
Converting Optical Videos to Infrared Videos Using Attention GAN and Its Impact on Target Detection and Classification Performance

 , ,
, ,  ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Image-to-Image Translation Using GANs
2.2. Image Conversion between Visible and IR Domains
2.3. Video Super-Resolution
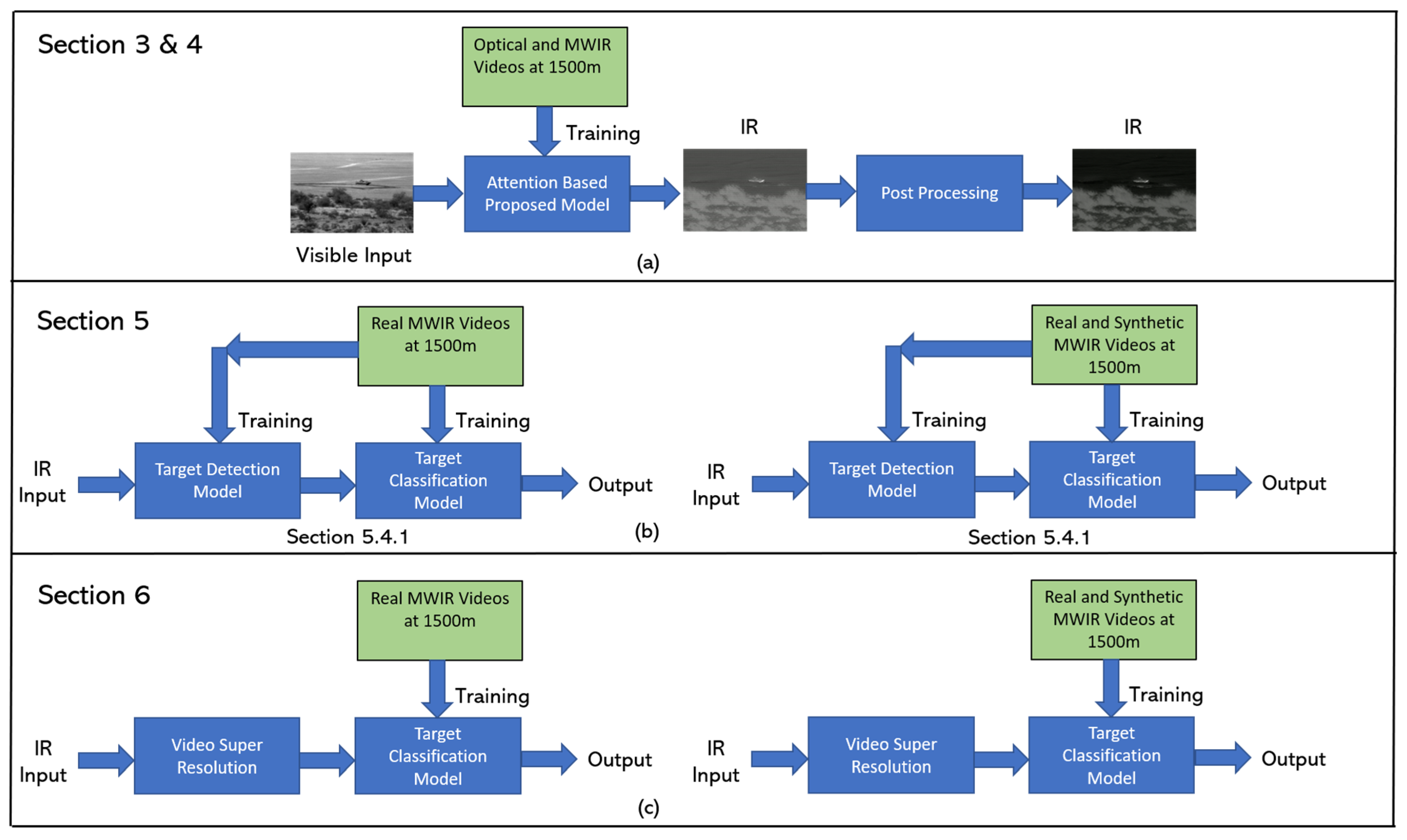
3. Converting Optical Videos to Infrared Videos
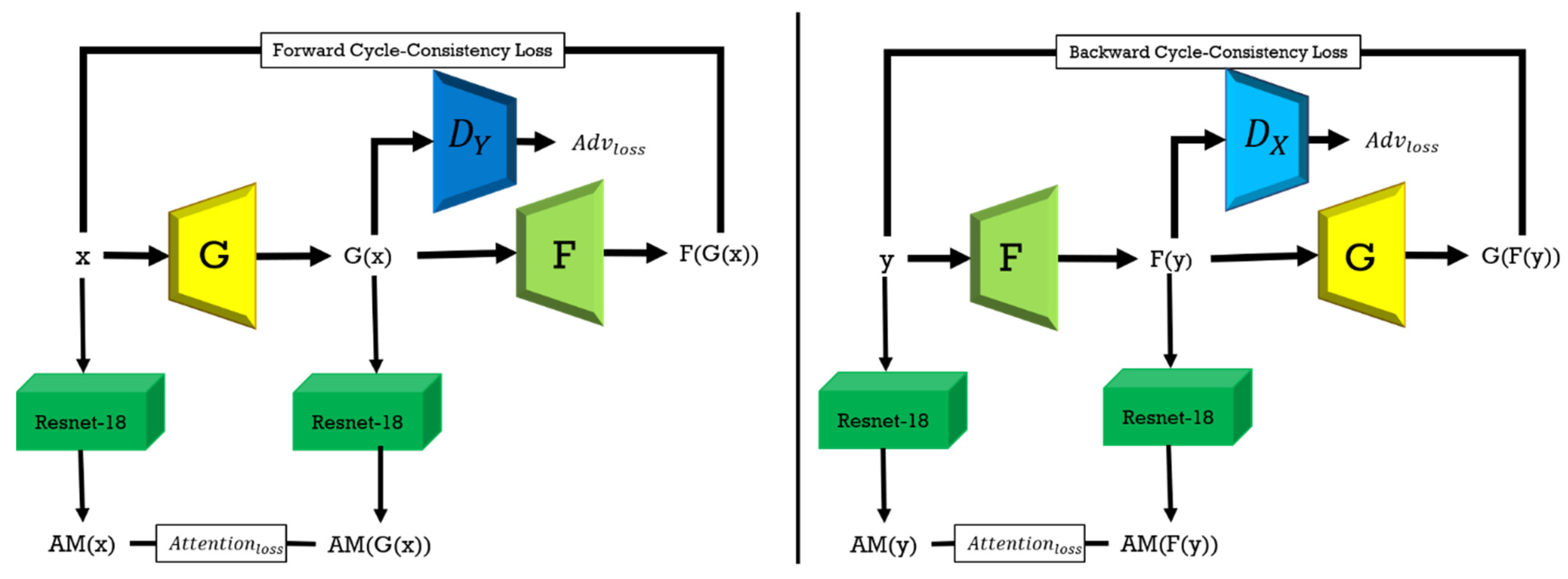
3.1. Architecture of the Proposed Model
3.2. Objective Function
4. Performance Evaluation of Attention GAN for Converting Optical Videos to Infrared Videos
4.1. DSIAC Data
4.2. Training
4.3. Evaluation Metrics for Assessing the Conversion Performance
4.3.1. Inception Score (IS)
4.3.2. Frechet Inception Distance (FID)
4.3.3. Kernel Inception Distance (KID)
4.4. Conversion Results
4.4.1. Attention Maps
4.4.2. Qualitative Comparison
4.4.3. Quantitative Comparison
5. Impact of Converted Videos on Target Detection and Classification Performance
5.1. YOLO for Target Detection
5.2. ResNet for Target Classification
5.3. Performance Metrics for Assessing Target Detection and Classification Performance
5.4. Training and Testing Procedures
5.4.1. Baseline Results Using Only 1500 m Infrared Videos for Training
5.4.2. Results with Attention GAN Augmented Data
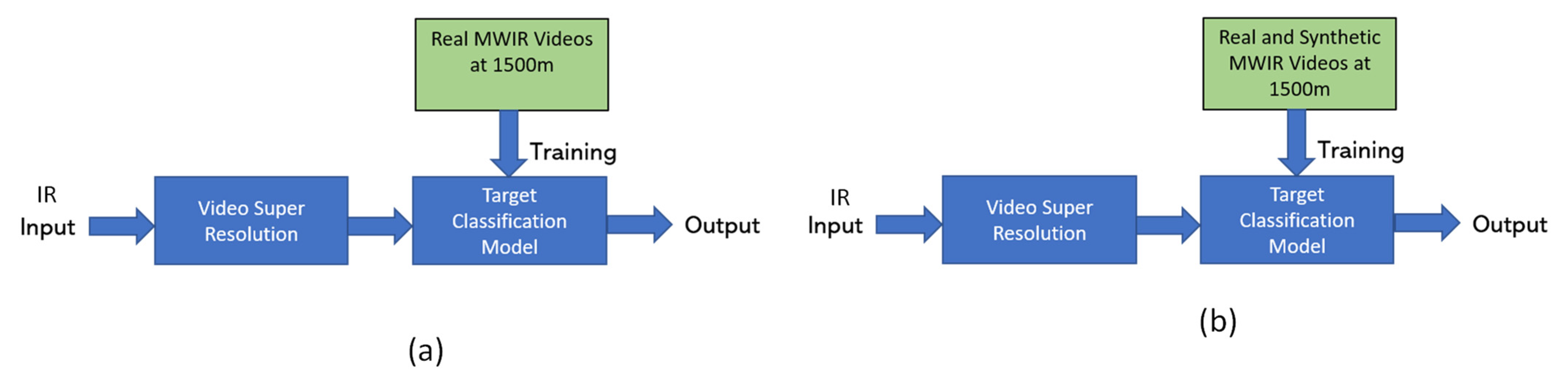
6. Enhancement of Target Classification Using Super-Resolution Videos
6.1. Vehicle Classification Architecture with Video Super-Resolution
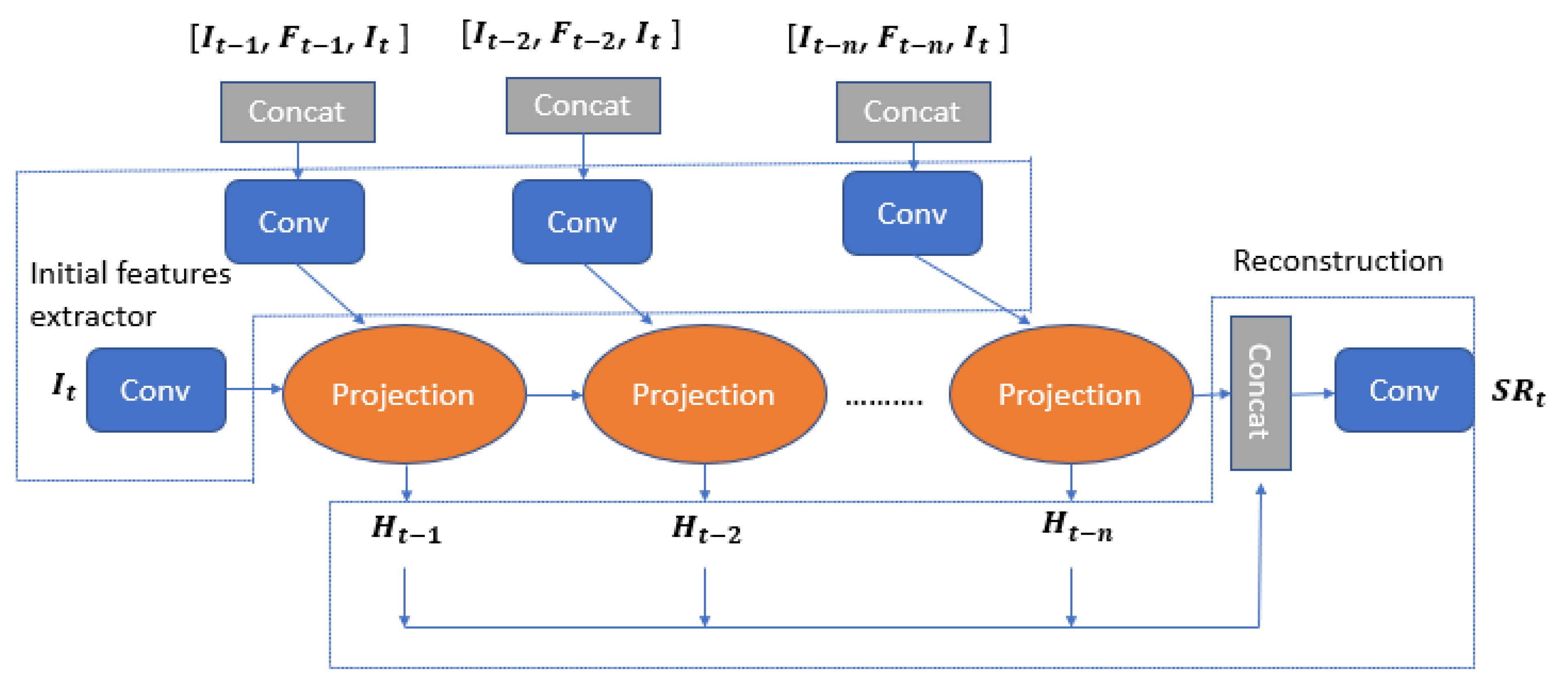
6.2. Video Super-Resolution Algorithm
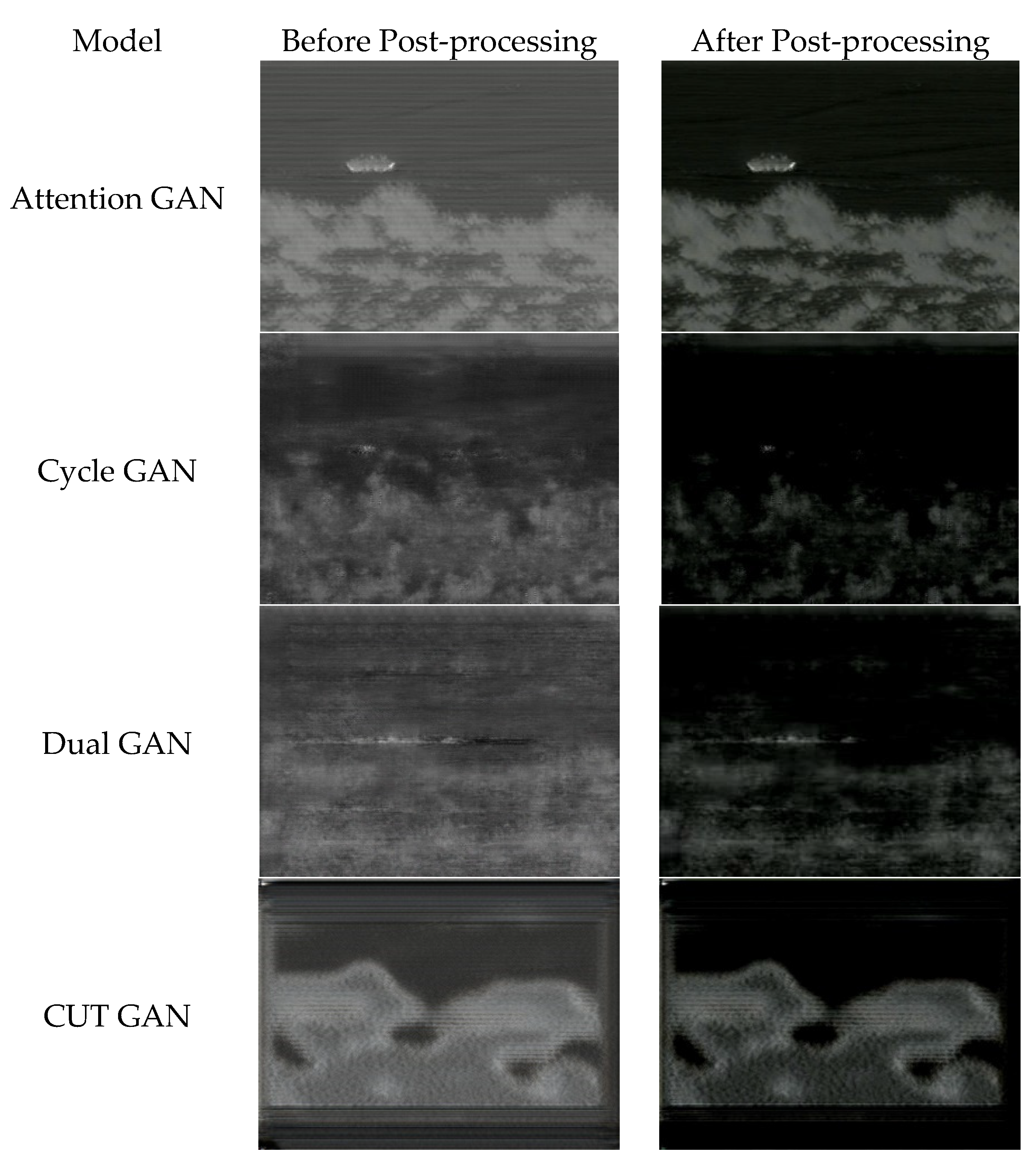
6.3. Results
- Testing on MWIR daytime videos.
- Testing on MWIR nighttime videos.
7. Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kwan, C.; Chou, B.; Kwan, L.M. A Comparative Study of Conventional and Deep Learning Target Tracking Algorithms for Low Quality Videos. In Proceedings of the 15th International Symposium on Neural Networks, Minsk, Belarus, 25–28 June 2018. [Google Scholar] [CrossRef]
- Demir, H.S.; Cetin, A.E. Co-difference based object tracking algorithm for infrared videos. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 434–438. [Google Scholar] [CrossRef]
- Kwan, C.; Chou, B.; Yang, J.; Rangamani, A.; Tran, T.; Zhang, J.; Etienne-Cummings, R. Target tracking and classification directly using compressive sensing camera for SWIR videos. J. Signal Image Video Process. 2019, 13, 1629–1637. [Google Scholar] [CrossRef]
- Kwan, C.; Chou, B.; Yang, J.; Rangamani, A.; Tran, T.; Zhang, J.; Etienne-Cummings, R. Deep Learning based Target Tracking and Classification for Low Quality Videos Using Coded Aperture Camera. Sensors 2019, 19, 3702. [Google Scholar] [CrossRef] [Green Version]
- Lohit, S.; Kulkarni, K.; Turaga, P.K. Direct inference on compressive measurements using convolutional neural networks. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1913–1917. [Google Scholar] [CrossRef]
- Adler, A.; Elad, M.; Zibulevsky, M. Compressed Learning: A Deep Neural Network Approach. arXiv 2016, arXiv:1610.09615v1. [Google Scholar]
- Xu, Y.; Kelly, K.F. Compressed domain image classification using a Dynamic-rate neural network. arXiv 2019, arXiv:1901.09983. [Google Scholar]
- Wang, Z.W.; Vineet, V.; Pittaluga, F.; Sinha, S.N.; Cossairt, O.; Kang, S.B. Privacy-Preserving Action Recognition Using Coded Aperture Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Vargas, H.; Fonseca, Y.; Arguello, H. Object Detection on Compressive Measurements using Correlation Filters and Sparse Representation. In Proceedings of the European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1960–1964. [Google Scholar] [CrossRef]
- Değerli, A.; Aslan, S.; Yamac, M.; Sankur, B.; Gabbouj, M. Compressively Sensed Image Recognition. In Proceedings of the European Workshop on Visual Information Processing (EUVIP), Tampere, Finland, 26–28 November 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Latorre-Carmona, P.; Traver, V.J.; Sánchez, J.S.; Tajahuerce, E. Online reconstruction-free single-pixel image classification. Image Vis. Comput. 2018, 86, 28–37. [Google Scholar] [CrossRef]
- Li, C.; Wang, W. Detection and Tracking of Moving Targets for Thermal Infrared Video Sequences. Sensors 2018, 18, 3944. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tan, Y.; Guo, Y.; Gao, C.; Tan, Y.; Guo, Y.; Gao, C. Background subtraction based level sets for human segmentation in thermal infrared surveillance systems. Infrared Phys. Technol. 2013, 61, 230–240. [Google Scholar] [CrossRef]
- Berg, A.; Ahlberg, J.; Felsberg, M. Channel Coded Distribution Field Tracking for Thermal Infrared Imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1248–1256. [Google Scholar] [CrossRef] [Green Version]
- Kwan, C.; Gribben, D.; Chou, B.; Budavari, B.; Larkin, J.; Rangamani, A.; Tran, T.; Zhang, J.; Etienne-Cummings, R. Real-Time and Deep Learning based Vehicle Detection and Classification using Pixel-Wise Code Exposure Measurements. Electronics 2020, 18, 1014. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar] [CrossRef] [Green Version]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar] [CrossRef] [Green Version]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.Y. Contrastive learning for unpaired image-to-image translation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 319–345. [Google Scholar] [CrossRef]
- ATR Dataset. Available online: https://www.dsiac.org/resources/available-databases/atr-algorithm-development-image-database/ (accessed on 1 January 2020).
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar] [CrossRef]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar] [CrossRef]
- Kastaniotis, D.; Ntinou, I.; Tsourounis, D.; Economou, G.; Fotopoulos, S. Attention-aware generative adversarial networks (ATA-GANs). In Proceedings of the 2018 IEEE 13th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), Zagorochoria, Greece, 10–12 June 2018; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Tang, H.; Xu, D.; Sebe, N.; Yan, Y. Attention-guided generative adversarial networks for unsupervised image-to-image translation. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Sun, T.; Jung, C.; Fu, Q.; Han, Q. NIR to RGB domain translation using asymmetric cycle generative adversarial networks. IEEE Access 2019, 7, 112459–112469. [Google Scholar] [CrossRef]
- Perera, P.; Abavisani, M.; Patel, V.M. In2i: Unsupervised multi-image-to-image translation using generative adversarial networks. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 140–146. [Google Scholar] [CrossRef] [Green Version]
- Mehri, A.; Sappa, A.D. Colorizing near infrared images through a cyclic adversarial approach of unpaired samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar] [CrossRef]
- Suárez, P.L.; Sappa, A.D.; Vintimilla, B.X. Infrared image colorization based on a triplet dcgan architecture. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2017; pp. 18–23. [Google Scholar] [CrossRef]
- Liu, S.; John, V.; Blasch, E.; Liu, Z.; Huang, Y. IR2VI: Enhanced night environmental perception by unsupervised thermal image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1153–1160. [Google Scholar] [CrossRef] [Green Version]
- Berg, A.; Ahlberg, J.; Felsberg, M. Generating visible spectrum images from thermal infrared. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1143–1152. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Gonzalez-Garcia, A.; van de Weijer, J.; Danelljan, M.; Khan, F.S. Synthetic data generation for end-to-end thermal infrared tracking. IEEE Trans. Image Process. 2018, 28, 1837–1850. [Google Scholar] [CrossRef] [Green Version]
- Kniaz, V.V.; Knyaz, V.A.; Hladuvka, J.; Kropatsch, W.G.; Mizginov, V. Thermalgan: Multimodal color-to-thermal image translation for person re-identification in multispectral dataset. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Mizginov, V.A.; Danilov, S.Y. Synthetic thermal background and object texture generation using geometric information and gan. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W12, 149–154. [Google Scholar] [CrossRef] [Green Version]
- Kniaz, V.V.; Mizginov, V.A. Thermal texture generation and 3d model reconstruction using sfm and gan. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Tian, J.; Reinartz, P. Generating artificial near infrared spectral band from rgb image using conditional generative adversarial network. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2020, 3, 279–285. [Google Scholar] [CrossRef]
- Uddin, M.S.; Li, J. Generative Adversarial Networks for Visible to Infrared Video Conversion. In Recent Advances in Image Restoration with Applications to Real World Problems; IntechOpen: London, UK, 2020. [Google Scholar] [CrossRef]
- Yun, K.; Yu, K.; Osborne, J.; Eldin, S.; Nguyen, L.; Huyen, A.; Lu, T. Improved visible to IR image transformation using synthetic data augmentation with cycle-consistent adversarial networks. In Pattern Recognition and Tracking XXX; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10995, p. 1099502. [Google Scholar] [CrossRef] [Green Version]
- Abbott, R.; Robertson, N.M.; del Rincon, J.M.; Connor, B. Unsupervised object detection via LWIR/RGB translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 90–91. [Google Scholar] [CrossRef]
- Caballero, J.; Ledig, C.; Aitken, A.; Acosta, A.; Totz, J.; Wang, Z.; Shi, W. Real-time video super-resolution with spatio-temporal networks and motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4778–4787. [Google Scholar] [CrossRef] [Green Version]
- Jo, Y.; Oh, S.W.; Kang, J.; Kim, S.J. Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3224–3232. [Google Scholar] [CrossRef]
- Kappeler, A.; Yoo, S.; Dai, Q.; Katsaggelos, A.K. Video super-resolution with convolutional neural networks. IEEE Trans. Comput. Imaging 2016, 2, 109–122. [Google Scholar] [CrossRef]
- Drulea, M.; Nedevschi, S. Total variation regularization of local-global optical flow. In Proceedings of the 2011 14th International IEEE Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 318–323. [Google Scholar] [CrossRef]
- Liu, D.; Wang, Z.; Fan, Y.; Liu, X.; Wang, Z.; Chang, S.; Huang, T. Robust video super-resolution with learned temporal dynamics. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2507–2515. [Google Scholar] [CrossRef]
- Yu, H.; Wang, J.; Huang, Z.; Yang, Y.; Xu, W. Video paragraph captioning using hierarchical recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4584–4593. [Google Scholar] [CrossRef] [Green Version]
- Venugopalan, S.; Xu, H.; Donahue, J.; Rohrbach, M.; Mooney, R.; Saenko, K. Translating videos to natural language using deep recurrent neural networks. arXiv 2014, arXiv:1412.4729. [Google Scholar]
- Huang, Y.; Wang, W.; Wang, L. Bidirectional recurrent convolutional networks for multi-frame super-resolution. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 1, pp. 235–243. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar] [CrossRef]
- Sajjadi, M.S.; Vemulapalli, R.; Brown, M. Frame-recurrent video super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6626–6634. [Google Scholar] [CrossRef] [Green Version]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- MOT Challenge. Available online: Motchallenge.net/ (accessed on 1 December 2020).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the ADVANCES in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local Nash equilibrium. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6626–6637. [Google Scholar] [CrossRef]
- Bińkowski, M.; Sutherland, D.J.; Arbel, M.; Gretton, A. Demystifying mmd gans. arXiv 2016, arXiv:1801.01401. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Recurrent back-projection network for video super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3897–3906. [Google Scholar] [CrossRef] [Green Version]

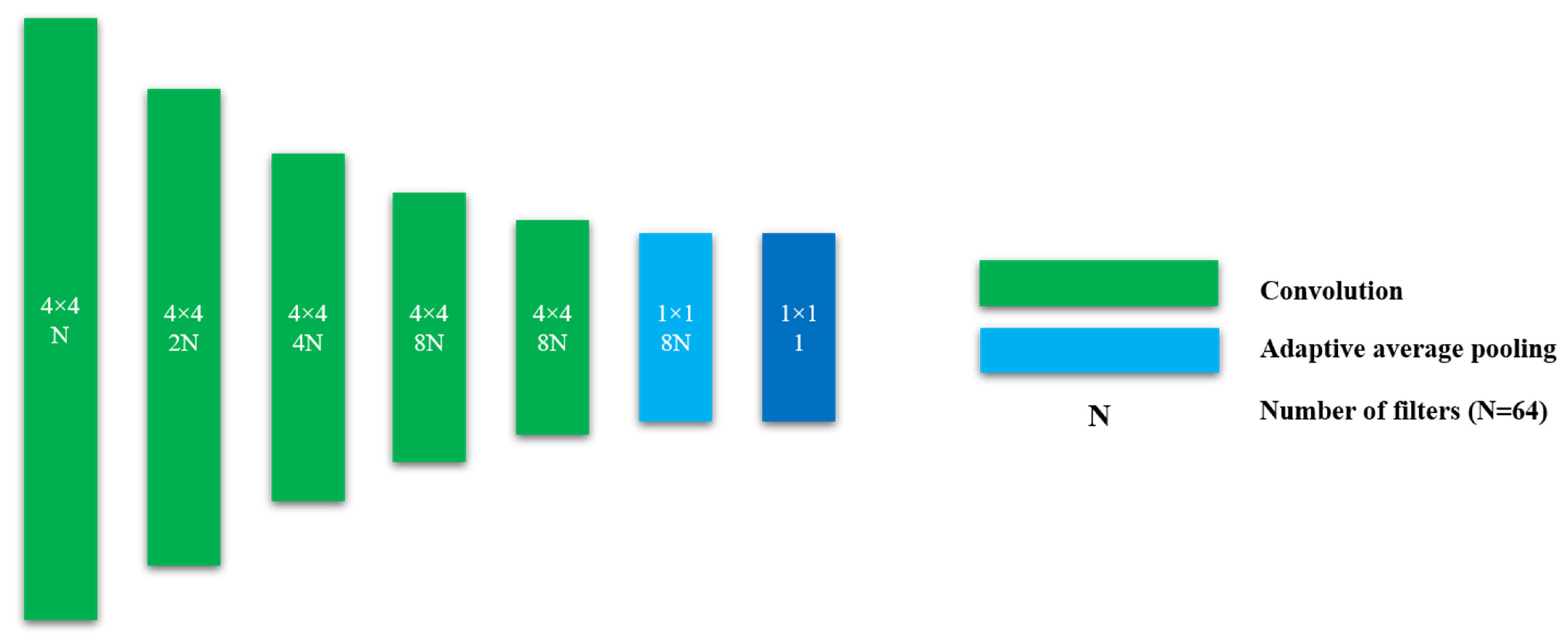










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vehicle | Distance | Cycle GAN | Dual GAN | CUTGAN | Our Method | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IS | FID | KID | IS | FID | KID | IS | FID | KID | IS | FID | KID | ||
| T72 | 1000 m | 1.12 | 3.16 | 48.57 | 1.13 | 3.39 | 53.29 | 1.10 | 3.52 | 55.41 | 1.17 | 2.98 | 46.45 |
| 2000 m | 1.11 | 3.15 | 49.40 | 1.08 | 3.09 | 49.09 | 1.08 | 3.35 | 51.37 | 1.17 | 3.00 | 48.98 | |
| BRDM2 | 1000 m | 1.11 | 2.96 | 46.41 | 1.05 | 4.02 | 70.04 | 1.06 | 3.63 | 57.91 | 1.14 | 3.49 | 58.70 |
| 2000 m | 1.16 | 3.16 | 49.11 | 1.06 | 2.71 | 42.82 | 1.06 | 3.33 | 50.94 | 1.11 | 3.26 | 52.48 | |
| BTR70 | 1000 m | 1.19 | 3.06 | 46.14 | 1.19 | 3.55 | 57.66 | 1.11 | 3.56 | 55.91 | 1.12 | 3.60 | 59.18 |
| 2000 m | 1.05 | 2.99 | 47.05 | 1.03 | 2.62 | 40.56 | 1.04 | 3.42 | 52.77 | 1.12 | 2.69 | 42.72 | |
| BMP2 | 1000 m | 1.12 | 3.28 | 49.71 | 1.14 | 3.77 | 61.56 | 1.15 | 3.54 | 55.38 | 1.23 | 2.94 | 45.91 |
| 2000 m | 1.05 | 2.85 | 45.14 | 1.05 | 2.32 | 35.98 | 1.04 | 3.41 | 52.63 | 1.19 | 3.01 | 48.51 | |
| ZSU23-4 | 1000 m | 1.15 | 3.18 | 48.68 | 1.12 | 3.38 | 53.14 | 1.08 | 3.54 | 55.67 | 1.27 | 2.94 | 46.64 |
| 2000 m | 1.24 | 2.84 | 44.15 | 1.04 | 3.24 | 53.48 | 1.05 | 3.37 | 52.12 | 1.14 | 2.98 | 48.48 | |
| Overall Scores | 1.13 | 3.06 | 47.44 | 1.09 | 3.21 | 51.76 | 1.08 | 3.47 | 54.01 | 1.17 | 3.09 | 49.81 | |
| Vehicle | Distance | Cycle GAN | Dual GAN | CUTGAN | Our Method | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IS | FID | KID | IS | FID | KID | IS | FID | KID | IS | FID | KID | ||
| T72 | 1000 m | 1.57 | 4.39 | 72.85 | 1.31 | 3.81 | 59.80 | 1.36 | 3.89 | 65.63 | 1.28 | 2.34 | 34.42 |
| 2000 m | 1.45 | 4.18 | 68.79 | 1.23 | 3.59 | 55.89 | 1.26 | 3.82 | 61.54 | 1.43 | 2.03 | 29.11 | |
| BRDM2 | 1000 m | 1.41 | 4.26 | 71.89 | 1.27 | 3.24 | 48.94 | 1.25 | 4.18 | 71.66 | 1.30 | 2.22 | 32.47 |
| 2000 m | 1.36 | 5.03 | 88.62 | 1.24 | 3.45 | 53.63 | 1.15 | 3.92 | 64.41 | 1.38 | 2.18 | 32.00 | |
| BTR70 | 1000 m | 1.65 | 4.27 | 66.91 | 1.35 | 3.65 | 55.78 | 1.35 | 4.23 | 72.63 | 1.28 | 2.23 | 32.56 |
| 2000 m | 1.35 | 5.32 | 96.93 | 1.23 | 3.65 | 58.30 | 1.12 | 3.99 | 66.44 | 1.25 | 1.96 | 28.72 | |
| BMP2 | 1000 m | 1.41 | 4.32 | 70.09 | 1.33 | 3.74 | 57.63 | 1.42 | 4.27 | 71.63 | 1.39 | 2.34 | 34.07 |
| 2000 m | 1.35 | 4.11 | 70.69 | 1.20 | 3.70 | 60.23 | 1.16 | 4.09 | 68.52 | 1.35 | 2.26 | 33.46 | |
| ZSU23-4 | 1000 m | 1.53 | 4.41 | 71.78 | 1.37 | 3.74 | 58.34 | 1.33 | 3.83 | 64.08 | 1.27 | 2.26 | 33.28 |
| 2000 m | 1.34 | 4.11 | 68.56 | 1.24 | 3.83 | 62.37 | 1.25 | 3.81 | 62.25 | 1.36 | 2.18 | 32.48 | |
| Overall Scores | 1.44 | 4.44 | 74.71 | 1.28 | 3.64 | 57.09 | 1.27 | 4.00 | 66.88 | 1.33 | 2.20 | 32.26 | |
| Vehicle | Distance | Before Post-Processing | After Post-Processing | ||||
|---|---|---|---|---|---|---|---|
| IS | FID | KID | IS | FID | KID | ||
| T72 | 1000 m | 1.17 | 2.98 | 46.45 | 1.28 | 2.34 | 34.42 |
| 2000 m | 1.17 | 3.00 | 48.98 | 1.43 | 2.03 | 29.11 | |
| BRDM2 | 1000 m | 1.14 | 3.49 | 58.70 | 1.30 | 2.22 | 32.47 |
| 2000 m | 1.11 | 3.26 | 52.48 | 1.38 | 2.18 | 32.00 | |
| BTR70 | 1000 m | 1.12 | 3.60 | 59.18 | 1.28 | 2.23 | 32.56 |
| 2000 m | 1.12 | 2.69 | 42.72 | 1.25 | 1.96 | 28.72 | |
| BMP2 | 1000 m | 1.23 | 2.94 | 45.91 | 1.39 | 2.34 | 34.07 |
| 2000 m | 1.19 | 3.01 | 48.51 | 1.35 | 2.26 | 33.46 | |
| ZSU23-4 | 1000 m | 1.27 | 2.94 | 46.64 | 1.27 | 2.26 | 33.28 |
| 2000 m | 1.14 | 2.98 | 48.48 | 1.36 | 2.18 | 32.48 | |
| Overall Scores | 1.17 | 3.09 | 49.81 | 1.33 | 2.20 | 32.26 | |
| 1000 m | CLE | DP | EinGT | IoU | % det. |
|---|---|---|---|---|---|
| BTR70 | 4.075 | 100.00% | 100.00% | 61.90% | 97.78% |
| BRDM2 | 3.194 | 100.00% | 100.00% | 76.89% | 95.72% |
| BMP2 | 4.038 | 100.00% | 100.00% | 73.90% | 88.33% |
| T72 | 3.574 | 100.00% | 100.00% | 73.87% | 96.33% |
| ZSU23-4 | 3.607 | 100.00% | 100.00% | 74.04% | 99.61% |
| Avg | 3.698 | 100.00% | 100.00% | 72.12% | 95.56% |
| 1500 m | CLE | DP | EinGT | IoU | % det. |
| BTR70 | 1.201 | 100.00% | 100.00% | 70.56% | 91.17% |
| BRDM2 | 1.279 | 100.00% | 100.00% | 78.54% | 91.06% |
| BMP2 | 1.092 | 100.00% | 100.00% | 87.70% | 91.06% |
| T72 | 1.497 | 100.00% | 100.00% | 85.21% | 91.11% |
| ZSU23-4 | 1.233 | 100.00% | 100.00% | 77.58% | 90.00% |
| Avg | 1.260 | 100.00% | 100.00% | 79.92% | 90.88% |
| 2000 m | CLE | DP | EinGT | IoU | % det. |
| BTR70 | 1.861 | 100.00% | 100.00% | 30.64% | 93.44% |
| BRDM2 | 3.023 | 100.00% | 100.00% | 37.74% | 90.50% |
| BMP2 | 3.542 | 100.00% | 100.00% | 58.01% | 41.83% |
| T72 | 2.276 | 100.00% | 100.00% | 39.80% | 98.44% |
| ZSU23-4 | 8.953 | 97.83% | 97.83% | 38.11% | 84.56% |
| Avg | 3.931 | 99.57% | 99.57% | 40.86% | 81.76% |
| 1000 m | BTR70 | BRDM2 | BMP2 | T72 | ZSU23-4 | |
|---|---|---|---|---|---|---|
| BTR70 | 1839 | 24 | 8 | 17 | 79 | |
| BRDM2 | 0 | 2107 | 2 | 3 | 0 | |
| BMP2 | 0 | 7 | 1412 | 275 | 17 | |
| T72 | 43 | 2 | 251 | 2070 | 92 | |
| ZSU23-4 | 1 | 85 | 40 | 127 | 1982 | |
| Class Stats | OA | 89.76% | AA | 89.74% | kappa | 0.900 |
| 1500 m | BTR70 | BRDM2 | BMP2 | T72 | ZSU23-4 | |
| BTR70 | 1849 | 0 | 0 | 0 | 2 | |
| BRDM2 | 0 | 1808 | 0 | 0 | 0 | |
| BMP2 | 0 | 0 | 1800 | 0 | 0 | |
| T72 | 0 | 0 | 0 | 1829 | 0 | |
| ZSU23-4 | 0 | 0 | 0 | 0 | 1882 | |
| Class Stats | OA | 99.98% | AA | 99.98% | kappa | 1.00 |
| 2000 m | BTR70 | BRDM2 | BMP2 | T72 | ZSU23-4 | |
| BTR70 | 1511 | 49 | 167 | 56 | 84 | |
| BRDM2 | 0 | 1834 | 18 | 12 | 37 | |
| BMP2 | 7 | 30 | 715 | 0 | 2 | |
| T72 | 15 | 272 | 159 | 1739 | 95 | |
| ZSU23-4 | 0 | 90 | 191 | 0 | 1472 | |
| Class Stats | OA | 84.99% | AA | 86.50% | kappa | 0.85 |
| 1000 m | CLE | DP | EinGT | IoU | % det. |
|---|---|---|---|---|---|
| BTR70 | 3.208 | 100.00% | 100.00% | 69.02% | 99.78% |
| BRDM2 | 3.140 | 100.00% | 100.00% | 75.59% | 95.61% |
| BMP2 | 3.326 | 100.00% | 100.00% | 80.30% | 99.89% |
| T72 | 3.568 | 99.84% | 99.88% | 76.50% | 99.61% |
| ZSU23-4 | 2.879 | 100.00% | 100.00% | 75.79% | 100.00% |
| Avg | 3.224 | 99.97% | 99.98% | 75.44% | 98.98% |
| 1500 m | CLE | DP | EinGT | IoU | % det. |
| BTR70 | 1.342 | 100.00% | 100.00% | 79.79% | 100.00% |
| BRDM2 | 2.361 | 100.00% | 100.00% | 73.46% | 97.67% |
| BMP2 | 1.134 | 100.00% | 100.00% | 87.77% | 100.00% |
| T72 | 2.076 | 100.00% | 100.00% | 77.60% | 99.94% |
| ZSU23-4 | 2.782 | 99.39% | 99.39% | 79.47% | 100.00% |
| Avg | 1.939 | 99.88% | 99.88% | 79.62% | 99.52% |
| 2000 m | CLE | DP | EinGT | IoU | % det. |
| BTR70 | 1.192 | 100.00% | 100.00% | 52.53% | 98.44% |
| BRDM2 | 4.781 | 99.28% | 99.28% | 49.90% | 89.28% |
| BMP2 | 2.343 | 99.83% | 99.83% | 72.53% | 66.00% |
| T72 | 2.151 | 99.88% | 99.88% | 67.05% | 98.28% |
| ZSU23-4 | 1.786 | 100.00% | 100.00% | 64.00% | 87.67% |
| Avg | 2.451 | 99.80% | 99.80% | 61.20% | 87.93% |
| 1000 m | BTR70 | BRDM2 | BMP2 | T72 | ZSU23-4 | |
|---|---|---|---|---|---|---|
| BTR70 | 1528 | 831 | 2 | 54 | 53 | |
| BRDM2 | 220 | 1708 | 2 | 5 | 0 | |
| BMP2 | 20 | 306 | 1413 | 340 | 56 | |
| T72 | 93 | 1235 | 38 | 971 | 252 | |
| ZSU23-4 | 226 | 975 | 2 | 228 | 321 | |
| Class Stats | OA | 54.26% | AA | 54.30% | kappa | 0.4283 |
| 1500 m | BTR70 | BRDM2 | BMP2 | T72 | ZSU23-4 | |
| BTR70 | 1258 | 455 | 0 | 79 | 3 | |
| BRDM2 | 117 | 2082 | 1 | 121 | 0 | |
| BMP2 | 6 | 171 | 1592 | 3 | 3 | |
| T72 | 17 | 347 | 0 | 1787 | 14 | |
| ZSU23-4 | 33 | 513 | 12 | 55 | 1030 | |
| Class Stats | OA | 79.89% | AA | 78.94% | kappa | 0.7487 |
| 2000 m | BTR70 | BRDM2 | BMP2 | T72 | ZSU23-4 | |
| BTR70 | 127 | 267 | 0 | 1192 | 0 | |
| BRDM2 | 41 | 546 | 3 | 544 | 0 | |
| BMP2 | 0 | 8 | 1 | 5 | 179 | |
| T72 | 6 | 32 | 0 | 1279 | 0 | |
| ZSU23-4 | 29 | 702 | 0 | 826 | 0 | |
| Class Stats | OA | 33.75% | AA | 30.76% | kappa | 0.1719 |
| Type of Data | Resolution | Number of Frames Per Class | ||||
|---|---|---|---|---|---|---|
| BTR70 | BRDM2 | BMP2 | T72 | ZSU23-4 | ||
| MWIR Day | 1000 m | 1800 | 1800 | 1800 | 1800 | 1800 |
| 2000 m | 1800 | 1800 | 1800 | 1800 | 1800 | |
| MWIR Night | 1000 m | 1800 | 1800 | 1800 | 1800 | 1800 |
| 2000 m | 1800 | 1800 | 1800 | 1800 | 1800 | |
| Video Type | Range | Models | Accuracy w/o Augmentation Using Attention GAN | Accuracy w Augmentation Using Attention GAN |
|---|---|---|---|---|
| (a) Test results using daytime infrared videos | ||||
| MWIR Day | 1000 m | Without VSR | 36.45 | 60.01 |
| With VSR | 85.56 | 85.83 | ||
| 2000 m | Without VSR | 53.95 | 46.46 | |
| With VSR | 81.23 | 92.562 | ||
| (b) Test results using nighttime infrared videos | ||||
| MWIR Night | 1000 m | Without VSR | 76 | 91.82 |
| With VSR | 76.51 | 64.206 | ||
| 2000 m | Without VSR | 87.2 | 71.94 | |
| With VSR | 69.98 | 77.92 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uddin, M.S.; Hoque, R.; Islam, K.A.; Kwan, C.; Gribben, D.; Li, J. Converting Optical Videos to Infrared Videos Using Attention GAN and Its Impact on Target Detection and Classification Performance. Remote Sens. 2021, 13, 3257. https://doi.org/10.3390/rs13163257
Uddin MS, Hoque R, Islam KA, Kwan C, Gribben D, Li J. Converting Optical Videos to Infrared Videos Using Attention GAN and Its Impact on Target Detection and Classification Performance. Remote Sensing. 2021; 13(16):3257. https://doi.org/10.3390/rs13163257
Chicago/Turabian StyleUddin, Mohammad Shahab, Reshad Hoque, Kazi Aminul Islam, Chiman Kwan, David Gribben, and Jiang Li. 2021. "Converting Optical Videos to Infrared Videos Using Attention GAN and Its Impact on Target Detection and Classification Performance" Remote Sensing 13, no. 16: 3257. https://doi.org/10.3390/rs13163257
APA StyleUddin, M. S., Hoque, R., Islam, K. A., Kwan, C., Gribben, D., & Li, J. (2021). Converting Optical Videos to Infrared Videos Using Attention GAN and Its Impact on Target Detection and Classification Performance. Remote Sensing, 13(16), 3257. https://doi.org/10.3390/rs13163257