Abstract
Deep neural networks have underpinned much of the recent progress in the field of hyperspectral image (HSI) classification owing to their powerful ability to learn discriminative features. However, training a deep neural network often requires the availability of a large number of labeled samples to mitigate over-fitting, and these labeled samples are not always available in practical applications. To adapt the deep neural network-based HSI classification approach to cases in which only a very limited number of labeled samples (i.e., few or even only one labeled sample) are provided, we propose a novel few-shot deep learning framework for HSI classification. In order to mitigate over-fitting, the framework borrows supervision from an auxiliary set of unlabeled samples with soft pseudo-labels to assist the training of the feature extractor on few labeled samples. By considering each labeled sample as a reference agent, the soft pseudo-label is assigned by computing the distances between the unlabeled sample and all agents. To demonstrate the effectiveness of the proposed method, we evaluate it on three benchmark HSI classification datasets. The results indicate that our method achieves better performance relative to existing competitors in few-shot and one-shot settings.
1. Introduction
Hyperspectral images (HSIs) collect the continuous reflectance of the imaging scene under a wide spectral range, which is often represented as a three-dimensional (3D) data cube and consists of hundreds of narrow spectral bands with a high spectral resolution [1]. Because they contain abundant spectral information, HSIs have been widely employed in many remote sensing-related applications [1,2,3,4,5,6], including environmental monitoring, target localization, military surveillance, and terrain classification, etc.
Among the various HSI-related applications, one of the most essential tasks is HSI classification, which aims at assigning a predefined class label to each pixel. Although many conventional machine learning-based methods, e.g., support vector machine (SVM) and k-nearest neighbors ( NN) [7] etc., have been proposed for HSI classification, the inherently shallow structures of their feature extraction models prevent these methods from learning discriminative features, as well as from appropriately generalizing to challenging cases. As a result, performance may be further improved. Other mathematics based methods are also used in the HSI classification tasks with effective results [8,9].
Unlike conventional machine learning-based methods, deep neural networks can cast feature representation and classifier construction to train an end-to-end hierarchical network with labeled samples. Due to their deep structures, deep neural networks have the powerful ability to learn discriminative features for classification [10,11,12,13,14,15]. To date, extensive deep neural network-based methods for HSI classification [16,17,18,19,20,21] have been proposed and have achieved promising classification performance. For example, Liang et al. [16] propose extracting the deep feature representation of the samples using a stacked denoising auto encoder (SDAE), which is learned without supervision, to then predict the label of samples with a trained back-propagation network under supervision. In [18], Lakhal et al. introduce a deep recurrent neural network that incorporates high-level feature descriptors to tackle the challenging HSI classification problem. After witnessing the success of deep convolution neural networks (DCNNs) in various computer vision tasks [22,23], an increasing number of deep HSI classification methods have adopted the DCNN structure as their backbone. For example, Chen et al. [22] employed several 3D convolutional and pooling layers for deep feature extraction. Moreover, several other strategies to mitigate over-fitting, such as regularization and dropout, have been investigated. In [23], Gong et al. propose integrating the DCNN with multi-scale convolution with determinantal point process-based diversity-promoting deep metrics to obtain discriminative features for HSI classification. Recent progress has shown that due to the gradient vanishing problem, it is difficult to train a deep neural network as the network depth increases. To address this problem, He et al. [24] proposed a novel residual learning structure that can successfully mitigate the gradient vanishing problem. Inspired by this, many recent HSI classification methods have also begun to take advantage of residual learning for training deeper neural networks. For example, Zhang et al. [25] employed a 3D densely connected convolutional neural network (3D-DenseNet) to learn the spectral-spatial features of HSIs for classification. With its densely connected structure, the deeper network can be easier to train. Zhong et al. [26] develop an end-to-end spectral-spatial residual network (SSRN) that takes raw 3D cubes as input data, then employs residual blocks to connect every other 3D convolutional layer through identity mapping for HSI classification purposes.
Compared with conventional machine learning-based HSI classification methods, deep neural network-based methods often achieve much better performance. In order to succeed, these approaches require the network to be trained with sufficient labeled samples. In the HSI classification task, labeled samples are obtained by manually annotating some samples in the given HSI data set with a set of predefined class labels. In practice, since manually annotating an HSI pixel is generally laborious, time-consuming, and can only be accomplished by experts, the labeled samples obtained are always insufficient or even deficient. In such cases, the trained networks are prone to be overfitting (i.e., fail to appropriately generalize to the unseen test samples). To alleviate this problem, some transfer learning-based methods [27,28,29] have been developed. These methods aim to train on an HSI dataset (i.e., source domain) and classify the pixels of same classes on another HSI dataset (i.e., target domain).
However, this kind of method requires a large number of labeled samples to be available in the source domain, which is still unfeasible for lots of applications. Thus, some methods [30,31,32] propose utilizing data augmentation to increase the number of labeled training samples on the given dataset (i.e., target domain), without relying on another, similar dataset (i.e., source domain). For example, in [30], Li et al. proposed to substantially increase the number of labeled training samples using a novel pixel-pair strategy, which combines two pixels (to form a pair of pixels) and then classifies the pixel-pair using a trained DCNN. Although methods of this kind can generate more labeled samples from the existing labeled ones, they rely heavily on those samples. Once the number of the labeled samples has been heavily limited (i.e., providing only one labeled sample per class), the labeled samples generated will still be insufficient to overcome the overfitting problem. Other methods emphasize the need to find a suitable way to use the unlabeled samples, since there are plenty of unlabeled samples in real applications. These methods are also denoted as semi-supervised methods [33,34,35,36,37,38,39]. Such methods have been explored in the context of conventional machine learning-based approaches. For example, Yang et al. [39] proposed a new spatio-spectral Laplacian support vector machine (SS-LapSVM) method for semi-supervised HSI classification, which utilizes a clustering assumption on spectral vectors and the neighborhood spatial constraints of the given HSI to formulate a manifold regularizer and a spatial regularizer separately. These regularizers are then utilized to regularize the classification results of the conventional SVM-based methods. Meanwhile, the semi-supervised methods have been applied in deep learning-based methods. The main idea of Zhu et al. [39] is based on an auxiliary classifier generative adversarial network (ACGAN) [40], which uses a generator that regards the label and noise information as input to create fake data in order to train the discriminator jointly with the labeled data. Liu et al. [38] proposed a multi-task framework based on a ladder network [41] that combines an encoder-decoder for utilizing the unlabeled data. Although the above methods can to some extent mitigate the problem resulting from insufficient labeled samples, few of them have attempted to deal with a more challenging deep learning-based HSI classification problem in which only a few or even only one labeled sample per class is provided for training. For simplicity, we refer to this problem as few-shot or one-shot HSI classification.
To adapt the deep neural network-based HSI classification method to cases with few or even only one labeled sample, we propose a novel few-shot deep learning framework for HSI classification, which aims to appropriately mitigate the overfitting problem resulting from a limitation in the number of labeled samples. To this end, we first revisit the HSI utilized for classification. More specifically, in HSI, there are a large number of unlabeled samples in addition to a few labeled ones. These unlabeled samples have underlying relations with the labeled samples (e.g., intra-class similarity or inter-class dissimilarity). Inspired by this observation, we propose to annotate these unlabeled samples with pseudo-labels by using their relation to the labeled samples as an auxiliary dataset, then incorporate this dataset into a joint learning framework in order to assist in training the network on a few labeled samples. In more detail, we first develop a new two-heads DCNN architecture in which the labeled and unlabeled samples share the same feature extractor sub-network, but two different classifier sub-networks (i.e., heads) to achieve classification on the few provided labeled samples and the auxiliary unlabeled dataset separately. To this end, by considering each labeled sample as a reference agent, we assign each unlabeled sample a soft pseudo-label by computing the distances between the unlabeled sample and all agents, which is a totally different approach from that adopted by the existing semi-supervised HSI classification method. Through joint learning on both labeled and unlabeled samples, the proposed framework automatically borrows the weak supervision from the unlabeled samples in order to enhance the supervision from the labeled samples for feature learning purposes, and thus appropriately mitigates overfitting. It is notable that the proposed framework provides a general learning framework, through the use of which any kind of deep neural network can be exploited as the feature extractor. With extensive experiments on three HSI classification benchmark datasets, the proposed method exhibits obvious superiority over existing competitors in few-shot and one-shot settings.
The main contributions of this study can be summarized as follows:
(1) We propose a novel few-shot deep learning framework for HSI classification, which borrows the supervision from the unlabeled samples to assist in training the deep neural network on a few labeled samples with a joint learning strategy.
(2) A soft pseudo-label learning method is proposed to assign soft pseudo-labels to unlabeled samples for joint learning.
(3) The proposed framework provides a general learning framework, with which any kind of deep neural network can be exploited as the feature extractor sub-network.
(4) The proposed method demonstrates state-of-the-art few-shot and one-shot HSI classification performance on three benchmark HSI classification datasets.
2. The Proposed Methods
2.1. The Proposed Few-Shot Deep Learning Framework
In this study, we denote the labeled training samples and unlabeled samples as and , respectively. denotes the -th -dimensional labeled sample, is the class label of and is the -th unlabeled sample.
In essence, the HSI classification method aims to learn a mapping function between the training sample and its label , then exploits the learned function to predict the label of the unlabeled sample . Since the deep neural network has a powerful non-linearity representation ability, it is suitable for building such a mapping function. Thus, large numbers of deep learning-based methods have been proposed for HSI classification, among which DCNNs and residual networks have attracted significant attention.
An important aspect underpinning the success of deep learning-based methods is the training of a deep neural network containing large numbers of parameters with sufficient training samples. However, due to the high cost of labeling in real applications, only a few labeled samples (i.e., is very small) or even only one labeled sample per class can be provided for network training, which results in the deep network overfitting, i.e., fails to appropriately generalize to the unseen test samples. It is therefore necessary to adapt the deep learning-based method to a few labeled training samples in real applications.
Although collecting labeled samples is difficult, a large number of unlabeled samples are always available (i.e., can be very large). More importantly, these unlabeled samples exhibit underlying relations to these labeled ones, such as intra-class similarity or inter-class dissimilarity, which inspires us to capture the underlying relations and exploit these relations for few-shot HSI classification. In more detail, we propose to exploit pseudo-labels to reflect such underlying relations, then annotate the unlabeled samples with those pseudo-labels, from which an auxiliary dataset containing pseudo-labels can be obtained (the details of this pseudo-label learning can be seen in Section 2.2). Based on the generated auxiliary dataset, we then borrow the supervision from the auxiliary unlabeled dataset to assist the feature in learning on a few labeled samples, which allows us to appropriately mitigate the overfitting problem.
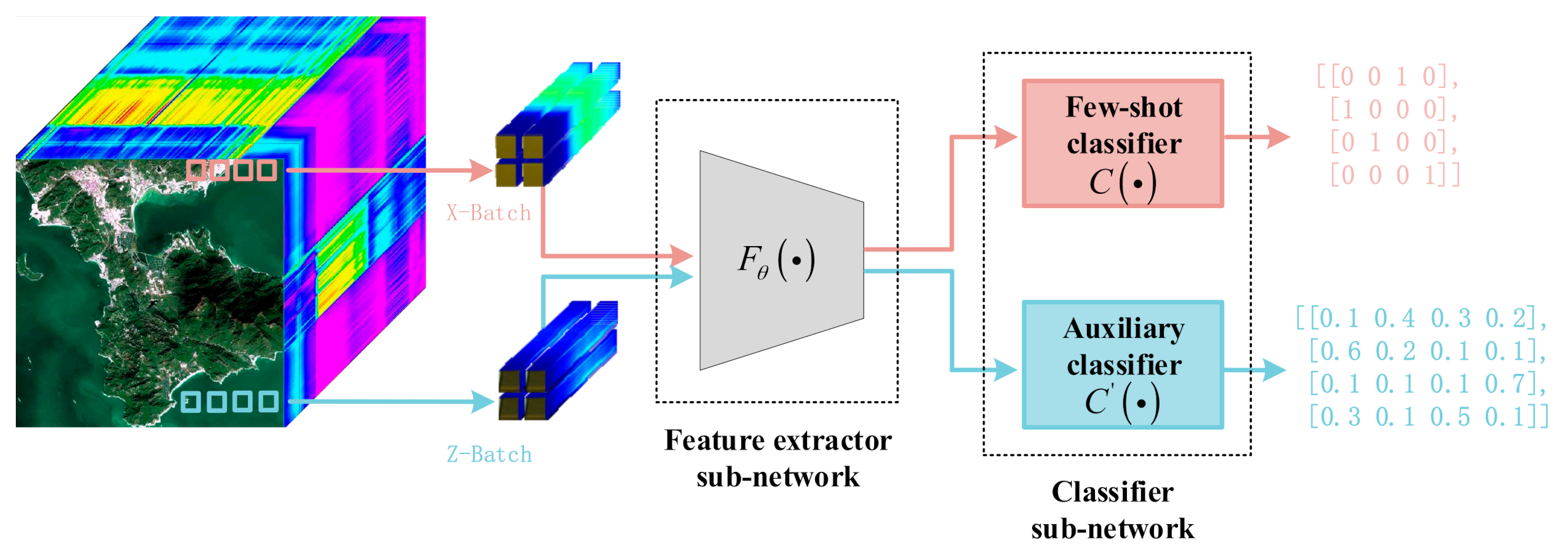
In line with this concept, we propose a two-heads few-shot deep learning framework, illustrated in Figure 1. Two different classifier sub-networks, and separately achieve classification on and , but share a common feature extractor sub-network , denotes the parameters in the feature extractor sub-network. For the classification branch on , the predicted label can be obtained as follows:
where denotes the predicted label for sample . In addition, for the classification branch on , the relationship between the pseudo-label and the sample is formulated as follows:
in which is the predicted label for the unlabeled sample .
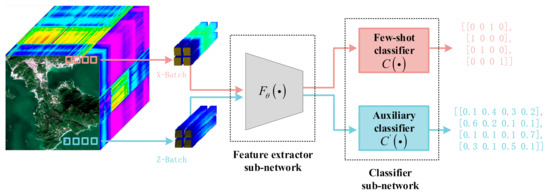
Figure 1.
Pipeline of the proposed two-branch few-shot deep learning framework for HSI classification.
We regard four samples as one batch just for convenience, though it is irrelevant to the real settings in experiments. Thanks to the shared feature extractor sub-network, both labeled and unlabeled samples are integrated into one framework, to which more samples are introduced in order to regularize the original few-shot supervised branch. Through joint learning the proposed network via a back-propagation algorithm, the supervision from the auxiliary unlabeled dataset is exploited to appropriately mitigate the overfitting problem resulting from the existence of few labeled samples, i.e., the auxiliary dataset acts as a regularizer that trains the feature extractor. The details of training the proposed model can be seen in Section 2.4.
It is notable that the proposed framework is a general learning framework, through the use of which any kind of deep neural network can be exploited as the feature extractor sub-network. In this paper, we use DCNNs and residual networks, two state-of-the-art network structures, to construct the extraction sub-network. The details are outlined in Section 2.3.
2.2. Soft Pseudo-Label Learning
The proposed framework is trained in a supervised manner using both the labeled and unlabeled samples with pseudo-labels. To achieve this, we require a suitable strategy that assigns a pseudo-label to each unlabeled sample. Some semi-supervised methods conduct clustering (e.g., -means algorithm) on the unlabeled samples to obtain the cluster labels [42], and the cluster labels are then exploited as the pseudo-labels. The -means method can only assign each unlabeled sample a specific unique cluster label that is equivalent to the hard label. For this reason, we use the resulting cluster labels obtained via -means clustering as the hard pseudo-labels. However, this simple strategy has a number of limitations. First, it ignores the relationship between the labeled samples. Second, the hard label cannot adequately represent samples in which the distance to one cluster center is closer than the distances to the other cluster centers. Thus, the classification performance of these methods using hard pseudo-labels is still limited, especially in the few-shot or one-shot setting.
In contrast to hard labels, soft labels have high entropy, and can thus convey more valuable information during the classification process. In addition, soft labels can lead to continuous gradients during network training, which is beneficial for convergence and mitigates the problem of the algorithm becoming trapped into bad local minima [43]. Inspired by this, we propose a soft pseudo-label learning method that operates by exploiting the underlying relation between the labeled and unlabeled sample. In particular, we conclude that specific underlying relations exist such as intra-class similarity and inter-class dissimilarity between the unlabeled sample and the labeled sample. Samples (labeled or not) that belong to the same class show high similarity, while samples (labeled or not) that belong to different classes exhibit obvious difference, and vice versa. Therefore, by considering each labeled sample as a reference agent, we can assign each unlabeled sample a soft pseudo-label by computing the distances between the unlabeled sample and all agents.
In more detail, taking an unlabeled sample as an example, we generate its soft pseudo-label as follows. Firstly, each labeled sample is adopted as an agent, i.e.,
in which denotes the -th training sample from -th class. We then compute the distances between the unlabeled sample and all agents as follows:
Here, is the distance between the agent and the unlabeled sample , which is calculated via the similarity function . For simplicity, we utilize the Euclidean distance as the function , the features used in the function are the original pixel of the HSI. From the distances between and all agents in class , we select the one with the smallest distance as the reference agent in the -th class as follows:
Then, the -th element of pseudo-label can thus be obtained via
By applying the same operations on all classes, the soft pseudo-label of the unlabeled sample can be finally represented as:
It should be noted that all labeled samples of each class are exploited as agents in the proposed method. Although we can average the labeled samples to create a representative agent, this averaging strategy is likely to impair the underlying relation to some extent. For example, some samples are more similar to a specific agent than the average agent, and thus degrade the performance of the proposed method. The experimental results can be seen from the ablation study in Section 3.4.
2.3. The Architecture of the Adopted Feature Extractor Sub-Network and Classifier Sub-Network
Figure 1 illustrates the pipeline of the proposed two-heads few-shot deep learning framework, which includes one shared-feature extractor sub-network, one few-shot classifier sub-network for labeled data, and one auxiliary classifier sub-network for unlabeled data with soft pseudo-labels. Because both labeled and unlabeled data are utilized for training, the proposed method can be seen as a semi-supervised deep learning method. If we utilized a feature extractor sub-network and a few-shot classifier sub-network only within the proposed framework, the proposed framework would degenerate into a standardly used supervised deep learning method. Thus, by comparing the proposed method with its supervised counterpart (i.e., utilizing the feature extractor sub-network and few-shot classifier sub-network only), the advantage of introducing unlabeled data for HSI classification can be observed. For this reason, we refer to the supervised counterpart as the backbone. It is notable that the proposed network is a two-head network structure, while its supervised counterpart is a one-head network structure (with a few-shot classifier sub-network, but without an auxiliary classifier sub-network).
The proposed framework is a general learning framework, which enables any kind of deep neural network to be exploited as the feature extractor sub-network. In various applications, to demonstrate the adaptability of the proposed framework to different network structures, two network structures that are widely used for HSI classification (i.e., 3D-CNN and SSRN) are adopted as the feature extraction sub-network. It is notable that the structure of the classifier sub-network (i.e., the heads) is fixed because it is rather simple (i.e., the classifier sub-network is implemented via a fully connected layer).
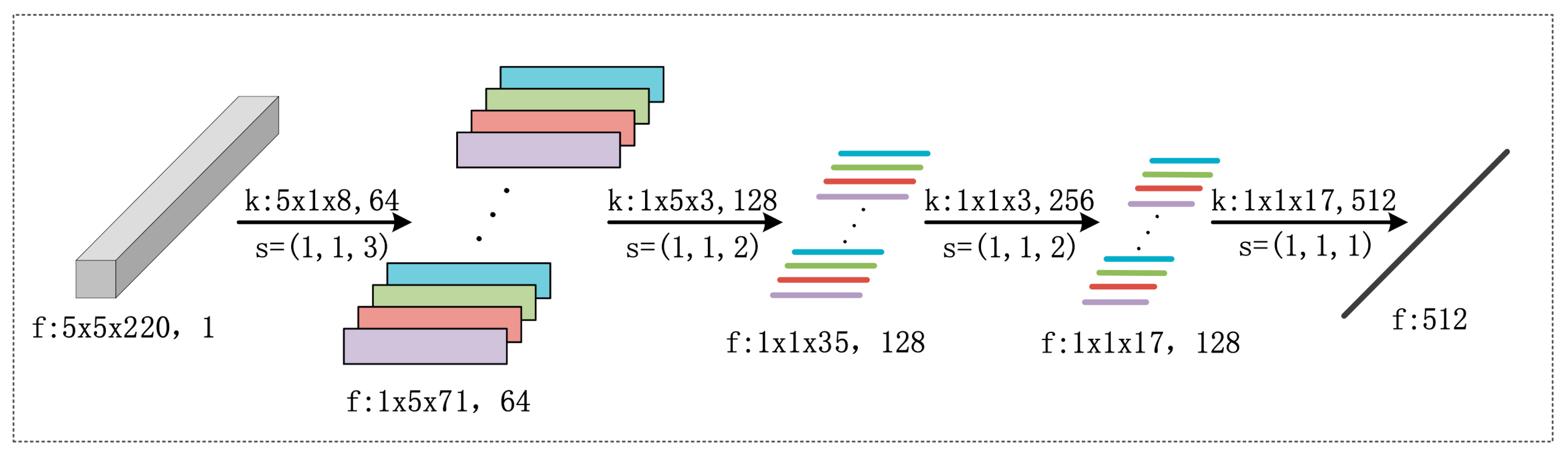
(1) 3D-CNN feature extractor sub-network: It has been demonstrated that a 3D-CNN structure that utilizes both spatial and spectral information can result in better HSI classification performance when compared with a method which utilizes only the spectrum information. This is because HSI data is inherently a 3D data cube that contains both spatial and spectral information, which makes 3D-CNN a natural structure choice. Thus, 3D-CNN is adopted as the first backbone network for feature extraction. By following the settings of existing 3D-CNN structures for HSI classification, we constructed a 3D-CNN network for feature extraction, as illustrated in Figure 2. The network consists of four convolutional layers, each of which is equipped with 3D convolutional kernels for feature extraction. The detailed parameter settings (such as convolution kernels and stride) are also included in Figure 2. The network contains 3 convolutional layers and a fully connected layer. In the first convolutional layer, the kernel size is 5 × 1 × 8 and 64 feature maps; in the second convolutional layer, the kernel size is 1 × 5 × 3 and 128 feature maps; in the third convolutional layer, the kernel size is 1 × 1 × 3 and 256 feature maps, s is the step size. The finally fully connected layer includes 512 nodes.
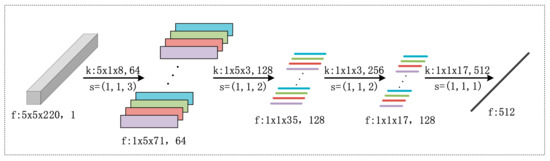
Figure 2.
Illustration of the adopted 3D-CNN architecture for the feature extractor sub-network, together with parameter settings (such as dimension of feature (f), convolution kernels (k) and stride (s)) for all convolutional layers and feature maps.
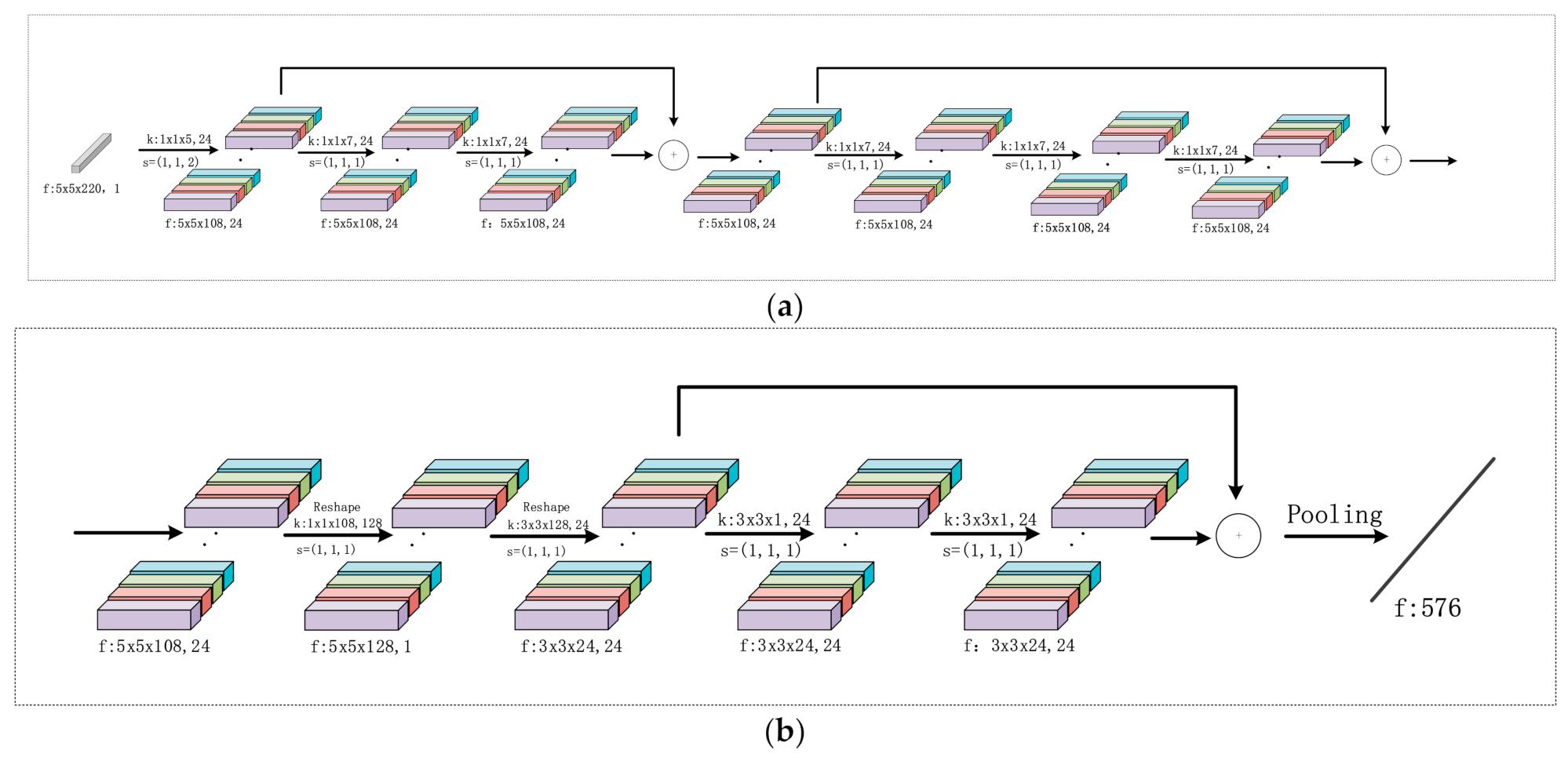
(2) SSRN feature extractor sub-network: Although DCNN has a strong feature extraction ability, due to the gradient vanishing problem it becomes difficult to train a deep neural network as the network depth increases. To overcome the gradient vanishing problem due to increasing network depth, He et al. propose a novel residual learning structure that can successfully mitigate the gradient vanishing problem [24]. The key to residual learning is to introduce a shortcut connection into the original network structure, with which the gradient vanishing problem can be well mitigated. Inspired by this, many recent HSI classification methods have also begun to take advantage of residual learning to train a deeper neural network. For this purpose, SSRN, a typical residual learning structure-based network, is exploited as the feature extractor sub-network within the proposed network. More specifically, we constructed a spectral-spatial residual network to capture both the spectral and spatial information. In this network, the spectral and spatial information is extracted consecutively based on the spectral and spatial residual blocks. For the spectral residual learning block, the convolutional layers, together with two shortcut connections, are utilized to extract the spectral features. For the spatial residual learning block, the convolutional layers, together with one shortcut connection, are exploited to extract spatial information. The details of the modeled residual network can be seen in Figure 3, which also includes the architecture and the parameter settings.
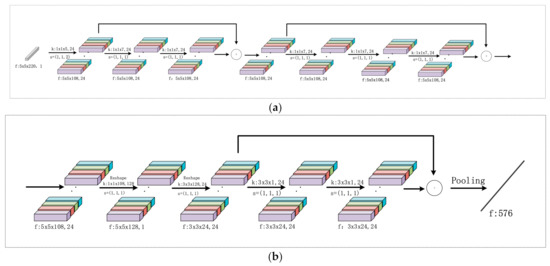
Figure 3.
Illustrations of the adopted SSRN architecture for the feature extractor sub-network, together with parameter settings (such as dimension of feature (f), convolution kernels (k) and stride (s)) for all layers and feature maps. (a) Spectral residual learning block, (b) spatial residual learning block. The two residual learning blocks contain shortcut connections between the two convolutional layers.
(3) Classifier sub-network: In general, the classifier sub-network adopts a much simpler architecture when compared with the feature extractor sub-network above. For the supervised deep learning-based classification task, it often consists of a fully connected layer. In this study, we use two fully connected layers to form the classifier sub-networks on and independently.
2.4. Loss Function
The constructed deep neural network contains a number of unknown parameters. To train and determine those parameters using a back-propagation algorithm, an appropriate loss needs to be defined beforehand.
Since the proposed network is a two-branch network, which includes two separate classification tasks on and , for the classification branch on , we adopt the cross-entropy loss, defined as follows:
Here, is an -dimensional vector calculated via Equation (1), which predicts the label of .
It is notable that this achieves a classification task with very limited labeled samples. However, a deep neural network with a large number of parameters will confront a heavily ill-posed problem when provided with few labeled training samples (e.g., five samples per class) for an HSI classification task. This is primarily because a large number of parameters cannot be fully and directly trained with a small number of labeled training samples; i.e., the parameters obtained by optimizing Equation (8) are unstable.
To resolve this issue, an effective method in the machine learning field is to enforce a suitable regularization item into Equation (8), from which the solution space can be effectively reduced to find a stable parameter. Inspired by this, we propose utilizing the unlabeled data with soft labels (i.e., the classification task on the auxiliary dataset ) as the regularization item, as follows:
where is an -dimensional vector calculated by Equation (2).
With these two loss functions defined above, we can formulate the overall loss function of the proposed two-branch network as follows:
where is a predefined weighting factor. It is notable that the shared feature extractor module can guarantee these two branches are trained jointly. Then, by minimizing the loss , the parameters can be trained with the back-propagation algorithm.
3. Experiments
To demonstrate the effectiveness of the proposed method in terms of few-shot HSI classification, we conducted experiments on three benchmark HSI datasets. In the below, we will first introduce the adopted benchmark HSI datasets and the experimental settings. We will next explain the undertaken appropriate and adequate comparison experiments between the proposed method and some state-of-the-art HSI classification methods in various cases, followed by some ablation studies.
3.1. Datasets
In this study, three benchmark HSI datasets were adopted to verify the efficacy of the proposed method including the Pavia University (PaviaU) dataset, the Salinas dataset, and the Indian Pines dataset [44].
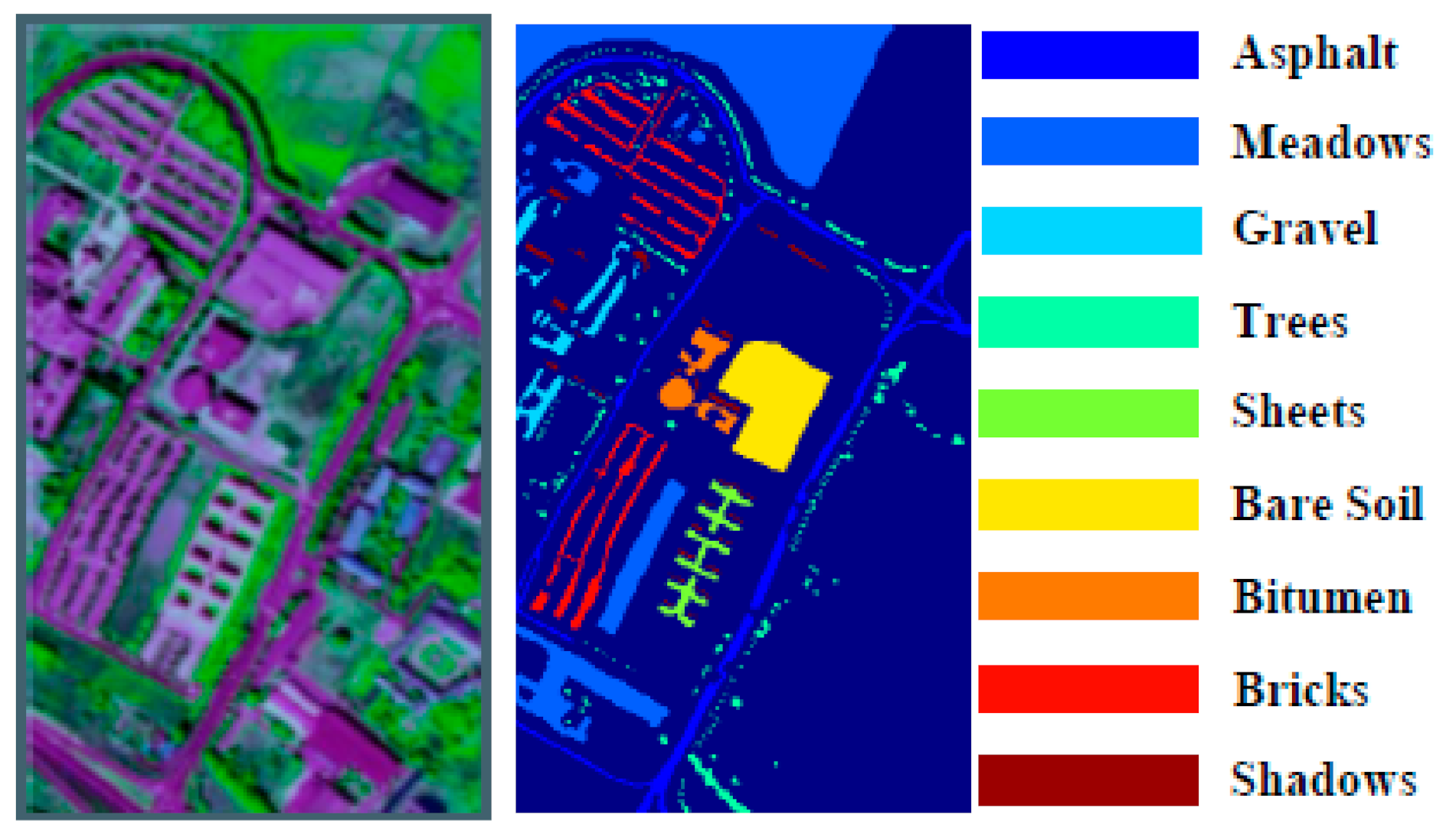
PaviaU dataset: The PaviaU dataset was acquired by a sensor during a flight campaign over the university of Pavia, Italy, and includes 9 classes and pixels, as shown in Table 1. In addition, the false color image and the ground truth map are shown in Figure 4. For the PaviaU dataset, each pixel has 103 spectral reflectance bands ranging from 430 to 860 nm, and the spatial resolution is 1.3 m. In these experiments, all bands are utilized for HSI classification.

Table 1.
The name and number of samples per class on the Indian Pines dataset, PaviaU dataset, and Salinas dataset respectively.

Figure 4.
The false color images and ground truth map of the PaviaU dataset. The original image size is pixels.
Salinas dataset: The Salinas dataset was acquired using the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) from California, which includes 16 classes and pixels (shown in Table 1). The spatial resolution is 3.7 m. The false color image and the ground truth map are shown in Figure 5. For this dataset, each pixel has 224 bands ranging from 400 to 2450 nm. After the water-absorption bands were removed, 204 bands were retained for the experiments.

Figure 5.
The false color image and ground truth map of the Salinas dataset. The original image size is pixels.
Indian Pines dataset: The Indian Pines dataset was collected by AVIRIS from the agricultural Indiana Pines test site in northwestern Indiana. It contains 16 land cover classes and images of pixels. The detailed class name, the numbers of labeled pixels and the class map can be seen in Table 1 and Figure 6. The spatial resolution of HSI in this dataset is about 20 m. Each pixel has 220 spectral reflectance bands ranging from 400 to 2450 nm. All 220 bands were utilized for HSI classification in this experiment.

Figure 6.
The false color image and ground truth map of the Indian Pines dataset. The original image size is pixels.
These three datasets have a public characteristic, which are all unbalanced datasets.
3.2. Comparison Methods and Measures
To verify the performance of the proposed method, we compared it with Support Vector Machine (SVM), Spatio-Spectral Laplacian Support Vector Machine (SS-LapSVM) [37], 3D-GAN [39], SS-CNN [38], 3D-CNN, SSRN [26], and 3D Densely Connected Convolutional Network (3D-Densenet) [25]-based HSI classification methods. Among these competing methods, the SVM-based method is a conventional machine learning-based method that specializes in dealing with small sample problems. SS-LapSVM is a traditional semi-supervised method that utilizes both labeled and unlabeled samples. 3D-GAN and SS-CNN are deep learning-based methods for semi-supervised HSI classification. 3D-CNN and SSRN are two representative deep learning-based methods, which utilize the labeled samples only for classification and also serve as the backbone for feature extraction. Based on these two backbone feature extractor networks, we obtained two different versions of the proposed method. For the sake of simplicity, we denote the proposed method based on 3D-CNN and SSRN as and , respectively. To facilitate further comparison, variants of the proposed two-branch networks were specifically designed so that only the soft pseudo-labels are replaced by the hard pseudo-labels generated via k-means clustering [42]. We denote these two variant methods as and . For the adopted k-means clustering method, the number of clusters is set equal to the categories within the HSI dataset (e.g., we set the number of clusters to 16, since there are 16 categories in the Indian Pines dataset). To further testify the effectiveness of proposed soft pseudo-labels, we generate the hard label via the proposed soft pseudo-label learning method, in which one sample can only belong to one category. The proposed method with hard pseudo-label is denoted as and . In addition, 3D-Densenet, a newly proposed deep learning-based method that achieves excellent HSI classification performance when provided with plenty of labeled samples was also introduced as a competing method.
As for the evaluation measurement, three conventional evaluation metrics including overall accuracy (OA), average accuracy (AA) and the Kappa coefficient were adopted to evaluate the HSI classification performance of different methods.
3.3. Experimental Results
In this subsection, we focus primarily on comparing the proposed method with other competing methods in order to demonstrate its effectiveness in the field of HSI classification under few-shot and one-shot settings. Since the problem we are addressing involves obtaining an appropriate deep learning-based method when heavily limited labeled samples are provided for training, we conducted experiments with three and five labeled samples per class and experiments with one labeled sample per class. In more detail, the experiments with three and five labeled samples per class correspond to the few-shot HSI classification problem, while the experiments with one labeled sample are for a more challenging one-shot HSI classification task.
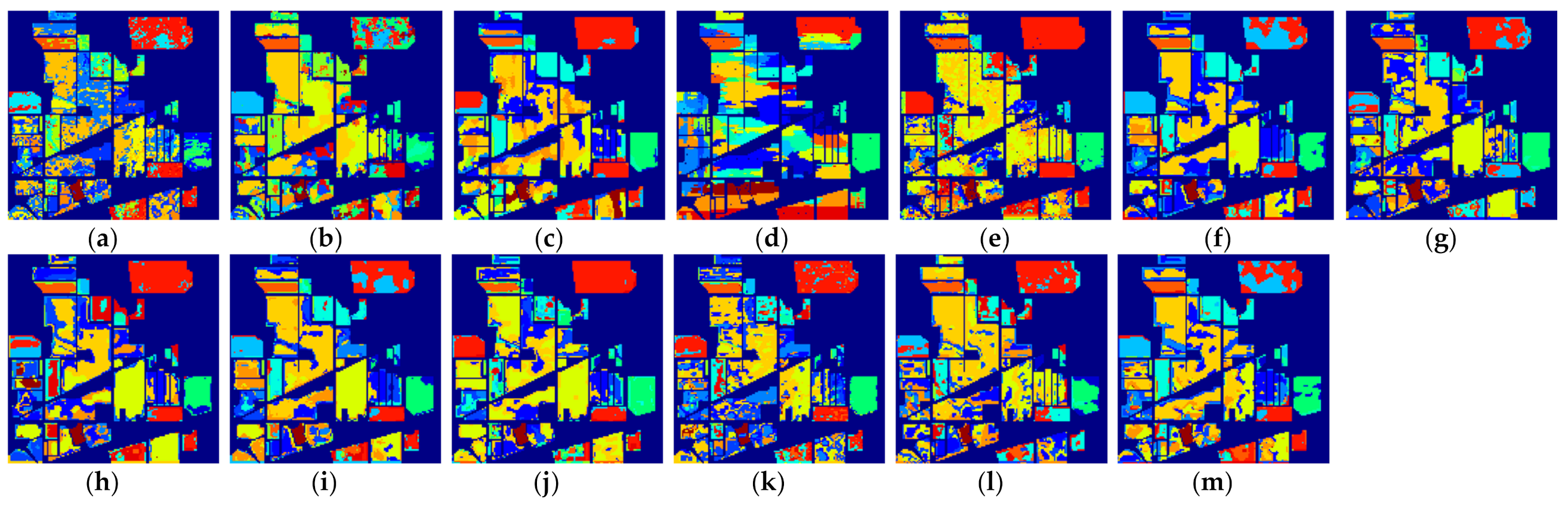
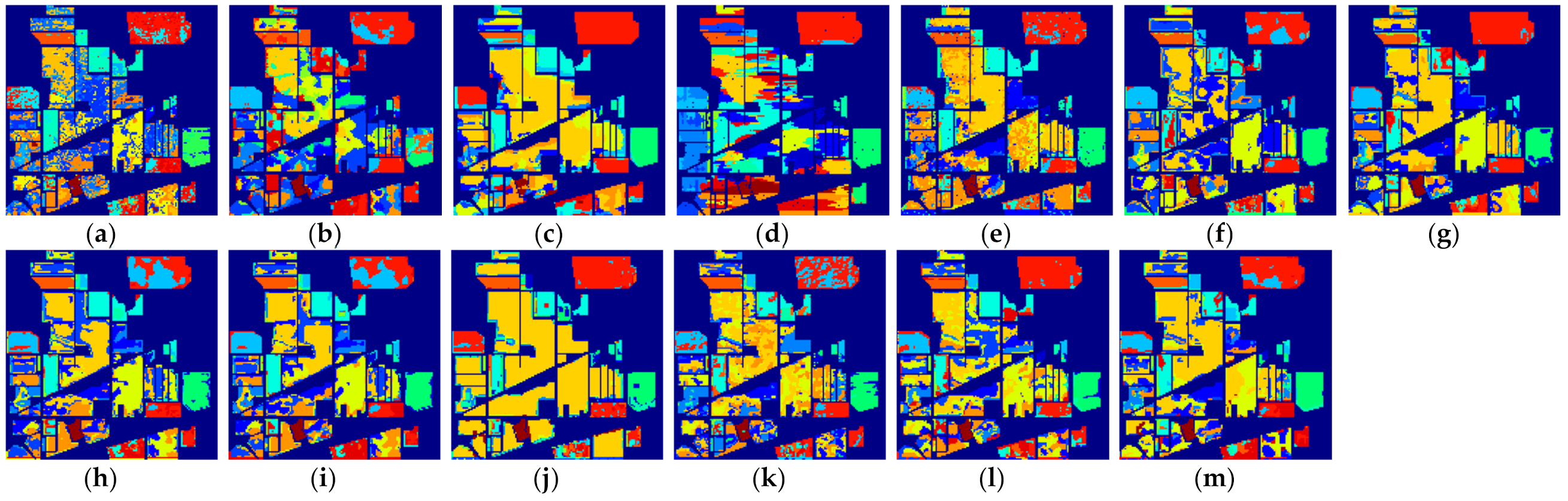
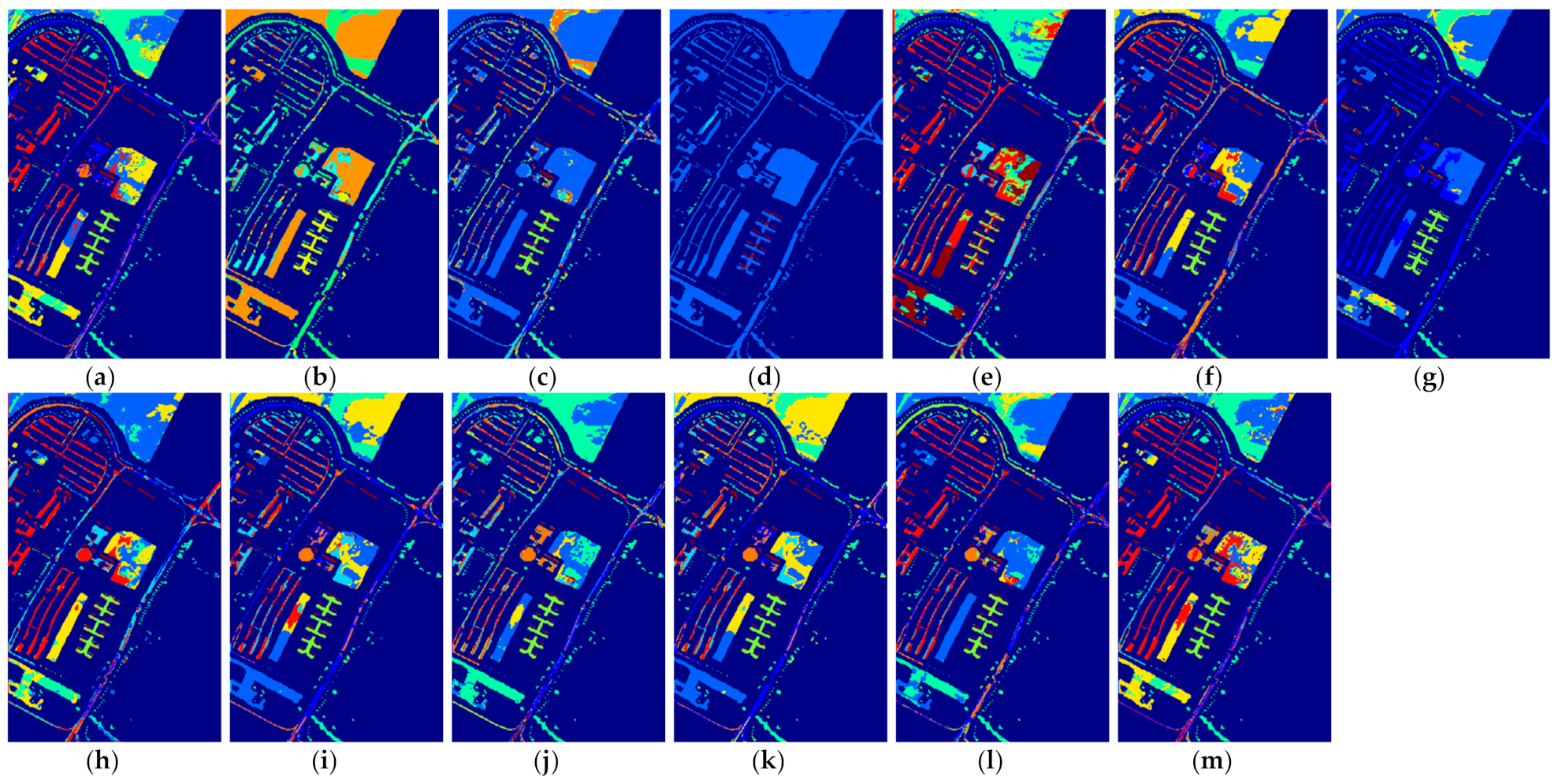
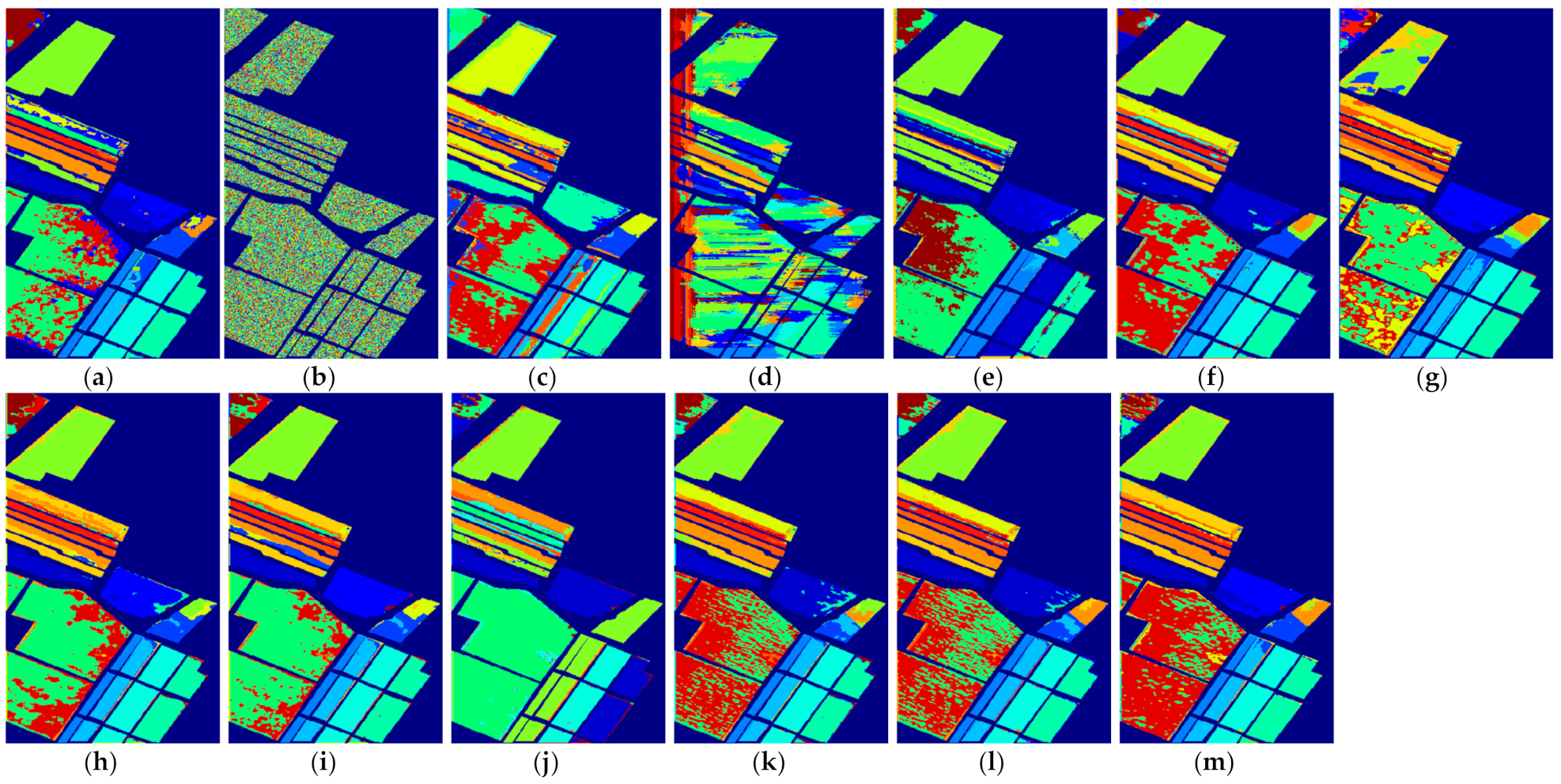
We repeated the same HSI classification process for each number of labeled samples. Taking three labeled samples as an example, we randomly chose three labeled samples per class as the training set, then treated the rest of the samples as the test set in the classification experiments. To eliminate the influence of randomness on classification accuracy when selecting training samples, the final classification accuracy for each method was calculated by averaging the classification results independently obtained from ten random training and testing rounds. The average classification results for all methods on different datasets are summarized and reported in Table 2, Table 3, Table 4, Table 5, Table 6, Table 7, Table 8, Table 9 and Table 10. To more accurately assess the performance of the different methods, the classification maps of these methods on three datasets are also visualized in Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13, Figure 14 and Figure 15, where (a)–(m) represent the results from different classification methods. From these listed results, we obtained the following conclusions.
Table 2.
Classification accuracy (%) for all methods with three training samples on the PaviaU dataset. Best results are in bold. The numbers in parentheses are standard variances (%).
Table 3.
Classification accuracy (%) for all methods with five training samples on the PaviaU dataset.
Table 4.
Classification accuracy (%) for all methods with three training samples on the Salinas dataset.
Table 5.
Classification accuracy (%) for all methods with five training samples on the Salinas dataset.
Table 6.
Classification accuracy (%) for all methods with three training samples on the Indian Pines dataset.
Table 7.
Classification accuracy (%) for all methods with five training samples on the Indian Pines dataset.
Table 8.
Classification accuracy (%) for all methods with one training samples on the PaviaU dataset.
Table 9.
Classification accuracy (%) for all methods with one training sample on the Salinas dataset. The symbol ‘-’ means the method failed to classify.
Table 10.
Classification accuracy (%) for all methods with one training sample on the Indian Pines dataset. The symbol ‘-’ means the method is failed to classify.
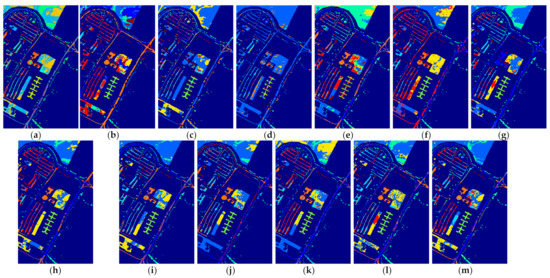
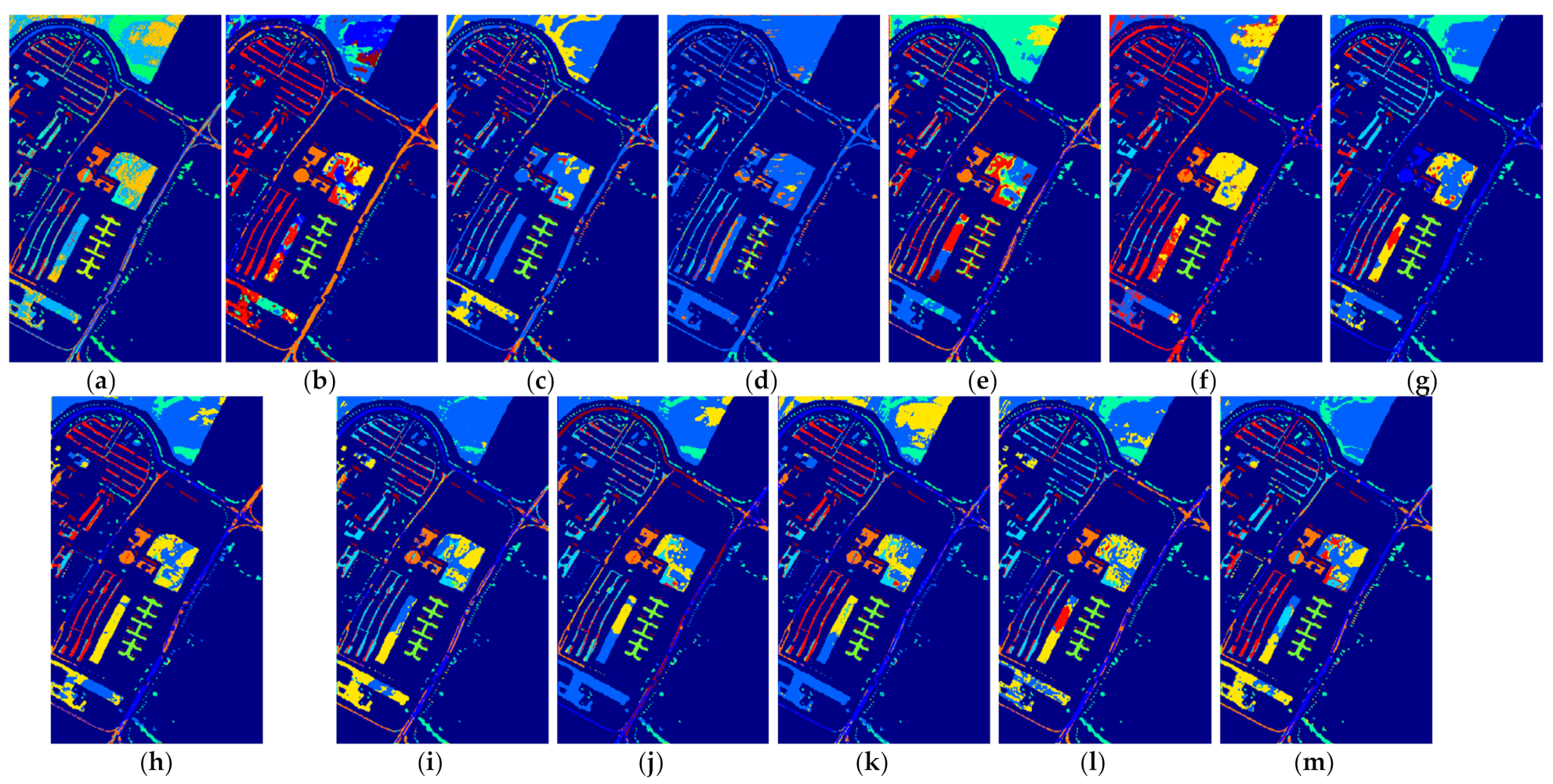
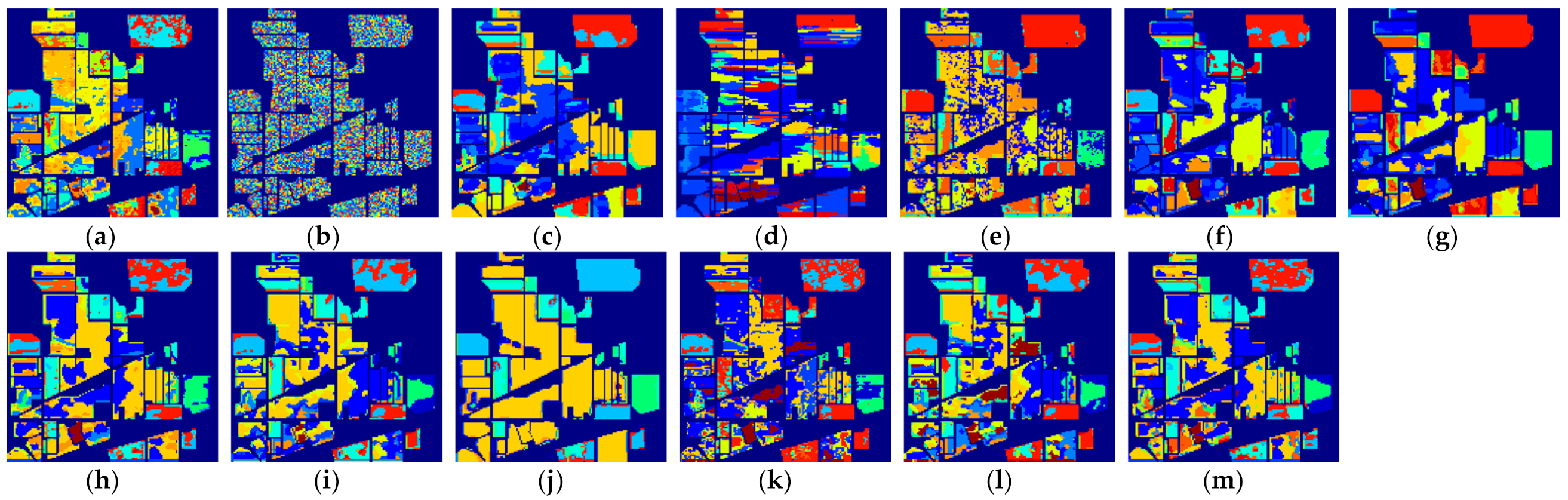
Figure 7.
The classification maps of all methods with three samples on PaviaU dataset. (a) SVM; (b) SS-LapSVM; (c) 3D-DENSEnet; (d) 3D-Gan; (e) SS-CNN; (f) 3D-CNN; (g)
(h) ; (i) ; (j) SSRN; (k) ; (l) ; (m) .
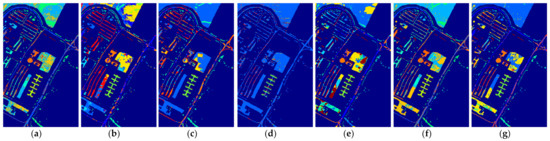

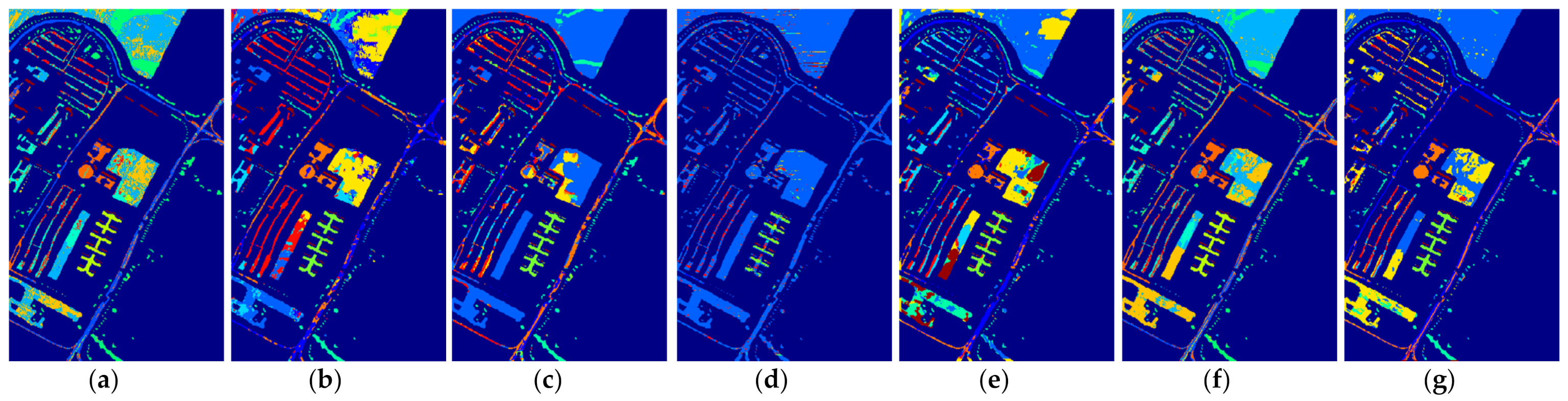
Figure 8.
The classification maps of all methods with five samples on PaviaU dataset. (a) SVM; (b) SS-LapSVM; (c) 3D-DENSEnet; (d) 3D-Gan; (e) SS-CNN; (f) 3D-CNN; (g)
(h) ; (i) ; (j) SSRN; (k) ; (l) ; (m) .


Figure 9.
The classification maps of all methods with three samples on Salinas dataset. (a) SVM; (b) SS-LapSVM; (c) 3D-DENSEnet; (d) 3D-Gan; (e) SS-CNN; (f) 3D-CNN; (g)
(h) ; (i) ; (j) SSRN; (k) ; (l) ; (m) .

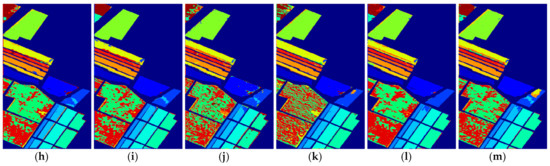
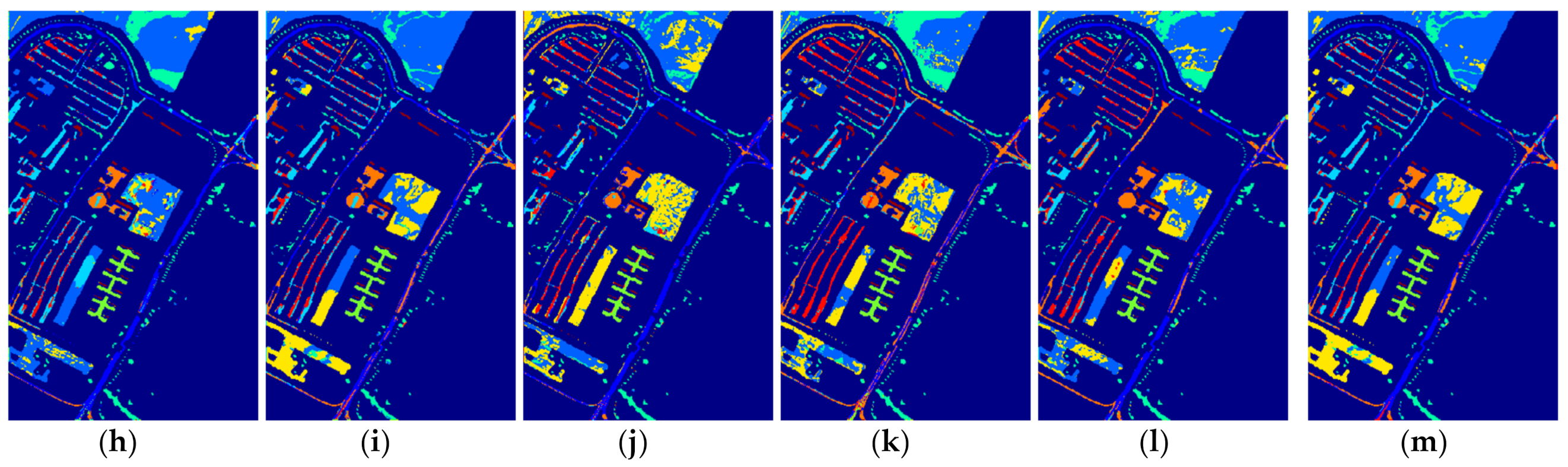
Figure 10.
The classification maps of all methods with five samples on Salinas dataset. (a) SVM; (b) SS-LapSVM; (c) 3D-DENSEnet; (d) 3D-Gan; (e) SS-CNN; (f) 3D-CNN; (g)
(h) ; (i) ; (j) SSRN; (k) ; (l) ; (m) .
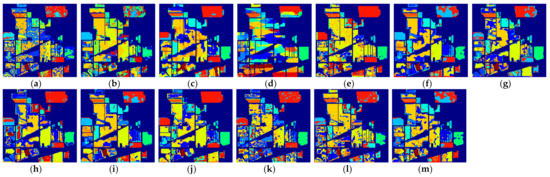
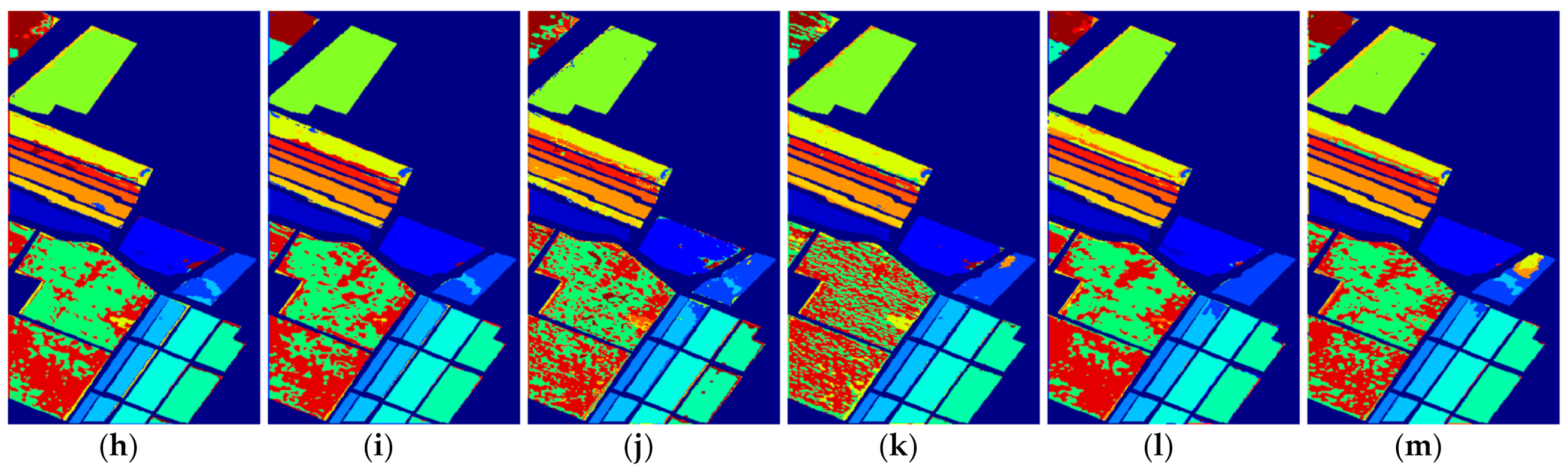
Figure 11.
The classification maps of all methods with three samples on Indian Pines dataset. (a) SVM; (b) SS-LapSVM; (c) 3D-DENSEnet; (d) 3D-Gan; (e) SS-CNN; (f) 3D-CNN; (g)
(h) ; (i) ; (j) SSRN; (k) ; (l) ; (m) .
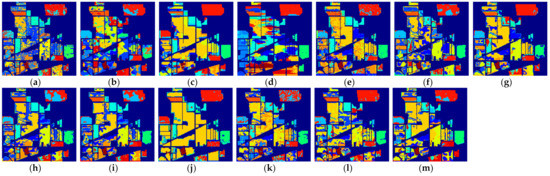
Figure 12.
The classification maps of all methods with five samples on Indian Pines dataset. (a) SVM; (b) SS-LapSVM; (c) 3D-DENSEnet; (d) 3D-Gan; (e) SS-CNN; (f) 3D-CNN; (g)
(h) ; (i) ; (j) SSRN; (k) ; (l) ; (m) .
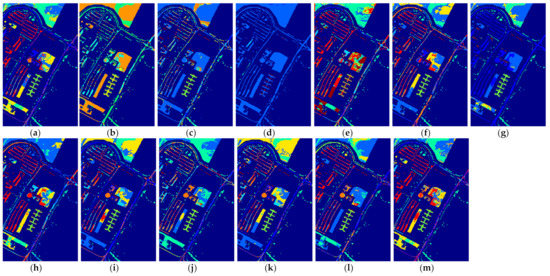
Figure 13.
The classification maps of all methods with one sample on PaviaU dataset. (a) SVM; (b) SS-LapSVM; (c) 3D-DENSEnet; (d) 3D-Gan; (e) SS-CNN; (f) 3D-CNN; (g)
(h) ; (i) ; (j) SSRN; (k) ; (l) ; (m) .
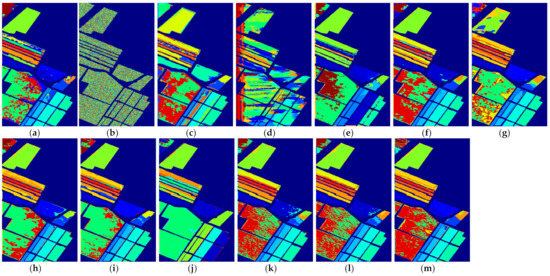
Figure 14.
The classification maps of all methods with one sample on Salinas dataset. (a) SVM; (b) SS-LapSVM; (c) 3D-DENSEnet; (d) 3D-Gan; (e) SS-CNN; (f) 3D-CNN; (g) -means method, soft label with the proposed method. The experiments were conducted with five training samples per class on the Indian Pines and PaviaU dataset.
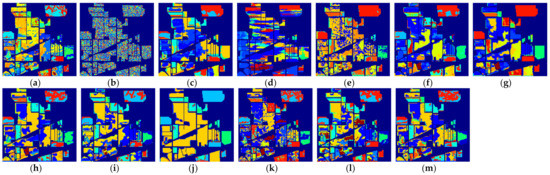
Figure 15.
The classification maps of all methods with one sample on Indian Pines dataset. (a) SVM; (b) SS-LapSVM; (c) 3D-DENSEnet; (d) 3D-Gan; (e) SS-CNN; (f) 3D-CNN; (g)
(h) ; (i) ; (j) SSRN; (k) ; (l) ; (m) .
(1) Comparison with conventional machine learning-based method: Although the effectiveness of the deep learning-based methods has been demonstrated when a large number of labeled samples are provided for training, it can be seen from the results in Table 2 that the performance of the deep learning-based methods cannot be guaranteed when only a few labeled samples are provided. In most cases, the performance of 3D-Densenet and are even inferior to that of SVM. This is because deep structured network-based methods are prone to overfitting when few labeled training samples are provided. Nevertheless, the proposed deep learning methods obtain better performance in the majority of cases than SVM. For example, the proposed method improves OA over SVM by about 5.52% when five labeled samples in PaviaU dataset are provided, which demonstrates that the proposed networks can better adapt to the few-shot HSI classification problem.
(2) Comparison with semi-supervised method: In all methods, SS-LapSVM, 3D-GAN, SS-CNN, the proposed methods (i.e., and ), two variants of our methods (including and ), and the proposed method with hard pseudo-label (including and ) are semi-supervised methods. From the results, we can observe that the proposed methods have obvious advantages over the competing semi-supervised methods in terms of HSI classification when only a very limited number of training samples are provided for training. It is notable that the traditional semi-supervised method SS-LapSVM achieves almost the worst performance out of all comparison methods. Compared with deep learning-based semi-supervised methods such as 3D-GAN and SS-CNN, the proposed method (i.e., ) shows promising results with a higher accuracy. Considering all these methods are semi-supervised methods, we can conclude that the proposed method can better utilize the unlabeled data for better HSI classification results. In addition, by comparing the performance of the proposed methods with and as well as and , we can see that the soft pseudo-labels also contribute to the improvement of HSI classification.
(3) Comparison with deep learning-based method: 3D-Densenet, 3D-CNN, SSRN, the proposed methods ( and ) and the two variants of the proposed methods ( and ) are all deep learning-based methods. From the results, we can see that the proposed methods achieve better classification performance than other competing deep learning-based methods. This is because the competing methods, such as 3D-Densenet, are more likely to be overfitting when heavily few-labeled samples are available for HSI classification. By contrast, with the regularization from the auxiliary dataset with soft pseudo-labels, the overfitting problem of the proposed method can be effectively reduced, with which the classification accuracy is improved.
(4) Applicability to different kinds of networks: The proposed framework is a general semi-supervised framework, with which the unlabeled samples could be effectively used to mitigate overfitting and improve the HSI classification accuracy. To demonstrate the applicability of the proposed framework to different kinds of networks, we used a 3D-CNN and SSRN as the backbones (i.e., only utilizing the labeled samples for training). By comparing the results between (i.e., the proposed method) and 3D-CNN, we can find that the proposed method based on the structure could obtain better performance on three datasets with different number of training samples. For example, when provided five labeled training samples on the PaviaU dataset, the average OA of is improved by 3.89% over 3D-CNN. Similar, the experimental results from SSRN and also reflect that the obtains better classification results. In summary, from the results of both 3D-CNN and SSRN, we can conclude that the proposed framework is applicable to different kinds of networks for few-shot learning.
(5) Applicability to one-shot HSI classification: The proposed methods do not only improve the few-shot HSI classification with heavily limited training samples (i.e., three and five labeled samples), but can also improve the one-shot HSI classification when only one training sample per class is provided. Although the performance from the one-shot classification cannot be compared with that of the few-shot classification for all methods, it can be observed in Table 8 that the proposed methods still achieve better performance relative to the other comparison methods. For example, the proposed method outperforms SVM by 8.68% in terms of OA on the Indian Pines dataset. In addition, it can be observed that when only one labeled sample is provided, the SS-LapSVM method even fails to classify the test samples in these benchmark datasets, which indicates the difficulty of utilizing the unlabeled samples with only one labeled training sample. Nevertheless, the proposed method effectively utilizes the unlabeled samples and thus yields better classification results. We can therefore conclude that the proposed method is also effective for one-shot classification.
3.4. Ablation Study
(1) Effectiveness of the reference agent: In this paper, a group of agent references were adopted to assign soft pseudo-labels, among which all labeled samples of each class were exploited as agents. In addition to this strategy, we also average all labeled samples to generate a representative agent for each class, then utilized the representative agent to obtain the soft pseudo-label, which is referred to as Average in this study. To demonstrate the superiority of the proposed agent learning method, we conducted comparison experiments between Ours and Average. Table 11 reports the comparison results, in which 3D-CNN was adopted as the backbone and five labeled samples were provided for training. It can thus be seen that the performance of Ours achieves promising results with a higher accuracy than that of Average, as shown in Table 11. For example, the OA of Ours outperforms Average by 1.45%. This is because the underlying relation is impaired to some extent when averaging all labeled samples of each class, whereas the method we adopt preserves these relations.
Table 11.
Classification accuracy of 3D-CNN with five training samples via average and ours on the PaviaU dataset respectively.
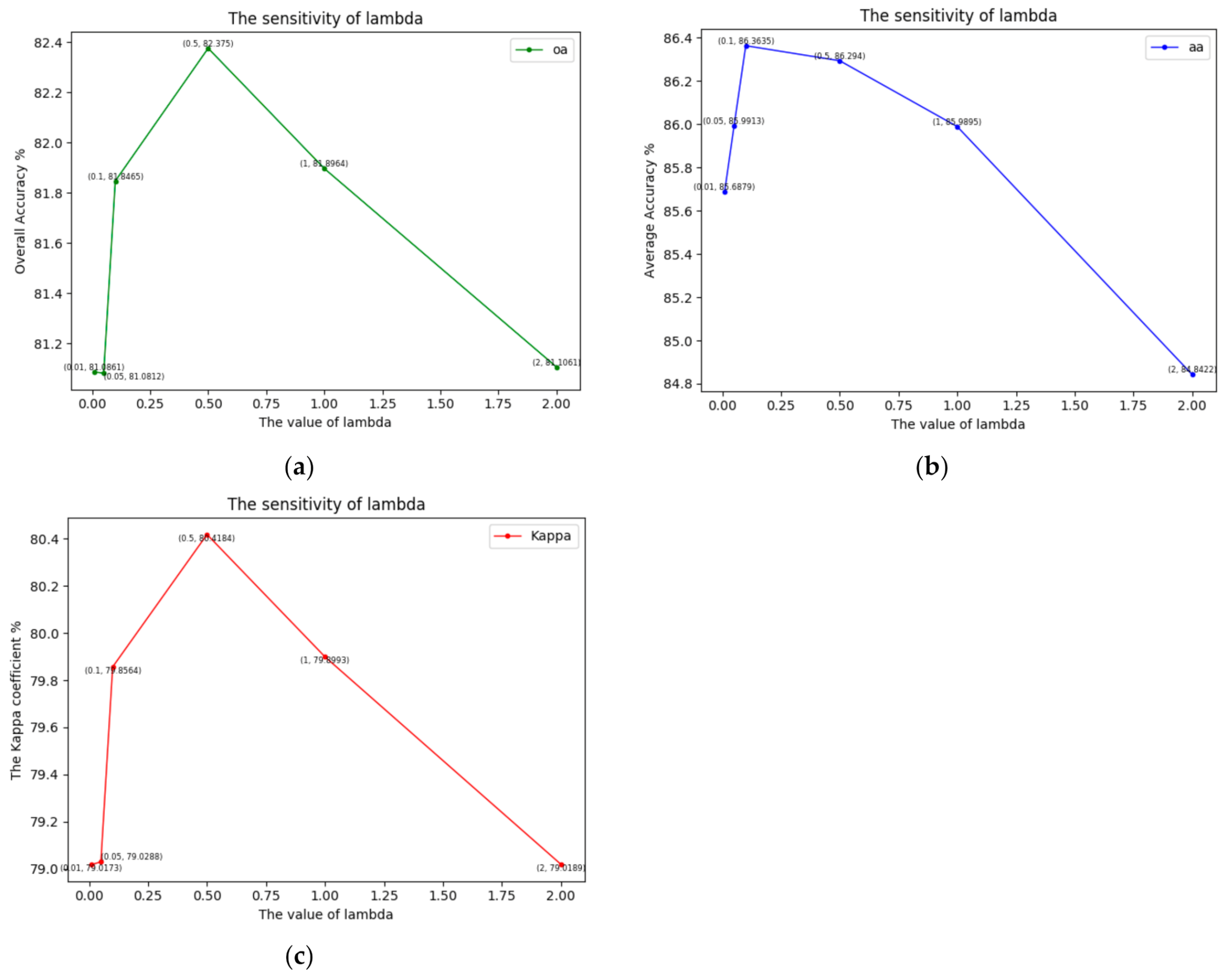
(2) Sensitivity of : We used the loss function defined in Equation (10) to train and determine the parameters contained in the proposed two-branch deep neural network, where was used to balance the loss function from each branch. Figure 16 illustrates the performance of OA, AA and the Kappa coefficient κ as it varies with different , in which the OA, AA and the Kappa coefficient are average results from 10 rounds of experiments with the 3D-CNNours feature extractor, trained with three labeled samples. From the results, we can determine that the classification performance of the proposed method first increases and then decreases as increases from 0 to 2. When λ is around 0.5, the proposed method can obtain its best performance.
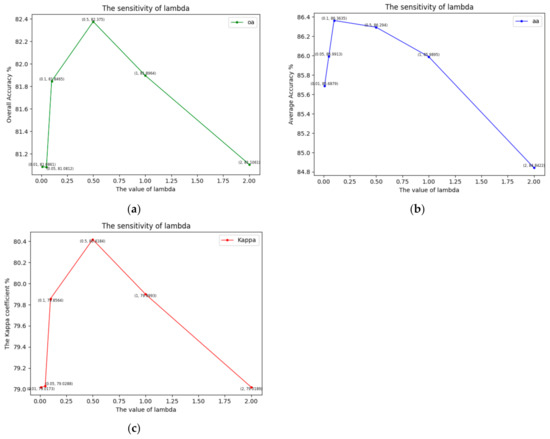
Figure 16.
Illustration of the sensitivity of . It reflects the classification accuracy of OA, AA and with different values of . (a) OA; (b) AA; (c) .
(3) The impact of feature extraction: According to the proposed framework, the features were automatically extracted from the data since the proposed method is an end-to-end deep learning-based method. To verify that the proposed network may also be utilized with other feature extraction methods (i.e., we input the extracted feature rather than the original data into the constructed network), we utilized a commonly used feature extraction method termed principal component analysis (PCA) for experiments. More specifically, we extract the PCA features from the original spectrum for each pixel, then input the PCA feature instead of the original spectrum into the constructed two-head network. The results are summarized in the following Table 12. It can be seen that the proposed method still achieves better performance when input with PCA features.
Table 12.
Classification accuracy (%) with five training samples of the Salinas dataset after using PCA to reserve 100 important bands.
(4) Effectiveness of the two-head network: To demonstrate the effectiveness of the constructed two-head network, we constructed a one-head network structure which includes only the shared feature extraction module and one classification module. Both labeled data (with true-class label) and un-labeled data (with pseudo-label) were trained with the same network structure. In this case, the only difference between the proposed method and this competing method is that the proposed method utilizes a two-branch network structure while the competing method utilizes a one-branch network. Results from the experiments conducted on the PaviaU dataset are summarized in Table 13. It can be clearly seen that the constructed two-head network obtains better performance compared with the one-head structure-based method in most cases, to which we can attribute the improvement of the proposed method over one-head 3D-CNN to the two-branch strategy.
Table 13.
Classification accuracy (%) of the proposed two-head network and the comparison one-head network. The experiment is conducted with one, three and five training samples per class on the PaviaU dataset.
(5) Effect of the proposed pseudo-label generation method: To further verify the effectiveness of the adopted soft pseudo-label generation method based on reference agent, we further conducted a comparison method, in which only the soft pseudo-labels were generated based on the k-means method. Specifically, we first run -means to get the cluster centers, and then utilized the distances between the unlabeled data and the cluster centers to compute the soft-labels for the unlabeled data. The relative experiments are summarized in Table 14. It can be clearly seen that the proposed pseudo-label generation method based on a reference agent has better performance compared with the pseudo-label generation method based on -means.
Table 14.
Classification accuracy (%) with hard label obtained from -means method, soft label with the proposed method. The experiments were conducted with five training samples per class on the Indian Pines and PaviaU dataset.
4. Conclusions
The training process of deep neural networks usually depends on the availability of a large number of training labeled samples. However, owing to the heavy labeling cost for HSI data, the number of labeled samples available in practical applications is heavily limited, resulting in the deep neural network-based HSI classification method overfitting and achieving a poor generalization ability. To address this issue, this paper has proposed a novel few-shot learning method for HSI classification, which borrows the supervision from the auxiliary dataset with soft pseudo-labels in order to train the feature extractor on the few-shot dataset. By employing joint training on both a few-shot dataset and auxiliary dataset with soft pseudo-labels, the proposed method can achieve better classification results on both few-shot HSI classification and one-shot HSI classification tasks. Experimental results demonstrate the superiority of the proposed approach on three hyperspectral benchmark datasets, compared with other competing methods.
Author Contributions
All of the authors made significant contributions to this work. C.D., W.W. and L.Z. devised the approach and analyzed the data; L.Z., Y.Z. and W.W. helped design the remote sensing experiments and provided advice for the preparation and revision of the work; and Y.L., Y.W. and M.Z. performed the experiments. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundations of China (Grant no.61901369 and Grant no.62071387), the Foundation of National Engineering Laboratory for Integrated Aero-Space-Ground-Ocean Big Data Application Technology (Grant No.20200203) and the National Key Research and Development Project of China (No. 2020AAA0104603).
Data Availability Statement
Not applicable.
Acknowledgments
The paper is funded by the key discipline special fund construction project of Shaanxi Province. We acknowledge the author for the HSI datasets.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ghamisi, P.; Yokoya, N.; Li, J.; Liao, W.; Liu, S.; Plaza, J.; Rasti, B.; Plaza, A. Advances in Hyperspectral Image and Signal Processing: A Comprehensive Overview of the State of the Art. IEEE Geosci. Remote Sens. Mag. 2017, 5, 37–78. [Google Scholar] [CrossRef] [Green Version]
- Wei, W.; Zhang, L.; Jiao, Y.; Tian, C.; Wang, C.; Zhang, Y. Intracluster Structured Low-Rank Matrix Analysis Method for Hyperspectral Denoising. IEEE Trans. Geosci. Remote Sens. 2018, 57, 866–880. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Liu, C.; Li, S. Recent Advances on Spectral-Spatial Hyperspectral Image Classification: An Overview and New guidelines. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1579–1597. [Google Scholar] [CrossRef]
- Guerra, R.; Barrios, Y.; Díaz, M.; Santos, L.; López, S.; Sarmiento, R. A new algorithm for the on-board compression of hyperspectral images. Remote Sens. 2018, 10, 428. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Wei, W.; Bai, C.; Gao, Y.; Zhang, Y. Exploiting Clustering Manifold Structure for Hyperspectral Imagery Super-Resolution. IEEE Trans. Image Process. 2018, 27, 5969–5982. [Google Scholar] [CrossRef] [PubMed]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Tu, B.; Wang, J.; Kang, X.; Zhang, G.; Ou, X.; Guo, L. KNN-Based Representation of Superpixels for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4032–4047. [Google Scholar] [CrossRef]
- Andriyanov, N.; Dementiev, V.; Kondratiev, D. Tracking of Objects in Video Sequences. Intell. Decis. Technol. 2021, 253–262. [Google Scholar]
- Andriyanov, N.A.; Vasil’ev, K.K.; Dement’ev, V.E. Investigation of Filtering and Objects Detection Algorithms for A Multizone Image Sequence. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 4, 7–10. [Google Scholar] [CrossRef] [Green Version]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3588–3597. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context Encoding for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar]
- Yalniz, I.Z.; Jégou, H.; Chen, K.; Paluri, M.; Mahajan, D. Billion-scale semi-supervised learning for image classification. arXiv 2019, arXiv:1905.00546. [Google Scholar]
- Liang, P.; Shi, W.; Zhang, X. Remote Sensing Image Classification Based on Stacked Denoising Autoencoder. Remote Sens. 2017, 10, 16. [Google Scholar] [CrossRef] [Green Version]
- Paul, S.; Kumar, D.N. Spectral-spatial classification of hyperspectral data with mutual information based segmented stacked autoencoder approach. ISPRS J. Photogramm. Remote Sens. 2018, 138, 265–280. [Google Scholar] [CrossRef]
- Lakhal, M.I.; Çevikalp, H.; Escalera, S.; Ofli, F. Recurrent neural networks for remote sensing image classification. IET Comput. Vis. 2018, 12, 1040–1045. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Yu, X.; Zhang, P.; Yu, A.; Fu, Q.; Wei, X. Supervised Deep Feature Extraction for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1909–1921. [Google Scholar] [CrossRef]
- Jiao, L.; Liang, M.; Chen, H.; Yang, S.; Liu, H.; Cao, X. Deep Fully Convolutional Network-Based Spatial Distribution Prediction for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5585–5599. [Google Scholar] [CrossRef]
- Haut, J.M.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Li, J. Hyperspectral Image Classification Using Random Occlusion Data Augmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1751–1755. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Gong, Z.; Zhong, P.; Yu, Y.; Hu, W.; Li, S.A. Cnn with multiscale convolution and diversified metric for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3599–3618. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, C.; Li, G.; Du, S.; Tan, W.; Gao, F. Three-dimensional densely connected convolutional network for hyperspectral remote sensing image classification. J. Appl. Remote Sens. 2019, 13, 016519. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Qu, Y.; Baghbaderani, R.K.; Qi, H. Few-Shot Hyperspectral Image Classification Through Multitask Transfer Learning. In Proceedings of the 2019 10th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 24–26 September 2019; pp. 1–5. [Google Scholar]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G.; Wang, R. Deep Few-Shot Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2290–2304. [Google Scholar] [CrossRef]
- Masarczyk, W.; Glomb, P.; Grabowski, B.; Ostaszewski, M. Effective transfer learning for hyperspectral image classification with deep convolutional neural networks. arXiv 2019, arXiv:1909.05507. [Google Scholar]
- Li, W.; Wu, G.; Zhang, F.; Du, Q. Hyperspectral Image Classification Using Deep Pixel-Pair Features. IEEE Trans. Geosci. Remote Sens. 2016, 55, 844–853. [Google Scholar] [CrossRef]
- Wei, W.; Zhang, J.; Zhang, L.; Tian, C.; Zhang, Y. Deep Cube-Pair Network for Hyperspectral Imagery Classification. Remote Sens. 2018, 10, 783. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Chen, C.; Zhang, M.; Li, H.; Du, Q. Data Augmentation for Hyperspectral Image Classification with Deep CNN. IEEE Geosci. Remote Sens. Lett. 2018, 16, 593–597. [Google Scholar] [CrossRef]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Sakai, T.; Plessis MC du Niu, G.; Sugiyama, M. Semi-supervised classification based on classification from positive and unlabeled data. In Proceedings of the ICML’17 Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, NSW, Australia, 6–11 August 2017; pp. 2998–3006. [Google Scholar]
- Liao, R.; Brockschmidt, M.; Tarlow, D.; Gaunt, A.; Urtasun, R.; Zemel, R. Graph Partition Neural Networks for Semi-Supervised Classification. arXiv 2018, arXiv:1803.06272. [Google Scholar]
- Tan, K.; Hu, J.; Li, J.; Du, P. A novel semi-supervised hyperspectral image classification approach based on spatial neighborhood information and classifier combination. ISPRS J. Photogramm. Remote Sens. 2015, 105, 19–29. [Google Scholar] [CrossRef]
- Yang, L.; Yang, S.; Jin, P.; Zhang, R. Semi-Supervised Hyperspectral Image Classification Using Spatio-Spectral Laplacian Support Vector Machine. IEEE Geosci. Remote Sens. Lett. 2013, 11, 651–655. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.; Zhang, P.; Tan, X.; Yu, A.; Xue, Z. A semi-supervised convolutional neural network for hyperspectral image classification. Remote Sens. Lett. 2017, 8, 839–848. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative Adversarial Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier GANs. In Proceedings of the ICML’17 Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, NSW, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Rasmus, A.; Valpola, H.; Honkala, M.; Berglund, M.; Raiko, T. Semi-supervised learning with Ladder networks. In Proceedings of the NIPS’15 the 28th International Conference on Neural Information Processing Systems-Volume 2, Montreal, QC, Canada, 7–12 December 2015; Volume 28, pp. 3546–3554. [Google Scholar]
- Zhang, J.; Wei, W.; Zhang, L.; Zhang, Y. Improving Hyperspectral Image Classification with Unsupervised Knowledge Learning. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 June–2 August 2019; pp. 2722–2725. [Google Scholar]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Aviris, N. Indianas indian pines 1992 data, s.e.t. 2012. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).