2.1. Method
Let Y be a continuous random variable, as slope or orientation, and let be a set of thresholds defining a partition of the random variable into k disjoint intervals. So, k categories can be defined in the following way: for those values of Y less than or equal to , the categories are defined by the interval and the category for the rest of values of Y (greater than ). In accordance with this categorization, given a random sample of size n from Y, the random vector whose components count the number of events falling into each category, say , follows a multinomial distribution with parameters n and , where stands for the true occurrence probability of the ith category. In short, .
Let
be a fixed point of
which represents the classification adopted on the reference dataset. The hypothetical probabilities
represent the quality requirements to be achieved by the product, that is, the ideal proportions. Deciding whether or not the quality requirements are fulfilled by a product is tantamount to testing the hypotheses
Recall that the critical region of a test is built so that the probability of rejecting the null hypothesis when it is true is bounded by a quantity, usually denoted by
, called the significance level. In other words, when the null hypothesis is rejected either we are making the correct decision or we are wrong, and the probability of the latter is less than
, that is, the probability of a false rejection is controlled. By contrast, when the null hypothesis is accepted, either we are making the correct decision or we are wrong and, in most cases, the probability of being wrong is unknown, that is, the probability of a false acceptance is unknown. Many tests are available for the testing problem (
1) (see, e.g., references [
17,
18]). Because of the above explanation, those tests are applied when
is expected to be rejected, since when
is not rejected it cannot be concluded that
because the probability of making an incorrect decision is unknown and could be arbitrarily high.
When the interest is centred in proving that
, the hypotheses in (
1) must be adequately switched, and an equivalence test should be applied, see [
19]. With this aim, the user must fix a distance or dissimilarity measure on
, say
H, and a positive quantity, say
, and now the hypotheses to be tested become
Notice that with this approach, the equality of probability vectors has been replaced by a larger subset of . Specifically, the subset has been enlarged through adding an indifference zone or a neighborhood around in the parametric space , . In this setting, if is rejected then it is concluded that P and are equal except for practically irrelevant deviations whenever is small enough.
Therefore, when one is interested in proving that a product meets the quality requirements stated by
, a test of (
2) must be applied. In [
19] a test of (
2) is proposed for
H the Euclidean distance. Nevertheless, other choices for
H are possible. Previous research related to tests for the similarity between spatial point patterns and tests for the thematic-accuracy quality control suggested that the Hellinger distance may be an appealing choice for this goal [
20,
21,
22]. For two multinomial probability distributions, their Hellinger distance is equal to the Euclidean norm of the difference of the square root vectors. To avoid dealing with square roots, from now on we will work with the square of the Hellinger distance, defined as follows:
Notice that
and that
if and only if
. So, for fixed small
,
P and
will be considered equivalent according to (
3) if
, implying that both distributions are equal except for insignificant deviations.
To derive a critical region for (
2), with
H as in (
3), we proceed as follows. Let
be the vector of relative frequencies,
From Corollary 3.1 in [
23], for each
(
), one gets
as
, where
and
denotes convergence in distribution. For
, it follows that
as
, for each
. So, for
, the decision rule is:
where
stands for the
-percentile of the standard normal distribution. The critical point
in (
4) has been taken from the asymptotic distribution of
, that is, the level of the test is (exactly) equal to
for infinite sample sizes. To study the behaviour of test (
4) for finite sample sizes, we carried out a simulation study, which is described in the next section.
Note that the equivalence test proposed is developed in the context of the multinomial law underlying a categorization scheme. So, it can be also applied not only for classifications of slopes and orientations, but also for other geospatial thematic products (e.g., land covers maps, land uses, maps, etc.).
Simulation Results
For feasibility reasons (e.g., economic, temporal, etc.), quality controls are usually carried out based on sampling. When interest is centred on proving that a product meets the quality requirements stated by
, test (
4) can be applied. As observed before, that test is based on asymptotic results. To study numerically its behavior for small and moderate sample sizes, we carried out some simulation experiments.
In these experiments, we considered the testing problem
vs.
with
for
. This particular choice of
is not casual. It has been considered in previous simulation studies involving inference research over the multinomial distribution (see [
24,
25,
26], among others). The values of
k were chosen because they conform to the most usual number of categories in the slope classifications from the literature revised [
27,
28,
29,
30,
31,
32]. Finally, several values for
were taken, in particular,
covering reasonable thresholds of closeness between
P and
.
The first part of the simulation is devoted to studying the actual level of the equivalence test (
4). For this task, as usual, we have to simulate data under the null hypothesis
, that is, for configurations of
P such that
. Here, we considered a set of configurations of
P verifying that
for
as before.
Table 1,
Table 2 and
Table 3 display the considered configurations. For each scenario, a random sample of size
was generated and the decision rule (
4) was applied for the nominal level
. After 100,000 repetitions, the rejection percentage was collected. The whole experiment was repeated for
for
and
for
, respectively.
Table 4 and
Table 5 show the rejection percentages obtained which estimate the actual level of the test for the nominal value
.
Looking at
Table 4 and
Table 5, we observe that for
small sample sizes are needed for the actual level to match the nominal level for all considered values of
. However, when the number of categories increases, larger sample sizes are required for the simulation results to reach the nominal level (
for
and
for
).
To study the power of the proposal, that is, the probability of rejecting the null hypothesis when it is false, we generated a random sample of size
from a
for
and we applied the decision rule in (
4) for
and
. After 100,000 repetitions, we collected the proportion of rejections which are now the estimated power associated with the nominal level
. The experiment was repeated for
,
and
.
Table 6 shows the estimated power. As can be seen, in all the tried cases, the power is very high, that is, the procedure makes the correct decision with a probability close to 1. According to these findings, the usefulness of test (
4) as a tool for quality control is evidenced.
2.2. Materials
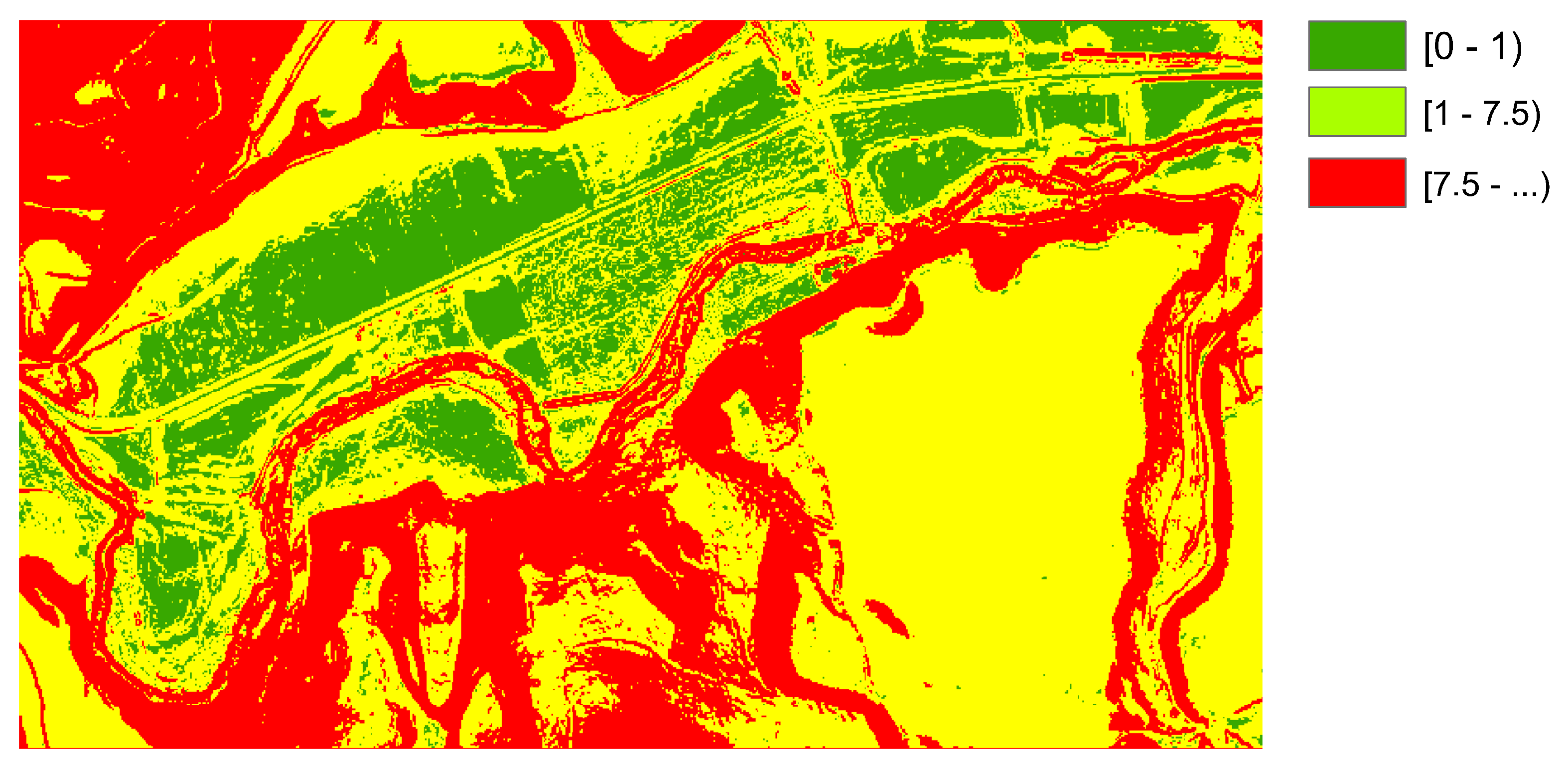
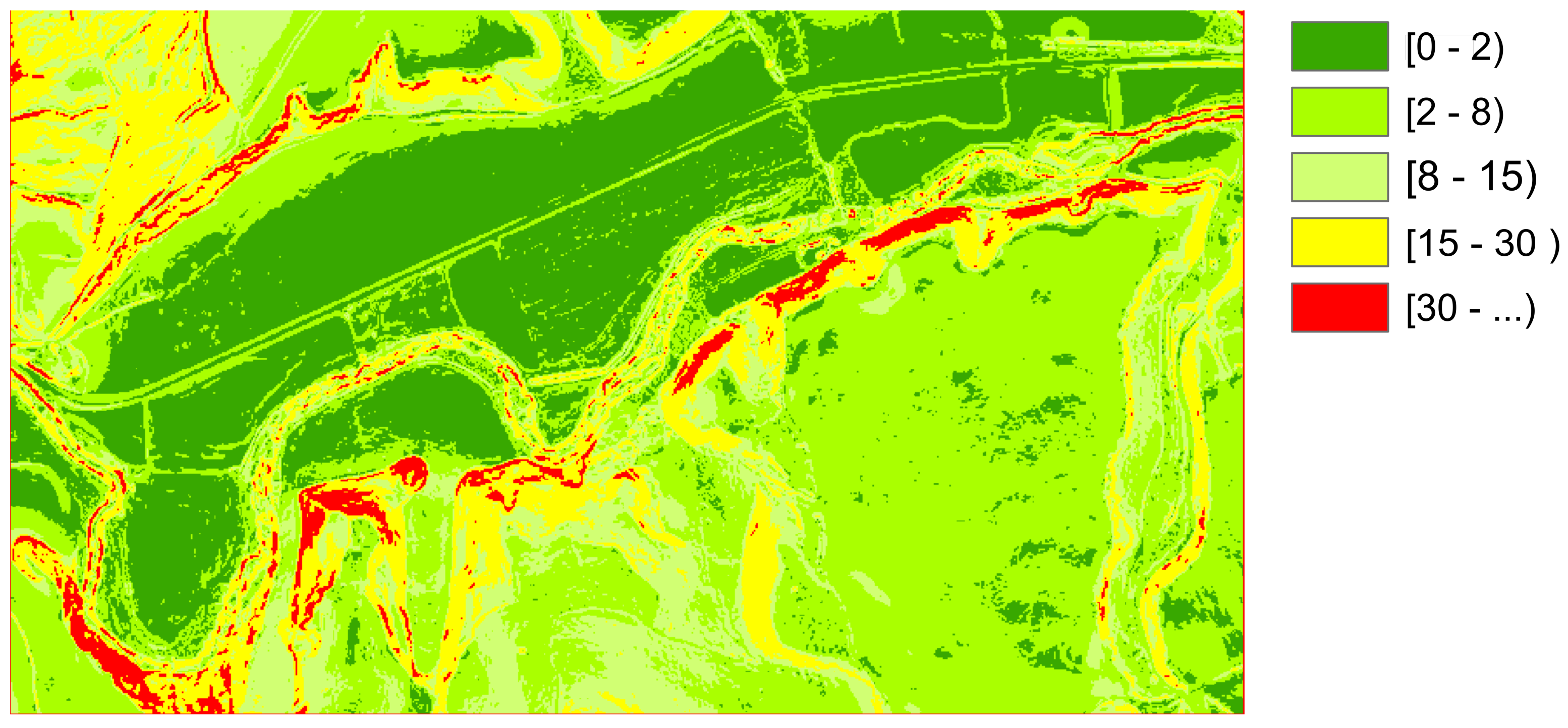
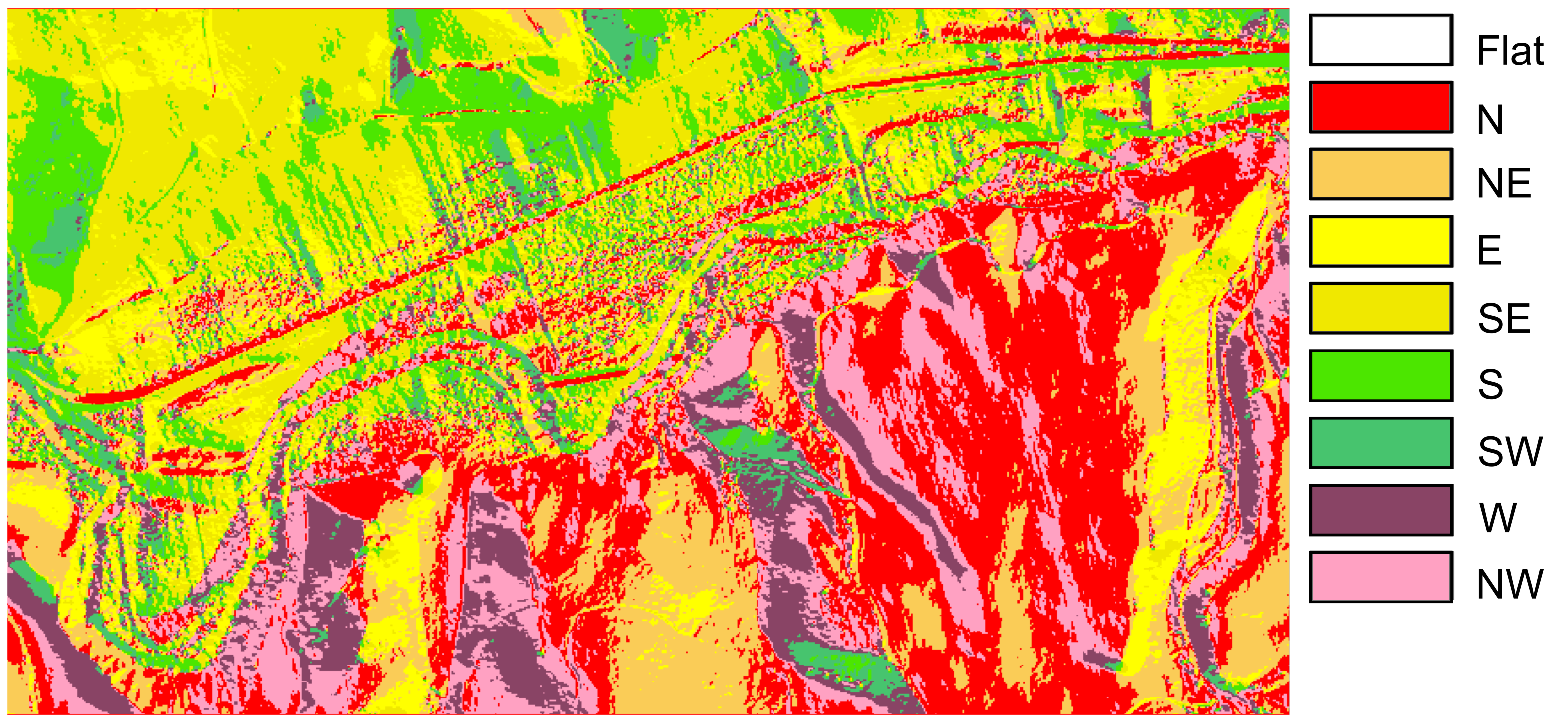
To show an example of an application on real data, a study area around Allo (Navarra, Spain) was considered using the following digital models:
SLM02 & ASM02. Both slope (SLM02) and aspect (ASM02) models were derived by GIS operations from a DEM (the DEM02). The DEM02 is a DEM grid with
m resolution, generated in the year 2017 and its primary data source is a Lidar survey (second coverage of the PNOA-LiDAR project
https://pnoa.ign.es/estado-del-proyecto-lidar/segunda-cobertura, accessed on 21 May 2021). Both datasets are considered as references in this example.
SLM05 & ASM05. Both slope (SLM05) and aspect (ASM05) models were derived by GIS operations from a DEM (the DEM05). The DEM05 is a DEM grid with a resolution of
m, generated in the year 2012 and its primary data source is a Lidar survey (first coverage of the PNOA-LiDAR project
https://pnoa.ign.es/estado-del-proyecto-lidar/primera-cobertura, accessed on 21 May 2021).
Both DEM datasets come from the IGN (Spain) and are freely available. In both cases, GIS operations (slope and aspect) are those implemented by ArcGIS (TM) in its Spatial Analyst toolbox.
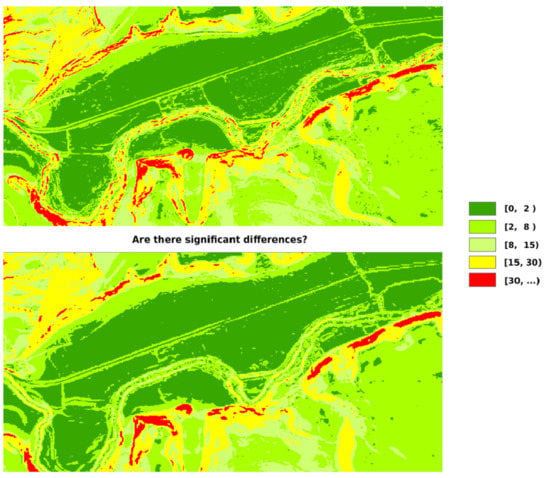
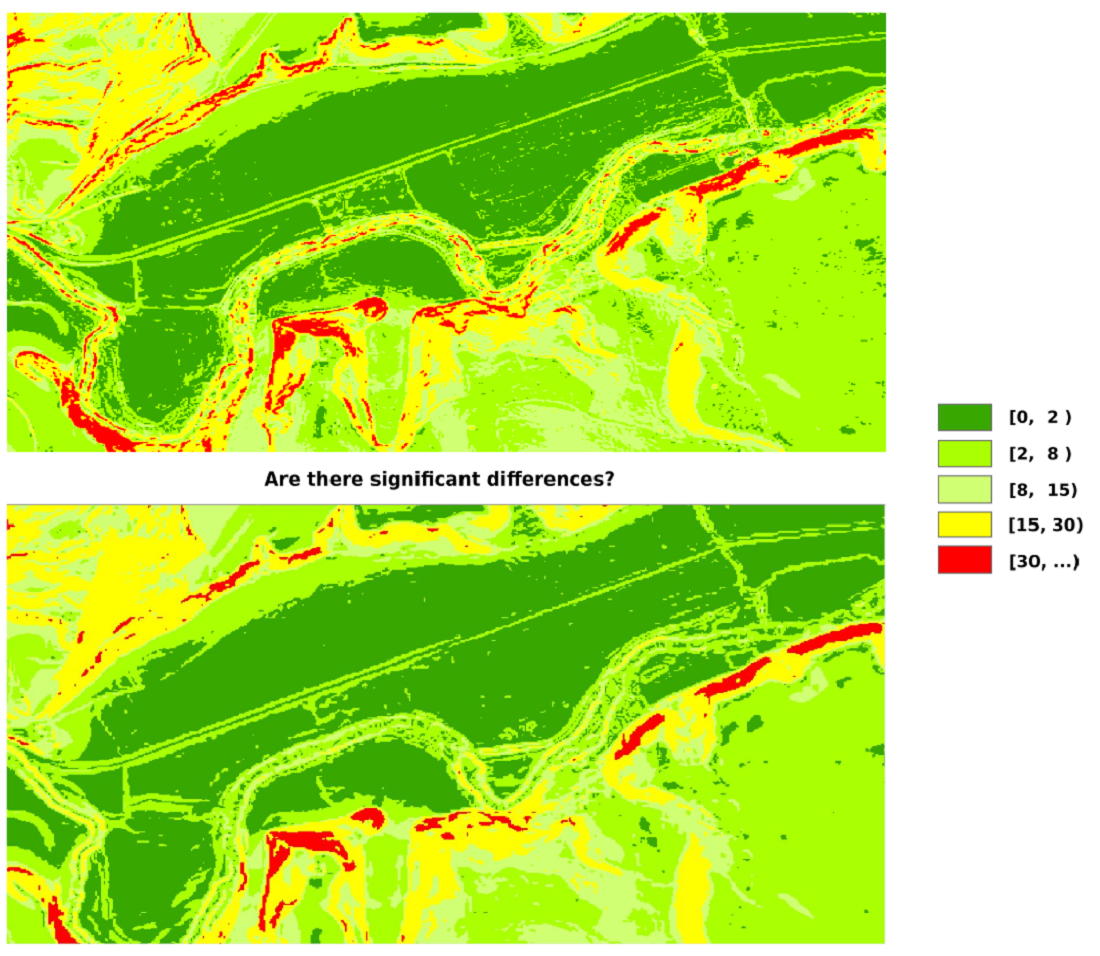
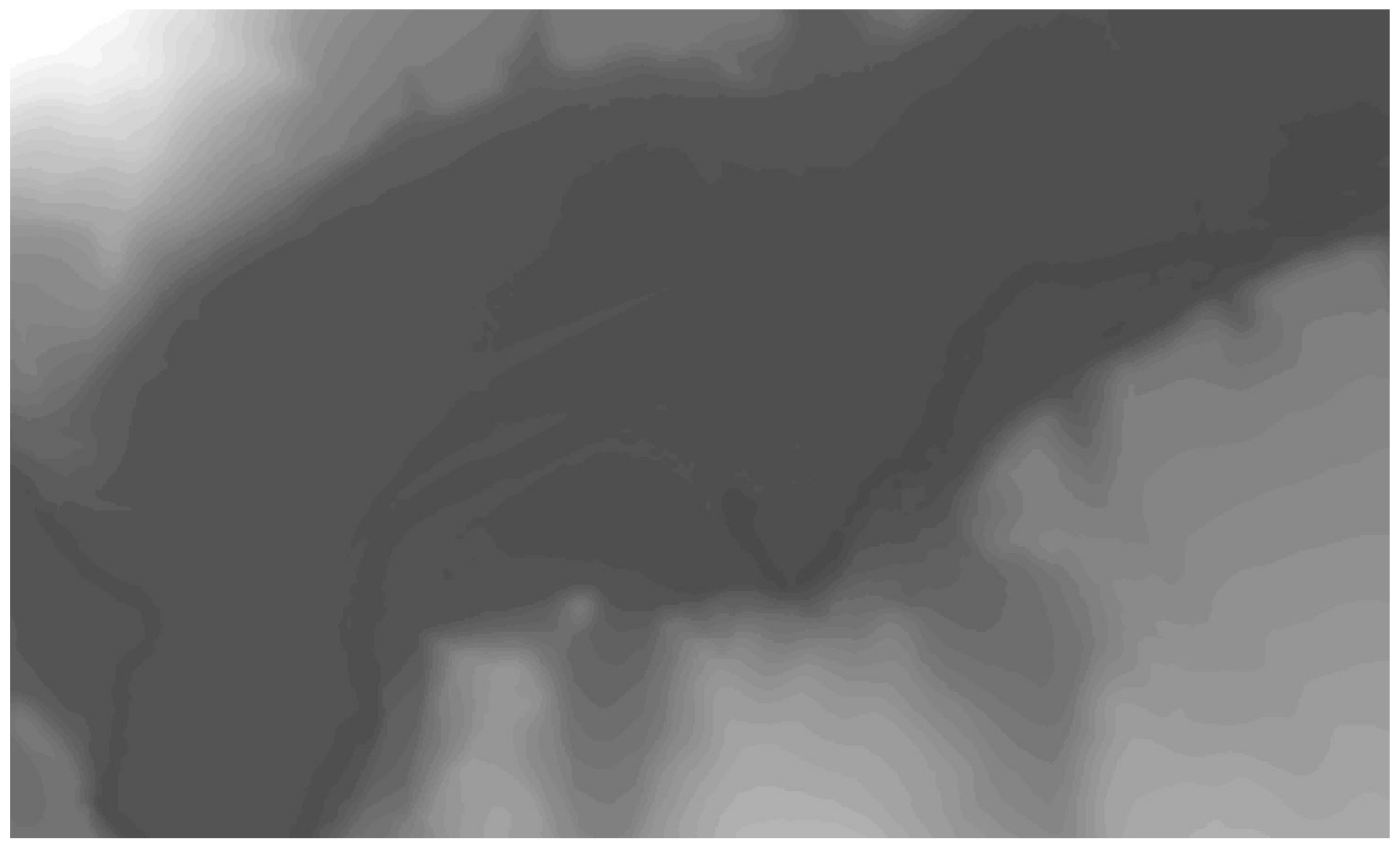
Concerning the study area,
Figure 1 shows its corresponding DEM, and
Figure 2 a zoom to a smaller area to have a detailed view to appreciate differences. The area is 504 km
, and it has a varied relief, but not abrupt, with valleys of different widths, and areas with different degrees of undulation. The elevation is in the interval 316–1046 m, mean value is 468 m and the standard deviation 92.8 m.
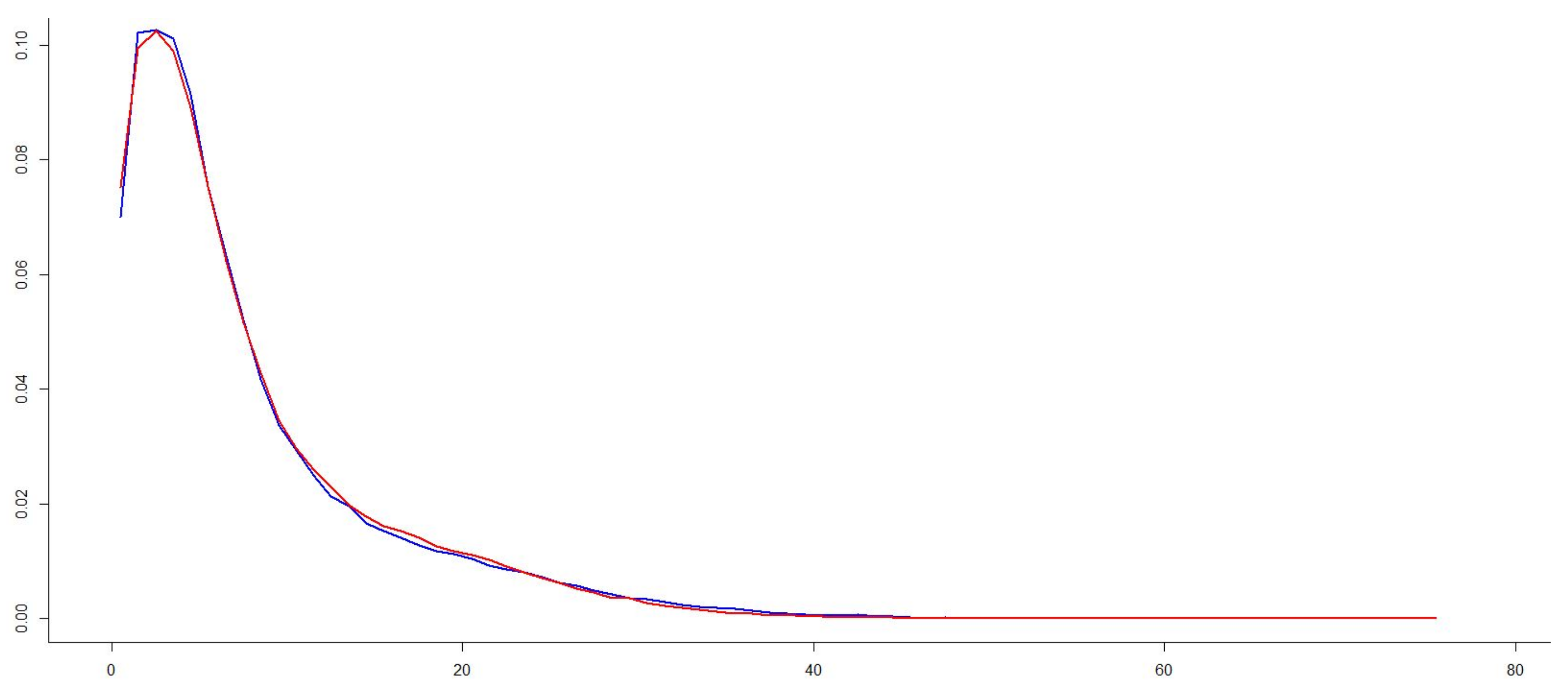
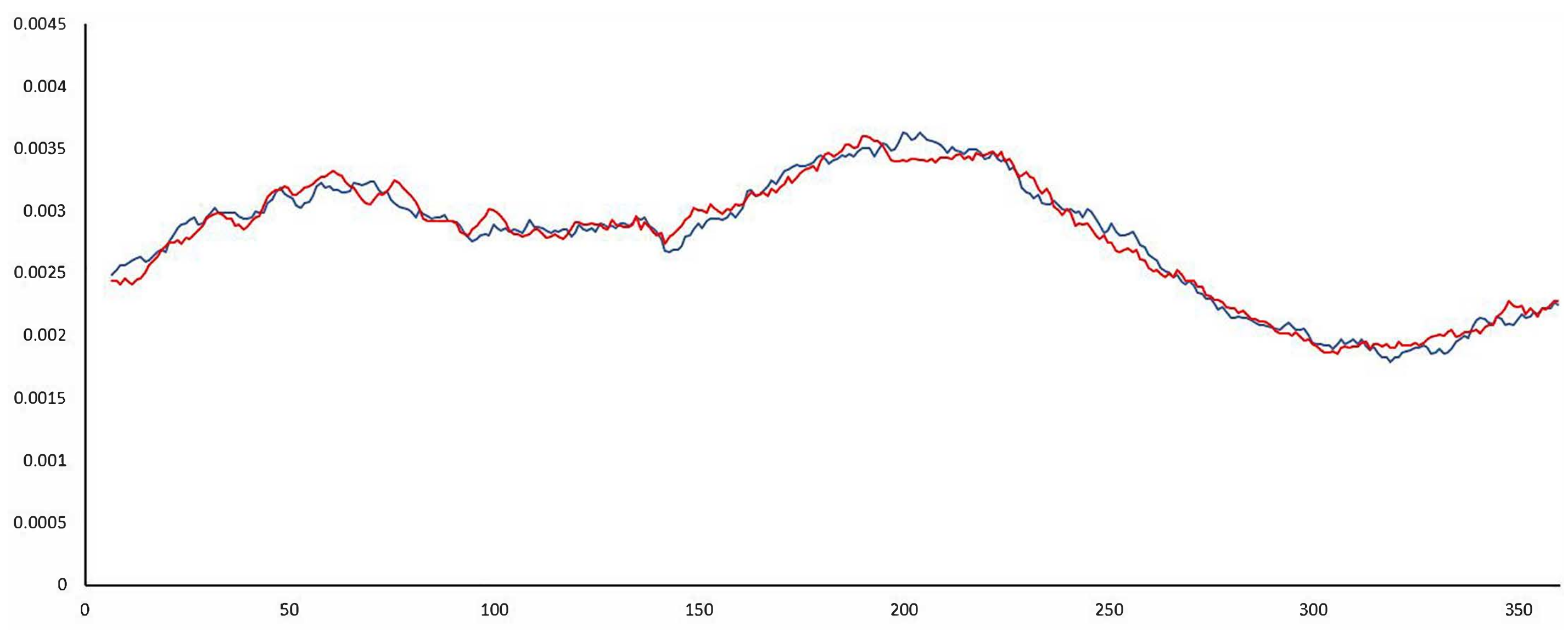
Figure 3 and
Figure 4 show the observed values of slopes and aspects, respectively. In general, there are small differences between the curves corresponding to SLM02 vs. SLM05 and ASM02 vs. ASM05, respectively. The differences are minor because they are high-quality products, relatively close in time and for a territory in which there have not been major changes. The curves of the slopes (SLM02 in blue and SLM05 in red) show considerable similarity between the two datasets. Clearly, areas are observed where one curve occurs over the other, and these areas have a certain amplitude. The curves of the orientation (ASM02 in blue and ASM05 in red) show more tremor than the slope curves; this is logical since the orientation is more sensitive than the slope to small changes in elevation. On the other hand, it is observed that the curve corresponding to case ASM02 has more variability than that of case ASM05, which is also logical because it comes from a more detailed model. Furthermore, it is observed that the two curves intersect, although these crosses occur with a relatively wide length between them, which implies a certain bias. It should be remembered that the proposed analysis method is not based on the use of these frequency distributions, which have helped us to better understand the data, but on the comparison of the proportions between categories defined on them and that the differences that are worked with will be those that exist between the proportions corresponding to those classes. In this case, given the statistical control to be applied, the most important thing is to analyze whether, given a categorization of the two variables of interest (slope and orientation) applied under the two models, the hypothetical probability vector for the reference DEM02 (
m) is close enough the true one of DEM05 (
m). If this fact is confirmed via an equivalence test, it will mean that the quality conditions of the reference DEM02 are achieved by the product DEM05 to be controlled, except for irrelevant deviations.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}