
Improved Fusion of Spatial Information into Hyperspectral Classification through the Aggregation of Constrained Segment Trees: Segment Forest



Abstract
:1. Introduction
- The spatial information of the HSI image was used to construct the segment forest, and the spectral information of the HSI image was combined to improve the classification accuracy and calculation efficiency;
- Based on the segment tree method, the merging and filtering of trees are improved. The reason for accuracy improvement is discussed from the perspective of spatial information;
- The existing spatial–spectral methods are comprehensively summarized and validated on three data sets, respectively. Experimental results show that the proposed method is superior to other HSI classification methods. The characteristics and problems of spatial–spectral classification are discussed based on classification results.
2. Materials and Methods
2.1. Materials
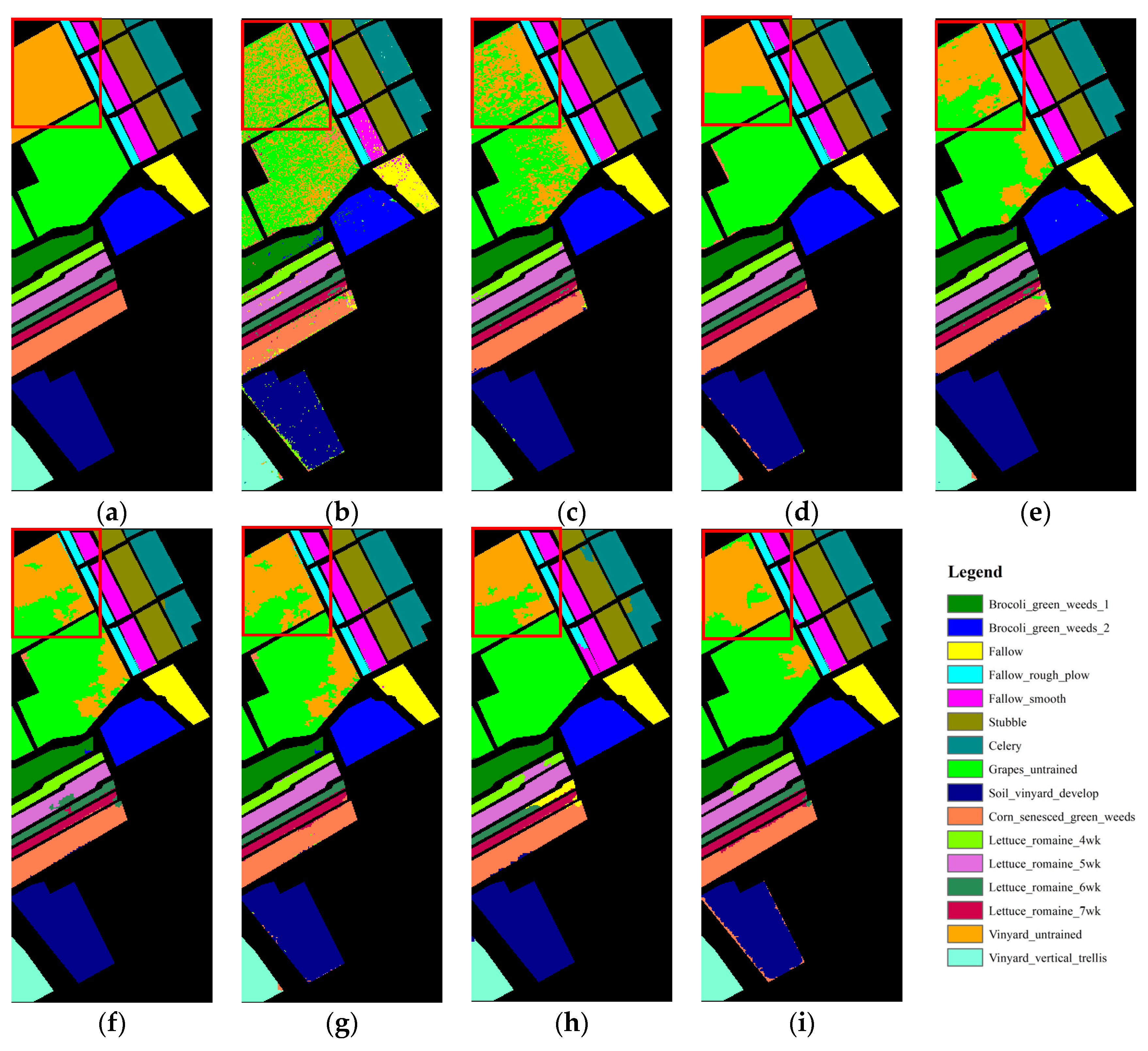
- Salinas. The Salinas hyperspectral data were collected by NASA’s AVIRIS sensor in California’s Salinas Valley, one of the most fertile agricultural regions in the United States. The data consist of 224 bands with 512 × 217 and a spatial resolution of 3.7 m. The corresponding truth value images include 16 categories, including Fallow, Celery and Grapes_untrained, etc. In the training set, 30 points of each type were selected from the labeled data for training, and the test set was the labeled data in the panoramic image.
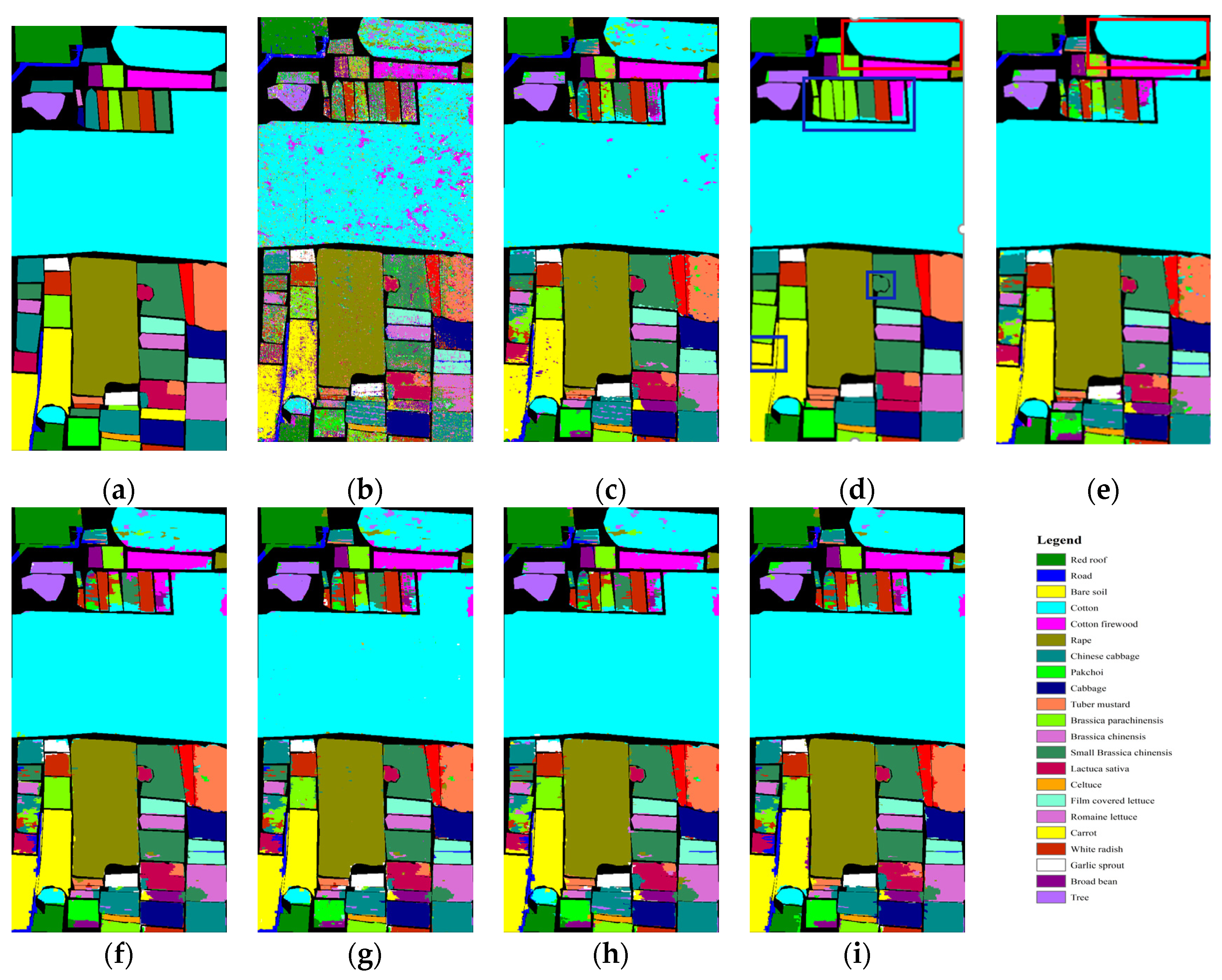
- WHU-Hi-HongHu. The data set was collected on 20 November 2017, in HongHu City, Hubei Province, using a 17 mm focal headwall nanoscale super-resolution imaging sensor on the DJI Matrix 600 Pro UAV platform. The image size is 940 × 475 pixels, with a total of 270 bands, and the spatial resolution is about 0.043 m. The experimental area is a complex agricultural landscape with various crops, including Cabbage, Rape, Celtuce, Broad Bean, tree, and 22 types. The training set selects 100 points from each category of labeled data for training and the test set is the labeled data in the panoramic image.
- XiongAn. XiongAn hyperspectral data developed by the Chinese Academy of Sciences, Shanghai Institute of Technical Physics, high particular aviation system full spectrum section of the multimodal imaging spectrometer, the main gathering area, male Ann, for China’s Hebei province under the jurisdiction of the national district, located in the hinterland of Beijing, Tianjin, and Baoding. There are 256 bands of data, the image size is 3750 × 1580, and the spatial resolution is 0.5 m. The true value of the corresponding image includes Willow, Rice, White wax, rice stubble, Bare area, Pear, Architecture, and a total of 20 kinds of feature classes. Labels are mainly composed of the land for agriculture and forestry. The training set selects 100 points from each category of labeled data for training, and the test set is the labeled data in the panoramic image.
2.2. Methods
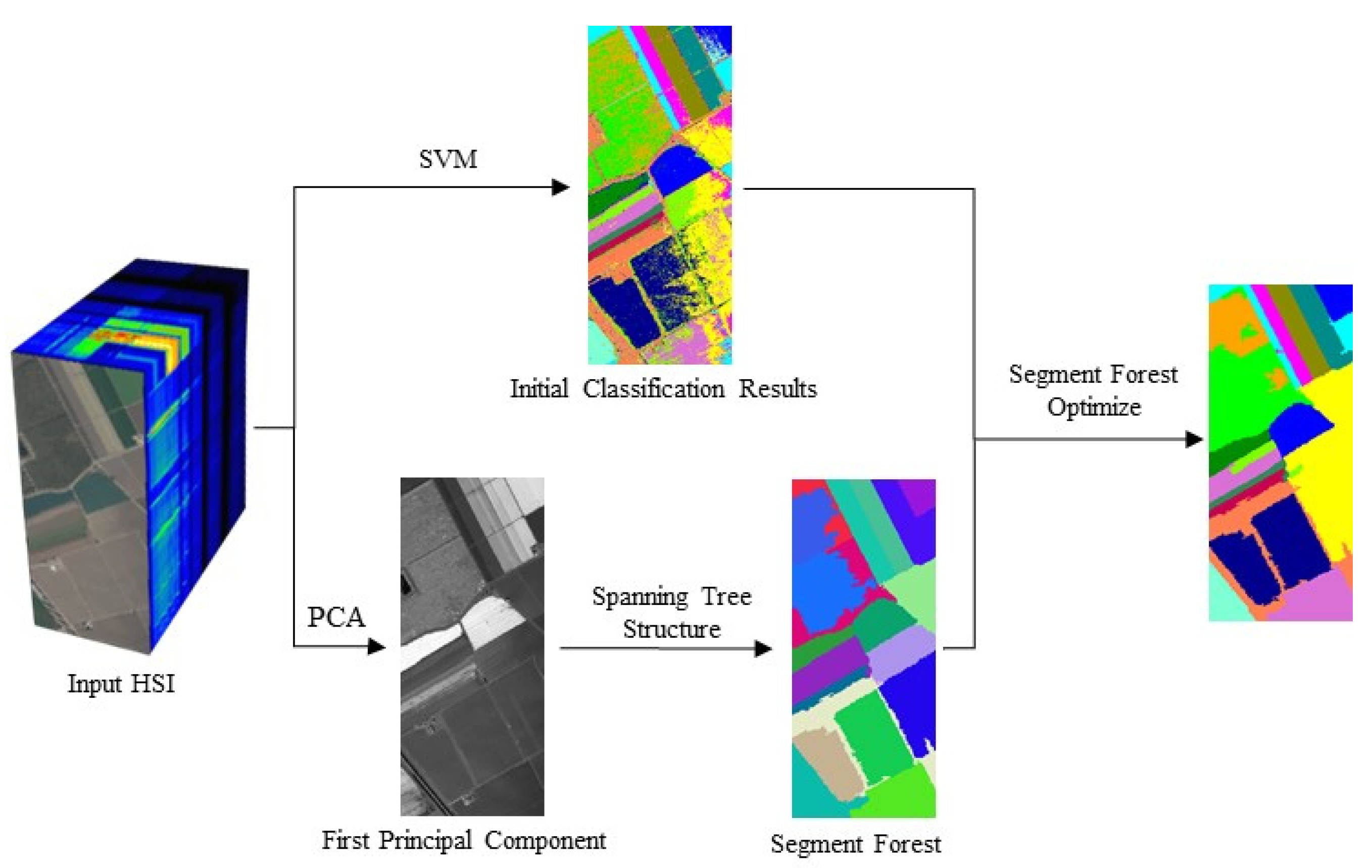
- Obtain the initial classification results. Part of the labeled data was extracted as training data and input into SVM to obtain the probability value of initial classification.
- Obtain the first principal component of the original hyperspectral image. In order to improve the efficiency of the algorithm, principal component analysis (PCA) was used to project the original image hyperspectral data onto a new orthogonal space and extract the first main component.
- According to the weights of the edges in the tree structure, the vertices are combined to construct a segment forest. The vertices are combined by calculating the weights of edges in the first principal component of the image. In order to prevent all vertices from merging into a single tree, the subtree is merged if the edge weight is less than a certain value. Finally, to prevent noise from affecting the subsequent result, subtrees with less than a fixed number of vertices in the tree are merged into the tree with the lowest weight.
- Calculate the aggregation probability of vertices in the tree and determine the classification of each vertex. To carry out the filtering inside the independent tree of forest segmentation, not only to calculate the aggregation probability of each vertex, but also to complete the filtering from leaf to root and root to leaf and obtain the final classification result. Figure 2 shows the technical roadmap.
2.2.1. The Initial Classification Results
2.2.2. Constituting the Segment Forest
2.2.3. Segment Forest Optimization Classification
3. Results
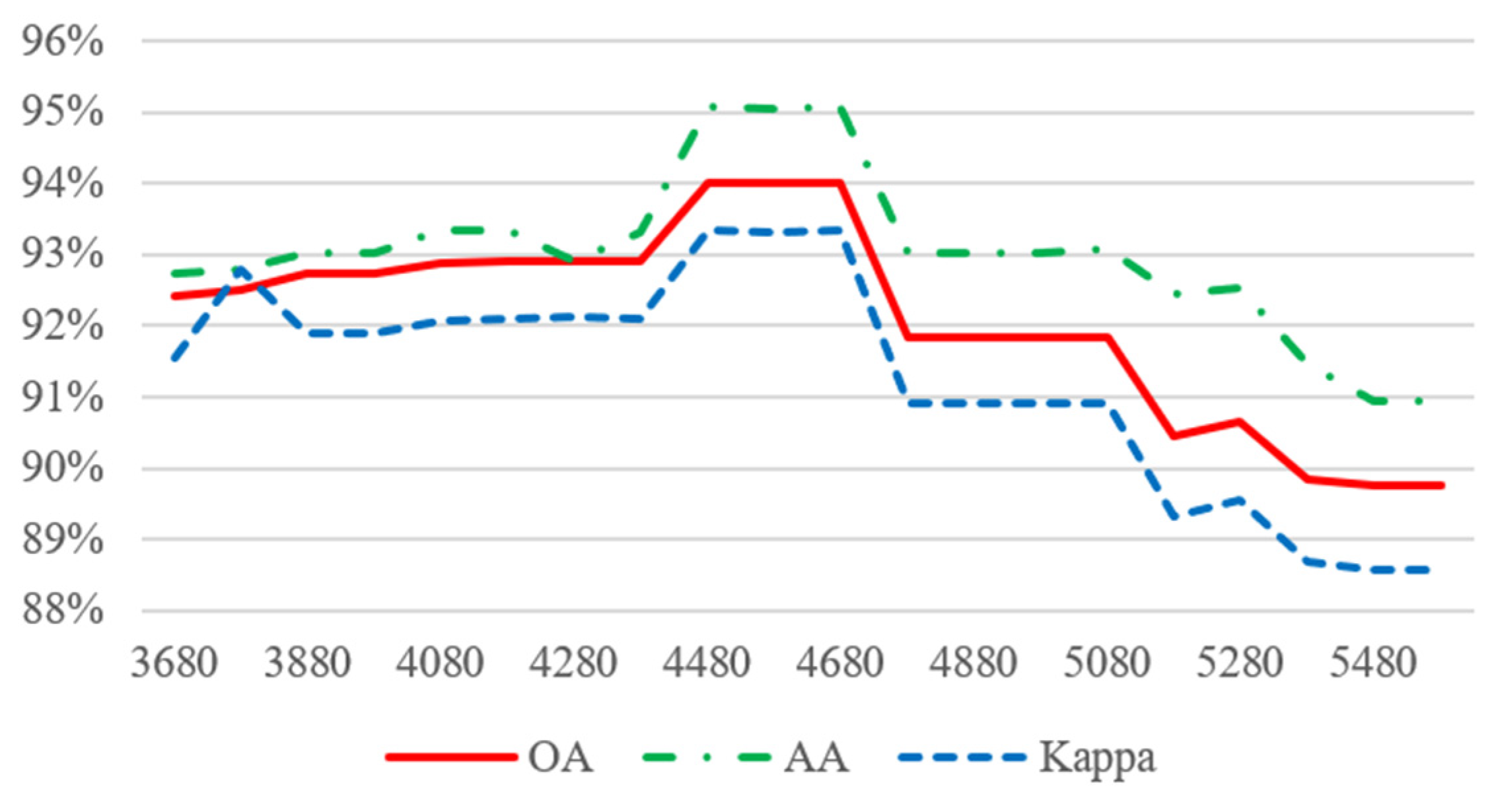
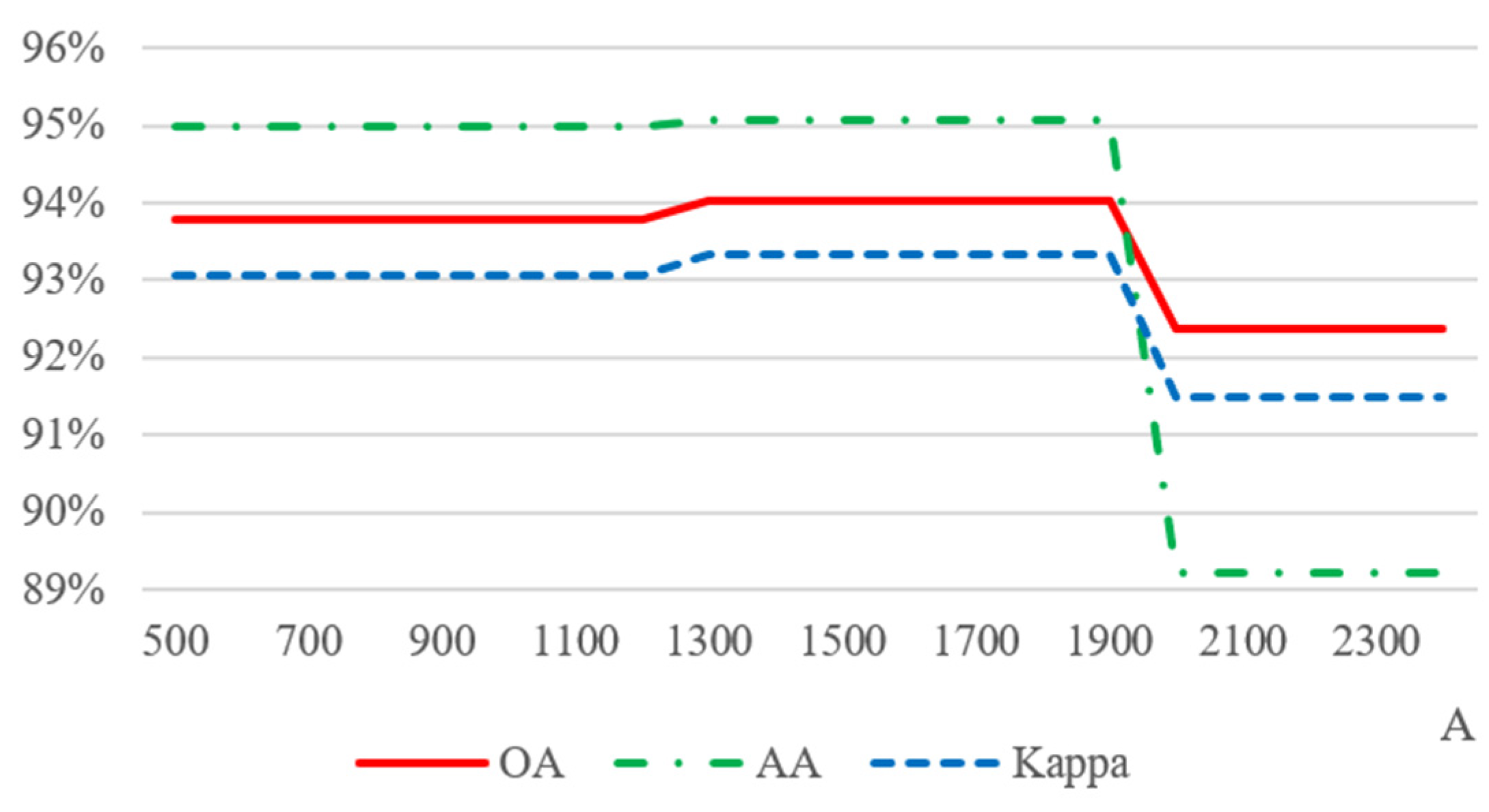
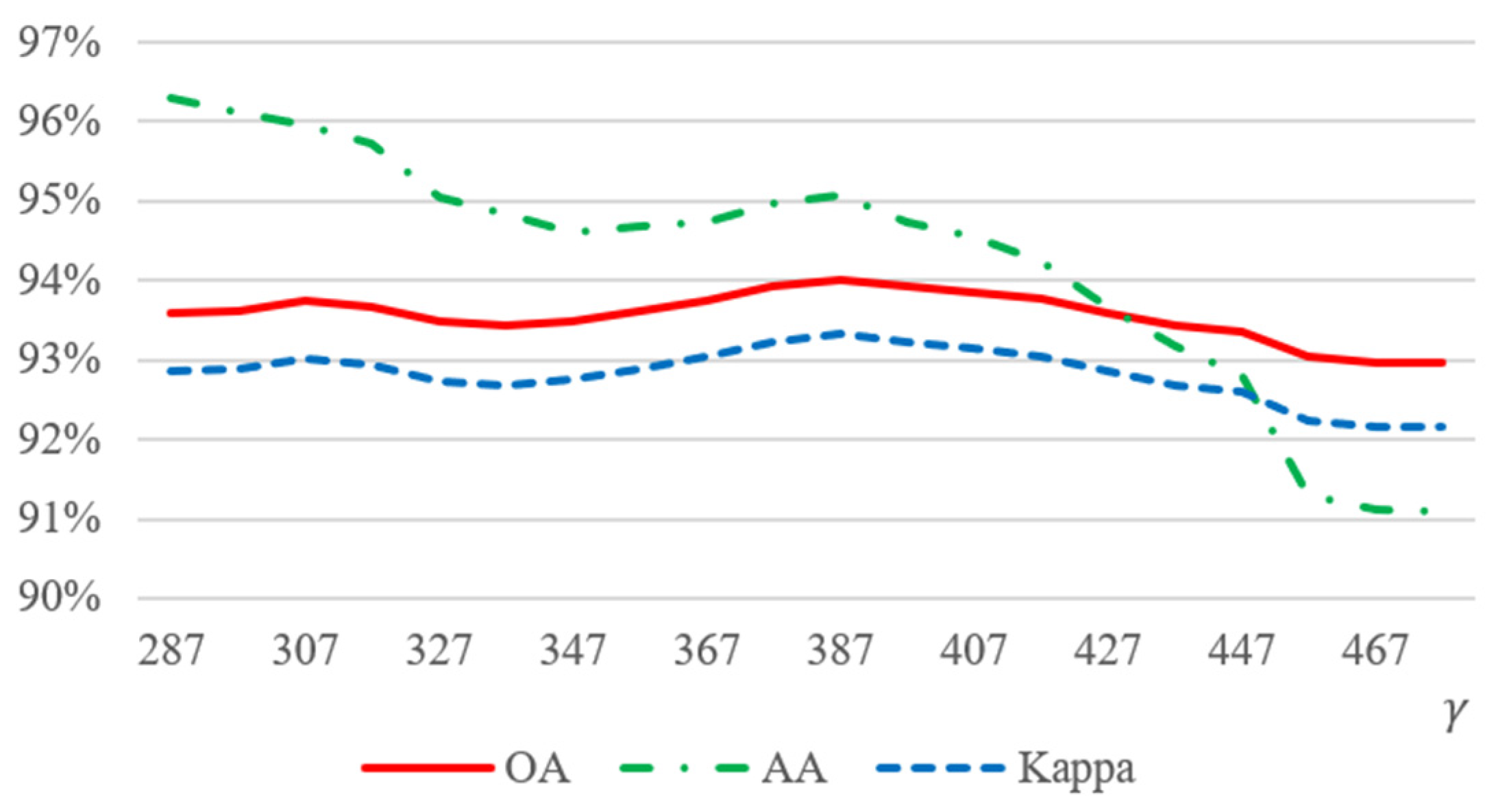
3.1. Parameter Analysis
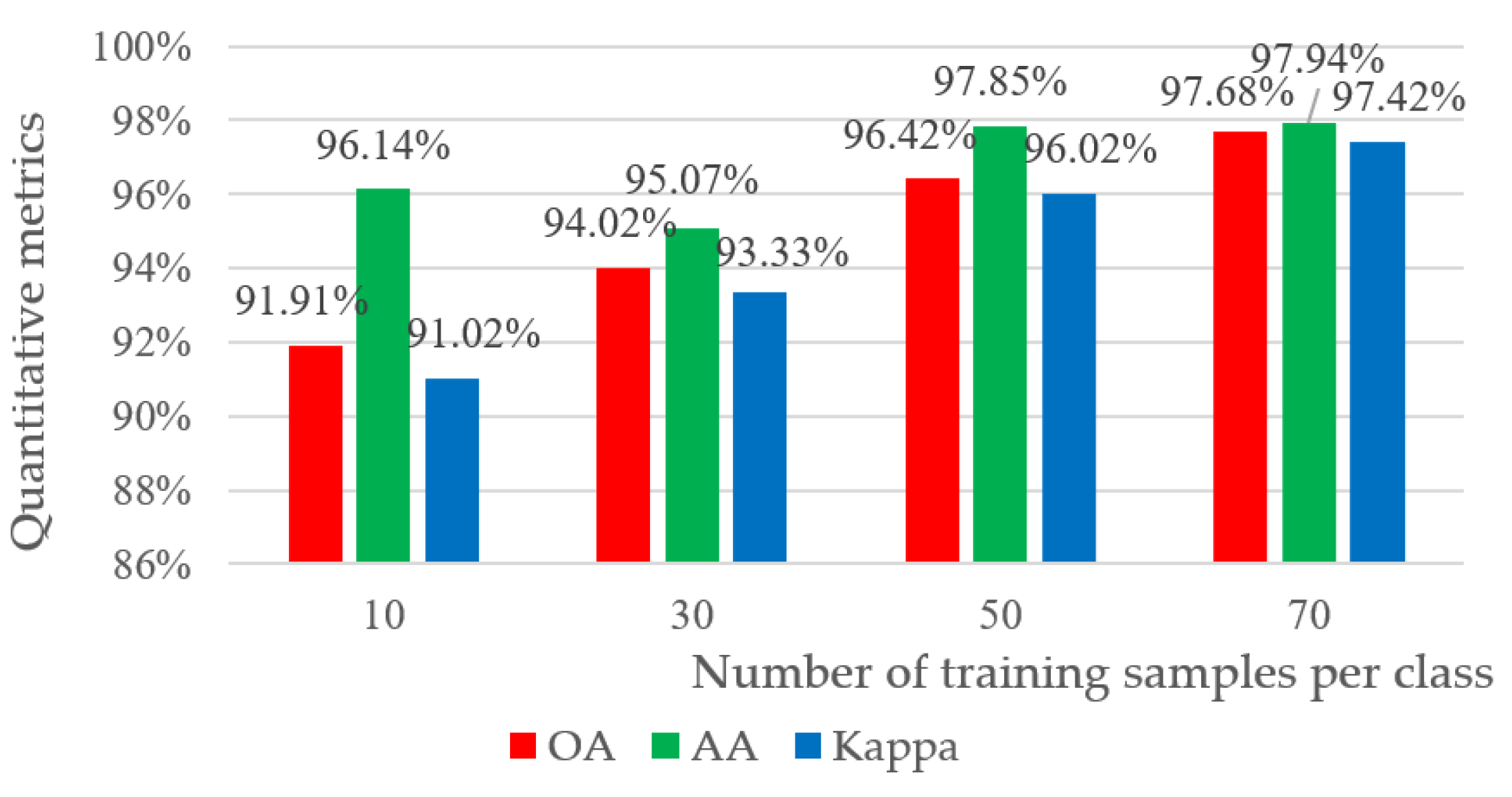
3.2. Influence of Training Data Set
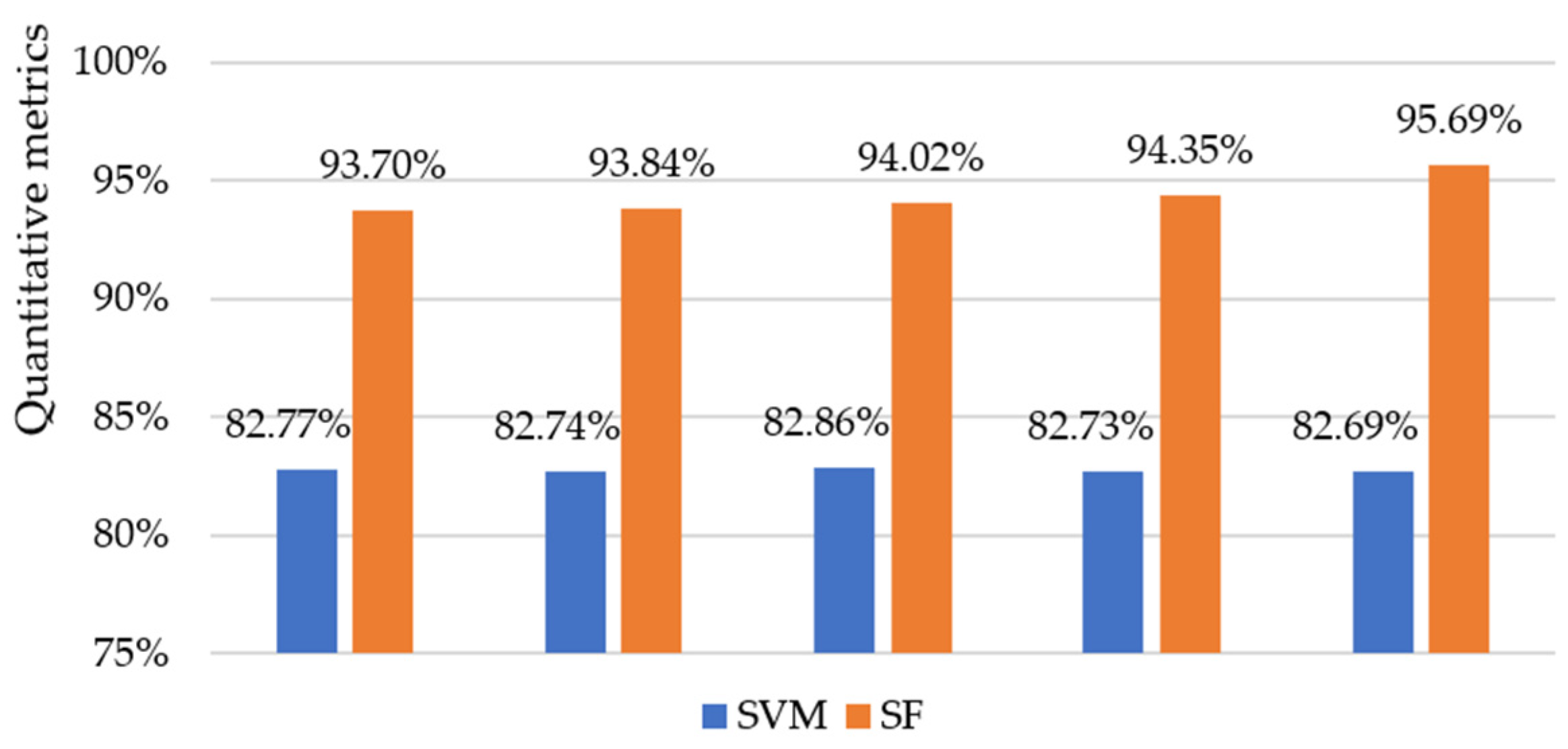
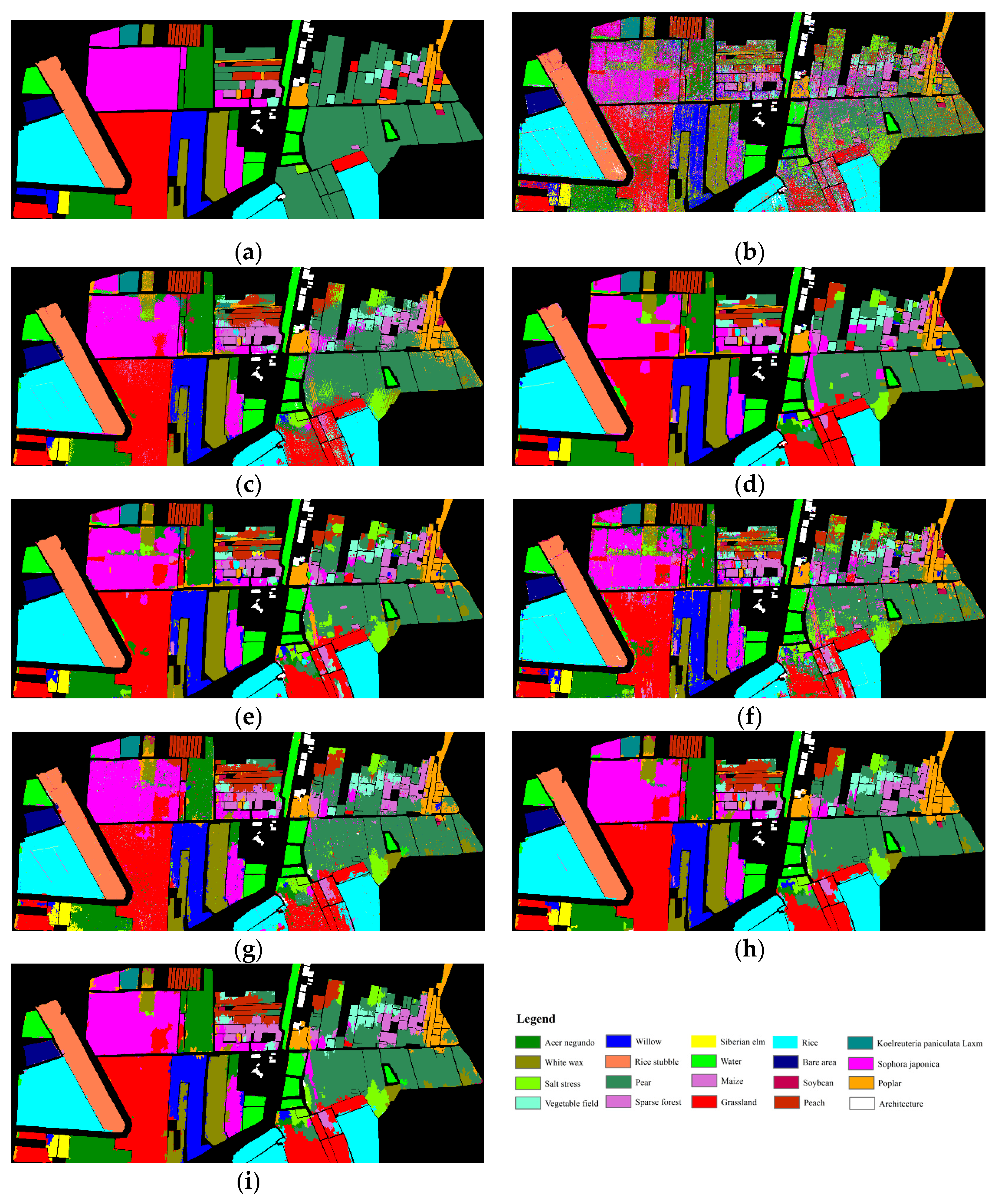
3.3. Comparison of Different Spatial–Spectral Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Poojary, N.; D’Souza, H.; Puttaswamy, M.R.; Kumar, G.H. Automatic target detection in hyperspectral image processing: A review of algorithms. In Proceedings of the International Conference on Fuzzy Systems & Knowledge Discovery, Changsha, China, 13–15 August 2016. [Google Scholar]
- Kalluri, H.R.; Prasad, S.; Bruce, L.M. Decision-level fusion of spectral reflectance and derivative information for robust hyperspectral land cover classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4047–4058. [Google Scholar] [CrossRef]
- Klaus, A.; Sormann, M.; Karner, K. Segment-based stereo matching using belief propagation and a self-adapting dissimilarity measure. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006. [Google Scholar]
- LU, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Tuia, D.; Ratle, F.; Pacifici, F.; Kanevski, M.F.; Emery, W.J. Active learning methods for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2218–2232. [Google Scholar] [CrossRef]
- Böhning, D. Multinomial logistic regression algorithm. Ann. Inst. Statal Math. 1992, 44, 197–200. [Google Scholar] [CrossRef]
- Ratle, F.; Camps-Valls, G.; Weston, J. Semisupervised neural networks for efficient hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2271–2282. [Google Scholar] [CrossRef]
- Yi, C.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification via kernel sparse representation. IEEE Trans. Geosci. Remote Sens. 2013, 51, 217–231. [Google Scholar]
- Gittins, R. Canonical Analysis: A Review with Applications in Ecology; Springer: Berlin/Heidelberg, Germany, 1985. [Google Scholar]
- Du, Q.; Fowler, J.E. Hyperspectral image compression using JPEG2000 and principal component analysis. IEEE Geosci. Remote Sens. Lett. 2007, 4, 201–205. [Google Scholar] [CrossRef]
- Li, C.H.; Kuo, B.C.; Lin, C.T. LDA-Based Clustering Algorithm and Its Application to an Unsupervised Feature Extraction. IEEE Trans. Fuzzy Syst. 2011, 19, 152–163. [Google Scholar] [CrossRef]
- Jia, X.; Kuo, B.C.; Crawford, M.M. Feature mining for hyperspectral image classification. Proc. IEEE 2013, 101, 676–697. [Google Scholar] [CrossRef]
- Vandenbroucke, N.; Porebski, A. Multi color channel vs. multi spectral band representations for texture classification. In Pattern Recognition. ICPR International Workshops and Challenges; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Le-fei, Z.; Bo, D.; Liang-pei, Z.; Zeng-mao, W. Based on texture feature and extend morphological profile fusion for hyperspectral image classification. Acta Photonica Sin. 2014, 43, 810002. [Google Scholar]
- Fang, L.; Li, S.; Kang, X.; Benediktsson, J.A. Spectral–spatial hyperspectral image classification via multiscale adaptive sparse representation. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7738–7749. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Su, H.; Du, Q. Local binary patterns and extreme learning machine for hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3681–3693. [Google Scholar] [CrossRef]
- Kang, X.; Li, S.; Benediktsson, J.A. Spectral–spatial hyperspectral image classification with edge-preserving filtering. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2666–2677. [Google Scholar] [CrossRef]
- Li, W.; Prasad, S.; Fowler, J.E. Hyperspectral image classification using gaussian mixture models and markov random fields. IEEE Geosci. Remote Sens. Lett. 2013, 11, 153–157. [Google Scholar] [CrossRef] [Green Version]
- Grady, L. Multilabel random walker image segmentation using prior models. In Proceedings of the Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015. [Google Scholar]
- Patel, H.; Upla, K.P. A shallow network for hyperspectral image classification using an autoencoder with convolutional neural network. In Multimedia Tools and Applications; Springer: Boca Raton, USA, 2021; pp. 1–20. [Google Scholar]
- As, A.; St, A. Deep neural networks-based relevant latent representation learning for hyperspectral image classification. Pattern Recognit. 2021, 121, 108224. [Google Scholar]
- Cao, X.; Zhou, F.; Xu, L.; Meng, D.; Xu, Z.; Paisley, J. Hyperspectral image classification with markov random fields and a convolutional neural network. IEEE Trans. Image Process. 2018, 27, 2354–2367. [Google Scholar] [CrossRef] [Green Version]
- Yao, X.; Li, G.; Xia, J.; Jin, B.; Zhu, D. Enabling the big earth observation data via cloud computing and dggs: Opportunities and challenges. Remote Sens. 2019, 12, 62. [Google Scholar] [CrossRef] [Green Version]
- Shuai, Y.; Xyab, C.; Dzab, C.; Dla, B.; Lin, Z.; Gya, B.; Bgab, C.; Jyab, C.; Wyab, C. Large-scale crop mapping from multi-source optical satellite imageries using machine learning with discrete grids. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102485. [Google Scholar]
- Cheriton, D.; Tarjan, R.E. Finding minimum spanning trees. Siam J. Comput. 1976, 5, 724–742. [Google Scholar] [CrossRef]
- Li, L.; Wang, C.; Chen, J.; Ma, J. Refinement of hyperspectral image classification with segment-tree filtering. Remote Sens. 2017, 9, 69. [Google Scholar] [CrossRef] [Green Version]
- Yza, D.; Xin, H.A.; Chang, L.A.; Xw, B.; Ji, Z.C.; Lz, A. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF—ScienceDirect. Remote Sens. Environ. 2020, 250, 112012. [Google Scholar]
- Cen, Y.; Zhang, L.; Zhang, X.; Wang, Y.; Qi, W.; Zhang, P. Aerial hyperspectral remote sensing classification dataset of Xiongan New Area(Matiwan Village). J. Remote Sens. 2020, 24, 10–17. [Google Scholar]
- Farrell, M.D., Jr.; Mersereau, R.M. On the impact of PCA dimension reduction for hyperspectral detection of difficult targets. IEEE Geosci. Remote Sens. Lett. 2005, 2, 192–195. [Google Scholar] [CrossRef]
- Cao, P. Automatic Segmentation Algorithm for Magnetic Resonance Imaging Based on Improved MRF Parameter Estimation; Zhejiang University: Zhejiang, China, 2013. [Google Scholar]
- Sun, H.; Wang, W. A new algorithm for unsupervised image segmentation based on D-MRF model and ANOVA. In Proceedings of the IC-NIDC 2009, IEEE International Conference on Network Infrastructure and Digital Content, Beijing, China, 6–8 November 2009. [Google Scholar]
- Eigen. Available online: https://eigen.tuxfamily.org/index.php?title=Main_Page (accessed on 8 November 2021).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bands | Image Size | Spatial Resolution | Feature Classes | Number of Training Samples per Class | |
|---|---|---|---|---|---|
| Salinas | 224 | 512 × 217 | 3.7 m | 16 | 30 |
| WHU-Hi-HongHu [29] | 270 | 940 × 475 | 0.043 m | 22 | 100 |
| XiongAn [30] | 256 | 3750 × 1580 | 0.5 m | 20 | 100 |
| SF Parameter | Salinas | XiongAn | WHU-Hi-HongHu |
|---|---|---|---|
| K | 4680 | 20000 | 2630 |
| A | 1500 | 16000 | 710 |
| γ | 387 | 1490 | 115 |
| Data Set | Evaluation Index | SVM | GF | MRF | RW | MST | MST+ | ST | SF |
|---|---|---|---|---|---|---|---|---|---|
| Salinas | OA | 82.86% | 88.13% | 93.72% | 90.87% | 90.50% | 90.99% | 92.54% | 94.02% |
| AA | 90.72% | 94.29% | 96.67% | 95.31% | 95.03% | 95.66% | 91.26% | 95.07% | |
| Kappa | 80.96% | 86.78% | 92.98% | 89.82% | 89.41% | 89.96% | 91.66% | 93.33% | |
| Time(s) | \ | 3.194 | 0.372 | 7.36 | 0.368 | 0.333 | 0.317 | 0.283 | |
| WHU-Hi-HongHu | OA | 75.87% | 90.82% | 91.44% | 91.48% | 91.01% | 90.95% | 90.86% | 91.76% |
| AA | 72.95% | 89.15% | 87.97% | 86.12% | 87.88% | 87.50% | 87.26% | 87.79% | |
| Kappa | 70.65% | 88.45% | 89.20% | 89.18% | 88.67% | 88.60% | 88.46% | 89.59% | |
| Time(s) | \ | 17.970 | 5.922 | 56.860 | 3.587 | 1.281 | 1.162 | 0.709 | |
| XiongAn | OA | 61.15% | 79.28% | 80.08% | 79.40% | 74.10% | 78.83% | 80.59% | 80.71% |
| AA | 72.62% | 84.56% | 91.21% | 90.45% | 86.85% | 84.12% | 84.87% | 82.46% | |
| Kappa | 57.17% | 76.77% | 77.66% | 76.98% | 71.21% | 76.27% | 78.23% | 78.35% | |
| Time(s) | \ | 207.295 | 261.480 | 842.326 | 445.684 | 42.691 | 59.706 | 36.571 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ling, J.; Li, L.; Wang, H. Improved Fusion of Spatial Information into Hyperspectral Classification through the Aggregation of Constrained Segment Trees: Segment Forest. Remote Sens. 2021, 13, 4816. https://doi.org/10.3390/rs13234816
Ling J, Li L, Wang H. Improved Fusion of Spatial Information into Hyperspectral Classification through the Aggregation of Constrained Segment Trees: Segment Forest. Remote Sensing. 2021; 13(23):4816. https://doi.org/10.3390/rs13234816
Chicago/Turabian StyleLing, Jianmei, Lu Li, and Haiyan Wang. 2021. "Improved Fusion of Spatial Information into Hyperspectral Classification through the Aggregation of Constrained Segment Trees: Segment Forest" Remote Sensing 13, no. 23: 4816. https://doi.org/10.3390/rs13234816
APA StyleLing, J., Li, L., & Wang, H. (2021). Improved Fusion of Spatial Information into Hyperspectral Classification through the Aggregation of Constrained Segment Trees: Segment Forest. Remote Sensing, 13(23), 4816. https://doi.org/10.3390/rs13234816