Structured Object-Level Relational Reasoning CNN-Based Target Detection Algorithm in a Remote Sensing Image

Abstract
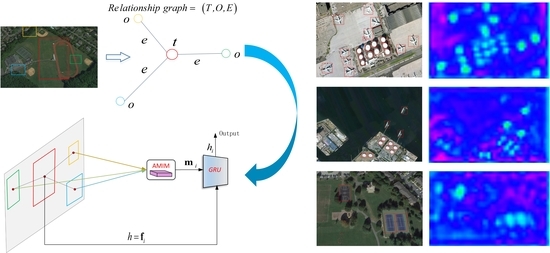
1. Introduction
2. Materials and Methods
2.1. Multi-Scale Local Context Region Proposal Network (MLC-RPN)
2.2. Object-Level Relationships Context-Based Target Detection Network (ORC-TDN)
2.2.1. Problem Statement
2.2.2. Attentional Message Integrated Module (AMIM)
2.2.3. Object Relational Structured Graph (ORSG)
2.2.4. Target Detection Process
| Algorithm 1: The target detection method for remote sensing images based on structured object-level relational reasoning. |
| Input: Remote sensing image dataset |
| Output: Bounding boxes and target category of multi-class targets |
| 1. Get ROIs (region proposals) through MLC-RPN. 1.1. Set: The feature map from conv3 , The feature map from conv5 1.2. Get the fused features 1.3. Perform convolution on and send it to the full connection layer. 1.4. Get ROIs |
| 2. The ROIs are fed to ORC-TDN. 2.1. Establish the ORSG and AMIM 2.2. ORSG includes node , node and edge , edge is determined by relative object feature and position in ROIs 2.3. Calculate the message from node to node through Formula (12)–(14) 2.4. Obtain the channel attention map and spatial attention map of through Formula (5)–(10). |
| 2.5. Obtain the integrated message of the object context through Formula (11) |
| 2.6. The context information and appearance feature of target are taken as the input of GRU. Obtain the output of GRU through (15). |
| 2.7. The output of GRU is fed into the full connection layer. 3. Obtain bounding boxes and target category of multi-class targets from the full connection layer of ORC-TDN. |
3. Results
3.1. Dataset Description and Experimental Settings
3.2. Evaluation Metrics
3.3. Target Detection Results on NWPU VHR-10 Dataset
3.4. Target Detection Results of the Collected Dataset
4. Discussion
4.1. Analysis of Multi-Scale Feature Settings
4.2. Analysis of MLC-RPN
4.3. Analysis of Structured Object-Level Relational Reasoning
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | convolutional neural network |
| DCIFF-CNN | diversified context information fusion framework based on convolutional neural network |
| MLC-RPN | multi-scale local context region proposal network |
| ORC-TDN | object-level relationships context target detection network |
| AMIM | attentional message integrated module |
| ORSG | object relational structured graph |
| TP | true positives |
| FP | false positives |
| FN | false negatives |
| AP | average precision |
| mAP | mean average precision |
| AC | accuracy ratio |
References
- Hu, Y.; Li, X.; Zhou, N.; Yang, L.; Peng, L.; Xiao, S. A Sample Update-Based Convolutional Neural Network Framework for Object Detection in Large-Area Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 947–951. [Google Scholar] [CrossRef]
- Yang, Y.; Zhuang, Y.; Bi, F.; Shi, H.; Xie, Y. M-FCN: Effective Fully Convolutional Network-Based Airplane Detection Framework. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1293–1297. [Google Scholar] [CrossRef]
- Zhu, M.; Xu, Y.; Ma, S.; Li, S.; Ma, H.; Han, Y. Effective Airplane Detection in Remote Sensing Images Based on Multilayer Feature Fusion and Improved Nonmaximal Suppression Algorithm. Remote Sens. 2019, 11, 1062. [Google Scholar] [CrossRef]
- Cheng, H.Y.; Weng, C.C.; Chen, Y.Y. Vehicle detection in aerial surveillance using dynamic Bayesian networks. IEEE Trans. Image Process. 2012, 21, 2152–2159. [Google Scholar] [CrossRef]
- Stankov, K.; He, D.-C. Detection of Buildings in Multispectral Very High Spatial Resolution Images Using the Percentage Occupancy Hit-or-Miss Transform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4069–4080. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Wolff, E. Very High Resolution Object-Based Land Use–Land Cover Urban Classification Using Extreme Gradient Boosting. IEEE Geosci. Remote Sens. Lett. 2018, 15, 607–611. [Google Scholar] [CrossRef]
- Zhang, T.; Huang, X. Monitoring of Urban Impervious Surfaces Using Time Series of High-Resolution Remote Sensing Images in Rapidly Urbanized Areas: A Case Study of Shenzhen. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2692–2708. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Chaudhuri, D.; Kushwaha, N.K.; Samal, A. Semi-Automated Road Detection From High Resolution Satellite Images by Directional Morphological Enhancement and Segmentation Techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1538–1544. [Google Scholar] [CrossRef]
- Stankov, K.; He, D.-C. Building Detection in Very High Spatial Resolution Multispectral Images Using the Hit-or-Miss Transform. IEEE Geosci. Remote Sens. Lett. 2013, 10, 86–90. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Cheng, X.; Chen, W.; Chen, G.; Liu, S. Identification of Forested Landslides Using LiDar Data, Object-based Image Analysis, and Machine Learning Algorithms. Remote Sens. 2015, 7, 9705–9726. [Google Scholar] [CrossRef]
- Leninisha, S.; Vani, K. Water flow based geometric active deformable model for road network. ISPRS J. Photogramm. Remote Sens. 2015, 102, 140–147. [Google Scholar] [CrossRef]
- Ok, A.O.; Senaras, C.; Yuksel, B. Automated Detection of Arbitrarily Shaped Buildings in Complex Environments From Monocular VHR Optical Satellite Imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1701–1717. [Google Scholar] [CrossRef]
- Ok, A.O. Automated detection of buildings from single VHR multispectral images using shadow information and graph cuts. ISPRS J. Photogramm. Remote Sens. 2013, 86, 21–40. [Google Scholar] [CrossRef]
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int. J. Remote Sens. 2012, 34, 45–59. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Liu, Z.; Bu, S.; Ren, J. Effective and Efficient Midlevel Visual Elements-Oriented Land-Use Classification Using VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4238–4249. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Scalable multi-class geospatial object detection in high-spatial-resolution remote sensing images. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014. [Google Scholar]
- Yu, L.; Xian, S.; Hongqi, W.; Hao, S.; Xiangjuan, L. Automatic Target Detection in High-Resolution Remote Sensing Images Using a Contour-Based Spatial Model. IEEE Geosci. Remote Sens. Lett. 2012, 9, 886–890. [Google Scholar]
- Bai, X.; Zhang, X.; Zhou, J. VHR Object Detection Based on Structural Feature Extraction and Query Expansion. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6508–6520. [Google Scholar]
- Dingwen, Z.; Junwei, H.; Gong, C.; Zhenbao, L.; Shuhui, B.; Lei, G. Weakly Supervised Learning for Target Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 701–705. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Qian, X.; Zhou, P.; Yao, X.; Hu, X. Object detection in remote sensing imagery using a discriminatively trained mixture model. ISPRS J. Photogramm. Remote Sens. 2013, 85, 32–43. [Google Scholar] [CrossRef]
- Tao, C.; Tan, Y.; Cai, H.; Tian, J. Airport Detection from Large IKONOS Images Using Clustered SIFT Keypoints and Region Information. IEEE Geosci. Remote Sens. Lett. 2011, 8, 128–132. [Google Scholar] [CrossRef]
- Eikvil, L.; Aurdal, L.; Koren, H. Classification-based vehicle detection in high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2009, 64, 65–72. [Google Scholar] [CrossRef]
- Aytekin, Ö.; Zongur, U.; Halici, U. Texture-Based Airport Runway Detection. IEEE Geosci. Remote Sens. Lett. 2013, 10, 471–475. [Google Scholar] [CrossRef]
- De Morsier, F.; Tuia, D.; Borgeaud, M.; Gass, V.; Thiran, J.-P. Semi-Supervised Novelty Detection Using SVM Entire Solution Path. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1939–1950. [Google Scholar] [CrossRef]
- Das, S.; Mirnalinee, T.T.; Varghese, K. Use of Salient Features for the Design of a Multistage Framework to Extract Roads From High-Resolution Multispectral Satellite Images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Fukun, B.; Bocheng, Z.; Lining, G.; Mingming, B. A Visual Search Inspired Computational Model for Ship Detection in Optical Satellite Images. IEEE Geosci. Remote Sens. Lett. 2012, 9, 749–753. [Google Scholar] [CrossRef]
- Ma, L.; Crawford, M.M.; Tian, J. Local Manifold Learning-Based k-Nearest-Neighbor for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4099–4109. [Google Scholar] [CrossRef]
- Blanzieri, E.; Melgani, F. Nearest Neighbor Classification of Remote Sensing Images with the Maximal Margin Principle. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1804–1811. [Google Scholar] [CrossRef]
- Tuermer, S.; Kurz, F.; Reinartz, P.; Stilla, U. Airborne Vehicle Detection in Dense Urban Areas Using HoG Features and Disparity Maps. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2327–2337. [Google Scholar] [CrossRef]
- Zhenwei, S.; Xinran, Y.; Zhiguo, J.; Bo, L. Ship Detection in High-Resolution Optical Imagery Based on Anomaly Detector and Local Shape Feature. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4511–4523. [Google Scholar] [CrossRef]
- Leitloff, J.; Hinz, S.; Stilla, U. Vehicle Detection in Very High Resolution Satellite Images of City Areas. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2795–2806. [Google Scholar] [CrossRef]
- Wegner, J.D.; Hansch, R.; Thiele, A.; Soergel, U. Building Detection from One Orthophoto and High-Resolution InSAR Data Using Conditional Random Fields. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 83–91. [Google Scholar] [CrossRef]
- Li, E.; Femiani, J.; Xu, S.; Zhang, X.; Wonka, P. Robust Rooftop Extraction from Visible Band Images Using Higher Order CRF. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4483–4495. [Google Scholar] [CrossRef]
- Lei, Z.; Fang, T.; Huo, H.; Li, D. Bi-Temporal Texton Forest for Land Cover Transition Detection on Remotely Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1227–1237. [Google Scholar] [CrossRef]
- Benedek, C.; Shadaydeh, M.; Kato, Z.; Szirányi, T.; Zerubia, J. Multilayer Markov Random Field models for change detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2015, 107, 22–37. [Google Scholar] [CrossRef]
- Dong, Y.; Du, B.; Zhang, L. Target Detection Based on Random Forest Metric Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1830–1838. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN-Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. In Computer Vision and Pattern Recognition; IEEE Press: Salt Lake City, UT, USA, 2018. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot Multi Box Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN:Object Detection via Region-based Fully Convolutional Networks. In Computer Vision and Pattern Recognition; IEEE Press: Las Vegas, Nevada, USA, 2016. [Google Scholar]
- Wang, C.; Bai, X.; Wang, S.; Zhou, J.; Ren, P. Multiscale Visual Attention Networks for Object Detection in VHR Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 310–314. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-Merged Single-Shot Detection for Multiscale Objects in Large-Scale Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3377–3390. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Ma, A.; Han, X.; Zhao, J.; Liu, Y.; Zhang, L. HyNet: Hyper-scale object detection network framework for multiple spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2020, 166, 1–14. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object Detection in Optical Remote Sensing Images Based on Weakly Supervised Learning and High-Level Feature Learning. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3325–3337. [Google Scholar] [CrossRef]
- Chen, Q.; Song, Z.; Dong, J.; Huang, Z.; Hua, Y.; Yan, S. Contextualizing Object Detection and Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 13–27. [Google Scholar] [CrossRef] [PubMed]
- Choi, M.J.; Lim, J.J.; Torralba, A.; Willsky, A.S. Exploiting Hierarchical Context on a Large Database of Object Categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; Volume 1, pp. 129–136. [Google Scholar]
- Liu, Y.; Wang, R.; Shan, S.; Chen, X. Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships. In Conference on Computer Vision and Pattern Recognition; IEEE Press: Salt Lake City, UT, USA, 2018; pp. 6985–6994. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-Outside Net-Detecting Objectsin Contextwith Skip Poolingand Recurrent Neural Networks. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Galleguillos, C.; Belongie, S. Context based object categorization: A critical survey. Comput. Vis. Image Underst. 2010, 114, 712–722. [Google Scholar] [CrossRef]
- Shrivastava, A.; Gupta, A. Contextual Priming and Feedback for Faster R-CNN. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Mottaghi, R.; Chen, X.; Liu, X.; Cho, N.-G.; Lee, S.-W.; Fidler, S.; Urtasun, R.; Yuille, A. The Role of Context for Object Detection and Semantic Segmentation in the Wild. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 891–898. [Google Scholar]
- Zeng, X.; Ouyang, W.; Yang, B.; Yan, J.; Wang, X. Gated Bi-directional CNN for Object Detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Li, J.; Wei, Y.; Liang, X.; Dong, J.; Xu, T.; Feng, J.; Yan, S. Attentive Contexts for Object Detection. IEEE Trans. Multimed. 2017, 19, 944–954. [Google Scholar] [CrossRef]
- Song, X.; Jiang, S.; Wang, B.; Chen, C.; Chena, G. Image Representations with Spatial Object-to-Object Relations for RGB-D Scene Recognition. IEEE Trans. Image Process. 2019, 29, 525–537. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Bahdanau, D. On the Properties of Neural Machine Translation: Encoder–Decoder approaches. In Proceedings of the Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation (SSST-8), Doha, Qatar, 25 October 2014. [Google Scholar]
- Xu, D.; Zhu, Y.; Chozy, C.B.; Fei-Fei, L. Scene Graph Generation by Iterative Message Passing. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Deng, Z.; Vahdat, A.; Hu, H.; Mori, G. Structure Inference Machines: Recurrent Neural Networks for Analyzing Relations in Group Activity Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4772–4781. [Google Scholar]
- Hu, H.; Zhou, G.-T.; Deng, Z.; Liao, Z.; Mori, G. Learning Structured Inference Neural Networks with Label Relations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA,, 27–30 June 2016. [Google Scholar]
- Seo, Y.; Defferrard, M.E.; Vandergheynst, P.; Bresson, X. Structured Sequence Modeling with Graph Convolutional Recurrent Networks. Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017.
- Marino, K.; Salakhutdinov, R.; Gupta, A. The More You Know: Using Knowledge Graphs for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 20–28. [Google Scholar]
- Fan, Q.; Zhuo, W.; Tang, C.-K.; Tai, Y.-W. Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhu, Y.; Zhao, C.; Guo, H.; Wang, J.; Zhao, X.; Lu, H. Attention CoupleNet: Fully Convolutional Attention Coupling Network for Object Detection. IEEE Trans. Image Process. 2019, 28, 113–126. [Google Scholar] [CrossRef]
- Song, K.; Yang, H.; Yin, Z. Multi-Scale Attention Deep Neural Network for Fast Accurate Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2972–2985. [Google Scholar] [CrossRef]
- Sanghyun, W.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Computer Vision and Pattern Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-J.M. YOLOv4 Optimal Speed and Accuracy of Object Detection. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Classes | Target Numbers (Pixels) | Target Sizes (Pixels) |
|---|---|---|
| Airplane | 757 | 50 × 77–104 × 117 |
| Ship | 302 | 20 × 40–30 × 52 |
| Storage tank | 655 | 27 × 22–61 × 51 |
| Baseball diamond | 390 | 66 × 70–109 × 129 |
| Tennis court | 524 | 45 × 54–122 × 127 |
| Basketball court | 159 | 52 × 52–179 × 179 |
| Ground track field | 163 | 195 × 152–344 × 307 |
| Harbor | 224 | 95 × 32–175 × 50 |
| Bridge | 124 | 88 × 90–370 × 401 |
| Vehicle | 477 | 20 × 41–45 × 80 |
| Target | Target Context | Image Size (Pixel) | Number of Targets |
|---|---|---|---|
| airplane | runway | 877 768 | 1500 |
| Ship | sea | 1104 740 | 1000 |
| Ship | river | 1104 740 | 1000 |
| car | road | 1280 720 | 1500 |
| Method | FRCNN-ZF | FRCNN-VGG | MSCNN | SSD | YOLO1 | YOLO2 | YOLO3 | DCIFF-CNN |
|---|---|---|---|---|---|---|---|---|
| Mean times(s) (Testing for per image) | 1.31 | 1.55 | 1.62 | 1.22 | 0.94 | 1.03 | 1.15 | 1.20 |
| Target | Index | FRCNN-ZF | FRCNN-VGG | YOLO4 | DCIFF-CNN |
|---|---|---|---|---|---|
| Airplane | AC | 76.93% (1154/1500) | 85.00% (1275/1500) | 87.20% (1308/1500) | 90.05% (1358/1500) |
| PR | 76.88% (1154/1501) | 85.40% (1275/1493) | 87.32% (1308/1498) | 92.57% (1358/1467) | |
| Ship | AC | 78.55% (1571/2000) | 81.05% (1621/2000) | 83.60% (1672/2000) | 88.60% (1772/2000) |
| PR | 76.90% (1571/2043) | 84.25% (1621/1924) | 84.32% (1672/1983) | 91.10% (1772/1945) | |
| Car | AC | 76.13% (1142/1500) | 83.07% (1246/1500) | 89.40% (1341/1500) | 89.07% (1336/1500) |
| PR | 70.06% (1142/1630) | 83.01% (1246/1501) | 89.88% (1341/1492) | 92.27% (1336/1488) |
| Multi-Scale Settings | MLC-RPN (Conv5) | MLC-RPN (Conv4 + Conv5) | MLC-RPN (Conv3 + Conv5) | MLC-RPN (Conv3 + Conv4 + Conv5) |
|---|---|---|---|---|
| Airplane | 0.9086 | 0.9083 | 0.9065 | 0.9063 |
| Ship | 0.8756 | 0.8754 | 0.8959 | 0.8954 |
| Storage tank | 0.8035 | 0.8010 | 0.8833 | 0.8866 |
| Baseball diamond | 0.9954 | 0.9959 | 0.9946 | 0.9946 |
| Tennis court | 0.9020 | 0.8992 | 0.9052 | 0.9051 |
| Basketball court | 0.8962 | 0.8970 | 0.8984 | 0.8984 |
| Ground track field | 0.9091 | 0.9972 | 0.9086 | 0.9086 |
| Harbor | 0.9047 | 0.9030 | 0.9083 | 0.9083 |
| Bridge | 0.8953 | 0.8994 | 0.9091 | 0.9091 |
| Vehicle | 0.8846 | 0.8791 | 0.8914 | 0.8893 |
| mAP | 0.8976 | 0.9056 | 0.9101 | 0.9102 |
| Method | Without ORSG and AMIM | With ORSG and Max-Pooling | With ORSG and Average Pooling | With ORSG and AMIM |
|---|---|---|---|---|
| mAP | 0.8682 | 0.8909 | 0.8979 | 0.9101 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, B.; Li, Z.; Xu, B.; Yao, X.; Ding, Z.; Qin, T. Structured Object-Level Relational Reasoning CNN-Based Target Detection Algorithm in a Remote Sensing Image. Remote Sens. 2021, 13, 281. https://doi.org/10.3390/rs13020281
Cheng B, Li Z, Xu B, Yao X, Ding Z, Qin T. Structured Object-Level Relational Reasoning CNN-Based Target Detection Algorithm in a Remote Sensing Image. Remote Sensing. 2021; 13(2):281. https://doi.org/10.3390/rs13020281
Chicago/Turabian StyleCheng, Bei, Zhengzhou Li, Bitong Xu, Xu Yao, Zhiquan Ding, and Tianqi Qin. 2021. "Structured Object-Level Relational Reasoning CNN-Based Target Detection Algorithm in a Remote Sensing Image" Remote Sensing 13, no. 2: 281. https://doi.org/10.3390/rs13020281
APA StyleCheng, B., Li, Z., Xu, B., Yao, X., Ding, Z., & Qin, T. (2021). Structured Object-Level Relational Reasoning CNN-Based Target Detection Algorithm in a Remote Sensing Image. Remote Sensing, 13(2), 281. https://doi.org/10.3390/rs13020281