A2S-Det: Efficiency Anchor Matching in Aerial Image Oriented Object Detection


Abstract
1. Introduction
- We propose an anchor selection method combining horizontal features and rotating features. For the set of candidate anchors, a self-adaptive threshold module based on sample balance is adopted to determine a threshold, which divides these candidate anchors into positive and negative anchors. There are larger improvements in DOTA [4] compared with the baseline for objects with large aspect ratios.
- For bounding box prediction, the coordinate regression of the relative reference module can predict box more precisely and be to the benefit of more rigorous evaluations, like .
2. Materials and Methods
2.1. Data
2.2. Related Work
2.3. Method
2.3.1. Network Architecture
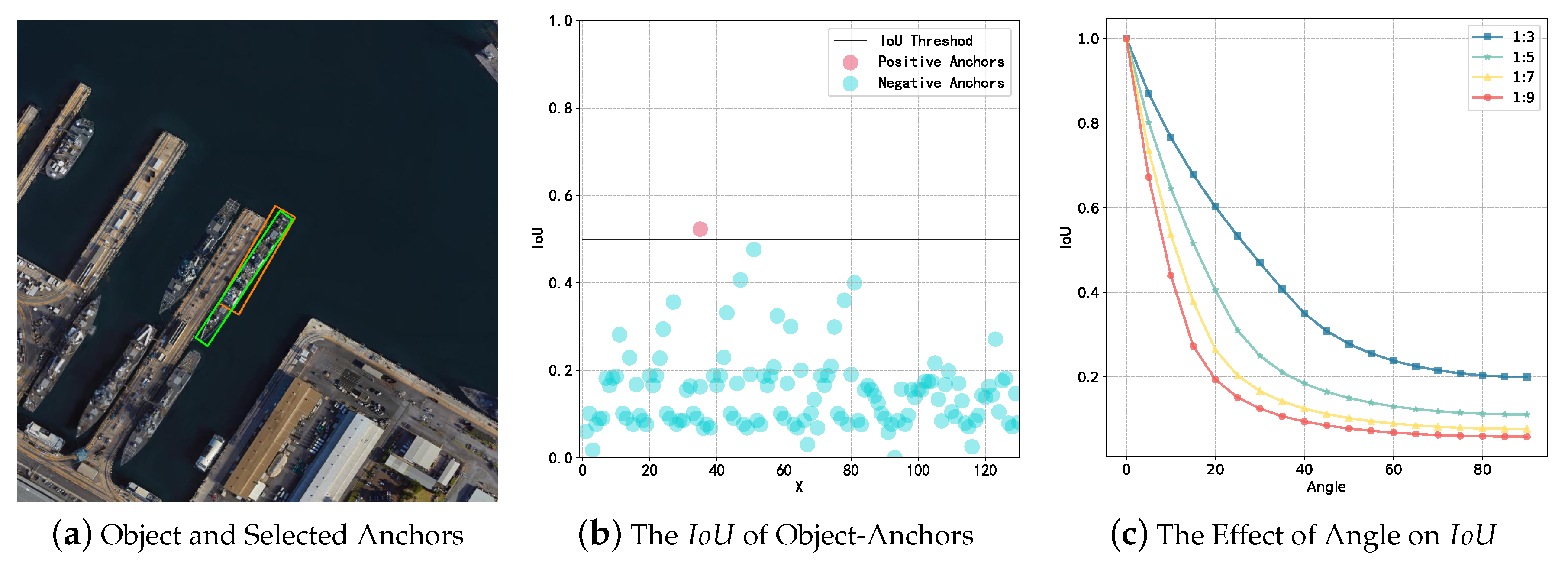
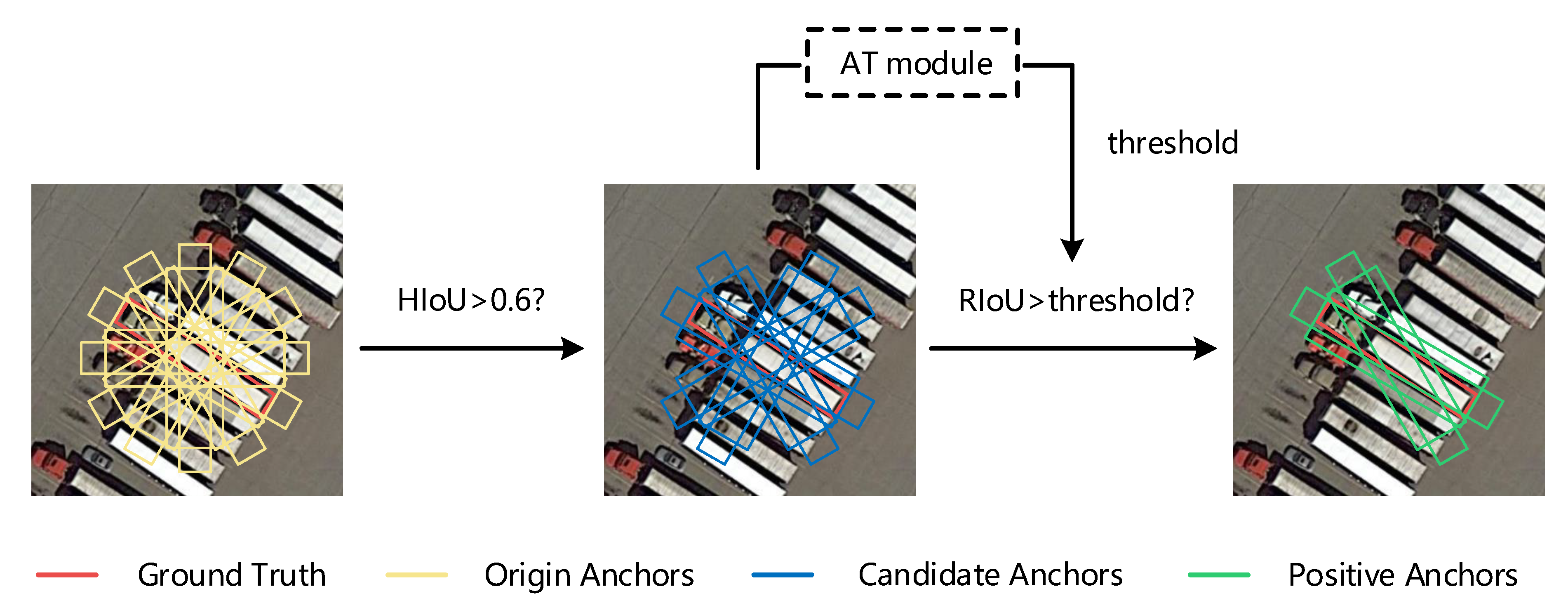
2.3.2. Self-Adaptive Anchor Selection
| Algorithm 1 Self-Adaptive Anchor Selection |
|
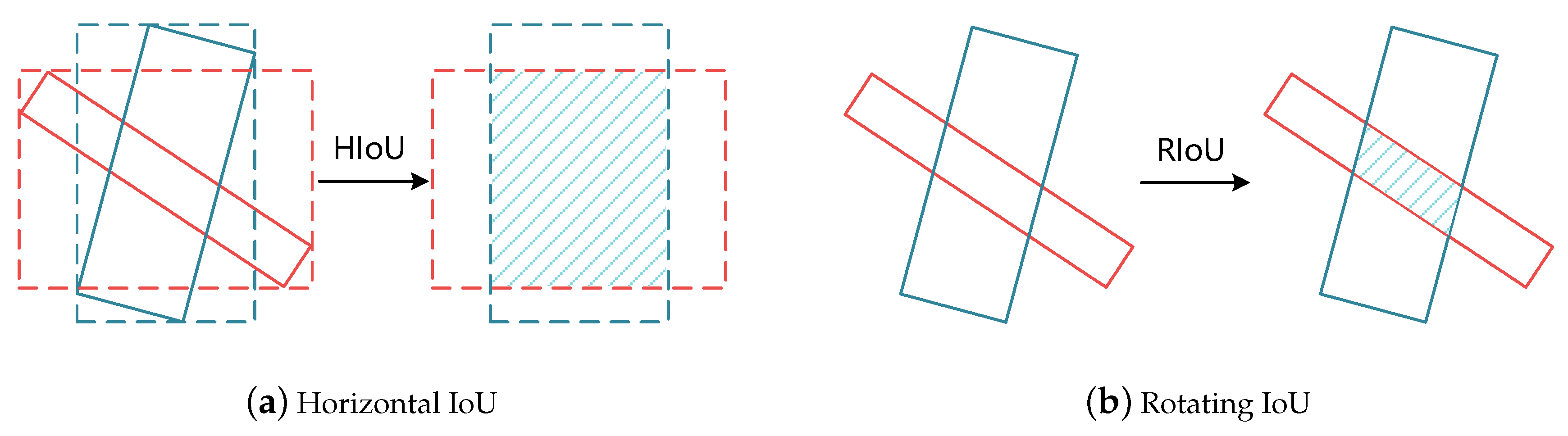
2.3.3. Self-Adaptive Threshold Based on Sample Balance
2.3.4. Coordinate Regression of Relative Reference
2.3.5. Loss
2.3.6. Implementation Details
3. Results
4. Discussion
4.1. Effectiveness of Self-Adaptive Anchor Selection
4.2. Effectiveness of C Module
4.3. Advantages and Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| S-Det | self-adaptive anchor selection |
| coordinate regression of relative reference | |
| self-adaptive threshold | |
| intersection over unit | |
| non-maximum suppression | |
| baseball diamond | |
| ground track field | |
| SV | small vehicle |
| large vehicle | |
| tennis court | |
| basketball court | |
| storage tank | |
| soccer ball field | |
| roundabout | |
| swimming pool | |
| helicopter | |
| standard deviation | |
| average precision |
References
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2017, 20, 3111–3122. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2cnn: Rotational region cnn for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Yang, X.; Liu, Q.; Yan, J.; Li, A.; Zhang, Z.; Yu, G. R3det: Refined single-stage detector with feature refinement for rotating object. arXiv 2019, arXiv:1908.05612. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:cs.CV/1506.01497. [Google Scholar] [CrossRef]
- Kaiming, H.; Georgia, G.; Piotr, D.; Ross, G. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Gong, Y.; Xiao, Z.; Tan, X.; Sui, H.; Xu, C.; Duan, H.; Li, D. Context-Aware Convolutional Neural Network for Object Detection in VHR Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 34–44. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. East: An efficient and accurate scene text detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2642–2651. [Google Scholar]
- Liu, L.; Pan, Z.; Lei, B. Learning a rotation invariant detector with rotatable bounding box. arXiv 2017, arXiv:1711.09405. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. Textboxes: A fast text detector with a single deep neural network. arXiv 2016, arXiv:1611.06779. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for detecting oriented objects in aerial images. arXiv 2018, arXiv:1812.00155. [Google Scholar]
- Xiao, Z.; Qian, L.; Shao, W.; Tan, X.; Wang, K. Axis Learning for Orientated Objects Detection in Aerial Images. Remote Sens. 2020, 12, 908. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, Y.; Chang, Z.; Li, H.; Wang, H.; Sun, X. Oriented Objects as pairs of Middle Lines. arXiv 2020, arXiv:cs.CV/1912.10694. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Xian, S.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. arXiv 2018, arXiv:cs.CV/1811.07126. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yang, W.; Li, H.; Zhang, H.; Xia, G. Learning Center Probability Map for Detecting Objects in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 1–17. [Google Scholar] [CrossRef]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection. arXiv 2019, arXiv:cs.CV/1912.02424. [Google Scholar]
- Zhang, X.; Wan, F.; Liu, C.; Ji, R.; Ye, Q. FreeAnchor: Learning to Match Anchors for Visual Object Detection. arXiv 2019, arXiv:cs.CV/1909.02466. [Google Scholar]
- Ke, W.; Zhang, T.; Huang, Z.; Ye, Q.; Liu, J.; Huang, D. Multiple Anchor Learning for Visual Object Detection. arXiv 2019, arXiv:cs.CV/1912.02252. [Google Scholar]
- Cao, Y.; Chen, K.; Loy, C.C.; Lin, D. Prime Sample Attention in Object Detection. arXiv 2019, arXiv:cs.CV/1904.04821. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8026–8037. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Lin, Y.; Feng, P.; Guan, J. IENet: Interacting Embranchment One Stage Anchor Free Detector for Orientation Aerial Object Detection. arXiv 2019, arXiv:cs.CV/1912.00969. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Backbone | Plane | BD | Bridge | GTF | SV | LV | Ship | TC | BC | ST | SBF | RA | Harbor | SP | HC | mAP | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| two-stage detectors | FR-O [6] | ResNet-101 | 79.09 | 69.12 | 17.17 | 63.49 | 34.20 | 37.16 | 36.20 | 89.19 | 69.60 | 58.96 | 49.4 | 52.52 | 46.69 | 44.80 | 46.30 | 52.93 |
| R-DFPN [32] | ResNet-101 | 80.92 | 65.82 | 33.77 | 58.94 | 55.77 | 50.94 | 54.78 | 90.33 | 66.34 | 68.66 | 48.73 | 51.76 | 55.10 | 51.32 | 35.88 | 57.94 | |
| CNN [2] | VGG16 | 80.94 | 65.67 | 35.34 | 67.44 | 59.92 | 50.91 | 55.81 | 90.67 | 66.92 | 72.39 | 55.06 | 52.23 | 55.14 | 53.35 | 48.22 | 60.67 | |
| RRPN [1] | VGG16 | 88.52 | 71.20 | 31.66 | 59.30 | 51.85 | 56.19 | 57.25 | 90.81 | 72.84 | 67.38 | 56.69 | 52.84 | 53.08 | 51.94 | 53.58 | 61.01 | |
| RoI-Transformer [18] | ResNet-101 | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 | |
| one-stage detectors | SSD [29] | SSD | 39.83 | 9.09 | 0.64 | 13.18 | 0.26 | 0.39 | 1.11 | 16.24 | 27.57 | 9.23 | 27.16 | 9.09 | 3.03 | 1.05 | 1.01 | 10.59 |
| YOLOv2 [30] | DarkNet-19 | 39.57 | 20.29 | 36.58 | 23.42 | 8.85 | 2.09 | 4.82 | 44.34 | 38.35 | 34.65 | 16.02 | 37.62 | 47.23 | 25.5 | 7.45 | 21.39 | |
| IENet [31] | ResNet-101 | 57.14 | 80.20 | 64.54 | 39.82 | 32.07 | 49.71 | 65.01 | 52.58 | 81.45 | 44.66 | 78.51 | 46.54 | 56.73 | 64.40 | 64.24 | 57.14 | |
| Axis-Learning [19] | ResNet-101 | 79.53 | 77.15 | 38.59 | 61.15 | 67.53 | 70.49 | 76.30 | 89.66 | 79.07 | 83.53 | 47.27 | 61.01 | 56.28 | 66.06 | 36.05 | 65.98 | |
| RetinaNet-R [12] | ResNet-50 | 88.03 | 71.04 | 40.27 | 50.70 | 71.33 | 72.99 | 84.83 | 90.76 | 77.12 | 82.95 | 38.38 | 58.91 | 55.08 | 67.41 | 54.29 | 66.94 | |
| -DNet [20] | 104-Hourglass | 89.31 | 82.14 | 47.33 | 61.21 | 71.32 | 74.03 | 78.62 | 90.76 | 82.23 | 81.36 | 60.93 | 60.17 | 58.21 | 66.98 | 61.03 | 71.04 | |
| R3Det [3] | ResNet-101 | 89.54 | 81.99 | 48.46 | 62.52 | 70.48 | 74.29 | 77.54 | 90.80 | 81.39 | 83.54 | 61.97 | 59.82 | 65.44 | 67.46 | 60.05 | 71.69 | |
| proposed | S-Det | ResNet-50 | 89.45 | 78.52 | 42.78 | 53.93 | 76.37 | 74.62 | 86.03 | 90.68 | 83.35 | 83.55 | 48.58 | 60.51 | 63.46 | 71.33 | 53.10 | 70.42 |
| S-Det | ResNet-101 | 89.59 | 77.89 | 46.37 | 56.47 | 75.86 | 74.83 | 86.07 | 90.58 | 81.09 | 83.71 | 50.21 | 60.94 | 65.29 | 69.77 | 50.93 | 70.64 |
| Methods | DataAug | AT | C | Plane | BD | Bridge | GTF | SV | LV | Ship | TC | BC | ST | SBF | RA | Harbor | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RetinaNet-R [12] | - | - | - | 88.03 | 71.04 | 40.27 | 50.70 | 71.33 | 72.99 | 84.83 | 90.76 | 77.12 | 82.95 | 38.38 | 58.91 | 55.08 | 67.41 | 54.29 | 66.94 |
| S-Det | - | - | - | 89.05 | 69.67 | 40.84 | 56.88 | 75.95 | 72.94 | 84.13 | 90.66 | 73.39 | 82.15 | 41.90 | 62.12 | 55.86 | 70.17 | 50.60 | 67.75 |
| - | ✓ | - | 89.09 | 68.68 | 42.73 | 56.94 | 74.39 | 73.24 | 84.68 | 90.74 | 73.80 | 82.95 | 44.03 | 59.63 | 59.81 | 69.64 | 50.50 | 68.06 | |
| - | ✓ | ✓ | 89.08 | 70.53 | 43.28 | 55.89 | 74.20 | 73.54 | 84.92 | 90.48 | 74.42 | 84.05 | 42.70 | 62.63 | 60.31 | 68.38 | 52.36 | 68.45 | |
| ✓ | ✓ | ✓ | 89.45 | 78.52 | 42.78 | 53.93 | 76.37 | 74.62 | 86.03 | 90.68 | 83.35 | 83.55 | 48.58 | 60.51 | 63.46 | 71.33 | 53.10 | 70.42 |
| Methods | Evaluation | C | Plane | BD | Bridge | GTF | SV | LV | Ship | TC | BC | ST | SBF | RA | Harbor | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S-Det | - | 89.01 | 58.36 | 31.82 | 44.35 | 53.50 | 71.34 | 86.40 | 90.37 | 54.91 | 85.27 | 32.97 | 58.13 | 51.17 | 52.14 | 39.59 | 59.95 | |
| ✓ | 89.12 | 59.64 | 29.59 | 45.10 | 58.08 | 72.52 | 86.13 | 90.23 | 56.67 | 84.98 | 34.76 | 56.08 | 50.82 | 51.37 | 36.52 | 60.11 | ||
| S-Det | - | 51.23 | 9.76 | 3.03 | 20.93 | 19.41 | 31.30 | 34.12 | 80.53 | 30.73 | 43.24 | 5.57 | 22.73 | 6.94 | 6.36 | 9.70 | 25.04 | |
| ✓ | 54.18 | 8.65 | 4.55 | 23.49 | 19.21 | 34.85 | 34.82 | 80.36 | 37.20 | 40.31 | 9.04 | 22.55 | 7.95 | 4.32 | 8.77 | 26.02 | ||
| S-Det | - | 50.72 | 24.47 | 10.69 | 21.98 | 27.20 | 37.31 | 42.51 | 70.42 | 29.82 | 46.95 | 11.28 | 29.26 | 17.83 | 17.73 | 18.06 | 30.42 | |
| ✓ | 53.89 | 25.13 | 10.32 | 22.67 | 26.76 | 38.55 | 42.65 | 70.19 | 34.54 | 46.63 | 13.21 | 29.73 | 17.33 | 16.96 | 15.22 | 30.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, Z.; Wang, K.; Wan, Q.; Tan, X.; Xu, C.; Xia, F. A2S-Det: Efficiency Anchor Matching in Aerial Image Oriented Object Detection. Remote Sens. 2021, 13, 73. https://doi.org/10.3390/rs13010073
Xiao Z, Wang K, Wan Q, Tan X, Xu C, Xia F. A2S-Det: Efficiency Anchor Matching in Aerial Image Oriented Object Detection. Remote Sensing. 2021; 13(1):73. https://doi.org/10.3390/rs13010073
Chicago/Turabian StyleXiao, Zhifeng, Kai Wang, Qiao Wan, Xiaowei Tan, Chuan Xu, and Fanfan Xia. 2021. "A2S-Det: Efficiency Anchor Matching in Aerial Image Oriented Object Detection" Remote Sensing 13, no. 1: 73. https://doi.org/10.3390/rs13010073
APA StyleXiao, Z., Wang, K., Wan, Q., Tan, X., Xu, C., & Xia, F. (2021). A2S-Det: Efficiency Anchor Matching in Aerial Image Oriented Object Detection. Remote Sensing, 13(1), 73. https://doi.org/10.3390/rs13010073