
Remote Sensing Scene Image Classification Based on Dense Fusion of Multi-level Features



Abstract
:
1. Introduction
2. Methods
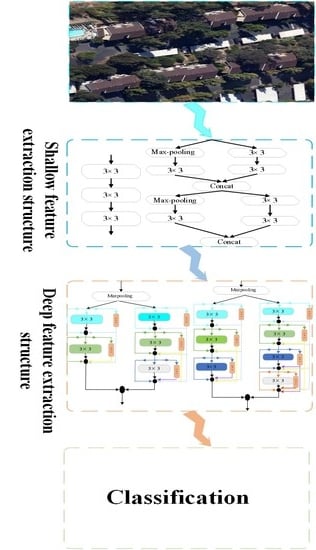
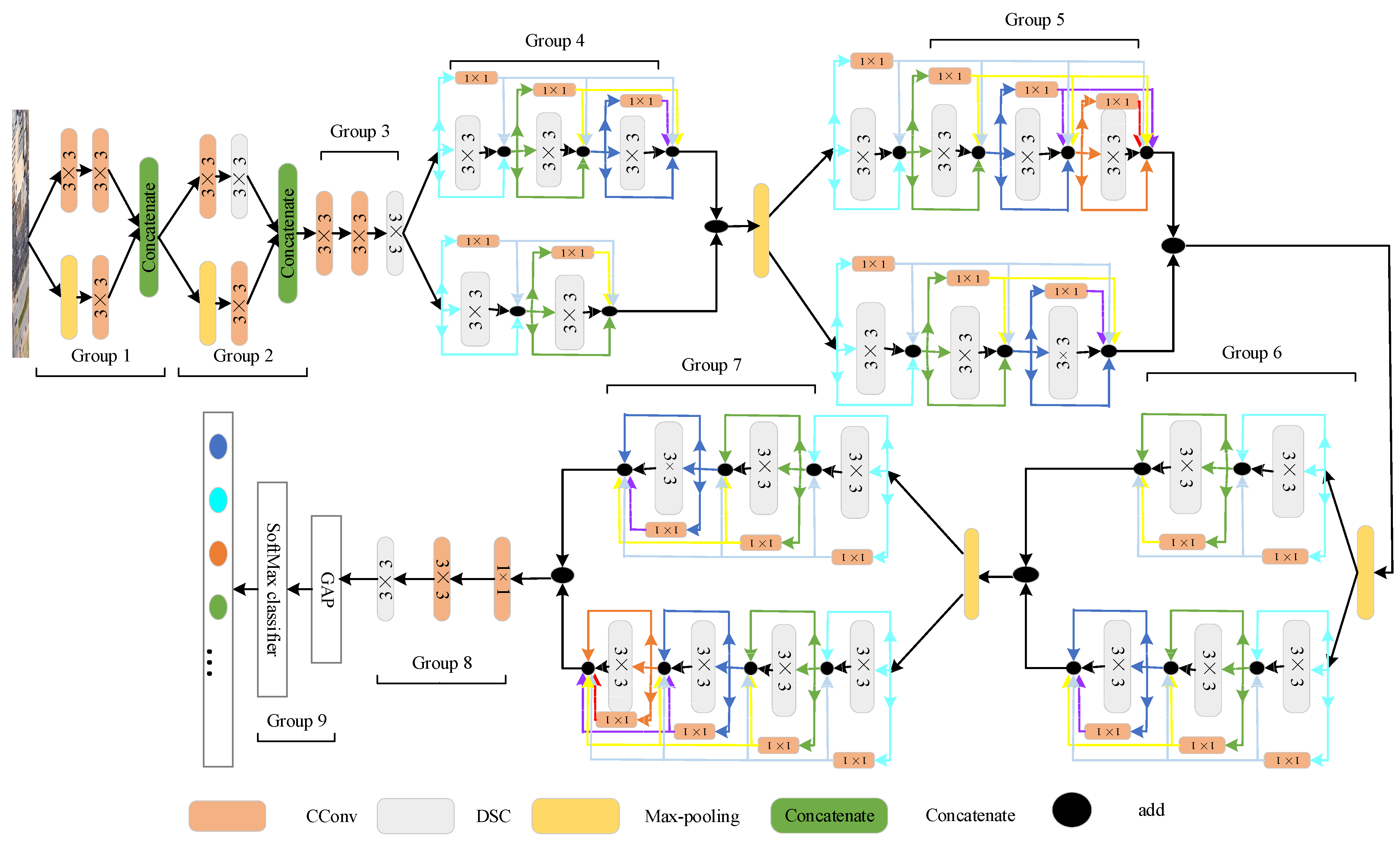
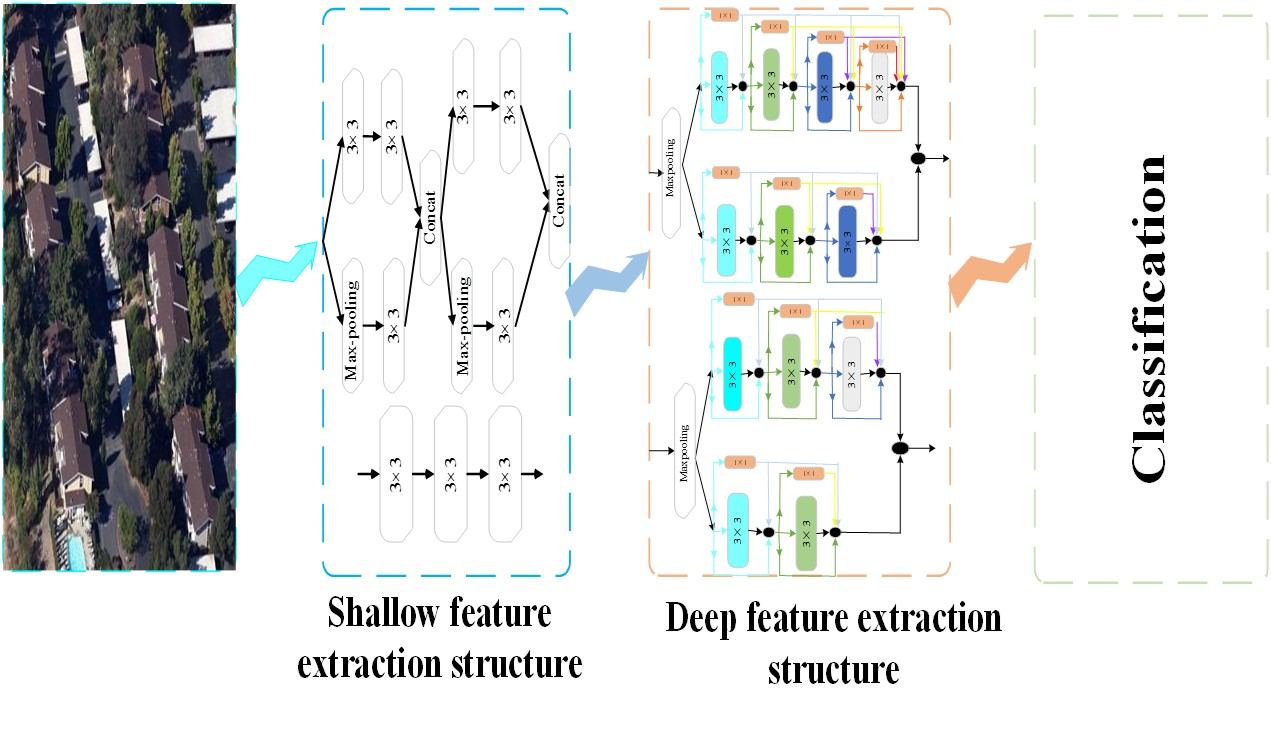
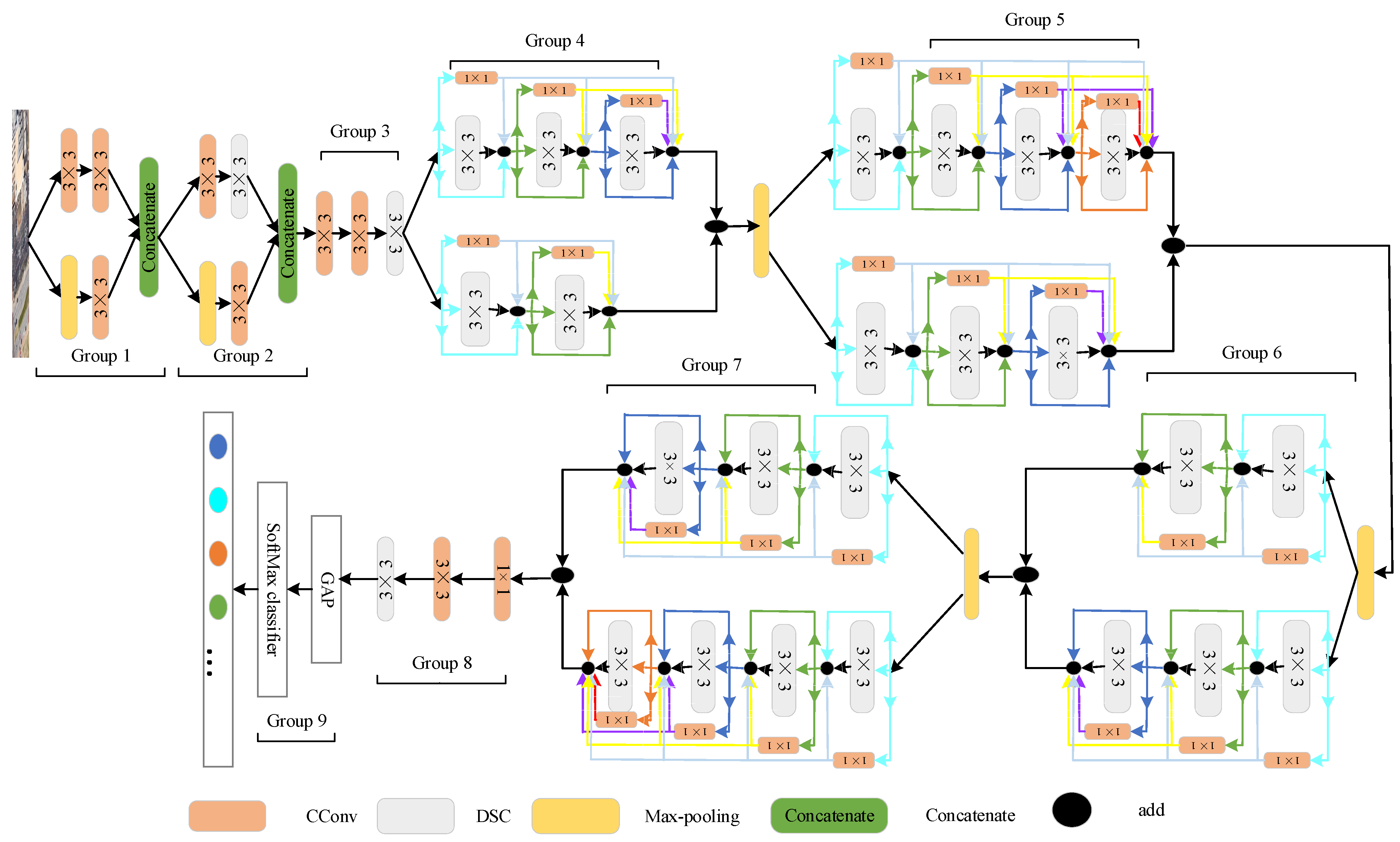
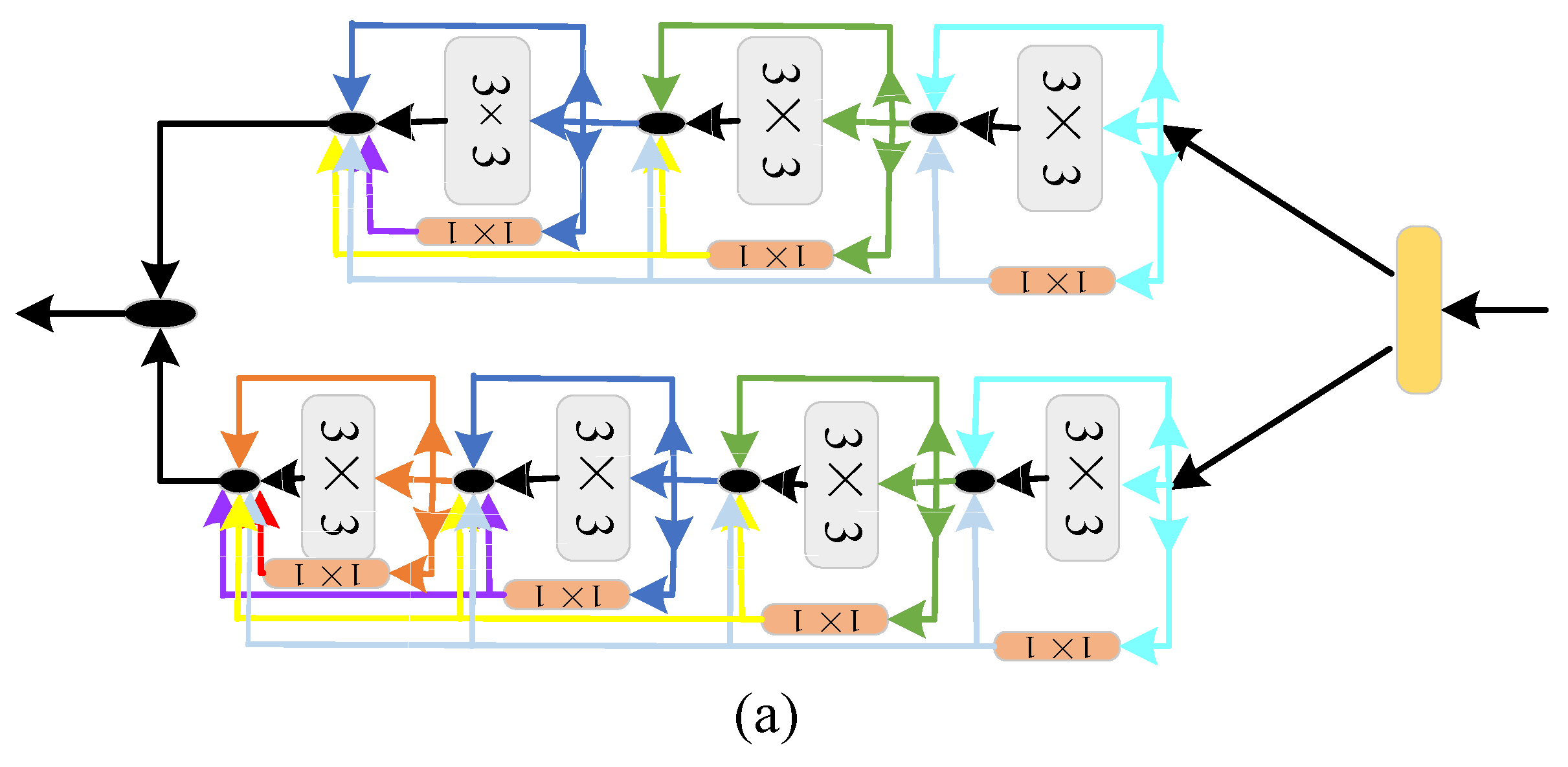
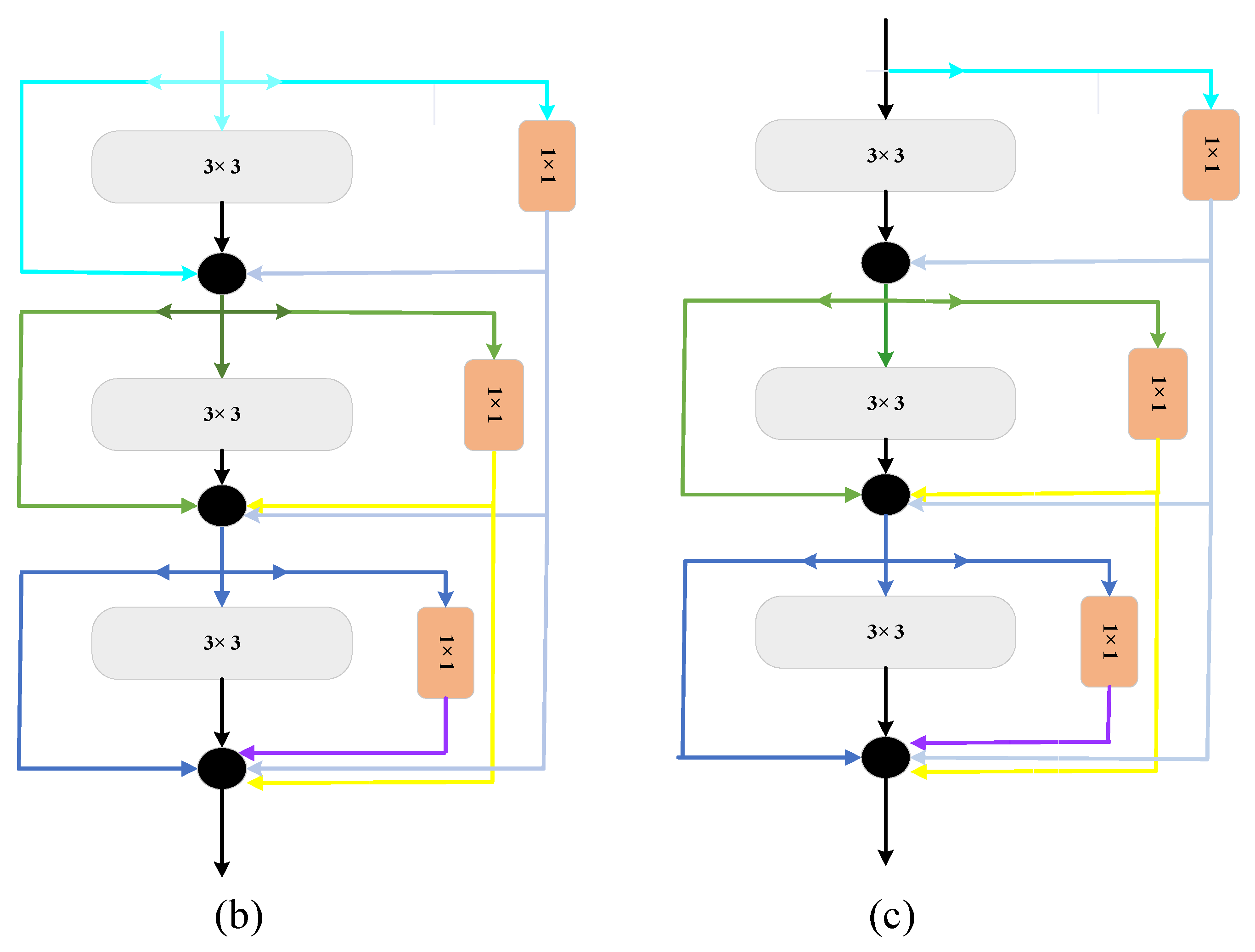
2.1. The Structure of the Proposed Method
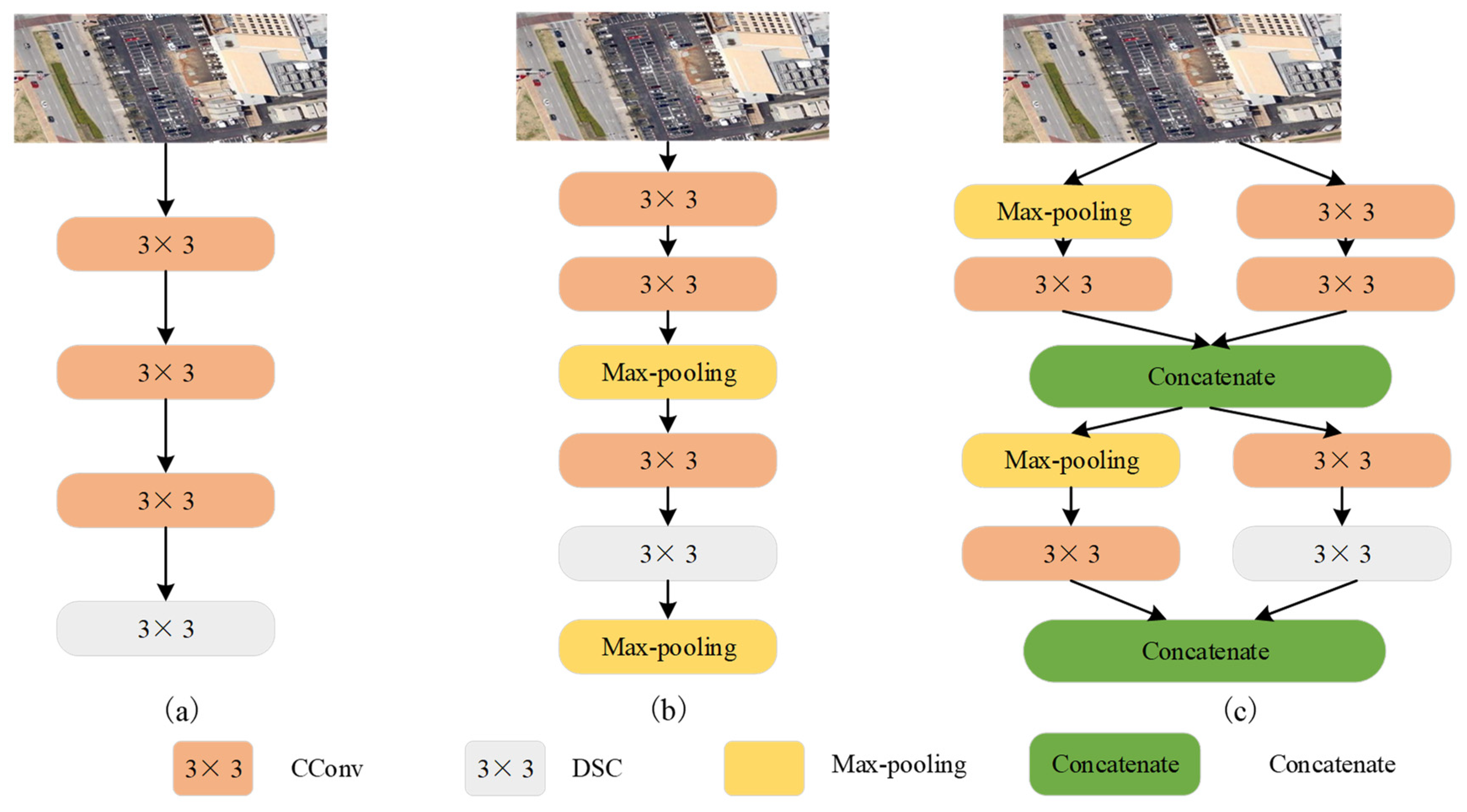
2.2. Shallow Feature Extraction Strategy
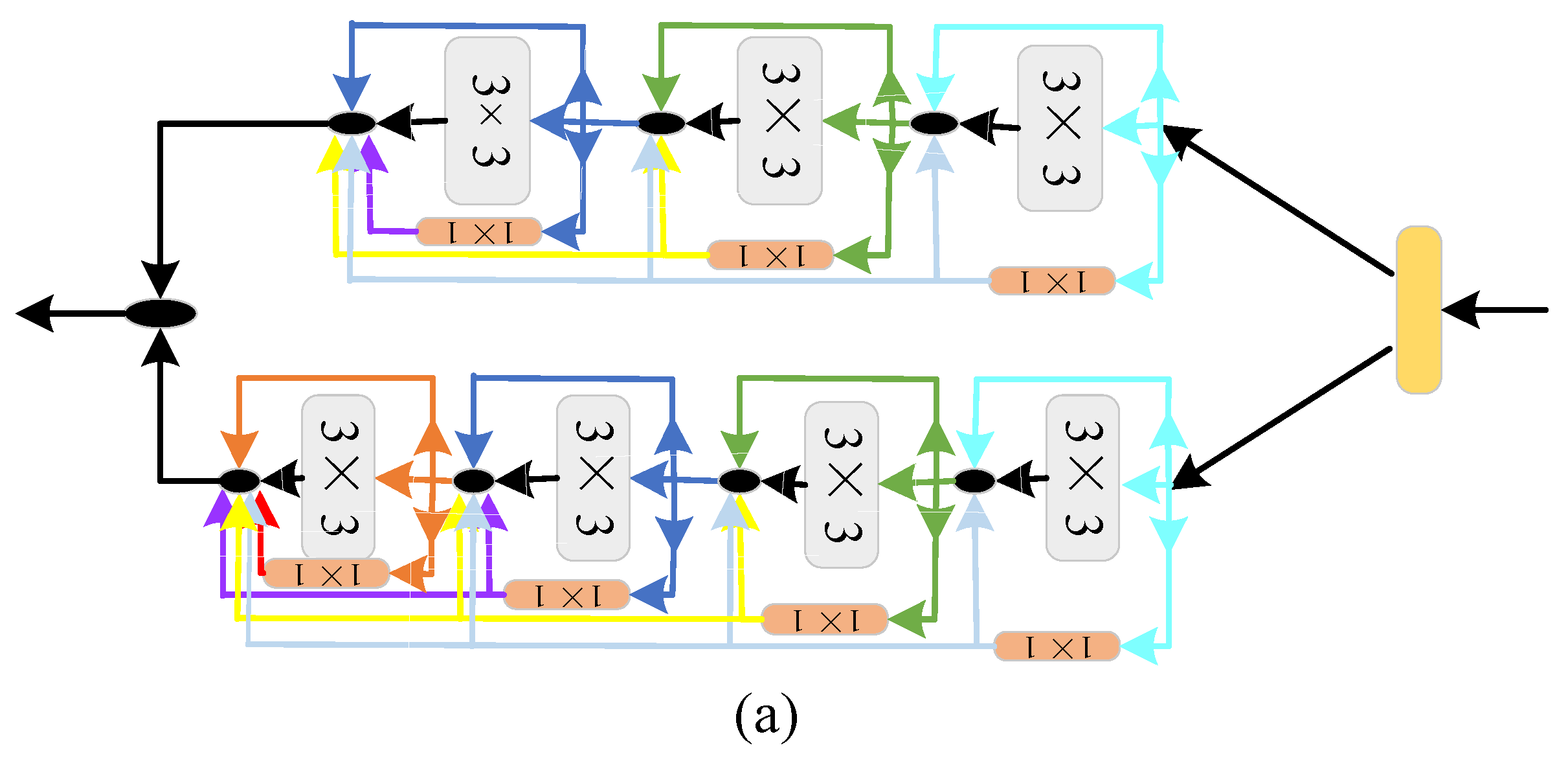
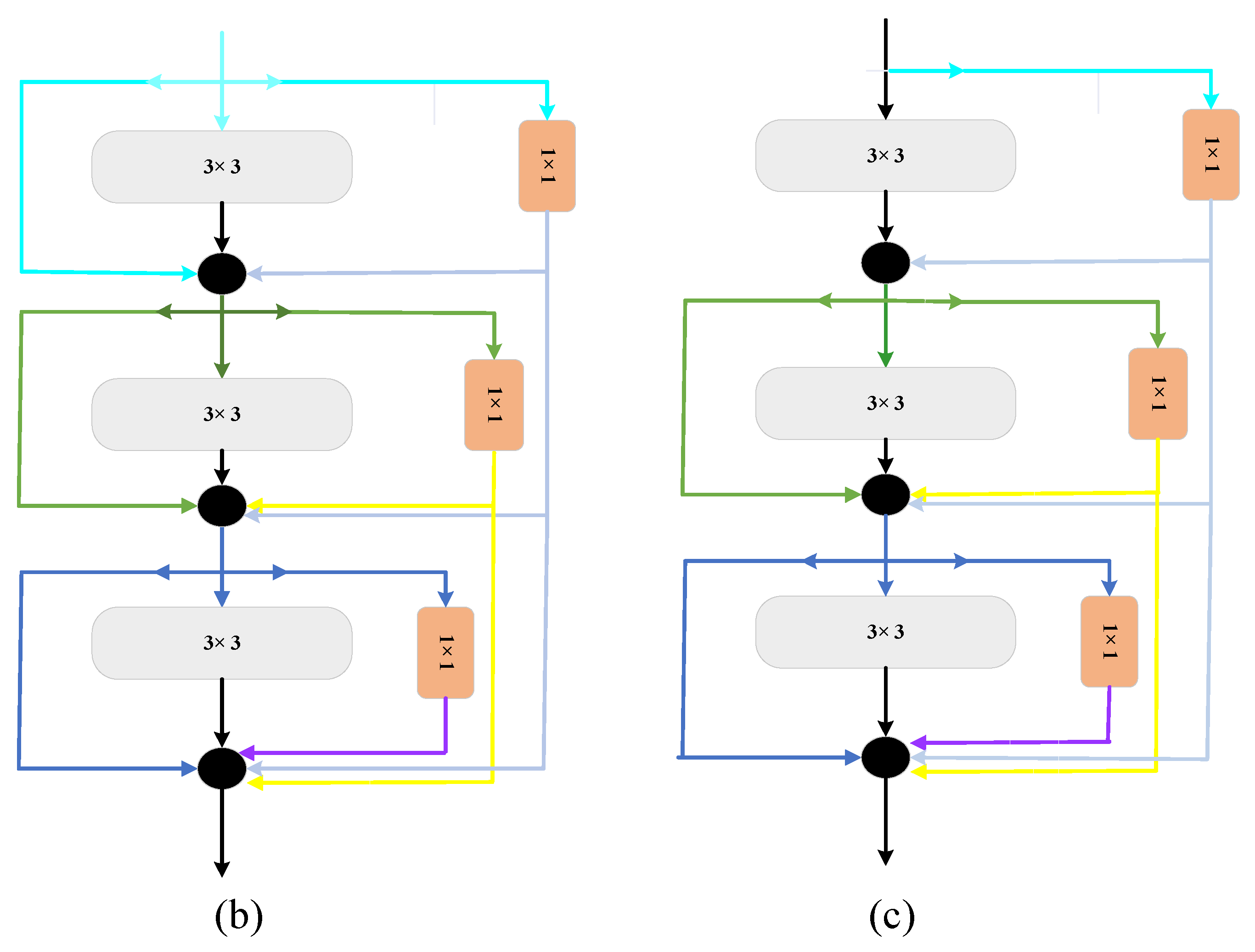
2.3. Strategies to Optimize Time and Space Complexity
2.3.1. Replace the Full Connection Layer with Global Average Pooling
2.3.2. Replacing Standard Convolution with Depthwise Separable Convolution
2.3.3. Identity
3. Results
3.1. Dataset Settings
3.2. Setting of the Experiments
- (1)
- Multiplying all pixels of the input image by a scaling factor, which was set to 1/255, reduced the pixel value to between 0 and 1 and favored convergence of the model.
- (2)
- Select the appropriate angle to rotate the input image to change the orientation of the image content. Here, we chose a rotation angle of 0–60.
- (3)
- The input image was translated horizontally and vertically with a shift factor of 0.2.
- (4)
- The input image was randomly flipped to horizontal or vertical.
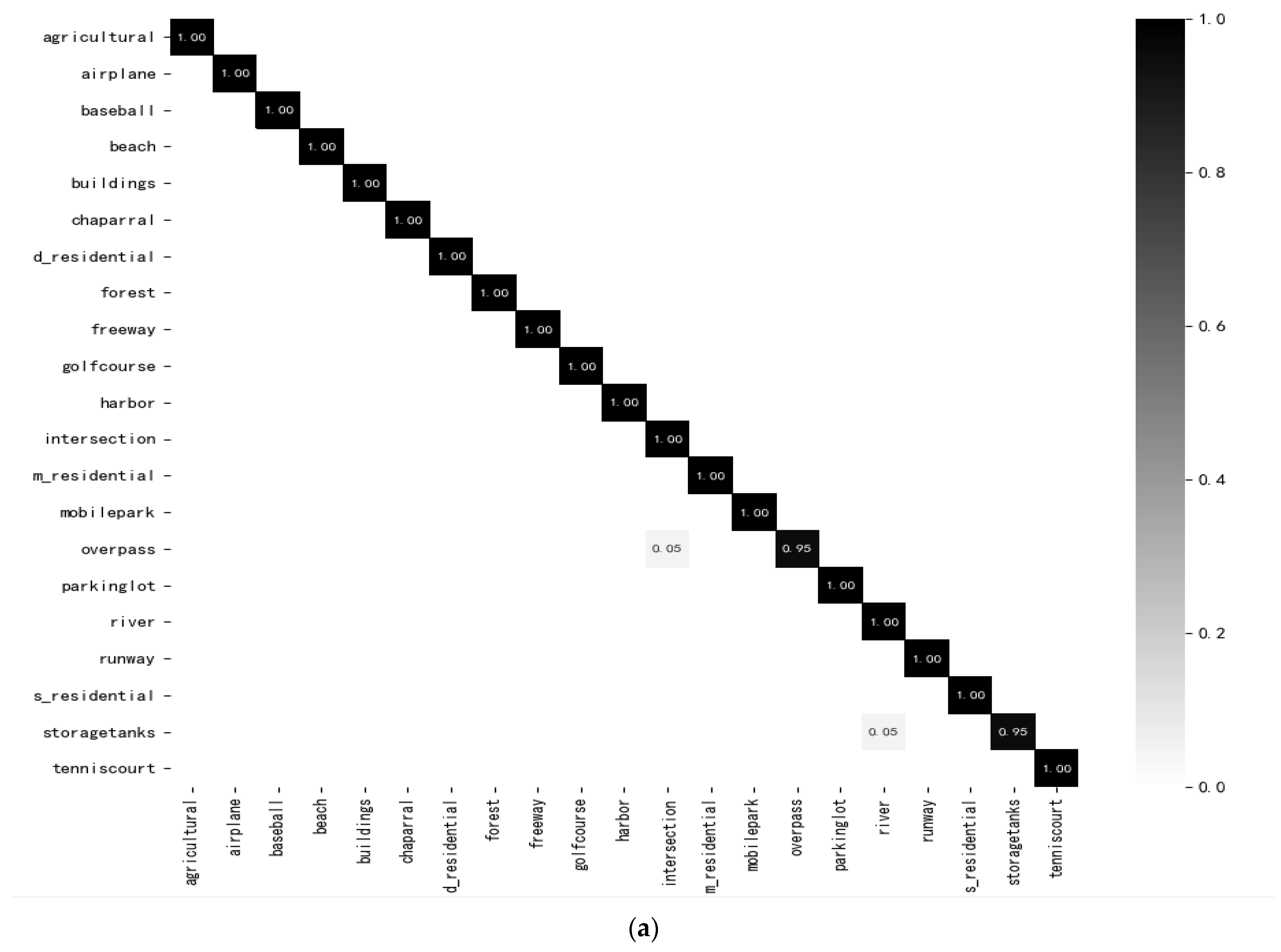
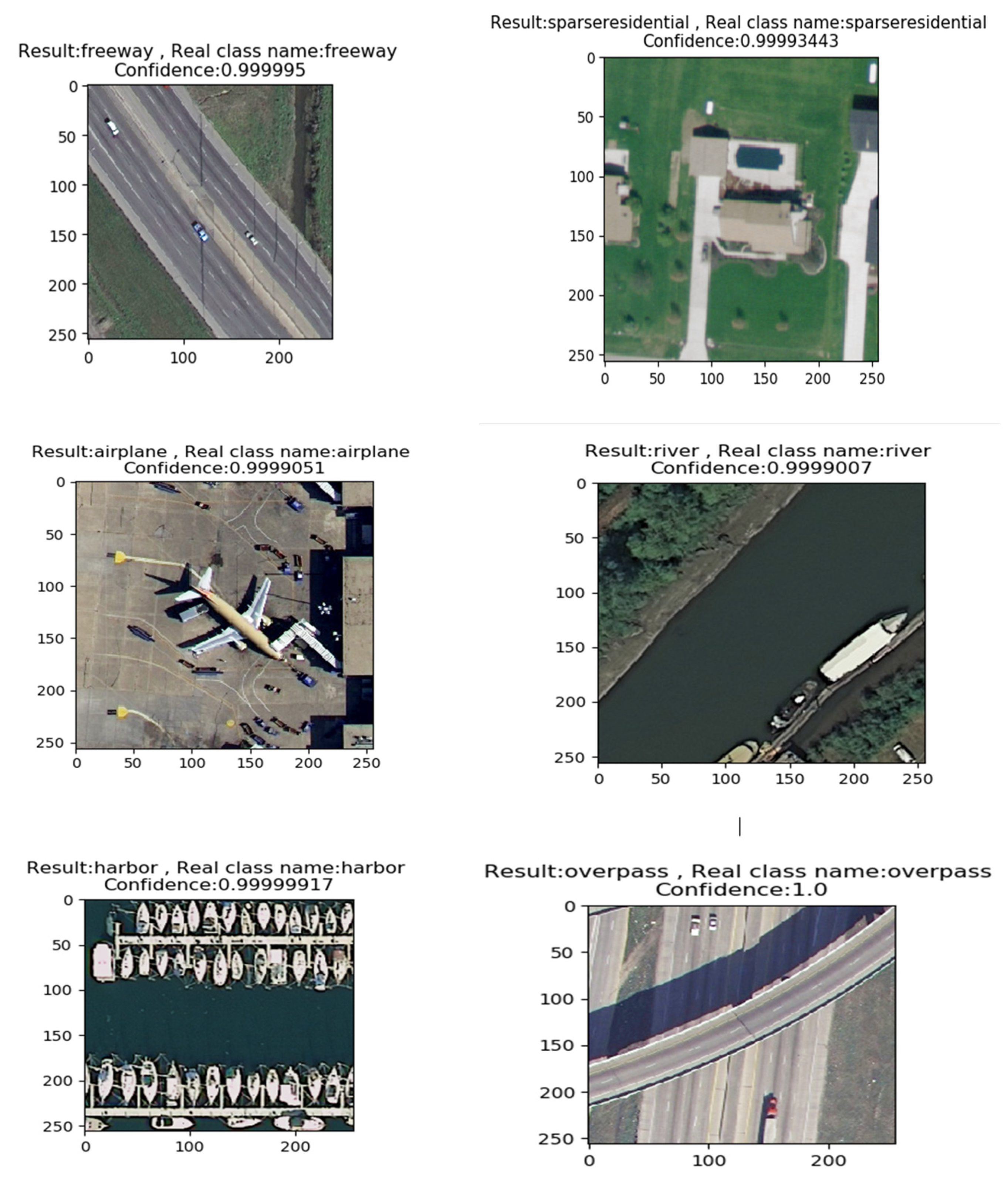
3.3. The Performance of the Proposed Model
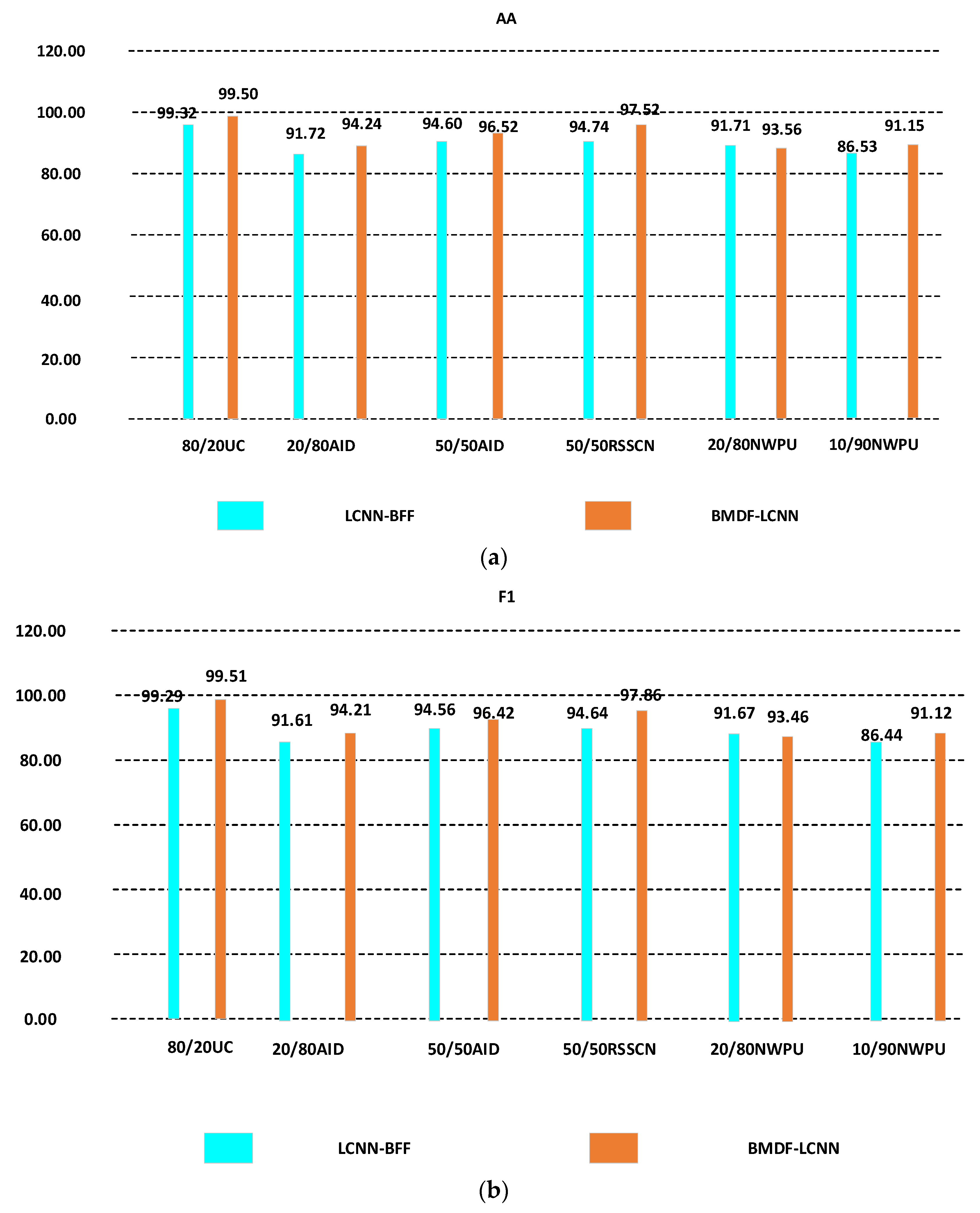
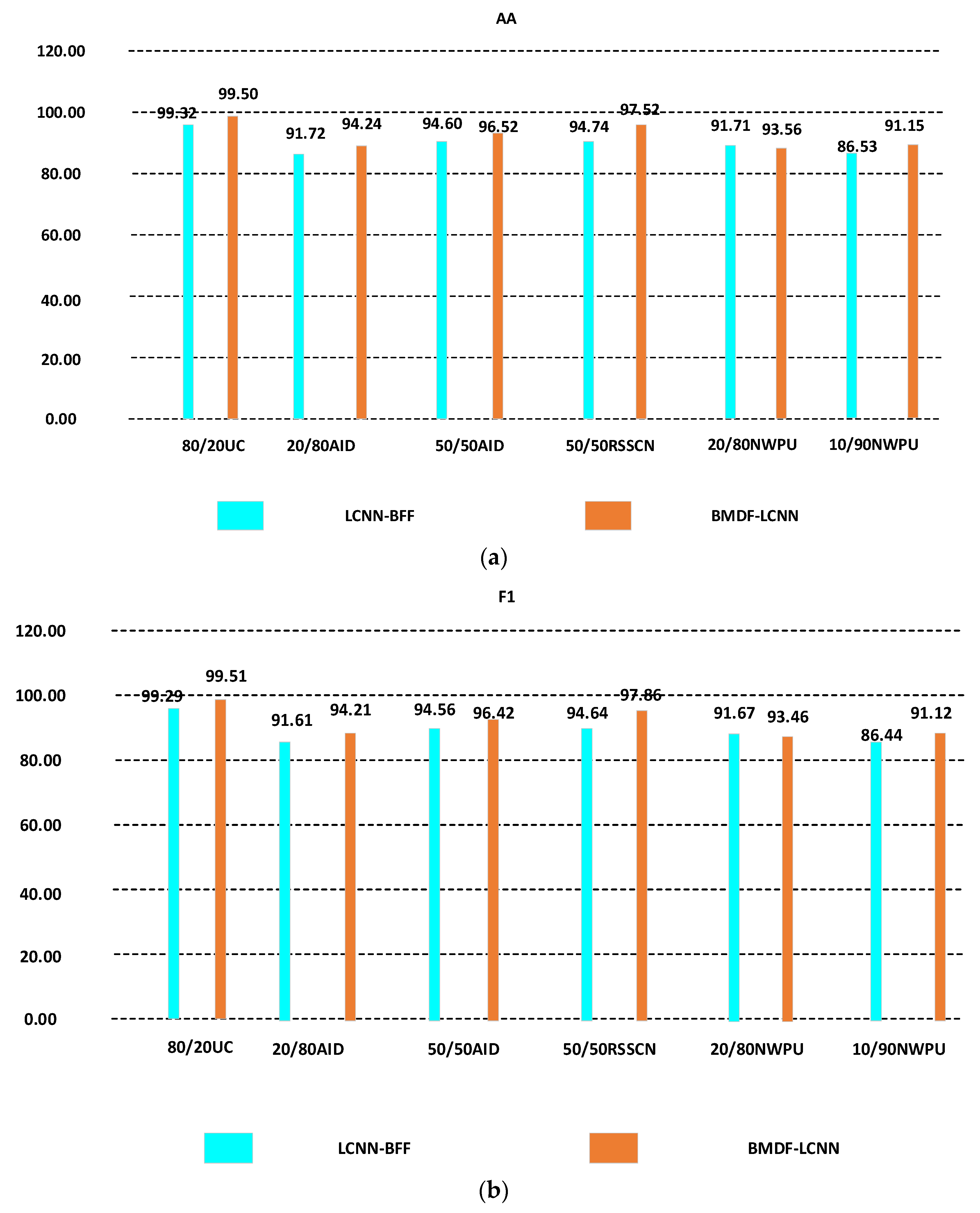
3.4. Comparison with Advanced Methods
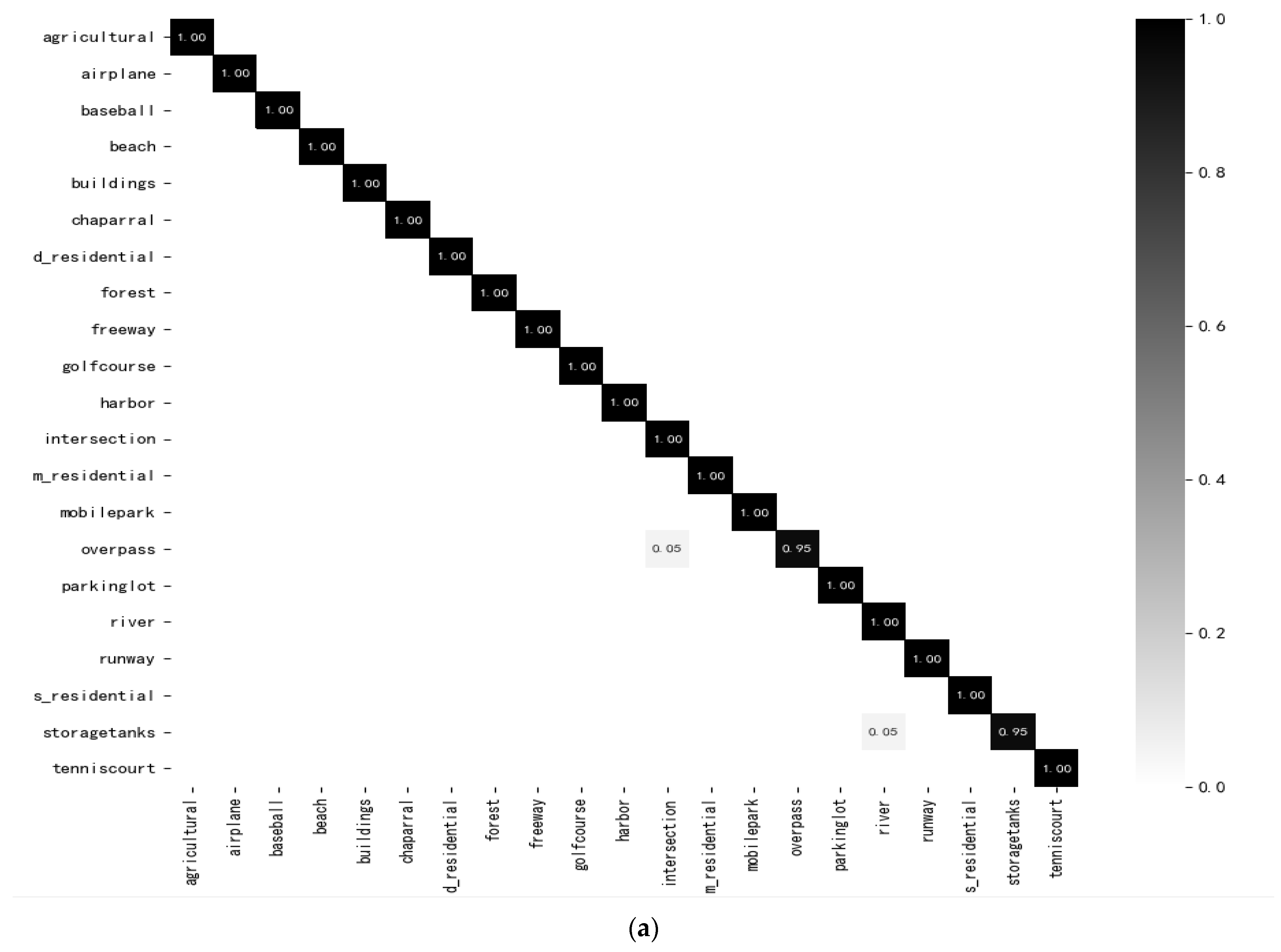
3.4.1. Experimental Results on UC-Merced Datasets
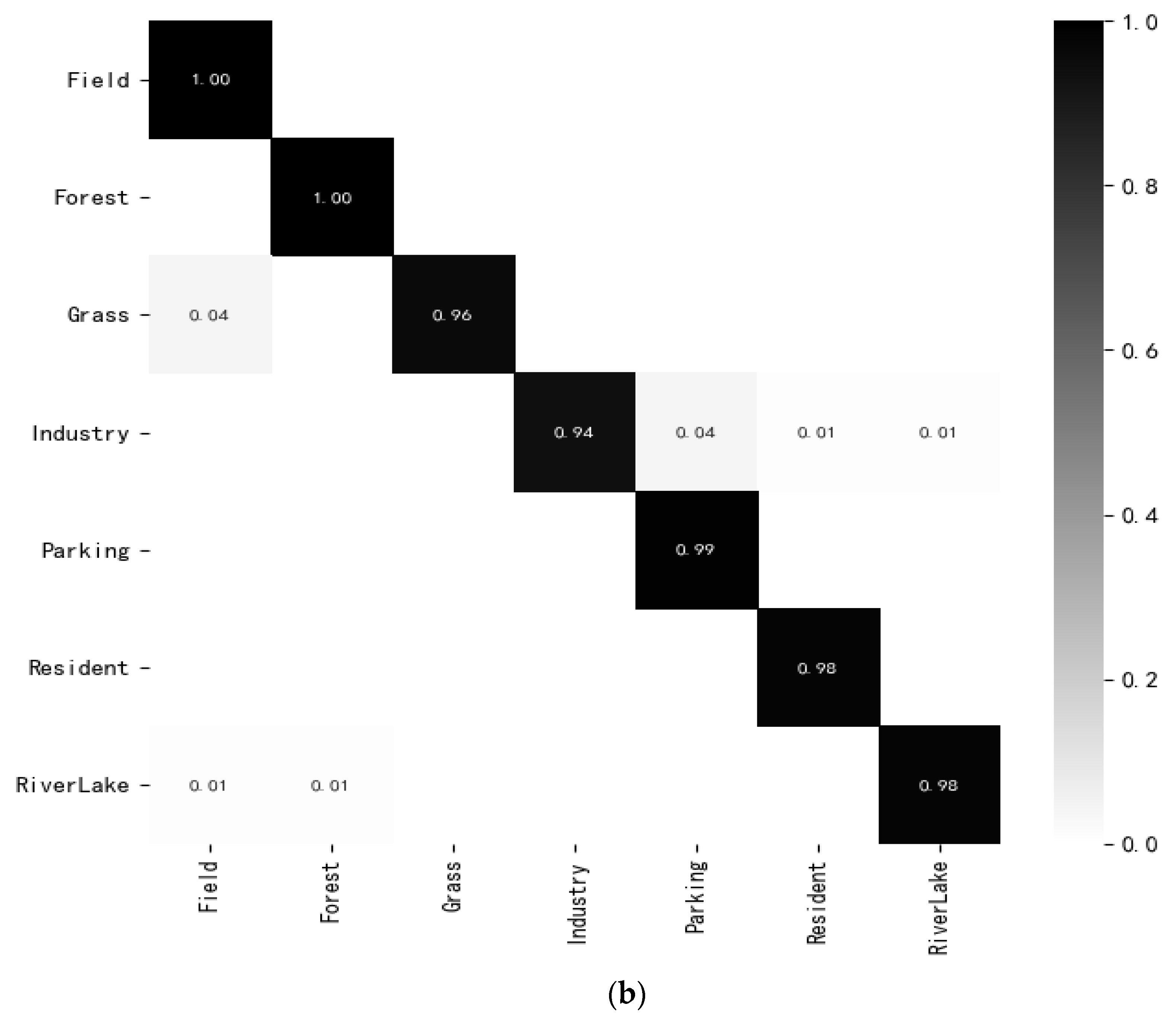
3.4.2. Experimental Results on RSSCN Datasets
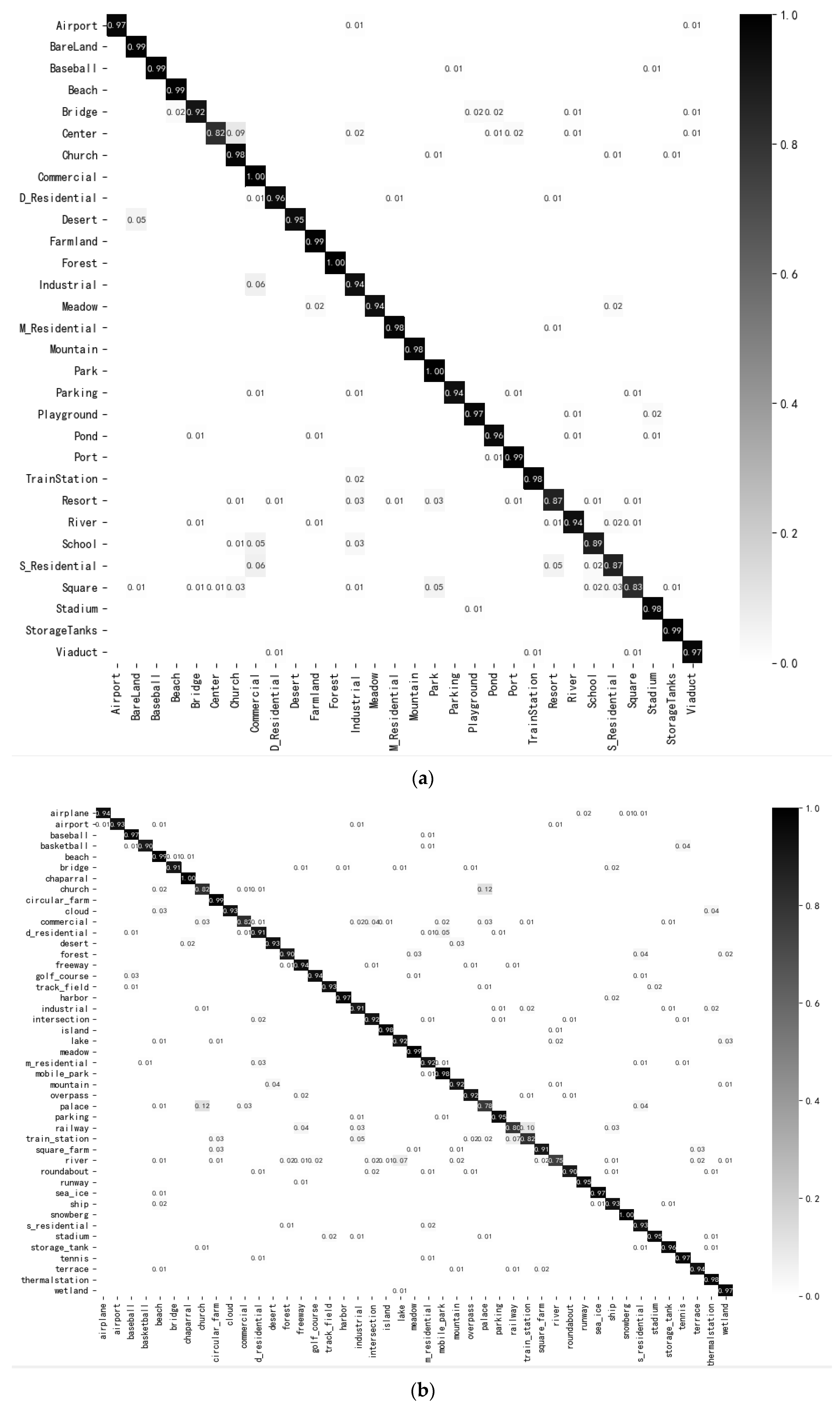
3.4.3. Experimental Results on AID Datasets
3.4.4. Experimental Results on NWPU Dataset
3.5. Comparison of Three Downsampling Methods
3.6. Evaluation of Size of Models
4. Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classifification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Zhou, F.; Hang, R.; Yuan, X. Bidirectional-convolutional LSTM based spectral-spatial feature learning for hyperspectral image classifification. Remote Sens. 2017, 9, 1330. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Yuan, Y.; Zheng, X. Joint dictionary learning for multispectral change detection. IEEE Trans. Cybern. 2017, 47, 884–897. [Google Scholar] [CrossRef]
- Li, Y.; Peng, C.; Chen, Y.; Jiao, L.; Zhou, L.; Shang, R. A deep learning method for change detection in synthetic aperture radar images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5751–5763. [Google Scholar] [CrossRef]
- Peng, C.; Li, Y.; Jiao, L.; Chen, Y.; Shang, R. Densely based multiscale and multi-modal fully convolutional networks for high-resolution remote-sensing image semantic segmentation. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2019, 12, 2612–2626. [Google Scholar] [CrossRef]
- Ghamisi, P.; Maggiori, E.; Li, S.; Souza, R.; Tarablaka, Y.; Moser, G.; Chen, Y. New frontiers in spectral-spatial hyperspectral image classifification: The latest advances based on mathematical morphology, Markov random fifields, segmentation, sparse representation, and deep learning. IEEE Geosci. Remote Sens. Mag. 2018, 6, 10–43. [Google Scholar] [CrossRef]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classifification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Song, C.; Yang, F.; Li, P. Rotation invariant texture measured by local binary pattern for remote sensing image classifification. In Proceedings of the 2nd International Workshop on Education Technology and Computer Science, ETCS, Wuhan, China, 6–7 March 2010; Volume 3, pp. 3–6. [Google Scholar]
- Oliva, A.; Antonio, T. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the CVPR, IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 886–893. [Google Scholar]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Nice, France, 13–16 October 2003; p. 1470. [Google Scholar]
- Zhou, Y.; Liu, X.; Zhao, J.; Ma, D.; Yao, R.; Liu, B.; Zheng, Y. Remote sensing scene classifification based on rotationinvariant feature learning and joint decision making. EURASIP J. Image Video Process. 2019, 2019, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Lin, W.; Tang, P. Multiple resolution block feature for remote-sensing scene classifification. Int. J. Remote Sens. 2019, 40, 6884–6904. [Google Scholar] [CrossRef]
- Lienou, M.; Maitre, H.; Datcu, M. Semantic annotation of satellite images using latent Dirichlet allocation. IEEE Geosci. Remote Sens. Lett. 2010, 7, 28–32. [Google Scholar] [CrossRef]
- Beltran, R.F.; Haut, J.M.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Pla, F. Multimodal probabilistic latent semantic analysis for sentinel-1 and sentinel-2 image fusion. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1347–1351. [Google Scholar] [CrossRef]
- Li, Y.; Jin, X.; Mei, J.; Lian, X.; Yang, L.; Zhou, Y.; Bai, S.; Xie, C. Neural architecture search for lightweight non-local networks. In Proceedings of the CVPR, IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10294–10303. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep feature fusion for VHR remote sensing scene classifification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- Lu, X.; Ji, W.; Li, X.; Zheng, X. Bidirectional adaptive feature fusion for remote sensing scene classifification. Neurocomputing 2019, 328, 135–146. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, F.; Zhang, H.; Liang, Z. Convolutional neural network based heterogeneous transfer learning for remote-sensing scene classifification. Int. J. Remote Sens. 2019, 40, 8506–8527. [Google Scholar] [CrossRef]
- Zhao, F.; Mu, X.; Yang, Z.; Yi, Z. A novel two-stage scene classifification model based on feature variable signifificance in high-resolution remote sensing. Geocarto Int. 2020, 1603–1614. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classifification using CNNCapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the CVPR, IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State-of-the-art; IEEE: Piscataway, NJ, USA, 2017; Volume 105, pp. 1865–1883. [Google Scholar]
- Boualleg, Y.; Farah, M.; Farah, I.R. Remote sensing scene classifification using convolutional features and deep forest classififier. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1944–1948. [Google Scholar] [CrossRef]
- Xie, J.; He, N.; Fang, L.; Plaza, A. Scale-free convolutional neural network for remote sensing scene classifification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6916–6928. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, Y.; Zhao, J.; Yao, R.; Liu, B.; Zheng, Y. Siamese convolutional neural networks for remote sensing scene classifification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1200–1204. [Google Scholar] [CrossRef]
- Liu, B.; Meng, J.; Xie, W.; Shao, S.; Li, Y.; Wang, Y. Weighted spatial pyramid matching collaborative representation for remote-sensing-image scene classifification. Remote Sens. 2019, 11, 518. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model sizee. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Effificient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, B.; Zhang, Y.; Wang, S. A lightweight and discriminative model for remote sensing scene classifification with multidilation pooling module. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2019, 12, 2636–2653. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the CVPR, IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27-28 October 2019. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Wan, H.; Chen, J.; Huang, Z.; Feng, Y.; Zhou, Z.; Liu, X.; Yao, B.; Xu, T. Lightweight Channel Attention and Multiscale Feature Fusion Discrimination for Remote Sensing Scene Classification; IEEE: Piscataway, NJ, USA, 2021; Volume 9, pp. 94586–94600. [Google Scholar]
- Bai, L.; Liu, Q.; Li, C.; Zhu, C.; Ye, Z.; Xi, M. A Lightweight and Multiscale Network for Remote Sensing Image Scene Classifification. IEEE Trans. Geosci. Remote Sens. 2021, 18, 1–5. [Google Scholar] [CrossRef]
- Li, J.; Weinmann, M.; Sun, X.; Diao, W.; Feng, Y.; Fu, K. Random Topology and Random Multiscale Mapping: An Automated Design of Multiscale and Lightweight Neural Network for Remote-Sensing Image Recognition. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Shi, C.; Wang, T.; Wang, L. Branch Feature Fusion Convolution Network for Remote Sensing Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 5194–5210. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vision 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Lin, M.; Chen, Q.; Yan, S. Network in network. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, MT, Canada, 14–16 April 2014; pp. 1–10. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classifification. In Proceedings of the ACM International Symposium on Advances in Geographic Information, San Josem, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classifification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Liu, X. AID: A benchmark data set for performance evaluation of aerial scene classifification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- He, N.; Fang, L.; Li, S.; Plaza, J.; Plaza, A. Skip-connected covariance network for remote sensing scene classifification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1461–1474. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Li, N.; Ye, Q. Positional context aggregation network for remote sensing scene classifification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 943–947. [Google Scholar] [CrossRef]
- Liu, M.; Jiao, L.; Liu, X.; Li, L.; Liu, F.; Yang, S. C-CNN: Contourlet convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 2636–2649. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. Robust joint representation of intrinsic mean and kernel function of lie group for remote sensing scene classifification. IEEE Geosci. Remote Sens. Lett. 2021, 18, 796–800. [Google Scholar] [CrossRef]
- Li, B.; Su, W.; Wu, H.; Li, R.; Zhang, W.; Qin, W.; Zhang, S. Aggregated deep fifisher feature for VHR remote sensing scene classifification. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2019, 12, 3508–3523. [Google Scholar] [CrossRef]
- Wang, S.; Guan, Y.; Shao, L. Multi-granularity canonical appearance pooling for remote sensing scene classifification. IEEE Trans. Image Process. 2020, 29, 5396–5407. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote sensing scene classifification by gated bidirectional network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 82–96. [Google Scholar] [CrossRef]
- Lu, X.; Sun, H.; Zheng, X. A feature aggregation convolutional neural network for remote sensing scene classifification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7894–7906. [Google Scholar] [CrossRef]
- Yan, P.; He, F.; Yang, Y.; Hu, F. Semi-supervised representation learning for remote sensing image classifification based on generative adversarial networks. IEEE Access 2020, 8, 54135–54144. [Google Scholar] [CrossRef]
- Cao, R.; Fang, L.; Lu, T.; He, N. Self-attention-based deep feature fusion for remote sensing scene classifification. IEEE Geosci. Remote Sens. Lett. 2021, 18, 43–47. [Google Scholar] [CrossRef]
- Pour, A.M.; Seyedarabi, H.; Jahromi, S.H.A.; Javadzadeh, A. Automatic detection and monitoring of diabetic retinopathy using effificient convolutional neural networks and contrast limited adaptive histogram equalization. IEEE Access 2020, 8, 136668–136673. [Google Scholar] [CrossRef]
- Alhichri, H.; Alswayed, A.S.; Bazi, Y.; Ammour, N.; Alajlan, N.A. Classification of Remote Sensing Images Using EfficientNetB3 CNN Model With Attention. IEEE Access 2021, 9, 14078–14094. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Ding, L. Scene classification based on two-stage deep feature fusion. IEEE Geosci. Remote Sens. Lett. 2018, 15, 183–186. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. A lightweight intrinsic mean for remote sensing classifification with lie group kernel function. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1741–1745. [Google Scholar] [CrossRef]
- Li, W.; Wang, Z.; Wang, Y.; Wu, J.; Wang, J.; Jia, Y.; Gui, G. Classifification of high-spatial-resolution remote sensing scenes method using transfer learning and deep convolutional neural network. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2020, 13, 1986–1995. [Google Scholar] [CrossRef]
- Xue, W.; Dai, X.; Liu, L. Remote Sensing Scene Classification Based on Multi-Structure Deep Features Fusion. IEEE Access 2020, 8, 28746–28755. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
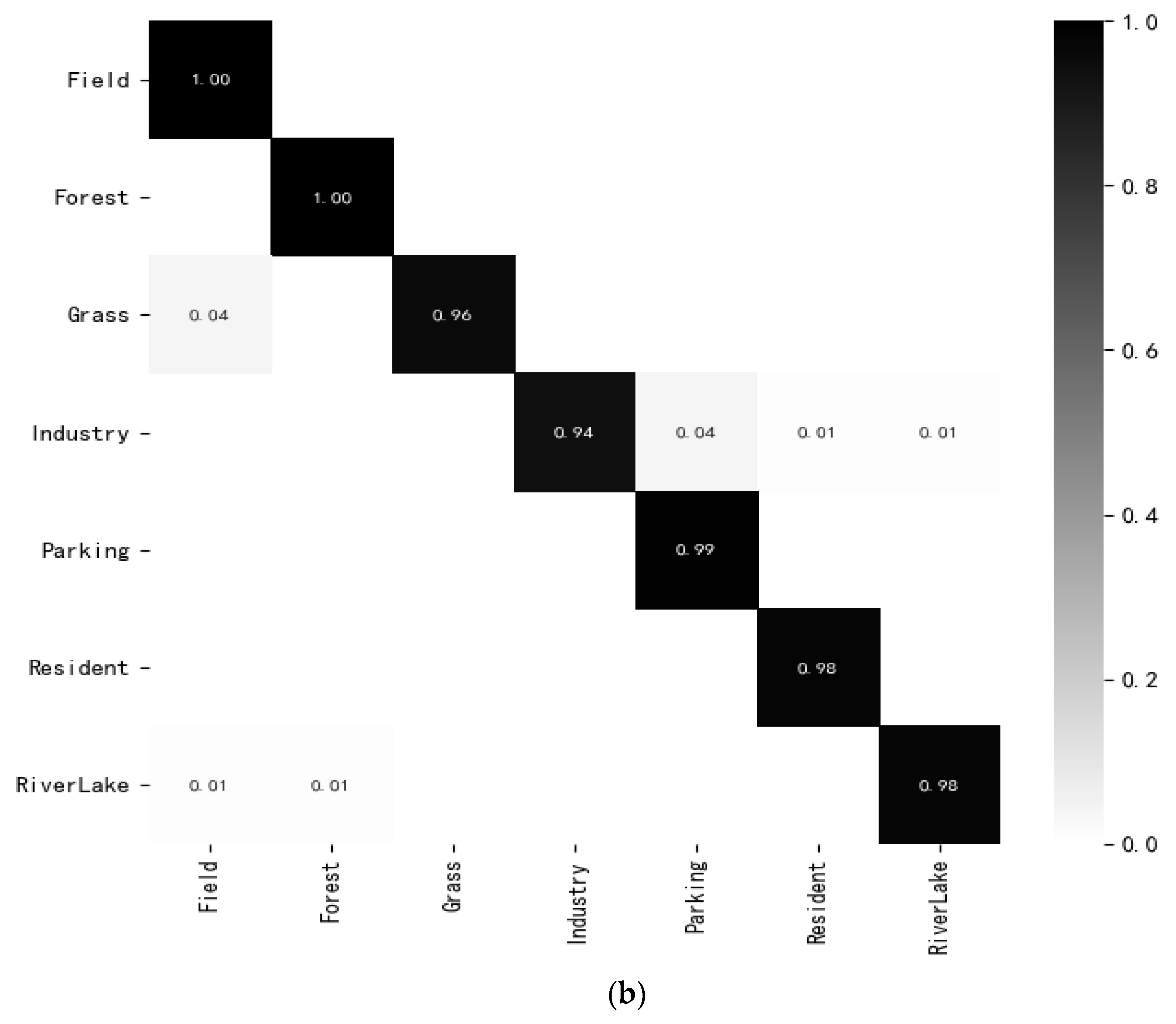{kind=link}
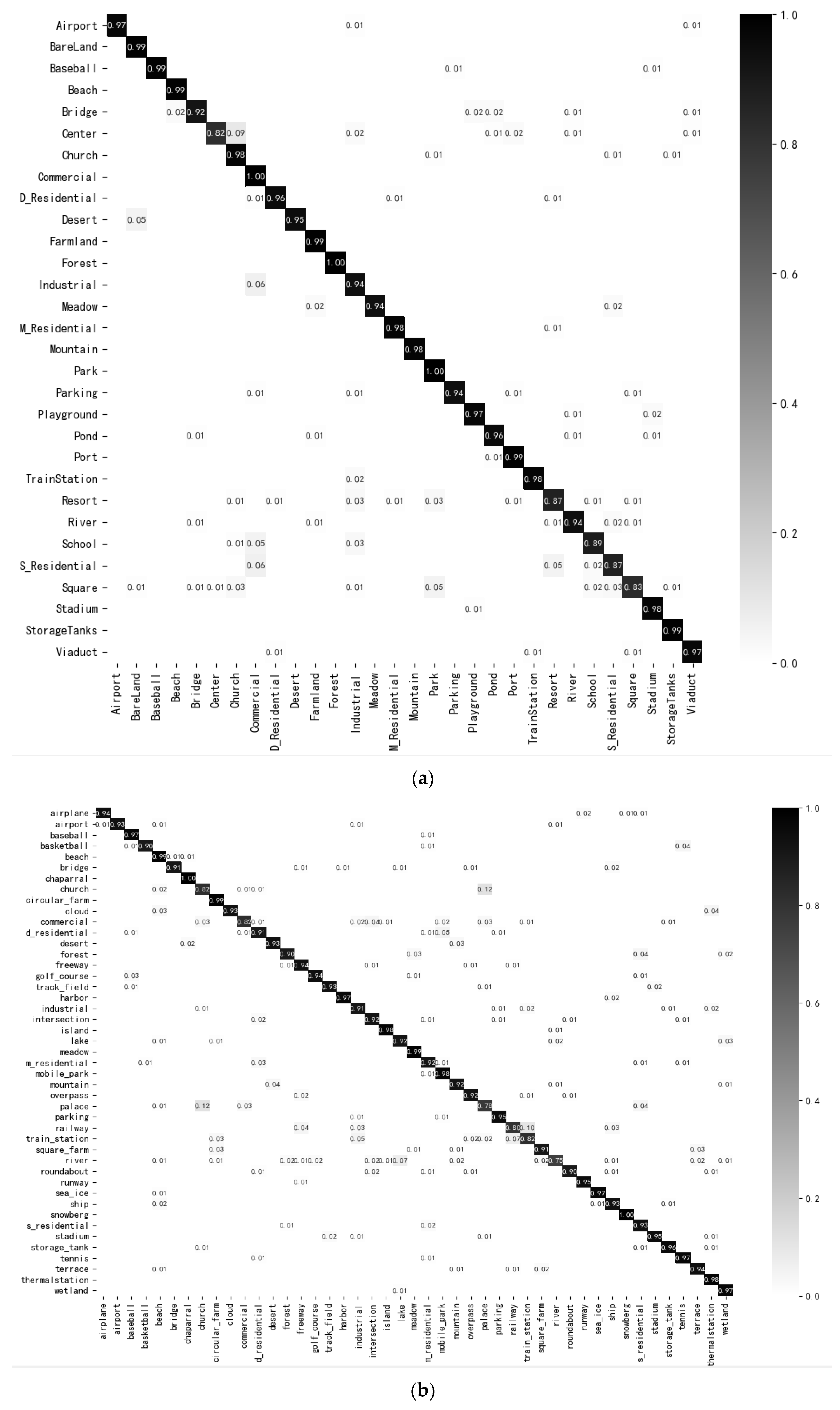{kind=link}
{kind=link}
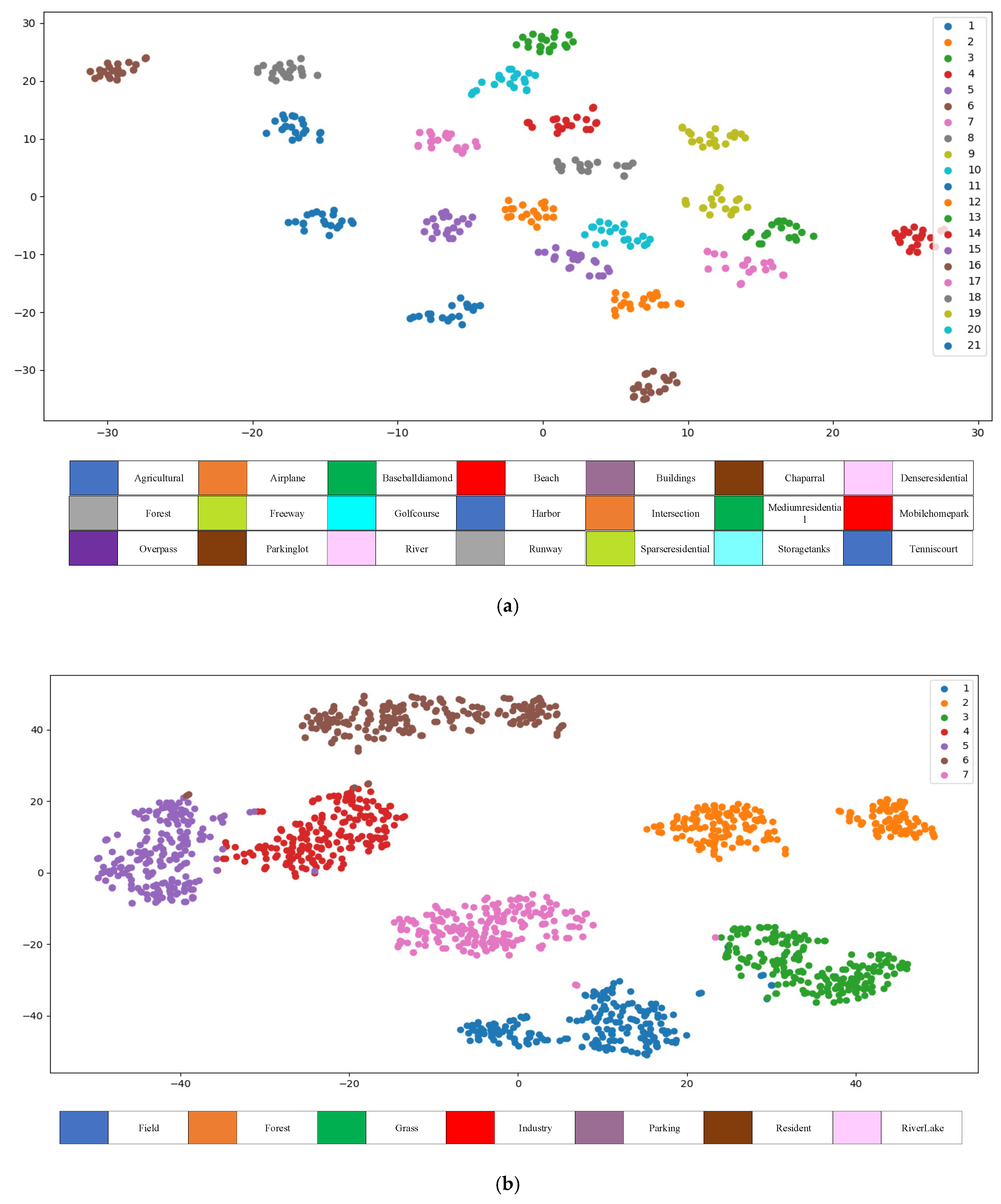{kind=link}
{kind=link}
| BMDF-LCNN | LCNN-BFF | |||
|---|---|---|---|---|
| OA (%) | Kappa (%) | OA (%) | Kappa (%) | |
| 80/20UC | 99.53 | 99.50 | 99.29 | 99.25 |
| 50/50RSSCN | 97.86 | 97.50 | 94.64 | 93.75 |
| 20/80AID | 94.46 | 94.26 | 91.66 | 91.37 |
| 50/50AID | 96.76 | 96.24 | 94.62 | 94.41 |
| 10/90NWPU | 91.65 | 90.65 | 86.53 | 86.22 |
| 20/80NWPU | 93.57 | 93.42 | 91.73 | 91.54 |
| The Network Model | OA (%) | AA (%) | F1 | Number of Parameters |
|---|---|---|---|---|
| MRBF [14] | 94.19 ± 1.5 | 94.25 ± 0.52 | 94.19 ± 0.26 | 89M |
| VWMF [23] | 97.79 | 96.85 | 96.51 | 35M |
| VGG16-DF [27] | 98.97 | 98.86 | 98.23 | 130M |
| BAFF [30] | 95.48 | 95.69 | 94.96 | 130M |
| SF-CNN with VGGNet [32] | 99.05 ± 0.27 | 98.89 ± 0.12 | 98.76 ± 0.15 | 130M |
| WSPM-CRC [33] | 97.95 | 98.02 | 97.89 | 23M |
| Inception-v3-CapsNet [35] | 99.05 ± 0.24 | 99.10 ± 0.15 | 99.05 ± 0.46 | 22M |
| ADFF [52] | 98.81 ± 0.51 | 97.95 ± 0.92 | 97.84 ± 0.25 | 23M |
| MG-CAP(Bilinear) [53] | 98.60 ± 0.26 | 98.50 ± 1.5 | 98.46 ± 0.18 | 45M |
| SCCov [48] | 98.04 ± 0.23 | 98.35 ± 0.48 | 98.02 ± 0.29 | 6M |
| LiG with sigmoid kernel [51] | 98.92 | 98.75 | 98.59 | 23M |
| GBNet + global feature [54] | 98.57 ± 0.48 | 98.46 ± 0.43 | 98.32 ± 0.62 | 138M |
| FACNN [55] | 98.81 ± 0.24 | 98.86 ± 0.19 | 98.76 ± 0.38 | 130M |
| SSRL [56] | 94.05 ± 1.2 | 94.35 ± 0.09 | 94.05 ± 0.27 | 210M |
| VGG_VD16 + SAFF [57] | 97.02 ± 0.78 | 96.56 ± 0.29 | 96.49 ± 0.21 | 15M |
| PANNet [49] | 99.21 ± 0.18 | 98.26 ± 0.51 | 98.10 ± 0.27 | 28M |
| EfficientNet [58] | 94.37 | 93.59 | 93.38 | 65M |
| EfficientNet-B3-Attn-2 [59] | 99.21 ± 0.22 | 99.05 ± 0.19 | 98.98 ± 0.13 | 15M |
| Siamese [50] | 94.29 | 93.56 | 93.37 | 21M |
| Contourlet CNN [50] | 98.97 | 98.27 | 98.09 | 12.6M |
| BMDF-LCNN (Proposed) | 99.53 ± 0.24 | 99.50 ± 0.15 | 99.51 ± 0.27 | 6M |
| The Network Model | Year | Kappa (%) |
|---|---|---|
| R.D [13] | 2019 | 94.50 |
| LiG with sigmoid kernel [51] | 2020 | 97.63 |
| EfficientNet [58] | 2020 | 92.37 |
| SE-MDPMNet [34] | 2019 | 97.74 |
| Fine-tune MobileNet [34] | 2019 | 96.92 |
| Siamese [50] | 2019 | 94.00 |
| Contourlet CNN [50] | 2020 | 97.81 |
| BMDF-LCNN (Proposed) | 2021 | 99.50 |
| The Network Model | ATT(s) |
|---|---|
| GBNet [54] | 0.053 |
| GBNet + global feature [54] | 0.039 |
| Siamese [50] | 0.052 |
| Siamese [50] | 0.048 |
| BMDF-LCNN (Proposed) | 0.017 |
| The Network Model | Year | OA (%) | AA (%) | F1 | Number of Parameters |
|---|---|---|---|---|---|
| VWMF [23] | 2019 | 89.10 | 88.96 | 88.69 | 35 M |
| WSPM-CRC [33] | 2019 | 93.60 | 94.01 | 93.60 | 23 M |
| SPM-CRC [33] | 2019 | 93.86 | 93.79 | 93.75 | 23 M |
| VGG16 + SVM [47] | 2017 | 87.18 | 87.09 | 86.95 | 130 M |
| ADFF [52] | 2019 | 95.21 ± 0.50 | 95.35 ± 0.67 | 94.87 ± 0.56 | 23 M |
| Two-stage deep feature fusion [60] | 2018 | 92.37 ± 0.72 | 92.09 ± 0.53 | 92.35 ± 0.45 | 18 M |
| Fine-tune MobileNet [34] | 2019 | 94.71 ± 0.15 | 93.52 ± 0.25 | 94.59 ± 0.19 | 3.5 M |
| SE-MDPMNet [34] | 2019 | 92.46 ± 0.66 | 93.08 ± 0.42 | 92.46 ± 0.26 | 5.17 M |
| EfficientNet-B3-Attn-2 [59] | 2021 | 96.17 ± 0.23 | 95.68 ± 0.35 | 95.53 ± 0.76 | 15 M |
| Contourlet CNN [50] | 2020 | 95.54 ± 0.17 | 95.62 ± 0.26 | 95.06 ± 0.62 | 12.6 M |
| BMDF-LCNN (Proposed) | 2021 | 97.86 ± 0.25 | 97.52 ± 0.10 | 97.86 ± 0.19 | 6 M |
| The Network Model | OA (20/80) (%) | AA (20/80) (%) | OA (50/50) (%) | AA (50/50) (%) | Number of Parameters |
|---|---|---|---|---|---|
| BAFF [30] | 91.23 | 90.65 | 93.56 | 93.42 | 130 M |
| VGG16-CapsNet [35] | 91.63 ± 0.19 | 91.26 ± 0.59 | 94.74 ± 0.17 | 94.65 ± 0.36 | 22 M |
| MG-CAP(Bilinear) [53] | 92.11 ± 0.15 | 92.28 ± 0.25 | 95.14 ± 0.12 | 95.26 ± 0.24 | 130 M |
| SCCov [48] | 91.10 ± 0.15 | 91.35 ± 0.16 | 93.30 ± 0.13 | 93.45 ± 0.49 | 6 M |
| GBNet [54] | 90.16 ± 0.24 | 89.94 ± 0.27 | 93.72 ± 0.34 | 93.68 ± 0.56 | 18 M |
| GBNet + global feature [54] | 92.20 ± 0.23 | 91.87 ± 0.36 | 95.48 ± 0.12 | 94.97 ± 0.16 | 138 M |
| FACNN [55] | 90.87 ± 0.53 | 91.05 ± 0.48 | 95.45 ± 0.11 | 95.62 ± 0.19 | 25 M |
| VGG_VD16 + SAFF [57] | 90.25 ± 0.29 | 90.25 ± 0.68 | 93.83 ± 0.16 | 93.76 ± 0.28 | 15 M |
| InceptionV3 [62] | 93.27 ± 0.17 | 94.05 ± 0.49 | 95.07 ± 0.22 | 95.38 ± 0.17 | 45.37 M |
| ResNet50 [62] | 92.39 ± 0.15 | 91.69 ± 0.72 | 94.69 ± 0.19 | 95.02 ± 0.26 | 25.61 M |
| VGG19 [62] | 87.73 ± 0.25 | 87.80 ± 0.16 | 91.71 ± 0.42 | 91.54 ± 0.65 | 19 M |
| EfficientNet [58] | 86.56 ± 0.17 | 87.06 ± 0.15 | 88.35 ± 0.16 | 88.56 ± 0.53 | 65 M |
| LiG with RBF kernel [61] | 94.17 ± 0.25 | 94.05 ± 0.52 | 96.19 ± 0.28 | 96.27 ± 0.39 | 2.07 M |
| Fine-tune MobileNetV2 [34] | 94.13 ± 0.28 | 94.20 ± 0.18 | 95.96 ± 0.27 | 95.06 ± 0.28 | 10 M |
| MSDFF [63] | 93.47 | 93.56 | 96.74 | 96.46 | 15 M |
| BMDF-LCNN (proposed) | 94.46 ± 0.15 | 94.24 ± 0.10 | 96.76 ± 0.18 | 96.52 ± 0.23 | 6 M |
| The Network Model | OA (50%) | Kappa (%) |
|---|---|---|
| VGG19 [62] | 91.71 | 90.06 |
| ResNet [62] | 94.69 | 93.47 |
| InceptionV3 [62] | 95.07 | 93.91 |
| EfficientNet [58] | 88.35 | 87.21 |
| LiG with RBF kernel [61] | 96.19 | 94.33 |
| Fine-tune MobileNet V2 [34] | 95.96 | 94.83 |
| BMDF-LCNN (Proposed) | 96.76 | 96.24 |
| The Network Model | OA (10/90) (%) | AA (10/90) (%) | OA (20/80) (%) | AA (20/80) (%) | Number of Parameters | Year |
|---|---|---|---|---|---|---|
| R.D [13] | 89.36 | 89.05 | 91.03 | 90.68 | 20 M | 2019 |
| VGG16-CapsNet [35] | 85.08 ± 0.13 | 85.12 ± 0.22 | 89.18 ± 0.14 | 89.32 ± 0.19 | 22 M | 2019 |
| MG-CAP with Bilinear [53] | 89.42 ± 0.19 | 89.06 ± 0.16 | 91.72 ± 0.16 | 90.95 ± 0.33 | 45 M | 2020 |
| SCCov [48] | 84.33 ± 0.26 | 83.56 ± 0.48 | 87.30 ± 0.23 | 97.41 ± 0.53 | 6 M | 2020 |
| LiG with sigmoid kernel [51] | 90.19 ± 0.11 | 89.57 ± 0.36 | 93.21 ± 0.12 | 93.05 ± 0.15 | 23 M | 2020 |
| VGG_VD16 + SAFF [57] | 84.38 ± 0.19 | 84.23 ± 0.23 | 87.86 ± 0.14 | 88.03 ± 0.10 | 15 M | 2021 |
| VGG19 [62] | 81.34 ± 0.32 | 81.02 ± 0.64 | 83.57 ± 0.37 | 83.69 ± 0.23 | 19 M | 2020 |
| Inception V3 [62] | 85.46 ± 0.33 | 84.87 ± 0.15 | 87.75 ± 0.43 | 86.25 ± 0.45 | 45.37 M | 2020 |
| ResNet50 [62] | 86.23 ± 0.41 | 85.73 ± 0.28 | 88.93 ± 0.12 | 88.42 ± 0.16 | 25.61 M | 2020 |
| EfficientNet [58] | 78.57 ± 0.15 | 78.42 ± 0.18 | 81.83 ± 0.15 | 81.58 ± 1.19 | 65 M | 2020 |
| LiG with RBF kernel [61] | 90.23 ± 0.13 | 89.28 ± 0.32 | 93.25 ± 0.12 | 92.82 ± 0.64 | 2.07 M | 2020 |
| MSDFF [63] | 91.56 | 90.86 | 93.55 | 92.76 ± 0.35 | 15 M | 2020 |
| Contourlet CNN [50] | 85.93 ± 0.51 | 86.05 ± 0.26 | 89.57 ± 0.45 | 89.08 ± 0.25 | 12.6 M | 2020 |
| BMDF-LCNN (Proposed) | 91.65 ± 0.15 | 91.15 ± 0.10 | 93.57 ± 0.22 | 93.56 ± 0.35 | 6 M | 2021 |
| The Network Model | OA (20%) | Kappa (%) |
|---|---|---|
| VGG19 [62] | 83.57 | 82.17 |
| ResNet [62] | 88.93 | 87.61 |
| InceptionV3 [62] | 87.75 | 86.46 |
| EfficientNet [58] | 81.83 | 79.53 |
| LiG with RBF kernel [61] | 93.25 | 93.02 |
| Fine-tune MobileNet V2 [34] | 93.00 | 92.93 |
| BMDF-LCNN (Proposed) | 93.57 | 93.42 |
| Downsampling Method | OA (80/20UC) (%) | Kappa (80/20UC) | OA (50/50RSSCN) (%) | Kappa (50/50RSSCN) |
|---|---|---|---|---|
| CD | 99.29 | 99.15 | 94.56 | 94.30 |
| MD | 98.81 | 98.53 | 93.64 | 93.25 |
| Proposed | 99.53 | 99.50 | 97.86 | 97.50 |
| The Network Model | OA (%) | Number of Parameters | FLOPs |
|---|---|---|---|
| LCNN-BFF [41] | 94.64 | 6.1 M | 24.6 M |
| GoogLeNet [47] | 85.84 | 7 M | 1.5 G |
| CaffeNet [47] | 88.25 | 60.97 M | 715 M |
| VGG-VD-16 [47] | 87.18 | 138 M | 15.5 G |
| MobileNetV2 [34] | 94.71 | 3.5 M | 334 M |
| SE-MDPMNet [34] | 92.46 | 5.17 M | 3.27 G |
| Contourlet CNN [50] | 95.54 | 12.6 M | 2.1 G |
| BMDF-LCNN (Proposed) | 97.86 | 6 M | 24 M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, C.; Zhang, X.; Sun, J.; Wang, L. Remote Sensing Scene Image Classification Based on Dense Fusion of Multi-level Features. Remote Sens. 2021, 13, 4379. https://doi.org/10.3390/rs13214379
Shi C, Zhang X, Sun J, Wang L. Remote Sensing Scene Image Classification Based on Dense Fusion of Multi-level Features. Remote Sensing. 2021; 13(21):4379. https://doi.org/10.3390/rs13214379
Chicago/Turabian StyleShi, Cuiping, Xinlei Zhang, Jingwei Sun, and Liguo Wang. 2021. "Remote Sensing Scene Image Classification Based on Dense Fusion of Multi-level Features" Remote Sensing 13, no. 21: 4379. https://doi.org/10.3390/rs13214379
APA StyleShi, C., Zhang, X., Sun, J., & Wang, L. (2021). Remote Sensing Scene Image Classification Based on Dense Fusion of Multi-level Features. Remote Sensing, 13(21), 4379. https://doi.org/10.3390/rs13214379