1. Introduction
With the advancement of imaging technology, remote sensing (RS) images have a higher resolution than before. At present, RS images have been used in many research domains, including object detection [
1,
2,
3], image retrieval [
4,
5], change detection [
6,
7], land use classification [
8] and environmental monitoring [
9]. The RS image scene classification task, which tries to allocate a scene category to each RS image on the basis of its semantic information, has great significance in practical applications.
In the earlier researches, scene classification was accomplished by using the low-level features, including color histograms (CH) [
10], texture [
11,
12] and scale invariant feature transform (SIFT) [
13]. However, these methods relied on engineering skills and experts’ experiences to construct feature representations, which have limitations in describing abundant scene information.
To resolve the limitation of the low-level feature-based classification methods, many methods, which aggregate the extracted local low-level visual features to generate mid-level scene representation, have been proposed to achieve good performance on the scene classification task. As one of the most commonly used methods based on mid-level visual features, Bag-of-visual-words (BoVW) [
14] used the k-means clustering to obtain a visual dictionary and then performs feature encoding to generate mid-level visual features. The BoVW and its improved version have been widely used to complete scene classification [
15,
16,
17]. In addition, there are some other classical methods based on mid-level features, such as spatial pyramid matching (SPM) [
18], improved fisher kernel (IFK) [
19] and vectors of locally aggregated descriptors (VLAD) [
20].
However, the aforementioned methods, using low-level and mid-level features extracted from RS images, are not in a deep manner and cannot represent the semantic information of images very well [
21,
22,
23]. Recently, deep learning methods, especially CNN, have shown excellent performance in computer vision tasks because of their strong feature extraction ability. Moreover, RS image scene classification belongs to the high-level task in image processing, which is closely related to computer vision. At an early age, RS images have a low resolution, and the scenes to be classified are the large-area land cover, which is different from the natural images used in computer vision that focus on small-scale objects. Therefore, it has difficulty introducing deep learning-based methods to RS image scene classification. However, now RS image has a high spatial resolution, and the difference between natural image and RS image has been reduced, which provides the feasibility of introducing computer vision into remote sensing image processing.
Recently, many CNN-based methods have been introduced to complete scene classification tasks [
24,
25,
26,
27,
28]. Instead of using low-level and mid-level features, CNN-based methods can extract deep features from RS images by hierarchical feature extraction. In addition, most of CNN-based methods use the models pre-trained on ImageNet [
29], such as AlexNet [
30], VGG [
31], ResNet [
32] and DenseNet [
33]. Hu et al. [
24] verified the effectiveness of CNN models by using features extracted from convolutional layers. In [
27], Li et al. proposed a novel filter bank to capture local and global features at the same time to improve classification performance. Moreover, the influence of different training strategies on classification performance has been studied. There were three training strategies, including utilizing pre-trained CNN models as features extractors, utilizing pre-trained CNN models for fine-tuning, and fully trained models. The experimental results demonstrated that the fine-tuning strategy could obtain higher classification accuracy compared with the other two strategies [
8,
34].
To further improve the classification performance of CNN-based methods, some other advanced technologies, such as attention mechanism and feature fusion, have been introduced. The attention mechanism was introduced to enable deep models to focus on the important regions in RS images [
35,
36,
37,
38]. In [
35], Bi et al. combined the attention pooling and dense blocks to extract features from different levels. In [
36], Wang et al. proposed the recurrent attention structure to make models focus on important regions and high-level features. In addition, feature fusion was also an important method in scene classification [
39,
40,
41,
42,
43]. In [
40], Yu et al. combined the saliency coded and CNN model to complete the feature-level fusion. In [
42], Lu et al. proposed a coding module and an advanced fusion strategy to make full use of intermediate features.
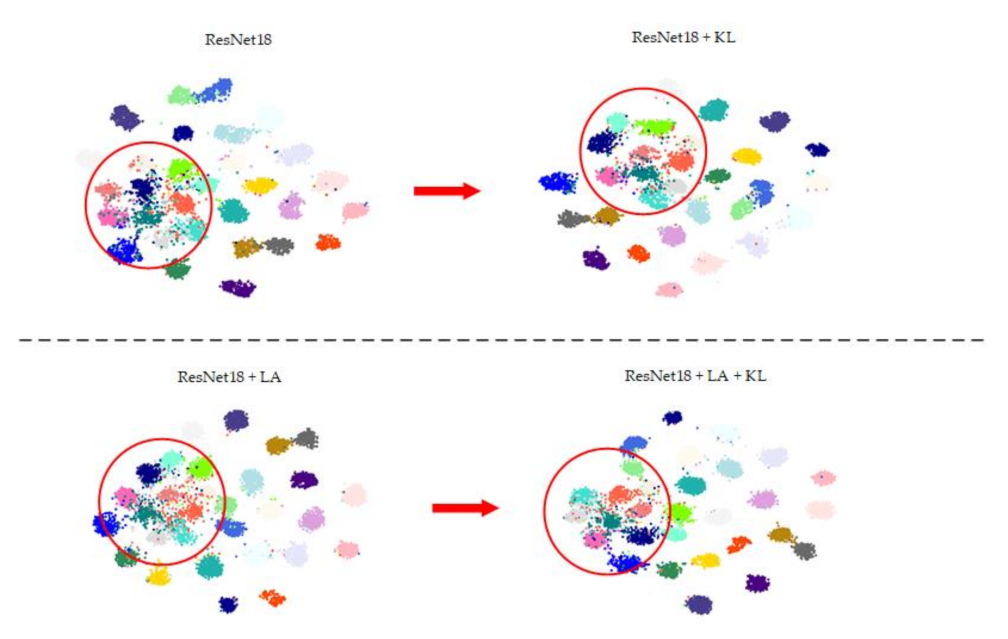
Although most existing CNN-based methods have achieved good performance on scene classification, the limited number of training images is still an important challenge. Deep learning methods rely on abundant labeled samples (e.g., ImageNet), but for remote sensing data, the acquisition of labeled samples is difficult. Compared with ImageNet, the number of images in RS datasets is small, which easily leads to overfitting. Even though the parameters of the pre-trained model are used for initialization, the overfitting problem still exists. In order to alleviate the overfitting, data augmentation has been widely used to expand the training set. However, when using data augmentation, most of the existing methods keep the original label while changing the content of the image, which is inappropriate. To address the above issue and fully use the training samples, we propose a method titled label augmentation that considers the label and data augmentation at the same time.
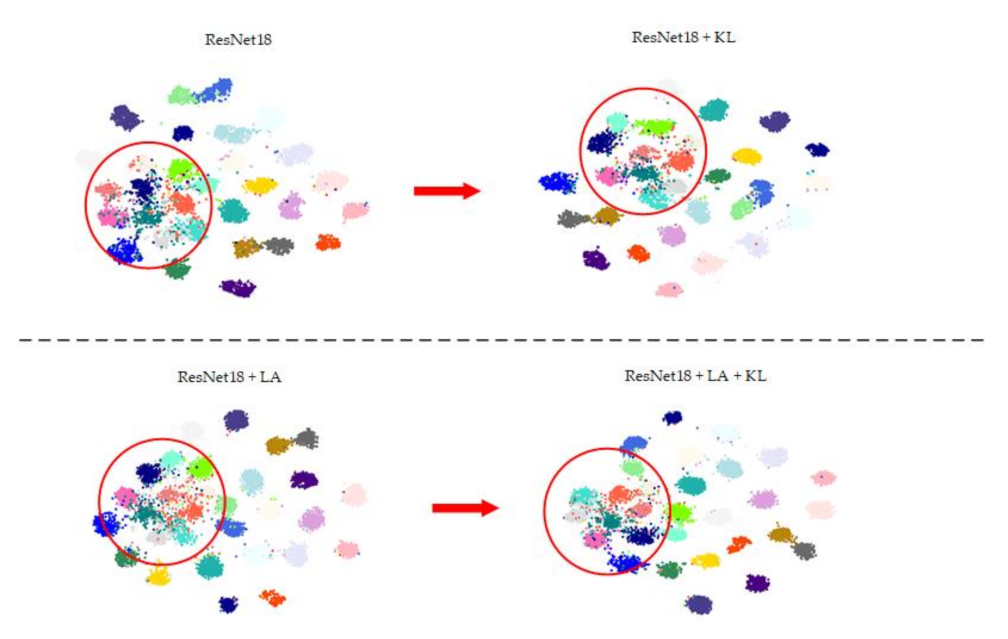
Moreover, label augmentation provides more training samples having accurate category information while also increasing intra-class diversity among the training set. It is necessary to impose a constraint on intra-class diversity to improve classification accuracy when using label augmentation. Therefore, we propose an intra-class constraint that utilizes KL divergence to constrain the output distribution of two RS images with the same scene category to reduce the intra-class diversity.
In this study, two methods are proposed to enhance the classification performance of RS images. First, the label augmentation is proposed to make full use of training samples, and then we utilize KL divergence to reduce the intra-class diversity among training sets caused by label augmentation. The major contributions of this study are summarized as follows:
In order to fully use RS images, we use label augmentation (LA) to obtain more accurate category information by assigning a joint label to each generated image.
To solve the intra-class diversity of training set caused by label augmentation, we use KL divergence to impose a constraint on the output distribution of two images with the same scene category.
We combine the label augmentation and intra-class constraint to further improve the remote sensing image classification accuracy. The generalization ability of the proposed method is evaluated and discussed.
The remainder of this paper is organized as follows.
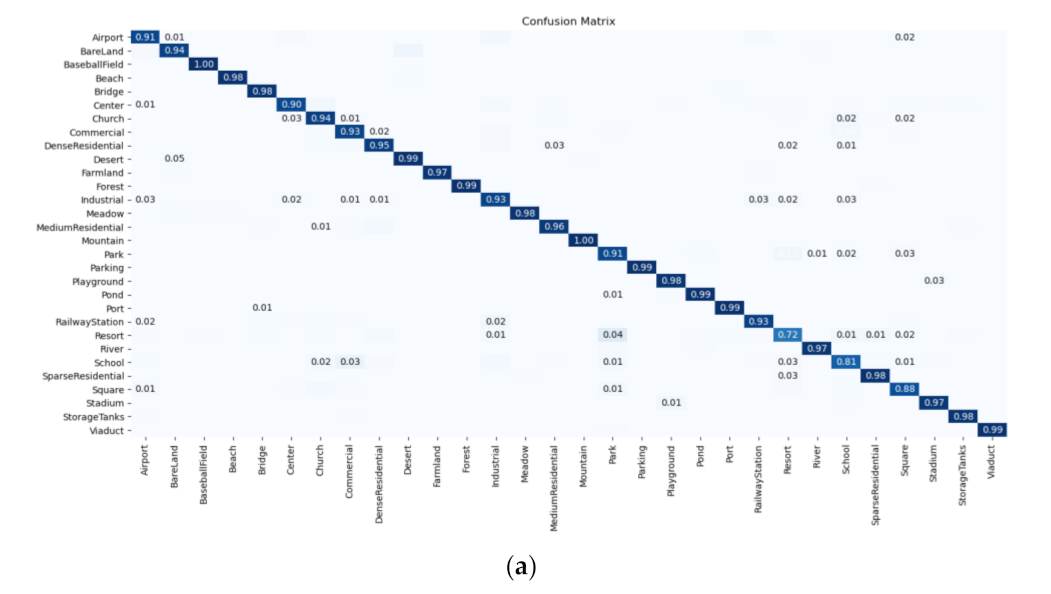
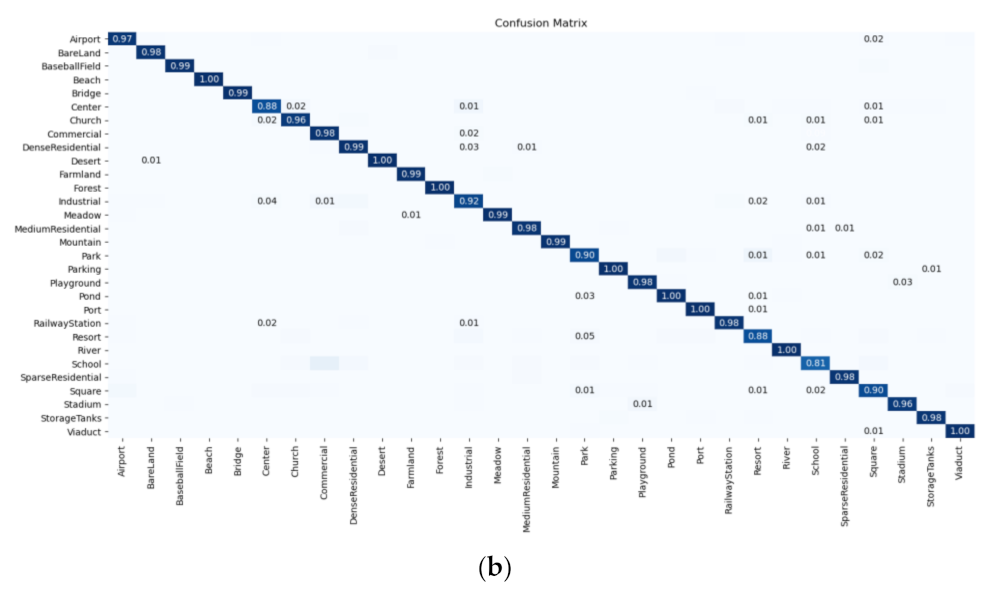
Section 2 introduces the proposed methods, including label augmentation, intra-class constraint and their combination. The used datasets, experimental setup, and results are shown in
Section 3. The experimental results are discussed and analyzed in
Section 4. Finally, we conclude this paper in
Section 5.
2. Methods
In this section, we describe the proposed methods in detail, including label augmentation, intra-class constraint and their combination.
2.1. Label Augmentation-Based RS Image Scene Classification
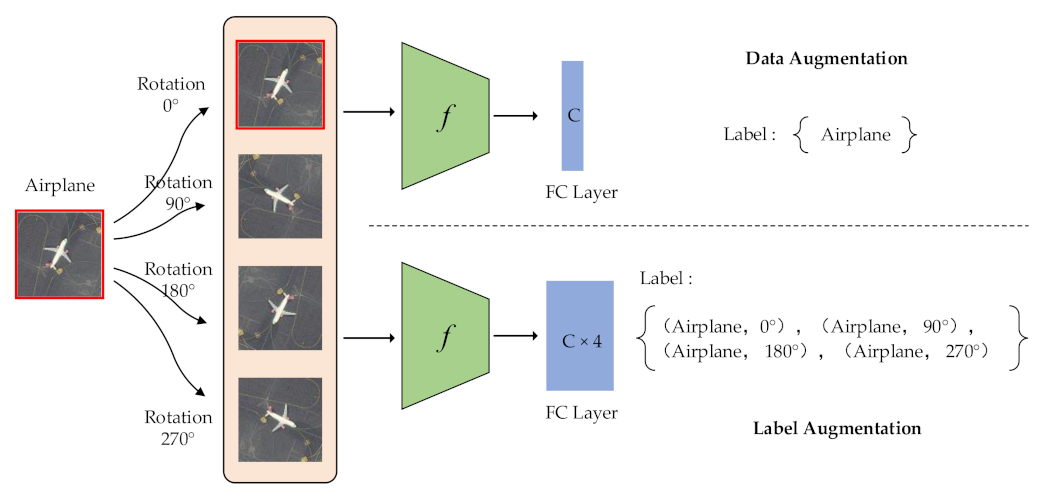
The label augmentation can be seen as an improvement of data augmentation. In the scene classification task, data augmentation can expand the training set to alleviate the overfitting problem. However, when an image is transformed by different data augmentation methods, the newly generated image keeps its original label, which imposes invariance to transformations on the classifier. To address the above issue, we propose the label augmentation, which considers the scene category and transformation of the remote sensing image at the same time and assigns a joint label to each generated image to effectively use training samples.
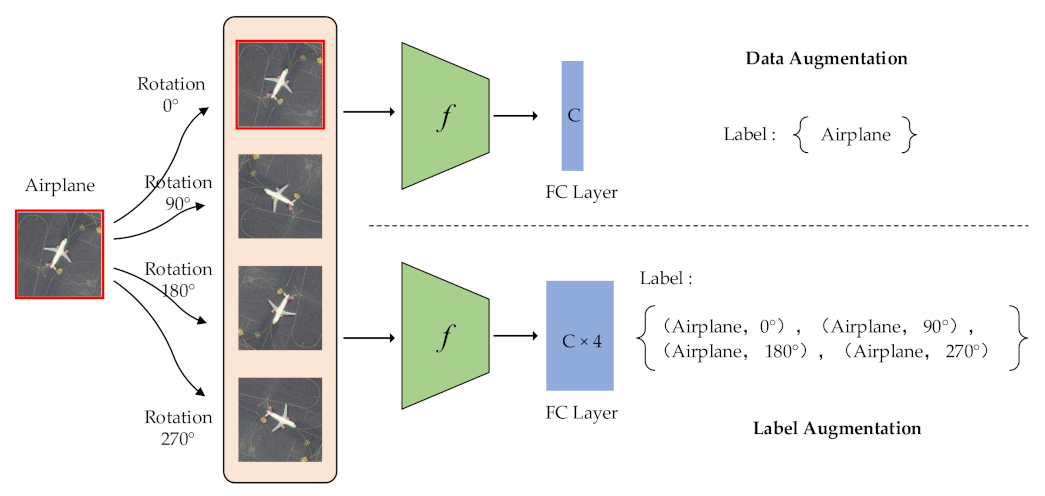
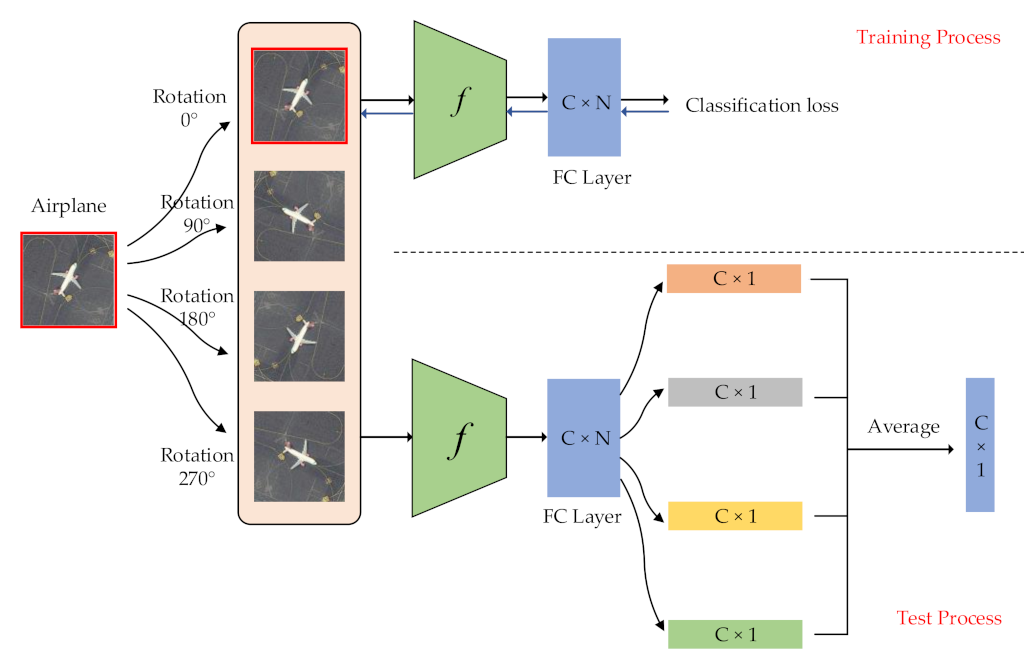
In
Figure 1, we take the rotation transformations of a sample as an example to show the difference between data augmentation and label augmentation. We rotate the original image by 0°, 90°, 180° and 270° to generate four images. When we use data augmentation, all 4 images are labeled with the category airplane. When using label augmentation, the rotation information is added to the label. In this manner, a joint label for each generated image can be obtained [
44]. Therefore, the category is expanded four-fold. The labels of four images are (airplane, 0°), (airplane, 90°), (airplane, 180°) and (airplane, 270°). Label augmentation can make each remote sensing image obtain more accurate category information than data augmentation.
With the increase in categories, the design of the classifier needs to be adjusted. We use
to represent a training sample, and it has a label
, where
is the number of categories. When we use data augmentation, the loss function can be expressed as:
where
is obtained by applying the rotation transformation to the original training sample
.
represents the cross-entropy loss function, and
represents the parameters of network
.
However, when applying the label augmentation, the joint label is used to increase category information, and the loss function of label augmentation can be expressed as:
where
is the number of images obtained by label augmentation. In
Figure 1, we use 4 rotation transformations to obtain 4 images, so
is equal to 4. There is a 4-fold increase in categories, so the dimension of the fully connected layer (FC) is also expanded 4-fold to
.
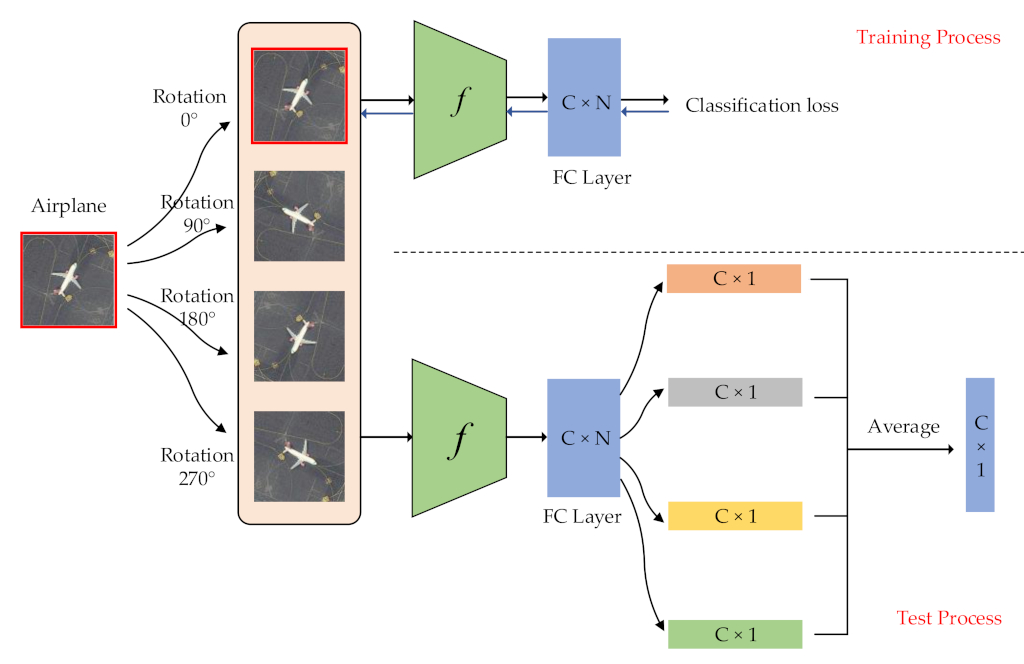
We show the training and test process of the label augmentation in
Figure 2. During the training process, we train the model using the standard cross-entropy loss and update the parameters
of the network
using a backpropagation algorithm. During the test process, we first aggregate outputs by calculating the average of
output vectors as follows:
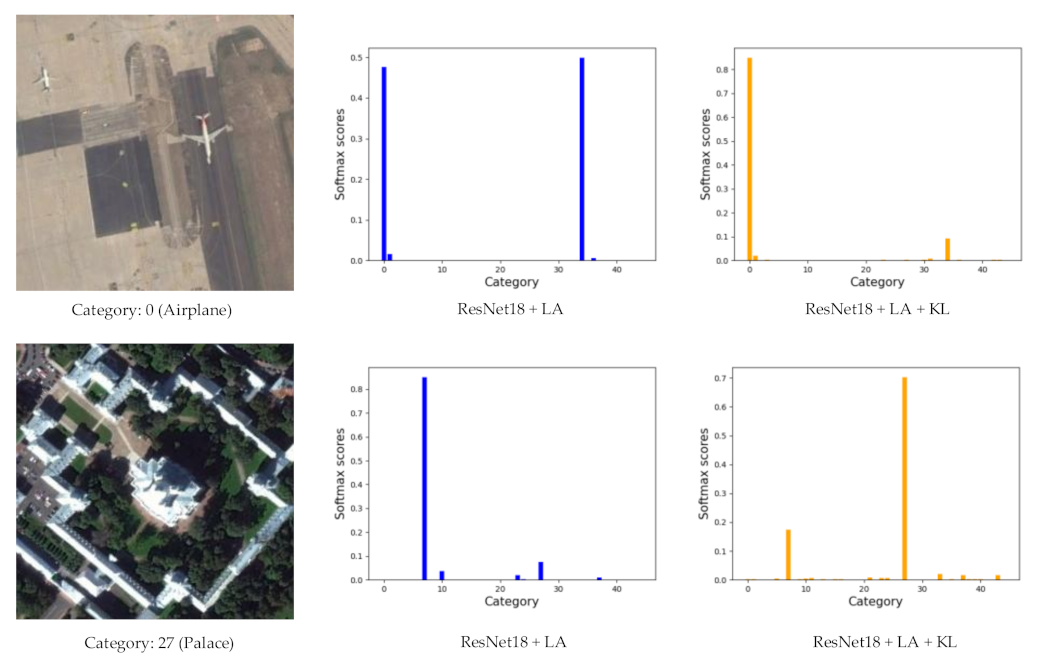
Then, we can calculate the softmax probability by:
With the label augmentation, we can use a single CNN model to identify scene category and rotation transformation at the same time, which fully uses the training set to enhance classification performance.
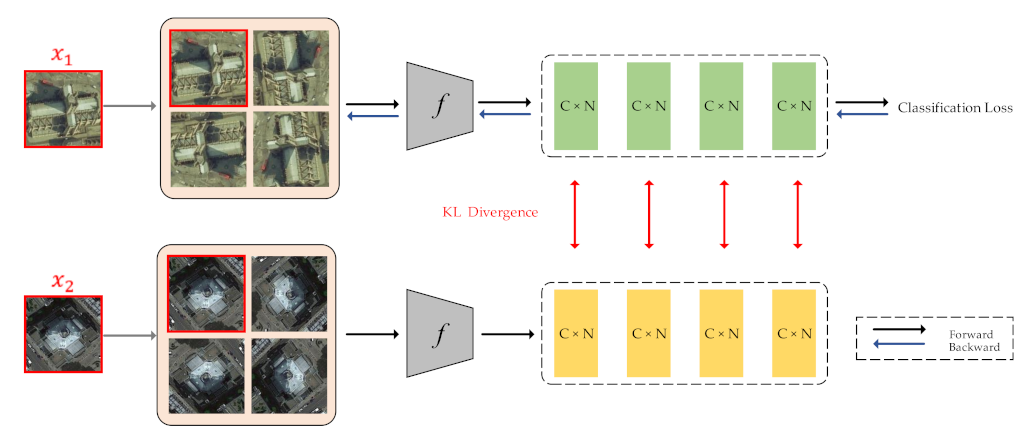
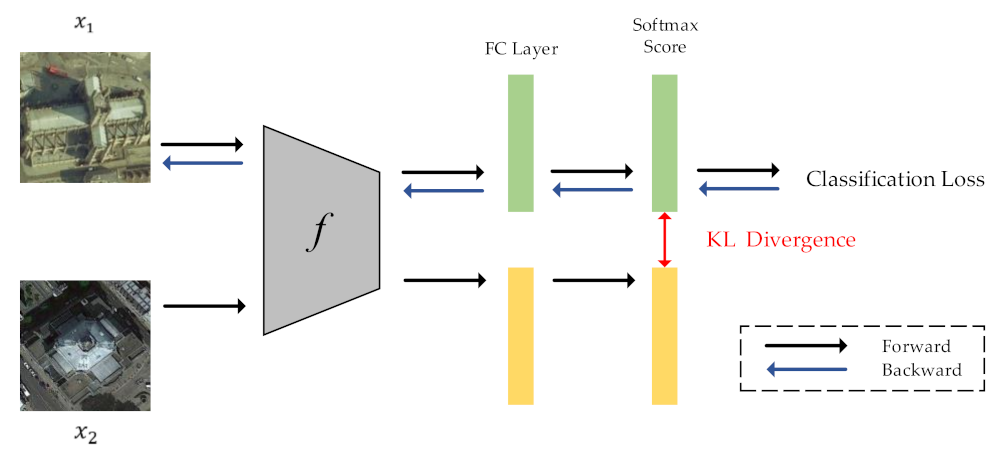
2.2. Intra-Class Constraint for RS Image Scene Classification
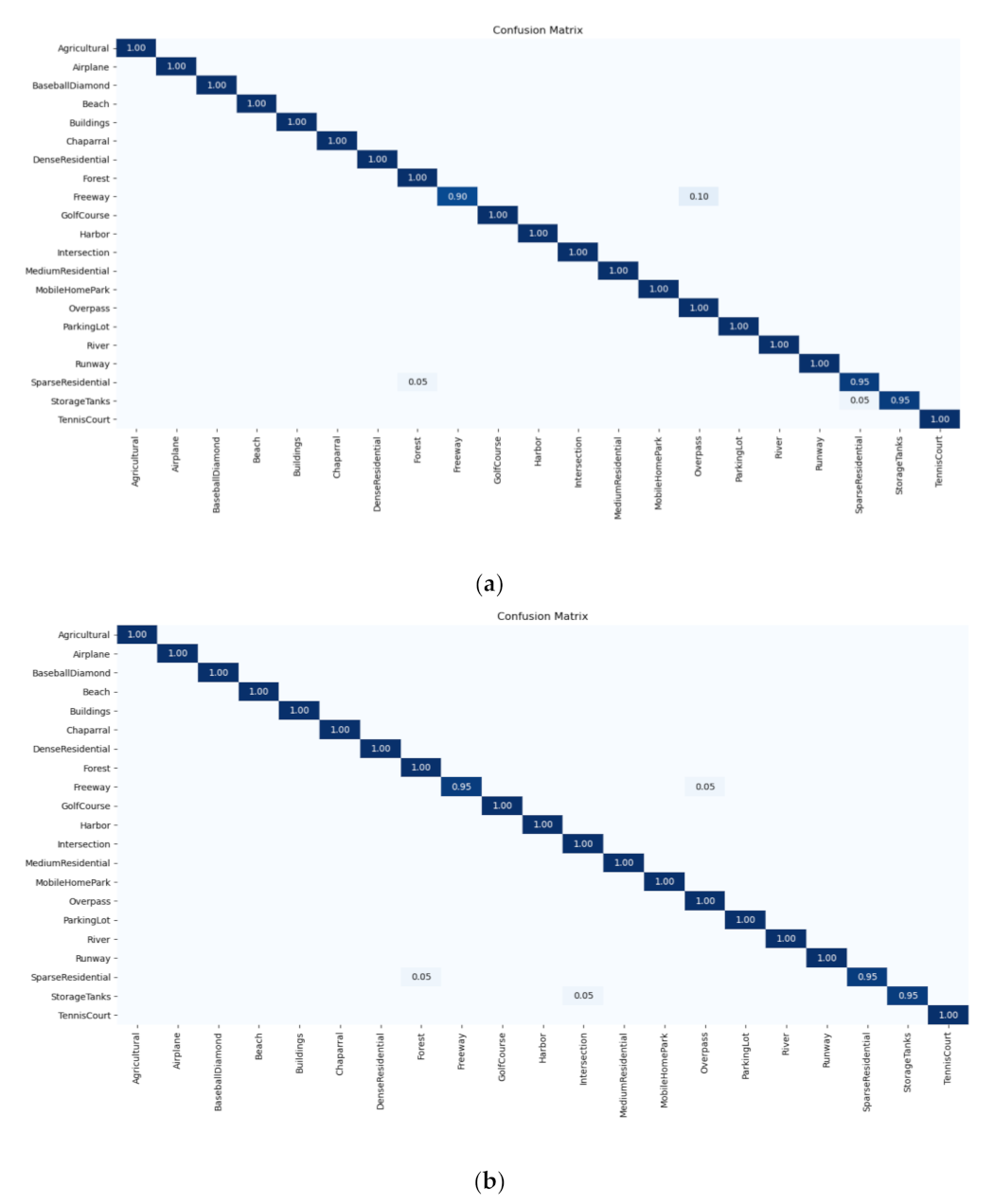
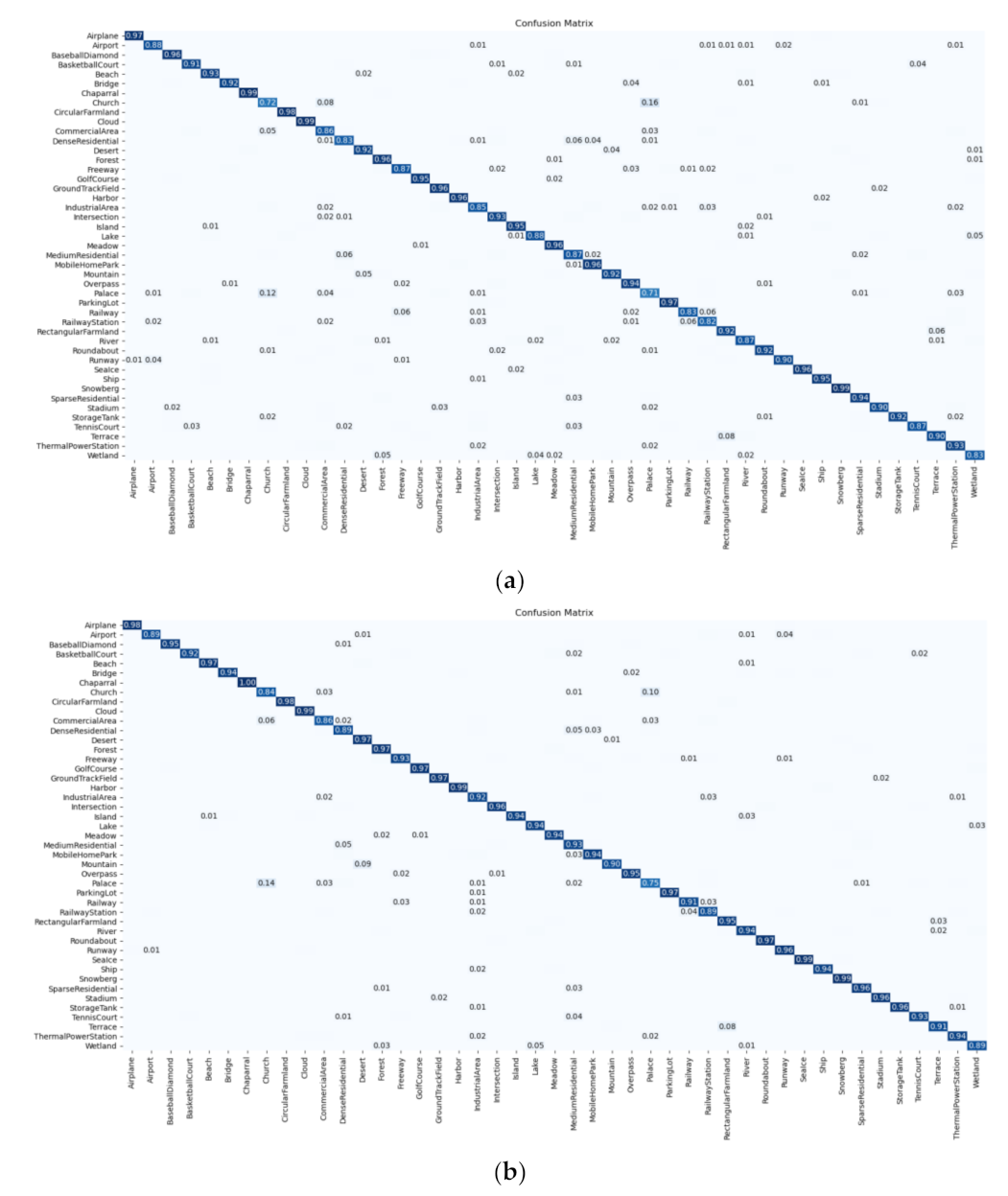
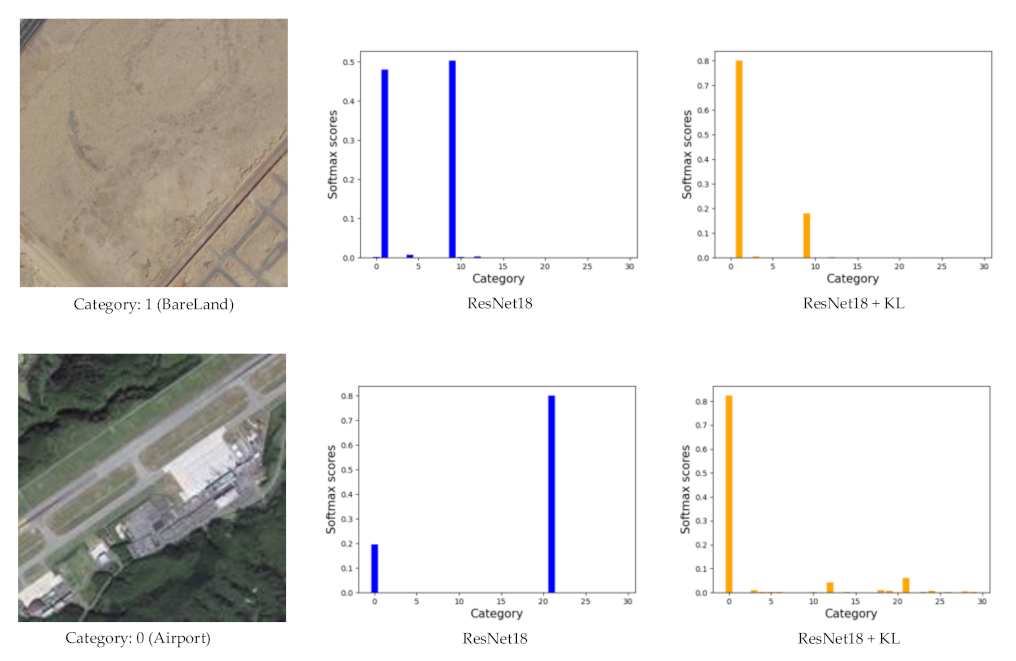
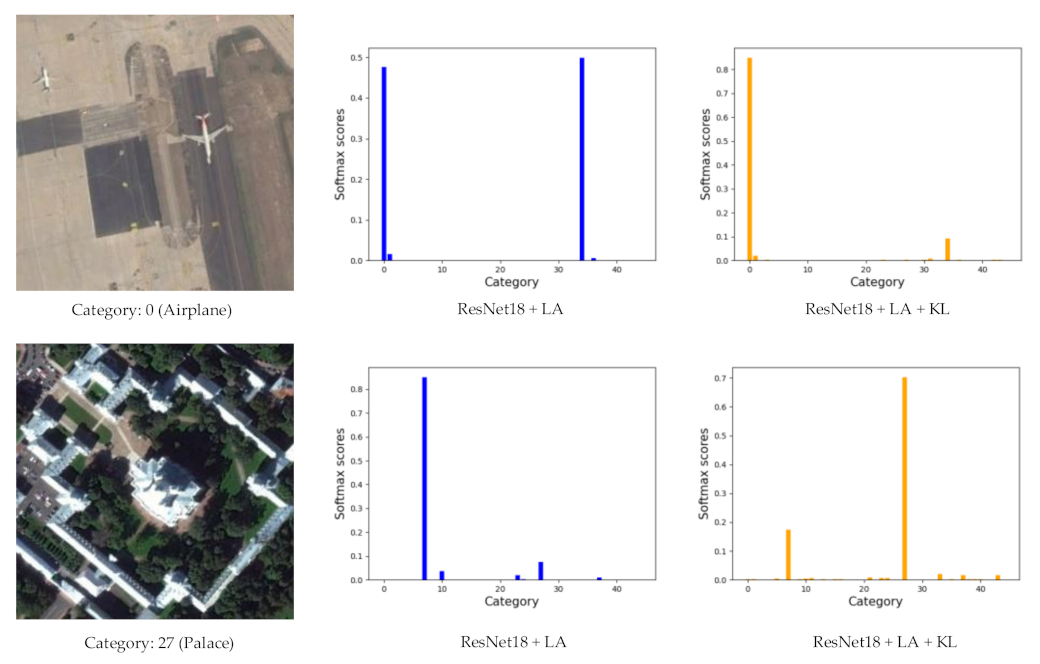
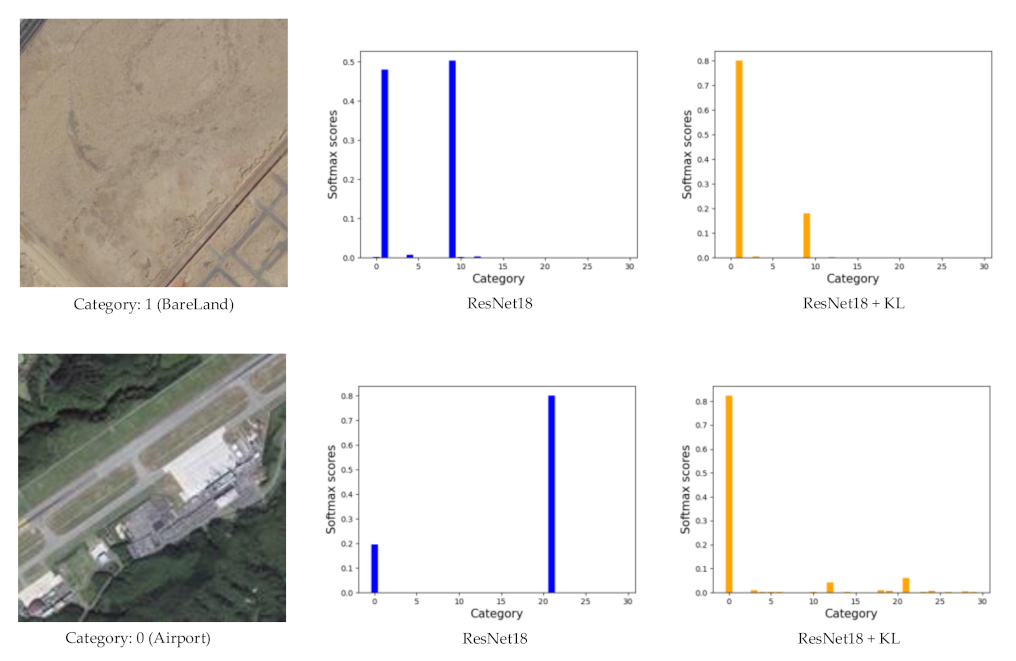
Although label augmentation can provide more training samples having accurate category information, it also increases the intra-class diversity among the training set. The intra-class diversity has an important influence on test accuracy. To address this issue, we utilize KL divergence as a regularization term to impose intra-constraint. In detail, we input two training samples with the same category into the network and obtain their output distribution. Since the input images have the same category, their output distribution should be similar. Therefore, we calculate the KL divergence of the two output distributions as the regularization term.
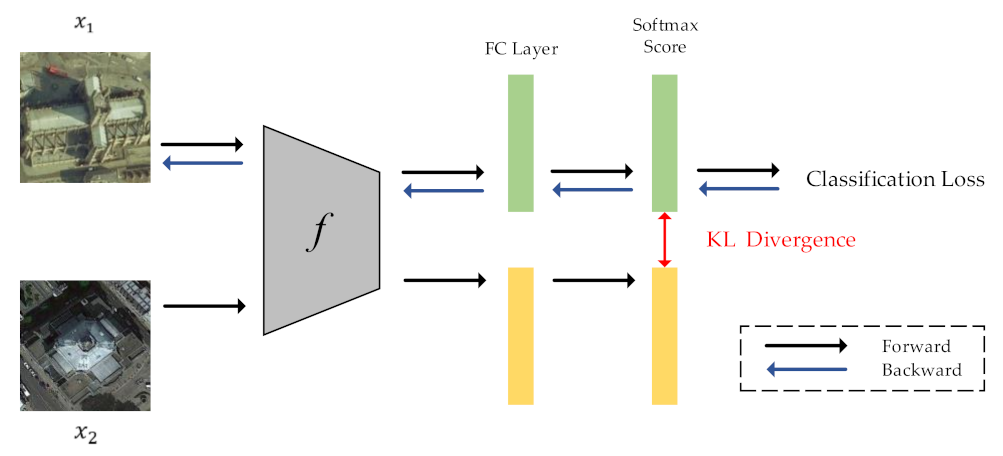
The framework of intra-class constraint is shown in
Figure 3. During the training process, in addition to the current training sample
, we input another randomly selected sample
with the same category as sample
into the network. The KL divergence is used to match the output distribution of two training samples.
The output distribution of input image is defined as follows:
where
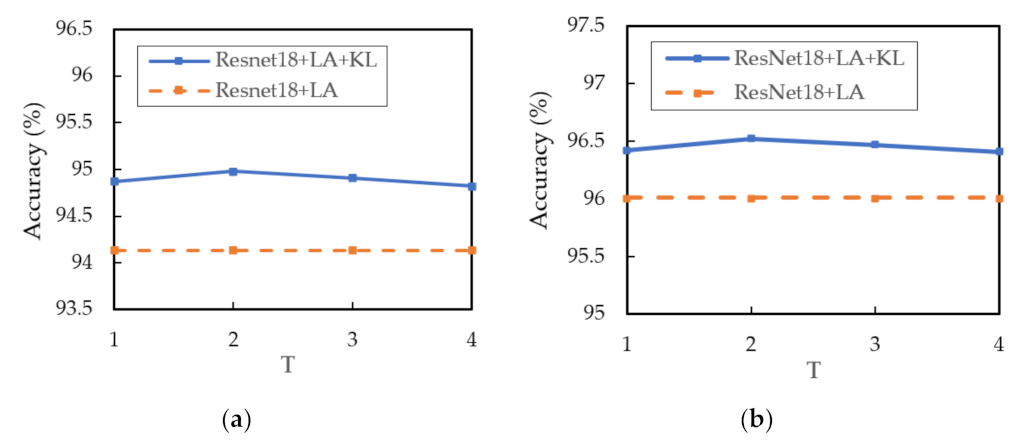
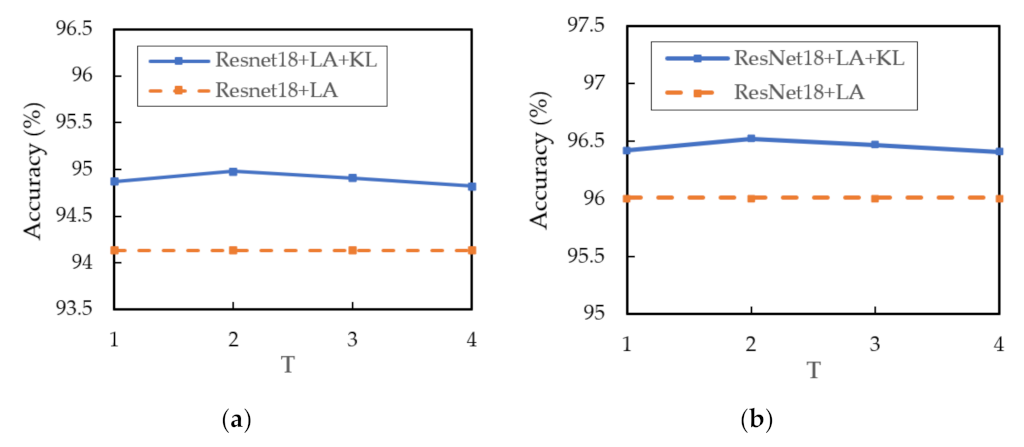
is the distillation temperature, which is used to soften the output distribution. Then, we propose the following KL divergence regularization term to impose intra-constraint:
The total loss can be obtained by combining cross-entropy loss function and KL divergence regularization term:
where
represents the cross-entropy loss, and
is the coefficient of the KL divergence. We set
to 1 to indicate that cross-entropy loss and KL divergence regularization term have same importance in our method.
Moreover, we only perform backpropagation for the training sample . The training sample is only used to calculate the value of KL divergence, and the process of backpropagation is not necessary.
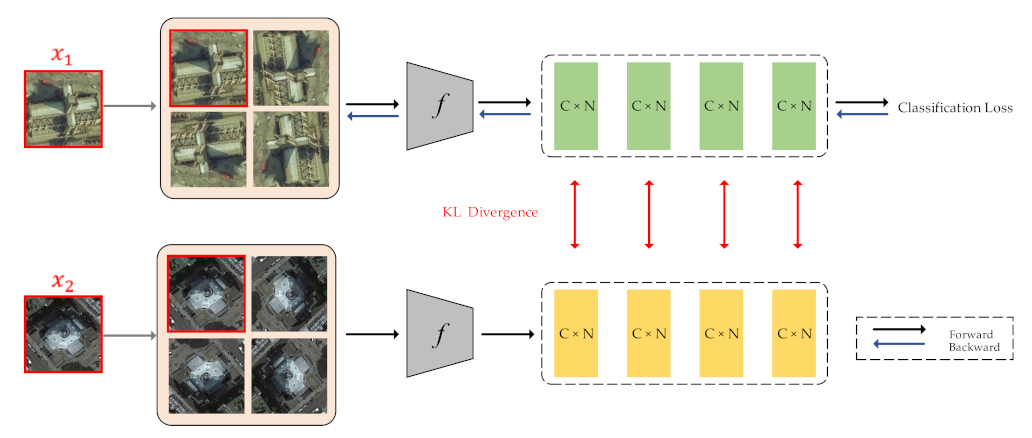
2.3. Combination of LA and Intra-Class Constraint for RS Image Scene Classification
In this sub-section, we combine the above two methods, i.e., LA and Intra-class Constraint, to further enhance the classification performance.
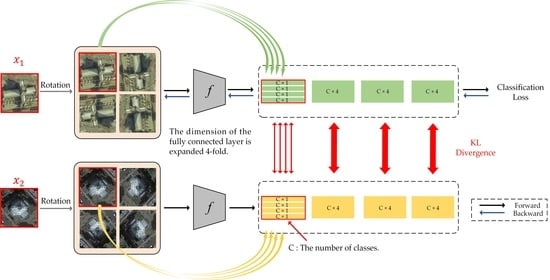
Figure 4 displays the overall framework of the proposed method.
Similar to the intra-class constraint, we have a current input image
and a randomly selected image
with the same category as sample
. By applying label augmentation to samples
and
, the number of images and categories has increased by
N times. As shown in
Figure 4, for each input image, we use 4 rotation transformations to obtain four images with the joint label. Then, we calculate the KL divergence of these four pairs of images. The total loss can be calculated by combining loss
and KL divergence:
Moreover, the backpropagation process is only for samples and its augmented samples, and the training sample is only used to calculate the value of KL divergence.
Algorithm 1 shows the workflow of the proposed method. The combination of label augmentation and intra-class constraint enables us to fully use the training set to enhance the classification performance.
| Algorithm 1: The workflow of label augmentation and intra-class constraint. |
| 1. begin |
| 2. randomly select the RS images to generate the training set and test set |
| 3. initialize the model with the parameters w of the model pre-trained on the ImageNet |
| 4. Train model: |
| 5. for epoch in 1: epochs: |
| 6. sample a batch (x, y) from the training set |
| 7. sample another batch (, y) with the same category y from the training set |
| 8. apply LA to each image in two batches to generate four new images and their joint labels |
| 9. calculate the cross-entropy loss |
| 10. obtain output distributions of the two samples with the same location in two batches |
| 11. calculate the KL divergence of two output distributions |
| 12. update parameters w by minimizing the loss |
| 10. Test: |
| 11. apply LA to each image in the test set |
| 12. output = model (test image) |
| 13. aggregate the output and calculate the softmax probability |
| 14. end |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}