
Earthquake-Damaged Buildings Detection in Very High-Resolution Remote Sensing Images Based on Object Context and Boundary Enhanced Loss

 ,
,  ,
,  , ,
, ,
Abstract
:
1. Introduction
- (1)
- We develop the improved DeepLabv3+ and UNet networks embedded with the OCR module respectively, which realize the significant enhancement of the feature representation ability.
- (2)
- We propose the BCI to quantitatively describe the spatial position of pixels in objects. Furthermore, a novel BE loss is developed to enhance the segmentation accuracy of the boundaries. This loss automatically assigns pixels with different weights and drives the network to strengthen the training of boundary pixels.
2. Related Work
2.1. FCN for Semantic Segmentation
2.2. Spatial Context
2.3. Object Context
2.4. Boundary Refinement
3. Methodology
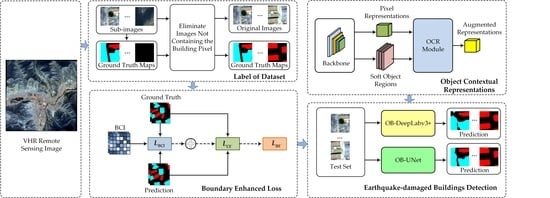
3.1. Model Overview
- (1)
- (2)
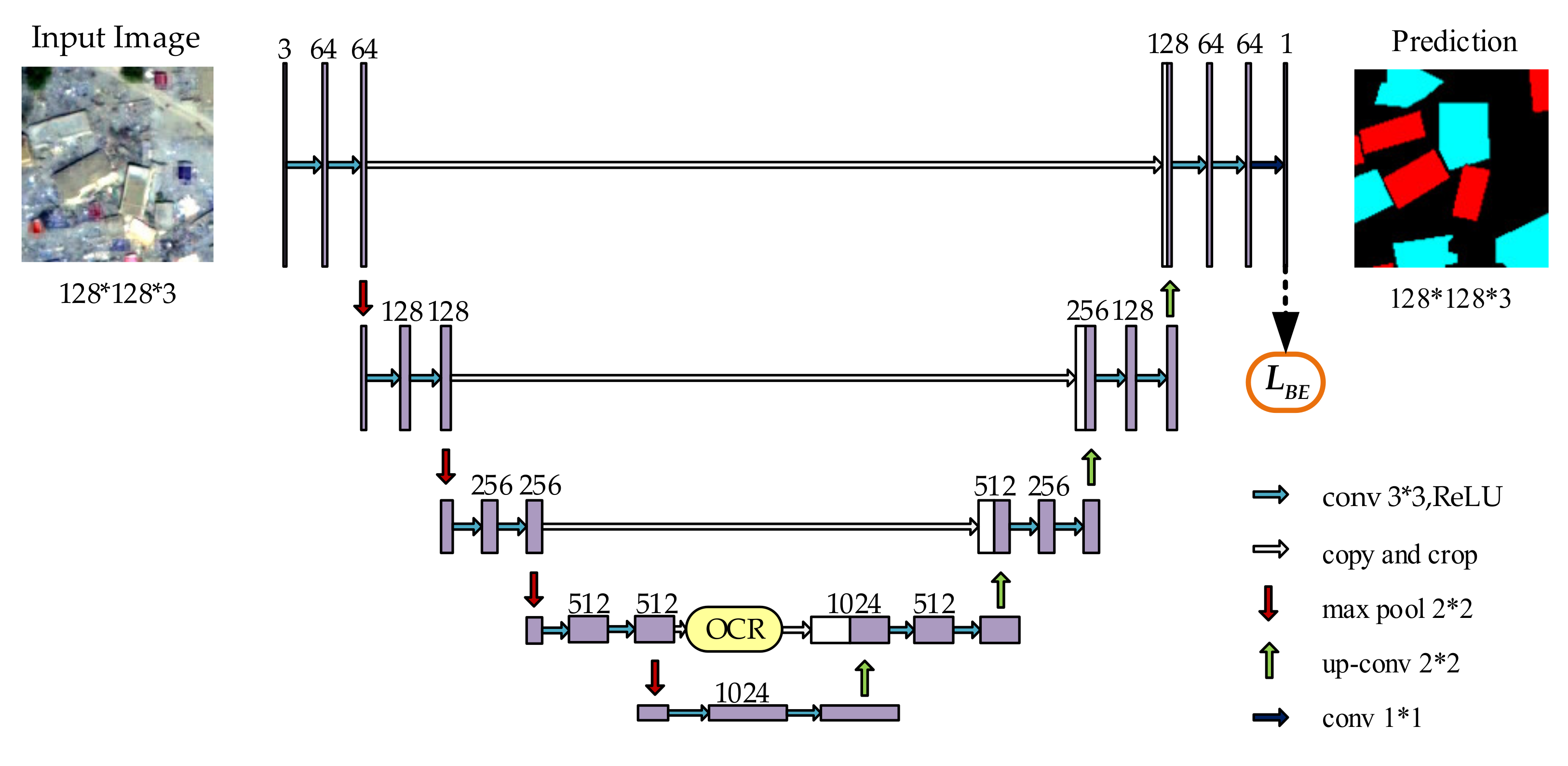
- OB-UNet: The OCR modules are connected to shortcut connection in the fourth layer of UNet in series considering the symmetry of UNet network structure, as shown in Figure 3 The design aims to, on the one hand, attain a favorable coarse segmentation result from high-level features; on the other hand, high-level features tend to contain numerous semantic features while losing some detail features. Thus, introducing the object contextual attention is favorable for restoring the details of earthquake-damaged buildings.
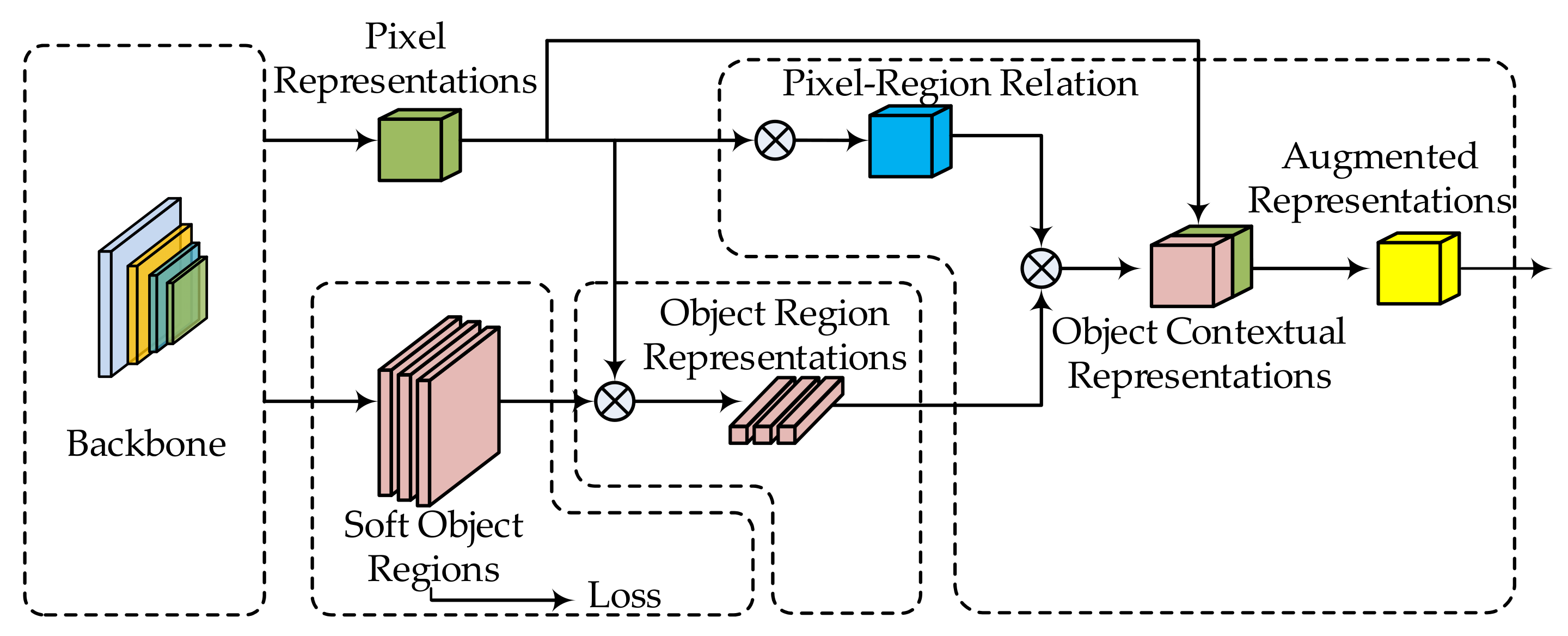
3.2. OCR Module
- (1)
- Partition of soft object regions: The coarse semantic segmentation of the image is performed by using the backbone network for feature extraction, which is taken as an input for the OCR module. On the basis of the coarse segmentation result, the image is partitioned into K soft object regions, each of which separately represents a class k.
- (2)
- Object region feature representation: Within the kth object region, all pixels are subjected to the weight sum according to their membership degree in the region. In this way, the feature representation of the region is obtained:where, , and denote the pixel set in the kth object region, the feature representation of the pixel output by the highest level of the network and the normalization degree of the pixel belonging to the kth object region obtained by spatial softmax, respectively.
- (3)
- The augmented feature representation by object context: The relationship between and is calculated by applying Equation (2):where refers to the unnormalized relationship function; and are two transformation functions. On this basis, the object contextual representation of each pixel is calculated according to Equation (3), that is OCR:where and denote the transformation functions. Afterward, the final augmented feature representation is obtained after aggregating with :where stands for the transformation function for fusing and .
3.3. Boundary Enhanced Loss
- Step 1: A 3 × 3 window is established centered on a pixel c in a ground truth map, which is used as the initial neighborhood. If a pixel e with a classification label different from that of c is present in the current neighborhood, the neighborhood serves as the final neighborhood; otherwise, the domain is expanded at the step length of 1 until a pixel e showing classification label different from that of c appears in the current neighborhood. The current window size W × W acts as the final neighborhood. Besides, to decrease the difference in different directions, four points at vertexes of the neighborhood are removed to make the neighborhood approximate to a circle. For example, the final neighborhoods when W equals 5 and 9 are shown in Figure 5.
- Step 2: Owing to objects c and e belong to different classes, the distance between c and e reflects the degree of closeness of c with the object boundary. Based on the assumption, a boundary measurement index corresponding to c is defined as . It is possible to attain the set D of the initial boundary measurement indexes by traversing all pixels.
- Step 3: As different surface feature objects probably greatly differ in their size and shape, quite large outliers are likely to occur in set D, thus triggering the bias of the statistical results. Hence, the maximum corresponding to each of the K classes of pixel points is separately computed in set D and defined as . Furthermore, the minimum in is taken as the upper limit of all in set D to attain the updated set of the boundary measurement indexes.
- Step 4: Assuming that the boundary measurement index of c in set is and normalized, the corresponding BCI of c is defined as follows:A larger of a pixel means that the pixel is more likely to occur at the boundary of the object; on the contrary, the pixel is more likely to lie in the interior of the object.
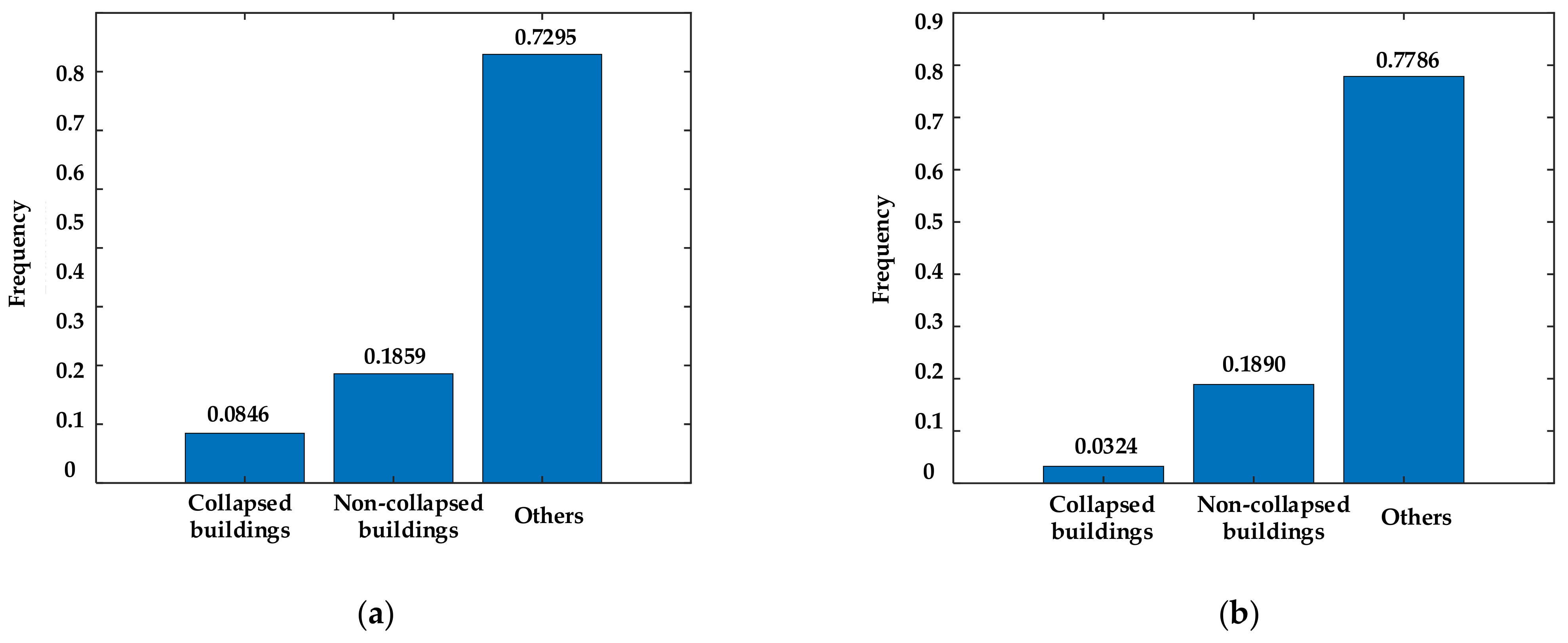
- Step 5: Given that Focal loss can effectively relieve the problems concerning class imbalance of samples and classification of hard samples, the BCI loss is defined as follows according to BCI and Focal loss:where and separately refer to the number of pixels within a batch and the true label encoded by one-hot corresponding to the nth pixel. Thus, the pixel closer to the boundary makes a greater contribution to the total loss in , that is, driving the network to strengthen the training of boundary pixels. Moreover, refers to the focusing parameter of hard and easy samples, aiming to reduce the weight of the easy samples and further making the network pay more attention to the hard samples during the training. The parameter is generally set as 2 [43]. The introduction of the classification weight aims to relieve the class imbalance of the training samples, which is calculated as follows:where and denote the frequency of the kth class of pixels and the median of the frequency of the K classes of pixels, respectively.
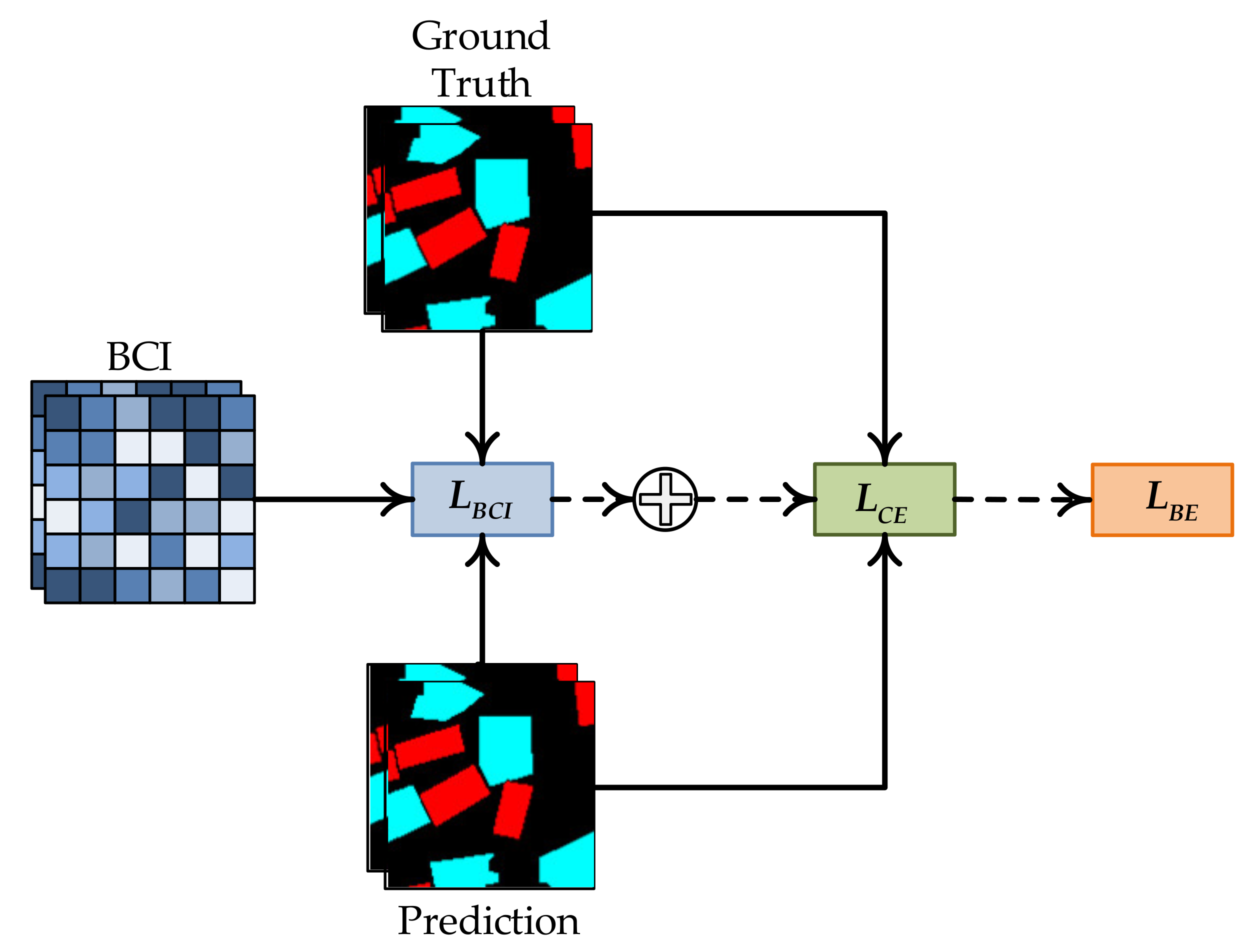
- Step 6: BE loss is defined as follows:where represents the general cross-entropy loss [44]. The purpose of introducing is to prevent the network from being hard to converge due to quite a large of the boundary in the later training period of the network. Figure 6 shows the schematic diagram of the proposed .
4. Experiments and Results
4.1. Datasets
4.1.1. Research Region
4.1.2. Label of Dataset
4.2. Experimental Settings
4.3. Comparison of Performances of Different Networks
4.3.1. Visualization Results
- (1)
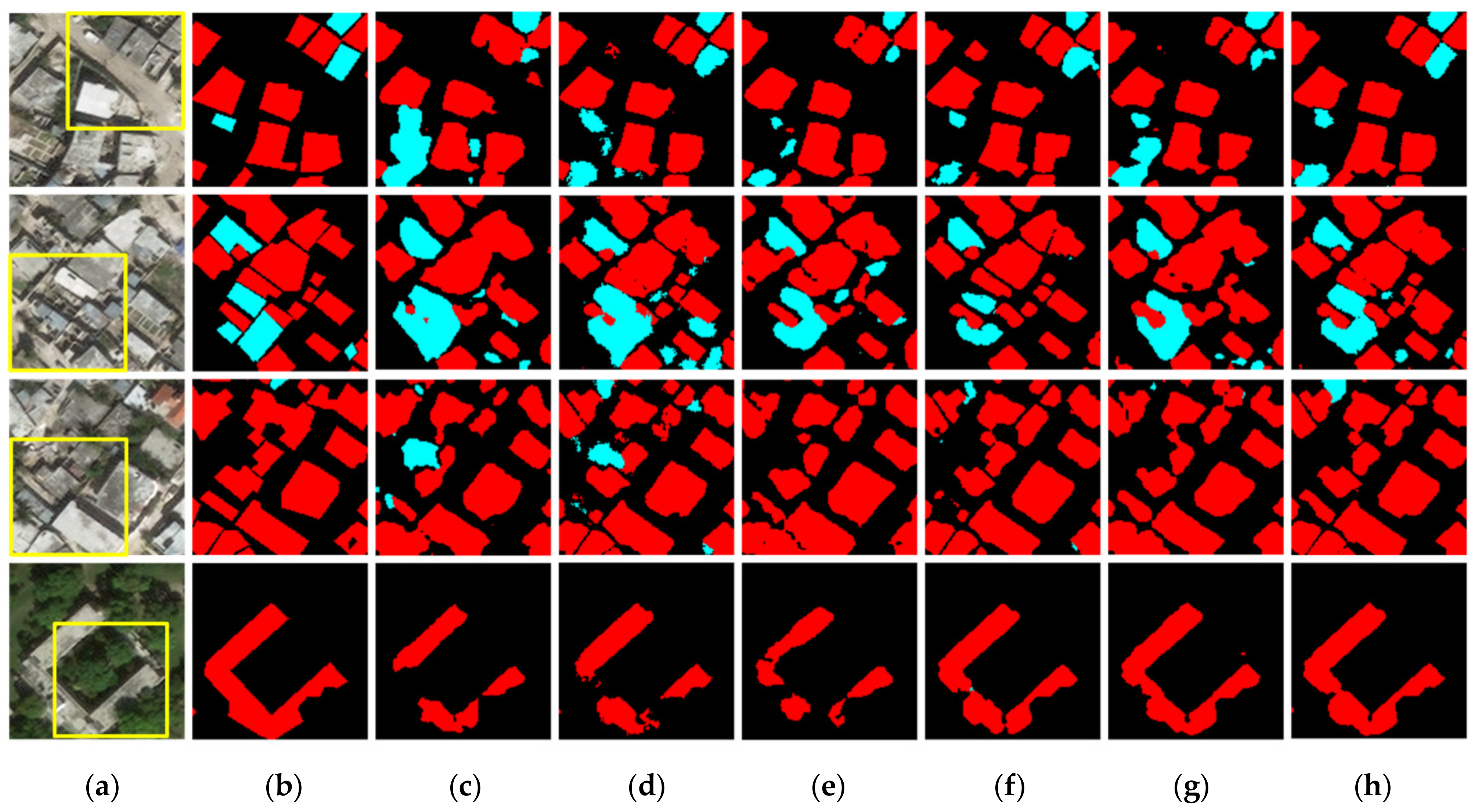
- YSH dataset: The experimental results on the YSH dataset for different networks are shown in Figure 9. It can be seen that the proposed OB-DeepLabv3+ and OB-UNet yield more complete detection results and recover more abundant boundaries and details. DeepLabv3+, UNet, OB-DeepLabv3+ and OB-UNet all exhibit a favorable detection effect when detecting non-collapsed buildings with regular shapes and definite boundaries, basically showing no missing detection. As in the second row of Figure 9, only the DeepLabv3+ shows incomplete boundary extraction for non-collapsed buildings. This indicates that the multi-scale context used by DeepLabv3+ is not enough for recovering the abundant details in VHR remote sensing images. However, DeepLabv3+ and UNet show a high probability of missing detection (as shown in rows 1, 3 and 4 in Figure 9c,d) when detecting collapsed buildings without definite boundaries and regular textures; moreover, the regions detected by using the two methods are scattered. In comparison, the proposed OB-DeepLabv3+ and OB-UNet, as shown in Figure 9g,h), reduce the probability of the missing detection for collapsed buildings to some extent; besides, the integrity of the regions detected thereby is strengthened. Therefore, our improvement of the base networks is conducive to the complete extraction of building profiles and accurate location of boundaries.
- (2)
- HTI dataset: Figure 11 illustrates the detection results of different methods for the HTI dataset. When detecting large-scale buildings, relatively complete buildings are detected only in the fourth row of Figure 11g,h, while the other methods (the fourth row of Figure 11c,f) show different degrees of missing detection and error detection. This indicates that the method of aggregation of the multi-scale context alone is not enough in missions involving greatly varying scales. Compared with the YSH dataset, buildings in the HTI dataset are smaller and distributed more densely, which makes the categorization of seismic damages and prediction of boundaries more difficult. It can be seen that some small-scale non-collapsed buildings are not completely detected when using the UNet and UNet 3+ methods, such as those in the third row of Figure 12d,f. In comparison, OB-UNet completely detects these buildings, such as those in the third row of Figure 12h. These results suggest that it is difficult to completely extract the context of pixels through the aggregation of multi-scale context alone; while attributed to the introduction of object context, OB-UNet significantly improves the completeness of the extracted profiles. Compared with the two methods without OCR module and BE loss (Figure 11c,d), the proposed methods greatly improve the detection accuracy. For example, in the second and third rows of Figure 11, many non-collapsed buildings and the others are detected as collapsed ones in both Figure 11c,d, and the boundaries of non-collapsed buildings are indiscernible; while these problems are well solved in Figure 11g,h. This again demonstrates that the improvement of the base networks in the research is effective.
4.3.2. Quantitative Evaluation
5. Discussion
5.1. Analysis of the Embedment Effect of the OCR Module
5.2. Analysis of the Effectiveness of BE Loss
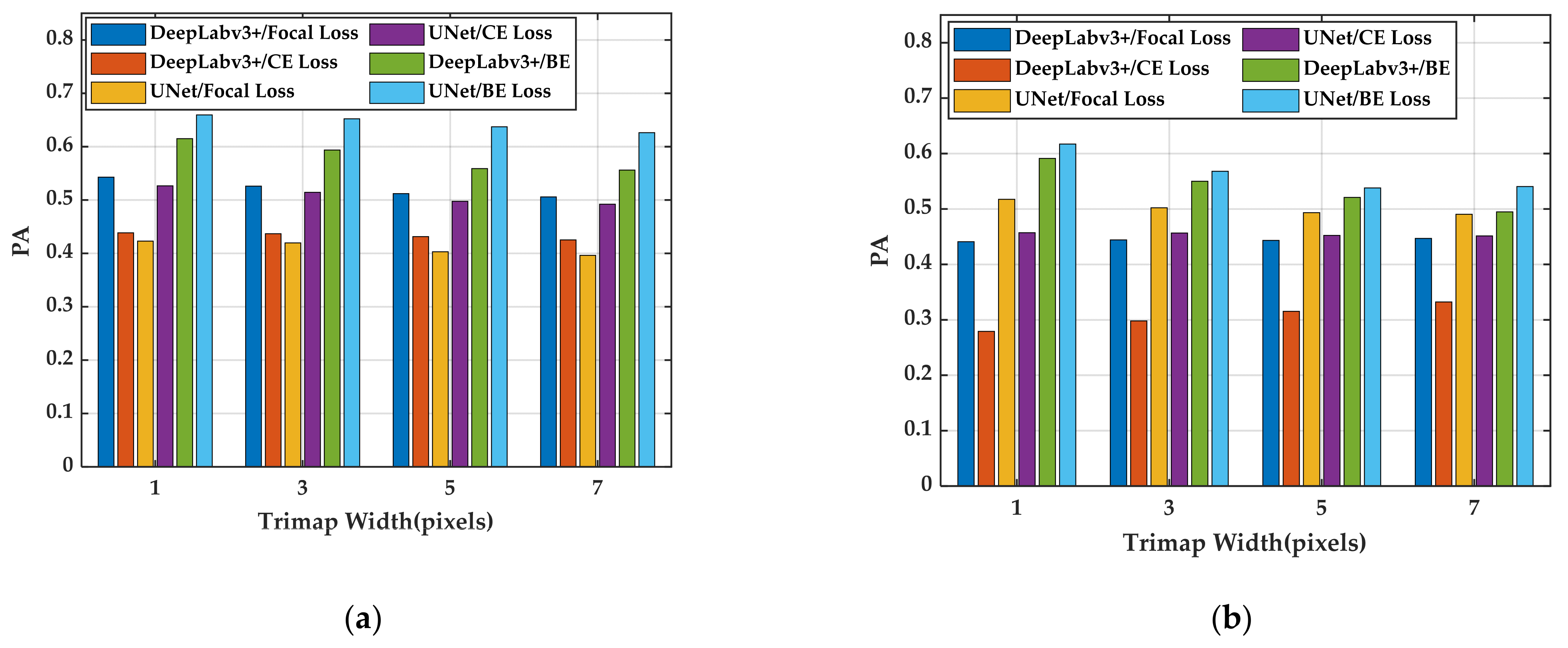
5.3. Analysis of the Influence of BE Loss on the Segmentation Effect of the Boundary
5.4. Analysis of the Setting of in BE Loss
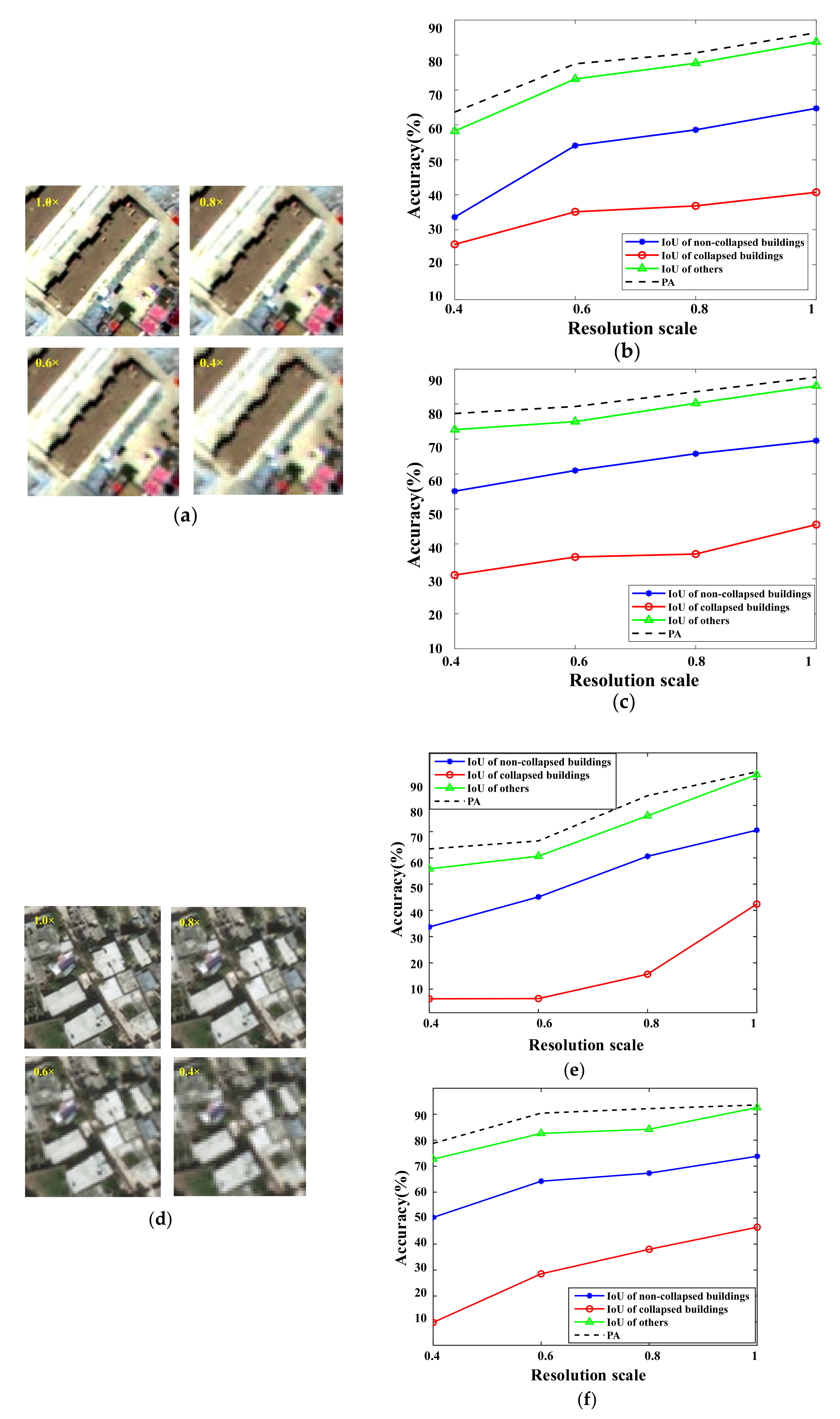
5.5. Analysis of the Influence of the Image Resolution
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FCN | Fully Convolutional Network |
| VHR | Very High-resolution |
| OCR | Object Contextual Representations |
| BE | Boundary Enhanced |
| CNN | Convolutional Neural Network |
| PPM | Pyramid Pooling Module |
| ASPP | Atrous Spatial Pyramid Pooling |
| AFP | Adaptive Feature Pooling |
| CE | Cross Entropy |
| BCI | Boundary Confidence Index |
| PA | Pixel Accuracy |
| IoU | Intersection over Union |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| SAR | Synthetic Aperture Radar |
| DR-Net | Dense Residual Neural Network |
| LDA | Light-weight Dual Attention |
| FEFP | Feature Enhancement Feature Pyramid |
| GCN | Graph Convolutional Neural |
References
- Li, J.; Zhao, S.; Jin, H.; Li, Y.; Guo, Y. A method of combined texture features and morphology for building seismic damage information extraction based on GF remote sensing images. Acta Seismol. Sin. 2019, 5, 658–670. [Google Scholar]
- Jiang, X.; He, Y.; Li, G.; Liu, Y.; Zhang, X.-P. Building Damage Detection via Superpixel-Based Belief Fusion of Space-Borne SAR and Optical Images. IEEE Sens. J. 2019, 20, 2008–2022. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Meng, L. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Wang, C.; Qiu, X.; Liu, H.; Li, D.; Zhao, K.; Wang, L. Damaged buildings recognition of post-earthquake high-resolution remote sensing images based on feature space and decision tree optimization. Comput. Sci. Inf. Syst. 2020, 1, 619–646. [Google Scholar] [CrossRef]
- Janalipour, M.; Mohammadzadeh, A. A novel and automatic framework for producing building damage map using post-event LiDAR data. Int. J. Disaster Risk Reduct. 2019, 39, 101238. [Google Scholar] [CrossRef]
- Carvalho, J.; Fonseca, J.; Mora, A. Terrain Classification Using Static and Dynamic Texture Features by UAV Downwash Effect. J. Autom. Mob. Robot. Intell. Syst. 2019, 13, 84–93. [Google Scholar] [CrossRef]
- Matos-Carvalho, J.; Fonseca, J.; Mora, A. UAV downwash dynamic texture features for terrain classification on autonomous navigation. In Proceedings of the 2018 Federated Conference on Computer Science and Information Systems, Poznan, Poland, 9–12 September 2018; pp. 1079–1083. [Google Scholar]
- Buslaev, A.; Seferbekov, S.; Iglovikov, V.; Shvets, A. Fully Convolutional Network for Automatic Road Extraction from Satellite Imagery. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 197–200. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; Wu, J.; Liu, L.; Zhao, W.; Tian, F.; Shen, Q.; Zhao, B.; Du, R. DR-Net: An Improved Network for Building Extraction from High Resolution Remote Sensing Image. Remote. Sens. 2021, 13, 294. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Jia, J. Pyramid Scene Parsing Network. IEEE Comput. Soc. 2016, 1, 6230–6239. [Google Scholar]
- Yang, M.; Yu, K.; Chi, Z.; Li, Z. Dense ASPP for Semantic Segmentation in Street Scenes. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Huang, R.; Xu, Y.; Hong, D.; Yao, W.; Ghamisi, P.; Stilla, U. Deep point embedding for urban classification using ALS point clouds: A new perspective from local to global. ISPRS J. Photogramm. Remote. Sens. 2020, 163, 62–81. [Google Scholar] [CrossRef]
- Ma, H.; Liu, Y.; Ren, Y.; Wang, D.; Yu, L.; Yu, J. Improved CNN Classification Method for Groups of Buildings Damaged by Earthquake, Based on High Resolution Remote Sensing Images. Remote Sens. 2020, 12, 260. [Google Scholar] [CrossRef] [Green Version]
- Nong, Z.; Su, X.; Liu, Y.; Zhan, Z.; Yuan, Q. Boundary-Aware Dual-Stream Network for VHR Remote Sensing Images Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5260–5268. [Google Scholar] [CrossRef]
- Berger, L.; Hyde, E.; Jorge Cardoso, M.; Ourselin, S. An Adaptive Sampling Scheme to Efficiently Train Fully Convolutional Networks for Semantic Segmentation; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Ryan, S.; Corizzo, R.; Kiringa, I.; Japkowicz, N. Pattern and Anomaly Localization in Complex and Dynamic Data. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1756–1763. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. Comput. Sci. 2014, 40, 357–361. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- He, J.; Deng, Z.; Qiao, Y. Dynamic Multi-Scale Filters for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3561–3571. [Google Scholar]
- Zhang, X.; Wang, B.; Yuan, D.; Xu, Z.; Xu, G. FPAENet: Pneumonia Detection Network Based on Feature Pyramid Attention Enhancement. arXiv 2020, arXiv:2011.08706. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid Attention Network for Semantic Segmentation. arXiv 2018, arXiv:1805.10180v3. [Google Scholar]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2020, 13, 71. [Google Scholar] [CrossRef]
- Lin, L.; Jian, L.; Min, W.; Zhu, H. A Multiple-Feature Reuse Network to Extract Buildings from Remote Sensing Imagery. Remote Sens. 2018, 10, 1350. [Google Scholar]
- Yan, Z.; Weihong, L.; Weigou, G.; Wang, Z.; Sun, J. An Improved Boundary-Aware Perceptual Loss for Building Extraction from VHR Images. Remote Sens. 2020, 12, 1195. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. arXiv 2020, arXiv:1904.11492. [Google Scholar]
- Tong, W.; Chen, W.; Han, W.; Li, X.; Wang, L. Channel-Attention-Based DenseNet Network for Remote Sensing Image Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, Y.; Li, Z.; Hong, Z.; Liu, J.; Ma, F.; Han, J.; Ding, E. ACFNet: Attentional Class Feature Network for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6797–6806. [Google Scholar]
- Ding, L.; Zhang, J.; Bruzzone, L. Semantic Segmentation of Large-Size VHR Remote Sensing Images Using a Two-Stage Multiscale Training Architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5367–5376. [Google Scholar] [CrossRef]
- Si, Y.; Gong, D.; Guo, Y.; Zhu, X.; Huang, Q.; Evans, J.; He, S.; Sun, Y. An Advanced Spectral–Spatial Classification Framework for Hyperspectral Imagery Based on DeepLab v3+. Appl. Sci. 2021, 11, 5703. [Google Scholar] [CrossRef]
- Krhenbühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. arXiv 2012, arXiv:1210.5644. [Google Scholar]
- Yuan, Y.; Xie, J.; Chen, X.; Wang, J. SegFix: Model-Agnostic Boundary Refinement for Segmentation. In Computer Vision—ECCV 2020, Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Eds.; Springer: Cham, Switzerland, 2020; Volume 12357, pp. 489–506. [Google Scholar]
- Ouyang, S.; Li, Y. Combining Deep Semantic Segmentation Network and Graph Convolutional Neural Network for Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2020, 13, 119. [Google Scholar] [CrossRef]
- Cheng, H.K.; Chung, J.; Tai, Y.-W.; Tang, C.-K. CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement. arXiv 2020, arXiv:2005.02551v1. [Google Scholar]
- Touzani, S.; Granderson, J. Open Data and Deep Semantic Segmentation for Automated Extraction of Building Footprints. Remote Sens. 2021, 13, 2578. [Google Scholar] [CrossRef]
- Yang, N.; Tang, H. Semantic Segmentation of Satellite Images: A Deep Learning Approach Integrated with Geospatial Hash Codes. Remote Sens. 2021, 13, 2723. [Google Scholar] [CrossRef]
- McGlinchy, J.; Muller, B.; Johnson, B.; Joseph, M.; Diaz, J. Fully Convolutional Neural Network for Impervious Surface Segmentation in Mixed Urban Environment. Photogramm. Eng. Remote. Sens. 2021, 87, 117–123. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 173–190. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 99, 2999–3007. [Google Scholar]
- Qu, Z.; Mei, J.; Liu, L.; Zhou, D.-Y. Crack Detection of Concrete Pavement With Cross-Entropy Loss Function and Improved VGG16 Network Model. IEEE Access 2020, 8, 54564–54573. [Google Scholar] [CrossRef]
- Grunthal, G. European Macroseismic Scale (EMS-98); European Seismological Commission: Luxembourg, 1998. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.-W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. arXiv 2020, arXiv:2004.08790. [Google Scholar]
- Jin, Y.; Xu, W.; Zhang, C.; Luo, X.; Jia, H. Boundary-Aware Refined Network for Automatic Building Extraction in Very High-Resolution Urban Aerial Images. Remote. Sens. 2021, 13, 692. [Google Scholar] [CrossRef]


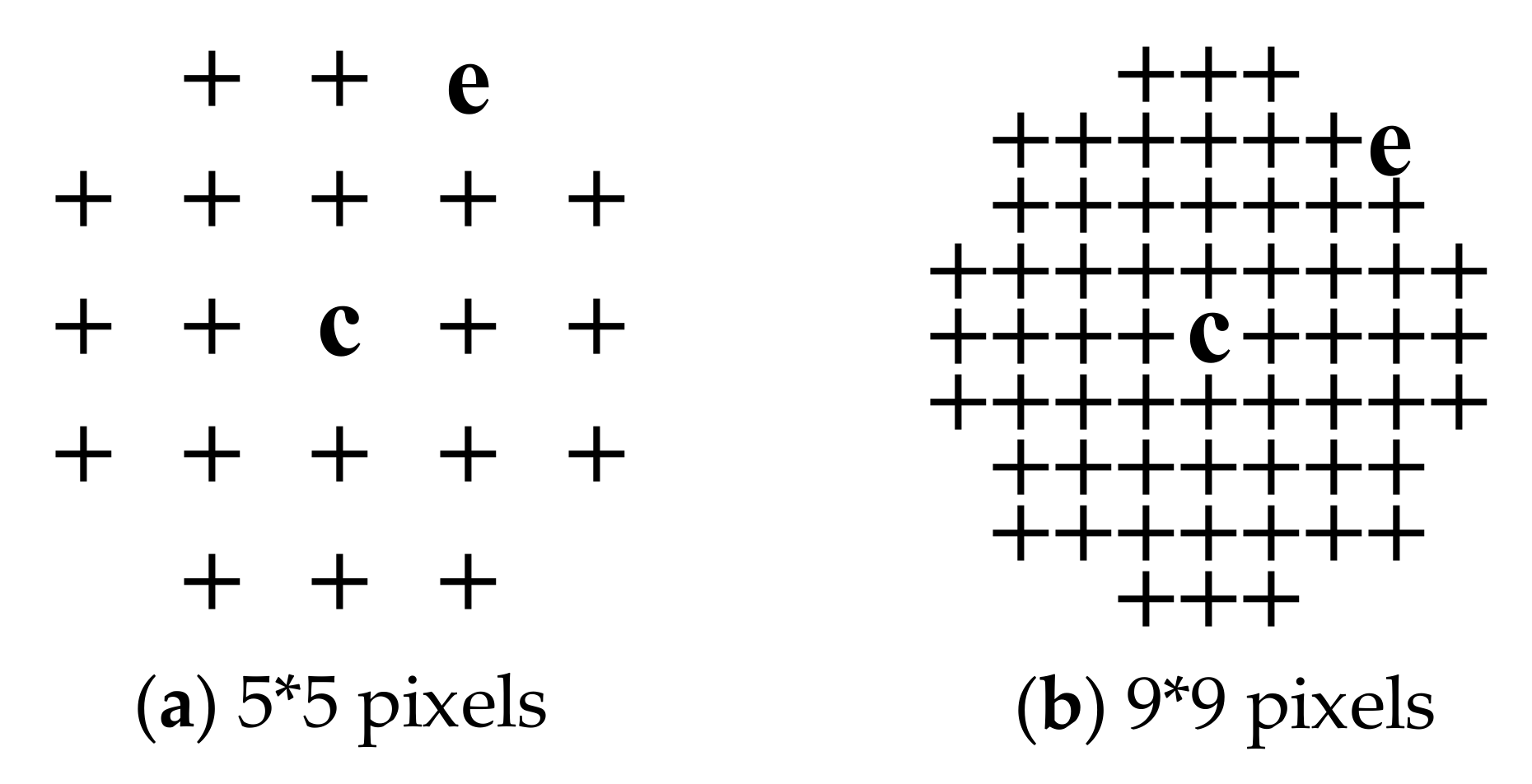








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Methods | Object Class IoU (%) | mIoU (%) | PA (%) | mRecall (%) | mF1 (%) | ||
|---|---|---|---|---|---|---|---|---|
| Non-Collapsed | Collapsed | Others | ||||||
| YSH | DeepLabv3+ | 60.87 | 34.48 | 82.81 | 59.39 | 85.29 | 67.67 | 72.67 |
| UNet | 66.98 | 45.12 | 83.42 | 65.31 | 86.63 | 67.33 | 71.33 | |
| MobileNetV2+CA [46] | 61.65 | 42.33 | 80.60 | 61.53 | 83.77 | 76.66 | 74.67 | |
| UNet 3+ [47] | 66.81 | 42.50 | 82.38 | 63.90 | 85.27 | 78.33 | 76.67 | |
| OB-DeepLabv3+ (ours) | 64.74 | 40.73 | 83.77 | 63.08 | 86.37 | 72.67 | 76.00 | |
| OB-UNet (ours) | 69.54 | 45.53 | 85.24 | 66.77 | 87.72 | 77.33 | 79.00 | |
| HTI | DeepLabv3+ | 57.29 | 39.45 | 88.91 | 61.88 | 90.03 | 75.00 | 74.67 |
| UNet | 67.40 | 40.39 | 91.52 | 66.44 | 92.52 | 73.33 | 78.33 | |
| MobileNetV2+CA [46] | 68.96 | 39.66 | 91.26 | 66.63 | 92.36 | 75.67 | 78.00 | |
| UNet 3+ [47] | 71.32 | 39.64 | 92.17 | 67.71 | 93.11 | 76.00 | 78.67 | |
| OB-DeepLabv3+ (ours) | 70.56 | 42.39 | 91.76 | 68.24 | 92.80 | 78.00 | 79.67 | |
| OB-UNet (ours) | 73.80 | 46.49 | 92.56 | 70.95 | 93.58 | 79.67 | 81.33 | |
| Datasets | Networks | OCR | BE Loss | Object Class IoU (%) | mIoU (%) | PA (%) | ||
|---|---|---|---|---|---|---|---|---|
| Non-Collapsed | Collapsed | Others | ||||||
| YSH | DeepLabv3+ | – | √ | 60.98 | 38.07 | 82.95 | 60.67 | 85.51 |
| DeepLabv3+ | √ | √ | 64.74 | 40.73 | 83.77 | 63.08 | 86.37 | |
| UNet | – | √ | 69.73 | 39.63 | 85.11 | 64.83 | 87.56 | |
| UNet | √ | √ | 69.54 | 45.53 | 85.24 | 66.77 | 87.72 | |
| HTI | DeepLabv3+ | – | √ | 67.61 | 40.82 | 91.22 | 66.55 | 92.28 |
| DeepLabv3+ | √ | √ | 70.56 | 42.39 | 91.76 | 68.24 | 92.80 | |
| UNet | – | √ | 70.52 | 43.04 | 91.98 | 68.51 | 93.01 | |
| UNet | √ | √ | 73.80 | 46.49 | 92.56 | 70.95 | 93.58 | |
| Datasets | Networks | Loss | Object Class IoU (%) | mIoU (%) | PA (%) | ||
|---|---|---|---|---|---|---|---|
| Non-Collapsed | Collapsed | Others | |||||
| YSH | DeepLabv3+ | CE loss | 63.41 | 18.98 | 82.46 | 54.95 | 84.89 |
| DeepLabv3+ | Focal loss | 60.87 | 34.48 | 82.81 | 59.39 | 85.29 | |
| DeepLabv3+ | BE loss | 60.98 | 38.07 | 82.95 | 60.67 | 85.51 | |
| UNet | CE loss | 66.63 | 27.39 | 83.84 | 59.15 | 85.82 | |
| UNet | Focal loss | 66.98 | 45.12 | 83.42 | 65.17 | 86.63 | |
| UNet | BE loss | 69.73 | 39.63 | 85.11 | 64.83 | 87.56 | |
| HTI | DeepLabv3+ | CE loss | 58.22 | 32.70 | 89.06 | 59.99 | 90.21 |
| DeepLabv3+ | Focal loss | 57.29 | 39.45 | 88.91 | 61.88 | 90.03 | |
| DeepLabv3+ | BE loss | 67.61 | 40.82 | 91.22 | 66.55 | 92.28 | |
| UNet | CE loss | 67.03 | 39.85 | 91.19 | 66.02 | 92.29 | |
| UNet | Focal loss | 67.40 | 40.39 | 91.52 | 66.44 | 92.52 | |
| UNet | BE loss | 70.52 | 43.04 | 91.98 | 68.51 | 93.01 | |
| Datasets | Methods | 0.5 | 1 | 1.5 | 2 | 2.5 | 3 | 3.5 | 4 | 4.5 | 5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YSH | OB-DeepLabv3+ | PA | 85.09 | 85.57 | 85.90 | 86.37 | 86.03 | 86.04 | 85.85 | 85.83 | 85.58 | 85.81 |
| OB-UNet | PA | 86.90 | 87.10 | 87.39 | 87.72 | 87.38 | 87.13 | 87.32 | 87.41 | 87.73 | 87.91 | |
| HTI | OB-DeepLabv3+ | PA | 92.10 | 92.37 | 92.42 | 92.80 | 92.40 | 92.28 | 92.20 | 92.47 | 92.64 | 92.62 |
| OB-UNet | PA | 93.31 | 93.48 | 93.54 | 93.58 | 93.31 | 93.43 | 93.45 | 93.52 | 93.46 | 93.55 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Qiu, X.; Huan, H.; Wang, S.; Zhang, Y.; Chen, X.; He, W. Earthquake-Damaged Buildings Detection in Very High-Resolution Remote Sensing Images Based on Object Context and Boundary Enhanced Loss. Remote Sens. 2021, 13, 3119. https://doi.org/10.3390/rs13163119
Wang C, Qiu X, Huan H, Wang S, Zhang Y, Chen X, He W. Earthquake-Damaged Buildings Detection in Very High-Resolution Remote Sensing Images Based on Object Context and Boundary Enhanced Loss. Remote Sensing. 2021; 13(16):3119. https://doi.org/10.3390/rs13163119
Chicago/Turabian StyleWang, Chao, Xing Qiu, Hai Huan, Shuai Wang, Yan Zhang, Xiaohui Chen, and Wei He. 2021. "Earthquake-Damaged Buildings Detection in Very High-Resolution Remote Sensing Images Based on Object Context and Boundary Enhanced Loss" Remote Sensing 13, no. 16: 3119. https://doi.org/10.3390/rs13163119
APA StyleWang, C., Qiu, X., Huan, H., Wang, S., Zhang, Y., Chen, X., & He, W. (2021). Earthquake-Damaged Buildings Detection in Very High-Resolution Remote Sensing Images Based on Object Context and Boundary Enhanced Loss. Remote Sensing, 13(16), 3119. https://doi.org/10.3390/rs13163119