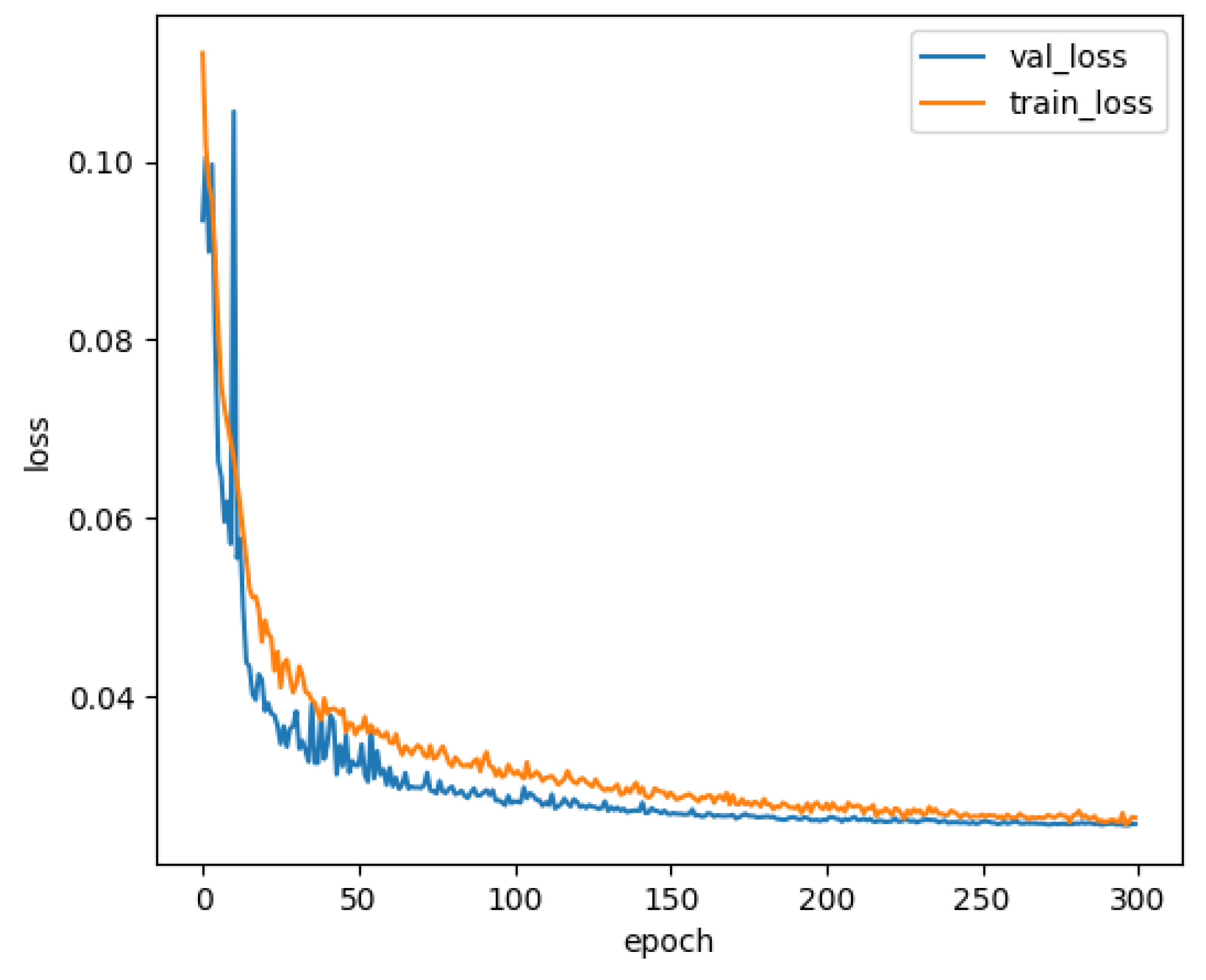
4. Experimental Analysis
4.1. Experimental Setup
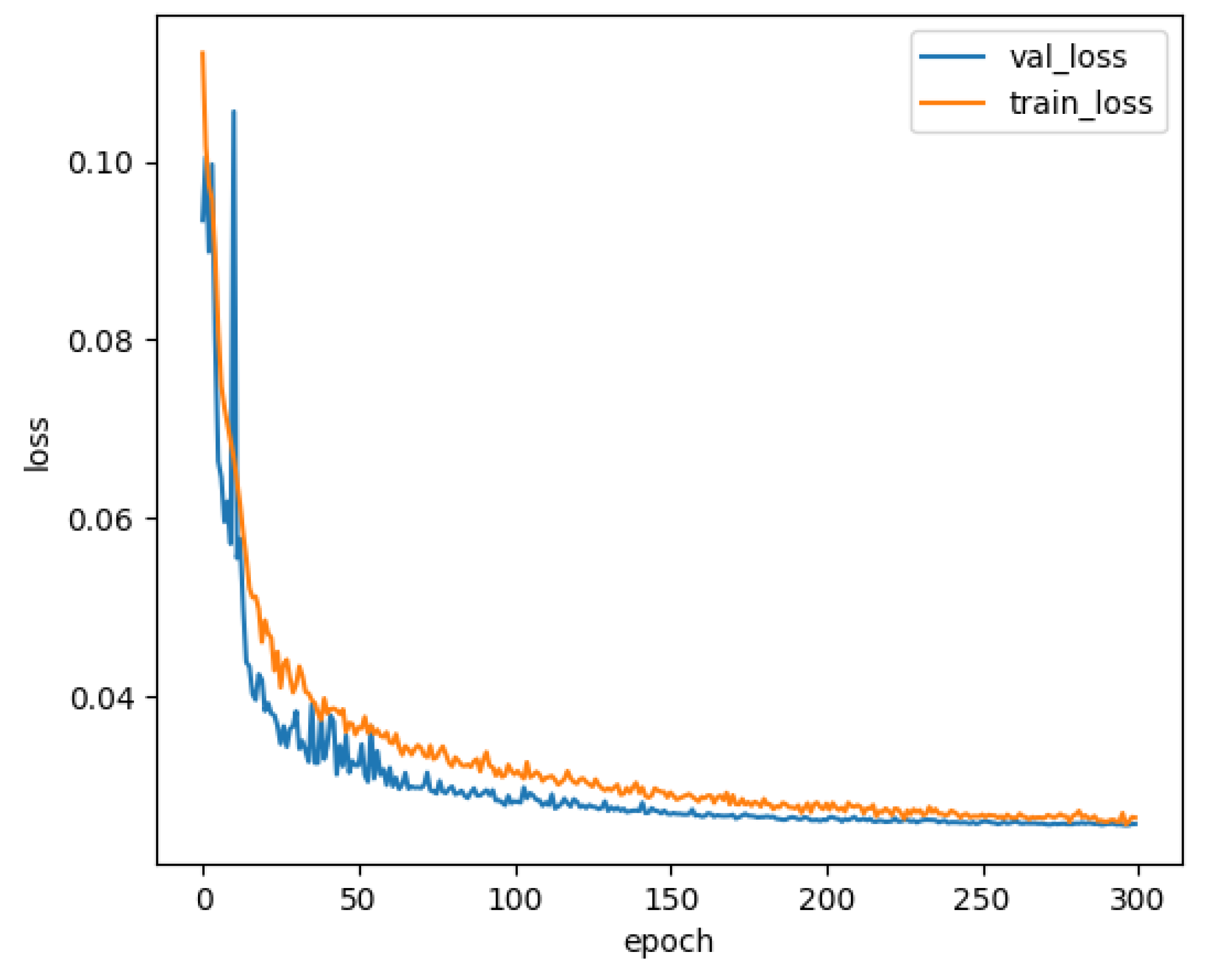
4.2. Implementation Details
4.3. Ablation Analysis
4.4. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kanjir, U.; Greidanus, H.; Oštir, K. Vessel detection and classification from spaceborne optical images: A literature survey. Remote Sens. Environ. 2018, 207, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Zhou, F.; Zheng, Y.; Bai, X. Saliency detection based on foreground appearance and background-prior. Neurocomputing 2018, 301, 46–61. [Google Scholar] [CrossRef]
- Hu, J.; Zhi, X.; Zhang, W.; Ren, L.; Bruzzone, L. Salient Ship Detection via Background Prior and Foreground Constraint in Remote Sensing Images. Remote Sens. 2020, 12, 3370. [Google Scholar] [CrossRef]
- Lin, H.; Shi, Z.; Zou, Z. Fully convolutional network with task partitioning for inshore ship detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1665–1669. [Google Scholar] [CrossRef]
- Hu, J.; Zhi, X.; Shi, T.; Zhang, W.; Cui, Y.; Zhao, S. PAG-YOLO: A Portable Attention-Guided YOLO Network for Small Ship Detection. Remote Sens. 2021, 13, 3059. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Jiang, W.; Liu, M.; Peng, Y.; Wu, L.; Wang, Y. HDCB-Net: A Neural Network with the Hybrid Dilated Convolution for Pixel-Level Crack Detection on Concrete Bridges. IEEE Trans. Ind. Inform. 2020, 17, 5485–5494. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. The role of context in object recognition. Trends Cogn. Sci. 2007, 11, 520–527. [Google Scholar] [CrossRef]
- Jeon, M.; Jeong, Y.S. Compact and accurate scene text detector. Appl. Sci. 2020, 10, 2096. [Google Scholar] [CrossRef] [Green Version]
- Vu, T.; Van Nguyen, C.; Pham, T.X.; Luu, T.M.; Yoo, C.D. Fast and efficient image quality enhancement via desubpixel convolutional neural networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 243–259. [Google Scholar]
- Ji, Y.; Zhang, H.; Zhang, Z.; Liu, M. CNN-based encoder-decoder networks for salient object detection: A comprehensive review and recent advances. Inf. Sci. 2021, 546, 835–857. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, R.; Xu, K.; Wang, J.; Sun, W. R-CNN-based ship detection from high resolution remote sensing imagery. Remote Sens. 2019, 11, 631. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Xu, J.; Wang, W.; Wang, H.; Guo, J. Multi-model ensemble with rich spatial information for object detection. Pattern Recognit. 2020, 99, 107098. [Google Scholar] [CrossRef]
- Qu, J.; Su, C.; Zhang, Z.; Razi, A. Dilated convolution and feature fusion SSD network for small object detection in remote sensing images. IEEE Access 2020, 8, 82832–82843. [Google Scholar] [CrossRef]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Detnet: Design backbone for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 334–350. [Google Scholar]
- Mou, L.; Chen, L.; Cheng, J.; Gu, Z.; Zhao, Y.; Liu, J. Dense dilated network with probability regularized walk for vessel detection. IEEE Trans. Med. Imaging 2019, 39, 1392–1403. [Google Scholar] [CrossRef] [Green Version]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Fu, J.; Zheng, H.; Mei, T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4438–4446. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, R.; Ma, B.; Chang, H.; Gu, X.; Shan, S.; Chen, X. IAUnet: Global context-aware feature learning for person reidentification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4460–4474. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 173–190. [Google Scholar]
- Liu, J.; Li, C.; Liang, F.; Lin, C.; Sun, M.; Yan, J.; Ouyang, W.; Xu, D. Inception convolution with efficient dilation search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 11486–11495. [Google Scholar]
- Guo, Z.; Zhang, X.; Mu, H.; Heng, W.; Liu, Z.; Wei, Y.; Sun, J. Single path one-shot neural architecture search with uniform sampling. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 544–560. [Google Scholar]
- Fang, J.; Sun, Y.; Peng, K.; Zhang, Q.; Li, Y.; Liu, W.; Wang, X. Fast neural network adaptation via parameter remapping and architecture search. arXiv 2020, arXiv:2001.02525. [Google Scholar]
- Liu, Y.; Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G.; Tan, K.C. A survey on evolutionary neural architecture search. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–21. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Nie, T.; Han, X.; He, B.; Li, X.; Liu, H.; Bi, G. Ship detection in panchromatic optical remote sensing images based on visual saliency and multi-dimensional feature description. Remote Sens. 2020, 12, 152. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Mou, L.; Liu, Q.; Wang, Y.; Zhu, X.X. HSF-Net: Multiscale deep feature embedding for ship detection in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7147–7161. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shapes | ResNet50 + Proposed DRS (%) | ResNet101 + Proposed DRS (%) |
|---|---|---|
| Square | 42.00 | 46.53 |
| Vertical | 28.00 | 24.75 |
| Horizontal | 30.00 | 28.72 |
| Methods | Multi-Scale Extraction Module | Attention Module | AP@0.5 (%) | AP@0.75 (%) | AP (%) |
|---|---|---|---|---|---|
| Faster R-CNN | ResNet50 | - | 83.50 | 72.79 | 68.52 |
| Faster R-CNN | ResNet101 | - | 84.44 | 73.87 | 69.38 |
| Faster R-CNN | ResNet50 + proposed DRS | - | 84.71 | 74.32 | 69.94 |
| Faster R-CNN | ResNet101 + proposed DRS | - | 86.08 | 76.98 | 70.72 |
| Faster R-CNN | ResNet50 | Proposed AFR | 85.37 | 75.72 | 69.71 |
| Faster R-CNN | ResNet101 | Proposed AFR | 86.14 | 77.85 | 71.19 |
| Faster R-CNN | ResNet50 + proposed DRS | Proposed AFR | 87.23 | 76.43 | 71.56 |
| Faster R-CNN | ResNet101 + proposed DRS | Proposed AFR | 87.65 | 79.81 | 72.68 |
| Methods | Backbone | Input Image Size | AP(%) | FAR(%) |
|---|---|---|---|---|
| SDVS | - | 768 × 768 | 62.67 | 12.39 |
| Faster R-CNN | ResNet50 | 1000 × 600 | 68.52 | 8.12 |
| Faster R-CNN | ResNet101 | 1000 × 600 | 69.38 | 7.84 |
| YOLOv4 | CSPDarknet53 | 608 × 608 | 69.64 | 6.69 |
| HSF-Net | VGG-16 | 500 × 500 | 71.37 | 5.84 |
| Proposed | ResNet101 + proposed DRS | 1000 × 600 | 72.68 | 5.65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, J.; Zhi, X.; Shi, T.; Yu, L.; Zhang, W. Ship Detection via Dilated Rate Search and Attention-Guided Feature Representation. Remote Sens. 2021, 13, 4840. https://doi.org/10.3390/rs13234840
Hu J, Zhi X, Shi T, Yu L, Zhang W. Ship Detection via Dilated Rate Search and Attention-Guided Feature Representation. Remote Sensing. 2021; 13(23):4840. https://doi.org/10.3390/rs13234840
Chicago/Turabian StyleHu, Jianming, Xiyang Zhi, Tianjun Shi, Lijian Yu, and Wei Zhang. 2021. "Ship Detection via Dilated Rate Search and Attention-Guided Feature Representation" Remote Sensing 13, no. 23: 4840. https://doi.org/10.3390/rs13234840
APA StyleHu, J., Zhi, X., Shi, T., Yu, L., & Zhang, W. (2021). Ship Detection via Dilated Rate Search and Attention-Guided Feature Representation. Remote Sensing, 13(23), 4840. https://doi.org/10.3390/rs13234840