
Building Function Mapping Using Multisource Geospatial Big Data: A Case Study in Shenzhen, China



Abstract
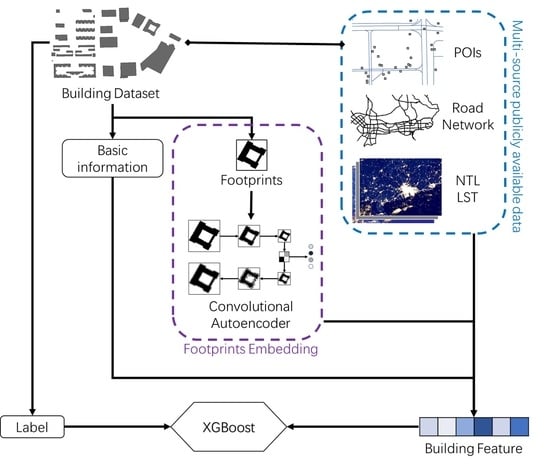
:
1. Introduction
2. Materials and Methods
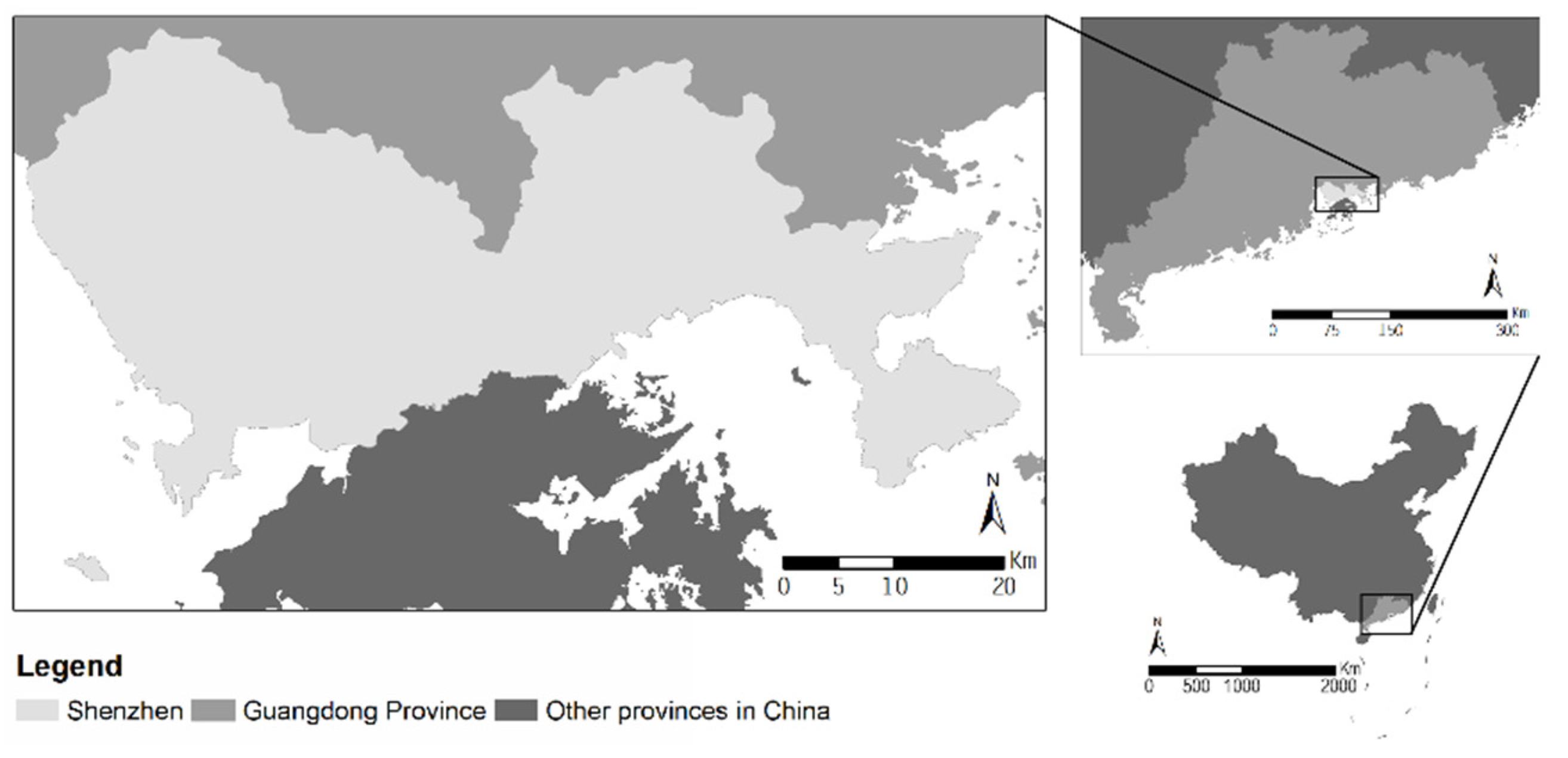
2.1. Study Area
2.2. Data Collection
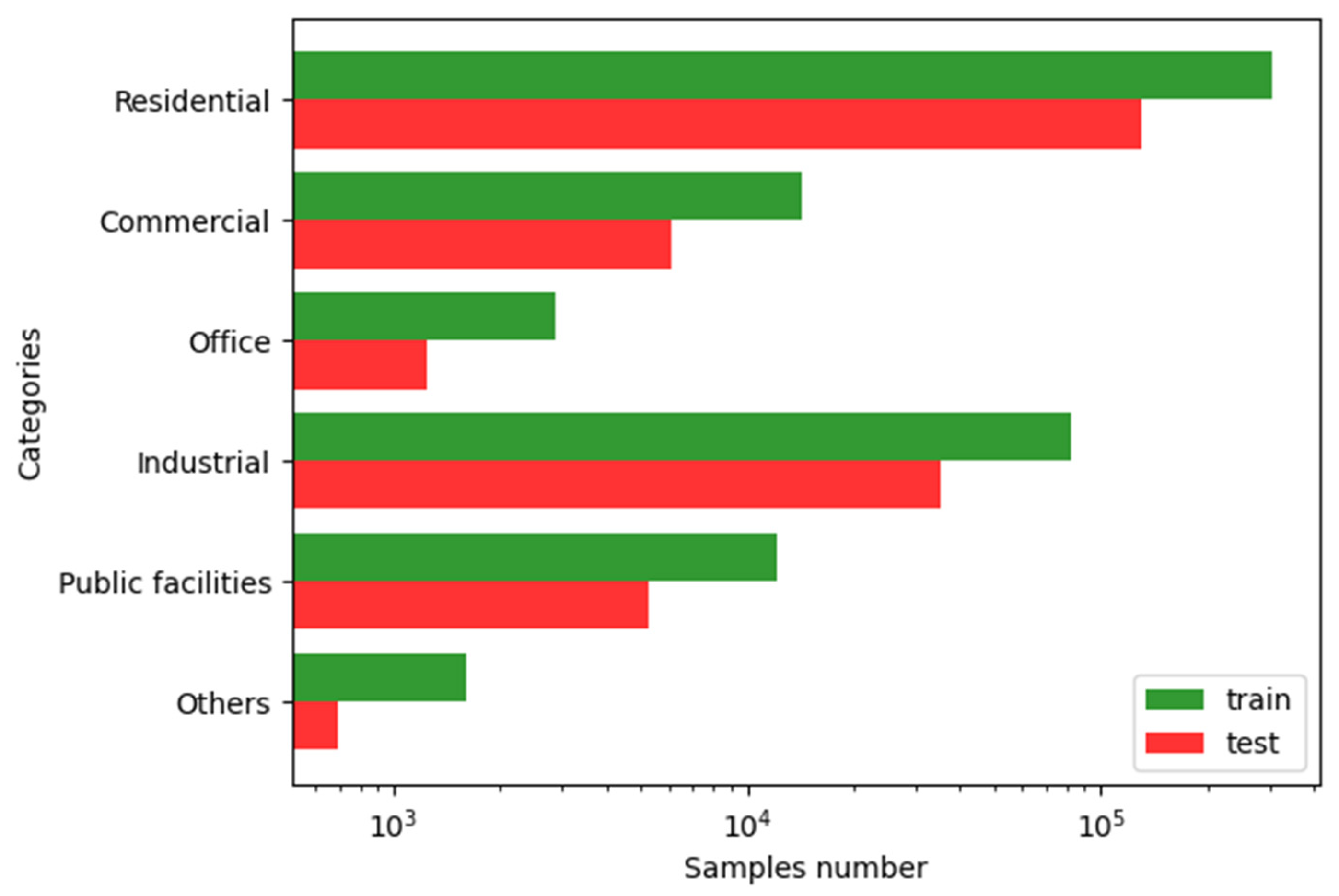
- The building dataset contains 599,457 buildings. A manually labelled building class is provided for each building. The building height, perimeter, area, floor area ratio, and lowest/highest floor number are also recorded. The building footprint geometry is recorded in polygon format in an ArcGIS shapefile.
- The POI dataset includes 991,362 POIs in Shenzhen, China. The dataset was retrieved from Gaode Map (https://lbs.amap.com/api/webservice/guide/, accessed on 19 January 2021), one of the most popular map platforms in China, and the POIs are labelled with 20 primary classifications and 984 secondary classifications.
- The road network dataset, including 109,551 road links, was collected from OpenStreetMap (OSM), a collaborative open-source map project. The roads in the OSM (https://wiki.openstreetmap.org/wiki/Key:highway, accessed on 19 January 2021) dataset are labelled based on 74 categories and reclassified into 13 categories: motorway, primary, secondary, tertiary, trunk, track, ordinary road, residential, cycleway, path, service road, linking road, and unclassified road. The distance from a building to the nearest road of each type is calculated and used as a proxy to represent the ambient road network. The location of a building is generally related to its use, and the distance to various kinds of roads can represent the ambient road network. For instance, residential buildings are usually close to residential roads, and industrial buildings are usually near trunk roads for transportation purposes.
- For the NTL dataset, we use an annual product (Annual VNL V2) based on a cloud-free day–night band (DNB) composite from Visible Infrared Imaging Radiometer Suite (VIIRS). The gridded image aggregating yearly NTL in 2015 is downloaded from the website of Earth Observation Group (https://eogdata.mines.edu/products/vnl/, accessed on 19 January 2021). The spatial resolution of the image is 500 × 500 m2. The pixels where a building is located are directly retrieved as the NTL features for a building.
- The LST images with spatial resolution of 0.05 deg/pixel are from a monthly Moderate Resolution Imaging Spectroradiometer (MODIS) product (MYD11C3v006) which is publicly available on the NASA EarthData site (https://lpdaac.usgs.gov/products/myd11c3v006/, accessed on 19 January 2021). Eight images are used, including the monthly average daytime and nighttime land surface temperatures in January, April, September, and October 2015. Each building is assigned a digital number (DN) based on that of the nearest pixel to the centroid point for a given building.
2.3. Methodology
2.3.1. Building Label
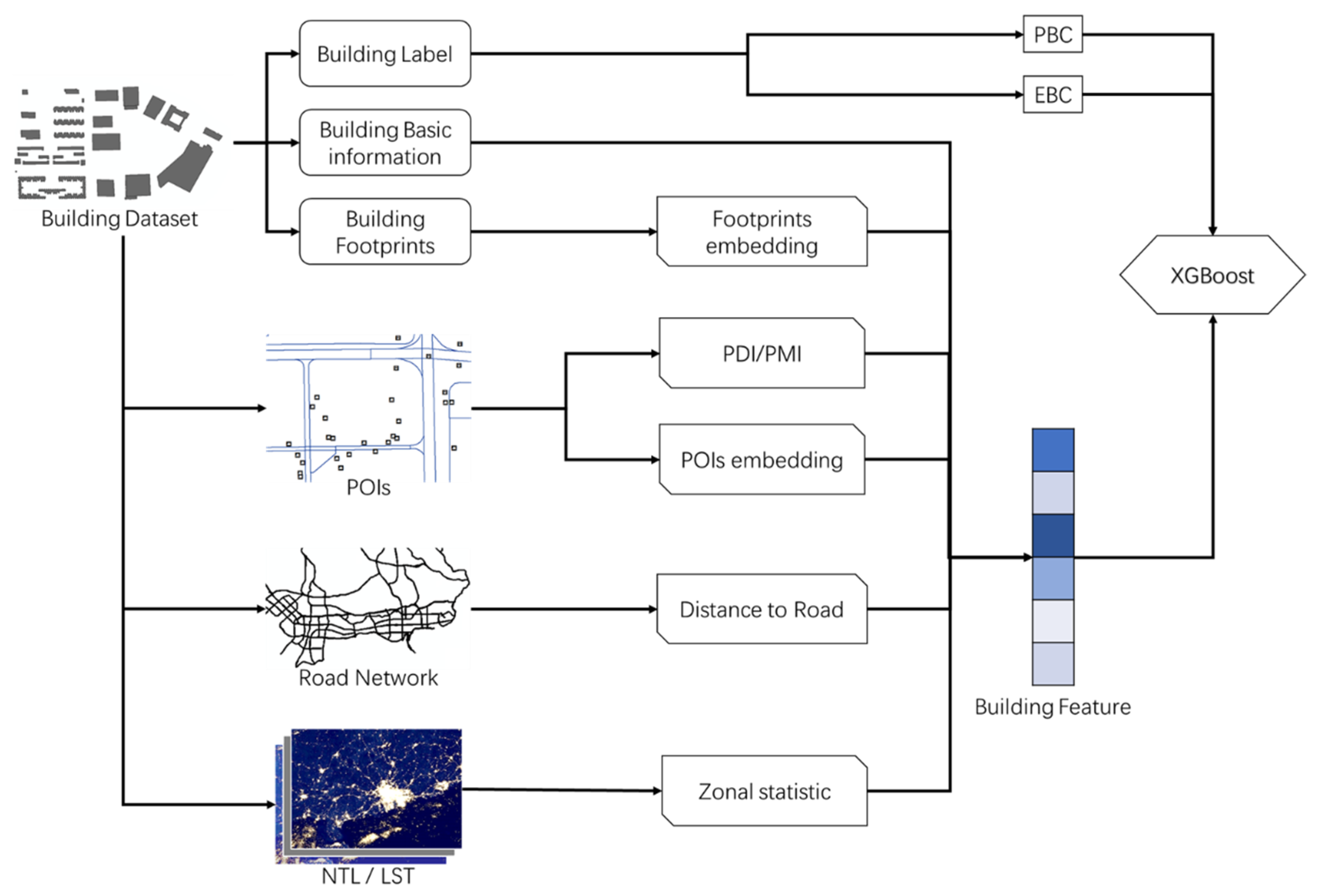
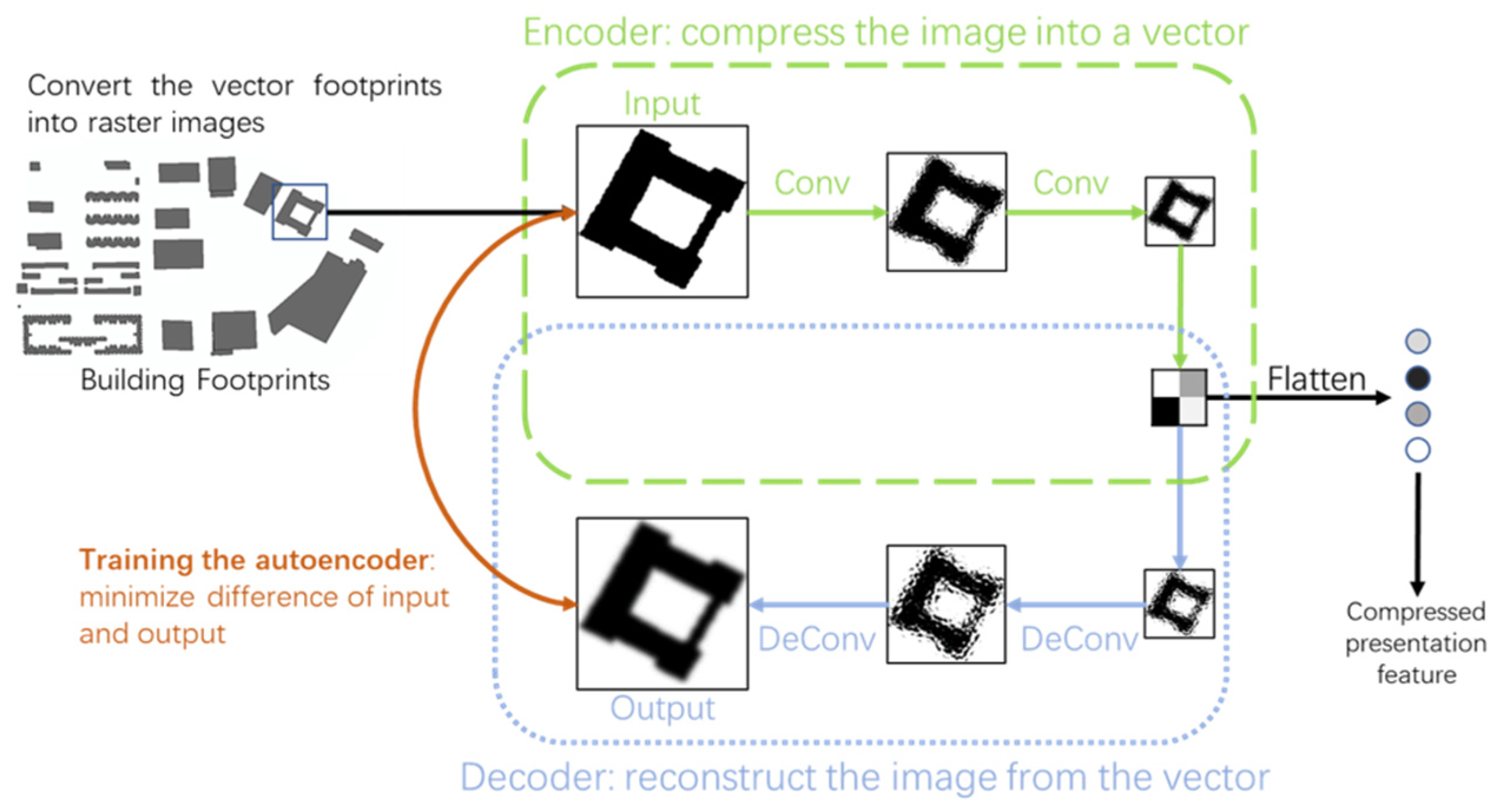
2.3.2. Building Features
2.3.3. Extreme Gradient Boosting (XGBoost)
2.3.4. Accuracy Assessment
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yuan, N.J.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering urban functional zones using latent activity trajectories. IEEE Trans. Knowl. Data Eng. 2014, 27, 712–725. [Google Scholar] [CrossRef]
- Gao, S.; Janowicz, K.; Couclelis, H. Extracting urban functional regions from points of interest and human activities on location-based social networks. Trans. GIS 2017, 21, 446–467. [Google Scholar] [CrossRef]
- Voltersen, M.; Berger, C.; Hese, S.; Schmullius, C. Object-based land cover mapping and comprehensive feature calculation for an automated derivation of urban structure types at block level. Remote Sens. Environ. 2014, 154, 192–201. [Google Scholar] [CrossRef]
- Song, Y.; Long, Y.; Wu, P.; Wang, X. Are all cities with similar urban form or not? Redefining cities with ubiquitous points of interest and evaluating them with indicators at city and block levels in China. Int. J. Geogr. Inf. Sci. 2018, 32, 2447–2476. [Google Scholar] [CrossRef]
- Niu, N.; Liu, X.; Jin, H.; Ye, X.; Liu, Y.; Li, X.; Chen, Y.; Li, S. Integrating multi-source big data to infer building functions. Int. J. Geogr. Inf. Sci. 2017, 31, 1871–1890. [Google Scholar] [CrossRef]
- Hoffmann, E.J.; Wang, Y.; Werner, M.; Kang, J.; Zhu, X.X. Model Fusion for Building Type Classification from Aerial and Street View Images. Remote Sens. 2019, 11, 1259. [Google Scholar] [CrossRef] [Green Version]
- Saito, K.; Spence, R. Mapping urban building stocks for vulnerability assessment–preliminary results. Int. J. Digit. Earth 2011, 4, 117–130. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, X.; Li, X.; Liu, X.; Yao, Y.; Hu, G.; Xu, X.; Pei, F. Delineating urban functional areas with building-level social media data: A dynamic time warping (DTW) distance based k-medoids method. Landsc. Urban Plan. 2017, 160, 48–60. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, W.; Ghadimi, N. Electricity load forecasting by an improved forecast engine for building level consumers. Energy 2017, 139, 18–30. [Google Scholar] [CrossRef]
- Newsham, G.R.; Birt, B.J. Building-level occupancy data to improve ARIMA-based electricity use forecasts. In Proceedings of the 2nd ACM Workshop on Embedded Sensing Systems for Energy-Efficiency in Building, Zurich, Switzerland, 2 November 2010; pp. 13–18. [Google Scholar]
- Xing, H.; Meng, Y. Integrating landscape metrics and socioeconomic features for urban functional region classification. Comput. Environ. Urban Syst. 2018, 72, 134–145. [Google Scholar] [CrossRef]
- Wegener, M. From macro to micro—How much micro is too much? Transp. Rev. 2011, 31, 161–177. [Google Scholar] [CrossRef]
- Zhou, Y.; Lau, B.P.L.; Yuen, C.; Tunçer, B.; Wilhelm, E. Understanding urban human mobility through crowdsensed data. IEEE Commun. Mag. 2018, 56, 52–59. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Meng, Q.; Zhang, J.; Zhang, L.; Jancso, T.; Vatseva, R. An effective Building Neighborhood Green Index model for measuring urban green space. Int. J. Digit. Earth 2016, 9, 387–409. [Google Scholar] [CrossRef]
- International Energy Agency. Directorate of Sustainable Energy Policy. Transition to Sustainable Buildings: Strategies and Opportunities to 2050; Organization for Economic: Paris, France, 2013. [Google Scholar]
- Robinson, C.; Dilkina, B.; Hubbs, J.; Zhang, W.; Guhathakurta, S.; Brown, M.A.; Pendyala, R.M. Machine learning approaches for estimating commercial building energy consumption. Appl. Energy 2017, 208, 889–904. [Google Scholar] [CrossRef]
- Yu, Z.; Fung, B.C.M.; Haghighat, F.; Yoshino, H.; Morofsky, E. A systematic procedure to study the influence of occupant behavior on building energy consumption. Energy Build. 2011, 43, 1409–1417. [Google Scholar] [CrossRef] [Green Version]
- Lloyd, C.T.; Sorichetta, A.; Tatem, A.J. High resolution global gridded data for use in population studies. Sci. Data 2017, 4, 170001. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smith, A.; Bates, P.D.; Wing, O.; Sampson, C.; Quinn, N.; Neal, J. New estimates of flood exposure in developing countries using high-resolution population data. Nat. Commun. 2019, 10, 1814. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ural, S.; Hussain, E.; Shan, J. Building population mapping with aerial imagery and GIS data. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 841–852. [Google Scholar] [CrossRef]
- Yao, Y.; Liu, X.; Li, X.; Zhang, J.; Liang, Z.; Mai, K.; Zhang, Y. Mapping fine-scale population distributions at the building level by integrating multisource geospatial big data. Int. J. Geogr. Inf. Sci. 2017, 31, 1220–1244. [Google Scholar] [CrossRef]
- Gago, E.J.; Roldan, J.; Pacheco-Torres, R.; Ordóñez, J. The city and urban heat islands: A review of strategies to mitigate adverse effects. Renew. Sustain. Energy Rev. 2013, 25, 749–758. [Google Scholar] [CrossRef]
- Barrios García, J.A.; Rodríguez Hernández, J.E. Housing demand in Spain according to dwelling type: Microeconometric evidence. Reg. Sci. Urban Econ. 2008, 38, 363–377. [Google Scholar] [CrossRef]
- Thacher, J.D.; Poulsen, A.H.; Raaschou-Nielsen, O.; Jensen, A.; Hillig, K.; Roswall, N.; Hvidtfeldt, U.; Jensen, S.S.; Levin, G.; Valencia, V.H.; et al. High-resolution assessment of road traffic noise exposure in Denmark. Environ. Res. 2020, 182, 109051. [Google Scholar] [CrossRef] [PubMed]
- Sritarapipat, T.; Takeuchi, W. Building classification in Yangon City, Myanmar using Stereo GeoEye images, Landsat image and night-time light data. Remote Sens. Appl. Soc. Environ. 2017, 6, 46–51. [Google Scholar] [CrossRef]
- Rahman, M.M.; Avtar, R.; Ahmad, S.; Inostroza, L.; Misra, P.; Kumar, P.; Takeuchi, W.; Surjan, A.; Saito, O. Does building development in Dhaka comply with land use zoning? An analysis using nighttime light and digital building heights. Sustain. Sci. 2021, 16, 1323–1340. [Google Scholar] [CrossRef]
- Zhuo, L.; Shi, Q.; Zhang, C.; Li, Q.; Tao, H. Identifying building functions from the spatiotemporal population density and the interactions of people among buildings. ISPRS Int. J. Geo-Inf. 2019, 8, 247. [Google Scholar] [CrossRef] [Green Version]
- Zhong, C.; Huang, X.; Arisona, S.M.; Schmitt, G.; Batty, M. Inferring building functions from a probabilistic model using public transportation data. Comput. Environ. Urban Syst. 2014, 48, 124–137. [Google Scholar] [CrossRef]
- Srivastava, S.; Vargas-Muñoz, J.E.; Swinkels, D.; Tuia, D. Multilabel Building Functions Classification from Ground Pictures using Convolutional Neural Networks. In Proceedings of the 2nd ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, Seattle, WA, USA, 6 November 2018; pp. 43–46. [Google Scholar]
- Kang, J.; Körner, M.; Wang, Y.; Taubenböck, H.; Zhu, X.X. Building instance classification using street view images. ISPRS J. Photogramm. Remote Sens. 2018, 145, 44–59. [Google Scholar] [CrossRef]
- Wurm, M.; Taubenbock, H.; Roth, A.; Dech, S. Urban structuring using multisensoral remote sensing data: By the example of the German cities Cologne and Dresden. In Proceedings of the 2009 Joint Urban Remote Sensing Event, Shanghai, China, 20–22 May 2009; pp. 1–8. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Cheng, Z.; Sun, H.; Takeuchi, M.; Katto, J. Deep convolutional autoencoder-based lossy image compression. In Proceedings of the 2018 Picture Coding Symposium (PCS), San Francisco, CA, USA, 24–27 June 2018; pp. 253–257. [Google Scholar]
- Hong, Y.; Yao, Y. Hierarchical community detection and functional area identification with OSM roads and complex graph theory. Int. J. Geogr. Inf. Sci. 2019, 33, 1569–1587. [Google Scholar] [CrossRef]
- Huang, B.; Zhou, Y.; Li, Z.; Song, Y.; Cai, J.; Tu, W. Evaluating and characterizing urban vibrancy using spatial big data: Shanghai as a case study. Environ. Plan. B Urban Anal. City Sci. 2020, 47, 1543–1559. [Google Scholar] [CrossRef]
- Hoyer, P.O. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2004, 5, 1457–1469. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning. Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Xie, J.; Zhou, J. Classification of Urban Building Type from High Spatial Resolution Remote Sensing Imagery Using Extended MRS and Soft BP Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3515–3528. [Google Scholar] [CrossRef]
- Steiniger, S.; Lange, T.; Burghardt, D.; Weibel, R. An Approach for the Classification of Urban Building Structures Based on Discriminant Analysis Techniques. Trans. GIS 2008, 12, 31–59. [Google Scholar] [CrossRef]
- Arunplod, C.; Nagai, M.; Honda, K.; Warnitchai, P. Classifying building occupancy using building laws and geospatial information: A case study in Bangkok. Int. J. Disaster Risk Reduct. 2017, 24, 419–427. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wei, Y.; Zhang, X.; Shi, Y.; Xia, L.; Pan, S.; Wu, J.; Han, M.; Zhao, X. A review of data-driven approaches for prediction and classification of building energy consumption. Renew. Sustain. Energy Rev. 2018, 82, 1027–1047. [Google Scholar] [CrossRef]
- Oliveti, M. Analysis of Mobility Patterns in Different Neighbourhoods, Integrating GPS Tracks with OpenStreetMap Data. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 2015. [Google Scholar]
- Kwok, Y.T.; De Munck, C.; Schoetter, R.; Ren, C.; Lau, K.K.-L. Refined dataset to describe the complex urban environment of Hong Kong for urban climate modelling studies at the mesoscale. Theor. Appl. Climatol. 2020, 142, 129–150. [Google Scholar] [CrossRef]
- Fleischmann, M. MOMEPY: Urban morphology measuring toolkit. J. Open Source Softw. 2019, 4, 1807. [Google Scholar] [CrossRef] [Green Version]
- Dai, Y.; Gong, J.; Li, Y.; Feng, Q. Building segmentation and outline extraction from UAV image-derived point clouds by a line growing algorithm. Int. J. Digit. Earth 2017, 10, 1077–1097. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PBC | EBC | Description |
|---|---|---|
| Residential | Residential buildings | Buildings for residential usage |
| Residential support facilities | Supporting facilities (e.g., power distribution, pump, and guard buildings) | |
| Commercial | Super-specialty stores | Large stores selling furniture, clothing, and sporting goods |
| Commercial streets | Streets with stores alongside it | |
| Shopping malls | Large indoor shopping centers | |
| Restaurants | Buildings providing food service | |
| Hotels | Buildings providing hotel service | |
| Other stores | Other buildings for commercial usage | |
| Office | Office buildings | Buildings for office usage |
| Industrial | Industrial buildings | Factories and buildings for industrial usage |
| Warehouses | Buildings for storing goods | |
| Public facilities | Schools | Nurseries, kindergartens, primary and secondary schools, higher vocational schools, universities |
| Medical buildings | Medical centers, hospitals, clinics, and medical emergency centers | |
| Sports | Stadiums, gyms, and sports clubs | |
| Subway | Subway stations | |
| Railway | Railway stations | |
| Traffic | Other traffic facilities | |
| Public support facilities | Municipal facilities and community support facilities | |
| Others | Others | Other buildings |
| Source | Features | Dimension | Descriptions |
|---|---|---|---|
| Basic building information | Basic attributes | 6 | Building height (m), perimeter (m), area (m2), floor area ratio, lowest/highest floor number 1 |
| Footprint embedding | 4 | Compressed presentation of the building footprint | |
| POIs | POI embedding | 4 | Compressed presentation of POIs |
| POI index | 2 | PDI and PMI | |
| Road network information | Distance to roads | 13 | Distance to the nearest road (by type) |
| Nighttime light value | 1 | Annually averaged NTL value | |
| Land surface temperature | 8 | Daytime and nighttime land surface temperatures in January, April, September, and October. |
| (a) | ||||
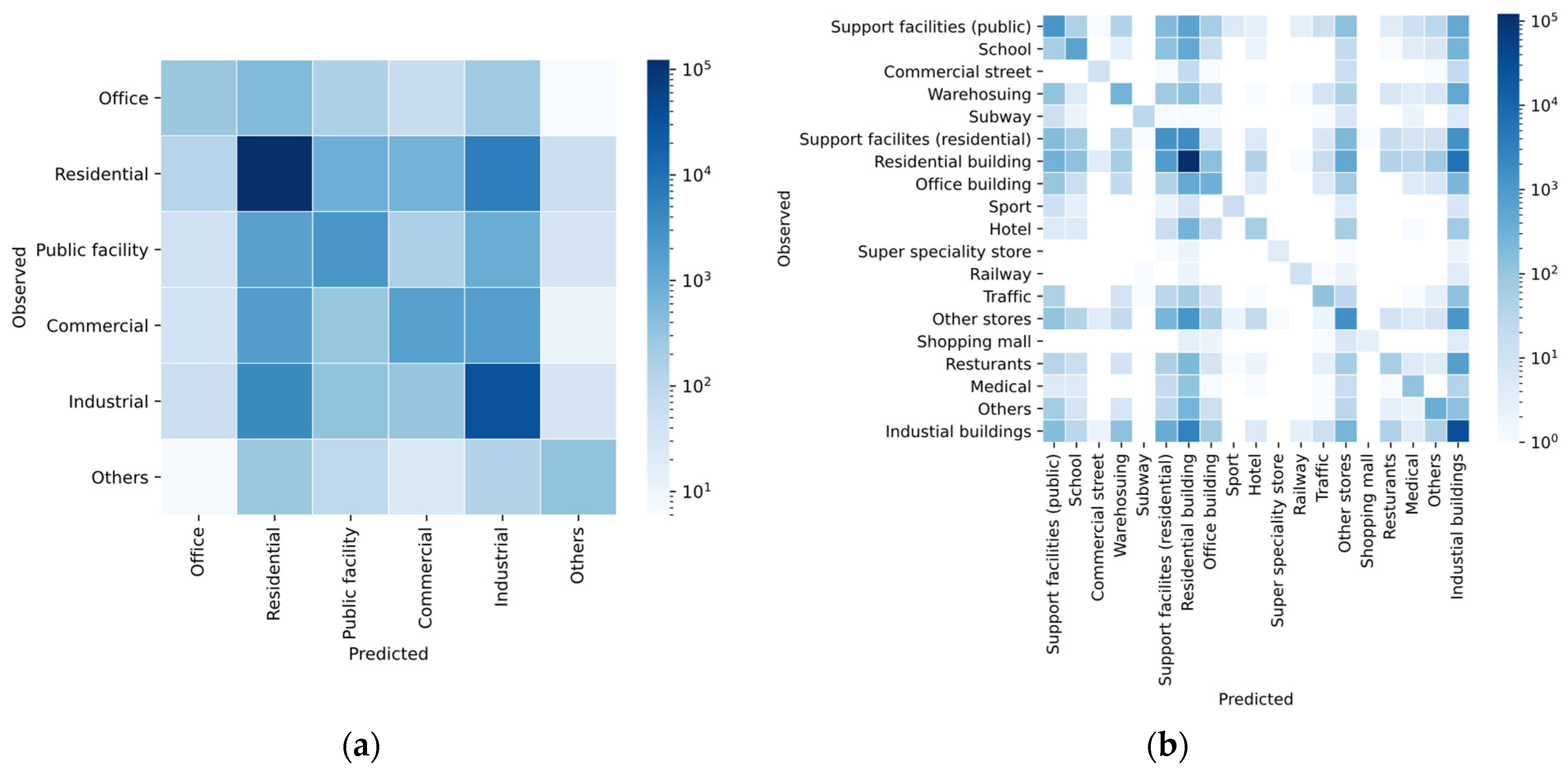
| PBC | Precision | Recall | F1 | Support |
| Office | 49.23% | 22.97% | 31.33% | 1245 |
| Industrial | 76.02% | 86.74% | 81.03% | 35,517 |
| Commercial | 55.79% | 29.04% | 38.20% | 5557 |
| Others | 70.22% | 39.39% | 50.47% | 886 |
| Residential | 93.80% | 93.56% | 93.68% | 131,502 |
| Public facility | 58.20% | 47.36% | 52.22% | 5131 |
| (b) | ||||
| EBC | Precision | Recall | F1 | Support |
| Commercial street | 45.45% | 14.49% | 21.98% | 69 |
| Hotel | 42.03% | 11.74% | 18.35% | 494 |
| Industrial buildings | 73.69% | 87.88% | 80.16% | 34,353 |
| Medical | 60.71% | 37.90% | 46.67% | 314 |
| Office building | 45.04% | 25.54% | 32.60% | 1245 |
| Other stores | 52.59% | 36.89% | 43.36% | 4321 |
| Others | 66.67% | 40.18% | 50.14% | 886 |
| Railway | 62.50% | 47.62% | 54.05% | 21 |
| Residential building | 93.15% | 93.63% | 93.39% | 125,867 |
| Restaurants | 30.89% | 5.18% | 8.88% | 1138 |
| School | 62.36% | 38.55% | 47.65% | 1564 |
| Shopping mall | 60.00% | 15.79% | 25.00% | 19 |
| Sport | 56.00% | 28.00% | 37.33% | 50 |
| Subway | 84.38% | 47.37% | 60.67% | 57 |
| Super-specialty store | 100.00% | 40.00% | 57.14% | 10 |
| Support facilities (residential) | 40.06% | 26.47% | 31.88% | 5141 |
| Support facilities (public) | 49.07% | 41.86% | 45.18% | 2697 |
| Traffic 1 | 64.09% | 27.10% | 38.10% | 428 |
| Warehousing | 44.98% | 23.11% | 30.53% | 1164 |
| Feature Type | PBC | EBC |
|---|---|---|
| Footprint perimeter | 2.11% | 1.29% |
| Height | 5.74% | 3.46% |
| Area | 1.62% | 2.13% |
| Floor area ratio | 1.78% | 1.19% |
| Lowest floor number | 0.94% | 1.26% |
| Highest floor number | 10.80% | 7.97% |
| Distance to roads | 11.76% | 12.34% |
| NTL | 1.02% | 1.04% |
| LST | 10.10% | 11.70% |
| Compressed POI representation | 46.74% | 50.18% |
| Compressed building footprint representation | 7.40% | 7.44% |
| Classifier | PBC | EBC | ||
|---|---|---|---|---|
| OA | Kappa | OA | Kappa | |
| MLP | 81.80% | 0.53 | 79.00% | 0.49 |
| DT | 80.90% | 0.55 | 78.25% | 0.54 |
| RF | 87.47% | 0.68 | 85.17% | 0.66 |
| XGBoost | 88.15% | 0.72 | 85.56% | 0.69 |
| Footprint Features | PBC | EBC | ||
|---|---|---|---|---|
| OA | Kappa | OA | Kappa | |
| Morphologic (5 Dimensions) | 73.14% | 0.45 | 67.90% | 0.41 |
| Morphologic (18 Dimensions) | 75.30% | 0.48 | 71.08% | 0.45 |
| Autoencoder (4 Dimensions) | 73.38% | 0.46 | 68.52% | 0.42 |
| Autoencoder (8 Dimensions) | 75.58% | 0.48 | 71.60% | 0.45 |
| Autoencoder (16 Dimensions) | 76.24% | 0.49 | 72.68% | 0.46 |
| Autoencoder (32 Dimensions) | 77.00% | 0.49 | 73.65% | 0.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Luo, H.; Li, W.; Huang, B. Building Function Mapping Using Multisource Geospatial Big Data: A Case Study in Shenzhen, China. Remote Sens. 2021, 13, 4751. https://doi.org/10.3390/rs13234751
Wang J, Luo H, Li W, Huang B. Building Function Mapping Using Multisource Geospatial Big Data: A Case Study in Shenzhen, China. Remote Sensing. 2021; 13(23):4751. https://doi.org/10.3390/rs13234751
Chicago/Turabian StyleWang, Jionghua, Haowen Luo, Wenyu Li, and Bo Huang. 2021. "Building Function Mapping Using Multisource Geospatial Big Data: A Case Study in Shenzhen, China" Remote Sensing 13, no. 23: 4751. https://doi.org/10.3390/rs13234751
APA StyleWang, J., Luo, H., Li, W., & Huang, B. (2021). Building Function Mapping Using Multisource Geospatial Big Data: A Case Study in Shenzhen, China. Remote Sensing, 13(23), 4751. https://doi.org/10.3390/rs13234751