
EAAU-Net: Enhanced Asymmetric Attention U-Net for Infrared Small Target Detection


Abstract
:1. Introduction
- (1)
- We propose EAAU-Net, a lightweight network for single-frame infrared small target detection, and experimentally demonstrate its ability to effectively segment the details of images of small targets and obtain satisfactory results.
- (2)
- We present an EAA module designed to not only focus on spatial and channel information within layers, but also to apply cross-layer attention from shallow to deep layers to perform feature fusion. This module dynamically senses the fine details of infrared small targets and processes detailed target information.
- (3)
- Experiments on the SIRST dataset show that our proposed EAAU-Net has the capacity to achieve better performance than existing methods and exhibits greater robustness to complex background clutter and weak texture information.
2. Related Work
2.1. Infrared Small Target Detection
2.2. Attention and Cross-Layer Feature Fusion
3. Proposed Method
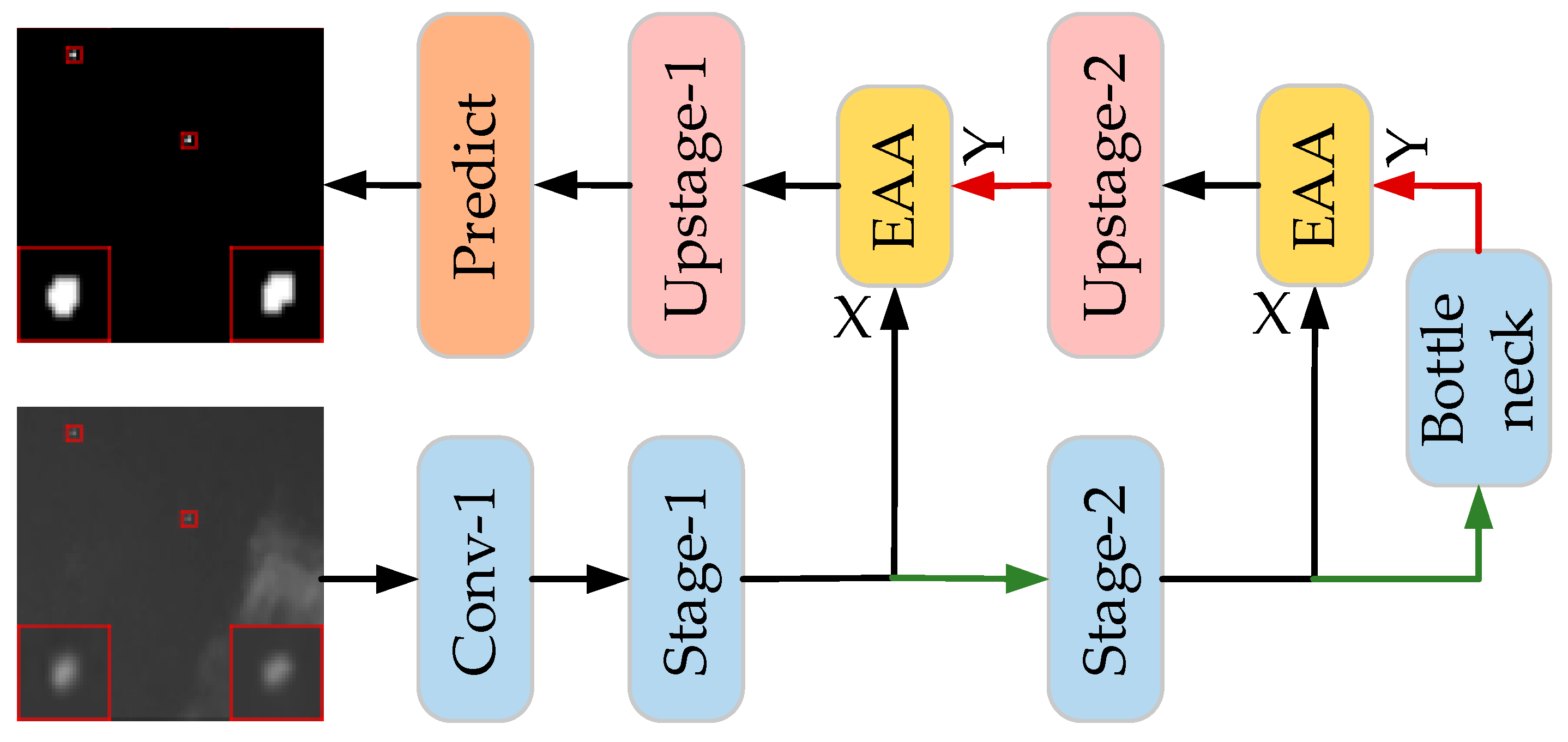
3.1. Network Architecture
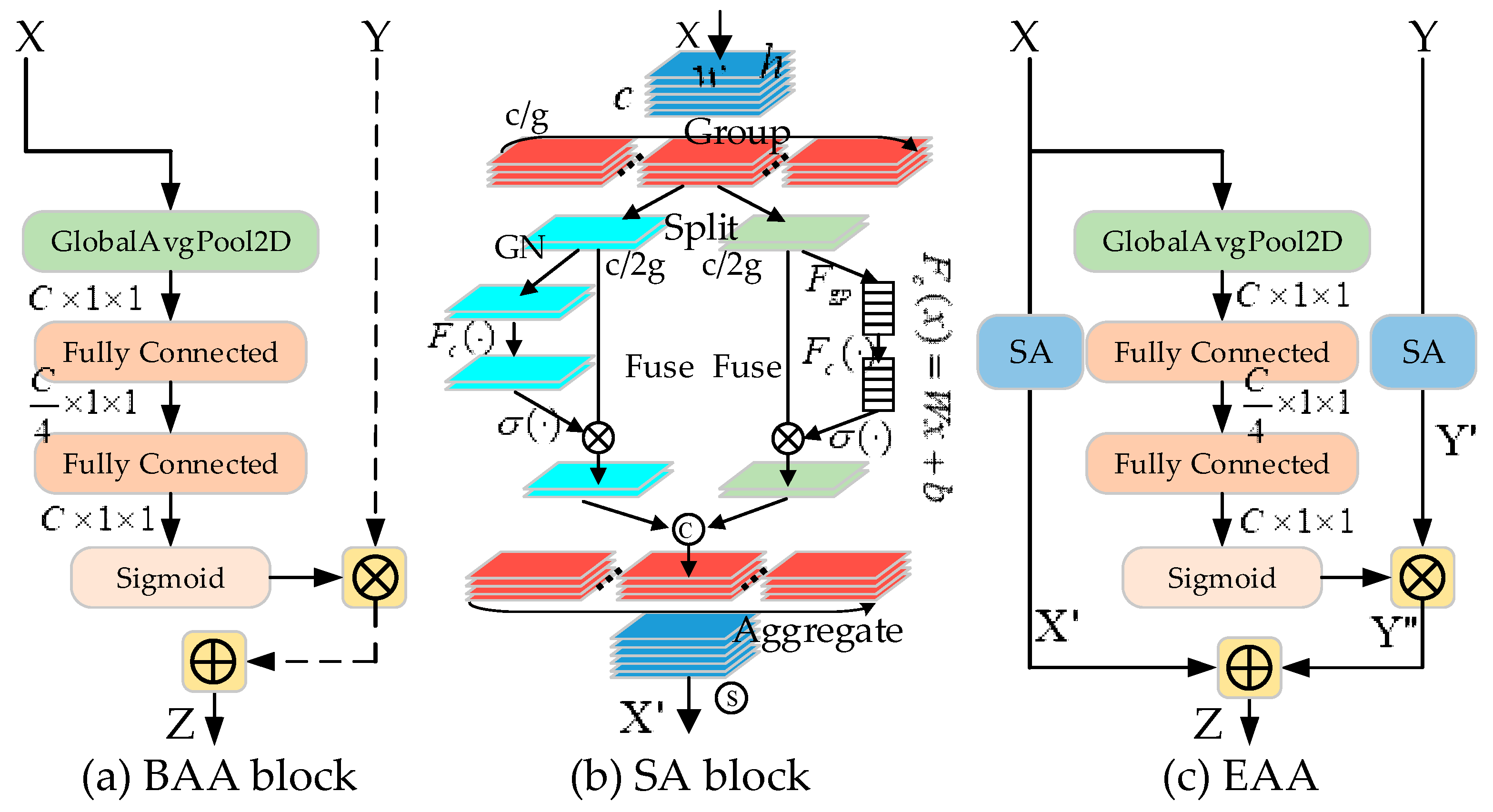
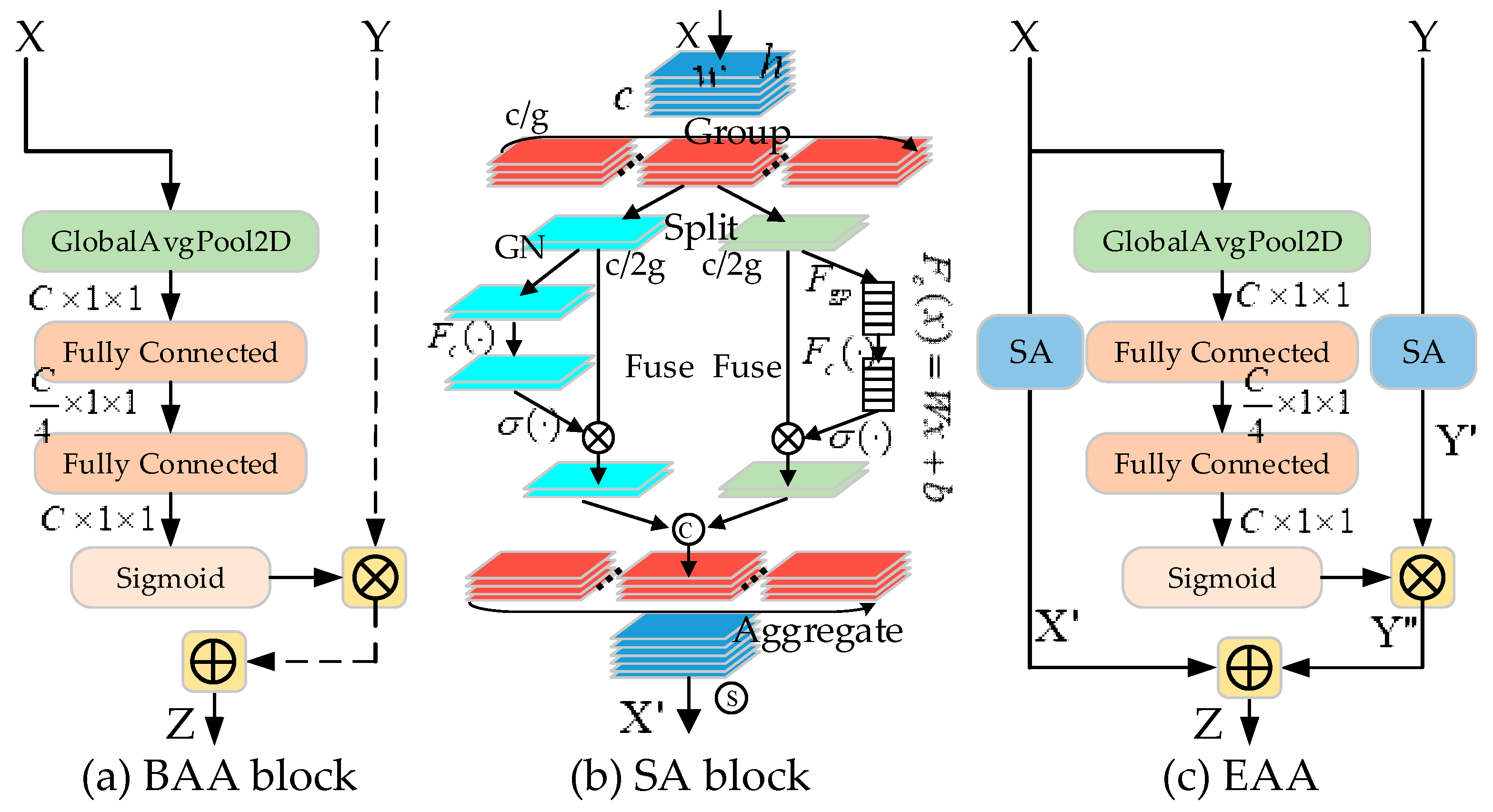
3.2. Enhanced Asymmetric Attention (EAA) Module
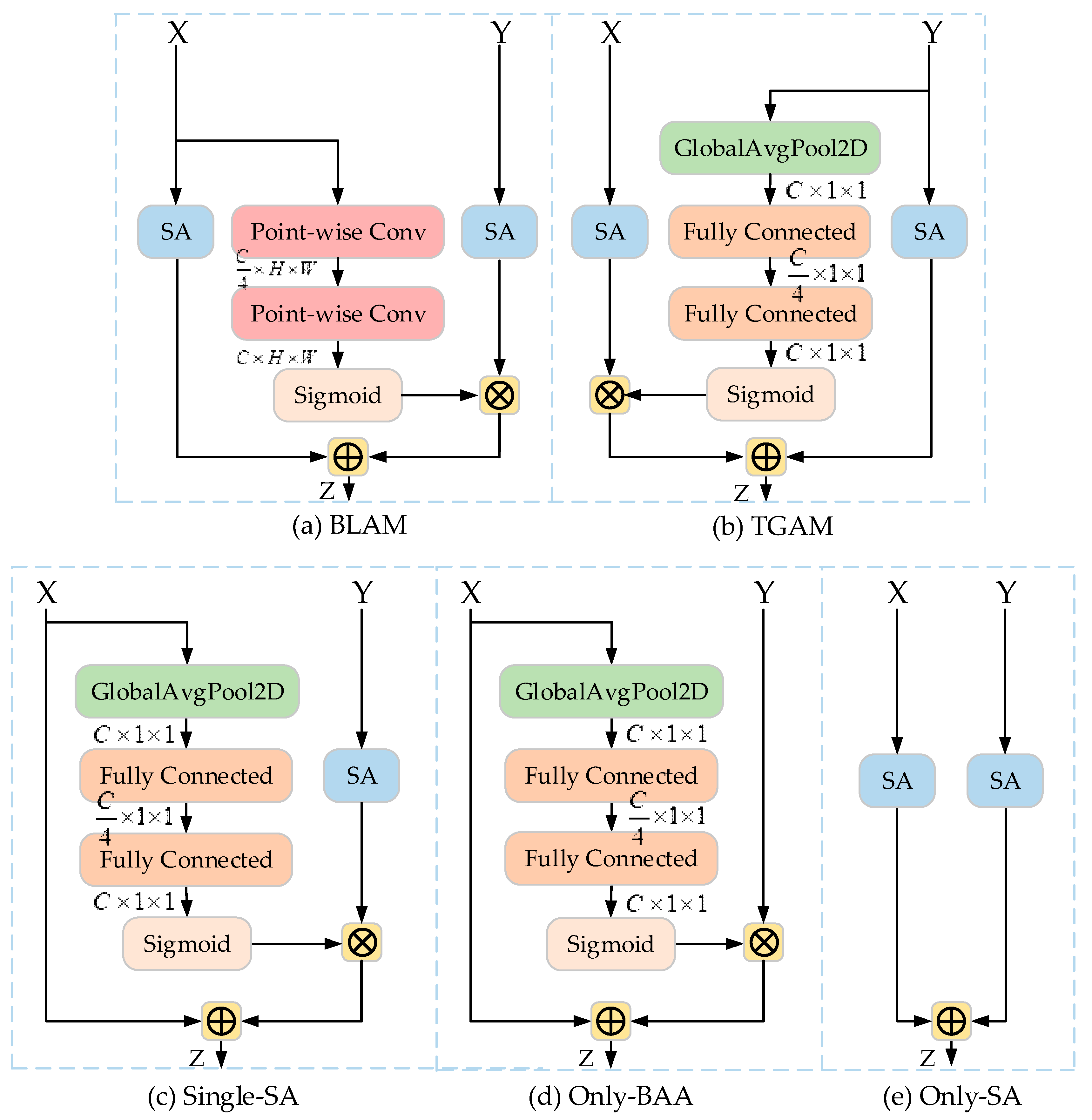
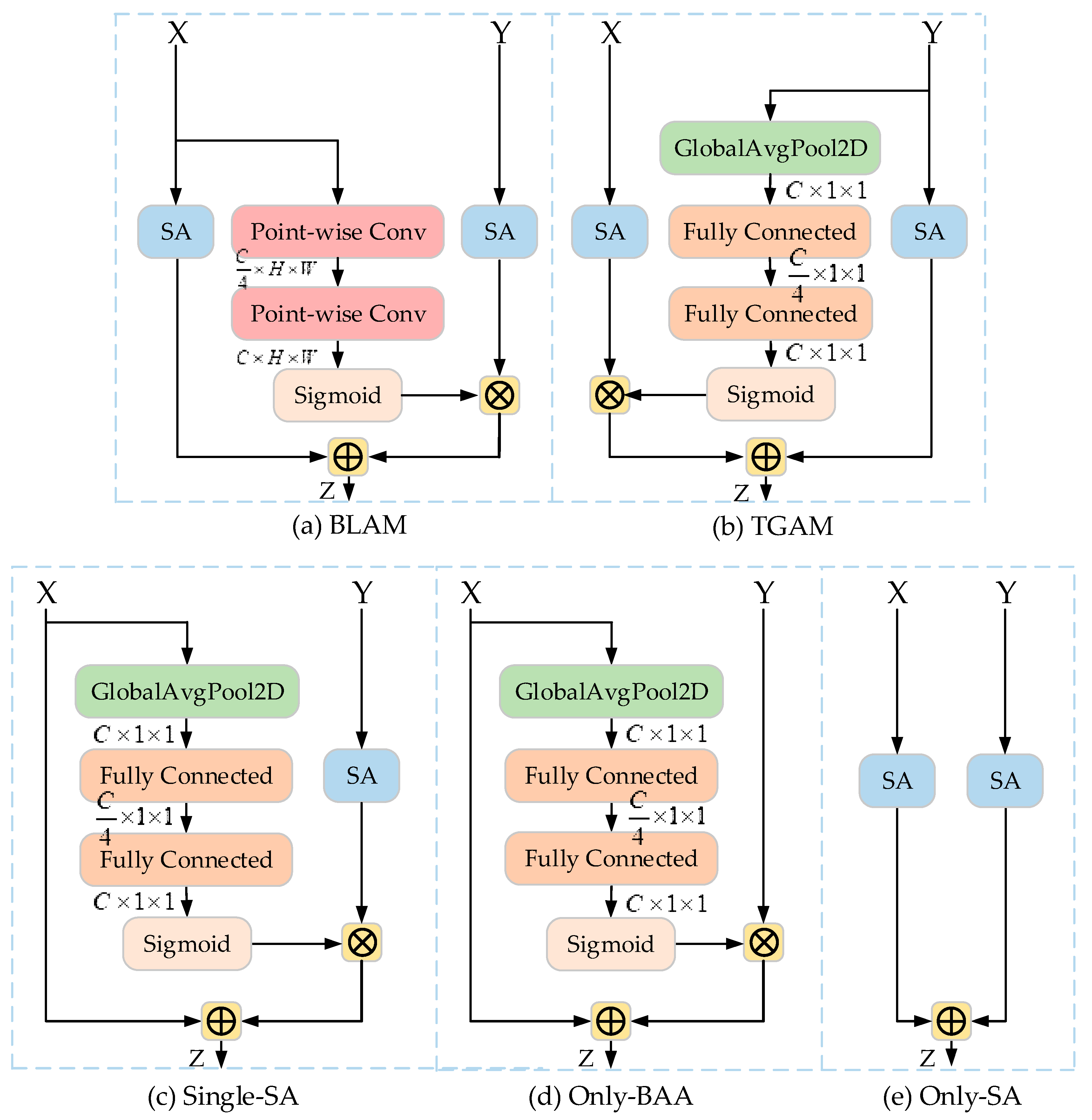
3.2.1. Bottom-Up Asymmetric Attention (BAA) Block
3.2.2. Shuffle Attention (SA) Block
3.2.3. EAA Module
3.3. Loss Function
4. Experimental Evaluation
4.1. Evaluation Metrics
- (1)
- Intersection-over-union (IoU). IoU is a pixel-level evaluation metric that evaluates the contour description capability of the algorithm. It is calculated as the ratio of the intersection and union regions between predictions and labels, as follows:
- (2)
- Normalised IoU (nIoU). To avoid the impact of the network segmentation of large targets on the evaluation metrics and to better measure the performance of network segmentation of infrared small targets, nIoU is specifically designed for infrared small target detection. It is defined as follows:
- (3)
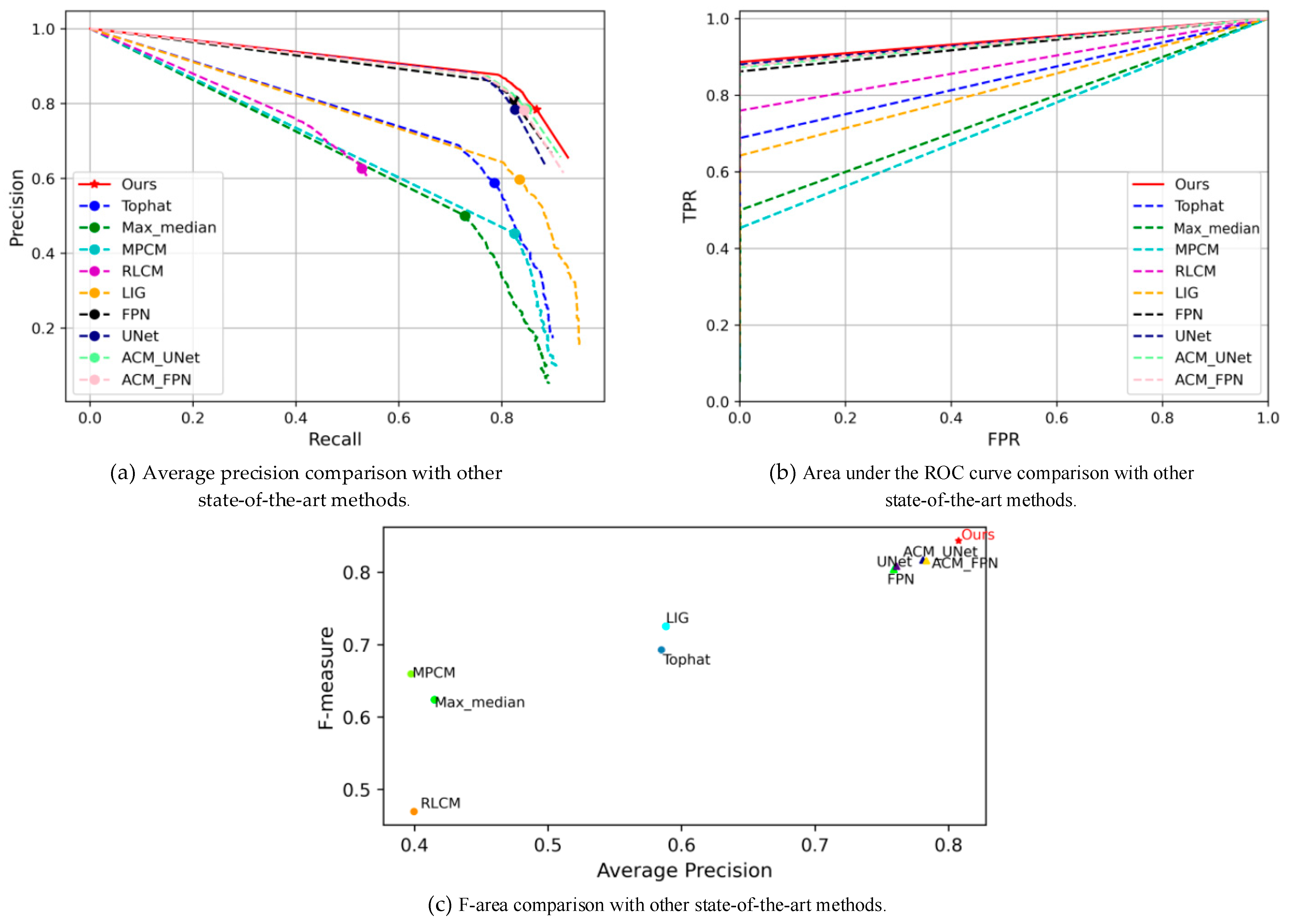
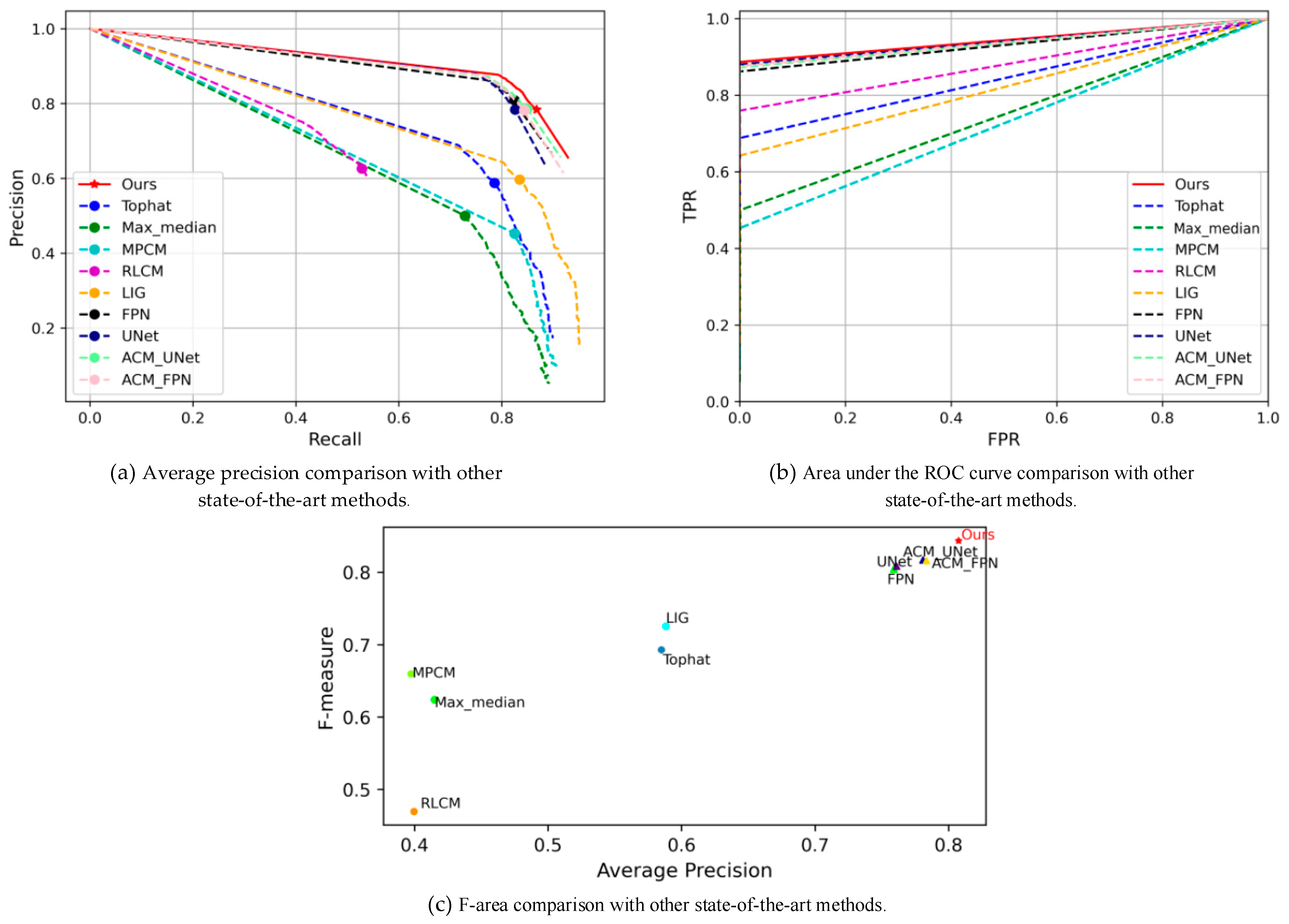
- PR curve: Precision is used as the vertical axis and recall as the horizontal axis. The closer the curve is to the top right, the better the performance when using the PR curve to show the trade-off between precision and recall for the classifier:
- (4)
- Receiver operating characteristic: The ROC is used to describe the changing relationship between the true positive rate (TPR) and the false positive rate (FPR). They are defined as:
- (5)
- New metric: F-area. F-measure is a precision- and recall-weighted summed average to measure the performance of the harmony. When operating with a fixed threshold, these methods do not sufficiently improve the average accuracy, which is valuable for practical applications. F-area considers both F-measure and average accuracy, taking into account the harmony and potential performance aspects of any technique. It is expressed as given below, where .
4.2. Implementation Details
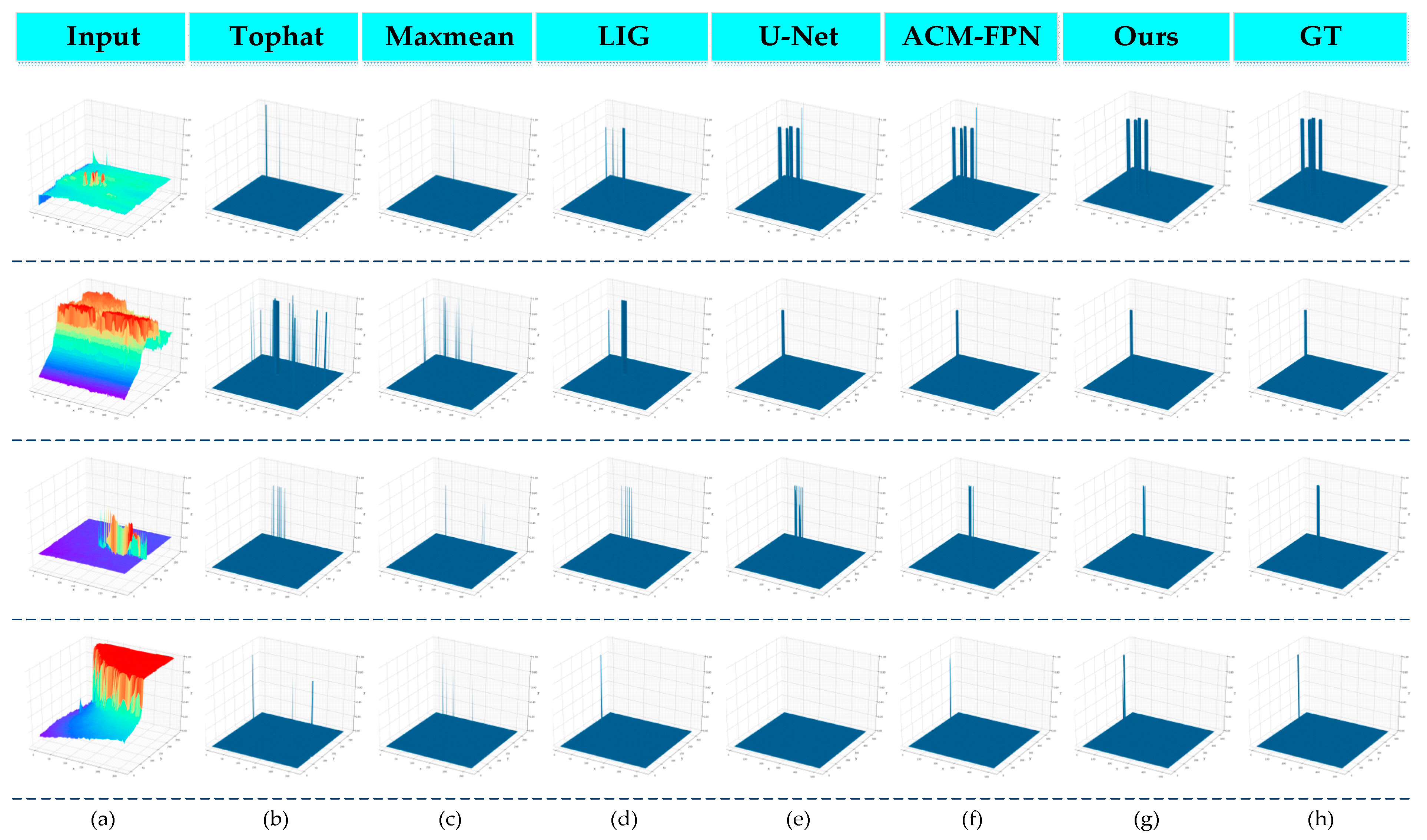
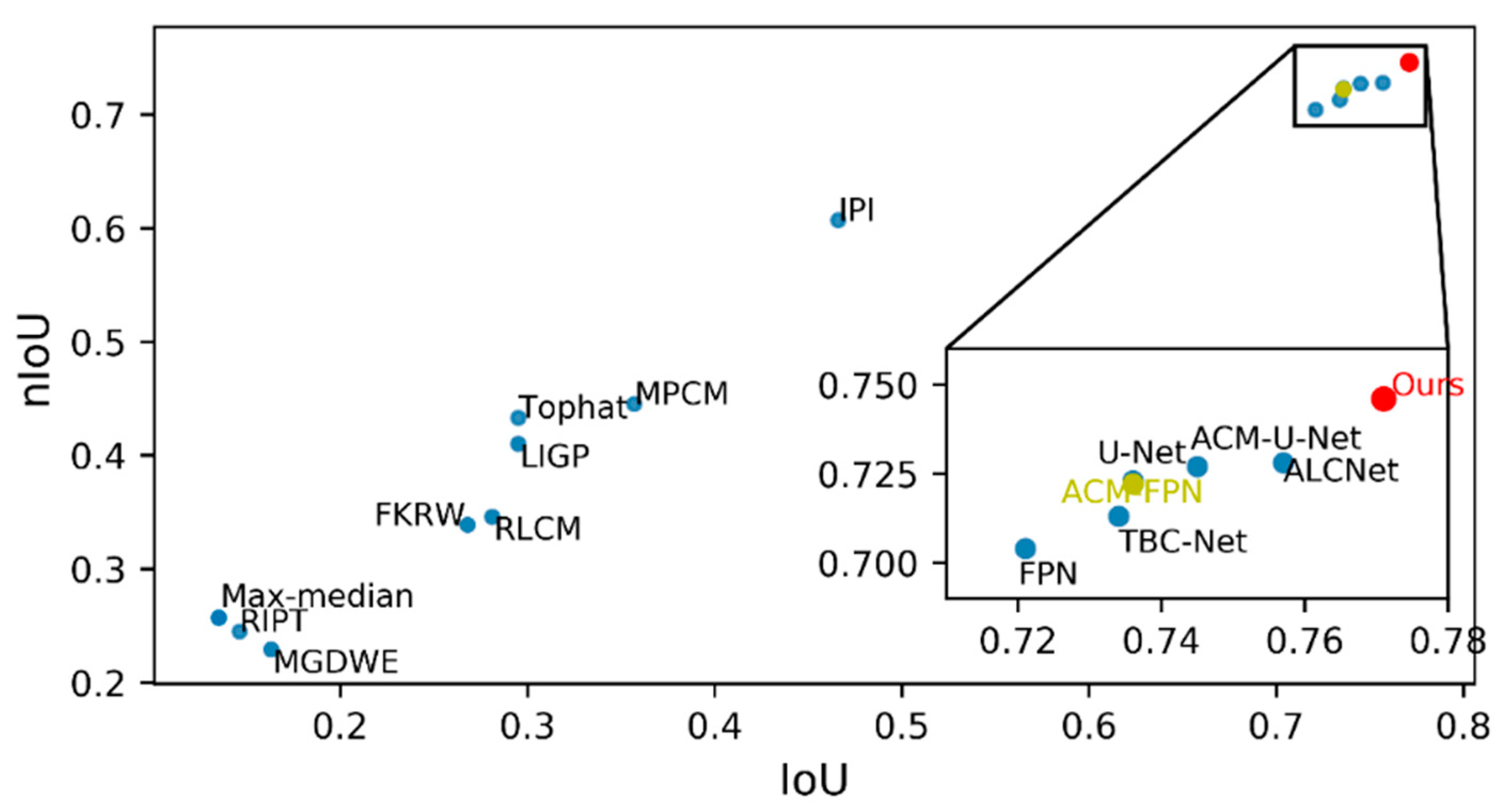
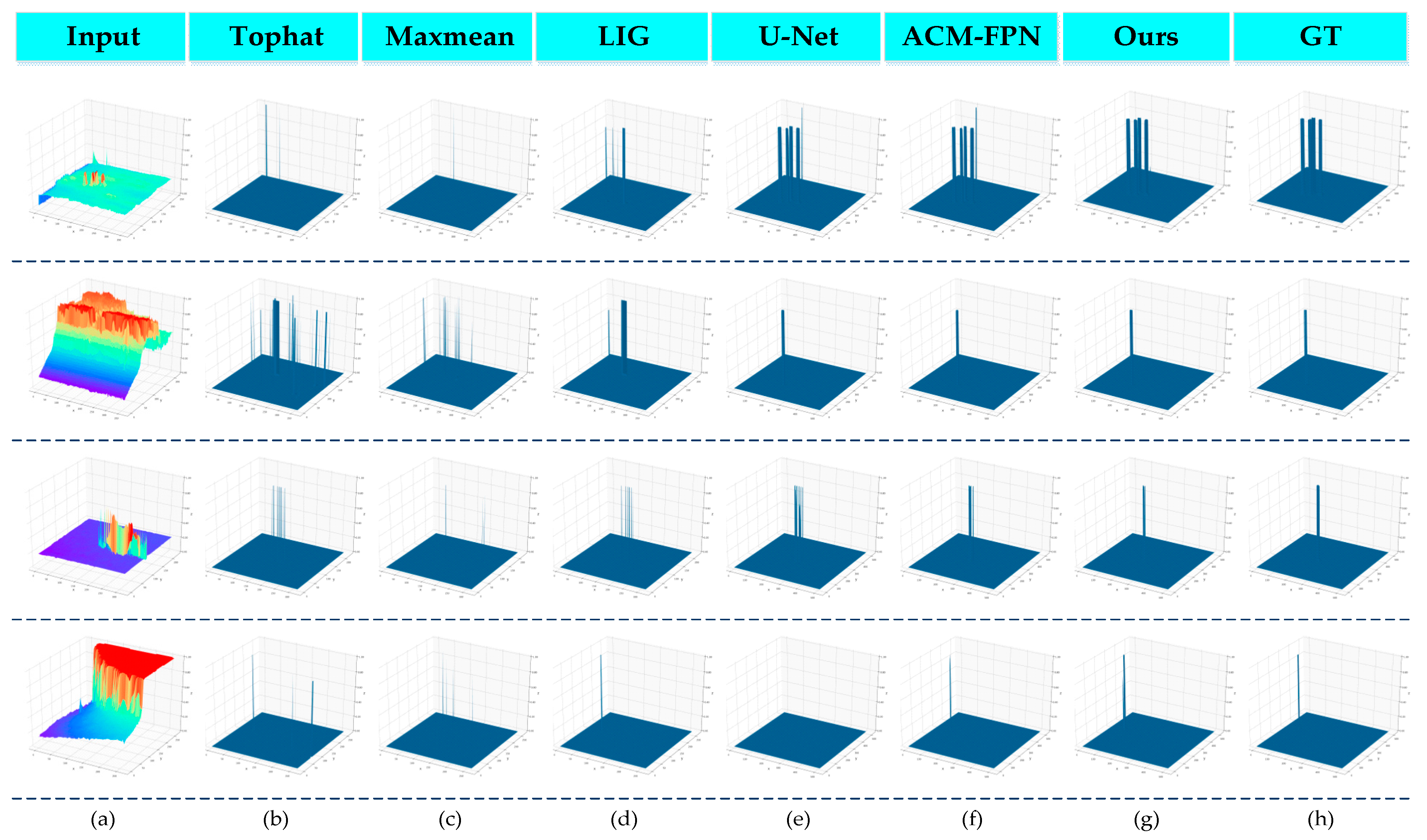
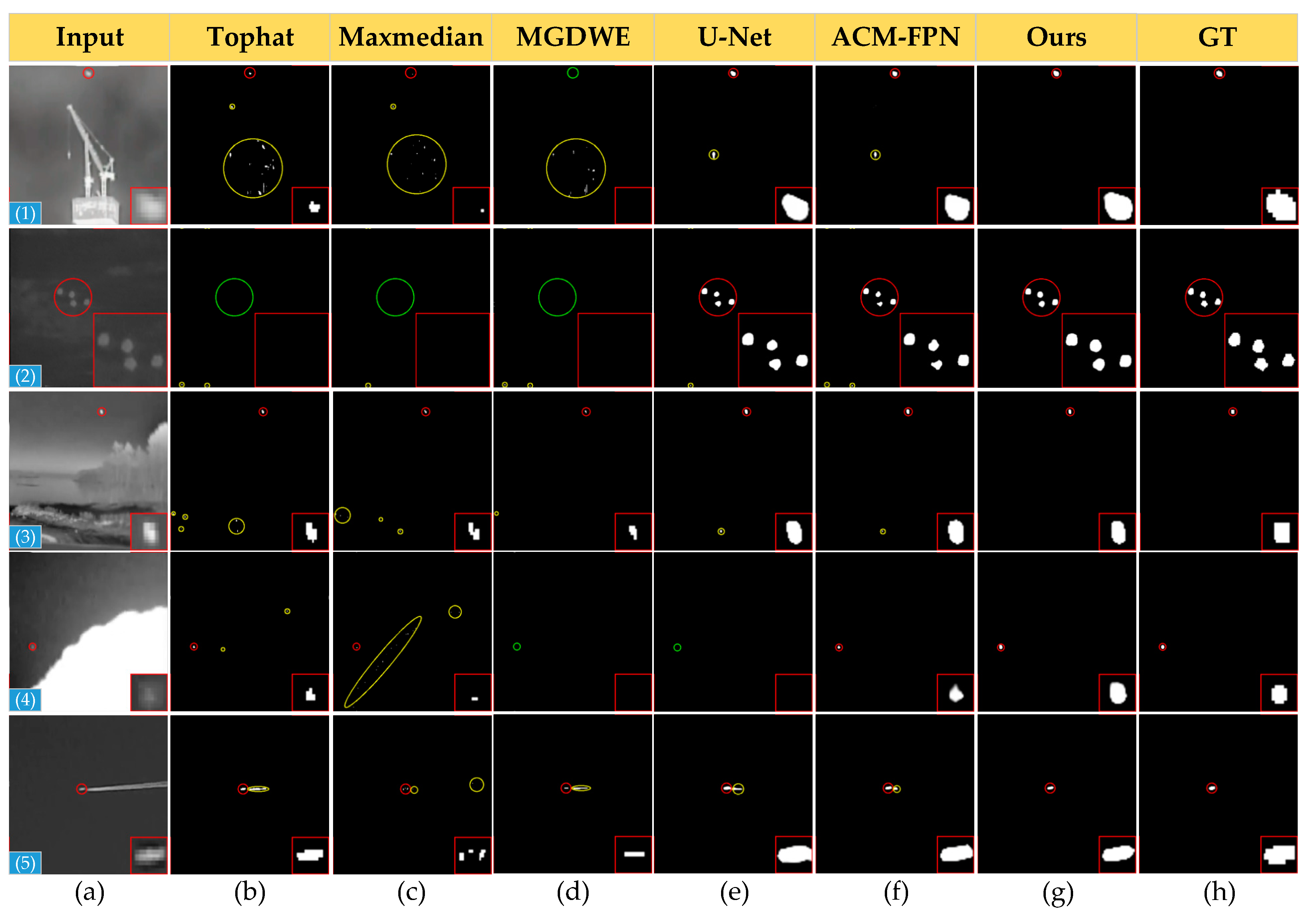
4.3. Comparison to State-of-the-Art Methods
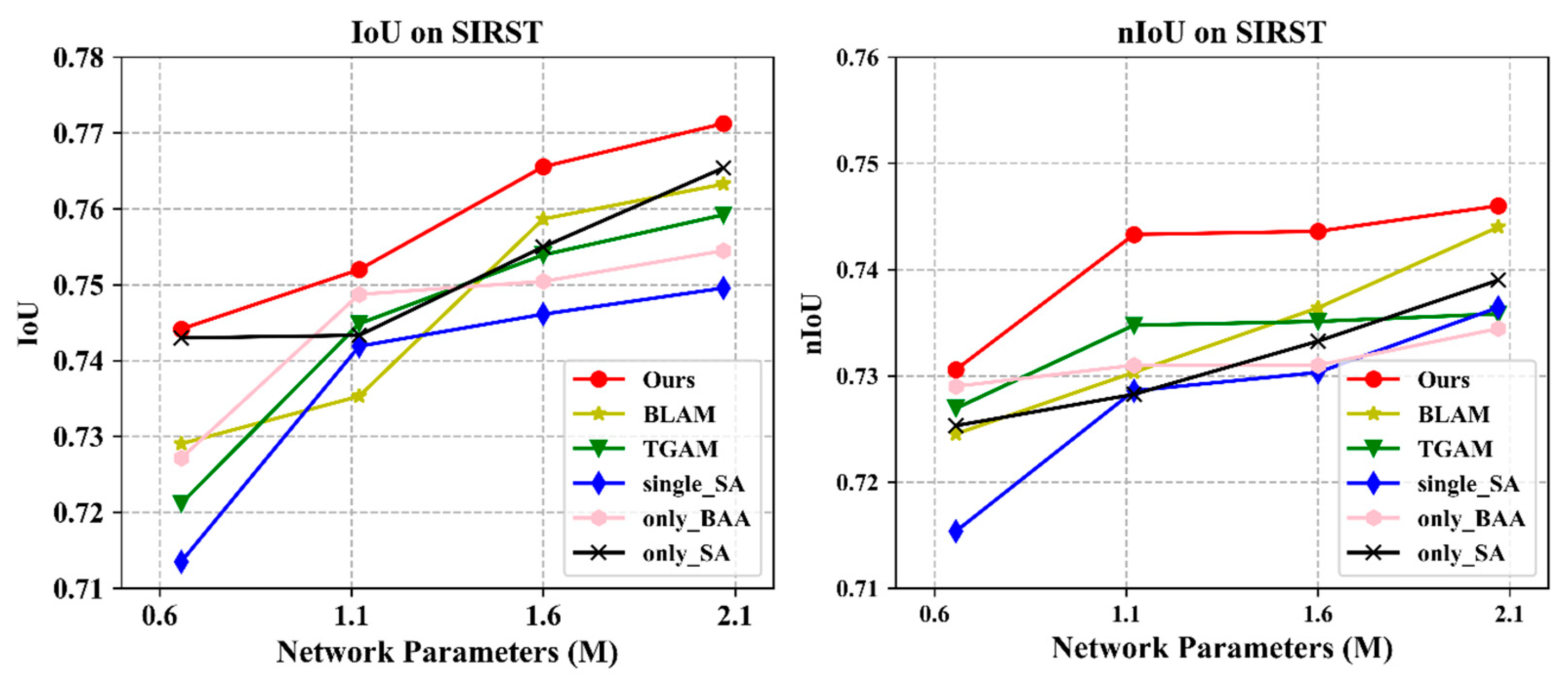
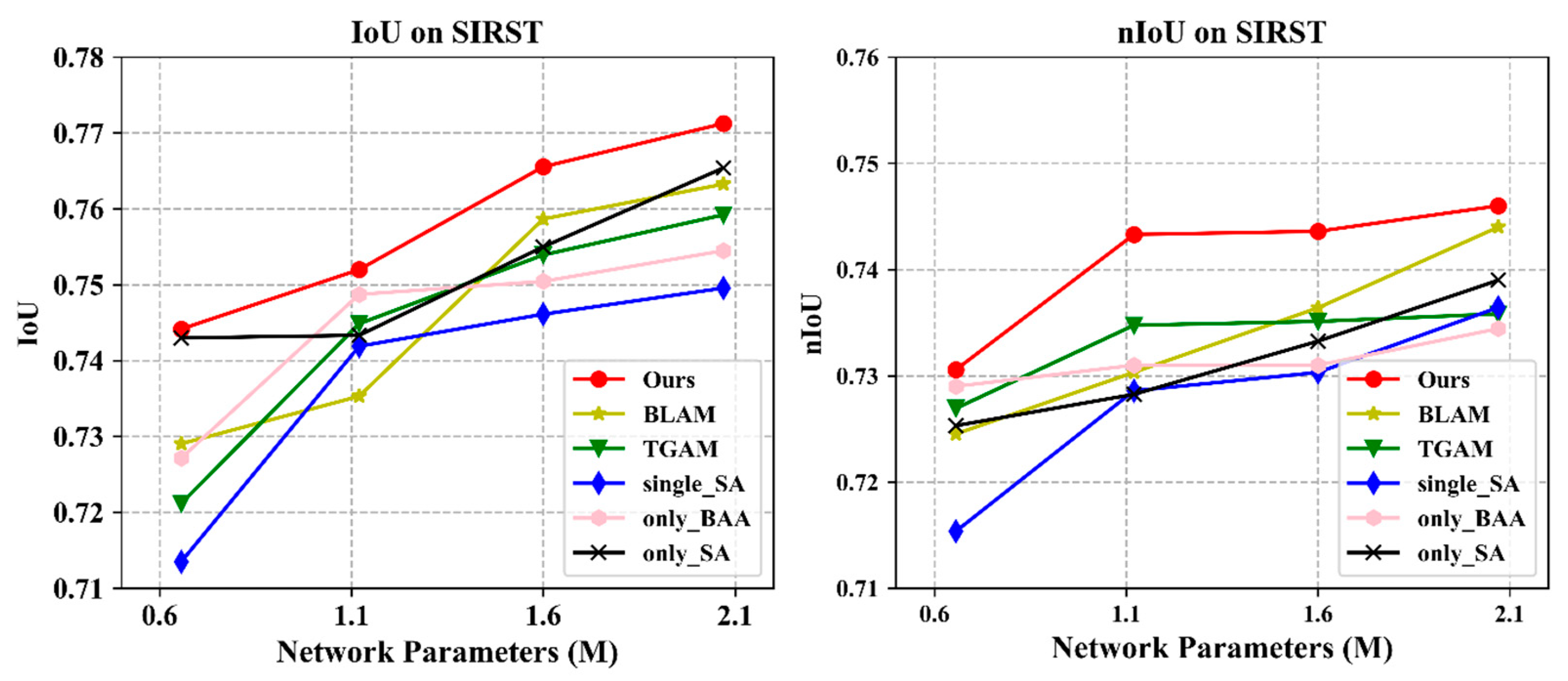
4.4. Ablation Study
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rawat, S.; Verma, S.K.; Kumar, Y. Review on recent development in infrared small target detection algorithms. Procedia Comput. Sci. 2020, 167, 2496–2505. [Google Scholar] [CrossRef]
- Qian, K.; Zhou, H.; Rong, S.; Wang, B.; Cheng, K. Infrared dim-small target tracking via singular value decomposition and improved Kernelized correlation filter. Infrared Phys. Technol. 2017, 82, 18–27. [Google Scholar] [CrossRef]
- Wang, H.; Shi, M.; Li, H. Infrared dim and small target detection based on two-stage U-skip context aggregation network with a missed-detection-and-false-alarm combination loss. Multimed. Tools Appl. 2020, 79, 35383–35404. [Google Scholar] [CrossRef]
- Rivest, J.; Fortin, R. Detection of dim targets in digital infrared imagery by morphological image processing. Opt. Eng. 1996, 35, 1886–1893. [Google Scholar] [CrossRef]
- Deshpande, S.D.; Er, M.; Venkateswarlu, R.; Chan, P. Max-Mean and Max-Median Filters for Detection of Small Targets. In Proceedings of the SPIE’s International Symposium on Optical Science, Engineering, and Instrumentation, Denver, CO, USA, 18–23 July 1999. [Google Scholar] [CrossRef]
- Chen, C.; Li, H.; Wei, Y.; Xia, T.; Tang, Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sens. 2014, 52, 574–581. [Google Scholar] [CrossRef]
- Han, J.; Ma, Y.; Zhou, B.; Fan, F.; Liang, K.; Fang, Y. A Robust Infrared Small Target Detection Algorithm Based on Human Visual System. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2168–2172. [Google Scholar]
- Han, J.; Moradi, S.; Faramarzi, I.; Liu, C.; Zhang, H.; Zhao, Q. A Local Contrast Method for Infrared Small-Target Detection Utilizing a Tri-Layer Window. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1822–1826. [Google Scholar] [CrossRef]
- Han, J.; Moradi, S.; Faramarzi, I.; Zhang, H.; Zhao, Q.; Zhang, X.; Li, N. Infrared Small Target Detection Based on the Weighted Strengthened Local Contrast Measure. IEEE Geosci. Remote Sens. Lett. 2020, 2020, 1–5. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A. Infrared Patch-Image Model for Small Target Detection in a Single Image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y. Reweighted Infrared Patch-Tensor Model With Both Nonlocal and Local Priors for Single-Frame Small Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3752–3767. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared Small Target Detection via Non-Convex Rank Approximation Minimization Joint l2, 1 Norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Peng, Z. Infrared Small Target Detection Based on Partial Sum of the Tensor Nuclear Norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Du, H.; Zhao, Y.; Dong, L.; Hui, M.; Wang, S.X. Image Small Target Detection based on Deep Learning with SNR Controlled Sample Generation. In Current Trends in Computer Science and Mechanical Automation Vol.1; Wang, S.X., Ed.; De Gruyter Open Poland: Warsaw, Poland, 2018; pp. 211–220. [Google Scholar] [CrossRef]
- Gao, Z.; Dai, J.; Xie, C. Dim and small target detection based on feature mapping neural networks. J. Vis. Commun. Image Represent. 2019, 62, 206–216. [Google Scholar] [CrossRef]
- McIntosh, B.; Venkataramanan, S.; Mahalanobis, A. Infrared Target Detection in Cluttered Environments by Maximization of a Target to Clutter Ratio (TCR) Metric Using a Convolutional Neural Network. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 485–496. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric Contextual Modulation for Infrared Small Target Detection. arXiv 2020, arXiv:2009.14530. [Google Scholar]
- Hou, Q.; Wang, Z.-p.; Tan, F.-j.; Zhao, Y.; Zheng, H.; Zhang, W. RISTDnet: Robust Infrared Small Target Detection Network. IEEE Geosci. Remote Sens. Lett. 2021, 2021, 1–5. [Google Scholar]
- Fang, H.; Xia, M.; Zhou, G.; Chang, Y.; Yan, L. Infrared Small UAV Target Detection Based on Residual Image Prediction via Global and Local Dilated Residual Networks. IEEE Geosci. Remote Sens. Lett. 2021, 2021, 1–5. [Google Scholar]
- Huang, L.; Dai, S.; Huang, T.; Huang, X.; Wang, H. Infrared Small Target Segmentation with Multiscale Feature Representation. Infrared Phys. Technol. 2021, 116, 103755. [Google Scholar] [CrossRef]
- Zhang, Q.-L.; Yang, Y. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. arXiv 2021, arXiv:2102.00240. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional Local Contrast Networks for Infrared Small Target Detection. arXiv 2020, arXiv:2012.08573. [Google Scholar]
- Zhao, M.; Cheng, L.; Yang, X.; Feng, P.; Liu, L.; Wu, N. TBC-Net: A real-time detector for infrared small target detection using semantic constraint. arXiv 2020, arXiv:2001.05852. [Google Scholar]
- Qin, Y.; Li, B. Effective Infrared Small Target Detection Utilizing a Novel Local Contrast Method. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1890–1894. [Google Scholar] [CrossRef]
- Liu, J.; He, Z.; Chen, Z.; Shao, L. Tiny and Dim Infrared Target Detection Based on Weighted Local Contrast. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1780–1784. [Google Scholar] [CrossRef]
- Yang, J.; Gu, Y.; Sun, Z.; Cui, Z. A Small Infrared Target Detection Method Using Adaptive Local Contrast Measurement. In Proceedings of the 2019 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Auckland, New Zealand, 9 September 2019; pp. 1–6. [Google Scholar]
- Deng, Q.; Lu, H.; Tao, H.; Hu, M.; Zhao, F. Multi-Scale Convolutional Neural Networks for Space Infrared Point Objects Discrimination. IEEE Access 2019, 7, 28113–28123. [Google Scholar] [CrossRef]
- Shi, M.; Wang, H. Infrared Dim and Small Target Detection Based on Denoising Autoencoder Network. Mob. Netw. Appl. 2020, 25, 1469–1483. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, B.; Wang, C.-p.; Fu, Q.; Han, Z.-s. A Novel Pattern for Infrared Small Target Detection With Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4481–4492. [Google Scholar] [CrossRef]
- Wang, K.; Li, S.; Niu, S.; Zhang, K. Detection of Infrared Small Targets Using Feature Fusion Convolutional Network. IEEE Access 2019, 7, 146081–146092. [Google Scholar] [CrossRef]
- Du, J.; Huanzhang, L.; Hu, M.; Zhang, L.; Xinglin, S. CNN-based infrared dim small target detection algorithm using target oriented shallo—Deep features and effective small anchor. IET Image Process 2021, 15, 1–15. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. arXiv 2018, arXiv:1809.02983. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S. S^3FD: Single Shot Scale-Invariant Face Detector. arXiv 2017, arXiv:1708.05237. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L. SNIPER: Efficient Multi-Scale Training. arXiv 2018, arXiv:1805.093000. [Google Scholar]
- Hu, P.; Ramanan, D. Finding Tiny Faces. arXiv 2016, arXiv:1612.04402. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context Encoding for Semantic Segmentation. arXiv 2018, arXiv:1803.08904. [Google Scholar]
- Shrivastava, A.; Gupta, A. Contextual Priming and Feedback for Faster R-CNN. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef]
- Fourure, D.; Emonet, R.; Fromont, É.; Muselet, D.; Trémeau, A.; Wolf, C. Residual Conv-Deconv Grid Network for Semantic Segmentation. arXiv 2017, arXiv:1707.07958. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.B.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. arXiv 2014, arXiv:1411.5752v2. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid Attention Network for Semantic Segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Yuan, W.; Wang, S.; Li, X.; Unoki, M.; Wang, W. A Skip Attention Mechanism for Monaural Singing Voice Separation. IEEE Signal Process. Lett. 2019, 26, 1481–1485. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. arXiv 2016, arXiv:1603.05027. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. arXiv 2018, arXiv:1803.08494. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation. In Proceedings of the ISVC 2016: Advances in Visual Computing, Las Vegas, NV, USA, 12–14 December 2016. [Google Scholar] [CrossRef]
- Duchi, J.C.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization; In Proceedings of COLT 2010 - The 23rd Conference on Learning Theory, Haifa, Israel, 27–29 June 2010.
- Bai, X.; Zhou, F. Analysis of new top-hat transformation and the application for infrared dim small target detection. Pattern Recognit. 2010, 43, 2145–2156. [Google Scholar] [CrossRef]
- Han, J.; Liang, K.; Zhou, B.; Zhu, X.; Zhao, J.; Zhao, L. Infrared Small Target Detection Utilizing the Multiscale Relative Local Contrast Measure. IEEE Geosci. Remote Sens. Lett. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Deng, H.; Sun, X.; Liu, M.; Ye, C.; Zhou, X. Small Infrared Target Detection Based on Weighted Local Difference Measure. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4204–4214. [Google Scholar] [CrossRef]
- Deng, H.; Sun, X.; Liu, M.; Ye, C.; Zhou, X. Infrared small-target detection using multiscale gray difference weighted image entropy. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 60–72. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, L.; Yuan, D.; Chen, H. Infrared small target detection based on local intensity and gradient properties. Infrared Phys. Technol. 2018, 89, 88–96. [Google Scholar] [CrossRef]
- Qin, Y.; Bruzzone, L.; Gao, C.; Li, B. Infrared Small Target Detection Based on Facet Kernel and Random Walker. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7104–7118. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Output | Backbone |
|---|---|---|
| Conv-1 | 480 × 480 | |
| Stage-1/UpStage-1 | 480 × 480 | |
| Stage-2/UpStage-2 | 240 × 240 | |
| Bottleneck | 120 × 120 |
| Methods | Hyper-Parameter Settings |
|---|---|
| Top-hat | Patch size = 3 × 3 |
| Max-median | Patch size median = 3 × 3 |
| RLCM | Sub-block size = 8 × 8, sliding step = 4, threshold factor k = 1. |
| MPCM | |
| MGDWE | r = 2, window size = 7 × 7 |
| LIGP | k = 0.2, window size = 11 × 11 |
| FKRW | K = 4, p = 6, β = 200, window size = 11 × 11 |
| IPI | Patch size = 50 × 50, stride = 10, , L = 4.5, threshold factor k = 10, |
| RIPT | Patch size = 50 × 50, stride = 10, , L = 0.001, |
| Methods | IoU | nIoU | Time on CPU/s | Para (M) | Methods | IoU | nIoU | Time on CPU/s | Para (M) |
|---|---|---|---|---|---|---|---|---|---|
| Top-hat | 0.295 | 0.433 | 0.006 | — | RIPT | 0.146 | 0.245 | 6.398 | — |
| Max-median | 0.135 | 0.257 | 0.007 | — | FPN | 0.721 | 0.704 | 0.075 | 1.6 |
| RLCM | 0.281 | 0.346 | 6.850 | — | U-Net | 0.736 | 0.723 | 0.144 | 2.2 |
| MPCM | 0.357 | 0.445 | 0.347 | — | TBC-Net | 0.734 | 0.713 | 0.049 | 6.93 |
| MGDWE | 0.163 | 0.229 | 1.670 | — | ACM-FPN | 0.736 | 0.722 | 0.067 | 1.6 |
| LIGP | 0.295 | 0.410 | 0.877 | — | ACM-U-Net | 0.745 | 0.727 | 0.156 | 2.2 |
| FKRW | 0.268 | 0.339 | 0.399 | — | ALCNet | 0.757 | 0.728 | 0.378 | 1.44 |
| IPI | 0.466 | 0.607 | 11.699 | — | Ours | 0.771 | 0.746 | 0.179 | 2.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tong, X.; Sun, B.; Wei, J.; Zuo, Z.; Su, S. EAAU-Net: Enhanced Asymmetric Attention U-Net for Infrared Small Target Detection. Remote Sens. 2021, 13, 3200. https://doi.org/10.3390/rs13163200
Tong X, Sun B, Wei J, Zuo Z, Su S. EAAU-Net: Enhanced Asymmetric Attention U-Net for Infrared Small Target Detection. Remote Sensing. 2021; 13(16):3200. https://doi.org/10.3390/rs13163200
Chicago/Turabian StyleTong, Xiaozhong, Bei Sun, Junyu Wei, Zhen Zuo, and Shaojing Su. 2021. "EAAU-Net: Enhanced Asymmetric Attention U-Net for Infrared Small Target Detection" Remote Sensing 13, no. 16: 3200. https://doi.org/10.3390/rs13163200
APA StyleTong, X., Sun, B., Wei, J., Zuo, Z., & Su, S. (2021). EAAU-Net: Enhanced Asymmetric Attention U-Net for Infrared Small Target Detection. Remote Sensing, 13(16), 3200. https://doi.org/10.3390/rs13163200