AF-EMS Detector: Improve the Multi-Scale Detection Performance of the Anchor-Free Detector

 ,
,
Abstract
1. Introduction
- Methods using data preprocessing, which can be represented by multi-scale training and testing methods and algorithms such as SNIP [17] and SNIPER [18]. These methods leverage multi-scale image pyramids which have been proved useful in both hand-crafted feature-based methods and current CNN-based detection framework [19]. In the data preprocessing stage, these methods scale origin images to different sizes and send them to the network. Input images of different sizes ensure that objects of different sizes acquire sufficient training samples. SNIP and SNIPER improve the training strategy and simplify multi-scale object detection problems. They only detect objects in a specific scale range in input images with various sizes, and solve multi-scale problems without changing the network structure. However, these methods consume more computing and storage resources, and cannot be applied when resources are limited.
- Methods based on feature layer design, including Feature Pyramid Network (FPN), which is widely used to solve the problem of multi-scale object detection. Also, the method based on feature layer design is widely used in the field of remote sensing object detection. In [20], Zhang et al. indicate that the commonly used ResNet [21] detection backbone structure reduces the spatial resolution of deep feature maps, which makes the information inevitably weaker and affects the detection of small objects. Therefore, they proposed a new DetNet-FPN to effectively enhance the feature representation ability. To obtain better multi-scale feature representation, Fu et al. propose a new feature fusion structure in [5] and use bottom-up or top-down paths to combine different information into each level of feature maps.
- Methods based on the design and selection of the candidate region, including face detection algorithms such as S3FD [22] and DSFD [23], and some multi-class object detection method used in remote sensing imagery [24,25]. In order to effectively detect targets of different sizes in images, this type of methods promote targets of different sizes to obtain more accurate anchors in the process of network training, and this improves the algorithm’s multi-scale detection performance.
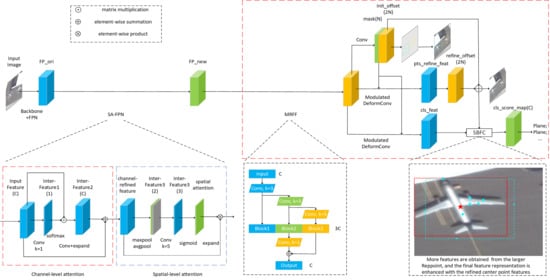
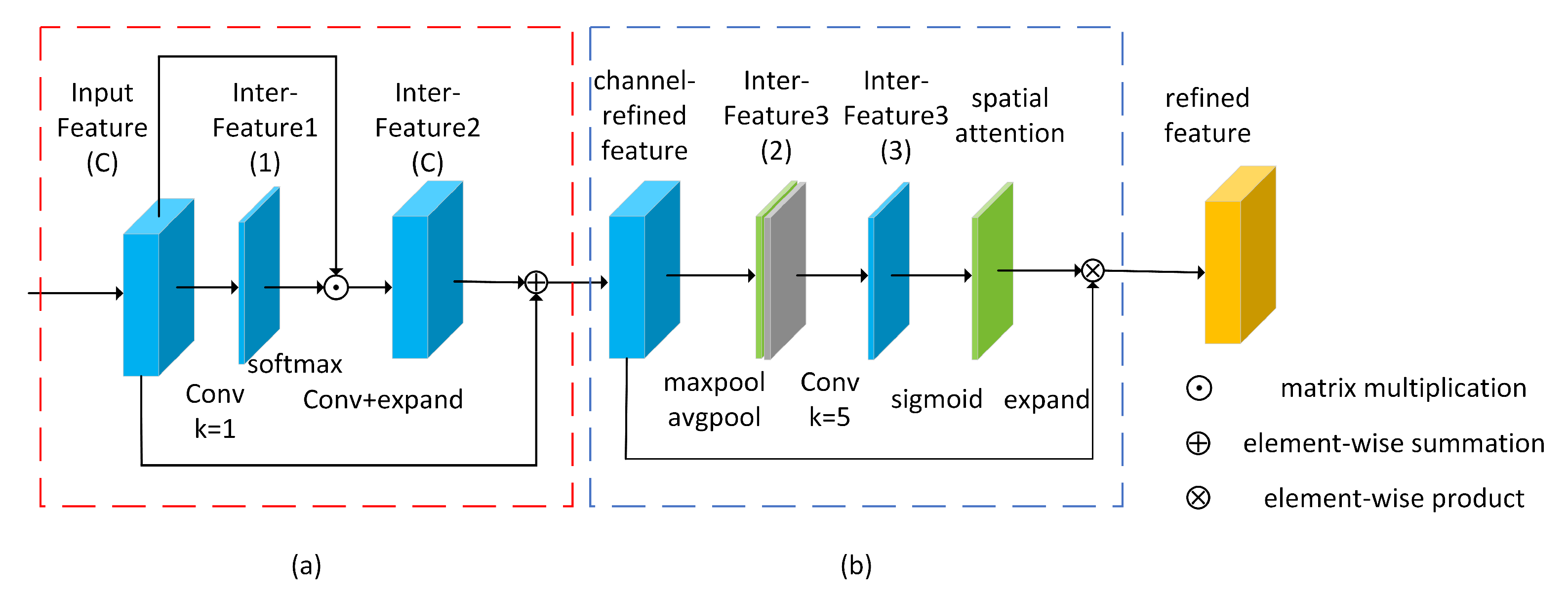
- We analyze the suitable attention mechanisms on feature map layers of different sizes, and combine actual experiment results to obtain a feature pyramid (SA-FPN) that is more suitable for multi-scale object detection.
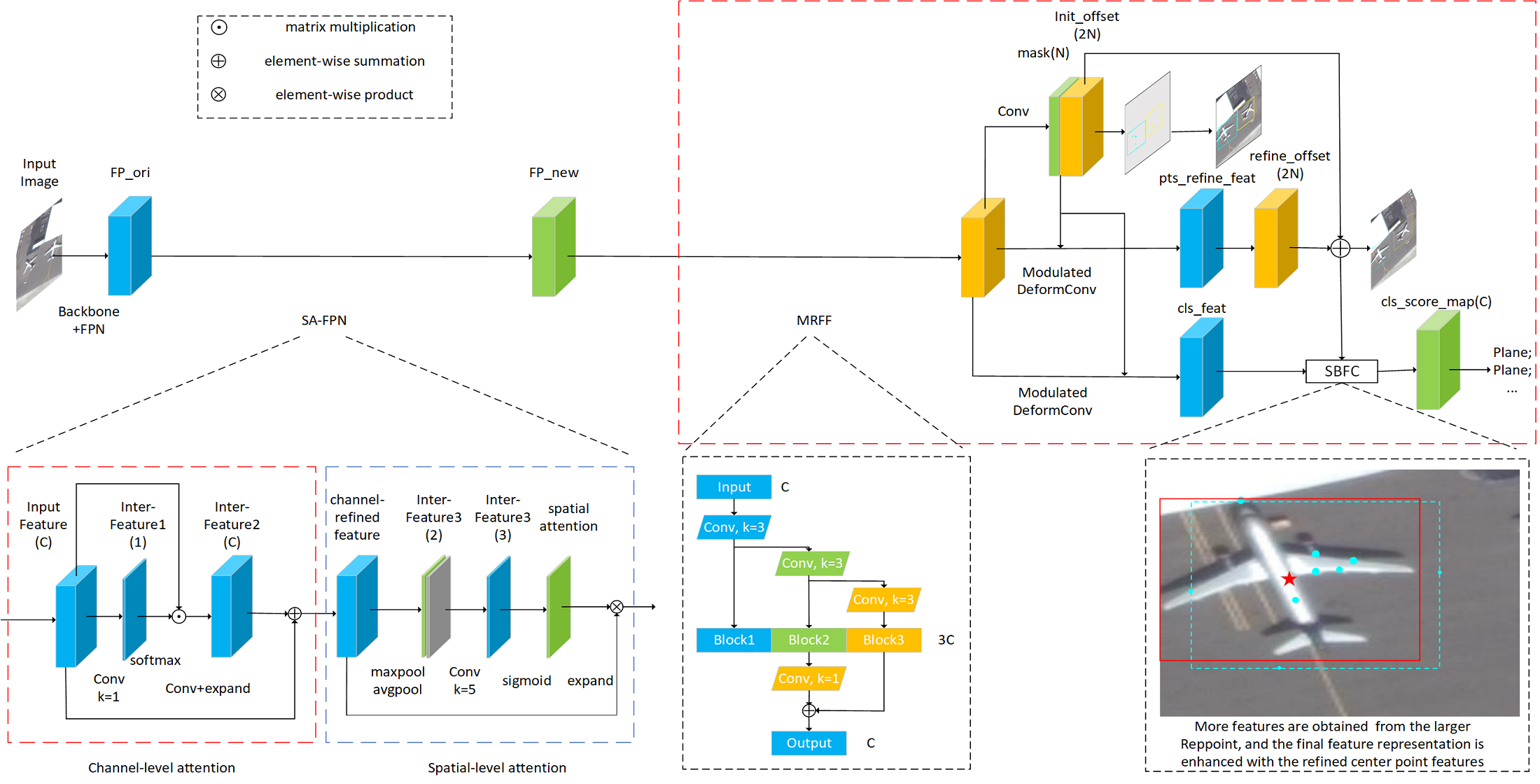
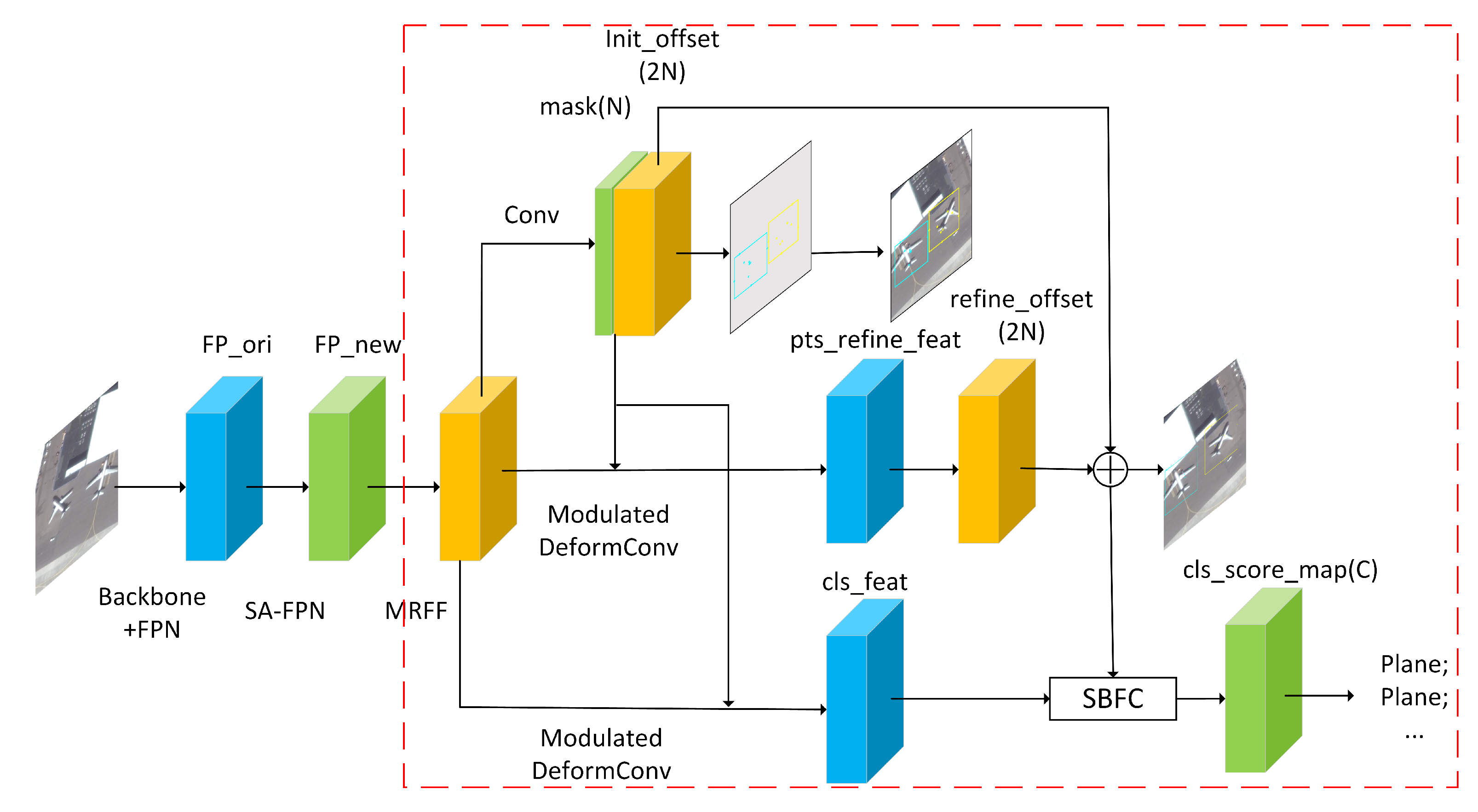
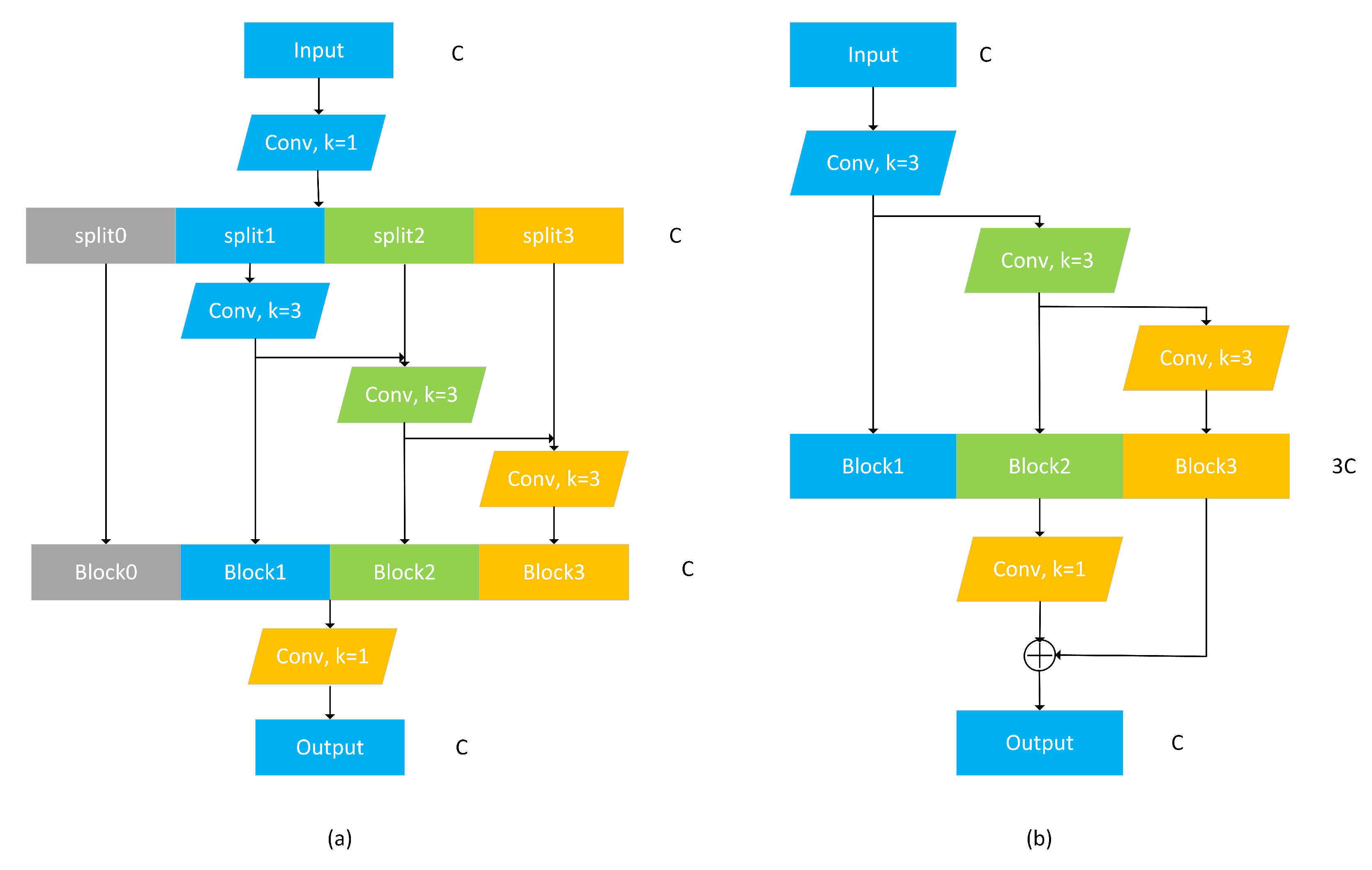
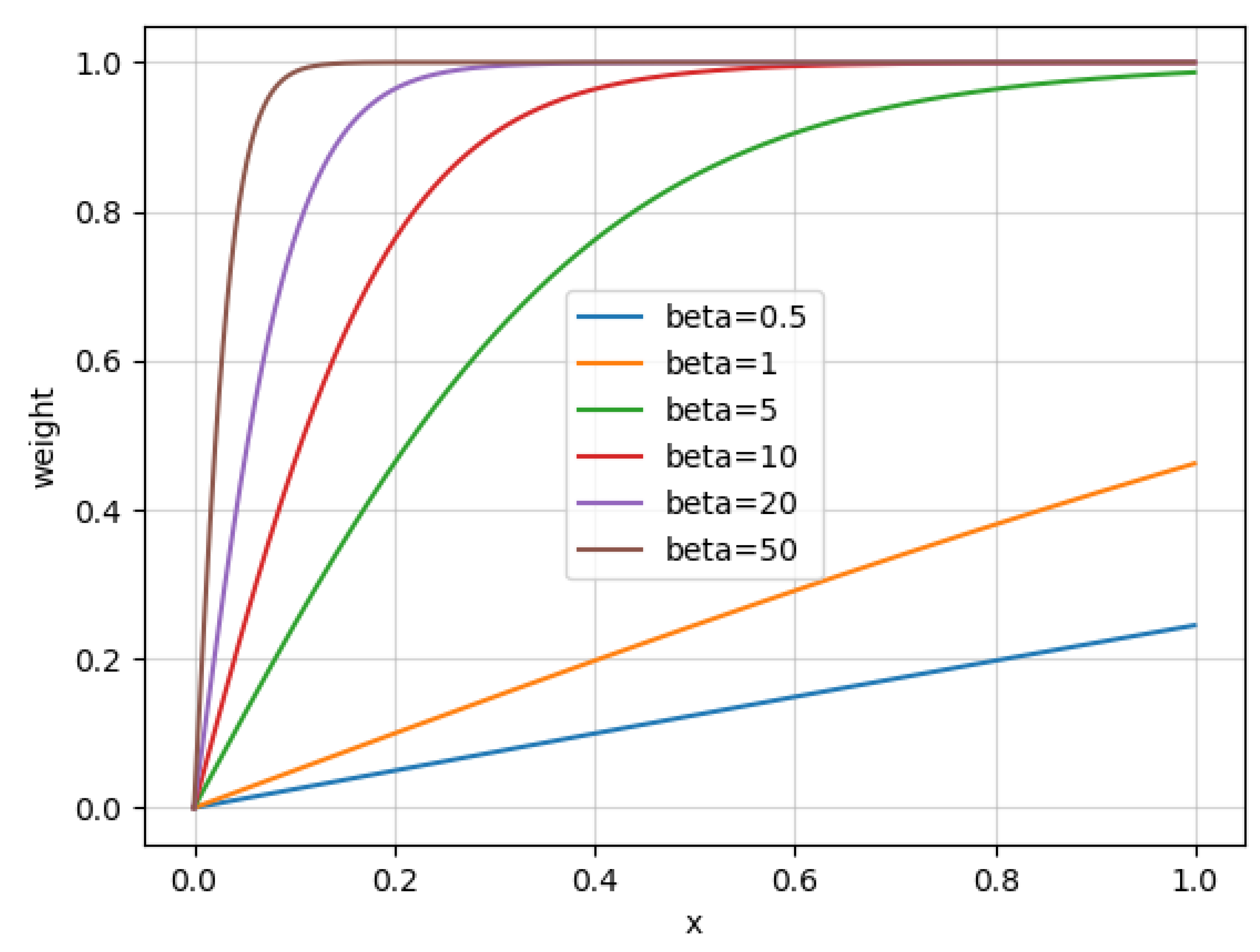
- To obtain better multi-scale feature expression, we design the MRFF module to replace the original stacked convolution structure in the detection head. With this modification, the model can perform more refined multi-scale features for objects corresponding to the same feature map layer. In addition, we propose a feature compensation module SBFC, which can be weighted based on object size, to solve the problem that the anchor-free algorithm is insufficient to express the objects in the corresponding area based on the features on their key points. Combining with the differences in feature extraction of objects in different sizes, the model can express objects in the candidate regions more effectively.
- Experiments on three challenging datasets show that our approach performs favorably against the baseline methods in terms of the popular evaluation metrics. In addition, our Anchor-Free Enhance Multi-Scale (AF-EMS) detector can get better multi-scale detection performance consistently when it is used on datasets of different distributions without any modification, which verifies the generalization and transferability of the proposed method.
2. Related Work
3. Method
3.1. SA-FPN
3.2. Scale-Aware Detection Head
3.2.1. MRFF
3.2.2. SBFC
4. Experiment and Results
4.1. Datasets and Evaluation
4.2. Ablation Experiments
4.2.1. Specific Attention FPN Module
4.2.2. Scale-Aware Detection Head
4.2.3. Size-Based Feature Compensation
4.2.4. Parameters and the Detection Speed
4.3. Comparison with State-of-the-Art Methods
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FPN | Feature Pyramid Network |
| IoU | Intersection-over-Union |
| SA-FPN | Specific-Attention FPN |
| MRFF | Multi-Receptive Feature Fusion |
| SBFC | Size-based Feature Compensation |
References
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 2015 International Conference on Learning Representations (ICLR), Santiago, Chile, 7–9 May 2015. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. Comput. Vis. Pattern Recognit. 2016. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Pietikinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Kun, F.; Zhonghan, C.; Yue, Z.; Guangluan, X.; Keshu, Z.; Xian, S. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Yi, L.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets v2: More Deformable, Better Results. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9308–9316. [Google Scholar]
- Yang, X.; Sun, H.; Sun, X.; Yan, M.; Guo, Z.; Fu, K. Position Detection and Direction Prediction for Arbitrary-Oriented Ships via Multitask Rotation Region Convolutional Neural Network. IEEE Access 2018, 6, 50839–50849. [Google Scholar] [CrossRef]
- Yang, X.; Liu, Q.; Yan, J.; Li, A. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), Virtual Conference, 2–9 February 2021; Available online: https://aaai.org/Conferences/AAAI-21/ (accessed on 23 November 2020).
- Prasomphan, S.; Tathong, T.; Charoenprateepkit, P. Traffic Sign Detection for Panoramic Images Using Convolution Neural Network Technique. In Proceedings of the the 2019 3rd High Performance Computing and Cluster Technologies Conference, Guangzhou, China, 22–24 June 2019; pp. 128–133. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point Set Representation for Object Detection. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9657–9666. [Google Scholar]
- Singh, B.; Davis, L.S. An Analysis of Scale Invariance in Object Detection-SNIP. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3578–3587. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient Multi-Scale Training. In Proceedings of the Thirty-second Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 2–8 February 2018; pp. 9333–9343. [Google Scholar]
- Chen, Z.; Wu, K.; Li, Y.; Wang, M.; Li, W. SSD-MSN: An Improved Multi-Scale Object Detection Network Based on SSD. IEEE Access 2019, 7, 80622–80632. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, Y.; Liu, X.; Lv, B.; Wang, J. Adaptive Anchor Networks for Multi-Scale Object Detection in Remote Sensing Images. IEEE Access 2020, 8, 57552–57565. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. S3FD: Single Shot Scale-invariant Face Detector. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 192–201. [Google Scholar]
- Li, J.; Wang, Y.; Wang, C.; Tai, Y.; Qian, J.; Yang, J.; Huang, F. DSFD: Dual Shot Face Detector. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5055–5064. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Xian, S.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Yan, J.; Wang, H.; Yan, M.; Diao, W.; Sun, X.; Li, H. IoU-Adaptive Deformable R-CNN: Make Full Use of IoU for Multi-Class Object Detection in Remote Sensing Imagery. Remote Sens. 2019, 11, 286. [Google Scholar] [CrossRef]
- Tychsen-Smith, L.; Petersson, L. DeNet: Scalable Real-Time Object Detection with Directed Sparse Sampling. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 428–436. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; Loy, C.C.; Lin, D. Region Proposal by Guided Anchoring. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2965–2974. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Laurens, V.D.M.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the 2016 International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-Aware Trident Networks for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Gao, S.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Torr, P.H.S. Res2Net: A New Multi-scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Cai, L.; Chen, Y.; Ling, H. M2Det: A Single-Shot Object detector based on Multi-Level Feature Pyramid Network. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 821–830. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Yan, J.; Zhang, Y.; Chang, Z.; Zhang, T.; Sun, X. FAS-Net: Construct Effective Features Adaptively for Multi-Scale Object Detection. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.J.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Korner, M.; Reinartz, P. Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery. In Proceedings of the 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 150–165. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neck Structure | mAP | |||
|---|---|---|---|---|
| FPN | 44.99 | 72.14 | 72.01 | 68.02 |
| FPN+SNL | 45.54 | 72.11 | 73.21 | 68.17 |
| FPN+CBAM | 44.57 | 72.15 | 73.36 | 68.23 |
| FPN+CBAMv2 | 45.10 | 72.34 | 73.98 | 68.65 |
| SA-FPN | 47.36 | 72.48 | 73.63 | 68.77 |
| Method | Plane | BD | Bridge | GTF | SV | LV | Ship | TC |
|---|---|---|---|---|---|---|---|---|
| baseline | 92.29 | 71.00 | 48.70 | 64.16 | 48.22 | 74.71 | 91.29 | 91.56 |
| baseline+MRFF | 91.98 | 73.74 | 48.75 | 66.07 | 50.32 | 74.76 | 91.56 | 91.31 |
| baseline+DCNv2 | 90.97 | 68.69 | 52.61 | 68.05 | 48.98 | 74.31 | 90.43 | 91.07 |
| baseline+DCNv2+SBFC | 92.46 | 73.65 | 49.33 | 63.39 | 50.22 | 74.59 | 90.54 | 92.12 |
| baseline+scale-aware detection head | 93.11 | 73.70 | 48.95 | 63.03 | 50.85 | 75.65 | 91.54 | 92.57 |
| Method | BC | ST | SBF | RA | harbor | SP | HC | mAP |
| baseline | 50.74 | 71.64 | 46.78 | 65.85 | 79.97 | 67.27 | 56.18 | 68.02 |
| baseline+MRFF | 53.86 | 72.44 | 49.29 | 66.24 | 80.97 | 68.48 | 51.38 | 68.74 |
| baseline+DCNv2 | 54.60 | 70.14 | 47.32 | 69.46 | 79.81 | 68.64 | 51.16 | 68.42 |
| baseline+DCNv2+SBFC | 53.98 | 73.12 | 47.34 | 66.20 | 80.23 | 66.90 | 60.30 | 68.96 |
| baseline+scale-aware detection head | 59.29 | 73.17 | 49.87 | 69.00 | 81.79 | 66.99 | 58.33 | 69.86 |
| SBFC | mAP | |||
|---|---|---|---|---|
| None | 45.55 | 64.77 | 85.92 | 81.16 |
| V1 | 42.89 | 65.23 | 86.40 | 81.71 |
| V2 | 45.37 | 66.12 | 87.07 | 82.17 |
| V3 | 45.45 | 68.09 | 86.45 | 82.19 |
| V4 | 49.53 | 66.27 | 86.76 | 82.36 |
| mAP | ||||
|---|---|---|---|---|
| 0.5 | 42.76 | 65.75 | 87.03 | 82.41 |
| 1 | 49.67 | 65.53 | 87.24 | 82.46 |
| 20 | 49.44 | 64.82 | 86.92 | 82.16 |
| 35 | 49.53 | 66.27 | 86.76 | 82.36 |
| 50 | 50.28 | 65.34 | 86.53 | 82.13 |
| 100 | 44.55 | 65.32 | 86.41 | 81.85 |
| Detector | Parameters (M) | Detection Speed (FPS) | mAP |
|---|---|---|---|
| Faster-RCNN | 41.20 | 8.60 | 68.62 |
| RPDet | 36.61 | 14.80 | 68.02 |
| RPDet+Res101backbone | 55.60 | 9.30 | 68.57 |
| AF-EMS | 37.61 | 12.50 | 70.32 |
| AP0.5 | ||||
|---|---|---|---|---|
| baseline | 45.55 | 64.77 | 85.92 | 81.16 |
| AF-EMS | 50.19 | 70.10 | 89.13 | 84.83 |
| mAP | AP0.5 | AP0.75 | ||||
|---|---|---|---|---|---|---|
| baseline | 21.31 | 40.2 | 49.02 | 36.86 | 56.62 | 39.55 |
| AF-EMS | 22.29 | 41.3 | 49.46 | 37.62 | 58.35 | 40.49 |
| Method | YOLOv2 | SSD | Faster R-CNN | RFCN | Azimi et al. [49] | Yan et al. [25] | RPDet | AF-EMS |
|---|---|---|---|---|---|---|---|---|
| Plane | 76.53 | 57.85 | 79.36 | 81.63 | 90.00 | 88.62 | 88.53 | 89.89 |
| BD | 34.26 | 32.78 | 79.32 | 78.69 | 77.71 | 80.22 | 73.94 | 77.45 |
| Bridge | 25.35 | 16.39 | 39.32 | 36.85 | 53.38 | 53.18 | 54.40 | 54.61 |
| GTF | 34.58 | 19.35 | 68.42 | 72.48 | 73.26 | 66.97 | 70.36 | 65.11 |
| SV | 36.58 | 7.36 | 62.14 | 59.60 | 73.46 | 76.30 | 54.35 | 66.05 |
| LV | 32.24 | 37.35 | 58.32 | 53.66 | 65.02 | 72.59 | 76.83 | 80.12 |
| Ship | 53.24 | 25.63 | 57.10 | 56.36 | 78.22 | 84.07 | 85.25 | 87.00 |
| TC | 61.65 | 81.14 | 89.36 | 92.70 | 90.79 | 90.66 | 90.87 | 90.88 |
| BC | 48.52 | 28.47 | 69.65 | 80.10 | 79.05 | 80.95 | 75.06 | 82.87 |
| ST | 35.54 | 48.35 | 59.12 | 67.58 | 84.81 | 86.50 | 80.74 | 85.92 |
| SBF | 28.94 | 15.36 | 59.23 | 67.32 | 57.20 | 57.12 | 56.87 | 60.89 |
| RA | 36.14 | 36.25 | 54.53 | 63.74 | 62.11 | 66.65 | 41.55 | 44.47 |
| harbor | 37.25 | 14.35 | 57.32 | 65.81 | 73.45 | 74.08 | 76.75 | 77.62 |
| SP | 38.21 | 9.36 | 56.23 | 63.29 | 70.22 | 66.36 | 65.63 | 75.20 |
| HC | 10.37 | 9.87 | 49.52 | 59.36 | 58.08 | 56.85 | 52.95 | 71.53 |
| mAP | 39.29 | 29.32 | 62.60 | 66.60 | 72.45 | 72.72 | 69.61 | 73.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, J.; Zhao, L.; Diao, W.; Wang, H.; Sun, X. AF-EMS Detector: Improve the Multi-Scale Detection Performance of the Anchor-Free Detector. Remote Sens. 2021, 13, 160. https://doi.org/10.3390/rs13020160
Yan J, Zhao L, Diao W, Wang H, Sun X. AF-EMS Detector: Improve the Multi-Scale Detection Performance of the Anchor-Free Detector. Remote Sensing. 2021; 13(2):160. https://doi.org/10.3390/rs13020160
Chicago/Turabian StyleYan, Jiangqiao, Liangjin Zhao, Wenhui Diao, Hongqi Wang, and Xian Sun. 2021. "AF-EMS Detector: Improve the Multi-Scale Detection Performance of the Anchor-Free Detector" Remote Sensing 13, no. 2: 160. https://doi.org/10.3390/rs13020160
APA StyleYan, J., Zhao, L., Diao, W., Wang, H., & Sun, X. (2021). AF-EMS Detector: Improve the Multi-Scale Detection Performance of the Anchor-Free Detector. Remote Sensing, 13(2), 160. https://doi.org/10.3390/rs13020160