
Semi-Supervised Convolutional Long Short-Term Memory Neural Networks for Time Series Land Cover Classification



Abstract
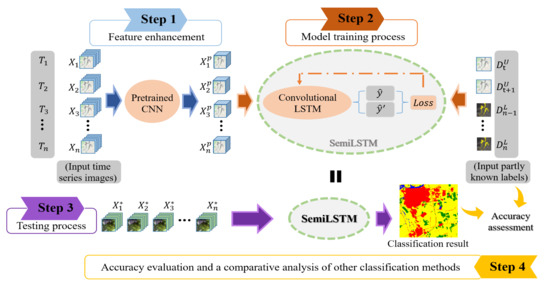
:
1. Introduction
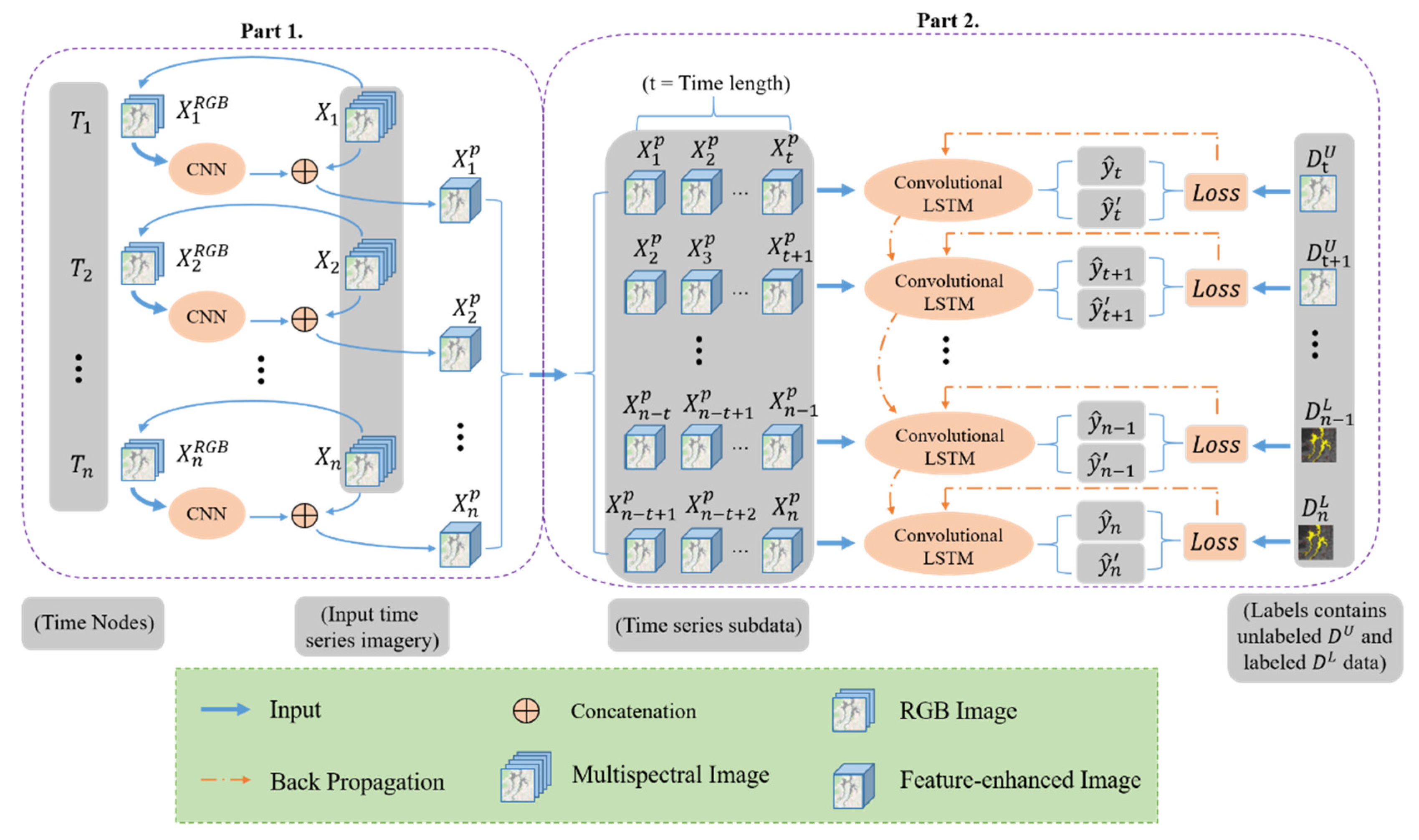
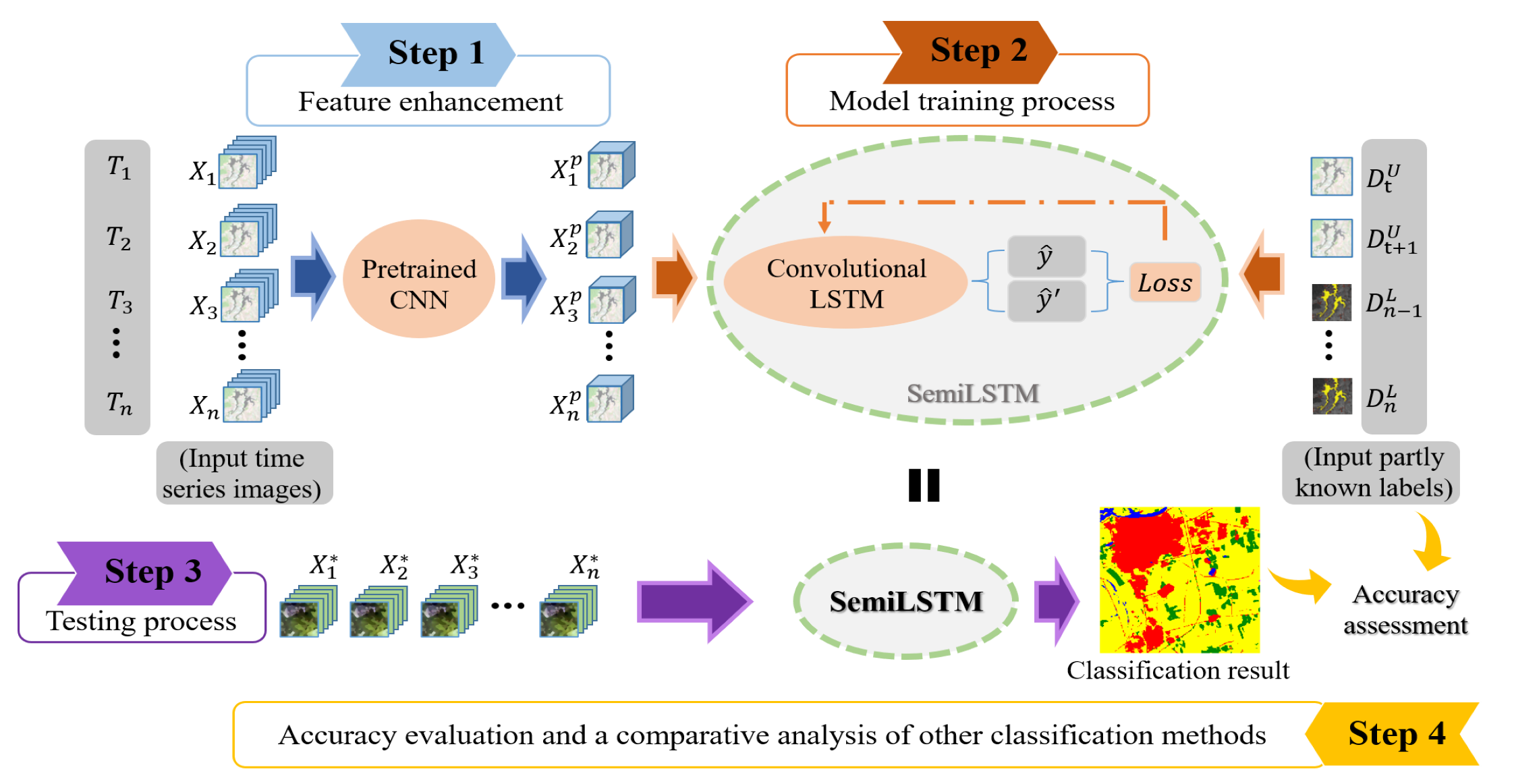
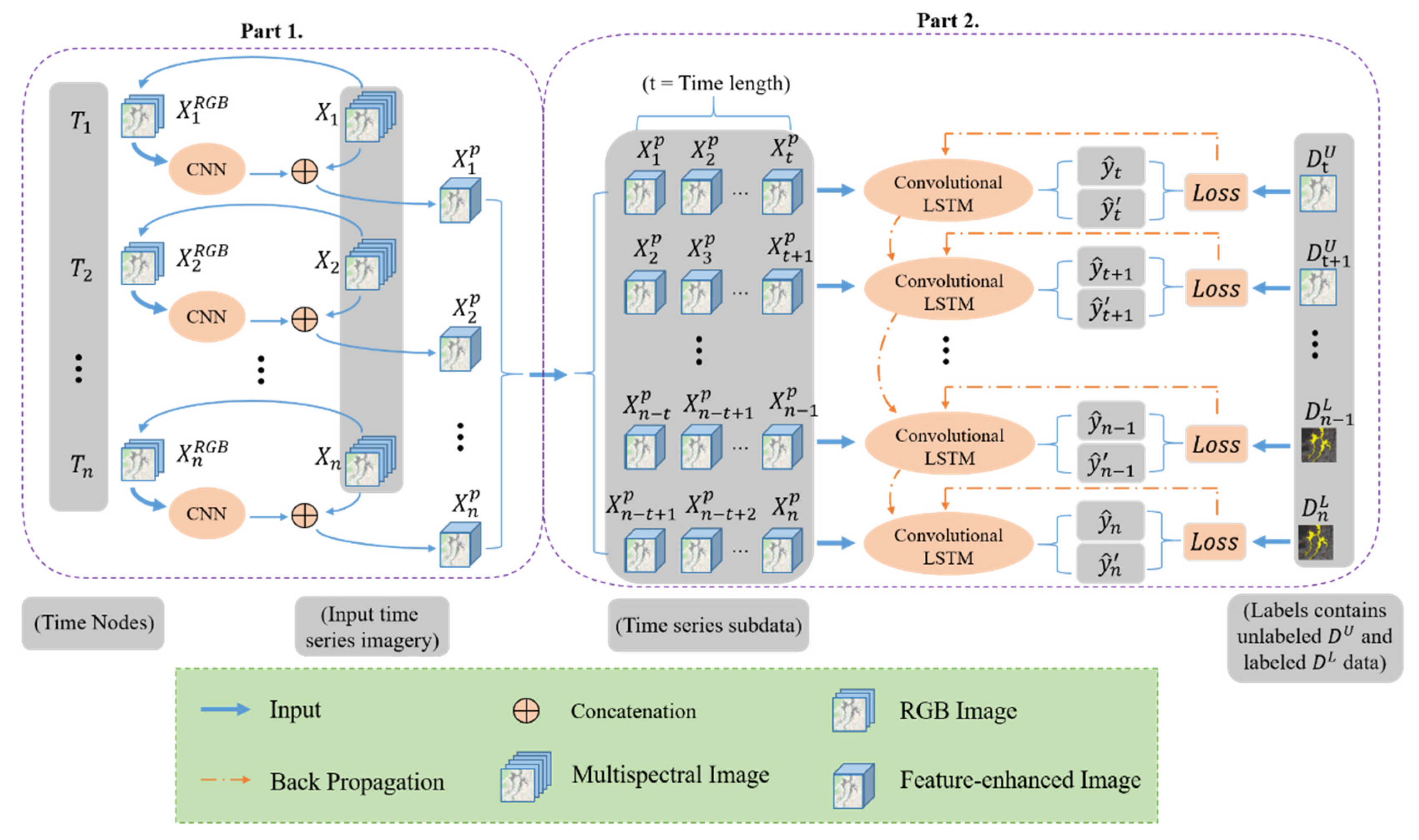
2. Methodology
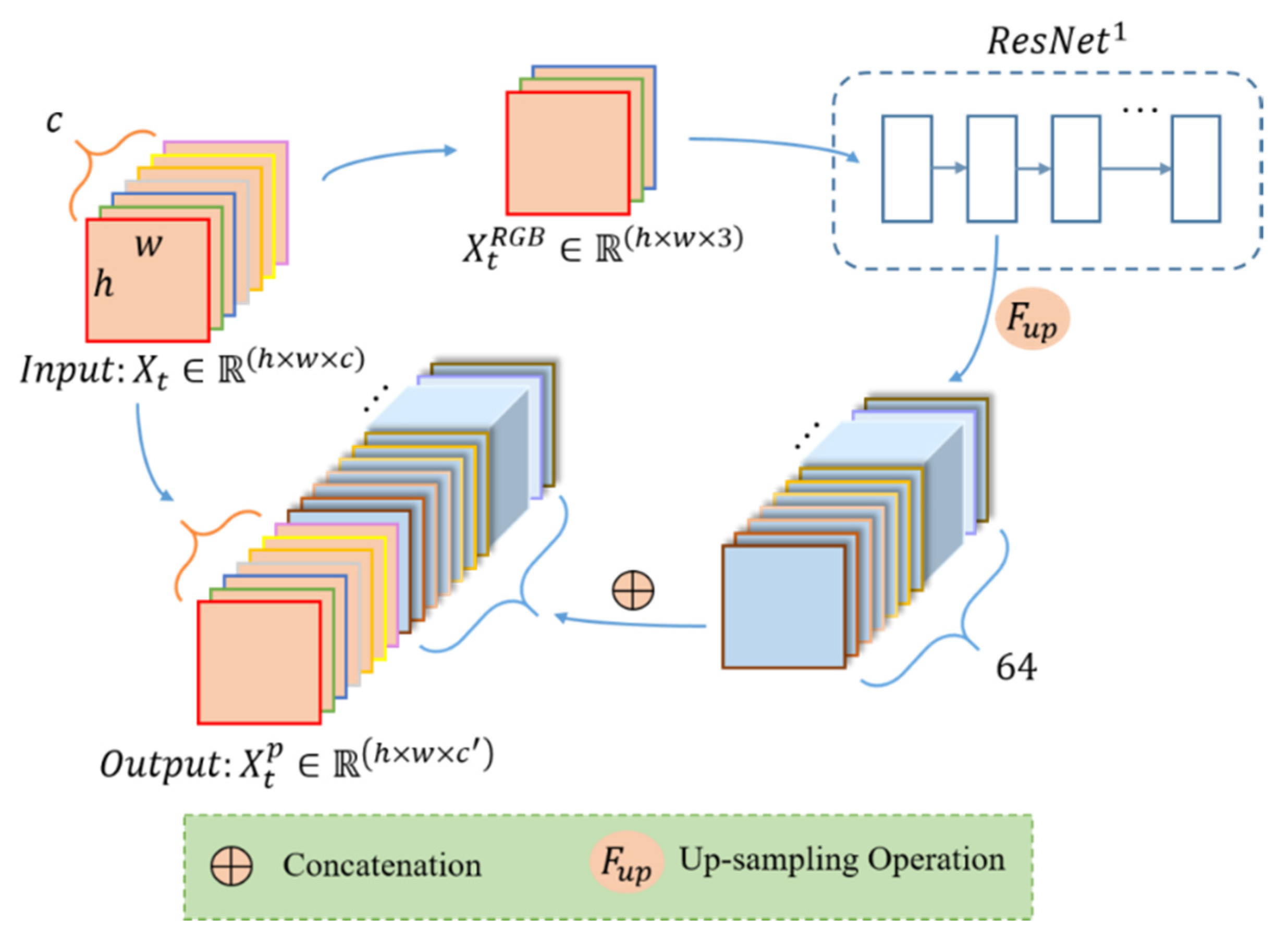
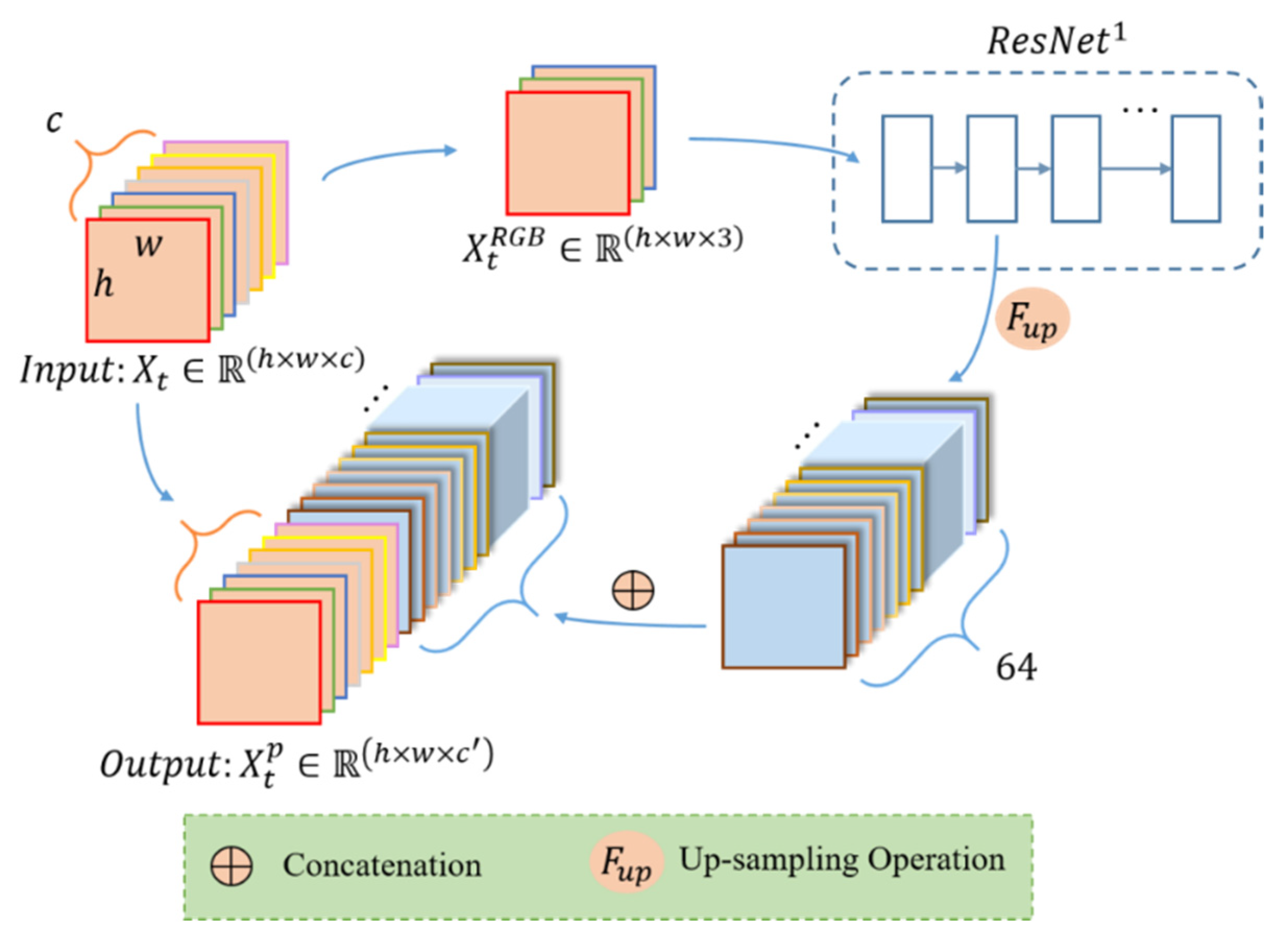
2.1. The Pretrained Model
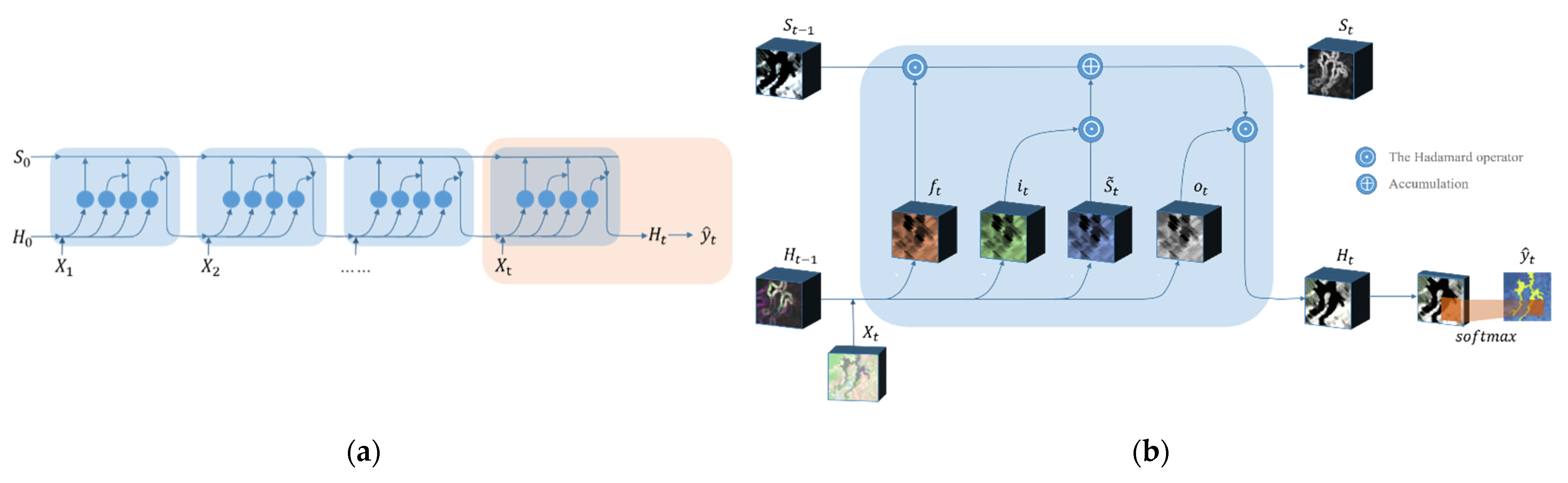
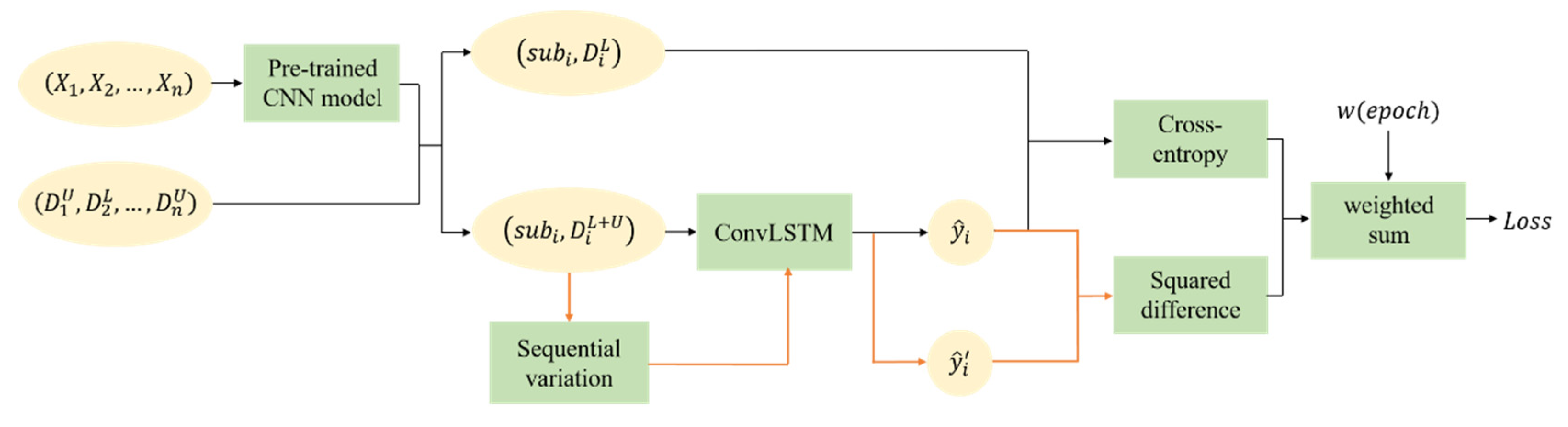
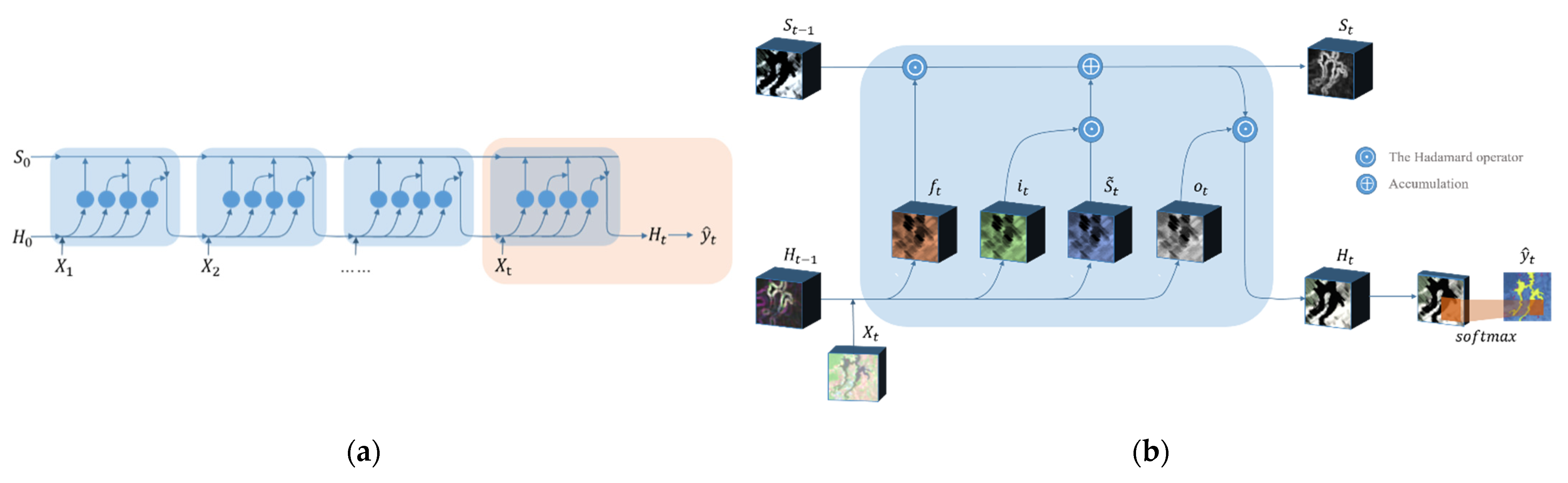
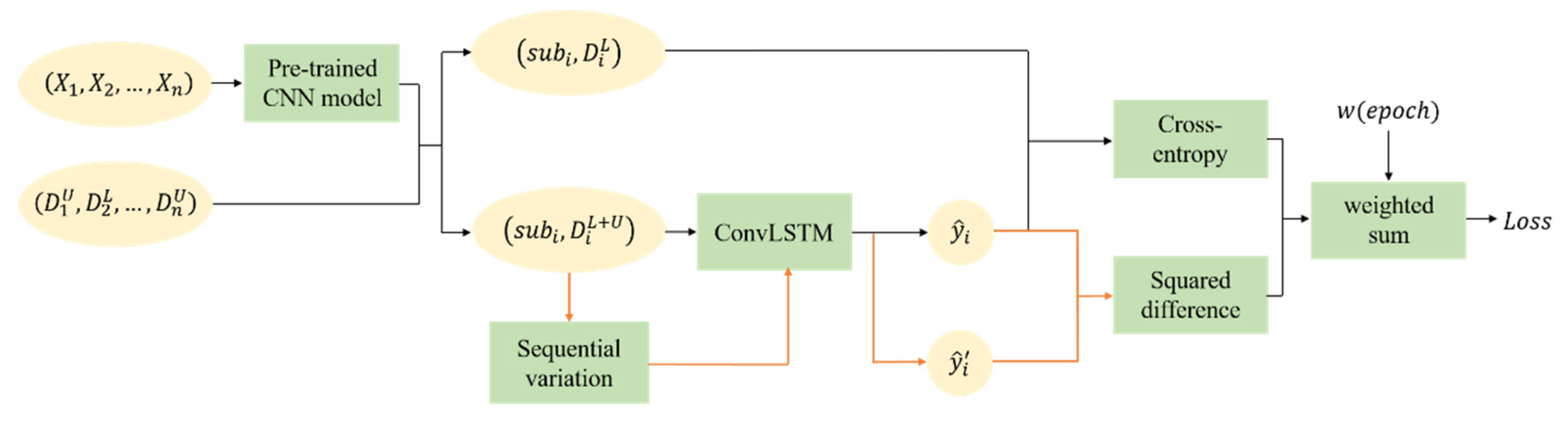
2.2. The Semi-Supervised Convolutional LSTM
| Algorithm 1. The training pseudocode of SemiLSTM. | |
| Require:, the time series subdata sets with the same time length (t) after pre-trained model ), for example, === ; | |
| Require: is the label corresponding to the last phase of , where unlabeled samples are represented as (C is the number of classes), and labeled samples are represented as ; | |
| Require:, the unsupervised weight ramp-up function; | |
| Require:, the convolutional LSTM with trainable parameters ; | |
| Require:, the time series input with random sequential variation function; | |
| Require:, the balance factor, is a constant vector whose length is the number of categories C; | |
| Require:, the tunable focusing parameter, is a constant. | |
| for epoch in [1, num_epochs] do: | |
| for i in [1, ] do: | |
| ▪Predictions for original sequential input | |
| ▪Again, with random sequential variation | |
| ▪Unsupervised loss component | |
| ▪Supervised loss component | |
| update using, e.g., | ▪Update network parameters |
|
end for end for | |
| return , | |
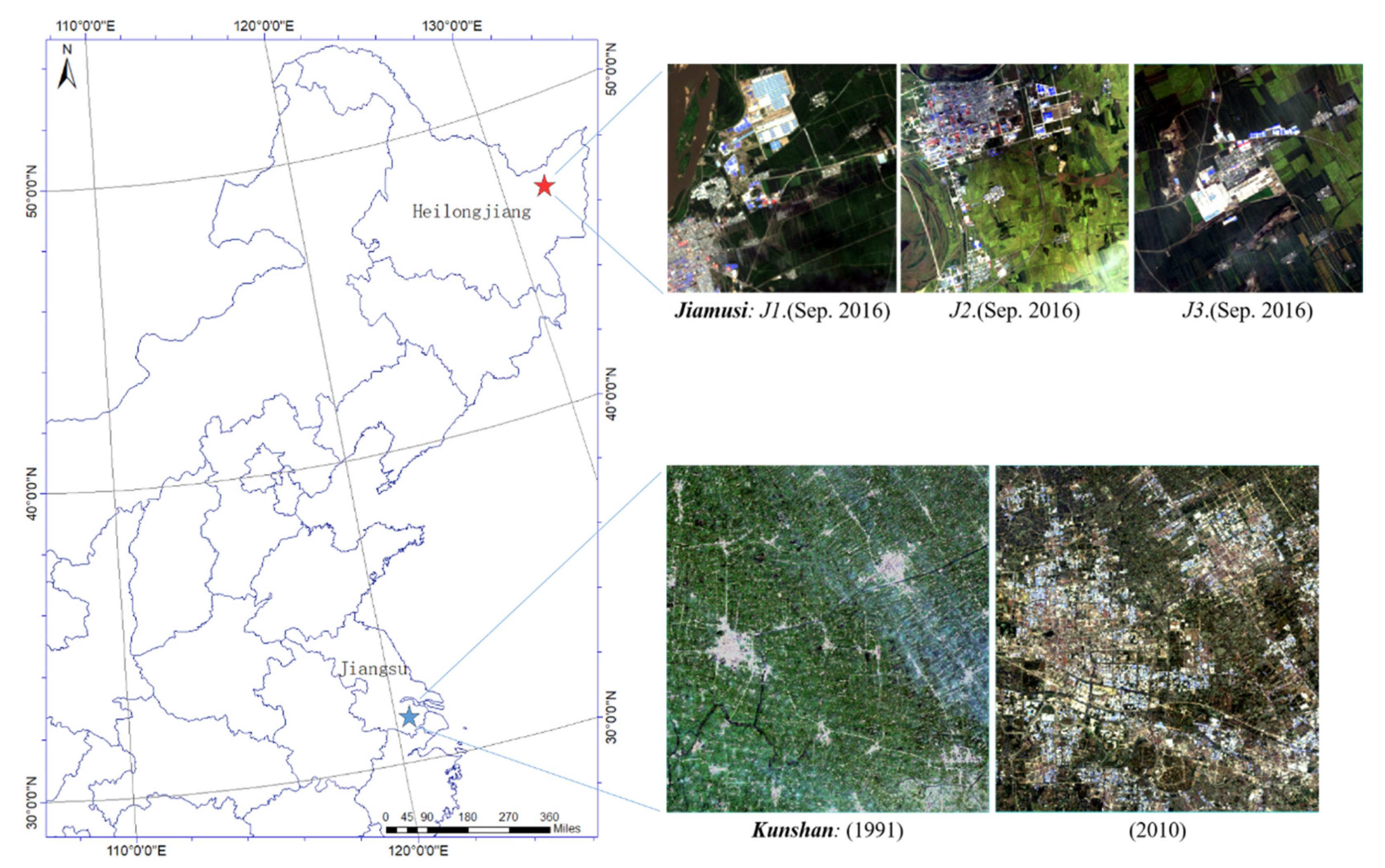
3. Study Areas and Data Sets
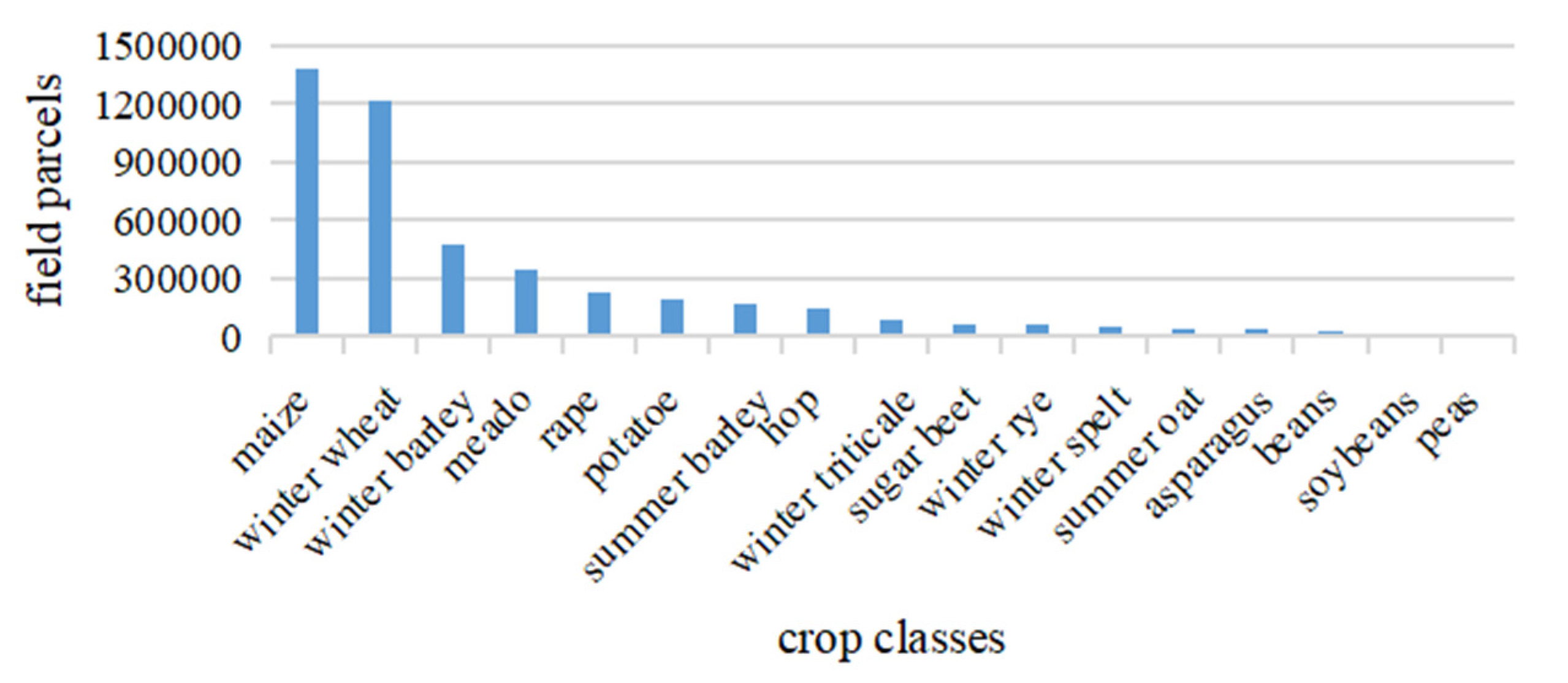
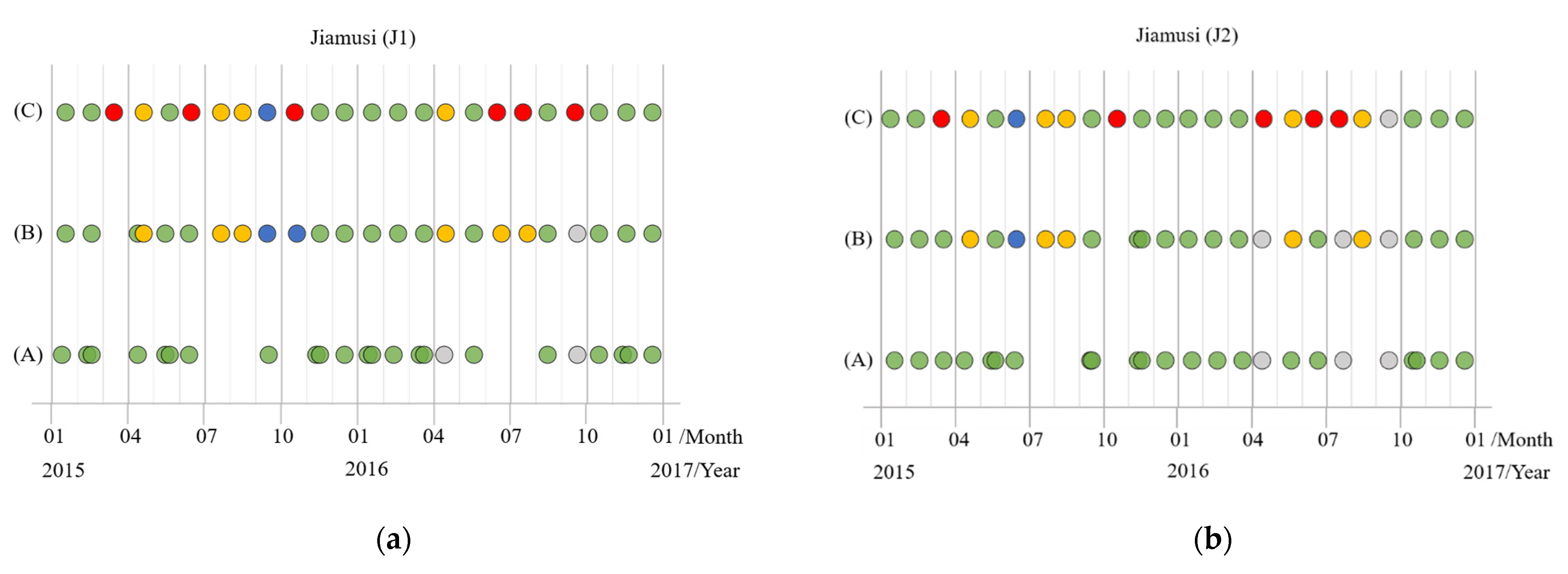
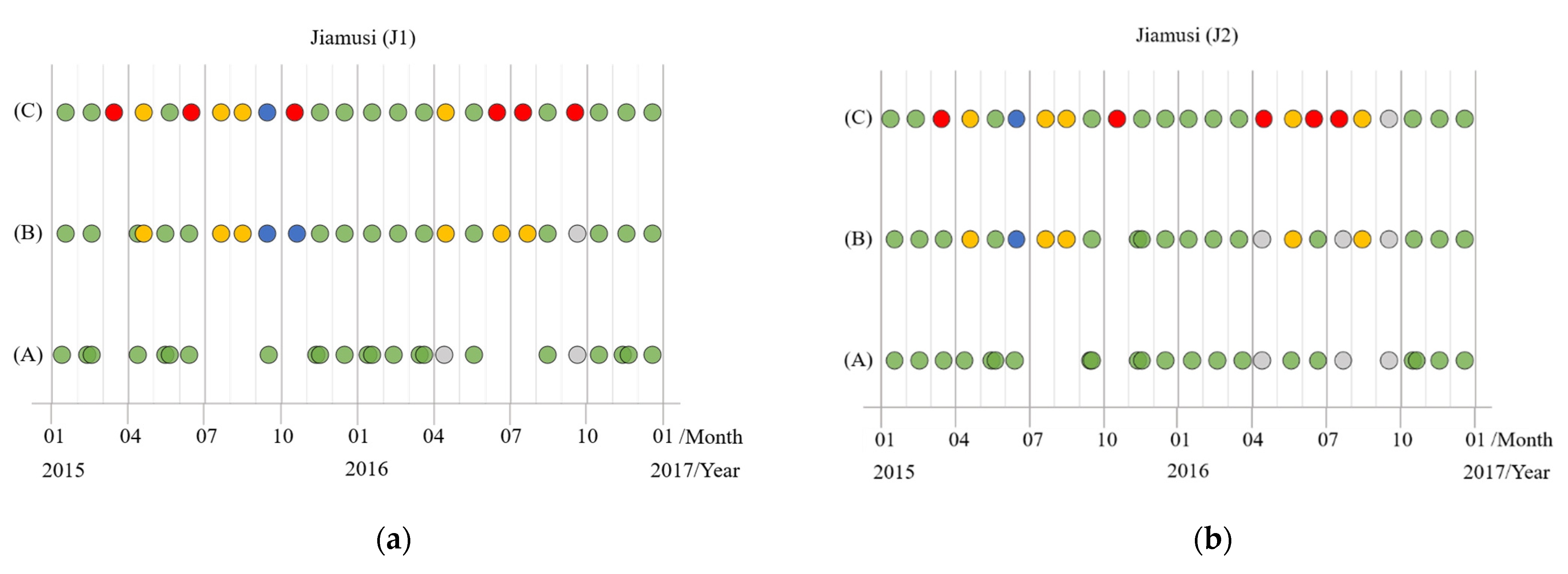
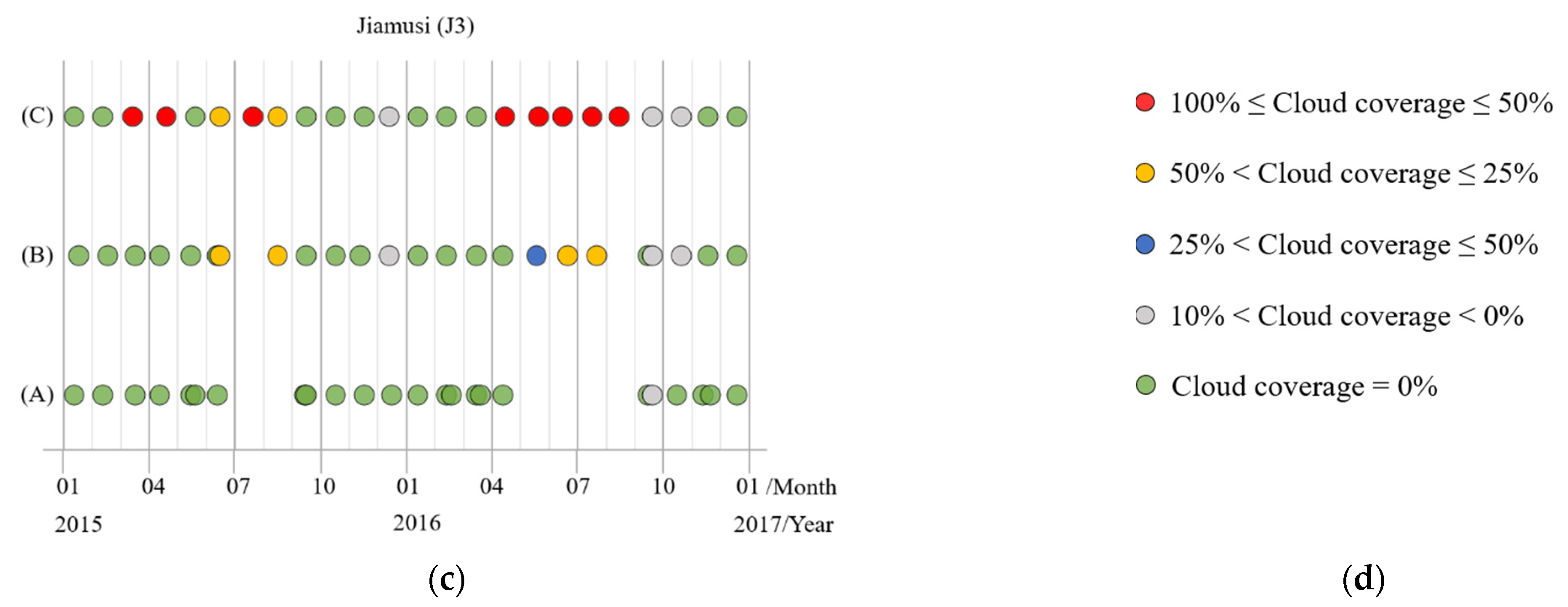
3.1. Jiamusi
3.2. Kunshan
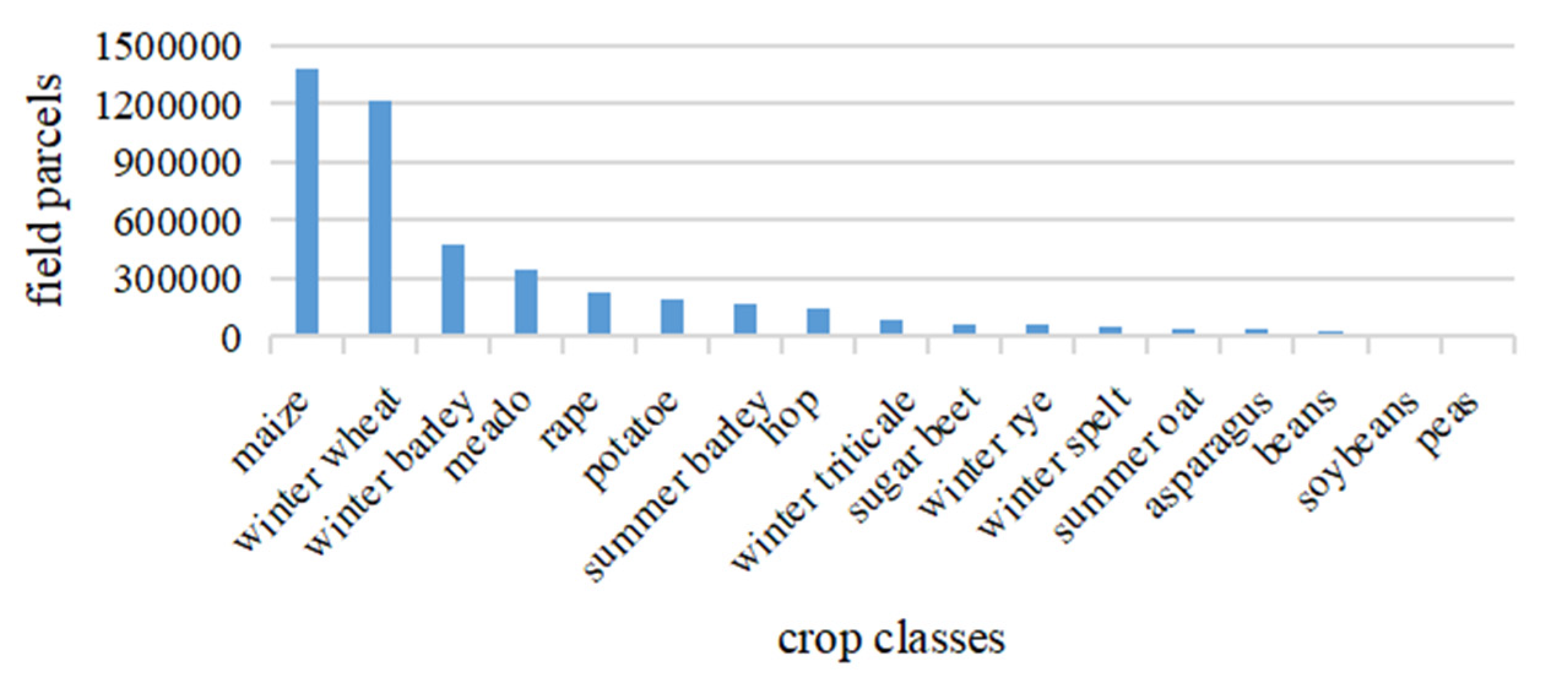
3.3. Munich
4. Experiments and Results
4.1. Experiments Setup
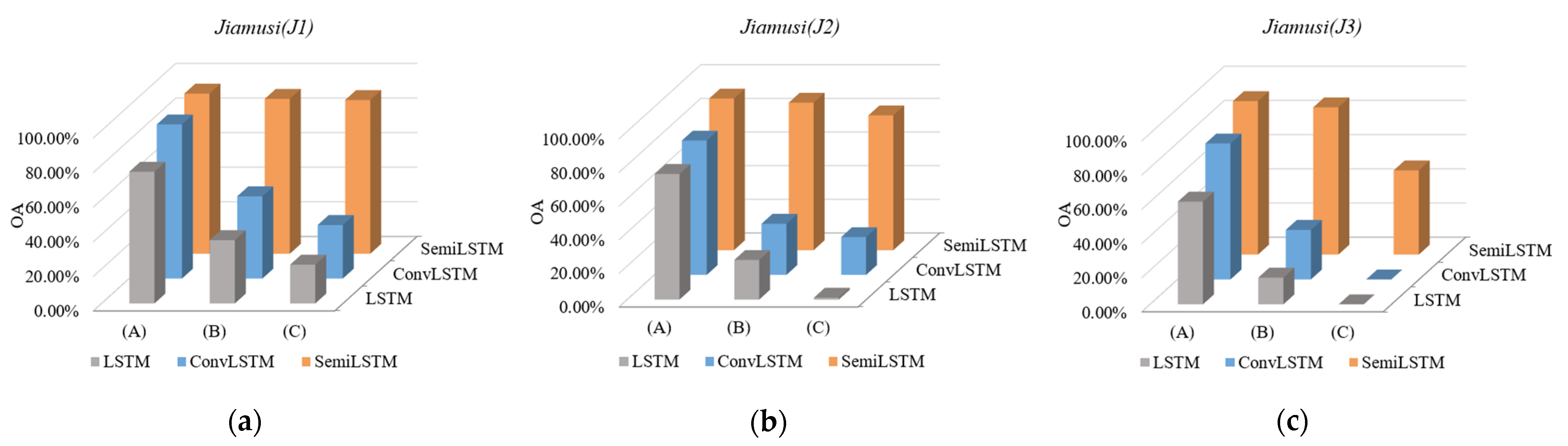
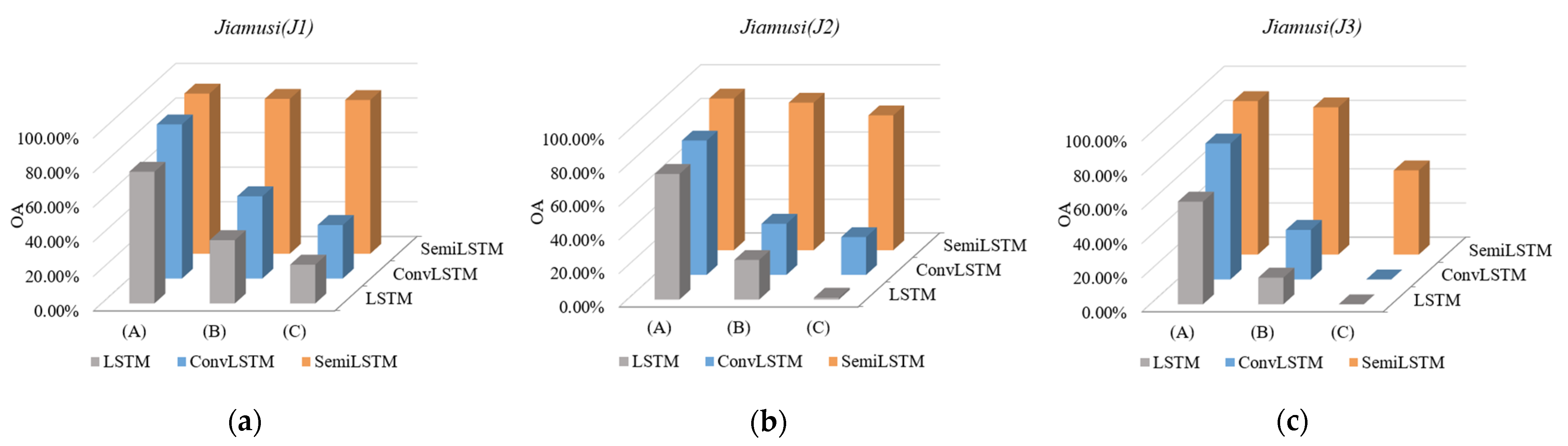
4.2. Accuracy Assessment of Classification
5. Discussion
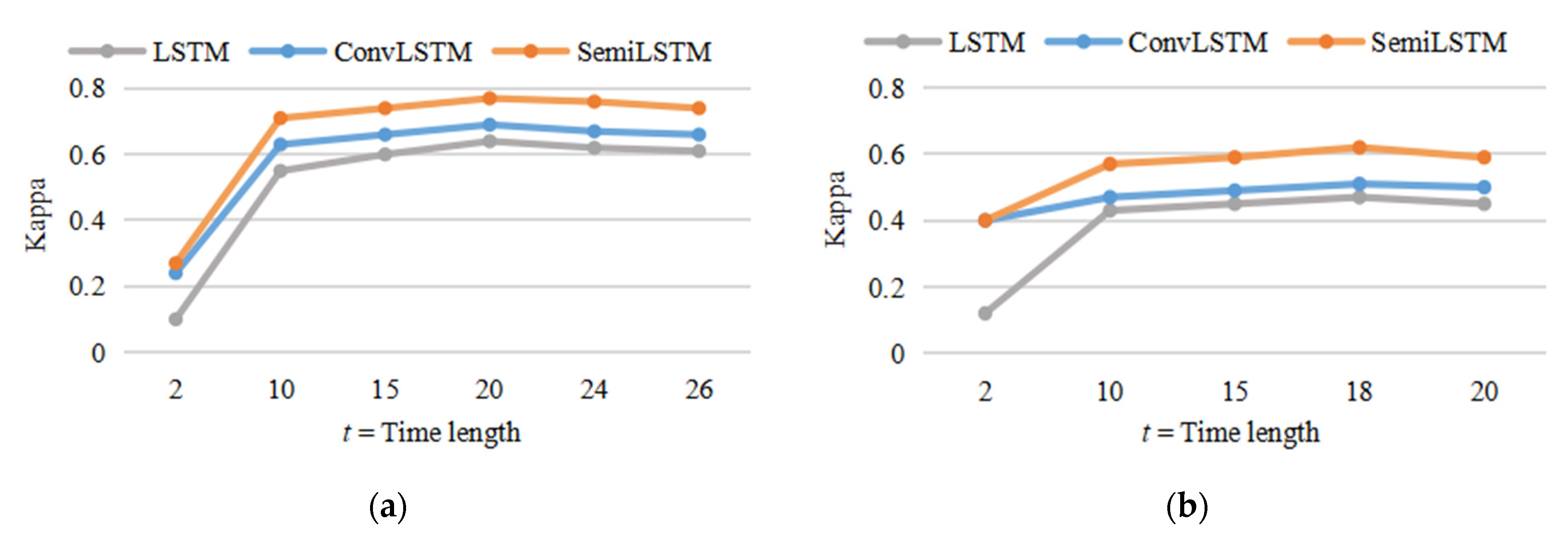
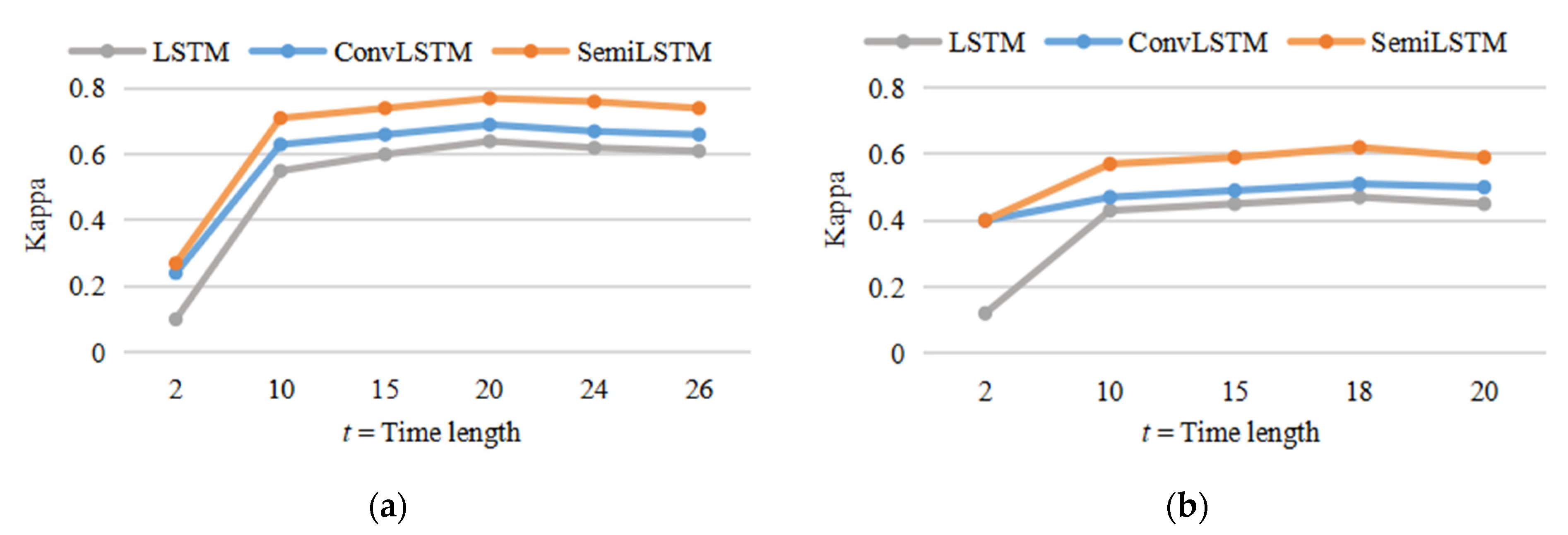
5.1. The Importance of Temporal Context Information
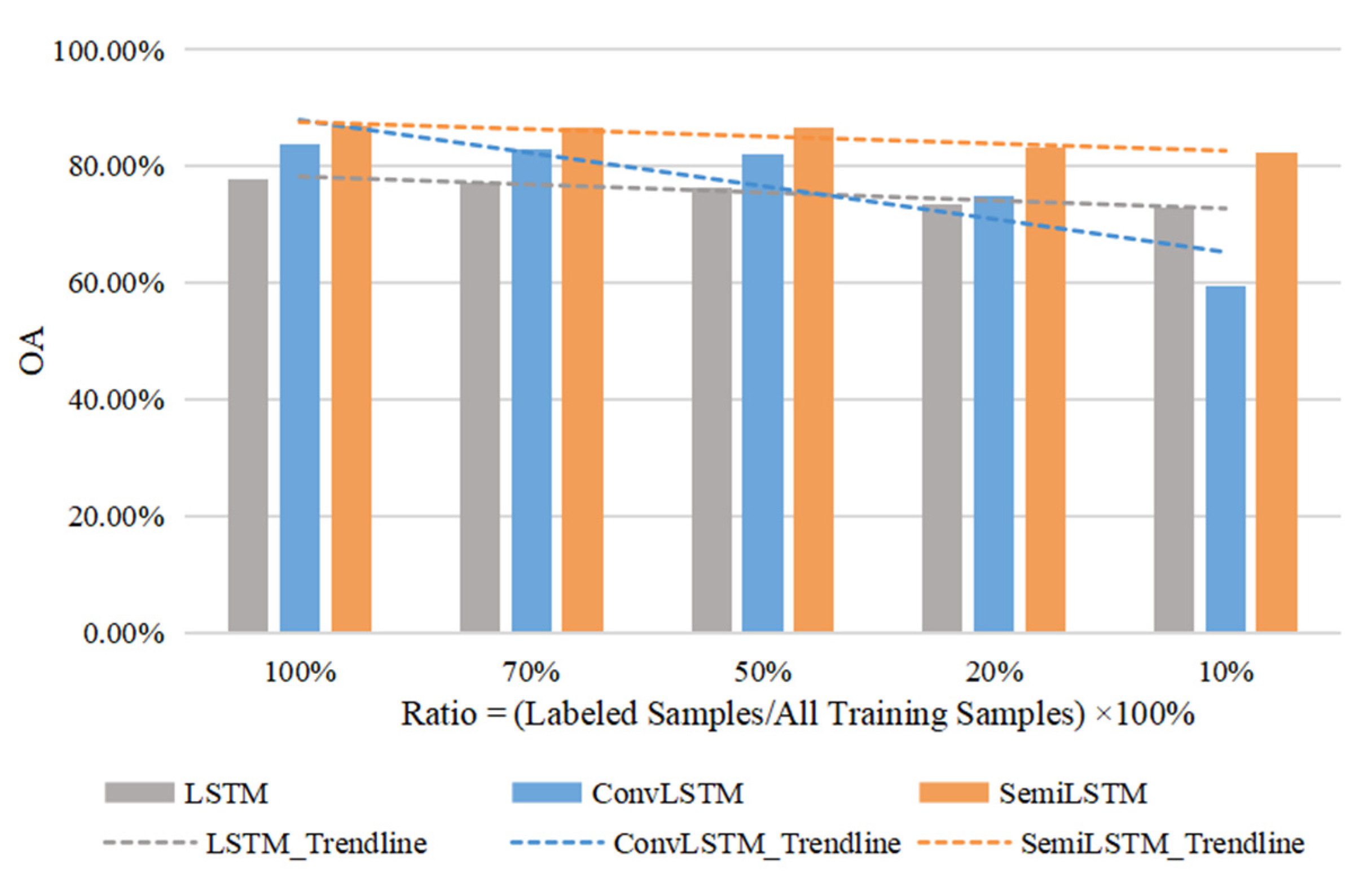
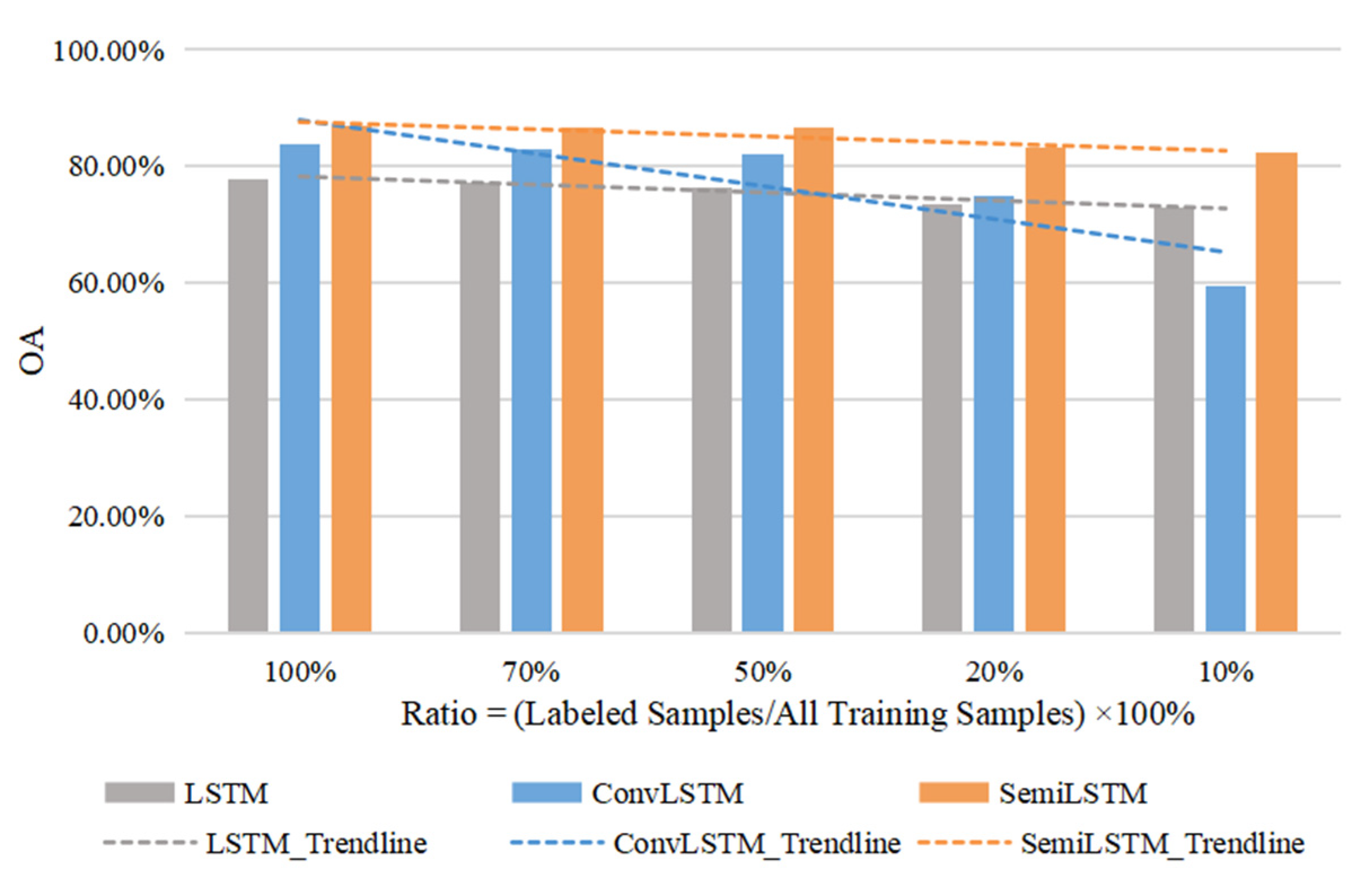
5.2. Appropriate Number of Labeled Training Data
5.3. Cloud-Robust
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Giri, C.; Pengra, B.; Long, J.; Loveland, T.R. Next generation of global land cover characterization, mapping, and monitoring. Int. J. Appl. Earth Obs. Geoinf. 2013, 25, 30–37. [Google Scholar] [CrossRef]
- Gross, J.E.; Goetz, S.J.; Cihlar, J. Application of remote sensing to parks and protected area monitoring: Introduction to the special issue. Remote Sens. Environ. 2009, 113, 1343–1345. [Google Scholar] [CrossRef]
- Hansen, M.C.; Egorov, A.; Potapov, P.V.; Stehman, S.V.; Bents, T. Monitoring conterminous united states (conus) land cover change with web-enabled landsat data (weld). Remote Sens. Environ. 2014, 140, 466–484. [Google Scholar] [CrossRef] [Green Version]
- Jin, S.; Yang, L.; Danielson, P.; Homer, C.; Xian, G. A comprehensive change detection method for updating the national land cover database to circa 2011. Remote Sens. Environ. 2013, 132, 159–175. [Google Scholar] [CrossRef] [Green Version]
- Lasanta, T.; Vicente-Serrano, S.M. Complex land cover change processes in semiarid mediterranean regions: An approach using landsat images in northeast spain. Remote Sens. Environ. 2012, 124, 1–14. [Google Scholar] [CrossRef]
- Xian, G.; Homer, C.; Fry, J. Updating the 2001 national land cover database land cover classification to 2006 by using landsat imagery change detection methods. Remote Sens. Environ. 2009, 113, 1133–1147. [Google Scholar] [CrossRef] [Green Version]
- Boles, S.H.; Xiao, X.; Liu, J.; Zhang, Q.; Munkhtuya, S.; Chen, S.; Ojima, D. Land cover characterization of temperate east asia using multi-temporal vegetation sensor data. Remote Sens. Environ. 2004, 90, 477–489. [Google Scholar] [CrossRef]
- Chen, Y.; Peng, G. Clustering based on eigenspace transformation—CBEST for efficient classification. ISPRS J. Photogramm. Remote Sens. 2013, 83, 64–80. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Bagan, H.; Wang, Q.; Watanabe, M.; Yang, Y.; Jianwen, M.A. Land cover classification from modis evi times-series data using som neural network. Int. J. Remote Sens. 2005, 26, 4999–5012. [Google Scholar] [CrossRef]
- Maulik, U.; Chakraborty, D. Learning with transductive svm for semisupervised pixel classification of remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2013, 77, 66–78. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Lu, W.; Wang, H.; Li, H. Remote sensing image scene classification with self-supervised paradigm under limited labeled samples. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Xu, P.; Song, Z.; Yin, Q.; Song, Y.Z.; Wang, L. Deep self-supervised representation learning for free-hand sketch. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1503–1513. [Google Scholar] [CrossRef]
- Jamshidpour, N.; Homayouni, S.; Safari, A. Graph-based semi-supervised hyperspectral image classification using spatial information. In Proceedings of the 2016 8th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Los Angeles, CA, USA, 21–24 August 2016. [Google Scholar]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef] [Green Version]
- Jia, K.; Liang, S.; Wei, X.; Yao, Y.; Su, Y.; Bo, J.; Wang, X. Land cover classification of landsat data with phenological features extracted from time series modis ndvi data. Remote Sens. 2014, 6, 11518–11532. [Google Scholar] [CrossRef] [Green Version]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. Lstm: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Rubwurm, M.; Korner, M. Temporal vegetation modelling using long short-term memory networks for crop identification from medium-resolution multi-spectral satellite images. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1496–1504. [Google Scholar]
- Scott, G.J.; England, M.R.; Starms, W.A.; Marcum, R.A.; Davis, C.H. Training deep convolutional neural networks for land–cover classification of high-resolution imagery. IEEE Geoence Remote Sens. Lett. 2017, 14, 549–553. [Google Scholar] [CrossRef]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 905–909. [Google Scholar] [CrossRef]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 924–935. [Google Scholar] [CrossRef] [Green Version]
- Gomez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Chen, W.; Zhang, Y.; Tao, C.; Tan, Y. Accurate cloud detection in high-resolution remote sensing imagery by weakly supervised deep learning. Remote Sens. Environ. 2020, 250, 112045. [Google Scholar] [CrossRef]
- Brooks, E.B.; Thomas, V.A.; Wynne, R.H.; Coulston, J.W. Fitting the multitemporal curve: A fourier series approach to the missing data problem in remote sensing analysis. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3340–3353. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Meng, Y.; Lin, L.; Sahli, H.; Yue, A.; Chen, J.; Zhao, Z.; Kong, Y.; He, D. Continuous change detection and classification using hidden markov model: A case study for monitoring urban encroachment onto farmland in beijing. Remote Sens. 2015, 7, 15318–15339. [Google Scholar] [CrossRef] [Green Version]
- Jing, S.; Chao, T. Time series land cover classification based on semi-supervised convolutional long short-term memory neural networks. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 1521–1528. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep learning earth observation classification using imagenet pretrained networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 105–109. [Google Scholar] [CrossRef] [Green Version]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. Learning low dimensional convolutional neural networks for high-resolution remote sensing image retrieval. Remote Sens. 2016, 9, 489. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing higher-layer features of a deep network. Univ. Montr. 2009, 1341, 1. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. Available online: https://arxiv.org/abs/1311.2901 (accessed on 28 November 2013).
- Gers, F.A.; Schmidhuber, J.; Cummins, F.A. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Laine, S.M.; Aila, T.O. Temporal ensembling for semi-supervised learning. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, PP, 2999–3007. [Google Scholar]
- Chren, W.A. One-hot residue coding for high-speed non-uniform pseudo-random test pattern generation. In Proceedings of the International Symposium on Circuits and Systems, Scottsdale, AZ, USA, 26–19 May 2002. [Google Scholar]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Carrao, H.; Goncalves, P.; Caetano, M. Contribution of multispectral and multitemporal information from modis images to land cover classification. Remote Sens. Environ. 2008, 112, 986–997. [Google Scholar] [CrossRef]
- Lawrence, R.L.; Wood, S.D.; Sheley, R.L. Mapping invasive plants using hyperspectral imagery and breiman cutler classifications (randomforest). Remote Sens. Environ. 2006, 100, 356–362. [Google Scholar] [CrossRef]
- Shi, D.; Yang, X. An assessment of algorithmic parameters affecting image classification accuracy by random forests. Photogramm. Eng. Remote Sens. 2016, 82, 407–417. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, L.; Yao, F. Improved maize cultivated area estimation over a large scale combining modis–evi time series data and crop phenological information. ISPRS J. Photogramm. Remote Sens. 2014, 94, 102–113. [Google Scholar] [CrossRef]
- Na, X.; Zhang, S.; Li, X.; Yu, H.; Liu, C. Improved land cover mapping using random forests combined with landsat thematic mapper imagery and ancillary geographic data. Photogramm. Eng. Remote Sens. 2010, 76, 833–840. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RF | SVM | LSTM | ConvLSTM | SemiLSTM | ||
|---|---|---|---|---|---|---|
| Jiamusi | OA | 54.04% | 53.87% | 77.67% | 83.50% | 86.61% |
| K | 0.17 | 0.21 | 0.64 | 0.69 | 0.77 | |
| WF1 | 0.44 | 0.48 | 0.62 | 0.78 | 0.83 | |
| Kunshan | OA | 40.56% | 45.32% | 65.58% | 72.11% | 77.69% |
| K | 0.15 | 0.19 | 0.46 | 0.51 | 0.62 | |
| WF1 | 0.30 | 0.35 | 0.57 | 0.64 | 0.75 | |
| Munich | OA | 38.35% | 47.68% | 78.27% | 80.58% | 87.24% |
| K | 0.21 | 0.33 | 0.53 | 0.59 | 0.63 | |
| WF1 | 0.19 | 0.46 | 0.77 | 0.82 | 0.88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, J.; Tao, C.; Qi, J.; Wang, H. Semi-Supervised Convolutional Long Short-Term Memory Neural Networks for Time Series Land Cover Classification. Remote Sens. 2021, 13, 3504. https://doi.org/10.3390/rs13173504
Shen J, Tao C, Qi J, Wang H. Semi-Supervised Convolutional Long Short-Term Memory Neural Networks for Time Series Land Cover Classification. Remote Sensing. 2021; 13(17):3504. https://doi.org/10.3390/rs13173504
Chicago/Turabian StyleShen, Jing, Chao Tao, Ji Qi, and Hao Wang. 2021. "Semi-Supervised Convolutional Long Short-Term Memory Neural Networks for Time Series Land Cover Classification" Remote Sensing 13, no. 17: 3504. https://doi.org/10.3390/rs13173504
APA StyleShen, J., Tao, C., Qi, J., & Wang, H. (2021). Semi-Supervised Convolutional Long Short-Term Memory Neural Networks for Time Series Land Cover Classification. Remote Sensing, 13(17), 3504. https://doi.org/10.3390/rs13173504