
A Framework of Filtering Rules over Ground Truth Samples to Achieve Higher Accuracy in Land Cover Maps




Abstract
:
1. Introduction
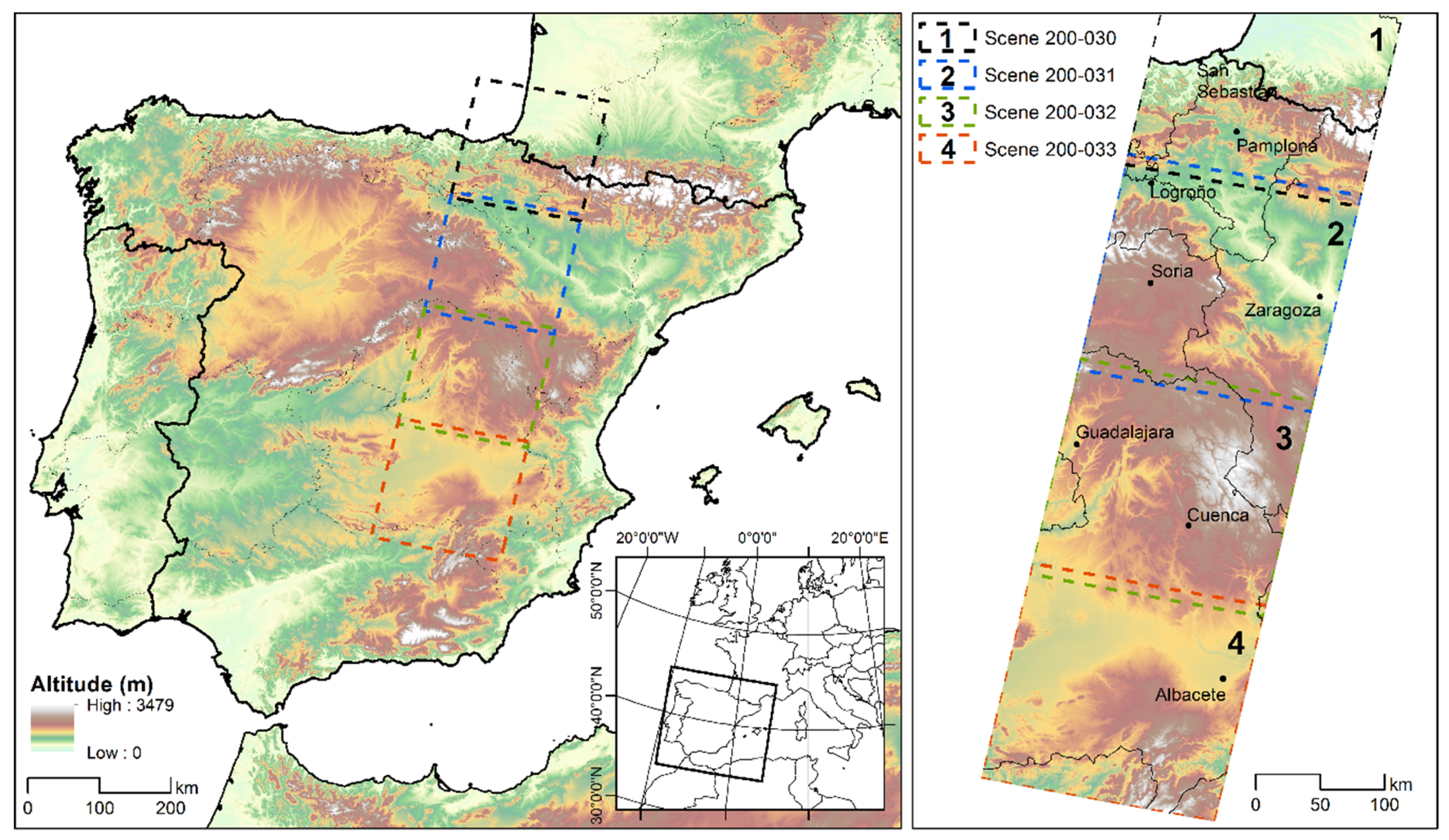
2. Study Area
3. Materials
3.1. Remote Sensing Images
3.2. Ancillary Data
- (1)
- A summer solar radiation surface (10 kJ/(m2 × day × µm)), following the procedure described in Pons and Ninyerola [80] and implemented in the InsolDia module of MiraMon.
- (2)
- A slope surface (in degrees), using the Pendent module.
3.3. Ground Truth from a Reference Dataset (rDS)
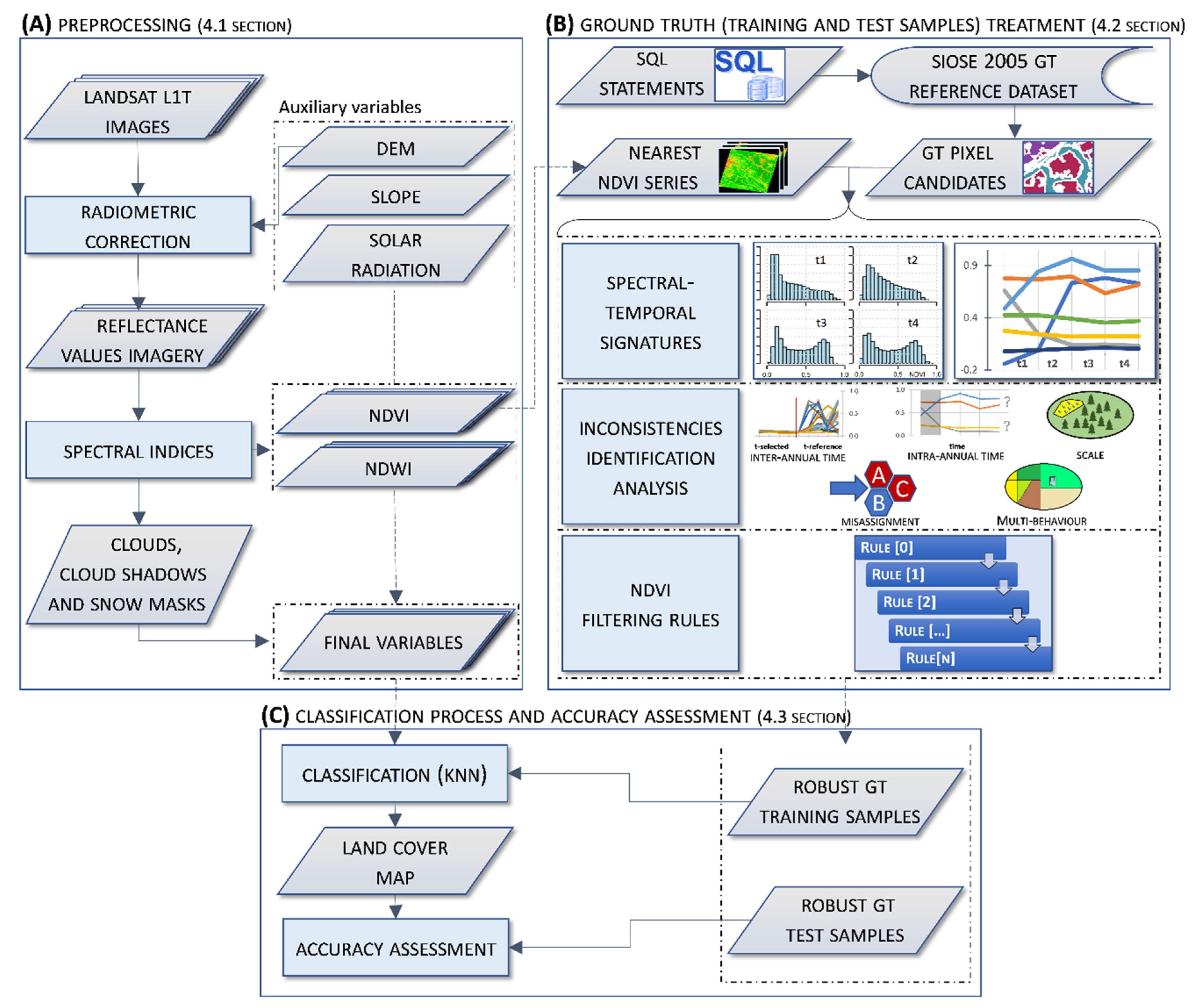
4. Methods
4.1. Image Pre-Processing
4.1.1. Geometric and Radiometric Correction
4.1.2. Spectral Indices
4.2. Ground Truth (Training and Test Samples) Treatment
4.2.1. Spectral-Temporal Signatures
4.2.2. Identification and Analysis of Inconsistencies
- (a)
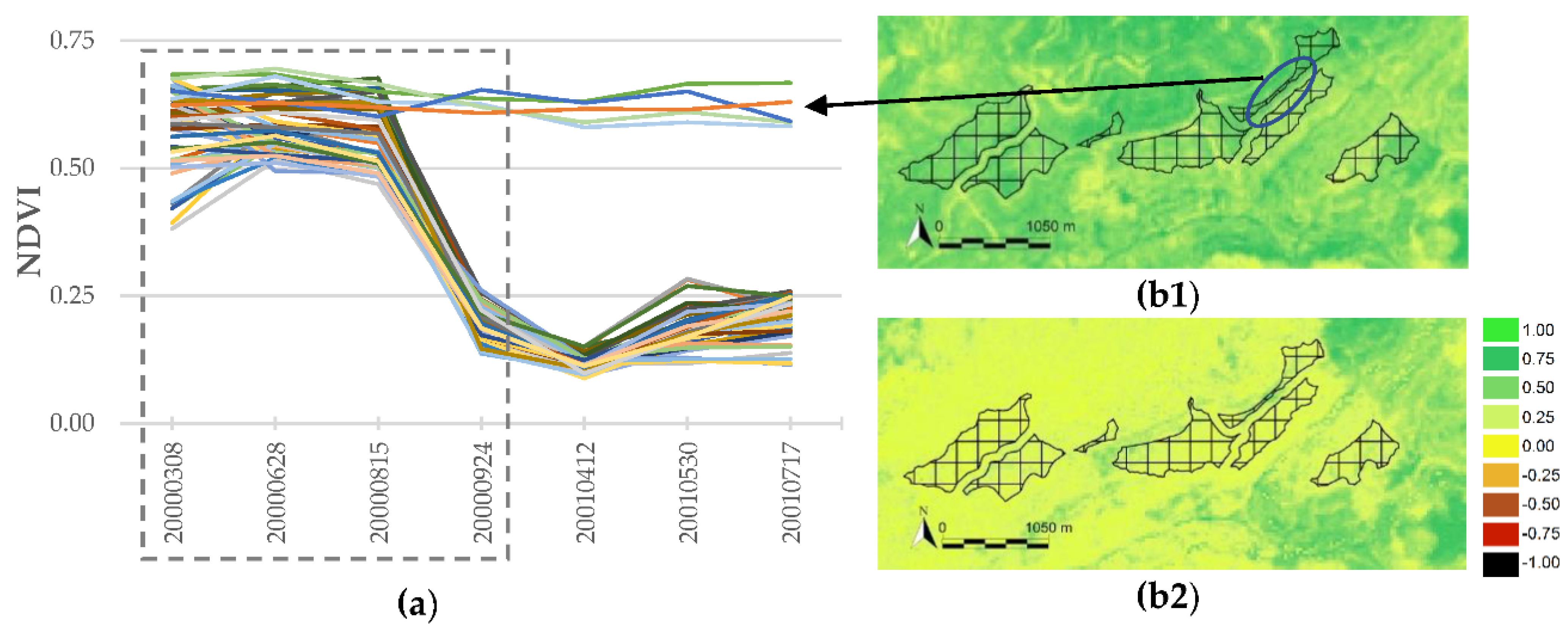
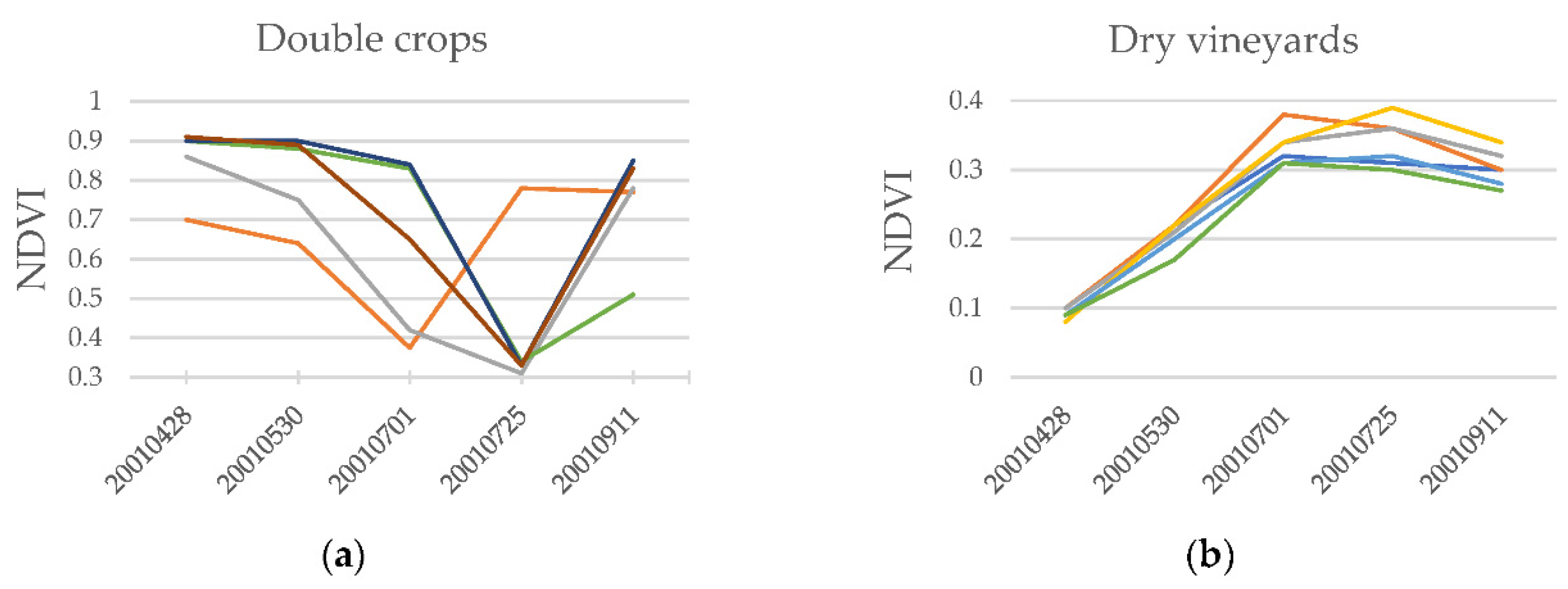
- The inter-annual time difference between the rDS and imagery dates. There is a temporal lag between rDS and LCM-2002 imagery. Figure 4 depicts the NDVI temporal activity of several irrigated herbaceous crop patches (tiles) where no photosynthetic signal is detected during the summer dates of the years previous to 2005. Dry herbaceous crops or fallow practices were predominant in this area before irrigation plans were implemented in this geographic context. The set of patches occupies 787 ha, resulting in a significant error source that affects the identification of irrigated and dry herbaceous crop classes.
- (b)
- The intra-annual time series collect annual phenology, which is constrained by the availability of the imagery. Some intra-annual events (forestry clear-cutting practices and fire disturbances) causes abrupt phenology changes at an intra-annual time scale. These events should be managed (selected/excluded/reclassified) in GT candidate samples. In Figure 5, a forestry clear-cutting practice in a coniferous plantation is shown; the coniferous phenological activity drops on 24 September 2000, affecting an area of 176 ha. The polygons that are not affected show a steady temporal profile.
- (c)
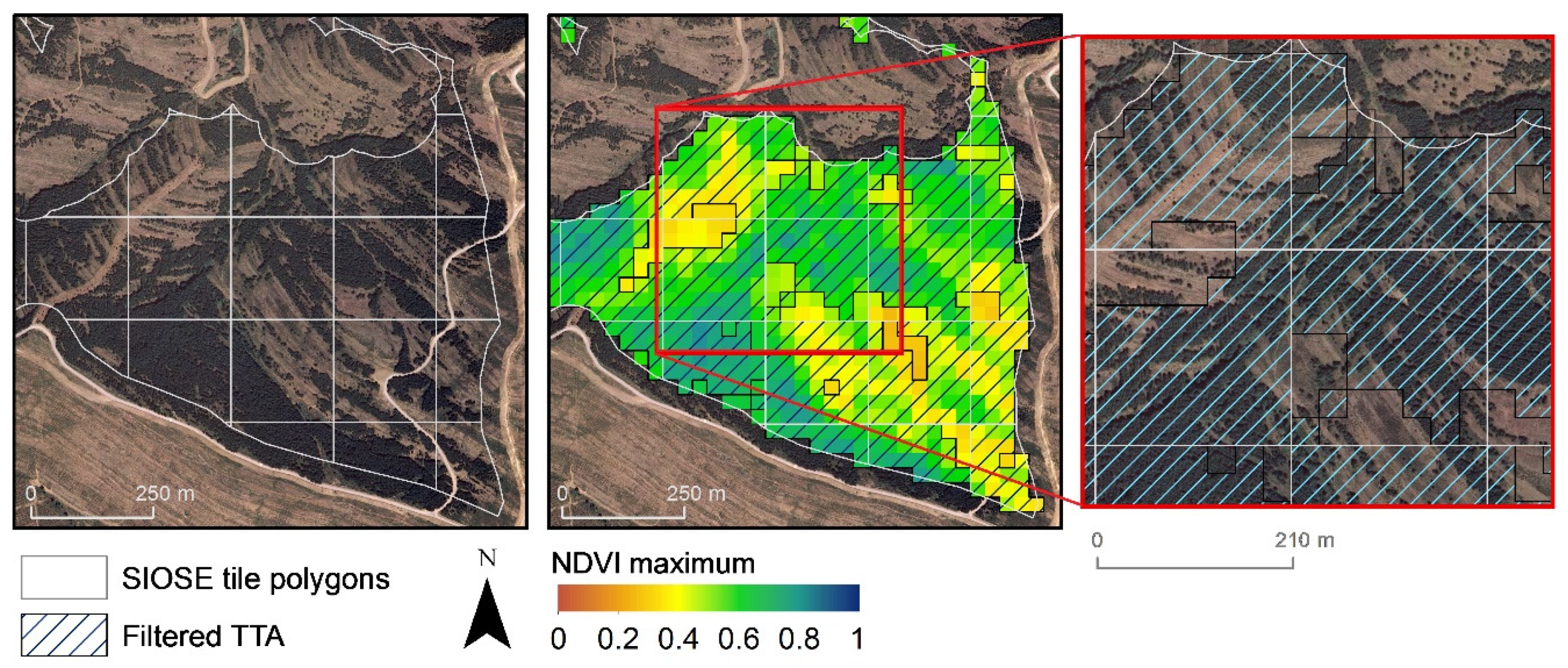
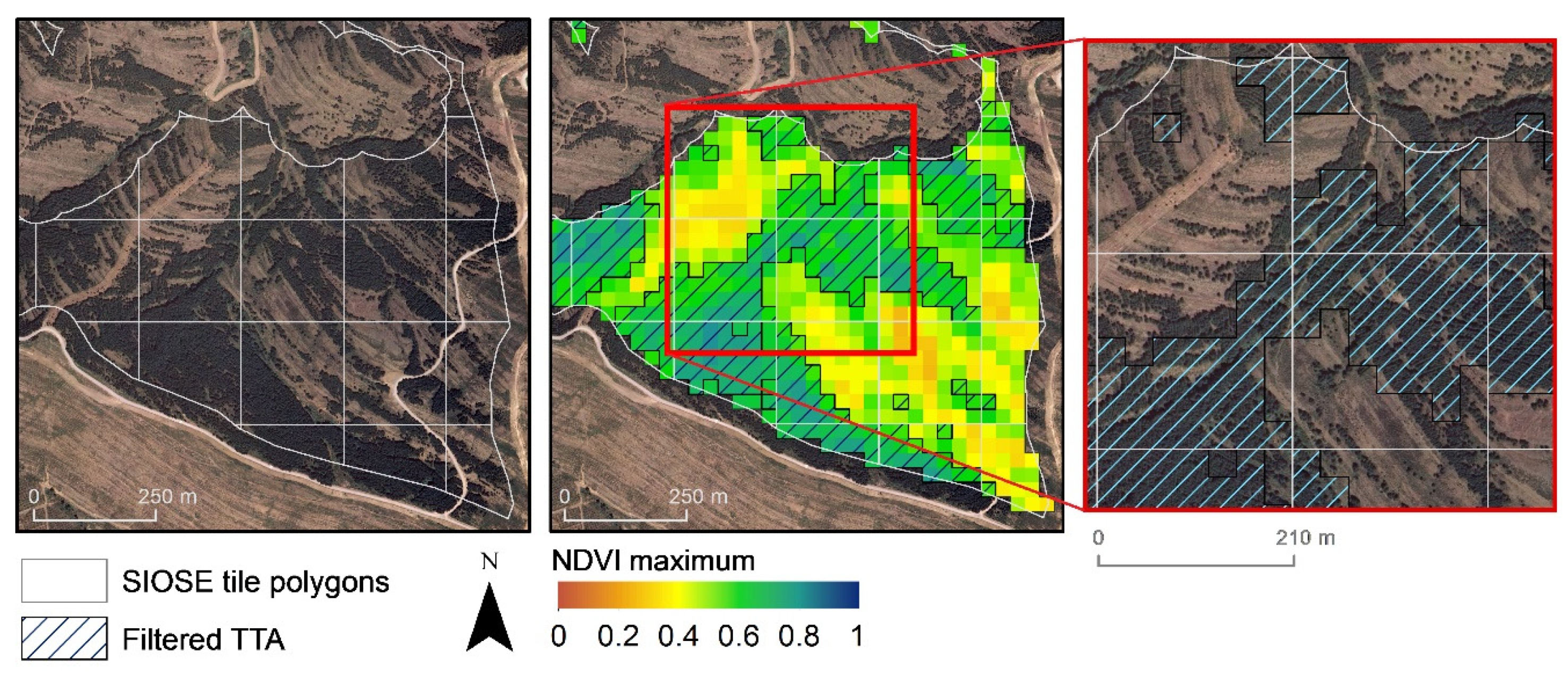
- Scale errors are associated with the conflict between the rDS minimum mapping unit (SIOSE with values of 0.5, 1 or 2 ha, depending on the cover type) and the Landsat spatial resolution (30 m). SIOSE composite land cover polygons circumscribed different phenological responses in the imagery resolution, as shown in Table 1. Figure 6 shows a composite land cover polygon with an association of 70% coniferous, 20% pasture and 10% shrublands. Coniferous forest and sparsely vegetated plots can be identified in the orthophotography on 28 April, 2001, NDVI, where the lower values are pastures/grasslands.
- (d)
- Labelling errors in rDS feature labels can be due to the subjectivity of photointerpretation or human errors when the polygons label are assigned. Figure 7 shows an almost pure polygon defined as an association of 95% broadleaf evergreen forest and 5% shrublands. Despite its definition, the observed phenology conforms to deciduous patterns. In (a), a dense forest structure can be recognised, which corresponds with dominant deciduous species (Fagus sylvatica, Quercus pyrenaica) inventoried in the NFI plots. In (b) and (c), 28 April 2001, and 25 July 2001, NDVI showed a clear increase in NDVI values between the dates. The polygon occupies 198 ha, which can become a source of characterisation errors between evergreen and deciduous forest classes.
- (e)
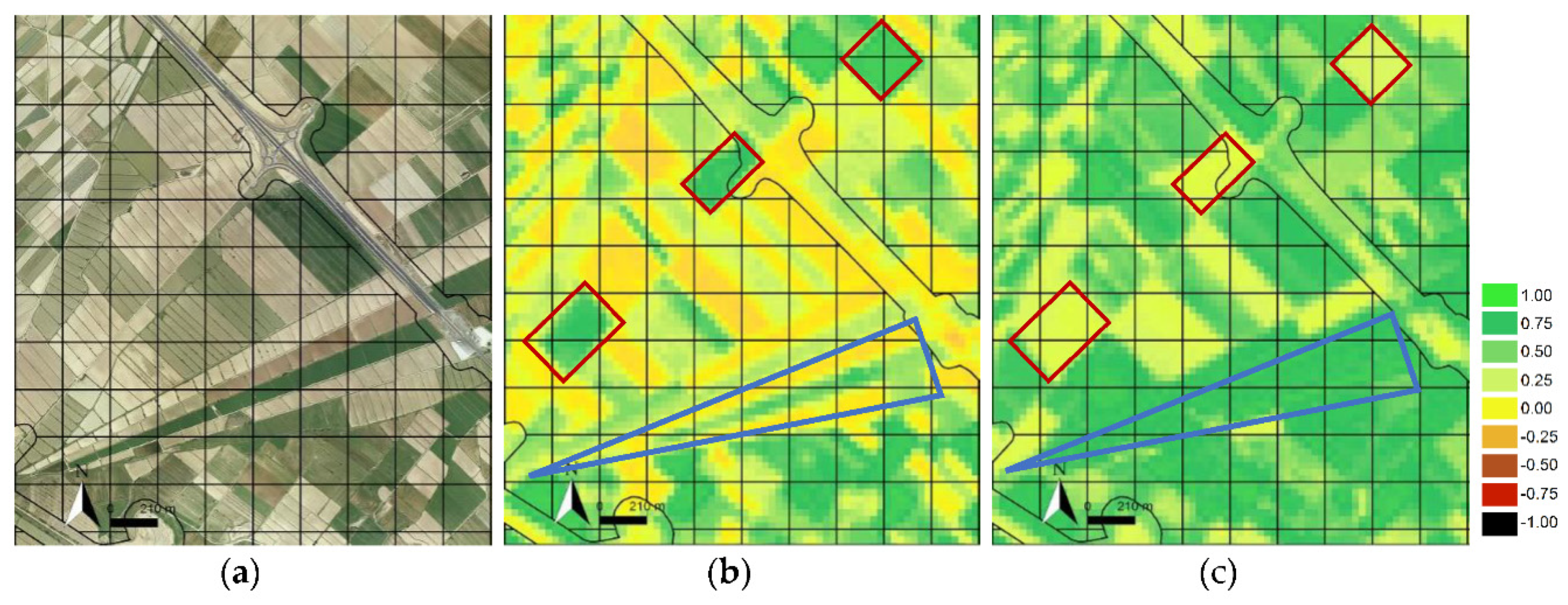
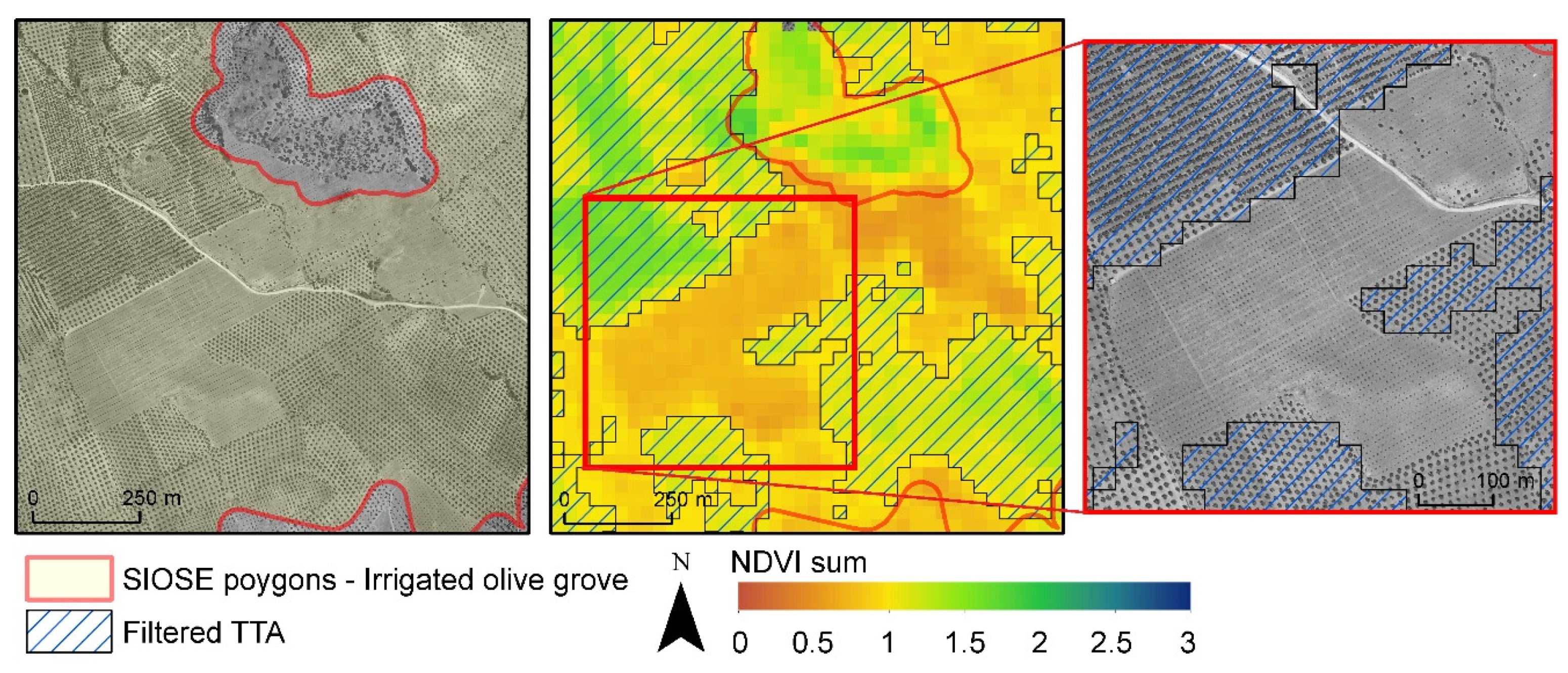
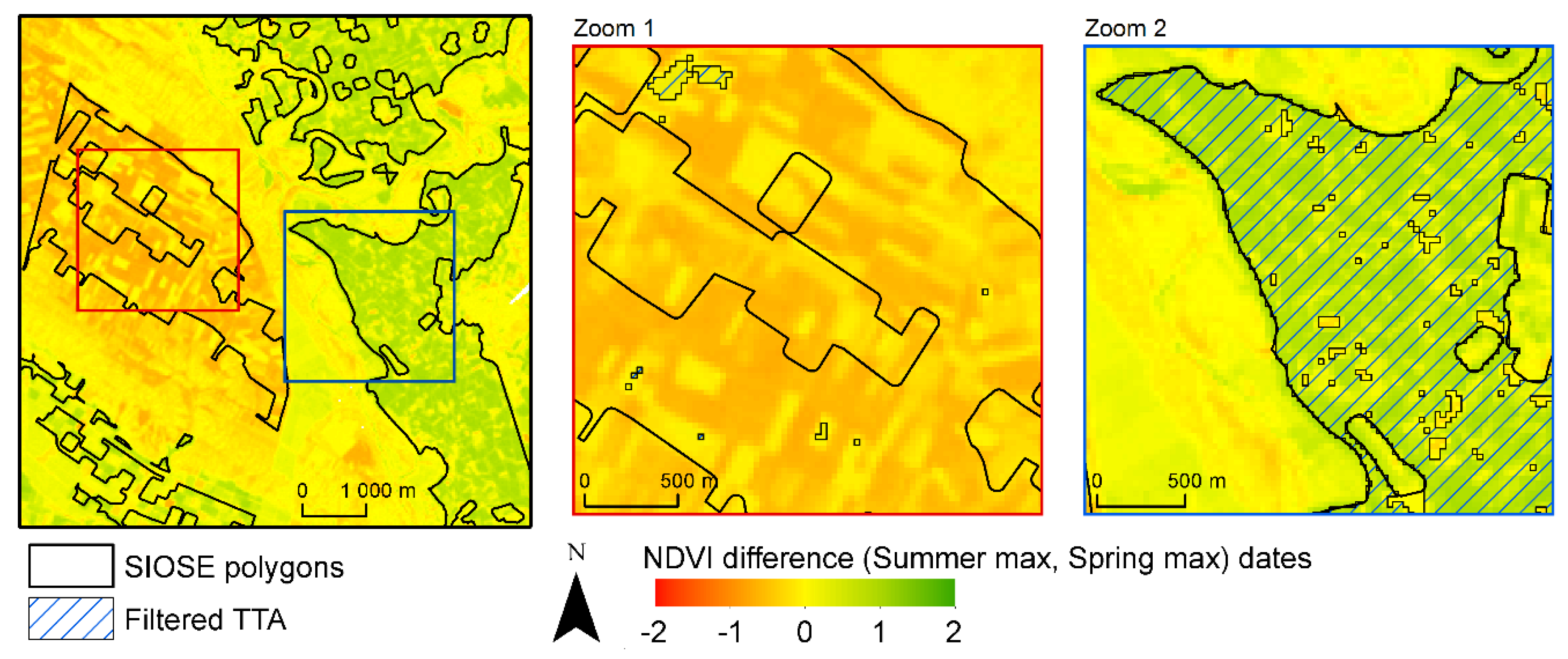
- Multiple (phenological) behaviours are mainly associated with agriculture categories. Crop phenology is complex, and there is a large chance that two neighbouring crop fields within a polygon can be in very different phenological stages (active crops, fallow patterns), as well as belong to different categories (winter crops, summer crops or woody crops). Examples of multiple behaviours were detected in dry and irrigated herbaceous crop polygons. The latter is exemplified in Figure 8. Only part of the entire polygon is displayed due to the large area occupied by the irrigated crops in this area. In (a), the orthophotography depicts the spatial variability, different sizes and phenological states of crop fields. In (b), 28 April 2001, NDVI denotes active winter (red rectangles), perennial crops and other inactive fields. In contrast, on 25 July 2001, NDVI denotes that (c) active summer crops (blue triangle) and inactive fields dominate the area. The contrasting phenological behaviours in large irrigated crop polygons become a source of error and confusion between winter/summer crop categories.
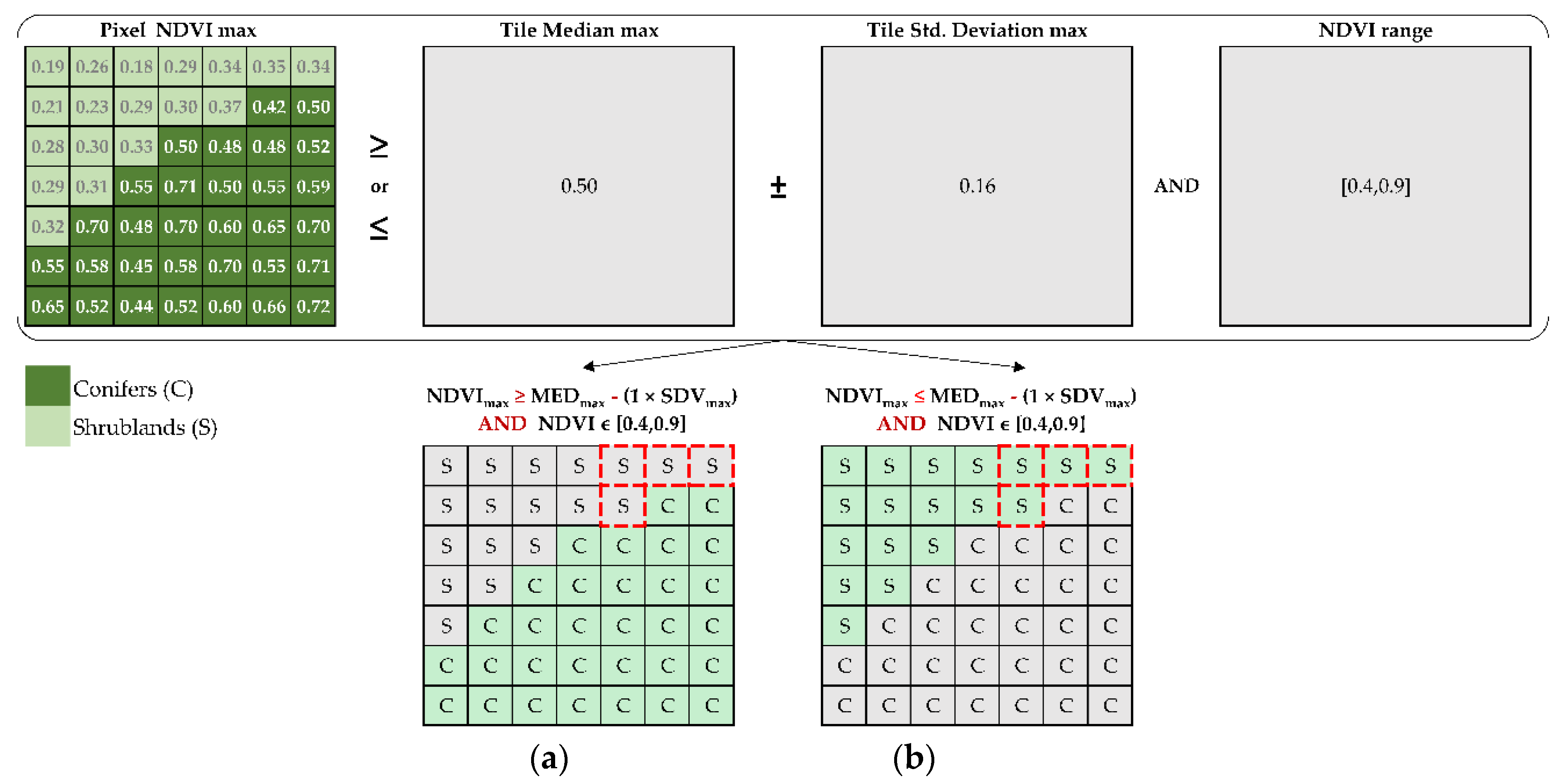
4.2.3. NDVI Filtering Rules
∈ [r4_a,r4_b]; r4_a,r4_b ∈ [−2,2]
NDVI Summer date or, NDVI max|min Summer dates ≥ | ≤ r5_b
NDVI Autumn date or, NDVI max|min Autumn dates ≥ | ≤ r5_c
NDVI max|min Spring dates ≥ | ≤ NDVI max|min Summer dates
NDVI max|min Summer dates ≥ | ≤ NDVI max|min Autumn dates
NDVI max|min Spring dates ≥ | ≤ NDVI max|min Autumn dates,
r5_a,r5_b,r5_c ∈ [−1,1]
4.3. Classification Process and Accuracy Assessment
5. Results
5.1. The Performance of the Rules in Visual Examples
5.2. The Performance of the Rules in Confusion Matrices
6. Discussion
7. Limitations and Future Research
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Peraza-Castro, M.; Ruiz-Romera, E.; Meaurio, M.; Sauvage, S.; Sánchez-Pérez, J.M. Modelling the impact of climate and land cover change on hydrology and water quality in a forest watershed in the Basque Country (Northern Spain). Ecol. Eng. 2018, 122, 315–326. [Google Scholar] [CrossRef]
- Rogger, M.; Agnoletti, M.; Alaoui, A.; Bathurst, J.C.; Bodner, G.; Borga, M.; Chaplot, V.; Gallart, F.; Glatzel, G.; Hall, J.; et al. Land use change impacts on floods at the catchment scale: Challenges and opportunities for future research. Water Resour. Res. 2017, 53, 5209–5219. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Biro, K.; Pradhan, B.; Buchroithner, M.; Makeschin, F. Land Use/Land Cover Change Analysis And Its Impact On Soil Properties In The Northern Part Of Gadarif Region, Sudan. Land Degrad. Dev. 2013, 24, 90–102. [Google Scholar] [CrossRef]
- Abd El-Kawy, O.R.; Rød, J.K.; Ismail, H.A.; Suliman, A.S. Land use and land cover change detection in the western Nile delta of Egypt using remote sensing data. Appl. Geogr. 2011, 31, 483–494. [Google Scholar] [CrossRef]
- Rodríguez-Rodríguez, D.; Martínez-Vega, J.; Echavarría, P. A twenty year GIS-based assessment of environmental sustainability of land use changes in and around protected areas of a fast developing country: Spain. Int. J. Appl. Earth Obs. Geoinf. 2019, 74, 169–179. [Google Scholar] [CrossRef]
- Heidrich, O.; Reckien, D.; Olazabal, M.; Foley, A.; Salvia, M.; de Gregorio Hurtado, S.; Orru, H.; Flacke, J.; Geneletti, D.; Pietrapertosa, F.; et al. National climate policies across Europe and their impacts on cities strategies. J. Environ. Manag. 2016, 168, 36–45. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reckien, D.; Salvia, M.; Heidrich, O.; Church, J.M.; Pietrapertosa, F.; De Gregorio-Hurtado, S.; D’Alonzo, V.; Foley, A.; Simoes, S.G.; Krkoška Lorencová, E.; et al. How are cities planning to respond to climate change? Assessment of local climate plans from 885 cities in the EU-28. J. Clean. Prod. 2018, 191, 207–219. [Google Scholar] [CrossRef]
- Estrela, T.; Sancho, T.A. Drought management policies in Spain and the european union: From traditional emergency actions to drought management plans. Water Policy 2016, 18, 153–176. [Google Scholar] [CrossRef]
- Colwell, R.N. (Ed.) Manual for Photographic Interpretation; The American Society of Photogrammetry: Washington, DC, USA, 1960. [Google Scholar]
- Cihlar, J. Land cover mapping of large areas from satellites: Status and research priorities. Int. J. Remote Sens. 2000, 21, 1093–1114. [Google Scholar] [CrossRef]
- Aplin, P. Remote sensing: Land cover. Prog. Phys. Geogr. 2004, 28, 283–293. [Google Scholar] [CrossRef]
- Lambin, E.F.; Helmut, G. Land-Use and Land-Cover Change: Local Processes and Global Impacts; Springer: Berlin, Germany; New York, NY, USA, 2006; ISBN 978-3-540-32201-6. [Google Scholar]
- Calderón-Loor, M.; Hadjikakou, M.; Bryan, B.A. High-resolution wall-to-wall land-cover mapping and land change assessment for Australia from 1985 to 2015. Remote Sens. Environ. 2021, 252, 112148. [Google Scholar] [CrossRef]
- Pan, D.; Domon, G.; De Blois, S.; Bouchard, A. Temporal (1958–1993) and spatial patterns of land use changes in Haut-Saint-Laurent (Quebec, Canada) and their relation to landscape physical attributes. Landsc. Ecol. 1999, 14, 35–52. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, X.; Fang, G.; Li, Z.; Wang, F.; Qin, J.; Sun, F. Potential risks and challenges of climate change in the arid region of northwestern China. Reg. Sustain. 2020, 1, 20–30. [Google Scholar] [CrossRef]
- Mishra, P.K.; Rai, A.; Rai, S.C. Land use and land cover change detection using geospatial techniques in the Sikkim Himalaya, India. Egypt. J. Remote Sens. Space Sci. 2020, 23, 133–143. [Google Scholar] [CrossRef]
- Azimi Sardari, M.R.; Bazrafshan, O.; Panagopoulos, T.; Sardooi, E.R. Modeling the Impact of Climate Change and Land Use Change Scenarios on Soil Erosion at the Minab Dam Watershed. Sustainability 2019, 11, 3353. [Google Scholar] [CrossRef] [Green Version]
- Serneels, S.; Lambin, E.F. Impact of land-use changes on the wildebeest migration in the northern part of the Serengeti-Mara ecosystem. J. Biogeogr. 2001, 28, 391–407. [Google Scholar] [CrossRef]
- Laney, R.M. A process-led approach to modeling land change in agricultural landscapes: A case study from Madagascar. Agric. Ecosyst. Environ. 2004, 101, 135–153. [Google Scholar] [CrossRef]
- Crews-Meyer, K.A. Agricultural landscape change and stability in northeast Thailand: Historical patch-level analysis. Agric. Ecosyst. Environ. 2004, 101, 155–169. [Google Scholar] [CrossRef]
- Gabiri, G.; Diekkrüger, B.; Näschen, K.; Leemhuis, C.; van der Linden, R.; Mwanjalolo Majaliwa, J.G.; Obando, J.A. Impact of climate and land use/land cover change on thewater resources of a tropical inland valley catchment in Uganda, East Africa. Climate 2020, 8, 83. [Google Scholar] [CrossRef]
- Rogan, J.; Miller, J.; Stow, D.; Franklin, J.; Levien, L.; Fischer, C. Land-cover change monitoring with classification trees using Landsat TM and ancillary data. Photogramm. Eng. Remote Sens. 2003, 69, 793–804. [Google Scholar] [CrossRef] [Green Version]
- MacDonald, G.M. Water, climate change, and sustainability in the southwest. Proc. Natl. Acad. Sci. USA 2010, 107, 21256–21262. [Google Scholar] [CrossRef] [Green Version]
- Homer, C.G.; Huang, C.; Yang, L.; Wylie, B.K.; Coan, M. Development of a 2001 National Land Cover Database for the United States. Photogramm. Eng. Remote Sens. 2004, 70, 829–840. [Google Scholar] [CrossRef] [Green Version]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM + data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef] [Green Version]
- Song, X.-P.; Hansen, M.C.; Stehman, S.V.; Potapov, P.V.; Tyukavina, A.; Vermote, E.F.; Townshend, J.R. Global land change from 1982 to 2016. Nature 2018, 560, 639–643. [Google Scholar] [CrossRef] [PubMed]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef] [Green Version]
- Woodcock, C.; Allen, R.; Anderson, M.; Belward, A.; Bindschadler, R.; Cohen, W.; Gao, F.; Goward, S.; Helder, D.; Helmer, E.; et al. Free Access to Landsat Imagery. Science 2008, 320, 1011. [Google Scholar] [CrossRef]
- Zhu, Z.; Wulder, M.A.; Roy, D.P.; Woodcock, C.E.; Hansen, M.C.; Radeloff, V.C.; Healey, S.P.; Schaaf, C.; Hostert, P.; Strobl, P.; et al. Benefits of the free and open Landsat data policy. Remote Sens. Environ. 2019, 224, 382–385. [Google Scholar] [CrossRef]
- Wulder, M.A.; Masek, J.G.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Opening the archive: How free data has enabled the science and monitoring promise of Landsat. Remote Sens. Environ. 2012, 122, 2–10. [Google Scholar] [CrossRef]
- Jutz, S.; Milagro-Pérez, M.P. Copernicus program. In Comprehensive Remote Sensing; Elsevier: Oxford, UK, 2017; Volume 1, ISBN 9780128032206. [Google Scholar]
- Wulder, M.A.; Coops, N.C.; Roy, D.P.; White, J.C.; Hermosilla, T. Land cover 2.0. Int. J. Remote Sens. 2018, 39, 4254–4284. [Google Scholar] [CrossRef] [Green Version]
- Saunier, S.; Beaton, A.; Lavender, S.; Galli, L.; Ferrara, R.; Mica, S.; Biasutti, R.; Goryl, P.; Gascon, F.; Meloni, M. Bulk processing of the Landsat MSS/TM/ETM+ archive of the European Space Agency: An insight into the Level 1 MSS processing. In Proceedings of the Image and Signal Processing for Remote Sensing XXIII, Warsaw, Poland, 11–14 September 2017; Bruzzone, L., Ed.; 2017; Volume 10427, pp. 1–16. [Google Scholar] [CrossRef]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef] [Green Version]
- Sishodia, R.P.; Ray, R.L.; Singh, S.K. Applications of Remote Sensing in Precision Agriculture: A Review. Remote Sens. 2020, 12, 3136. [Google Scholar] [CrossRef]
- Tuia, D.; Camps-Valls, G. Recent advances in remote sensing image processing. Proc. Int. Conf. Image Process. ICIP 2009, 3705–3708. [Google Scholar] [CrossRef]
- Gómez, C.; Alejandro, P.; Hermosilla, T.; Montes, F.; Pascual, C.; Ruiz, L.A.; Álvarez-Taboada, F.; Tanase, M.; Valbuena, R. Remote sensing for the Spanish forests in the 21st century: A review of advances, needs, and opportunities. For. Syst. 2019, 28, eR001. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef] [Green Version]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231. [Google Scholar] [CrossRef]
- Millard, K.; Richardson, M. On the Importance of Training Data Sample Selection in Random Forest Image Classification: A Case Study in Peatland Ecosystem Mapping. Remote Sens. 2015, 7, 8489–8515. [Google Scholar] [CrossRef] [Green Version]
- Rozenstein, O.; Karnieli, A. Comparison of methods for land-use classification incorporating remote sensing and GIS inputs. Appl. Geogr. 2011, 31, 533–544. [Google Scholar] [CrossRef]
- Gašparović, M.; Zrinjski, M.; Gudelj, M. Automatic cost-effective method for land cover classification (ALCC). Comput. Environ. Urban Syst. 2019, 76, 1–10. [Google Scholar] [CrossRef]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring issues of training data imbalance and mislabelling on random forest performance for large area land cover classification using the ensemble margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Fritz, S.; McCallum, I.; Schill, C.; Perger, C.; See, L.; Schepaschenko, D.; van der Velde, M.; Kraxner, F.; Obersteiner, M. Geo-Wiki: An online platform for improving global land cover. Environ. Model. Softw. 2012, 31, 110–123. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Griffiths, P.; Kuemmerle, T.; Baumann, M.; Radeloff, V.C.; Abrudan, I.V.; Lieskovsky, J.; Munteanu, C.; Ostapowicz, K.; Hostert, P. Forest disturbances, forest recovery, and changes in forest types across the carpathian ecoregion from 1985 to 2010 based on landsat image composites. Remote Sens. Environ. 2014, 151, 72–88. [Google Scholar] [CrossRef]
- Elmes, A.; Alemohammad, H.; Avery, R.; Caylor, K.; Eastman, J.R.; Fishgold, L.; Friedl, M.A.; Jain, M.; Kohli, D.; Bayas, J.C.L.; et al. Accounting for training data error in machine learning applied to earth observations. Remote Sens. 2020, 12, 1034. [Google Scholar] [CrossRef] [Green Version]
- Ye, S.; Pontius, R.G.; Rakshit, R. A review of accuracy assessment for object-based image analysis: From per-pixel to per-polygon approaches. ISPRS J. Photogramm. Remote Sens. 2018, 141, 137–147. [Google Scholar] [CrossRef]
- Foody, G.M. Assessing the accuracy of land cover change with imperfect ground reference data. Remote Sens. Environ. 2010, 114, 2271–2285. [Google Scholar] [CrossRef] [Green Version]
- Fuller, R.M.; Smith, G.M.; Devereux, B.J. The characterisation and measurement of land cover change through remote sensing: Problems in operational applications? Int. J. Appl. Earth Obs. Geoinf. 2003, 4, 243–253. [Google Scholar] [CrossRef]
- Vidal-Macua, J.J.; Zabala, A.; Ninyerola, M.; Pons, X. Developing spatially and thematically detailed backdated maps for land cover studies. Int. J. Digit. Earth 2017, 8947, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanian, A.; Kakooei, M.; Amani, M.; Mahdavi, S.; Mohammadzadeh, A.; Hasanlou, M. Improved land cover map of Iran using Sentinel imagery within Google Earth Engine and a novel automatic workflow for land cover classification using migrated training samples. ISPRS J. Photogramm. Remote Sens. 2020, 167, 276–288. [Google Scholar] [CrossRef]
- Sankey, T.T. Scale, Effects. In Encyclopedia of GIS; Shekhar, S., Xiong, H., Eds.; Springer US: Boston, MA, USA, 2008; pp. 1021–1026. ISBN 978-0-387-35973-1. [Google Scholar]
- Bossard, M.; Feranec, J.; Otahel, J. CORINE Land Cover Technical Guide: Addendum 2000. In CORINE Land Cover Technical Guide; European Environment Agency: Copenhagen, Denmark, 2000; ISBN 9282625788. [Google Scholar]
- Buyantuyev, A.; Wu, J. Effects of thematic resolution on landscape pattern analysis. Landsc. Ecol. 2007, 22, 7–13. [Google Scholar] [CrossRef]
- Lechner, A.M.; Rhodes, J.R. Recent Progress on Spatial and Thematic Resolution in Landscape Ecology. Curr. Landsc. Ecol. Rep. 2016, 1, 98–105. [Google Scholar] [CrossRef] [Green Version]
- De Fries, R.S.; Hansen, M.; Townshend, J.R.G.; Sohlberg, R. Global land cover classifications at 8 km spatial resolution: The use of training data derived from Landsat imagery in decision tree classifiers. Int. J. Remote Sens. 1998, 19, 3141–3168. [Google Scholar] [CrossRef]
- Anderson, J.R.; Hardy, E.E.; Roach, J.T.; Witmer, R.E. A Land Use and Land Cover Classification System for Use with Remote Sensor Data; U.S. Geological Survey Professional Paper 964; U.S. Geological Survey: Reston, VA, USA, 1976; 28p.
- Federal Geographic Data Committee National Vegetation Classification Standard. Available online: https://www.fgdc.gov/standards/projects/vegetation/standards/projects/vegetation/vegclass.pdf (accessed on 11 January 2021).
- Scott, J.M.; Jennings, M.D. Large-Area Mapping of Biodiversity. Ann. Mo. Bot. Gard. 1998, 85, 34–47. [Google Scholar] [CrossRef]
- Gregorio, A.D.; Jansen, L.J.M. Land Cover Classification System (LCCS): Classification Concepts and User Manual. FAO 2000, 53, 179. [Google Scholar]
- Silla, C.N.; Freitas, A.A. A survey of hierarchical classification across different application domains. Data Min. Knowl. Discov. 2011, 22, 31–72. [Google Scholar] [CrossRef]
- European Environment Agency Corine Land Cover Update 2000-Technical Guidelines. Available online: https://land.copernicus.eu/user-corner/technical-library/techrep89.pdf (accessed on 5 July 2021).
- Del Barrio, G.; Creus, J.; Puigdefabregas, J. Thermal seasonality of the high mountain belts of the Pyrenees. Mt. Res. Dev. 1990, 10, 227–233. [Google Scholar] [CrossRef]
- Comín, F.A. Management of the Ebro River Basin: Past, present and future. Water Sci. Technol. 1999, 40. [Google Scholar] [CrossRef]
- Sangüesa-Barreda, G.; Camarero, J.J.; García-Martín, A.; Hernández, R.; De la Riva, J. Remote-sensing and tree-ring based characterization of forest defoliation and growth loss due to the Mediterranean pine processionary moth. For. Ecol. Manag. 2014, 320, 171–181. [Google Scholar] [CrossRef] [Green Version]
- USA Geological Survey EarthExplorer. Available online: https://earthexplorer.usgs.gov/ (accessed on 8 June 2021).
- Dubayah, R.; Rich, P.M. Topographic solar radiation models for GIS. Int. J. Geogr. Inf. Syst. 1995, 9, 405–419. [Google Scholar] [CrossRef]
- Olpenda, A.S.; Stereńczak, K.; Będkowski, K. Modeling Solar Radiation in the Forest Using Remote Sensing Data: A Review of Approaches and Opportunities. Remote Sens. 2018, 10, 694. [Google Scholar] [CrossRef] [Green Version]
- Eiumnoh, A.; Shrestha, R.P. Application of DEM data to Landsat image classification: Evaluation in a tropical wet-dry landscape of Thailand. Photogramm. Eng. Remote Sens. 2000, 66, 297–304. [Google Scholar]
- Hutchinson, C.F. Techniques for combining Landsat and ancillary data for digital classification improvement. Photogramm. Eng. Remote Sens. 1982, 48, 123–130. [Google Scholar]
- Jones, A.R.; Settle, J.J.; Wyatt, B.K. Use of digital terrain data in the interpretation of SPOT-1 HRV multispectral imagery. Int. J. Remote Sens. 1988, 9, 669–682. [Google Scholar] [CrossRef]
- Palacio-Prieto, J.L.; Luna-González, L. Improving spectral results in a GTS context. Int. J. Remote Sens. 1996, 17, 2201–2209. [Google Scholar] [CrossRef]
- Bahadur, K.C.K. Improving Landsat and IRS Image Classification: Evaluation of Unsupervised and Supervised Classification through Band Ratios and DEM in a Mountainous Landscape in Nepal. Remote Sens. 2009, 1, 1257–1272. [Google Scholar] [CrossRef] [Green Version]
- Aerial Orthophotography National Plan (PNOA). Available online: https://pnoa.ign.es/el-proyecto-pnoa-lidar (accessed on 10 February 2021).
- Pons, X. 2004. MiraMon. Geographic Information System and Remote Sensing Software. Centre de Recerca Ecològica i Aplicacions Forestals, CREAF. Bellaterra. Available online: https://www.miramon.cat/Index_usa.htm (accessed on 5 July 2021).
- Pons, X.; Ninyerola, M. Mapping a topographic global solar radiation model implemented in a GIS and refined with ground data. Int. J. Climatol. 2008, 28, 1821–1834. [Google Scholar] [CrossRef]
- González-Guerrero, O.; Pons, X. The 2017 Land Use/Land Cover Map of Catalonia based on Sentinel-2 images and auxiliary data. Rev. Teledetec. 2020, 55, 81–92. [Google Scholar] [CrossRef]
- Egenhofer, M.; Frank, A. Object-Oriented Modeling for GIS. URISA J. 2001, 4, 3–19. [Google Scholar]
- Pons, X.; Pesquer, L.; Cristóbal, J.; González-Guerrero, O. Automatic and improved radiometric correction of landsat imagery using reference values from MODIS surface reflectance images. Int. J. Appl. Earth Obs. Geoinf. 2014, 33, 243–254. [Google Scholar] [CrossRef] [Green Version]
- Padró, J.-C.; Pons, X.; Aragonés, D.; Díaz-Delgado, R.; García, D.; Bustamante, J.; Pesquer, L.; Domingo-Marimon, C.; González-Guerrero, Ò.; Cristóbal, J.; et al. Radiometric Correction of Simultaneously Acquired Landsat-7/Landsat-8 and Sentinel-2A Imagery Using Pseudoinvariant Areas (PIA): Contributing to the Landsat Time Series Legacy. Remote Sens. 2017, 9, 1319. [Google Scholar] [CrossRef] [Green Version]
- Griffiths, P.; van der Linden, S.; Kuemmerle, T.; Hostert, P. A Pixel-Based Landsat Compositing Algorithm for Large Area Land Cover Mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2088–2101. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef] [Green Version]
- Ouma, Y.; Tateishi, R. A water index for rapid mapping of shoreline changes of five East African Rift Valley lakes: An empirical analysis using Landsat TM and ETM + data. Int. J. Remote Sens. 2006, 27, 3153–3181. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Kyle, H.L.; Curran, R.J.; Barnes, W.L.; Escoe, D. A cloud physics radiometer. In Proceedings of the Third Conference on Atmospheric Radiation, Davis, CA, USA, 28–30 June 1978; pp. 107–109. [Google Scholar]
- Dozier, J. Spectral signature of alpine snow cover from the landsat thematic mapper. Remote Sens. Environ. 1989, 28, 9–22. [Google Scholar] [CrossRef]
- Herrero, J.; Polo, M.J.; Losada, M. Snow evolution in Sierra Nevada (Spain) from an energy balance model validated with Landsat TM data. Proc. SPIE Int. Soc. Opt. Eng. 2011, 8174. [Google Scholar] [CrossRef]
- Klein, A.G.; Hall, D.K.; Riggs, G.A. Improving snow cover mapping in forests through the use of a canopy reflectance model. Hydrol. Process. 1998, 12, 1723–1744. [Google Scholar] [CrossRef]
- Negi, H.S.; Kulkarni, A.V.; Semwal, B.S. Estimation of snow cover distribution in Beas basin, Indian Himalaya using satellite data and ground measurements. J. Earth Syst. Sci. 2009, 118, 525–538. [Google Scholar] [CrossRef]
- Land Occupation Information System of Spain (SIOSE). Available online: https://www.siose.es/ (accessed on 5 July 2021).
- Serra, P.; Pons, X.; Saurí, D. Post-classification change detection with data from different sensors: Some accuracy considerations. Int. J. Remote Sens. 2003, 24, 3311–3340. [Google Scholar] [CrossRef]
- Ameijeiras-Alonso, J.; Crujeiras, R.M.; Rodríguez-Casal, A. Multimode: An R Package for Mode Assessment. arXiv 2018, arXiv:1803.00472. [Google Scholar]
- Nunes, L.; Moreno, M.; Alberdi, I.; Álvarez-González, J.G.; Godinho-Ferreira, P.; Mazzoleni, S.; Castro Rego, F. Harmonized Classification of Forest Types in the Iberian Peninsula Based on National Forest Inventories. Forests 2020, 11, 1170. [Google Scholar] [CrossRef]
- Pontius, R.G.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Amani, M.; Brisco, B.; Afshar, M.; Mirmazloumi, S.M.; Mahdavi, S.; Mirzadeh, S.M.J.; Huang, W.; Granger, J. A generalized supervised classification scheme to produce provincial wetland inventory maps: An application of Google Earth Engine for big geo data processing. Big Earth Data 2019, 3, 378–394. [Google Scholar] [CrossRef]
- Friedl, M.A.; Sulla-Menashe, D.; Tan, B.; Schneider, A.; Ramankutty, N.; Sibley, A.; Huang, X. MODIS Collection 5 global land cover: Algorithm refinements and characterization of new datasets. Remote Sens. Environ. 2010, 114, 168–182. [Google Scholar] [CrossRef]
- Xie, Z.; Chen, Y.; Lu, D.; Li, G.; Chen, E. Classification of land cover, forest, and tree species classes with Ziyuan-3 multispectral and stereo data. Remote Sens. 2019, 11, 164. [Google Scholar] [CrossRef] [Green Version]
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sens. 2017, 9, 95. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Land Cover Composition | SIOSE_CODE Database Field | Visual Example |
|---|---|---|
| Simple | CHLsc 1 |  |
| Composite in Regular Mosaic | R(55FDP_45CHLsc) 2 |  |
| Composite in Irregular Mosaic | I(50CHLsc_35FDP_15PST) 2 |  |
| Composite in Association | A(40CNF_40PST_20MTR) 2 |  |
| Classified Map | Unfiltered Ground Truth Samples | Total | CE (%) | UA (%) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CoF | BDF | BEF | Shl | Grl | BrS | Urb | WaB | IHC | DHC | IWC | DWC | RiC | ||||
| (CoF) Coniferous forest | 50,907 | 823 | 1058 | 1612 | 295 | 34 | 31 | 25 | 11 | 55 | 15 | 29 | 1 | 54,895 | 7.3 | 92.7 |
| (BDF) Broadleaf deciduous forest | 1044 | 67,728 | 1403 | 1884 | 1077 | 91 | 0 | 11 | 163 | 173 | 59 | 0 | 0 | 73,634 | 8.0 | 92.0 |
| (BEF) Broadleaf evergreen forest | 5640 | 1644 | 60,658 | 7398 | 785 | 109 | 5 | 26 | 41 | 197 | 5 | 27 | 0 | 76,534 | 20.7 | 79.3 |
| (Shl) Shrublands | 3715 | 1587 | 3007 | 115,688 | 9356 | 938 | 160 | 105 | 301 | 2450 | 180 | 2154 | 7 | 139,649 | 17.2 | 82.8 |
| (Grl) Grasslands | 504 | 678 | 429 | 13,544 | 86,142 | 1135 | 39 | 18 | 824 | 8148 | 224 | 1252 | 11 | 112,948 | 23.7 | 76.3 |
| (BrS) Bare soils | 64 | 54 | 52 | 488 | 1214 | 3545 | 78 | 0 | 58 | 625 | 23 | 67 | 0 | 6268 | 43.4 | 56.6 |
| (Urb) Urban areas and Infrastructures | 1 | 3 | 0 | 66 | 53 | 57 | 2802 | 7 | 48 | 300 | 57 | 112 | 1 | 3507 | 20.1 | 79.9 |
| (WaB) Water bodies | 1 | 10 | 0 | 5 | 9 | 2 | 0 | 1488 | 1 | 22 | 0 | 4 | 0 | 1543 | 3.5 | 96.5 |
| (IHC) Irrigated herbaceous crops | 17 | 184 | 3 | 424 | 868 | 155 | 145 | 13 | 37,114 | 5524 | 1526 | 825 | 304 | 47,100 | 21.2 | 78.8 |
| (DHC) Dry herbaceous crops | 55 | 51 | 43 | 1647 | 1853 | 636 | 293 | 82 | 6709 | 175,596 | 984 | 2764 | 17 | 190,729 | 7.9 | 92.1 |
| (IWC) Irrigated woody crops | 26 | 146 | 12 | 274 | 231 | 101 | 226 | 12 | 2154 | 921 | 9841 | 4011 | 27 | 17,982 | 45.3 | 54.7 |
| (DWC) Dry woody crops | 99 | 11 | 22 | 1614 | 545 | 124 | 368 | 26 | 967 | 2748 | 3098 | 29,232 | 12 | 38,866 | 24.8 | 75.2 |
| (RiC) Rice crops | 5 | 11 | 0 | 20 | 12 | 1 | 6 | 4 | 667 | 34 | 10 | 2 | 1494 | 2267 | 34.1 | 65.9 |
| NoData | 31 | 120 | 51 | 84 | 111 | 149 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 547 | ||
| Total | 62,110 | 73,049 | 66,739 | 144,748 | 102,552 | 7077 | 4153 | 1817 | 49,057 | 196,793 | 16,021 | 40,479 | 1875 | 766,469 | OA = 83.8% | |
| OE (%) | 18.0 | 7.3 | 9.1 | 20.1 | 16.0 | 49.9 | 32.5 | 18.1 | 24.3 | 10.8 | 38.6 | 27.8 | 20.3 | OAw = 88.6% | ||
| PA (%) | 82.0 | 92.7 | 90.9 | 79.9 | 84.0 | 50.1 | 67.5 | 81.9 | 75.7 | 89.2 | 61.4 | 72.2 | 79.7 | k = 0.7 | ||
| Classified Map | Filtered Ground Truth Samples | Total | CE (%) | UA (%) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CoF | BDF | BEF | Shl | Grl | BrS | Urb | WaB | IHC | DHC | IWC | DWC | RiC | ||||
| (CoF) Coniferous forest | 46,959 | 226 | 525 | 311 | 222 | 0 | 0 | 0 | 3 | 4 | 4 | 0 | 0 | 48,254 | 2.7 | 97.3 |
| (BDF) Broadleaf deciduous forest | 388 | 83,499 | 330 | 55 | 906 | 0 | 0 | 0 | 94 | 0 | 33 | 0 | 0 | 85,306 | 2.1 | 97.9 |
| (BEF) Broadleaf evergreen forest | 4891 | 934 | 52,718 | 3278 | 300 | 0 | 0 | 0 | 7 | 17 | 13 | 0 | 0 | 62,157 | 15.2 | 84.8 |
| (Shl) Shrublands | 1634 | 311 | 1889 | 115,291 | 6468 | 97 | 39 | 0 | 15 | 410 | 337 | 1178 | 0 | 127,670 | 9.7 | 90.3 |
| (Grl) Grasslands | 48 | 342 | 18 | 4281 | 84,012 | 32 | 13 | 0 | 66 | 3616 | 14 | 1481 | 0 | 93,924 | 10.6 | 89.4 |
| (BrS) Bare soils | 0 | 0 | 0 | 16 | 33 | 10,379 | 494 | 0 | 0 | 1711 | 0 | 60 | 0 | 12,692 | 18.2 | 81.8 |
| (Urb) Urban areas and Infrastructures | 0 | 0 | 0 | 4 | 1 | 79 | 5678 | 0 | 0 | 220 | 1 | 133 | 0 | 6117 | 7.2 | 92.8 |
| (WaB) Water bodies | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1578 | 0 | 0 | 0 | 0 | 0 | 1578 | 0.0 | 100.0 |
| (IHC) Irrigated herbaceous crops | 2 | 84 | 0 | 15 | 134 | 0 | 0 | 0 | 27,676 | 181 | 507 | 0 | 5 | 28,603 | 3.2 | 96.8 |
| (DHC) Dry herbaceous crops | 0 | 0 | 0 | 57 | 624 | 874 | 759 | 0 | 23 | 189,497 | 13 | 1344 | 0 | 193,191 | 1.9 | 98.1 |
| (IWC) Irrigated woody crops | 16 | 277 | 18 | 232 | 296 | 0 | 18 | 0 | 1640 | 183 | 25,474 | 90 | 0 | 28,244 | 9.8 | 90.2 |
| (DWC) Dry woody crops | 1 | 0 | 0 | 1422 | 1208 | 333 | 0 | 0 | 9 | 5266 | 96 | 68,756 | 0 | 77,090 | 10.8 | 89.2 |
| (RiC) Rice crops | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 201 | 0 | 0 | 0 | 958 | 1159 | 17.3 | 82.7 |
| NoData | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| Total | 53,939 | 85,672 | 55,499 | 124,963 | 94,204 | 11,794 | 7002 | 1578 | 29,735 | 201,105 | 26,492 | 73,042 | 963 | 765,986 | OA = 93.0% | |
| OE (%) | 12.9 | 2.5 | 5.0 | 7.7 | 10.8 | 12.0 | 18.9 | 0.0 | 6.9 | 5.8 | 3.8 | 5.9 | 0.5 | OAw = 95.9% | ||
| PA (%) | 87.1 | 97.5 | 95.0 | 92.3 | 89.2 | 88.0 | 81.1 | 100.0 | 93.1 | 94.2 | 96.2 | 94.1 | 99.5 | k = 0.9 | ||
| LCM-1987 | LCM-2012 | LCM-2017 | LCM-2002 * | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OE (%) | CE (%) | OE (%) | CE (%) | OE (%) | CE (%) | OE (%) | CE (%) | |||||||||
| uf. | f. | uf. | f. | uf. | f. | uf. | f. | uf. | f. | uf. | f. | uf. | f. | uf. | f. | |
| CoF | 22.9 | 16.8 | 18.8 | 8.7 | 12.0 | 10.0 | 5.3 | 2.1 | 17.9 | 11.5 | 11.1 | 3.5 | 13.5 | 7.4 | 15.2 | 6.1 |
| BDF | 25.0 | 3.8 | 21.2 | 2.8 | 5.2 | 2.6 | 7.1 | 1.4 | 21.1 | 2.6 | 14.2 | 3.3 | 22.2 | 6.9 | 26.1 | 15.3 |
| BEF | 10.3 | 5.8 | 25.5 | 16.0 | 7.5 | 3.3 | 15.7 | 13.5 | 9.8 | 3.3 | 19.9 | 13.4 | 15.3 | 6.6 | 18.3 | 11.6 |
| Shl | 36.6 | 5.4 | 20.7 | 9.3 | 17.4 | 4.7 | 17.7 | 5.9 | 41.5 | 6.0 | 25.1 | 6.2 | 49.2 | 30.6 | 33.1 | 16.7 |
| Grl | 26.3 | 12.9 | 23.5 | 11.2 | 16.2 | 7.1 | 20.5 | 8.8 | 19.6 | 9.2 | 24.5 | 12.1 | 15.4 | 8.5 | 16.9 | 9.8 |
| BrS | 45.1 | 9.3 | 40.3 | 12.2 | 47.5 | 13.9 | 32.4 | 18.5 | 51.2 | 6.3 | 41.9 | 22.2 | 49.2 | 19.5 | 41.9 | 19.9 |
| Urb | 56.0 | 10.4 | 15.3 | 19.4 | 19.6 | 12.3 | 10.4 | 6.0 | 27.1 | 8.6 | 15.2 | 26.7 | 46.4 | 38.2 | 30.5 | 14.2 |
| WaB | 21.8 | 0.0 | 3.3 | 0.0 | 3.9 | 0.2 | 2.5 | 0.0 | 5.3 | 0.0 | 4.1 | 0.0 | 13.7 | 0 | 6.4 | 0 |
| IHC | 31.5 | 7.3 | 23.7 | 6.4 | 19.0 | 2.6 | 23.8 | 4.9 | 29.2 | 2.9 | 32.1 | 6.3 | 17.5 | 0.7 | 20.8 | 1.3 |
| DHC | 16.4 | 6.8 | 11.2 | 1.4 | 11.1 | 5.1 | 6.8 | 1.3 | 15.0 | 5.1 | 8.8 | 1.4 | 9.5 | 6.9 | 4.2 | 1.6 |
| IWC | 37.7 | 7.4 | 50.6 | 13.5 | 34.8 | 12.2 | 40.4 | 6.5 | 42.0 | 14.9 | 48.9 | 5.9 | 40.2 | 2.6 | 60.4 | 3.4 |
| DWC | 15.2 | 4.8 | 28.2 | 10.7 | 34.5 | 4.6 | 25.1 | 16.0 | 20.2 | 17.8 | 28.3 | 15.4 | 12.8 | 2.6 | 15.6 | 12.6 |
| RiC | 66.7 | 0.0 | 59.8 | 0.0 | 18.8 | 5.0 | 17.8 | 1.6 | 13.4 | 7.1 | 43.5 | 17.6 | -- | -- | -- | -- |
| OA | 77.5 | 92.5 | 85.6 | 94.2 | 78.7 | 93.4 | 85.1 | 92.3 | ||||||||
| K | 0.7 | 0.9 | 0.8 | 0.9 | 0.7 | 0.9 | 0.8 | 0.9 | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Padial-Iglesias, M.; Serra, P.; Ninyerola, M.; Pons, X. A Framework of Filtering Rules over Ground Truth Samples to Achieve Higher Accuracy in Land Cover Maps. Remote Sens. 2021, 13, 2662. https://doi.org/10.3390/rs13142662
Padial-Iglesias M, Serra P, Ninyerola M, Pons X. A Framework of Filtering Rules over Ground Truth Samples to Achieve Higher Accuracy in Land Cover Maps. Remote Sensing. 2021; 13(14):2662. https://doi.org/10.3390/rs13142662
Chicago/Turabian StylePadial-Iglesias, Mario, Pere Serra, Miquel Ninyerola, and Xavier Pons. 2021. "A Framework of Filtering Rules over Ground Truth Samples to Achieve Higher Accuracy in Land Cover Maps" Remote Sensing 13, no. 14: 2662. https://doi.org/10.3390/rs13142662
APA StylePadial-Iglesias, M., Serra, P., Ninyerola, M., & Pons, X. (2021). A Framework of Filtering Rules over Ground Truth Samples to Achieve Higher Accuracy in Land Cover Maps. Remote Sensing, 13(14), 2662. https://doi.org/10.3390/rs13142662