
Moving Car Recognition and Removal for 3D Urban Modelling Using Oblique Images



Abstract
:1. Introduction
- Geometric Deformation. If a car is stationary and then leaves during image acquisition, parts of the images will contain car information, and the other parts will not contain car information. The texture inconsistency will lead to mismatching and mesh deformations in the reconstructed 3D model. As shown in Figure 1a, the car in the red selection box was stationary and then left the region during data collection, which resulted in geometric deformations in the generated triangle mesh.
- Error Texture Mapping. In the texture generation stage of 3D model reconstruction, moving cars will influence texture selection. If there is no pre-processing to identify moving cars, the incorrect moving-car texture information may be selected for mesh patches, resulting in texture mapping errors. As shown in Figure 1b, there are many moving cars at the intersection, and there is a large traffic flow. Due to incorrect texture selection problems caused by the moving cars in road regions, the texture of the reconstructed 3D model looks very disorganized and is quite different from the 3D model of a common road area (e.g., most of the white road marks in front of the zebra crossing are contaminated by car textures).

2. Related Work
2.1. Object Detection
2.2. Moving Object Detection
2.3. Multiview 3D Reconstruction
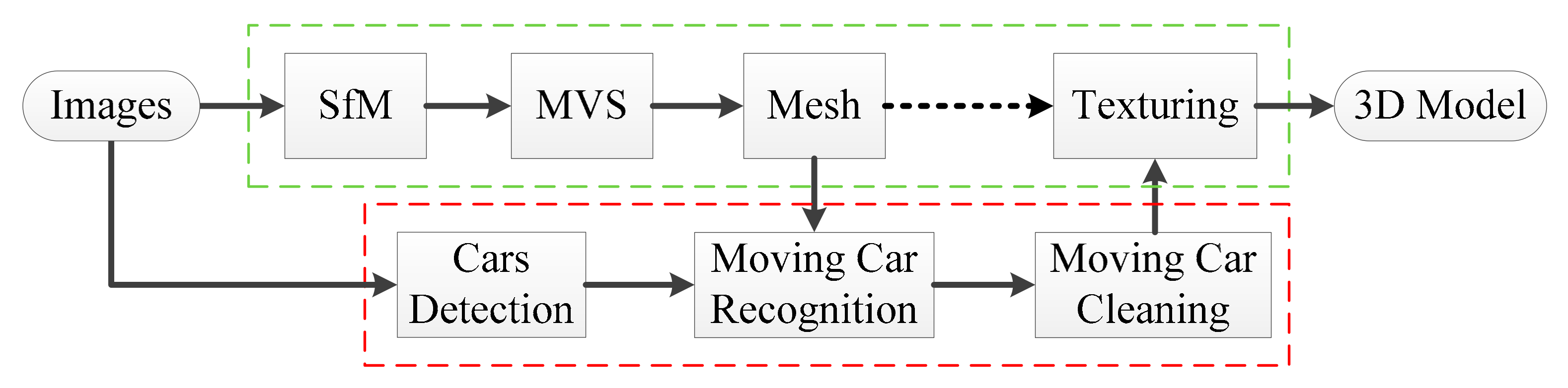
3. Method
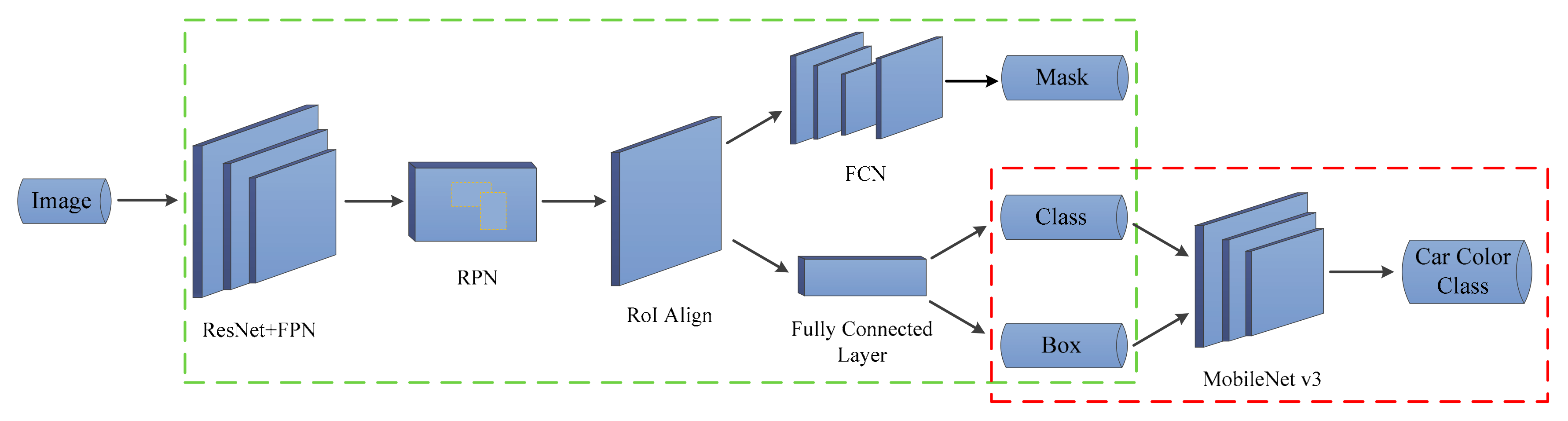
3.1. Cars Detection Using Mask R-CNN
3.2. Moving Car Recognition Based on Multiview Constraints
3.2.1. Definition of the Car Moving State (CMS)
3.2.2. Moving Car Recognition
- Overview
- Detailed Procedure for Moving Car Recognition
- For each image , sequentially remove the car mask () that has not yet been processed in . According to the set of triangles () that is visible on , we can obtain by collecting the triangles whose projected positions are within the area of (the green marked region in Figure 7).
- Count the number of other images (denoted by ) that are also visible to but were not processed during the previous step. Count the number of detected car masks (denoted by ) that overlap with the projection region of in these images. If , only a very small number of cars passed by during image collection, and and the other car masks should be marked as moving. Then, apply this process to the next car mask . Otherwise, go to the next step.
- If , there were cars parked in for a period of time during the image collection. Then, the states of these car masks should be marked as short stay, and the next car mask should be in the processing sequence. Otherwise, the local region is always occupied by the car; hence, go to the next step.
- Calculate the colour histogram of these car masks and find the largest peak value . If , the detected corresponding texture patches of the area of in the multiview images are consistent and should be considered the same car. Then, the states of these masks are marked as stationary. Otherwise, the car in has changed, so the states of these masks are recorded as short stay. Continually apply these steps to all the unprocessed masks of cars sequentially until there are no unprocessed masks.
| Algorithm 1. Car Moving State Recognition. |
| Input: The urban scene mesh , car masks of each image |
| Output: The moving state of every car in each image |
| 1. Set , , , |
| 2. while do |
| 3. Get car masks of current image and set |
| 4. while do |
| 5. if the state of in is unknown |
| 6. Count the number of other visible images () to and count the number of detected car masks () that overlap with the projection region of |
| 7. if |
| 8. The CMS is moving |
| 9. else if |
| 10. The CMS is short-stay |
| 11. else |
| 12. Calculate the colour histogram of these car masks and find |
| the largest peak value |
| 13. if |
| 14. The CMS is short-stay |
| 15. else |
| 16. The CMS is stationary |
| 17. end if |
| 18. end if |
| 19. end if |
| 20. |
| 21. end while |
| 22. |
| 23. end while |
| stop |
3.3. Moving Car Cleaning
3.3.1. Mesh Clean
3.3.2. Texture Preprocessing
4. Experiments and Discussion
4.1. Data Description
4.2. Car Detection
- Difficult samples, such as cars that are difficult to distinguish from the background, are not easy to notice. For example, a black car in a shadow is not detected (see the green box in Figure 9c).
- It is challenging to detect cars occluded by a large region, as shown in Figure 9c in the red wireframe. Compared to the other two experimental scenes (Figure 9a,b), the third scene (Figure 9c) with a lower recall rate conforms to reality. On the one hand, there are more occlusion cases in oblique images. On the other hand, there are more shadow areas in urban scenes when light is sufficient.
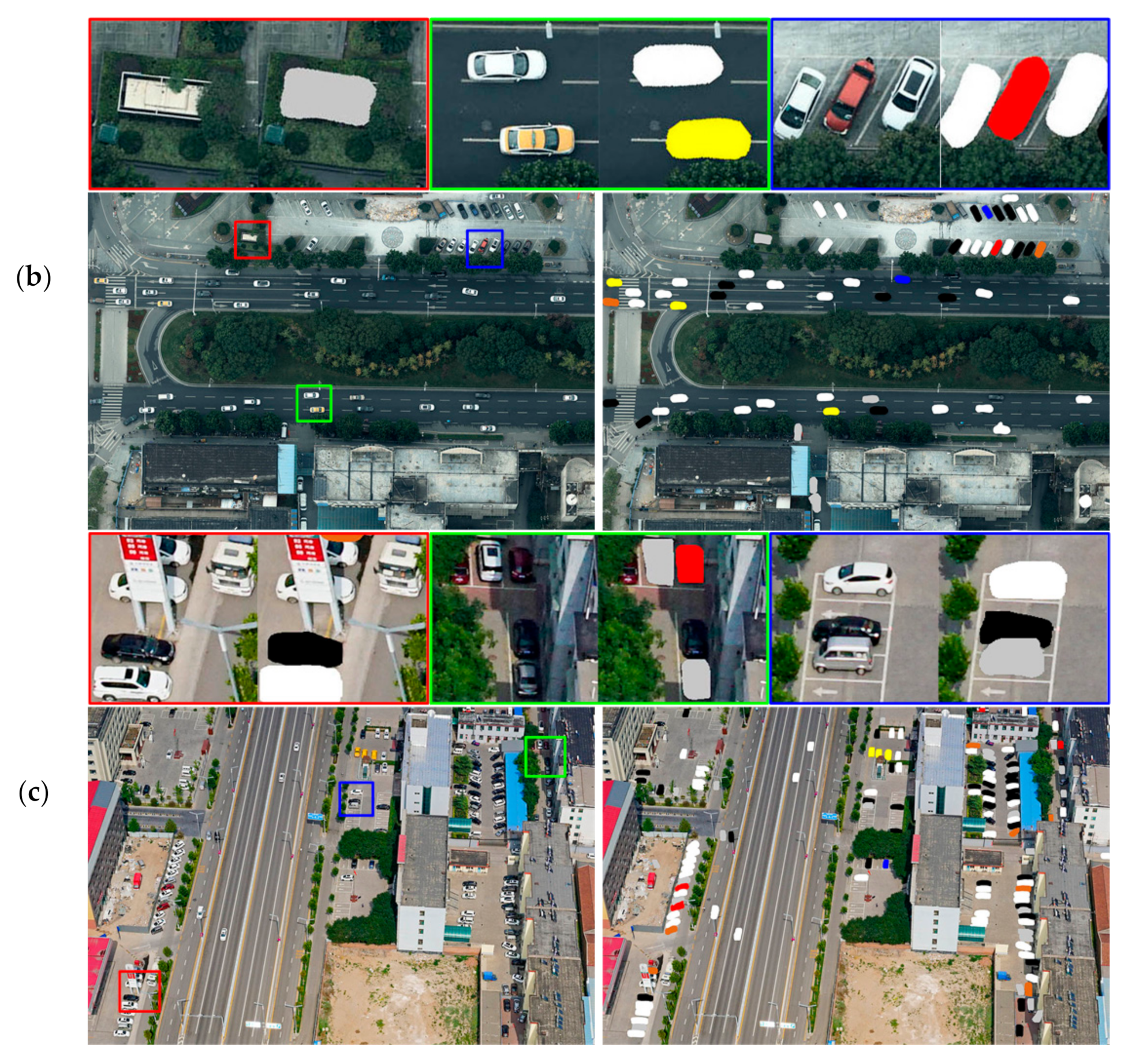
4.3. Moving Car Recognition
4.4. Moving Car Cleaning
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, B.; Dong, Z.; Liu, Y.; Liang, F.; Wang, Y. Computing multiple aggregation levels and contextual features for road facilities recognition using mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2017, 126, 180–194. [Google Scholar] [CrossRef]
- Toschi, I.; Ramos, M.M.; Nocerino, E.; Menna, F.; Remondino, F.; Moe, K.; Poli, D.; Legat, K.; Fassi, F. Oblique photogrammetry supporting 3D urban reconstruction of complex scenarios. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-1/W1, 519–526. [Google Scholar] [CrossRef] [Green Version]
- Jiang, S.; Jiang, W.S.; Huang, W.; Yang, L. UAV-Based Oblique Photogrammetry for Outdoor Data Acquisition and Offsite Visual Inspection of Transmission Line. Remote Sens. 2017, 9, 278. [Google Scholar] [CrossRef] [Green Version]
- Moulon, P.; Monasse, P.; Marlet, R. Global fusion of relative motions for robust, accurate and scalable structure from motion. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 3–6 December 2013; pp. 3248–3255. [Google Scholar] [CrossRef] [Green Version]
- Han, Y.L.; Liu, W.; Huang, X.; Wang, S.G.; Qin, R.J. Stereo Dense Image Matching by Adaptive Fusion of Multiple-Window Matching Results. Remote Sens. 2020, 12, 3138. [Google Scholar] [CrossRef]
- Xu, Z.Q.; Xu, C.; Hu, J.; Meng, Z.P. Robust resistance to noise and outliers: Screened Poisson Surface Reconstruction using adaptive kernel density estimation. Comput. Graph. 2021, 97, 19–27. [Google Scholar] [CrossRef]
- Waechter, M.; Moehrle, N.; Goesele, M. Let There Be Color! Large-Scale Texturing of 3D Reconstructions. In Computer Vision—ECCV 2014. ECCV 2014. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 869, pp. 836–850. [Google Scholar] [CrossRef]
- Verykokou, S. Georeferencing Procedures for Oblique Aerial Images. Ph.D. Thesis, National Technical University of Athens, Athens, Greece, 2020. [Google Scholar]
- Zhu, Q.; Shang, Q.S.; Hu, H.; Yu, H.J.; Zhong, R.F. Structure-aware completion of photogrammetric meshes in urban road environment. ISPRS J. Photogramm. Remote Sens. 2021, 175, 56–70. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A General Framework for Object Detection. In Proceedings of the Sixth International Conference on Computer Vision, Bombay, India, 7 January 1998; pp. 555–562. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Gray Scale and Rotation Invariant Texture Classification with Local Binary Patterns. In Computer Vision—ECCV 2000. ECCV 2000. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1842, pp. 404–420. [Google Scholar] [CrossRef] [Green Version]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Kononenko, I. Semi-naive Bayesian Classifier. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1991; Volume 482, pp. 206–219. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Lukas, L.; Dooren, V.P.; Moor, D.B.; Vandewalle, J. Least Squares Support Vector Machine Classifiers: A Large Scale Algorithm. In Proceedings of the European Conference on Circuit Theory and Design, Stresa, Italy, 29 August–2 September 1999; pp. 839–842. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1999, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chu, W.T.; Chao, Y.C.; Chang, Y.S. Street sweeper: Detecting and removing cars in street view images. Multimed. Tools Appl. 2015, 74, 10965–10988. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.B.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 10 July 2021).
- Rukhovich, D.; Vorontsova, A.; Konushin, A. ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection. arXiv 2021, arXiv:2106.01178. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, A.; Gupta, S.; Singh, D.K. Review of optical flow technique for moving object detection. In Proceedings of the 2016 2nd International Conference on Contemporary Computing and Informatics (IC3I), Greater Noida, India, 14–17 December 2017; pp. 409–413. [Google Scholar]
- Barnich, O.; Droogenbroeck, M.V. ViBe: A universal background subtraction algorithm for video sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef] [Green Version]
- Romanoni, A.; Matteucci, M.; Sorrenti, D.G. Background subtraction by combining temporal and spatio-temporal histograms in the presence of camera movement. Mach. Vis. Appl. 2014, 25, 1573–1584. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.W.; Yun, K.; Yi, K.M.; Kim, S.J.; Choi, J.Y. Detection of moving objects with a moving camera using non-panoramic background model. Mach. Vis. Appl. 2013, 24, 1015–1028. [Google Scholar] [CrossRef]
- Postica, G.; Romanoni, A.; Matteucci, M. Robust Moving Objects Detection in Lidar Data Exploiting Visual Cues. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems, Daejeon, Korea, 9–14 October 2016; pp. 1093–1098. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.H.; Wang, C.C. Deep learning of spatio-temporal features with geometric-based moving point detection for motion segmentation. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; pp. 3058–3065. [Google Scholar] [CrossRef]
- Vallet, B.; Xiao, W.; Bredif, M. Extracting mobile objects in images using a velodyne lidar point cloud. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 1, 247–253. [Google Scholar] [CrossRef] [Green Version]
- Hara, Y.; Tomono, M. Moving object removal and surface mesh mapping for path planning on 3D terrain. Adv. Robot. 2020, 34, 375–387. [Google Scholar] [CrossRef]
- Bundy, A.; Wallen, L. Dempster-Shafer Theory; Springer: Berlin/Heidelberg, Germany, 1984. [Google Scholar]
- Yan, L.; Fei, L.; Chen, C.H.; Ye, Z.Y.; Zhu, R.X. A Multi-View Dense Image Matching Method for High-Resolution Aerial Imagery Based on a Graph Network. Remote Sens. 2016, 8, 799. [Google Scholar] [CrossRef] [Green Version]
- Bleyer, M.; Rhemann, C.; Rother, C. PatchMatch Stereo-Stereo Matching with Slanted Support Windows. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; pp. 1–11. [Google Scholar] [CrossRef] [Green Version]
- Pan, H.L.; Guan, T.; Luo, K.Y.; Luo, Y.W.; Yu, J.Q. A visibility-based surface reconstruction method on the GPU. Comput. Aided Geom. Des. 2021, 84, 101956. [Google Scholar] [CrossRef]
- Bi, S.; Kalantari, N.K.; Ramamoorthi, R. Patch-based optimization for image-based texture mapping. ACM Trans. 2017, 36, 106. [Google Scholar] [CrossRef]
- Google Earth. Available online: https://www.google.com/earth/ (accessed on 10 July 2021).
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.J.; Chen, L.C.; Tan, M.X.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Yu, J.H.; Lin, Z.; Yang, J.M.; Shen, X.H.; Lu, X.; Huang, T. Free-Form Image Inpainting with Gated Convolution. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4470–4479. [Google Scholar] [CrossRef] [Green Version]
- OpenMVG. Available online: https://github.com/openMVG/openMVG (accessed on 10 July 2021).
- OpenMVS. Available online: https://github.com/cdcseacave/openMVS (accessed on 10 July 2021).
- OpenMesh. Available online: https://www.graphics.rwth-aachen.de/software/openmesh/ (accessed on 10 July 2021).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Version |
|---|---|
| OS | Ubuntu 16.04 |
| CPU | Intel Core i7-7700K@4.20GHz |
| GPU | NVIDIA GeForce RTX 2070 |
| Language | Python 3.6 |
| Framework | TensorFlow v1.14.0 + Keras v2.1.5 |
| Accelerator Library | CUDA v10.0 + CUDNN v7.6 |
| Scene | Car Detection | Car Colour | |
|---|---|---|---|
| Precision | Recall | Precision | |
| Ortho + Sunny | 0.954 | 0.946 | 0.868 |
| Ortho + Cloudy | 0.971 | 0.953 | 0.891 |
| Oblique + Sunny | 0.937 | 0.925 | 0.852 |
| Region | nk | n1 | ratio1 | n2 | ratio2 | State |
|---|---|---|---|---|---|---|
| Red Box | 175 | 2 | 0.011 | -- | -- | Moving |
| Blue Box | 168 | 60 | 0.357 | -- | -- | Short stay |
| Yellow Box | 190 | 183 | 0.963 | 112 | 0.612 | Short stay |
| Green Box | 207 | 195 | 0.942 | 173 | 0.887 | Stationary |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, C.; Zhang, F.; Gao, Y.; Mao, Z.; Li, L.; Huang, X. Moving Car Recognition and Removal for 3D Urban Modelling Using Oblique Images. Remote Sens. 2021, 13, 3458. https://doi.org/10.3390/rs13173458
Yang C, Zhang F, Gao Y, Mao Z, Li L, Huang X. Moving Car Recognition and Removal for 3D Urban Modelling Using Oblique Images. Remote Sensing. 2021; 13(17):3458. https://doi.org/10.3390/rs13173458
Chicago/Turabian StyleYang, Chong, Fan Zhang, Yunlong Gao, Zhu Mao, Liang Li, and Xianfeng Huang. 2021. "Moving Car Recognition and Removal for 3D Urban Modelling Using Oblique Images" Remote Sensing 13, no. 17: 3458. https://doi.org/10.3390/rs13173458
APA StyleYang, C., Zhang, F., Gao, Y., Mao, Z., Li, L., & Huang, X. (2021). Moving Car Recognition and Removal for 3D Urban Modelling Using Oblique Images. Remote Sensing, 13(17), 3458. https://doi.org/10.3390/rs13173458