1. Introduction
Obtained from hyperspectral sensors, a hyperspectral image (HSI) is a collection of tens to hundreds of images at different wavelengths for the same area. It contains three-dimensional hyperspectral (
x,
y,
) data, where
x and
y represent the horizontal and vertical spatial dimensions, respectively, and
represents the spectral dimension. Compared to previous imaging techniques such as multi-spectral imaging, hyperspectral imaging has much narrower bands, resulting in a higher spectral resolution. Hyperspectral remote sensing imagery has a wide variety of studies from target detection, classification, and feature analysis, and has many practical applications in mineralogy, agriculture, medicine, and other fields [
1,
2,
3,
4,
5,
6,
7]. Consequently, higher spatial-spectral resolution of hyperspectral images allows a more efficient way to explore and classify surface features.
To ensure the reception of high-quality signals with low signal-to-noise ratio, there is a trade-off between the spatial and spectral resolution of the imaging process [
8,
9,
10]. Accordingly, HSIs are often accessed under relatively low spatial resolution, which would impede the perception of details and learning of discriminative structural features, as well as further analysis in related applications. With the hope of recovering spatial features economically, post-processing techniques such as super-resolution are an ideal way to restore details from a low-resolution hyperspectral image.
Generally, there exist two prevailing methods to enhance the spatial details, i.e., the fusion-based HSI super-resolution and single HSI super-resolution approaches. For the former category, Palsson et al. [
11] proposed a 3D convolutional network for HSI super-resolution by incorporating an HSI and a multispectral image. Han et al. [
12] first combined a bicubic up-sampled low-resolution HSI with a high-resolution RGB image into a CNN. Dian et al. [
13] propose a CNN denoiser based method for hyperspectral and multispectral image fusion, which overcomes the difficulty of not enough training data and has achieved outstanding performance. Nevertheless, auxiliary multispectral images have fewer spectral bands than HSIs, which will cause spectral distortion of the reconstructed images. To address these drawbacks, some improvements have been made in subsequent works [
14,
15,
16,
17,
18]. However, the premise is that the two images should be aligned, otherwise the performance will be significantly degraded [
19,
20,
21]. Compared with the former, single HSI super-resolution methods require no auxiliary images, which are more convenient to apply to the real scenario. Many approaches such as sparse regularization [
22] and low rank approximation [
21,
23] have been proposed in this direction. However, such hand-crafted priors are time-consuming and have limited generalization ability.
Currently, the convolutional neural network (CNN) has achieved great success in RGB image super-resolution tasks, and was introduced to restore the HSI. Compared with RGB image super resolution, HSI super-resolution is more challenging. On the one hand, HSIs have far more bands than RGB images and most of the bands are useful for actual analysis of surface features, but unfortunately several public datasets have much smaller training sets compared to RGB images. Hence, the network needs to preserve the spectral information and avoid distortion while increasing the spatial resolution of HSI and the design needs to be delicate enough to refrain from overfitting caused by insufficient data. To handle this problem, there have been many attempts in recent years. For instance, Li et al. [
24] proposed a spatial constraint method to increase the spatial resolution as well as preserve the spectral information. Furthermore, Li et al. [
25] presented a grouped deep recursive residual network (GDRRN) to find a mapping function between the low-resolution HSI and high-resolution HSI. They first combined the spectral angler mapping (SAM) loss with the mean square error (MSE) loss for network optimization, reducing the spectral distortion. Nonetheless, the spatial resolution is relatively low. To better learn spectral information, Mei et al. [
26] proposed a novel three-dimensional full convolutional neural network (3D CNN), which can better learn the spectral context and alleviate distortion. In addition, [
27,
28] applied 3D convolution to their network. However, the use of 3D convolution requires a huge amount of computation due to the high-dimensional nature of HSI. On the other hand, there exists a large amount of unrelated redundancy in the spatial dimension, which hinders the effective processing of images. Although existing approaches try to extract texture features, it is still difficult to recover the delicate texture in the reconstructed high-resolution HSI [
29,
30]. For example, Jiang et al. [
30] introduced a deep residual network with a channel attention module (SSPSR) and applied a skip-connection mechanism to help promote attention to high-frequency information.
To deal with the hyperspectral image super-resolution (HSI SR) problem, we propose a difference curvature multidimensional network (DCM-Net) in this paper. First, we group the input images in a band-wise manner and feed them into several parallel branches. In this way, the number of parameters can be reduced while the performance can also be improved as evidenced by the experimental results. Then, in each branch, we devise a novel multidimensional enhanced block (MEB), consisting of several cascaded multidimensional enhanced convolution (MEC) units. MEC can exploit long-range intra- and inter-channel correlations through bottleneck projection and spatial and spectral attention. In addition, we design a difference curvature branch (DCB) to facilitate learning edge information and removing unwanted noise. It consists of five convolutional layers with different filters and can easily be applied to the network to recalibrate features. Extensive evaluation of three public datasets demonstrates that the proposed DCM-Net can increase the resolution of HSI with sharper edges as well as preserving the spectral information better than state-of-the-art (SOTA) methods.
In summary, the contributions of this paper are threefold.
- 1.
We propose a novel difference curvature multidimensional network (DCM-Net) for hyperspectral image super-resolution, which outperforms existing methods in both quantitative and qualitative comparisons.
- 2.
We devise a multidimensional enhanced convolution (MEC), which leverages a bottleneck projection to reduce the high dimensionality and encourage inter-channel feature fusion, as well as an attention mechanism to exploit spatial-spectral features.
- 3.
We propose an auxiliary difference curvature branch (DCB) to guide the network to focus on high-frequency components and improve the SR performance on fine texture details.
The rest of the paper is organized as follows. In
Section 2 we present the proposed method. The experimental results and analysis are presented in
Section 3. Some ablation experiments and a discussion are presented in
Section 4. Finally, we conclude the paper in
Section 5.
2. Materials and Methods
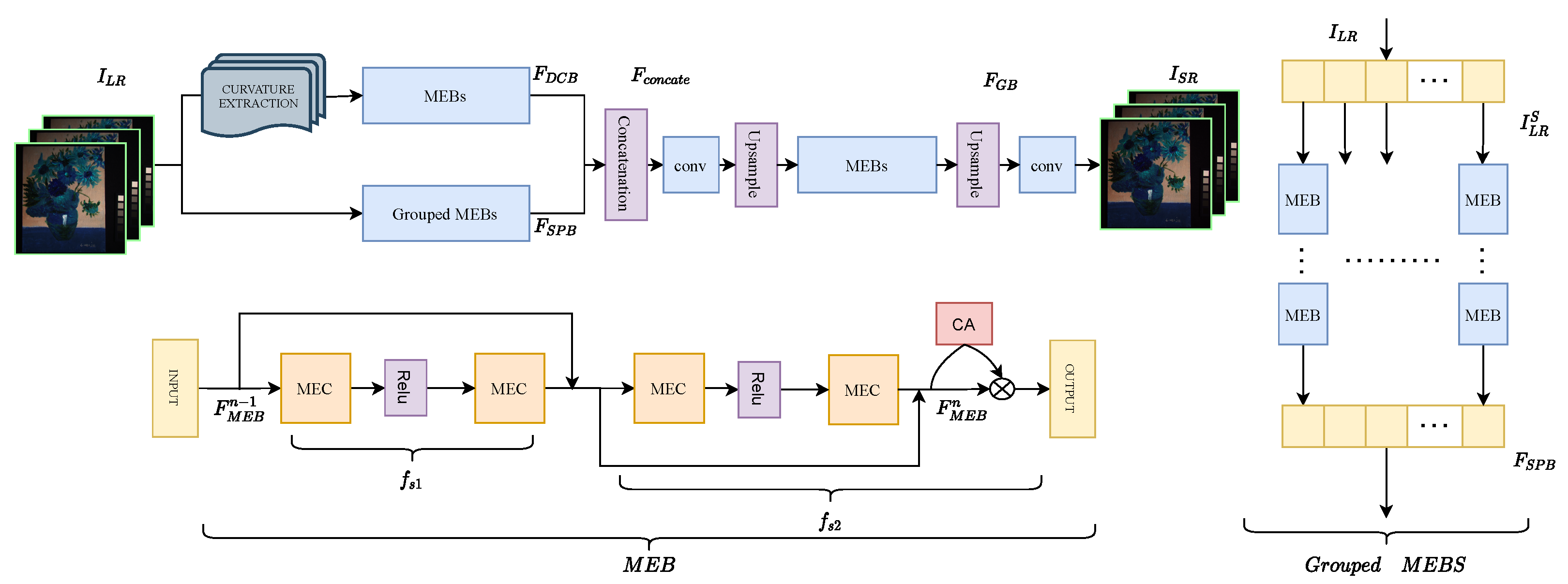
In this section, we present the proposed DCM-Net in detail, including the network structure, the multidimensional enhanced block (MEB), the difference curvature-based branch (DCB), and the loss function. The overview network structure of the proposed DCM-Net is illustrated in
Figure 1.
2.1. Network Architecture
The network of DCM-Net mainly consists of two parts: a two-step network for deep feature extraction and a reconstruction layer. Given the input low-resolution HSI , we want to reconstruct the corresponding high-resolution HSI , where H and W (h and w) denote the height and width of the high-resolution (low-resolution) image, and C represents the number of spectral bands.
First, we feed the input
to two branches, a difference curvature-based branch (DCB), which is designed to further exploit the texture information, and a structural-preserving branch (SPB), which can be formulated as follows:
where
,
,
,
stand for the output feature maps and the functions of DCB and SPB, respectively. The two branches both use MEB as the basic unit while in the SPB a group strategy inspired by [
24] is adopted: we channel-wisely split the input image to several groups, by which we can reduce the parameters needed for the network, thus lowering the burden on the device. More importantly, given the strong correlation between adjacent spectral bands, we adopt such group strategy to promote the interaction between channels with strong spatial-spectral correlation to a certain extent.
Given that the input is
, it can be divided into multiple groups:
. Let the number of groups be S, we feed these groups
into multiple MEBs to obtain the deep spatial-spectral feature, where we use a novel convolutional operation that can promote channel-wise interaction as well as exploit the long-range spatial dependency:
where
denotes the function of the MEBs, which we will thoroughly demonstrate in the following part.
After obtaining the outputs of both branches, we concatenate them for further global feature extraction and this can be written as
. To lower the parameters needed and computational complexity, a convolutional layer is applied to reduce the dimension. It is worth noting that, considering that the pre-upsampling approach not only brings about the growth of the number of parameters but also brings about problems such as noise amplification and blurring, and post-upsampling makes it difficult to learn the mapping function directly when the scaling factor is large, we adopt a progressive upsampling method, hoping that through such a compromise, we can avoid the problems brought about by the above two upsampling methods [
31,
32,
33]. The up-sampled values will be noted in the implementation details.
Finally, after obtaining the output of the global branch, we use a convolution layer for reconstruction:
where
denotes the reconstruction layer and
denotes the final output of the network.
2.2. Multidimensional Enhanced Block (MEB)
2.2.1. Overview
The structure of MEB is shown in
Figure 2, which is designed to better learn the spectral correlation and the spatial details. Denoting
and
as the input and output of the block, and
and
as the stacked multidimensional enhanced convolution (MEC) layers, we have:
where
and
stand for the two steps of the block. The details of MEC will be thoroughly discussed as follows.
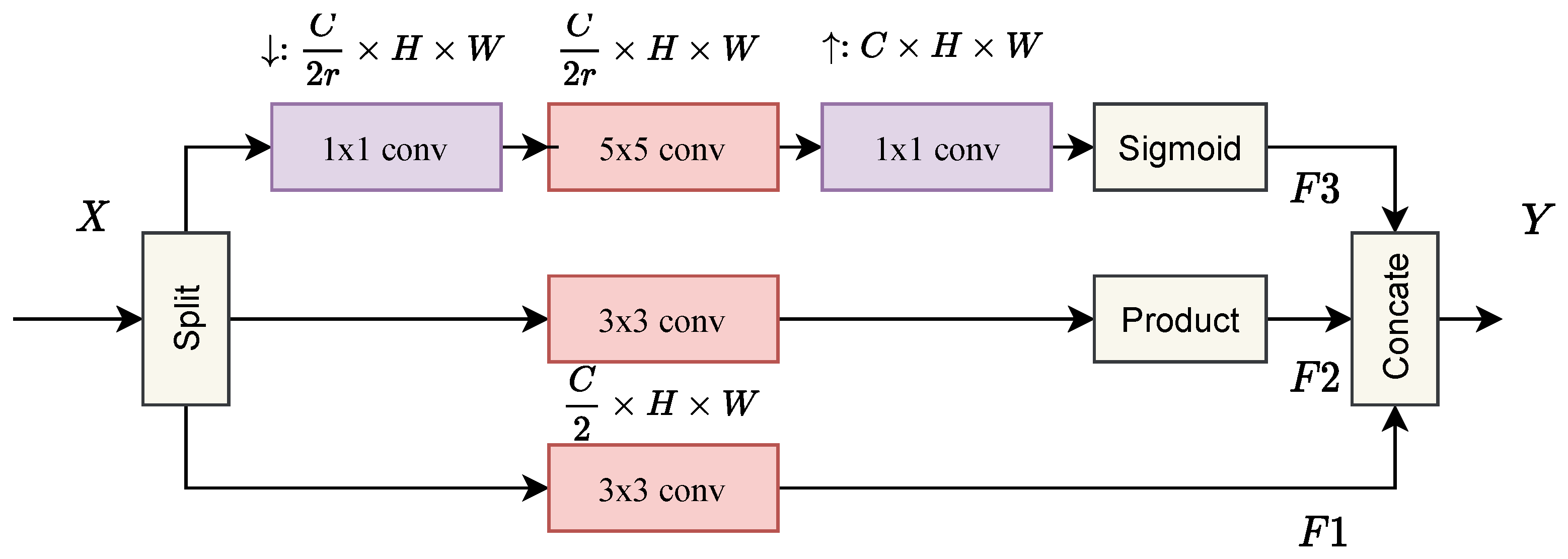
2.2.2. Multidimensional Enhanced Convolution (MEC)
The residual network structure proposed by He et al. [
34] has been widely used in many image restoration tasks and achieved impressive performance. However, as mentioned before, dealing with HSI is more tricky, since standard 2D convolution is inadequate to explicitly extract discriminating feature maps from the spectral dimensions, while 3D convolution is more computationally costly. To address this issue, we introduce an effective convolution block to better exploit spectral correlation and reduce the redundancy in the spectral dimension while preserving more useful information.
Specifically, given the input
X, we first channel-wisely split it into two groups to reduce the computational burden. Furthermore, we add a branched path in one of the groups; in this path,
convolution is applied as cross-channel pooling [
35] to reduce the spectral dimensionality instead of spatial dimensionality, which indeed performs a linear recombination on the input feature maps and allows information interaction between channels. Besides, the structure builds long-range spatial-spectral dependencies, which can further improve the network’s performance. In addition, the parameters can also be reduced, which allows us to apply
convolution and enlarge the fields of view. Given the input
, the formulation is presented as follows:
where
and
denote
convolution and
convolution, respectively.
and
are the outputs of the upper and lower branches in
Figure 2.
is the sigmoid function; the setting of
r will be mentioned in the implementation details.
2.2.3. Attention-Based Guidance
The attention mechanism is a prevalent practice in CNNs nowadays. It allows the network to attend to specific regions in the feature maps to emphasize important features. To further improve the ability of spectral correlation learning, we apply the channel attention module proposed by Zhang et al. [
36] in the final part of the MEB. Specifically, with the input
, a spatial global pooling operation is used to aggregate the spatial information:
where
denotes the spatial global pooling. Then, a simple gating mechanism with a sigmoid function is applied:
where
denotes the gating mechanism.
is the attention map, which is used to re-scale the input
via an element-wise multiplication operation:
2.3. Difference Curvature-Based Branch (DCB)
In the field of computer vision, there is a long history of using the gradient or curvature to extract texture features. For example, Chang et al. [
37] simply concatenated the first-order and second-order gradients for feature representation based on the luminance values of the pixels in the patch. Zhu et al. [
38] proposed a gradient-based super-resolution method to exploit more expressive information from the external gradient patterns. In addition, Ma et al. [
39] applied a first-order gradient to a generative adversarial network (GAN)-based method as structure guidance for super-resolution. Although they can extract high-frequency components, simple concatenation of gradients also brings undesired noise, which hinders feature learning. Compared with the gradient-based method, curvature is better for representing high-frequency features. There exist three main kinds of curvature: Gaussian curvature, mean curvature, and difference curvature. Chen et al. [
40] proposed and applied difference curvature as an edge indicator for image denoising, which is able to distinguish isolated noise from the flat and ramp edge regions and outperforms Gaussian curvature and mean curvature. Later, Huang et al. [
41] applied difference curvature for selective patch processing and learned the mixture prior models in each group. As for the hyperspectral image, due to its high dimensionality and relatively low spatial resolution, it is necessary to extract fine texture information efficiently to increase the spatial resolution.
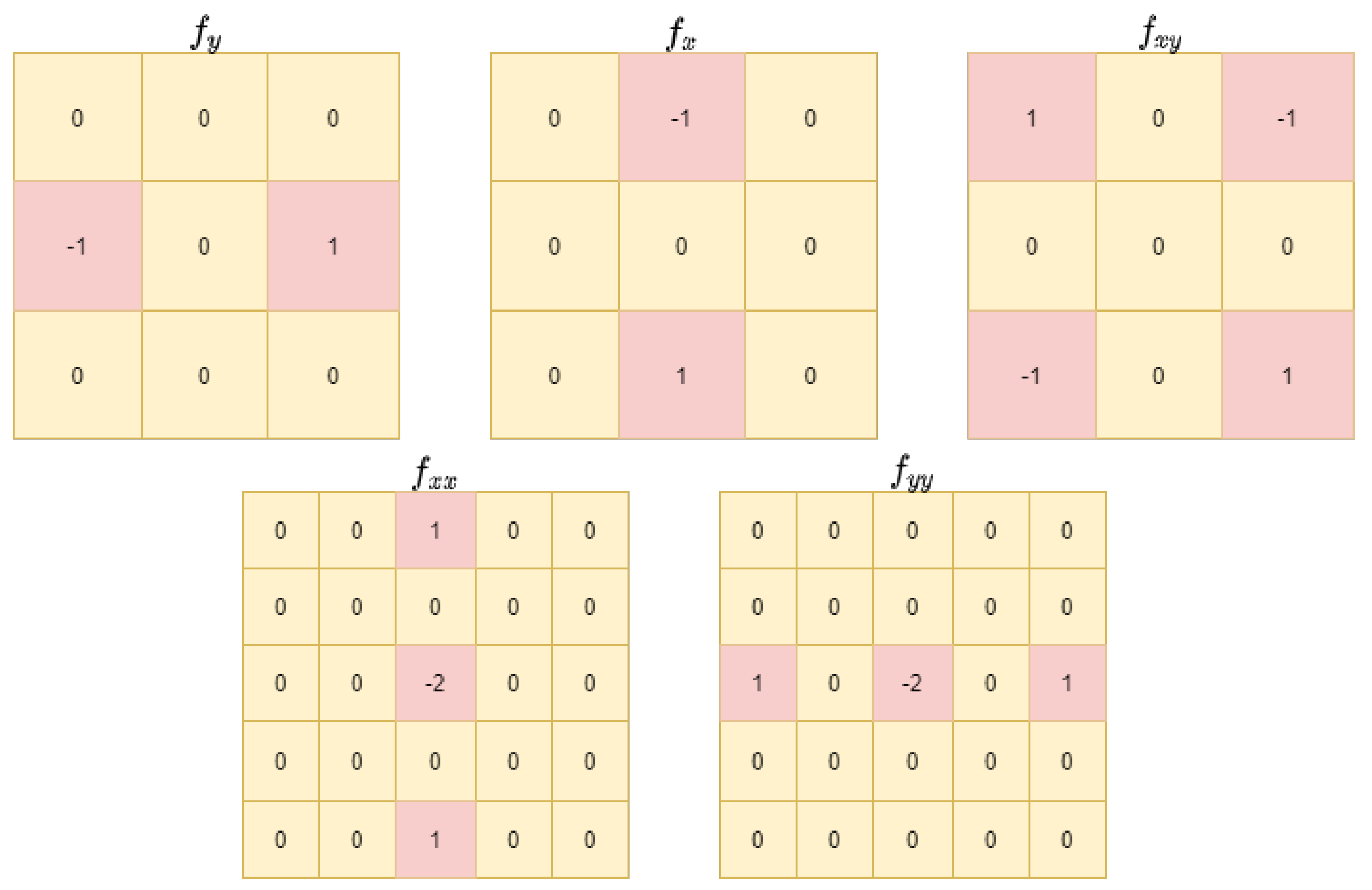
To efficiently exploit the texture information of HSI, we designed an additional DCB to help the network focus on high-frequency components. Compared with traditional gradient-based guidance, which cannot effectively distinguish between edges and ramps, difference curvature combines the first- and second-order gradients, which are more informative. Consequently, it can effectively distinguish edges and ramps together whiling removing unwanted noise. The difference curvature can be defined as follows:
where
and
are defined as:
As demonstrated in
Figure 3, the curvature calculation is easy to implement by using five convolution kernels
to extract the first- and second-order gradients. The five kernels are
,
,
, , and .
Based on these, the calculated difference-curvature has the following properties in different image regions. (1)
is large but
is small for edges, so
is large; (2) for smooth regions,
and
are both small, so
is small; and (3) for noise,
is large but
is also large, so
is small. Therefore, most parts of the curvature map have small values, and only high frequency information is preserved. After the extraction module, we feed the curvature map into multiple MEBs to obtain higher-level information. Then, as shown in
Figure 1, the output of the branch is fused with the features from the main branch. In this way, DCB guides the network to focus on high-frequency components and improve the SR performance on fine texture details.
2.4. Loss Function
In previous image restoration works in recent years, L1 loss and MSE loss have been two widely used losses for network optimization. In the field of HSI super-resolution, previous works have also explored other losses, such as SAM loss [
24] and SSTV loss [
30], considering the special characteristics of HSI. These losses encourage the network to preserve the spectral information. Following the practice, we add the SSTV loss to the L1 loss [
30] as the final training objective of our DCM-Net, i.e.,
where
and
represent the
n-th low-resolution image and its corresponding high-resolution one.
denotes the proposed network.
,
, and
denote the horizontal, vertical, and spectral gradient calculation operators, respectively. The setting of the hyper-parameter
that balances the two losses follows the previous work [
30], i.e., it is set to
in this paper.
2.5. Evaluation Metrics
We adopted six prevailing metrics to evaluate the performance from both the spatial and spectral aspects. These metrics include the peak signal-to-noise ratio (PSNR), structure similarity (SSIM) [
42], spectral angle mapper (SAM) [
43], cross correlation (CC) [
44], root mean square error (RMSE), and erreur relative globale adimensionnelle de synthese (ERGAS) [
45]. PSNR and SSIM are widely used to assess the similarities between images, while the remaining four metrics are often used to evaluate the HSI: CC is a spatial measurement, SAM is a spectral measurement, RMSE and ERGAS are global measurements. In the following experiments, we regard PSNR, SSIM, and SAM as the main metrics, which are defined as follows:
where
denotes the maximum pixel value in the
l-th band, and
,
represent the mean of
and
, respectively.
and
denote the variance of
and
in the
l-th band while
is the covariance of
and
in the
l-th band.
denotes the dot product operation.
2.6. Datasets
- 1.
Chikusei dataset [
46]: the Chikusei dataset (
https://www.sal.t.u-tokyo.ac.jp/hyperdata/ accessed on 29 July 2014) was taken by the Headwall Hyperspec-VNIR-C imaging sensor over agricultural and urban areas in Chikusei, Ibaraki, Japan. The central point of the scene is located at coordinates 36.294946N, 140.008380E. The hyperspectral dataset has 128 bands in the spectral range from 363 nm to 1018 nm. The scene consists of 2517 × 2335 pixels and the ground sampling distance was 2.5 m. A ground truth of 19 classes was collected via a field survey and visual inspection using high-resolution color images obtained by a Canon EOS 5D Mark II together with the hyperspectral data.
- 2.
Cave dataset [
47]: the Cave dataset (
https://www.cs.columbia.edu/CAVE/databases/multispectral/ accessed on 29 April 2020) was obtained from Cooled CCD camera and contains full spectral resolution reflectance data from 400 nm to 700 nm at a resolution of 10 nm (31 bands in total), covering 32 scenes of everyday objects. The image size is 512 × 512 pixels and each image is stored as a 16-bit grayscale PNG image per band.
- 3.
Harvard dataset [
48]: the Harvard Dataset (
http://vision.seas.harvard.edu/hyperspec/index.html accessed on 29 April 2020) contains fifty images captured under daylight illumination from a commercial hyperspectral camera (Nuance FX, CRI Inc. in U.S.), which is capable of acquiring images from 420 nm to 720 nm at a step of 10 nm (31 bands in total).
2.7. Implementation Details
Because the numbers of spectral bands in the three datasets are different, the experiment setting varies. For the Chikusei dataset, we divided 128 bands into 16 groups, i.e., 8 bands per group. For the Cave and Harvard datasets, which both have 31 bands, we put 4 bands in one group with an overlap of one band between each group (10 groups). The number of MEBs was set to 3 for Chikusei and 6 for Cave and Harvard. As for the MEC module, we applied two convolutions to reduce the dimension by half. For the convolution, to keep the spatial size of feature maps, the padding size was set to 1. We implemented the network with PyTorch and optimized it using the ADAM optimizer with an initial learning rate of , which was halved by every 15 epochs. The batch size was 16.











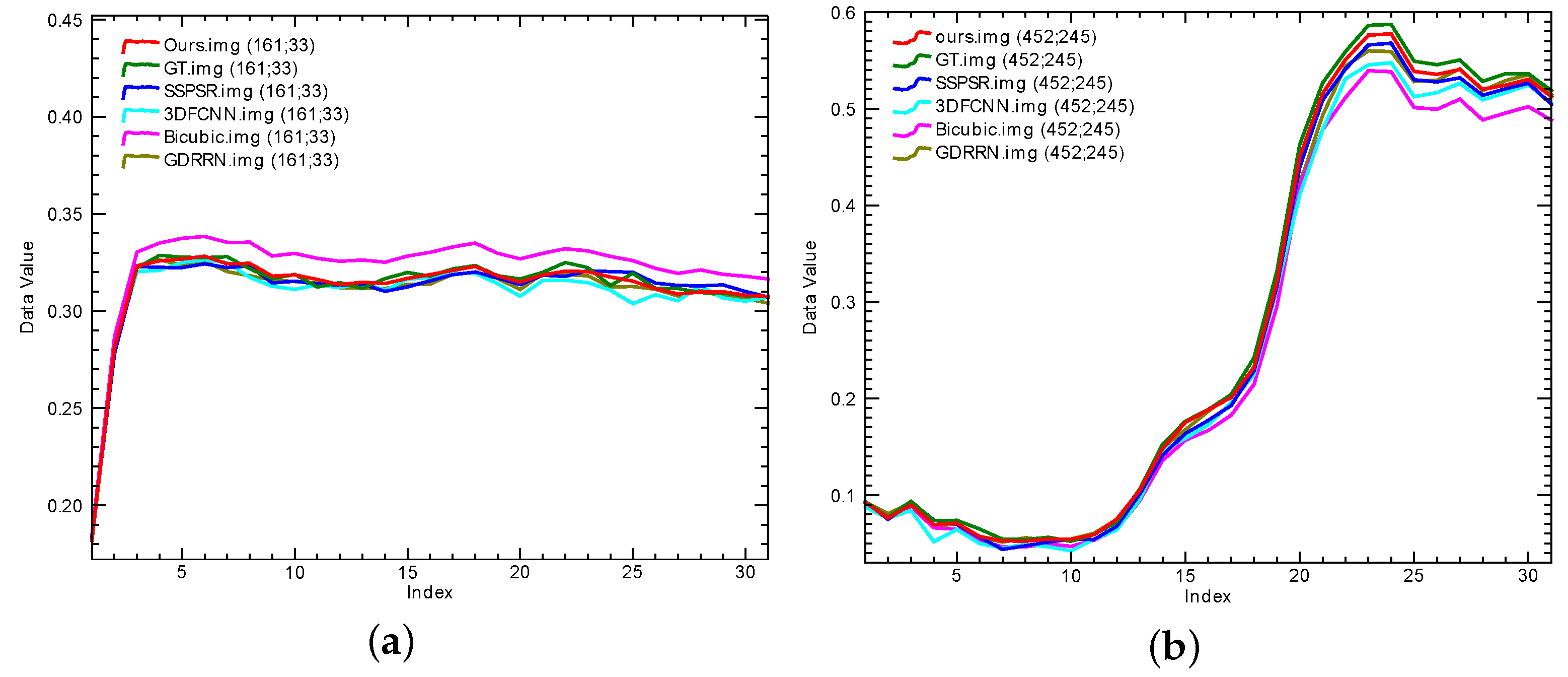





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}