
Semantic Boosting: Enhancing Deep Learning Based LULC Classification




Abstract
:1. Introduction
- (1)
- The development and application of a Semantic Boosting approach, for fusing remotely sensed imagery with geospatial semantics (obtained from vector data) for LULC classification based on deep learning;
- (2)
- A quantitative analysis investigating the potential of geospatial semantics for LULC classification in depth;
- (3)
- A qualitative analysis focusing on understanding and explaining when and why Semantic Boosting can be beneficial for LULC classification.
- Geospatial semantic data from the LinkedGeoData platform [14].
- CORINE LULC (Level 2) data (https://land.copernicus.eu/pan-european/corine-land-cover/clc2018 accessed on 23 January 2021).
- Remotely sensed imagery from Sentinel-2 (https://apps.sentinel-hub.com/mosaic-hub/#/ accessed on 23 January 2021).
2. Related Work
2.1. Land Use and Land Cover Semantics
2.2. New Forms and Sources of LULC-Related Information
2.3. Summary
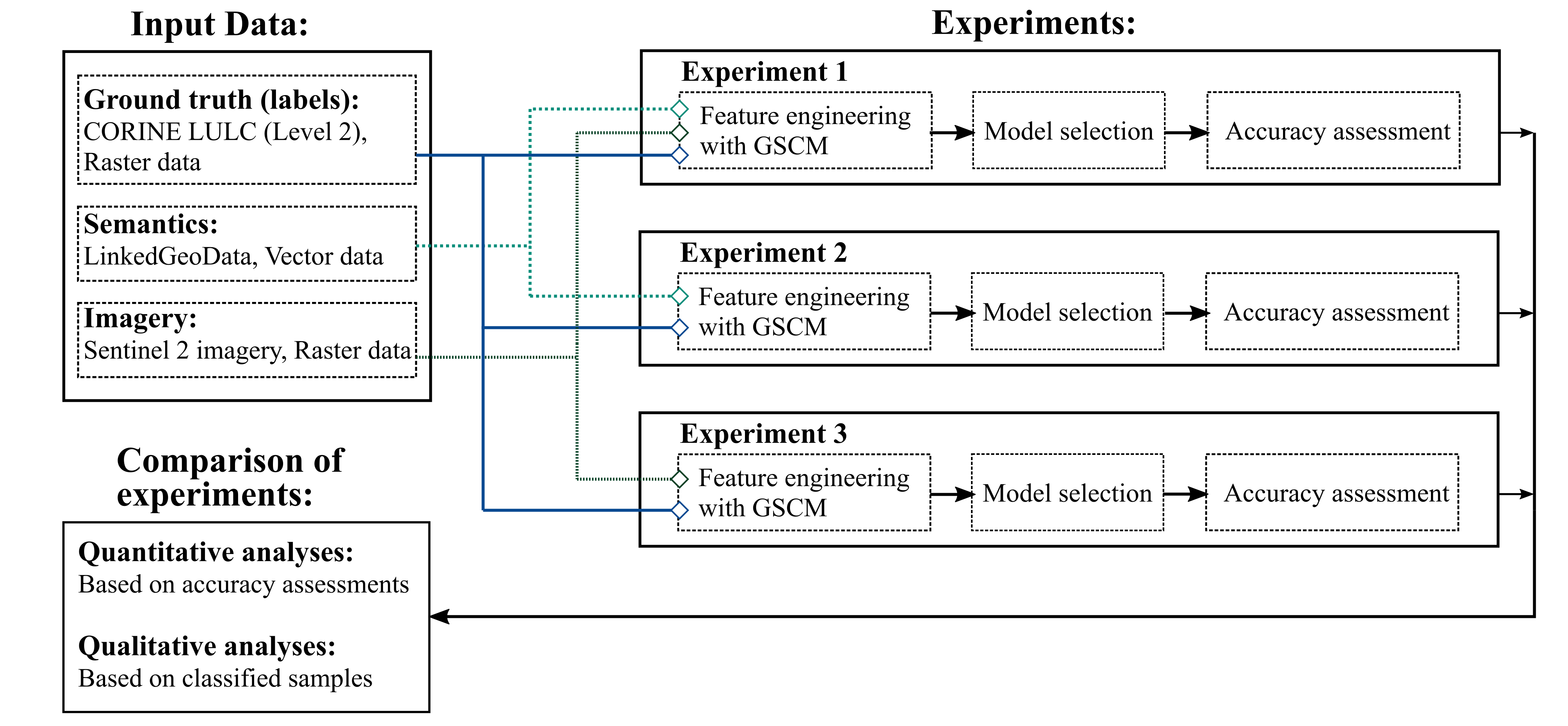
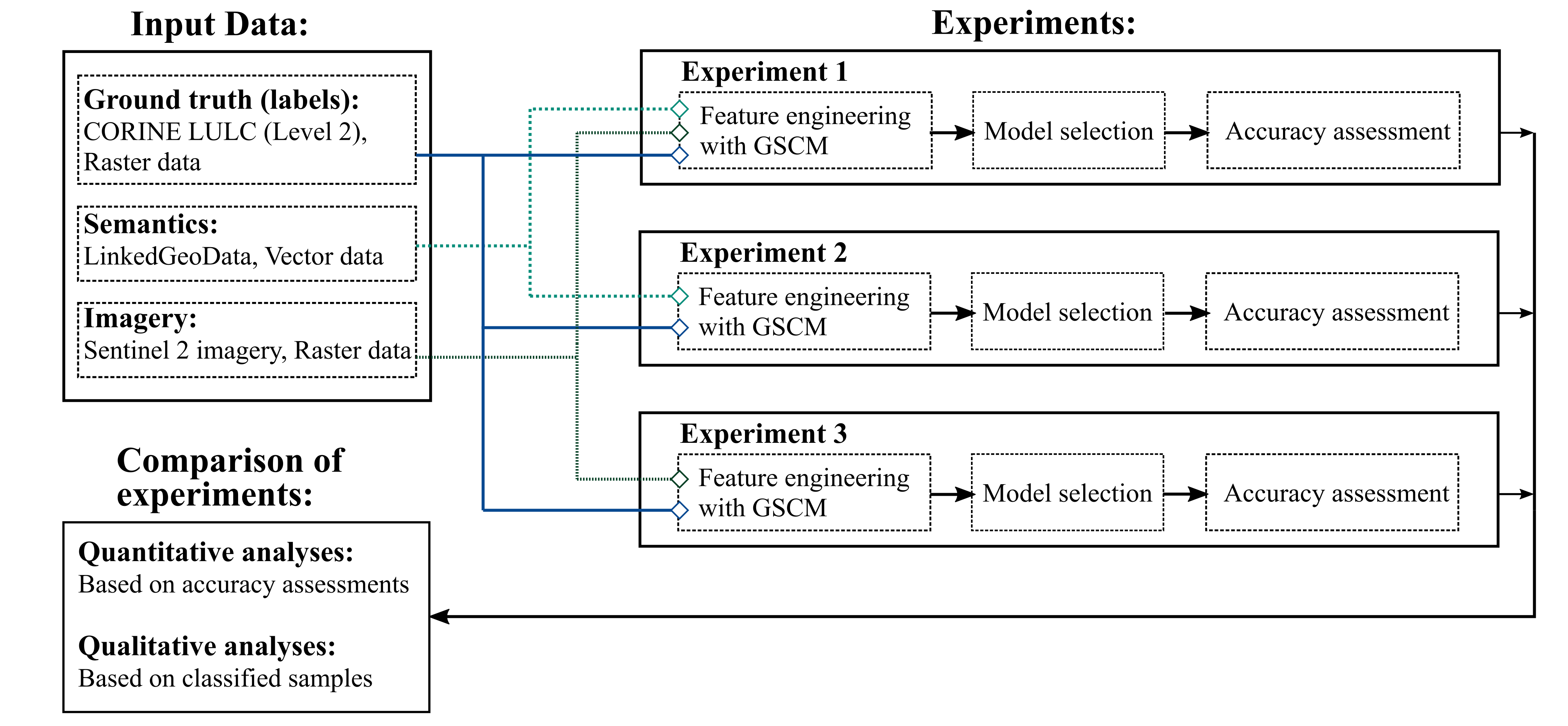
3. Methodology
- Geospatial semantics synthesised with remotely sensed imagery (experiment 1);
- Geospatial semantics only (Experiment 2);
- Remotely sensed imagery only (Experiment 3).
3.1. Data
3.1.1. CORINE Land Cover
3.1.2. Sentinel-2 Imagery
3.1.3. LinkedGeoData
3.2. Data Preparation and Preprocessing
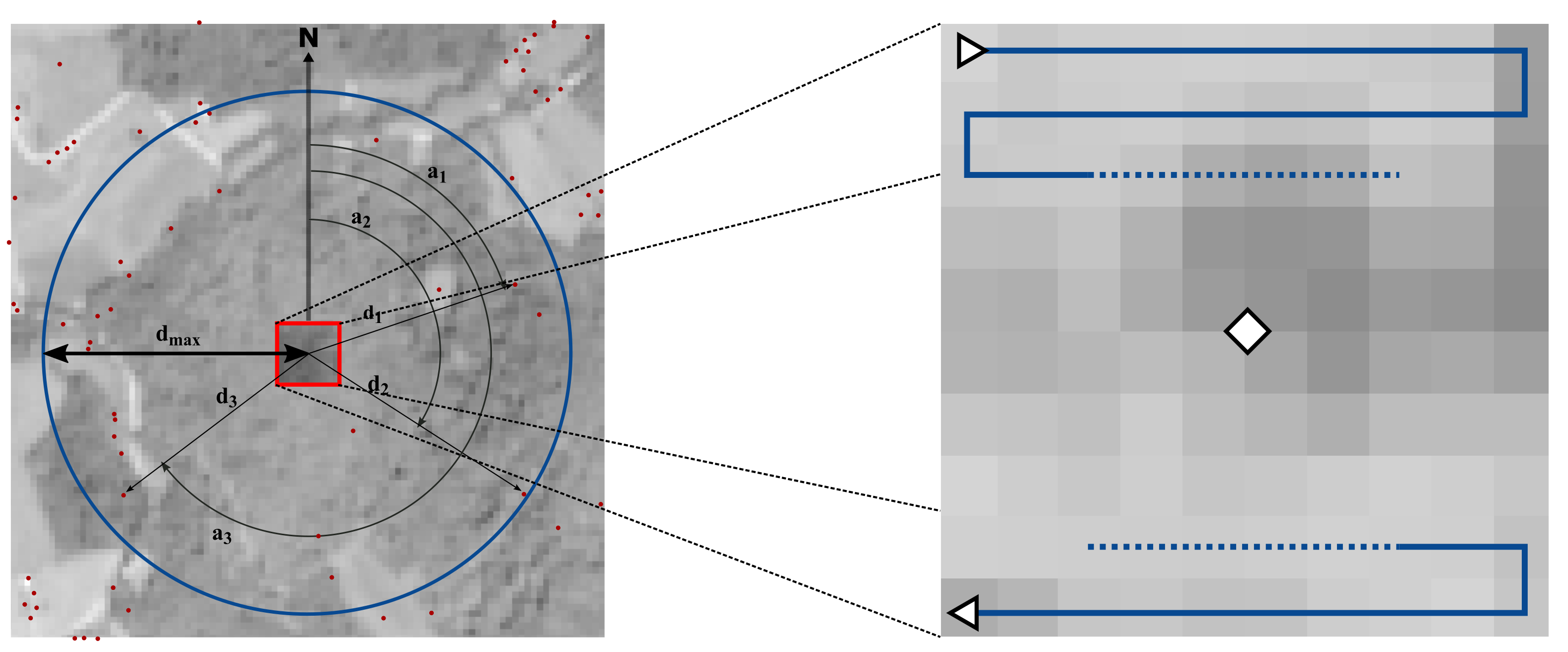
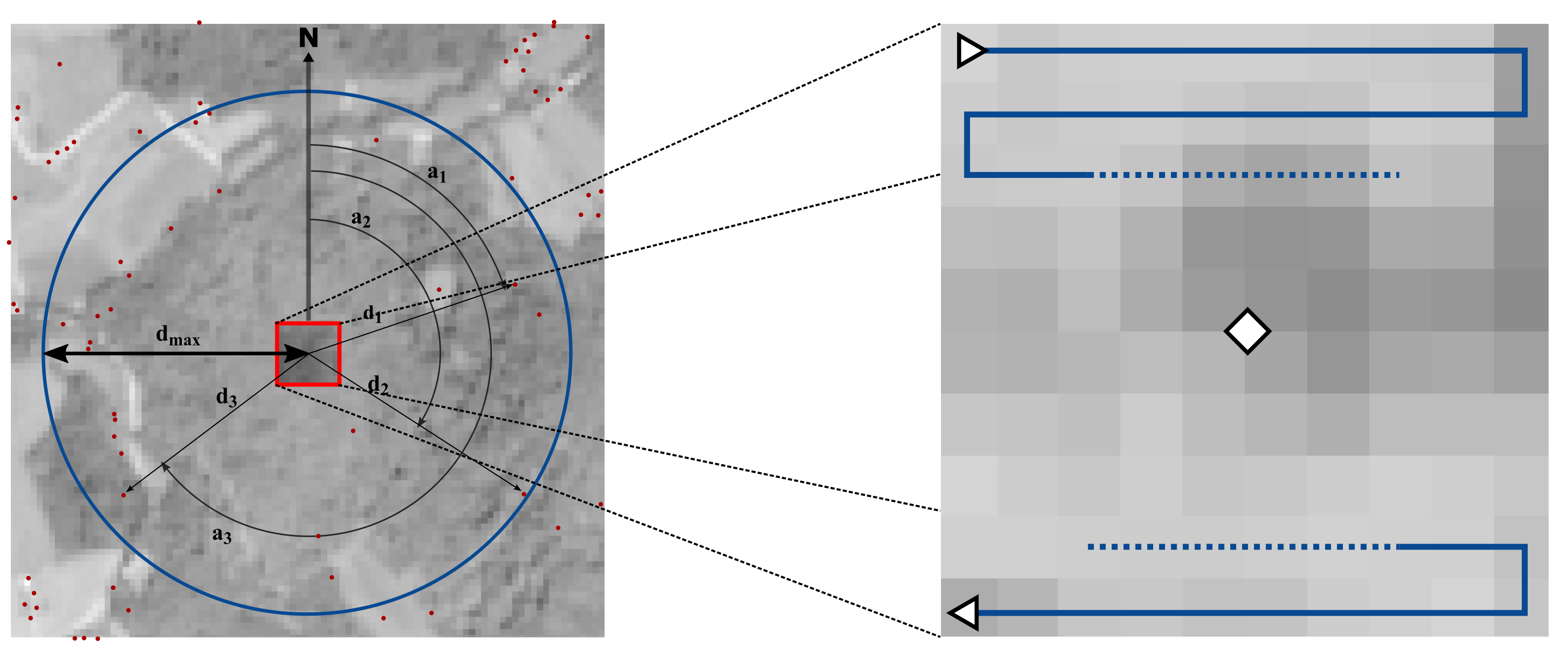
3.2.1. GSCM Construction
3.2.2. Linking Semantic and Image Information
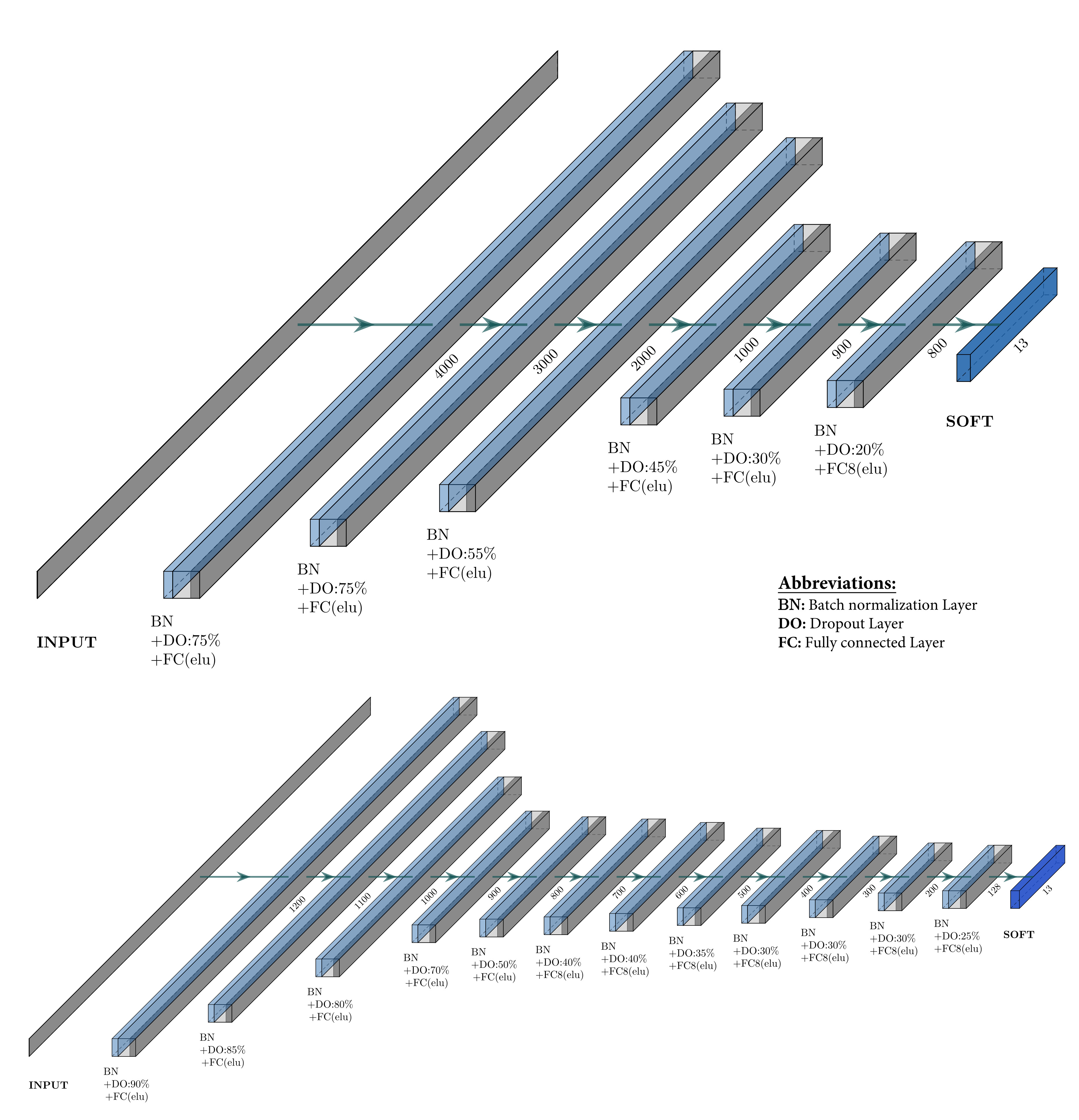
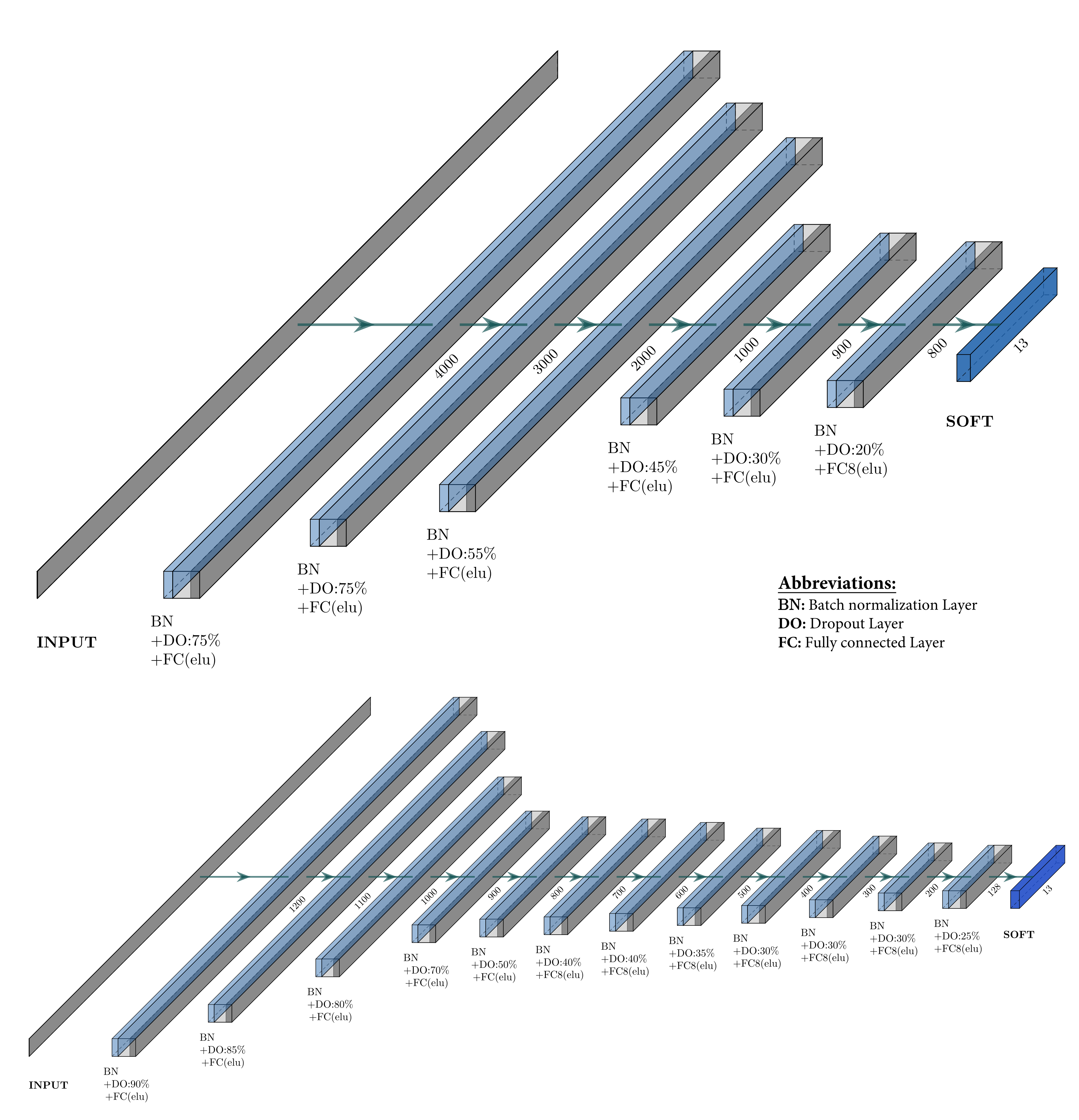
3.2.3. Model Selection and Evaluation
3.2.4. Analyses
- (1)
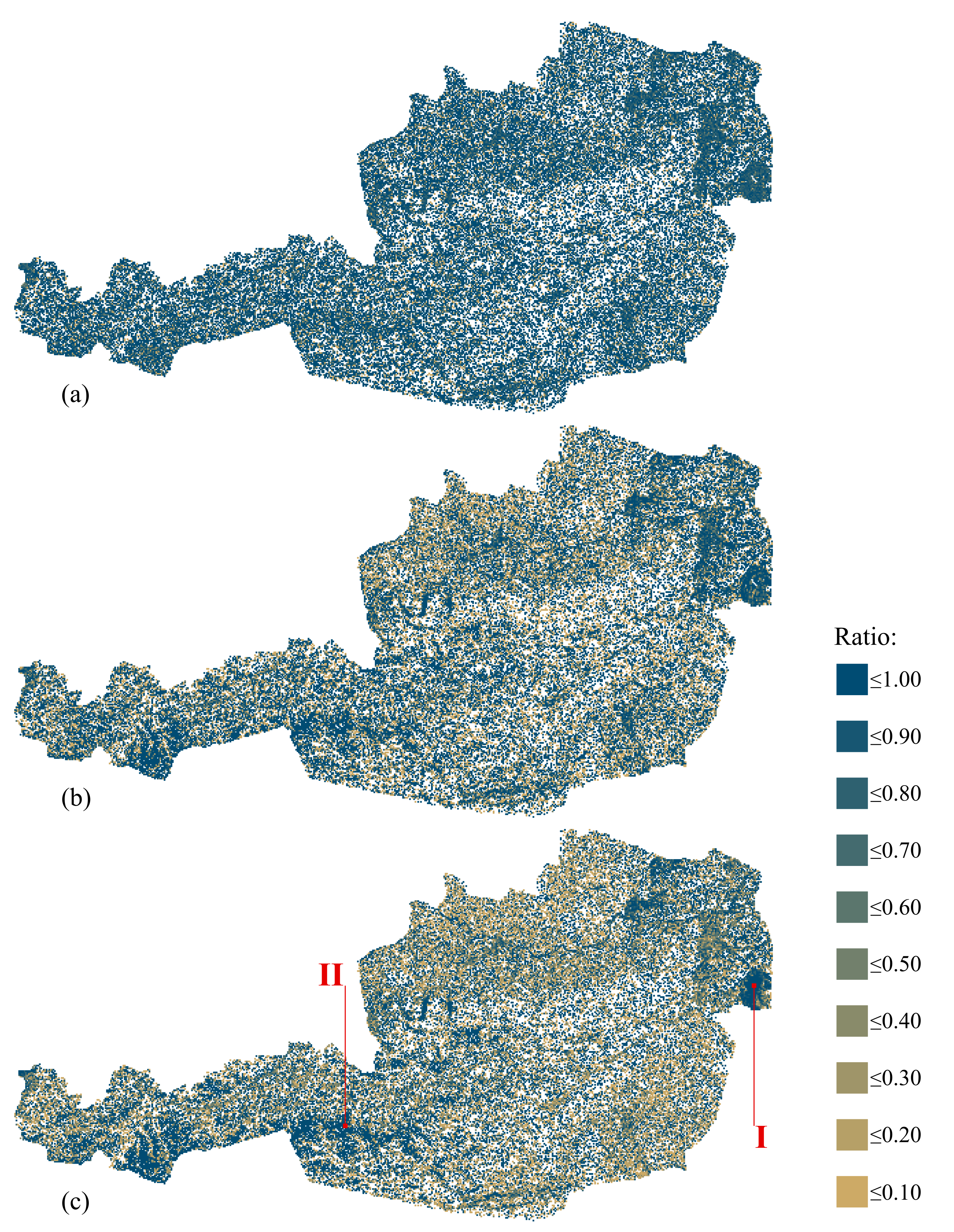
- The geographical distribution of the classification error. Here, a grid covering the study area was used and the ratio of correctly versus incorrectly samples was computed for each grid cell. The grid cell size was set by the value which yielded the highest classification scores;
- (2)
- Selected samples and their surrounding were then visually explored. For this purpose, the Sentinel-2 image was extracted around the corresponding grid cells. This enabled insights to be gained on the characteristics of the input data used. For example, some samples were classified correctly with using semantics only but not using imagery only. This might be due to the surrounding geo-objects as well as the imagery. The aim here was to examine classified samples and to determine potential characteristics in common. Four types of samples were defined: (1) samples correctly classified in Experiment 2 (semantics only) but not in Experiment 3 (imagery only) to examine the potential advantages of using semantics only over using imagery only. (2) samples classified correctly in Experiment 3 but not in Experiment 2. These samples illustrate cases where the imagery only approach provides higher classification accuracy than using semantics only. (3) samples which were correctly classified in both Experiment 2 and Experiment 3. (4) samples classified correctly in Experiment 1 but not in Experiments 2 and 3. These samples highlight situations when semantics as well as imagery only were not sufficient alone to classify correctly but were once fused.
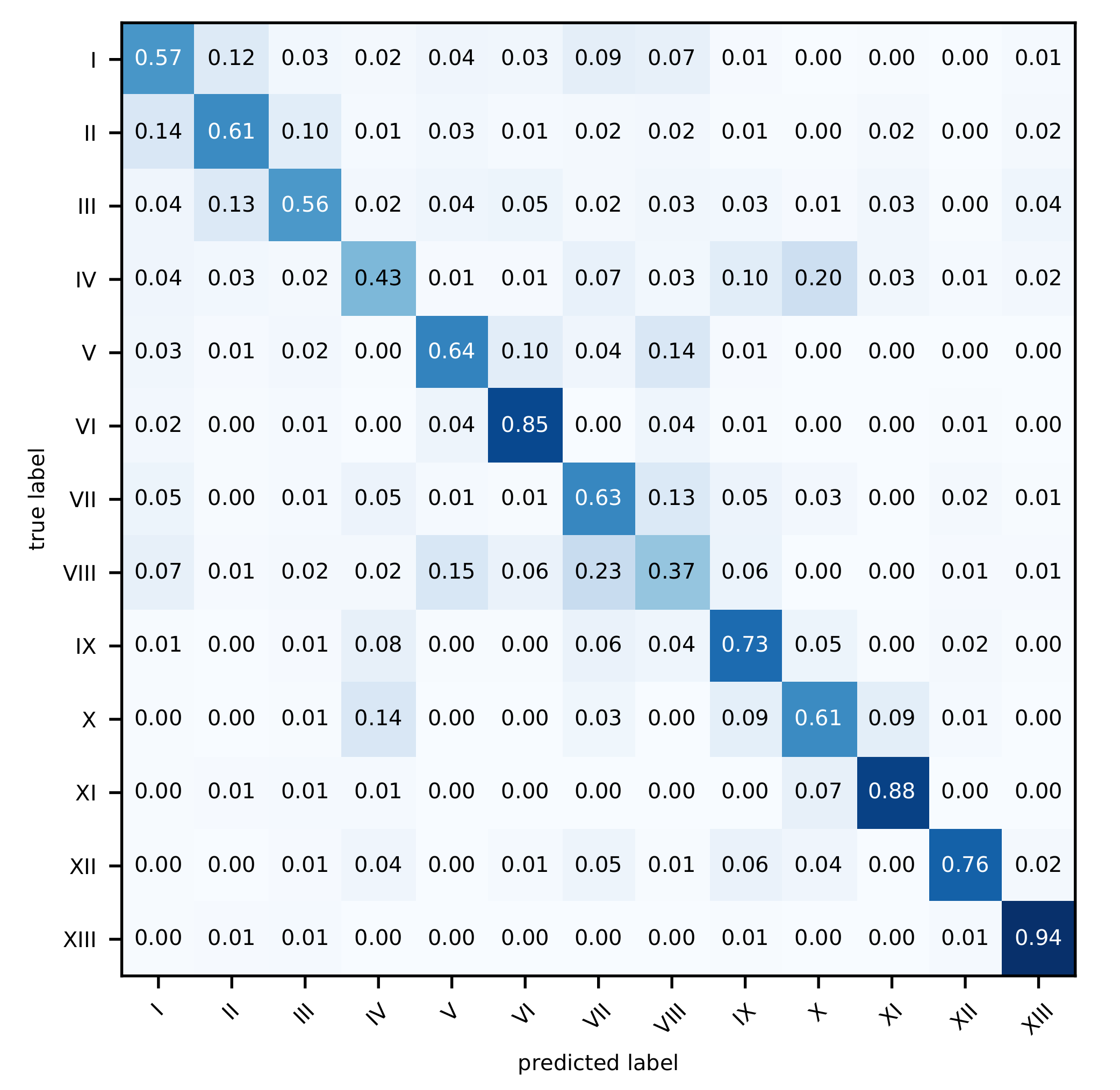
4. Results and Analysis
5. Discussion
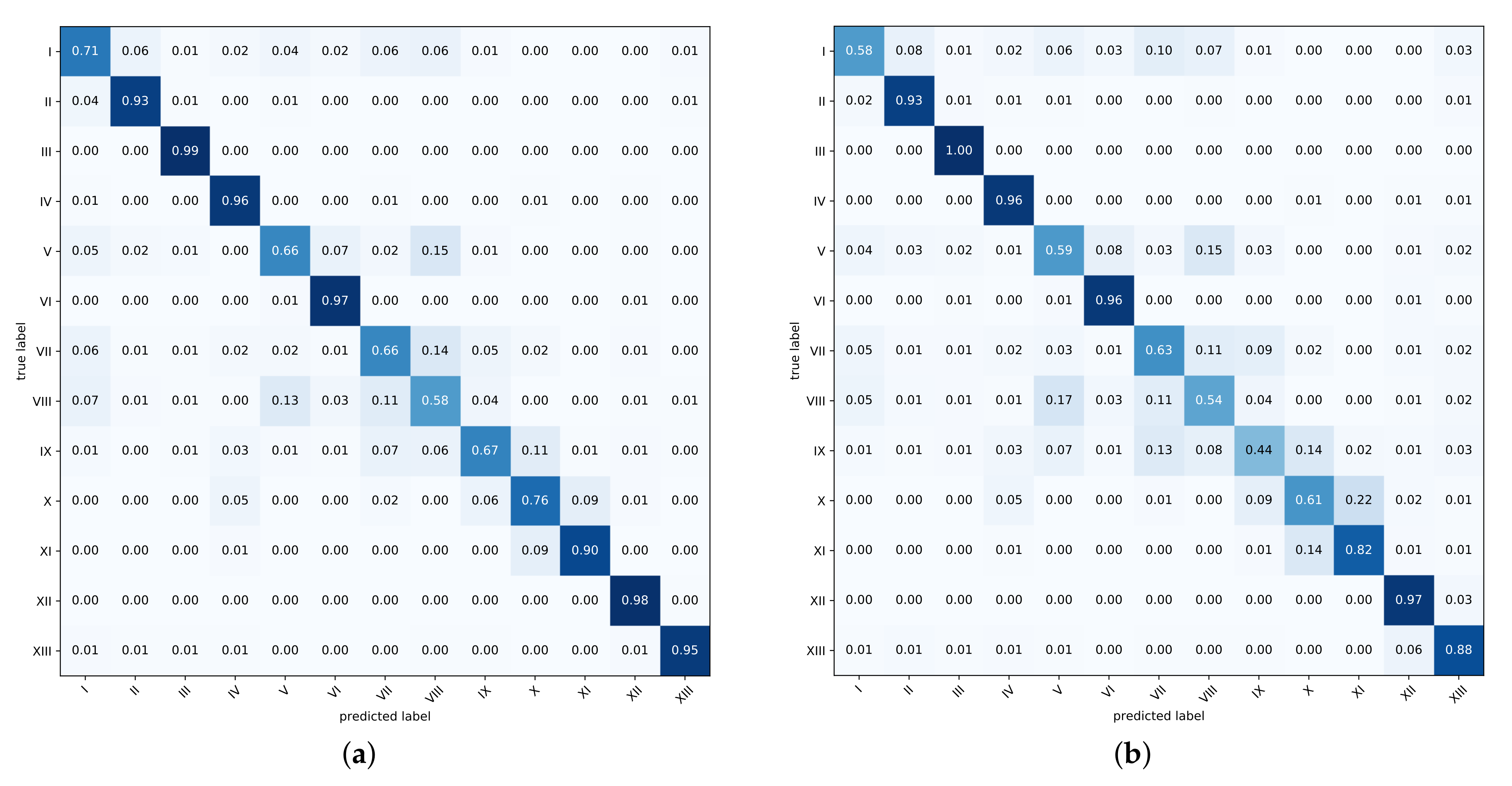
5.1. Overall Classification Results
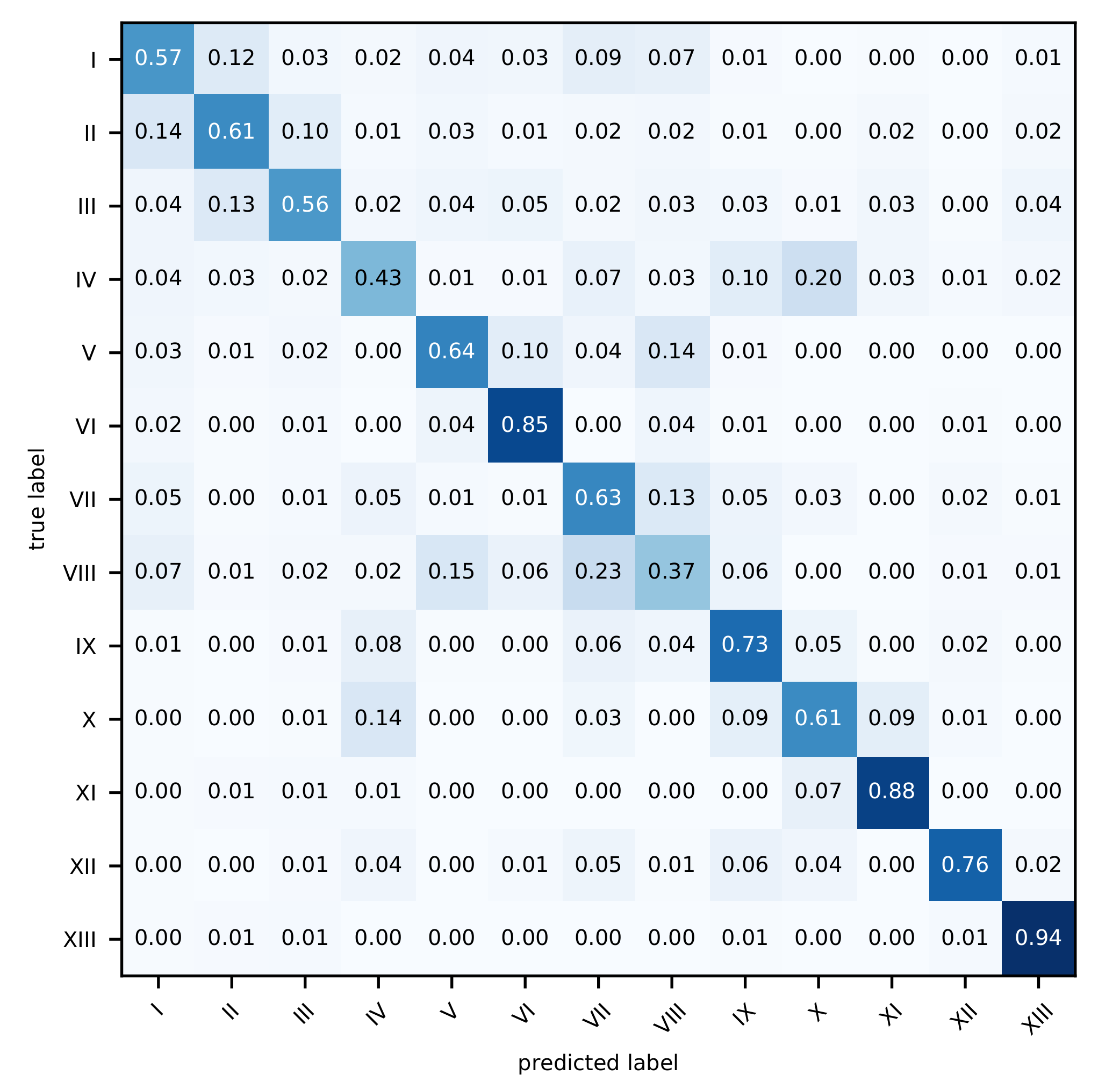
5.2. Classifications of Single Classes
5.3. Semantics for LULC Classification
5.4. Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Comber, A.; Fisher, P.; Wadsworth, R. What is Land Cover? Environ. Plan. B Plan. Des. 2005, 32, 199–209. [Google Scholar] [CrossRef] [Green Version]
- Fisher, P. The pixel: A snare and a delusion. Int. J. Remote Sens. 1997, 18, 679–685. [Google Scholar] [CrossRef]
- Foody, G.M. Harshness in image classification accuracy assessment. Int. J. Remote Sens. 2008, 29, 3137–3158. [Google Scholar] [CrossRef] [Green Version]
- Foley, J.A. Global Consequences of Land Use. Science 2005, 309, 570–574. [Google Scholar] [CrossRef] [Green Version]
- Pielke, R.A. Land Use and Climate Change. Science 2005, 310, 1625–1626. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Turner, B.L.; Lambin, E.F.; Reenberg, A. The emergence of land change science for global environmental change and sustainability. Proc. Natl. Acad. Sci. USA 2007, 104, 20666–20671. [Google Scholar] [CrossRef] [Green Version]
- Polasky, S.; Nelson, E.; Pennington, D.; Johnson, K.A. The Impact of Land-Use Change on Ecosystem Services, Biodiversity and Returns to Landowners: A Case Study in the State of Minnesota. Environ. Resour. Econ. 2011, 48, 219–242. [Google Scholar] [CrossRef]
- De Chazal, J.; Rounsevell, M.D. Land-use and climate change within assessments of biodiversity change: A review. Glob. Environ. Chang. 2009, 19, 306–315. [Google Scholar] [CrossRef]
- Kuhn, W. Geospatial Semantics: Why, of What, and How. In Journal on Data Semantics III; Spaccapietra, S., Zimányi, E., Eds.; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 2005; pp. 1–24. [Google Scholar]
- Bengana, N.; Heikkilä, J. Improving Land Cover Segmentation Across Satellites Using Domain Adaptation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1399–1410. [Google Scholar] [CrossRef]
- Antropov, O.; Rauste, Y.; Šćepanović, S.; Ignatenko, V.; Lönnqvist, A.; Praks, J. Classification of Wide-Area SAR Mosaics: Deep Learning Approach for Corine Based Mapping of Finland Using Multitemporal Sentinel-1 Data. In Proceedings of the IGARSS 2020 IEEE International Geoscience and Remote Sensing Symposium, Ahmedabad, Gujarat, India, 2–4 December 2020; pp. 4283–4286. [Google Scholar] [CrossRef]
- Balado, J.; Arias, P.; no, L.D.V.; González-deSantos, L.M. Automatic CORINE land cover classification from airborne LIDAR data. Procedia Comput. Sci. 2018, 126, 186–194. [Google Scholar] [CrossRef]
- Balzter, H.; Cole, B.; Thiel, C.; Schmullius, C. Mapping CORINE Land Cover from Sentinel-1A SAR and SRTM Digital Elevation Model Data using Random Forests. Remote Sens. 2015, 7, 14876–14898. [Google Scholar] [CrossRef] [Green Version]
- Stadler, C.; Lehmann, J.; Höffner, K.; Auer, S. LinkedGeoData: A Core for a Web of Spatial Open Data. Semant. Web J. 2012, 3, 333–354. [Google Scholar] [CrossRef]
- Pielke, R.A., Sr.; Pitman, A.; Niyogi, D.; Mahmood, R.; McAlpine, C.; Hossain, F.; Goldewijk, K.K.; Nair, U.; Betts, R.; Fall, S.; et al. Land use/land cover changes and climate: Modeling analysis and observational evidence. WIREs Clim. Chang. 2011, 2, 828–850. [Google Scholar] [CrossRef]
- Tayebi, M.; Fim Rosas, J.T.; Mendes, W.D.S.; Poppiel, R.R.; Ostovari, Y.; Ruiz, L.F.C.; dos Santos, N.V.; Cerri, C.E.P.; Silva, S.H.G.; Curi, N.; et al. Drivers of Organic Carbon Stocks in Different LULC History and along Soil Depth for a 30 Years Image Time Series. Remote Sens. 2021, 13, 2223. [Google Scholar] [CrossRef]
- Li, Z.; White, J.C.; Wulder, M.A.; Hermosilla, T.; Davidson, A.M.; Comber, A.J. Land cover harmonization using Latent Dirichlet Allocation. Int. J. Geogr. Inf. Sci. 2020, 35, 1–27. [Google Scholar] [CrossRef]
- Craglia, M.; de Bie, K.; Jackson, D.; Pesaresi, M.; Remetey-Fülöpp, G.; Wang, C.; Annoni, A.; Bian, L.; Campbell, F.; Ehlers, M.; et al. Digital Earth 2020: Towards the vision for the next decade. Int. J. Digit. Earth 2012, 5, 4–21. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Guo, H.; Annoni, A.; Bian, L.; de Bie, K.; Campbell, F.; Craglia, M.; Ehlers, M.; van Genderen, J.; Jackson, D.; et al. Next-generation Digital Earth. Proc. Natl. Acad. Sci. USA 2012, 109, 11088–11094. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goodchild, M. The use cases of digital earth. Int. J. Digit. Earth 2008, 1, 31–42. [Google Scholar] [CrossRef]
- Metzger, M.; Rounsevell, M.; Acosta-Michlik, L.; Leemans, R.; Schröter, D. The vulnerability of ecosystem services to land use change. Agric. Ecosyst. Environ. 2006, 114, 69–85. [Google Scholar] [CrossRef]
- Ma, J.; Heppenstall, A.; Harland, K.; Mitchell, G. Synthesising carbon emission for mega-cities: A static spatial microsimulation of transport CO2 from urban travel in Beijing. Comput. Environ. Urban Syst. 2014, 45, 78–88. [Google Scholar] [CrossRef]
- Fu, P.; Weng, Q. A time series analysis of urbanization induced land use and land cover change and its impact on land surface temperature with Landsat imagery. Remote Sens. Environ. 2016, 175, 205–214. [Google Scholar] [CrossRef]
- Debbage, N.; Shepherd, J.M. The urban heat island effect and city contiguity. Comput. Environ. Urban Syst. 2015, 54, 181–194. [Google Scholar] [CrossRef]
- Fuller, R.; Smith, G.; Devereux, B. The characterisation and measurement of land cover change through remote sensing: Problems in operational applications? Int. J. Appl. Earth Obs. Geoinf. 2003, 4, 243–253. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Tewkesbury, A.P.; Comber, A.J.; Tate, N.J.; Lamb, A.; Fisher, P.F. A critical synthesis of remotely sensed optical image change detection techniques. Remote Sens. Environ. 2015, 160, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Grekousis, G.; Mountrakis, G.; Kavouras, M. An overview of 21 global and 43 regional land-cover mapping products. Int. J. Remote Sens. 2015, 36, 5309–5335. [Google Scholar] [CrossRef]
- Thanh Noi, P.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2017, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Comber, A.; Fisher, P.; Wadsworth, R. Integrating land-cover data with different ontologies: Identifying change from inconsistency. Int. J. Geogr. Inf. Sci. 2004, 18, 691–708. [Google Scholar] [CrossRef] [Green Version]
- Mishra, V.N.; Prasad, R.; Kumar, P.; Gupta, D.K.; Dikshit, P.K.S.; Dwivedi, S.B.; Ohri, A. Evaluating the effects of spatial resolution on land use and land cover classification accuracy. In Proceedings of the 2015 International Conference on Microwave, Optical and Communication Engineering (ICMOCE), Odisha, India, 18–20 December 2015; pp. 208–211. [Google Scholar]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Comber, A.J.; Wadsworth, R.A.; Fisher, P.F. Using semantics to clarify the conceptual confusion between land cover and land use: The example of ’forest’. J. Land Use Sci. 2008, 3, 185–198. [Google Scholar] [CrossRef] [Green Version]
- Winter, S. Unified Behavior of Vector and Raster Representation; GeoInfo/GeoInfo, Inst. for Geoinformation, Ed.; University of Technology Vienna: Vienna, Austria, 2000. [Google Scholar]
- Comber, A.; Fisher, P.; Wadsworth, R. You know what land cover is but does anyone else?… An investigation into semantic and ontological confusion. Int. J. Remote Sens. 2005, 26, 223–228. [Google Scholar] [CrossRef] [Green Version]
- Ríos, S.A.; Muñoz, R. Land Use detection with cell phone data using topic models: Case Santiago, Chile. Comput. Environ. Urban Syst. 2017, 61, 39–48. [Google Scholar] [CrossRef]
- Jeawak, S.S.; Jones, C.B.; Schockaert, S. Predicting the environment from social media: A collective classification approach. Comput. Environ. Urban Syst. 2020, 82, 101487. [Google Scholar] [CrossRef]
- Schultz, M.; Voss, J.; Auer, M.; Carter, S.; Zipf, A. Open land cover from OpenStreetMap and remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2017, 63, 206–213. [Google Scholar] [CrossRef]
- Arsanjani, J.J.; Helbich, M.; Bakillah, M.; Hagenauer, J.; Zipf, A. Toward mapping land-use patterns from volunteered geographic information. Int. J. Geogr. Inf. Sci. 2013, 27, 2264–2278. [Google Scholar] [CrossRef]
- Mc Cutchan, M.; Özdal Oktay, S.; Giannopoulos, I. Semantic-based urban growth prediction. Trans. GIS 2020, 24, 1482–1503. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.; Tu, W.; Mai, K.; Yao, Y.; Chen, Y. Functional urban land use recognition integrating multi-source geospatial data and cross-correlations. Comput. Environ. Urban Syst. 2019, 78, 101374. [Google Scholar] [CrossRef]
- Mc Cutchan, M.; Giannopoulos, I. Geospatial Semantics for Spatial Prediction. In Leibniz International Proceedings in Informatics (LIPIcs), Proceedings of the 10th International Conference on Geographic Information Science (GIScience 2018), Melbourne, Australia, 28–31 August 2018; Winter, S., Griffin, A., Sester, M., Eds.; Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik: Dagstuhl, Germany, 2018; Volume 114, pp. 451–456. [Google Scholar] [CrossRef]
- DuCharme, B. Learning SPARQL; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2011. [Google Scholar]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; IEEE: New York, NY, USA, 2017; pp. 1–6. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Vali, A.; Comai, S.; Matteucci, M. Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review. Remote Sens. 2020, 12, 2495. [Google Scholar] [CrossRef]
- Stromann, O.; Nascetti, A.; Yousif, O.; Ban, Y. Dimensionality Reduction and Feature Selection for Object-Based Land Cover Classification based on Sentinel-1 and Sentinel-2 Time Series Using Google Earth Engine. Remote Sens. 2020, 12, 76. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | CLC Level 2 LULC Class |
|---|---|
| I | Urban fabric |
| II | Industrial, commercial, and transport units |
| III | Mine, dump, and construction sites |
| IV | Artificial, non-agricultural vegetated areas |
| V | Arable land |
| VI | Permanent crops |
| VII | Pastures |
| VIII | Heterogeneous agricultural areas |
| IX | Forest |
| X | Scrub and/or herbaceous vegetation associations |
| XI | Open spaces with little or no vegetation |
| XII | Inland wetlands |
| XIII | Inland waters |
| Overall Accuracy (OA) | |||||||
|---|---|---|---|---|---|---|---|
| Semantics and Imagery (Experiment 1) | |||||||
| 20 [m] | 50 [m] | 500 [m] | 1 [km] | 5 [km] | 10 [km] | 30 [km] | |
| OA [%] | 56.22 | 54.44 | 78.78 | 82.18 | 82.06 | 81.17 | 79.38 |
| +/− | 1.52 | 0.57 | 0.38 | 0.29 | 0.31 | 0.21 | 0.24 |
| Semantics only (Experiment 2) | |||||||
| OA [%] | 46.12 | 42.46 | 70.30 | 76.11 | 74.60 | 73.18 | 70.57 |
| +/− | 1.01 | 0.93 | 0.51 | 0.25 | 0.5 | 0.3 | 0.44 |
| Images only (Experiment 3) | |||||||
| OA [%] | 65.52 | ||||||
| +/− | 0.44 | ||||||
| KAPPA () | |||||||
| Semantics and imagery (Experiment 1) | |||||||
| 20 [m] | 50 [m] | 500 [m] | 1 [km] | 5 [km] | 10 [km] | 30 [km] | |
| 0.4412 | 0.4764 | 0.7699 | 0.8069 | 0.8056 | 0.7960 | 0.7766 | |
| +/− | 0.0149 | 0.0066 | 0.0041 | 0.0032 | 0.0031 | 0.0023 | 0.0026 |
| Semantics only (Experiment 2) | |||||||
| 0.2868 | 0.3312 | 0.6780 | 0.7412 | 0.7248 | 0.7095 | 0.6810 | |
| +/− | 0.0140 | 0.0103 | 0.0056 | 0.0027 | 0.0054 | 0.0032 | 0.0047 |
| Images only (Experiment 3) | |||||||
| 0.6264 | |||||||
| +/− | 0.0047 | ||||||
| Parameter | Experiment 1 and 2 | Experiment 3 |
|---|---|---|
| Optimizer | Adamax | Adamax |
| Learning rate (optimizer) | 0.001 | 0.001 |
| Learning rate decay (optimizer) | 8 × 10 | 5 × 10 |
| (optimizer) | 1 × 10 | 1 × 10 |
| (optimizer) | 0.999 | 0.999 |
| (optimizer) | 0.999 | 0.999 |
| Number of epochs | 1200 | 1200 |
| Batch size | 2000 | 1000 |
| Producer’s Accuracy (Recall) | Users’s Accuracy (Precision) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CLASS | 20 [m] | 50 [m] | 500 [m] | 1 [km] | 5 [km] | 10 [km] | 30 [km] | 20 [m] | 50 [m] | 500 [m] | 1 [km] | 5 [km] | 10 [km] | 30 [km] |
| I | 0.76 | 0.68 | 0.75 | 0.71 | 0.60 | 0.60 | 0.59 | 0.61 | 0.57 | 0.714 | 0.74 | 0.75 | 0.71 | 0.65 |
| II | 0.63 | 0.66 | 0.92 | 0.93 | 0.90 | 0.88 | 0.83 | 0.70 | 0.69 | 0.879 | 0.89 | 0.88 | 0.87 | 0.86 |
| III | 0.26 | 0.39 | 0.95 | 0.99 | 0.99 | 0.99 | 0.97 | 0.43 | 0.56 | 0.923 | 0.95 | 0.93 | 0.93 | 0.92 |
| IV | 0.44 | 0.53 | 0.90 | 0.96 | 0.96 | 0.95 | 0.92 | 0.55 | 0.61 | 0.858 | 0.87 | 0.86 | 0.86 | 0.84 |
| V | 0.19 | 0.35 | 0.61 | 0.66 | 0.69 | 0.69 | 0.66 | 0.30 | 0.38 | 0.722 | 0.74 | 0.71 | 0.69 | 0.68 |
| VI | 0.67 | 0.74 | 0.94 | 0.97 | 0.98 | 0.98 | 0.97 | 0.53 | 0.63 | 0.824 | 0.86 | 0.87 | 0.87 | 0.85 |
| VII | 0.25 | 0.43 | 0.63 | 0.66 | 0.69 | 0.65 | 0.64 | 0.42 | 0.42 | 0.638 | 0.70 | 0.70 | 0.70 | 0.67 |
| VIII | 0.24 | 0.31 | 0.50 | 0.58 | 0.61 | 0.58 | 0.55 | 0.27 | 0.31 | 0.528 | 0.58 | 0.61 | 0.60 | 0.57 |
| IX | 0.26 | 0.46 | 0.69 | 0.67 | 0.64 | 0.65 | 0.64 | 0.29 | 0.45 | 0.744 | 0.78 | 0.78 | 0.77 | 0.76 |
| X | 0.22 | 0.35 | 0.73 | 0.76 | 0.80 | 0.79 | 0.78 | 0.25 | 0.33 | 0.726 | 0.77 | 0.75 | 0.75 | 0.74 |
| XI | 0.48 | 0.60 | 0.88 | 0.90 | 0.90 | 0.89 | 0.88 | 0.53 | 0.61 | 0.883 | 0.89 | 0.89 | 0.89 | 0.90 |
| XII | 0.18 | 0.34 | 0.90 | 0.98 | 0.99 | 0.98 | 0.98 | 0.23 | 0.42 | 0.902 | 0.94 | 0.93 | 0.92 | 0.91 |
| XIII | 0.51 | 0.65 | 0.92 | 0.95 | 0.95 | 0.95 | 0.95 | 0.54 | 0.63 | 0.943 | 0.95 | 0.96 | 0.96 | 0.95 |
| Producer’s Accuracy (Recall) | User’s Accuracy (Precision) | P.A. | U.A. | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CLASS | 20 [m] | 50 [m] | 500 [m] | 1 [km] | 5 [km] | 10 [km] | 30 [km] | 20 [m] | 50 [m] | 500 [m] | 1 [km] | 5 [km] | 10 [km] | 30 [km] | CLASS | ||
| I | 0.79 | 0.70 | 0.69 | 0.58 | 0.29 | 0.24 | 0.21 | 0.51 | 0.49 | 0.72 | 0.76 | 0.75 | 0.72 | 0.60 | I | 0.57 | 0.57 |
| II | 0.47 | 0.55 | 0.93 | 0.93 | 0.93 | 0.92 | 0.88 | 0.53 | 0.55 | 0.85 | 0.86 | 0.81 | 0.79 | 0.75 | II | 0.61 | 0.65 |
| III | 0.15 | 0.25 | 0.97 | 1.00 | 1.00 | 1.00 | 1.00 | 0.31 | 0.36 | 0.88 | 0.92 | 0.90 | 0.89 | 0.86 | III | 0.56 | 0.69 |
| IV | 0.36 | 0.45 | 0.91 | 0.96 | 0.96 | 0.96 | 0.95 | 0.34 | 0.48 | 0.85 | 0.86 | 0.83 | 0.82 | 0.78 | IV | 0.43 | 0.52 |
| V | 0.09 | 0.15 | 0.43 | 0.59 | 0.60 | 0.58 | 0.54 | 0.26 | 0.26 | 0.55 | 0.63 | 0.59 | 0.58 | 0.54 | V | 0.64 | 0.65 |
| VI | 0.48 | 0.57 | 0.90 | 0.96 | 0.98 | 0.97 | 0.95 | 0.36 | 0.41 | 0.79 | 0.85 | 0.84 | 0.83 | 0.81 | VI | 0.85 | 0.73 |
| VII | 0.53 | 0.30 | 0.56 | 0.63 | 0.60 | 0.58 | 0.57 | 0.23 | 0.22 | 0.55 | 0.62 | 0.59 | 0.56 | 0.54 | VII | 0.63 | 0.51 |
| VIII | 0.03 | 0.13 | 0.49 | 0.54 | 0.53 | 0.53 | 0.49 | 0.13 | 0.24 | 0.49 | 0.56 | 0.58 | 0.55 | 0.51 | VIII | 0.37 | 0.42 |
| IX | 0.00 | 0.05 | 0.42 | 0.44 | 0.41 | 0.37 | 0.28 | 0.06 | 0.17 | 0.51 | 0.62 | 0.53 | 0.53 | 0.53 | IX | 0.73 | 0.63 |
| X | 0.04 | 0.12 | 0.45 | 0.61 | 0.62 | 0.59 | 0.60 | 0.20 | 0.21 | 0.58 | 0.66 | 0.69 | 0.68 | 0.65 | X | 0.61 | 0.60 |
| XI | 0.20 | 0.41 | 0.78 | 0.82 | 0.90 | 0.89 | 0.84 | 0.33 | 0.40 | 0.70 | 0.77 | 0.75 | 0.72 | 0.74 | XI | 0.88 | 0.82 |
| XII | 0.10 | 0.14 | 0.87 | 0.97 | 0.98 | 0.98 | 0.97 | 0.28 | 0.35 | 0.76 | 0.86 | 0.90 | 0.88 | 0.84 | XII | 0.76 | 0.88 |
| XIII | 0.13 | 0.19 | 0.78 | 0.88 | 0.91 | 0.91 | 0.89 | 0.45 | 0.39 | 0.78 | 0.82 | 0.81 | 0.79 | 0.77 | XIII | 0.94 | 0.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mc Cutchan, M.; Comber, A.J.; Giannopoulos, I.; Canestrini, M. Semantic Boosting: Enhancing Deep Learning Based LULC Classification. Remote Sens. 2021, 13, 3197. https://doi.org/10.3390/rs13163197
Mc Cutchan M, Comber AJ, Giannopoulos I, Canestrini M. Semantic Boosting: Enhancing Deep Learning Based LULC Classification. Remote Sensing. 2021; 13(16):3197. https://doi.org/10.3390/rs13163197
Chicago/Turabian StyleMc Cutchan, Marvin, Alexis J. Comber, Ioannis Giannopoulos, and Manuela Canestrini. 2021. "Semantic Boosting: Enhancing Deep Learning Based LULC Classification" Remote Sensing 13, no. 16: 3197. https://doi.org/10.3390/rs13163197
APA StyleMc Cutchan, M., Comber, A. J., Giannopoulos, I., & Canestrini, M. (2021). Semantic Boosting: Enhancing Deep Learning Based LULC Classification. Remote Sensing, 13(16), 3197. https://doi.org/10.3390/rs13163197