1. Introduction
Forests are the ecosystems with the richest biodiversity on land and represent an important factor affecting global carbon, water cycles, biodiversity, land-use change, and climate change [
1,
2,
3,
4,
5,
6,
7]. China’s Three-North Shelter Forest Program (TNSFP) [
8] is the largest artificial afforestation project in the world, covering more than 40% of China’s land area and serving as an important ecological barrier in northern China [
9,
10]. TNSFP not only holds important economic benefits but also plays an important role in preventing wind, fixing sand, regulating water and heat, improving the microclimate, soil, and water conservation, reducing natural disasters, and realizing the sustainable and healthy development of the ecological environment [
11]. Owing to the fragility and complexity of the ecological environment in the Three-North Region (TNR), the vegetation ecosystem in this region is affected by ever-changing land use/cover, and forest coverage information is an important factor used to characterize the ecological environment. It is of great significance to obtain timely and accurate forest coverage information and temporal and spatial changes in this region to study the ecological environment and vegetation coverage changes, sustainable management of land use and forests, and climate change in the TNR [
12,
13,
14].
Although several studies extracted forest cover information from 1-km AVHRR, 500-m and 250-m MODIS, and other remote sensing (RS) images [
15,
16,
17], in heterogeneous forests areas, forests and forest disturbances might be small and fragmented, resulting in many pixels that are spectrally mixed between disturbed forests, undisturbed forests, and non-forest classes [
18,
19]. In addition, in the change products defined based on the forest cover change, forest disturbances smaller than the pixel scale may be ignored, and the classification results cannot fully represent the intra-class heterogeneity problem within a certain pixel. Therefore, coarse-resolution RS images have obvious limitations in terms of representing the forest cover [
19,
20,
21]. Heterogeneous landscape can be better represented by plotting the coverage percentage of the land elements on a continuous scale [
22,
23]. Currently, several parameters can represent forest cover information on a continuous scale, such as forest canopy cover is defined as the proportion of the forest floor covered by the vertical projection of the tree crowns [
24]. The canopy closure, also known as crown closure, is an integrated measure of the canopy “over a segment of the sky hemisphere above one point on the ground” [
25]. The canopy cover refers to the proportion of the forest floor covered by the vertical projection of the tree crown [
26]. The percent tree cover is defined as the percentage of the ground surface area that is covered by a vertical projection of the outermost perimeter of the natural spread of the plant’s foliage, and small openings in the crown are included [
27]. The Fractional Forest Cover (FFC) represents the ratio of the forest canopy cover area to the entire pixel as viewed from above (vertical direction) [
14,
16]. They have different definitions in terms of the observation angle, estimation method, and estimated area. This article uses Landsat RS images with a resolution of 30 m, so the FFC in this article represents the proportion of the forest on a spatial scale of 30 × 30 m. The accurate estimation of the FFC on the pixel scale can describe the detailed forest stand status and the forest proportion, which can be used to understand the distribution characteristics of the forest cover in more detail. The FFC can reflect the state and changes in the trend of the forest on the pixel scale [
22,
23].
RS is a key technology for achieving this goal [
23]. Global-scale RS products such as the Global Forest Change (GFC) product [
28], the Moderate-resolution Imaging Spectroradiometer Vegetation Continuous Fields (MOD44B) [
29], and the Global Land Survey Landsat Tree Canopy Cover Continuous Fields (GLS_TCC) [
21] have enhanced our understanding of the global distribution of the FFC. However, global-scale data cannot reasonably represent changes in the regional land cover. Moreover, different studies may have different accuracies within the same region and even may reach opposite conclusions [
30,
31].
In FFC research, methods based on spectral analysis are generally used in small-scale research due to the complexity of the environment and the forest characteristics [
32,
33]. MLAs have promoted the improvement of the performance of the regression process based on RS methods [
34]. Senf et al. [
20] selected annual Landsat images and used a generalized regression-based unmixing approach (depending on RF regression and SVR) to estimate forest cover fractions. Baumann, et al. [
23] combined Landsat-8 and sentinel-1 images and used the gradient boosting regression (GBR) method to model continuous fields of tree cover at 30-m resolution. The regression tree (RT) algorithm is the most widely used for estimating the FFC [
35,
36]. Selkowitz [
37] used different combinations of Landsat, MODIS, MISR input data and used the RT model to estimate the fractional canopy. Donmez et al. [
36] chose the regression tree (RT) algorithm and used multi-time Landsat TM/ETM data and land cover information to estimate the tree coverages of various forest stands in the Mediterranean. The MLA ensembles have good robustness and generalization, but there are still few applications in the FFC estimation [
38,
39]. In addition, the performance of MLAs will vary greatly due to differences in the input parameters, estimated parameters, and/or research area [
40,
41,
42], and there is a lack of comparison of multiple algorithms in FFC estimation. To choose a more robust estimation model, it is necessary to verify the performances of the different algorithms in FFC estimation.
Considering the uneven spatial distribution of a forest, a large number of training samples need to be selected and labeled [
32]. In FFC research, although the method based on field sampling can be used to obtain more accurate sample data, this method is expensive and can only be used in small research areas [
43,
44]; UAV RS can be used to obtain a larger range of sample data, but it is limited by the availability and timeliness of the data [
20,
45,
46,
47]. High-resolution satellite remote sensing imagery (HRSRS) is characterized by a high spatial resolution and wide imaging range and has obvious advantages in terms of ground object recognition. HRSRS is widely used to obtain reference datasets in the research involving estimating the FFC [
22,
23,
34,
47,
48,
49]. For example, Baumann, et al. [
23], Godinho et al. [
34] used high-resolution Google Earth images to collect reference datasets, while Gessner, et al. [
22] used the results of classification and aggregation of IKONOS and QuickBird as a reference dataset. The spatial resolution of the GaoFen-2 (GF-2) satellite data is better than 1 m, and fused GF-2 data can provide a richer texture and geometric information and can make it easier to distinguish between surface forest and non-forest cover [
50,
51,
52]. In this study, GF- 2 was selected as the main source of the reference dataset.
In this study, the FFC in the TNR was drawn by using Landsat-8 RS images and was based on the research ideas of MLAs fusion. First, this research combines RS images of different resolutions (Landsat-8 and GaoFen-2) to construct a sample set for estimating the FFC, and then a multi-algorithm integrated machine learning model is constructed based on existing MLAs The performance of the MLAs estimating the FFC is evaluated and compared, and finally, a robust estimation model is established to estimate the FFC of the TNR.
3. Methodology
The methodology and experimental setup for this study are outlined in
Figure 2. First, preprocess the selected RS images and auxiliary data to construct the dataset required by the machine learning model. Next, select MLAs and determine the optimal parameter combination of the model through parameter tuning. Then, use cross-validation (CV), independent validation, reference image data comparison, and other methods to compare and evaluate these algorithms, and select the algorithm with the best stability and robustness as the final estimation model. Finally, use the final model to estimate the FFC of TNR.
3.1. Reference Data Sampling and Preprocessing
This subsection mainly describes the process of generating high-quality data for the development of the model. It mainly includes the processing of GF-2 images, the matching and processing of Landsat-8 RS images and reference data, and the construction and processing of the reference FFC dataset:
- (a)
Choose 1-m resolution GF-2 images as reference image data. To extract forest and non-forest information from it, we used the eCognition Developer (Version 9.0) software combined with visual interpretation to realize the classification of GF-2 images (in
Figure 3) [
80,
81]. In the process of visual interpretation, forestland and non-forest land are distinguished and judged according to the color, shape, and texture of the ground objects and the spatial distribution characteristics of the shadow between the ground objects, and then the wrong classification is manually edited and modified. Then, extract sparse or independently distributed trees in the image to ensure that the extraction of forestland is correct. Finally, obtain the forest classification result of the reference image.
- (b)
Extract the surface reflectance data of Landsat-8 images in the reference area, and calculate the vegetation index based on the reflectance data. Register GF-2 classification results with Landsat-8 data, and use a 5 × 5 sampling window for Landsat sampling, because a larger sampling window will lose small areas or fragmented forest cover, while a smaller sampling window will increase the spatial position inconsistency between different data sources because of registration errors [
23,
82]. Calculate the FFC in the corresponding sampling window.
- (c)
Construct a dataset with surface reflectance, vegetation indices, and terrain factors as predictors, and FFC as the response variables. Divide the dataset into a training set, test set, and independent validation set, and then train, verify, and evaluate the model.
The performance of MLAs depends on the quality of training samples. Because of noise problems, unbalanced distribution of data samples, and the lack of representativeness of samples, the data obtained according to the above methods cannot be directly used as input for MLAs. We need to preprocess the data, including the detection of outliers, the processing of missing and repeated values, data standardization, and feature selection [
83].
Feature selection can reduce the computation time, prevent the model from being too complex and which can lead to overfitting, and facilitate a better understanding of the learning model or data by removing irrelevant and redundant data [
84,
85]. The RF provides an assessment of the importance of the different feature variables in the prediction process. To evaluate the importance of each feature (e.g., the satellite image band and vegetation index), the RF switches one of the input random variables while keeping the rest constant, and it measures the decrease in the accuracy using the OOB error estimation and the decrease in the Gini index [
86,
87]. In this study, we used the RF model to analyze the importance of the selected feature variables to the target value and ranked the importance of the features, which is presented in
Figure 4.
The feature importance ranking results indicate that SAVI and SWIR_2 are the main contributors to the models, and these two features are highly sensitive to soil and vegetation. The topographic information in the DEM makes a high contribution, and the contribution of the image spectrum is ranked in the middle level. Some features have low importance scores (IPVI, NDVI, and DVI), but this does not indicate that these features are not sufficiently related to the FFC. This may be because the top-ranked features have a higher correlation with the FFC, or because there is autocorrelation between the features. Using the RF to rank the importance of the features allows for the selection of the features with higher relevance to the target value. We eliminated the features with importance scores of less than 0.01. We compared the accuracy of the model before and after the feature selection, there is no obvious change, which demonstrates that the eliminated features had no obvious effect on the model. In general, the selection of appropriate spectral indices, topographical information, and other features has a significant impact on the estimation of FFC. Finally, the estimation of the FFC can be interpreted as FFC = f(SAVI, SWIR_2, Blue, DEM, GRVI, ARVI, Green, NIR, Slope, EVI, SWIR_1, RDVI).
3.2. Machine Learning Algorithms
MLAs have a wide range of applications in the field of RS. To obtain a model suitable for this research, it was necessary to conduct a comprehensive comparative analysis of each MLA.
Table 4 lists the selected MLAs, including the ensemble algorithms (bagging and boosting), MLP, DTR, LR, Ridge, ENe, LASSO, and KNN.
The bagging ensemble algorithm uses a decision tree as the base-learner and employed bagging sampling to extract
n samples from the original sample set, with k extractions, to obtain k subsets of data, and finally, k models are trained. For the regression problem, the mean of the k models is taken as the final result. The representative algorithms are the RF [
88], and the bagged decision trees [
89]. The boosting ensemble algorithm combines multiple weak learners into a strong learner through iteration. The training of each learner depends on the results of the previous learner, and each time the samples that are incorrectly estimated are weighted and the samples that are correctly estimated are down-weighted. Finally, the multiple weak learners are weighted and combined. Its representative algorithms include GBR [
34] and Extreme Gradient Boosting (XGBoost) [
38].
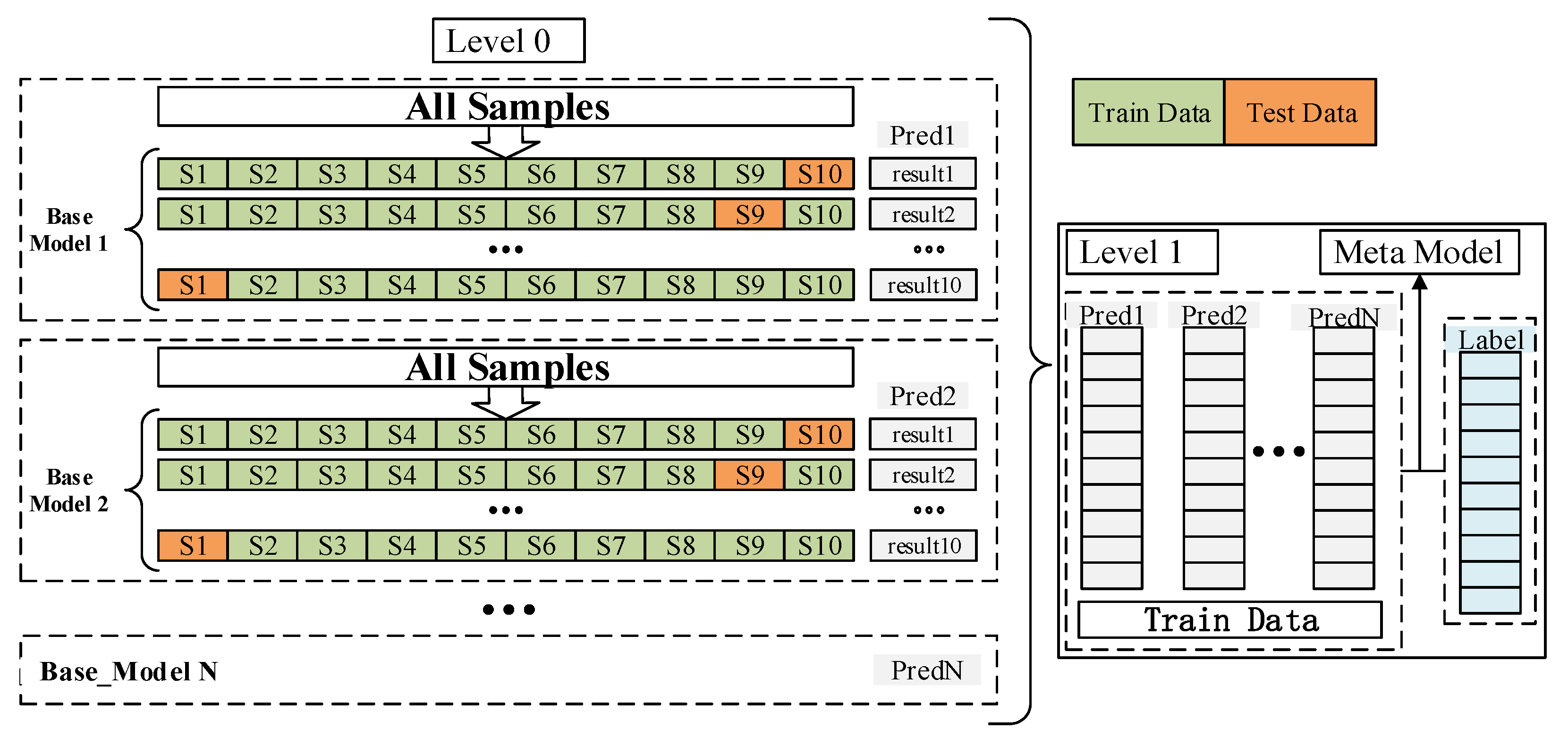
Stacked generalization (SG) is a layered ensemble algorithm [
90]. Take two layers as an example. The first layer is called the base model, and its input is the original training set, which is trained using a k-fold crossover. The second layer is called the meta-model, and the output of the first layer is used as the training set for the retraining to obtain a complete stacking model [
91]. In contrast to bagging and boosting, the base model in the SG method should be accurate and different. They can be bagging- and boosting-type algorithms, or KNN, SVR, and so on, but they have to have both less similarity and better estimation ability. The meta-model uses the estimation results of the base model as the input data for the training. The meta-model can be a single model or an ensemble model [
39,
92]. The construction process of the SG algorithm is shown in
Figure 5. The optimal algorithm among the various algorithms was selected as the base model through model comparison, and different meta-models were chosen to construct the SG model.
Each algorithm has a different performance when using different parameters, and tuning the parameter is required to obtain the best estimation capability for each model. In the process of model tuning, root mean squared error (RMSE) was used as the evaluation metric of the model, and each set of parameters was evaluated using a grid search and repeated 10-fold CV. Finally, the set of parameters with the smallest RMSE was selected as the best combination of parameters for the model [
93].
Table 4 lists the best parameter combinations for each machine learning algorithm. After tuning, we used 80% of the data in the entire dataset to train the model and used the other 20% of the data as the validation set to verify the estimation performance of the selected parameters. (In the experiment, we used scikit-learn to implement the required MLAs and the related processes based on Python 3.7.1
http://scikit-learn.org, (accessed on 31 May 2020)).
Table 4.
Statistics of selected algorithms.
Table 4.
Statistics of selected algorithms.
| Methods | Name | Optimal Parameters | References |
|---|
| Bagging | Bagging Regressor (BAG) | max_samples = 1.0 | [94] |
| n_estimators = 100 |
| Random Forest (RF) | n_estimators = 425 | [88,95] |
| min_samples_split = 10 |
| min_samples_leaf = 10 |
| Boosting | Ada Boost (ADA) | learning_rate = 0.03 | [96] |
| n_estimators = 225 |
| Cat boost (CBR) | Iterations = 575 | [97] |
| learning_rate = 0.02 |
| Gradient Boosting (GBR) | n_estimators = 650 | [34] |
| learning_rate = 0.1 |
| Light GBM (LGBM) | n_estimators = 815 | [98] |
| learning_rate = 0.12 |
| Extreme Gradient Boosting (XGBoost) | n_estimators = 620 | [99,100] |
| max_depth = 5 |
| learning_rate = 0.05 |
| Stacking | Stacked Generalization(SG) | Depends on the base models | [33,101] |
| Linear | Linear Regression (LR) | Default | [102] |
| Ridge | Default | [103] |
| ElasticNet (ENe) | Default | [104] |
| Lasso (LASSO) | Default | [105] |
| Neural Networks | Multi-layer perceptron (MLP) | solver = ‘adam’ | [14,104] |
| activation = ‘relu’ |
| hiden_layer_sizes = (100,100) |
| Tree-based | Decision Tree Regressor (DTR) | Default | [16,22,37] |
| | K-Neighbors Regression (KNN) | Default | [106] |
3.3. Evaluation Approaches
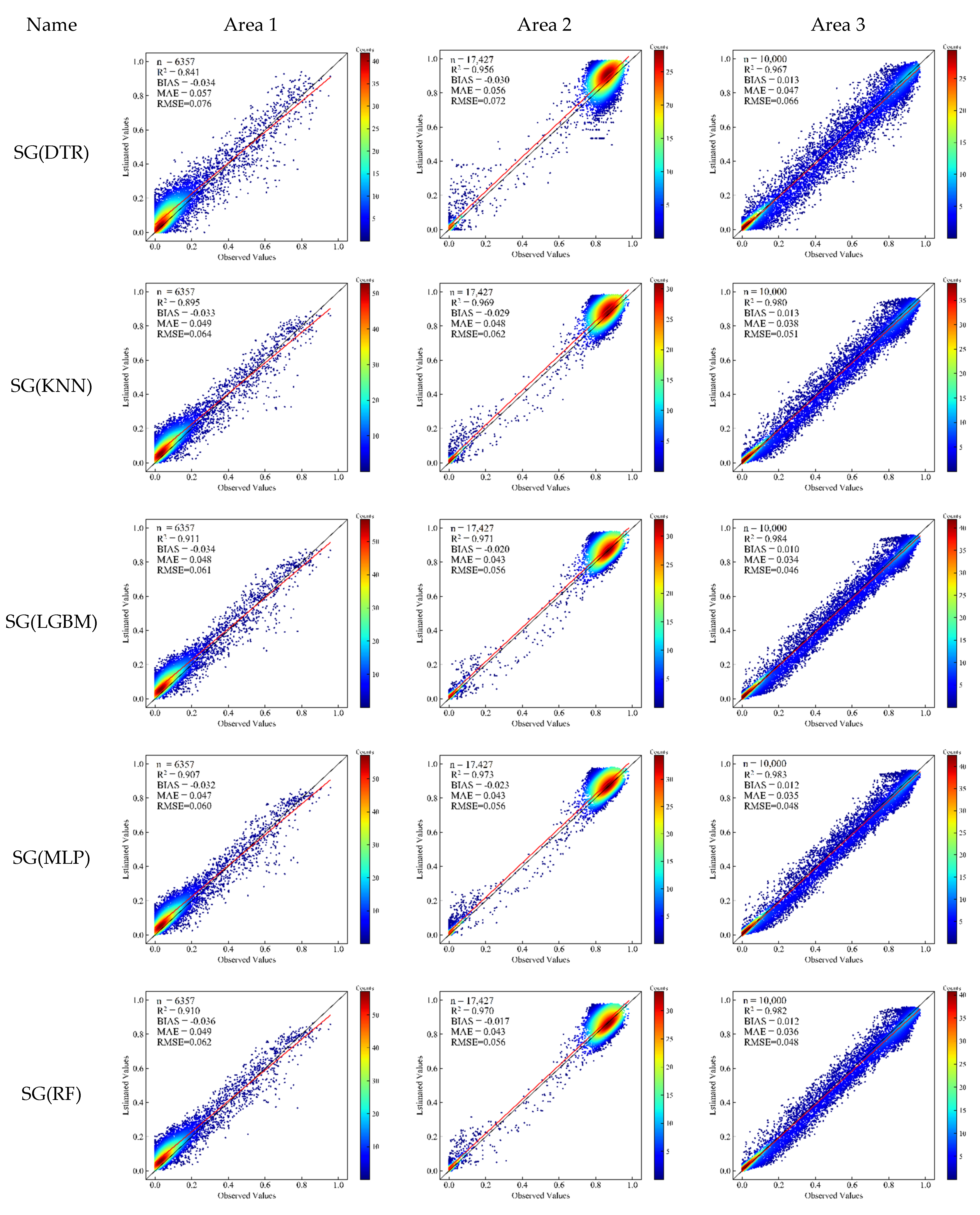
This study used three validation schemes to verify the model and experimental results: model-based cross-validation, validation based on independent samples, and comparative analysis with existing datasets.
In this paper, the correlation coefficient (R
2 Equation (1)), mean absolute error (MAE, Equation (2)), and root mean square error (RMSE, Equation (3)) were selected as the evaluation indicators of the model’s performance [
42,
87,
109].
In the equations and are the original values, the prediction results, and the average value of the observations, respectively, and n is the number of observations.
6. Conclusions
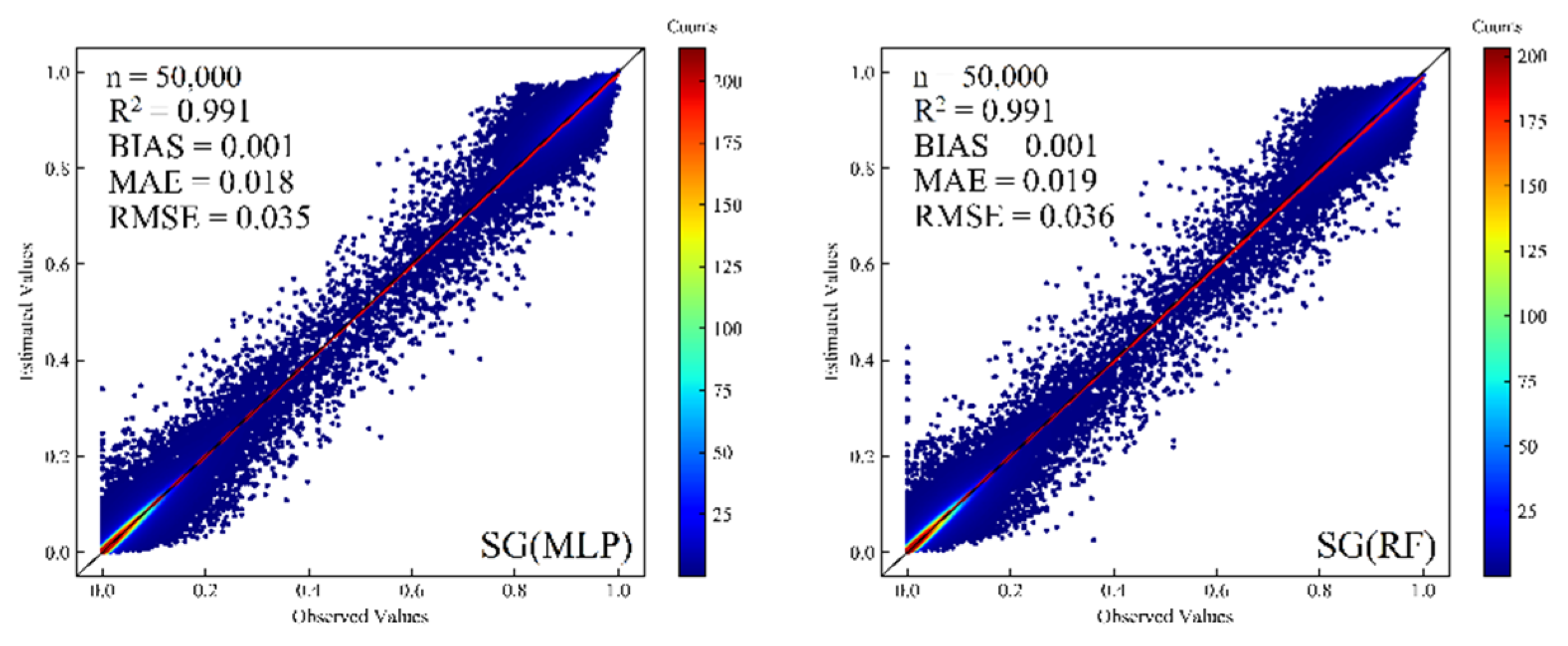
This study aimed to estimate the 30-m resolution FFC in the TNR of China. Landsat RS images were used to obtain band information and the vegetation index, GF-2 RS images were used as reference image data to obtain forest coverage information in the study area combined with auxiliary topographic factors, and machine learning methods were used to construct a method for estimating forest coverage in China’s TNR model. The results of the cross-validation and independent validation indicate that simple linear models cannot accurately represent the relationships between features and the FFC. The performance of ensemble models was better than that of other types of models, and RF (R2 = 0.991, MAE = 0.019, RMSE = 0.035) and LGBM (R2 = 0.991, MAE = 0.019, RMSE = 0.035) were the best of bagging ensemble models and boosting ensemble models, respectively. In this study, five models (RF, LGBM, MLP, DTR, KNN) with lower correlations but better performances were selected as the base models, and multiple SG algorithms were constructed using different meta-models. The results show that the selection of the meta-model is one factor that affects the performance of the SG algorithms. Moreover, the best SG model SG(LGBM) (R2 = 0.991, MAE = 0.018, RMSE = 0.034) had a better performance than the DTR (R2 = 0.980, MAE = 0.026, RMSE = 0.053). The results of stratification statistics indicate that when the coverage is below 0.2 and the coverages are above 0.8. The model has better performance, but the estimation ability of the model decreases between the coverages of 0.2 and 0.8. There are two possible reasons for this: (1) the number of samples in the range of 0.2 to 0.8 is small during the model training and model validation, so the model’s estimation ability in this range is weak; (2) Because the forest is not completely closed within the 0.2–0.8 cover range, the surface coverage is complex and the heterogeneity is high, which also indicates that further research is needed for areas with high surface heterogeneity. Through the comparative analysis of the dataset in the independent validation area, the GLS_TCC data were underestimated in the validation area, and the GFC data were underestimated in the high-value area, and through comparison with the forest aggregation map of the validation area, the forest distribution of the FFC had better consistency with the reference data and showed more detailed forest distribution trends. In addition, we also need to implement a more accurate validation of the estimated FFC and compare it with previous studies and data, as well as a more detailed study of the FFC for regions with a high surface heterogeneity.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}