
Using Discrete-Point LiDAR to Classify Tree Species in the Riparian Pacific Northwest, USA

Abstract
:
1. Introduction
2. Materials and Methods
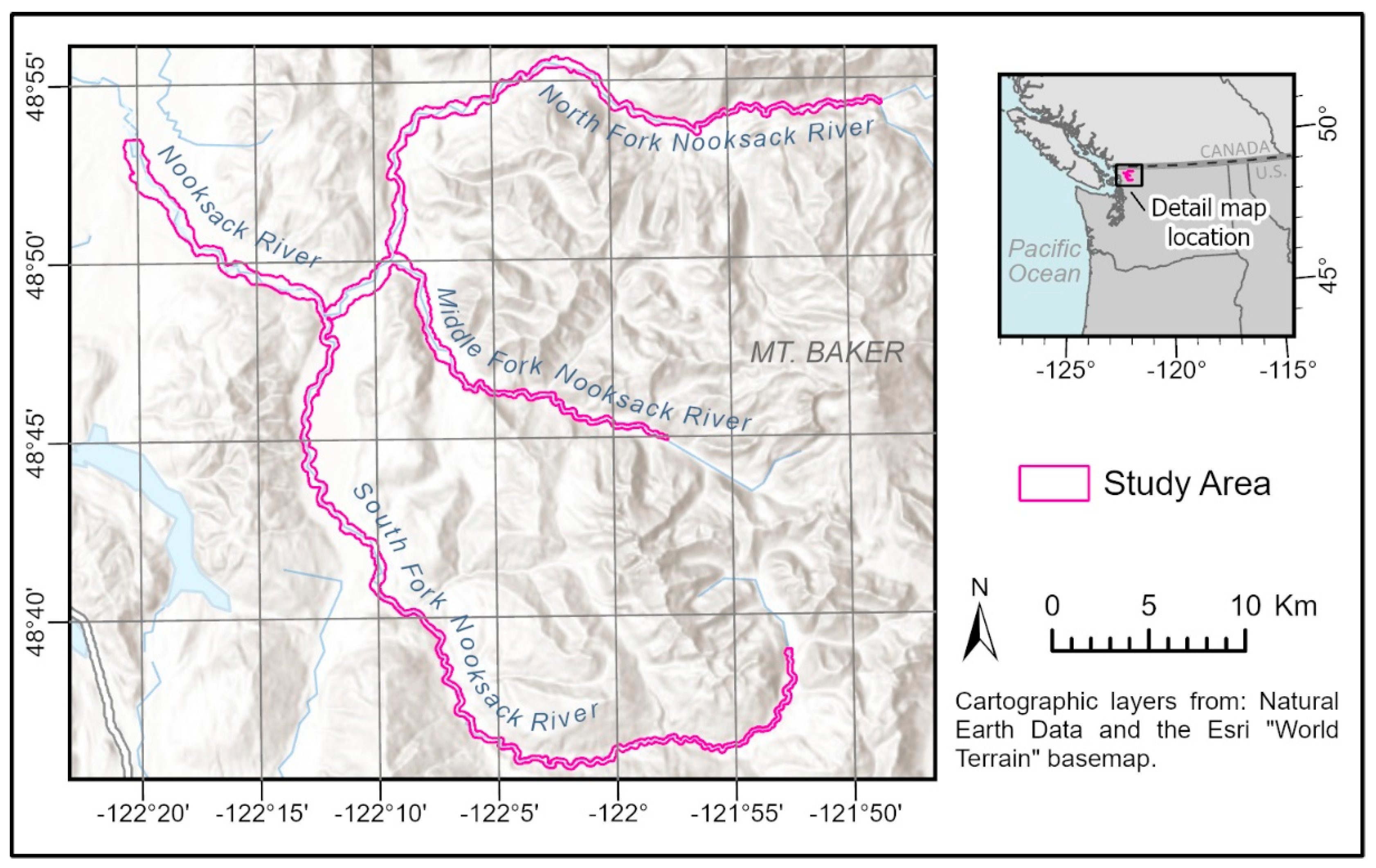
2.1. Study Area
2.2. LiDAR Data and Pre-Processing
2.3. Ground-Truth Data Collection and Pre-Processing
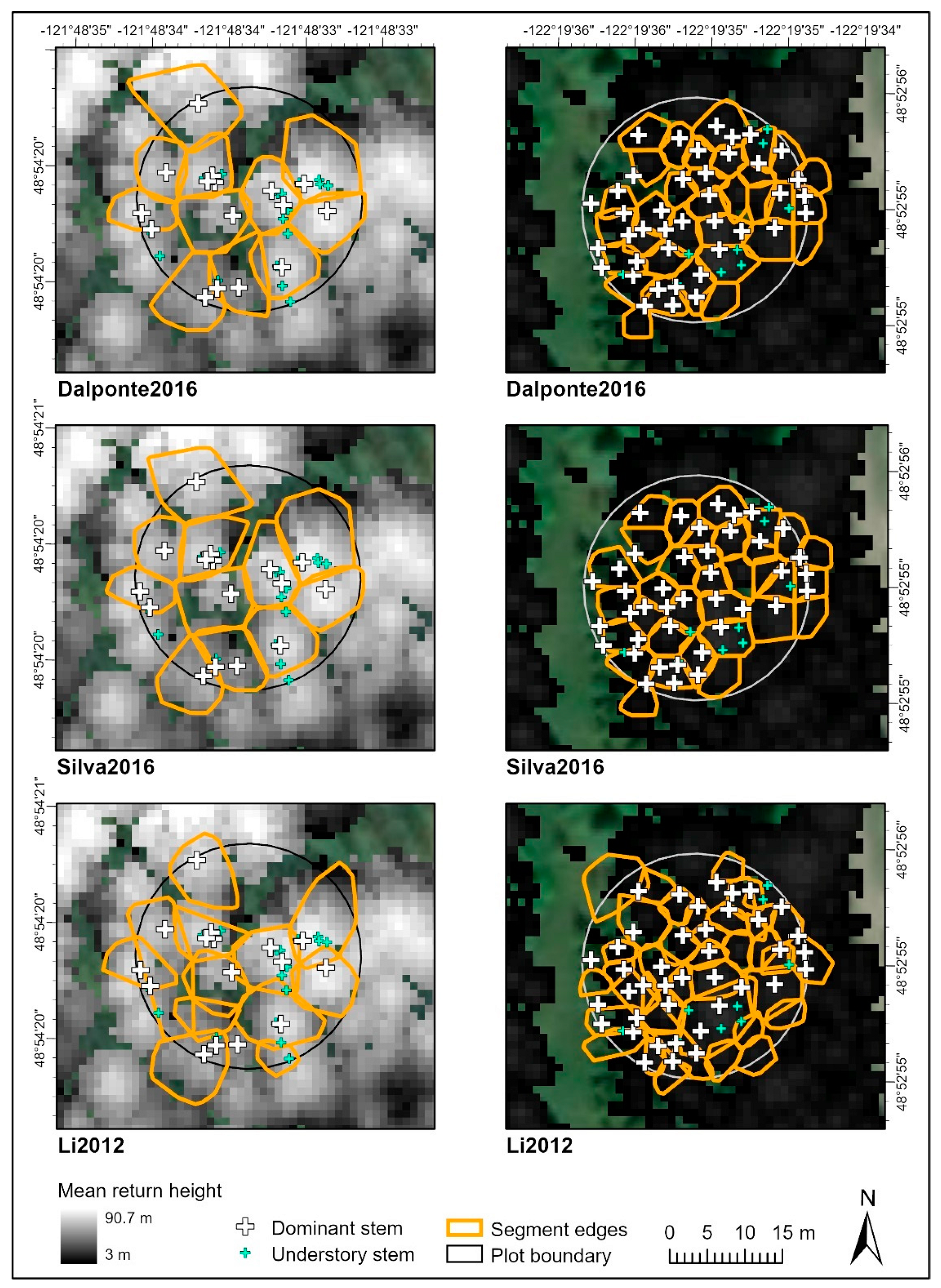
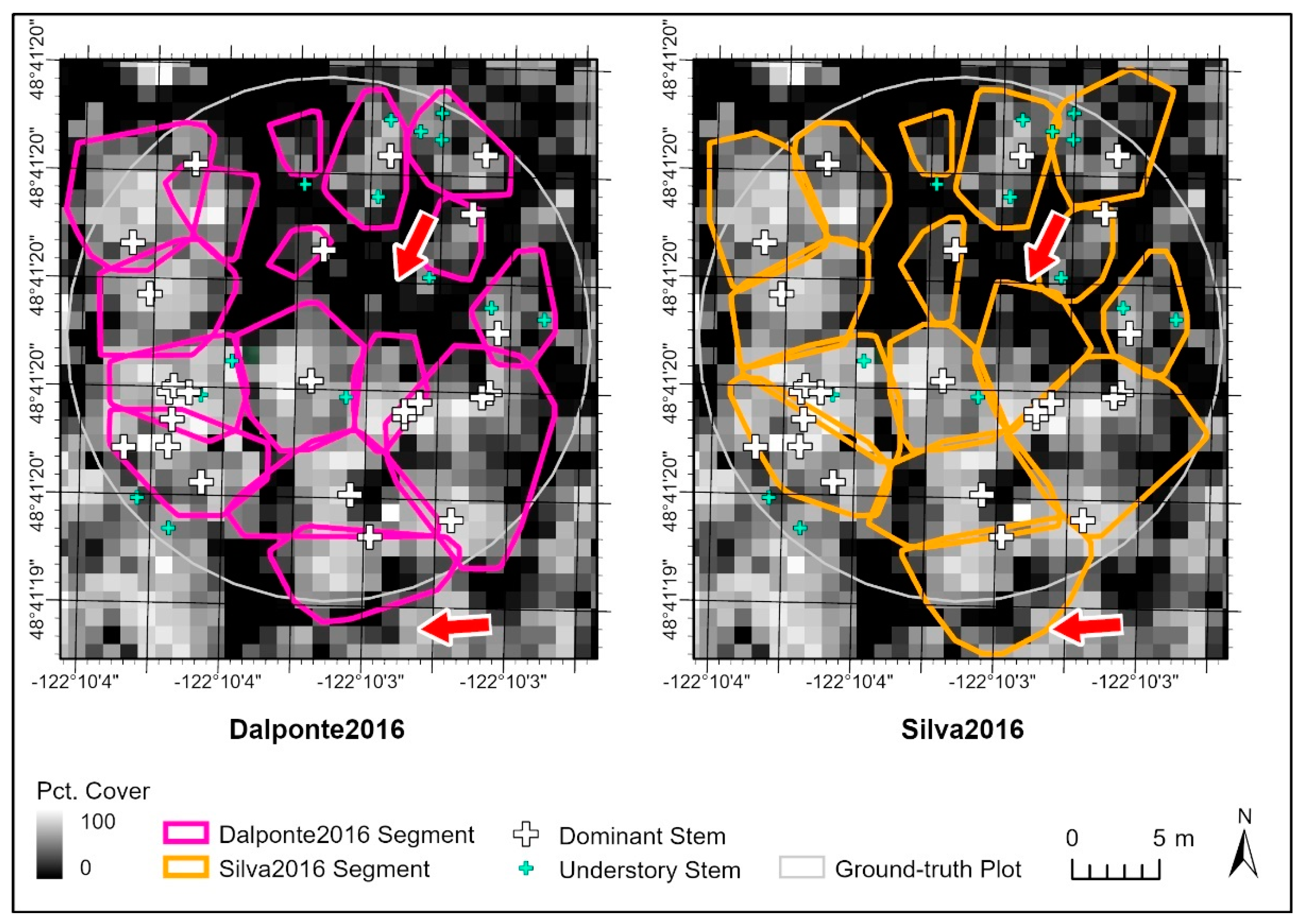
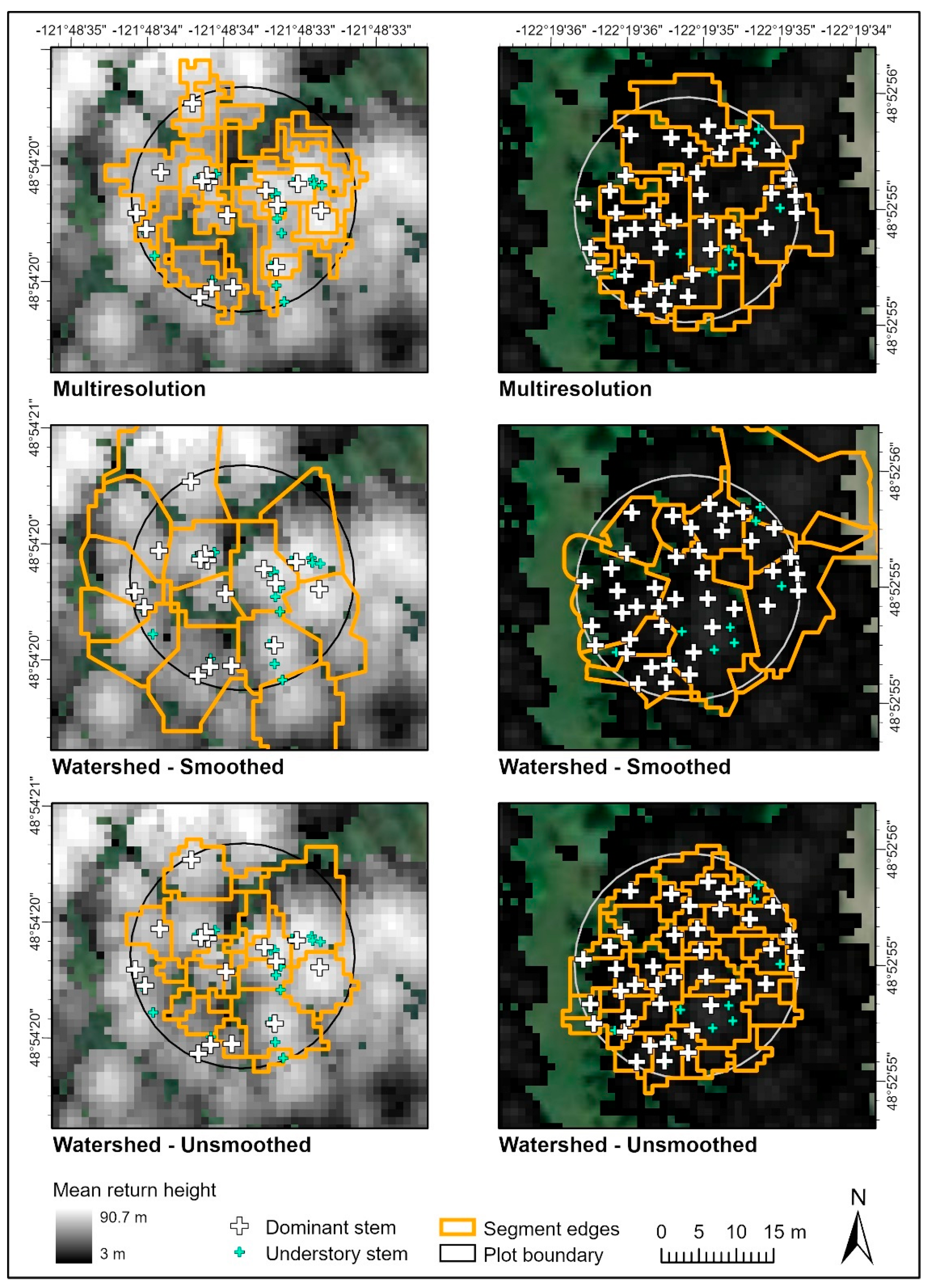
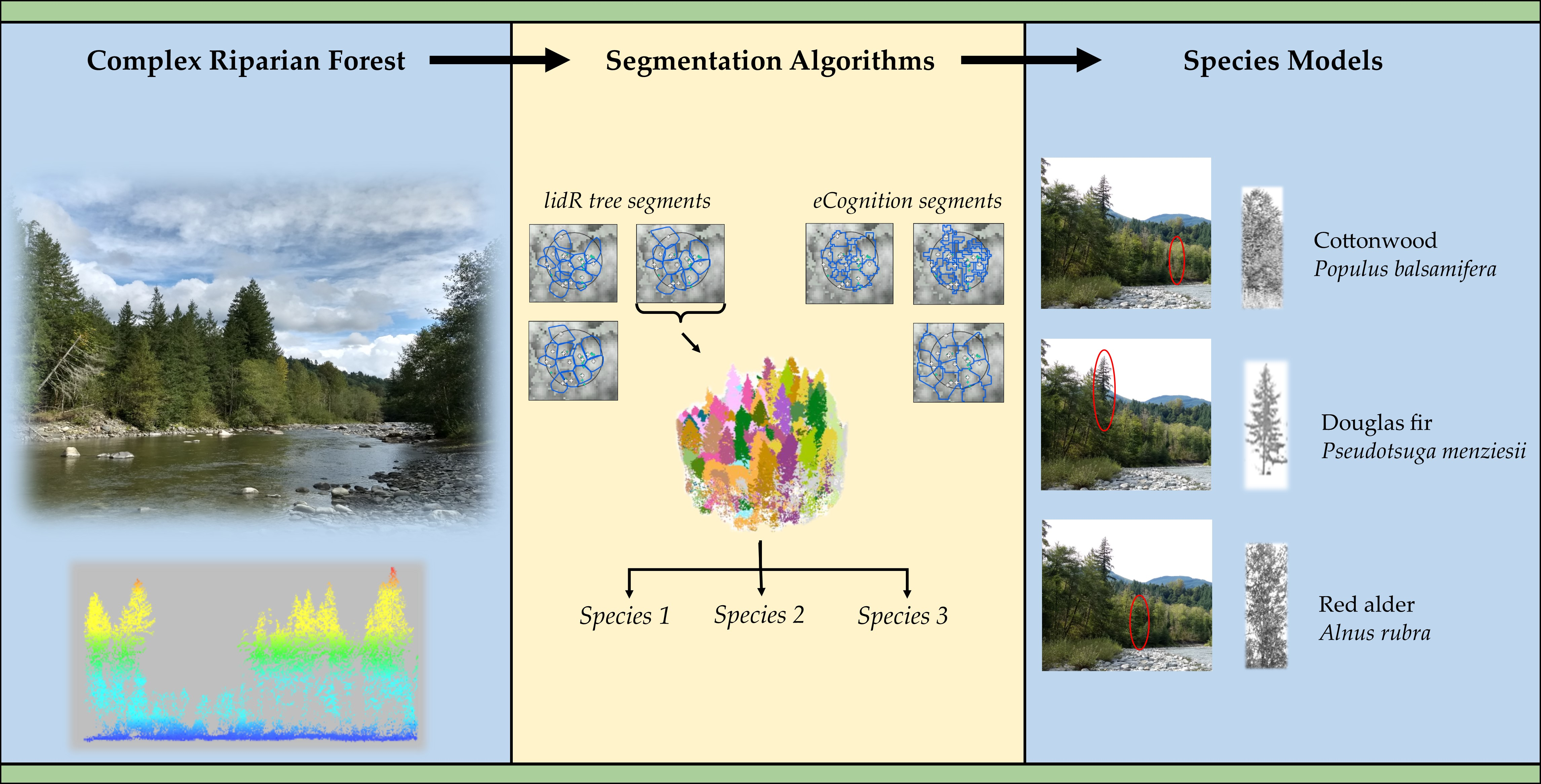
2.4. Individual Tree Segmentation
2.5. Individual Tree Metrics
2.6. Tree Species Classification
3. Results
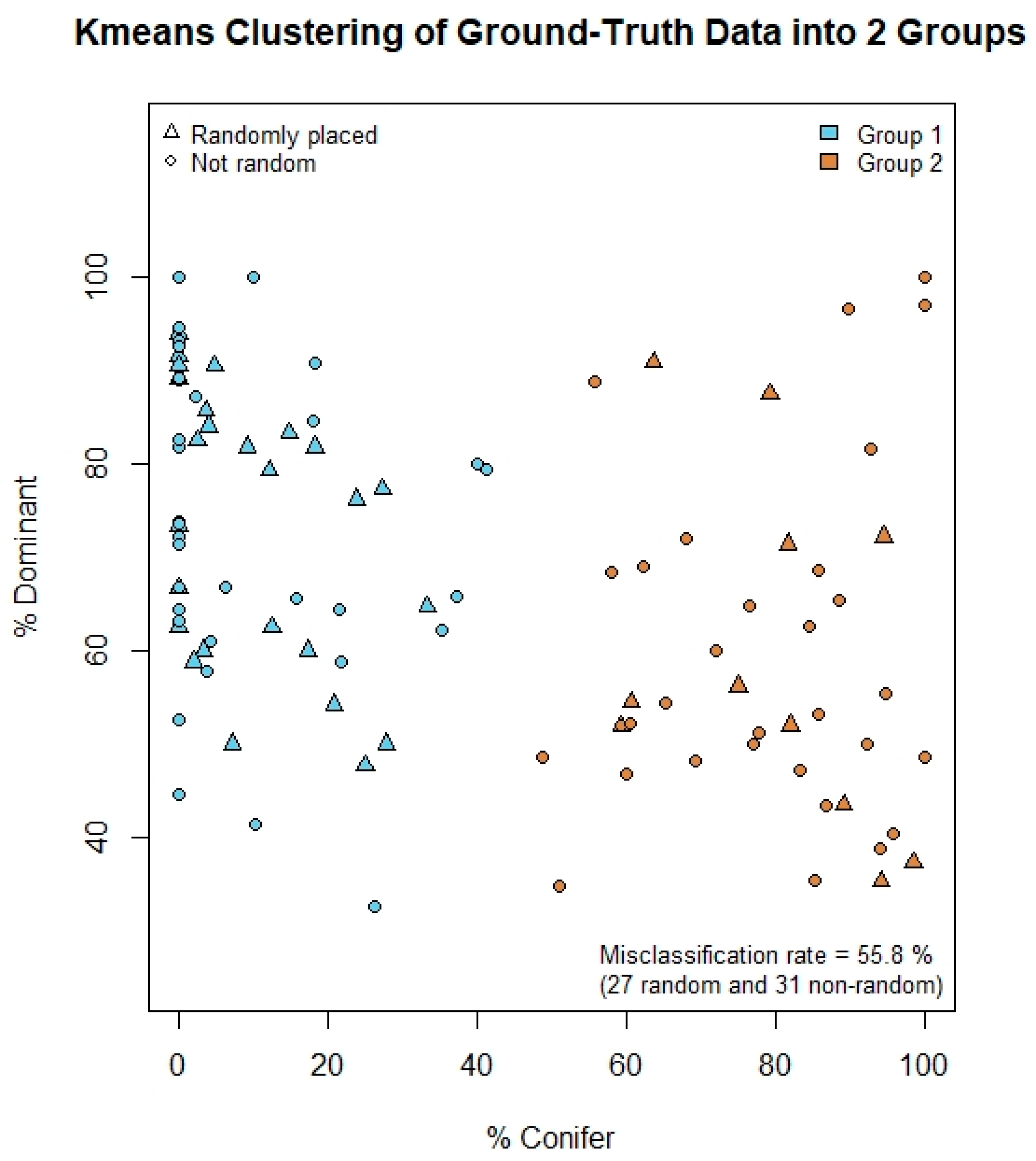
3.1. Segmentation Model Accuracy
3.2. Height, Diameter, and Coniferous/Deciduous Classification
3.3. Species Classification
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Schimel, D.S.; Asner, G.P.; Moorcraft, P. Observing changing ecological diversity in the Anthropocene. Front. Ecol. Environ. 2013, 11, 129–137. [Google Scholar] [CrossRef] [Green Version]
- Fassnacht, F.E.; Latifi, H.; Sterenczak, K.; Modzelewska, A.; Lefski, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote sensing technologies for enhancing forest inventories: A review. Can. J. Remote Sens. 2021, 42, 619–641. [Google Scholar] [CrossRef] [Green Version]
- Michalowska, M.; Rapiński, J. A review of tree species classification based on airborne LiDAR data and applied classifiers. Remote Sens. 2021, 13, 353. [Google Scholar] [CrossRef]
- Ørka, H.O.; Dalponte, M.; Gobakken, T.; Nӕsset, E.; Ene, L.T. Characterizing forest species composition using multiple remote sensing data sources and inventory approaches. Scand. J. Forest Res. 2013, 28, 677–688. [Google Scholar] [CrossRef]
- Vauhkonen, J.; Ørka, H.O.; Holmgren, J.; Dalponte, M.; Heinzel, J.; Koch, B. Tree species recognition based on airborne laser scanning and complementary data sources. In Forestry Applications of Airborne Laser Scanning; Maltamo, M.E., Nӕsset, E., Vauhkonen, J., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 135–156. [Google Scholar]
- Pauses, J.G.; Austin, M.P.; Noble, I.R. A forest simulation model for predicting Eucalypt dynamics and habitat quality for arboreal marsupials. Ecol. Appl. 1997, 7, 921–933. [Google Scholar] [CrossRef]
- Gabbe, A.P.; Robinson, S.K.; Brawn, J.D. Tree-species preferences of foraging insectivorous birds: Implications for floodplain forest restoration. Conserv. Biol. 2002, 16, 462–470. [Google Scholar] [CrossRef] [Green Version]
- Prescott, C.E. The influence of the forest canopy on nutrient cycling. Tree Physiol. 2002, 22, 1193–1200. [Google Scholar] [CrossRef] [Green Version]
- Bisson, P.A.; Bilby, R.E.; Bryant, M.D.; Dolloff, C.A.; Grette, G.B.; House, R.A.; Murphy, M.L.; Koski, K.V.; Sedell, J.R. Large woody debris in forested streams of the Pacific Northwest: Past, present, and future. In Streamside Management: Forestry and Fishery Interactions; Salo, E.O., Cundy, T.W., Eds.; College of Forest Resources, University of Washington: Seattle, WA, USA, 1987; pp. 143–190. [Google Scholar]
- Zhou, L.; Dai, L.; Gu, H.; Zhong, L. Review on the decomposition and influence factors of coarse woody debris in forest ecosystem. J. For. Res. 2007, 18, 48–54. [Google Scholar] [CrossRef]
- Bendix, J.; Cowell, M.C. Fire, floods, and woody debris: Interactions between biotic and geomorphic processes. Geomorphology 2010, 116, 297–304. [Google Scholar] [CrossRef]
- Hamann, A.; Wang, T. Potential effects of climate change on ecosystem and tree species distribution in British Columbia. Ecology 2006, 87, 2773–2786. [Google Scholar] [CrossRef] [Green Version]
- Koeng, K.; Höfle, B. Full-waveform airborne laser scanning in vegetation studies—A review of point cloud and waveform features for tree species classification. Forests 2016, 7, 198. [Google Scholar] [CrossRef] [Green Version]
- Jones, T.G.; Coops, N.C.; Sharma, T. Assessing the utility of airborne hyperspectral and LiDAR data for species distribution mapping in the coastal Pacific Northwest, Canada. Remote Sens. Environ. 2010, 114, 2841–2852. [Google Scholar] [CrossRef]
- Vauhkonen, J.; Ene, L.; Gupta, S.; Heinzel, J.; Holmgren, J.; Pitӓkanen, J.; Solberg, S.; Wang, H.; Weinacker, H.; Hauglin, K.M.; et al. Comparative testing of single-tree detection algorithms under different types of forest. Forestry 2012, 85, 27–40. [Google Scholar] [CrossRef] [Green Version]
- Holmgren, J.; Persson, Å. Identifying species of individual trees using airborne laser scanner. Remote Sens. Environ. 2004, 90, 415–423. [Google Scholar] [CrossRef]
- Kim, S.; McGaughey, R.J.; Andersen, H.E.; Schreuder, G. Tree species differentiation using intensity data derived from leaf-on and leaf-off airborne laser scanner data. Remote Sens. Environ. 2009, 113, 1575–1586. [Google Scholar] [CrossRef]
- Vaughn, N.R.; Moskal, L.M.; Turnblom, E.C. Tree species detection accuracies using discrete point lidar and airborne waveform lidar. Remote Sens. 2012, 4, 377–403. [Google Scholar] [CrossRef] [Green Version]
- Korpela, I.; Ørka, H.; Maltamo, M.; Tokola, T.; Hyyppä, J. Tree species classification using airborne LiDAR—effects of stand and tree parameters, downsizing of training set, intensity normalization, and sensor type. Silva Fenn. 2010, 44, 319–339. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Hyyppä, J. A comprehensive but efficient framework of proposing and validating feature parameters from airborne LiDAR data for tree species classification. Int. J. Appl. Earth Obs. 2016, 46, 45–55. [Google Scholar] [CrossRef]
- Shi, Y.; Wang, T.; Skidmore, A.K.; Heurich, M. Important LiDAR metrics for discriminating forest tree species in Central Europe. ISPRS J. Photogramm. Remote Sens. 2018, 137, 163–174. [Google Scholar] [CrossRef]
- Jeronimo, S.M.A.; Kane, V.R.; Churchill, D.J.; McGaughey, R.J.; Franklin, J.F. Applying LiDAR individual tree detection to management of structurally diverse forest landscapes. J. For. 2018, 116, 336–346. [Google Scholar] [CrossRef] [Green Version]
- Richardson, J.J.; Moskal, L.M. Strengths and limitations of assessing forest density and spatial configuration with aerial LiDAR. Rem. Sens. Environ. 2011, 115, 2640–2651. [Google Scholar] [CrossRef]
- Wulder, M.A.; Bater, C.W.; Coops, N.C.; Hilker, T.; White, J.C. The role of LiDAR in sustainable forest management. For. Chron. 2008, 84, 807–826. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Hinckley, T.; Briggs, D. Classifying individual tree genera using stepwise cluster analysis based on height and intensity metrics derived from airborne laser scanner data. Remote Sens. Environ. 2011, 115, 3329–3342. [Google Scholar] [CrossRef]
- Pollock, M.M. Biodiversity. In River Ecology and Management: Lessons from the Pacific Coastal Ecoregion; Naiman, R.J., Bilby, R.E., Eds.; Springer: New York, NY, USA, 1998; pp. 430–452. [Google Scholar]
- Gregory, S.V.; Swanson, F.J.; McKee, W.A.; Cummins, K.W. An ecosystem perspective of riparian zones. Bioscience 1991, 41, 540–551. [Google Scholar] [CrossRef]
- Everest, F.H. Riparian and Aquatic Habitats of the Pacific Northwest and Southeast Alaska: Ecology, Management History, and Potential Management Strategies; U.S. Department of Agriculture, Forest Service, Pacific Northwest Research Station: Portland, OR, USA, 2007. [Google Scholar] [CrossRef] [Green Version]
- Moskal, M.L.; Cooke, A.; Axe, T.; Comnick, J.M. Extensive Riparian Vegetation Monitoring—Remote Sensing Pilot Study; Agreement No. IAA 16-205; Washington Department of Natural Resources: Sedro Woolley, WA, USA, 2017. Available online: https://www.dnr.wa.gov/publications/bc_tfw_ripmonitor_20170831.pdf (accessed on 13 April 2021).
- Naiman, R.J.; Bilby, R.E.; Bisson, P.A. Riparian ecology and management in the Pacific Coastal Rain Forest. Bioscience 2000, 50, 996–1011. [Google Scholar] [CrossRef]
- Anderson, S.W.; Konrad, C.P. Downstream-propagating channel responses to decadal-scale climate variability in a glaciated river basin. J. Geophys. Res. Earth 2019, 124, 902–919. [Google Scholar] [CrossRef]
- Collins, B.; Sheikh, A.J. Historical Channel Locations of the Nooksack River; Report to Whatcom County Public Works Department: Bellingham, DC, USA, 2004; Available online: https://salmonwria1.org/sites/default/files/2019-09/part%201-Collins_Sheikh%202004%20Part%201_1.pdf (accessed on 4 July 2021).
- National Hydrography Dataset; United States Geologic Survey. Available online: https://www.usgs.gov/core-science-systems/ngp/national-hydrography (accessed on 10 May 2018).
- Lowe, A.; Selko, T.; Silvia, E.P. North Puget 2017: Western Washington 3DEP LiDAR Technical Data Report; United States Geologic Survey and Quantum Spatial LLC.: Corvallis, OR, USA. Available online: http://lidarportal.dnr.wa.gov (accessed on 21 May 2018).
- North Puget 2017. Washington LiDAR Portal; Washington State Department of Natural Resources. Available online: http://lidarportal.dnr.wa.gov/ (accessed on 8 March 2018).
- McGaughey, R. FUSION/LDV: Software for LiDAR Analysis and Visualization; Version 3.78; United States Forest Service: Seattle, WA, USA, 2018; Available online: https://forsys.cfr.washinton.edu.fusion.html/ (accessed on 26 May 2018).
- Frazer, G.W.; Magnussen, S.; Wulder, M.A.; Niemann, K.O. Simulated impact of sample plot size and co-registration error on the accuracy and uncertainty of LiDAR-derived estimates of forest stand biomass. Remote Sens. Environ. 2011, 115, 636–649. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Nelson, R.F.; Næsset, E.; Ørka, H.O.; Coops, N.C.; Hilker, T.; Bater, C.W.; Gobakken, T. Lidar sampling for large-area forest characterization: A review. Remote Sens. Environ. 2012, 121, 196–209. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; Version 3.6; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: https://www.R-project.org/ (accessed on 30 January 2021).
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley and Sons: New York, NY, USA, 1977; pp. 89–96. [Google Scholar]
- Pebsma, E.J. Multivariable geostatistics in S: The gstat package. Comput. Geosci. 2004, 30, 683–691. [Google Scholar] [CrossRef]
- Grӓler, B.; Pebsma, E.; Heuvelink, G. Spatio-temporal interpolation using gstat. R. J. 2016, 8, 204–218. Available online: https://cran.r-project.org/web/packages/gstat/vignettes/spatio-temporal-kriging.pdf (accessed on 13 April 2021). [CrossRef]
- Trimble. eCognition Developer; Version 9.5; Trimble Geospatial, Inc.: Sunnyvale, CA, USA, 2020; Available online: https://geospatial.trimble.com/products-and-solutions/ecognition (accessed on 30 January 2021).
- Roussel, J.R.; Auty, D. LiDr: Airborne LiDAR Data Manipulation and Visualization for Forestry Applications, R Package Version 3.0.3; 2020. Available online: https://CRAN.R-project.org/package=lidR (accessed on 17 September 2020).
- Dalponte, M.; Coomes, D.A. Tree-centric mapping of forest carbon density from airborne laser scanning and hyperspectral data. Methods Ecol. Evol. 2016, 7, 1236–1245. [Google Scholar] [CrossRef] [Green Version]
- Silva, C.A.; Hudak, A.T.; Vierling, L.A.; Loudermilk, E.L.; O’Brian, J.J.; Hiers, J.K.; Jack, S.B.; Gonzalez-Benecke, C.; Lee, H.; Falkowski, M.J.; et al. Imputation of individual Longleaf Pine (Pinus palustris Mill.) tree attributes from field and LiDAR data. Can. J. Remote Sens. 2016, 42, 554–573. [Google Scholar] [CrossRef]
- Li, W.; Guo, Q.; Jakubowski, M.K.; Kelly, M. A new method for segmenting individual trees from the lidar point cloud. Photogramm. Eng. Rem. Sens. 2012, 78, 75–84. [Google Scholar] [CrossRef] [Green Version]
- Hijams, R.J. Raster: Geographic Data Analysis and Modeling, R Package Version 3.1-5; 2020. Available online: https://CRAN.R-project.org/package=raster (accessed on 30 January 2021).
- Roussel, J.R.; Goodbody, T.R.H.; Tompalski, P. The lidR Package. 2020. Available online: https://jean-romain.github.io/lidRbook/ (accessed on 18 September 2020).
- Bates, D.; Maechler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Pinheiro, J.; Bates, D.; DebRoy, S.; Sarkar, D.; The R Core Team. Nlme: Linear and Nonlinear Mixed Effects Models, R package Version 3.1-144; 2020. Available online: https://CRAN.R-project.org/package=nlme> (accessed on 15 September 2020).
- Story, M.; Congalton, R. Accuracy assessment: A user’s perspective. Photogramm. Eng. Remote Sens. 1986, 52, 395–399. [Google Scholar]
- Heurich, M.; Persson, Å.; Kennel, E. Detecting and measuring individual trees with laser scanning in mixed mountain forest of Central Europe using an algorithm developed for Swedish boreal forest conditions. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 36, 307–312. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.222.2818&rep=rep1&type=pdf (accessed on 13 April 2021).
- Korpela, I.; Dahlin, B.; Schäfer, H.; Brunn, E.; Haapaniemi, F.; Honkasalo, J.; Ilvesniemi, S.; Kuutti, V.; Linkosalmi, M.; Mustonen, J.; et al. Single-tree forest inventory using lidar and aerial images for 3D treetop positioning, species recognition, height and crown width estimation. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2007, 36, 227–233. Available online: https://www.isprs.org/proceedings/xxxvi/3-w52/final_papers/Korpela_2007.pdf (accessed on 13 April 2021).
- Pirotti, F.; Kobal, M.; Roussel, J.R. A comparison of tree segmentation methods using very high density airborne laser scanning data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 285–290. [Google Scholar] [CrossRef] [Green Version]
- Gatziolis, D.; Fried, J.S.; Monleon, V.S. Challenges to estimating tree height via LiDAR in closed-canopy forests: A parable from Western Oregon. For. Sci. 2010, 56, 139–155. [Google Scholar] [CrossRef]
- North, M.P.; Kane, J.T.; Asner, G.P.; Berigan, W.; Churchill, D.J.; Conway, S.; Gutiérrez, R.J.; Jeronimo, S.; Keane, J.; Koltunov, A.; et al. Cover of tall trees best predicts California spotted owl habitat. For. Ecol. Manag. 2017, 405, 166–178. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gridmetrics Output | Description |
|---|---|
| Elev_mean | Mean return height |
| Elev_sd | Standard deviation return height |
| Elev_var | Variance of return height |
| Elev_P10–P99 | Mean return height of 10th–90th, 95th, and 99th percentiles |
| Relief ratio | Canopy relief ratio ((mean–min)/(max–min)) |
| Int_mean | Mean return intensity |
| Int_sd | Standard deviation intensity |
| Int_var | Variance of intensity |
| Int_P10–P99 | Mean intensity of 10th–90th, 95th, and 99th percentiles |
| Percent cover | (All returns above 3 m)/(total first returns)*100 |
| 1st returns above 3 m | Percentage of 1st returns above the height cutoff |
| All returns above 3 m | Percentage of all returns above the height cutoff |
| 1st returns above mean | Percentage of first returns above the mean height |
| All returns above mean | Percentage of all returns above the mean height |
| Attribute | Description |
|---|---|
| Plot location | GPS coordinates of plot center |
| Stem ID | Unique ID for the stem |
| Tree ID | Unique ID for the tree |
| Height | Stem height |
| DBH | Stem diameter measured at breast height (1.37 m) |
| Species | Tree species |
| Dominance Y/N | Canopy should be visible from above |
| Snag Y/N | Whether the stem was alive or dead |
| Broken Y/N | Whether the top of the stem was broken off |
| Forked Y/N | Stem forked above breast height |
| Leaning Y/N | Canopy substantially offset from base |
| Stem location | XY location of the stem relative to plot center |
| lidR Parameter | Description |
|---|---|
| DALPONTE 2016 | |
| th_tree = 3 m | Threshold below which a pixel cannot be a tree |
| th_seed = 0.45 | Growing threshold 1—default value. See Dalponte and Coomes [46] |
| th_cr = 0.55 | Growing threshold 2—default value. See Dalponte and Coomes [46] |
| max_cr = 15 m | Maximum allowable crown diameter |
| SILVA 2016 | |
| max_cr_factor = 0.6 | Maximum crown diameter, given as proportion of tree height |
| exclusion = 0.3 | Minimum height threshold: Pixels below the tree height times this factor are removed |
| LI 2012 | |
| dt1 = 1.5 m | Threshold number 1—default value. See Li et al. [48] |
| dt2 = 2 m | Threshold number 2—default value. See Li et al. [48] |
| R = 2 m | Search radius for local maxima. |
| Zu = 15 m | Height threshold determining whether threshold 1 or 2 is used. |
| hmin = 5 m | Minimum allowed height of a detected tree. |
| speed_up = 15 m | Maximum radius of a crown. |
| Method | Recall | Precision | F-Score | Parameters |
|---|---|---|---|---|
| Multiresolution | 0.51 ± 0.17 | 0.42 ± 0.19 | 0.41 ± 0.11 | scale = 10 shape = 0.1 compactness = 0.5 Input raster: canopy height model from mean height of first returns |
| Watershed (smoothed) | 0.43 ± 0.15 | 0.78 ± 0.17 | 0.52 ± 0.13 | Input surface: raster (1 m resolution, smoothed over a 3 × 3 window) of 80th percentile height returns |
| Watershed (unsmoothed) | 0.61 ± 0.16 | 0.40 ± 0.18 | 0.44 ± 0.13 | Input surface: canopy height model from mean height of first returns |
| Dalponte2016 | 0.50 ± 0.17 | 0.80 ± 0.20 | 0.58 ± 0.14 | th_tree = 3 m th_seed = 0.45 th_cr = 0.55 max_cr = 15 m |
| Silva2016 | 0.51 ± 0.21 | 0.80 ± 0.19 | 0.59 ± 0.13 | max_cr_factor = 0.6 exclusion = 0.3 |
| Li2012 | 0.54 ± 0.18 | 0.58 ± 0.20 | 0.52 ± 0.13 | dt1 = 1.5 m dt2 = 2 m R = 2 m Zu = 15 m hmin = 5 m speed_up = 15 m |
| Method | r (Dominant) | r (All Stems) | Mode, Median, and Maximum Dominant Stems per Segment |
|---|---|---|---|
| Multiresolution | −0.27 | −0.00 | Mode: 0 stems (64%) Median: 0 stems Max.: 16 stems (0.04%) |
| Watershed (smoothed) | −0.07 | −0.15 | Mode: 1 stem (29%) Median: 2 stems Max.: 20 stems (0.12%) |
| Watershed (unsmoothed) | 0.35 | 0.14 | Mode: 0 stems (65%) Median: 0 stems Max.: 10 stems (0.03%) |
| Dalponte2016 | 0.61 | 0.34 | Mode: 1 stem (34%) Median: 1 stem Max.: 10 stems (0.07%) |
| Silva2016 | 0.61 | 0.34 | Mode: 1 stem (37%) Median: 1 stem Max.: 8 stems (0.07%) |
| Li2012 | 0.50 | 0.23 | Mode: 0 stems (42%) Median: 1 stem Max.: 24 stems (0.05%) |
| Segment-Based Analysis–Smoothed Watershed Method | |||
| RMSE ± std. dev. | Model | Parameters | |
| Mean height (dominant) | 2.26 ± 1.75 m (2.87 ± 2.70 m) | Linear mixed-effect model (lme4 package) | 95th percentile LiDAR return height |
| Mean height (all trees) | 2.38 ± 1.80 m (3.14 ± 3.02 m) | Linear mixed-effect model (lme4 package) | 95th percentile LiDAR return height |
| Maximum height | 7.16 ± 5.30 m (3.30 ± 2.92 m) | Linear mixed-effect model (lme4 package) | 95th percentile LiDAR return height |
| Mean DBH (dominant) | 19.60 ± 13.58 cm (6.73 ± 6.71 cm) | Linear mixed-effect model (nlme package) Fixed variances | 95th percentile LiDAR return height |
| Mean DBH (all trees) | 13.08 ± 10.25 cm (6.32 ± 6.32 cm) | Linear mixed-effect model (nlme package) Fixed variances | 95th percentile LiDAR return height |
| Segment-Based Analysis–Dalponte 2016 Method | |||
| RMSE ± std. dev. | Model | Parameters | |
| Tree height | 2.50 ± 2.46 m (6.63 ± 5.22 m) | Linear mixed-effect model (lme4 package) | Height of LiDAR-derived tree top |
| Tree DBH | 9.10 ± 10.56 cm (13.13 ± 9.21 cm) | Linear mixed-effect model (nlme package) Fixed variances | Height of LiDAR-derived tree top |
| Segment-Based Analysis–Smoothed Watershed Method | |||
| Field Control | |||
| Conifer | Deciduous | Row total | |
| Classification | |||
| Conifer | 97 | 13 | 110 |
| Deciduous | 16 | 204 | 220 |
| Column total | 113 | 217 | 330 |
| Producer’s accuracy | User’s accuracy | ||
| Conifer = 97/113 = 86% Deciduous = 204/217 = 94% Overall accuracy = (97 + 204)/330 = 91% Kappa = 0.80 | Conifer = 97/110 = 88% Deciduous = 204/220 = 93% | ||
| Segment-Based Analysis–Dalponte2016 Method | |||
| Field Control | |||
| Conifer | Deciduous | Row total | |
| Classification | |||
| Conifer | 295 | 30 | 325 |
| Deciduous | 65 | 682 | 747 |
| Column total | 360 | 712 | 1072 |
| Producer’s accuracy | User’s accuracy | ||
| Conifer = 295/360 = 82% Deciduous = 682/712 = 96% | Conifer = 295/325 = 91% Deciduous = 682/747 = 91% | ||
| Overall accuracy = (295 + 682)/1072 = 91% Kappa = 0.80 | |||
| Field Control | |||
|---|---|---|---|
| Cottonwood | Other Species | Row Total | |
| Classification | |||
| Cottonwood | 67 | 11 | 78 |
| Other species | 25 | 211 | 236 |
| Column total | 92 | 222 | 314 |
| Producer’s accuracy | User’s accuracy | ||
| Cottonwood = 67/92 = 73% Other species = 211/222 = 95% | Cottonwood = 67/78 = 86% Other species = 211/236 = 89% | ||
| Overall accuracy = (67 + 211)/314 = 89% Kappa = 0.71 | |||
| Field Control | |||
|---|---|---|---|
| Douglas Fir | Other Species | Row Total | |
| Classification | |||
| Douglas fir | 26 | 7 | 33 |
| Other species | 14 | 189 | 203 |
| Column total | 40 | 196 | 236 |
| Producer’s accuracy | User’s accuracy | ||
| Douglas fir = 26/40 = 65% Other species = 189/196 = 96% | Douglas fir = 26/33 = 79% Other species = 189/203 = 93% | ||
| Overall accuracy = (26 + 189)/236 = 91% Kappa = 0.66 | |||
| Field Control | |||
|---|---|---|---|
| Red Alder | Other Species | Row Total | |
| Classification | |||
| Red alder | 46 | 12 | 58 |
| Other species | 42 | 214 | 256 |
| Column total | 88 | 226 | 314 |
| Producer’s accuracy | User’s accuracy | ||
| Red alder = 46/88 = 52% Other species = 214/226 = 95% | Red alder = 46/58 = 79% Other species = 214/256 = 84% | ||
| Overall accuracy = (46 + 214)/314 = 83% Kappa = 0.52 | |||
| Field Control | |||
|---|---|---|---|
| Cottonwood | Other Species | Row Total | |
| Classification | |||
| Cottonwood | 189 | 23 | 212 |
| Other species | 61 | 757 | 818 |
| Column total | 250 | 780 | 1030 |
| Producer’s accuracy | User’s accuracy | ||
| Cottonwood = 189/250 = 76% Other species = 757/780 = 97% | Cottonwood = 189/212 = 89% Other species = 757/818 = 93% | ||
| Overall accuracy = (189 + 757)/1030 = 92% Kappa = 0.66 | |||
| Field Control | |||
|---|---|---|---|
| Douglas Fir | Other Species | Row Total | |
| Classification | |||
| Douglas fir | 119 | 25 | 144 |
| Other species | 64 | 822 | 886 |
| Column total | 183 | 847 | 1030 |
| Producer’s accuracy | User’s accuracy | ||
| Douglas fir = 119/183 = 65% Other species = 822/847 = 97% | Douglas fir = 119/144 = 83% Other species = 822/886 = 93% | ||
| Overall accuracy = (119 + 822)/1030 = 91% Kappa = 0.68 | |||
| Field Control | |||
|---|---|---|---|
| Red Alder | Other Species | Row Total | |
| Classification | |||
| Red alder | 214 | 43 | 257 |
| Other species | 121 | 652 | 773 |
| Column total | 335 | 695 | 1030 |
| Producer’s accuracy | User’s accuracy | ||
| Red alder = 214/335 = 64% Other species = 652/695 = 94% | Red alder = 214/257 = 83% Other species = 652/773 = 84% | ||
| Overall accuracy = (214 + 652)/1030 = 84% Kappa = 0.61 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tatum, J.; Wallin, D. Using Discrete-Point LiDAR to Classify Tree Species in the Riparian Pacific Northwest, USA. Remote Sens. 2021, 13, 2647. https://doi.org/10.3390/rs13142647
Tatum J, Wallin D. Using Discrete-Point LiDAR to Classify Tree Species in the Riparian Pacific Northwest, USA. Remote Sensing. 2021; 13(14):2647. https://doi.org/10.3390/rs13142647
Chicago/Turabian StyleTatum, Julia, and David Wallin. 2021. "Using Discrete-Point LiDAR to Classify Tree Species in the Riparian Pacific Northwest, USA" Remote Sensing 13, no. 14: 2647. https://doi.org/10.3390/rs13142647
APA StyleTatum, J., & Wallin, D. (2021). Using Discrete-Point LiDAR to Classify Tree Species in the Riparian Pacific Northwest, USA. Remote Sensing, 13(14), 2647. https://doi.org/10.3390/rs13142647